






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于分类风险的半监督集成学习算法
[何玉林1, 2  , 朱鹏辉
, 朱鹏辉2 , 黄哲学1, 2 , PHILIPPE Fournier-Viger2 ]
, 朱鹏辉, 黄哲学, PHILIPPE Fournier-Viger]
|
|



作者简介:

朱鹏辉,硕士研究生,主要研究方向为数据挖掘、机器学习.E-mail:1007435023@qq.com.

黄哲学,博士,特聘教授,主要研究方向为数据挖掘、机器学习、大数据系统计算技术.E-mail:zx.huang@szu.edu.cn.

PHILIPPE Fournier-Viger,博士,特聘教授,主要研究方向为数据挖掘、人工智能、知识表示和推理、认知模型建构等.E-mail:philfv@szu.edu.cn.
针对当前半监督集成学习算法对无标记样本预测时容易出现的标注混沌问题,文中提出基于分类风险的半监督集成学习算法(Classification Risk-Based Semi-supervised Ensemble Learning Algorithm, CR-SSEL).采用分类风险作为无标记样本置信度的评判标准,可有效衡量样本标注的不确定性程度.迭代地训练分类器,对高置信度样本进行再强化,使样本标注的不确定性逐渐降低,增强半监督集成学习算法的分类性能.在多个标准数据集上验证CR-SSEL的学习参数影响、训练过程收敛和泛化性能提升,实验表明随着基分类器个数的增加,CR-SSEL的训练过程呈收敛趋势,获得较优的分类精度.
About Author:
ZHU Penghui, Master student. His research interests include data mining and machine learning.
HUANG Zhexue, Ph.D., distinguished professor. His research interests include data mining, machine learning and big data system computing technologies.
PHILIPPE Fournier-Viger, Ph.D., distinguished professor. His research interests include data mining, artificial intelligence, knowledge representation and inference and cognitive model construction.
The existing semi-supervised ensemble learning algorithms commonly encounter the issue of information confusion in predicting unlabeled samples. To address this issue, a classification risk-based semi-supervised ensemble learning(CR-SSEL) algorithm is proposed. Classification risk is utilized as the criterion for evaluating the confidence of unlabeled samples. It can measure the degree of sample uncertainty effectively. By iteratively training classifiers and restrengthening the high confidence samples,the uncertainty of sample labeling is reduced and thus the classification performance of SSEL is enhanced. The impacts of learning parameters, training process convergence and improvement of generalization capability of CR-SSEL algorithm are verified on multiple standard datasets. The experimental results demonstrate that CR-SSEL algorithm presents the convergence trend of training process with an increase in the number of base classifiers and it achieves better classification accuracy.
半监督集成学习(Semi-supervised Ensemble Lear-ning, SSEL)[1, 2, 3]是一种将半监督学习和集成学习进行融合的机器学习范式, 近年来受到学者们的广泛关注.SSEL利用大量无标记样本对集成学习进行扰动, 增强集成学习的多样性, 并进一步提升半监督学习的性能.
半监督学习[4, 5]通过少量有标记样本建立初始分类器, 利用大量无标记样本提升分类器性能.基于有标记样本和无标记样本来自同一分布的假设, 大量无标记样本可帮助算法挖掘数据分布的潜在信息, 构建具有强泛化能力的模型.集成学习[6, 7]采用特定策略训练多个分类器, 预测样本类别时, 融合多个分类器的输出, 获得最终结果.半监督学习和集成学习分别着重考虑模型的输入和输出, 结合二者可共同提升模型的泛化性能.Zhou[8]从基于分歧的半监督学习方法出发, 同时考虑半监督学习与集成学习的特性, 证实SSEL的合理性与有效性.
根据是否需要划分数据集的特征空间, SSEL可分为基于单视图的SSEL和基于多视图的SSEL.一个数据集可能有多个属性集, 因此每个样本可同时拥有多个表现形式的属性集, 每个不同的属性集称为数据的“ 视图” .周志华[9]指出, 多视图学习任务的前提条件是数据具有两个及以上的充分冗余且满足条件独立性的视图.“ 充分” 意味每个视图含有丰富的信息, 能生成最佳的分类器, 而针对某一个视图, 其余视图是“ 冗余” 的.同时, 对无标记样本的预测, 这两个视图互不影响、相互独立.
然而, 视图条件独立性这一假设较苛刻, 在实际应用中很难满足.另外, 模型训练会受到“ 噪声” 等因素的影响, 仅以Co-training[10]通过分类器相互提供伪标记的方式难以获得最佳分类器.如果分类器在预测样本时, 评判样本的置信度, 可有效缓解噪声等因素对模型产生的影响, 从而利用无标记样本提升模型性能, 因此基于多视图的SSEL多以Co-training为基础展开[11].Wang等[12]将二视图扩展为多视图, 提出RASCO(Random Sub-space Co-trai-ning), 分析数据特征的划分和分类器个数对算法性能的影响, 再利用无标记样本扩大训练集.Yaslan等[13]指出, 如果存在许多不相关的特征, RASCO并不能获得最优子空间, 因此提出Rel-RASCO(Re-levant RASCO), 利用特征和类之间的互信息生成相关的随机子空间, 避免选择不相关的特征, 可有效改进RASCO.
盛小春等[14]采用粗糙集属性简约的方式, 提出基于粗糙子空间的协同决策算法.先分割数据属性, 训练两个差异化明显的分类器, 再引入决策粗糙集理论, 筛选无标记样本, 形成最小风险代价决策, 扩展子空间的训练集.Kim等[15]提出MCT(Multi-co-training), 将协同训练的二视图扩展为三视图, 结合文档表示的特定方案生成三个视图.与协同训练的算法一致, MCT将高置信度文档加入另外两个视图的训练集中, 有效解决文档分类中信息缺乏的缺陷.陈圣楠等[16]提出基于多视图SSEL的人体动作识别算法, 以Co-training为基础, 通过收集穿戴设备的行为数据构成不同视图, 并且利用LightGBM[17]的策略构建多个分类器.算法拥有接近于全量标签样本的训练效果, 可有效解决人体动作识别难以获得大量标签样本的问题.
Wang等[18]证明基于分歧的学习方法并不一定要求多视图, 仅要求分类器存在适当的分歧, 多视图的优越性在于使分类器产生更大分歧, 提高学习过程的多样性, 若视图划分不当, 反而会导致分类器的性能恶化.与多视图任务不同, 基于单视图的SSEL不需要划分训练集的特征空间, 仅利用多个分类器间的分歧挖掘数据中的信息, 这种分歧可通过训练集样本、基分类器以及优化基分类器的超参数等方面产生, 因此适用范围更广泛.
基于单视图的SSEL起源于Tri-training[19], 利用Bootstrap[20]选取三个不同的训练集训练三个分类器, 利用三个有差异的分类器预测无标记样本, 并且采用“ 少数服从多数” 的原则对无标记样本加以利用, 从而达到提升分类器泛化性能的目的.Livieris等[21]基于Self-training[22]、Co-training及Tri-trai- ning, 提出CST-Voting.不同于Tri-training对样本集扰动增加集成多样性的方式, CST-Voting直接利用三种不同的算法对输出进行扰动.集成后的性能优于单种算法的性能, 并成功应用于生物医学领域.de Vries等[23]提出RESSEL(Reliable SSEL Method), 在单个视图下使用Self-training训练初始分类器, 利用集成的方式使自训练过程对初始配置的敏感度达到平均.由于自训练算法的不确定性, 基分类器被训练后将更多样化, 从而提升集成学习的多样性.
Marak等[24]初始选取K近邻(K-Nearest Neigh-bor, KNN)[25]、支持向量机(Support Vector Machine, SVM)[26]及随机森林(Random Forest, RF)[27]这三种不同的分类器, 定义新的置信度判定标准, 计算每两类间的得分差筛选样本, 提高算法性能.Wu等[28]针对推荐系统中出现的数据稀疏性问题, 提出SSEF(Semi-supervised Ensemble Filtering), 引入三个不同的滤波算法训练初始学习器, 合并其中两个学习器, 同时针对分类器的特点引入不同的置信度评判准则.赵静等[29]结合现实应用, 提出基于集成SVM和Bagging[20]的未知恶意流量检测算法, 利用Multi-SMOTE策略及谱聚类的特点, 筛选高质量训练样本.再采用Bagging的集成策略, 训练多个SVM分类器, 通过对错误样本的反复迭代, 获取最优参数.
无论是多视图任务还是单视图任务, 当多个分类器对样本类别进行判定时, 如果样本的预测类别信息处于混沌状态, 那么最终输出类别标签不可靠.因此, 本文针对多个分类器预测样本过程中出现的标注混沌问题, 提出基于分类风险的半监督集成学习算法(Classification Risk-Based Semi-supervised En- semble Learning Algorithm, CR-SSEL).分类风险[30]能有效衡量样本标注的不确定性程度, 利用分类风险指标可有效判定样本标注的置信度大小.在CR-SSEL迭代训练的过程中, 通过对分类器的不断强化, 使每个样本在加入训练集时, 分类风险最小, 同时利用集成学习降低模型误差, 进一步提升模型的分类性能.另外, 虽然高置信度样本的伪标记通常被认为是正确的, 但若被错误估计, 并不能保证分类性能的提高, 同时会使后续迭代过程分类器性能降低.因此, CR-SSEL设置一个可信队列, 对高置信度样本进行再评判, 将分类风险最小的一部分高置信度样本加入训练集中进行训练, 并对剩余的高置信度样本再强化, 而低置信度样本加入后续的迭代中, 等待更新后的分类器对其重新预测.因此, CR-SSEL可对低置信度样本重新标注, 并对高置信度样本的伪标记重新判定, 从而进一步提升高置信度样本的置信度.
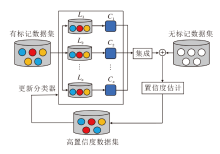
半监督集成学习(SSEL)通过结合特定领域的知识或其它优化算法, 利用半监督学习和集成学习的特性对模型不断迭代更新, 使模型性能不断增强.SSEL框架如图1所示.具体执行步骤如下.
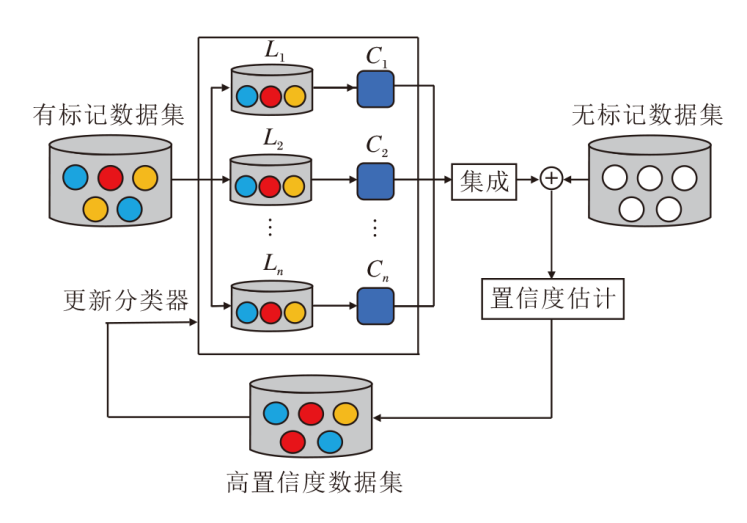 | 图1 SSEL框架图Fig.1 Framework of SSEL algorithm |
step 1 依据需要划分数据集的特征空间, 利用特定的数据生成策略从数据集D上获取训练集L.
step 2 在训练集L上训练n个不同的基分类器C1, C2, …, Cn.
step 3 基分类器C1, C2, …, Cn对无标记样本集U上的每个样本Ui(i=1, 2, …, k)进行伪标记的标注, 得到高置信度样本集
step 4 高置信度样本集
step 5 从无标记样本集U中删除高置信度样本集
step 6 重复step 2~step 5, 直至终止条件.
从SSEL框架中可发现, 划分视图、训练有分歧的分类器、置信度评判及终止是SSEL的关键步骤.
对于多视图任务, 训练有分歧的分类器是通过将数据集划分为不同的特征子空间这一方式进行的, 常见的划分方式有随机划分、均匀划分、有序划分等.对于单视图任务, 可将数据集划分为多个不同的训练子集, 常见策略是选择不同的分类器、优化分类器超参数或Boosting的训练方式等.
置信度评判标准是对无标记样本有效利用的准则, 若置信度评判标准选择恰当, 能最大限度发挥无标记样本的作用, 提升分类器性能.反之, 分类器的性能将在迭代过程中不断下降, 导致过拟合现象的出现.针对不同问题, 置信度评判标准有不同的选择方式, 如分类器的预测概率、数据的相似性结构等.
算法最终停止需要满足终止条件.一种常见的方式是将无标记样本全部打上伪标记, 并加入训练集中, 这种方式可能会引入一些误分类的样本, 导致分类器分类性能的下降.另一种常见的方式是到达指定的迭代次数之后停止训练, 此时会丢弃一些无标记样本.这种方式有利于加快分类器的训练速度, 但不利于提升模型的泛化能力.
在机器学习中, 有多种不同形式的不确定性, 最常见的是模型输出的概率分布.一般而言, 不确定性主要分为模型的不确定性和数据的不确定性.
1)模型的不确定性.模型自身对输入数据的估计可能因为训练不佳、训练数据不够等原因而不准确, 与某一单独的数据无关.因此, 这种不确定性可通过增加训练数据的数量、对数据进行预处理、调节模型的超参数等方式降低不确定性.
2)数据的不确定性.描述数据中内在的噪声, 该噪声无法忽视, 这个现象不能通过增加采样数据以避免.例如, 拍照的手略微颤抖画面就会模糊, 这种数据不能简单的通过增加拍照次数消除.因此, 解决这类问题的方式一般是提升数据采集时的稳定性、使用平滑技术、进行异常值处理或采用特定领域的知识.上述方式虽然不能完全避免“ 噪声” 的影响, 但也能尽量减少这一负面因素对分类器性能的影响.
在机器学习中, 分类风险[30]是指分类模型对新样本进行分类时可能引入的错误或不确定性, 是评估模型准确性和鲁棒性的重要指标之一.分类风险除了可以帮助预测类别标签以外, 还可以估计模型对样本分类的不确定性.本文使用正态分布刻画分类器对样本进行标注的风险, 即计算样本类间正态分布的交叠面积, 这个交叠面积即为分类风险的值, 以此度量不确定性的标准, 它可用于对比样本所属的不同类之间的相似性.
对于一个m分类任务{P1i, P2i, …, Pni}, i=1, 2, …, m, 对应的概率密度函数为:
${{P}_{i}}(x)=\frac{1}{\sqrt{2\pi }{{\sigma }_{i}}}\exp \left[ -\frac{1}{2}{{\left( \frac{x-{{\mu }_{i}}}{{{\sigma }_{i}}} \right)}^{2}} \right]$.(1)
其中均值和标准差计算如下:
${{\mu }_{i}}=\frac{1}{n}\overset{n}{\mathop{\underset{j=1}{\mathop \sum }\, }}\, {{P}_{ji}}$,
${{\sigma }_{i}}\text{=}\sqrt{\frac{1}{n-1}\overset{n}{\mathop{\underset{j=1}{\mathop \sum }\, }}\, {{({{P}_{ji}}-{{\mu }_{i}})}^{2}}}$.
类u和类v的分类风险可由概率密度函数之间的相交面积进行估计, 即
$Ris{{k}_{uv}}=\underset{-\infty }{\overset{+\infty }{\mathop \int }}\, \min \{{{p}_{u}}(x), {{p}_{v}}(x)\}\text{d}x$.(2)
可通过概率密度函数(式(1))和分类风险(式(2))计算相交区域的面积.
在二分类任务下, 对于某一个无标记样本, 利用多个分类器对其进行预测, 可得到图2所示的分类风险图.若得到图2(a)的分类风险图, 不难看出, 类1和类2的相交区域面积过大, 表明该样本的分类风险较高.
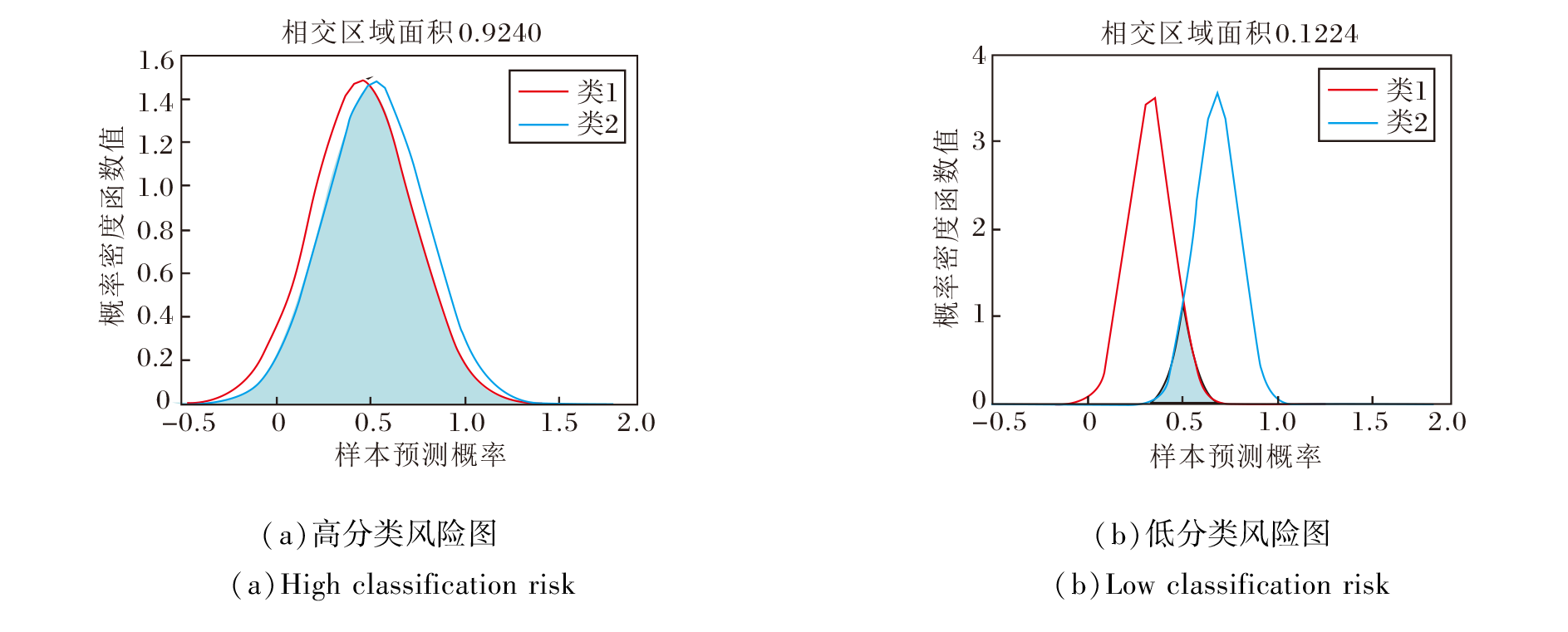 | 图2 二分类任务下的分类风险图Fig.2 Classification risk for binary classification |
分类风险能表示类间的区分度, 它的区分度越小, 越不利于对无标记样本的类别进行判定.若得到图2(b)的分类风险图, 类1和类2的相交区域面积很小, 说明该样本的分类风险较低, 分类的准确性和稳定性较高, 因此有较大把握确定该样本的类别为类2, 从而使样本能够被正确分类.
在多分类任务下, 假设有3类样本, 对于某一个无标记样本, 利用多个分类器对其进行预测.从图3的高分类风险图中不难看出, 类1和类2、类1和类3以及类2和类3的相交区域面积都很大, 无法判定样本类别.从图4的低分类风险图中可看出, 类1和类2的相交区域面积较大, 类3和类1、类2的相交区域面积较小.由于分类风险表示类间的区分度, 类3与其余两类的区分度较明显, 表明该样本的分类风险较低, 分类的准确性和稳定性较高, 因此将样本类别判定为类3.
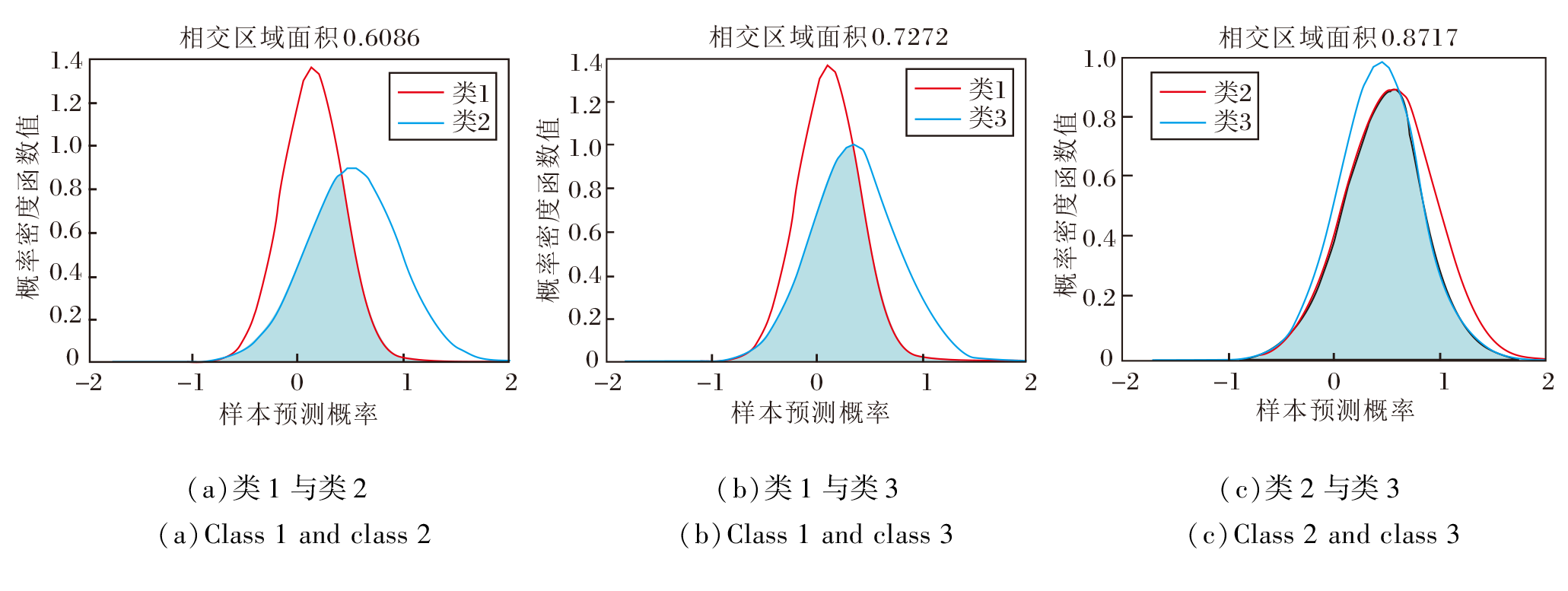 | 图3 多分类任务下的高分类风险图Fig.3 High classification risk for multi-class classification |
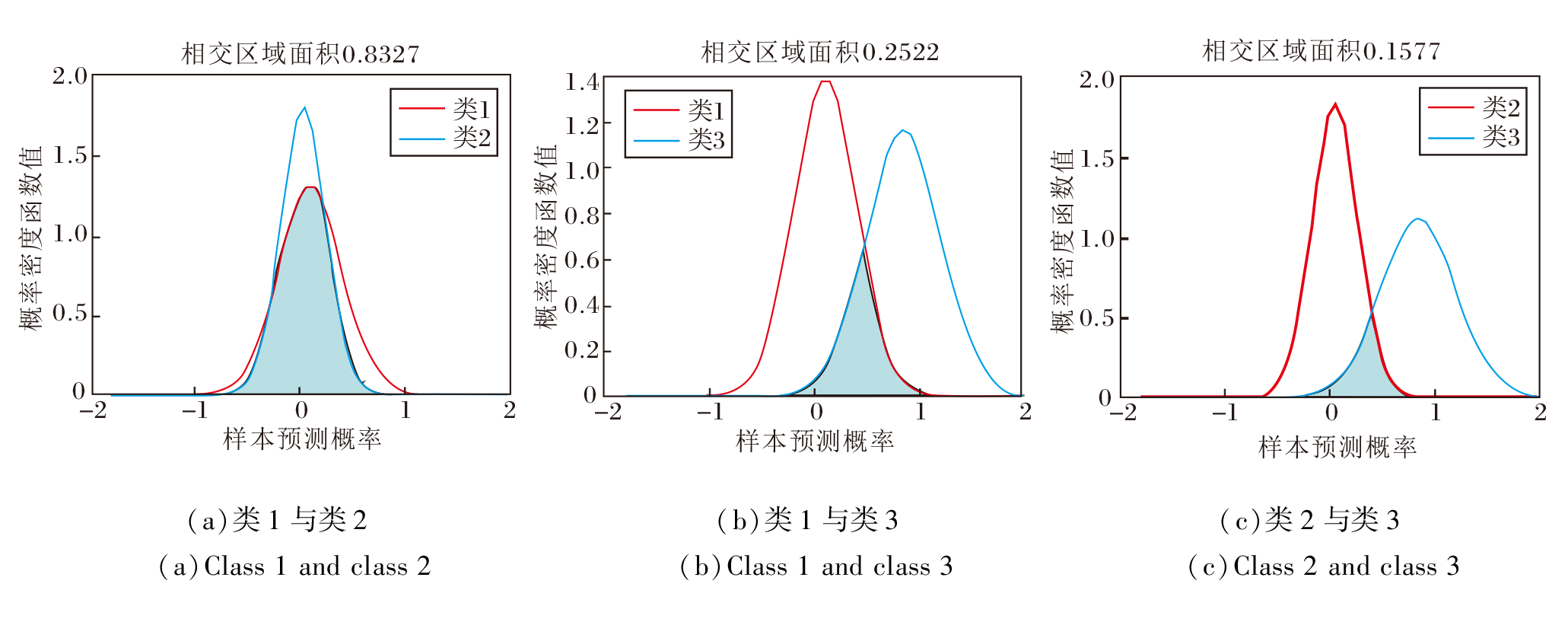 | 图4 多分类任务下的低分类风险图Fig.4 Low classification risk for multi-class classification |
给定若干分类器, 在极端情况下, 每个分类器对样本的预测概率均为(0.33, 0.34, 0.33), 每个分类器对样本的预测结果均为第2类样本, 那么传统的半监督集成学习算法将样本结果预测为第2类, 并且样本的置信度非常高.事实上, 每个分类器对样本预测的不确定性都非常大, 并无很大把握将其正确分类, 若强行分类会增大误分类风险, 使分类器性能恶化.由图3可知, 分类风险使用正态分布拟合每一类别对应的输出, 根据式(2)计算的类间交叠面积会非常大, 则将该样本判定为低置信度样本, 通过后续迭代重新对其预测, 从而避免出现在不确定性较大的情况下强行分类的现象.
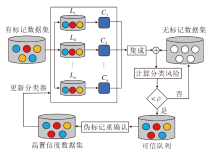
本文提出基于分类风险的半监督集成学习算法(CR-SSEL), 框架如图5所示.具体执行步骤如下.
 | 图5 CR-SSEL框架图Fig.5 Framework of CR-SSEL |
step 1 利用Bootstrap策略获取有标记样本集L, 并训练n个基分类器C1, C2, …, Cn.
step 2 基分类器C1, C2, …, Cn对无标记样本集中的样本Ui进行预测, 得到样本的不确定性, 然后计算该样本的分类风险, 若它小于设定的置信因子∂ , 加入可信队列Q中, 打上伪标记, 否则加入低置信度样本集U中.
step 3 将可信队列Q中样本分类风险最小的γ × 100%样本加入训练集L中进行训练, 更新分类器C1, C2, …, Cn.
step 4 利用更新后的分类器对可信队列Q中剩余样本进行预测, 若样本的分类风险小于设定的置信因子∂ , 且与当前的伪标记一致, 加入训练集L中进行训练, 否则加入低置信度样本集U中, 并将该伪标记擦除.
step 5 重复step 2~step 4, 直至所有的无标记样本集U为Ø .
从上述算法描述可知, CR-SSEL含有两个关键的学习参数:置信因子$\partial$和可信队列阈值γ .$\partial$用于筛选高置信度样本, γ 用于对高置信度样本的伪标记重新确认, 目的是最小化训练过程中样本的不确定性.CR-SSEL的核心是利用分类风险挑选高置信度样本和低置信度样本, 当样本的分类风险越低, 它的概率分布越会呈现出集中于某一类的现象, 而当样本的分类风险越高时, 它的概率分布越会出现难以判断的现象.将高置信度的样本存于可信队列Q中, 低置信度样本加入低置信度样本集U, 便于更新后的分类器对其进行重新预测, 达到对高置信度样本和低置信度样本重复利用的目的.
本文采用的基分类器为神经网络, 神经网络的输出层通过Softmax回归后, 分类结果会转化为概率分布, 那么, 可通过分类结果的概率分布计算样本的分类不确定性.假设存在n个分类器, 有m类样本, 则概率分布
$P=\left[ \begin{array}{* {35}{l}} {{p}_{11}} & {{p}_{12}} & \ldots & {{p}_{1m}} \\ {{p}_{21}} & {{p}_{22}} & \ldots & {{p}_{2m}} \\ \vdots & \vdots & \text{ }\!\!~\!\!\text{ } & \vdots \\ {{p}_{n1}} & {{p}_{n2}} & \ldots & {{p}_{nm}} \\ \end{array} \right]$, (3)
其中
$\overset{m}{\mathop{\underset{i=1}{\mathop \sum }\, }}\, {{p}_{ki}}=1, k=1, 2, \ldots , n$.
将每一类别的概率转化为正态分布, 概率密度函数为:
$\begin{align} & {{f}_{i}}(x)=\frac{2}{\sqrt{2\pi }{{\sigma }_{i}}}\exp \left( -\frac{x-{{\mu }_{i}}}{2\sigma _{i}^{2}} \right) \\ & i=1, 2, \ldots , m, \\ \end{align}$ (4)
其中
${{\mu }_{i}}=\frac{1}{n}\overset{n}{\mathop{\underset{j=1}{\mathop \sum }\, }}\, {{p}_{ji}}$,
${{\sigma }_{i}}\text{=}\sqrt{\frac{1}{n-1}\overset{n}{\mathop{\underset{j=1}{\mathop \sum }\, }}\, {{({{p}_{ji}}-{{\mu }_{i}})}^{2}}}$
累积分布函数为:
${{F}_{i}}(x)=\underset{-\infty }{\overset{x}{\mathop \int }}\, {{f}_{i}}(x)\text{d}x$.
假设第i类样本服从${{X}_{i}}\tilde{\ }N({{\mu }_{i}}, \sigma _{i}^{2})$, 第j类样本服从${{X}_{j}}\tilde{\ }N({{\mu }_{j}}, \sigma _{j}^{2})$, μ i< μ j, 则它们的交叠面积
$\begin{align} & \varepsilon =P({{X}_{i}}> c)+P({{X}_{j}}< c)= \\ & 1-{{F}_{i}}(c)+{{F}_{j}}(c)= \\ & 1-\frac{1}{2}erf\left( \frac{c-{{\mu }_{i}}}{\sqrt{2}{{\sigma }_{i}}} \right)+\frac{1}{2}erf\left( \frac{c-{{\mu }_{j}}}{\sqrt{2}{{\sigma }_{j}}} \right) \\ \end{align}$ (5)
其中, erf(· )表示自变量的误差函数,
$c=\frac{1}{\sigma _{i}^{2}-\sigma _{j}^{2}}\left[ {{\mu }_{j}}\sigma _{i}^{2}-{{\sigma }_{j}}\left( {{\mu }_{i}}{{\sigma }_{j}}+{{\sigma }_{i}}\sqrt{{{({{\mu }_{i}}-{{\mu }_{j}})}^{2}}+2\left( \sigma _{i}^{2}-\sigma _{j}^{2} \right)\text{log}\left( \frac{{{\sigma }_{i}}}{{{\sigma }_{j}}} \right)} \right) \right]$
将交叠面积ε 作为分类风险的值.CR-SSEL的伪代码如算法1所示.
算法1 CR-SSEL
输入 有标记数据集L, 无标记数据集U, 分类器Ci(i=1, 2, …, n), 可信队列Q
输出 训练后的分类器Ci(i=1, 2, …, n)
for i=1, 2, …, n do
Li← BootstrapSample(L)
Ci← Learn(Li)
end for
while len(U) > 0:
for Ui∈ U do
for i=1, 2, …, m do
构造式(4)
end for
for i=1, 2, …, m do
for j=1, 2, …, n do
计算式(5), 得到ε
end for
if count[i]< ∂ ==m-1:
Q← {Ui, y'}
end if
end for
end for
for i=1, 2, …, Q.size()* γ do
L← Qi
end for
for i=1, 2, …, Q.size() do
y← predict(Qi)
if y≠ y'
U← Qi
end if
end for
end while
下面通过一个具体的示例演示算法1的核心执行过程.设置置信因子∂ =0.35, 可信队列γ =1.0, γ 表示在每轮迭代过程中, 将高置信度样本集上的所有样本用于训练分类器.
无标记样本的标注过程如图6所示.在第1轮迭代过程中, 初始分类器的性能较弱, 如(a)所示, 分类器对样本进行预测, 计算可得样本分类风险值为0.926 1, 此时该样本被判定为低置信度样本.将第1轮迭代过程中筛选的高置信度样本加入训练集中, 分类器对高置信度样本训练.然后进行第2轮迭代训练, 从(b)中容易看出, 此时样本的分类风险为0.755 0, 明显低于上一轮.说明分类器通过对上一轮筛选的高置信度样本训练后性能得到提升, 预测样本更稳定可靠.
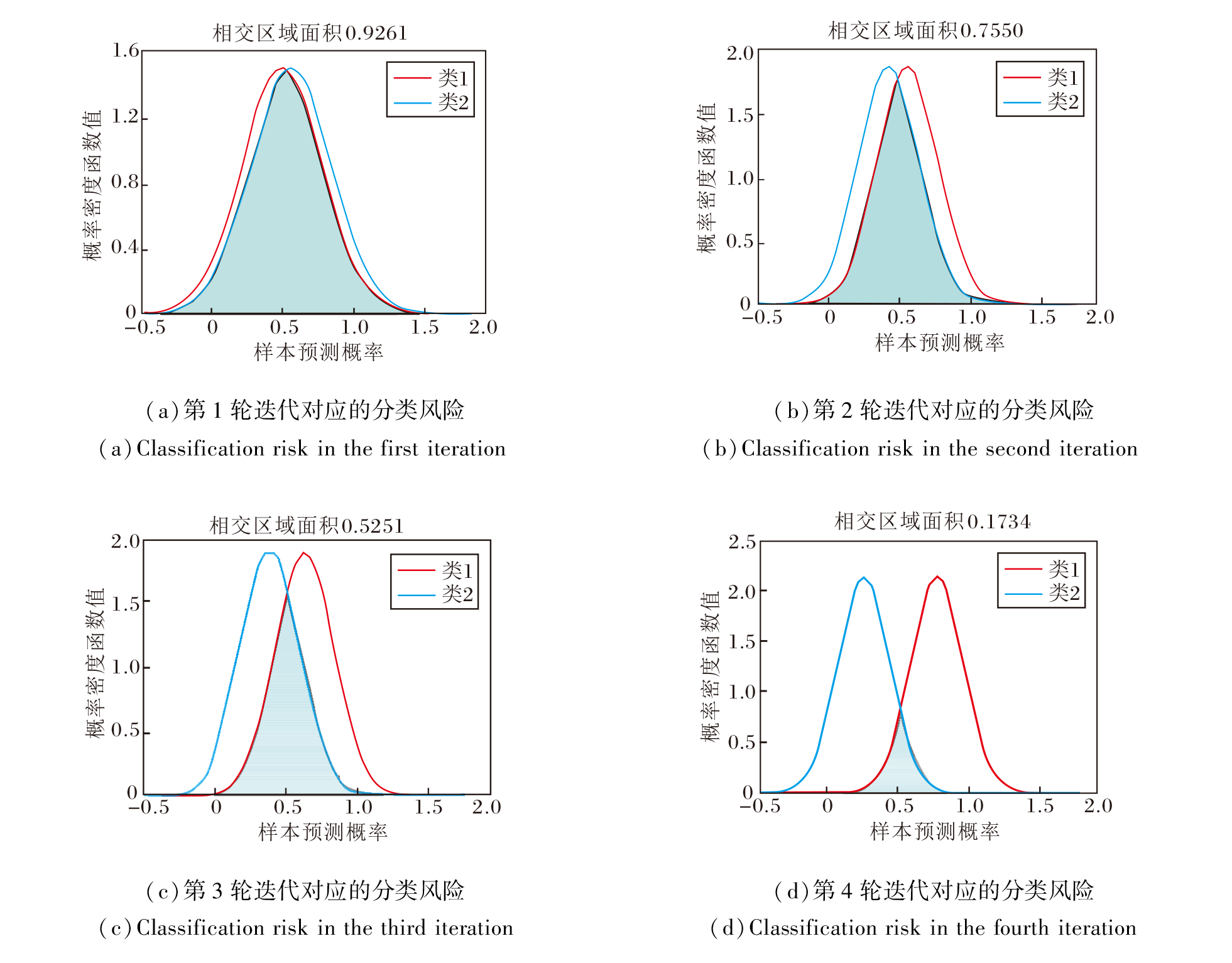 | 图6 无标记样本的标注过程Fig.6 Labelling process of unlabeled samples |
最终, 通过四轮的迭代训练, 样本的分类风险的值为0.173 4, 小于预设的置信因子∂ , 此时样本判定为高置信度样本, 并且类别标签判定为第1类, 将其加入训练集, 用于强化分类器的性能.
通过该示例可知, 在CR-SSEL中, 随着迭代次数的增加以及分类器对高置信度样本的不断训练, 分类器的性能逐渐增强, 直到无标记样本全部被标注完成为止.
下面分析CR-SSEL的时空复杂度.首先, CR-SSEL采用Bootstrap的方式训练分类器, 时间复杂度为O(K), 其中K表示有标记样本个数.其次, CR-SSEL利用多个分类器对无标记样本进行预测, 通过式(3)生成概率密度函数, 并构造类间的分类风险, 时间复杂度为O(k(nm+mm)), 其中, k表示无标记样本数量, n表示分类器个数, m表示样本类别数量.最后, CR-SSEL设置一个可信队列, 对每轮筛选的高置信度样本进行伪标记重确认, 时间复杂度为O(Tk), 空间复杂度为O(k), 其中T表示迭代次数.
进行多轮迭代, 直到无标记样本全部标注完成为止.因此, CR-SSEL总的时间复杂度为
O(K+Tk(nm+mm)+Tk),
空间复杂度为O(k).
本文在挑选的UCI、KEEL数据集上开展实验, 数据集信息如表1所示.数据集划分成类别分布近似一致的70%训练集和30%测试集.为了符合半监督集成学习的实验环境, 去除训练集上一部分有标记样本标签, 作为无标记样本.
| 表1 实验数据集信息 Table 1 Details of experimental datasets |
实验采取分类精度作为模型的评判标准, 所有结果均是重复10次以上的独立实验的分类精度平均值.
实验中算法使用Python语言实现.在Intel(R) Core(TM) 3.41 GHz i7-6700 CPU以及8 GB内存配置的电脑上进行实验.
本节主要验证分类风险作为置信度的评判标准以及使用可信队列的可行性.选取messidor_fea-tures、pima、biodeg这3个典型数据集, 检验分类风险对CR-SSEL性能的影响.在实验中, 实验结果均是重复10次的独立训练的平均分类精度, 有标记样本占训练样本总量的20%, 分类器个数设置为100.
设定置信因子$\partial$=0.05, 0.10, …, 1.10, 则$\partial$对CR-SSEL性能的影响如图7所示.由图可见, 在messidor_features数据集上, CR-SSEL在∂ =0.25时, 分类精度达到最高值, 并且∂ 取值在0.20~0.45之间时, CR-SSEL拥有较优的分类性能.在pima数据集上, CR-SSEL在∂ =0.40时, 达到最高的分类精度, 并且∂ 取值在0.25~0.50之间时, 分类性能达到较优水平.在biodeg数据集上, CR-SSEL在∂ =0.30时, 分类精度达到最高值, 并且∂ 取值在0.25~0.50之间时, 拥有较高的分类性能.
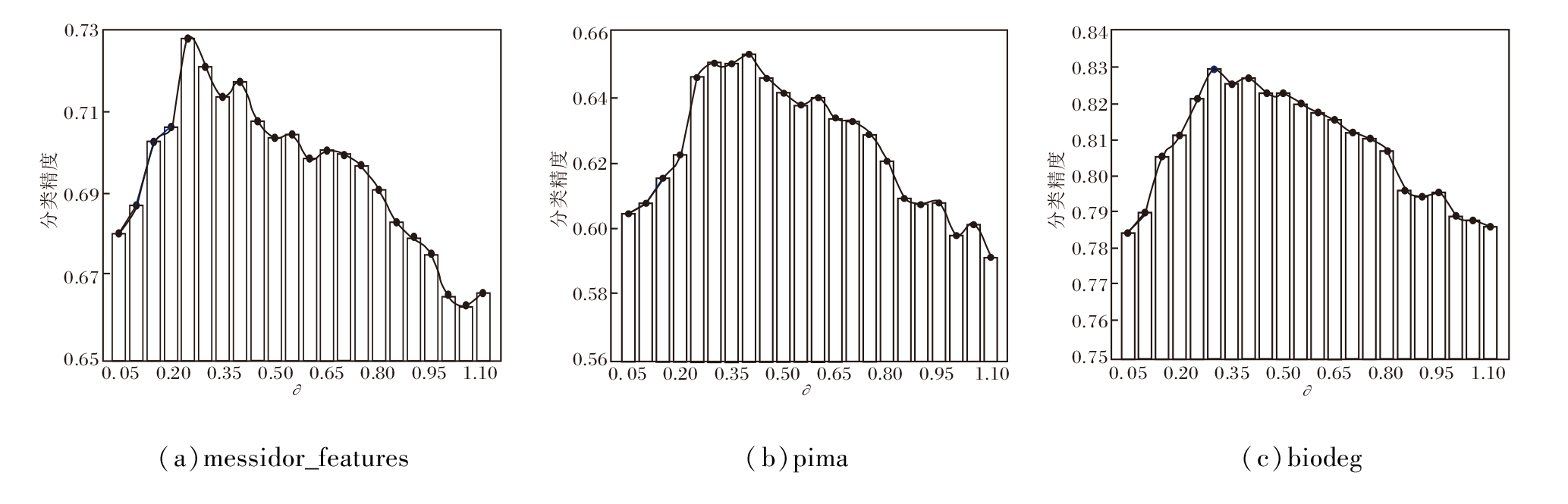 | 图7 置信因子$\partial$对CR-SSEL性能的影响Fig.7 Impact of confidence factor $\partial$ on performance of CR-SSEL algorithm |
通过在这3个数据集上的实验结果可知, ∂ 的取值不宜过小, 也不能过大, ∂ 的取值在0.20~0.45之间较合适.当∂ 取值过小时, 只有少数高置信度样本可加入训练集, 若此时这些样本分类错误, 会导致CR-SSEL的分类性能下降, 并持续恶化.当∂ 取值过大时, 初始会有大量无标记样本被打上伪标记, 加入高置信度样本集, 而此时CR-SSEL的分类性能偏弱, 会出现较多的误分类样本, 当利用这类样本对CR-SSEL进行训练时, 也会导致性能下降.
固定置信因子∂ 不变, 设置可信队列阈值γ =0.1, 0.2, …, 1.0, 则γ 对CR-SSEL性能的影响如图8所示.γ 表示在每轮迭代时, 选择分类风险最小的γ × 100%高置信度样本加入训练集, 当γ 设置合理时, 在3个数据集上均能提升CR-SSEL的分类精度, 当γ 设置不当时, 会产生负面作用.由图可看出, γ 对分类精度的影响较明显, 当γ 取值为0.5左右时拥有较高的分类精度, 使用可信队列这种优化方案平均提升1.91%左右的分类精度.
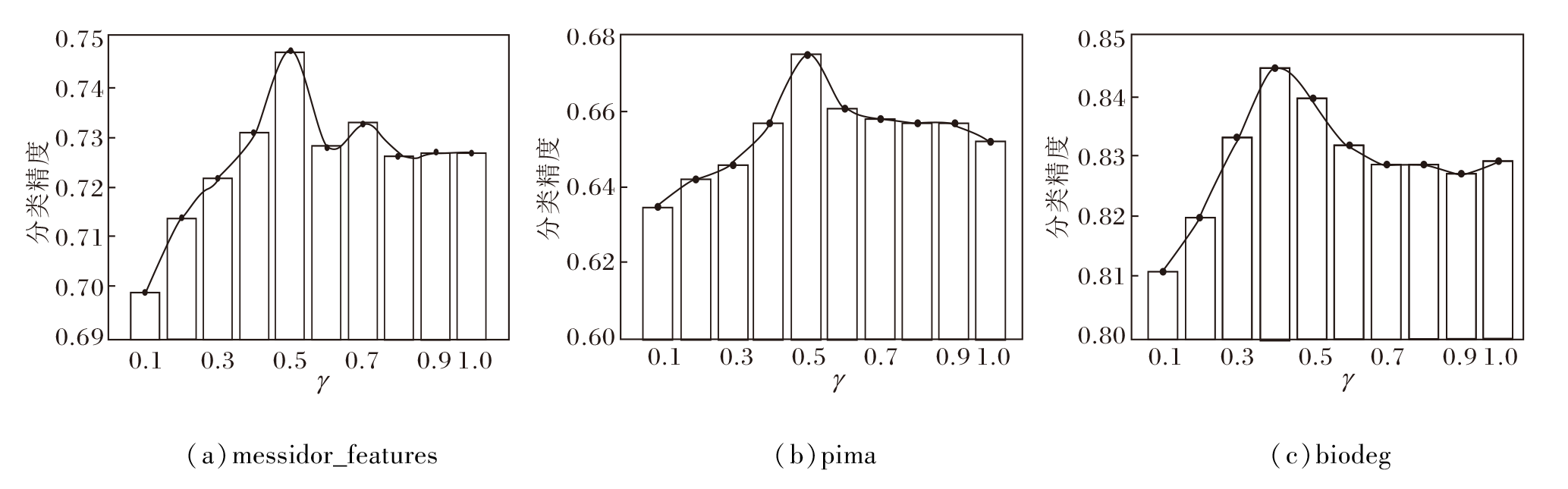 | 图8 可信队列阈值γ 对CR-SSEL性能的影响Fig.8 Impact of confidence queue factor γ on performance of CR-SSEL algorithm |
综上所述, 本节通过对置信因子∂ 以及可信队列阈值γ 的实验验证, 为CR-SSEL提供有效的参数选择依据, 同时也证实CR-SSEL的可行性.
本节验证分类器个数对CR-SSEL性能的影响, 即集成学习能否进一步提升半监督学习的分类性能.选择在messidor_features、pima、biodeg数据集上进行验证, 有标记样本占训练样本总量的20%, 实验结果均是重复10次独立训练的平均分类精度.
为了验证分类器个数对CR-SSEL性能的影响, 基于3.2节的实验结果, 固定置信因子∂ =0.3, 阈值γ =0.5, 设置分类器个数为20, 40, …, 200.具体实验结果如图9所示, 由图9可发现, 在messidor_features数据集上, 分类器个数设置为100时, CR-SSEL的分类精度到达峰值, 随后略有浮动, 但偏差不大, 最终趋于平稳.在pima数据集上, 随着分类器个数的增加, CR-SSEL的分类精度呈上升态势, 最终收敛.在biodeg数据集上, 当分类器个数到达120时, CR-SSEL的分类精度达到最高值, 最终趋于稳定.
 | 图9 分类器个数对CR-SSEL性能的影响Fig.9 Impact of number of classifiers on performance of CR-SSEL algorithm |
不难发现, 在3个数据集上, 随着分类器个数的增加, CR-SSEL的分类精度都呈现逐渐提升、最终收敛的趋势, 由此证实CR-SSEL的合理性, 即集成学习对以风险最小化为导向的半监督学习的性能提升是有帮助的.
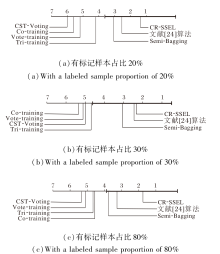
本节分别选取有标记样本占训练样本总量20%、30%、80%的场景开展对比实验, 其中有标记样本占比20%和30%的场景用于模拟样本标签大量不足的情况.
本文选取如下6种代表性的半监督集成学习算法作为对比算法.
1)基于多视图的半监督集成学习算法:Co- training[10].
2)基于单视图的半监督集成学习算法:Tri- training[19]、CST-Voting[21]、文献[24]算法、Vote- training[31]、Semi-Bagging[32].
对比结果为重复10次独立实验的平均分类精度.当有标记样本占比分别为20%、30%、80%时, 各算法的分类精度对比如表2~表4所示, 表中黑体数字表示最优值.由表可观察到, 相比其它算法:有标记样本占比为20%时, CR-SSEL平均精度提高约3.21%; 有标记样本占比为30%时, CR-SSEL平均精度提高约3.11%; 有标记样本占比为80%时, CR-SSEL平均精度提高约2.88%.
| 表2 有标记样本占比为20%时各算法的分类精度对比 Table 2 Comparison of classification accuracies of different algorithms with a labeled sample proportion of 20% |
| 表3 有标记样本占比为30%时各算法的分类精度对比 Table 3 Comparison of classification accuracies of different algorithms with a labeled sample proportion of 30% |
| 表4 有标记样本占比为80%时各算法的分类精度对比 Table 4 Comparison of classification accuracies of different algorithms with a labeled sample proportion of 80% |
可通过临界差值(Critical Difference, CD)图进行统计分析, 证实CR-SSEL的良好性能.基于10次实验结果的平均值, 在有标记数据占比为20%、30%、80%时, 13个数据集上的分类精度CD图如图10所示, 图中纵轴表示各算法, 横轴表示算法的平均排序值.
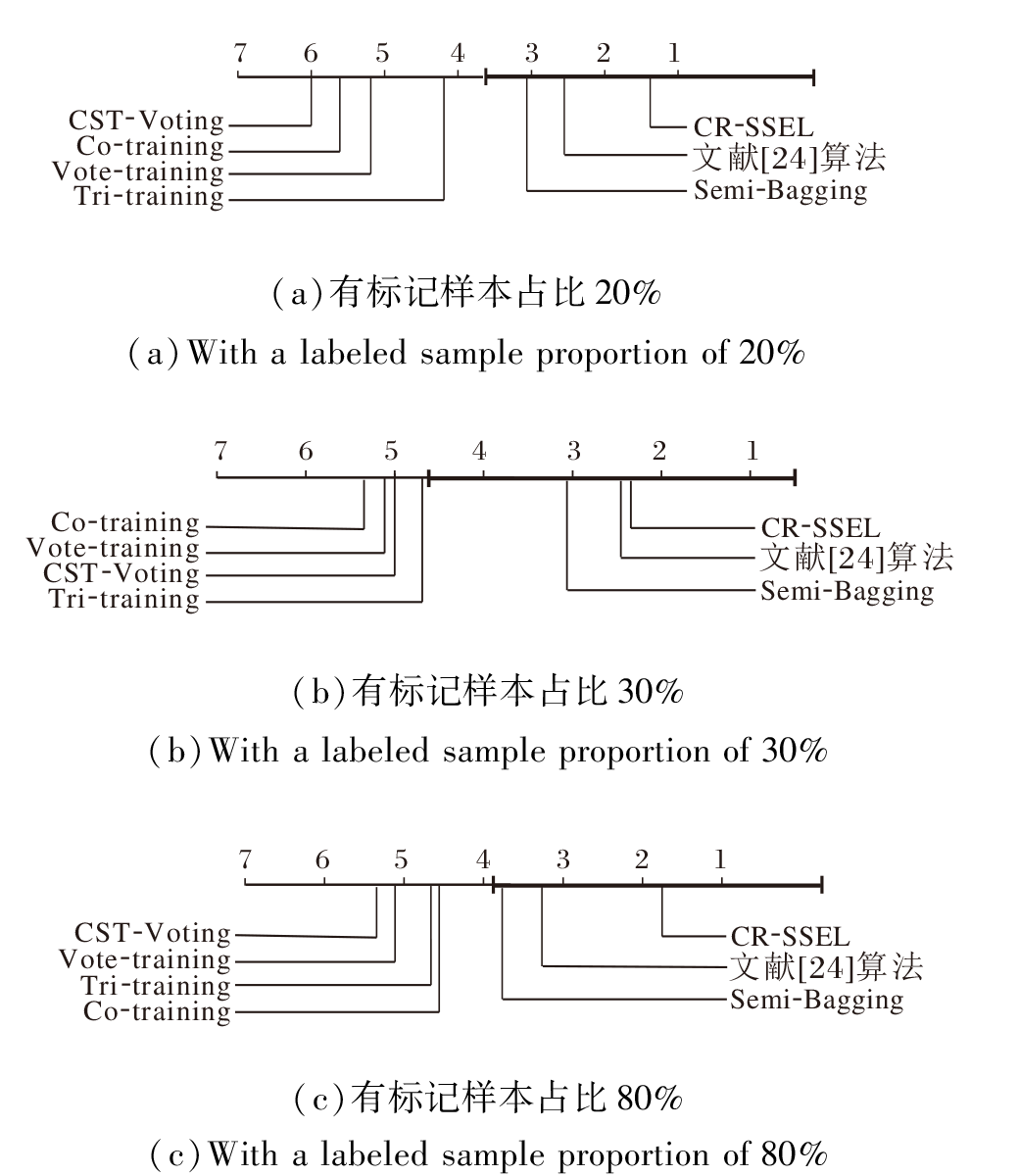 | 图10 有标记样本占比不同时的分类精度CD图Fig.10 CD diagram for classification accuracy with different labeled sample proportions |
对于给定的0.05的显著性水平, 临界差值的数值计算为
$CD={{q}_{0.05}}\times \sqrt{\frac{7\times \left( 7+1 \right)}{6\times 13}}\approx 2.769$,
其中, q0.05=3.268为Tukey分布的临界值.
从图10可看到, CR-SSEL在3种有标记样本占比的情况下都获得最低的平均排序值, 说明其具有更优的分类性能, 同时分类精度显著优于Tri-trai-ning、Vote-training和CST-Voting.特别地, 当样本标签大量不足(有标记样本占比20%和30%)时, CR-SSEL的分类精度还是显著高于Co-training.
实验结果以及统计分析结论证实CR-SSEL能有效处理半监督学习问题, 具有泛化性能上的优势.
为了解决分类器预测无标记样本过程中出现的标注混沌问题, 本文提出基于分类风险的半监督集成学习算法(CR-SSEL).依托半监督集成学习框架, 利用分类风险作为置信度的评判标准, 可有效衡量无标签样本的不确定性程度.通过设置可信队列, 对高置信度样本进行再强化, 并在迭代训练过程中对低置信度样本重复利用, 有效提升处理半监督学习问题的效率.在标准数据集上的对比实验验证CR-SSEL的有效性.今后将在如下3个方面进行更深入的研究, 期待进一步完善和改进CR-SSEL的性能.
1)随着迭代次数的不断增加, 每个分类器的训练集会加入相同的高置信度样本, 导致分类器越来越相似.因此, 如何降低分类器分歧的衰减程度是今后的一个探索方向.
2)CR-SSEL利用神经网络作为基分类器, 取得一定效果, 今后的另一个探索方向是使用更多样的基分类器, 如决策树、朴素贝叶斯、支持向量机等, 提升CR-SSEL的性能.
3)今后会考虑将CR-SSEL用于只含有少量有标记样本、并拥有大量无标记样本的实际应用中, 如医院的肿瘤预测、光伏发电预测及群调群控等.
本文责任编委 高阳
Recommended by Associate Editor GAO Yang
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|