
{kind=link}
{kind=link}
{kind=link}
基于多层次融合的弱监督目标检测网络
[曹环1  , 陈曾平
, 陈曾平1 ]
, 陈曾平]
|
|



作者简介:

曹 环,博士研究生,主要研究方向为深度学习、计算机视觉.E-mail:caohuan_sysu@163.com.
由于缺少精确的边界框注释,弱监督目标检测器依赖预训练图像分类模型对候选区域进行分类.然而,预训练模型通常对具有鉴别性的区域而非完整的目标产生高响应,导致局部主导、实例丢失和非紧密框等问题.为此,文中提出基于多层次融合的弱监督目标检测网络,从增强对弱鉴别性空间特征的学习、类内样本特征丰富性和可信伪标签权重的角度提升检测性能.首先,幂池化层利用幂函数加权融合邻域内的激活值,减少弱鉴别性特征的信息损失.其次,特征混合方法随机融合候选区域的特征向量,丰富训练样本特征的多样性.最后,基于置信度的样本重加权策略融合预测值和伪标签的置信度,调节伪标签对训练的影响.在3个基准数据集上的实验表明文中网络性能较优.
About Author:
CAO Huan, Ph.D. candidate. His research interests include deep learning and computer vision.
Due to the lack of precise bounding box annotations, weakly supervised object detectors rely on the pretrained image classification model to classify candidate regions. However, the pretrained model often produces high responses for discriminative regions rather than complete objects, resulting in the problems of part domination, instance missing and untight boxes. To address these issues, a multi-level fusion based weakly supervised object detection network is proposed. The detection performance is improved from the perspectives of enhancing the weak discriminative spatial feature learning, enriching intra-class sample features and weighting reliable pseudo-labels. Firstly, a power function is utilized to weight and fuse the activation values within the neighborhood by the power pooling layer to reduce information loss of weak discriminative features. Secondly, the feature vectors of candidate regions are randomly fused by the feature mixing method to enrich the diversity of training sample features. Finally, the confidence of predictions and pseudo-labels is fused via the confidence-based sample re-weighting strategy to adjust the influence of pseudo-labels on training. Experiments on three benchmarks demonstrate the superiority of the proposed network.
目标检测旨在识别并定位图像中预先规定的类别内的物体, 被广泛应用于自动驾驶[1]、智慧医疗[2]、智能视频监控[3]等领域.随着深度学习的高速发展, 全监督目标检测方法[4, 5, 6]产生卓越的性能.然而, 此类方法的训练需要大规模实例级标签(即目标的边界框及类别), 标注过程费时费力.这促使越来越多的研究人员关注弱监督目标检测(Weakly Supervised Object Detection, WSOD), 原因是它训练检测器时仅需图像类别标签(即目标种类), 不需任何边界框标注.
现阶段前沿的WSOD大多采用两阶段学习范式, 包括实例挖掘阶段和实例细化阶段.在第1阶段, 网络基于多实例学习对候选框进行分类, 即至少有一个候选框属于图像中的正类, 且所有候选框均不属于负类.在第2阶段, 根据候选框分类的置信度选择正负样本作为实例级伪标签, 监督后续实例分类器的训练以细化目标位置.然而, 由于伪标签中常存在错误, 致使WSOD面临如下3类问题.
1)局部主导.检测器仅发现目标最具有鉴别性的部位而非完整区域, 如定位到动物头部.为了定位完整的目标区域而不仅仅是显著的区域, 一些研究聚焦于优化特征学习.Huang等[7]汇总来自不同图像输入变换和不同网络层的提案特征, 实现目标部位的互补.Shen等[8]结合深度残差学习提取更丰富的特征.此外, 一些工作利用上下文信息[9, 10, 11]、边界框回归[12]和显著区域移除[13]等, 推测出更完整的目标区域.
2)实例丢失.仅检测图像中显著目标, 漏检其它目标.为了挖掘尽可能多的目标, 以往的工作大多采取扩充类内训练样本的多样性.Tang等[10]根据提案分数的聚类中心选择正样本.Lin等[14]结合提案置信度和提案间的特征相似性选择样本.Ren等[15]根据图像初始提案的数量推断目标数量.Wu等[16]根据提案置信度的分布特征自适应决策目标数量.
3)非紧密框.定位框过大或过小, 未紧密围绕目标区域.为了定位紧密包围目标的边界框, Cheng等[17]探索如何生成更多与目标真实位置交并比(Intersection over Union, IoU)高的提案.Wu等[18]增加可靠的训练样本对训练的权重.
不同于以往的方法, 为了分别解决上述3个问题, 本文提出基于多层次融合的弱监督目标检测网络, 通过激活值融合、特征融合和置信度融合实现WSOD的精准定位.下面依次介绍提出的3个层次的融合方法.
1)幂池化层.局部主导产生的原因是目标的某个部位具有主导图像分类的空间特征.在全监督目标检测中, 网络可在精确的位置标签指导下学习非显著部位的特征, 而在WSOD中, 网络依赖于预训练分类模型的特征提取力选择候选框生成伪标签.由于图像分类模型倾向于利用目标具有鉴别性的部位识别目标, 故WSOD网络也往往对仅包含该部位的候选框置信度较高, 进而选其作为正样本用于训练.在此类错误伪标签的指导下, 模型在应用时也容易产生局部主导问题.因此, 核心问题在于如何让网络学到弱鉴别性区域对应的空间特征.
在WSOD中, 骨干网络用于提取空间特征, 包含卷积层和用于下采样的最大池化层.最大池化仅保留矩形邻域内的最大激活值, 而忽略其它激活值.显然, 这导致非显著特征的损失.为了减少信息损失, 本文提出幂池化层, 通过幂函数计算邻域内激活值的加权和.该操作的优势在于:(1)确保邻域内的每个元素对输出均有影响, 激活值越大, 影响越大.影响程度可通过指数值调节.(2)可微的, 即在反向传播计算过程中所有激活都被赋予梯度值.(3)不包含可学习参数, 因此直接使用它替换最大池化层不会破坏原预训练模型的可用性.此外, 相比其它基于特征学习优化的方法, 幂池化层未引入额外的训练分支或网络层, 可在几乎不增加训练和推理开销的前提下提升模型性能.
2)特征混合方法.WSOD训练时通常将高置信度的候选框设为正样本[19], 导致忽略低置信度的目标实例, 网络学习到的目标尺寸和表观变化有限.因此在应用时, 检测器难以识别训练样本分布之外的实例.尽管以往的研究尝试挖掘尽量多的正样本用于训练, 但也引入一些低质量的伪标签(与目标真实位置IoU较低的候选框), 从而对训练产生负面影响.
为了避免上述问题, 本文从特征增强角度解决实例丢失问题.由于网络利用提取的候选框特征进行分类, 因此丰富类内训练样本的本质是丰富类内特征, 直接构造丰富的候选框特征是合理的.为此, 本文提出特征混合方法, 通过随机混合两个候选框的特征向量以扩充训练数据的分布.一方面, 方法重用已提取的特征, 故计算开销可忽略不计.另一方面, 与其它方法相互独立, 可联合应用以实现更大的性能提升.
3)基于置信度的样本重加权策略.为了进一步缓解因低质量伪标签导致的检测器陷入次优解(非紧密框)的问题, 本文提出基于置信度的样本重加权策略.首先, 综合预测值和伪标签的置信度以评估伪标签的质量, 再设计一个与量化质量呈正相关的调制因子作为softmax损失的权重.这一设计的依据如下:高置信度的候选框与目标真实位置的IoU通常较高, 但弱监督训练存在偏差, 故低质量伪标签也可能具有较高的置信度.而经过一轮训练之后, 模型可能从其它高质量监督信息中获得更强的目标定位能力, 修正以往的错误判断.因此, 融合置信度可更全面地衡量伪标签的质量.
在PASCAL VOC 2007[20]、PASCAL VOC 2012[20]、MS COCO 2014[21]数据集上进行的大量实验表明, 本文网络可显著提升WSOD的性能.
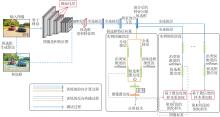
本文提出基于多层次融合的弱监督目标检测网络, 总体架构如图1所示.
 | 图1 本文网络总体架构Fig.1 Overall structure of the proposed network |
给定一幅输入图像I, 由选择性搜索算法[22]等候选框生成算法生成候选框集:
P=
其中R表示候选框的数量.图像的类别标签
x=
其中, xi=1表示图像中至少有一个目标属于第i类, xi=0表示图像中没有目标属于第i类.C表示数据集中的类别总数.
首先, 将图像和候选框集输入骨干网络中提取特征, 采用幂池化层作为下采样操作, 使用空间金字塔池化(Spatial Pyramid Pooling, SPP)为每个候选框生成尺寸一致的卷积特征.通过2个全连接层提取候选框的特征向量.然后, 利用提出的特征混合方法生成混合后的特征向量, 并馈入K+1个分支中:1个用于实例挖掘, 其它用于实例细化.
在实例挖掘阶段, 特征向量被输入到2个并行的全连接层中, 得到矩阵Xcls∈ RC× R, Xdet∈ RC× R.Xcls、Xdet分别输入沿类别和候选框两个不同维度的softmax层, 第r个候选框属于第c类的概率为:
第r个候选框对图像包含第c类目标的归一化贡献为:
然后, 通过逐元素乘法计算候选框置信度:
φ 0=σ(Xcls)☉σ(Xdet).
沿着候选框维度相加, 得到图像包含每个类别的目标的置信度:
ϕc=
因为图像中包含的目标类别已知, 可使用多类别交叉熵函数
L0=-
训练该阶段.
在实例细化阶段, 对于第k个分支, 通过沿类别维度的softmax层生成候选框置信度φ k∈ R(C+1)× R(第C+1维表示背景).本文采用OICR(Online Instance Classifier Refinement)[19]中根据上一分支的候选框置信度筛选正负样本以监督当前分支训练的方式, 并使用具有基于置信度的样本重加权策略的softmax损失函数Lk.
最后, 联合上述损失函数
L=
训练整个框架.
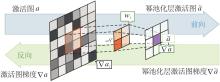
为了更好地理解本文网络, 首先给出池化操作的输出:
$\tilde{a}=\sum_{i \in \mathbb{R}} w_{i} a_{i}=\sum_{i \in \mathbb{R}}\left(\frac{p\left(a_{i}\right) a_{i}}{\sum_{j \in \mathscr{R}} p\left(a_{j}\right)}\right)$
其中, ai表示核邻域R内的激活值, wi表示ai对
最大池化满足p(ai')=1且p(ai″)=0, i″≠ i', 其中ai'表示邻域内的最大激活值.在反向传播中, 梯度仅分配给第i'个激活.显然, 最大池化仅关注邻域内的最大激活值, 这可能会导致模型陷入局部最优.
为了缓解这一问题, 本文提出的池化层设计要求如下:1)邻域内的所有激活值对输出均有影响, 较大的激活值的影响更大; 2)p(·)最好是可调节的, 以适用于不同的模型或数据集; 3)p(·)最好不包含可学习参数, 以免影响预训练模型的可用性.为此, 本文选择采用一系列幂函数作为p(·), 即
p(ai)=
其中n为调节重要程度的超参数.理论上, 当n→ ¥ 时, 幂池化近似于最大池化.在本文中, n=1时性能最佳.
幂池化层总体架构如图2所示.
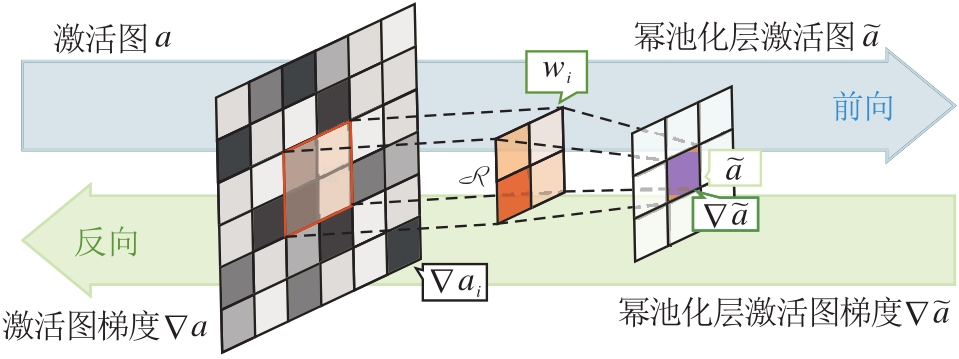 | 图2 幂池化层的总体架构Fig. 2 Overall structure of power pooling layer |
由图2可见, 邻域内的每个激活值都对输出有影响, 并且由于操作是可微的, 因此在反向传播过程中, 激活图中的每个位置都被分配了梯度.
图像中可能存在属于同一类别的多个目标, 然而仅有部分目标能被发现并用于训练, 这导致网络可学到的尺寸和表观变化有限, 故在应用时往往会漏检与训练样本相似度较低的目标实例.为了解决这一问题, 以往的工作[7, 10, 14, 15, 23]致力于挖掘尽可能多的正样本, 即丰富类内实例的多样性.
然而, 发现更多正样本的同时, 难免也会引入更多对训练有不利影响的低质量伪标签.考虑到WSOD使用提取的特征进行分类, 本文认为类内实例多样性的本质是类内特征的多样性.为此, 探索如何在不改变正样本数量的前提下直接丰富实例特征.具体地, 采用如下方式随机混合2个候选框特征向量fi和fj, i=1, 2, …, R, j=1, 2, …, R, 则混合后的特征向量:
f'i=λ fi+(1-λ )fj,
其中λ 表示两个向量的混合比例.本文将λ 设置为[α , 1]区间内的随机数, α ∈ (0, 1).显然, 这一操作可有效扩充训练特征的分布.
由于缺少精确的边界框注释, 当前分支的伪标签是由上一分支的候选框置信度决定的.显然, 高质量的伪标签对训练产生积极影响, 而低质量的伪标签对训练产生负面作用.因此, 在训练过程中应减少低质量标签的影响.然而, 常规的softmax损失函数平等对待这些伪标签, 可能致使模型陷入次优解, 即对非紧密框具有较高的置信度.
从上述分析中可看出, 核心问题在于如何衡量伪标签的质量.以往的工作[14, 16, 19]通常假设置信度高的候选框质量更高, 但考虑到在不够准确的监督信息的指导下, 低质量的候选框也可能获得较高的置信度.为了缓解这一问题, 本文综合上一分支和当前分支的候选框置信度, 用于衡量伪标签的质量q:
其中r表示被标记为正样本的候选框.这一操作的合理性在于, 经过一轮训练之后, 模型从其它正样本中学到的知识可能会修正以往错误的判断.因此, 预测值和伪标签的置信度融合可更好地评估伪标签的质量.
然后, 本文设计一个与q相关的因子作为softmax损失的权重, 提升高质量标签对训练的正面作用, 削弱低质量标签的负面影响.具有基于置信度的样本重加权策略的softmax损失表示如下:
Lk=-
其中
本文在PASCAL VOC 2007[20]、PASCAL VOC 2012[20]、MS COCO 2014[21]基准数据集上评估网络.PASCAL VOC 2007数据集包含来自20个类别的9 963幅图像, 其中5 011幅图像用于训练和验证, 其余图像用于测试.PASCAL VOC 2012数据集包含22 531幅图像, 其中11 540幅图像用于训练和验证, 其余图像用于测试.在MS COCO 2014数据集中, 训练集有82 783幅图像, 验证集有40 504幅图像.
对于PASCAL VOC 2007、PASCAL VOC 2012数据集, 在测试集上采用平均精确度(Mean Average Precision, mAP), 在训练集上采用正确定位(Correct Localization, CorLoc)评估网络性能.mAP的评估标准是当预测框与真值框之间的IoU> 0.5且类别一致时, 预测被视为正确.CorLoc表示训练图像中正类置信度最高的候选框与真值框之间的IoU> 0.5的百分比.对于MS COCO 2014数据集, 在验证集上使用平均精度(Average Precision, AP), 即IoU阈值从0.5开始, 以0.05为步长, 增至0.95为止时的平均值, 以及AP50(IoU阈值取0.5, 与PASCAL VOC数据集上的mAP相同).
本文采用OICR[19]作为基线方法.在ImageNet[24]上预训练的VGG16作为骨干网络, 不同于原始的VGG16网络, 最后的最大池化层被空间金字塔池化层代替.选择性搜索[22]和多尺度组合分组[25]算法分别在PASCAL VOC、MS COCO数据集上提供候选框.在实例细化阶段, K设置为3.训练时图像被随机水平翻转和随机裁剪为5个尺寸(短边为{480, 576, 688, 864, 1 200}, 长边不超过2 000), 测试时每幅图像的10种增强方式均被用于数据增强.框架通过随机梯度下降算法优化, 权重衰减参数设置为5e-4, 动量为0.9, 批大小为4.在PASCAL VOC 2007、PASCAL VOC 2012、MS COCO 2014数据集上, 最大迭代次数分别为37 500、55 000和200 000.在PASCAL VOC 2007、PASCAL VOC 2012数据集上, 初始学习率为5e-4, 分别在27 500次和47 500次迭代后衰减为5e-5.在MC COCO 2014数据集上, 前50 000次迭代的学习率为1e-3, 后50 000次迭代的学习率为1e-4.
本文在PASCAL VOC 2007数据集上进行4组消融实验, 并使用mAP和CorLoc作为评估指标.
首先验证幂池化层的有效性.骨干网络中的最大池化层被替换为具有不同n值的幂池化层(见第1.2节), n=1, 2, 3.因为它们均不含可学习参数, 所以原预训练模型是可用的.不同配置的幂池化层的消融实验结果如表1所示, 表中黑体数字表示最优值.由表可见, OICR在PASCAL VOC 2007数据集上达到48.3%的mAP 和64.4%的CorLoc.当n=1时, 幂池化层达到最佳性能.相比采用最大池化的OICR, 实现1.5%的mAP 和1.5%的CorLoc性能提升.随着n值的增加, 性能趋近于最大池化.实验表明, 在WSOD任务中, 不应该忽略邻域内的非显著特征.
| 表1 不同配置的幂池化层的消融实验结果 Table 1 Ablation experiment results of power pooling layer with different configurations |
再验证特征混合方法的有效性.在OICR的基础上, 定义特征混合方法中参数α =0.70, 0.75, …, 0.95, 具体消融实验结果如表2所示, 表中黑体数字表示最优值.
| 表2 不同配置的特征混合方法的消融实验结果 Table 2 Ablation experiment results of feature mixing method with different configurations |
由表2可见, 当α =0.90时, 特征混合方法实现最显著的性能提升, mAP值从48.3%提升至51.2%, CorLoc值从64.4%提升至66.6%.但在一定范围内, 特征混合方法对α 的取值不敏感, 均可带来明显的性能提升.
下面验证基于置信度的样本重加权策略的有效性.定义3种配置.1)配置a:OICR.2)配置b:仅用伪标签的置信度衡量质量.3)配置c:综合伪标签和预测的置信度以评估伪标签质量.
不同配置的消融实验结果如表3所示, 表中黑体数字表示最优值.从表中可看出, 配置b的性能明显高于配置a的性能, 这说明候选框置信度是衡量伪标签质量的有效手段.配置c可带来更显著的性能提升, 这充分体现通过置信度融合评估标签质量的优越性.
| 表3 不同配置的基于置信度的样本重加权策略的消融实验结果 Table 3 Ablation experiment results of confidence-based sample re-weighting strategy with different configurations % |
最后对提出的幂池化层、特征混合方法、基于置信度的样本重加权策略进行排列组合, 验证其有效性, 其中超参数设置采用表1~表3中的最佳配置.具体消融实验如表4所示, 表中黑体数字表示最优值.由表可见, 组合可以进一步提升性能.提出的完整网络达到54.6%的mAP和70.2%的CorLoc, 超过OICR的6.3%的mAP和5.8%的CorLoc.
| 表4 不同组合的消融实验结果 Table 4 Ablation experiment results of different combinations % |
本文选择如下21种WSOD进行对比实验:文献[9]网络、PCL(Proposal Cluster Learning)[10]、ESFL(Enhanced Spatial Feature Learning)[11]、SLV(Spatial Likelihood Voting)[12]、C-MIDN(Coupled Multiple Instance Detection Network)[13]、OIM(End-to-End Object Instance Mining)[14]、AIR(Adaptive Instance Refinement)[16]、PG-PS[17]、BUAA(Bottom-Up Aggregated Attention)[18]、OICR[19]、IM-CFB(Instance Mining with Class Feature Banks)[23]、TS2C(Tight Box Mining with Surrounding Segmentation Context)[26]、文献[27]网络、MELM(Min-Entropy Latent Model)[28]、CSC(Category-Aware Spatial Constraint)[29]、C-MIL(Continuation Multiple Instance Learning)[30]、WS-JDS(Weakly Supervised Joint Detec-tion and Segmentation)[31]、SDCN(Segmentation-Detec-tion Collaborative Network)[32]、Pred Net[33]、WSOD2(WSOD Framework with Objectness Distillation)[34]、D-MIL(Discrepant Multiple Instance Learning)[35].
各网络在PASCAL VOC 2007数据集上的mAP和CorLoc指标值对比如表5和表6所示, 从表中可看出, 本文网络在mAP指标上取得最优值, 在CorLoc指标上也取得具有竞争力的结果.具体地, 本文网络比次优的BUAA提升0.3%的mAP和0.2%的CorLoc, 比IM-CFB提升0.3%的mAP.值得注意的是, 本文网络的计算开销低于BUAA和IM-CFB.BUAA需要计算来自多个网络层的注意力图, IM-CFB需要在训练中动态更新、存储、对比候选框之间的特征.这些操作均会导致明显的计算量增加, 而本文提出的三个模块增加的计算开销可忽略不计.
| 表5 各网络在PASCAL VOC 2007数据集上的mAP值对比 Table 5 mAP value comparison of different networks on PASCAL VOC 2007 dataset % |
| 表6 各网络在PASCAL VOC 2007数据集上的CorLoc值对比 Table 6 CorLoc value comparison of different networks on PASCAL VOC 2007 dataset % |
各网络在PASCAL VOC 2012数据集上的mAP和CorLoc指标值对比如表7和表8所示.由表可见, 本文网络在2个指标上均取得最高值.相比OICR, 本文网络实现5.6%的mAP和4.9%的CorLoc的性能增益, 这进一步展示其有效性.
| 表7 各网络在PASCAL VOC 2012数据集上的mAP值对比 Table 7 mAP value comparison of different networks on PASCAL VOC 2012 dataset % |
| 表8 各网络在PASCAL VOC 2012数据集上的CorLoc值对比 Table 8 CorLoc value comparison of different networks on PASCAL VOC 2012 dataset % |
为了进一步验证本文网络的有效性, 在更具有挑战性的MS COCO 2014数据集上进行实验.由于只有部分工作报告它们的结果, 仅选取如下13种方法进行对比:文献[9]网络、PCL[10]、ESFL[11]、C-MIDN[13]、AIR[16]、PG-PS[17]、BUAA[18]、OICR[19]、MELM[28]、CSC[29]、WS-JDS[31]、WSOD2[34]、D-MIL[35].具体AP50和AP值对比如表9所示.由表可见, 本文网络取得第三高的AP50和次高的AP.上述结果表示本文从增强对弱鉴别性空间特征的学习、类内样本特征丰富性和可信伪标签权重三个方面展开研究, 全方位提升优越性.
| 表9 各网络在MS COCO 2014数据集上的指标值对比 Table 9 Index value comparison of different networks on MS COCO 2014 dataset % |
OICR和本文网络的可视化对比如图3所示.在图中, 蓝色矩形框表示至少有一个预测框与之相交的真值框, 黄色框表示没有预测结果与之相交的真值框, 绿色框表示成功的预测结果, 红色框表示失败的结果.由图可以看出, 本文网络可覆盖更完整的目标区域, 而不仅仅是突出的部位.同时检测到OICR漏检的目标, 如小目标、罕见视角的目标和模糊目标.本文网络可更好地处理复杂场景, 如目标和周遭背景的纹理或颜色相近的情况.可视化结果进一步验证本文网络的有效性.
 | 图3 OICR和本文网络的可视化对比Fig.3 Visualization comparison between OICR and the proposed network |
本文深入研究弱监督目标检测面临的局部主导、实例丢失、非紧密框等缺陷.为了解决局部主导问题, 提出幂池化层, 全面考虑邻域内的每个激活值, 减少非显著特征的信息损失.对于实例丢失问题, 设计特征混合方法, 融合候选框特征, 丰富训练样本的多样性.针对非紧密框问题, 综合伪标签和预测值的置信度, 评估伪标签质量, 并基于质量调节伪标签对训练的影响程度.通过这三个层次的简单有效的融合策略, 提出基于多层次融合的弱监督目标检测网络, 可缩小弱监督目标检测和全监督目标检测之间的性能差距.今后将进一步探索更多的信息融合策略, 提升弱监督目标检测算法的性能.
本文责任编委 张军平
Recommended by Associate Editor ZHANG Junping
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|