
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
稀疏奖励场景下基于状态空间探索的多智能体强化学习算法
[方宝富1, 2  , 余婷婷
, 余婷婷1, 2 , 王浩1, 2 , 王在俊3 ]
, 余婷婷, 王浩, 王在俊]
|
|



作者简介:

余婷婷,硕士研究生,主要研究方向为多智能体深度强化学习.E-mail:185137760@qq.com.

王 浩,博士,教授,主要研究方向为分布式智能系统、机器人.E-mail:jsjxwangh@hfut.edu.cn.

王在俊,硕士,研究员,主要研究方向为多机器人任务分配、人工智能.E-mail:tiantian20030315@126.com.
多智能体的任务场景往往伴随着庞大、多样的状态空间,而且在某些情况下,外部环境提供的奖励信息可能非常有限,呈现出稀疏奖励的特征.现有的大部分多智能体强化学习算法在此类稀疏奖励场景下效果有限,因为算法仅依赖于偶然发现的奖励序列,会导致学习过程缓慢和低效.为了解决这一问题,文中提出基于状态空间探索的多智能体强化学习算法,构建状态子集空间,从中映射出一个状态,并将其作为内在目标,使智能体更充分利用状态空间并减少不必要的探索.将智能体状态分解成自身状态与环境状态,结合这两类状态与内在目标,生成基于互信息的内在奖励.构建状态子集空间和基于互信息的内在奖励,对接近目标状态的状态与理解环境的状态给予适当的奖励,以激励智能体更积极地朝着目标前进,同时增强对环境的理解,从而引导其灵活适应稀疏奖励场景.在稀疏程度不同的多智能体协作场景中的实验验证文中算法性能较优.
About Author:
YU Tingting, Master student. Her research interests include multi-agent deep reinforcement learning.
WANG Hao, Ph.D., professor. His research interests include distributed intelligent systems and robots.
WANG Zaijun, Master, professor. Her research interests include multi-robot task allocation and artificial intelligence.
In multi-agent task scenarios, a large and diverse state space is often encountered. In some cases, the reward information provided by the external environment may be extremely limited, exhibiting sparse reward characteristics. Most existing multi-agent reinforcement learning algorithms present limited effectiveness in such sparse reward scenarios, as relying only on accidentally discovered reward sequences leads to a slow and inefficient learning process. To address this issue, a multi-agent reinforcement learning algorithm based on state space exploration(MASSE) in sparse reward scenarios is proposed. MASSE constructs a subset space of states, maps one state from this subset, and takes it as an intrinsic goal, enabling agents to more fully utilize the state space and reduce unnecessary exploration. The agent states are decomposed into self-states and environmental states, and the intrinsic rewards based on mutual information are generated by combining these two types of states with intrinsic goals. By constructing a state subset space and generating intrinsic rewards based on mutual information, the states close to the target states and the states understanding the environment are rewarded appropriately. Consequently, agents are motivated to move more actively towards the goal while enhancing their understanding of the environment, guiding them to flexibly adapt to sparse reward scenarios. The experimental results indicate the performance of MASSE is superior in multi-agent collaborative scenarios with varying degrees of sparsity.
近年来, 强化学习(Reinforcement Learning, RL)在自动驾驶[1]、交通信号灯控制[2]、多机器人协作[3]和多人视频游戏[4]等多个复杂领域取得令人瞩目的成就.多智能体强化学习[5]是多智能体系统在强化学习领域的延伸, 为一些复杂决策问题提供有效的方法.多智能体强化学习允许智能体相互协作, 主动适应环境, 在训练过程中不断更新参数, 最终实现奖励回报最大化.
在多智能体强化学习中, 智能体依据奖励信号优化策略.然而, 在稀疏奖励场景下[6], 智能体往往难以获得及时、有效的奖励信号, 在训练中途或在成功完成任务后的奖励信号不足以支持智能体在限定时间内学到一个良好的策略.此外, 局部可观测的多智能体系统需要智能体相互协作才能拥有良好的策略.随着智能体数量的增加和环境复杂程度的提高, 状态空间呈指数型增长, 让原本稀疏的奖励信号变得更稀少, 算法效率受到严重影响.值得注意的是, 并非所有状态都能带来奖励, 也并非所有状态都值得深入探索.例如:在机器人足球中, 智能体需要通过传球与配合实现进球赢得比赛, 状态空间庞大、复杂, 而奖励信号却仅在进球时刻才产生.这使得智能体在辨别哪些状态具有探索价值时面临巨大的挑战.因此提高多智能体在稀疏奖励场景下的探索效率和状态空间利用率, 对提升算法效率具有重要作用.
应对稀疏奖励问题的常用方法是对奖励函数进行塑造[7].Ng等[8]利用专家数据学习智能体的奖励函数, 但Inverse RL(IRL)过分利用专家数据, 无法让智能体通过自身探索塑造奖励函数, 并且只适用于特定场景.仅通过有限的稀疏奖励, 智能体无法判断自身行为优劣, 因此需要引入内在奖励作为一种学习机制, 以促进更有效的探索.在智能体决策策略的学习过程中, 内在奖励能与外在奖励一同指导多智能体学习, 有效减少学习缓慢甚至无法学习的情况.Chitnis等[9]使用内在奖励捕捉智能体动作组合的优劣, 让智能体学到协同的行为, 但对多智能体的任务来说, 探索全部动作组合并求得最优动作序列十分困难, 导致算法收敛速度下降.Tang等[10]提出基于计数的内在奖励, 通过状态的访问次数衡量状态的新颖程度, 促使智能体寻求新颖的状态, 然而智能体在训练过程中很难遇到完全相同的状态, 不能仅通过简单计数来判断状态的新颖性.
传统的探索算法在一定程度上也能缓解稀疏奖励问题.QMIX[11]和Centrally-Weighted(CW)QMIX[12]都通过设计混合网络拟合全局状态动作值函数, 采用基于噪声的探索策略, 具有一定的随机性和适应性.但是这些基于噪声的探索策略往往不能快速有效引导智能体朝最优的方向前进.在面对复杂环境和任务时, 仍面临学习缓慢、效果不佳的问题.Ma等[13]提出ELIGN(Expectation Alignment), 量化智能体的行为对相邻智能体预期行为的影响, 鼓励多智能体之间的协调探索.Mahajan等[14]提出MAVEN(Multi-agent Variational Exploration), 设计共享潜在变量, 调节智能体的行为以促进探索.上述方法一定程度上限定探索的范围, 指导智能体的方向, 但无法有效利用智能体的探索空间, 导致在多智能体异构协作场景下效率不佳.
人类拥有自我意识[15], 能自然地区分身体部分与环境, 并根据环境信息调整行为和决策.海豚和大象也表现出一定程度的自我意识, 可通过镜子实验展示对自己身体的认知, 并与镜中反射的自己互动.这种自我意识能力在生物决策中起到核心作用, 使它们能灵活适应环境的变化.智能体与周围环境存在清晰的界限, 区分自身和环境可提高智能体的对环境的理解能力.马尔科夫决策过程(Markov Deci-sion Process, MDP)[16]在RL中通常用于描述智能体的任务, 但MDP忽略自身与环境分离, 只是将自身状态与环境状态叠加为一个单一状态, 然而现实任务中状态并不能仅使用堆叠的单一向量描述.
借鉴探索状态空间的重要性, 以及自我意识对决策的作用, 本文提出基于状态空间探索的多智能体强化学习算法(Multi-agent Reinforcement Learning Algorithm Based on State Space Exploration, MASSE).MASSE构建状态子集空间, 并以从中映射出的状态作为内在目标, 将智能体状态拆分为自身状态与环境状态, 随后结合内在目标、自身状态及环境状态, 生成一个基于互信息的内在奖励.在每个时间步都为智能体分配即时明确的奖励信号, 指导智能体更精准地朝着有利于任务完成的方向进行探索, 确保算法在稀疏奖励场景中仍能保持学习的动力.在稀疏程度不同的多智能体协作仿真平台上对MASSE进行全面评估, 实验结果表明算法的有效性和鲁棒性.
完全合作的多智能体任务可描述为Dec-POMDP(Decentralized Partially Observable MDP)[17].Dec-POMDP可定义为一个九元组
<N, S, U, P, r, O, Z, n, γ>.
其中:N={1, 2, …, n}, 表示有限数量智能体的集合; S表示环境状态的集合, s∈S表示环境的真实状态; U表示联合动作空间, 每个智能体i∈N选择一个动作ui∈Ui组成联合动作u∈U; 智能体在环境中通过状态转移方程
P(s'|s, u)∶ S×U×S→ [0, 1]
得到下一步状态s'; O表示联合观测的集合; Z表示观测概率函数;
r(s, u)∶ S×U→ R
表示奖励函数; γ∈[0, 1]表示折扣因子.在一个局部可观测的环境中, 每个智能体仅能根据观测函数
Z(s, u)∶ S×U→ O
得到自己的观测(局部状态)oi∈O.每个智能体有自己的动作观测历史
τi∈T≡ (O×Ui)*,
并遵循随机策略
π (ui, τi)∶ T×U→ [0, 1].
联合策略π 在时刻t拥有联合状态动作值函数:
$ Q_{t}^{\operatorname{lot}}\left(s_{t}, u_{t}\right)=E_{s_{t+1: \infty}, u_{t+1: \infty}}\left[\sum_{k=0}^{\infty}\left(\gamma^{k} r_{t+k} \mid s_{l}, u_{t}\right)\right] .$
在多智能体强化学习中, 一个智能体将其它智能体作为环境的一部分, 每个智能体又根据自身观测独立行动, 但在训练过程中团队需要全局信息才能寻找到最优策略.CTDE(Centralized Training and Decentralized Execution)[18]是近年来应对这一挑战的流行范式.在CTDE范式下, 智能体以集中式的方式访问全局信息学习策略, 并以分散式的方式依赖自身观测执行动作.研究者们对范式中的全局状态动作值函数
其中, st表示环境状态, ut表示联合动作,
近年来, 在Value-Decomposition Networks的基础上, 学者们提出许多改进算法.Rashid等[11]提出QMIX, 整合智能体个体状态动作值函数, 得到全局状态动作值函数.Son等[20]提出QTRAN, 引入传输网络, 更好地利用全局信息, 并用于智能体之间的信息传输.Rashid等[12]提出(CW)QMIX, 引入动态权重调整机制, 使智能体能根据任务需求和环境变化动态调整网络权重, 提高算法在不同场景中的性能.
在遵循CTDE范式的基础上, 智能体团队会寻找最优全局状态动作值函数
$ \mathcal{L}(\theta)= E_{r, u^{\prime}, s, u}\left[R_{t}+ \gamma \max _{u^{\prime}}\left(Q_{\iota}^{\mathrm{tot}}\left(s_{\iota+1}, u^{\prime} ; \theta^{\prime}\right)\right)-Q_{\iota}^{\mathrm{tot}}\left(s_{\iota}, u_{\iota} ; \theta\right)\right]^{2}, $
其中, θ'表示智能体网络的权重参数, 并由θ更新,
互信息(Mutual Information, MI)[21]是信息论中量化两个变量之间相似程度的度量标准, 能提取变量与变量之间的非线性统计依赖.并使用香农熵或KL散度(Kullback-Leibler)衡量随机变量X与Y之间的互信息:
$ \begin{array}{l} I(X, Y)=H(X)-H(X \mid Y)= \\ \quad \iint \mathbb{P}_{X Y} \ln \left(\frac{\mathbb{P}_{X Y}}{\mathbb{P}_{X} \otimes \mathbb{P}_{Y}}\right) \mathrm{d} X \mathrm{~d} Y=D_{\mathrm{KL}}\left(\mathbb{P}_{X Y} \| \mathbb{P}_{X} \otimes \mathbb{P}_{Y}\right), \end{array}$
其中, H(·)表示香农熵, H(X|Y)表示给定X的Y的条件熵, PXY表示X和Y的联合分布, PXPY表示X和Y边缘分布的乘积, DKL(·)表示KL散度.Belghazi等[22]提出MINE(MI Neural Estimation), 计算高维连续随机变量的互信息, 训练一个神经网络F, 估计变量的非线性关系, 将KL散度表示为一个表达式的上确界:
$ \begin{aligned} D_{\mathrm{KL}}\left(\mathbb{P}_{X Y}\right. & \left.\| \mathbb{P}_{X} \otimes \mathbb{P}_{Y}\right)= \\ & \sup _{F: \Omega \rightarrow R} E_{\mathbb{P}_{X Y}}[F]-\ln \left(E_{\mathbb{P}_{X} \otimes \mathbb{P}_{Y}}\left[e^{F}\right]\right) \geqslant \\ & \sup _{\phi \in \Phi} \mathbb{E}_{\mathbb{P}_{X Y}}\left(F_{\phi}\right)-\ln \left(\mathbb{E}_{\mathbb{P}_{X} \otimes \mathbb{P}_{Y}}\left(e^{F_{\phi}}\right)\right) . \end{aligned}$
其中, F∶ Ω → R表示一个从采样空间Ω 映射到实数R的神经网络.神经网络F输入经验样本, 网络参数ϕ∈Φ , 随后采用梯度上升, 使互信息的估计逼近其值.互信息能帮助智能体理解环境, 使智能体做出更准确的决策.Cheng等[23]提出CLUB(Contrastive Log-Ratio Upper Bound), 这是一种用于估计状态动作值函数的强化学习算法.该算法基于互信息和对比学习的原理, 解决在强化学习中的探索和利用之间的平衡问题.Li等[24]提出PMIC(Progressive MI Collaboration), 通过最大化优势动作间的互信息, 区分经验池中数据的好坏, 避免智能体陷入次优.但PMIC很大程度上依赖经验池中的数据, 如果经验池中数据不足, 算法可能无法判断动作的好坏, 从而影响训练效率.Wang等[25]提出EITI(Exploration via Information-Theoretic Influence), 计算当前状态和其它智能体候选状态动作之间的互信息, 量化动作对其它智能体的影响, 引导智能体倾向选择互信息较高的动作, 以便学到更有效的策略, 以此指导智能体的探索.
在人类心理学中, 内在激励是指人类追求发展或享受活动的一种动力, 这源于人类内部的愿望和需求, 并且与个人动机、满意度、创造力和持久性等密切相关.通过构建智能体中的内在激励机制, 产生额外的内在奖励信号, 能激发智能体探索环境的欲望和动力, 促进尝试新的行为策略.内在奖励不依赖于外在奖励, 能与外在复杂环境区分, 并且比外在奖励更稳定, 可以让智能体适应多变的环境, 提高学习的效率.Pathak等[26]提出ICM(Intrinsic Curiosity Module), 将前向网络
其中比例因子η >0.ICM鼓励智能体对环境的探索, 但期望智能体能访问完整的环境状态是不现实的.Burda等[27]提出RND(Random Network Distilla-tion), 旨在提高智能体对环境的探索能力, 利用随机网络
RND的内在奖励信号可帮助智能体识别和探索环境中的新颖状态和动作, 促进学习过程, 但当拓展到多智能体环境中时, 状态动作空间增加, 算法本身状态转移的随机性较强, 与动作决策关联性较小, 导致智能体的探索效率低下.Li等[28]提出IRAT(In-dividual Reward Assisted Team Policy Learning), 分别构建个体策略和团队策略, 并把个体奖励添加到团队奖励中生成内在奖励函数, 再利用内在奖励辅助团队策略学习, 让二者同时进行学习更新.IRAT融合个体策略和团队策略, 保证策略团队最优, 但是在稀疏奖励中个体能获得奖励的情况很少, 个体策略对团队贡献相对较小, 会干扰团队策略, 导致策略偏移.Jeon等[29]提出MASER(Multi-agent RL with Subgoals Generated from Experience Replay Buffer), 根据个体状态动作值函数和全局状态动作值函数, 自动在经验池中生成子目标, 并将子目标与每个智能体当前状态的负欧氏距离作为内在奖励.Na等[30]提出EMU(Efficient Episodic Memory Utiliza-tion), 创建一个情景记忆缓冲区, 利用情景记忆近似下一状态的状态值函数V(s'), 并基于这个预测值与目标网络预测的状态动作值函数Q(s', a')之间的差距, 构造内在奖励, 加速智能体的学习.
本文提出基于状态空间探索的多智能体强化学习算法(MASSE), 增强智能体在任务场景下的探索效率, 缓解稀疏奖励问题.MASSE遵循集中式训练分散式执行的范式, 构建一个可扩展的状态子集空间, 从中选取状态作为内在目标, 再将该内在目标和智能体区分的状态(自身状态、环境状态)结合生成基于互信息的内在奖励.算法通过状态子集空间的探索、基于互信息的内在奖励的生成, 能有效提高智能体的探索效率, 在外在奖励信号缺失时依旧能保持学习的动力.
智能体所处环境的复杂程度决定其状态空间的大小.为了在保证获取关键信息的同时降低计算复杂度, MASSE构建状态子集空间映射内在目标, 实现对经验池中状态的管理, 帮助智能体更倾向于探索价值更高的状态空间, 提高状态空间利用率.
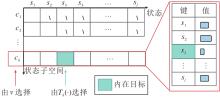
状态子集空间C是由多个状态子空间c构成的集合.如图1所示, MASSE从状态子集空间中选择一个状态子空间, 并且在拓展过程中绑定计数器, 记录该状态在所选状态子空间中出现的次数, 最后从状态子空间中选择出现次数最少的一个状态作为智能体的内在目标.次数最少的状态往往包含更多信息, 将其作为内在目标g, 能提高智能体对于尚未得到充分探索区域的探索效率, 促使智能体更快学到一个良好的策略.
 | 图1 状态子集空间Fig.1 State subset space |
为了丰富状态子集空间并容纳更多的状态信息, 算法每经过N_rounds回合, 会依据当前的最大状态子空间, 抽取经验池中的状态信息以生成新的状态子空间, 从而进一步扩展和动态更新状态子集空间.在初始化阶段, 状态子集空间C会抽取经验池中状态, 创建第一个状态子空间c1=S, 其中, S∈D表示经验池中均匀采样的状态, D表示经验池.经过h-1次拓展的状态子空间
ch=ch-1∪S, (1)
包含第h-1个状态子空间ch-1和经验池中抽取的状态S.
在选定状态子空间以生成内在目标g的过程中, MASSE会为每个状态子空间赋予一个效用值v, 并以此衡量该状态子空间的重要程度.每个状态子空间均绑定一个计数器T(·), 用于记录各状态在该状态子空间中出现的次数.状态作为键, 状态出现的次数作为值, 并且仅在选中该状态子空间时, 才会进行更新操作, 以此减少不必要的计算开销.使用归一化熵的机制计算状态子空间ch的效用值:
vh=-
其中, Hmax, h表示ch中随机变量的最大熵, Hh表示ch中随机变量的熵,
ph(·)=
表示对计数器Th(·)归一化得到概率分布.尚未得到充分探索的状态子空间拥有较高的效用值v.每N_rounds个回合从状态子集空间中选取高效用值的状态子空间, 再从中筛选次数最少的状态, 并将其作为内在目标:
g=arg
智能体若能意识到自己与环境的状态是自然可区分的, 可提升智能体对环境的理解程度, 在面对动态变化环境时保持一定的适应能力.此外, 互信息作为两变量间衡量相似程度的工具, 融入智能体的内在激励机制中, 作为生成内在奖励的关键要素时, 能使智能体在稀疏奖励场景中保持学习的驱动力.
基于上述特点, 本文提出基于互信息的内在奖励.MASSE分离智能体自身状态与环境状态, 计算环境状态和自身状态的互信息, 以及环境状态与内在目标之间的互信息, 并将这两部分互信息的总和作为内在奖励.这使智能体能更好地理解自身、环境与内在目标之间的关系, 促进智能体之间更高效的协作与探索.
智能体i将状态区分为环境状态
$ \begin{aligned} I\left(s_{i}^{e} ; s_{i}^{a}\right)= & D_{\mathrm{KL}}\left(\mathbb{P}_{s_{s}^{s} i_{i}^{a}} \| \mathbb{P}_{s_{i}} \otimes \mathbb{P}_{s_{i}^{a}}\right) \geqslant \\ & \sup _{\phi \in \Phi} \mathbb{E}_{\mathbb{P}_{s_{i}^{s} s_{i}}}\left(F_{\phi}\right)-\ln \left(\mathbb{E}_{\mathbb{P}_{s_{i}}^{e} \otimes \mathbb{P}_{s_{i}}}\left(e^{F_{\phi}}\right)\right):= \\ & I_{\phi}\left(s_{i}^{e} ; s_{i}^{a}\right), \end{aligned}$
其中, $ \mathbb{P}_{s_{i}{ }^{e} s_{i}}$表示环境状态
在智能体对环境的认识不断加深, 逐步接近乃至最终成功实现其内在目标的过程中, 内在奖励会呈现上升趋势, 能更默契地协同工作, 进一步激发智能体团队向着更高目标迈进.并且基于互信息的内在奖励是根据智能体对环境的理解和内在目标动态变化, 因此智能体通过调整其策略最大化内在奖励, 进而探索与内在目标更接近的状态.利用随机梯度下降更新互信息计算网络F权重参数ϕ:
$ \begin{aligned} L(\phi)= & -\mathbb{E}_{\mathbb{P}_{s_{i} s_{i}^{a}}}\left(F_{\phi_{1}}\right)+\ln \left(\mathbb{E}_{\mathbb{P}_{s_{i}^{e}}^{e} \otimes \mathbb{P}_{s_{i}}}\left(e^{F_{\phi_{1}}}\right)\right)- \\ & \mathbb{E}_{\mathbb{P}_{s_{i s} s_{s}}}\left(F_{\phi_{2}}\right)+\ln \left(\mathbb{E}_{\mathbb{P}_{s_{i}} \otimes \mathbb{P}_{g}}\left(e^{F_{\phi_{2}}}\right) .\right. \end{aligned}$(4)
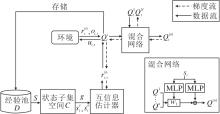
MASSE框架图如图2所示, 显示该算法如何利用状态子集空间得出智能体内在奖励参与训练以实现内在目标的过程.
 | 图2 MASSE框架图Fig.2 Framework of MASSE |
在每N_rounds个回合中, MASSE从经验池中取出状态更新状态子集空间, 在状态子集空间中选择状态子空间提取一个状态, 并将该状态作为智能体的内在目标.分离自身状态和环境状态, 增强对环境特征的了解.将内在目标、自身状态、环境状态作为输入, 传递给互信息估计器进行处理, 为每个智能体提供明确的基于互信息的内在奖励.随后将得到的经验序列存储在经验池中.最后, 所有个体状态动作值函数被输入混合网络中, 计算全局状态动作值函数.这不仅能最大化全局状态动作值函数, 还能使智能体优化个体状态动作值函数, 充分利用经验池中的状态, 实现智能体策略最优.
MASSE遵循集中式训练分散式执行范式, 在时刻t分解联合状态动作值函数
Rt=
其中,
$ \begin{aligned} \mathcal{L}_{\mathrm{TD}}(\theta)= & E_{R, u^{\prime}, s, u}\left[R_{t}+\gamma \max _{u^{\prime}}\left(Q_{t}^{\text {lot }}\left(s_{l+1}, u^{\prime} ; \theta^{\prime}\right)\right)-\right. \\ & \left.Q_{t}^{\mathrm{lot}}\left(s_{t}, u ; \theta\right)\right]^{2} . \end{aligned}$ (5)
MASSE步骤如算法1所示.
算法1 MASSE训练过程
输入 智能体观测oi, 全局状态s, 经验池大小d,
输入批大小b, 训练总情节数E,
训练时间步T_steps, 更新周期N_rounds,
内在奖励权重参数λ
输出 混合网络的权重参数θ
初始化 混合网络权重参数θ、θ',
互信息计算网络权重参数ϕ、ϕ',
经验池D, 策略π , 状态子集空间C,
计数器T, 状态子集空间大小h
for episode = 1 to E do
for t = 1 to T_steps do
智能体根据Q利用∈-贪婪策略选择动作u
执行动作u=(u1, u2, …, uN), 得到外在奖励rex、
下一状态s'和观测o'
在经验池D中存储(s, o, u, r, s', o')
根据式(3)生成基于互信息的内在奖励rin
s← s'
从经验池D中随机采样
使用式(4)更新互信息计算网络权重参数ϕ
使用式(5)更新混合网络权重参数θ
if episode mod N_rounds = 0 then
使用式(1)拓展状态子集空间C
根据效用值v在状态子集空间C中选择状态
子空间c
更新状态子空间c的计数器T
使用式(2)生成共享目标g
end if
end for
end for
实验场景选择星际争霸(StarCraft Multi-agent Challenge, SMAC)[31]作为基准测试平台.星际争霸是一款即时战略游戏, 专注于微观管理(Micro-Mana- gement)的多智能体协作对抗场景, 要求智能体对团队内每个单位进行精细控制以对抗敌方作战单位.SMAC可全面有效评估多智能体强化学习算法合作完成对战任务的能力.
在SMAC中, 智能体的视野范围是固定的, 其中智能体的观测信息包括相对距离、坐标、健康值、防护值及单位类型, 并且只能在存活状态下观测其它单位.智能体的动作(移动、攻击、停止)是离散的, 只能攻击视野范围内的敌人.当智能体消灭一个敌方作战单位会获得奖励10, 当智能体赢得对战时会获得奖励200.
本文选择如下稀疏程度不同的多智能体协作任务中的基线算法.1)文献[19]算法.经典的强化学习算法, 把全局状态动作值函数分解为每个智能体的个体状态动作值函数.2)QMIX[11].文献[19]算法的一个改进版本, 学习全局状态动作值函数和个体状态动作值函数之间的加权单调关系.3)EITI[25].利用互信息量化智能体探索对其它智能体的影响程度.4)MASER[29].结合自我模仿学习和经验回放机制, 在每个时间步提出一个子目标, 计算子目标与当前状态的距离作为智能体的内在奖励, 为智能体在稀疏奖励场景下提供行动指南.5)EMU[30].创建情景缓冲区, 利用情景记忆构建内在奖励, 优化智能体策略.
所有算法与难度为“ 7” 的人工智能进行对抗[30], 最大情节数为20 000, 经验池包含最近4 000条完整历史轨迹.每个智能体分散使用∈-贪婪策略选择自己的执行动作.随着训练过程的进行, ∈在50 000时间步中从1.0线性衰减到0.05, 并在以后的训练过程保持不变.每次更新过程从经验池中均匀采样32个批量样本, 并由RMSProp(Root Mean Square Propagation)优化器[32]进行训练.设置学习率为0.000 5, 折扣因子γ=0.9, N_rounds=32, h初始化为1, λ=0.3.当我方作战单位击败敌方作战单位或达到规定时间步时, 一个情节结束.在每100个情节后暂停训练, 独立运行20个情节评估当前算法性能, 网络的权重参数每 200 个情节更新1次.
在SMAC的稀疏奖励场景中, 选择在如下5个场景上进行实验:3个陆战队员对战3个陆战队员(表示为3m)、2个追猎者对战1个爬虫(表示为2s_vs_1sc)、8个陆战队员对战8个陆战队员(表示为8m)、3个追猎者和5个狂热者对战3个追猎者和5个狂热者(表示为3s5z)、3个追猎者和5个狂热者对战3个追猎者和6个狂热者(表示为3s5z_vs_3s6z).具体场景信息如表1所示.
| 表1 SMAC中用于测试的5个场景 Table 1 Five scenarios used for testing in SMAC |
实验图中的实线表示每种算法依据不同随机种子运行5次得到的运行结果均值, 提供一个综合的性能指标, 图中阴影部分表示5次运行结果的95%置信区间.
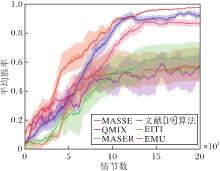
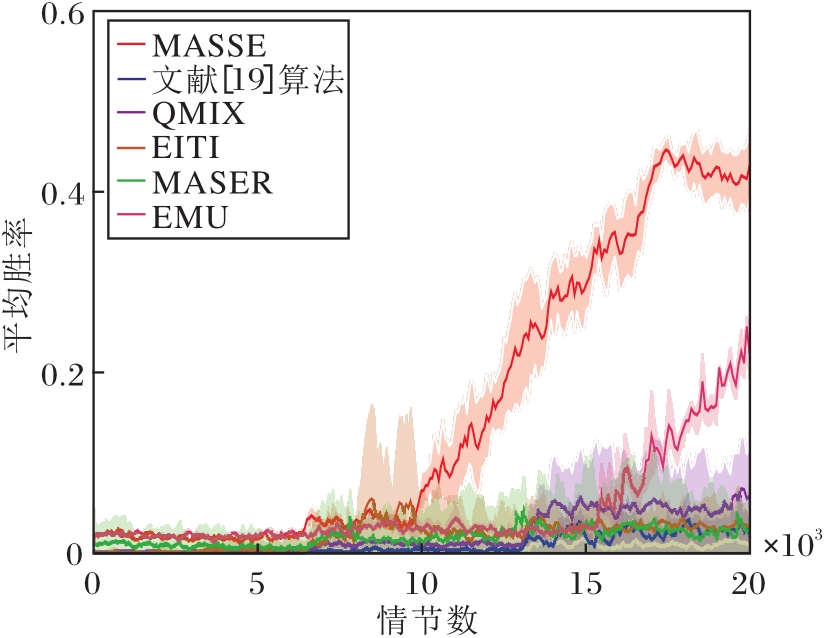
3.3.1 3m场景
3m场景中各算法平均胜率对比如图3所示.由图可见, MASSE在早期阶段胜率表现尤为突出, 这凸显算法在应对同构且数量对称的多智能体协作任务时的优势.文献[19]算法在初期阶段表现得相对保守.这是因为算法需要为每个智能体合理分配奖励才能激励它们做出更好的策略, 而文献[19]算法采用整体奖励训练智能体, 没有为每个智能体量化奖励贡献.但是, 随着训练的深入, 文献[19]算法通过对个体状态动作值函数线性加和, 能逐渐学习全局状态动作值函数, 并在中期阶段展现出卓越性能.在4 500个情节数之前, MASSE的表现明显优于文献[19]算法, 展现出更高的平均胜率.MASSE能为每个智能体提供明确的奖励, 使它们从奖励中得到反馈, 从而更迅速地收敛至最优策略.
 | 图3 3m场景中各算法平均胜率对比Fig.3 Comparison of average winning rates of 6 algorithms in 3m scenario |
QMIX在训练前期阶段的表现虽然一般, 但整体表现稳定.与文献[19]算法类似, QMIX也采用整体奖励的概念, 在一定程度上影响前期表现.不过在训练后期阶段, QMIX通过集中式网络中的目标网络, 选择累计期望最大奖励的动作, 使智能体的平均胜率也保持在较高水平, 显示出其稳健的学习能力.
MASER在训练初期速度相对较慢, 这主要是因为其生成的子目标往往是基于当前状态和动作的局部最优解, 在训练初期并不能产生合适的子目标.但是, 在2 000个情节数后, MASER通过结合全局动作值函数, 逐渐克服局部最优的问题, 并在我方与敌方作战单位同构对称环境中学到良好的策略.
EITI和EMU的效果与QMIX相近.这主要得益于它们都能基于环境构建智能体的内在奖励, 缓解稀疏奖励问题.EITI能促使同构智能体之间状态动作互信息的利用, 有助于促进算法的训练.然而, EITI可能过于强调智能体之间的协调, 忽略必要的探索过程, 算法的收敛速度变慢.并且EITI主要依赖当前状态和候选动作之间的信息增益以做出决策, 这也可能导致其忽略某些全局信息, 算法陷入局部最优, 无法找到全局最优策略, 影响最终的学习性能.EMU将高回报轨迹存储于情景记忆缓冲区中, 再基于缓冲区中的轨迹生成内在奖励, 可引导智能体学习其中的轨迹.EMU为智能体团队生成一个内在奖励, 而这些奖励无法直接分配给个体成员, 在一定程度上影响算法的学习效率.
3.3.2 2s_vs_1sc场景
2s_vs_1sc场景中各算法的平均胜率对比如图4所示.由图可见, 在双方智能体异构且数量不对称的场景中, 算法性能与双方智能体同构的场景(3m)相比有所下降.MASSE与文献[19]算法在该场景上的表现最佳.在10 000个情节数之后, MASSE通过对状态子集空间中状态信息的利用, 显著提升状态空间的探索效率和利用率, 展现出比其它算法更卓越的性能表现.文献[19]算法仅对值函数进行简单的加和, 使用线性网络时不需要进行额外的训练, 适合智能体数量较少的异构场景, 但因为文献[19]算法优化复杂度低, 导致训练后期效果和稳定性差于MASSE.
 | 图4 2s_vs_1sc场景中各算法平均胜率对比Fig.4 Comparison of average winning rates of 6 algorithms in 2s_vs_1sc scenario |
QMIX在文献[19]算法的基础上增加一个额外的网络进行训练, 可较好处理全局状态动作值函数和个体状态动作值函数之间的关系, 不过这会增加智能体训练时间, 非线性表征能力有限, 不能更好地学习全局状态动作值函数, 智能体系统的不稳定性也导致训练后期平均胜率出现波动的现象.QMIX与EITI、MASER的效果相似, 但EITI与MASER在训练后期表现更稳定.EITI需要两两计算智能体之间的状态动作互信息, 但在双方智能体异构时, 这种计算可能失去意义, 所以即使智能体数量较少, 依旧会导致训练速率较慢, 训练后期胜率不佳.
EMU在训练前期学习效率不稳定, 后期稳定且效果较优.主要原因在于早期智能体团队在异构场景中对环境的了解有限, 情景记忆缓冲区中的轨迹不够丰富, 导致生成的内在奖励不够准确, 影响学习效率.随着时间的推移, 情景记忆缓冲区中会逐渐积累更多的高回报轨迹, 因此在训练后期, 学习效率得以稳步提升, 最终展现出较优效果.
MASSE将智能体状态和环境状态的互信息以及环境状态和内在目标的互信息之和作为内在奖励, 在智能体异构场景中可发挥强大优势.MASER在每个时间步都需要提取子目标, 这同样影响学习速率.相比之下, MASSE通过每N_rounds个回合更新内在目标, 实现更快的学习速度.这表明在双方智能体异构且数量不对称的场景中, MASSE能更快地学到适应性更强的策略, 并且训练后期表现也更稳定, 具有显著优势.
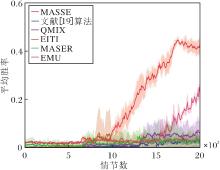
3.3.3 8m场景
8m场景中各算法平均胜率对比如图5所示.由图可知MASSE的性能最优, 在智能体数量增加时依旧能发挥它的优势, 这是因为MASSE能在限定状态空间中生成内在目标, 利用互信息为每个智能体生成内在奖励, 并且在面对庞大状态空间时, 能有效缩减搜索空间, 加快学习速度, 避免陷入局部最优解.
 | 图5 8m场景中各算法平均胜率对比Fig.5 Comparison of average winning rates of 6 algorithms in 8m scenario |
文献[19]算法与QMIX在处理智能体数量较多的场景时, 集中式网络在智能体数量增多时可能积累高方差, 导致算法效果较差.文献[19]算法主要关注当前时刻的奖励和动作选择, 缺乏长期规划能力, 导致在11 000个情节数时出现性能下降.
EITI通过评估智能体当前状态和其它智能体动作之间的互信息以指导智能体的探索, 并且倾向于选择互信息度较高的动作, 但是在智能体数量增加的场景中, EITI会忽略全局信息, 只关注自身的信息, 这可能导致智能体在探索过程中盲目尝试各种可能的行为, 学习效率低下.
MASSE隔一段时间从状态子集空间中生成内在目标, 可较好规避上述问题.MASER能在每个时间步生成子目标并通过内在激励机制促进探索, 但是算法过于关注子目标的生成而忽略全局任务的目标, 导致在训练初期无法有效利用这些子目标, 影响训练效率.
EMU在智能体数量较多的场景下, 状态空间膨胀导致情景记忆缓冲区存储的信息增加, 从而难以全面准确存储有效的轨迹, 影响内在奖励的生成, 导致智能体团队难以达到理想效果.
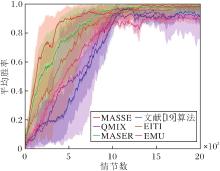
3.3.4 3s5z场景
相比3m、2s_vs_1sc、8m场景, 3s5z场景更复杂, 尽管我方与敌方作战单位智能体构成相同, 均为3个追猎者和5个狂热者, 但由于我方拥有的智能体是异构的, 需要训练的智能体数量是2s_vs_1sc场景的4倍.因此, 算法性能低于我方拥有智能体同构的场景.具体平均胜率对比如图6所示.由图可知, 在我方拥有的智能体异构场景下, MASSE通过区分自身状态与环境状态, 能较好地学习环境特征, 发挥将状态空间映射为状态子集空间的优势, 训练结果超越对比算法, 并且优于我方拥有的智能体同构的场景, 这充分展现其强大的鲁棒性和泛化能力.
 | 图6 3s5z场景中各算法平均胜率对比Fig.6 Comparison of average winning rates of 6 algorithms in 3s5z scenario |
在3s5z场景上, QMIX与文献[19]算法在初期学习效率相当, 但训练后期QMIX表现更佳.这得益于QMIX采用非线性方式分解全局状态动作值函数, 并通过混合网络约束全局状态动作值函数, 使其更适应复杂场景.相比之下, 文献[19]算法仅依赖于简单的状态动作值函数相加, 算法的线性表征能力有限, 在智能体数量增多且异构的情况下, 后期训练表现乏力, 甚至出现下滑趋势.文献[19]算法性能在3m、2s_vs_1sc场景中优于QMIX, 但是在8m、3s5z场景中差于QMIX.这是因为在我方同构且数量较少的简单场景中, QMIX需要额外训练一个网络, 而文献[19]算法直接对状态动作值函数进行线性加和, 让智能体更迅速学到一个优秀的策略.在我方异构的复杂场景中, 文献[19]算法的线性加和不能更完善提取智能体状态动作值函数的特征, QMIX的非线性加和能更好提取其特征.
EITI与MASER在该场景下表现并不理想.EITI在我方异构智能体数量增多的情况下几乎失效, 因为EITI在计算同构智能体时更具优势, 对于异构智能体状态动作的互信息计算并不奏效.MASER在庞大的状态空间中效果不佳, 训练后期的平均胜率极低, 仅为0.05左右.这是因为在该场景中, MASER基于个体和全局状态动作值函数生成的子目标难以与全局任务目标保持一致, 并且智能体数量增加会导致子目标大量生成, 使智能体难以有效管理这些子目标.
在该场景下, EMU前期效果较优, 但后期平均胜率只能稳定在0.36左右.这是因为智能体数量较多且我方智能体异构, 每个智能体的策略变化都会对整体环境产生影响, 导致环境变得更加非平稳.EMU依据情景记忆进行训练, 在应对这种快速变化的环境时难以保持内在奖励的稳定性和准确性, 从而影响智能体团队的策略优化.
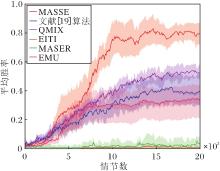
3.3.5 3s5z_vs_3s6z场景
3s5z_vs_3s6z场景中各算法平均胜率对比如图7所示.由图可见, 该场景双方智能体异构并且智能体数量较多, 我方智能体在数量上处于弱势, 导致算法性能不佳.但是在10 000个情节数之后, MASSE能逐渐学到一个高效的策略, 并且在17 500个情节数左右达到稳定的性能表现.
 | 图7 3s5z_vs_3s6z场景中各算法平均胜率对比Fig.7 Comparison of average winning rates of 6 algorithms in 3s5z_vs_3s6z scenario |
在该场景下, EMU在大约15 000个情节数时显示出学习策略的能力, 并最终达到0.29的平均胜率.由于EMU在异构场景下未能充分考虑环境及其它智能体的影响, 因此学习速率较慢.
其它算法几乎未能成功学习到有效的策略, 而MASSE通过区分自身状态和环境状态, 再利用状态子集空间生成内在目标, 有效管理状态空间, 并计算智能体在该状态下的互信息作为内在奖励, 能克服智能体数量增多和环境复杂化的挑战, 在3s5z_vs_3s6z的复杂场景中取得卓越效果.
文献[19]算法和QMIX通过分解状态动作值函数, 能显著降低时间复杂度, 达到Ο (n|U|)级别[14].这使得它们在之前的4个场景中均取得显著的性能提升, 并且在3s5z_vs_3s6z场景中后期平均胜率也有上升的趋势.EITI需要考虑一个智能体对其它智能体预期价值产生的影响, 因此时间复杂度从Ο (n|U|)升至Ο (|S||U|n), 大幅增加计算负担.因此在异构场景中, EITI的性能表现不佳, 而在同构场景中虽然有一定效果, 但学习速率相对一般.
MASER、EMU的时间复杂度为Ο (n|U|).虽然MASSE的时间复杂度也为Ο (n|U|), 但在生成内在奖励的机制上与它们不同.MASSE间隔一定回合更新状态子集空间和内在目标, 避免过于频繁的更新, 从而确保信息的有效性和算法的高效性.相比之下, MASER每个时间步都产生一个子目标, EMU每个时间步更新情节记忆缓冲区, 这种高频次的更新在一定程度上削弱算法的整体效率.在这5个场景中, MASSE的算法效率优于其它算法, 并且取得一个较高的平均胜率.
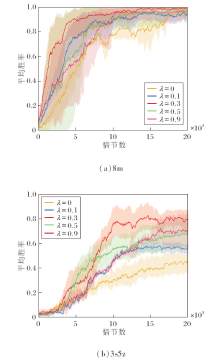
本节对MASSE进行进一步的消融研究, 探究不同权重参数λ值对算法性能的影响.选择在星际争霸8m、3s5z场景中进行讨论.分别选取λ=0, 0.1, 0.3, 0.5, 0.9进行测试, 具体结果如图8所示.当λ=0时可视作取消基于互信息的内在奖励模块、仅有混合网络的MASSE.算法依据不同的随机种子运行5次, 误差带为5次运行结果的95%置信区间.
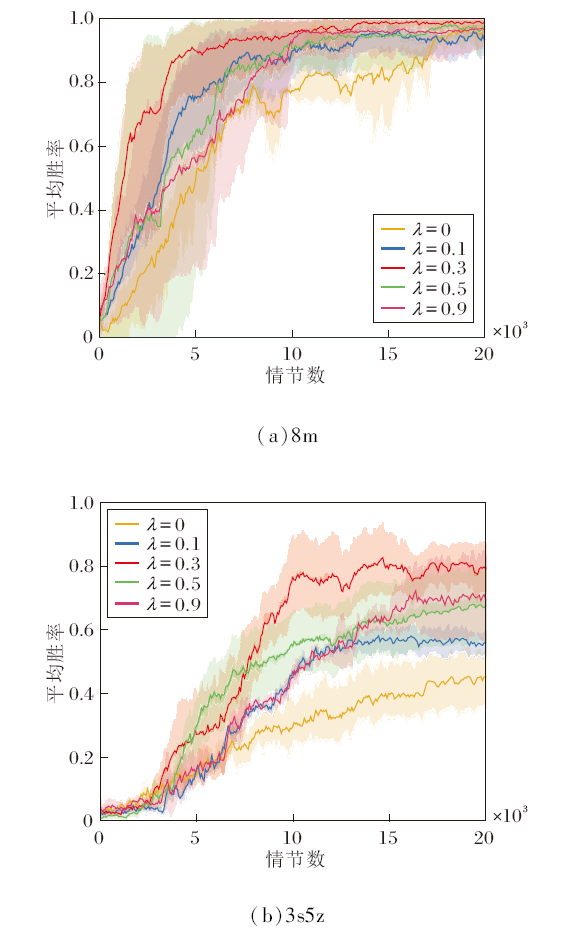 | 图8 两个场景中λ不同时的消融实验结果Fig.8 Results of ablation experiments with different λ in two scenarios |
λ为内在奖励的权重, 用于调节智能体在训练过程中对外在奖励和内在奖励的平衡.从图8中可看出, 当λ值较高时, 算法性能不佳, 这是因为智能体过于关注发现新的行为, 忽视能从环境中获得的外在奖励.当λ值过低时, 智能体过分依赖外在奖励, 限制智能体对环境探索.当λ=0, 即内在奖励模块被移除时, 在2个场景中性能都有所下降, 这表明内在奖励能促进智能体学到一个良好的策略.因此, λ=0.3是一个相对合适的选择, 有助于智能体在训练过程中实现最佳性能.
针对多智能体强化学习中稀疏奖励场景下的探索效率问题, 本文提出基于状态空间探索的多智能体强化学习算法(MASSE), 旨在提高算法在复杂多智能体协作场景下的性能.算法构建状态子集空间, 映射出一个状态作为内在目标, 并区分自身状态和环境状态.基于内在目标、自身状态及环境状态, 进一步生成基于互信息的内在奖励, 使智能体在提升对环境理解的同时, 进行有效探索.在不同稀疏奖励程度的多智能体协作场景中进行实验, 验证MASSE的优越性.由于内在激励机制在强化学习中的重要作用, 今后会着重研究如何对智能体进行情感建模.引入情感这一概念, 可让智能体的行为策略更像人类.通过情感对周围环境进行感知和理解, 可促进智能体适应不同的环境, 并做出更优决策.
本文责任编委 兰旭光
Recommended by Associate Editor LAN Xuguang
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|