



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于相机感知的域自适应行人重识别模型
[杨章静1  , 吴数立
, 吴数立1 , 黄璞1 , 杨国为1 ]
, 吴数立, 黄璞, 杨国为]
|
|



作者简介:

杨章静,博士,副教授,主要研究方向为计算机视觉、模式识别.E-mail:yzj@nau.edu.cn.

吴数立,硕士研究生,主要研究方向为模式识别、机器学习.E-mail:244581258@qq.com.

杨国为,博士,教授,主要研究方向为机器智能理论与方法、智能系统、模式识别.E-mail:ygw_ustb@163.com.
针对行人重识别在损坏场景下训练集和测试集分布差距过大、背景复杂度过高和噪声种类过多导致识别性能过低的问题,提出基于相机感知的域自适应行人重识别模型,引入并充分利用相机信息,在训练阶段对齐不同摄像机的图像分布,在测试阶段利用时序信息进行排序优化,减少训练集和测试集分布差异带来的影响,有效应对背景复杂度和噪声种类的问题.模型不仅从数据集处理角度有效减轻损坏图像的影响,还对排序优化进行二次加权,显著提高其在损坏场景中的性能.在Market-1501、DukeMTMC-reID、CUHK03数据集上的实验表明文中模型的有效性.
About Author:
YANG Zhangjing, Ph.D., associate professor. His research interests include compu-ter vision and pattern recognition.
WU Shuli, Master student. His research interests include pattern recognition and machine learning.
YANG Guowei, Ph.D., professor. His research interests include machine intelligence theory and methods,intelligent systems and pattern recognition.
To solve the problem of low performance in person re-identification caused by large distribution differences between the training and testing sets in corruption scenarios, high background complexity and excessive noise types, a domain adaptive person re-identification model based on camera perception is proposed. The model aligns the image distribution of different cameras during the training phase by introducing and fully utilizing camera information. During the testing phase, temporal information is employed for ranking optimization, reducing the impact of distribution differences between the training and testing sets. The issues of background complexity and noise types are effectively addressed. The model not only effectively mitigates the impact of damaged images from the perspective of dataset processing but also significantly improves the performance of the model in corruption scenarios through quadratic weighting of sorting optimization. Experiments on Market-1501, DukeMTMC-reID and CUHK03 datasets demonstrate the effectiveness of the proposed algorithm.
行人重识别(Person Re-identification, ReID)是利用计算机视觉技术判断图像或视频序列中是否存在特定行人的技术, 涉及在海量图库中对行人图像进行精确匹配和排序[1], 广泛应用于智能安防、视频监控、客流统计等多个领域.然而, 在实际监控环境中, 图像通常会出现模糊、分辨率过低等各种损坏.
现有ReID模型[2, 3, 4, 5, 6]在识别损坏图像时性能下降严重, 这表明模型在损坏图像上的识别能力仍有较大的改进空间.因此, 学者们开始研究面向损坏场景的行人重识别.损坏场景行人重识别主要面临如下挑战.1)损坏场景的行人重识别是开放世界的研究, 所以测试集和训练集的分布会出现较大差异, 原先模型在训练集上学到的知识并不能有效应用到未知场景中.2)损坏场景也面临拍摄视角差异、人物姿势及遮挡等传统行人重识别的问题.此前, 研究者们已提出一系列解决方案, 如数据去噪[7](稀疏和冗余表示[8])、非局部算法[9]、去噪自编码器[10].然而这些方法只能去除特定噪声, 无法提高对不可见噪声的鲁棒性.
为了解决上述问题, 学者们提出各种改进方法, 如数据增强技术和缓解数据集分布差异方法.数据增强技术是预先对数据集进行微小改动, 使其一部分生成新的数据, 从而使网络能针对问题的困难程度进行训练.例如:自随机擦除技术[11]可选择性擦除图像中的区域, 并使用随机像素代替, 同时保持原始元素的比例, 以增强模型的损坏鲁棒性.Ford等[12]将高斯噪声应用于图像增强, 增加对损坏场景的鲁棒性.Mikołajczyk等[13]对图像应用一组随机的操作, 增强训练集.Hendrycks等[14]使用一种混合多幅增强图像的方式改善模型, 在ImageNet-C数据集上获得显著改进.不过, 这些预处理方法只能略微增强数据集, 在损坏程度不大的场景下取得良好效果, 如果图像本身背景复杂度过高或损坏类型过多, 则该类方法的泛化性不强.
因此, 学者们提出一些专注于数据集分布差异的方法[15, 16, 17, 18].Zhang[19]在ResNet50架构中集成一个来自信号处理域的抗混叠模块, 用于恢复在深度网络中可能丢失的平移等方差.这既提高对干净数据的准确性, 也增加对损坏图像样本的泛化.Xie等[20]证明更多的训练数据或更强的骨干网络能显著提高模型对损坏的鲁棒性.
上述研究集中在增加训练数据的多样性以缓解数据集分布的差异性, 却未能解决遮挡问题, 在损坏场景中的识别性能有限, 为此, 学者设计复杂的数据集增强管道, 凝聚多种技术同时使用[21].然而方法的局限性在于很难找出对鲁棒性有重要作用的特定模块, 而且高复杂性使其在ReID任务中很难实行.
综上所述, 缓解训练集和测试集之间的分布差异是解决损坏场景下行人重识别问题的重要方向之一, 但现有方法仅使用更多的训练数据和组合各种数据增强的方法以增加训练集的多样性.Geirhos等[22]指出, 用一种特定类型的噪声进行增强可提高模型对目标噪声的性能, 但并不能推广到所有的损坏场景下, 同时还会降低模型在干净数据集上的性能.
在损坏场景下的行人重识别任务中, 来自不同相机的图像存在明显的数据分布差异.处理相机之间的分布差异对于缓解数据集的分布差异至关重要, 但在单个相机内学习知识要容易得多.此外, 在训练集上学习相关的知识与这些特定摄像机之间的联系强相关, 使模型在由测试摄像机组成的损坏场景中推广性很差.在一个数据集上学到的ReID模型对于描述损坏数据集图像的能力往往有限, 而且由于缺乏弥合数据集上所有摄像机之间的分布差距的能力, 导致现有ReID模型的泛化能力较差.
基于上述分析, 本文提出基于相机感知的域自适应行人重识别模型.模型主要分为两部分:基于损坏场景的批量标准化(Batch Normalization for Corru- ption Scenarios, BC)层和时序信息(Temporal Infor- mation, TI)模块.它们充分利用相机信息和时序信息, 减轻各种损坏场景的影响.针对损坏场景的影响导致的数据集分布不一致问题, 分解ReID数据集, 并根据每个摄像机的视角独立对齐, 从而最大限度地降低模型学习与特定摄像机之间的相关性.在训练阶段, 每个批次的数据集都根据摄像机ID分别进行标准化处理.在测试阶段, 使用少量损坏样本近似测试摄像机的批量标准化统计量, 并将输入映射到训练集的分布上.针对过强泛化性导致的性能下降问题, 引入基于无模型时空共现的分数加权方法, 并通过TI模块重新计算每个检索对象的排序权值.TI模块可针对每个检索对象动态计算, 无需预先进行统计学习.实验表明本文模型具有较高的鲁棒性.
行人重识别与图像检索[23]一样, 都是根据外观匹配个人身份.传统的ReID模型将数据集视为一个整体, 通过训练提取身份间的相关性和摄像机内的联系.具体地, {gi}
i*=arg
其中d(·; ·)表示计算两个特征相似性的函数.
由于损坏场景的数据集有相当一部分损坏的图像, 因此训练一个鲁棒的模型非常具有挑战性, 即
d(qj,
其中,
鉴于上述挑战, 本文认为现有ReID模型在损坏场景下存在一定缺陷.首先, 不同相机拍摄的相同身份的行人图像会呈现不同的分布特点.然后, 模型在训练过程中学到的知识, 不仅用于区分不同的行人身份, 还会对训练时使用的摄像机之间的连接进行编码.这种与特定摄像机关联的知识有时难以推广到其它摄像机, 特别是当面对以前未见过的摄像机分布时.例如:一个在干净数据集上训练的ReID模型, 如果不经过针对损坏场景的微调, 准确率可能会大幅下降.
因此, 在损坏场景中进行行人重识别时, 需要重新设计传统模型的目标, 以更好地适应所有摄像机的分布.这可能涉及到开发新的算法或技术, 以便更有效地处理不同摄像机之间的分布差异, 从而提高在复杂和多变场景中的行人重识别性能.
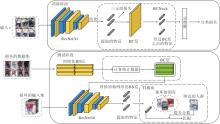
本文提出基于相机感知的域自适应行人重识别模型, 旨在抑制特定摄像机之间的分布差距.模型具体框图如图1所示, 将BC层取代BNNeck(Batch Nor- malization Neck)[24], 称为基于损坏场景的BNNeck (BNNeck for Corruption Scenarios, BCNeck).
 | 图1 本文模型框图Fig.1 Structure of the proposed model |
目前行人重识别大多数研究工作将分类损失和三元组损失[25]结合后训练ReID模型.分类损失构造多个超平面, 将嵌入空间划分为不同的子空间, 确保每类的特征分布在不同的子空间中.在这种情况下, 在推理阶段, 使用分类损失优化的模型更合适, 因为它能提供更清晰的类别划分.另一方面, 三元组损失旨在增强欧氏空间中类内的紧凑性和类间的可分性, 但是三元组损失不能提供全局最优约束, 会导致类间距离小于类内距离.此外, 对于嵌入空间中的图像, 分类损失主要优化嵌入空间中的余弦距离, 而三元组损失主要优化欧氏距离.当同时使用这两个损失优化同个特征向量时, 会出现目标不一致的情况, 导致一种损失减少而另一种损失振荡甚至增加.
因此本文在训练阶段使用通过BCNeck之前的特征和之后的特征分别计算分类损失和三元组损失, 这样可在一定程度上分离两种损失的优化目标.这些特征在超球面附近呈高斯分布, 有助于分类损失收敛.在测试阶段使用经过BCNeck层之前的特征, 利用高置信度样本同时结合时序信息, 对初始搜索结果进行排序优化(Re-ranking, RK), 进一步增强ReID模型的判别能力.
本文模型的整体流程如下.给定一批检索图像, 根据每幅图像的摄像机ID分成多个小批次图像, 主干网络对这些小批次图像进行特征提取并进行池化操作, 从而生成该批次图像的特征映射.再经过BCNeck之前的特征映射学习度量损失, 减少类内间距和增加类间距以显著提高模型性能.最后, 将BCNeck处理后的特征传递给分类器, 学习身份特征.在测试阶段, 首先取少量损坏场景数据集的图像计算统计数据, 生成BC层并替换原始主干网络的BN层, 在获取主干网络的特征映射后进行检索及排序优化, 得到排序优化的检索结果后使用TI模块, 利用检索图像附近的人群信息, 对得分进行二次加权, 得到最终的检索结果.
由于模型不仅要学习如何区分个人身份, 还要隐含地编码摄像机之间的关系, 因此有必要强制所有摄像机的特征分布保持一致, 以缓解分布差距, 减少训练过程中对摄像机相关信息的依赖.虽然BC层可提高损坏的鲁棒性, 但过度泛化性使模型在干净数据集上的判别能力下降.因此, 可使用时序信息模块提高模型在干净数据集的性能, 同时保持模型的损坏鲁棒性.
本文模型核心是以摄像机为单位进行批量标准化(Batch Normalization, BN)[26], 以调整与每个摄像机相关的分布.为了实现这一目标, 本文提出BC层, 可估算与摄像机相关的统计数据, 而不是依赖整个数据集的统计数据.BC层是从BN批量标准化修改而成.
BN的原理是减少内部协变量的位移.在训练过程中, 使用小批量统计数据近似标准化和记录全局统计数据.给定输入图像xi, BN层的输出图像为:
Xi=γ
其中, μ、σ2表示训练集总体的均值和方差, γ、 β表示在训练过程中学到的两个参数.虽然在大部分ReID模型中, BN层应用很普遍, 但直接将其应用于ReID模型有两个缺点.1)BN层要求测试图像服从训练图像相同的分布, 这一假设极大限制ReID模型的应用, 因为只有当训练集和测试集在同一台摄像机上拍摄时, 训练集和测试集的分布才相同.2)在损坏场景中, BN层未考虑到在同一摄像机拍摄的图像中存在雨、雪等因素也会干扰数据分布, 从而影响模型检索损坏图像的能力.
基于上述分析, 本文在BN层的基础上, 设计BCNeck.在训练阶段, BC层根据相机ID对来自任意数量相机的小批采样图像进行聚类, 再根据每台摄像机计算的平均值和方差, 将所有特征与相应的统计数据标准化.然后, BC层与所有摄像机共享可学习的权重和偏置参数.这种方法允许模型从不变的输入分布中学习和收集信息.
在测试阶段, 首先BC层随机收集一些未标注的损坏图像, 用于更新每个测试相机及其相关统计数据, 从而实现分布对齐.给定来自摄像机c的损坏图像
$X_{\text {corruption }}=\gamma\left(\frac{x_{\text {corruption }}-\mu_{(c)}}{\sqrt{\sigma_{(c)}^{2}+\varepsilon}}\right)+\beta, $
其中,
$\begin{aligned} \mu_{(c)} & =\frac{1}{M} \sum_{c=1}^{M} x_{\text {corruption }}^{(c)}, \\ \sigma_{(c)}^{2} & =\frac{1}{M} \sum_{c=1}^{M}\left(x_{\text {corruption }}^{(c)}-\mu_{(c)}\right)^{2} . \end{aligned}$
利用上述方法获得统计数据, 将其输入BC层, 生成一个特定的测试摄像机, 所有图像都通过该特定相机生成最终特征.当所有相机的图像处理结束后, 整个测试过程结束.
考虑到BCNeck是一个批量标准化层, 可加快分类损失的收敛速度, 因此本文提出BCNeck的目标和BC层一样, 根据每个摄像机调整输入分布, 具体框架如图2所示.
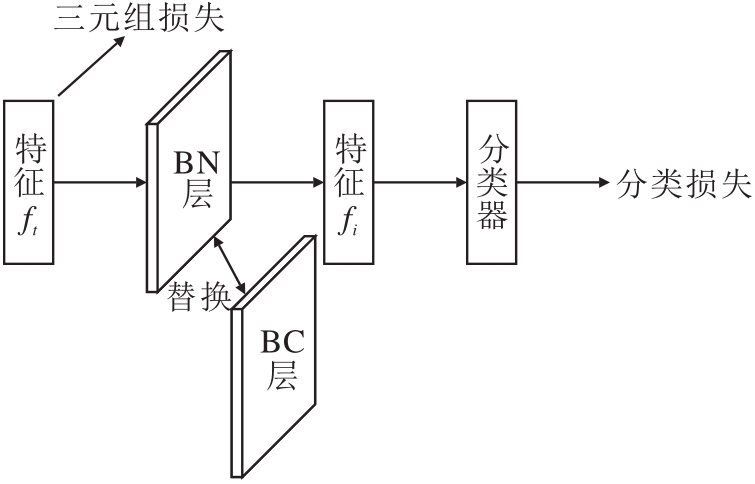 | 图2 BCNeck框架图Fig.2 Framework of BCNeck |
BCNeck在主干网络之后和分类器全连接层(Fully Connected Layer)之前添加一个BN层.在训练阶段使用BN层前的特征ft计算三元组损失, 使用BN层后的特征fi计算分类损失.
本文设计BC层替代BN层, 其主要目的是最大限度降低模型学习与特定摄像机之间的相关性, BC层能在某种程度上减少由于不同摄像机视角、光照条件等因素导致的特征分布差异, 从而提高模型的泛化能力和鲁棒性.因此为了让BNNeck也具备降低模型与摄像机相关性的特性, 可以将BNNeck中的BN层替换为BC层, 替换后, BNNeck使用BC层对特征进行归一化处理, 再分别计算三元组损失和身份损失, 这样的设计有望使模型在面对不同摄像机的数据时更稳定、准确.
但在测试阶段, 本文选择使用BCNeck之前的特征执行ReID任务, 因为损坏测试集的统计特征与干净训练集的统计特征有较大不同, 导致严重的不匹配, 即使从采样图像中收集的统计数据应用到BN层, 得到的模型的损坏鲁棒性也会降低.
BC层缓解不同摄像机之间的分布差距, 防止模型过度拟合到特定摄像机.因此, 使用BC层代替BN层能使模型更鲁棒, 但过强的泛化性使模型在干净数据集上的判别能力下降.在ReID模型中, 通常使用排序优化(RK)提高性能, 利用高置信度的样本对初始的检索结果重新排序.作为一种后处理方法, RK广泛运用于行人重识别、车辆重识别等图像检索任务.
RK主要分为两类:基于特征相似度的方法和基于邻近样本相似度的方法.特征相似度通过特征间的欧氏距离计算, 而邻近样本相似度通过初始检索结果的Top-k中共有样本计算, 如果两个样本的检索列表Top-k中共享的样本越多, 邻近样本相似度越高, 因此相比特征相似度方法, 邻近样本相似度方法性能更优.
实验结果表明, RK可提高ReID模型在干净数据集和损坏数据集上的准确率.例如:k-reciprocal编码[27]需要先用检索图像检索到Top-k的邻近样本, 然后通过这些样本再次重新检索并取交集对比, 这样引入大量的额外计算, 虽然提高性能, 但无法在速度和性能之间平衡.
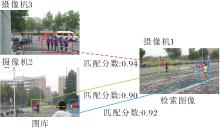
因此本文引入QAConv(Query-Adaptive Convo- lution)[28], 对RK得到的分数重新校准.其基本原理是:在某个摄像机拍摄的行人出现在另一个摄像机的视野中时, 通过分析不同摄像机视角之间的人物关联性以提高或降低匹配分数.如果该行人在拍摄待检索图像的摄像机下出现, 增加该检索图像的最终匹配分数.具体过程如图3所示, 给定一幅在摄像机1中的待检索图像A, 观察到摄像机3中的人群E的匹配分数高于摄像机2中图像A'的匹配分数, 但观察到摄像机1中图像A附近的图像B也在摄像机2中出现, 因此A'的匹配分数得到提高, 而人群E的匹配分数降低, 因为E的附近没有B'.
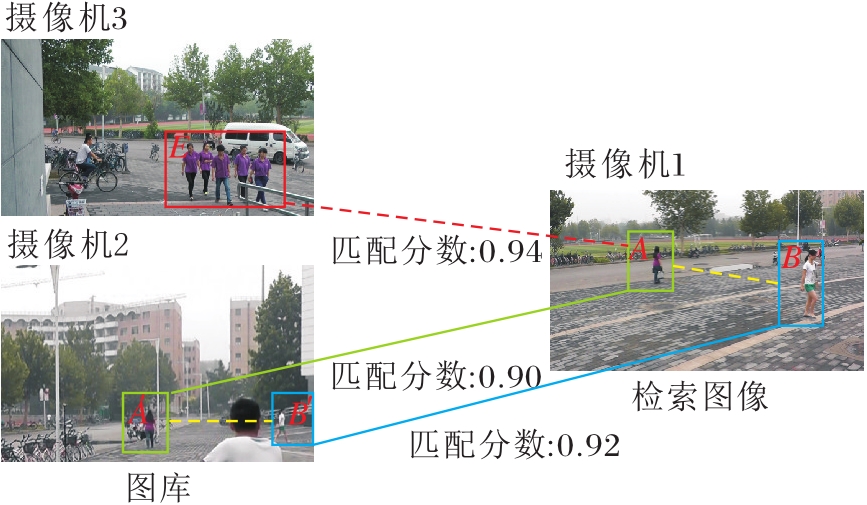 | 图3 基于无模型时空共现的分数加权过程Fig.3 Process of model-free spatio-temporal co-occurrence based score weighting |
这种方法不依赖于任何特定的模型, 可动态计算.使用摄像机视频中的图像帧数计算时间, 不需要考虑图像背景中噪声对特征的干扰, 因此可避免受到损坏场景的影响, 提高模型的鲁棒性.
基于上述分析, 本文设计时序信息(TI)模块, 对k-reciprocal编码得到的分数进行二次加权, 使检索性能得到显著提升.时序信息是指数据集上行人图像拍摄的时间节点, 通过获取每幅图像处于视频段中的帧数计算周边行人与待检索行人之间的时间差.通过对比时间差, 可判断两位行人是否在相近的时间内出现, 从而辅助判断该行人是否为检索图像身边的行人.
TI模块具体计算流程如下:假设A是由摄像机Q拍摄的检索图像, 可将摄像机Q中A附近的人的集合定义为
R={B|ΔTAB<τ, ∀B∈Q},
其中, TAB表示由同一摄像机拍摄到的A和B之间的时间差, τ表示是否是检索图像附近的人的阈值.通过RK, 得到图库R中排名前k的检索结果, 在摄像机G中检索到这些检索结果, 定义为集合P.再利用P中每个人重新计算A和摄像机G中每个人的时间匹配概率:
$p_{t}=\frac{1}{|P|} \sum_{B \in P} \exp \left(-\frac{\Delta T_{A B}^{2}}{\sigma^{2}}\right), $
其中σ表示时间差的灵敏度参数.
根据上述分析, 可清楚了解时序信息在整个框架哪部分使用, 以及会产生何种影响.因此, 本文对RK后的相似度得分进行重新加权:
p(A, X)=(pt(A, X)+α)pα(A, X),
其中, pa(·, ·)表示查询图像与图库中图像的匹配分数, α表示正则化参数.这样集合P附近的人检索分数得到提升, 而远离集合P的分数将被降低.此外时序信息会分别计算每幅检索图像的最终权重, 因此不需要花费额外的时间训练模型.在RK中加入时序信息模块需要少量的计算开销, 但能显著增强模型的判别能力.
本文模型旨在根据个人的独特身份对其进行分类.为了实现该目标, 采用交叉熵损失[29].具体地, 给定一幅检索图像, y表示真实标签, pi表示类别的身份预测对数, 则分类损失为:
LID=
其中, N表示类别数量.模型可通过最小化LID提高识别性能.
然而, 在某些ReID应用, 如跟踪任务中, 确定距离阈值以区分正负对象至关重要.为了解决该问题, 采用三元组损失, 侧重于计算相对距离:
LTri=[dp-dn+α]+,
其中, dp表示正样本对的特征距离, dn表示负样本对的特征距离, α表示计算三元组损失时使用的边际值.
三元组损失能增加正样本对的类内紧密性, 使追踪任务变得更容易.
在计算损失时, 本文未使用文献[30]的一致性损失.一致性损失是为了增强模型在干净集上的判别能力, 但在使用时序信息模块后, 一致性损失的性能会受到限制, 鲁棒性会下降.
为了验证本文方法的有效性, 在Market- 1501[31]、CUHK03[32]、DukeMTMC-reID[33] 这3个主流数据集上进行实验.这些数据集包含大量的行人图像, 具有不同的挑战因素, 如视角变化、遮挡等, 具体信息如表1所示.
| 表1 实验数据集信息 Table 1 Information of experimental datasets |
为了确保评估结果的客观性和公正性, 根据文献[34]将每个数据集分成训练集和测试集, 评估包括来自ImageNet-C数据集上的15种损坏图像、Extra ImageNet-C数据集上的4种损坏图像以及文献[30]中提出的雨水损坏类型.这些损坏类型涵盖噪声、模糊、天气和数码等多个方面, 包括:噪声(高斯分布、脉冲和斑点)、模糊(失焦、磨砂、变焦和高斯分布)、天气(雪、霜、雾、高亮、飞溅和雨)和数字(对比度、弹性转换、像素、JPEG压缩和饱和度).
同时, 为了更全面评估模型的鲁棒性, 本文改变每种损坏的程度, 生成100种不同损坏的综合数据集.这样可模拟不同程度的损坏对模型性能的影响, 从而更全面评估模型的鲁棒性和泛化能力.
与图像分类不同, ReID任务涉及使用检索图像和图库进行图像匹配的测试.为了全面评估对损坏的鲁棒性, 本文展示3种不同的损坏场景:检索图像和图库都损坏、仅检索图像损坏、仅图库损坏.这些场景代表实际监控环境中可能出现的各种情况, 其中检索对象是指需要进行匹配的查询图像, 图库则包含一组待匹配的图像.
实验采用特征表示能力强以及在多种视觉任务中表现良好而广受欢迎的ResNet50作为主干网络.以文献[30]模型为基准模型, 批量大小为64.为了适应模型输入要求, 所有图像均调整为256×128.为了使模型学到每位行人的多角度和多姿态表示, 每位行人有4幅图像.时序信息模块的参数t=100, σ=200, K=10, α=0.2.在训练阶段, 模型执行120个训练周期.在测试阶段, 模型会从每个测试相机中选择一些未标记的样本, 估计与相机相关的统计数据.
为了进行这些场景的评估, 首先为每幅图像随机选择一种损坏类型和损坏程度, 形成检索图像和图库的集合, 这样可确保评估的随机性和公正性.再使用与干净测试集大小相同的检索图像和图库进行10次重复评估.全面评估模型在不同损坏场景下的性能.
在行人重识别任务中, 每位行人都被视为一个类别, 因此需要使用平均精度均值(Mean Average Precision, mAP)衡量模型在所有类别上的性能.mAP反映在检索过程中正确的图像在排序列表中排名靠前的程度, 计算公式如下:
mAP=
其中, C表示总类别数, 即行人数量.
Rank-k表示按照相似度排序后的前k幅图像中, 存在至少一幅与查询图像属于同一行人(同一ID)的准确率.检测样本的准确率如下:
Precision=
其中, TP表示模型正确预测的正样本个数, FP表示模型错误预测的正样本个数.
为了验证各模块在模型中的作用, 在Market-1501、CUHK03数据集上进行消融实验, 同时控制其它因素不变, 分别分析每个组件的具体作用.
首先分析BC层的性能, 对比BN层及在训练阶段使用BC层进行训练而在测试阶段使用原来的BN层(记为BC*).三者对比结果如表2所示, 表中黑体数字表示最优值, +BC表示全程使用BC层, +BC*表示只在训练阶段使用BC层.
| 表2 BC层的消融实验结果 Table 2 Ablation experiment results of BC layer % |
由表2可见, 在使用BC*对干净测试集进行采样和统计估计时, mAP和Rank-1指标在2个数据集上都低于文献[30]模型.此外, 在干净测试集上, 所有性能指标都有所下降.这说明仅使用干净测试集调整数据集分布并不能有效提高鲁棒性, 原因是在测试集中添加损坏图像会影响估计的统计数据, 导致在测试阶段, 模型在损坏测试集上并不鲁棒.因此在对损坏测试集进行采样后, 相比文献[30]模型, BC层在损坏场景的评估中, mAP值分别提升2.17%和0.88%.
对比BC层和文献[30]模型的结果可看出, BC层使模型在干净数据集上的性能不可避免地出现下降, 这是由于缓解训练阶段隐含编码的摄像机之间的关系, 导致学到的与摄像机相关的知识大幅减少.虽然模型泛化能力得到进一步提高, 但在干净测试集上的性能却略有下降, mAP指标分别下降1.95%和1.46%.这表明BC层可进一步提高模型在损坏场景上的准确性, 但略微降低在干净测试集上的性能.
在了解TI模块效果前, 有必要分析排序优化(RK)影响并深入了解其作用.因此, 本文在一些方法上使用k-reciprocal编码方法.TI模块的消融实验结果如表3所示, 表中黑体数字表示最优值, +RK表示单独使用k-reciprocal编码, +TI表示在k-reciprocal的基础上使用TI模块, +BC(RK)和+BC(TI)表示在原来的基础上使用BC层.
| 表3 TI模块的消融实验结果 Table 3 Ablation experiment results of TI module % |
由表3可见, 使用k-reciprocal以后, 文献[30]模型在Market-1501数据集上的性能获得大幅提高, 在检索图像和图库都损坏的情况下, mAP和Rank-1指标分别提高11.03%和1.6%.此外, 基于BC的改进比文献[30]模型更显著, 在两个数据集的损坏场景评估中, 相比文献[30]模型, mAP指标分别增加4.2%和1.14%.因为缓解摄像机之间的差异以后, 可以更好地测量图像之间的相似性, 从而改进k-reciprocal编码排序优化的效果, 提高主干网络的特征提取能力, 增强模型的重识别能力.
此外, 本文还评估基于BC和k-reciprocal编码的TI模块对模型的影响.从表3可看出, TI模块显著增强现有损坏场景下的识别性能.在损坏场景的Market-1501数据集上, 相比+RK, +TI的mAP指标从38.93%提至48.59%, Rank-1指标从56.38%提至69.69%.此外, 将BC和TI结合也能改善效果, 相比+TI, +BC(TI)的mAP和Rank-1指标分别提高4.09%和2.99%, 而在干净的数据集上也能保持具有竞争性的性能.在CUHK03数据集上也得出类似的结论.
上述实验表明, 将TI模块和k-reciprocal结合是相辅相成的, 而单独使用排序优化需要额外的处理时间, 且提升的性能有限, 无法兼顾复杂性和识别性能.相比之下, TI模块只依赖于时序信息, 不需要额外的训练时间, 提升的指标值更大.
在不同的损坏场景设置下组合使用BC层和TI模块的效果如表4和表5所示, 表中黑体数字表示最优值.由表4所示, 分别引入BC层和TI模块后, 在Market-1501数据集上的mAP指标分别提高2.17%和20.69%, 在CUHK03数据集上的mAP指标分别提高0.88%和6.39%.同时使用这两个模块后, 在Market-1501、CUHK03数据集上的mAP指标分别达到52.68%和30.28%.在表5中的另外两个损坏场景的设置下也达到最优性能.实验结果验证BC层、TI模块和整体框架的有效性.
| 表4 检索图像和图库都损坏时模型组件的消融实验结果 Table 4 Ablation experiment results of model components with corrupted retrieval images and gallery % |
| 表5 仅检索图像损坏或图库损坏的模型组件消融实验 Table 5 Ablation experiment of model components with either corrupted retrieval images or corrupted gallery % |
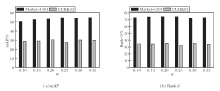
为了研究准确逼近相机相关统计数据所需的最少样本数, 使用不同批次的图像数量, 每个数量进行10次实验, 使用BC层在Market-1501、CUHK03数据集上获得的mAP和方差如图4所示, 注意:如果每台摄像机的图像数量不足, 将使用所有可用图像.
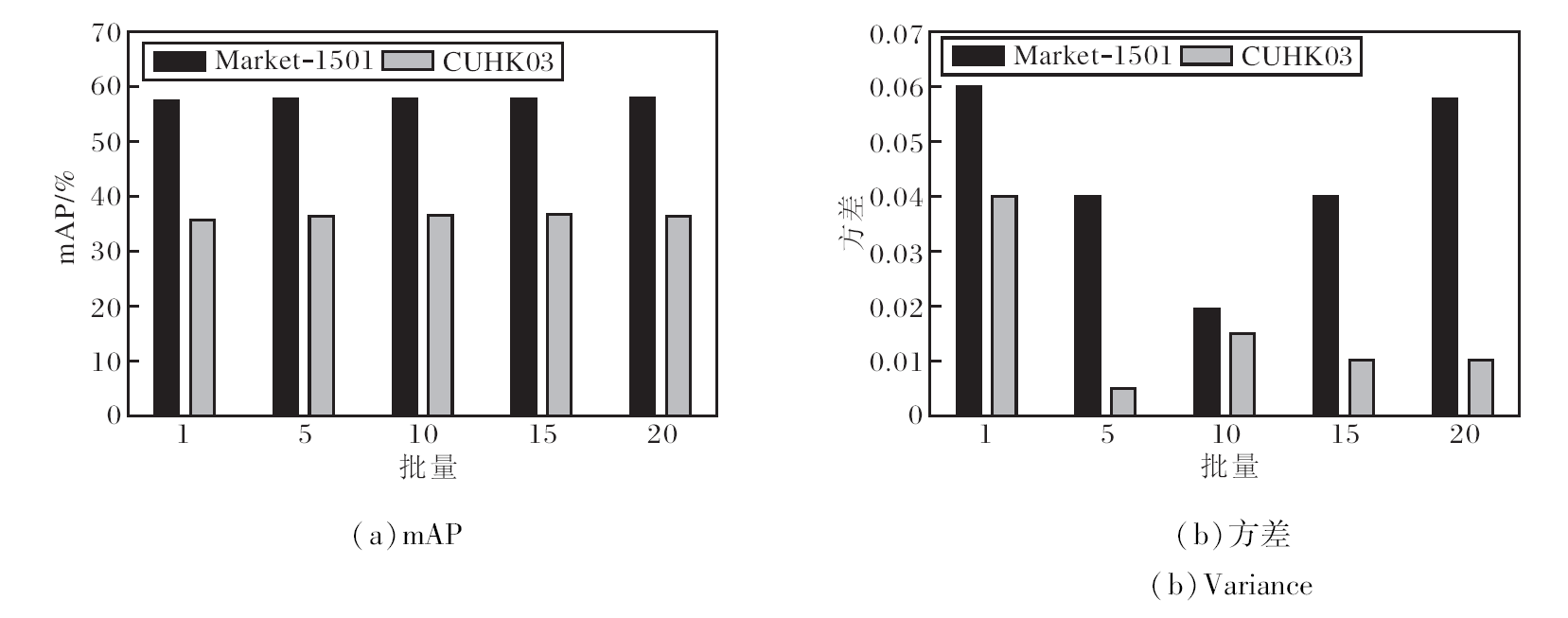 | 图4 BC层所需最少样本数不同对模型性能的影响Fig.4 Effect of different minimum numbers of samples required for BC layer on model performance |
从图4可看出, 当使用不同样本量估算与摄像机相关的统计数据时, 整体性能波动不大, 但随着样本量增加, 性能略有上升, 并变得更稳定.此外, 只使用10个批量进行实验时, 结果已较好, 因此为了兼顾性能和复杂性, 本文实验都使用10个批量进行评估.
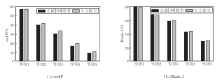
下面分析TI模块的权重参数α在损坏场景下对模型性能的影响.定义
α=0.10, 0.15, 0.20, 0.25, 0.30, 0.35,
在Market-1501、CUHK03数据集上的mAP和Rank-1指标值如图5所示.由图可见, 当α=0.1时, 在损坏场景下的Market-1501、CUHK03数据集上, 文献[30]模型的mAP指标分别达到50.40%和28.72%.当α=0.2时, mAP值提升至52.68%和30.28%, 取得最佳性能.这表明参数过低时, 模型正常排序优化得分的权重过低, 使模型很难与困难样本分开, 导致性能受到影响.然而过分增加α会减弱时序信息匹配概率的权重, 导致模型泛化能力较差.
 | 图5 不同α对模型性能的影响Fig.5 Effect of different α on model performance |
为了验证BC层在高复杂度背景下的有效性, 本文对比文献[30]模型和BC层在不同类型和损坏严重程度下的结果, 进一步评估模型的鲁棒性.
如图6所示, 当只用BC层代替BN层时, 本文模型的Rank-1在等级1和等级2中略低于文献[30]模型, 而mAP略高于文献[30]模型.当损坏严重程度不断提高时, 本文模型性能超过文献[30]模型.这说明当使用BC层将数据分布与损坏测试集对齐时, 随着损坏严重程度的增加, BC层后的数据分布与损坏的测试集更接近, 因此性能得到提高.
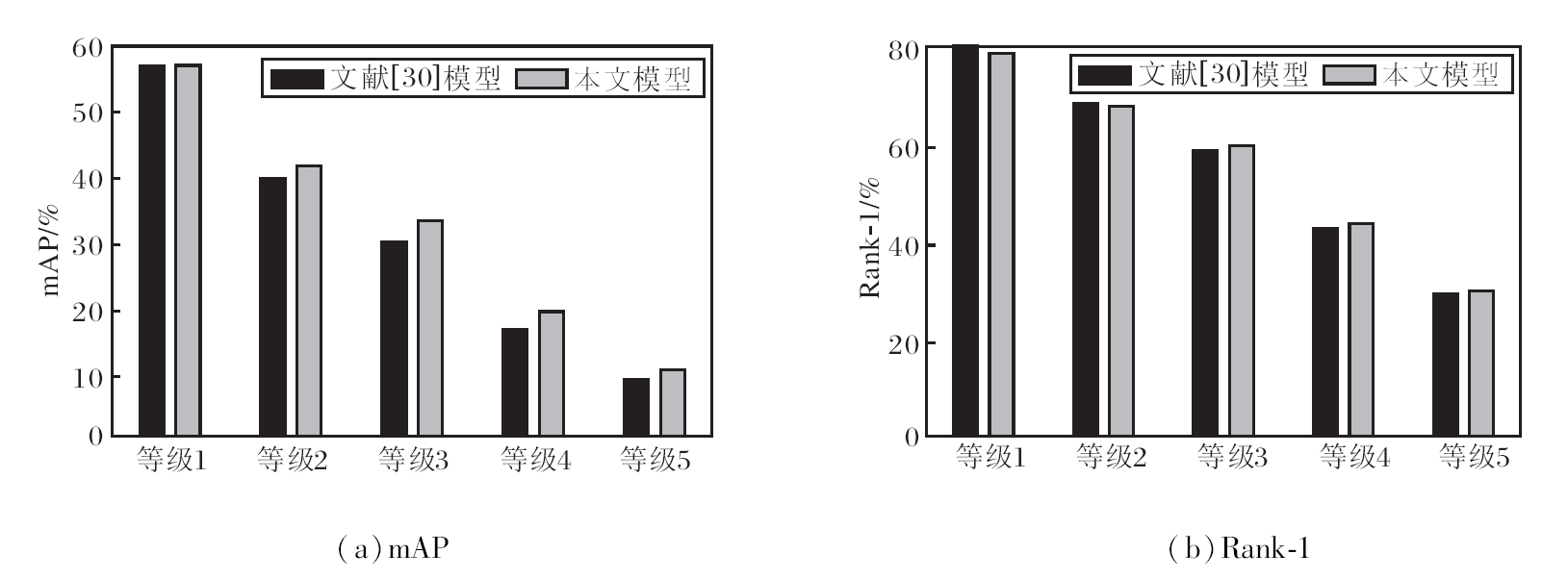 | 图6 不同损坏严重程度对模型性能的影响Fig.6 Effect of different degrees of corruption on model performance |
如图7所示, 在大多数损坏场景中, BC层提高模型性能, 但在某些场景下效果并不理想.因此本文对效果降低的损坏场景图像进行可视化.在霜、玻璃模糊和JPEG压缩三种损坏场景下的图像样例如图8所示.由图可发现, 在这3种损坏场景中, 损坏图像的像素与干净图像的像素仍然非常相似, 因此模型的高泛化性导致识别性能降低.
 | 图7 不同损坏场景对模型性能的影响Fig.7 Effect of different corruption scenarios on model performance |
 | 图8 3种损坏场景下的可视化样例Fig.8 Visualization examples of 3 corruption scenarios |
ResNet50是上述消融实验的基本框架, 主干网络的选择对模型性能影响很大.为了评估主干网络对模型性能影响, 本文将其与ResNet101、SENet(Squeeze-and-Excitation Network)[35]和IBN-Net[36]进行对比, 具体实验结果如表6所示, 表中黑体数字表示最优值, ResNet50-IBN-Net和ResNet101-IBN-Net表示IBN-Net中两种不同深度的网络.由表可见, 实验结果符合一般共识:即网络越深越大, 性能越高.在Market-1501、CUHK03数据集上进行损坏评估后, ResNet101的mAP值分别比ResNet50提高5.06%和4.44%.
| 表6 不同主干网络对模型性能的影响 Table 6 Effect of different backbone networks on model performance % |
此外, SENet的通道注意力也略微提高性能, 说明注意力能在损坏场景下捕捉到一些显著性线索, 但过高的复杂度使提升效果甚微.IBN-Net用实例BN层取代BN层, 与BC层一起在损坏评估中取得最高性能.这是因为IBN-Net学到的特征在外观变化时是不变的, 因此将其添加到网络架构中可提高对损坏的鲁棒性.ResNet101-IBN-Net因其网络深度的原因在Market-1501、CUHK03数据集上的性能得到进一步提升.实验结果表明, IBN-Net最适用于处理损坏场景任务.
为了验证损坏测试集的统计特征会影响模型的鲁棒性, 在测试阶段分别使用BCNeck之前或之后的特征进行实验, 具体结果如表7所示, 表中黑体数字表示最优值.由表可见, 在不同的损坏场景设置下使用BCNeck之前的特征进行测试能达到更优性能.在检索图像和图库都损坏的情况下, 本文模型在Market-1501数据集上使用BCNeck之前的特征获得的mAP值比使用BCNeck之后的特征提高7.47%.在CUHK03数据集上可得到相同的结论.实验结果表明使用BCNeck之前的特征更适合处理损坏场景的任务.
| 表7 使用BCNeck之前或之后特征的实验结果 Table 7 Experimental results of features before and after using BCNeck % |
为了验证本文模型在损坏场景和干净数据集上有更好的重识别能力, 本文选择如下一些目前先进的重识别模型进行对比实验:BNNeck[24]、文献[30]方法、AlignedReID++[37]、LightMBN[38]、Top-DB-Net(Top DropBlock Network)[39]、PLR-OSNet[40]、LGPR(Local Grayscale Patch Replacement)[41]、GGPR(Global Grayscale Patch Replacement)[41]、AGW(Attention Generalized Mean Pooling with Weighted Triplet Loss)[42].
各模型在3个数据集上的结果如表8~表10所示, 表中黑体数字表示最优值, 表8中Light MBN、PLR-OS使用的网络为OS-Net(Omni-Scale Net-work)[43], 本文模型(BC)层表示仅使用BC层, 本文模型(BC, TI)层表示同时使用BC层和TI模块.由于使用TI模块时需要使用排序优化(RK), 因此本文也提供对比模型使用RK后的结果, 在模型后加上(RK)表示该模型使用RK.
| 表8 各方法在Market-1501数据集上的对比实验结果 Table 8 Results of contrast experiments of different methods on Market-1501 dataset % |
| 表9 各方法在CUHK03数据集上的对比实验结果 Table 9 Results of contrast experiments of different methods on CUHK03 dataset % |
| 表10 各方法在DukeMTMC-reID数据集上的对比实验结果 Table 10 Results of contrast experiments of different methods on DukeMTMC-reID dataset % |
由表8~表10所示, 在干净的Market-1501、Duke-MTMC-reID数据集上, 本文模型(BC, TI)的Rank-1值比文献[30]模型分别提高1.33%和1.14%.在CUHK03数据集上, 相比文献[30]模型, 本文模型(BC, TI)达到具有竞争性的性能.就干净数据集上的性能而言, 当只使用BC层时, 本文模型与其它模型相比略显逊色, 因为BC层只考虑在损坏场景下的泛化性, 导致模型学到的特定知识减少, 而在使用TI模块后, 因为时序信息对干净场景下的图像也有效, 明显改进因为泛化问题导致的识别能力下降.
在检索图像和图库都损坏的情况下, 只使用BC层时本文模型在3个数据集上就获得最高指标值, 实验结果证明在最贴近损坏场景的情况下, 本文模型具有很强的泛化性.
在加入TI模块后, 相比文献[30]模型, 本文模型在Market-1501数据集上提高13.78%的mAP值和16.42%的Rank-1值, 说明TI模块将时序信息加入最后得分的权重, 使模型能抑制损坏场景的影响, 大幅提升其识别能力.在另外两个数据集上也可得到相同结论.
在仅检索图像损坏和仅图库损坏的情况下, 相比文献[30]模型, 只使用BC层的本文模型在某些情况下指标值略低, 这是因为在检索图像或图库中为干净图像时, BC层的强泛化性使模型无法学到干净图像与特定摄像机之间的相关性, 导致模型在干净数据集上的性能不稳定.因此在加入TI模块之后, 利用时序信息校准这一缺陷, 同样大幅提高识别性能.
本文提出基于相机感知的域自适应行人重识别模型, 专注于解决损坏图像对行人重识别模型性能的影响.模型从处理数据集的角度出发, 直接面对由于图像质量不佳带来的挑战.不同于以往模型只考虑对数据集进行增强, 本文设计BC层, 不仅缓解数据分布不一致的问题, 还有助于提升模型的鲁棒性.同时为了解决模型在干净数据集上由于泛化性过强而导致的性能下降问题, 设计TI模块, 将时序信息引入排序优化中, 通过二次加权修正检索图像的匹配分数, 在不增加额外训练成本的情况下显著提升性能.本文模型在设计和实现上考虑成本与性能的平衡, 特别是TI模块, 能在不增加额外训练负担的情况下提升性能, 这对于实际应用中的部署和维护至关重要.
虽然深度神经网络在一系列复杂的认知任务中已超过人类表现, 但在损坏场景上的识别能力仍落后于人类.即使对人类来说难以察觉的干扰, 也可能严重影响神经网络的预测.因此本文的研究成果为实际应用中的行人重识别任务提供有力的支持, 还为解决类似问题提供新的思路和方向.
本文责任编委 封举富
Recommended by Associate Editor FENG Jufu
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|
| [40] |
|
| [41] |
|
| [42] |
|
| [43] |
|