
{kind=link}
{kind=link}
{kind=link}
{kind=link}
特征增强与残差重塑的多重一致性约束半监督视频动作检测
[胡正平1, 2  , 张琦明
, 张琦明1 , 王雨露1 , 张和浩1 , 邸继锐1 ]
, 张琦明, 王雨露, 张和浩, 邸继锐]
|
|



作者简介:

张琦明,硕士研究生,主要研究方向为半监督视频动作检测.E-mail:zhangqiming@stumail.ysu.edu.cn.

王雨露,硕士研究生,主要研究方向为基于骨骼的人体动作识别.E-mail:hiwangyulu@163.com.

张和浩,博士研究生,主要研究方向为3D人体姿态估计.E-mail:zhanghh@stumail.ysu.edu.cn.

邸继锐,博士研究生,主要研究方向为细粒度动作识别.E-mail:dijirui123@163.com.
一致性正则化半监督视频动作检测方法对原始数据和增广数据进行特征表示时容易引起两类数据间判别域偏差,导致判别结果无法拟合.针对该问题,文中提出特征增强与残差重塑的多重一致性约束半监督视频动作检测方法.首先,将基础动作特征描述子在时空维进行连续性增强编码,获取视频动作理解中至关重要的上下文信息.然后,在通过残差特征重塑模块获得多尺度残差信息的同时进行特征重塑.为了降低不同数据间的判别偏差,分别从分类特征与动作定位特征角度对原始数据和增广数据施加多重一致性约束,实现模型对增广数据和原始数据判别结果和特征表示的匹配.最后,在JHMDB-21、UCF101-24数据集上的实验表明,文中方法能有效提高少样本标记条件下视频动作检测准确度,具有较强的竞争力.
About Author:
ZHANG Qiming, Master student. His research interests include semi-supervised video action detection.
WANG Yulu, Master student. Her research interests include skeleton-based human action recognition.
ZHANG Hehao, Ph.D. candidate. His research interests include 3D human pose estimation.
DI Jirui, Ph.D. candidate. His research interests include fine-grained action recognition.
The feature representations of both original data and augmented data in the consistency regularized semi-supervised video action detection method tend to induce discriminative domain bias between two types of data, thereby resulting in inadequate fitting of the discriminative results. To address this issue, a multi-consistency constrained semi-supervised video action detection method based on feature enhancement and residual reshaping is proposed in this paper. Firstly, the basic action feature descriptors are continuously enhanced and encoded in the spatiotemporal dimension to obtain crucial contextual information for video action understanding. Subsequently, a residual feature reshaping module is employed to obtain multi-scale residual information while reshaping the features. To reduce the discriminative bias between different types of data, multiple consistency constraints are applied to the original data and the augmented data from the perspectives of classification features and action localization features, achieving a match between discriminative results and feature representation of the augmented data and the original data. Experimental results on JHMDB-21 and UCF101-24 datasets demonstrate the effectiveness of the proposed method in improving video action detection accuracy under the condition of limited labeled samples and strong competitiveness.
视频动作分类是计算机视觉热门研究方向之一, 在卷积架构[1]和深度学习框架[2]推动下, 视频动作分类取得巨大进展[3, 4, 5, 6, 7, 8], 然而方法性能提升却依赖于大规模数据集的使用[9, 10, 11].
相比视频动作分类, 视频动作检测更具有挑战性, 不但需要预测视频中动作类别, 还要对动作进行时空定位.为视频动作检测准备大规模数据集则更加困难, 因为它不仅需要视频级别的类别标注, 还需要帧级别的定位标注, 这无疑是一项需要大量时间和人力的工作.
由于训练传统深度神经网络在数据层面的局限性和人们对降低数据标记成本的迫切需求, 半监督学习受到学者们的关注.与全监督学习不同, 半监督学习仅需要少量带标注的样本和大量无标注的样本进行训练, 这不仅有效降低标注难度和成本, 还可充分利用未标注的数据训练模型, 有效避免过拟合问题.
半监督学习相关工作可分为伪标签法和一致性正则化法.伪标签法首先利用标记样本对模型进行初训练, 然后使用模型对无标签数据进行分类预测, 将预测结果作为伪标签, 赋予无标签样本, 最后将伪标签样本输入模型进行迭代训练.Lee等[12]首先将伪标签法Pseudo-Label应用于半监督学习, 在模型微调阶段产生伪标签, 特征通过Softmax层, 将分类预测中最大的概率设置为1, 其它概率设置为0, 得到One-Hot标签并用于模型训练.对无标签样本进行伪标签标记时, 聚类过程会产生伪标签噪声, 使模型在目标域上表征能力下降, 为此Hu等[13]提出Pseu-doProp, 首先利用视频帧运动的连续性作为约束条件, 提高伪标签的鲁棒性, 然后使用双向伪标签传播法进行错误补偿, 最后使用特征融合技术抑制伪标签噪声.由于训练域与测试域之间存在差异, 模型不可避免地产成错误伪标签并影响训练.为了克服由于训练域和测试域之间的差异而导致伪标签的错误预测问题, Zheng等[14]提出在训练过程中显式估计预测的不确定性, 以纠正错误的伪标签.对伪标签加入不确定性估计可减少错误伪标签的数量, 但会降低模型对低置信度标签的利用效率.针对该问题, Wang等[15]计算模型预测的熵, 分离特征中低置信度像素, 并将每个不可靠像素推送到负样本类别队列中, 使用高置信度像素训练模型, 有效提高标签利用效率.针对半监督学习中数据不平衡、类间相似度高和域不匹配问题, Chang等[16]提出BiSTF(Bila-teral-Branch Self-Training Framework), 有效降低类不平衡和域移动问题对模型的影响.
虽然伪标签法能有效利用无标签样本, 但不可避免地产生错误的伪标签, 这种错误会影响下一轮训练, 进而造成错误传播问题.此外, 伪标签法是一种迭代计算方法, 计算成本较高, 不适合计算量较大的视频动作检测.
一致性正则化法是通过对输入数据加入一定扰动, 期望模型对增广数据的预测结果与原始数据的预测结果保持一致, 以此提高模型的自适应性.在训练中, 为了加强样本数据间的相干性, Luo等[17]利用教师网络的概率图与学生网络的嵌入图两者结构一致的思想, 将教师网络预测概率与输入数据类别结合, 构建多维关系矩阵, 利用多维关系矩阵与学生网络嵌入图设计结构一致性约束, 最终有效平滑特征空间, 提高模型预测准确率.Berthelot等[18]融合一致性正则化法[19]、最小化熵法[20]及MixUp, 提出MixMatch, 对无标签数据使用K种不同的方式进行增强, 预测K个类别概率, 再将K个类别概率的平均值作为预测结果.
为了避免主要背景对检测性能的负面影响, Jeong等[21]提出CSD(Consistency-Based Semi-super-vised Learning for Object Detection), 对定位结果施加一致性约束.一致性正则化方法通过缩小增强样本特征之间的距离以增强不变性, Fan等[22]发现, 增加这种距离能使特征分布更规范化, 为此提出FeathDistLoss, 分别在分类器和判别特征上施加一致性约束和等变性, 用于提高模型性能.同样是针对背景问题, Zhong等[23]基于削弱背景中动态信息的方法, 提出BWCC(Background-Weakening with Calibra-tion Constraint), 计算经过背景削弱的视频与原始视频预测的一致性, 弱化背景信息的负面影响.
由上述分析可知, 半监督一致性正则化方法鼓励模型对原始数据与增广数据之间施加一致性约束, 该约束能促使模型在无标签数据之间建立有效关联, 提高模型的泛化能力和性能.为了在时空维度建立更深层的一致性约束, 本文对于模型输出的动作定位特征, 从定位结果、相邻帧的方差和相邻帧的梯度三个不同的角度施加一致性约束, 提出特征增强与残差重塑的多重一致性约束半监督视频动作检测方法.为了加强多重一致性约束深度, 首先对模型输出的基础动作特征描述子进行时空连续性增强编码, 在相邻帧层面对特征空间进行时间维度分割, 使其不仅包含当前帧的动作信息, 同时融合相邻若干帧同类动作信息, 实现增强编码.为了捕获多尺度残差信息, 加强模型对不同尺度信息的表征能力, 设计残差特征重塑(Residual Feature Reshaping, RFR)模块, 有效融合多尺度信息.最后, 分别从类别特征、定位特征、邻帧方差及特征梯度平滑多个角度对原始数据和增广数据之间施加一致性正则化约束, 提高模型对增广数据与原始数据的拟合能力, 有效利用无标签样本.
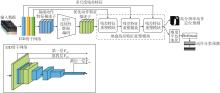
本文提出特征增强与残差重塑的多重一致性约束半监督视频动作检测方法, 具体框图如图1所示.
 | 图1 本文方法框图Fig.1 Structure of the proposed method |
I3D(Inflated 3D ConvNet)[24]以相对较小的模型参数量和优异的性能被广泛应用于视频理解领域, 本文以Kinetics数据集[10]和Charades数据集[25]上预先训练权重的I3D作为骨干网络, 用于提取视频数据中的基础动作特征描述子.
本文方法对特征处理的流程如图1所示.首先, 将分辨率为224×224的视频数据V={V1, V2, …, Vn}输入I3D骨干网络, 提取视频的基础动作特征描述子F, 将F通过时空连续性增强编码, 使模型在预测时, 不仅关注当前帧的动作信息, 同时关注相邻帧的动作信息.然后通过堆叠残差特征重塑(RFR)模块, 依次提取I3D骨干网络中第一层FR1、第四层FR4以及最后一层FRn的多尺度残差信息, 在训练时同时关注宏观动作特征和抽象语义特征.最后, 输出动作分类预测PC及高分辨率动作定位预测loc.对PC施加增广数据与原始数据之间的分类一致性约束, 提高模型对复杂动作预测的准确性.高分辨率动作定位预测loc∈RC×T×H×W, 其中, C表示特征维度, T表示输入视频片段帧数, 在本文中T=8, H、W分别表示特征矩阵的高度和宽度, 在本文中H=W=224.loc中每个元素值表示对应像素点为动作区域的概率, 对loc从定位特征空间、邻帧方差及特征梯度平滑角度构建增广数据与原始数据之间的一致性约束, 旨在提高半监督模型对增广数据和原始数据的拟合能力.
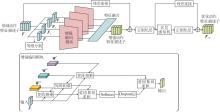
I3D骨干网络输出的基础动作特征只能捕获局部时空信息, 关注范围小且缺乏全局建模能力.为了提取视频数据中至关重要的全局上下文信息, 融入Self-Attention机制[26], 设计时空连续性增强编码网络.由于相邻帧的动作具有相似姿势, 因此相邻帧对应的特征表示也应是相似的.利用这种数据内部的依赖关系, 对F进行时空连续性增强编码, 使模型不仅关注当前帧的动作信息, 同时关注相邻若干帧的动作信息, 进而使模型学到更具全局性的特征.模型进行全局建模后可提供更优质的动作特征描述子.时空连续性增强编码网络结构如图2所示.
 | 图2 时空连续性增强编码网络结构图Fig.2 Structure of spatiotemporal continuity enhancement encoding network |
在传统注意力模型中, 权重矩阵Q、键值矩阵K、数值矩阵V由可学习的线性层进行建模, 但线性层难以充分提取高维特征空间的非线性信息, 因此本文使用二维卷积矩阵进行权重建模.为了增强模型对视频动作的时序建模能力, 将基础动作特征按照时间维度进行等维分割和聚合.具体地, 经过裁剪后的视频数据长度为8帧, 对应骨干网络提取的基础动作特征描述子F∈RC×T×H×W, 其中, C表示通道数, T=8, 表示帧数, H、W表示特征矩阵的高和宽.将F在第2个维度等维分割4层:
F=[F1, F3, F5, F7],
其中, Fi∈RC×2×H×W, i=1, 3, 5, 7, 表示第i帧与第i+1帧特征的组合.
为了加入优化特征表示, 将Fi通过卷积空间分别映射至查询特征空间、键值特征空间与数值特征空间, 并得到查询矩阵Q、键值矩阵K和数据矩阵V:
Qi=
其中, i=1, 3, 5, 7,
为了计算查询矩阵Qi与键值矩阵Ki的相关性矩阵, 引入爱因斯坦求和, 它是一种对数据进行相乘求和的方法, 处理高维矩阵时较有效.对Qi与Ki使用爱因斯坦求和, 得到相关性矩阵:
Pi=
将Pi输入Softmax层, 得到注意力权重矩阵, 值越高表示模型对该区域关注的程度越大.为了防止模型过拟合, 使用Dropout层舍弃Pi的少量权重, 将Pi与权值矩阵Vi进行爱因斯坦求和, 得到关注上下文信息的输出特征:
其中
FConnect=CNT(
其中CNT(·)表示维度连接.
为了减轻梯度消失现象并增强时空连续性, 增强编码网络的学习能力, 将原始输入作为残差项进行连接, 最后通过全连接层与归一化层, 得到时空连续性增强动作特征:
Fout=LN(FRes+MLP(FRes))∈RC×8×H×W,
其中
FRes=LN(FConnect+F),
LN(·)表示层归一化, MLP(·)表示全连接层.
Fout使模型不仅关注相邻帧的短时序局部信息, 经过特征融合后, 还包含长时序全局信息.经过增强编码后, 模型具有更强的自适应性, 特征包含的时序信息更丰富, 有效改善半监督模型施加一致性约束时的效果.
为了捕获多尺度残差信息, 提高模型的表征能力, 本文在骨干网络中提取3种尺度的残差特征, 并设计残差特征重塑(RFR)模块进行特征融合.具体地, RFR模块通过残差支路获取多尺度动作特征, 通过特征重塑支路对动作特征描述子进行复原, 两个支路的信息通过维度连接实现多尺度特征融合, RFR模块结构如图3所示.
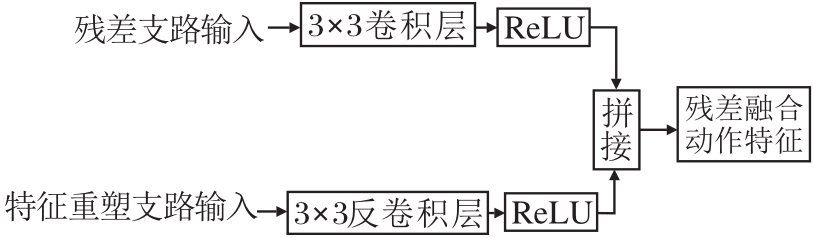 | 图3 RFR模块结构图Fig.3 Structure of RFR module |
首先残差支路将残差输入FRes∈RC×8×H×W馈送给卷积层进行高维表示, 然后通过ReLU层激活残差特征, 即
R=Relu(Conv(FRes)),
其中Conv(·)表示卷积操作.
对于特征重塑支路, 首先将经过时空连续性增强编码的动作特征描述子Fout∈RC×8×H×W馈送给反卷积层进行特征重塑, 通过反卷积将抽象语义信息恢复至高宽为224×224的高分辨率特征, 同时使用ReLU层对多尺度信息进行激活, 即
F'=Relu(Dconv(Fout)),
其中Dconv(·)表示反卷积操作.连接残差支路特征与特征重塑支路特征, 得到RFR模块的输出:
F=CNT(R, F').
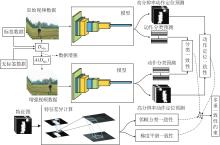
在一致性正则化方法中, 对原始数据进行增强, 将增广数据和原始数据输入模型中进行预测, 由于增广数据和原始数据属于同一类别, 因此模型对两类数据的预测应保持尽可能一致.为了在时空维度建立更深层的一致性约束, 本文从多个角度对模型的输出施加一致性约束, 具体如图4所示, 图中DMix表示经过随机打乱并混合的标签数据与无标签数据, A(DMix)表示数据增强.
 | 图4 多重一致性约束流程图Fig.4 Flow chart of multiple consistency constraint |
多重一致性约束过程如下:模型输出的动作分类结果用于构成分类一致性约束, 模型输出的高分辨率动作定位特征用于构成动作定位一致性约束、邻帧方差一致性约束及梯度平滑一致性约束.
1.3.1 分类一致性约束
尽管增强样本与原始样本存在一定差异, 但它们的动作应属于一个类别.根据此特性, 设计分类一致性约束, 描述如下.将原始样本的分类特征与增强样本的分类特征之间的距离作为评价指标.度量距离差异的指标有KL散度(Kullback-Leibler Diver-gence).P(x)与Q(x)为模型分别对原始数据和增强数据的分类结果, 即
$K L(P \| Q)=\sum_{i=1}^{N}\left(P\left(x_{i}\right) \cdot \log _{2}\left(\frac{P\left(x_{i}\right)}{Q\left(x_{i}\right)}\right)\right) .$
P(x)与Q(x)相似度越高, KL散度越小.由于KL散度不具备对称性, 即KL(P‖ Q)≠KL(Q‖ P), 并且值域范围大, 因此本文实验在KL散度基础上, 对两个预测结果分别赋予二分之一权重并相加, 对上述过程进行两次对称计算, 使值域限制在[0, 1]内, 保持良好的对称性.当P(x)与Q(x)判别域欧氏距离过大时, 计算结果接近1; 当P(x)与Q(x)判别域欧氏距离较小时, 计算结果接近0.最终分类一致性约束的目标函数为:
$\begin{aligned} L_{c}^{\text {const }}= & \frac{1}{2} K L\left(P(x) \| \frac{P(x)+Q(x)}{2}\right)+ \\ & \frac{1}{2} K L\left(Q(x) \| \frac{P(x)+Q(x)}{2}\right) . \end{aligned}$
1.3.2 动作定位一致性约束
在动作定位一致性约束中, 半监督模型预测视频中动作的位置, 原始样本V通过模型M后输出高分辨动作定位预测loc∈RC×8×H×W, 这是像素级的预测.loc中每个值的大小, 表示该像素是动作的概率.当特征值映射区域为背景时, 模型更多将其判别为不是动作像素; 当特征值映射区域为动作前景时, 模型应尽可能大地将其判别为是动作像素.
在半监督模型训练过程中, 模型对原始样本V进行变换增强, 得到A(V), A(·)表示数据增强操作.输出的动作定位预测loc+∈RC×8×H×W为变换增强后模型的预测.在本文中, 使用水平反转以增强数据, 由于水平反转后, 动作位置发生变化, 因此检测结果也会水平地发生变化.为了确保原始数据与增广数据定位结果的一致性, 对增广数据动作定位结果进行逆增强处理Λ (loc+), 其中Λ (·)表示逆增强.在动作定位一致性约束下, 模型应一致预测原始数据动作区域loc与经过逆增强后的增广数据的动作区域Λ (loc+).对原始数据与增广数据输出动作定位预测进行相似性计算以缩小两类数据输出差异, 本文使用均方误差(Mean Square Error, MSE)度量两者的相似性, 为此动作定位一致性约束为:
1.3.3 邻帧方差一致性约束
邻帧方差一致性约束是指在时间维度下, 由于动作的连续性, 视频中特定帧的动作区域与其相邻帧的动作区域差异不能过大.通过固定当前帧动作区域的像素, 并与未来帧动作区域的像素点计算像素位移方差以度量这种差异.将像素位移方差计算结果称为邻帧方差映射图Mdst∈RC×7×H×W.邻帧方差一致性通过捕获动作区域在时间维度的相对变化, 使模型学习更高维连续动作特征, 提高模型时序建模能力.利用邻帧方差映射图Mdst实现邻帧方差一致性约束, 本节同样使用MSE损失衡量原始数据Mdst与增广数据Mdst+之间的相似性, 邻帧方差一致性约束为:
其中, w表示邻帧方差一致性约束的权重因子, 第i帧的方差映射图
i=1, 2, …, 7,
loci∈RC×1×H×W表示第i帧的动作定位结果, H、W分别表示矩阵高度和宽度, μi表示第i帧的像素平均值.
在训练初期, 模型仅具备I3D骨干网络经过预训练后的初级判别信息, 无法对视频中的动作前景做出准确判断, 因此在训练初期将权重因子w设置为0.随着模型训练轮次增加, 判别置信度逐渐提高, 邻帧方差一致性损失权重w随训练轮次呈指数级增加, 进而使模型更多关注于时间维度的一致性.
1.3.4 梯度平滑一致性约束
梯度平滑一致性是从特征沿时间维度变化的角度对动作定位特征进行约束, 使模型更多地关注高分辨率定位特征中的突变位置.具体地, 在短时间跨度内, 动作区域的像素由于人物运动, 像素值会产生较大变化, 而背景区域的像素由于相对统一, 变化相对较小, 因此沿时间维度计算动作定位预测的一阶导数, 得到一阶时间梯度流图, 该流图应在背景区域和静态区域变化较小, 保持平滑性, 而在动作区域变化显著.
为了增强模型对动作前景检测能力, 同时削弱无关背景, 对一阶梯度流图再次求导.根据一阶梯度流图背景及静态区域平滑的特点, 二阶时间梯度流图Mgrad∈RC×7×H×W在变化相对较小的平滑区域趋于0, 在动作边界表示为尖峰值.通过对尖峰值的学习, 模型能更好地捕捉动作边界.特征梯度平滑约束损失为:
其中, Mgrad表示原始数据的二阶时间梯度流图, Mgrad+表示增广数据的二阶时间梯度流.第i帧的像素梯度图为:
其中,
dist表示相邻帧距离.
模型整体损失由标签约束Llabel与多重一致性正则化约束Lconst组成.针对有标签样本, 同时使用标签约束与多重一致性约束训练模型.针对无标签样本, 仅通过多重一致性约束训练模型, 总体损失函数如下:
L=Llabel+Lconst.
使用有标签数据的类别标签和定位标签进行监督约束, 则
$\begin{aligned} L_{\text {label }}= & -\frac{1}{N} \sum_{i=1}^{N}\left[y_{i} \log _{2}\left(P\left(y_{i}\right)\right)+\right. \\ & \left.\left(1-y_{i}\right) \log _{2}\left(1-P\left(y_{i}\right)\right)\right]+ \\ & \left(1-\frac{2\left|X_{i} \cap Y_{i}\right|}{\left|X_{i}\right|+\left|Y_{i}\right|}\right), \end{aligned}$
其中, N表示视频数, yi表示真实类别标签, P(yi)表示模型预测结果, Xi表示动作定位标签, Yi表示模型预测动作定位.
多重一致性约束如下:
Lconst=
其中,
为了更清晰地阐明训练过程和提高模型一致性的方式, 使用伪代码设计本文算法.标记样本集
XL={
未标记样本集
XU={
混合标记样本集XL与未标记样本集XU作为原始训练样本X, 将原始训练样本X与增强训练样本A(X)作为模型输入, 动作检测模型M用于预测动作标签与高分辨率动作定位.
算法 1 特征增强与残差重塑的多重一致性约束半监督视频动作检测方法
输入 视频数据X, 权重参数θ, 网络模型M, 学习率lr, 阈值thn
输出 分类判别特征PC, 高分辨率动作定位特征FL
for i in length X do
对视频数据X进行数据增强, 得到A(X)
end for
for epoch in 1, 2, …, Epochmax do
if loss decrease do
增广数据A(X)与原始数据X输入网络模型M, 求得高分辨率动作定位特征与分类预测结果
if 标签数据do
计算损失Llabel+Lconst
end if
if无标签数据do
计算分类一致性损失
计算动作定位一致性损失
计算邻帧方差一致性损失
计算梯度平滑一致性损失
end if
进行反向传播与优化器优化更新权重参数θ
else if损失连续thn个epoch没有下降减小学习率lr=0.1lr
end if
end for
为了验证本文方法的有效性, 在半监督视频动作检测常用的基准数据集JHMDB-21[9]、UCF101-24[11]上开展实验, 并与现有方法进行对比.
JHMDB-21数据集是HMDB数据集的二次标注, 即Joint-annotated HMDB, 数据集样本经过修剪精练, 删除原HMDB数据集上人体行为动作相对不明显样本, 质量更高.数据集共包含928个视频, 21个视频类, 这些类主要为运动类, 每类有36~55个视频样本, 每个样本包括人体行为起始时间和终止时间, 每个样本视频包含14~40帧, 原始分辨率为320×240, 共标注31 383幅图像.
UCF101-24数据集从包含101个动作类原始UCF101数据集上进行次采样得到, 共包含3 207个未修剪视频, 24个动作类, 主要包括人与物体交互、肢体动作、人与人交互、使用生活工具等, 训练视频设置为2 284个, 测试视频设置为923个.每个视频样本约包含150帧, 动作时长约占视频总时长的78%, 帧分辨率与JHMDB-21数据集相同.
实验采用帧-度量平均精度(Frame-Mean Average Precision, f-mAP)与视频-度量平均精度(Video-Mean Average Precision, v-mAP)作为评价指标, 评估动作检测模型性能.f-mAP根据给定交并比(Intersection over Union, IoU)情况下结合标签样本中视频帧重叠数计算得到.v-mAP根据标签样本视频段重叠数计算得到.评价指标f-mAP@0.2、f-mAP@0.5、v-mAP@0.2、v-mAP@0.5的数字表示交并比为0.2和0.5.
2.2.1 JHMDB-21数据集上实验结果
为了使卷积神经网络更好地进行训练, 将视频的高宽设置为224×224, 在每个批次的样本数据中, 随机打乱有标签样本与无标签样本, 对每个视频样本进行裁剪, 经过裁剪后帧数为8.考虑JHMDB-21数据集规模较小, 在数据量上存在限制, 为使模型充分训练并防止过拟合, 数据集上标记样本和未标记样本数量比设置为3∶ 7, 即使用30%有标签样本, 剩余70%为无标签样本.
本文选择如下方法进行对比:Pseudo-Label[12]、MixMatch[18]、CSD[21]、BWCC[23]、文献[27]方法、GLNet(Global Local Network)[28].
各方法在JHMDB-21数据集上的实验结果如表1所示.由表可知, 本文方法的f-mAP@0.5值比BWCC提升1.8%, 表明在帧层面对高分辨率动作特征施加动作定位一致性约束, 可更好地将增广数据判别结果与原始数据之间的定位进行拟合.同时引入梯度平滑一致性约束, 能将动作边界体现在尖峰值上, 学习尖峰值可有效提升帧层面检测性能.相比f-mAP, v-mAP对模型时序建模能力要求更高, 相比BWCC, 本文方法在v-mAP@0.5指标上提升显著, 精度上升3.4%.在v-mAP@0.2指标上, 各方法准确率已达到较高水平, 但相比BWCC, 本文方法仍有0.9%提升.
| 表1 各方法在JHMDB-21数据集上的指标值对比 Table 1 Index value comparison of different methods on JHMDB-21 dataset % |
实验表明, 本文方法能更好地捕捉动作实例上下文信息, 基础动作特征描述子经过时空连续性增强编码, 有效扩大时间维度感受野, 相比从单帧维度出发, 从视频维度出发可提供更多的判别信息.同时, 强化邻帧方差一致性约束对不同时刻视频帧之间差异进行建模, 进一步提高模型时序建模能力, 并从时间维度保持模型对增广数据和原始数据之间预测一致性, 表明本文方法具有较优性能.
2.2.2 UCF101-24数据集上实验结果
在UCF101-24数据集上, 实验使用20%的数据作为有标签样本, 剩余80%的数据作为无标签样本.视频高宽及裁剪帧数等参数设置均与JHMDB-21数据集上一致.
选择如下对比方法:Pseudo-Label[11]、MixMa-tch[18]、CSD[21]、BWCC[23]、文献[27]方法、GL-Net[28]、文献[29]方法、文献[30]方法、文献[31]方法、文献[32]方法、文献[33]方法.
各方法在UCF101-24数据集上的实验结果如表2所示.
| 表2 各方法在UCF101-24数据集上的指标值对比 Table 2 Index value comparison of different methods on UCF101-24 dataset % |
由表2可知, 相比BWCC:在f-mAP@0.5指标上, 本文方法提升0.6%; 在v-mAP@0.2指标上, 本文方法提升0.3%; 在v-mAP@0.5指标上, 本文方法性能相当.
整体实验结果表明, 本文方法在JHMDB-21、UCF101-24数据集上都表现出较优性能, 具有一定普适性.
2.2.3 全监督方法对比结果
为了研究方法在全监督条件下的性能, 使用样本的全部标签进行训练, 并与如下全监督视频动作检测方法进行对比:文献[27]方法、文献[34]方法、T-CNN(Tube Convolutional Neural Network)[35]、ACT-detector(Action Tubelet Detector)[36]、VideoCapsule-Net[37]、TACNet(Transition-Aware Context Network)[38]、文献[39]方法、MOC-detector(MovingCenter Detec-tor)[40]、SAMOC(Self-Attention MovingCenter Detec-tor)[41]、CSTA-Net(Cascading Spatio-Temporal Atten-tion Network)[42].
各方法在JHMDB-21数据集上的实验结果如表3所示.
| 表3 全监督条件下各方法的指标值对比 Table 3 Index value comparison of different methods under fully supervised condition % |
由表3可知, 本文方法在v-mAP@0.2指标上优于大部分全监督方法, 在f-mAP@0.5与v-mAP@0.5指标上同样表现出不错的性能, 但未超过所有方法, 这是因为相比全监督学习是针对数据与标签间映射关系的研究, 本文方法更多地关注无标签数据间的联系, 侧重于加强方法对无标签扰动数据预测的一致性.实验表明, 在使用训练数据全部标签的情况下, 本文方法能达到与全监督方法相当的性能, 具备普适性.
为了研究本文方法中各一致性约束与模块对整体性能的影响, 展开消融实验.由于在大规模数据集上训练模型周期较长, 为了减小计算量并缩短实验周期, 在数据量相对较小的JHMDB-21数据集上进行实验, 对实验所得3次结果求平均值.
2.3.1 时空连续性增强编码网络消融实验
为了更深入研究时空连续性增强编码网络对其它位置特征的影响, 分别将时空连续性增强编码网络对方法中不同的特征描述子进行增强, 即联合特征描述子、输出特征描述子、基础动作特征描述子.其中:联合特征描述子为动作特征与类别预测矩阵的融合, 包含更多不同种类的信息; 输出特征描述子为方法最后输出的判别特征矩阵; 基础动作特征描述子为骨干网络输出的基础特征.具体消融实验结果如表4所示.
| 表4 时空连续性增强编码的消融实验结果 Table 4 Ablation experiment results of spatiotemporal continuity enhancement encoding network % |
由表4可见, 将时空连续性增强编码网络应用于输出特征描述子并未改善方法检测效果, 反而导致性能断崖式下降, 这主要是因为增强编码直接作用于动作定位矩阵, 使方法判别混乱, 容易受到其它视频实例干扰, 进而降低判别的稳定性和鲁棒性.但将时空连续性增强编码网络应用于联合特征描述子或基础动作特征描述子时, 性能得到显著提升.这表明方法可较好地利用动作特征连续性进行建模, 提高视频和帧层面检测精度.相比之下, 基础动作特征描述子仅包含局部时空信息, 缺少视频维度全局上下文信息, 通过优化编码后, 可有效提升动作特征感受野深度, 在判别时从时间维度出发, 全面考虑当前帧及相邻帧动作信息.
实验表明, 时空连续性增强编码网络对提升方法性能较有效.然而, 将时空连续性增强编码网络应用于联合特征描述子时, 实际模态复杂, 连续性编码可能导致两种矩阵信息混淆, 反而对性能提升产生负面影响, 因此本文增强基础动作特征描述子.
2.3.2 多重一致性约束消融实验
为了验证多重一致性约束各部分对方法性能的影响, 分别对分类一致性约束、动作定位一致性约束、邻帧方差一致性约束和梯度平滑一致性约束展开消融实验.分类一致性约束是对方法输出的类别预测施加一致性约束; 动作定位一致性约束、邻帧方差一致性约束以及梯度平滑一致性约束是对高分辨率动作定位特征施加一致性约束.因此根据对类别预测与高分辨率动作定位特征处理的不同, 将多重一致性约束分为两部分:Consistence-Class和Consis-tence-Loc.具体消融实验结果如表5所示.
| 表5 多重一致性约束的消融实验结果 Table 5 Ablation experiment results of multiple consistency constraints % |
由表5可见, 仅添加Consistence-Class与仅添加Consistence-Loc都可提升指标值, 由此表明, 对类别特征与高分辨率动作定位特征施加一致性约束能有效提高方法检测性能.此外, Consistence-Class对帧层面精度提升显著, Consistence-Loc对视频层面效果提升明显, 这是因为Consistence-Loc是从时间维度捕获特征之间的一致性, 能有效提高模型时序建模能力.
在使用分类一致性约束基础上, 采用控制变量法分别验证动作定位一致性约束、邻帧方差一致性约束与梯度平滑一致性约束对方法性能的影响, 具体消融实验结果如表6所示, 表中Baseline表示仅添加分类一致性约束.
由表6可知, 动作定位一致性约束、邻帧方差一致性约束与梯度平滑一致性约束都能提升方法性能, 并且同时添加3种一致性约束时, 方法在v-mAP@0.5上性能提升幅度高于在f-mAP@0.5上的, 由此说明, 相比帧层面检测更多从时间维度出发, 上述一致性约束依据相邻时间动作特征的关系进行建模, 有助于提高模型在时间维度的建模能力.
| 表6 3种一致性约束的消融实验结果 Table 6 Ablation experiment results of 3 consistency constraints % |
为了降低半监督方法对原始数据与增广数据之间的判别偏差, 提高模型拟合能力, 本文提出特征增强与残差重塑的多重一致性约束半监督视频动作检测方法.传统半监督一致性正则化方法仅关注低维描述子, 视角单一, 无法在高维特征层面抽取原始数据和变换增强数据间深层联系.在使用少量标签样本与大量无标签样本条件下, 设计时空连续性增强编码网络, 对骨干网络提取的基础动作描述子进行特征增强, 提高多重一致性约束质量, 加强时序建模能力.设计堆叠残差特征重塑模块, 在特征流中融合多尺度残差信息, 融合后的特征不仅包含粗粒度宏观特征, 还保留细粒度动作细节.基于多重一致性约束, 有效拉近原样本与增广样本在输出类别特征与高分辨动作定位特征间的距离.实验表明, 本文方法在半监督与全监督条件下均展示出较优性能, 表明方法的有效性与通用性.今后将进一步构建更高效的多尺度融合网络, 提高模型对不同尺度信息的整合能力, 细化动作检测边界.此外, 还计划研究本文方法在其它领域的性能, 如目标跟踪和分割.
本文责任编委 黄 华
Recommended by Associate Editor HUANG Hua
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|
| [40] |
|
| [41] |
|
| [42] |
|