


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于特征聚合和传播网络的图像超分辨率重建
[薄阳瑜1  , 刘晓晶
, 刘晓晶1 , 武永亮1 , 王学军1 ]
, 刘晓晶, 武永亮, 王学军]
|
|



作者简介:

薄阳瑜,硕士研究生,主要研究方向为图像处理、深度学习等.E-mail:1202110001@stdu.edu.cn.

刘晓晶,硕士研究生,主要研究方向为图像处理、深度学习等.E-mail:liuxiaojing0510@163.com.

武永亮,博士,讲师,主要研究方向为机器学习、自然语言处理等.E-mail:wuyongliang@stdu.edu.cn.
基于深度学习的图像超分辨率重建通过网络加深提升图像重建性能,但复杂网络会导致参数量急剧增加,限制其在资源受限设备上的应用.针对此问题,文中提出基于特征聚合和传播网络的图像超分辨率重建方法,采用逐步提取融合特征的方式获取图像丰富的内部信息.首先,提出上下文交互注意力模块,使网络学习到特征图丰富的上下文信息,提高特征的利用率.然后,设计多维注意力增强模块,提高网络对关键特征的判别能力,分别在通道和空间两个维度提取高频信息.最后,提出特征聚合传播模块,有效聚合深层细节信息,去除冗余信息,并促进有效信息在网络中传播.在Set5、Set14、BSD100、Urban100等基准数据集上的测试实验表明,文中方法性能较优,重建后的图像细节纹理较清晰.
About Author:
BO Yangyu, Master student. Her research interests include image processing and deep learning.
LIU Xiaojing, Master student. Her research interests include image processing and deep learning.
WU Yongliang, Ph.D., lecturer. His research interests include machine learning and natural language processing.
Image super-resolution reconstruction based on deep learning improves the image reconstruction performance by deepening the network. However, its application on resource-limited devices is limited due to the sharp increase in the number of parameters caused by complex networks. To solve this problem, an image super-resolution reconstruction method based on feature aggregation and propagation network is proposed, enriching internal information of images by extracting and fusing features step by step. Firstly, a contextual interaction attention block is proposed to enable the network to learn the rich contextual information of feature maps as well as improve the utilization of features. Then, a multi-dimensional attention enhancement block is designed to improve the network's ability to discriminate the key features and extract high-frequency information in channel dimension and spatial dimension, respectively. Finally, a feature aggregation and propagation block is proposed to effectively aggregate deep detail information, remove redundant information and promote the propagation of effective information in the network. Experimental results on Set5,Set14,BSD100 and Urban100 datasets demonstrate the superiority of the proposed method with clearer details of reconstructed images.
图像超分辨率(Super-Resolution, SR)重建[1]是计算机视觉领域中提高图像分辨率的重要处理方法之一, 旨在将低分辨率(Low-Resolution, LR)图像转换为高分辨率(High-Resolution, HR)图像, 在医学成像[2]、图像识别[3]等领域中具有重要的应用价值.
早期的SR方法[4, 5, 6]可分为三种:基于插值的超分辨率重建方法、基于退化模型的超分辨率重建方法和基于学习的超分辨率重建方法.尽管这些方法的重建效果在一定程度上得到提升, 但是在高质量信息获取方面仍存在一定的局限性, 限制图像的重建效果.
近年来, 深度学习的迅速发展使研究人员开始使用卷积神经网络(Convolutional Neural Networks, CNN)解决SR问题[7, 8].Dong等[9]提出SRCNN(Su-per-Resolution CNN), 首次使用CNN学习LR图像到HR图像的端到端映射, 但由于网络较浅, 重建效果仍有待提升.随后, 研究者通过增加网络的深度和宽度以提高SR性能.Lim等[10]提出EDSR(En-hanced Deep Super-Resolution Network), 参数量高达43 M.Zhang等[11]提出RCAN(Very Deep Residual Cha-nnel Attention Networks), 使用残差块叠加的方式, 加深网络结构, 在网络性能提升的同时参数量大幅增加.尽管上述方法通过加深网络的方式扩大网络感受野, 但提升网络性能的同时也占用大量内存, 增加计算的复杂度.
针对上述问题, 研究人员逐渐致力于在模型性能和复杂度之间建立平衡, 提出一些更高效的SR方法.Kim等[12]结合递归学习和全局残差学习, 提出DRCN(Deeply-Recursive Convolutional Network), 在简化训练过程的同时提升SR重建效果.Hui等[13]提出IDN(Information Distillation Network), 采用蒸馏机制提取图像信息, 同时保证网络的实时性和有效性.之后, Hui等[14]又提出IMDN(Lightweight Information Multi-distillation Network), 基于通道进行特征蒸馏, 并根据特征的重要性融合提取到的不同特征.Kong等[15]提出RLFN(Residual Local Feature Network), 采用ESA(Enhanced Spatial Attention), 加快网络的收敛速度.基于自校准卷积, Zhao等[16]提出PAN(Pixel Attention Network), 使网络关注到更精细的细节信息.Chen等[17]提出A2N(Attention in Attention Network), 构建非注意力分支和耦合注意力分支, 提高网络的特征表达能力.Zhang等[18]提出HIT-Net(Heat Transfer-Inspired Network), 利用二阶混合差分方程重新设计残差网络, 充分利用多个分支信息, 在保证模型实时性的同时实现更精准的重建.
基于上述情况, 本文在充分获取图像内部高频信息的基础上, 以网络的连接方式、不同状态信息融合方式、图像信息细化三个方面为出发点, 提出基于特征聚合和传播网络(Feature Aggregation and Pro-pagation Network, FAPN)的图像超分辨率重建方法, 在复杂度和重建性能两方面达到较好的平衡.首先, 设计上下文交互注意力模块(Contextual Interac-tion Attention Block, CIAB)和多维注意力增强模块(Multi-dimensional Attention Enhancement Block, MAEB), 丰富网络的特征表示.CIAB结合空洞卷积与门通道注意力机制(Gated Channel Transforma-tion, GCT)[19], 获取网络不同尺度的上下文信息.MAEB结合通道注意力机制(Channel Attention, CA)[20]与空间注意力机制(Spatial Attention, SA)[20], 使网络更关注图像复杂的空间结构信息, 并强调通道特征包含的重要信息.此外, MAEB还包含一个特征细化单元(Feature Refinement Unit, FRU), 增强提取的多维信息.最后, 提出特征聚合传播模块(Fea-ture Aggregation and Propagation Block, FAPB), 自适应聚合不同状态的特征信息, 再通过生成可训练的权重的方式筛选初步聚合的信息, 使网络根据特征重要性选择关键的特征, 以此提高FAPN对高频细节特征的鉴别能力, 实现在网络中传播更精准的信息的功能.
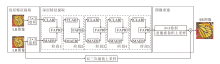
本文提出基于特征聚合和传播网络(FAPN)的图像超分辨率重建方法, 总体架构如图1所示.
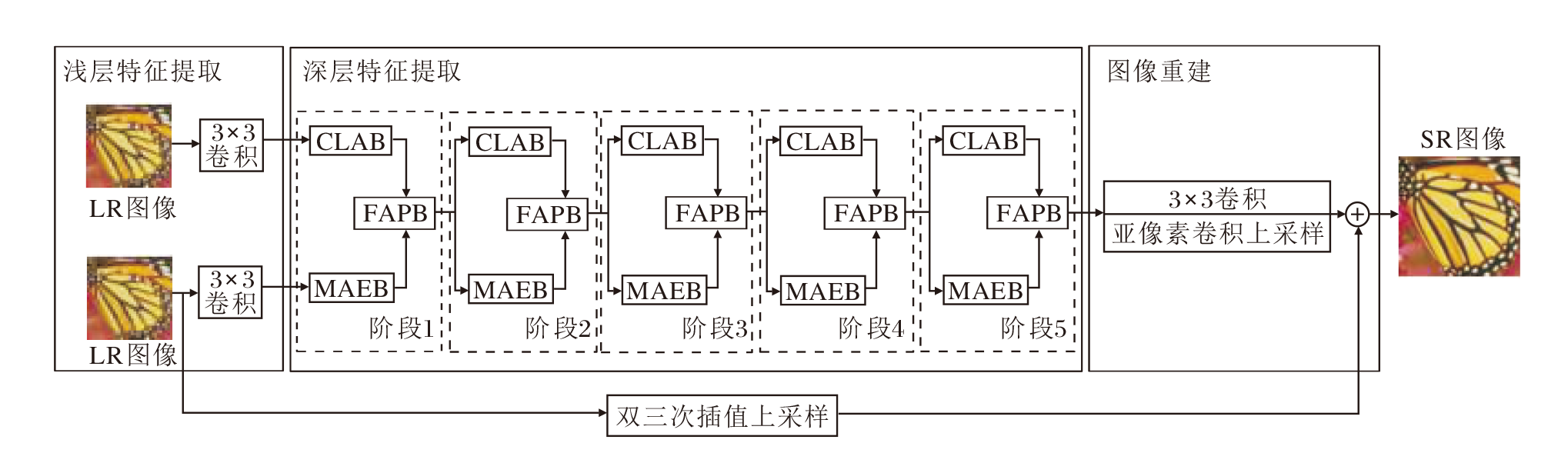 | 图1 FAPN整体架构Fig.1 Overall architecture of FAPN |
给定的低分辨率LR图像ILR, 由2个3× 3卷积进行特征提取后, 得到浅层特征F'0和F″0:
F'0=f3× 3(ILR), F″0=f3× 3(ILR),
其中f3× 3(· )表示3× 3卷积函数.
随后, F'0和F″0进入深度特征提取的第1个阶段, 由CIAB、MAEB、FAPB处理后得到深层特征F1.F1再逐步进入深层特征提取模块剩余的每个阶段, 以此提取图像丰富的深层特征, 第n个阶段的输出特征:
${{F}_{n}}=f_{\text{stage}}^{n}~({{F}_{n}}_{-1}), n=2, 3, \ldots , N$,
其中, $f_{\text{stage}}^{n}(\cdot )$表示第n个阶段函数, Fn-1表示第n-1个阶段的输出特征.
最后, 深层特征Fn进入图像重建阶段, 获得精细的高分辨率图像:
ISR=fBicubic(ILR)+fPS( f3× 3(Fn)),
其中, fPS(· )表示亚像素卷积上采样, f3× 3(· )表示 3× 3卷积函数, fBicubic(· )表示双三次插值上采样.
为了使FAPN更充分地获取不同区域的上下文信息, 提高特征表达能力, 本文提出上下文交互注意力模块(CIAB), 详细结构如图2所示.
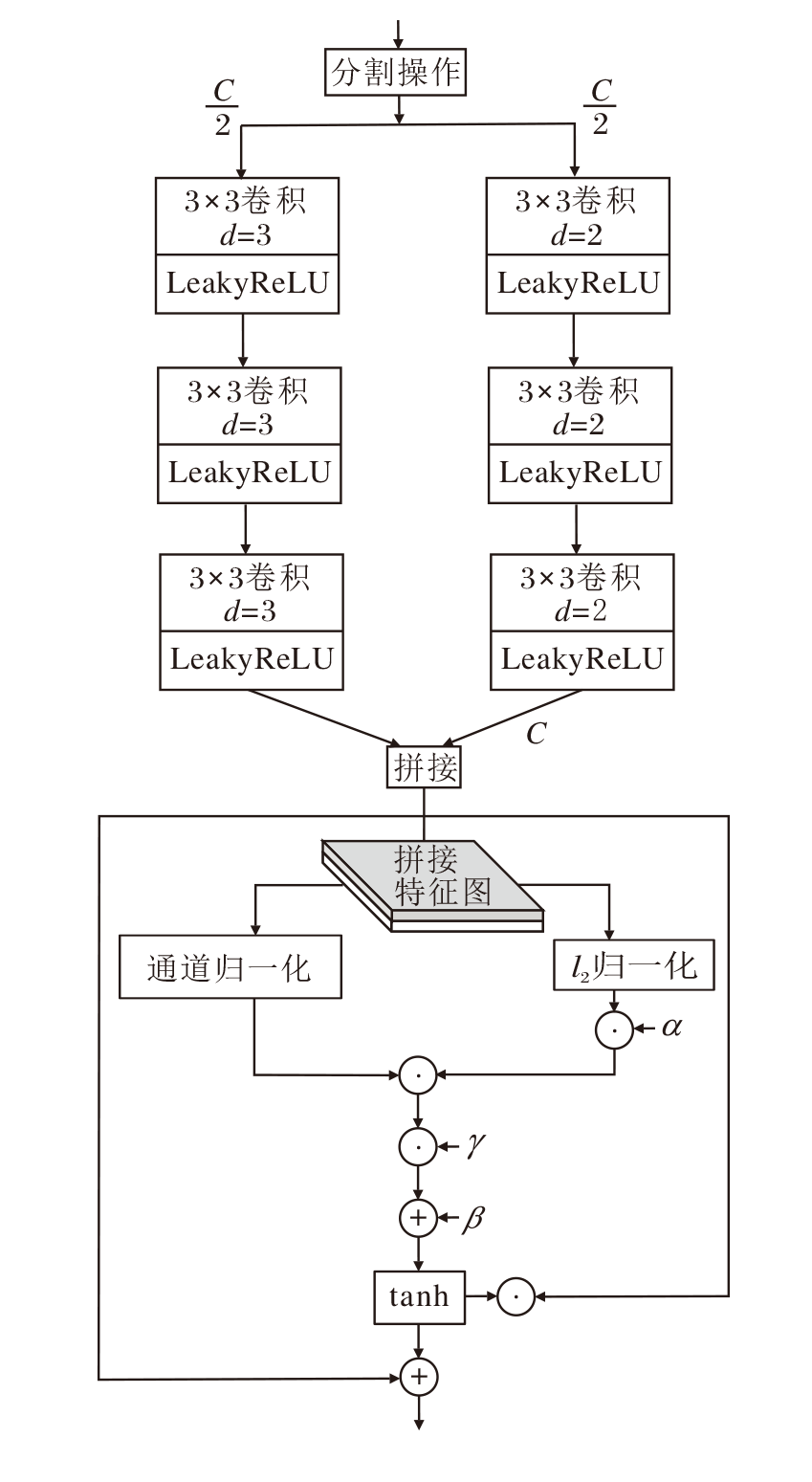 | 图2 CIAB结构图Fig.2 Architecture of CIAB |
首先, 基于空洞卷积, 秉承不增加额外参数量的情况下有效扩大网络感受野的原则, 构建一个双分支结构, 采用不同扩张率的空洞卷积获取图像内部不同尺度的信息分量.如图2所示, 本文首先基于通道维度将输入特征划分成相等的两部分, 一个分支采用扩张率为2的3× 3空洞卷积, 另一个分支采用扩张率为3的3× 3空洞卷积, 2个分支的感受野分别为5× 5和7× 7, 以此捕捉图像内部丰富的上下文信息.假定每个分支的输入特征通道数为C, 相比使用标准的5× 5卷积和7× 7卷积, 参数量减少603 K.再将2个分支提取到的特征进行拼接, 使网络获得完整的特征表示.具体过程如下:
FConcat=Concat(F', F″),
其中
$F'={{f}_{LR}}(f_{3\times 3}^{2}(\cdots {{f}_{LR}}(f_{3\times 3}^{2}({{F}_{1}}))))$,
$F''={{f}_{LR}}(f_{3\times 3}^{3}(\cdots {{f}_{LR}}(f_{3\times 3}^{3}({{F}_{2}}))))$,
$f_{3\times 3}^{i}(\cdot )$是扩张率为i的3× 3空洞卷积, fLR(· )表示LeakyReLU激活函数.
为了充分利用多尺度上下文信息, 进一步增强特征的表达能力, 本文引入门通道注意力机制(GCT)[19]取代普通卷积层, 采用规范化操作鼓励浅层通道特征之间相互合作、深层通道特征之间相互竞争.首先通过全局上下文算子α 嵌入已提取的全局上下文信息, 控制归一化前每个特征通道的权重, 经过归一化操作后由门控自适应算子γ 、 β 实现门控注意力机制, 根据归一化结果调整已提取的拼接特征FConcat, 得到CIAB的输出特征:
Fout=tanh(F2γ +β )FConcat+FConcat,
其中,
F2=Nc(F1),
${{F}_{1}}={{N}_{{{l}_{2}}}}({{F}_{\text{Concat}}})\alpha $,
α 、γ 、 β 表示可学习参数, α 有利于嵌入全局信息的自适应性, γ 、 β 用于控制激活门限; tanh(· )表示双曲正切S型函数, ${{N}_{{{l}_{2}}}}(\cdot )$表示l2归一化操作, Nc(· )表示通道归一化操作.
相比简单的多尺度特征提取模块, 本文不仅利用不同扩张率的空洞卷积, 捕获更丰富的上下文信息, 还引入GCT, 在不引入额外参数的情况下, 通过鼓励浅层通道特征之间相互合作、深层通道特征之间相互竞争, 进一步学习每个通道丰富的特征信息.
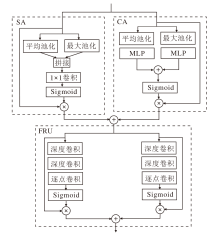
如图3所示, 多维注意力增强模块(MAEB)由通道注意力(CA)[20]、空间注意力(SA)[20]和特征细化单元(FRU)三部分构成.CA负责调整网络对通道信息的关注度, 引导网络聚焦于更可靠的信息.SA关注空间特征信息, 保证空间信息的完整性.通过并行的方式组合CA和SA, 提取多维特征信息, 同时增强网络对关键特征的判别能力.之后, 通过FRU有针对性地对已提取的多维特征再次进行权重学习, 提升信息提取的可靠性.
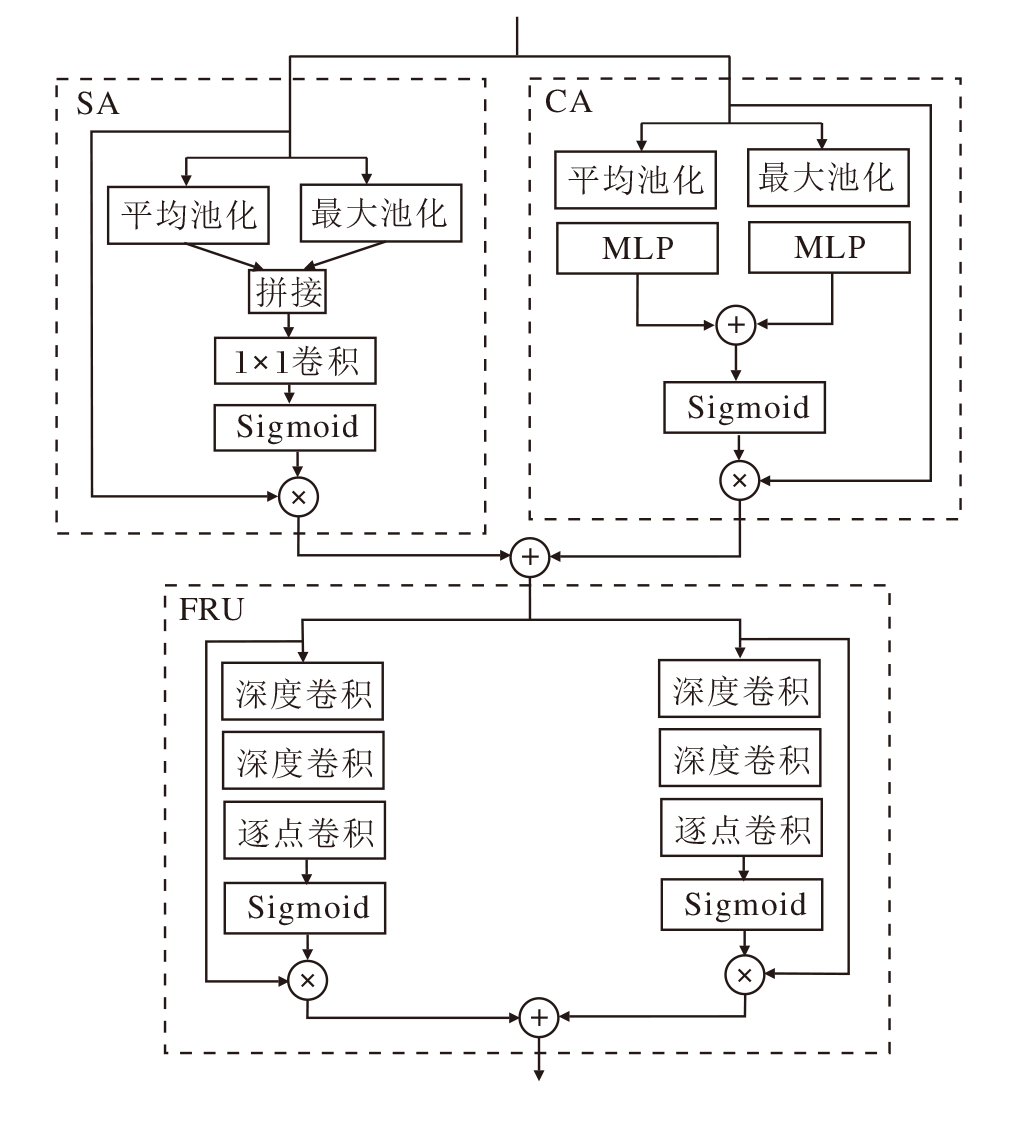 | 图3 MAEB结构图Fig.3 Architecture of MAEB |
上支路的CA模块首先通过全局平均池化和最大池化将特征图F转换为一维向量, 再送入MLP后相加, 使用Sigmoid函数获得注意力权重, 将其与特征F逐像素相乘后, 得到通道注意力加权后的特征:
FCA=δ (MLP(Avg(F))+MLP(Max(F)))· F,
其中, Avg(· )表示全局平均池化操作, Max(· )表示最大池化操作, MLP(· )表示MLP(Multilayer Per-ceptron)函数, δ (· )表示Sigmoid函数.
下支路的SA模块首先将特征图F沿空间维度进行平均池化和最大池化, 将生成的2个一维向量拼接后进行卷积操作, 得到二维的空间注意力.再将其与F相乘后, 得到空间注意力加权后的特征:
FSA=δ [ f1× 1(Avg(F); Max(F))]· F,
其中, Avg(· )表示全局平均池化操作, Max(· )表示最大池化操作, δ (· )表示Sigmoid函数, f1× 1(· )表示1× 1卷积函数.
最后, 将2个支路的输出特征FCA和FSA逐像素相加, 得到融合后的多维特征:
FCS=FCA+FSA,
这使提取到的不同维度的特征更具体.
通常, 在使用不同注意力机制的过程中, 都是采用串联或并联的方式, 直接将产生的不同特征融合, 而未考虑到不同注意力机制提取的图像特征重要程度不同, 导致在之后的处理过程中耗费大量计算资源在相似的特征信息上.为此, 本文构建FRU, 对提取的多维信息再次进行权重学习, 自适应选择重要的特征信息.
FRU由2条注意力支路构成:一条支路由5× 5深度卷积、7× 7深度卷积、逐点卷积和Sigmoid函数构成; 另一条支路由3× 3深度卷积、5× 5深度卷积、逐点卷积和Sigmoid函数构成.假设输入特征图的通道数为C, 卷积核大小为k× k, 使用标准卷积时参数量为
k× k× C× C=k2C2.
在使用深度卷积的情况下, 对输入特征图的每个通道都采用一个大小为k× k× 1的卷积核进行卷积, 则参数量为
k× k× C=k2C.
逐点卷积的卷积核大小为1× 1, 参数量为
1× 1× C× C=C2.
由此可见, 深度卷积的参数量及深度卷积和逐点卷积参数量之和远小于标准卷积参数量.
这两条支路在不同大小的感受野下再次有侧重地学习多维特征FCS, 进一步增强网络对关键特征的判别能力.FRU的输出特征为:
FFRU=FCS· σ ( f1× 1( f7× 7( f5× 5(FCS))))+FCS· σ ( f1× 1(f5× 5(f3× 3(FCS)))),
其中, f3× 3(· )表示3× 3深度卷积函数, f5× 5(· )表示5× 5深度卷积函数, f7× 7(· )表示7× 7深度卷积函数, f1× 1(· )表示逐点卷积, σ (· )表示Sigmoid函数.
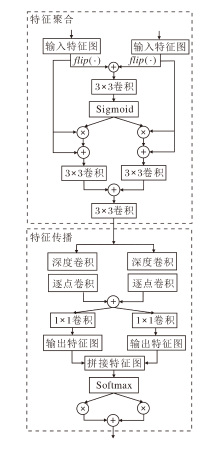
网络中各个模块由不同的卷积层构成, 功能各不相同, 并且随着网络逐渐加深, 不同卷积层提取的特征具有不同的状态, 在重建过程中, 不同状态的特征信息重要性不同.通常情况下, 直接平等对待所有特征, 将其直接相加或串联拼接可能会导致一些重要信息被忽略.针对该问题, 本文提出特征聚合传播模块(FAPB), 分为特征聚合(Feature Aggregation, FA)和特征传播(Feature Propagation, FP)两部分.首先自适应地聚合不同分支的信息, 再生成不同的权重, 进一步筛选聚合信息, 使更强大的特征表示能在网络中传播.FAPB详细结构如图4所示.
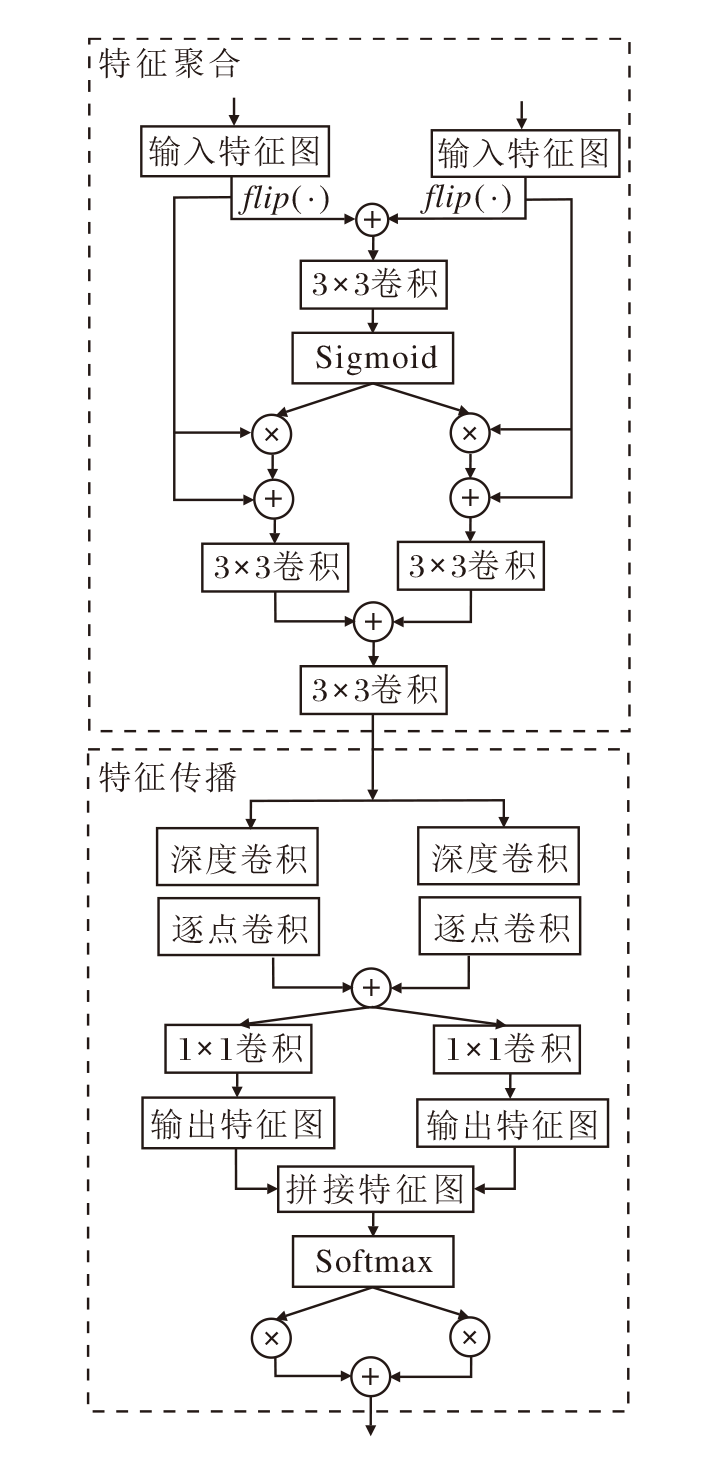 | 图4 FAPB结构图Fig.4 Architecture of FAPB |
特征聚合部分包含2个并行的输入, 分别是CIAB和MAEB的输出F'和F″, 使用翻转操作对深度特征图进行增强, 之后逐像素相加, 得到特征
Fm=f3× 3( flip(F')+flip(F″)),
获得更全面的特征信息, 其中, f3× 3(· )表示3× 3卷积函数, flip(· )表示图像翻转函数.
接下来, Fm通过Sigmoid函数得到归一化权重, 并与输入F'和F″分别点乘, 使网络捕捉不同层次特征之间的相关性, 增强网络对关键特征的关注.此外, 引入残差连接, 充分融合图像的浅层特征和深层特征, 以此保留输入特征的原始信息, 提升网络对图像浅层特征的利用率.具体过程如下:
$F_{Agg}^{1}=\delta ({{F}_{m}})\otimes F'+F'$,
$F_{Agg}^{2}=\delta ({{F}_{m}})\otimes F\prime\prime +F\prime\prime $,
其中δ (· )表示Sigmoid函数.
然后使用3× 3卷积进一步处理$F_{Agg}^{1}$和$F_{Agg}^{2}$后, 逐像素相加, 得到聚合特征
${{F}_{Agg}}={{f}_{3\times 3}}({{f}_{3\times 3}}(F_{Agg}^{1})+{{f}_{3\times 3}}(F_{Agg}^{2}))$,
进一步增强网络的特征表达能力, 其中 f3× 3(· )表示3× 3卷积函数.
特征传播部分首先对聚合特征FAgg使用3× 3深度卷积、1× 1逐点卷积序列、5× 5深度卷积、1× 1逐点卷积序列进行卷积操作, 再逐像素相加, 使不同感受野下的信息互相补充, 得到更精细的深层信息, 具体过程如下:
FDepth=FDepth1+FDepth2,
其中
FDepth1=fPW1× 1( fDW3× 3(FAgg)),
FDepth2=fPW1× 1(fDW5× 5(FAgg)),
fDW3× 3(· )表示3× 3深度卷积函数, fDW5× 5(· )表示5× 5深度卷积函数, fPW1× 1(· )表示逐点卷积函数.
然后, 通过1× 1卷积, 进一步对FDepth进行特征映射, 得到2个不同的特征向量
g1=f1× 1(FDepth)∈ R1× W× H,
g2=f1× 1(FDepth)∈ R1× W× H,
其中f1× 1(· )表示1× 1卷积函数.
通过拼接操作, 合并映射后的2个特征, 得
g3=Concat(g1, g2)∈ R2× W× H.
最后, 通过Softmax操作获得2个互补权重:
$w_{1}^{\left( i, j \right)}=\frac{\text{exp}\left( g_{1}^{\left( i, j \right)} \ \ \right)}{\text{exp}\left( g_{1}^{\left( i, j \right)} \ \ \right)+\text{exp}\left( g_{2}^{\left( i, j \right)} \ \ \right)}$,
$w_{2}^{\left( i, j \right)}=\frac{\text{exp}\left( g_{2}^{\left( i, j \right)} \ \ \right)}{\text{exp}\left( g_{1}^{\left( i, j \right)} \ \ \right)+\text{exp}\left( g_{2}^{\left( i, j \right)} \ \ \right)}$
其中, $g_{1}^{\left( i, j \right)}$、$g_{2}^{\left( i, j \right)}$分别表示特征图g1、g2第(i, j)个位置的权重.最后与FDepth1和FDepth2进行相应加权操作, 进而求和, 得到传播过程中的输出特征
$F_{\text{prop}}^{p\left( i, j \right)}=w_{1}^{\left( i, j \right)}F_{\text{Depth}1}^{\left( i, j \right)}+w_{2}^{\left( i, j \right)}F_{\text{Depth}2}^{\left( i, j \right)}$,
使网络提取到更有效的高频信息.
本文采用DIV2K数据集[21]上的800幅图像作为训练数据集.使用双三次下采样对数据集进行处理, 得到对应的低分辨率图像, 同时将这些图像旋转90° 、180° 、270° 进行数据增强, 最后将高分辨率图像和对应的低分辨率图像裁剪为64× 64的图像块.同时, 采用Set14[19]、Set5[20]、BSD100[22]、Urban100[23]数据集作为实验的测试数据集.
选用如下评价指标:峰值信噪比(Peak Signal-to-Noise Ratio, PSNR)和结构相似度(Structural Similarity, SSIM)[24].
FAPN使用Adam(Adaptive Moment Estima-tion)优化器训练网络及优化参数, 指数衰减率设为β 1=0.9, β 2=0.999, 数值稳定常数ε =10-8.采用l1损失函数[25], 训练迭代轮次为1 000, 批处理大小设为16, 学习率设为10-4, 每训练250个回合, 学习率下降一半.
实验使用Platinum 8255C CPU处理器, 内存40 GB, GPU为RTX 3090, 显存10 GB.深度学习框架使用Pytorch, 版本为1.8.1, 编程语言使用Python, 版本为3.7.
2.2.1 上下文交互注意力模块
本文在CIAB中引入GCT, 采用规范化操作, 鼓励浅层通道特征之间相互合作、深层通道特征之间相互竞争.为了验证 GCT的有效性, 将CIAB与去除GCT的CIAB进行性能对比, 在4个基准数据集上进行4倍的超分辨率重建, 具体PSNR结果如表1所示.由表可看出, 包含GCT的CIAB在4个基准数据集上均取得最优的PSNR, 由此说明GCT可使网络进一步学习每个通道内的信息.
| 表1 GCT对重建性能的影响 Table 1 Effect of GCT on reconstruction performance dB |
此外, 为了分析CIAB中不同数目的3× 3空洞卷积对CIAB重建性能的影响, 在4个数据集上进行重建效果对比, 具体PSNR结果如表2所示, 表中黑体数字为最优值.由表可知, 随着卷积个数增加, 取得的PSNR值逐渐提高, 当卷积次数为3时, 在Set5、Urban100数据集上取得最优的PSNR值, 当卷积次数为4时, 在Set14、BSD100数据集上取得最优的PSNR值.然而考虑到卷积次数增加会导致参数量增大, 本文将CIAB中的空洞卷积提取次数设置为3.
| 表2 CIAB中特征提取次数对重建性能的影响 Table 2 Effect of feature extraction times of CIAB on reconstruction performance dB |
2.2.2 多维注意力增强模块
为了进一步探究MAEB各组成结构对重建性能的影响, 设计如下3种方案:1)只使用通道注意力机制(CA); 2)在1)的基础上进一步引入空间注意力(SA); 3)在2)的基础上, 添加特征细化单元(FRU).表3是上述方案在4个数据集上4倍SR的PSNR值对比.由表可见, 与方案1)只采用CA捕捉通道上下文信息相比, 方案2)引入SA, 在重建过程中进一步专注于图像的空间结构信息.考虑到使用不同注意力机制提取的信息重要性也有所不同, 方案3)在方案2)的基础上继续引入FRU, 通过生成权重的方式再次学习提取的多维度信息, 从而进一步强化网络对关键细节信息的判别能力, 提升网络的特征表达能力.
| 表3 MAEB各组成结构对重建性能的影响 Table 3 Effect of each component in MAEB on reconstruction performance dB |
2.2.3 特征聚合传播模块
为了验证FAPB融合特征的有效性, 将网络中的FAPB替换为逐像素相加操作(Add)和特征拼接操作(Concat), 替换前后PSNR结果如表4所示.由表可见, 相比Add和Concat, 使用FAPB时FAPN取得最优的重建性能, 说明FAPB不仅可融合不同层次的特征, 还可使网络从已提取特征中学习到更丰富的信息, 促进有益的信息在网络中的传播.
| 表4 FAPB对重建性能的影响 Table 4 Effect of FAPB on reconstruction performance dB |
为了进一步验证FAPB的有效性, 首先在整体网络中使用特征聚合(FA)进行超分辨率重建, 再加入特征传播(FP), 具体PSNR结果如表5所示.由表可见, 当引入FP后, 在4个测试集上的PSNR都有所提高, 表明FAPB组合的有效性.
| 表5 FAPB不同组成部分对重建性能的影响 Table 5 Effect of different components of FAPB on reconstruction performance dB |
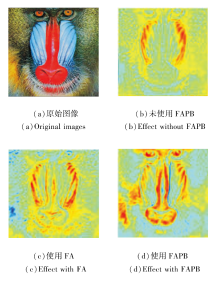
同时为了更直观展示FAPB在图像重建过程中的作用, 对上述实验过程效果进行对比, 结果如图5所示.采用热力图表示网络对特征的关注程度, 暖色表示网络对该区域特征关注较多, 冷色表示对该特征区域关注较少.由图可见, 相比未使用FAPB, 使用FA后方法对纹理丰富的区域关注增多, 说明FA自适应融合来自CIAB和MAEB不同状态的特征信息, 使网络更全面学习图像内部重要信息.在此基础上继续添加FP后(图5(d)), 暖色区域范围更广, 并且集中于一些复杂纹理区域(如猩猩毛发、鼻部和眼部纹理), 说明FP可再次筛选初步聚合的信息, 使图像内部的高频信息更突出, 促进关键信息在网络中的传播.
 | 图5 FAPB作用的可视化效果Fig.5 Visualization effect of FAPB |
2.2.4 网络深度分析
为了分析网络深度对方法重建性能的影响, 对FAPN分别采用1、3、5、7个阶段, 进行4倍的超分辨率重建, PSNR结果如表6所示, 表中黑体数字表示最优值.
| 表6 网络深度对重建性能的影响 Table 6 Effect of network depth on reconstruction performance dB |
由表6可知, 网络深度越深, 性能越优.当网络深度由3增至5时, 各数据集上的PSNR都有所提升; 当增至7时, 在Set5、Set14、BSD100数据集上的PSNR有所下降.因此, 本文将FAPN的网络深度设置为5, 采用5个阶段逐步提取图像特征.
FAPN共包含5个阶段, 每个阶段都将MAEB和CIAB提取到的不同状态的先验信息输入FAPB进行聚合.为了验证FAPN的有效性, 输出网络中第1阶段、第3阶段、第5阶段中各模块得到的特征图, 显示其所包含的低频信息和高频信息, 具体如图6所示.从图中可得出一些较直观的结论.
 | 图6 FAPN可视化效果Fig.6 Visualization effect of FAPN |
1)在每个阶段中, 与CIAB和MAEB提取到的特征相比, FAPB得到的特征图包含的信息更丰富, 表明通过FAPB对层次化信息融合及筛选能生成更好的特征表示.
2)FAPB输出特征中的边缘纹理和细节逐渐清晰, 平滑的低频分量逐渐被抑制.这说明FAPN不仅充分学习图像包含的丰富信息, 并且将不同状态信息层次化融合, 通过融合前面的分支特征生成更强大的特征表示.此外, FAPN将每个阶段获得的细节信息作为下一阶段的先验信息, 从而达到浅层特征指导深层特征表示的目的, 使图像中的高频信息分量逐渐突出, 以此保证重建图像具有更好的主观质量.
为了验证FAPN的性能, 选取如下16种方法进行客观定量和主观视觉效果对比: DRCN[12]、IMDN[14]、RLFN[15]、CBPN(Compact Backprojection Network)[26]、LapSRN(Laplacian Pyramid Super-Re-solution Network)[27]、CARN(Cascading Residual Network)[28]、SMSR(Sparse Mask SR)[29]、LFFN(Light-weight Feature Fusion Network)[30]、MSRN(Multi-scale Residual Network)[31]、FCCSR(Feature Cheap Convolution SR)[32]、LCRCA(Lightweight Skip Con-catenated Residual Channel Attention Network)[33]、DRSAN-48m(Dynamic Residual Self-Attention Net-work-48m)[34]、基于区域互补注意力和多维注意力的轻量级图像超分辨率网络(Lightweight Image Super-Resolution Network Based on Regional Com-plementary Attention and Multi-dimensional Attention, RCA-MDA)[35]、RSANet-L(Large-Scale Residual Shu-ffle Attention Network)[36]、EMASRN+(Lightweight Single Image Super-Resolution Network with an Ex-pectation-Maximization Attention Mechanism+)[37]、轻量化逆可分离残差信息蒸馏网络(Lightweight Inverse Separable Residual Information Distillation Network, LIRDN)[38].
在4个测试数据集上分别进行2倍、3倍、4倍的超分辨率重建, 各方法的平均PSNR和SSIM值对比如表7~表9所示, 表中黑体数字表示最优值.
| 表7 放大倍数为2时各方法在4个数据集上的指标值对比 Table 7 Index comparison of different methods at a magnification factor of 2 on 4 datasets |
| 表8 放大倍数为3时各方法在4个数据集上的指标值对比 Table 8 Index comparison of different methods at a magnification factor of 3 on 4 datasets |
| 表9 放大倍数为4时各方法在4个数据集上的指标值对比 Table 9 Index comparison of different methods at a magnification factor of 4 on 4 datasets |
由表7~表9可知, FAPN在4个公开测试数据集上都取得最优或次优的PSNR和SSIM值.RCA-MDA采用区域互补注意力块(Region Comple-mentary Attention Block, RCAB)和多维注意力块(Multi-dimensional Attention Block, MDAB)捕捉图像局部、非局部以及不同维度的信息.RSANet-L提出RSAB(Residual Shuffle Attention Block), 捕获特征分组中的细节信息.然而, 上述方法虽然学习图像丰富的内部信息, 但是未充分将其利用.对于SR来说, 整合不同状态的信息也至关重要.本文首先基于注意力机制、空洞卷积和深度卷积提出MAEB和CIAB, 获取图像内部不同尺度的上下文信息, 强化视觉特征中包含的空间结构信息和语义信息, 丰富网络的特征表示.之后设计FAPB, 首先使网络自适应聚合来自上述两个模块不同状态的特征信息, 再通过生成可训练权重的方式使网络保留更关键的特征.FAPN通过这3个模块的相互协作, 充分学习并利用不同状态的特征信息, 更好地执行SR任务.
下面进行模型参数量的对比.从表7~表9可看出, 相比RLFN、FCCSR和LCRCA, 虽然FAPN的参数量有所增加, 但FAPN的PSNR和SSIM值显著提升.相比MSRN, FAPN的参数量约为其1/5, 然而取得的平均PSNR值显著提高.
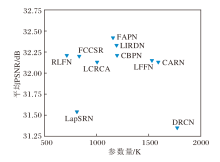
放大倍数为4时各方法在Set5数据集上的平均PSNR和参数量对比如图7所示.由图可知, FAPN能在模型性能和参数量之间取得较好的平衡.
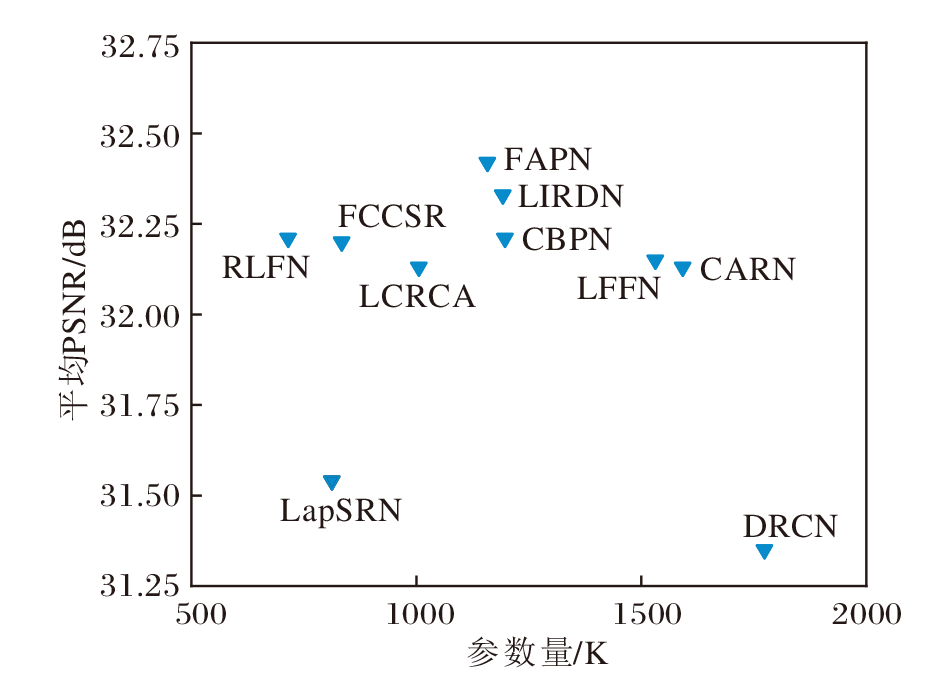 | 图7 放大倍数为4时, 各方法在Set5数据集上的参数量和平均PSNR对比Fig.7 Comparison of parameters and average PSNR of different methods at a magnification factor of 4 on Set5 dataset |
图8展示FAPN对图像细节的重建效果, 从Urban100数据集上选取3幅纹理结构较丰富的图像, 与其它主流方法进行4倍超分辨率重建效果对比.
 | 图8 放大倍数为4时各方法在Urban100测试集上的重建效果对比Fig.8 Reconstruction effect comparison of different methods at a magnification factor of 4 on Urban100 test set |
图8(a)中DRCN和MSRN重建出的图像模糊失真严重, CARN、IMDN、RLFN重建出的图像存在不同程度的伪影, 而FAPN重建的图像更接近原始图像, 未出现严重的失真扭曲现象, 并且只存在较少的伪影.
在图8(b)和(d)中, 其它方法重建图像都存在边缘虚化的现象, 而FAPN重建图像的轮廓更真实, 与原始图像更接近.
图8(c)中的图像重建更具挑战性, 其它方法的重建图像都存在一定程度的伪影, 而FAPN重建图像的细节纹理更清晰, 同时伪影较少.
本文提出基于特征聚合和传播网络(FAPN)的图像超分辨率重建方法.引入上下文交互注意力模块(CIAB), 基于空洞卷积和通道门控机制, 学习丰富的上下文信息.提出多维注意力增强模块(MAEB), 突出图像重要的纹理结构信息及通道信息, 并进一步调制和增强注意力机制提取到的信息.最后通过特征聚合传播模块(FAPB)自适应聚合不同状态信息并对其进行选择, 增强网络中有效信息的流动.本文通过提取图像内部深层特征, 学习不同状态特征的高效融合, 使网络性能得以提升, 但对于一些局部纹理细节的重建仍不够真实.今后将进一步探索如何获取图像高阶特征中包含的高层语义信息, 通过高层语义信息引导网络学习更多的纹理细节信息, 从而进一步提升重建性能.
本文责任编委 黄华
Recommended by Associate Editor HUANG Hua
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|