{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于异构网络语言形式背景的知识发现及规则提取
[沙立伟1  , 杨政
, 杨政1 , 刘红平2 , 邹丽1 ]
, 杨政, 刘红平, 邹丽]
|
|



作者简介:

沙立伟,硕士研究生,主要研究方向为智能信息处理、非经典逻辑、不确定性推理.E-mail:19819791939@163.com.

杨 政,硕士研究生,主要研究方向为智能信息处理、非经典逻辑、不确定性推理.E-mail:yzharder@163.com.

刘红平,博士,副教授,主要研究方向为模糊拓扑、Domain理论、智能信息处理等.E-mail:liuhongping@sdjzu.edu.cn.
在不确定性环境下,如何处理具有复杂关系的数据是研究热点之一.网络形式背景将复杂网络分析和形式概念分析结合,为复杂关系数据的知识发现提供一种有效的数学工具.文中首先从网络结构的异构性出发,提出异构网络语言形式背景.异构网络包含专家给出的主观网络,又包含通过对象的特征挖掘的客观网络.然后,考虑网络的连通性,得到全局和局部异构网络语言概念,并给出异构网络下的全局连通及局部连通知识发现算法.最后,基于异构网络语言形式背景构建关联规则提取模型,通过实例验证知识发现及规则提取的合理性和有效性.
About Author:
SHA Liwei, Master student. His research interests include intelligent information processing, non-classical logic and uncertainty reasoning.
YANG Zheng, Master student. His research interests include intelligent information processing, non-classical logic and uncertainty reasoning.
LIU Hongping, Ph.D., associate profe-ssor. Her research interests include fuzzy topology, Domain theory and intelligent information processing.
One of the research hotspots is how to handle data with complex relationships under the uncertainty environment. The network formal context combines complex network analysis and formal concept analysis to provide an effective mathematical tool for knowledge discovery of complex relational data. In this paper, the heterogeneous network linguistic formal context is firstly proposed based on the heterogeneity of network structure. The heterogeneous network contains a subjective network given by experts and an objective network mined by the features of objects. Then, global and local heterogeneous network language concepts are obtained by considering the connectivity of the network, and the algorithms for global and local connectivity knowledge discovery in heterogeneous networks are provided. Finally, an association rule extraction model is constructed based on the heterogeneous network linguistic formal context, and the rationality and effectiveness of knowledge discovery and rule extraction are verified by examples.
形式概念分析(Formal Concept Analysis, FCA)[1]是一种强大的数学工具, 用于数据处理和规则提取.作为基于形式背景的一种重要的数据处理和可视化方法, FCA通过对象与属性的关联获取潜在的概念知识, 目前已在知识发现、数据挖掘、机器学习、特征选择等领域[2, 3, 4, 5, 6, 7]得到广泛应用.Wu等[8]将粒计算思想融入形式概念分析, 研究概念格的粒度结构在知识约简中的应用.Wang等[9]受粗糙集理论启发, 从近似算子角度研究形式背景, 并构建概念格.Zhi等[10]基于形式概念分析定义新的三支概念, 提出一种快速冲突分析信息融合方法.
在经典的形式背景中, 通常使用0或1表示对象和属性之间是否存在关系, 而在实际生活中, 人们更习惯使用语言值表达信息.Zadeh[11, 12]提出模糊集和语言变量的概念, 可有效描述使用语言值表达的信息.近年来, 学者们研究和扩展模糊集和语言变量理论.Herrera等[13]提出语言术语集, 描述离散语言变量.Xu[14]研究基于概率语言信息的聚合算子.Zou等[15]提出语言概念形式背景, 用于处理现实生活中使用语言值描述的数据.Pang等[16]利用语言真值格蕴含代数构建多专家语言形式背景, 提出一种有效的多属性群决策意见聚合方法.
模糊聚类是一种基于模糊集理论的聚类方法, 与传统的硬聚类方法不同, 它允许对象同时属于多个类别, 并给出每个对象属于每个聚类类别的概率.模糊C均值聚类(Fuzzy C-means, FCM)[17, 18, 19]作为常用的模糊聚类方法之一, 因为开销低和鲁棒性而广泛应用于图像分割、故障诊断等[20, 21]领域.研究发现, 模糊聚类可帮助建模复杂网络中的模糊关系, 通过将节点聚类为模糊群集, 可更好地描述网络中的模糊关联.
复杂网络分析理论可更好地处理对象节点间复杂的模糊关联信息.复杂网络分析是一种研究复杂系统中节点之间相互关系和结构特征的方法, 通过帮助揭示网络中的隐藏结构、关键节点和子群体, 分析网络的内部机制和特点.近年来, 学者们拓展与研究复杂网络分析理论.Zhao等[22]将复杂动态网络完全视为由两个相互耦合的子系统组成的动态复合系统, 提出一种跟踪控制方案.Fan等[23, 24]结合复杂网络分析与形式概念分析, 提出网络形式背景, 并研究知识发现与更新、规则提取等问题.在结构上看, 复杂网络可分为同构网络和异构网络.相比同构网络, 异构网络在现实生活中更常见.
综合异构网络与形式概念分析, 本文提出异构网络语言形式背景, 使用语言值更好地描述偏好关系, 并且异构网络包含对象之间由专家给出的主观关系, 又包含通过对象的特征挖掘的客观关系, 其中客观关系利用FCM将对象聚类为模糊群集, 反映网络中的模糊关联.在此基础上, 分析网络的连通性, 定义全局和局部异构网络语言概念, 并讨论和证明异构网络语言概念的相关性质.由于在不同的认知环境下, 判断物体间是否存在关系的标准不同, 又基于异构网络语言形式背景, 提出两种知识发现算法, 进而提取关联规则.最后, 通过实例验证算法及规则的合理性和有效性.本文的理论和方法可应用于数据挖掘及推荐系统等领域.
定义1[25] 设
S={st|t=-τ, …, -1, 0, 1, …, τ}
表示由奇数个语言项组成的有限语言项集, 其中τ表示正整数, 若S符合
1)有序性:si≥sj⇔i≥j,
2)负算子:Neg(s-i)=si, 特别的, Neg(s0)=s0,
3)最大算子:si≥sj⇔max(si, sj)=si,
4)最小算子:si≤sj⇔min(si, sj)=si,
则称集合S为下标对称的语言术语集.
定义2[1] 称三元组(U, A, I)为一个形式背景, 其中U={x1, x2, …, xn}表示非空有限的对象集, A={a1, a2, …, am}表示非空有限的属性集, I⊆U×A表示U与A之间的二元关系.对于∀x∈U, a∈A, 如果(x, a)∈I, 则称对象x拥有属性a, 记为xIa.
定义3[25] 称三元组(U,
$\begin{aligned} L_{S_{\alpha}}= & \left\{l_{-t}^{1}, \cdots, l_{0}^{1}, \cdots, l_{t}^{1}, l_{-t}^{2}, \cdots, l_{0}^{2}, \cdots, l_{t}^{2}, \cdots, \right. \\ & \left.l_{-t}^{n}, \cdots, l_{0}^{n}, \cdots, l_{t}^{n}\right\}, \end{aligned}$
表示非空有限的语言概念集, I⊆U×
定义4[25] 设F=(U,
$\begin{array}{l} X^{\prime}=\left\{l_{s_{a}}^{i} \in L_{S_{\alpha}} \mid x I l_{s_{a}}^{i}, \forall x \in X\right\}, \\ B_{S_{\alpha}}^{\prime}=\left\{x \in U \mid x I l_{s_{a}}^{i}, \forall l_{s_{a}}^{i} \in B_{S_{\alpha}}\right\}, \end{array}$
X'表示X中所有对象共同拥有的语言概念集, B
若X'=
对于
(X1,
定义(X1,
(X1,
L(U,
(X1,
(X1,
定义5[23] 四元组(U, M, A, I)为一个网络形式背景, U={x1, x2, …, xn}表示一个有限非空对象集, M={m1, m2, …, mp}表示一个网络邻接矩阵集, mi(1, 2, …, p)为n×n的网络邻接矩阵, A={a1, a2, …, am}表示一个非空有限属性集,
I={Is|i=1, 2, …, p+1},
其中, I1, I2, …, Ip表示笛卡尔积U×U上的二元关系, (xi, xj)∈Ik表示对象i、 j是k阶邻接的, Ip+1表示笛卡尔积U×A上的二元关系, (xi, aq)∈Ip+1表示对象xi具有属性aq.
异构网络由多种类型的节点组成, 还包含不同节点间的复杂关系.本节结合异构网络理论与形式概念分析理论, 介绍异构网络语言形式背景.使用语言值描述偏好关系, 并且融合FCM[26, 27]挖掘对象间的相似关系及专家事先给出的对象间关系, 重新计算网络邻接矩阵.
FCM使用隶属度表示每个样本属于各个聚类的程度, 根据隶属度的大小将样本集上的每个样本模糊分配到不同的聚类中.通过算法迭代后可得到聚类中心矩阵
C=
和隶属度矩阵
U=
定义6 设(U,
Si
其中, q表示FCM中给定的类别数,
表示对象xi、xj在第q类中的欧氏距离.
性质1 对于∀xi∈U, xj∈U, 对象xi、xj在第q类中满足
1)Si
2)当i=j时, Si
3)
4)Si
证明 1)、2)由定义6显然得证.
下证3).根据定义6可知两个对象在同类中的距离越大, 则这两个对象在这类中的相似度越低; 反之, 两个对象在同类中的距离越小, 则这两个对象在这类中的相似度越高.
最后证4).由于FCM计算的模糊隶属矩阵元素μiq、 μjq取值范围为[0, 1], 因此
例1 表1为一个语言概念形式背景(U,
表示对应的语言概念集.
| 表1 语言概念形式背景(U, |
基于表1语言概念形式背景中的数据, 取类别数q=3, 根据FCM计算模糊隶属矩阵, 如表2所示.
| 表2 隶属度矩阵 Table 2 Affiliation matrix |
根据式(1)分别计算对象x1、x2在c1类的相似度:
$ \begin{array}{c} \operatorname{Sim}_{11}^{c_{1}}=1-d_{11}^{c_{1}}=1-\sqrt{\left(\mu_{1 c_{1}}-\mu_{1 c_{1}}\right)^{2}}= \\ 1-\sqrt{(0.2-0.2)^{2}}=1 . \end{array}$
定义7 设四元组(U,
$ \begin{aligned} L_{S_{\alpha}}= & \left\{l_{-t}^{1}, \cdots, l_{0}^{1}, \cdots, l_{t}^{1}, l_{-t}^{2}, \cdots, l_{0}^{2}, \cdots, l_{t}^{2}, \cdots, \right. \\ & \left.l_{-t}^{n}, \cdots, l_{0}^{n}, \cdots, l_{t}^{n}\right\} \end{aligned}$
表示非空有限的语言概念集, I∈U×
WMs={SM1, SM2, …, SMk, OM}
表示k+1个不同的邻接矩阵,
SMm=
表示具有n个顶点的第m个主观网络邻接矩阵,
$ S D_{i j}^{m}=\left\{\begin{array}{ll} 1, & i=j \text { 或对象 } i 、 j \text { 之间存在关系 } \\ 0, & \text { 其它 } \end{array}\right.$
OM=
$ O D_{i j}=\frac{1}{q}\left(\sum_{n=1}^{q} \operatorname{Sim}_{i j}^{n}\right), $
q表示FCM中给定的类别数.
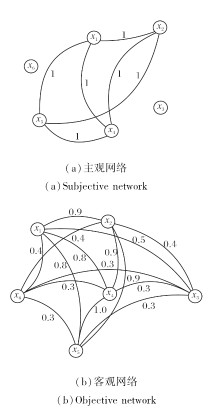
图1分别表示一个主观网络和一个客观网络.
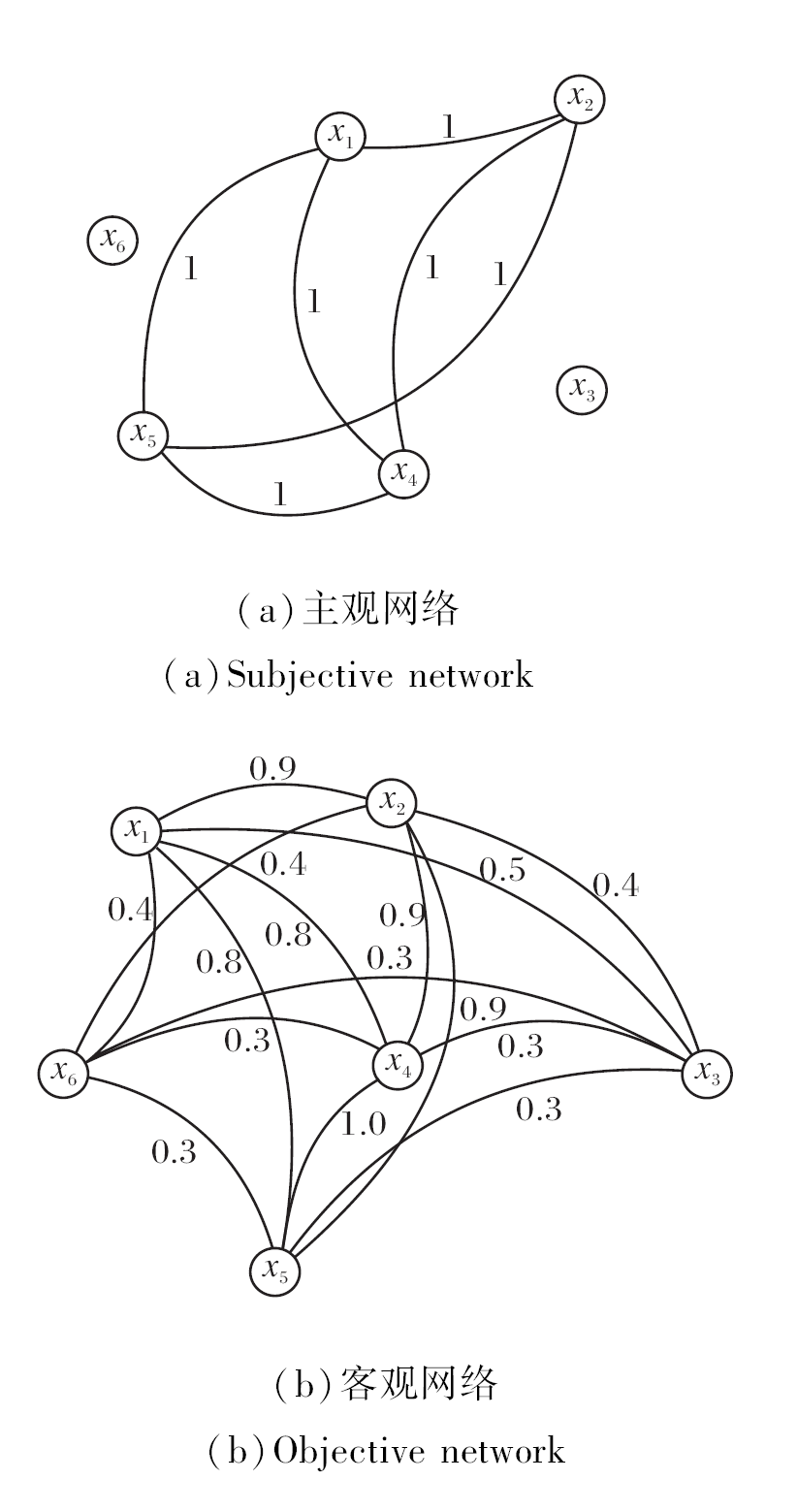 | 图1 对象异构网络Fig.1 Heterogeneous networks of objects |
定义8 设四元组(U,
WMs={SM1, SM2, …, SMk, OM},
如果
∀xi∈X, xj∈X, ∀m∈[1, k] , ODij≥λ
且
S
则称xi、xj连通, 如果X中任意子网络是连通的, 则称X是在λ下连通的.若X∪Y在λ下连通, 则X与Y在λ下连通.
定义9 设四元组(U,
定义10 设四元组(U,
注 本文把OOLLλ-concept与POLLλ-concept统称为异构网络语言概念.
例2 (续例1) 根据定义10, 专家确定对象x1、x2、x4、x5具有关系, 因此得到主观网络邻接矩阵SM; 同时通过对6个对象的属性进行模糊聚类, 得到客观网络邻接矩阵OM.进而构建异构网络语言形式背景(U,
| 表3 对象间存在的关系 Table 3 Relationship between objects |
| 表4 对象与属性间的关系 Table 4 Relationship between objects and attributes |
性质2 设四元组(U,
1)OverLλ(U,
2)OverLλ(U,
3)L(U,
4)若μ≥λ, 则
OverLμ(U,
5)若μ≥λ, 则
PartLμ(U,
证明 根据定义5和定义9, 1)显然得证.根据定义9和定义10, 2)显然得证.
下证3)根据定义5和定义10可知, POLLλ-concept和语言概念知识的外延都需满足X'=
再证4).根据定义8和定义9可知, OOLLλ-con-cepts满足X'=
最后, 根据4), 5)同理可证.
由于在不同的认知和环境下, 判断对象与对象之间是否具有关系的准则是不同的, 所以通过规定对象间的相似度阈值可得到相似度较高的模糊集群.在本节中, 基于异构网络语言形式背景, 根据网络的全局连通及局部连通, 提出两种知识发现算法.
全局连通性描述整个网络中所有节点之间的连接情况.一个网络是全局连通的, 意味着任意两个节点之间都存在路径相连, 无论路径的长度或是否经过其它节点.具体步骤如算法1所示.
算法1 全局网络语言概念挖掘
输入 (U,
输出OverLλ(U,
1.for X⊆2U do
2. if X在λ下连通 then
3. X=X″,
4. else
5. 计算X的最大连通子集X1, 令X=X1, 跳转2
6. end if
7. if
8. return (X,
9. else if X″在λ下连通 then
10. 令X=X″,
11. return (X,
12. else
13. return (X,
14. end if
15.end for
局部连通性是指网络中某个节点与其相邻节点之间的连接情况.在一个网络中, 某个节点是否与其相邻节点直接相连或通过其它节点间接相连, 这种连通性称为局部连通性.具体步骤如算法2所示.
算法2 局部网络语言概念挖掘
输入 (U,
输出PartLλ(U,
1. for X⊆2U do
2. if X在λ下连通then
3. if x∈X″-X与X在λ下不连通 then
4.
5. else
6. X=X∪{x},
7. end if
8. if
9. return (X,
10. else
11. return (X,
12. end if
13. else
14. 计算X的最大连通子集X1, 令 X=X1, 跳转2
15. end if
16.end for
关联规则[28]是数据挖掘中一种用于发现数据集中项之间关联的技术.为了进一步挖掘在对象具有关系的情况下产生的属性之间的关联性, 本节提出基于异构网络语言形式背景的关联规则提取算法.
定义11 设四元组(U,
(X,
X≠Ø , 任意S⊆
定义12 设S为基于异构网络语言形式背景的数据项集, 则S的支持度定义为
Support(S)=
定义13 设S为基于异构网络语言形式背景的数据项集, 进行关联规则提取的S必须满足给定的最小阈值, 这一阈值可定义为最小支持度, 支持度大于最小支持度的数据项集称为频繁项集.
定义14 设S为基于异构网络语言形式背景的频繁项集, 则基于异构网络语言形式背景的关联规则可表示为A⇒ B, 其中
A⊆S, B=S-A,
A为关联规则的前件, B为关联规则的后件.
定义15 对于基于异构网络语言形式背景的关联规则A⇒ B, 其中
A⊆S, B=S-A.
规则R的置信度定义为
Confidence(R)=
定义16 设A⇒ B为基于异构网络语言形式背景的关联规则, 为了筛选置信度较高的关联规则, 给定一个阈值, 保留的关联规则置信度要满足给定的最小阈值, 这一阈值可定义为最小置信度.
定义17 设四元组(U,
基于定义11~定义17, 概念的内涵能发掘可进行关联规则提取的数据项集, 而概念的外延可辅助计算数据项集的支持度及关联规则的置信度.因此, 可构建一种基于异构网络语言形式背景的关联规则提取模型, 主要步骤如算法3所示.
算法3 基于异构网络语言形式背景的关联规则
提取模型
输入 (U,
输出 关联规则
step 1 基于算法1提取异构网络语言形式背景的OverLλ(U,
step 2 计算所有类别的概念中的数据项集, 基于式(2)计算所有数据项集的支持度.
step 3 基于给定的最小支持度筛选频繁项集.
step 4 根据频繁项集及定义14计算每个类别所有的关联规则.
step 5 基于式(3)计算所有关联规则的置信度, 并根据定义17删除冗余关联规则.
step 6 基于给定的最小置信度筛选可靠的关联规则.
在社交网络分析中, 全局连通性可帮助揭示整个社交网络的结构和影响力传播路径.了解社交网络的全局连通性有助于理解信息传播、疾病传播等现象, 因此, 本文在后文实验中只进行全局异构网络语言概念的关联规则研究, 获取强连通的更准确有效的规则.
例3 (续例2) 关联规则提取的具体过程如下.基于算法1, 提取OverL0.4(U,
$\begin{array}{l} \left(x_{1} x_{2} x_{4} x_{5}, l_{s_{1}}^{1} l_{s_{0}}^{3}\right), \left(x_{1} x_{4} x_{5}, l_{s_{1}}^{1} l_{s_{0}}^{3} l_{s_{0}}^{4}\right), \left(x_{2} x_{4} x_{5}, l_{s_{1}}^{1} l_{s_{1}}^{2} l_{s_{0}}^{3}\right), \\ \left(x_{4} x_{5}, l_{s_{1}}^{1} l_{s_{1}}^{2} l_{s_{0}}^{3} l_{s_{0}}^{4}\right), \left(x_{1}, l_{s_{1}}^{1} l_{s_{0}}^{2} l_{s_{0}}^{3} l_{s_{0}}^{4}\right), \left(x_{2}, l_{s_{1}}^{1} l_{s_{1}}^{2} l_{s_{0}}^{3} l_{s_{1}}^{4}\right), \\ \left(x_{3}, l_{s_{-1}}^{1} l_{s_{0}}^{2} l_{s_{-1}}^{3} l_{s_{1}}^{4}\right), \left(x_{6}, l_{s_{1}}^{1} l_{s_{1}}^{2} l_{s_{1}}^{3} l_{s_{-1}}^{4}\right) . \end{array}$
设置最小支持度为0.5, 基于式(2)计算项集支持度, 如表5所示.
| 表5 频繁数据项集支持度 Table 5 Frequent data item set support |
设置最小置信度为1.0, 根据定义14和式(3)计算得到的无冗余关联规则及规则置信度, 如表6所示.
| 表6 关联规则表 Table 6 Association rule table |
本文使用公开的kaggle数据集上德国Ebay网站二手车相关数据集.二手车原始数据集包括车辆的使用情况、交易地区、成交价格等, 数据集常用于进行成交价格预测等相关研究.在原有数据集上剔除一些冗余及不相关属性后, 每个样本都含有一个关系属性(Name)、4个特征属性(Year、Kilometers_Driven、Power、New_Price), 具体信息如表7所示.
| 表7 二手车数据集特征属性 Table 7 Feature attributes of used car dataset |
选取数据集上3种品牌的汽车的交易情况, 共138条数据, 5个属性列, 本文在此数据集上展开研究.
实验在Windows(64位)系统上使用PyCharm工具、Python3.9.由于表7中的Year、Kilometers_Driven、Power、New_Price都是连续型的变量, 为了构造(U,
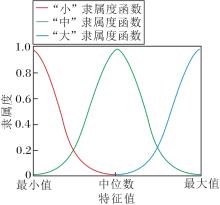
S={s-1=小, s0=中, s1=大},
描述特征属性的情况.例如:首次上牌时间(Year)情况“ 早” 是指上牌时间久远, 已行驶里程“ 大” 是指行驶距离大等描述.语言术语集中的语言术语分别对应3个模糊集.为3个模糊集合选取适当的隶属度函数, 具体如图2所示.
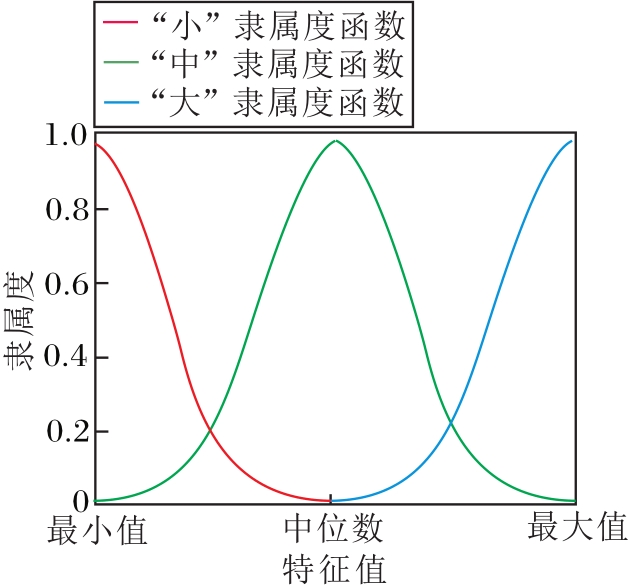 | 图2 隶属度函数图像Fig.2 Image of affiliation function |
分别计算每个元素相对3个隶属函数的隶属度, 隶属度最大的即为样本在对应属性的语言变量.模糊化后所得异构网络语言形式背景(U,
U={x1, x2, …, x138}
| 表8 异构网络语言形式背景(U, |
表示138个销售样本,
表示具有4个属性且每个属性具有3个语言项的语言概念集, 其中, l1表示Year, l2表示Kilometers_Driven, l3表示Power, l4表示New_Price, I⊆U×
WMs={SM, OM}
表示2个邻接矩阵, SM=
SDij=
OM=
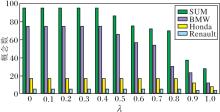
针对表8调用算法1中OverLλ(U,
 | 图3 三种车型概念数随λ的变化情况Fig.3 Concept numbers for 3 vehicle types changing with λ |
经典语言形式概念L(U,
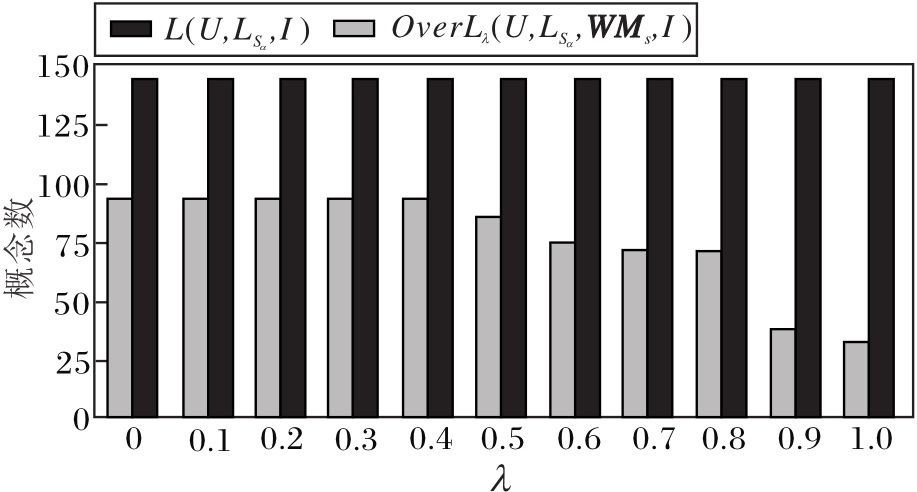 | 图4 L(U, |
在相似度阈值λ=0.6时, 设置最小支持度为0.1, 最小置信度为0.6.按照算法3, 根据BMW品牌汽车相关的概念计算所得无冗余关联规则8条, 如表9所示.根据Honda品牌汽车相关的概念计算所得无冗余关联规则7条, 如表10所示.根据Renault品牌汽车相关的概念计算所得无冗余关联规则5条, 如表11所示.
| 表9 BMW汽车关联规则 Table 9 Association rules of BMW car |
| 表10 Honda汽车关联规则 Table 10 Association rules of Honda car |
| 表11 Renault汽车关联规则 Table 11 Association rules of Renault car |
选取2个提取的Renault品牌汽车相关的关联规则作文字表述如下.
r1:若汽车发动机动力“ 一般” , 则新车价格“ 低” .
r2:若汽车首次上牌时间“ 早” , 已行驶里程“ 中等” , 则新车价格“ 低” .
汽车的新车价格受多种因素影响, 其中发动机动力作为衡量汽车配置的重要指标之一, 因此通常价格较高的汽车发动机动力较大.而汽车的首次上牌时间体现汽车的使用时间, 使用时间越长的汽车通常已行驶里程较大.
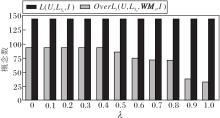
为了进一步说明基于异构网络语言形式背景的关联规则提取模型的有效性, 将所得的无冗余的关联规则(表9~表11)与经典语言形式概念L(U,
| 表12 L(U, |
在相同的数据集上, 按照经典语言形式概念L(U,
经实验分析可知, 异构网络语言形式背景下的关联规则提取具有可行性及可信性, 具有的优势如下.1)语言值描述的规则更具有可解释性, 可通俗理解.2)可针对不同种类的对象挖掘每类对象特有的关联规则, 并且避免出现大规模的规则冗余状况.
本文提出一种异构网络语言形式背景, 通过对象相似度建立网络邻接矩阵, 挖掘潜在对象间的客观关系.对应的异构网络语言概念更具有代表性, 一定程度上剔除部分冗余概念.简化后的概念格不仅考虑对象与属性之间的关系, 而且考虑对象之间的联系, 提取的关联规则关联性和代表性更强, 又因为形式背景结合语言概念, 关联规则的可解释性更强.在实验阶段, 采用模糊控制中的数据模糊化方法, 实现客观的语言评价, 以概念格的方式实现模糊推理, 但一个完整的模糊系统需要对输出进行去模糊化, 实现这样一个理想的模糊控制是今后重要研究方向之一.
本文责任编委 苗夺谦
Recommended by Associate Editor MIAO Duoqian
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|