





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
面向高动态范围成像的内容恢复和鬼影抑制网络
[杨珍妹1  , 李华锋
, 李华锋1 , 张亚飞1 ]
, 李华锋, 张亚飞]
|
|



作者简介:

杨珍妹,硕士研究生,主要研究方向为模式识别、图像处理.E-mail:yangtongxue123_km@163.com.

张亚飞,博士,副教授,主要研究方向为图像处理、模式识别.E-mail:zyfeimail@163.com.
基于多曝光融合的高动态范围(High Dynamic Range, HDR)成像旨在整合多幅低动态范围图像(Low Dynamic Range, LDR)的信息,以生成高质量的HDR图像.然而,抑制运动区域的鬼影信息和恢复过饱和区域的缺失信息仍是HDR成像面临的两大挑战.为了综合考虑对参考图像缺失内容的恢复和运动区域鬼影的抑制,文中提出面向HDR成像的内容恢复和鬼影抑制网络.在内容恢复方面,引入基于预测滤波的内容恢复块.由内容恢复块预测到的滤波核对参考图像特征进行滤波,整合参考图像和非参考图像中的关键信息,为有效进行缺失内容的重建提供更丰富的信息.为了抑制运动区域的鬼影信息并充分利用非参考图像中的互补信息,引入可变形卷积,将非参考图像特征与参考图像特征对齐.此外,为了提升网络的HDR图像重建能力,构建三支路图像重建模块,包括一条主支路和两条辅助支路,辅助支路协助主支路在HDR结果的生成过程中更好地保留细节.实验表明,文中网络在主观视觉和客观指标上均具有较优表现.
About Author:
YANG Zhenmei, Master student. Her research interests include pattern recognition and image processing.
ZHANG Yafei, Ph.D., associate profe-ssor. Her research interests include image processing and pattern recognition.
High dynamic range(HDR) imaging based on multi-exposure fusion aims to generate high-quality HDR images by integrating the information from multiple low dynamic range(LDR) images. However, HDR imaging is faced with two major challenges, ghosting artifact suppression in motion regions and lost information restoration in over-saturated areas. To comprehensively address the challenges of restoring missing content from reference images and suppressing ghosting artifacts in motion regions, a missing content restoration and ghosting suppression network for high dynamic range imaging is proposed in this paper. In terms of content restoration, a predictive filtering-based content restoration block is introduced. The filtering kernel predicted by the content restoration block is employed to filter reference image features, integrating key information from both reference images and non-reference images to provide richer information for effective reconstruction of missing content. To suppress ghosting artifacts in motion regions and fully exploit complementary information from non-reference images, deformable convolutions are introduced to align features from non-reference images with those from the reference image. Additionally, to enhance the HDR image reconstruction capability of the network, a three-branch image reconstruction module is constructed, including a main branch and two auxiliary branches. The auxiliary branches assist the main branch with better preserved details during the generation of HDR results. Experimental results demonstrate superior performance of the proposed network.
动态范围是图像能够展示的最暗部分和最亮部分之间亮度差异的范围, 值越大, 图像在亮度上呈现的细节丰富度越高.尽管自然场景涵盖广泛的动态范围, 一般的数码相机由于其传感器的限制, 只能捕获有限的动态范围, 导致拍摄的图像通常难以呈现理想的视觉效果.为了克服这些限制, 高动态范围(High Dynamic Range, HDR)成像技术应运而生.HDR成像的一种常见方法是多曝光融合(Multi-exposure Fusion, MEF)技术.该技术通过融合在不同曝光度下获得的一系列低动态范围(Low Dynamic Range, LDR)图像, 生成具备高质量视觉信息和广泛亮度范围的HDR图像.
当融合在静态场景下捕捉的LDR图像序列进行HDR图像重建时[1, 2, 3, 4], 可获得较高质量的HDR图像.然而, 在现实场景中, 由于目标物的运动或相机的抖动, 捕获到的LDR图像往往存在错位现象.因此, 动态场景下的多曝光图像融合方法常伴随引入鬼影的风险.为了解决动态场景下多曝光图像融合导致的运动鬼影问题, 早期的研究者们主要提出两类方法:基于图像配准的方法[5, 6, 7, 8]和基于运动检测的方法[9, 10, 11, 12].
基于图像配准的方法首先通过在全局或局部上的配准步骤, 校准输入的LDR图像序列, 然后合并配准后的多曝光LDR图像, 以此重建出HDR图像.Ward[5]采用中值阈值位图方法, 计算相邻曝光图像的像素偏移, 再利用简单的水平和垂直位移操作, 实现整体的图像配准.Zimmer等[6]采用光流算法[13], 计算多曝光LDR图像序列间的光流, 再利用估算出的光流将非参考图像转换到参考图像的运动状态, 实现LDR图像的配准.Sen等[7]和Hu等[8]摒弃先进行图像配准再融合配准后图像的方法, 采用基于图像块的策略, 通过联合优化的方式结合LDR图像的配准与HDR图像的重建.尽管上述方法在HDR重建方面取得一定效果, 但在处理饱和区域较大的图像和存在大幅运动的场景时, 效果受到一定限制, 而且通常伴随较高的计算成本.
基于运动检测的方法首先对输入图像的所有像素进行标记, 分类为动态像素和静态像素.在融合过程中, 丢弃动态像素, 将静态像素合并到最终的HDR图像中.Raman等[9]通过超像素分组提出一种自下而上的分割算法, 检测场景运动区域, 并在梯度域中使用基于分段块的合成方法, 直接生成动态场景的无鬼影HDR图像.Yan等[10]提出基于稀疏表示框架的无鬼影HDR图像合成算法, 将HDR图像重建过程划分为运动目标检测和无鬼影HDR生成两个步骤, 并将运动目标检测问题表述为稀疏表示.Ma等[11]提出SPD-MEF(Structural Patch Decompo-sition Based Multi-exposure Image Fusion), 将图像块分解为信号强度、信号结构和均值强度3个独立的组成部分, 并通过结构向量估计图像中的运动区域.分别融合这3个组成部分后, 重建需要的块, 并重新整合到融合图像中.该方法在处理鬼影效应时表现出较强的鲁棒性.随后Li等[12]在此基础上提出Fast SPD-MEF, 引入多尺度方法, 提高图像融合效果, 同时还省略正则化步骤, 加快运算速度.然而, 上述方法在生成最终HDR图像时, 因为舍弃运动区域的内容, 可能会丢失许多细节, 从而影响HDR图像的重建效果.
为了克服传统方法的弊端, 研究者提出基于深度学习的方法[14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24], 解决动态场景下的多曝光图像融合.Kalantari等[14]使用光流算法, 对齐输入的非参考图像与参考图像, 再融合对齐后的结果, 重建HDR图像.Wu等[15]提出非光流的深度学习框架, 使用编码解码结构的卷积神经网络(Convolutional Neural Networks, CNN)实现HDR图像的重建.
鉴于注意力机制在全局关联性探索方面展现出强大潜力, Yan等[16]提出AHDRNet(Attention-Guided End-to-End Deep Neural Network), Deng等[17]提出SK-AHDRNet(End-to-End Attention Guided Network for HDR Reconstruction), 利用注意力机制抑制运动区域的内容, 增强对HDR重建有用的信息.进一步, Yan等[18]提出NHDRRnet(Non-Local HDR Reconstruc-tion Network), 在中间层特征嵌入非局部注意力的U-net架构, 计算输入图像中的非局部相关性, 去除HDR重建中引入的鬼影.Pu等[19]提出PAMnet(Py-ramidal Alignment and Masked Merging Network)、Liu等[20]提出ADNet(Attention-Guided Deformable Convolutional Network)和Tan等[21]提出DHDRNet(End-to-End Deformable HDR Imaging Network), 均采用可变形卷积进行特征对齐, 再融合对齐后的图像特征, 重建无鬼影的HDR图像.Prabhakar等[22]提出一种使用BGU(Bilateral Guided Upsampler)的高效HDR去鬼影方法, 通过运动估计和运动补偿重建HDR图像.Chen等[23]提出APNT-Fusion(Attention-Guided Progressive Neural Texture Fusion).Chung等[24]将运动对齐问题转换为简单的亮度调整问题, 利用非参考图像特征对参考图像特征进行亮度调节, 生成对齐良好的多曝光特征, 并据此重建HDR图像.
鉴于视觉Transformer(Vision Transformer, ViT)[25]能有效建模图像的长距离依赖关系[26, 27, 28], 近年来, HDR图像重建任务中出现许多基于Transformer的算法.Song等[29]通过生成的“ 鬼区域” 掩码, 将输入图像分为“ 鬼区域” 和“ 非鬼区域” , 再根据需要自适应选择使用CNN或Transformer, 重建HDR图像.Liu等[30]提出CA-ViT(Context-Aware ViT), 结合CNN提取局部信息和Transformer捕获全局信息的优势, 生成无鬼影的HDR图像.在此基础上, Yan等[31]构建HyHDRNet(Hybrid HDR Deghosting Net-work), 从多曝光的LDR图像中重建HDR图像, 网络由一个基于CNN的内容对齐子网络和一个基于Transformer的融合子网络组成.Yan等[32]还提出SAME(Saturated Mask Autoencoder), 先使用自监督机制生成饱和区域的内容, 再通过迭代的半监督学习框架解决鬼影问题.Chen等[33]提出HFT(HDR Fusion Transformer), 同样采用CNN+Transformer架构, 整个网络分为对齐、融合和重建三部分.先用可变形卷积对齐LDR图像的特征, 再通过金字塔融合模块融合不同曝光图的特征, 并在最小尺度的特征上使用Transformer建模远距离关系, 最后利用以通道注意力为基础单元的重建网络, 将融合后的特征重建为HDR图像.然而, 上述方法主要关注鬼影对重建结果的影响, 限制重建结果的视觉质量提升.
为了恢复参考图像中由于曝光不均匀而导致的缺失内容, 充分利用非参考图像中的互补信息, 并重建内容完整且无鬼影的HDR图像, 本文设计面向HDR成像的内容恢复和鬼影抑制网络, 在一个框架内同时解决参考图像中丢失信息的恢复和运动区域鬼影的抑制问题.网络包括特征提取模块、特征融合模块、图像重建模块.在特征融合模块中, 引入基于预测滤波的内容恢复块, 根据输入的内容自适应地预测合适的滤波核, 并利用预测到的滤波核对参考图像特征进行滤波, 更有效整合参考图像和非参考图像中对重建HDR图像有益的关键信息, 实现对参考图像中缺失信息的重建.同时, 为了充分利用非参考图像中的有效信息而不引入运动鬼影, 构建由可变形卷积构成的空间对齐块.此外, 与以往在HDR重建阶段采用单支网络结构的方法不同, 本文设计一个三支路重建模块, 由两条辅助支路和一条主支路构成, 两条辅助支路的作用是协助主支路生成内容更丰富的HDR图像.在3个具有挑战性的数据集上的实验充分验证本文方法在HDR图像重建上的有效性.
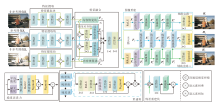
多曝光图像融合是指利用非参考图像中的互补信息补充参考图像, 以生成亮度范围更广、信息更丰富的HDR图像.本文提出面向HDR成像的内容恢复和鬼影抑制网络, 总体框架如图1所示.网络由特征提取模块、特征融合模块和图像重建模块构成.特征提取模块主要负责从输入的LDR图像中提取包含丰富信息的图像特征.特征融合模块的主要任务是将来自参考图像和非参考图像的互补信息整合到参考图像中, 从而增强对HDR图像重建有用的信息.图像重建模块负责将这些特征表示映射到图像表示, 生成HDR图像.
 | 图1 本文网络总体框架Fig.1 Overall framework of the proposed network |
为了恢复参考图像中因曝光不均而缺失的信息和抑制运动区域的鬼影, 在特征融合模块中引入基于预测滤波的内容恢复块(Content Restoration Block, CRB)和由可变形结构构成的空间对齐块(Spatial Alignment Block, SAB).此外, 为了充分挖掘对HDR图像重建有用的信息, 图像重建模块包括两条辅助支路和一条主支路, 辅助支路协助主支路, 共同提升HDR图像的视觉质量.
给定不同曝光水平的LDR图像序列
{L1, L2, …, LN},
HDR图像重建的目的是将这些图像序列合并成一幅无鬼影的HDR图像.根据文献[14], 本文使用3幅LDR图像{L1, L2, L3}作为输入.L2设置为参考图像, 其内容在空间上完全对齐于标签; L1、L3定义为非参考图像.
多曝光图像融合旨在将非参考图像中的互补信息整合到参考图像中, 生成高质量的HDR图像.同时, 为了得到内容丰富的重构结果, 先对LDR图像{L1, L2, L3}进行gamma校正, 即将LDR图像映射到对应的HDR域, 得到对应的HDR图像{H1, H2, H3}:
${{H}_{i}}=\frac{L_{i}^{\gamma }}{{{t}_{i}}}, i=1, 2, 3$, (1)
其中, ti为Li的曝光时间, γ 为gamma的校正参数, 根据经验设置为2.2[34].校正后的Hi和Li在通道上拼接, 得到
Xi=[Li, Hi],
作为特征提取网络的输入.
1.3.1 特征提取模块
如图1所示, 每个特征提取块(Feature Extrac-tion Block, FEB)均由带有LeakyReLU激活函数的3× 3卷积层组成, 且特征提取块间参数不共享.对于由式(1)得到的输入Xi∈ RC× H× W(i=1, 2, 3), Xi经过j个卷积层后的输出为:
Fi, j=Convj(Xi), i=1, 2, 3, j=1, 2, 3,
其中Convj(· )表示第j个带LeakyReLU激活函数的3× 3卷积层.FEB最终的输出特征为:
Fi=Conv([Fi, 1, Fi, 2, Fi, 3])∈ RC× H× W,
其中, Conv(· )表示带LeakyReLU激活函数的3× 3卷积层.[· , · ]表示沿通道拼接.
然后, 将特征F1、F2和F3送入特征融合模块, 进行鬼影的抑制和缺失信息的恢复.
1.3.2 特征融合模块
1.3.2.1 内容恢复块
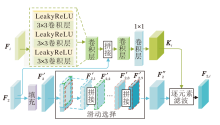
预测滤波是一种图像恢复技术, 能根据不同的输入场景自适应地预测合适的滤波核, 并通过相邻像素重建受损的像素[35, 36, 37].受此启发, 本文将参考图像中缺失信息的重建任务视为图像恢复问题, 提出基于预测滤波的内容恢复块(CRB).由非参考图像特征和参考图像特征作为引导, 通过预测出的滤波核, 对参考图像特征进行滤波, 整合参考图像和非参考图像的相关特征, 实现对参考图像中缺失信息的恢复.CRB具体结构如图2所示.
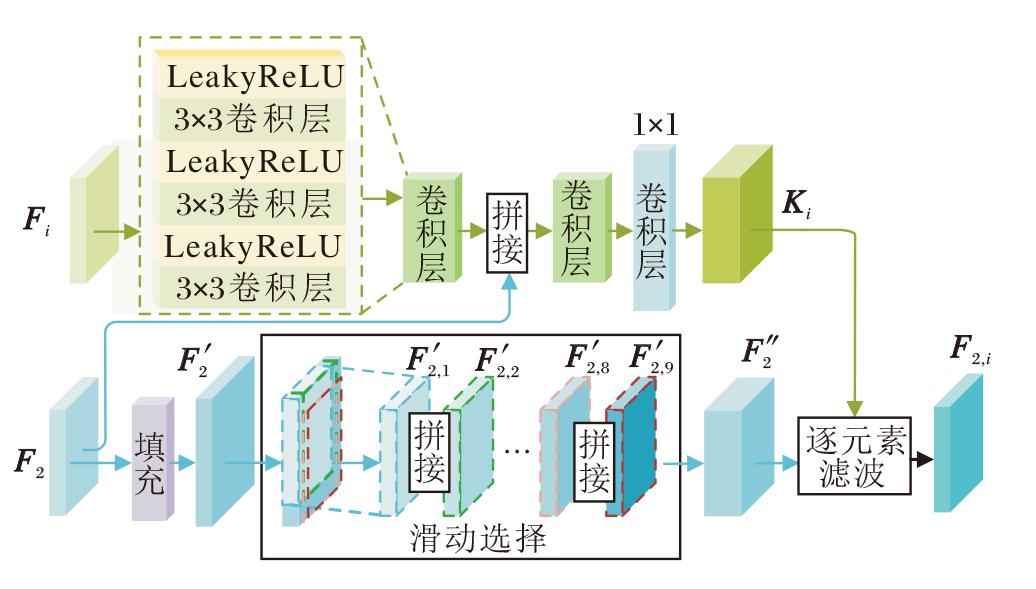 | 图2 CRB结构图Fig.2 Structure of CRB |
给定参考图像特征和非参考图像特征, CRB的作用是根据得到的融合特征自适应预测合适的滤波核, 并利用预测到的滤波核对参考图像特征进行滤波处理, 以恢复参考图像中缺失的内容.具体地, CRB包括核预测分支和特征滤波分支.在核预测分支中, 根据参考图像特征F2和非参考图像特征F1、F3的融合特征, 自适应预测合适的滤波核:
Ki=Conv1× 1(Conv3([F2, Conv6(Fi)]))∈ R9C× H× W, i=1, 3,
其中, Conv1× 1(· )表示卷积核大小为1× 1的卷积层, Conv3(· )和Conv6(· )分别表示3个和6个带有LeakyReLU激活函数的3× 3卷积层, .
在特征滤波分支中, 先对参考图像特征F2∈ RC× H× W进行填充操作, 得到特征F'2∈ RC× H'× W'(H'> H, W'> W), 再利用滑动窗口W∈ RH× W对特征F'2进行滑动选择, 得到9组特征F'2, k∈ RC× H× W(k=1, 2, …, 9), 并将这9组特征进行拼接, 得到新的特征F″2∈ R9C× H× W.接下来, 利用核预测分支得到的滤波核Ki对特征F″2进行滤波, 得到缺失内容被重建后的参考图像特征:
${{F}_{2, i}}=F{{\prime\prime }_{2, i}}\circledast{{K}_{i}}, i=1, 3$,
其中$\circledast$表示逐元素滤波操作.
1.3.2.2 空间对齐块
为了融合参考图像和非参考图像中的互补信息, 同时不引入运动鬼影, 本文引入由可变形卷积构成的空间对齐块(SAB), 在空间上对齐非参考图像特征和参考图像特征, 减少运动鬼影在最终重建结果中的影响.具体地, 使用参考图像特征F2和非参考图像特征F1、F3, 预测可学习的偏移量:
offseti=Conv3× 3([F2, Fi]), i=1, 3,
其中Conv3× 3(· )表示3× 3卷积层.然后通过一个可变形卷积层(Deformable Convolution)将非参考图像特征对齐于参考特征, 得到对齐于参考图像特征的非参考图像特征:
Fi, dc=DConv(Fi, offseti), i=1, 3,
其中DConv(· )表示可变形卷积.
在经过内容恢复块和空间对齐块后, 得到特征F2, 1、F2, 3、F1, dc和F3, dc.鉴于这些特征携带信息的不同, 在融合时引入可学习权重α 1、α 2、α 3和α 4, 调整F2, 1、F2, 3、F1, dc和F3, dc在HDR图像重建中的作用, 得到融合特征
Fm=Conv3× 3(Conv1× 1([α 1F2, 1, α 2F2, 3, α 3F1, dc, α 4F3, dc])),
并送入图像重建模块进行HDR图像的重建.
1.3.3 图像重建模块
鉴于特征传递过程中不可避免地存在信息流失的问题, 因此, 本文提出一个三支路结构的HDR图像重建模块.通过深入挖掘对重建HDR图像有益的信息, 解决图像重建过程中的信息丢失问题, 进一步提升HDR重建结果的质量.如图1所示, 该特征重建模块由两条辅助支路和一条主支路组成, 辅助支路向主支路提供额外信息和约束, 共同辅助主支路的HDR图像重建过程, 提高HDR图像的质量和信息丰富度.
具体地:本文利用ReLU激活函数(ReLU=max(0, x))激活融合特征Fm中对提升重建质量起积极作用且幅值大于0的特征; 引入逆ReLU激活函数(RReLU=-min(0, x))激活Fm中可能会被丢弃但对提升重建质量起积极作用且幅值小于0的特征.通过ReLU和RReLU激活函数后的融合特征Ft和Fb分别作为两条辅助支路的输入.
以辅助分支一为例, 首先, 输入特征Ft通过一个通道注意力块(Channel Attention Block, CAB)进行通道维度上的整合, 得到新的特征$F_{t}^{1}$.随后, $F_{t}^{1}$依次通过3个重构块(Reconstruction Block, RB)进行进一步特征映射, 第n个RB的输出为:
$F_{t}^{\text{n}+1}=f_{\text{RB}}^{n}(F_{t}^{n}), n=1, 2, 3$,
其中$f_{\text{RB}}^{n}~(\cdot )$表示第n个RB的映射函数.两条辅助支路的结构相同但参数不共享, 故辅助分支二中各模块的输出可分别表示为$F_{b}^{1}$、$F_{b}^{2}$、$F_{b}^{3}$和$F_{b}^{4}$.
主支路由4个残差重构块(Residual RB, RRB)构成, 每个RRB由一个1× 1卷积层和一个RB组成.当前RRB的输入包括参考图像特征F2或上一个RRB的输出和辅助支路一、二的中间特征$F_{t}^{n}$和$F_{b}^{n}$(n=1, 2, 3, 4), 第n个RRB输出特征:
$F_{m}^{n}\text{=}f_{\text{RRB}}^{n}\left( F_{m}^{\text{n}-1}, F_{t}^{n}, F_{b}^{n} \right), n=1, 2, 3, 4$,
其中$f_{\text{RRB}}^{n}\left( \cdot \right)$表示第n个RB的映射函数.特别地, 当n=1时, RRB的输入为F2、$F_{t}^{1}$和$F_{b}^{1}$.最后, 通过3组带有Sigmiod激活函数的3× 3卷积层, 分别将辅助支路和主支路的输出特征$F_{l}^{4}$ (l=t, m, b)映射为3通道的HDR图像:
${{H}_{l}}=Sigmoid(Con{{v}_{3\times 3}}(F\text{ }\!\!~\!\!\text{ }_{m, l}^{4})), l=t, m, b$,
其中, Ht为辅助支路一生成的HDR图像, Hm表示主支路生成的HDR图像, Hb表示辅助支路二生成的HDR图像.
本文网络是端到端的, 在损失函数的设计方面, Kalantari等[14]表明, 在色调映射图像上训练网络比直接在HDR域上训练更有效.给定HDR域中的图像H, 本文使用μ -law实现HDR图像H的色调映射, 色调映射后的图像为:
$T\left( H \right)=\frac{\text{ln}\left( 1+\mu H \right)}{\text{ln}\left( 1+\mu \right)}$,
其中μ 表示压缩量的参数.根据文献[14], 本文将μ 设为5 000.在训练过程中, 采用如下损失函数更新网络参数:
L=Lt+Lm+Lb,
其中, Lt表示用于辅助支路一的损失函数, Lb表示用于辅助支路二的损失函数, Lm表示主支路的损失函数.则Lt、Lm、Lb可表示为
Ll=Ll, re+α Ll, gradient, l=t, m, b, (2)
α 表示超参数, Ll, gradient表示梯度损失, Ll, re表示重构损失,
Ll, re=‖ T(Hl)-T(Hg)‖ 1, l=t, m, b,
Ht、Hm、Hb分别表示3条支路生成的HDR图像, Hg表示标签.
为了保证生成的HDR图像中包含更多的边缘细节, 使用Sobel算子估计生成的HDR图像与标签的梯度图, 对估计的梯度图计算l1损失, 则
Ll, gradient=‖ Ñ (Hl)-Ñ (Hg)‖ 1, l=t, m, b,
其中Ñ (· )为Sobel算子.
为了验证本文网络的有效性, 在Kalantari[14]、Sen[7]、Tursun[38]这3个公开数据集上进行实验.Kalantari数据集包含74组训练集样本和15组测试集样本, 每组样本包含3幅曝光值分别为(-2, 0, 2)或(-3, 0, 3)的LDR图像, 每组图像都有相应的标签.Sen数据集提供8个场景的多曝光LDR图像, Tursun数据集提供16个场景的多曝光LDR图像, 这两个数据集均不包含标签信息.
本文利用Kalantari数据集的训练集对本文网络进行训练, 并在Kalantari数据集的测试集以及Sen、Tursun数据集上进行测试, 验证网络的有效性和泛化性能.
为了定量评估重建结果的质量, 采用如下客观评价指标评估Kalantari数据集上的重建质量:PSNR(Peak Signal-to-Noise Ratio)-L、SSIM(Struc-tural Similarity)-L、PSNR-μ 、SSIM-μ 、HDR-VDP-2[39].对于无标签的Sen、Tursun数据集, 使用BTMQI(Blind Tone-Mapped Quality Index)[40]、MEF-SSIMd[41]及UDQM(Unified Deghosting Quality Me-tric)[38]评价重建质量.
PSNR-L和SSIM-L计算线性域上重构的HDR图和标签间的PSNR和SSIM, 评估重构结果和标签在线性域上的相似性.PSNR-μ 和SSIM-μ 计算由μ -law色调映射后生成的结果和标签之间的PSNR和SSIM, 评估重建结果的质量.HDR-VDP-2预测重建的HDR图像和标签之间的差异, 评估重建的HDR图像的视觉质量.BTMQI测量色调映射HDR图像的信息熵、自然度和结构信息, 评价图像的整体质量.MEF-SSIMd单独测量动态区域和静态区域对应序列之间的SSIM, 再对这两个区域的质量测量求平均, 评估HDR重建图像的综合评价.UDQM从QB(混合度量)、QG(梯度不一致度量)、QV(视觉差度量)和QD(动态范围度量)4个方面综合评价重构HDR图像的重影和伪影抑制效果.
在训练阶段, 通过随机裁剪将输入图像尺寸裁剪为128× 128, 并通过水平、垂直翻转实现数据增强.在实验中, 批量大小设置为2, 并采用参数β 1=0.9、β 2=0.999和λ =1e-8的Adam(Adaptive Moment Estimation)优化器[42]更新网络参数.同时, 使用warm-up学习率调整策略[43], 初始学习率为2e-4, 每训练2 000轮学习率衰减1次, 衰减率为0.1.网络总共训练5 000轮, 选出性能最高的一轮参数作为最终的网络参数.
本文网络在PyTorch框架下实现, 并在1张NVIDIA 3090 GPU上训练完成.
为了验证本文网络的有效性, 选择如下性能较优的网络进行对比:文献[7]网络、文献[14]网络、文献[15]网络、AHDRNet[16]、NHDRRnet[18]、文献[24]网络、SGARN(Structure-Embedded Ghosting Artifact Suppression Network)[34]、HDR-GAN[44]、HSTHdr[45]和SCTNet(Alignment-Free Network with Semantics Consistent Transformer)[46].
为了确保公平性, 所有对比网络的结果均由官方公布的代码获得, 并使用相同参数设置的Photo- matix Pro[15]对最终的HDR图像进行色调映射.
2.2.1 Kalantari数据集上的对比实验
本文首先在Kalantari数据集上对比不同网络的性能.各网络在Kalantari测试集上的重建结果如图3和图4所示, 这两组测试样本均包含大幅度的前景运动和极端的局部饱和区域.为了便于观察对比, 对每幅HDR图像的对应标记区域进行放大处理, 并置于每幅图像的下方.
 | 图3 各网络在Kalantari测试集上007场景下的视觉效果Fig.3 Visual results of different networks in 007 scene from Kalantari test set |
 | 图4 各网络在Kalantari测试集上009场景下的视觉效果Fig.4 Visual results of different models in 009 scene from Kalantari test set |
从图3可看出, 文献[7]网络在不同饱和度的图像间寻找对应的图像块时容易出错, 导致在重建结果中引入畸变, 并且对细节内容的恢复还不够理想.在文献[14]网络中, 光流算法难以准确估计运动变化, 而其设计的网络较简单, 不能较好地处理光流估计引入的误差, 导致重建质量不理想.
文献[15]网络未对参考图像中因曝光不均匀而缺失的信息进行恢复处理, 因此生成的HDR图像中存在较明显的内容缺失和颜色失真.AHDRNet 利用注意力抑制运动鬼影, 但仍会在重建结果中引入鬼影, 并且对缺失内容的恢复仍存在较大的提升空间.NHDRRnet 和HDR-GAN由于未考虑运动目标物造成的信息在空间上的不一致, 使重建结果中出现明显的鬼影, 细节内容也不够丰富.
文献[24]网络因未充分考虑参考图像中丢失内容的恢复问题, 导致重建的HDR图像中存在较严重的有效内容缺失、细节不清晰等问题.由于只输入2幅LDR图像, HSTHdr缺乏足够的互补信息, 导致生成的HDR图像在视觉上较模糊, 存在轻微的鬼影信息.SGARN虽然通过结构嵌入网络使重建结果中保留更多的边缘结构, 但其抑制运动鬼影的能力还有待提高.虽然SCTNet利用输入图像的上下文信息(包括动态语义和静态语义), 更好地生成图像, 并使用同时包含空间和通道注意模块的语义一致Transformer解决HDR图像重建问题, 但未考虑到饱和区域缺失信息的恢复问题, 导致网络无法重建出具有清晰内容的HDR图像, 同时其去除鬼影的能力也还有待提高.
相比之下, 本文网络通过内容恢复块和可变形卷积填补参考图像中缺失的内容、抑制非参考图像中的鬼影信息, 并通过辅助重建支路促进主重建支路生成最终的HDR图像, 在鬼影抑制和内容恢复方面表现出卓越性能.从图4中同样可观察到, 本文网络在抑制运动鬼影和恢复缺失内容方面均具有显著的优越性.
为了客观评价网络的HDR图像重建效果, 使用PSNR-μ 、PSNR-L、SSIM-L、SSIM-μ 、HDR-VDP-2评价指标, 在Kalantari数据集的15个测试场景上进行客观对比.各网络得到的评价指标的平均值如表1所示, 表中黑体数字表示最优值, 斜体数字表示次优值.由表可见, 本文网络在PSNR-μ 、PSNR-L、SSIM-L和SSIM-μ 指标上均取得最佳性能, 同时在HDR-VDP-2指标上也获得次优表现, 这进一步说明本文网络的有效性.
| 表1 各网络在Kalantari数据集的测试集上的定量评估结果 Table 1 Quantitative evaluation results of different networks on Kalantari test set |
2.2.2 Sen数据集上的对比实验
本节在Sen数据集上进行深入对比, 分析各网络的重建性能, 具体视觉效果如图5所示, 本组测试样本包含极端的过曝光区域.
 | 图5 各网络在Sen数据集上HighChair场景下的视觉效果Fig.5 Visual results of different networks in HighChair scene from Sen dataset |
从图5中局部放大区域可观察到, 相比其它对比网络, 本文网络在恢复细节内容方面呈现出更清晰的效果, 减小图像失真的程度, 这表明本文方法在视觉效果上的优越性.
此外, 各方法的定量评估结果如表2所示, 表中黑体数字表示最优值, 斜体数字表示次优值.由表可见, 本文网络在BTMQI、MEF-SSIMd指标上优于其它网络, 这进一步突出本文网络在Sen数据集上的优势.
| 表2 各网络在2个数据集上的定量评估结果 Table 2 Quantitative evaluation results of different networks on 2 datasets |
2.2.3 Tursun数据集上的对比实验
各方法在Tursun数据集上的视觉效果对比如图6所示, 测试样本组中不仅存在大面积的暗区域, 还存在大幅度的前景运动.从图中可观察到, 对比网络均未能有效恢复过暗区域的细节和颜色, 导致重建结果中的颜色和内容发生畸变.在运动区域, 对比网络未能有效处理非参考图像中的鬼影信息, 在重建结果中不可避免地引入与参考图像不一致的信息, 并在前景目标人物的头部和背部产生鬼影.相比之下, 本文网络更有效综合源图中未对齐区域的信息, 减少鬼影对重建结果的影响.
 | 图6 各网络在Tursun数据集上64场景下的视觉效果Fig.6 Visual results of different networks in 64 scene from Tursun dataset |
此外, 表2中的数据表明, 在Tursun数据集上, 本文网络同样表现出优越的性能.在BTMQI、UDQM指标上获得最佳值, 在MEF-SSIMd指标上也获得次优值, 这进一步证明本文网络在Tursun数据集上的有效性.
本节采用消融实验, 评估各模块的有效性.实验中通过从完整网络结构中移除需要验证的模块或分支, 评估不同模块或分支对整体性能的贡献.定义如下:w/o CRB表示在整体网络结构中去除内容恢复块(CRB); w/o SAB表示在整体网络结构中去除空间对齐块(SAB); 单支网络表示重建模块仅由主支路构成; 主+辅助一表示重建模块由辅助支路一和主支路组成; 主+辅助二表示重建模块由辅助支路二和主支路组成.
消融实验中的实验设置与2.1节描述的内容相同.使用图3中场景图像进行HDR图像重建, 局部结果如图7所示.各部分的定量评估结果如表3所示.
 | 图7 本文网络各部分有效性的视觉效果Fig.7 Visual results of effectiveness of different components in the proposed network |
| 表3 各部分有效性的定量评估结果 Table 3 Quantitative evaluation results of effectiveness of different components |
内容恢复块(CRB)主要通过整合参考图像和非参考图像的信息, 恢复参考图像中的缺失内容.从图7(a)可看出, 去除CRB后, 网络不能重建内容丰富的HDR图像, 抑制鬼影的能力也不及完整网络.此外, 从表3的指标值也可看出, 完整网络在去除CRB后, 整体性能有所下降, 由此证明CRB在内容恢复上的有效性, 并且在抑制鬼影方面也有一定的效果.
空间对齐块(SAB)主要采用可变形卷积, 将非参考图像特征对齐于参考图像特征, 并使用非参考图像中的互补信息对参考图像中的信息进行补充.从图7(b)可以看出, 去掉SAB后的模型重建出的HDR图像上有明显的鬼影.从表3也可看出, 去掉SAB后, 所有评价指标值均有所下降, 这验证SAB的有效性.
本文在重建模块中设计三分支结构, 以两个辅助分支协助主分支生成高质量的HDR图像.从图7(c)~(e)可看出, 两个辅助分支均对HDR图像重建中的内容恢复和鬼影抑制起到积极的作用.表3的客观评价数据也进一步证实该结构在HDR图像重建上的有效性.
本文涉及的超参数为式(2)中的α , 用于平衡结构相似性损失Ll, gradient的贡献.在Kalantari数据集的测试集上分析α 不同时网络性能的变化, 具体如图8所示.
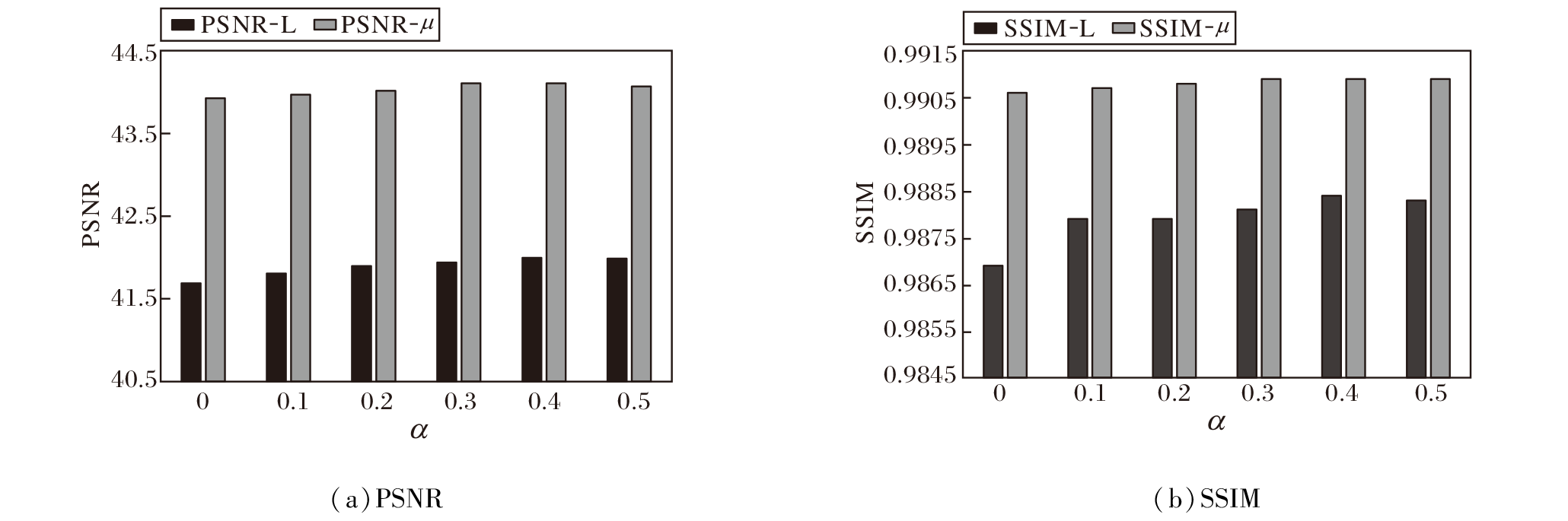 | 图8 在Kalantari测试集上α 变化对网络性能的影响Fig.8 Effect of α on network performance on Kalantari test set |
由图8可看出, 当α =0.4时, 指标值都达到最优.因此, 本文将α 设置为0.4.
为了对比不同网络的模型参数量、计算复杂度和执行时间, 从模型参数量、浮点运算数(Floating Point Operations, FLOPs)和推理时间上分析不同网络的计算复杂度, 结果如表4所示.推理时间为生成Kalantari测试数据集上15个场景图像所需的平均时间.在计算FLOPs时, 将输入图像的大小统一为128× 128.由表可以看出, 本文网络由于采用大尺度的基于预测滤波的内容恢复块和三支路的图像重建块, FLOPs值达到最高, 说明本文网络的计算复杂度整体高于其它网络.然而, 本文网络的推理时间仅为0.02 s, 推理速度较快, 且模型参数量适中, 为6.33 M.因此, 本文网络在经过训练后是可以在实际场景中应用的.
| 表4 各网络的复杂度分析结果 Table 4 Complexity analysis results of different networks |
综合考虑参考图像中缺失内容的恢复和运动区域鬼影的抑制问题, 本文提出面向HDR成像的缺失内容恢复和鬼影抑制网络.引入基于预测滤波的内容恢复块, 由参考图像和非参考图像的融合信息作为引导, 自适应生成合适的滤波核.通过对参考图像特征进行滤波, 有效重建参考图像中丢失的内容.为了进一步利用非参考图像中的互补信息且不引入运动鬼影, 采用可变形卷积对齐非参考图像特征和参考图像特征, 并将参考图像特征和对齐后的非参考图像特征进行融合, 丰富HDR图像的内容.同时, 为了充分挖掘对HDR图像重建有益的信息, 进一步提升网络重建HDR图像的能力, 设计包括两条辅助支路和一条主支路的图像重建模块, 通过辅助支路的协同作用使主支路生成内容清晰、无鬼影的HDR图像.在3个公共数据集上的实验表明, 本文网络在主观评价和客观评估上均取得较优性能, 为高质量HDR图像的生成提供新的有效途径.尽管本文网络已取得一定成果, 但浮点运算量偏高, 这说明本文网络在网络计算量方面存在较大的负担.因此, 未来的工作重点将放在不影响实验性能的前提下, 如何有效降低模型的计算量, 实现更高效的网络设计.
本文责任编委 杨健
Recommended by Associate Editor YANG Jian
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|
| [40] |
|
| [41] |
|
| [42] |
|
| [43] |
|
| [44] |
|
| [45] |
|
| [46] |
|