
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于混合知识分解的增强残差网络
[唐圣汲1  , 叶鹏
, 叶鹏1 , 林炜豪1 , 陈涛1 ]
, 叶鹏, 林炜豪, 陈涛]
|
|



作者简介:

唐圣汲,硕士研究生,主要研究方向为深度学习、模型高效化、模型设计与增强.E-mail:21210720037@m.fudan.edu.cn.

叶 鹏,博士研究生,主要研究方法为计算机视觉、模型设计和优化、人工智能探索科学.E-mail:20110720039@fudan.edu.cn.

林炜豪,博士研究生,主要研究方向为计算机视觉、图像识别、视频处理、模型压缩.E-mail:21110720038@m.fudan.edu.cn.
当前如刺激性训练、组知识训练等方法收集残差网络中浅层网络的组知识进行自蒸馏,可提升网络性能,然而上述方法获取的组知识面临知识更新较慢、难以与数据混合技术结合等问题.为了解决此问题,文中提出基于混合知识分解的增强残差网络,通过最小化分解误差,将混合知识分解建模为二次规划问题,从而能从混合知识中获取高质量的组知识.为了提升知识的鲁棒性与多样性,结合多种数据混合技术,构建复合数据混合技术.不同于效率较低的高精度优化算法,采用简单高效的线性知识分解方法,将先前的组知识作为知识基,并将混合知识分解到知识基上,利用增强后的组知识蒸馏采样的子网.在多个主流的残差模型及图像分类数据集上的实验验证文中网络的有效性.
About Author:
TANG Shengji, Master student. His research interests include deep learning, model efficiency, and model design and enhancement.
YE Peng, Ph.D. candidate. His research interests include computer science, model design and optimization, and artificial intelligence for science.
LIN Weihao, Ph.D. candidate. His research interests include computer vision, image recognition, video processing and model compression.
such as stimulative training and group knowledge based training are employed to collect group knowledge from shallow subnets in residual networks for self-distillation, thereby enhancing network performance. However, the group knowledge acquired by these methods suffers from issues such as slow updating and difficulties in combining with DataMix techniques. To address these issues, enhanced residual networks via mixed knowledge fraction(MKF) are proposed. The mixed knowledge is decomposed and modeled as quadratic programming by minimizing the fraction loss, and thus high-quality group knowledge is obtained from the mixed knowledge. To improve the robustness and diversity of the knowledge, a compound DataMix technique is proposed to construct a composite data augmentation method. Different from high-precision optimization algorithms with poor efficiency, a simple and efficient linear knowledge fraction technique is designed. The previous group knowledge is taken as knowledge bases, and the mixed knowledge is decomposed based on the knowledge bases. The enhanced group knowledge is then adopted to distill sampled subnetworks. Experiments on mainstream residual networks and classification datasets verify the effectiveness of MKF.
近年来, 深度学习在计算机视觉的图像分类[1, 2, 3, 4]、语义分割[5, 6, 7, 8]、物体检测[9, 10, 11, 12]等领域都取得一定成功, 其中残差结构[3]使得在几十层甚至上千层的神经网络上进行成功训练成为可能.为了理解残差结构在训练优化中的背后机理, 研究者们[13, 14, 15, 16]试图从不同的角度进行研究, 其中一个较主流的解释是残差神经网络可看作是多个浅层子网的隐式集成[15], 称为展开视角.对该集成的优化可减小梯度反传的长度, 减缓梯度消失和网络崩溃.同时, 集成的特性也为网络提供更大的泛化性.
Chang等[17]提出EnsembleScale, 发现Transfor- mer[18, 19, 20]结构的神经网络同样可进行残差展开.这种思路为残差网络的进一步优化提供一种新视角, 即可通过对集成网络中单个子网的训练以提升网络的性能和泛化性.
在神经网络增强训练领域, 通过训练隐式集成网络中的单个子网以增强整体网络是一种常用方法.Dropout[21]认为神经网络可看作是不同通道数量子网的隐式集成, 并在训练时随机丢失一定的神经元以增强网络的泛化性.GradAug(Gradient Augmentation)[22]同样随机丢失一部分网络通道以形成子网, 并通过主网的输出对子网进行蒸馏, 形成增强梯度, 优化主网性能.
不同于上述工作的宽度展开, 也有大量的方法通过残差网络的深度展开视角实现残差网络的增强式训练.早期的工作, 如Stochastic Depth[23]在神经网络训练时采样不同深度的子网, 并使用真实标签对其进行监督.而ST(Simulative Training)[24]发现网络存在网络惰化(Network Loafing)的现象, 即单一训练隐式集成网络容易导致其中单个子网的性能劣化, 从而影响整体性能.因此ST使用整体集成的网络产生的软标签作为监督, 通过知识自蒸馏加强每个网络的性能.
而GKT(Group Knowledge Based Training)[25]认为直接使用集成网络的知识对子网进行蒸馏并非是最优的, 因为网络之间容量相差过大时容易引发蒸馏差距[26, 27, 28]问题, 从而导致小网络难以从主网学到知识.因此GKT收集训练时不同大小网络的知识, 并采用阶梯式的蒸馏方案, 保持较小的蒸馏距离.GKT的核心在于使用更优知识以指导展开视角下的子网, 从而增强整体残差网络的性能.因此在无额外网络参与的情况下, 要进一步增强残差网络的关键在于如何为子网提供更丰富和高质量的知识.正如GKT中提及的, 一个常用方式是使用多个子网的组知识形成集成知识.集成知识的获取是当前自蒸馏领域的一个重点问题.在线蒸馏[29, 30, 31, 32]的工作中使用各种各样的知识生成手法, 用于产生多样的组知识, 但都会引入额外的网络结构或需要同时训练多组网络, 增大训练消耗, 因此需要寻找更高效的优质组知识生成方法.
近来, 数据混合技术(DataMix)[33, 34, 35, 36], 如Mix-up[33], CutMix[34]等, 可在几乎不添加额外计算量的前提下让网络学习到更泛化、鲁棒的知识.DataMix技术主要是混合网络输入, 并使用混合的标签进行监督, 可看作是在训练数据上的凸组合形式, 从而提供更多样性的输入, 使神经网络可学习到更泛化的知识.DataMix不仅可一次性前馈多幅图像, 实现知识的更快更新, 同时也能产生更丰富多样的输出知识.然而DataMix技术却不能直接应用在组知识聚合中, 这是因为组知识聚合一般是要记录下每幅图像对应的历史知识, 然而在进行DataMix后其输出将是两幅图像的混合值, 无法更新对应的组知识.
因此, 针对DataMix后组知识无法聚合的问题, 本文从分解误差的二次规划(Quadratic Progra-mming)角度进行讨论, 提出基于混合知识分解的增强残差网络(Enhanced Residual Networks via Mixed Knowledge Fraction, MKF).网络使用复合的DataMix技术混合两个批量的输入图像, 产生混合输入, 同时在残差网络的深度维度上采样子网.该混合输入输入采样子网并产生混合输出.该混合输出被真实混合标签监督并产生梯度更新网络权重, 同时先前储存的组知识也将用于蒸馏该采样子网.最后该混合输出将视为混合知识, 并被线性知识分解技术分解并存储更新组知识.在目前主流的多个数据集和残差网络结构上的实验均证明本文网络取得较显著的性能提升, 同时验证各模块的有效性.
作为残差网络的一个重点研究方向, 隐式集成揭示残差结构在深层优化中的有效性机理.为了简便起见, 这里仅讨论卷积神经网络(Convolutional Neural Network, CNN), 对于其它类型的残差网络, 如Transformer, 也可使用相似的推理过程进行分析.
一般的残差CNN是由大量的残差块堆叠而成, 每个残差块中包含残差跳连层、卷积运算层、激活层、批归一化层(Batch Normalization, BN)等.为了便于表示, 将其中除了残差跳连层的部分使用函数f(· )表示, 则第i个残差块的输出:
y=f(x)+x,
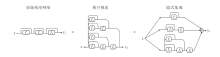
其中, x表示残差块的输入, 一般是图像的中间特征.y表示残差块的输出, 当多残差块堆叠时将会是顺序连接的形式, 以下标i表征其所在位置.以3个残差块组成的网络推导残差展开的过程, 具体如图1所示.
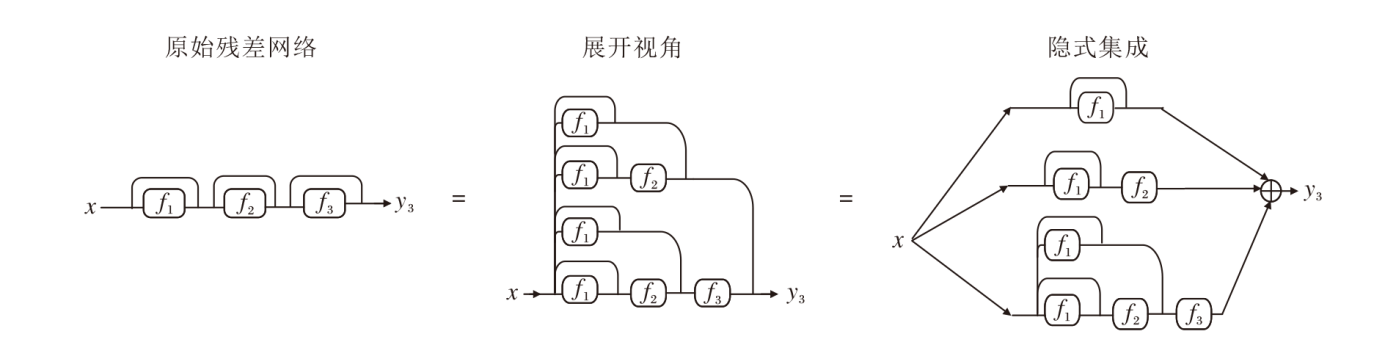 | 图1 残差网络的展开示意图Fig.1 Expanded diagram of residual networks |
图1中网络的输出:
y3=f3(y2)+y2=
f3[f2(y1)+y1]+f2(y1)+y1=
f3[f2(f1(x)+x)+f1(x)+x]+f2(f1(x)+x)+f1(x)+x,
展开后的每个分项, 如
f3[f2(f1(x)+x)+f1(x)+x],
f2(f1(x)+x), f1(x)+x,
分别表示深度为3, 2, 1的子网.因为y3去除中间变量, 仅用原始输入的表示是唯一的, 从而子网展开方式也是唯一的.需要说明的是, 为了简化表示, f1(x)与x合并写为深度为1的子网.通过不断进行等效替换可将残差网络的输出变为多个不同深度的子网的输出和, 对于更深的网络结构也可使用类似手法将其展开, 子网数量也会随着深度不断提升.
上述做法在深度维度上对网络输出进行子网分解, 揭示深度上的隐式集成.基于这种集成的思想, 组知识是通过知识聚合技术, 如对网络参数或特征输出的平均, 获取综合高质量的知识.相比网络中间层的输出, 网络最终层的输出经过多层映射, 具有最高度总结的抽象语义信息, 因此本文采用网络最终层的输出作为网络输出知识.这些组知识可用于对特定子网的监督, 从而促进残差网络的训练.
假设预先以网络参数量大小规定3个子网组, 不同大小的子网知识分别聚合形成不同的组知识.具体的聚合方式采用自监督领域中常用的指数滑动平均(Exponential Moving Average, EMA)[37], 可表示为
$K_{t}^{I}:=\alpha p({{\theta }_{t}}, x)+(1-\alpha )K_{t}^{I}$,
其中, x表示训练图像输入, I表示相应的图像在数据集上的编号, t表示当前采样子网对应的组编号, p表示网络输出的分类概率值, θ t表示当前子网的权重, α 表示EMA更新系数.
可发现, 知识聚合过程必须要获取当前网络输出对应的图像编号I以储存更新组知识.然而在DataMix技术中, 多幅图像将被混合, 导致无法使用I直接指导知识的更新位置.
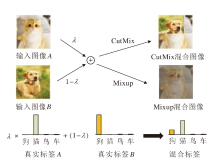
图2形象展示常用的两种DataMix技术— — CutMix和Mixup.
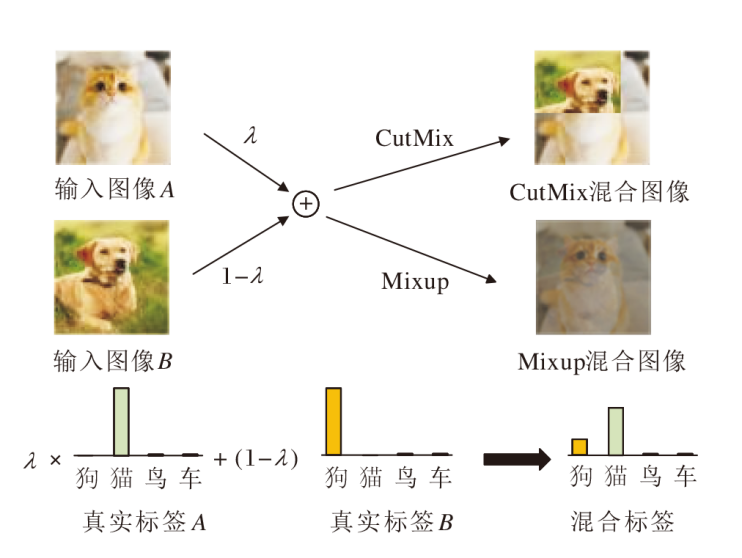 | 图2 DataMix示意图Fig.2 Explanation of DataMix |
Mixup是将两幅图像的像素值直接进行加权和, 可出现一种混叠的视觉效果; 而CutMix将一幅图像的某个区域裁剪并替换为另一幅图像的相应区域.DataMix技术通过产生额外的合成输入, 使网络能更好地关注到物体特征, 而不是背景等信息.
然而两种DataMix技术最终得到的混合图像包含两幅输入图像的特征, 这样得到的混合知识将不属于混合前的任意一幅图像, 难以利用.如果简单储存每种组合下的组知识, 由于混合加权系数是连续的, 会产生大量的组合, 导致难以忍受的储存开销, 同时混合的知识会对原有知识产生干扰, 从而提供混淆的监督.
因此, 本文引入知识分解技术, 将混合知识重新解耦, 分解到两幅图像对应的组知识上.
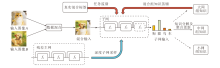
本文提出基于混合知识分解的增强残差网络(MKF), 整体框架如图3所示.图中, 子网的输出知识会根据当前组网的组别以更新对应的组知识, 因此知识分解与聚合的虚线部分表示每次输出可能更新的知识组, 图中以更新中网组知识作为示例.
 | 图3 MKF整体框架图Fig.3 Overall framework of MKF |
MKF主要包含如下步骤.
1)输入数据混合.不同于一般的单一输入, 为了提升组知识的鲁棒性, 首先从数据集上采样两批不同的图像, 然后利用本文提出的复合数据混合技术, 混合两组图像为单批图像, 作为网络输入.
2)继承式子网采样.从网络的深度维度对原始残差网络(主网)提取权重耦合的子网进行训练.同时, 该采样方法会依据采样的继承顺序确定该子网的组别归属.为了确保采样最终不会最后局限于最小的子网, 在经过一定的训练步骤后, 采样会重新从主网开始.
3)知识分解与聚合更新.混合输入提供给采样子网进行输出, 该输出作为混合知识.因为混合知识很难被直接利用, 因此采用线性分解的方式分解混合知识, 并使用EMA对相应的组知识进行聚合更新.
4)组知识蒸馏和真实标签监督.更新结束后会利用较大组别的复合组知识对采样子网进行蒸馏, 同时利用真实标签进行监督, 两个监督信息会同时反传进行网络优化.最终的优化损失:
Lall=Ltask+β LKD.
其中
Ltask=CE(p(θ t, x), y),
表示分类任务的交叉熵损失(Cross Entropy, CE);
${{L}_{KD}}=KL({{\hat{K}}^{{{^{t}}^{-1}}}}||p({{\theta }_{t}}, x))$,
表示使用较大的网络组复合组知识对当前采样子网的蒸馏监督, 其中采用KL散度(Kullback-Leibler Divergence)对其进行监督.值得注意的是, 这里使用的复合组织为两批图像对应组知识的线性加权和, 即
${{\hat{K}}^{^{t}}}=\lambda K_{{{I}_{1}}}^{t}+(1-\lambda )K_{{{I}_{2}}}^{t}$.
其中:I1、I2表示混合图像的序号, 如在数据集上的编号, 可单独分辨每幅图像; t表示网络所属的组号, 越大表示组内网络容量越小; λ 表示图像混合加权系数.
为了分解网络产生的混合输出, 建模网络的混合输出为网络对于两幅图像真实响应的线性组合, 即
$\tilde{p}(\theta , \tilde{x})=\lambda {{p}_{a}}(\theta , {{x}_{a}})+(1-\lambda ){{p}_{b}}(\theta , {{x}_{b}})$,
其中, $\tilde{x}$表示混合输入图像, λ 表示图像a对应的混合加权系数, θ 表示当前的网络系数.
为了简便, 在下面的公式中省略输入图像和相应的网络参数.目标是通过混合输出响应$\tilde{p}$及λ 估计pa与pb.该分解任务可建模为一个优化问题, 若采用均方损失作为最后的优化目标, 则可表示为一个二次规划问题:
$\arg \underset{\tilde{p}{{~}_{a}}, \tilde{p}{{~}_{b}}}{\mathop{\min }}\, \lambda \|{{\tilde{p}}_{a}}-{{p}_{a}}\|_{2}^{2}+(1-\lambda )\|{{\tilde{p}}_{b}}-{{p}_{b}}\|_{2}^{2}$,
$\text{s}\text{. t}\text{. }0\le {{\tilde{p}}_{a, i}}\le 1, \ 0\le {{\tilde{p}}_{b, i}}\le 1, i=1, 2, \ldots , n$,
$\overset{n}{\mathop{\underset{i=1}{\mathop \sum }\, }}\, {{\tilde{p}}_{a, i}}\text{=}1, \overset{n}{\mathop{\underset{i=1}{\mathop \sum }\, }}\, {{\tilde{p}}_{b, i}}\text{=}1$,
其中, ${{\tilde{p}}_{a}}$、${{\tilde{p}}_{b}}$表示真实响应的估计值, n表示分类数量.然而直接进行估计是不可能的, 因为该问题的真实响应pa与pb是未知的, 该问题是信息缺失的.因此, 本文引入之前对应得到的组知识Ka与Kb作为参照向量, 或称为知识基.知识基与真实响应间存在一定误差, 但是在充分训练后可与真实响应的方向相同.通过引入知识基, 本文将$\tilde{p}$分解到两个基上, 该二次规划问题可重写为
$\arg \underset{\tilde{p}{{~}_{a}}, \tilde{p}{{~}_{b}}}{\mathop{\min }}\, \lambda \|{{\tilde{p}}_{a}}-{{K}^{a}}\|_{2}^{2}+(1-\lambda )\|{{\tilde{p}}_{b}}-{{K}^{b}}\|_{2}^{2}$,
$\text{s}\text{. t}\text{. 0}\le {{\tilde{p}}_{a, i}}\le \text{1, 0}\le {{\tilde{p}}_{b, i}}\le \text{1, }i=1, 2, \ldots , n$,
$\overset{n}{\mathop{\underset{i=1}{\mathop \sum }\, }}\, {{\tilde{p}}_{a, i}}\text{=}1, \overset{n}{\mathop{\underset{i=1}{\mathop \sum }\, }}\, {{\tilde{p}}_{b, i}}=1$.
二次规划问题作为最优化领域的经典问题, 已有大量的优化算法, 如有效集法[38]、内点法[39, 40]等, 可对其进行求解.然而这些优化算法一般仅能在CPU(Central Processing Unit)上运行, 无法在GPU(Graphics Processing Unit)上进行并行化计算, 当引入训练流程后会严重影响速度, 特别是训练量较大的深度学习任务.因此本文尝试采用文献[41]中提出的可微二次优化层, 使用并行化求解算法进行加速, 下文称为OPT1方案.然而, 尽管OPT1已针对GPU进行优化, 但仍需要多轮数值迭代和判定, 当n增大时会大幅增加运算消耗, 在n=100时大约会造成2倍的训练时间开销, 当n进一步增大到1 000时, 将带来难以忍受的训练时间开销.
同时为了进一步对二次规划问题进行加速求解, 本文设计一种线性知识分解方法, 不会对该优化问题进行精确求解, 而是采用直接的线性估计以具有一定误差的方式求解, 估计的具体表达如下:
${{\tilde{p}}_{a}}=\frac{\tilde{p}-\left( 1-\lambda \right)K{{\text{ }\!\!~\!\!\text{ }}^{b}}}{\lambda }$,
${{\tilde{p}}_{b}}=\frac{\tilde{p}-\lambda K{{\text{ }\!\!~\!\!\text{ }}^{a}}}{1-\lambda }$.
该线性知识分解方法直接将组知识基直接作为另一幅图像响应的代理估计.假设其代理误差
Δ =K-p,
带入线性组合公式, 得
${{\tilde{p}}_{a}}=\frac{\lambda {{p}_{a}}+\left( 1-\lambda \right){{p}_{b}}-\left( 1-\lambda \right)\left( {{p}_{b}}+{{\Delta }_{b}} \right)}{\lambda }={{p}_{a}}-\text{ }\!\!~\!\!\text{ }\frac{1-\lambda }{\lambda }{{\Delta }_{b}}$,
${{\tilde{p}}_{b}}=\frac{\lambda {{p}_{a}}+\left( 1-\lambda \right){{p}_{b}}-\lambda \left( {{p}_{a}}+{{\Delta }_{a}} \right)}{1-\lambda }{{p}_{b}}-\frac{\lambda }{1-\lambda }{{\Delta }_{a}}$,
则其分解损失可写为
$\lambda \|{{\Delta }_{a}}\|_{2}^{2}+(1-\lambda )\|{{\Delta }_{b}}\|_{2}^{2}$.
该分解损失取决基与真实响应的差值.当基与真实响应的差值较小时, 该线性知识分解方法的误差较小, 而随着网络优化的进行, 网络的特征提取能力增强, 总结出的基与真实响应的误差也会逐渐减小.下文称为OPT2方案.相比OPT1方案, OPT2方案分解的误差较大, 但不涉及任何迭代, 计算量极小.
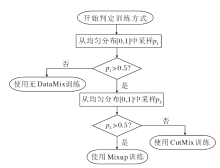
不同于一般方法中使用单一的DataMix, 本文采用复合的数据混合策略, 提供更鲁棒、高质量的组知识, 具体流程图如图4所示.
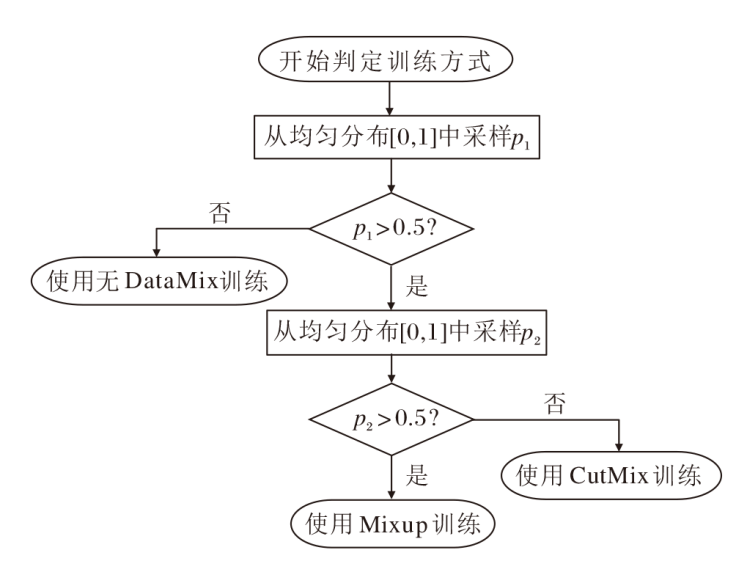 | 图4 复合数据混合流程图Fig.4 Flow chart of compound DataMix |
知识分解的质量取决于知识基(组知识)的质量, 因此在训练的早期将进行无DataMix的预热, 获取高质量的组知识.在预热完成后, 为了继续保持对组知识的高质量分解, 将以相同概率选择采用或不采用DataMix技术对输入进行混合.对于DataMix技术本身, 本文使用Mixup与CutMix等概率使用的策略, 从而大幅增加知识的丰富度.具体地, 在每次获取批量数据后会进行一次伯努利采样, 确定是否采用DataMix.如果采用DataMix, 会再次进行一次采样, 判定使用哪一种DataMix.
为了采样时能较容易地获取该次采样子网的组别, 本文采取一种继承式子网采样策略, 即每次采样时会将上一次采样的子网作为父网进行采样, 这样可保证每次采样的子网会小于上次采样的网络.继承式采样的顺序作为组标号, 标志采样的子网属于某个确定的组, 用于收集组知识, 其公式化表达为
$D_{t+1}^{r}=\Phi (D_{t}^{r})$.
其中:$D_{t}^{r}$表示第r次循环中, 组别为t的子网, 序号越大表示组中的子网越小, 总组数为T; Φ (· )表示深度采样, 为了使每次采样的子网不会过小, 本文采用指数分布的采样概率, 即后层丢失概率较大, 前层丢失概率较小, 二者概率呈现指数分布.
每次采样后子网的大小都会有所减小, 形成层级式的子网群, 更有利于之后的蒸馏中缩小蒸馏差距.同时小子网是从大子网采样中产生的, 自然形成一种阶梯式的子网大小分布, 可不用精准测定子网的容量大小确定其所属组编号.
本文选择中小型数据集CIFAR-100[42]、Tiny ImageNet, 大型数据集ImageNet[43], 在5种残差主干网络:ResNet50[3]、 ResNet34[3]、 WideResNet28-10[44]、WideResNet16-8[44]、MobileNetV3[45]上进行实验.ResNet为图像检测、分割等下游任务常用的主干网络, 用于验证MKF具有能在实际部署中取得性能增益的潜力.MobileNetV3是一种通过神经网络架构搜索得到的轻量化移动端模型架构, 用于验证MKF具有能与其它网络增强方案结合的能力.
所有实验均采用Pytorch作为深度学习架构, 并在英伟达Tesla V100上运行, 所得的训练时间均折算成单卡GPU时间.
为了保证对比公平, 所有对比方法均在同套基础训练参数下进行, 并使用对应的最优超参数.本文采取的基线训练算法, 即下文图表中的Baseline, 是采用标准的梯度下降算法对相应的神经网络进行训练.
对于MKF引入的少量超参数, 包括优化损失比例β , EMA更新系数α , 继承式子网采样的组数T, 可人工指定或使用网格搜索的方式确定.为了不引入过多的人为拟合偏置, 本文仅进行典型值设置, 对同个数据集上的所有网络都采用同组超参数.在所有数据集上α =0.5, T=3.而β 则在不同数据集上分别设置.
CIFAR-100数据集[42]为一个100类的自然图像分类数据集, 每幅图像为RGB三通道的彩色图像, 分辨率为32× 32.训练集包含50 000幅图像, 测试集包含10 000幅图像.在训练时, 本文使用SGD(Sto-chastic Gradient Descent)作为优化器, 采用余弦下降的学习率衰减策略.权重衰减系数为0.000 3.数据增强方面使用中心随机裁剪、随机颜色扰动、随机水平翻转.对于ResNet34、ResNet50、MobileNetV3, 总共训练周期为500, 每批图像数量为64, 初始学习率为0.05.对于WideResNet28-10、WideResNet16-8, 初始学习率为0.1, 总共训练周期为200, 每批图像数量为128.优化损失比例β =2.
Tiny ImageNet数据集为一个200类的自然图像分类集, 是从ImageNet数据集[43]上分离而来的子集.所含图像为RGB三通道彩色图像, 分辨率为64× 64.训练集包含100 000幅图像, 测试集包含10 000幅图像.本文采用和CIFAR-100数据集基本相同的实验设置, 不同之处在于, 对于ResNet34、ResNet50、MobileNetV3, 初始学习率为0.1, 同时采用阶段衰减的学习率衰减策略, 学习率在第250、375周期时都会衰减10倍.对于WideResNet28-10、WideRes-Net16-8, 初始学习率为0.2, 学习率在第100、150周期时都会衰减10倍.优化损失比例β =2.
ImageNet数据集[43]为自然图像分类领域使用最广泛的大型数据集, 包含大量高清、分辨率不同的RGB三通道彩色图像.标定1 000类, 训练集包含约1 280 000幅图像, 测试集包含50 000幅图像, 本文使用2012版本.训练中使用SGD作为优化器, 初始学习率为0.2, 并使用余弦下降的学习率衰减策略.权重衰减值为0.000 1, 每次训练的批大小为512.数据增强方面与CIFAR-100数据集基本相同, 唯一区别为使用随机分辨率缩放, 128× 128、144× 144、160× 160的等概率采样, 通过线性插值进行缩放, 进一步增强性能.优化损失比例β =0.5.
为了验证MKF的优越性, 在3个数据集以及残差网络上进行多组实验, 并和如下方法进行对比:基线方法(Baseline)、Stochastic Depth[23]、ST[24]、GKT[26]、ONE(On-the-Fly Native Ensemble)[29]、CS-KD(Class-Wise Self-Knowledge Distillation)[46]、PS-KD(Pro-gressive Self-Knowledge Distillation)[47]、LWR(Lear-ning with Retrospection)[48]、DLB(Self-Distillation from Last Mini-Batch)[49].
CIFAR-100、Tiny ImageNet数据集上的图像分类Top-1精确率结果如表1和表2所示, 表中黑体数字表示最优值.由表可观察到, 在2个数据集与多种残差网络结构下, 相比Baseline, MKF均可取得显著增益.相比Baseline, MKF能使ResNet50在CIFAR-100数据集上Top-1精确率提升5.28%, 使ResNet34在Tiny ImageNet数据集上Top-1精确率提升6.54%.这说明MKF是一种较通用的残差网络增强方法, 能较容易地部署到不同的网络结构与数据集上.同时, 相比自蒸馏增强方法或展开式增强方法, MKF也能持续的在各个网络结构和数据集上取得领先.在CIFAR-100、Tiny ImageNet数据集上, 相比次优方法, MKF的Top-1精确率也能分别提升1.66%与2.16%.这说明即使与当前的先进方法相比, MKF依然能取得具有相当竞争力的结果, 这进一步说明使用鲁棒知识蒸馏的方案能直接提升网络的泛化能力, 提升网络性能.
| 表1 各方法在CIFAR-100数据集上的Top-1精确率对比 Table 1 Top-1 precision comparison of different methods on CIFAR-100 dataset % |
| 表2 各方法在Tiny ImageNet数据集上的Top-1精确率对比 Table 2 Top-1 precision comparison of different methods on Tiny ImageNet dataset % |
各方法在ImageNet数据集上的ResNet50主干网络的Top-1精确率和显卡训练时间如表3所示, 表中黑体数字表示最优值.
| 表3 各方法在ImageNet数据集上的指标值对比 Table 3 Index value comparison of different methods on ImageNet dataset |
由表3可发现, 相比Baseline, MKF能取得较明显的性能增益(+1.25%), 同时仅有略微的训练时间增加.即使是在1 000类分类的困难任务及百万级别的大规模数据集上, MKF仍能持续提升网络性能, 这表明MKF在数据量及任务难度上的可拓展性.同时较小的训练时间负担也表明MKF并不是以更大的训练消耗换取的性能提升, 是一种轻负担的网络训练增强方法, 具有广泛应用于当前标准训练流程的潜力.同时, 相比其它增强方法, MKF也能取得最优的性能表现, 增加0.43%的Top-1精确率, 这表明MKF的优越性.
本文在CIFAR-100数据集上使用ResNet50, 逐渐去除主要组分, 探究各组分对MKF性能提升的贡献, 测试本文提出的各模块的有效性.
具体消融实验结果如表4所示, 表中第1行表示MKF的完整方法, 取得最优的性能表现.在第2行中直接使用混合知识更新较大系数图像对应的组知识, 去除知识分解的技术, 可观察到, 相比完整版本MKF, 出现性能下降, 这间接表明使用混合知识直接更新组知识可带来一定的性能提升, 但是不进行分解仍会带来干扰, 说明本文提出的知识分解技术的有效性.在第3行~第5行中进一步去除复合知识混合, 性能出现逐步下降的趋势, 这说明复合数据混合和组知识蒸馏的有效性.为了单独验证性能增益是否来自于复合数据混合, 第4行中还单独验证复合数据混合, 可看到, 相比第5行Baseline而言, 获得明显的性能提升, 然而相比第1行完整MKF, 仍有一定的性能下降, 这表明复合知识分解能带来性能增益, 但是并不是MKF获得性能提升的全部原因.
| 表4 各模块的消融实验结果 Table 4 Results of ablation experiments of different modules % |
本节对比OPT1和OPT2这2种知识分解方法, OPT1是使用文献[41]提出的二次规划优化算法得出的结果; OPT2是采用线性估计算法的结果; No OPT是直接使用混合知识更新较大系数的图像对应的组知识, 可看作是无知识分解的方案.使用Res-Net50主干网络在CIFAR-100数据集上的性能对比如表5所示, 表中黑体数字表示最优值.观察表可知, 在结合缓解措施后, 相比No OPT, OPT1和OPT2都可大幅提升网络性能, 同时相比OPT1, OPT2仅有少量的性能下降, 这说明OPT2也能进行相对高质量的分解, 带来的知识估计误差处于可容忍的水平.然而OPT1却会带来约2.1倍的训练时间.
| 表5 不同知识分解方法的指标值对比 Table 5 Index value comparison of different knowledge fraction methods |
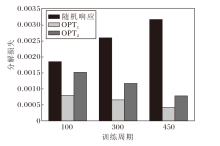
在不同训练阶段下的真实分解损失如图3所示, 图中添加随机响应作为对比基线方法, 以显示OPT1和OPT2对分解损失的减小.观察图可知, 相比随机响应, OPT1和OPT2都可明显降低分解损失, 这表明这两种分解方法在知识分解上的有效性.随着网络训练的进行, 随机响应的分解误差逐渐增大, 这是由于网络的预测在逐渐准确, 从而输出趋向于独热化, 与均匀的随机响应的误差逐渐增大.同时OPT1和OPT2的分解误差是在逐渐减小, 这是由于组知识基逐渐准确, 能更贴近真实的响应.在训练前期使用OPT2进行知识分解会带来较大的分解损失, 产生不良结果并大幅影响网络性能.因此本文为了缓解OPT2带来的分解不准确, 在训练前期(约10%的总训练周期)不进行DataMix作为预热阶段, 等待组知识基逐渐准确后再进行分解.同时采用复合式的DataMix策略, 在一半的训练时间不进行Data-Mix, 从而进一步使组知识基更准确.
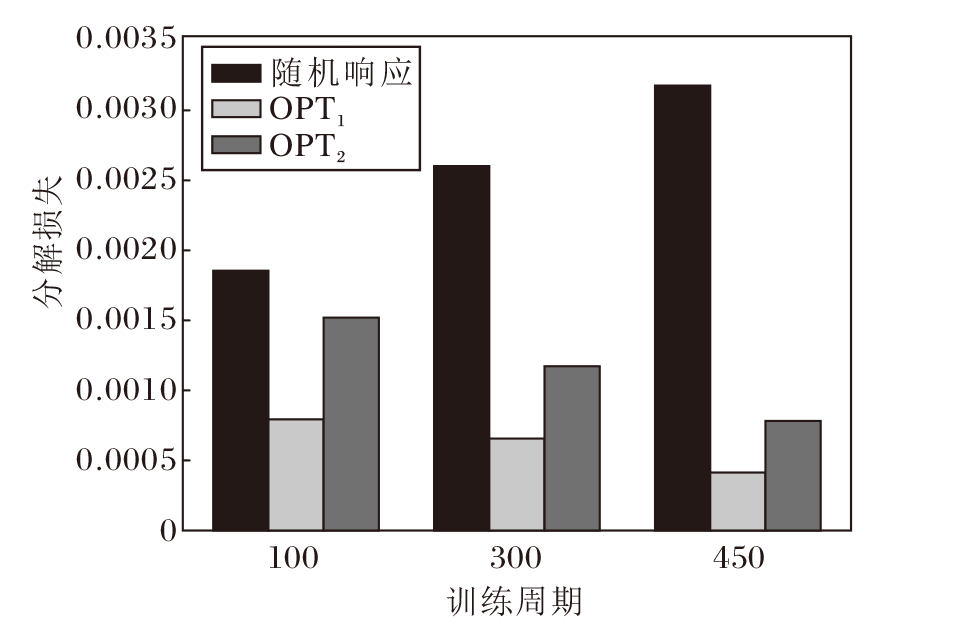 | 图5 不同训练周期下的分解损失Fig.5 Fraction loss in different training periods |
综合算法效率与性能, 本文采取OPT2作为默认的知识分解方法.
为了可视化评估MKF对网络图像特征提取能力的提升, 在ImageNet测试集上随机采样两幅图像, 使用ImageNet训练后的ResNet50作为测试方法, 因原始CAM(Class Activation Mapping)[50]需要进行额外的训练, 本文采用GradCAM(Gradient Weighted CAM)[51]对标准训练下的基线网络和MKF增强后的网络进行可视化分析.其中基线方法是指在2.1节参数配置下, 使用标准的梯度下降算法进行训练.
可视化分析结果如图6所示, 使用热力图表征网络的注意力分布情况, 越红的地方表示其对网络最后做出决断的影响越大.
 | 图6 各方法的可视化分析结果Fig.6 Visualization analysis of different methods |
由图6可见, 相比基线方法, MKF可更集中地提取图像的关键特征并排除背景的干扰, 例如:更关注飞鸟而不是天空, 更关注蜥蜴的全身而不是蜥蜴的头部.这种特征提取能力的增强源于复合数据混合会逐步排除无关背景的影响及组知识对于网络泛化性的增强.
本文分析目前残差神经网络中使用组知识进行自蒸馏方法面临的困境, 即知识丰富度不足、更新速度较慢, 并提出基于混合知识分解的增强残差网络(MKF), 强化网络的泛化性.为了将网络产生的混合知识进行分解, 将该分解问题看作一个二次规划问题, 并设计一种高效的线性分解方式, 产生高质量的组知识.在当前主流的数据集及残差网络上, 与当前的自蒸馏方法进行对比, 验证MKF的优越性.由于MKF的高效性和泛用性, 有潜力成为一种通用的增强残差网络的训练流程.然而MKF仍存在一些局限性.首先, 在储存组知识时会产生额外的储存开销, 在带来性能提升的同时会使训练流程变得更复杂.其次, 本文使用的OPT2虽然具有较快的计算速度, 但相比标准的OPT1, 仍会略微降低最终网络的性能.因此设计一种快速而更高质量的组知识分解方案是未来一个值得继续研究的方向.
本文责任编委 陈松灿
Recommended by Associate Editor CHEN Songcan
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|
| [40] |
|
| [41] |
|
| [42] |
|
| [43] |
|
| [44] |
|
| [45] |
|
| [46] |
|
| [47] |
|
| [48] |
|
| [49] |
|
| [50] |
|
| [51] |
|