
{kind=link}
{kind=link}
融合量子干涉信息的双重特征文本表示模型
[高珲1  , 张鹏
, 张鹏1 , 张静1 ]
, 张鹏, 张静]
|
|



作者简介:

高 珲,博士研究生,主要研究方向为量子语义理解、大语言模型评估.E-mail:hui_gao@tju.edu.cn.

张 静,博士研究生,主要研究方向为大模型压缩及加速、基于大模型的小样本学习.E-mail:zhang_jing@tju.edu.cn.
在信息检索领域,量子干涉理论已应用于文档相关性、次序效应等核心问题的研究中,旨在建模用户认知引起的类量子干涉现象.文中从语言理解的需求出发,利用量子理论的数学工具分析语义组合过程中存在的语义演化现象,提出融合量子干涉信息的双重特征文本表示模型(Quantum Interference Based Duet-Feature Text Representation Model, QDTM).模型以约化密度矩阵为语言表示的核心组件,有效建模维度级别的语义干涉信息.在此基础上,构建捕获全局特征信息与局部特征信息的模型结构,满足语言理解过程中不同粒度的语义特征需求.在文本分类数据集和问答数据集上的实验表明,QDTM的性能优于量子启发的语言模型和神经网络文本匹配模型.
About Author:
GAO Hui, Ph.D. candidate. Her research interests include quantum semantic understanding and evaluation of large language mo-dels.
ZHANG Jing, Ph.D. candidate. Her research interests include large model compre-ssion and acceleration, and few⁃shot learning based on large models.
In the field of information retrieval, quantum interference theory is applied to the study of core issues such as document relevance and order effects, aiming at modeling quantum-like interference phenomena caused by user cognition. Based on the language understanding task, the mathematical tools of quantum theory are utilized to analyze the semantic evolution phenomenon in the semantic combination process. A quantum interference based duet-feature text representation model(QDTM) is proposed. The reduced density matrix is taken as the core component of language representation to effectively model semantic interference information at the dimension-level. On this basis, a model structure is constructed to capture global and local feature information, meeting the semantic feature requirements of different granularities in the language understanding process. Experiments on text classification datasets and question and answering datasets show that QDTM outperforms quantum-inspired language models and neural network text matching models.
智能化场景的多样性进一步提高语言理解的难度, 自然语言处理任务也要求模型捕获更复杂的语义交互信息, 分析由于语义间相互影响而产生的内在演化逻辑[1, 2].在文本匹配任务中, 模型通常使用注意力机制计算单词之间的相关性得分, 以此建模单词级别的全局语义交互信息[3].然而, 上述语义交互方法局限于捕获单词级别的交互信息, 忽略维度级别的特征交互对语义理解带来的影响.事实上, 维度级别的语义交互现象广泛存在于语义组合中, 不同维度间的语义相互影响, 导致单词语义演化的多样性.
在人类理解语言的过程中, 单词通常暗含多种不同含义, 称为语义[4].在由词到句的组合过程中, 句子语义并非单词语义的机械性叠加, 语义间的相互影响会引发单词中某些语义的增强(或减弱)效应, 导致语义演化.分析预训练的单词表示及其近义词在二维坐标系下的分布, 可以反映单词在不同词组场景下语义的变化.以“ 苹果公司” 词组为例, 通过相似度分析已有的词向量表示后发现:“ 苹果” 与表示食物的词(“ 可乐” 、“ 冰淇淋” 等)相似度较高, 同时与少量的电子产品(“ eBay” 、“ 小米” )也有语义相似性; “ 公司” 一词与各种表示企业组织形式的词(“ 控股公司” 、“ 合资企业” 等)相关; “ 苹果公司” 与各类科技公司的位置更相近.这说明, 在组成词组“ 苹果公司” 的过程中, “ 苹果” 一词中表示电子产品的语义得到加强, 而表示食物的语义减弱, 语义由“ 食物或电子产品” 演化为较单一的“ 电子产品” .
近年来, 研究人员开始基于量子理论的微观视角研究语义理解、信息检索等与人类紧密相关场景, 相关研究成果在语言建模、文档检索等以语义理解为核心的任务中表现优异[5, 6].Sordoni等[7]率先提出QLM(Quantum Language Model), 用于建模文本中存在的词项依赖信息.该工作第一次从量子理论的角度建模文本间的词项依赖, 提出基于量子理论的词项表示以及模型训练的技术, 并应用于信息检索任务中.相比传统的词项依赖关系建模方法, QLM不需要扩展表示空间的维度, 也不需要耗费额外的计算资源, 就可有效表示依赖关系.首先, 在QLM中, 使用密度矩阵表示包含若干量子事件的文档; 然后, 定义将独立单词和词项依赖映射到量子基本事件的一般方法; 最后, 采用极大似然估计法更新密度矩阵的参数, 使用VN(Von Neumann)熵进行文档相关性函数计算.
Zhang等[8]进一步将量子语言模型扩展到神经网络的范畴, 提出NNQLM(Neural Network Based Quantum-Like Language Model), 将QLM拓展到神经网络领域, 并在问答任务中获得良好性能.首先, 选取具有全局语义信息的预训练词向量表示单词, 并使用密度矩阵表示单词以及问答句子的概率分布(表示单词的密度矩阵为纯态, 表示句子的密度矩阵为混合态).然后, 基于问句、答句的密度矩阵表示, 建立两个密度矩阵之间相互作用的联合表示.最后, 基于上述架构提出两个不同的问答模型:NNQLM-I和NNQLM-II.NNQLM-I采用迹内积计算问题与答案之间的语义重叠, 而NNQLM-II使用二维卷积网络学习问答的相似性表示, 特征提取之后通过全连接层获得最后的预测得分.
此后, 量子语言建模工作开始兴起[9, 10, 11].值得注意的是, Jiang等[12]受量子干涉的启发, 提出QINM(Quantum Interference Inspired Neural Matching Mo-del), 并应用于检索任务.上述研究表明, 量子理论与神经网络结合的工作以人类认知机制为出发点, 分析语言的内在逻辑, 有助于模型捕获传统语言模型忽略的细粒度语义交互信息[11].
近年来, 量子语言模型不断发展.一方面, 量子复值神经网络[13]、量子测量[14]等数学框架为语言编码与语义理解提供更新的视角; 另一方面, 基于量子张量网络的模型压缩技术[15]也为大型预训练语言模型的发展和应用带来新的可行性方案, 在模型参数、训练时间、计算复杂度等方面均有显著优化.关于更多量子语言模型的发展可参考文献[16]~文献[18].量子语言建模领域尽管取得一些进展, 但忽视语义演化在复杂语义建模过程中的重要性.在处理跨领域语义、时序文本时, 动态语义信息的建模确实可能会导致模型在处理多义词、歧义词和隐含语义等方面表现不佳.
本文基于量子理论, 推导语义组合过程中产生的类量子干涉项, 提出融合量子干涉信息的双重特征文本表示模型(Quantum Interference Based Duet-Feature Text Representation Model, QDTM).首先, 将词组视为量子复合系统, 单词视为量子子系统, 使用N阶约化密度矩阵(Reduced Density Matrix, RDM)表示复合词组系统中某一单词子系统的文本特征, 该文本表示模块在维度层面上有效构建语义组合带来的干涉项语义匹配信息.然后, 构造双重特征匹配模块, 其中, 局部匹配特征来自N阶RDM的主对角元素, 全局匹配特征来自经过卷积神经网络(Convo-lutional Neural Network, CNN)提取后的文本特征.最后, 通过全连接层得到最终的预测结果.相比神经网络匹配模型和量子启发的语言模型, QDTM在问答数据集和文本分类数据集上均取得较优性能.
在量子理论中, 每个系统可表示为希尔伯特空间中的单位列向量, 在本文中称为状态空间中的状态向量.在不引入观测的前提下, 一个系统可能同时处于多个状态, 由状态空间中多个单位正交的基态向量叠加表示:
$ \boldsymbol{u}=\sum_{i=0}^{m} \alpha_{i} \boldsymbol{e}_{i}$
其中:ei表示基态向量, 第i个位置为1, 其它位置为0; α i表示第i个基态向量的概率振幅, 满足
$ \sum_{i=0}^{m}\left|\alpha_{i}\right|^{2}=1$
系统的外积运算表示为uuT, 内积运算表示为uTu, 符合向量的运算规则.给定
u=[1 2]T, v=[3 4]T,
张量乘积表示为
u$\otimes$v=
密度矩阵是描述量子系统的另一种方式, 非对角元素可表示基态向量之间的相互作用.如果当前量子系统处在第i个系统φ i中的概率为pi, 密度矩阵定义为
ρ =
则密度矩阵是迹为1的正半定算子.当tr(ρ 2)=1时, 密度矩阵表示纯态, 当tr(ρ 2)< 1时, 密度矩阵表示混合态.
量子复合系统是指由两个及以上子系统组成的孤立系统, 复合系统的状态向量和状态空间分别表示为子系统的状态向量和状态空间的张量积形式.对于由n个子系统组成的复合系统Ψ , 通过状态空间Hi中的状态向量ψ i表示第i个子系统, 则复合系统Ψ 的状态向量为:
Ψ =ψ 1$\otimes$ψ 2$\otimes$…$\otimes$ψ n.
为了减少计算量, 通常采用RDM描述某一子系统的状态, 这一过程与复合系统的张量积过程相反, 通过偏迹运算获得.对于由子系统A和子系统B构成的复合系统ρ AB, 子系统A的RDM为:
ρ A=trB(ρ AB)=trB(a1
其中, trB(· )表示子系统B的偏迹操作, a1、a2表示子系统A的基态向量, b1、b2表示子系统B的基态向量.
本节采用量子测量分析文本匹配的一般过程, 推导语义组合带来的类量子干涉项[15].首先, 神经网络模型中文本匹配的本质是求解匹配概率.对于匹配文本q和查询文本s, 过程可形式化为条件概率P(q|s).
其次, 将文本匹配形式化为二维实数希尔伯特空间中对系统的观测过程.如图1(a)所示, 向量q表示匹配文本的状态向量, 向量s表示查询文本的状态向量, 由两个基态语义向量w1和w2的叠加态表示:
s=α w1+β w2,
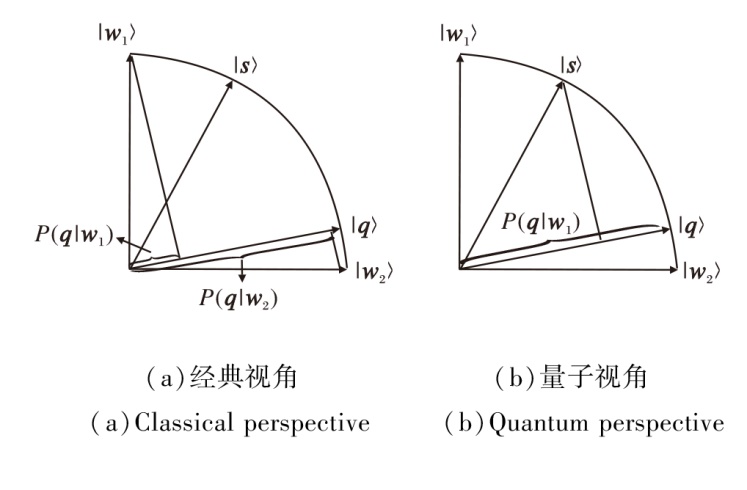 | 图1 基于投影测量的文本匹配过程Fig.1 Text matching process based on projection measurement |
其中α 和β 分别表示w1和w2的概率幅度.概率幅度的平方对应单词叠加态塌缩在某一语义基态向量的概率.
若将匹配文本看作测量算子, 可通过观测匹配文本对查询文本的测量结果, 即条件概率值P(q|s)获得塌缩的过程.通过投影测量形式化这一过程, 推导语义组合过程中的量子干涉项信息.
由匹配文本q构成的投影算子通过密度矩阵
Mq=qqT
进行表示.组成查询文本s的单词w1和w2塌缩在匹配文本q上的概率可通过投影测量获得, 即
$ \begin{array}{l} P\left(\boldsymbol{q} \mid \boldsymbol{w}_{1}\right)=\boldsymbol{w}_{1}^{\mathrm{T}} \boldsymbol{M}_{q} \boldsymbol{w}_{1}, \\ P\left(\boldsymbol{q} \mid \boldsymbol{w}_{2}\right)=\boldsymbol{w}_{2}^{\mathrm{T}} \boldsymbol{M}_{q} \boldsymbol{w}_{2} . \end{array}$
如果按照经典概率的方式将词组语义看作单词语义进行机械叠加, 不考虑单词组合过程中的语义组合变化(即单词之间相互独立), 文本匹配过程可表示为
$ \begin{aligned} P(\boldsymbol{q} \mid \boldsymbol{s})= & \alpha^{2} P\left(\boldsymbol{q} \mid \boldsymbol{w}_{1}\right)+\beta^{2} P\left(\boldsymbol{q} \mid \boldsymbol{w}_{2}\right)= \\ & \alpha^{2} \boldsymbol{w}_{1}^{\mathrm{T}} \boldsymbol{M}_{q} \boldsymbol{w}_{1}+\beta^{2} \boldsymbol{w}_{2}^{\mathrm{T}} \boldsymbol{M}_{q} \boldsymbol{w}_{2}, \end{aligned}$(1)
其中α 2和β 2对应于经典概率中发生s的前提下发生w1和w2的事件概率.这一条件概率在图1(a)中可表示为将两部分投影结果直接相加.
这种机械性的组合方式忽视由于单词组合带来的语义干涉信息.在测量过程中, 需将词组看作一个整体, 并直接将查询文本s投影到待匹配文本q上(参考图1(b)的投影过程), 则式(1)优化为
$ \begin{array}{l} P^{\prime}(\boldsymbol{q} \mid \boldsymbol{s})= \\ P\left(\boldsymbol{q} \mid \alpha \boldsymbol{w}_{1}+\beta \boldsymbol{w}_{2}\right)= \\ \left(\alpha \boldsymbol{w}_{1}+\beta \boldsymbol{w}_{2}\right)^{\mathrm{T}} \boldsymbol{M}_{q}\left(\alpha \boldsymbol{w}_{1}+\beta \boldsymbol{w}_{2}\right)= \\ \alpha^{2} \boldsymbol{w}_{1}^{\mathrm{T}} \boldsymbol{M}_{q} \boldsymbol{w}_{1}+\beta^{2} \boldsymbol{w}_{2}^{\mathrm{T}} \boldsymbol{M}_{q} \boldsymbol{w}_{2}+\alpha \beta\left(\boldsymbol{w}_{1}^{\mathrm{T}} \boldsymbol{M}_{q} \boldsymbol{w}_{2}+\boldsymbol{w}_{2}^{\mathrm{T}} \boldsymbol{M}_{q} \boldsymbol{w}_{1}\right)= \\ P(\boldsymbol{q} \mid \boldsymbol{s})+\underbrace{2 \alpha \beta \boldsymbol{w}_{1}^{\mathrm{T}} \boldsymbol{M}_{q} \boldsymbol{w}_{2}}_{\text {干濒 }} . \end{array}$
相比式(1), 上式中推导出类量子干涉项, 表达从单词到词组的过程中由于不同维度语义交互带来的额外类量子干涉信息.这一信息会对文本匹配过程中的语义匹配产生影响, 需要在模型设计中充分考虑这类语义信息.
在量子概率空间下进行语义建模具有一些独特的优势和必要性.首先, 量子概率空间是经典概率的推广, 希尔伯特空间下常通过量子叠加和量子纠缠等操作基本远离词语和文本之间的复杂语义关系, 可更全面表达词语之间的相互关联, 提高模型对语义信息的理解能力.其次, 量子干涉理论提供一种新的方式以处理特征之间的相互作用, 有助于提高模型的泛化能力和鲁棒性, 可解决随着任务语义复杂性增强, 建模空间指数级增大的问题.此外, 量子概率空间还具有并行计算的能力, 可加速模型的训练和推理过程.上述特性有望为自然语言处理领域带来新的突破和进展.
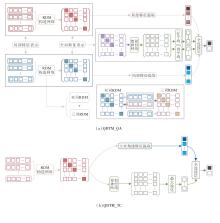
本节提出融合量子干涉信息的双重特征文本表示模型(QDTM).QDTM主要包括3部分:基于RDM的局部表示、联合文本对的全局表示、双重特征提取与融合.最后, 提出适用于问答任务和文本任务的模型结构QDTM_QA(QDTM for Question & Answer Task)和QDTM_TC(QDTM for Text Classification Task).
模型输入文本匹配对, 由预先训练的标准化词嵌入进行归一化处理, 然后进行表示.查询文本表示为向量序列S={s1, s2, …, sm}, si表示S的第i项词向量; 匹配文本表示为向量序列Q={q1, q2, …, qn}, qj表示Q的第j项词向量.
在文本匹配中, 将词组作为复合系统, 并将复合系统分成两组量子子系统A和B, 状态向量表示为ψ a和ψ b, 则复合系统可表示为
ψ =ψ a$\otimes$ψ b,
其中, $\otimes$表示张量积运算, 用于建模单词嵌入不同维度间的相互作用, 并捕获所有的语义组合特征.
从词组出发对单词的概率分布进行建模, 技术上通过偏迹操作获得RDM.首先, 以查询文本S为例, 讨论基于两个词形成量子复合系统的情况, 在此基础上可获得1阶RDM(1-Order RDM, 1-RDM).为了求解子系统A的RDM, 需要在复合系统中进行偏迹操作:
其中, sa表示子系统A的基态向量, sb表示子系统B的基态向量, tr(sb
其次, 讨论由三个词组成的量子复合系统.前两个单词视为量子子系统A, 第三个单词视为量子子系统B.在这种情况下,
其中
$ \begin{array}{l} \boldsymbol{s}_{a_{1}}=\left\{\omega_{1}, \omega_{2}, \cdots, \omega_{d}\right\}, \\ \boldsymbol{s}_{a_{2}}=\left\{\tau_{1}, \tau_{2}, \cdots, \tau_{d}\right\}, \end{array}$
将
$ \boldsymbol{S}_{a_{1}} \boldsymbol{s}_{a_{2}}^{\mathrm{T}}=\left[\begin{array}{cccc} \omega_{1} \tau_{1} & \omega_{1} \tau_{2} & \cdots & \omega_{1} \tau_{d} \\ \omega_{2} \tau_{1} & \omega_{2} \tau_{2} & \cdots & \omega_{2} \tau_{d} \\ \vdots & \vdots & & \vdots \\ \omega_{d} \tau_{1} & \omega_{d} \tau_{2} & \cdots & \omega_{d} \tau_{d} \end{array}\right]$
其中, 主对角元素ω iτ j(i=j)表示经典概率中的语义相似度匹配特征(余弦相似度), 非主对角元素ω iτ j(i≠ j)表示不同单词语义基态向量中的干涉项信息.
计算1-RDM和2-RDM的和作为最终的RDM:
ρ S=
通过式(2), 可获得查询文本和匹配文本的RDM表示ρ S和ρ Q.
将ρ S和ρ Q相乘, 得到一个二维联合概率表示, 用于构造全局特征文本对之间的信息.计算过程如下:
$ \begin{aligned} \boldsymbol{G}_{S Q}= & \boldsymbol{\rho}_{S} \cdot \boldsymbol{\rho}_{Q}= \\ & \left(\sum_{i=1}^{m} \boldsymbol{s}_{a_{i}} \boldsymbol{s}_{a_{i}}^{\mathrm{T}}+\sum_{i=1}^{m-1} \sum_{j=2}^{m} \boldsymbol{s}_{a_{i}} \boldsymbol{s}_{a_{j}}^{\mathrm{T}}\right) \cdot \\ & \left(\sum_{i=1}^{n} \boldsymbol{q}_{a_{i}} \boldsymbol{q}_{a_{i}}^{\mathrm{T}}+\sum_{i=1}^{n-1} \sum_{j=2}^{n} \boldsymbol{q}_{a_{i}} \boldsymbol{q}_{a_{j}}^{\mathrm{T}}\right)= \\ & \boldsymbol{E}_{S Q}+\boldsymbol{I}_{S}+\boldsymbol{I}_{Q}+\boldsymbol{I}_{S Q}, \end{aligned}$
其中· 表示矩阵的乘法运算.ESQ表示当前主流匹配模型中使用的经典理论的相似度计算评分:
$\boldsymbol{E}_{S Q}=\left(\sum_{i=1}^{m} \boldsymbol{s}_{a_{i}} \boldsymbol{s}_{a_{i}}^{\mathrm{T}}\right) \cdot\left(\sum_{i=1}^{n} \boldsymbol{q}_{a_{i}} \boldsymbol{q}_{a_{i}}^{\mathrm{T}}\right) .$
IS表示查询文本s内部的语义干涉信息与匹配单词经典特征信息的交互:
$\boldsymbol{I}_{S}=\left(\sum_{i=1}^{m-1} \sum_{j=2}^{m} \boldsymbol{s}_{a_{i}} \boldsymbol{S}_{a_{j}}^{\mathrm{T}}\right) \cdot\left(\sum_{i=1}^{n} \boldsymbol{q}_{a_{i}} \boldsymbol{q}_{a_{i}}^{\mathrm{T}}\right)$
IQ表示匹配文本q内部的语义干涉信息与查询单词经典特征信息的交互:
$\boldsymbol{I}_{Q}=\left(\sum_{i=1}^{m} \boldsymbol{s}_{a_{i}} \boldsymbol{s}_{a_{i}}^{\mathrm{T}}\right) \cdot\left(\sum_{i=1}^{n-1} \sum_{j=2}^{n} \boldsymbol{q}_{a_{i}} \boldsymbol{q}_{a_{j}}^{\mathrm{T}}\right)$
ISQ表示查询文本s和匹配文本q之间语义干涉信息的交互特征:
$\boldsymbol{I}_{S Q}=\left(\sum_{i=1}^{m-1} \sum_{j=2}^{m} \boldsymbol{s}_{a_{i}} \boldsymbol{s}_{a_{j}}^{\mathrm{T}}\right) \cdot\left(\sum_{i=1}^{n-1} \sum_{j=2}^{n} \boldsymbol{q}_{a_{i}} \boldsymbol{q}_{a_{j}}^{\mathrm{T}}\right) .$
提取问答匹配对的联合概率分布特征会失去原始问句和答句的局部匹配特征, 因此本文提出双重特征表示融合全局特征和局部特征信息.
首先, 基于RDM提取局部特征表示.对于ρ S和ρ Q, 提取对角元素信息并和原始特征拼接, 得到查询文本和匹配文本的局部特征表示FLS和FLQ:
FLS=[stS; DS; ρ S], FLQ=[stQ; DQ; ρ Q], (3)
其中, st(· )表示计算密度矩阵的对角线元素的总和, D(· )表示主对角线元素组成的向量, [; ]表示拼接操作.
其次, 利用二维CNN提取全局特征信息GSQ, 通过池化层得到最终的全局特征向量FG.最后, 结合全局特征向量和局部特征向量, 得到双重特征向量:
F=[FG; FLS; FLQ].
在上式中, 由于局部特征提取的主对角线维度与CNN处理后的特征维度并不相同, 因此选择拼接操作融合局部特征与全局特征.
本文提出分别应用于问答任务和文本任务的模型架构(QDTM_QA和QDTM_TC), 核心均为RDM表示, 模型架构如图2所示.
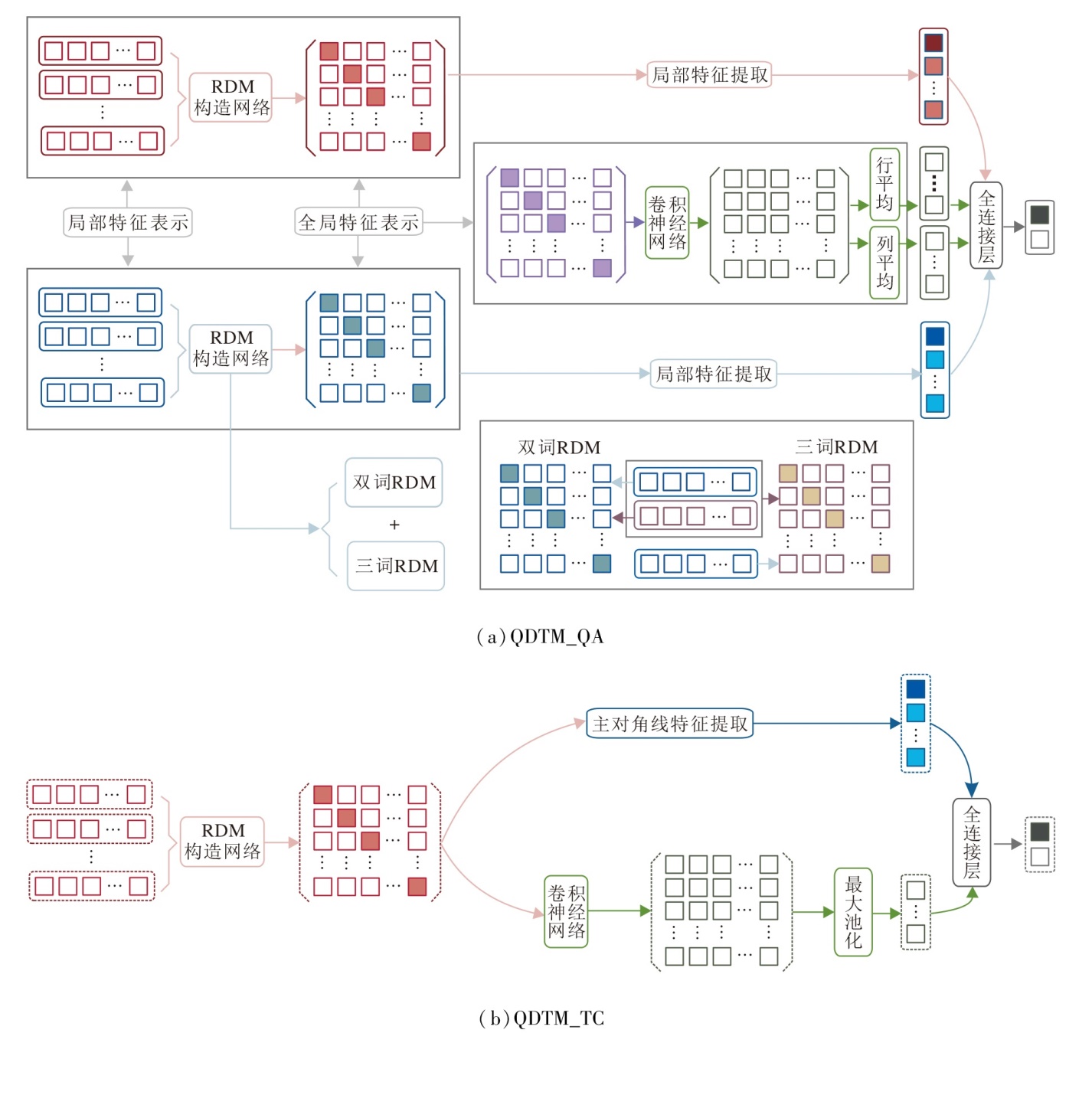 | 图2 QDTM架构图Fig.2 Architecture of QDTM |
QDTM_QA在相关性预测模块中, 由式(3)得到的双重特征表示通过全连接层获得二进制标签(0或1)的最终预测匹配得分:
Pi=Softmax(Wi× Fi+bi),
其中Wi和bi表示全连接层对应的可学习权值和偏差.在模型训练过程中, 使用交叉熵损失函数训练模型.
文本任务由于只包含单文本, 因此QDTM_TC只包含两个部分:基于RDM的局部特征表示模块, 双重特征提取和融合模块 (如图2(b)所示).由于联合表示模块的缺失, 模型的局部匹配信息来自文本RDM的主对角线之和stS与对角线元素组成的向量DS.全局语义信息来自于原始的RDM.最后, 得到的特征为:
F=[stS; DS; ρ S].
QDTM_TC的相关性预测与QDTM_QA相同.
对于文本任务, 本文选择MR[19]、CR[20]、SUBJ(
对于问答任务, 选择WikiQA[24]、TrecQA[25]数据集.WikiQA数据集是一个开放域的问答数据集, 数据全部来自微软的查询日志和维基百科.TrecQA数据集上数据均来自TREC-8至TREC-13中的问答数据集.
对于文本任务, 选择如下对比模型.
1)神经网络文本匹配模型:Transformer[3]、FastText[25]、文献[26]模型.
2)量子启发的语言模型:NNQLM-I[8]、NNQLM-II[8]、C-NNQLM-I(Complex-Valued Neural Network Based QLM-I)[13]、C-NNQLM-II(Complex-Valued Neu-ral Network Based QLM-II)[13]、QLM-EE(QLM with Entanglement Embedding)[27].
对于问答任务, 选择如下对比模型.
1)神经网络问答模型: 文献[28]模型、BLSTM(Bidirectional Long-Short Term Memory)[29].
2)量子启发语言模型:QLM[7]、QLM_T(QLM_Trace)[7]、NNQLM-I[8]、NNQLM-II[8]、QINM[12]、QLM-EE[27].
本文的模型均基于Python语言、Tensorflow 2.4.0框架构建, 部署于NVIDIA Tesla P40.实验中所有模型都使用50维全局向量词嵌入初始化输入部分, 在训练过程中单词嵌入保持不变, 以保证模型性能的稳定性.
在模型的全局特征提取层, 均使用一层二维卷积层与一层池化层的模型结构.在卷积层, 设置3个不同的卷积尺寸与个数; 在池化层, 选取最大池化方法.将3个卷积核的结果通过最大池化层后, 拼接并输入最后的全连接层.全连接层通过softmax获得最后的预测得分, 并通过argmax获得最后的文本分类结果.
在具体实验中, 设置L2正则化参数为0.000 1, 其余实验参数设置详见表1.
| 表1 实验参数设置 Table 1 Experimental parameter settings |
各模型在文本任务上的准确率对比如表2所示, 表中黑体数字表示最优值.除了QLM-EE以外, 其它实验结果均采用原论文数据, 所有结果均在30维词向量的基础上获得.由表可见, QDTM_TC的性能在MR、CR、SUBJ、MPQA数据集上均超越Fast-Text、文献[26]模型和Transformer等神经网络文本匹配模型, 这表明RDM可有效建模文本中的类量子语义干涉信息, 在局部特征提取方面的性能高于注意力机制、CNN等神经网络提取模块.相比量子语言模型NNQLM-I和NNQLM-II, QDTM_TC性能更优, 这表明本文提出的RDM模块可提取不同语义维度的量子干涉信息, 这种交互而非叠加的语义特征捕获方式优于基于密度矩阵特征提取模块.
| 表2 面向文本任务的QDTM在文本分类数据集上的准确率对比 Table 2 Accuracy comparison of text task-oriented QDTM on text classification datasets |
各模型在问答任务上的平均精度均值(Mean Average Precision, MAP)和平均倒数排名(Mean Reciprocal Rank, MRR)对比如表3所示, 表中黑体数字表示最优值.由表可见, QDTM_QA的性能在WikiQA、TrecQA数据集上都优于经典的神经网络匹配模型(文献[28]模型和BLSTM), 这表明量子启发文本表示和联合概率表示对于问答任务是有效的.在WikiQA数据集上, QDTM_QA性能也优于量子启发语言模型QLM、QLM_T、NNQLM-I、NNQLM-II, 这表明本文提出的双重特征提取模块可改进模型对于局部特征提取不足的问题, 比基于密度矩阵的文本表示更有效.其次, 在TrecQA数据集上, QDTM_QA未达到最佳性能, 劣于NNQLM-II, 这表明由于数据集的差异, 基于RDM的文本表示可能存在冗余信息, 导致实验结果不佳, 有待后续优化.
| 表3 面向问答任务的QDTM在问答数据集上的性能对比 Table 3 Performance comparison of QDTM for Q& A task on Q& A datasets |
为了验证模型中RDM文本表示和双重特征架构的有效性, 基于问答任务进行QDTM_QA的消融实验.定义QDTM_QA_D(QDTM_QA with Density Matrix)表示QDTM_QA使用密度矩阵的文本表示方法, QDTM_QA_G(QDTM_QA with Global Fea-ture)表示QDTM_QA只使用全局特征表示, 忽略局部特征表示.
在问答任务上的消融实验结果如表4所示, 表中黑体数字表示最优值.从结果可以看出, QDTM_QA性能高于QDTM_QA_G, 表明在问答任务中应同时考虑全局特征和局部特征, 确保模型性能.同时, QDTM_QA性能也高于QDTM_QA_D, RDM的文本表示方法可全面捕获问答任务中语义交互信息, 有效建模类量子干涉项.QDTM_QA_G和QDTM_QA_D在WikiQA数据集上的性能下降快于在TrecQA数据集上, 说明在小规模数据集上更依赖有效、多层次的语义特征捕获方式.
| 表4 各模型在问答数据集上的消融实验结果 Table 4 Results of ablation experiments of different models on QA datasets |
本文系统分析词组中单词语义干涉在预训练词向量中的表现, 同时基于量子测量理论分析这一现象, 推导文本匹配过程中的量子干涉项.该干涉项是语义干涉形成的额外信息, 而该信息无法在经典概率中进行建模.因此, 本文提出融合量子干涉信息的双重特征文本表示模型(QDTM), 基于量子复合系统的理论, 使用约化密度矩阵建模单词间的语义干涉信息, 在理论上基于这一结构捕捉类似于N-gram的语义非线性组合信息.进一步, 根据任务的不同属性, 提出面向问答任务的QDTM_QA和基于文本任务的QDTM_TC, 并进行实验验证, 证实模型的有效性.同时, 消融实验以及模型评价过程也表明QDTM中各组件及模型架构在性能提升方面的优越性.
今后一方面将深入研究基于RDM建模的优化技术, 降低信息冗余.一种可行的方法是基于施密特分解技术, 结合量子纠缠理论筛选更重要的特征信息建模.另一方面, 探索神经网络下的轻量化量子建模技术, 设计适用于神经网络的量子模型, 以便在计算和存储资源有限的情况下实现高效的量子建模.这些模型具有较低的参数量和计算复杂度, 同时保持较高的模型性能和泛化能力.
本文责任编委 林鸿飞
Recommended by Associate Editor LIN Hongfei
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|