{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于全局一致性增强的多偏好会话推荐模型
[吴江铭1  , 张晓堃
, 张晓堃1 , 徐博1 , 杨亮1 , 林鸿飞1 ]
, 张晓堃, 徐博, 杨亮, 林鸿飞]
|
|



作者简介:

吴江铭,硕士研究生,主要研究方向为推荐系统、自然语言处理等.E-mail:orangetc510@gmail.com.

张晓堃,博士研究生,主要研究方向为数据挖掘、推荐系统等.E-mail:dawnkun1993@gmail.com.

徐 博,博士,副教授,主要研究方向为信息检索、自然语言处理等.E-mail:xubo@dlut.edu.cn.

杨 亮,博士,副教授,主要研究方向为自然语言处理等.E-mail:liang@dlut.edu.cn.
基于会话的推荐旨在根据一组匿名会话预测用户下一个可能交互的物品.现有的基于图神经网络的会话推荐模型对全局信息的利用不足.为此,文中提出基于全局一致性增强的多偏好会话推荐模型(Global Consistency Augmented Multi-preference Session-Based Recommendation Model, GCAM).首先,在利用全局信息时,通过最短路径搜索算法构建一致性全局图,捕捉强依赖的物品关系,过滤不可靠的物品关系,从而保证全局信息的一致性.然后,应用一种多偏好标签平滑策略,从历史会话中充分挖掘协同信息,对标签进行平滑化,拟合用户偏好的真实分布.在3个数据集上的大量实验表明GCAM的优越性.
About Author:
WU Jiangming, Master student. His research interests include recommendation systems and natural language processing.
ZHANG Xiaokun, Ph.D. candidate. His research interests include data mining and recommendation systems.
XU Bo, Ph.D., associate professor. His research interests include information retrieval and natural language processing.
YANG Liang, Ph.D., associate professor. His research interests include natural language processing.
Session-based recommendation aims to predict the next item which a user is likely to interact with based on an anonymous session. However, existing session-based recommendation methods based on graph neural networks underutilize the global information. To address this issue, a global consistency augmented multi-preference session-based recommendation model(GCAM) is proposed. Firstly, a consistent global graph is constructed through the shortest path routing algorithm. The consistency of global information is ensured by capturing reliable item relationships and filtering out unreliable item relationships. Secondly, a multi-preference label smoothing strategy is applied to mine collaborative information from historical sessions to soften labels, and thereby the label can fit the true user preferences. Extensive experiments on three different datasets demonstrate the superiority of GCAM.
随着互联网上信息的爆炸式增长[1], 推荐系统变得至关重要, 因为它能从海量信息中提取用户真正感兴趣的个性化信息.推荐系统中传统的方法, 如协同过滤[2, 3], 通常依赖用户的个人信息和长期的交互历史以做出推荐.然而, 在很多实际场景中, 如在线购物平台和移动流媒体上, 可能无法获取这些信息[4].在用户信息不可知、用户长期历史行为难以获取的情况下, 为了准确建模用户的兴趣, 基于会话的推荐系统(Session-Based Recommendation, SBR)被提出, 它仅根据以时间顺序排列的匿名行为序列预测用户的下一步行为[5].
随着会话推荐相关研究的深入, 早期基于马尔可夫链[6]建模物品时序依赖关系的方法以及基于物品[7]、会话[8]相似度的最近邻方法逐渐被基于深度学习的方法替代.例如, 出现许多基于卷积神经网络(Convolutional Neural Networks, CNN)[9, 10]、基于循环神经网络(Recurrent Neural Network, RNN)[11, 12, 13, 14]、基于注意力机制[15]等的推荐方法.Hidasi等[11]将RNN应用于会话推荐算法, 利用门控循环单元(Gated Recurrent Unit, GRU)捕捉会话中的序列模式.Li 等[14]在文献[11]的基础上额外加入注意力机制, 提出 NARM(Neural Attentive Recommendation Machine).Liu 等[15]基于用户长期行为和当前兴趣, 提出STAMP(Short-Term Attention/Memory Priority).受Transformer[16]的启发, Kang等[17]提出SASRec(Self-Attention Based Sequential Recommendation Mo- del), 应用自注意力机制对用户历史行为建模, 捕捉序列中的物品相关性.
然而, 基于序列的方法仅通过建模相邻物品的序列模式以获取用户兴趣, 无法建模更复杂的物品间转换模式.因此, 学者们开始将会话建模为图, 使用图神经网络(Graph Neural Network, GNN)捕捉物品间的转换模式.因其强大的性能, 基于GNN的方法[18, 19, 20, 21]逐渐占据主流.Wu等[18]首先将GNN应用于会话推荐, 利用门控图神经网络(Gated Graph Neural Network, GGNN)学习物品间复杂的转换关系, 提出SR-GNN(Session-Based Recommendation with Graph Neural Networks).在SR-GNN的基础上, 为了解决GNN中缺少长距离依赖的问题, Xu等[20]结合自注意力机制, 提出GC-SAN(Graph Contextualized Self-Attention Model).Pan等[22]结合高速通路网络, 提出SGNN-HN(Star Graph Neural Networks with High- way Networks).Qiu等[23]设计加权的图注意力网络, 提出FGNN(Full Graph Neural Network).除了一般的图以外, Xia等[24]和Zhang等[25]还将超图引入会话推荐任务中, 以捕获物品间超越成对关系的高阶关系.
上述引入图结构先验知识的方法能增强会话推荐任务的表现, 此外, 基于GNN的方法取得成功还归因于其使用复杂的多层图或数据增强的图, 这是因为当前会话中的信息量有限, 这种方式能补充来自“ 跨会话” 的全局协同信息.例如:GCE-GNN(Glo-bal Context Enhanced Graph Neural Networks)[19]、 CGL(Collaborative Graph Learning)[21]、CA-TCN(Cross-Session Aware Temporal Convolutional Network)[26]均根据“ 会话内” 和“ 会话间” 物品的上下文信息构建一个全局图, 用于连接来自不同会话的物品, 并通过在全局图上进行信息聚合, 学习物品和会话的嵌入表示.Wang等[27]提出CSRM(Collaborative Session-Based Recommendation Machine), 通过门控网络自适应聚合来自邻居会话的协同信号, 获取“ 跨会话” 的全局信息.Han等[28]提出MGIR(Multi-faceted Global Item Relation), 学习与会话无关的多方面全局项目关系, 增强会话嵌入表示.
尽管现有的会话推荐方法利用当前会话以外的信息作为补充, 用于捕捉更准确的用户兴趣, 但仍忽略全局信息与局部会话信息的不一致性, 这种不一致性来自于全局图中引入的无关物品转换关系, 从而引入偏差, 影响推荐效果.
自监督学习[29, 30, 31]能从数据本身挖掘监督信号, 一定程度上缓解推荐系统的数据稀疏性问题, 因此广泛应用于许多关于推荐系统的工作中[32, 33, 34, 35, 36, 37].在基于协同过滤(Collaborative Filtering, CF)的推荐系统领域中, Wu等[32]提出SGL(Self-Supervised Graph Learning), 利用随机数据增强生成用户-项目图视图.Lin等[33]提出NCL(Neighborhood-Enriched Con-trastive Learning), 考虑不同的邻居进行对比.在序列/会话推荐中, Xie等[34]提出CL4SRec(Contrastive Learning for Sequential Recommendation), 引入序列数据增强技术, 将对比学习整合到序列表示学习中.通过使用图数据增强技术, 如删除节点或边扰动, Xia等[35]提出COTREC(Self-Supervised Graph Co-training Framework for Session-Based Recommenda-tion), 引入双通道超图, 捕捉成对之外的关系, 并应用自监督学习最大化两个会话表征之间的互信息.张莉等[36]提出解耦全局与局部偏好的会话推荐算法(Disentangling Global and Local Preference for Se-ssion-Based Recommendation, DGLSR), 对会话视图的全局与局部偏好进行对比式自监督学习, 实现解耦任务.王永贵等[37]提出融合自监督的协同注意图学习会话推荐模型(Recommendation Algorithm Based on Self-Supervised Co-attentive Graph Learning, SI-CAGL), 使用协同注意图学习与修改自注意力机制的方法进行自监督学习.
另外, 当前的会话推荐算法[14, 18, 19]通常假设每个会话仅对应单一偏好, 即使用目标物品对应的独热向量作为真实的用户偏好分布, 这种建模方式忽略用户偏好的多样性, 容易导致过拟合问题.
综上所述, 本文提出基于全局一致性增强的多偏好会话推荐模型(Global Consistency Augmented Multi-preference Session-Based Recommendation Model, GCAM).首先, 针对全局信息不一致的问题, 引入最短路径搜索算法, 搜索捷径边, 同时舍弃全局图中无关的物品连接, 过滤无关物品, 提高全局一致性, 从而构建一致性全局图(Global Consistent Graph, GCG).同时, 最短路径搜索的过程可视作全局图中边的稀疏化, 所以为了避免数据稀疏带来的问题, 还使用监督对比学习策略, 不同于之前工作[21, 38]中使用批次内随机样本作为负例的做法, GCAM挖掘困难负样本, 增强对比学习的效果.
其次, 针对用户偏好多样性的问题, 提出多偏好标签平滑(Multi-preference Label Smoothing, MLS)策略.目前绝大部分工作都使用独热向量作为用户唯一偏好, 为了缓解该方式带来的偏差和过拟合问题, 本文将相似历史会话的真实标签作为协同信号, 对标签进行平滑化, 与真实标签结合, 共同拟合多样的用户偏好.
令I={i1, i2, …, iN}表示物品集合, 其中N为物品数量.每个会话由按照时间顺序排序的物品组成, 定义为$s=[i_{1}^{s}, i_{2}^{s}, \cdots , i_{l}^{s}]$, 其中, l表示会话长度, $i_{j}^{s}$表示会话s中的第j个物品, 所有物品仅包含ID信息并表示为d维向量, 故物品集合可表示为X∈ RN× d.会话推荐的任务为根据给定的会话s, 预测下一个交互物品$i_{l+1}^{s}$.
为了捕捉会话中的所有物品关系, 本文定义一个全局有向加权图G=(V, ε ), 其中, V=I表示全体节点集合, 边集合ε ={ε ij}表示物品间的所有转化关系, ε ij表示节点vi到节点vj存在一条有向边, 即会话中先后出现ii、ij.每条边ε ij被赋予一个权重wij, 由相邻物品在所有会话中出现的频率决定.
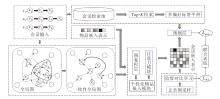
本文提出基于全局一致性增强的多偏好会话推荐模型(GCAM), 框架如图1所示.
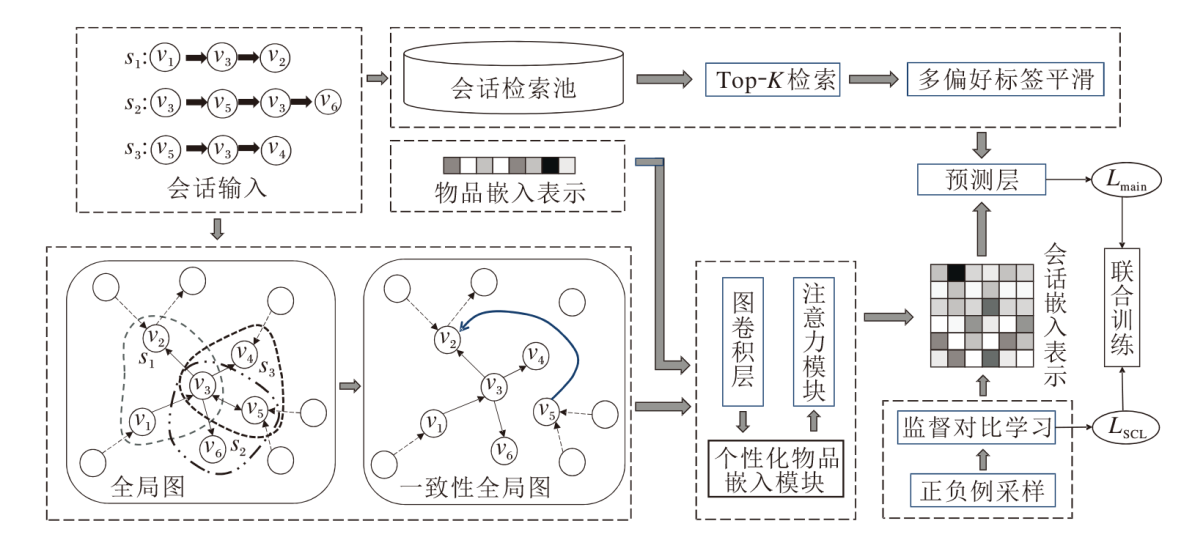 | 图1 GCAM框架图Fig.1 Framework of GCAM |
首先, 根据会话输入构建一致性全局图(GCG), 将该图作为个性化会话编码器(Personalized Se-ssion Encoder, PSE)的输入.然后, PSE联合监督对比学习模块(Supervised Contrastive Learning, SCL)和多偏好标签平滑(MLS)策略共同组成GCAM, 并通过多任务学习的方式联合训练.
2.1.1 一致性全局图
绝大多数基于GNN的会话推荐方法利用设计好的全局物品图作为GNN的建模对象, 但在设计中往往引入大量的邻居会话[13, 21, 27], 导致引入许多无关物品, 即破坏全局一致性.为了利用全局物品关系, 并且减少无关物品关系的影响, 本文在全局物品图构建过程中引入最短路径搜索算法, 寻找可靠的物品间捷径边, 缓解全局信息中的不一致性.
具体地, 受SPARE(Shortest-Path Relations)[39]启发, 本文采用类似的Dijsktra算法[40]高效进行最短路径搜索.将节点vi到节点vj的代价cij定义为所有边中的最大权重减去当前边的权重.根据定义的代价cij, 可基于路径中所有边的代价之和计算全局图G中每个节点到其它节点的最短路径.每个节点的感受野和图的稀疏度通过参数μ 控制, 故可过滤全局信息中不可靠的物品关系, 仅留下可靠的物品关系.通过最短路径搜索算法计算得到的边的代价:
${{\hat{c}}_{ij}}=\left\{ \begin{array}{* {35}{l}} {{\delta }_{ij}}, & {{\delta }_{ij}}\le \mu \\ 0, & {{\delta }_{ij}}> \mu \\ \end{array} \right.$
其中, 所有边的代价之和
${{\delta }_{ij}}=\overset{n-1}{\mathop{\underset{i=1}{\mathop \sum }\, }}\, {{c}_{i}}_{, i+1}$
是通过遍历所有可能节点, 并最小化长度为n的路径P={vi, vi+1, …, vj}得到.
最终的边权重定义如下:
${{\hat{w}}_{ij}}=\max \left( \overset{}{\mathop{C}}\, \right)-{{\hat{c}}_{ij}}$,
其中, $\overset{}{\mathop{C}}\, \in {{R}^{N}}^{\times N}$表示最终的代价矩阵, 每个元素${{\hat{c}}_{ij}}$表示从节点vi到节点vj的最小代价.
基于上述构建方法, 本文将物品间的协同信号通过最短路径边引入全局图中, 构成一致性全局图(GCG).之前的方法[19, 28]虽然引入全局图, 但也引入无关的物品转换边, 而GCAM可过滤这些冗余的边.同时, 通过这种方式引入的捷径边可保留物品间的重要性.该搜索过程可视为图神经网络多跳传播的高效实现.
2.1.2 个性化会话编码器
对于已构建好的GCG, 使用图卷积神经网络对其进行编码, 获取全局的物品嵌入表示:
$H={{\widehat{D}}^{-\frac{1}{2}}}\widehat{A}X{{\widehat{D}}^{-\frac{1}{2}}}$,
其中,
$\widehat{A}=A+I$,
A∈ RN× N表示邻接矩阵, I表示单位矩阵, X∈ RN× d表示物品嵌入矩阵, 再对$\widehat{A}$使用度矩阵$\widehat{D}$进行归一化.
不同于之前的方法[19, 28]使用注意力机制学习不同邻居间的重要性, 本文直接使用最短路径搜索算法得出的边权重作为邻居节点的重要性.这种方式不仅计算效率较高, 而且能充分利用从数据本身挖掘的节点关系.经过上述图卷积操作, 得到全局的会话图表示:
${{H}_{s}}=[{{h}_{v_{1}^{s}}}, {{h}_{v_{2}^{s}}}, \cdots , {{h}_{v_{l}^{s}}}]$.
本文也引入广泛应用的反向位置编码[19, 24, 28]建模会话中的序列关系.由于会话之间的长度不同, 相比一般的位置编码, 反向位置编码更能反映物品在会话中的重要性.对于长度为l的会话, 可学习的位置嵌入矩阵如下:
P=[p1, p2, …, pl],
其中pl-i+1对应会话中第i个物品的位置编码.通过向量拼接操作‖ 和非线性激活函数tanh将位置信息引入物品嵌入表示中, 即
$h_{i}^{g}=\tanh ({{W}_{1}}[{{h}_{v_{i}^{s}}}\|{{p}_{l}}_{-i+1}]+{{b}_{1}}), $ (1)
其中W1∈ Rd× 2d和b1∈ Rd为可学习参数.
注意到式(1)中的物品嵌入仅利用全局物品层级的上下文关系, 即全局的物品嵌入表示和具体会话中的位置关系.仅依靠位置编码难以表达不同用户对不同物品的兴趣差异, 故本文还引入会话层级的物品表示, 用于构建个性化物品嵌入(Persona-lized Item Embedding, PIE)表示, 从而捕捉动态变化的用户意图.
受文献[41]的启发, 本文向会话图中加入一个虚拟节点$\tilde{v}$, 用于连接单个会话图中的所有节点, 嵌入表示hs用于捕捉会话层级的用户兴趣.然后, 利用一个门控网络融合全局层级的物品嵌入和会话层级的物品嵌入, 最终得到PIE表示:
${{h}_{i}}=(1-{{\lambda }_{i}})h_{i}^{g}+{{\lambda }_{i}}{{h}^{s}}$,
其中
${{\lambda }_{i}}=Sigmoid\left( \frac{{{({{W}_{2}}h_{i}^{g})}^{\text{T}}}\left( {{W}_{3}}{{h}^{s}} \right)}{\sqrt{d}} \right)\in (0, 1)$,
表示门控权重, W2∈ Rd× d, W3∈ Rd× d表示可学习参数,
最后, 聚合会话中各物品的个性化嵌入表示, 得到最终的会话表示z, 本文使用广泛应用的软注意力机制[24, 28]进行聚合:
$z=\overset{l}{\mathop{\underset{i=1}{\mathop \sum }\, }}\, {{\alpha }_{i}}{{h}_{i}}$,
其中,
α i=qTSigmoid(W4hi+W5hs+b4)∈ (0, 1),
表示会话中每个物品的注意力权重, W4∈ Rd× d, W5∈ Rd× d, q∈ Rd, b4∈ Rd表示可学习参数.
2.1.3 多偏好标签平滑模块
大部分现有工作[18, 19]都使用标签对应的独热向量作为用户偏好的真实分布, 这可能难以反映用户的真实偏好, 并且可能带来过拟合问题.本文提出多偏好标签平滑(MLS)策略, 从历史会话中挖掘与当前会话的行为模式最相近的会话, 将其标签作为协同标签, 对独热标签进行平滑化.
MLS策略维护一个固定大小为T的会话检索池, 当给定一个会话s, 从中检索与会话s最相似的K个会话.为了提高检索效率, 应用SimHash[42]技术, 将会话嵌入作为SimHash函数的输入, 并生成二进制签名.Chen等[43]指出, 如果输入向量彼此相似, 那么SimHash的输出就满足局部敏感属性, 即输出也相似.在具体实现中, 首先将会话嵌入z投影到低维空间, 再使用hash函数将其映射为二进制签名:
e=hash(Hzs),
其中, H∈ Rd× m, m< d, 表示随机生成的固定投影矩阵.然后, 计算向量之间的汉明距离, 从会话检索池中选取与当前会话s最相似的前K个会话:
${{Y}_{s}}, w{{'}_{s}}=topK\left( -HammingDistance\left( e, \hat{e} \right) \right)$,
${{w}_{s}}\text{=}normalize(w{{'}_{s}})$,
其中,
$\hat{e}=hash\left( H{{{\hat{z}}}_{s}} \right)$,
$\hat{z}$表示会话检索池中的会话嵌入.Ys={ys, 1, ys, 2, …, ys, K}表示检索结果中所有会话的独热标签, ws={ws, 1, ws, 2, …, ws, K}表示归一化后的相似度权重.根据检索结果和会话s的原标签y, 构建出平滑后的新标签:
$\hat{y}=y+\beta \overset{K}{\mathop{\underset{i=1}{\mathop \sum }\, }}\, {{w}_{s}}_{, 1}{{y}_{s}}_{, i}$,
其中, β 表示可调整的超参数, 用于控制协同标签的平滑程度.
2.1.4 预测模块
会话推荐系统常伴随长尾分布的问题[44], 一个常见的做法是在预测层之前, 对物品和会话嵌入进行一次L2正则化, 本文也引入同样的正则化方法.通过预测模块得到在全体物品集上的打分yp, 并使用KL散度作为损失函数:
${{L}_{main}}=KLD(\tilde{y}, {{y}_{p}})=\overset{\left| I \right.~|}{\mathop{\underset{i=1}{\mathop \sum }\, }}\, \tilde{y}{{\log }_{2}}\left( \frac{\tilde{y}~}{{{y}_{p}}} \right)$, (2)
${{y}_{p}}=Softmax(z_{s}^{T}{{x}_{i}})$,
优化模型整个主要监督学习模块.
相比之前一些使用独热标签和交叉熵损失的工作, GCAM能产生相对平滑的标签分布, 捕捉更广泛的用户偏好, 并且防止模型过拟合.
以往将自监督学习应用于会话推荐的工作[24, 35]使用单个会话的不同视图作为监督正向信号(正样本), 使用批次中其它会话的视图作为负向信号(负样本), 并使用InfoNCE[45]进行学习.本文从训练数据的目标信息出发, 根据会话推荐任务的特点挖掘正样本和困难负样本, 称为困难负样本增强的监督对比学习.
基于文献[15]得出的结论:在会话推荐场景中, 最后一次点击的物品对预测下一物品最重要, 所以本文从与当前会话s具有相同标签的会话中随机采样k条作为正样本, 记为
根据InfoNCE, 结合会话上下文, 最大化最后点击的物品和目标物品的表示, 学习目标定义如下:
${{L}_{SCL}}=-{{\log }_{2}}\left( \frac{\mathop{\sum }_{\ i\in\ c_{k}^{{{s}^{+}}}}\ {{\psi }_{\tau }}\ \left(\ h_{s}^{last},\ {{z}_{s}},\ \ {{h}^{i}} \right)}{\mathop{\sum }_{i\in\ c_{k}^{{{s}^{+}}}}\ {{\psi }_{\tau }}\ \left(\ h_{s}^{last},\ {{z}_{s}},\ {{h}^{i}} \ \right)+\ \mathop{\sum }_{j\in\ c_{k}^{{{s}^{-}}}}\ {{\psi }_{\tau }}\ \left(\ h_{s}^{last},\ {{z}_{s}},\ h{{~}^{j}} \ \right)} \ \right)$, (3)
其中, $h_{s}^{\text{last}}$表示会话s最后时刻点击的物品的嵌入表示, ψ τ (x1, x2, x3)定义为温度系数为τ 的判别函数
$\exp \left( \frac{{{f}_{D}}\left( {{x}_{1}}+{{x}_{2}}, {{x}_{2}}+{{x}_{3}} \right)}{\tau } \right)$.
本文选择余弦函数作为计算两个向量一致性的判别函数fD(· ).这种对比学习方法优化最后点击的物品和目标物品的表示, 使模型能更有效区分正样本会话和“ 类似但目标物品不同的会话” 的场景.
根据式(2)和式(3), 分别得到主要监督学习损失和监督对比学习损失, 结合两者, 得到最终的损失:
L=Lmain+η LSCL,
其中η 表示平衡参数.
最后, 使用随时间反向传播(Back-Propagation Through Time, BPTT)优化最终的损失L.
本文在Tmall、LastFM、RetailRocket这3个常见的公开数据集上进行实验.Tmall数据集(https://tianchi.aliyun.com/dataset/dataDetail?dataId=42)包含在线购物平台的用户行为日志.LastFM数据集(http://ocelma.net/MusicRecommendationDataset/lastfm-1K.html)包含用户在音乐平台上的历史行为记录.RetailRocket数据集(http://ocelma.net/MusicRecommendationDataset/lastfm-1K.html)是由Kaggle竞赛发布的数据集, 包含六个月内的用户浏览行为.
本文根据之前工作[18, 19]采用的数据预处理方法对3个数据集进行预处理, 过滤长度为1的会话以及出现次数小于5次的物品, 截断长度超过50的会话.时序上最近的数据作为测试集, 其余作为训练集.此外, 还应用常见的数据增强方法:会话
s=[i1, i2, …in]
扩展成n-1条会话数据
([i1], i2), ([i1, i2], i3), …, ([i1, i2, …in-1], in),
其中截断的最后一个物品作为该会话的标签.预处理后的数据集统计信息如表1所示.
| 表1 数据集统计信息 Table 1 Statistics of datasets |
选取精确率P@k(Precision)和平均倒数排名M@k(Mean Reciprocal Rank, MRR)作为评价指标, 在3个数据集上, k值都取为20.
本文设置嵌入大小为100, 所有参数均使用均值为0、标准差为0.1的高斯分布进行初始化.使用Adam(Adaptive Moment Estimation)优化器, 设置学习率为1e-3, L2正则化系数为1e-5, 训练批量大小为100.此外, 设置学习率衰减策略, 每训练4个迭代周期, 学习率变为原来的十分之一.标签平滑系数
β =0.01, 0.1, 0.5, 1, 5, 10, 15, 20,
监督对比学习损失权重
η =0.001, 0.01, 0.05, 0.1, 0.15, 0.2, 0.25, 0.3, 0.4, 0.5,
对比学习采样数量
k=1, 2, 4, 8, 16, 32, 64, 128.
实验均在如下机器环境中完成:Python3.8.0、Pytorch1.10.1、Geforce RTX 3080.
本文选取目前具有代表性的一些会话推荐模型作为对比的基准模型.
1)文献[7]模型.向用户推荐与最后一次交互最相似的物品.
2)FPMC(Factorized Personalized Markov Chains Model)[6].基于一阶马尔可夫链和矩阵分解的经典方法, 捕捉成对的物品转换关系.
3)文献[11]模型.使用并行批处理技术和基于排序的损失函数训练, 利用GRU捕获用户行为的序列模式.
4)NARM[14].基于RNN的方法, 使用GRU建模序列行为, 利用注意力机制捕获用户的主要意图.
5)STAMP[15].完全基于注意力机制的方法, 捕捉长期用户兴趣和短期用户兴趣.
6)SR-GNN[18].将图神经网络应用于会话推荐任务的模型, 使用门控图神经网络学习物品嵌入, 利用注意力机制学习用户嵌入.
7)FGNN[23].将会话转化为有向图, 利用图注意力层学习物品嵌入.
8)GCE-GNN[19].构建会话层级的图和全局的共现图, 捕捉物品的局部信息和全局信息.
9)S2-DHCN(S2-Dual Channel Hypergraph Con-volutional Networks)[24].利用超图捕捉高阶物品关联, 引入自监督学习任务作为辅助任务, 改进推荐效果.
10)MGIR[28].通过学习多方面的会话无关的全局物品关系以增强会话嵌入表示.
11)COTREC[35].采用一种自监督联合训练的方式学习, 利用物品层级和会话层级的两种视角构建对比学习任务.
12)MTD(Multi-level Transition Dynamics)[46].整合一种考虑位置的双阶段注意网络和图层次关系编码器, 捕捉会话内的关系和跨会话的高阶项关系.
13)MTAW(Mining Interest Trends and Adap-tively Assigning Sample Weight)[47].挖掘用户兴趣的变化趋势, 自适应调整样本权重, 使用注意力机制捕捉用户的即时兴趣.
为了验证GCAM在3个数据集上的性能, 进行对比实验, 具体实验结果如表2所示, 表中黑体数字表示最优值, 斜体数字表示次优值.
| 表2 各算法在3个数据集上的指标值对比 Table 2 Index value comparison of different algorithms on 3 datasets % |
由表2可见, 基于KNN的文献[7]模型及基于马尔可夫链和矩阵分解的FPMC都属于传统算法, 表现远不如基于RNN的算法, 如文献[11]模型、NARM, 这表明使用RNN建模会话中序列信息的有效性.NARM和STAMP额外引入注意力机制学习物品重要性, 相比文献[11]模型, 各项指标都得到大幅提升.然而这些算法都不如基于GNN的会话推荐算法, 如SR-GNN.这些基于图的算法加入图结构的先验知识, 能捕捉复杂的项目转换关系.其中S2-DHCN、COTREC和MTD都使用对比学习作为辅助任务, 增强物品或会话的嵌入表示, 取得较有竞争力的实验结果, 由此说明自监督学习在会话推荐任务上的有效性.GCE-GNN和MGIR都探索如何利用跨会话的全局信息, 相比仅使用会话内信息的SR-GNN, 性能取得较大提升, 尤其是MGIR在3项指标上取得次优值.MTAW代表会话推荐领域的最新进展, 在2项指标上取得次优值, 在1项指标上取得最优值, 但GCAM在数据集上的整体表现仍略占优势.
GCAM在大部分指标上均取得最优值, 在LastFM数据集上的提升幅度最大, 分别在P@20和M@20指标上取得7.09%和6.49%的提升, 在Tmall数据集上P@20指标也取得7.96%的提升.注意到GCAM在Retailrocket数据集上的提升幅度较小, 但性能整体上与MTAW基本持平.
表2结果表明GCAM的优越性, 构建一致性全局图能在引入跨会话信息的同时过滤无关的物品关系, 通过对比学习和门控网络可进一步增强嵌入表示, 使用多偏好标签平滑策略能有效捕捉多样的用户偏好且避免过拟合问题.
为了探索GCAM各模块对算法整体的贡献, 设计变体以验证各模块的有效性, 具体包括:舍弃多偏好标签平滑模块(记为GCAMw/o[MLS])、舍弃监督对比学习模块(记为GCAMw/o[SCL])、舍弃个性化物品嵌入表示模块(记为GCAMw/o[PIE])和舍弃一致性全局图模块的变体(记为GCAMw/o[GCG]).
GCAM及各变体在3个数据集上的指标值如表3所示, 表中黑体数字表示最优值, 斜体数字表示次优值.由表可看出各模块都对算法整体表现有所贡献.
| 表3 GCAM及各变体在3个数据集上的消融实验结果 Table 3 Ablation studies of GCAM and its variants on 3 datasets % |
除了Retailrocket数据集的P@20指标以外, 其它所有指标的次优值都来自GCAMw/o[GCG], 表明通过最短路径搜索算法构建一致性全局图, 可有效过滤无关物品关系, 增强性能.在Retailrocket数据集的P@20指标上, GCAMw/o[GCG]取得最优值, 但对应的M@20指标却大幅降低, 这可能是因为最短路径搜索算法在全局图中总是保留最重要的边, 导致头部物品学习得更好, 从而排名靠前, 继而提高P@20指标, 但可能会牺牲一定精确率, 导致M@20指标下跌.相比GCAM, GCAMw/o[MLS]、GCAMw/o[SCL]和GCAMw/o[PIE]的各指标值都有一定程度的跌幅, 这表明多偏好标签平滑模块、监督对比学习模块及个性化物品表示模块的有效性.
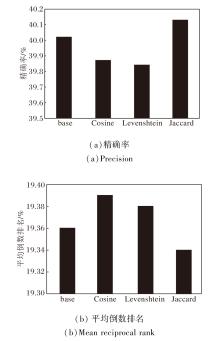
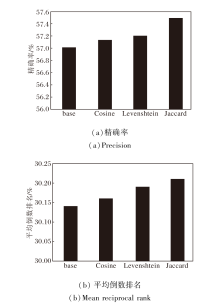
基于邻居的会话推荐方法[8, 13]常依赖会话间的相似度计算过滤无关会话, 为了验证本文使用Jaccard距离作为会话相似度的度量方法的有效性, 对比GCAM在使用不同相似度度量方法计算对比学习样本时的表现.本文将不含监督对比学习模块的变体(记为GCAMw/o[SCL])作为基准, 记为base, 与用于度量集合距离的余弦距离(记为Cosine)、Jaccard距离(记为Jaccard)、度量字符串编辑距离的Damerau-Levenshtein距离(记为Levenshtein)[48]进行对比, 具体实验结果如图2和图3所示.
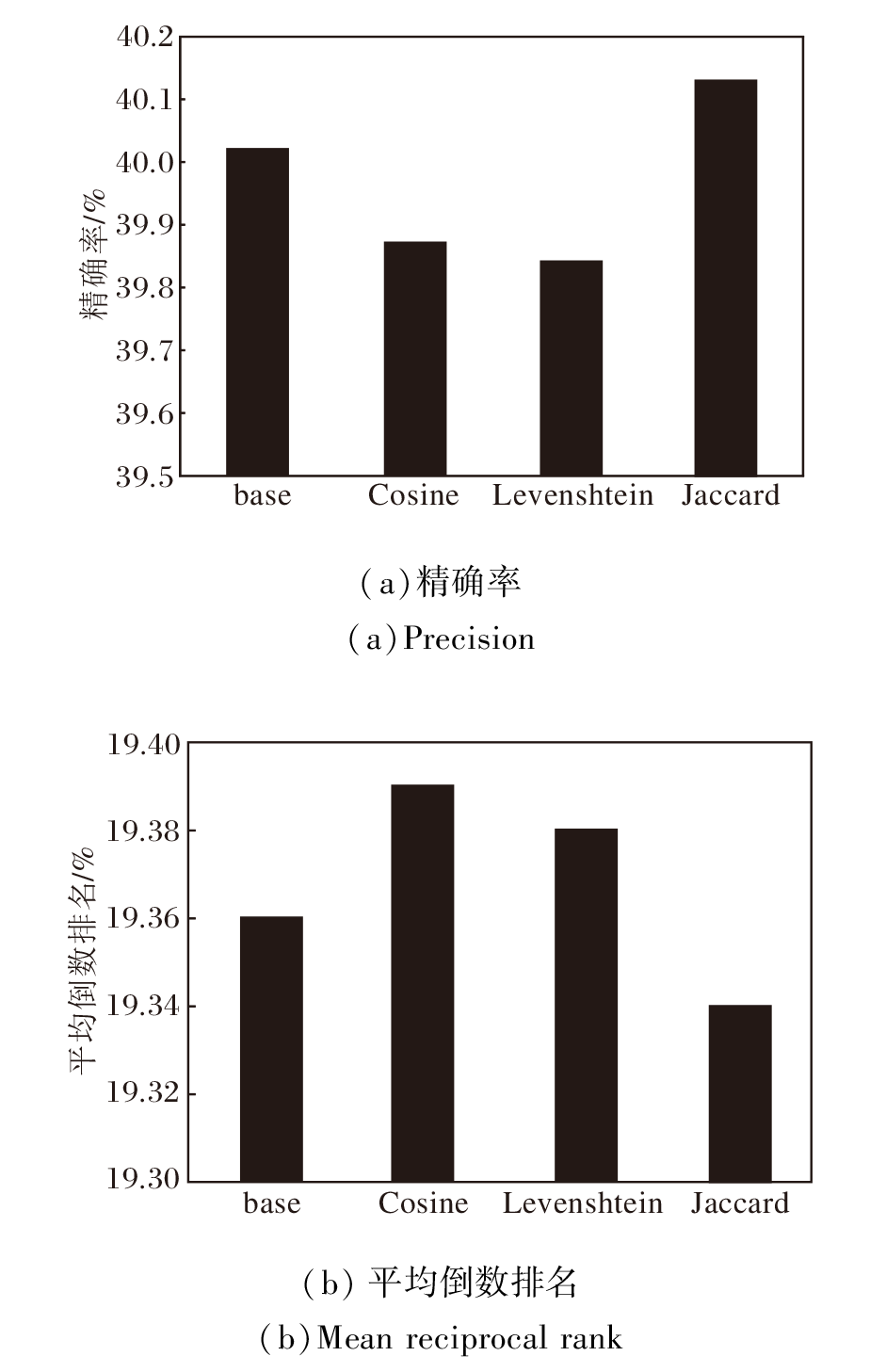 | 图2 Tmall数据集上不同度量方法的影响Fig.2 Effect of different metric methods on Tmall dataset |
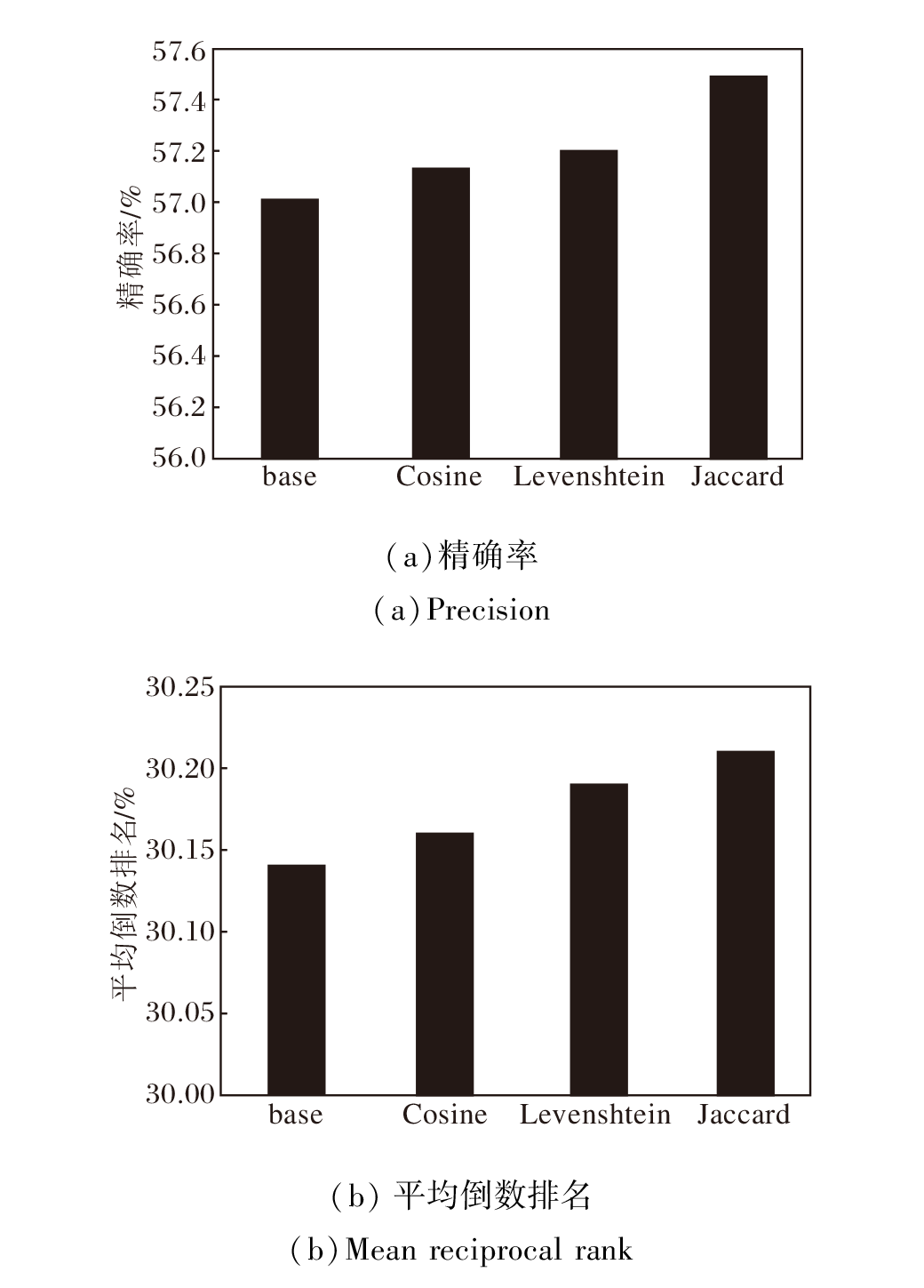 | 图3 Retailrocket数据集上不同度量方法的影响Fig.3 Effect of different metric methods on Retailrocket dataset |
由图2和图3可见, 在Tmall、RetailRocket数据集上, 大多数度量方法性能都比base有所提高, 余弦距离表现优于基于序列关系的Damerau-Levensh-tein距离, 这说明使用监督对比学习的积极作用, 同时也说明Jaccard距离更适合作为度量会话之间相似度的方法.
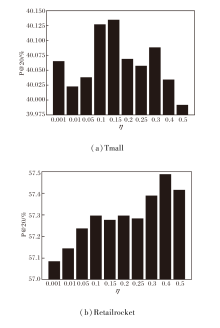
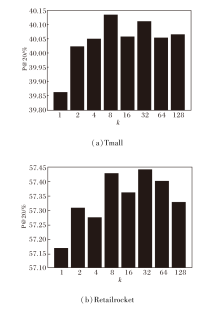
本文进一步研究3个关键超参数的影响.
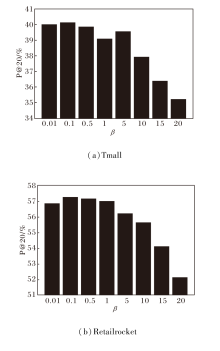
标签平滑系数
β =0.01, 0.1, 0.5, 1, 5, 10, 15, 20
时, 在Tmall、Retailrocket数据集上的P@20指标值如图4所示.由图可知, β =0.1时, 在2个数据集上都取得最优值, 当β 继续增大时, 效果逐渐劣化, 这是因为此时真实标签被过度平滑, 引入过多协同信息而过度弱化真实值.
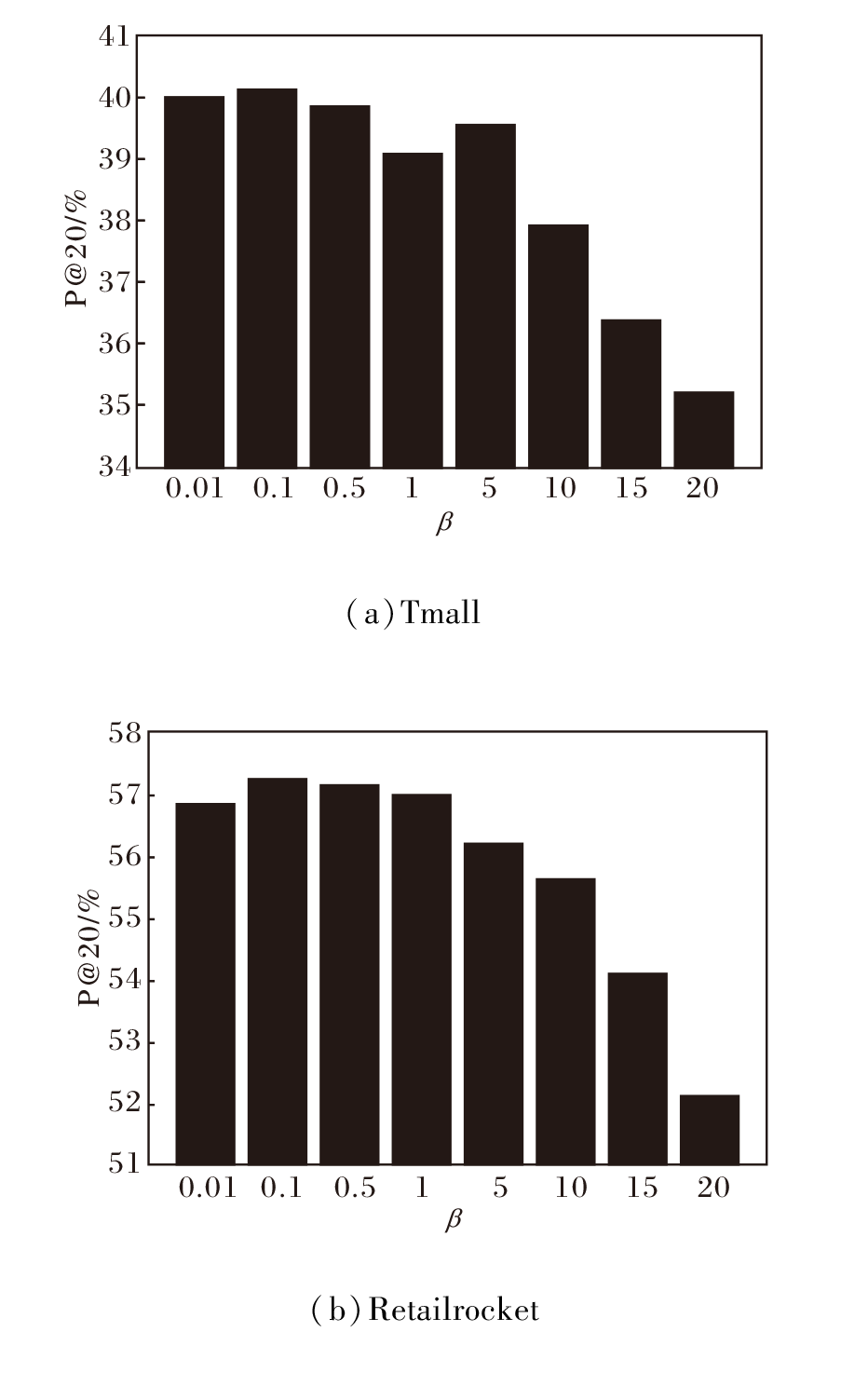 | 图4 β 不同时P@20指标值对比Fig.4 Comparison of P@20 with different β |
监督对比学习损失权重
η =0.001, 0.01, 0.05, 0.1, 0.15, 0.2, 0.25, 0.3, 0.4, 0.5
时, 在Tmall、Retailrocket数据集上的P@20指标值对比如图5所示.
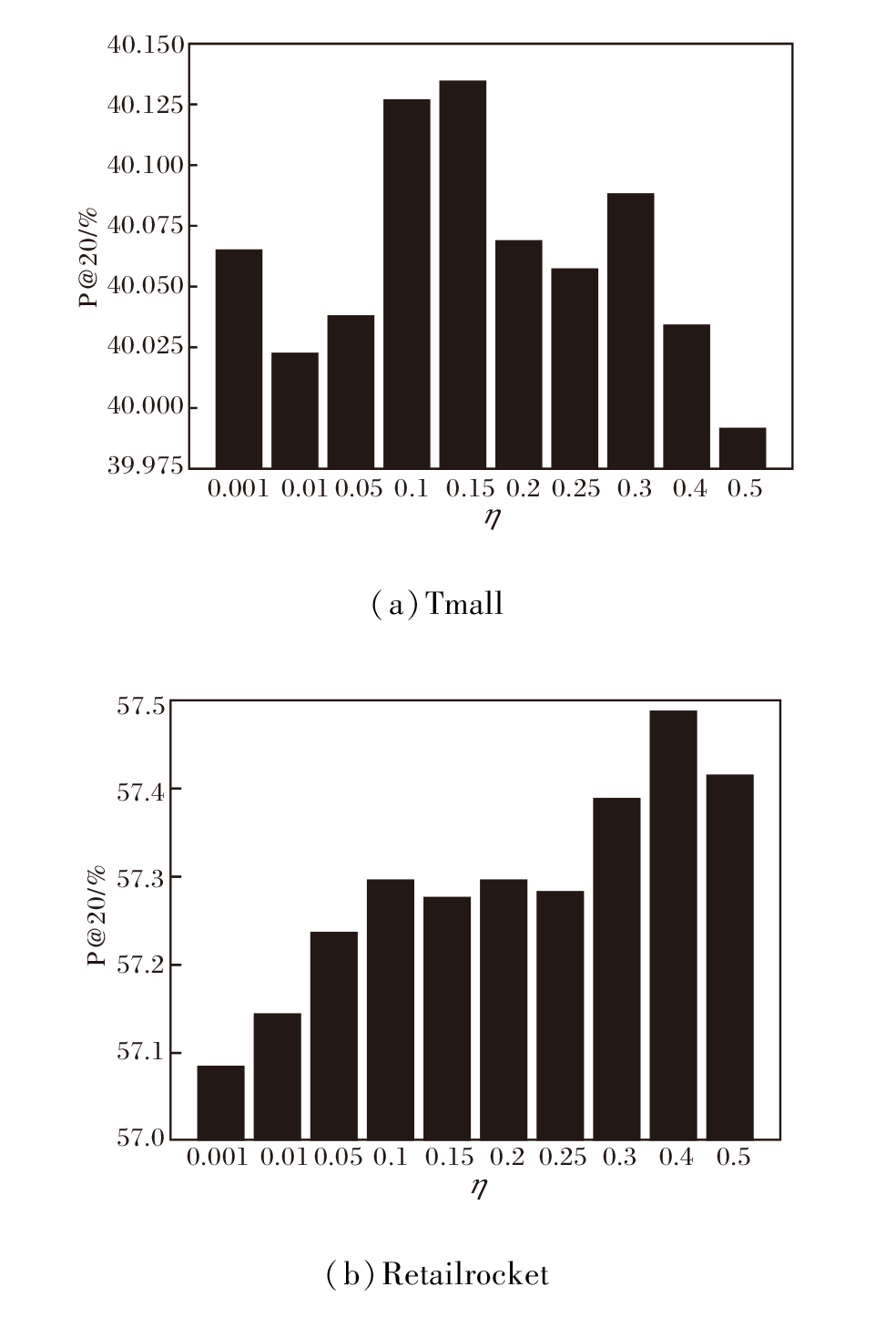 | 图5 η 不同时P@20指标值对比Fig.5 Comparison of P@20 with different η |
由图5可见, η =0.15, 0.4时, 在Tmall、Retail-rocket数据集上取得最优值.当训练过程过度侧重于对比学习任务或几乎不考虑对比学习任务时, 算法表现都欠佳, 当权重η 取到适当值时能平衡主要推荐任务和对比学习任务, 达到共同优化的效果.
对比学习采样数量
k=1, 2, 4, 8, 16, 32, 64, 128
时, 在Tmall、Retailrocket数据集上的P@20指标值对比如图6所示.由图可见, k=8, 32时, 分别在Tmall、Retailrocket数据集上取得最优值.在Tmall数据集上, k取值较小时能高效且高精度地完成推荐任务, 在Retailrocket数据集上, 需要较大的k值.
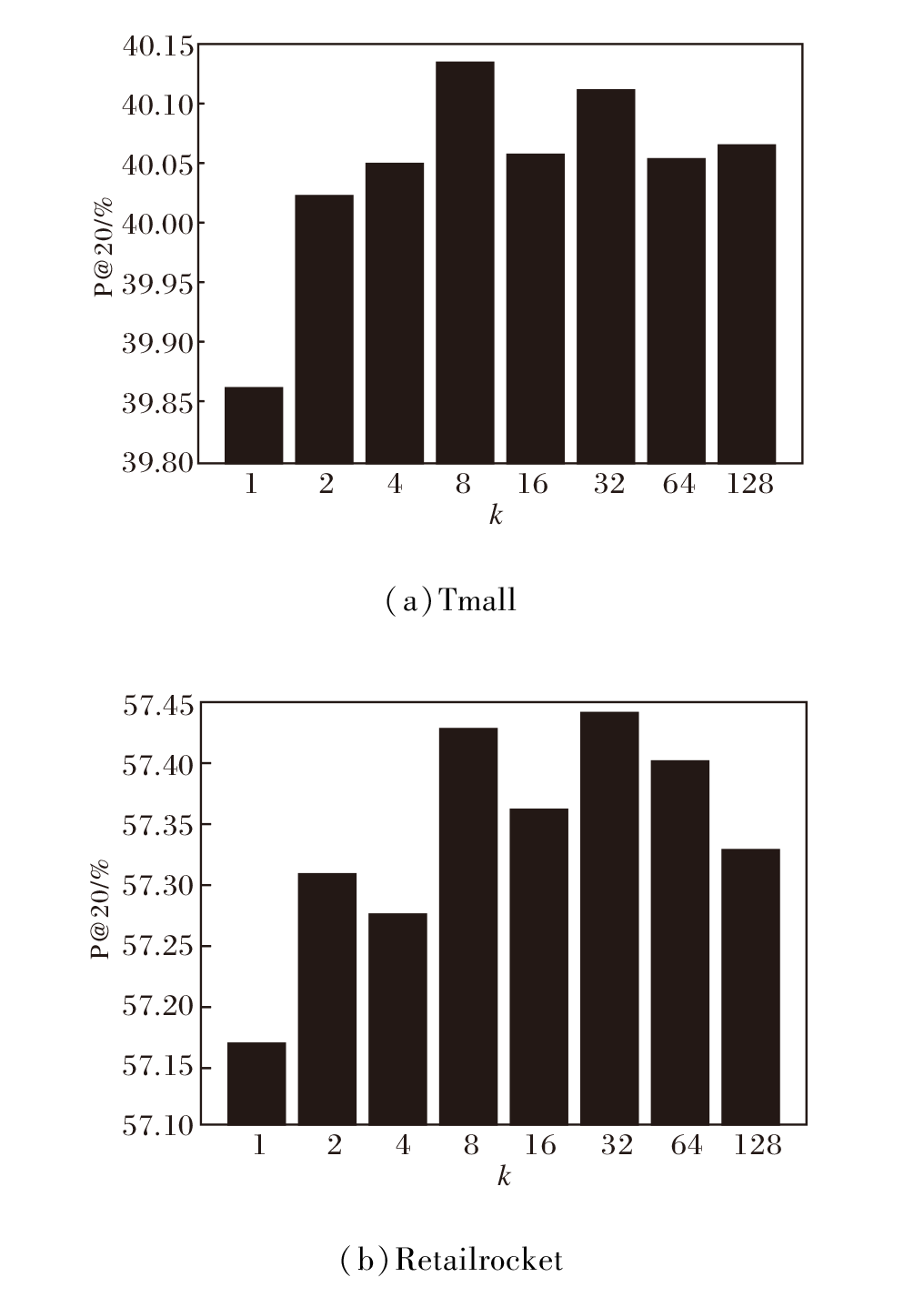 | 图6 k不同时P@20指标值对比Fig.6 Comparison of P@20 with different k |
本文提出基于全局一致性增强的多偏好会话推荐模型(GCAM), 通过最短路径搜索算法引入捷径边, 构建一致性全局图, 同时过滤全局信息中的无关信息.为了拟合用户偏好的多样性, 提出多偏好标签平滑策略.实验表明GCAM能有效利用跨会话的全局信息, 拟合用户多样性的偏好.在3个公开数据集上取得目前最优的效果.今后可继续探索构建多粒度的一致性全局图, 捕捉多层次的用户兴趣, 并且针对会话推荐中的流行度偏差做出优化.
本文责任编委 梁吉业
Recommended by Associate Editor LIANG Jiye
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|
| [40] |
|
| [41] |
|
| [42] |
|
| [43] |
|
| [44] |
|
| [45] |
|
| [46] |
|
| [47] |
|
| [48] |
|