









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于视觉语言模型的跨模态多级融合情感分析方法
[谢润锋1  , 张博超
, 张博超1 , 杜永萍1 ]
, 张博超, 杜永萍]
|
|



作者简介:

谢润锋,硕士研究生,主要研究方向为自然语言处理、多模态情感分析.E-mail:XRandomForest@emails.bjut.edu.cn.

张博超,硕士研究生,主要研究方向为自然语言处理.E-mail:zhangbochao555@126.com.
图文多模态情感分析旨在通过融合视觉模态和文本模态预测情感极性,获取高质量的视觉模态表征和文本模态表征并进行高效融合,这是解决图文多模态情感分析任务的关键环节之一.因此,文中提出基于视觉语言模型的跨模态多级融合情感分析方法.首先,基于预训练的视觉语言模型,通过冻结参数,采用低阶自适应方法微调语言模型的方式,生成高质量的模态表征和模态桥梁表征.然后,设计跨模态多头互注意力融合模块,分别对视觉模态表征和文本模态表征进行交互加权融合.最后,设计混合专家网络融合模块,将视觉、文本的模态表征和模态桥梁表征结合后进行深度融合,实现多模态情感分析.实验表明,文中方法在公开评测数据集MVSA-Single和HFM上达到SOTA.
About Author:
XIE Runfeng, Master student. His research interests include natural language processing and multimodal sentiment analysis.
ZHANG Bochao, Master student. His research interests include natural language processing.
Image-text multimodal sentiment analysis aims to predict sentimental polarity by integrating visual modalities and text modalities. The key to solving the multimodal sentiment analysis task is obtaining high-quality multimodal representations of both visual and textual modalities and achieving efficient fusion of these representations. Therefore, a cross-modal multi-level fusion sentiment analysis method based on visual language model(MFVL) is proposed. Firstly, based on the pre-trained visual language model, high-quality multimodal representations and modality bridge representations are generated by freezing the parameters and a low-rank adaptation method being adopted for fine-tuning the large language model. Secondly, a cross-modal multi-head co-attention fusion module is designed to perform interactive weighted fusion of the visual and textual modality representations respectively. Finally, a mixture of experts module is designed to deeply fuse the visual, textual and modality bridging representations to achieve multimodal sentiment analysis. Experimental results indicate that MFVL achieves state-of-the-art performance on the public evaluation datasets MVSA-Single and HFM.
随着社交网络平台的快速发展, 用户倾向于通过图像、文本及视频的方式分享生活.这些推文往往蕴含多种主题和发文者丰富的主观情感, 对其进行情感分析有助于平台根据发文者的情感进行信息推荐[1].多模态情感分析任务的关键挑战是如何提取及融合不同模态的表征, 目前一般采用深度学习的方法.Xu等[2]提出MultiSentiNet, 通过长短期记忆网络和卷积神经网络(Convolutional Neural Network, CNN)分别提取文本表征和视觉表征, 再融合以完成分类.Truong等[3]提出VistaNet(Visual Aspect Atten-tion Network), 将图像作为一种增强信息的表示, 通过层次注意力交互对齐视觉表征和文本表征, 解决不同模态间的对齐问题.
为了结合上下文信息进行多模态情感分析, Xu等[4]提出HSAN(Hierarchical Semantic Attentional Network), 通过层次注意力结构分别挖掘文本和图像字幕的语义表示, 进行上下文信息的学习.为了进一步挖掘文本和图像之间的关系, Xu等[5]提出MIMN(Multi-interactive Memory Network), 通过记忆网络模块对文本特征和图像表征进行交互学习, 再通过多层感知机(Multilayer Perceptron, MLP)和多个池化模块的堆叠完成特征融合.Yu等[6]提出TomBERT(Target-Oriented Multimodal Bidirectional En-coder Representations from Transformers), 通过BERT[7]提取文本模态的目标感知特征, 设计注意力机制, 提取基于视觉表示的目标感知特征并进行模态交互融合.为了进一步挖掘情绪感知的多模态表征, Yang等[8]提出MGNNS(Multi-channel Graph Neural Net-works with Sentiment-Awareness), 通过多通道图神经网络获取多模态表征, 并结合多头注意力机制进行预测.Khan等[9]提出Cap-TrBERT, 基于Transfor-mer[10]为图像模态生成可用的文本表示, 并将图像的文本表示及文本模态一同输入BERT进行情感分类.Li等[11]提出CLMLF(Contrastive Learning and Multi-layer Fusion), 通过多层的融合模块实现文本表征和图像表征在token-level上的对齐和融合, 在情感分析任务的基础上, 进一步设置两个对比学习任务, 有助于模型提取不同模态的共同特征.为了解决模态间分布不一致的问题, Wei等[12]提出MVCN(Multi-view Calibration Network), 设计多视图校准网络, 包括文本引导融合模块、基于情感的一致性约束和自适应损失校准策略, 系统解决不同视角下模态异质性的问题.
为了对齐图像和文本, Radford等[13]提出CLIP(Contrastive Language Image Pre-training), 通过视觉编码器和文本编码器分别提取模态表征, 再根据InfoNCE Loss(Info-Noise-Contrastive Estimation Loss)[14]在大量的图像文本对数据集上进行预训练, 使模型能更好地拉近相同类别样本的距离, 同时增加不同类别样本的距离.Li等[15]提出BLIP(Boots-trapping Language-Image Pre-training), 采用ViT(Vision Trans-former)[16]作为图像编码器, BERT作为文本编码器, 将图像文本对比学习、图像文本匹配学习和图像语言建模三个视觉语言目标进行联合预训练, 同时完成视觉理解任务和文本生成任务.
随着大语言模型的出现与快速发展, 其具备的强大的上下文理解能力和文本生成能力能再次赋能多模态模型, 其中OpenAI的多模态模型GPT4表现出优秀的多模态理解与生成能力.因此, Li等[17]提出BLIP-2, 由视觉编码器、大语言模型和Qformer(Querying Transformer)组成的多模态模型, 通过视觉编码器提取视觉表征, 大语言模型完成文本生成, Qformer对齐视觉表征和文本表征, 弥合模态间的差距, 具备优秀的视觉语言理解与生成能力.
由于算力与数据的限制, 端到端地训练一个多模态大模型极其困难, 因此, 不少研究通过冻结视觉编码器和大语言模型的参数, 采用一个可学习的线性投影层完成视觉模型和大语言模型的对齐.由于视觉语言模型通常在大规模的图像文本对数据集上进行充分的预训练, 能为多模态情感分析任务提供高质量的模态表征, 同时, 预训练的视觉语言模型具备的图文模态对齐能力能较好地解决模态间联系较弱、差异较大的问题, 因此, 将视觉语言模型应用于图文多模态情感分析任务是一项新颖的工作.
在多模态情感分析任务中, 常见的多模态数据通常为图文对或视频通常通过多模态表征提取和多模态表征融合两个步骤完成该任务.在多模态表征提取阶段, 设计表征提取模块, 将不同模态的数据转化为蕴含丰富信息的模态表征; 在多模态融合阶段, 整合来自不同模态的表征, 形成稳定的多模态表征.
目前, 图文多模态情感分析任务的研究工作存在如下问题.1)模态表征质量不高.模态表征提取是实现情感分析的基础, 然而, 大部分研究工作的表征提取模块较弱, 表征提取能力不足, 难以挖掘图像模态和文本模态中的深层次语义信息.2)模态表征间关联较弱.图像模态和文本模态之间存在一定关联, 这些重要但容易被忽略的信息是情感分析任务的关键.然而, 少有研究能在表征提取过程中挖掘不同表征之间的关联.3)多模态融合不充分.多模态融合是模型为情感分析任务提供稳定多模态表示的关键.现有工作通常存在融合机制单一及融合不足的问题.
为了解决上述问题, 本文提出基于视觉语言模型的跨模态多级融合情感分析方法(Cross-Modal Multi-level Fusion Sentiment Analysis Method Based on Vi-sual Language Model, MFVL).针对表征质量较低和模态表征之间关联较弱的问题, 通过冻结预训练的视觉语言模型, 采用低阶自适应微调方法微调语言模型, 生成高质量的视觉表征和文本表征, 同时生成图像模态和文本模态之间的桥梁表征.针对多模态信息融合不足的问题, 提出多级融合机制, 设计跨模态多头互注意力融合模块(Cross-Modal Multi-head Co-attention Fusion, CMA)作为一级融合模块, 挖掘视觉表征和文本表征中的关键信息.设计混合专家网络融合模块(Mixture of Experts Network Fusion, MoE)作为二级融合模块, 将模态表征和模态桥梁表征进行深度融合, 完成多模态情感分析任务.实验表明, MFVL在MVSA、HFM数据集上取得较优性能.
给定一个多模态语料库D={s1, s2, …,
多模态情感分析任务的目标是预测语料库D中的每个样本si对应的情感极性yi, 其中yi属于预定义的类别标签集合C中的一种情感极性.
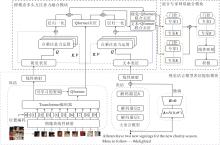
本文提出基于视觉语言模型的跨模态多级融合情感分析方法(MFVL), 框图如图1所示.具体包含3个模块:视觉语言模型表征提取模块(Visual Lan-guage Model Representation Extraction, VLM)、跨模态多头互注意力融合模块(CMA)、混合专家网络融合模块(MoE).
 | 图1 MFVL总体框图Fig.1 Overall structure of MFVL |
首先, 基于预训练的多模态视觉语言模型, 通过冻结视觉模型参数, 采用低阶自适应微调方法, 将图像模态和文本模态转化为对应的模态表征, 采用视觉语言模型中的Qformer实现图像与文本模态对齐.然后, 设计CMA作为一级融合模块, 对不同的模态表征进行加权融合, 获得联合模态表征.最后, 设计MoE作为二级融合模块, 将联合模态表征进行深入的转换与融合, 实现多模态情感分析.
为了提取图像模态数据和文本模态数据的表征, 基于预训练的视觉语言模型BLIP-2, 将两种模态转化为蕴含多模态信息的模态表征.BLIP-2是一种基于Transformer的多模态模型, 通过冻结预训练视觉模型和大语言模型的参数, 训练Qformer, 实现视觉模态和文本模态的对齐.Qformer是一个轻量化的Transformer, 在BLIP-2中发挥模态对齐的作用.在经过大量图文数据的预训练之后, BLIP-2中的特征提取模块能学到和文本最相关的视觉表示.同时, Qformer在大量的图文对齐训练中具备弥合视觉模态和文本模态之间差距的能力.因此, Qformer能在多模态情感分析的特征对齐阶段发挥重要作用.
对于多模态样本si, 采用冻结参数的ViT视觉模型作为视觉表征提取模型, 提取样本中图像模态数据siv的视觉表征:
其中Wv表示线性投影层的可学习参数.对于文本模态数据sit, 利用大语言模型强大的文本理解能力, 通过OPT(Open Pre-trained Transformer)[18]语言模型将其转化为对应的文本表征:
其中Wt表示线性投影层的可学习参数.为了弥补图像模态和文本模态之间的差距, 基于冻结参数的Qformer结构提供两种模态之间的桥梁表征:
HB=Qformer((siv, sit))∈Rn×d,
在文本模态表征提取过程中, 引入大语言模型的LoRA(Low-Rank Adaptation)[19], 冻结大语言模型参数、加入额外的网络层并训练其参数, 从而达到在微调极少量参数的同时获得和全模型参数微调可比的效果.因此, 基于LoRA降低大模型微调成本, 并在一定程度上拟合训练数据, 进一步提供高质量文本表征.
将OPT的参数矩阵记作θOPT, 在下游微调OPT时, 需要更新预训练模型参数, 即θOPT+Δθ, Δθ为需要更新的参数, 则LoRA的参数更新过程如下:
θOPT+Δθ=θOPT+B·A.
微调过程中A∈Rr×k和B∈Rl×r均为可学习参数.在前向传播过程中, θOPT和Δθ都会乘以相同的输入x并相加, 即
f=θOPT·x+Δθ·x=θOPT·x+B·A·x.
采用视觉语言模型分别提取图像模态表征和文本模态表征之后, 进行模态间的交互, 对不同模态的表征进行深层融合, 获得蕴含模态交互信息的模态间联合表征.因此, 设计跨模态多头互注意力融合模块(CMA), 作为一级融合模块, 分别对视觉表征
$ \begin{array}{l} \text { Co-Attention }\left(\widehat{\boldsymbol{H}}_{v}, \widehat{\boldsymbol{H}}_{t}\right)= \\ \quad \operatorname{Softmax}\left(\frac{\widehat{\boldsymbol{H}}_{v} \cdot \boldsymbol{W}^{\ell} \cdot\left(\widehat{\boldsymbol{H}}_{t} \cdot \boldsymbol{W}^{K}\right)^{\mathrm{T}}}{\sqrt{d}}\right) \cdot \widehat{\boldsymbol{H}}_{t} \cdot \boldsymbol{W}^{V}, \end{array}$
其中,
由于多头注意力机制可处理多角度的信息, 因此可较好地实现复杂信息的结合.假设有h个头, 每个head的含义为
hea
将多个head的输出进行连接, 获得CMA的输出.最终的视觉-文本多头互注意力输出为:
$ \begin{array}{l} \widehat{\boldsymbol{H}}_{v-t}= \\ \text { LayerNorm }\left(\text { Concat }\left(\left[\text { head }_{1}^{v}, \text { head }_{2}^{v}, \cdots, \text { head }_{h}^{v}\right]\right) \cdot \boldsymbol{W}^{v-t}\right), \end{array}$
其中, Wv-t表示线性投影层的可学习参数, LayerNorm(·)表示层归一化.
同理, 文本-视觉多头互注意力输出:
$ \begin{array}{l} \widehat{\boldsymbol{H}}_{t-v}= \\ \operatorname{LayerNorm}\left(\operatorname{Concat}\left(\left[\text { head }_{1}^{t}, \text { head }_{2}^{t}, \cdots, \text { head }{ }_{h}^{t}\right]\right) \cdot \boldsymbol{W}^{t-v}\right) \text {, } \\ \end{array}$
其中, Wt-v表示线性投影层的可学习参数.
通过对视觉表征和文本表征进行跨模态多头互注意力融合, 获得交互加权融合表示
$ \begin{aligned} \boldsymbol{H}_{v-t} & =\operatorname{Concat}\left(\left[\widehat{\boldsymbol{H}}_{v-t}, \boldsymbol{H}_{B}\right]\right), \\ H_{t-v} & =\operatorname{Concat}\left(\left[\widehat{\boldsymbol{H}}_{t-v}, \boldsymbol{H}_{B}\right]\right) . \end{aligned}$
在分别获得视觉-文本和文本-视觉联合表征之后, 设计混合专家网络融合模块(MoE)作为二级融合模块, 通过多个专家学习挖掘表征内部信息, 进行维度变换并完成多模态情感分析任务[20].设E(·)表示专家网络的输出, G(·)表示门控网络的输出, ei(·)对应专家第i个位置的输出, gi(·)对应门控第i个位置的输出.专家网络和门控网络接收相同的输入, 每位专家学习不同的特征, 门控函数根据输入为每位专家分配不同权重.
为了完成上述任务, 构建两层单门混合专家网络融合模块(One-Gate MoE).底层由2个单门MoE组成, 利用多位专家进一步挖掘视觉-文本联合表征Hv-t和文本-视觉联合表征Ht-v, 得到专家表征Hvt和Htv:
$ \begin{array}{l} \boldsymbol{H}_{v t}=E_{v-t}\left(\boldsymbol{H}_{v-t}\right) \cdot G_{v-t}\left(\boldsymbol{H}_{v-t}\right)=\sum_{i=1}^{n} e_{i}^{v t}\left(\boldsymbol{H}_{v-t}\right) \cdot g_{i}^{v t}\left(\boldsymbol{H}_{v-t}\right), \\ \boldsymbol{H}_{t v}=E_{t-v}\left(\boldsymbol{H}_{t-v}\right) \cdot G_{t-v}\left(\boldsymbol{H}_{t-v}\right)=\sum_{i=1}^{n} e_{i}^{w}\left(\boldsymbol{H}_{t-v}\right) \cdot g_{i}^{t v}\left(\boldsymbol{H}_{t-v}\right) . \end{array}$
并融合为最终的多模态表征:
Hm=Hvt·Htv.
顶层的单门MoE负责挖掘Hm, 最后预测该样本对应的情感极性y的概率:
$ p=\operatorname{Sigmoid}\left(\boldsymbol{W}^{m}\left(\sum_{i=1}^{n} e_{i}^{m}\left(\boldsymbol{H}_{m}\right) \cdot g_{i}^{m}\left(\boldsymbol{H}_{m}\right)\right)\right), $
其中专家由多层MLP构成, 门控函数为softmax, n表示专家数量, Wm表示可学习的线性投影层参数.
训练MFVL的损失函数为交叉熵损失函数:
L=
其中, yic表示取值为0或1的符号函数, 取值为1表示当前样本的标签为c, 否则取值为0.
本文选择在MVSA-Single[21]、MVSA-Multiple[21]、HFM[22]这3个公开评测数据集上设计实验, 验证方法的有效性, 数据集的统计信息如表1所示.
| 表1 实验数据集的统计信息 Table1 Statistical information of experimental datasets |
MVSA-Single、MVSA-Multiple数据集是2个常用的从推特中爬取的图像-文本对情感分析数据集, 包含3种情感类别:积极(Positive)、中性(Neu-tral)和消极(Negative).MVSA-Multiple数据集为MVSA-Single数据集的升级版本, 包含更丰富且更复杂的图像文本数据对.2个MVSA数据集的处理方式与文献[2]一致.HFM数据集上只包含积极和消极两种情感类别, 本文采用和文献[22]一样的数据预处理方式进行实验.
在表征提取阶段, 视觉表征提取模块为来自CLIP的ViT-L/14, 文本表征提取模块为OPT-2.7B, 生成模态桥梁表征的Qformer直接来自预训练的BLIP-2.在训练时冻结ViT、Qformer和OPT, 学习率设置为2e-5, 批尺寸大小为24, 训练6个迭代周期.训练时采用的优化器为AdamW(Adaptive Moment Estimation with Weight Decay), 其中∈=1e-8, β1和β2的组合设置为(0.9, 0.999).采用准确率(Accuracy, ACC)和F1作为性能评价指标.
ACC为多模态情感分类器正确分类的样本比例:
ACC=
其中, TP表示实际为正例且被多模态情感分类器划分为正例的数目, FP表示实际为负例但被多模态情感分类器划分为正例的数目, TN表示实际为正例但被多模态情感分类器划分为负例的数目, FN表示实际为负例且被多模态分类器划分为负例的数目.
F1为精确率(Precision)和召回率(Recall)的加权调和平均:
$ \begin{array}{l} F 1=\frac{2 \cdot \text { Precision } \cdot \text { Recall }}{\text { Precision }+ \text { Recall }}, \\ \text { Precision }=\frac{T P}{T P+F P}, \text { Recall }=\frac{T P}{T P+F N}, \end{array}$
其中, Precision表示多模态情感分类器识别为正例的样本中, 实际为正例的比例, Recall表示在所有正例样本中, 被多模态情感分类器正确识别为正例的比例.
所有的实验均在Linux平台上, 基于Pytorch2.0.1框架, 采用2个NVIDIA TESLA V100 32 GHz GPU完成.
为了充分验证MFVL的有效性, 分别选择单模态方法和多模态方法进行对比.
在单模态方法中, 对于文本模态, 选取文献[23]方法, Att-BLSTM(Attention-Based Bidirectional Long Short-Term Memory Networks)[24]和BERT[7]进行对比.对于视觉模态, 选取ResNet(Residual Net-work)[25]和ViT[16]进行对比.
在多模态方法中, 还包含部分多模态讽刺检测方法.多模态讽刺检测是一种通过联合多种模态以检测输入内容中是否包含讽刺情感的任务.讽刺是指用比喻、夸张等表现手法对人或事进行批判或嘲笑, 是人类情感表达的一种高级形式.因此, 多模态讽刺检测是情感分析中的一个重要应用.具体对比方法如下.
1)MultiSentiNet[2].使用目标特征向量、场景特征向量和词向量进行跨模态注意力融合, 赋予文本中与情感相关的词向量更高的权重, 用以完成多模态情感分析.
2)HSAN[4].利用层次注意力结构分别挖掘文本和图像字幕的语义表示, 学习上下文信息, 实现多模态情感分析.
3)MGNNS[8].基于多通道图神经网络捕捉情绪感知的多模态表示, 通过多头注意力机制进行情绪预测.
4)CLMLF[11].基于对比学习, 设计多层融合和对齐模块, 进行不同模态表示交互与融合, 进行下游情感分类.
5)MVCN[12].使用多视图校准网络, 包括文本引导融合模块、基于情感的一致性约束和自适应损失校准策略进行多模态情感分析.
6)文献[22]方法.通过层次融合结构将图像、属性和文本进行深度融合, 完成多模态讽刺检测任务.
7)CoMN-Hop6[26].使用交互式记忆网络对视觉信息和文本信息间的相互影响进行建模, 迭代地从文本和图像中获取关键信息.
8)文献[27]方法(简记为Concat).基于深度学习的方法, 设计深度网络直接连接视觉特征和文本特征进行多模态讽刺检测.在后文中, Concat-2表示连接图像特征和文本特征, Concat-3在Concat-2的基础上进一步连接图像的属性特征.
9)D& R Net(Decomposition and Relation Net-work)[28].构建分解和关系网络, 对跨模态对比和语义关联进行建模, 挖掘图像和文本之间的共性和差异, 完成多模态讽刺检测任务.
各方法在MVSA-Single、MVSA-Multiple、HFM数据集上的指标值对比结果如表2和表3所示, 表中黑体数字表示最优值.
| 表2 各方法在MVSA-Single、MVSA-Multiple数据集上的指标值对比 Table 2 Index value comparison of different methods on MVSA-Single and MVSA-Multiple dataset % |
| 表3 各方法在HFM数据集上的指标值对比 Table 3 Index value comparison of different methods on HFM dataset % |
由表2可见, 在MVSA-Single数据集上, MFVL在ACC和F1上均超过之前的SOTA.然而, MFVL在MVSA-Multiple数据集上的表现与对比方法仍存在一定的差距.由表3可见, 在HFM数据集上, MFVL的表现远超过所有的对比方法, 相比之前的SOTA, ACC和F1分别提升9.58%和10.18%.
为了探究MFVL的性能, 分别在MVSA-Single、MVSA-Multiple、HFM数据集上对跨模态多头互注意力融合模块中的超参数heads进行实验分析.由于MFVL中多头互注意力融合模块的输出维度为768, heads的合适取值为4, 6, 8, 12, 并且为了控制变量, 将混合专家网络融合模块中的专家数设置为8, 具体实验结果如图2和图3所示.由图可知, 在MVSA-Single数据集上, F1指标在heads=6时较优, ACC在heads=8时更高.在MVSA-Multiple、HFM数据集上, 当heads=8时MFVL表现均为最佳.综合上述实验结果, 取heads=8.
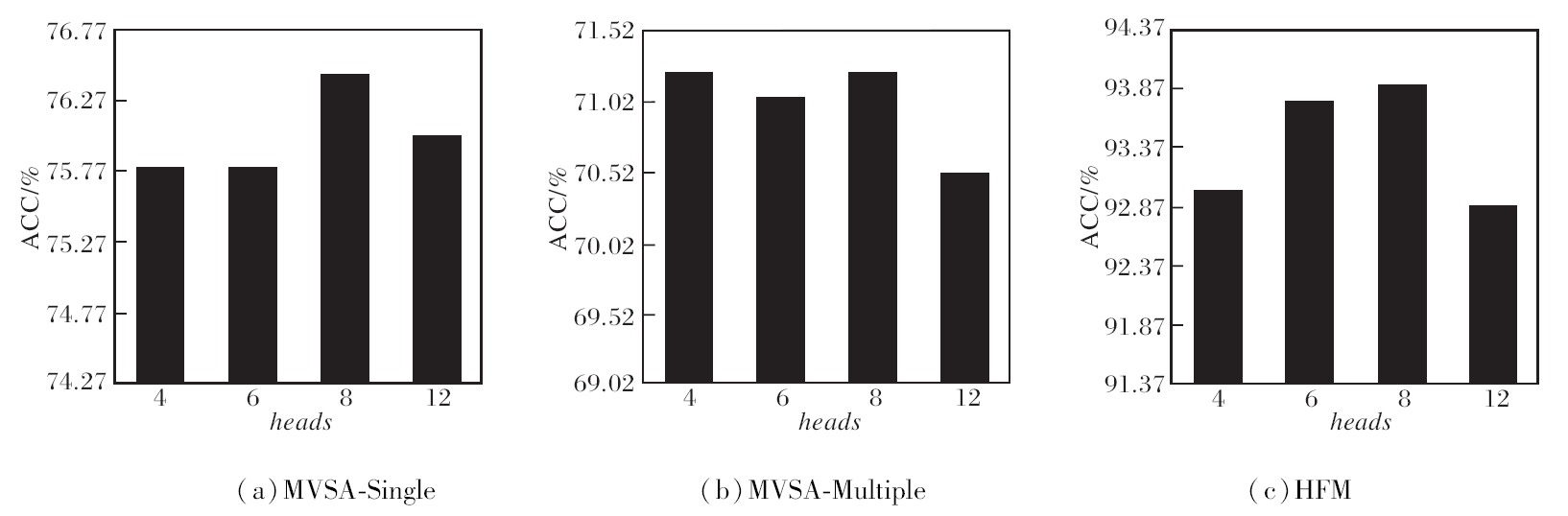 | 图2 heads不同时MFVL的ACC值对比Fig.2 ACC comparison of MFVL with different heads |
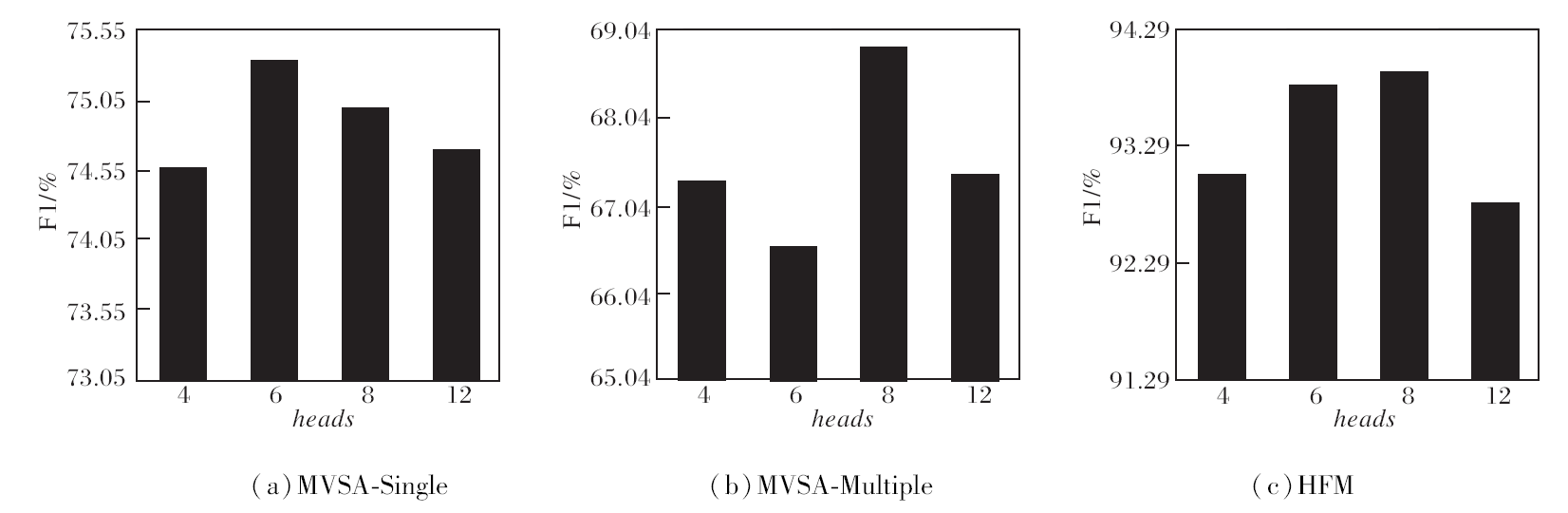 | 图3 heads不同时MFVL的F1值对比Fig.3 F1 comparison of MFVL with different heads |
同理, 当heads=8时, 分析混合专家网络融合模块中专家数量n, 设计n=4, 5, …, 10, n不同时MFVL在3个数据集上指标值结果如图4和图5所示.
 | 图4 n不同时MFVL的ACC值对比Fig.4 ACC comparison of MFVL with different n |
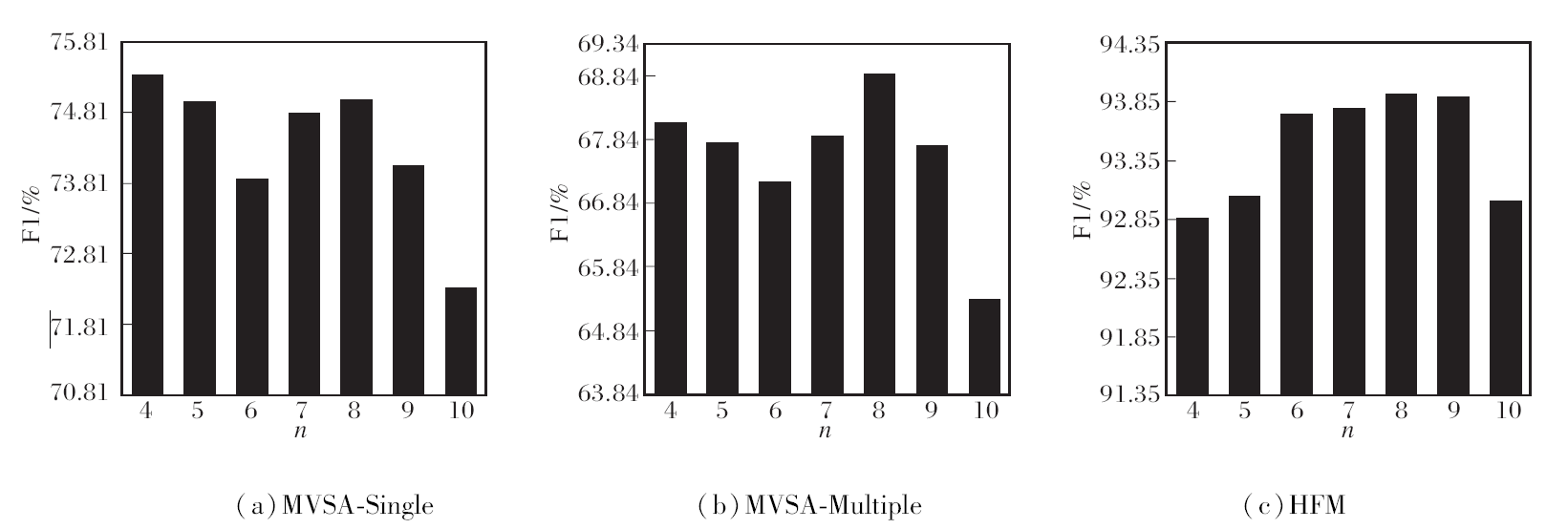 | 图5 n不同时MFVL的F1值对比Fig.5 F1 comparison of MFVL with different n |
由图4和图5可见, 在MVSA、HFM数据集上, n=8时MFVL性能最佳.
因此, 在实验中(heads, n)的最佳超参数组合设置为(8, 8).
为了探究MFVL中视觉语言模型特征提取模块(VLM)、跨模态多头互注意力融合模块(CMA)和混合专家网络融合模块(MoE)的有效性, 分别在MVSA-Single、MVSA-Multiple、HFM数据集上进行消融实验, 结果如表4所示.
| 表4 MFVL消融实验结果 Table 4 Ablation experimental results of MFVL % |
由表4可见, 在3个不同的数据集上, 本文提出的3个模块均能提升方法性能.其中VLM对性能影响最大, 在HFM数据集上, VLM带来的ACC和F1提升分别达到15.4%和15.2%.
在MVSA数据集上, 相比CMA和MoE, VLM也带来较大提升.这说明预训练的视觉语言模型能有效提取高质量的模态特征, 有利于方法在下游进行融合与分类.
为了进一步探究MFVL对多模态数据特征提取的有效性, 对提取到的图像模态表征进行可视化, 具体如表5所示.
| 表5 MFVL多模态特征可视化分析 Table 5 Visualization analysis of multimodal representations extracted by MFVL |
由表5可见, MFVL能注意到图像中的关键主体, 如狗、瀑布和浓烟.此外, MFVL提取到的图像主体语义与文本模态中的实体关键词以及情感词密切相关, 并且对情感极性的预测具有重要作用.
因此, MFVL具备关键表征挖掘能力和模态关联能力, 能正确结合图像模态和文本模态, 判断情感极性.
本文提出基于视觉语言模型的跨模态多级融合情感分析方法(MFVL).针对模态表征质量较低和模态间关联较弱的问题, 通过冻结预训练视觉语言模型BLIP-2的参数, 采用LoRA微调大语言模型, 生成蕴含模态信息的模态表征和弥补模态间差异的模态桥梁表征.进一步地, 设计跨模态多头互注意力模块和混合专家网络融合模块, 对模态表征进行深入挖掘和融合, 提升模型的多模态融合能力.实验表明, MFVL在MVSA、HFM数据集上的性能表现超过之前的SOTA, 在HFM数据集上ACC和F1值提升幅度分别达到9.58%和10.18%.
MFVL在图文多模态情感分析任务中取得不错的性能, 由于视觉语言模型具备强大的视觉理解和文本理解能力, 并在表征提取阶段表现优异, 今后, 将充分利用视觉语言模型的多模态表征能力, 提取连续多帧图像的关键表征及视频中文本上下文的表征, 进一步挖掘图像帧与文本的关联, 并将跨模态多级融合机制应用于包含视频模态的多模态情感分析任务中.
本文责任编委 粱吉业
Recommended by Associate Editor LIANG Jiye
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|