


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于对比学习和语义增强的多模态推荐算法
[张凯涵1  , 冯晨娇
, 冯晨娇2 , 姚凯旋3 , 宋鹏4 , 梁吉业3 ]
, 冯晨娇, 姚凯旋, 宋鹏, 梁吉业]
|
|



作者简介:

张凯涵,博士,讲师,主要研究方向为数据挖掘、推荐系统.E-mail:zhangkh@nuc.edu.cn.

冯晨娇,博士,副教授,主要研究方向为数据挖掘、推荐系统.E-mail:fengcj@sxufe.edu.cn.

姚凯旋,博士,讲师,主要研究方向为机器学习、数据挖掘.E-mail:ykx@sxu.edu.cn.

宋 鹏,博士,教授,主要研究方向为智能决策、数据挖掘.E-mail:songpeng@sxu.edu.cn.
产品的多模态数据通常被作为额外的辅助信息引入推荐算法中,丰富用户与产品的表示特征,有效融合用户与产品的交互信息和多模态信息是关键研究内容之一.现有方法在特征融合与语义关联建模上仍存在不足,对此,文中从特征融合视角出发,构建基于对比学习和语义增强的多模态推荐算法.首先,采用图神经网络与注意力机制充分融合协同特征与多模态特征.然后,以协同信息中的交互结构为指导,学习各模态内的语义关联结构.同时,采用对比学习范式捕捉跨模态的表征依赖关系,在对比损失中引入可靠性因子,自适应调整对多模态特征的约束强度,抑制数据噪声的影响.最后,联合优化上述任务,生成推荐结果.在4个真实数据集上的实验表明文中算法的优越性.
About Author:
ZHANG Kaihan, Ph.D., lecturer. Her research interests include data mining and recommender system.
FENG Chenjiao, Ph.D., associate profe-ssor. Her research interests include data mining and recommender system.
YAO Kaixuan, Ph.D., lecturer. His research interests include machine learning and data mining.
SONG Peng, Ph.D., professor. His research interests include intelligent decision and data mining.
The multimodal data of items is typically introduced into recommendation algorithms as additional auxiliary information to enrich the representation features of users and items. How to effectively integrate the interaction information with multimodal information of users and items is a key issue to the research. Existing methods are still insufficient in feature fusion and semantic association modeling. Therefore, a multimodal recommendation algorithm based on contrastive learning and semantic enhancement is proposed from the perspective of feature fusion. Firstly, the graph neural network and attention mechanism are adopted to fully integrate collaborative features and multimodal features. Next, the semantic association structures within each modality are learned under the guidance of the interaction structure in collaborative information. Meanwhile, the contrastive learning paradigm is employed to capture cross-modal representation dependencies. A reliability factor is introduced into the contrastive loss to adaptively adjust the constraint strength of the multimodal features, consequently suppressing the influence of data noise. Finally, the aforementioned tasks are jointly optimized to generate recommendation results. Experimental results on four real datasets show that the proposed algorithm yields excellent performance.
传统推荐算法以用户与产品的历史行为数据为输入, 预测用户对系统中产品的兴趣偏好[1].随着计算机多媒体技术的快速发展, 用户行为和产品属性展现出丰富多样的表现形式[2, 3].以电子商务网站(如淘宝、京东等)与社交媒体(如微博、抖音等)为代表的多种互联网服务中, 图像、文本、音频等作为信息的主要载体, 其丰富的多模态数据已成为推荐系统的重要信息来源.传统推荐算法难以适应多媒体时代用户的个性化推荐需求, 催生出多模态推荐算法的研究[4, 5].
在推荐系统中, 多模态数据主要是指从视觉、文本、听觉等角度对产品属性的描述信息, 是用户与产品行为数据的协同信息的重要补充, 可有效缓解传统推荐算法的稀疏性问题.因此, 如何将这两类信息有机融合, 深入挖掘用户与产品的多模态特征和协同特征, 捕获更全面、准确的用户偏好与产品表征是多模态推荐算法的关键.
在多模态推荐算法的研究中, 通常将多模态数据作为额外的附加信息引入系统中, 从数据融合角度展开建模.He等[6]提出VBPR(Visual Bayesian Personalized Ranking), 是早期多模态推荐算法的经典工作之一, 在矩阵分解(Matrix Factorization, MF)框架下, 将产品的视觉特征与ID表征融合, 从两方面同时建模产品特征.随着深度学习技术的发展, 注意力机制[7]也受到研究人员的关注.Liu等[8]提出DMRL(Disentangled Multimodal Representation Lear-ning), 设计多模态注意力机制, 捕捉用户对不同模态的偏好.进一步地, 图神经网络[9, 10]展现出的优异性能为多模态推荐算法带来新的启发.Wei等[11]提出MMGCN(Multi-modal Graph Convolution Network), 利用图卷积神经网络, 将产品的多模态特征在用户与产品的交互图上进行传播与聚合, 编码用户与产品的高阶模态表征.Liu等[12]提出MEGCF(Multi-modal Entity Graph Collaborative Filtering), 依据产品的多模态数据构造产品-实体隶属图, 与用户-产品行为图结合, 进而利用图卷积神经网络学习富含语义信息的用户表征与产品表征.
上述算法从多角度进行信息融合, 一定程度上提升系统的推荐性能.然而, 这些融合策略高度依赖多模态信息与协同信息的质量.在实际场景中, 由于用户行为的复杂性, 收集到的数据通常呈现极端稀疏、高噪声等特性, 低质量的输入数据严重制约此类算法的推荐效果.
对比学习作为自监督学习的代表性方法, 能有效缓解监督信息匮乏带来的不足, 提高信息的利用率.同时, 借助于图神经网络强大的表征能力, 将对比学习与图神经网络结合已成为推荐系统领域应对数据稀疏性与高噪声问题的重要解决方案[13, 14]之一.数据增强是对比学习方法的关键操作, 旨在通过对原始数据进行变换或扰动, 构造用户和产品在特征或交互关系层面的对比视图, 从而在此基础上实现正负样本的对比约束.围绕对比视图的构造, 研究人员设计多种方案.Wu等[15]提出的SGL(Self-Supervised Graph Learning), 在用户和产品的交互图上, 通过随机丢弃节点和边, 以及随机游走操作, 生成对比视图.这种随机采样虽然简单、容易操作, 但构造的对比视图缺乏语义信息.对此, Lin等[16]提出NCL(Neighborhood-Enriched Contrastive Learning), 同时考虑节点的结构和语义近邻信息, 并生成对比视图.进一步地, Yu等[17]发现, 在构造对比视图时, 给节点施加均匀噪声会取得更理想的推荐性能.此外, 臧秀波等[18]将对比学习应用在社交推荐中, 采用随机游走策略, 实现对用户社交图的增强.上述算法依据单一模态数据实现推荐场景中的对比学习任务, 缓解推荐系统中的数据稀疏性等问题, 但忽略多模态数据对用户兴趣建模与产品推荐的重要作用.
最近, 研究人员初步探索将对比学习应用在多模态推荐场景中.Yi等[19]提出MMGCL(Multi-modal Graph Contrastive Learning), 从结构层面构造对比视图, 设计模态内的边丢弃与模态掩码两种策略.此外, Tao等[20]提出SLMRec(Self-Supervised Learning-Guided Multimedia Recommendation), 从特征层面, 通过多模态特征丢弃与掩码等方式, 生成多模态对比视图.不同于上述人为设计的对比视图生成方法, Wei等[21]提出MMSSL(Multi-modal Self-Supervised Learning), 利用生成对抗网络自适应学习各模态的对比视图, 并联合优化多模态推荐任务与自监督学习任务.
从建模用户偏好角度而言, 协同信息是推荐系统中关键的监督信息.上述方法未充分建模多模态信息与协同信息的内在关联, 并且忽略模态特征之间的语义关联.此外, 在对比学习范式中, 对比损失对模型性能具有关键影响.然而上述方法主要围绕如何生成多模态对比视图, 忽略对比损失中样本对之间的约束差异.
为了解决上述问题, 本文提出基于对比学习和语义增强的多模态推荐算法(Multimodal Recommen-dation Algorithm Based on Contrastive Learning and Semantic Enhancement, CLSMRec).首先, 利用图神经网络与注意力机制, 充分融合协同特征与多模态特
征, 基于邻域聚合思想, 将初始多模态特征在交互图上扩散与聚合, 学习用户与产品的高阶多模态特征, 再采用注意力机制自适应融合多模态特征与协同特征.在此基础上, 在模态内部学习用户与产品之间的语义关联, 并约束它们与协同信息中的交互结构, 保持相近性.此外, 引入可靠性因子的对比学习范式, 捕捉跨模态的表征依赖关系.由于多模态数据是一种天然的增强信息, 为了避免随机采样或其它复杂的对比视图构造方法, 引入额外噪声, 直接采用同一用户或产品在不同模态下的表示特征与最终表征作为正样本对, 而不同用户或产品作为负样本.最后, 联合优化推荐任务与上述目标任务.在4个公开数据集上的实验表明, CLSMRec推荐性能较优.
本文提出基于对比学习和语义增强的多模态推荐算法(CLSMRec), 整体框架如图1所示.
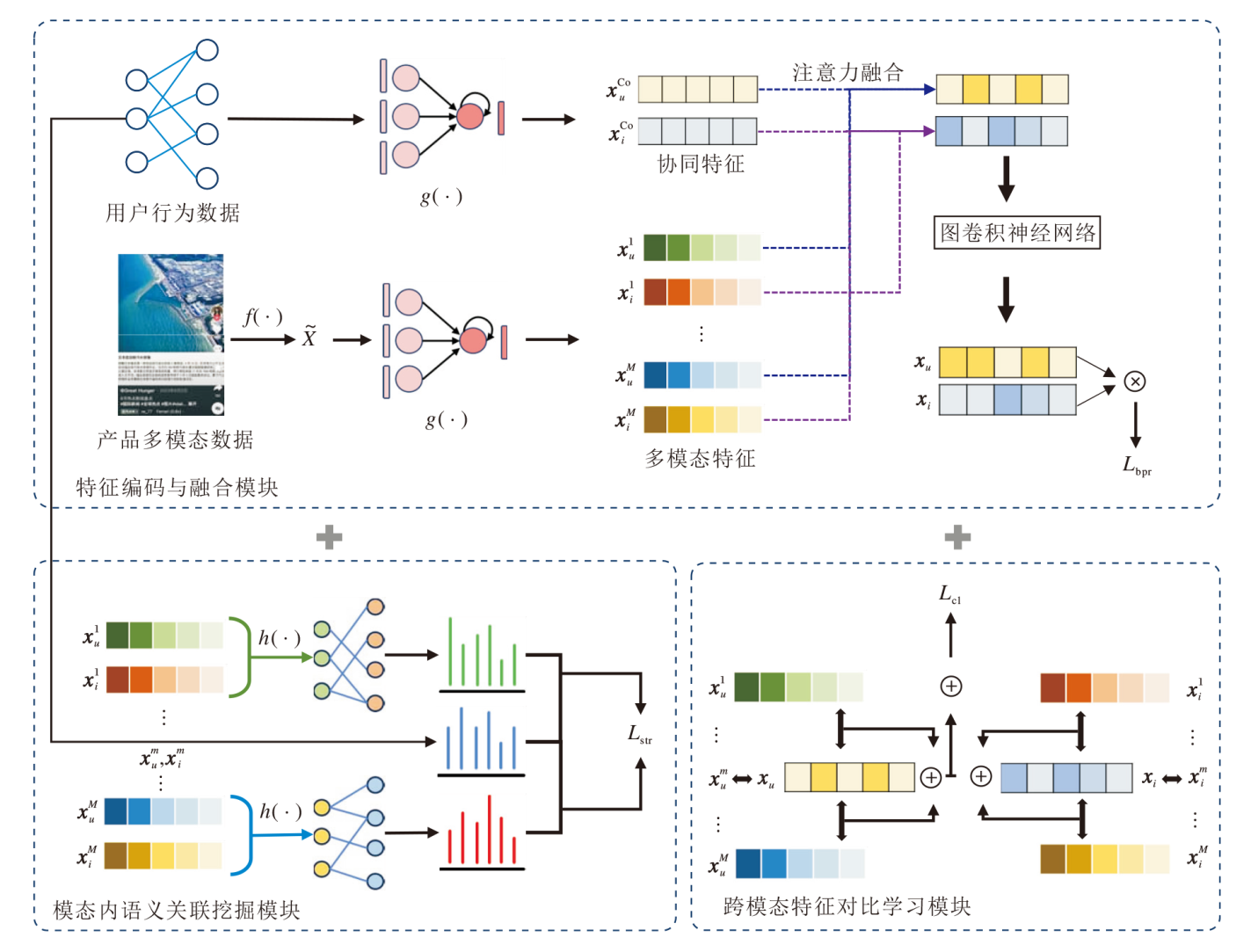 | 图1 CLSMRec框架图Fig.1 Framework of CLSMRec |
CLSMRec由3部分组成:1)特征编码与融合模块.分别编码用户和产品的协同特征与多模态特征, 并采用图神经网络与注意力机制自适应融合上述特征.2)模态内语义关联挖掘模块.在各模态内部, 学习用户与产品的语义关联, 并约束其与协同信息的一致性.3)跨模态特征对比学习模块.捕捉模态间的复杂依赖关系, 利用对比损失约束用户表征与产品表征.
本文使用
$G=\{(u, i)|u\in U, i=I\}$
表示用户与产品的交互图, U表示用户集合, I表示产品集合, 如果用户u与产品i之间有交互行为, 则图G中的边eui=1.产品的多模态特征
$\widetilde{X}=\{{{\tilde{X}}^{1}}, \text{ }{{\tilde{X}}^{2}}, \cdots , {{\tilde{X}}^{M}}\}$,
其中
${{\tilde{X}}^{m}}=\{\tilde{x}_{1}^{m}, \tilde{x}_{2}^{m}, \cdots , \tilde{x}_{|I|}^{m}\}$
表示经特征提取后产品的第m种模态特征.本文算法任务为输入交互图G与初始的多模态特征$\widetilde{X}$, 预测特定用户u对产品i的交互概率${{\hat{y}}_{ui}}$.
多模态推荐系统中, 输入信息包括用户与产品的交互数据和产品的多模态属性数据.因此, 特征编码与融合模块首先将交互数据和多模态数据编码为用户和产品的协同特征与多模态特征, 再采用图神经网络和注意力机制深度融合特征.
1.2.1 协同特征编码
用户与产品的交互数据可抽象为用户-产品二部图G, 对此, 首先采用独热编码嵌入用户和产品的ID特征, 并构建全连接层, 将其映射至低维潜在空间, 得到用户初始表征$x_{u}^{\text{ID}}$与产品初始表征$x_{i}^{\text{ID}}$.接下来, 利用消息传播与聚合机制[22], 获取用户与产品的协同特征:
$x_{u}^{\text{Co}}=g(x_{i}^{\text{ID}})=\underset{i\in {{N}_{u}}}{\mathop \sum }\, \frac{1}{\sqrt[]{\left| {{N}_{u}} \right|}\sqrt[]{\left| {{N}_{i}} \right|}}x_{i}^{\text{ID}}$,
$x_{i}^{\text{Co}}=g(x_{u}^{\text{ID}})=\underset{u\in {{N}_{i}}}{\mathop \sum }\, \frac{1}{\sqrt[]{\left| {{N}_{i}} \right|}\sqrt[]{\left| {{N}_{u}} \right|}}x_{u}^{\text{ID}}$
其中, Nu表示用户u的邻居集合, Ni表示产品i的邻居集合.
1.2.2 多模态特征编码
产品的多模态属性数据由文本、图像、音频等多种形式构成, 需要采用多模态特征提取技术对其进行处理, 对此, 本文采用文献[21]中提供的文本、图像等特征$\tilde{x}_{i}^{m}\in \text{R}_{m}^{d}$作为初始模态特征.首先将多种模态特征映射至同一语义空间:
$x_{i}^{m}=f(\tilde{x}_{i}^{m})\in {{R}^{d}}$,
其中, f=FullyConnected(· )表示全连接层, d≪dm.
交互数据反映用户对产品的历史兴趣, 为了捕捉用户在不同模态下的偏好, 在交互图G上利用消息传播与聚合机制, 学习用户的多模态特征.用户u在第m种模态下的偏好表征:
$x_{u}^{m}=g(x_{i}^{m})=\underset{i\in {{N}_{u}}}{\mathop \sum }\, \frac{1}{\sqrt[]{\left| {{N}_{u}} \right|}\sqrt[]{\left| {{N}_{i}} \right|}}x_{i}^{m}\in {{R}^{d}}$.
1.2.3 特征融合
用户与产品的协同特征与多模态特征能相互补充, 从多角度刻画用户偏好与产品特性.具体地, 用户与产品的协同特征反映用户对产品的历史喜好以及用户行为之间的相似性, 而多模态特征刻画产品在不同模态下的属性特征以及用户对不同模态的偏好.为了综合挖掘这些特征之间的内在关联, 学习统一的用户表征与产品表征, 采用注意力机制与图神经网络深层次融合上述特征.
首先, 采用注意力机制自适应融合用户与产品的协同特征与多模态特征:
$x{{'}_{u}}=\underset{j\in {{X}_{u}}}{\mathop \sum }\, {{\alpha }_{j}}j$,
$x{{'}_{i}}\text{=}\underset{j\in {{X}_{i}}}{\mathop \sum }\, {{\beta }_{j}}j$,
${{X}_{u}}=\left\{ x_{u}^{\text{Co}}, x_{u}^{1}, x_{u}^{2}, \cdots , x_{u}^{M} \right\}$,
${{X}_{i}}=\left\{ x_{i}^{\text{Co}}, x_{i}^{1}, x_{i}^{2}, \cdots , x_{i}^{M} \right\}$,
$\alpha =\sigma (x_{u}^{T}{{W}_{1}}+{{b}_{1}}){{V}_{1}}$,
$\beta =\sigma (x_{i}^{T}{{W}_{2}}+{{b}_{2}}){{V}_{2}}$,
其中, W1∈ Rd× d, W2∈ Rd× d, b1∈ Rd, b2∈ Rd, V1∈ Rd, V2∈ Rd, 表示可学习的模型参数.
为了进一步丰富用户和产品的特征表示并提升其表征能力, 依据图神经网络中邻域聚合的思想, 本文采用简单高效的LightGCN结构[22]学习用户和产品的高阶特征:
${{x}_{u}}=\overset{L}{\mathop{\underset{l=0}{\mathop \sum }\, }}\, {{\gamma }_{l}}x_{u}^{\left( l \right)}, {{x}_{i}}=\overset{L}{\mathop{\underset{l=0}{\mathop \sum }\, }}\, {{\gamma }_{l}}x_{i}^{\left( l \right)}$,
其中, L表示图神经网络的层数, 用户u在第l层的表示特征
$x_{u}^{\left( l+1 \right)}=\underset{i\in {{N}_{u}}}{\mathop \sum }\, \frac{1}{\sqrt[]{\left| {{N}_{u}} \right|}\sqrt[]{\left| {{N}_{i}} \right|}}x_{i}^{\left( l \right)}$,
产品i在第l层的表示特征
$x_{i}^{\left( l+1 \right)}=\underset{u\in {{N}_{i}}}{\mathop \sum }\, \frac{1}{\sqrt[]{\left| {{N}_{i}} \right|}\sqrt[]{\left| {{N}_{u}} \right|}}x_{u}^{\left( l \right)}$,
$x_{u}^{\left( 0 \right)}=x{{'}_{u}}, x_{i}^{\left( 0 \right)}=x{{'}_{i}}$,
γ l表示第l层表示特征的聚合权重, 本文采用γ l=1/(L+1).
至此, 得到用户与产品的表示特征xu和xi.
在各模态内, 用户与产品具有丰富的语义关联, 隐式反映用户与产品的潜在交互结构.因此, 学到用户与产品的多模态表征后, 通过用户与产品的交互图G与多模态特征挖掘模态内的语义关联关系.首先基于同质性假设学习模态内的语义关联关系, 即具有相似特征的用户与产品之间更容易形成连边.在第m种模态内的用户与产品潜在交互关系:
$A_{ui}^{m}=h(x_{u}^{m\text{T}}x_{i}^{m})=softmax(x_{u}^{m\text{T}}x_{i}^{m})\in [0, 1]$.
潜在交互关系体现用户对产品产生交互行为的可能性, 尽管不同模态内部潜在交互关系可能存在差异, 但是在各模态之间用户对产品的偏好分布以及观测到的交互结构中用户的偏好分布应具有一致性, 因此, 本文采用KL(Kullback-Leibler)散度度量模态间潜在结构的差异, 并计算结构一致性损失:
${{L}_{str}}=\overset{M}{\mathop{\underset{m=1}{\mathop \sum }\, }}\, KL({{A}_{u}}_{\cdot }\|A_{u\cdot }^{m})$,
其中
$KL(P\|Q)=\underset{i}{\mathop \sum }\, \underset{j}{\mathop \sum }\, {{p}_{ij}}\ln \left( \frac{{{p}_{ij}}}{{{q}_{ij}}} \right)$,
Au· 表示用户u在观测数据中的偏好分布,
在学习用户和产品表征的过程中, 受用户与产品交互数据的稀疏性影响, 模型在训练过程中由于监督信息匮乏难以得到精准训练.此外, 协同特征与多模态特征之间的复杂依赖关系也被忽略.对此, 本文采用基于InfoNCE的对比损失对用户与产品表征进行约束, 分别拉近同一用户或产品在不同模态下的表示特征与最终表征之间的距离、推远其它用户或产品表征.为了进一步减弱交互数据稀疏性带来的不利影响, 将用户或产品的交互数量表示为可靠性因子引入对比损失中, 自适应调整监督信息的约束大小, 当交互数量较少时意味着监督信息的质量较低, 因此降低监督信息的约束, 否则, 增大监督信息的约束.对用户表征的对比损失约束为
${{L}_{cl\_u}}=-\overset{M}{\mathop{\underset{m=1}{\mathop \sum }\,}}\,\underset{u\in U}{\mathop \sum }\,{{\zeta }_{u}}\cdot \ln \left( \frac{\ \ \ \exp \left( \ s\ \left(\ x_{u}^{m},\ {{x}_{u}}\ \right) \ \right)}{\mathop{\sum }_{u'\in U}\ \left( \exp \ \left(\ s\ \left( x_{u}^{m},\ {{x}_{u'}}\ \right) \ \right)+\exp \left(s \left(\ x_{u}^{m},\ x_{u'}^{m} \ \right) \right) \right)} \ \ \ \right)$
对产品表征的对比损失约束为
${{L}_{c{{l}_{i}}}}=-\overset{M}{\mathop{\underset{m=1}{\mathop \sum }\,}}\,\underset{i\in I}{\mathop \sum }\,{{\zeta }_{i}}\cdot \ln \left( \frac{\ \ \ \exp \left(\ s\ \left( x_{i}^{m},\ {{x}_{i}} \ \right) \ \right)}{\mathop{\sum }_{i'\in I}\ \left( \exp \left(\ s\ \left( \ x_{i}^{m},\ {{x}_{i'}} \ \right)\ \right)+\exp \left(\ s\ \left(\ x_{i}^{m},\ x_{i'}^{m}\ \right)\ \right) \ \right)} \ \ \right)$
用户侧可靠性因子为
${{\zeta }_{u}}=\frac{{{d}_{u}}-d_{\text{min}}^{\text{user}}}{d_{\text{max}}^{\text{user}}-d_{\text{min}}^{\text{user}}}$,
产品侧的可靠性因子为
${{\zeta }_{i}}=\frac{{{d}_{i}}-d_{\text{min}}^{\text{item}}}{d_{\text{max}}^{\text{item}}-d_{\text{min}}^{\text{item}}}$.
其中:度量
$s(a, b)=\frac{{{a}^{\text{T}}}b}{\tau \|a{{\|}_{2}}b{{\|}_{2}}}$,
表示a、b之间的相似性; τ 表示超参数针对不同分布的数据集进行的调整; u'表示u的负例, i'表示i的负例, 本文采用训练过程中同一批次中的其它用户和产品; du表示用户u的交互数量, di表示产品i的交互数量;
综合用户与产品的特征对比损失, 最终对比损失如下:
${{L}_{cl}}={{L}_{cl\_u}}+{{L}_{cl\_i}}$.
依据学到的用户与产品表征预测目标用户u对产品i的交互概率:
${{\hat{y}}_{ui}}=x_{u}^{T}{{x}_{i}}$.
CLSMRec包括如下3个优化任务:用户对产品的交互预测、模态内关联关系学习与跨模态特征对比学习.本文采用多任务学习机制联合优化上述任务.
用户对产品的交互预测任务采用推荐系统中经典的BPR(Bayesian Personalized Ranking)损失进行训练:
${{L}_{bpr}}=\underset{\left( u, i, i' \right)\in R}{\mathop \sum }\, -\ln (\sigma ({{\hat{y}}_{ui}}-{{\hat{y}}_{ui'}}))+\lambda \left\| \Theta \right\|_{2}^{2}$,
其中, R表示观测数据, 产品i表示用户u交互过的正样本, 产品i'表示未交互过的负样本, Θ 表示可学习参数, λ 表示正则化项权重.
此外, 模态内关联关系学习任务的损失为Lstr, 跨模态特征对比学习任务的损失为Lcl.最终模型的损失函数为:
$L={{L}_{bpr}}+\gamma ({{L}_{str}}+{{L}_{cl}})$,
其中γ 表示权重超参数.
本节分析CLSMRec的时间复杂度和空间复杂度.
1)时间复杂度.CLSMRec的计算开销主要集中在特征融合、关联关系学习和特征对比学习三部分.
在特征融合过程中, 计算成本主要为图卷积操作, 该步骤的时间复杂度相当于在LightGCN[22]时间复杂度的基础上增加多次模态特征聚合开销, 为O(ML|A|d), 其中, M表示模态数量, L表示卷积层数, |A|表示用户与产品的交互数量, d表示特征维度.
关联关系学习的时间复杂度为O(M|U|d), 特征对比学习的时间复杂度为
O(MB(|U|+|I|)d),
B表示每个训练批次中的样本数量, |U|表示用户数量, |I|表示产品数量.
综上, 令
Q=|A|+B|U|+B|I|,
CLSMRec的时间复杂度为
O(M|A|d+MB(|U|+|I|)d+|U|d)=O(MQd),
与观测数据量呈线性关系.相比先进的自监督推荐模型(如SGL、NCL)和多模态推荐模型(如MMS-SL[21]), CLSMREC的时间复杂度与其接近.
2)空间复杂度.CLSMRec中的参数主要包括用户和产品的ID表征与多模态表征, 以及注意力融合过程中的训练参数W和b, 空间开销分别为
O((M+1)(|U|+|I|)d), O(2d2+2d),
由于d≪|U|+|I|, 参数W和b的空间开销很小, 可忽略不计, 因此CLSMRec的空间开销可只考虑用户和产品的多种表征, 这与现有多模态推荐模型的空间复杂度基本一致, 无额外空间开销.
为了验证CLSMRec的性能, 本文在如下环境进行实验:Windows10 64位操作系统, Intel(R) Core(TM) i9-12900K CPU、64 GB内存、NVIDIA GeForce RTX 4090显卡、Pytorch框架.
本文选择在Tiktok、Allrecipes、Amazon Baby、Amazon Sports这4个真实的多模态推荐基准数据集上进行实验.Tiktok数据集收集自Tiktok短视频平台, 多模态特征包括短视频的文本、视频与音频.Allrecipes数据集收集自食物社交平台, 包含27种类别下52 821个食谱, 多模态特征由食谱的图像和烹饪流程组成.Amazon Baby、Amazon Sports数据集分别收集自亚马逊网站的Baby和Sports类别.这4个数据集的统计数据如表1所示.
| 表1 数据集统计信息 Table 1 Statistics of datasets |
实验采用如下3个广泛使用的Top-K推荐指标评估模型性能.
1)召回率(Recall@K).用于评估在长度为K的推荐列表中, 正样本集上的产品有多少被模型正确推荐, 计算公式如下:
$RecallK=\underset{u\in U}{\mathop \sum }\,\left( \frac{\left| {{R}_{u}}\ \cap \ {{T}_{u}} \right|}{\left| {{T}_{u}} \right|} \right)$,
其中, Ru表示模型推荐给用户u的产品集合, Tu表示测试集上用户u真实感兴趣的产品集合.
2)准确率(Precision@K).用于评估在长度为K的推荐列表中, 正样本占整个推荐列表的比例, 计算公式如下:
$PrecisionK=\frac{1}{K}\underset{u\in U}{\mathop \sum }\, \left( \left| {{R}_{u}}\cap {{T}_{u}} \right| \right)$.
3)归一化折损累计增益(Normalized Discoun-ted Cumulative Gain, NDCG@K).用于衡量在长度为K的推荐列表中, 正样本所处的排序, 计算公式如下:
$NDCGK=\frac{1}{\left| U \right|}\underset{u\in \left| U \right.|}{\mathop \sum }\,\left( \frac{\overset{K}{\mathop{\mathop{\sum }_{p=1}}}\,\left(\ \ \frac{\ {{r}_{u,p}}}{\text{lo}{{\text{g}}_{2}\ }\left( p+1 \right)\ }\ \ \right)}{\overset{K}{\mathop{\mathop{\sum }_{p=1}}}\,\left(\ \ \frac{\ 1}{\text{lo}{{\text{g}}_{2}}\left( p+1 \ \right)\ } \ \ \right)} \right)$
其中, ru, p表示用户u的推荐列表中第p个位置上推荐的产品是否为正确产品, 如果是, ru, p=1, 否则, ru, p=0.
基于Pytorch实现CLSMRec, 并采用Adam(Adap-tive Moment Estimation)作为模型优化器, 学习率的选择范围为{2.5e-4, 3e-4, 3.5e-4}, 设置训练批次大小为1 024.正则化项的系数λ 在{1.2e-2, 1.4e-2, 1.6e-2}中选择.为了保证公平性, 将CLSMRec与对比算法的特征嵌入维度均设置为64.此外, 在进行消融实验时, CLSMRec只改变待测试模块的参数, 其它模块保持原始参数.
为了验证CLSMRec的有效性, 本文选用如下15种算法进行对比实验, 主要分为4类.
1)传统推荐算法MF-BPR[23].基于矩阵分解(MF)的推荐算法, 采用BPR损失函数, 是传统推荐算法的代表性工作之一.
2)图神经网络推荐算法.
(1)LightGCN[22].相比传统图神经网络的推荐算法, 简化图卷积神经网络的计算过程, 只保留核心的消息传递和聚合过程, 移除特征变换和非线性激活操作.
(2)NGCF(Neural Graph Collaborative Filte-ring)[24].利用图卷积神经网络聚合用户和产品之间的高阶协同信息, 嵌入用户和产品表征中.
3)基于自监督学习的推荐算法.
(1)SGL[15].在传统协同过滤算法基础上, 引入自监督学习任务, 在用户和产品的交互图上设计3种操作(节点随机丢弃、边随机丢弃和随机游走), 生成多个视图, 实现数据增强.
(2)NCL[16].在自监督学习任务的数据增强过程中, 相比SGL的随机生成对比视图, NCL基于结构和语义近邻寻找节点的正样本, 并且模型的学习过程采用EM(Expectation Maximization)算法进行优化.
(3)HCCF(Hypergraph Contrastive Collabora-tive Filtering)[25].在协同过滤算法的基础上, 同时编码全局的超图结构和局部的协同关系, 设计超图对比学习机制, 联合优化推荐任务.
4)多模态推荐算法.
(1)VBPR[6].在MF框架下, 将产品的视觉特征融入潜在特征学习过程中, 是多模态推荐算法早期的经典工作之一.
(2)LightGCN-M[22].在LightGCN的基础上, 将产品的多模态特征嵌入图消息传播与聚合过程中.
(3)MMGCN[11].在各模态下充分利用用户和产品的交互关系, 设计多模态图卷积网络学习用户和短视频的多模态特征.
(4)MMGCL[19].将图对比学习用于多模态推荐任务中, 设计2种增强方法(模态边丢弃和模态掩码), 生成对比视图.
(5)SLMRec[20].联合优化多模态推荐任务与自监督学习任务, 设计3种对比视图增强方法(特征丢弃、特征掩码和特征的粗细粒度).
(6)MMSSL[21].采用模态感知对抗扰动方法捕捉用户的多模态偏好, 并引入跨模态的对比学习范式, 建模不同模态下用户偏好的依赖性.
(7)GRCN(Graph-Refined Convolutional Net-work)[26].利用产品的多模态信息修正用户和产品的交互关系, 删除具有高置信度的错误连边, 在修正的交互图上通过图卷积网络学习用户表征和产品表征.
(8)LATTICE(Latent Structure Mining Method for Multimodal Recommendation)[27].依据产品的多模态特征计算各模态下产品之间的关系, 生成产品潜在关系图, 利用图卷积网络学习产品的高阶表征.
(9)CLCRec(Contrastive Learning-Based Cold-Start Recommendation)[28].设计基于互信息的对比学习算法, 利用产品的多模态特征增强产品表征, 缓解推荐系统中的产品冷启动问题.
各对比算法在4个数据集上的实验结果如表2所示, 表中黑体数字表示最优值, 斜体数字表示次优值.R@20、P@20和N@20分别表示K=20时的召回率、准确率和NDCG指标.为了公平起见, CLSM-Rec为本文训练结果, 其它结果引用自文献[21].从表可看出, CLSMRec在3个数据集上的性能均有所提升, 这表明CLSMRec在实现多模态推荐任务上的有效性.
| 表2 各算法在4个数据集上的指标值对比 Table 2 Index value comparison of different algorithms on 4 datasets |
相比传统推荐算法MF-BPR, 图神经网络推荐算法(NGCF和LightGCN)性能取得明显提升, 这是由于图神经网络学习的高阶协同表征优于MF-BPR学习的浅层表征, 此外, LightGCN去除图神经网络中针对推荐任务不必要的特征变换与非线性激活操作, 取得优于NGCF的效果.在基于自监督学习的推荐算法中, SGL、NCL和HCCF都是在图神经网络的基础上加入对比学习范式, 从表2可见, NCL和HCCF性能略有提升, 这说明自监督学习对推荐任务的有效性, 而SGL性能较弱, 这是由于它采用忽略语义的随机采样策略构造对比视图.
相比上述两类方法, 多模态推荐算法在对比模型中表现出更优性能.在多模态推荐算法中, VBPR的效果最弱, 这是由于VBPR基于MF框架, 学到的表征较弱, 但是相比未考虑多模态信息的MF-BPR, VBPR性能仍有一定提升.LightGCN-M和MMGCN是较基础的利用图神经网络的多模态推荐算法, 但已取得较优效果, 说明多模态信息对推荐任务的重要性.在此基础上, MMGCL、SLMRec和MMSSL引入对比学习范式, 加强模态特征的学习, 又进一步提升算法性能.而CLSMRec利用图神经网络深度融合多模态特征与协同特征, 并且在模态内和模态间分别构建语义关联学习与特征对比学习任务, 增强特征的表达能力, 因此取得更优性能.
为了验证CLSMRec中各模块的有效性, 设计如下变体进行消融实验.
1)CLSMRec-CL_u.去除用户特征对比损失.
2)CLSMRec-CL_i.去除产品特征的对比损失.
3)CLSMRec-Str.去除结构一致性损失.
4)CLSMRec-ζ .去除对比损失中的可靠性因子.
5)CLSMRec-GCN.去除图神经网络.
各变体算法的性能结果如表3所示, 表中黑体数字表示最优值.由表可看出, 去除用户与产品特征的对比损失均会导致算法性能下降, 说明跨模态的特征对比学习有助于提升算法性能.去除对比损失中可靠性因子的结果也表明引入用户或产品的对比权重可有助于抑制数据噪声对模型的不利影响.去除图神经网络的算法性能最差, 这是由于用户与产品特征忽略高阶邻域信息, 表征能力较差.去除结构一致性损失的算法性能也较低, 这验证模态内语义关系学习对算法的积极作用.
| 表3 CLSMRec和各变体在4个数据集上的消融实验结果 Table 3 Ablation experiment results of CLSMRec and its variants on 4 datasets |
本节测试Top-K中K取不同值时, 算法的推荐性能, 分析测试特征维度d、图神经网络层数L、对比学习中的参数τ 和损失权重γ 对算法性能的影响.
为了测试K取不同值时算法的推荐性能, 将K设置为推荐系统中广泛采用的5、10、20、30、40, 结果如图2所示.由图可见, 随着K的增大, R@20和NDCG@20呈上升趋势, P@20呈下降趋势.
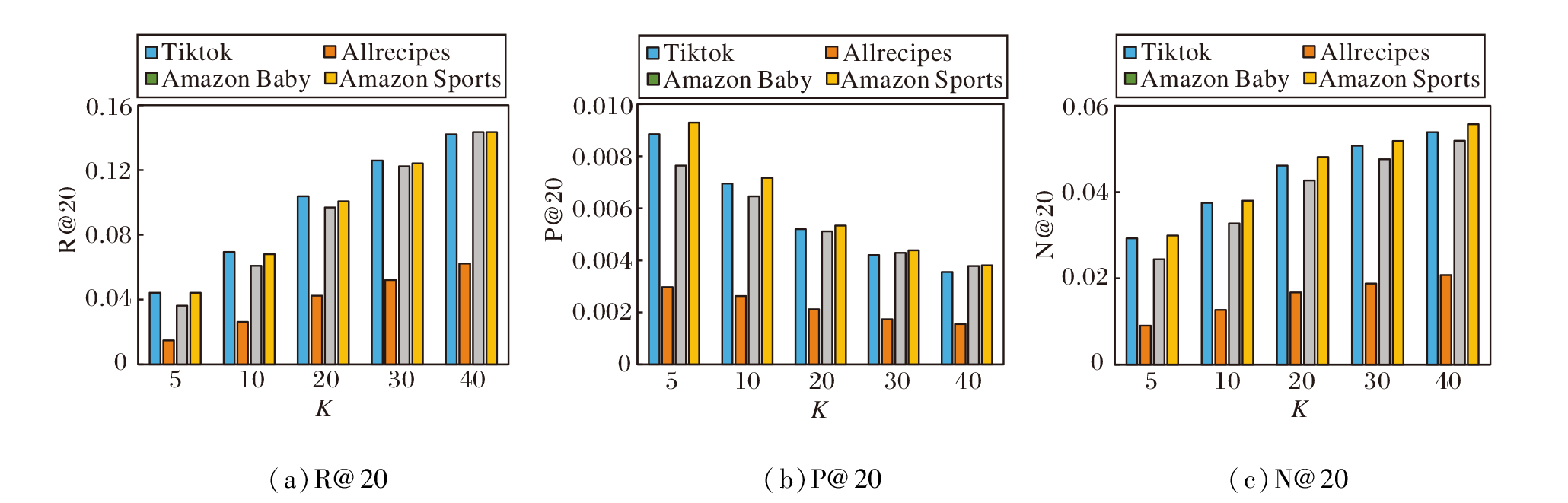 | 图2 K对算法性能的影响Fig.2 Effect of K on performance of different algorithms |
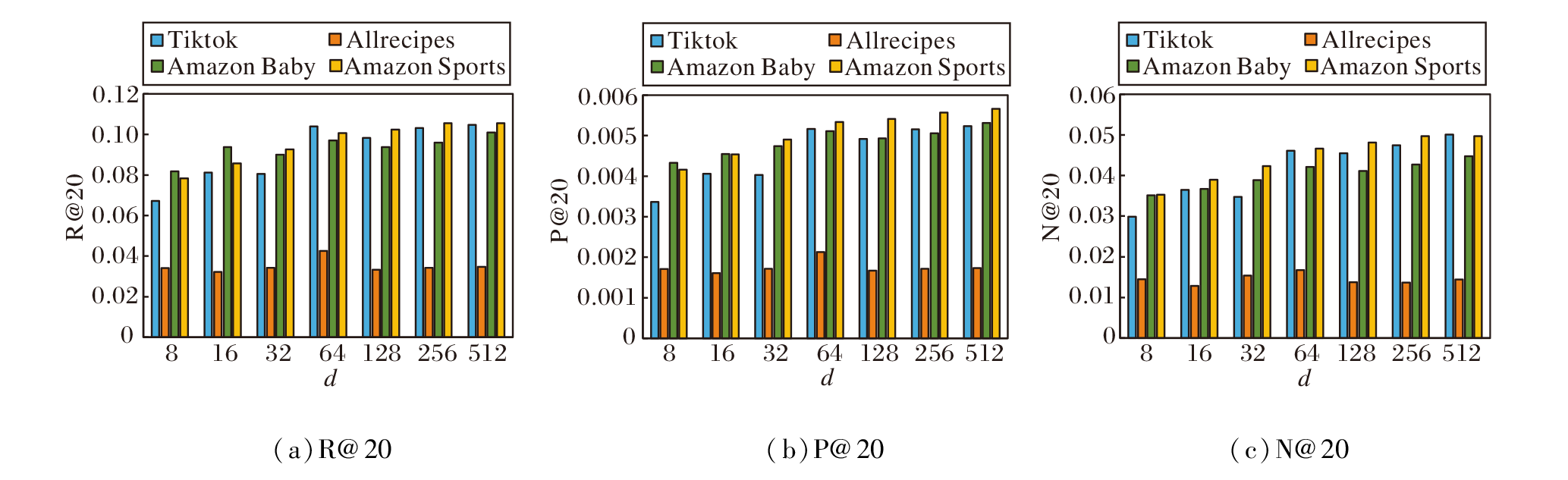
设置d=8, 16, 32, 64, 128, 256, 512, 不同评价指标结果如图3所示.
 | 图3 d对算法性能的影响Fig.3 Effect of d on performance of different algorithms |
由图3可见, 随着d的增大, CLSMRec在3个数据集上的性能均有所提升, 说明适当的d可有效增强算法性能, 但是过高的d会导致算法出现过拟合, 性能降低.
设置L=1, 2, 3, 4, 实验结果如表4所示, 表中黑体数字表示最优值.由表可见, 当L=2时, 算法取得最优效果, 随着L的增加, 过多的层数导致算法产生过平滑问题, 性能下降.
| 表4 L对算法性能的影响 Table 4 Effect of L on performance of different algorithms |
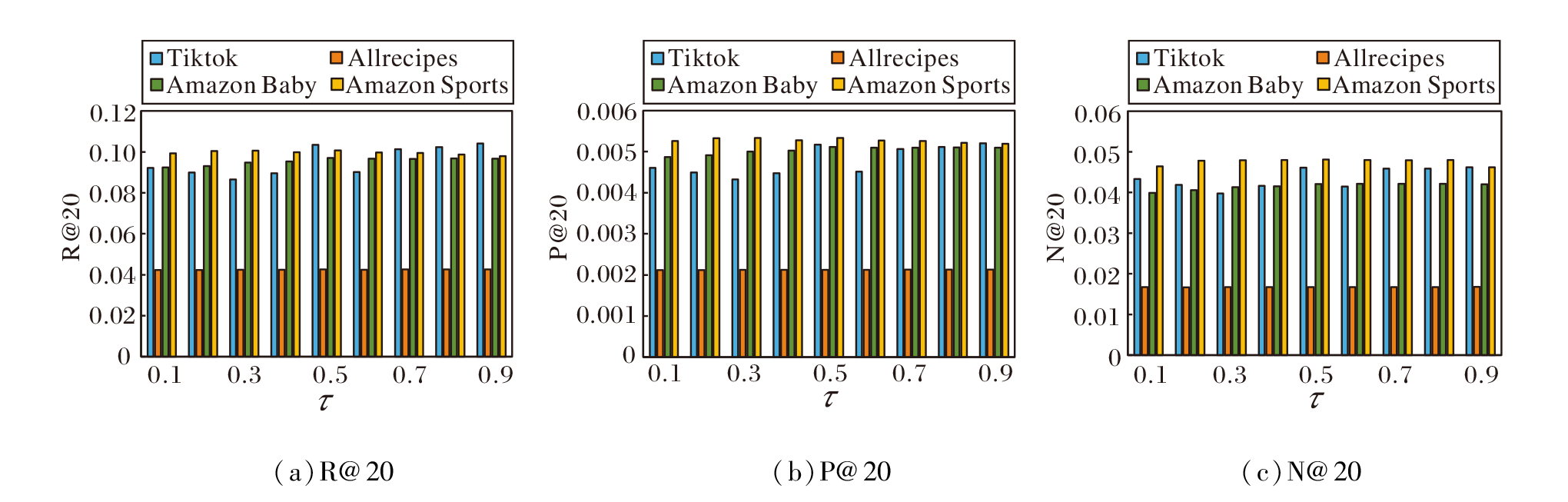
设置τ =0.1, 0.2, …, 0.9, τ 变化时算法性能如图4所示.由图可知:在Allrecipes、Amazon Baby、Amazon Sports数据集上, τ =0.5时性能最优; 在Tiktok数据集上, τ =0.9时取得最优值.
 | 图4 τ 对算法性能的影响Fig.4 Effect of τ on performance of different algorithms |
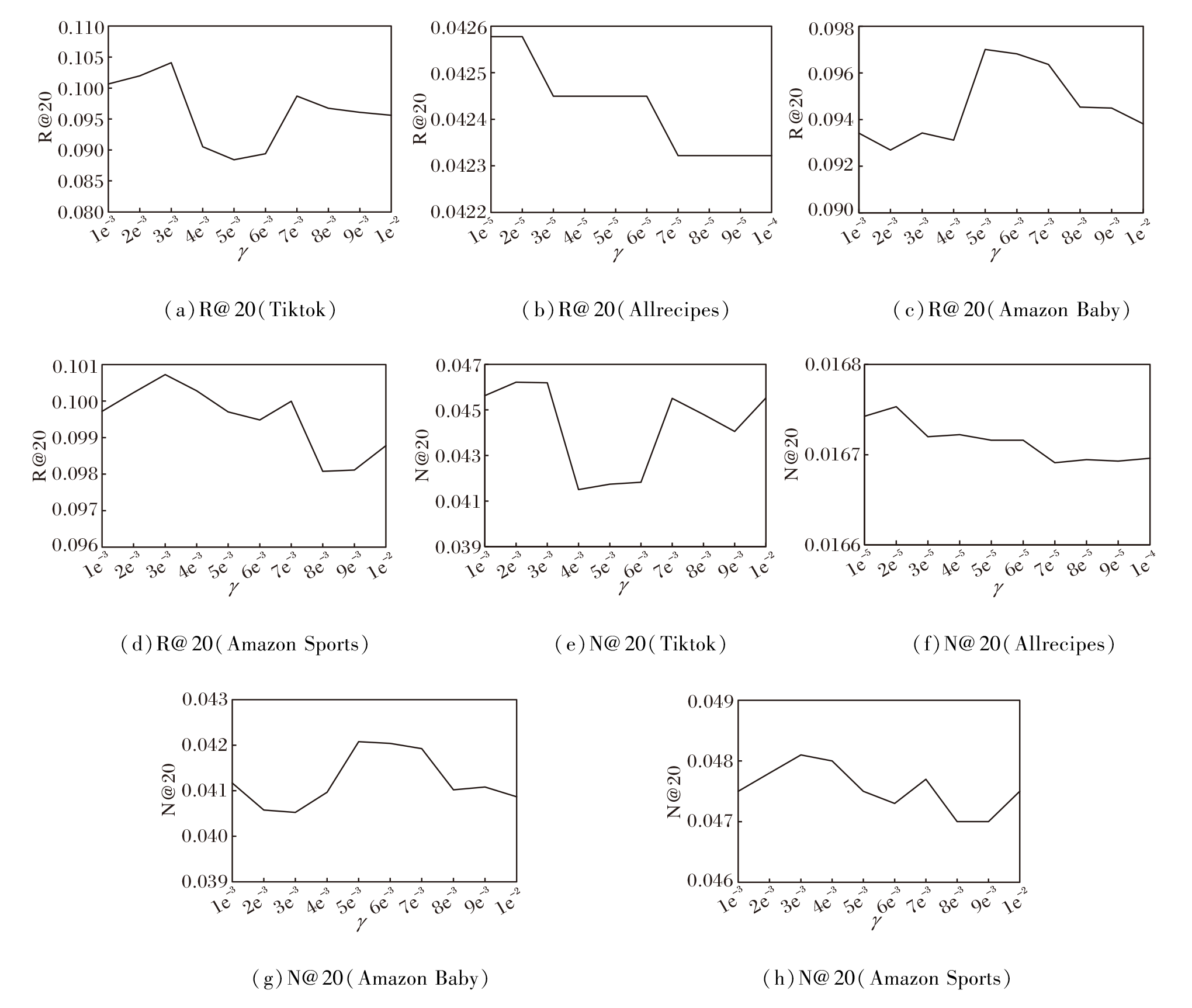
为了测试损失权重γ 对算法性能的影响, 在Tiktok、Amazon Baby、Amazon Sports数据集上设置γ 在[1e-3, 1e-2]内取值, 在Allrecipes数据集上设置γ 在[1e-5, 1e-4]内取值, 实验结果如图5所示.
 | 图5 γ 对算法性能的影响Fig.5 Effect of γ on performance of different algorithms |
由图5可见, 较低的γ 使训练过程中算法的对比损失和结构损失权重太小, 难以充分约束待学习的特征, 而过高的γ 会导致算法过度关注这两类损失.因此, 需选择合适的γ 使损失之间达到平衡.
本文提出基于对比学习和语义增强的多模态推荐算法(CLSMRec), 不仅充分融合用户与产品的多模态特征和协同特征, 还能捕获模态内的语义关联关系.同时引入可靠性因子的跨模态对比约束, 有效抑制数据噪声对算法的影响, 提升推荐性能.在4个数据集上的实验验证CLSMRec的有效性.今后将继续探索多模态特征的对齐与融合策略以及多模态推荐算法的可解释性问题.
本文责任编委 林鸿飞
Recommended by Associate Editor LIN Hongfei
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|