

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
邻域扩展机制增强的图平行聚焦注意力社会化推荐系统
[李伟玥1, 2  , 朱志国
, 朱志国1, 2 , 董昊1, 2 , 高明1, 2 , 张俊1, 2 , 刘子龙1, 2 ]
, 朱志国, 董昊, 高明, 张俊, 刘子龙]
|
|



作者简介:

李伟玥,博士研究生,主要研究方向为推荐系统.E-mail:dufe_phd_stu@stumail.dufe.edu.cn.

董 昊,博士研究生,主要研究方向为大语言模型、系统仿真.E-mail:donghao@stumail.dufe.edu.cn.

高 明,博士,教授,主要研究方向为云计算、大数据、人工智能.E-mail:gm@dufe.edu.cn.

张 俊,硕士研究生,主要研究方向为商务智能.E-mail:zhangjun05050@163.com.

刘子龙,博士,教授,主要研究方向为信息系统.E-mail:zilonglord@126.com.
社会化推荐系统旨在基于用户的评分历史和社交关系,预测其对未交互商品的评分.现有的社会化推荐系统大多基于图神经网络,然而,低效率的注意力机制和过度平滑问题在一定程度上限制评分预测的精准性和可解释性.为此,文中提出邻域扩展机制增强的图平行聚焦注意力社会化推荐系统.首先,平行图聚焦注意力网络,将用户的整体偏好分解为多方面的细粒度偏好,并引入聚焦注意力机制作为消息传递算法,根据用户-商品交互历史识别最符合用户相应偏好的商品,同时从社交网络中识别用户基于不同偏好的可信朋友.然后,提出邻域扩展机制,建立快捷链接的方式,直接实现中心节点与高阶节点间的消息传递,有效提升图聚焦注意力网络在高阶自我中心网络中捕获社交信息的能力.最后,在3个公开基准数据集上的实验表明文中系统在精准推荐方面的优越性,一系列可视化案例分析展示出其良好的可解释性.代码地址详见:https://github.com/usernameAI/NEGA.
About Author:
LI Weiyue, Ph.D. candidate. His research interests include recommender systems.
DONG Hao, Ph.D. candidate. His research interests include large language model and system simulation.
GAO Ming, Ph.D., professor. His research interests include cloud computing, big data and artificial intelligence.
ZHANG Jun, Master student. His research interests include business intelligence.
LIU Zilong, Ph.D., professor. His research interests include information systems.
Social recommender systems are designed to predict the ratings of users for unexplored items based on their historical ratings and social connections. Most existing social recommender systems are based on graph neural networks. However, the inefficiency of attention mechanisms and the over-smoothing problem limit the precision and interpretability of rating predictions. Therefore, a neighborhood extension mechanism enhanced graph parallel focused attention network is proposed to address these issues. The overall preferences of users are decomposed into nuanced facets and a focused attention mechanism is introduced as message passing algorithm to pinpoint the item most aligned with the preferences of users based on their interaction history. Meanwhile, the mechanism identifies trustworthy friends from the social network based on diverse preferences. Furthermore, a neighborhood extension mechanism is proposed, which establishes quick link to facilitate the direct message passing between central and higher-order nodes, effectively enhancing the ability of graph focused attention network to capture the social information in higher-order ego network. Experimental results on three public benchmark datasets demonstrate the superiority of the proposed system in accurate rating prediction. Moreover, a series of visual case studies illustrate the interpretability of the system. The code for this paper can be found at: https://github.com/usernameAI/NEGA.
实证研究表明[1], 超过80%的用户会在获取在线服务时使用社交媒体.并且随着Web 2.0的不断发展, 人们越来越热衷于在社交媒体上分享他们的消费体验[2].同时, 约60%的用户会在社交媒体上寻找可能感兴趣的商品, 约70%的用户会根据社交媒体上的信息制定购买决策[3].因此, 互联网行业的营销人员越来越关注网络营销策略对企业业绩的影响[4].社会化推荐系统在如今的在线平台上扮演着越来越重要的角色, 旨在根据用户的社交关系和历史评分记录提供个性化的商品推荐服务.
社会化推荐系统的提出有效缓解经典推荐算法面临的数据稀疏问题[5, 6, 7, 8, 9, 10, 11, 12, 13, 14].然而, 尽管一些知名社交媒体平台宣称他们的用户具有相当多的社交朋友[15], 但是在社交网络中充斥着大量不可信的社交关系, 限制社会化推荐系统提供高质量的信息推送服务.
近年来, 基于图神经网络(Graph Neural Net-works, GNN)的社会化推荐系统得到学者们的广泛关注.此类方法通常基于消息传递机制, 在更大的范围内探索间接社交朋友对目标用户偏好的影响[16, 17].虽然这些间接社交朋友(如朋友的朋友)暂时没有和目标用户建立社交关系, 但拥有相似的行为模式和兴趣偏好.因此, 这类方法在一定程度上缓解传统社交推荐系统感受野狭窄的问题.然而, 受过度平滑问题[18]的影响, 现有方法难以在高阶自我中心网络(Ego Network, EN)中进一步探索更可信的间接社交朋友, 导致社会化推荐的精准度仍较低.
另一方面, 尽管现有的社会化推荐系统[19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29]在提高评分预测精准度方面取得一定成果, 但大多数相关工作忽略推荐结果的可解释性.然而, 良好的可解释性有助于提升推荐系统的透明度[30], 从而说服用户接受来自系统的推荐结果[31].
当前社会化推荐系统可解释性较低的原因主要有两点:1)采用单一编码表征用户偏好, 忽略用户在不同方面的偏好具有差异性; 2)难以区分不同社交朋友对目标用户偏好的影响机制.具体来说, 用户兴趣往往呈现多样化, 在不同方面的兴趣存在复杂的关联性和差异性.例如:用户在制定购买决策时, 会根据目标商品多方面的特征进行综合评估, 也可能会向了解商品相应方面特征的社交朋友寻求建议.因此, 采用单一编码表征用户偏好, 会导致推荐系统难以捕捉用户在不同方面的细粒度兴趣, 降低推荐结果的个性化程度和精准性.此外, 社交朋友对目标用户兴趣的影响机制主要来自社会影响[32]和同质性[33].并且相比具有相似行为的同质化朋友, 目标用户更信任拥有较强社会影响力的直接朋友.因此, 揭示不同社交朋友对目标用户兴趣的影响机制对于提升社会化推荐结果的可解释性具有重要意义.
为了应对上述挑战, 本文提出邻域扩展机制增强的图平行聚焦注意力社会化推荐系统(Neighbor-hood Extension Mechanism Enhanced Graph Parallel Focused Attention Networks for Social Recommender System, NEGA), 将用户的整体偏好分解为多个细粒度偏好, 并从目标用户的交互历史中探索最吸引用户的关键商品.同时, 在高阶自我中心网络内探索可信社交朋友与具有相似偏好的朋友, 实现可解释的社会化推荐.NEGA首先根据所有用户的商品交互历史和社交关系记录分别构建用户-商品交互二部图和社交网络.然后对用户和商品进行统一嵌入编码, 分别采用图平行聚焦注意力机制学习隐藏在不同特征空间中的用户偏好和商品特征, 并采用多层感知机(Multilayer Perceptron, MLP)融合不同商品交互域和社交关系域的用户偏好表示.最后, 基于广义门控机制, 自适应融合用户表征和商品表征, 并基于简单线性投影预测目标用户对候选商品的评分.在社会化推荐领域的3个基准数据集Filmtrust、CiaoDVD和Yelp上的实验表明, NEGA具有较强的评分预测能力.
社交关系作为一类独特的辅助信息[34], 常用于缓解传统协同过滤算法中的数据稀疏和冷启动问题.经典的社会化推荐模型主要基于矩阵分解, 综合考虑用户个人信息、多种社交关系、历史交互商品特征、评论和评分等信息, 从社交关系矩阵和用户-商品交互矩阵中学习用户兴趣[15, 35].
受到贝叶斯个性化排序算法(Bayesian Persona-lized Ranking, BPR)的启发, Zhao等[36]提出SBPR(Social BPR), 进一步考虑社会化因素, 并假定用户更倾向于为朋友喜欢的商品打出更高评分.Jamali等[21]提出SocialMF, 将来自用户朋友的影响纳入评分预测的矩阵分解模型中, 并认为用户的偏好更接近其诸多朋友的平均偏好.SoRec(Social Recommendation)[19]基于概率矩阵分解思想进行社会化因子提取.TrustMF[37]基于用户间的信任关系进行矩阵分解.TrustSVD[38]进一步将目标用户信任朋友的评分作为辅助因素, 提升模型性能.RSTE(Recommen-dation with Social Trust Ensemble)[20]引入超参数的方式, 权衡用户自身偏好和朋友偏好对其的影响.此外, 不少学者将社交因素视为正则项以约束矩阵分解, 并以此提升推荐的准确度, 如文献[39]系统、SoDimRec[40]、ContextMF[41].
尽管这些工作在不同程度上基于用户的社交关系, 为用户提供个性化的推荐服务, 但是此类浅层模型仅能了解直接朋友对目标用户偏好的影响, 难以在更广泛的邻域范围内探索间接朋友对目标用户偏好的影响.
由于社交网络和用户-商品交互记录可被视为天然的图数据结构, 因此学者们提出基于随机游走的社会化推荐系统, 从图结构数据中挖掘用户的潜在偏好.Zhang等[22]提出CUNE(Collaborative User Network Embedding), 基于有偏的随机游走算法, 从邻域范围内选择间接朋友, 并基于Skip-gram算法学习间接朋友对目标用户偏好的语义影响.
随着GNN被证明可通过多种消息传递算法和特征传递算法进行更高效的图学习, 学者们提出基于GNN的社会化推荐系统, 如基于经典图注意力网络(Graph Attention Network, GAT)的GraphRec[23]和基于图卷积网络的HGSR(Hyperbolic Graph Lear-ning Based Social Recommendation)[14].由于注意力可帮助区分不同近邻的影响力, 因此近期的相关研究大多采用图注意力机制作为系统主体.例如:ConsisRec[26]通过近邻采样和关联注意力机制解决特征不连续性问题.GDSRec(Graph-Based Decentralized Collaborative Filtering for Social Recommendation)[28]关注用户和商品的偏置特征, 以及用户间社交关系的可微性.REST(Reconstructing Exposure Strate-gies)[11]通过显式重建观测数据背后的曝光策略, 解决社会化推荐中的选择偏差问题.CR-SoRec(BERT-Driven Consistency Regularization for Social Reco-mmendation)[12]融合BERT(Bidirectional Encoder Re- presentations from Transformers)的上下文建模能力和一致性正则化技术, 学习用户和项目的双向上下文感知表示.DSL(Denoised Self-Augmented Learning Paradigm)[13]中跨视图去噪自监督学习框架基于对抗学习方法, 有效提升社交信息的质量.
然而, 大多数相关工作在探索高阶邻域中的社交关系对用户偏好的影响时, 容易受到过度平滑问题的影响, 使现有工作大多局限于低阶自我中心网络中的社交信息, 无法充分挖掘隐藏在复杂社交关系中的用户偏好.
过度平滑是指随着图神经网络的深度增加时, 节点间的消息传递越来越频繁, 导致不同节点的特征表示趋于相似[42].虽然在图学习过程中, 适当的图平滑有助于提升模型性能[43], 但是随着平滑程度的加深, 节点的独特信息将在多层信息传递过程中被噪声信息淹没, 从而限制图神经网络的特征学习能力.近年来, 学者们已提出多种算法缓解过度平滑问题[42], 相关工作可分为如下3类.1)基于正则化的算法, 如节点间成对距离正则化算法[44].2)基于残差连接的算法, 如图残差学习框架[45].3)优化消息传递算法, 如图耦合网络中的隐式-显式时间步算法[46].
尽管相关工作从不同方面有效缓解过度平滑问题, 然而, 已有算法仍受到传统图学习范式的限制, 难以进一步提升性能.具体地, 远距离节点间的消息传递还是需要通过多个中间节点进行信息传输, 并依赖于多次消息传递与特征聚合计算, 而信息在多次转发的过程中不可避免地有所损失.
社会化推荐旨在基于历史商品评分记录和社交关系, 预测用户对于候选商品的评分, 因此, 本文的推荐问题可定义如下.定义无重复用户集合
$U=\{{{u}_{1}}, {{u}_{2}}, \ldots , {{u}_{i}}, \ldots , {{u}_{\left| U \right|}}\}$,
无重复商品集合
$V=\{{{v}_{1}}, {{v}_{2}}, \ldots , {{v}_{j}}, \ldots , {{v}_{\left| V \right|}}\}$.
评分矩阵R∈ R|U|× |V|记录所有用户对商品的评分记录, 元素rij∈ Q, 表示用户ui对商品vj的数字评分, 若未交互则记录为空值.社交关系矩阵S∈ R|U|× |U|记录用户间是否建立社交关系, 元素sab∈ S为布尔值, 若sab=1, 表示用户ua、ub间存在社交联系.
给定评分矩阵R和社交关系矩阵S, 社会化推荐的目标是预测目标用户ui对于候选项目vj的可能评分值${{\hat{r}}_{ij}}$.
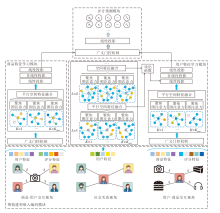
本文提出邻域扩展机制增强的图平行聚焦注意力社会化推荐系统(NEGA), 整体框图如图1所示.
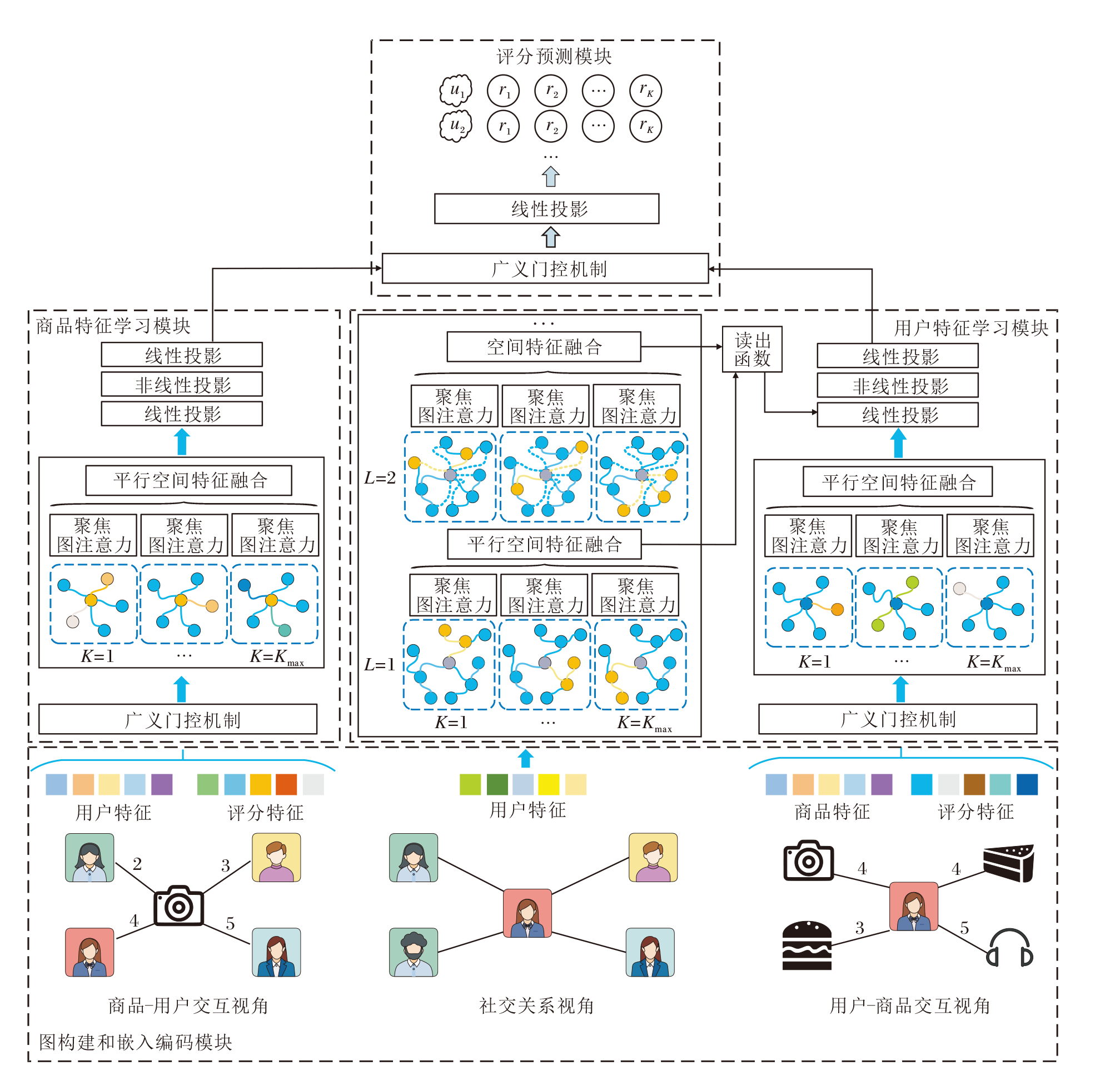 | 图1 NEGA框架图Fig.1 Architecture of NEGA |
NEGA主要由四个模块组成:图构建和嵌入编码模块、用户特征学习模块、商品特征学习模块和评分预测模块.
图构建和嵌入编码模块首先将评分矩阵R转换为用户-商品交互异构二部图GUV=(U∪ V, δ , ω ), 其中, 节点集合{U∪ V}由用户节点集合U与商品节点集合V共同组成, 边集合δ 反映用户与商品是否存在交互关系, 边权重集合ω 表示用户对商品的评分.同时, 该模块将社交关系矩阵S转换为社交网络GS=(U, ξ ), 其中, 节点集合U全部由用户节点组成, 边集合ξ 表示用户间是否存在社交关系.
然后, 分别将用户u、商品v和评分值r的独热编码转换为相应的嵌入(Embedding)特征向量, 可依次记为eu∈ Rd、ev∈ Rd、er∈ Rd, 其中d表示嵌入编码维度.
用户特征学习模块旨在根据目标用户对商品的评分记录学习其商品交互偏好特征$h_{{{u}_{i}}}^{I}\in {{R}^{d}}$, 同时根据目标用户与社交好友的偏好相似学习其社会化特征$h_{{{u}_{i}}}^{S}\in {{R}^{d}}$, 最后融合不同域的用户特征, 得到用户的综合偏好特征${{h}_{{{u}_{i}}}}\in {{R}^{d}}$.
从用户的视角上看, 目标用户对于商品的评分可表示其独特偏好.模型基于广义门控机制, 实现商品特征与评分特征的自适应融合, 用户ui对商品vj的消费偏好为:
${{p}_{ij}}={{\beta }_{ij}}\times {{e}_{{{v}_{j}}}}+(1-{{\beta }_{ij}})\times {{e}_{{{r}_{k}}}}$,
其中,
${{\beta }_{ij}}=Sigmoid({{W}_{\beta }}({{e}_{{{v}_{j}}}}\|{{e}_{{{r}_{k}}}}\|{{e}_{{{v}_{j}}}}\times {{e}_{{{r}_{k}}}})+{{b}_{\beta }})$,
${{e}_{{{v}_{j}}}}\in {{R}^{d}}$表示商品vj的嵌入特征${{e}_{{{r}_{k}}}}\in {{R}^{d}}$表示评分值rk的嵌入特征, × 表示哈达玛积运算, Sigmoid(· )表示非线性激活函数, Wβ ∈ R3d× d表示可学习的参数矩阵, bβ ∈ Rd表示可学习的偏置向量.
受到相关工作[47, 48]的启发, 本文设计基于α -entmax函数的平行聚焦注意力机制, 将目标用户的消费偏好pij作为图平行聚焦注意力网络的初始输入.下面将以单个平行特征空间的用户偏好学习过程为例进行说明.
用户ui在第z个平行特征空间中的偏好表示为:
$\hat{h}_{{{u}_{i}}}^{I, \left( z \right)}=ML{{P}_{neigh}}\left( \underset{j\in {{N}_{UI}}\ \left( {{u}_{i}} \right)}{\mathop \sum }\, \delta _{j}^{i}~{{p}_{ij}} \right)\in {{R}^{d}}$,
其中, MLPneigh(· )表示三层多层感知机网络,
$\delta _{j}^{i}=\alpha -entmax\left( \overset{}{\mathop{\delta }}\, _{j}^{i} \right)=\arg \underset{x\in {{\Delta }^{d}}}{\mathop{\max }}\, {{x}^{T}}\overset{}{\mathop{\delta }}\, _{j}^{i}+h_{\alpha }^{T}(x)\in {{R}^{d}}$,
表示聚焦注意力概率,
${{\Delta }^{d}}:=\left\{ x\in {{R}^{d}}\, \!:\text{ }\!\!~\!\!\text{ }\underset{w}{\mathop \sum }\, {{x}_{w}}=1 \right\}$,
表示概率单纯形(Probability Simplex),
$\overset{}{\mathop{\delta }}\, _{j}^{i}=ML{{P}_{att}}({{e}_{{{u}_{i}}}}\|{{p}_{ij}})\in {{R}^{d}}$,
表示聚焦注意力分数, ${{e}_{{{u}_{i}}}}\in {{R}^{d}}$为用户ui的特征表示, MLPatt(· )表示五层多层感知机网络,
$h_{\alpha }^{T}~(x)=\left\{ \begin{array}{* {35}{l}} \frac{1}{\alpha \left( \alpha -1 \right)}\underset{t}{\mathop \sum }\, \left( {{x}_{t}}-x_{t}^{\alpha } \right), & \alpha \ne 1 \\ -\underset{t}{\mathop \sum }\, {{x}_{t}}\cdot \text{log }\!\!~\!\!\text{ }x_{t}^{\alpha }, & \alpha =1 \\ \end{array} \right.$
表示萨里斯熵(Tsallis α -entropies)[49], α ≥ 1表示注意力聚焦程度的标量, α =1时, 聚焦注意力机制退化为基于Softmax函数的软注意力机制.
经典的图注意力网络可广泛应用于社会化推荐, 系统基于浅层的MLP和软注意力机制, 为邻域中的节点分配注意力权重.然而, 这种结构存在如下问题.1)浅层MLP的特征拟合能力有限, 难以在具有复杂拓扑结构的图中学到精准的注意力分数.2)软注意力机制依赖Softmax函数计算归一化的注意力概率, 但该函数会为任何特征分配非零权重.
在本文研究情景下, 用户的历史商品交互数量越多, 经典的软注意力越容易受到注意力涣散问题的影响, 难以识别最符合用户偏好的商品.
为了解决问题1), 本文借鉴底层神经元多于顶层神经元的深层塔式结构设计方法[50], 采用特征拟合能力更强的深层MLP学习注意力分数.为了解决问题2), 本文采用聚焦注意力机制.相比经典的软注意力, 聚焦注意力的特点在于它可以学习稀疏的后验分布, 并且能为不重要的特征分配零权重.该特点使该算法适合在邻域空间中探索少数关键近邻.此外, 相比固定参数的稀疏性, 自适应聚焦程度更有助于提高预测精度.受到文献[51]的启发, 本文采用自适应方法计算个性化的注意力聚焦程度, 用户ui对于消费偏好pij的聚焦程度标量为:
${{\alpha }_{ij}}=Sigmoid({{W}_{\alpha }}({{e}_{{{u}_{i}}}}\|{{p}_{ij}})+{{b}_{\alpha }})+1$,
其中, Wα ∈ Rd× d表示可学习的参数矩阵, bα ∈ Rd表示可学习的偏置向量.
为了防止过大的聚焦程度带来严重的过拟合问题, 本文采用Sigmoid激活函数和常数项, 将聚焦程度限制在(1, 2)内.
学到不同平行特征空间中的商品交互偏好表示后, 采用简单高效的均值池化算法融合各偏好特征:
$\hat{h}_{{{u}_{i}}}^{I}=Mean-pooling\left( \hat{h}_{{{u}_{i}}}^{I, \left( 1 \right)}, \hat{h}_{{{u}_{i}}}^{I, \left( 2 \right)}, \cdots , \hat{h}_{{{u}_{i}}}^{I, \left( y \right)} \right)$,
其中, Mean-pooling(· )表示均值池化运算, y表示平行特征空间的个数.
值得注意的是, 不同于解纠缠学习和经典多头机制将输入特征投影到子空间内, 平行注意力机制将输入特征投影到同样尺寸的平行特征空间, 从而避免特征降维带来的信息损失.
在学到综合的商品交互偏好之后, 还需要基于节点特征聚合算法, 考虑用户的自身偏好.系统仍基于广义门控机制, 自适应地更新商品交互偏好特征, 最终商品交互偏好为:
$h_{{{u}_{i}}}^{I}={{\gamma }_{{{u}_{i}}}}\times {{e}_{{{u}_{i}}}}+(1-{{\gamma }_{{{u}_{i}}}})\times \hat{h}_{{{u}_{i}}}^{I}\in {{R}^{d}}$,
其中,
${{\gamma }_{{{u}_{i}}}}=Sigmoid\left( {{W}_{\gamma }}\left( {{e}_{{{u}_{i}}}}\left\| \hat{h}_{{{u}_{i}}}^{i} \right\|{{e}_{{{u}_{i}}}}\times \hat{h}_{{{u}_{i}}}^{i} \right)+{{b}_{\gamma }} \right)$,
Wγ ∈ R3d× d表示可学习的参数矩阵, bγ ∈ Rd表示可学习的偏置向量.
简洁起见, 本文将上述过程定义为图平行聚焦注意力网络, 基于用户特征表示${{e}_{{{u}_{i}}}}$、历史交互商品${{e}_{{{v}_{j}}}}$及其相应评分${{e}_{{{r}_{k}}}}$的综合表示pij, 共同学习用户在商品交互历史中表现出的偏好:
$h_{{{u}_{i}}}^{I}=Parallel\_FGAT({{e}_{{{u}_{i}}}}, {{p}_{ij}})$.
在学到目标用户的商品交互偏好特征$h_{{{u}_{i}}}^{I}$后, 还需要基于目标用户与社交好友的偏好相似学习其社会化特征$h_{{{u}_{i}}}^{S}$.系统采用类似基于商品交互历史学习用户偏好的算法, 即
$\hat{h}_{{{u}_{i}}}^{S, \left( 1 \right)}=Parallel\_FGAT({{e}_{{{u}_{i}}}}, {{e}_{{{u}_{m}}}})$,
其中, ${{e}_{{{u}_{m}}}}\in N_{{{u}_{i}}}^{\left( 1 \right)}$表示目标用户ui一阶自我中心网络邻域范围内的社交朋友, 即直接朋友.在此过程中, 系统可识别少数对目标用户决策具有较大影响的可信直接朋友.
然而, 直接朋友的数量有限, 无法全面反映目标用户的偏好.为了在更大范围内的邻域空间中探索间接朋友对于目标用户偏好的影响, 本文提出邻域扩展机制, 用于提升图平行聚焦注意力网络的学习效率.定义基于邻域扩展机制的图平行聚焦注意力网络:
$\hat{h}_{{{u}_{i}}}^{S, \left( l \right)}=Parallel\_FGA{{T}^{(l)}}({{e}_{{{u}_{i}}}}, {{e}_{{{u}_{n}}}})$,
其中, ${{e}_{{{u}_{n}}}}\in N_{{{u}_{i}}}^{\left( l \right)}$表示目标用户ui在l阶自我中心网络邻域范围内的社交朋友, Parallel-FGAT(l)(· )表示基于l阶邻域范围的图平行聚焦注意力网络.
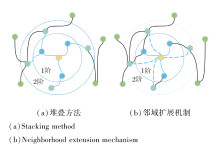
如图2所示, 传统堆叠方法通过低阶邻域(图中蓝色实线表示)中的节点感知高阶邻域中的节点, 而邻域扩展机制可直接感知高阶邻域中的节点, 无需依赖于任何中间节点传递信息(图中蓝色虚线表示).因此, 相比通过堆叠的方式逐渐扩大邻域感受野, 并依赖多个中间用户节点传递社交信息, 才能捕捉远距离间接朋友对目标用户偏好的影响, 邻域扩展机制使系统可直接学习远距离间接朋友对目标用户偏好的影响强度, 避免消息传递过程中的信息损失.
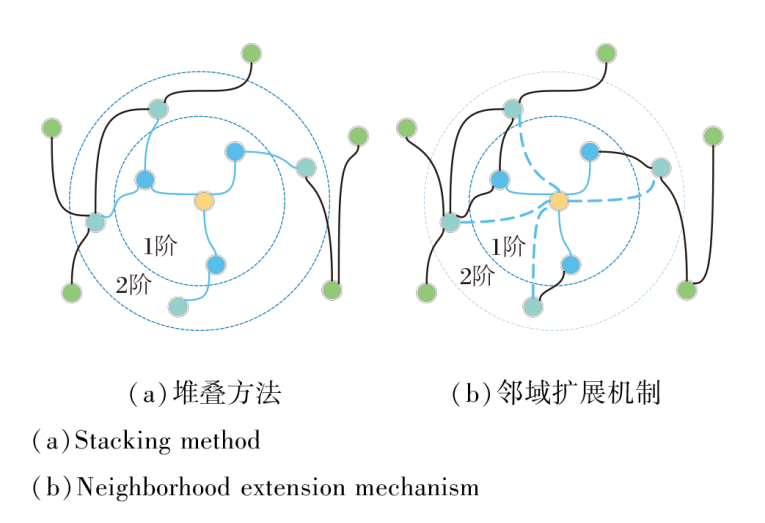 | 图2 2种方法的感受野变化Fig.2 Receptive field changes of 2 methods |
为了聚合不同阶自我中心网络邻域范围内的社交关系对目标用户偏好的影响, 本文借鉴LightGCN(Light Graph Convolution Network)[52]简单高效的读出函数:
$h_{{{u}_{i}}}^{S}=Mean-pooling\left( \hat{h}_{{{u}_{i}}}^{S, \left( 1 \right)}, \hat{h}_{{{u}_{i}}}^{S, \left( 2 \right)}, \cdots , \tilde{h}_{{{u}_{i}}}^{S, \left( z \right)} \right)$,
其中z表示最大邻域阶数.通过上述函数, 系统从多个平行特征空间和不同自我中心网络邻域范围内, 共同学习目标用户的社会化特征.
最后, 基于三层MLP融合来自用户-商品交互域和社交域的用户偏好表示:
$MLP_{{{u}_{i}}}^{\left( 0 \right)}=W_{{{u}_{i}}}^{\left( 0 \right)}(h_{{{u}_{i}}}^{I}\|h_{{{u}_{i}}}^{S})+b_{{{u}_{i}}}^{\left( 0 \right)}$,
$MLP_{{{u}_{i}}}^{\left( 1 \right)}\text{=}Selu(MLP_{{{u}_{i}}}^{\left( 0 \right)})$,
${{h}_{{{u}_{i}}}}=W_{{{u}_{i}}}^{\left( 1 \right)}Selu(MLP_{{{u}_{i}}}^{\left( 1 \right)})+b_{{{u}_{i}}}^{\left( 1 \right)}+h_{{{u}_{i}}}^{I}+h_{{{u}_{i}}}^{S}$,
其中, $W_{{{u}_{i}}}^{\left( 0 \right)}\in {{R}^{2d\times d}}$、$W_{{{u}_{i}}}^{\left( 1 \right)}\in {{R}^{d}}^{\times d}$为可学习参数矩阵, $b_{{{u}_{i}}}^{\left( 0 \right)}\in {{R}^{d}}$ , $b_{{{u}_{i}}}^{\left( 1 \right)}\in {{R}^{d}}$为可学习偏置向量.
残差连接缓解系统学习过程中底层信息的丢失.
从商品的角度上看, 与其交互过的用户和他们给出的评分反映商品自身的特征.因此, 系统采用类似基于商品交互历史学习用户偏好的算法, 从商品-用户交互的角度学习商品特征, 学到的最终商品特征表示:
${{h}_{{{v}_{j}}}}=Parallel\_FGAT({{e}_{{{v}_{j}}}}, {{e}_{{{u}_{i}}}}, {{e}_{{{r}_{k}}}})\in {{R}^{d}}$.
基于广义门控机制与线性投影, 评分预测模块以最终用户特征和商品特征为输入, 预测目标用户ui对候选商品vj的评分:
$\hat{r}_{{{v}_{j}}}^{{{u}_{i}}}={{W}^{pre}}\tilde{r}_{{{v}_{j}}}^{{{u}_{i}}}+{{b}^{pre}}$,
其中
$\tilde{r}_{{{v}_{j}}}^{{{u}_{i}}}={{\eta }_{ij}}\times {{h}_{{{u}_{i}}}}+(1-{{\eta }_{ij}})\times {{h}_{{{v}_{j}}}}$,
${{\eta }_{ij}}=Sigmoid({{W}_{\eta }}({{h}_{{{u}_{i}}}}\left\| {{h}_{{{v}_{j}}}} \right\|{{h}_{{{u}_{i}}}}\times {{h}_{{{v}_{j}}}})+{{b}_{\eta }})$,
Wη ∈ R3d× d表示可学习的参数矩阵, bη ∈ Rd、Wpre∈ Rd× 1表示可学习的偏置向量, bpre表示可学习的偏置标量.
最后, 通过最小化如下误差平方和(Mean Squared Error, MSE)目标函数以训练模型:
$Loss=\frac{1}{\left| O \right|}\underset{\left( {{u}_{i}}, {{v}_{j}} \right)\in O}{\mathop \sum }\, {{\left( r_{{{v}_{j}}}^{{{u}_{i}}}-\hat{r}_{{{v}_{j}}}^{{{u}_{i}}} \right)}^{2}}$,
其中, O表示评分集合, $r_{{{v}_{j}}}^{{{u}_{i}}}$为用户ui对商品vj打出的真实评分.
本文主要基于Pytorch, 在配置英特尔至强Platinum 8350C中央处理器(内存为48 GB, 主频为2.6 GHz)和8张GeForce RTX 3090显卡的服务器上进行实验.
为了保证实验的公平性, 本文选择社会化推荐领域的基准公开数据集Filmtrust[53]、CiaoDVD[54]、Yelp[55].Filmtrust数据集来源于某在线社交电影网站.CiaoDVD数据集来源于英国电商网站Ciao的DVD品类.Yelp数据集收集自美国著名商户点评网站Yelp.本文仅采用用户-商品评分数据与社交关系数据.为了尽可能还原真实的社会化推荐场景, 实验没有仿照此前相关工作过滤交互数量较少的用户和商品, 也没有去除出现在验证集和测试集, 但未出现在训练集中的用户和商品.
实验选用数据集的统计指标如表1所示.本文随机选取80%的数据作为训练集, 将其余数据平均划分为验证集与测试集.
| 表1 实验数据集部分统计指标 Table 1 Some statistical indexes of experimental datasets |
实验使用AdamW(Adam with Decoupled Weight Decay)优化器[56], 将初始学习率设定为0.001, 每训练3轮, 学习率衰减为原来的90%.此外, 在{1, 2, 3, 4, 5, 6}中搜寻最佳邻域扩展阶数, 在{8, 16, 32, 64, 128}中搜索最佳嵌入编码维度.为了缓解模型训练过程中的过拟合问题, 使用暂退法(Dropout), 神经元失活率设定为50%.
为了保证实验的公平性, 本文参照各基线系统的相关工作设置相应的最佳参数, 并记录各系统在各评估指标上的最优值.
由于本文关注社会化推荐系统在评分预测方面的准确性, 实验选取平均绝对误差(Mean Absolute Error, MAE)和均方误差(Root Mean Square Error, RMSE)评估系统性能:
$MAE=\frac{1}{\left| O \right|}\underset{\left( {{u}_{i}}, {{v}_{j}} \right)\in O}{\mathop \sum }\, \left| r_{{{v}_{j}}}^{{{u}_{i}}}-\hat{r}_{{{v}_{j}}}^{{{u}_{i}}} \right|$,
$RMSE=\frac{1}{\left| O \right|}\underset{\left( {{u}_{i}}, {{v}_{j}} \right)\in O}{\mathop \sum }\, \sqrt[]{\left( r_{{{v}_{j}}}^{{{u}_{i}}}-\hat{r}_{{{v}_{j}}}^{{{u}_{i}}} \right){{\text{ }\!\!~\!\!\text{ }}^{2}}}$.
这2个性能指标均衡量预测评分值与真实评分值之间的偏差程度, 并且均在[0, +¥ ]上取值, 指标值越小, 表示推荐系统的评分预测精准度越高.
受到社会化推荐领域相关工作的启发, 选择如下13个基准系统进行性能对比.这些基准系统可划分为3类.
1)传统机器学习推荐系统.
(1)MF(Matrix Factorization)[57].作为一种广泛使用的协同过滤算法, 基于用户-商品交互矩阵学习用户偏好和商品特征.
(2)PMF(Probabilistic MF)[58].基于高斯分布假设, 从用户-商品交互矩阵中学习用户偏好和商品特征.
(3)SVD++[59].基于用户偏好、商品特征、评分偏置和用户对商品的隐式反馈进行评分预测.
2)考虑社交关系的机器学习推荐系统.
(1)SoRec[19].基于特征共享的社交推荐系统, 联合分解评分矩阵和社交关系矩阵, 学习用户偏好.
(2)RSTE[20].基于概率矩阵分解算法学习用户和社交朋友的偏好.
(3)SocialMF[21].假设目标用户偏好与直接朋友的平均偏好相似.
(4)文献[39]系统.基于共同评分方法, 学习目标用户偏好与不同直接朋友的偏好相似度.
3)基于图的社会化推荐系统.
(1)REST[11].将推荐问题转换为反事实推理问题, 基于显式曝光重构策略进行去偏社会化推荐.
(2)CUNE-MF[22]:根据用户-商品评分矩阵, 采用随机游走和Skip-gram算法探索可靠的社交朋友.
(3)GraphRec[23].基于GNN的社会化推荐系统, 将评分矩阵和社交关系矩阵转换为图, 并基于图注意力网络学习用户和商品特征.
(4)ConsisRec[26].提出采样策略, 解决社交信息不一致性问题, 并基于关联注意力机制学习特征.
(5)GDSRec[28].基于图注意力的社会化推荐系统, 额外考虑用户和商品的偏置特征.
(6)CDRSB(Causal Disentanglement-Based Frame-work for Regulating Social Influence Bias in Social Recommendation)[60].基于解纠缠学习的因果推理框架, 调节社会推荐中的社会影响偏差.
各系统对比实验结果如表2所示, 表中黑体数字表示最优值, 斜体数字表示次优值.在大多数情况下, 传统机器学习推荐系统普遍在MAE和RMSE指标上高于考虑社交关系的机器学习推荐系统, 这表明社交信息对于提升评分预测准确性具有重要意义.
| 表2 各系统在3个数据集上的对比实验结果 Table 2 Contrast experiment results of different systems on 3 datasets |
在现实世界的推荐场景中, 用户的决策往往受到其社交网络中其它个体的影响.这种影响可能表现为信任的朋友对某个商品的评价、推荐或讨论, 从而使目标用户形成对该商品的预期和偏好.在推荐系统中引入用户间的社交关系, 可使系统不仅考虑历史行为数据中隐藏的用户偏好, 还能考虑社交网络中的潜在偏好, 从而使学到的用户偏好更全面.
此外, 社交信息扩展可用于推荐的数据量, 在一定程度上缓解数据稀疏性问题, 使推荐系统能更准确地捕捉冷启动用户的潜在兴趣, 并提供更精准的推荐.总之, 即使目标用户未对某些商品进行评分, 社会化推荐系统也可通过分析其社交朋友的偏好推测目标用户的预期偏好.
由表2还可观察到, 相比基于矩阵分解的推荐系统, 基于图的社会化推荐系统普遍表现出更精准的评分预测能力.该现象表明基于图的社会化推荐系统能更准确地模拟用户的社交行为和偏好传播路径, 提升评分预测的准确性.
具体地, 用户在社交网络中的互动关系往往呈现复杂的拓扑结构, 而图数据结构为社交网络中的多维关系提供一种直观、灵活的表示方法.这种表示方法不仅反映用户间的社交关系, 还有助于揭示潜在的社交圈子和社区结构, 从而为推荐系统提供更丰富的社交上下文信息.
此外, 基于图的社会化推荐系统通常采用图神经网络算法处理图结构数据, 能以直接或间接的方式, 利用图的拓扑特性挖掘用户的潜在偏好.在社会化推荐系统中, 用户的行为和偏好可能受到多种因素的影响, 这些因素之间存在复杂的相互作用, 而神经网络通过其非线性结构学习这些复杂关系, 提供更准确的用户偏好预测.总之, 神经网络的适应性和灵活性使这类系统能更好地探索社交网络和用户-商品交互二部图中的复杂模式.
值得注意地是, NEGA在所有情况下均取得最优性能, 充分展示出NEGA在社会化评分预测方面的优越性.最重要的原因在于聚焦注意力机制具有在探索邻域中发现重要近邻的特点, 有效增强社会化推荐系统在用户-商品二部图和社交网络的图学习能力.现有基于GNN的社会化推荐系统大都基于经典的图注意力机制, 这类图注意力机制通常基于Softmax函数进行注意力分数的归一化.然而, Soft- max函数会产生相应的全局注意力分布, 这意味着系统对邻域范围内的每个节点都分配一定的注意力权重, 从而带来计算冗余问题.因为系统还需要基于所有的注意力权重进行特征学习, 即使很多权重非常接近于0, 对学习用户偏好特征的意义不大.聚焦注意力机制将注意力权重集中在近邻节点集合中的少数关键节点, 这种稀疏性的注意力机制使系统能更专注于和用户偏好最相关的特征, 从而提升NEGA应对冷启动问题的能力.此外, 聚焦注意力机制强大的信息过滤能力使系统能学到具有泛化能力的特征, 从而提升系统的鲁棒性.
自适应的聚焦程度、平行注意力机制和邻域扩展机制在提升NEGA的评分预测能力方面也起到重要作用.
为了验证NEGA各模块的有效性, 进行3组消融实验.实验仅对各变体系统的结构进行相应调整, 并使用与NEGA一致的参数.具体消融实验结果如表3所示, 表中黑体数字表示最优值, 斜体数字表示次优值.
| 表3 各模块的消融实验结果 Table 3 Ablation experiment results of different modules |
在第1组消融实验中, 设置6种变体系统, 分别采用三层MLP和经典门控机制在NEGA的不同关键位置替代原有的广义门控机制.各变体系统的详细描述如下.
1)NEGA-OE-MLP.采用三层MLP学习用户对商品的消费偏好以及隐藏在评分特征和用户特征中的商品特征.
2)NEGA-OE-VG.采用经典门控机制学习用户对商品的消费偏好以及隐藏在评分特征和用户特征中的商品特征.
3)NEGA-FF-MLP.采用三层MLP作为节点特征聚合函数.
4)NEGA-FF-VG.采用经典门控机制作为节点特征聚合函数.
5)NEGA-P-MLP.采用三层MLP替代评分预测模块中的广义门控机制.
6)NEGA-P-VG.采用经典门控机制替代评分预测模块中的广义门控机制.
根据表3中结果, 经典门控机制与三层MLP网络在系统的不同位置各有优劣.当三层MLP网络作为预测函数时, 系统性能优于经典门控机制; 当需要学习用户对商品的消费偏好时, 经典门控机制性能更优; 当需要聚合邻域特征与节点自身特征时, 三层MLP在Filmtrust数据集上表现更佳, 经典门控机制在其余两个数据集上性能更优.三层MLP由于可学习参数更多、结构更深, 比浅层的经典门控机制具有更强的特征拟合能力.然而, 在底层模块中采用MLP时, 可能会带来过拟合的风险.经典门控作为线性浅层网络, 未考虑输入特征间的非线性关系, 但它可轻量高效地融合不同特征, 从而降低过拟合的风险, 在底层模块更具有表现力.
由表3还可以观察到, 本文采用的广义门控机制在所有情况下均取得具有竞争力的性能.广义门控机制在经典门控机制的基础上, 额外考虑输入特征间的逐元素乘积对门控权重的影响, 而哈达玛积可以捕捉输入特征之间的逐元素乘积关系, 增强信息之间的交互和关联性.这有助于系统更好地理解输入数据之间的复杂关系, 提高系统的表达能力和泛化能力.总之, 广义门控机制作为一种通用架构, 参数量少于三层MLP, 同时保持门控机制的可解释性, 对于提升系统性能具有重要价值.
在第2组消融实验中, 本文设置2种变体系统, 分别采用经典的软注意力和三层MLP替代原有的聚焦注意力机制.各变体系统的详细描述如下.
1)NEGA-MP-SA.采用经典的软注意力作为图神经网络的消息传递系统.
2)NEGA-MP-IP.采用内积注意力作为图神经网络的消息传递系统.
相比2种基于Softmax函数的注意力机制, 本文的聚焦注意力机制在大部分情况下带来最优性能.随着阶数的提升, 邻域扩展机制迅速扩大系统的感受野, 使邻域范围内的节点数量快速增加.经典的软注意力和内积注意力机制缺乏强大的噪声过滤能力, 导致严重的注意力涣散问题.该问题使系统难以有效识别具有丰富语义信息的关键节点, 将注意力权重分散在过多具有较少语义特征的非关键节点, 导致系统的特征学习能力欠佳.而聚焦注意力机制将注意力集中在邻域范围中少数几个重要的节点上, 而不是依赖大量的低相关性的邻域节点, 提高系统特征学习的效率和准确度.
此外, NEGA-MP-SA在一些情况下的评分预测精准度甚至高于GraphRec.这表明本文提出的邻域扩展机制具有一定的通用性, 可有效缓解局部邻域的数据稀疏问题, 帮助系统以高效率的方式在高阶邻域空间中捕捉重要信息.
值得关注的是, 基于内积的无参数注意力机制同样具有较强竞争力, 在大多数情况下甚至优于软注意力机制.这一现象启发学者们在今后的研究中设计更稳健、性能更优、参数化更低的注意力机制.
在第3组消融实验中, 本文设置仅移除邻域扩展机制的变体系统作为对照组.此外, 本文还设置2种变体系统, 分别采用节点特征正则化算法[44]和残差连接算法[45]替代原有的邻域扩展机制, 缓解过度平滑问题.各变体系统的详细描述如下.
1)NEGA-OS-RAW.仅移除邻域扩展机制, 未采用任何方法缓解过度平滑问题.
2)NEGA-OS-NORM.采用节点特征正则化算法缓解过度平滑问题.
3)NEGA-OS-RES.采用残差连接算法缓解过度平滑问题.
根据表3结果, NEGA-OS-RAW在3个数据集上的性能相对最低, 表明深度图神经网络容易出现梯度消失问题, 导致不同节点的特征趋于相似, 即出现严重的过度平滑问题.NEGA-OS-NORM和NEGA-OS-RES分别采用特征正则化和残差连接的方法, 有效缓解梯度消失带来的过度平滑问题, 并获得比NEGA-OS-RAW更优的性能.然而, 这两种系统仍依赖于多次消息传递才能感知远距离节点的影响, 性能仍有待提升.NEGA在3个数据集上均获得最佳性能, 表明邻域扩展机制能有效缓解过度平滑问题.相比依赖多个中间节点传递远距离信息, 邻域扩展机制添加目标节点与远距离节点间的快捷连接, 直接捕获远距离节点的影响, 避免多次消息传递带来的信息损失.在本文研究情景下, 邻域扩展机制提升系统捕获高阶社交信息的能力, 助力图平行聚焦注意力网络表现出强大的特征过滤能力, 从而使评分预测更精准.
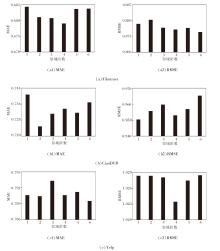
为了分析NEGA对于关键参数变动的敏感性, 本节实验在3个数据集上, 探索嵌入编码维度、注意力聚焦程度、邻域阶数和平行空间数量对于评分预测任务精准性的影响.
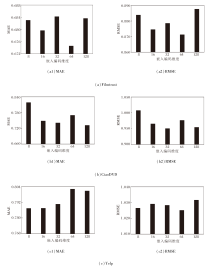
首先分析嵌入编码维度, 设置维度值为8, 16, 32, 64, 128, 在Filmtrust、CiaoDVD、Yelp数据集上分别计算MAE和RMSE, 结果如图3所示.
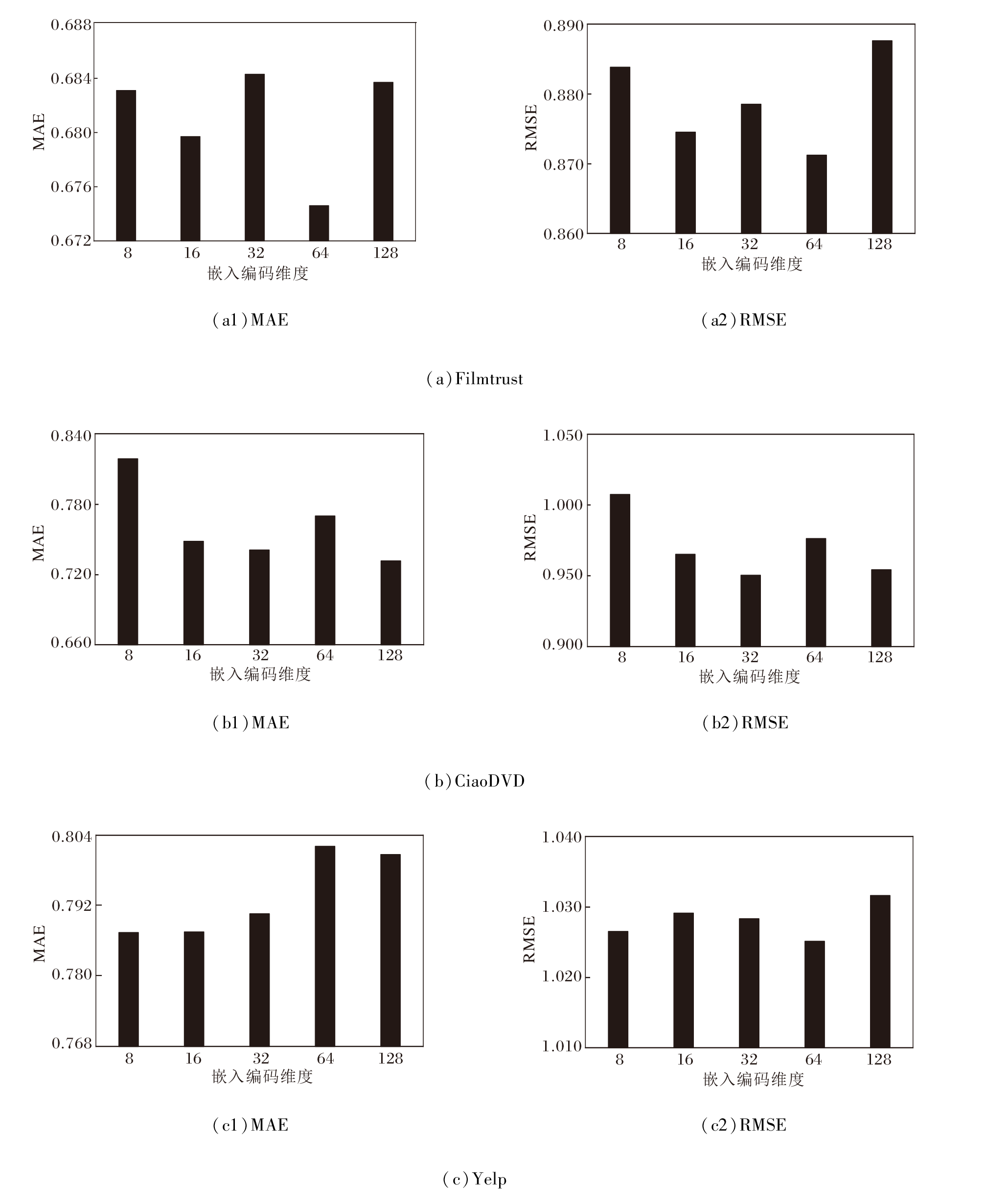 | 图3 嵌入编码维度不同时的超参数敏感性实验结果Fig.3 Results of sensitivity experiment of hyperparameters with different embedded dimensions |
由图3可见, 适当增加嵌入编码维度时, 评分预测精准度有所提高.当维度继续增加时, 评分预测精准度反而持续降低.结果表明, 在一定范围内, 增加嵌入编码维度有助于提升系统的表征学习能力.然而, 过多的嵌入编码维度不仅会带来更大的计算开销, 显著提升系统的复杂度, 还会带来严重的过拟合问题, 限制系统对用户兴趣的学习能力.因此, 需要找到合适的嵌入编码维度, 以权衡评分预测精准度和系统复杂度.
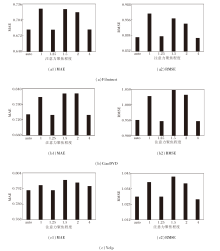
在注意力聚焦程度的实验中:auto表示系统采用自适应的聚焦程度学习方法; 在其它情况下, 聚焦程度被简单地视为超参数.设置聚焦程度为1, 1.25, 1.5, 2, 4, 在3个数据集上的MSE和RMSE结果如图4所示.
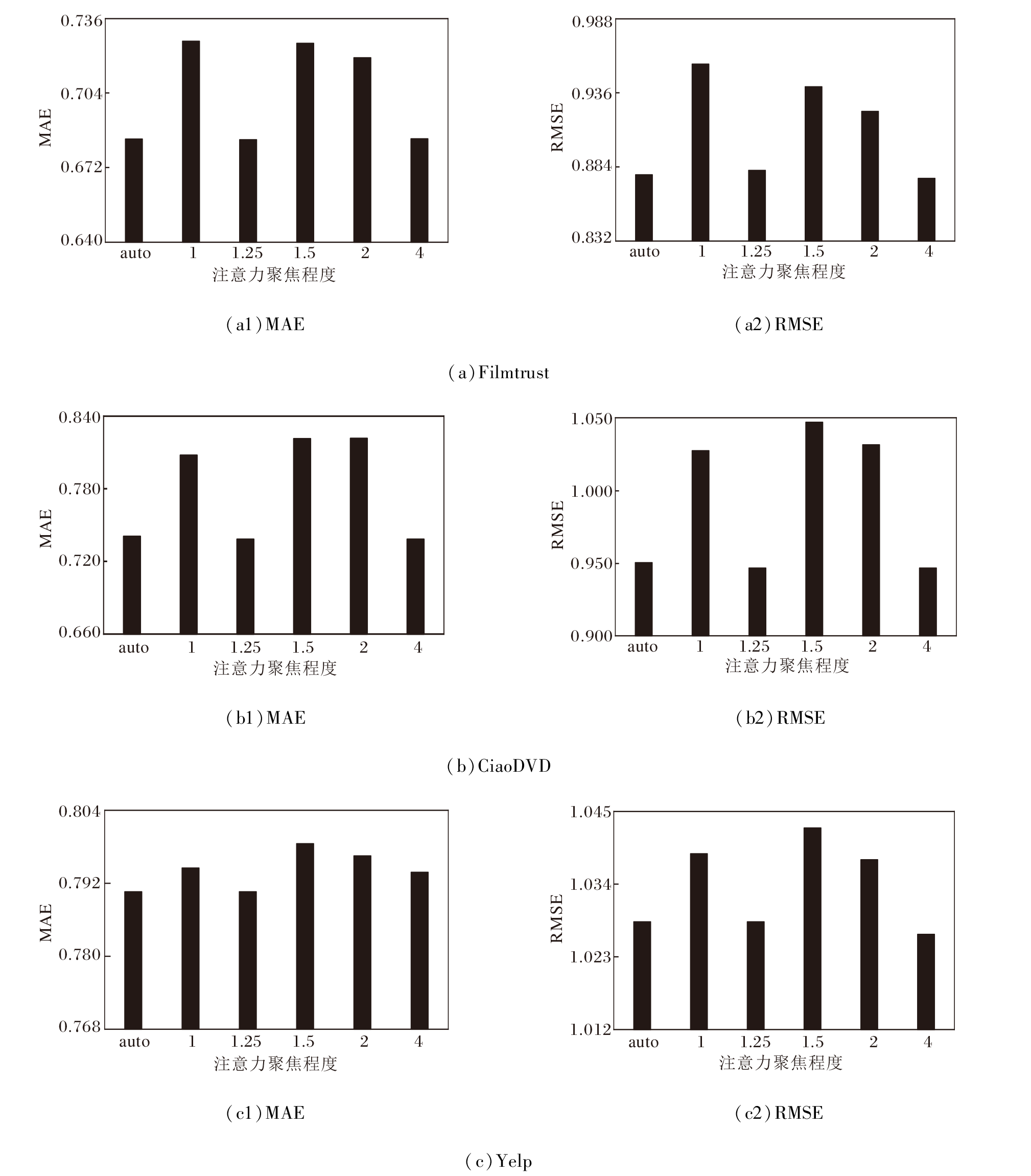 | 图4 注意力聚焦程度不同时的超参数敏感性实验结果Fig.4 Results of sensitivity experiment of hyperparameters with different degrees of focused attention |
由图4可见, 自适应算法在所有情况下均取得较优性能.尤其当聚焦程度为1, 即注意力基于Soft- max函数时, 自适应方法取得绝对优势, 表明Soft- max函数识别重要特征的能力有待提升.随着自我中心网络的扩张, 需要考虑的近邻节点数量快速增加, 基于Softmax函数的注意力机制倾向于为每个近邻节点分配非零权重, 使近邻之间的特征差异越来越小, 最终导致严重的注意力涣散问题.自适应方法可根据目标节点和近邻节点的特征动态调整注意力的聚焦程度, 有助于提升参数调整效率和泛化能力.
受到小世界现象研究的启发[61], 本文假定用户最多通过五个间接朋友即可找到具有强同质性的社交朋友.因此, 本组实验最高探索六阶自我中心网络中的社会信息对目标用户偏好的影响, 具体实验结果如图5所示.
 | 图5 邻域阶数不同时的超参数敏感性实验结果Fig.5 Results of sensitivity experiment of hyperparameters with different neighbourhood ranges |
由图5可见, 当邻域阶数为1, 即仅考虑直接朋友对目标用户的偏好影响时, 系统的评分精准度普遍较低, 表明间接朋友对于学习目标用户的偏好具有重要意义.在推荐系统中考虑更广泛的社交关系有助于捕获更多的社交信息, 从而提高评分预测的准确性.随着邻域范围的扩大, 系统能在更广泛的自我中心网络内探索同质性和社交影响传播对目标用户偏好的影响, 从而考虑到更多来自其他用户的社交偏好信息.通过分析这些社交信息, 推荐系统可以更好地理解自我中心网络中的整体趋势和偏好, 提供更准确的评分预测结果.在达到最佳邻域范围后, 继续扩大自我中心网络会导致系统性能出现波动.这是因为系统受到过拟合问题的影响, 对于间接朋友的识别出现偏差.
此外, 在不同数据集场景中的最佳邻域范围不同, 这可能是由于不同数据集的社交网络密度不同.聚焦注意力机制的核心在于寻找邻域范围中最重要的社交朋友.当社交网络较稀疏时, 在更高阶的自我中心网络内才能发现对消费者决策具有重要影响的社交朋友.当社交网络较密集时, 低阶自我中心网络内的用户数量相对较多, 因此找到具有相似偏好的消费者的概率更高.
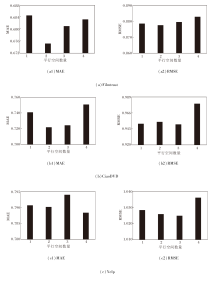
设置平行空间数量为1, 2, 3, 4, 在3个数据集上计算MAE和RMSE, 结果如图6所示.由图可见, 当平行空间数量为1, 即不考虑用户的多方面细粒度兴趣时, 系统的评分精准度较低.随着平行空间数量的逐渐增加, 评分精准度也逐渐提升.这表明平行注意力机制有助于系统从不同的特征空间中学习用户的多方面偏好, 提高系统对用户偏好的理解能力.此外, 由于平行机制在多个特征空间中进行学习, 即使某个平行空间中学到的特征出现偏误, 其它平行空间仍可提供有用的信息.一定程度的特征冗余提高系统的鲁棒性, 使系统在面对噪声信息时仍保持较高的性能.
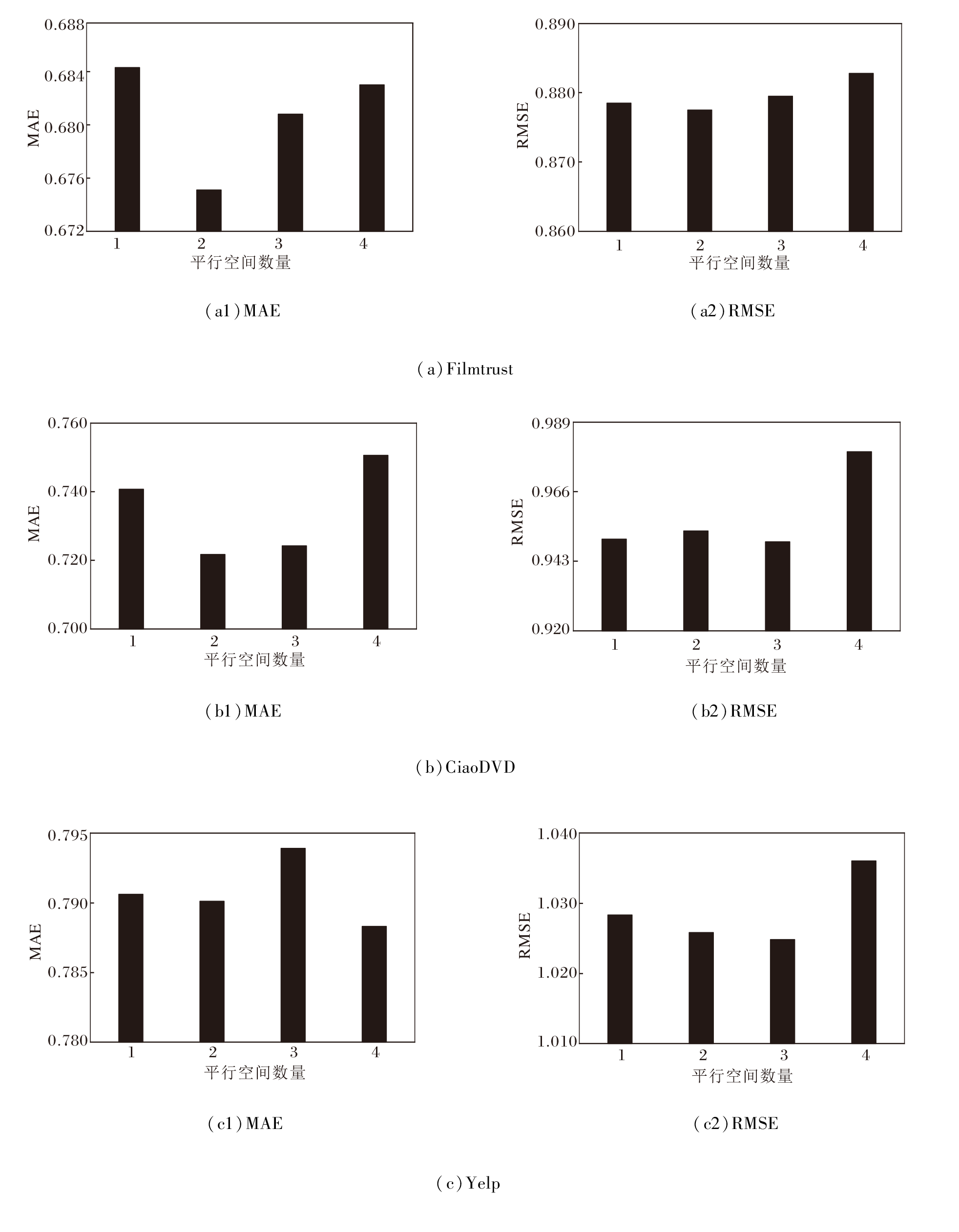 | 图6 平行空间数量不同时的超参数敏感性实验结果Fig.6 Results of sensitivity experiment of hyperparameters with different numbers of parallel spaces |
相比解纠缠学习, 平行机制避免额外的特征降维过程, 减少计算资源的消耗, 并且每个特征空间都保留输入数据的全部维度, 这对于捕获数据中的细微模式和复杂关系至关重要.然而, 过多的平行空间反而会带来严重的过拟合问题, 导致系统预测评分能力的降低.
本文从Filmtrust数据集上随机选取3位用户, 并可视化他们对各自评分过商品的偏好特征, 如图7所示.由图可看出, 无论用户是否真正对商品感兴趣, 基于Softmax函数的软注意力机制倾向于为所有交互过的商品分配非零权重.
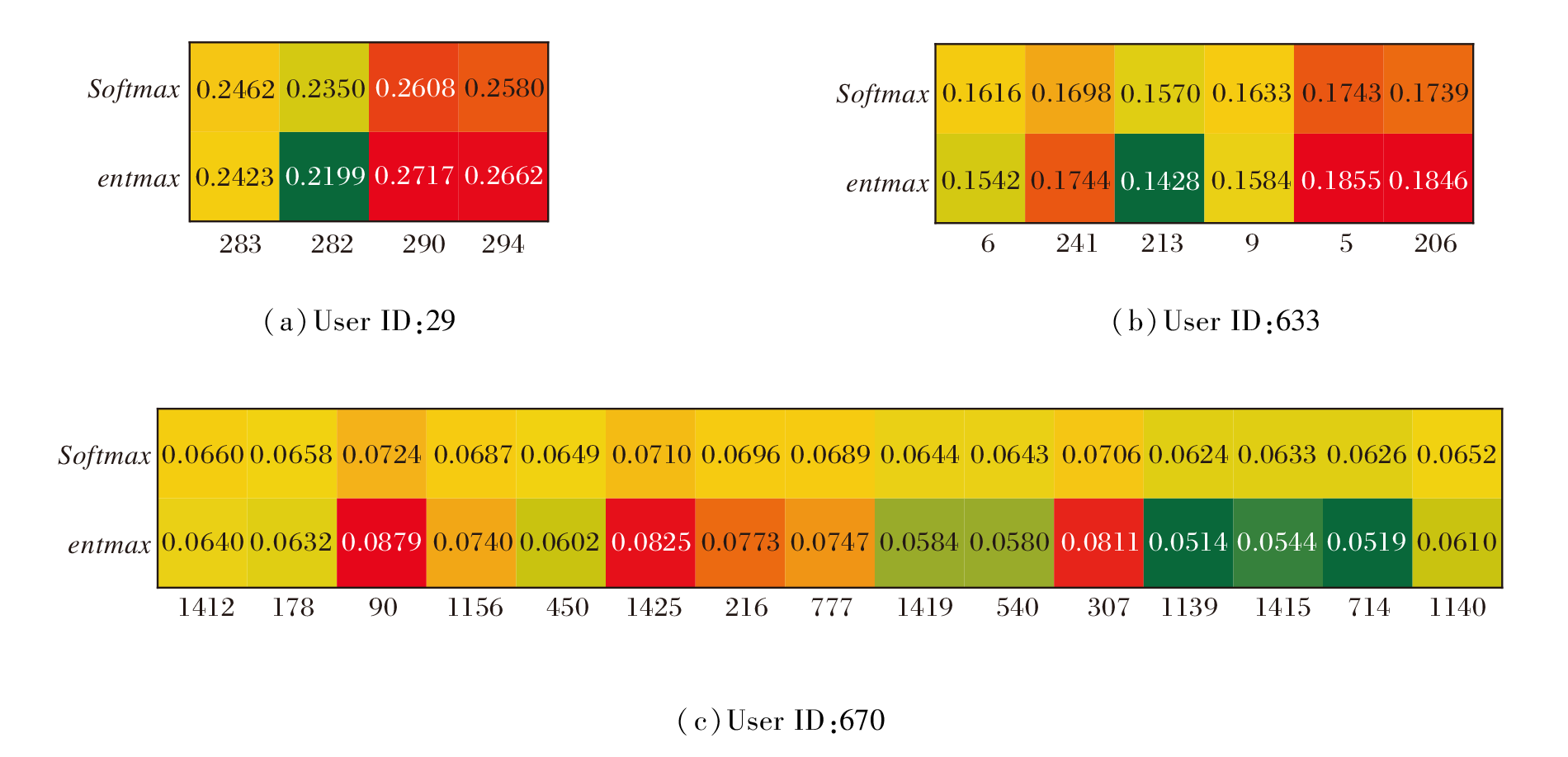 | 图7 聚焦注意力权重与经典注意力权重的热力图可视化Fig.7 Heatmap visualization of focused attention weights and traditional attention weights |
随着用户-商品交互数量的增加, 基于Softmax函数的注意力越来越难以捕捉用户最感兴趣的商品.本文将这一现象称为注意力涣散, 即系统认为用户最感兴趣和最不感兴趣商品的特征差异逐渐趋向于0.相比而言, 聚焦注意力机制能为用户不感兴趣的商品分配更低权重, 甚至是零权重, 从而保证系统始终专注于用户最感兴趣的商品, 有效提升NEGA的偏好特征学习能力.
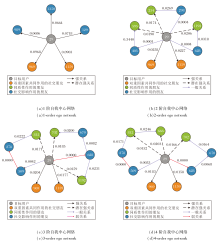
以Filmtrust数据集上ID为29的用户为实验对象.根据3.4节的超参数实验, 当邻域阶数为4时, NEGA取得最优评分预测精度, 因此依次可视化目标用户在一阶到四阶自我中心网络内最有影响力的5位社交朋友, 具体如图8所示.
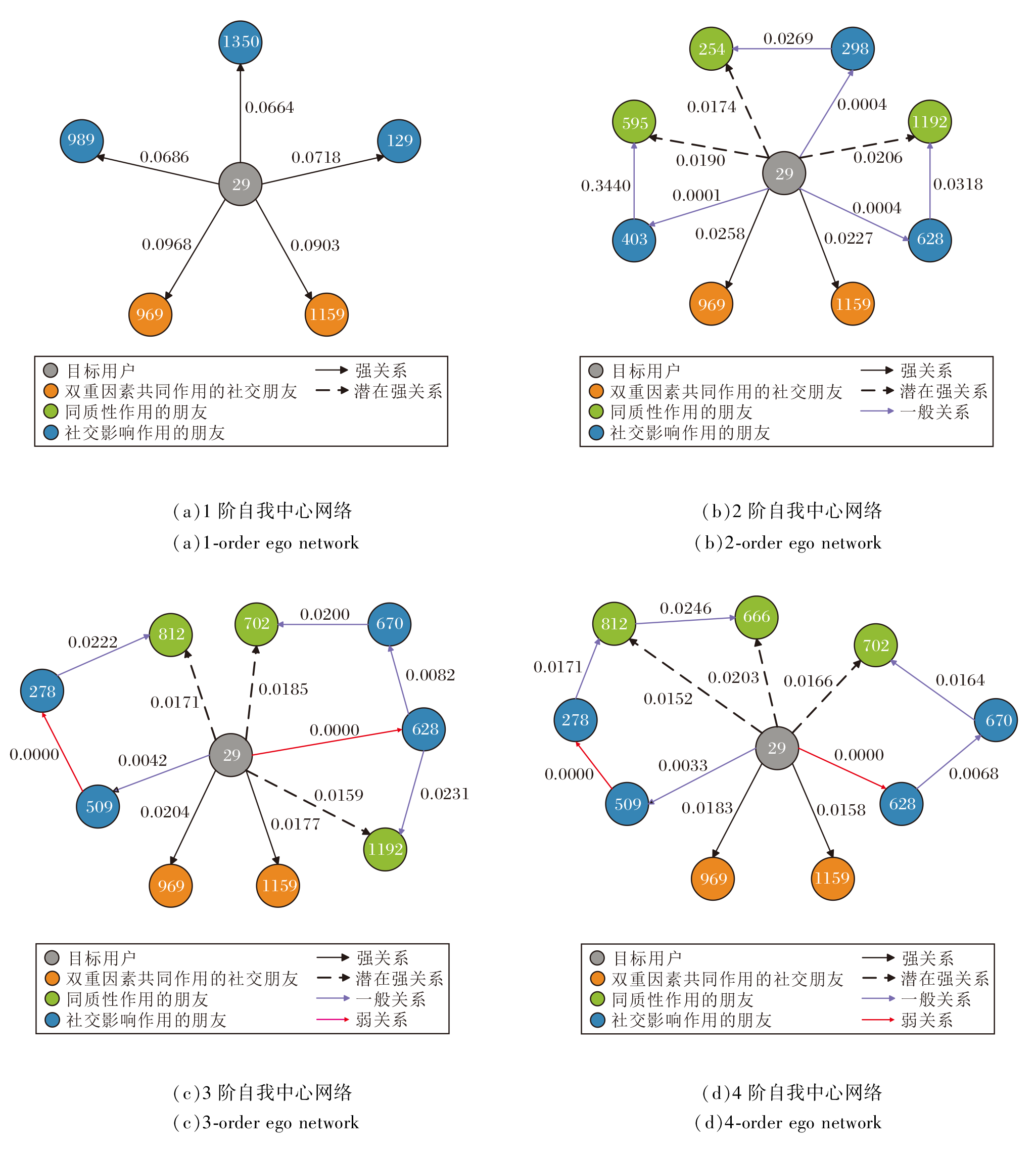 | 图8 不同阶自我中心网络中社交权重可视化Fig.8 Visualization of social weights in ego networks of different orders |
由图8可见, 在一阶自我中心网络中, 各直接朋友对目标用户决策的影响力不同, 表明不同社交关系存在差异性.因此, 平等看待所有直接朋友的社会化推荐系统往往性能较差, 如基于矩阵分解的社交推荐系统和基于图卷积网络的社交推荐系统.随着邻域的逐渐扩大, 自我中心网络内的用户节点数量迅速增加, 这为基于经典图注意力网络的社交推荐系统带来挑战.因为这些方法普遍假设邻域中的任何朋友都会影响目标消费者的偏好.然而, 用户偏好更有可能受到少数关键社交朋友影响[62].因此, 基于经典图注意力网络的社交推荐系统往往局限于低阶自我中心网络内, 难以在更大范围内探索更多社交信息的作用.
虽然现有的社交推荐相关工作[5, 6, 7, 8, 9, 10, 11, 12, 13, 14]均认为社交关系有助于提升推荐精准度, 但并未明确解释社交朋友如何影响目标消费者的偏好.受到相关研究[63, 64, 65]的启发, 在社交网络中影响用户偏好的3种主要机制分别是:社会影响(Social Influence)、同质性(Homophily)、两者同时存在.本文提出的邻域扩展机制能快速扩大系统的感受野, 促使系统分辨出不同社交朋友对目标用户偏好的影响机制.在图8(a)中, 在一阶邻域中, 不同机制纠缠在一起, 难以区分各社交朋友的影响机制.在(b)中, 在二阶邻域中, 一些直接朋友的影响力有所减弱, 同时系统识别到一些具有影响力的间接朋友.在(c)、(d)中, 随着邻域的继续扩大, 不同社交朋友的影响机制逐渐明晰.具体地, 直接朋友969和1 159与目标用户始终具有较高的社交链接权重, 表明他们通过同质性和社会影响同时作用于目标用户偏好, 而间接朋友666、702和812之所以能影响目标用户的决策, 只是因为他们具有相似的偏好特征, 即同质性.与目标用户存在直接或间接社交链接, 且社交链接权重不趋近于0的社交朋友, 对目标用户偏好的作用机制仅基于社会影响.
值得注意的是, 图中标识的社交链接权重为0并不表示用户之间无社交关系, 社交链接仅用于表示两位用户偏好的相似性.完全偏好不同的两位用户有可能偶然形成社交关系.例如:显性朋友509和目标消费者的行为模式不相似, 但他们之间仍存在社会影响.
另外, 各因素对目标用户偏好的影响力不同, 其稳定性也有所不同.根据社交链接的权重, 双重因素效应往往比单一的同质性更强, 而单一的社会影响机制作用最弱.从稳定性的角度上看, 具有双重因素的社交朋友稳定性最强.例如:社交朋友969和1 159在目标用户的1阶至4阶自我中心网络内, 都具有显著的影响力.
相比而言, 仅基于同质性因素影响目标用户偏好的间接朋友变动较频繁, 并且会随着自我网络的扩大逐渐趋向稳定.出现该现象的主要原因是平台用户普遍更信任具有相似偏好的其他用户, 因此具有相似偏好的直接朋友更容易得到目标用户的信任.即使在没有建立社交关系的情况下, 具有相似偏好的间接朋友也容易获得目标用户的信任.因此, 同质性对于推断目标用户偏好具有重要意义.由于在更大的邻域中找到具有更高同质性社交朋友的可能性更大, 所以这类社会朋友没有表现出较强的稳定性.
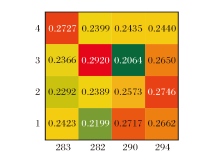
以Filmtrust数据集上ID为29的用户为实验对象.目标用户在4个平行特征空间中, 对各商品的不同偏好程度如图9所示.由图可见, 用户在为商品评分时考虑不同方面的特征, 如价格[66]、品牌[67]和个性化程度[68].
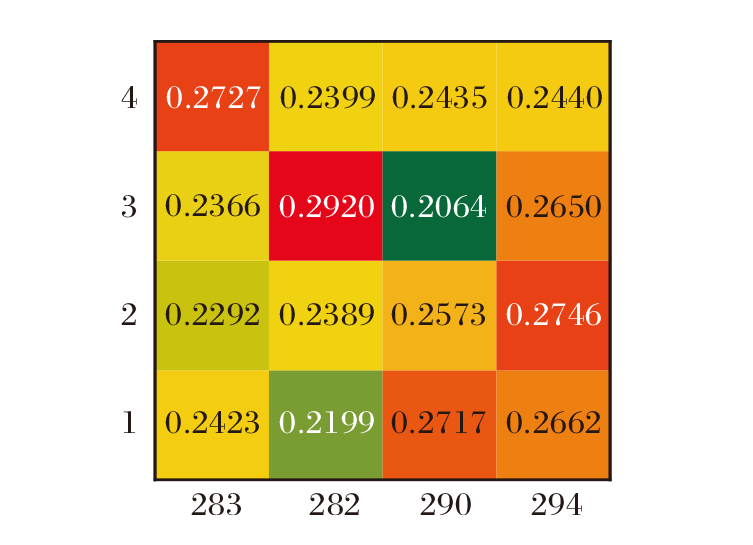 | 图9 不同平行空间中的商品特征注意力权重热力图Fig.9 Heatmap of attention weights of product features in different feature hidden spaces |
在不同平行特征空间中, 目标用户受到各直接朋友的不同影响如图10所示, 这可能是因为不同的朋友偏好各异, 目标用户往往会有选择地采纳来自不同朋友的建议.
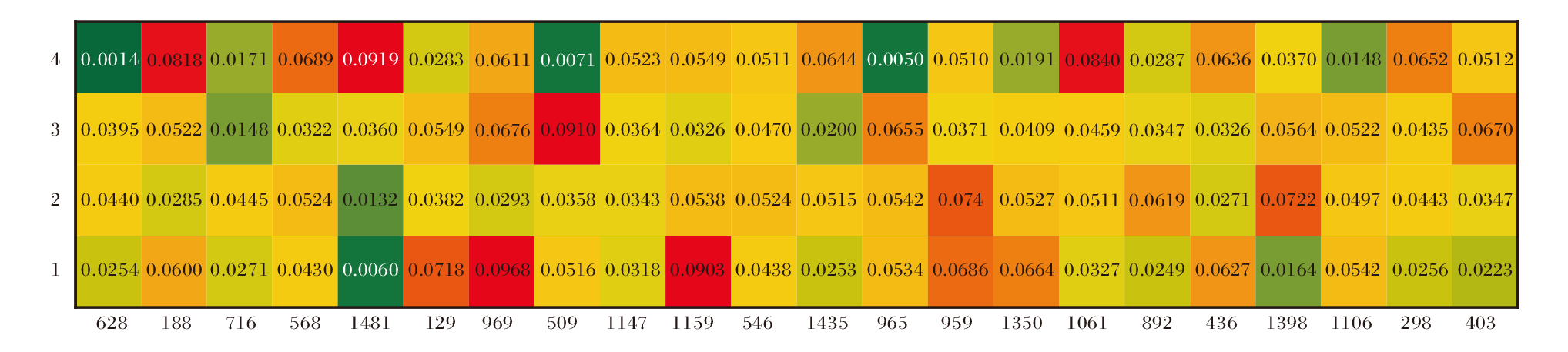 | 图10 不同平行空间中的社交朋友注意力权重热力图Fig.10 Heatmap of attention weights of social friends in different feature hidden spaces |
总之, 分析用户的多方面偏好不仅有助于提升评分预测精准度, 还有助于推断用户行为背后的逻辑.
随着可解释人工智能的快速发展, 可解释推荐系统逐渐成为具有发展潜力的前沿研究方向之一[69].此类推荐系统在为用户提供推荐结果的同时, 还会提供相应的解释, 有效提升推荐系统的透明度与可信度.
现有的相关工作已尝试基于多种信息解释推荐结果, 如评论信息[70]、商品图像[71].在众多解释信息源中, 社会化推荐的相关研究表明[72], 用户间的社交关系不仅有助于提升推荐准确度, 还可提升推荐的可解释性.例如:推荐系统常采用“ 您好友也感兴趣的商品” 这一类提示信息[73, 74], 利用社交认同感强化推荐的可接受性.
相比依赖商品属性或个体行为习惯的解释策略, 源自社交关系的解释更容易被用户理解和接纳[75].因此, 社交信息作为解释信息具有较大的潜在研究价值.
根据相关工作中的用户偏好学习算法和解释策略, 现有的可解释社会化推荐系统可分为事前/事中解释和事后解释两类.
基于事前/事中解释的相关工作采用以用户为中心的人机交互设计理念, 赋予用户更多的自主选择权, 如用户可根据自己的偏好或信息需求进一步过滤或重新排序推荐[72].然而, 此类工作往往基于传统机器学习方法或简单相似度计算, 从数据库中检索用户可能感兴趣的信息, 难以挖掘更深层次的用户偏好, 导致推荐精准度较低.
基于事后解释的可解释社会化推荐系统通常先采用因果推断[7, 11]、解纠缠学习[60, 76]等方式, 挖掘社交网络和历史交互记录中隐藏的用户偏好, 然后基于案例研究、特征可视化[77]等方式进行深入分析.然而, 现有相关研究大多基于整体层面的社交影响进行解释, 未能深入分析不同社交朋友对用户多元偏好的影响.
相比现有的基于深度学习的可解释社会化推荐系统, NEGA关注反映用户不同方面偏好的少数关键信息, 在提升推荐准确性的同时, 为用户提供更充分的推荐结果解释.
具体来说, 相比现有的解纠缠学习相关工作[78, 79], 本文的多方面偏好挖掘基于平行注意力机制, 在多个更大的特征空间中学习用户不同方面的细粒度偏好, 在一定程度上避免偏好不一致问题.此外, 相比将社交信息作为推荐结果解释的相关工作[76, 78], NEGA不仅能识别广泛邻域范围内的少数关键社交朋友, 还进一步揭示不同社交朋友对目标用户偏好的影响机制, 分别强调社会影响和同质化因素的独特意义.
最后, 本文研究结果为社交媒体平台进行精准营销提供重要依据.具体来说, 社交平台展示推荐结果时, 应优先考虑与目标用户具有相似偏好的直接朋友感兴趣的商品, 其次考虑与目标用户具有相似偏好的间接朋友感兴趣的商品.尽管一些直接朋友与目标用户的偏好并不一致, 但是适当考虑他们感兴趣的商品有望提升推荐结果的多样性与新颖性, 从而进一步提升用户对推荐结果的满意度.
推荐系统在社交商务场景中具有不可或缺的作用, 然而, 过度平滑问题和经典注意力的低效率限制社会化推荐系统在高阶自我中心网络中的信息探索能力, 导致评分预测精准度较低.为了应对上述挑战, 本文提出邻域扩展机制增强的图平行聚焦注意力社会化推荐系统(NEGA), 基于图平行聚焦注意力网络和邻域扩展机制, 有效提升评分预测的准确性.此外, 通过一系列可视化案例分析可知, NEGA不仅揭示不同社交朋友对目标用户偏好的影响机制, 还展现用户的多方面细粒度偏好, 从而证实其具备强大的可解释性.
然而, 本文还存在以下局限之处:1)在推荐任务方面, 仅关注系统在评分预测任务上的准确度, 忽略推荐结果的多样性和新颖性.2)NEGA仅基于用户-商品评分记录和社交关系记录学习用户和商品的特征表示, 并未探索多模态信息对评分预测的影响.3)最近的工作[80, 81]表明以图神经网络为主体的大模型具有强大的图推理能力, 而本文未考虑到大模型对于社会化推荐的影响.今后将尝试基于异质用户偏好提升推荐结果的多样性与新颖性, 同时考虑商品图像和用户评论文本等多模态信息, 进一步探索大模型如何赋能社会化推荐.
本文责任编委 林鸿飞
Recommended by Associate Editor LIN Hongfei
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|
| [40] |
|
| [41] |
|
| [42] |
|
| [43] |
|
| [44] |
|
| [45] |
|
| [46] |
|
| [47] |
|
| [48] |
|
| [49] |
|
| [50] |
|
| [51] |
|
| [52] |
|
| [53] |
|
| [54] |
|
| [55] |
|
| [56] |
|
| [57] |
|
| [58] |
|
| [59] |
|
| [60] |
|
| [61] |
|
| [62] |
|
| [63] |
|
| [64] |
|
| [65] |
|
| [66] |
|
| [67] |
|
| [68] |
|
| [69] |
|
| [70] |
|
| [71] |
|
| [72] |
|
| [73] |
|
| [74] |
|
| [75] |
|
| [76] |
|
| [77] |
|
| [78] |
|
| [79] |
|
| [80] |
|
| [81] |
|