
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于平滑图掩码编码器的顺序推荐模型
[刘洋1  , 夏鸿斌
, 夏鸿斌1, 2 , 刘渊1, 2 ]
, 夏鸿斌, 刘渊]
|
|



作者简介:

刘 洋,硕士研究生.主要研究方向为推荐系统、深度学习.E-mail:526047174@qq.com.

刘 渊,博士,教授,主要研究方向为网络安全、社交网络.E-mail:lyuan1800@sina.com.
针对现有顺序推荐模型在处理推荐任务时由于数据集标签稀缺和用户交互数据噪声导致性能降低的问题,提出基于平滑图掩码编码器的顺序推荐模型(Smoothing Graph Masked Encoder Recommender System, SGMERec).首先,设计数据平滑编码器处理数据,提升数据质量,降低极端值和数据噪声的负面影响.然后,设计图掩码编码器,自适应提取全局项目的转换信息,构造关系图帮助模型补全缺失的标签数据,提高模型对于标签稀缺问题的应对能力.最后,运用批标准化,归一化每个神经网络层的输入分布,确保每层输入的分布相对稳定,降低用户序列的稀缺标签比例.在3个真实数据集上的实验表明,SGMERec具有一定的性能提升.
About Author:
LIU Yang, Master student. His research interests include recommendation systems and deep learning.
LIU Yuan, Ph.D., professor. His research interests include network security and social network.
Aiming at the performance degradation problem of existing sequential recommendation models caused by label sparsity and user data noise, a sequential recommendation model based on smoothing graph masked encoder(SGMERec) is proposed. Firstly, a data smoothing encoder is designed to process the data, improve data quality and reduce the negative impact of extreme values and data noise. Secondly, a graph masked encoder is designed to adaptively extract transformation information from global items and a relational graph is constructed to help the model complete the missing label data, thereby enhancing the ability to deal with issues of label scarcity. Finally, batch normalization is employed to normalize the input distribution of each neural network layer. Thus, the stability of input distribution for each layer is guaranteed and the proportion of scarce labels in user sequences is reduced. Experimental results on three real datasets indicate the performance improvement of SGMERec.
用户在网络平台上进行操作和选择(如购物选择等)时, 其行为具有明显的时间序列性质, 同时用户的兴趣也会随时间而变化.顺序推荐就是根据用户的历史行为和偏好, 向其提供一系列按照特定顺序排列的推荐结果.顺序推荐通常考虑项目的顺序对用户产生的影响, 以及用户在不同时间点可能对不同项目的需求[1, 2].这项技术吸引相当多学者的关注, 因为用户的偏好在现实生活中是随时间变化的, 如电子商务和视频网站[3, 4].为了获得商品之间更精准的链接关系, 学者们对图神经网络(Graph Neural Network, GNN)进行更深层次的研究, 提出各种图神经网络, 用于在相似选项之间递归传播信息以改进推荐系统[5, 6].
顺序推荐模型近年来取得一系列进展, 但仍受到数据标签稀缺性和用户交互数据噪声问题的严重影响.
标签稀缺问题是指由于用户行为数据稀疏或物品标签信息不完整, 推荐模型无法准确建模某些物品或用户.在顺序推荐模型中, 用户行为序列通常呈现长尾分布, 大多数用户只与少量商品或视频互动, 在实际应用中难以获取足够的标签数据, 模型无法准确理解用户兴趣和物品特性, 导致性能下降, 推荐精准度降低[7].
数据噪音问题是指在推荐模型中存在的数据不准确、不完整或带有误导性的情况, 这些数据会增加数据分析的难度, 对准确性和性能产生负面影响[8].在顺序推荐中, 模型依赖用户的历史行为数据、偏好及其它相关信息, 为用户提供一个有序的推荐序列, 面对数据噪声, 顺序推荐模型会过拟合噪声标签, 导致性能下降[9, 10].
为了解决标签稀缺和数据噪声问题, 有研究者融合对比学习与顺序推荐, 为顺序推荐中的自监督学习提供辅助增强信号[11, 12].Xie等[13]提出CL4SRec(Contrastive Learning for Sequential Recommendation), 采用随机项目屏蔽和重新排序, 但若数据集上各项目标签不满足对比学习模型的要求, 模型性能也会显著下降.Ye等[14]提出MAERec(Graph Masked Auto-encoder-Enhanced Sequential Recommender System), 通过图掩码的自动编码器自适应动态提取全局项目过滤信息, 增强自监督信号, 有选择性地屏蔽具有更高帮助性的项目转换路径, 并输入图自动编码器进行重构.但是MAERec在编码器输入时, 仍会因数据噪声问题导致编码不规则, 在基于图掩码的自监督学习时, 因为标签稀缺生成的掩码可读性不高, 导致模型泛化性较低.
受MAERec的启发, 本文提出基于平滑图掩码编码器的顺序推荐模型(Smoothing Graph Masked Encoder Recommender System, SGMERec).首先, 在图掩码编码器的基础上添加数据平滑技术, 减少推荐模型中由于数据波动、噪声和异常值引起的不稳定性, 准确捕捉用户的行为趋势, 提高性能和推荐精准度.然后, 在图掩码的生成环节添加批标准化技术, 使生成的掩码子图具有更高的可读性, 提升整体模型的泛化性和鲁棒性.最后, 在掩码生成和编码器上添加动态规划正则化等技术, 以此控制模型复杂度, 平衡准确性和稳定性, 缓解长期依赖问题, 提升模型在时间序列数据上的推荐效果和性能.
传统的推荐模型主要基于内容和协同过滤, 忽略用户行为的时间序列信息.为了解决这一问题, 研究者开始使用Transformer和BERT(Bidirectional Encoder Representations from Transformer)等复杂神经网络架构, 捕捉长距离依赖关系, 理解用户行为序列的上下文信息.随着技术的发展, 出现更多编码序列行为模式的方法, 如递归神经网络(Recurrent Neu-ral Network, RNN)和卷积神经网络(Convolutional Neural Network, CNN)[15, 16].此外, 随着GNN的发展, 学者们在GNN的框架上建立图增强表示编码器, 通过多层消息传递捕获用户的长期序列偏好, 如SR-GNN(Session-Based Recommendation with GNN)[17] 、GCE-GNN(Global Context Enhanced GNN)[5]和SURGE(Sequential Recommendation with GNN)[18].然而, 大多数现有的监督方法都面临标签稀疏性问题, 限制推荐系统在实际应用中的性能.
对比学习在顺序推荐中是一种有效的学习方法, 通过对比用户的行为反馈以提高推荐模型的效果.在顺序推荐中, 通常会对比用户当前选项与其后续可能选项之间的差异, 以此调整推荐模型, 更贴近用户的真实偏好[19].对比学习在顺序推荐中的应用场景非常广泛.例如:在视频点播平台中, 可通过对比用户当前观看的视频与其后续观看的视频之间的关联性以改进推荐效果[20].
近年来许多顺序推荐模型都采用对比模型.例如:CL4SRec[13]使用序列随机掩蔽和重新排序操作, 建立增强的对比视图; DuoRec[11]应用模型级增强.
数据平滑(Date Smoothing)在顺序推荐中用于平滑推荐模型中的用户行为数据, 减少数据中的波动和噪声, 使其更具有可读性, 适用于进一步分析, 有助于提取数据中的趋势和联系, 提升模型性能和稳定性[21].
用户兴趣经常发生变化, 因此在顺序推荐中, 需要对用户兴趣进行平滑处理, 以便更好地理解用户行为的变化趋势.常见的方法是使用指数平滑法或移动平均法对用户偏好进行平滑处理, 通过加权计算用户历史行为数据的平均值, 减少突发行为的影响.物品流行度也是一个关键因素, 用于衡量物品的受欢迎程度.对于物品流行度数据, 可使用指数平滑法对物品的点击次数或购买次数进行平滑处理, 减少异常值的影响, 得到更准确的物品流行度估计[22, 23].
批标准化(Batch Normalization)是在深度学习模型中使用的一种正则化技术, 在顺序推荐中旨在改善模型的稳定性和泛化能力.顺序推荐涉及分布随时间变化的序列数据, 批标准化可使神经网络快速适应动态变化.批标准化将每层的输入规范化到固定的分布范围内, 以此解决梯度消失和梯度爆炸问题, 使神经网络稳定学习用户的行为模式, 提高推荐的准确性[24].
在顺序推荐模型中, 由于用户行为序列长度不一致, 批标准化需要将用户行为序列的长度进行截断或填充, 使每批次的输入样本长度相同, 再对每批次的输入样本进行批标准化处理.具体做法包括使用移动平均或指数加权移动平均估计数据的统计特性, 并在训练过程中动态更新均值和标准差[25, 26].
推荐模型
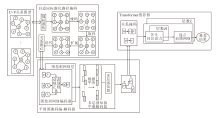
本文提出基于平滑图掩码编码器的顺序推荐模型(SGMERec), 具体结构如图1所示.
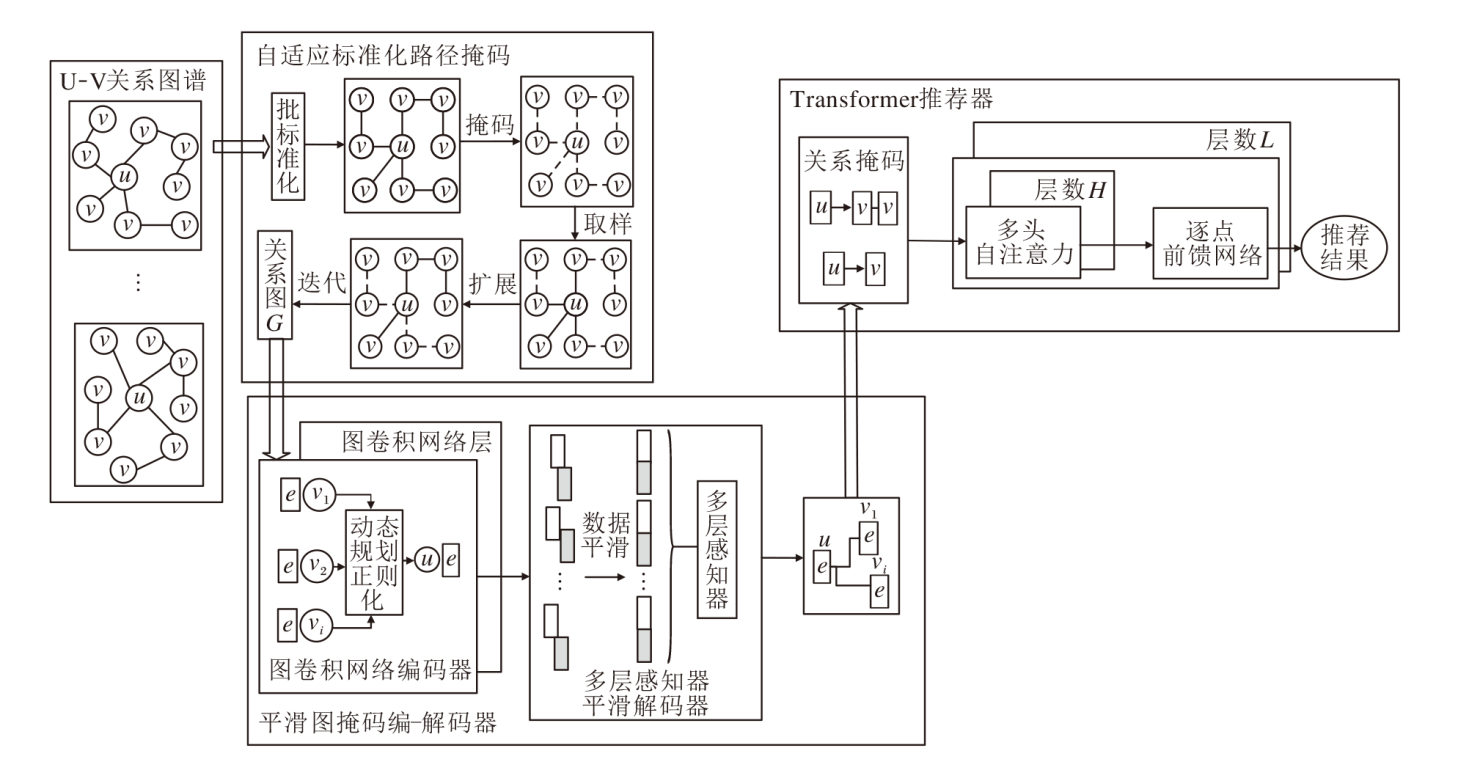 | 图1 SGMERec 结构图Fig.1 Structure of SGMERec |
假设U表示用户集合, V表示项目集合.每个用户(u∈ U)都与他们的历史交互项的时间顺序序列关联, 表示为
${{S}^{u}}=(s_{1}^{u}, s_{2}^{u}, \cdots , s_{{{l}_{u}}}^{u})$,
$s_{i}^{u}\in V$表示用户u的第i个相互作用项, lu表示用户u的项目序列Su的长度.
给定一个用户的交互序列Su, 顺序推荐的目标是预测用户u最有可能与之交互(点击或购买等操作)的下一个项目$s_{{{l}_{u}}+1}^{u}$.
为了更好地展示不同用户与项目之间的关系, 将各用户的行为序列生成图G=(V, E)表示各用户与项目之间的关系.其中V表示过渡图的顶点集, E表示边集.对于边集E, 遍历所有用户序列, 并在每个序列中的每个项目和它的h-hop邻居之间建立一条边, 同时只计算一次重复的边.形式上, 过渡图的边集表示如下:
$E=\{(s_{t}^{u}, s_{t'}^{u})\, \!:u\in U, \left| t-t' \right|\le h, 1\le t\le {{l}_{u}}, 1\le t'\le {{l}_{u}}\}$.
给定构建的项目转换图G=(V, E), 这种自适应路径掩蔽范式包含3个关键模块.1)学习掩码, 发现用于路径构建的锚节点集.2)转换路径掩蔽, 继承信息转换模式.3)任务自适应增强, 重新校准自监督图掩蔽过程.
为了解决标签稀缺问题, 需要修改掩蔽自编码器的随机掩蔽策略.同时, 为了增强SGMERec释放图屏蔽自动编码器的能力, 需要在序列上构建一个全局项目转换图.
为了解决内部协变量偏移和梯度爆炸问题, 在生成路径掩码前对U-V关系图谱进行批标准化.首先计算每个批次中每个特征的均值和方差, 再通过线性变换和平移操作重新缩放和偏移标准化后的数据, 以适应下一层的激活函数.引入可学习的缩放因子和偏移量参数, 用于调整标准化后的特征, 使模型能更平衡地处理各种标签情况, 包括训练数据中出现频率较低的稀有标签, 提高对稀有标签的泛化能力.
推导全局项目转换图G=(V, E)的图结构上的表示一致性, 度量项目之间的语义相关性.特别地, 对图G中的k-hop目标节点的跃点转换邻居生成过渡子图v, 并给定全局项目转移关系表示生成的过渡子图v周围的上下文.但是具有嘈杂交互或偏向流行性的数据在其嵌入中可能具有不同分布, 导致语义相关性降低.为了防止因为语义相关性较低而导致的推荐模型的精准度下降, 可将图G中语义关联性较高的样本当作锚节点Vα .定义语义相关性γ 在节点v(v∈ V)及其k阶子图如下:
$\gamma (v)=\frac{1}{\left| N_{v}^{k} \right|}\underset{v'\in N_{v}^{k}}{\mathop \sum }\,\frac{{{e}^{\text{T}}}_{v}\ {{e}_{v'}}}{\|{{e}_{v}}\|\|{{e}_{v'}}\|}$,
其中, $N_{v}^{k}$表示全局项目转移图G上节点v的k-hop相邻节点的集合, ev∈ Rd表示节点v的嵌入, ev'∈ Rd表示节点v'(v'∈ Nv)的嵌入.
锚节点集Vα 的大小为α , 根据节点的语义相关性进行排序, 并利用这个排序确定选择概率.语义相关性γ 较高的节点在其邻域中显示出更高的结构一致性.这表明, 通过这些节点生成的路径掩码能更有效地捕捉潜在的跨序列项目转换模式, 因为这些掩码包含更少的噪声.
在适应任务中, 自监督学习(Self-Supervised Lear-ning, SSL)可用于迁移学习或领域自适应, 通过在源领域上训练模型, 然后微调以适应到目标领域.为了增强学习掩码组件的鲁棒性, 引入Gumbel分布噪声到确定项目语义相关性的过程中, 即
γ '(v)=γ (v)-ln(-ln μ ), μ ~Uniform(0, 1).
获得学习掩码模块生成的锚节点集Vα , 可将具有图关系路径的项目-项目转换模式屏蔽为基于SSL的重建信号.转换路径掩蔽机制应有两个主要特性.1)重建的项目转换关系不仅应该考虑序列内项目之间的关联, 还应该涵盖序列间项目的依赖关系.2)该机制应保留各种顺序模式, 反映最近和过去交互之间的短期项目和长期项目的依赖性.
为了提高学习掩码组件对数据增强的适应性和可学习性, 将自监督学习信号引入语义相关性中, 定义增强损失目标Lmask作为学习掩码范式中引入的额外自我监督信号:
${{L}_{mask}}=-\underset{v\in V}{\mathop \sum }\, ~(\gamma '(v)\cdot \delta +\beta )$,
其中, δ 和β 表示标准化中可学习的向量, 用于调整归一化后的数据.
为了实现上述目标, 首先利用递归随机游动过程确定要屏蔽的路径, 这些路径包含在过渡图G=(V, E)上的一系列项连接中, 并给定关于表示一致性的第k阶语义相关性推导.然后, 选择断开节点连接的项目转换关系作为转换路径, 通过掩码自动编码器进行重建, 生成一个包含不同长度序列的锚节点的路径掩码, 最大长度为2k.
这种自动化的学习-屏蔽过程使其适应不断变化的推荐场景, 同时降低对标签数据的需求.
为了减少任务无关信息和数据方差的影响, 可通过任务自适应以增强模型的能力, 处理更广泛的用户行为序列.引入任务自适应函数, 指导学习屏蔽范式, 通过屏蔽更多信息的项目过渡路径进行自我监督, 提高模型的泛化能力.需要引入一个由r(· )表示的任务自适应函数:
$r({{L}_{rec}})=\left\{ \begin{array}{* {35}{l}} 1, & \nabla {{L}_{\text{rec}}}> \bar{\nabla }{{L}_{\text{rec}}} \\ \varepsilon , & 其它 \\ \end{array} \right.$
任务自适应增强在顺序推荐模型中的作用主要体现在提高泛化能力、增强鲁棒性等方面.动态调整的数据增强策略可使模型更好地适应不同的推荐任务和场景.
算法 1 数据平滑图掩码编-解码器伪代码
输入 关系图G
输出 项目关系掩码
step 1 初始化编码器图卷积网络(Graph Con-volutional Network, GCN)层、批标准化层、随机失活层和全连接层.
step 2 获取节点的初始特征表示.
step 3 获得初始特征表示列表, 包含初始的节点特征表示.
step 4
for i in batch定义值
for gcn in GCN层数
逐层传播和特征提取并更新列表
end for
end for
step 5 对所有GCN层的特征表示求和.
step 6 Leaky ReLU激活函数求值.
step 7 编码器输出图编码和特征表示.
step 8 初始化解码器多层感知器(Multilayer Perceptron, MLP)层, 新建平滑缓冲区.
step 9
if 平滑权重为空
获取平滑权重
else
更新平滑权重
end if
step 10 平滑节点样本特征表示.
step 11
for i in GCN层数
for j in GCN层数
计算正、负样本对的嵌入向量乘积
end for
end for
step 12 计算正负样本的嵌入向量乘积.
step 13 经过MLP层计算映射分数.
step 14 计算损失.
step 15 SSL构建关系掩码.
通过自适应路径掩蔽获得图G后, 输入平滑图掩码编-解码器框架, 执行自我监督的重构任务.
在对项目嵌入进行编码后, 解码器负责使用增广图G上的掩码路径重建缺失的项目转移关系.为了解决GCN的过平滑问题, 使用跨层MLP作为解码器.MLP包含若干线性层, 每个线性层后跟一个ReLU激活函数和一个随机失活层.最后一层是一个线性层, 输出一个标量值.这些嵌入张量被展平并连接, 分别输入MLP中, 得到对应分数.
对于隐藏的项目-项目边缘(v, v'), 在编码器的每层中使用项目嵌入v、v', 构建与项目过渡模式对应的边缘嵌入:
${{e}_{v}}_{, v'}=\underset{j=1}{\mathop{\overset{L}{\mathop{\underset{i=1}{\mathop{\left| \cdot \right|}}\, }}\, }}\, e_{v}^{i}e_{v'}^{j}$,
其中, L表示编码器GCN中的层数, |· |表示连接操作, ☉表示元素乘法.一旦构建边缘嵌入, 就输入MLP中, 预测目标项目转换路径的标签(真或假).假设pos表示正样本分数, neg表示负样本分数, 首先计算正负样本之间的分数差异, 再计算差异和1之间的差值.通过clamp函数将上述差值限制为非负数, 将小于0的值变为0.使用Pairwise Rank Loss计算所有样本的损失
$loss=\frac{\left( clamp\left( 1-pos-neg \right), \left\{ \text{min} \right\}=0 \right)}{mean\left( e_{v}^{L} \right)}$
的平均值, 作为最终损失值.
为了使MLP层更好地读懂项目嵌入, 在解码器中首先初始化为一个字典, 其中包含模型中所有可训练参数的名称和对应的数据副本.对于每个可训练参数, 使用指数加权平均的方式更新权重, 然后不断调整平滑系数, 使函数求得控制新旧参数值之间的最佳权重:
w[i]=s· w[i]+(1-s)· param[i],
其中, w[· ]表示参数平滑后的值, param[· ]表示当前时刻参数的原始值, s表示平滑系数, 控制新旧参数值之间的权重, 通常取值范围在0~1内.这个更新过程可看作是对参数值进行指数加权平均, s决定新的参数值对平均值的贡献程度.较大的s会使旧的参数值更快被遗忘, 而较小的s会使旧的参数值对平均值的影响更持久.
通过上述方法, 数据平滑能动态调整嵌入编码和优化MLP层的输出, 提升数据质量, 平衡数据稀疏性和丰富性, 降低极端值的影响, 特别是存在标签稀缺和数据噪声的情况下, 改善模型对未见用户或物品的泛化能力, 使模型能更好地捕捉真实的用户偏好, 减少不准确的推荐结果和异常情况, 更可靠地为用户提供个性化推荐服务.
Transformer作为序列编码器, 具备捕捉用户行为序列中长期依赖关系和潜在用户偏好的能力.这种能力使模型在标签数据稀缺或存在噪声的情况下, 可通过用户的历史行为序列学到更准确、丰富的用户偏好特征, 从而提高推荐的准确性和个性化程度.编码器-解码器结构可有效编码输入数据并解码输出结果, 在处理标签稀缺和噪声数据时表现出色, 通过信息提取和生成过程, 显著减少它们对最终推荐结果的负面影响.
首先给每个项目v∈ V分配一个可学习的嵌入eu, 用于在训练过程中生成过渡路径掩码和图编码.为了使每个嵌入值能最大限度地帮助模型预测用户的选择结果以及减少标签稀缺的负面影响, 在生成每个嵌入eu前都对其进行数据平滑和标准化的预处理, 以此达到更优效果.在Transformer的嵌入层中, 在输入序列i位置的项目的初始嵌入中添加一个可学习的位置嵌入Pi∈ R.用户u的长度为l的交互项序列Su的初始序列嵌入为
${{E}_{u}}=\left[ \left( {{{\tilde{e}}}_{s_{1}^{u}}}\cdot w[1]+{{p}_{1}} \right)\left( {{{\tilde{e}}}_{s_{2}^{u}}}\cdot w[2]+{{p}_{2}} \right)\cdots \left( {{{\tilde{e}}}_{s_{l}^{u}}}\cdot w[l]+{{p}_{l}} \right) \right]$.
Transformer架构的核心是多头注意力和自注意力机制.Transformer中的多头注意力机制能并行关注不同的子空间, 这有助于模型在处理复杂、噪声较多的推荐场景时, 提高推荐精度和鲁棒性.每个注意力头都可在不同方面关注序列中的信息, 减少噪声数据的负面影响.
Transformer中的自注意力机制允许模型动态分
配注意力权重, 根据输入序列的内容自适应加权处理信息, 使模型可在面对标签稀缺的情况下, 更精准捕捉用户与物品之间的关联和潜在的偏好, 即使只有少量的标签数据可用.同时, Transformer中的自注意力机制可有效捕获用户行为序列中的长期兴趣变化和短期兴趣变化, 提升推荐系统的准确性和个性化水平.此外, 自注意力机制还能处理不定长的用户行为序列, 并自动学习序列中不同行为之间的依赖关系和重要性.自注意力机制中与查询、键和值对应的第h(h=1, 2)个头部投影矩阵Wh和b1、b2形成一个点向前馈网络, 可根据当前序列嵌入$\overset{}{\mathop{E}}\, _{u}^{l}$求得下一级的序列长度:
$E_{u}^{l+1}=ReLU\left( \overset{}{\mathop{E}}\, \text{ }\!\!~\!\!\text{ }_{u}^{l}{{W}_{1}}+{{b}_{1}} \right){{W}_{2}}+{{b}_{2}}$.
最后利用残差连接得到最终的序列嵌入:
${{\overset{}{\mathop{E}}\, }_{u}}=\overset{L'}{\mathop{\underset{l=1}{\mathop \sum }\, }}\, E_{u}^{l}$,
其中L'表示多头自注意块总数.特别地, 值的层标准化和缺失以及每块输入都用于提高模型性能.
本文选择在Books、Toys、Retailrocket这3个真实世界数据集上进行实验.Books、Toys数据集来自亚马逊平台的Amazon Books和Amazon Toys, 记录用户在该平台上的书籍和玩具两类商品中的互动信息.Retailrocket数据集来自电子商务网站的Re-tailrocket.
实验之前, 先将3个数据集上的数据进行预处理, 并将生成的用户信息等数据汇总在表1中.
| 表1 数据集统计信息 Table 1 Dataset statistics |
所有实验都在NVIDIA GeForce RTX 2060 GPU(专用GPU内存为6.0 GB)上进行.实验采用PyTorch运行模型, 学习率为1e-2, 批处理大小为256.根据数据平滑图自动编码器原理, 将GNN的层数设置在{1, 2, 3}内.Transformer层数设置为2, 使用4个头进行多维表示.在自适应过渡路径掩蔽模块中, 每10个时期对Vα 进行一次采样, 用以提高效率.从{50、100、200、400}中搜索每个掩蔽步骤的锚定节点数α .数据平滑因子设定为0.99, 随机失活概率设定为0.2.
为了评估性能, 使用顺序推荐中常用的留一策略中的两个评估指标:命中率(Hit Rate, HR@K)和归一化贴现累计收益(Normalized Discounted Cumulative Gain, NDCG@K), 其中K=5, 10, 20.
本文选择11种常用的顺序推荐模型进行对比实验, 这些模型可分为如下4类.
1)基于RNN的模型.NARM(Neural Attentive Recommendation Machine)[27].通过自注意力机制(Self-Attention)捕捉会话中不同项目之间的关联性, 并据此进行推荐.
2)基于Transformer的模型.
(1)SASRec(Self-Attention Based Sequential Re-commendation Model)[28].专门用于序列推荐的深度学习模型, 通过自注意力机制学习序列中项目之间的关系, 实现精准和个性化的推荐.
(2)BERT4Rec[29].利用BERT的强大语义表示能力和上下文理解能力, 结合推荐模型领域的特点和需求, 实现精准、个性化的推荐, 提升用户体验和推荐效果.
3)基于GNN增强的模型.
(1)SR-GNN[17].用于会话级别推荐的GNN模型, 结合GNN的思想和会话级别推荐的需求, 旨在利用用户行为图的结构信息提高推荐效果.
(2)HyperRec[30].融合基于内容的推荐方法和协同过滤的推荐模型, 可提高推荐的准确性和个性化程度.
(3)SURGE[18].用于会话级别的推荐模型, 结合GNN和自注意力机制的优势, 可较好捕捉用户的短期兴趣和偏好, 提高推荐的准确性和个性化程度.
4)基于自监督学习的模型.
(1)DuoRec[11].结合多模态信息的推荐模型, 利用用户的文本行为和视觉行为进行推荐, 同时考虑文本信息和视觉信息, 提高推荐的准确性和个性化程度.
(2)MAERec[14].动态地自适应提取全局项目过渡信息, 以供自监督增强, 避免过度依赖构建高质量嵌入对比视图的问题.
(3)ContraRec[31].应用对比学习的思想进行序列推荐的模型, 结合顺序推荐和对比学习的概念, 提高推荐的准确性和个性化程度.
(4)CL4SRec[13].综合考虑内容和会话信息的推荐模型, 用于解决序列推荐问题, 结合项目的内容信息和用户的历史会话信息, 提高推荐的准确性和个性化程度.
(5)ICLRec(Intent Contrastive Learning for Se-quential Recommendation)[32].首先通过聚类学习潜在变量表示用户意图, 然后使序列与其对应的意图之间的一致性最大化.
各模型在Books、Toys、Retailrocket数据集上的实验结果如表2~表4所示, 表中黑体数字表示最优值.
由表2~表4可见, SGMERec在HR和NDCG指标上明显优于对比模型.
| 表2 各模型在Books数据集上的实验结果 Table 2 Experimental results of different models on Books dataset |
| 表3 各模型在Toys数据集上的实验结果 Table 3 Experimental results of different models on Toys dataset |
| 表4 各模型在Retailrocket数据集上的实验结果 Table 4 Experimental results of different models on Retailrocket dataset |
基于RNN的顺序推荐模型(NARM)主要关注用户历史行为序列, 对于其它非序列性特征(如用户属性、物品属性等)的利用较局限.在小样本数据集上或用户行为稀疏时, NARM容易过拟合, 特别是在用户行为的长尾部分, 导致模型在未知数据上的泛化能力不足.SGMERec搭配批标准化的图掩码生成器, 可增强模型的泛化能力, 在不同的时间序列数据上表现良好.此外, 通过在训练过程中引入额外约束, 可避免模型对于特定数据集的过拟合, 减少对输入分布的敏感度, 使模型更专注于学习数据的通用特征, 从而提高鲁棒性, 降低对数据噪声的敏感性.
基于Transformer的模型(SASRec, BERT4Rec)是基于自注意力机制构建的, 因此对序列中元素的顺序敏感, 这意味着如果序列中的元素顺序发生变化, 模型输出可能会有所不同.在推荐模型中, 用户行为序列的顺序可能不总是表示用户真实的兴趣和偏好, 这可能会导致模型的推荐结果不稳定.而SGMERec因为使用数据平滑编-解码器, 对数据进行平滑处理和滤波处理, 降低数据中的异常值和噪声点, 减少推荐模型中由于数据噪声和极端值引起的不稳定性.SGMERec同时填充或扩展标签信息, 使数据集上的标签更完整和可用, 减少因标签稀缺和冷启动问题带来的影响, 对用户偏好的学习稳定和可靠, 可充分利用数据进行个性化推荐.
在真实世界的推荐模型中, 用户行为数据往往是稀疏的, 即大多数用户只与少数物品进行交互.这种数据稀疏性可能导致图中节点之间连接较少, 影响GNN模型(SR-GNN、HyperRec、SURGE)学到有效的节点表示.特别是对于冷启动用户或物品, 缺乏足够的交互数据可能会导致GNN学到不准确的表示, 并且基于GNN的顺序推荐模型也面临冷启动问题, 尤其是针对新用户或新物品.对于缺乏历史交互数据的用户或物品, 可能无法提供准确的表示, 从而影响推荐结果的质量, 而SGMERec表现出更优的性能, 这说明基于数据平滑的图掩码编码器可利用基于群体行为或历史数据的分析, 为新用户和新项目提供初步的合理推荐, 降低冷启动的难度.并且通过分析和处理历史数据, 填补数据空白, 从而在一定程度上弥补个性化数据不足的问题, 缓解顺序推荐中的标签稀缺问题, 提高推荐模型对标签稀缺物品的理解能力和推荐准确性.
基于自监督学习的模型(ContraRec、 CL4SRec、DuoRec)虽然性能有一定提升, 但是自监督学习的模型可能会过度拟合训练数据, 导致泛化能力不足.特别是在数据稀疏或噪声较多的情况下, 模型可能会在推荐任务中表现不佳.而且, 虽然ICLRec、MAERec也采用掩码自监督学习, 但在标签稀缺的数据集上表现不佳.而SGMERec能一直保持较优性能, 这表明在标签稀缺的数据集上, 自监督学习依赖于对数据的丰富表示以学习有意义的特征的需求难以实现.通过数据平滑, 可生成许多变体的输入数据, 增加数据的多样性, 帮助模型更好地理解数据的不同方面, 同时数据平滑能扩展和补全标签数据, 增加系统对多样化物品的覆盖, 有助于构建更清晰的用户-项目关系图谱, 提高模型性能并克服标签稀缺性对自监督学习带来的负面影响.同时, 批标准化规范每个批次的输入, 可加速网络的收敛速度, 有助于减少梯度消失或梯度爆炸的问题, 使网络更容易学习.优化后的图掩码生成器可减少数据噪声对模型训练的影响, 使模型更稳定.
为了评估SGMERec中各模块对整体性能的影响, 分别进行如下调整, 并保持其它条件不变:1)-DS, 减去数据平滑; 2)-BS, 减去批标准化; 3)-Re, 减去正则化.在Books、Toys数据集上的消融实验结果如表5所示.
| 表5 各模块消融实验结果 Table 5 Ablation experiment results of different modules |
在SGMERec上减去数据平滑后, 各项指标都有一定程度的削弱.这是由于没有数据平滑模块处理序列数据中的噪声和突变, 模型的稳定性和预测准确性下降, 导致效果次优.
在SGMERec上减去批标准化模块后, 虽然在Books数据集上的表现有所改善, 但是在Toys数据集上的实验结果则有大幅降低, 尤其是HR@10指标.这是因为顺序推荐问题的特点可能会导致输入分布的变化模式与传统批标准化假设的不同, 从而影响模型性能.而在Toys数据集上减去批标准化模块后, 无论是在标签密度还是用户信息等方面均处于较差地位, 导致表现较差, 需要添加其它模块进行修正.
在SGMERec上减去正则化模块后, 各项指标都有一定程度的削弱.这是由于没有正侧化模块控制模型的复杂度, 模型容易过拟合, 无法实现特征选择, 鲁棒性也会降低, 进而导致性能和可靠性的降低.
3.4.1 用户序列长度
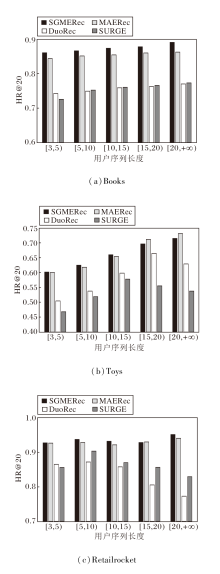
在日常推荐任务中经常会遇到数据集标签稀缺从而导致推荐结果误差较大的问题.为了检测SGMERec能否有效降低因为标签稀缺问题带来的负面影响, 根据用户序列的项目序列长度将用户序列分为5组: [3, 5)、[5, 10)、[10, 15)、[15, 20)、[20, +∞ ), 由此得到在Books、Toys、Retailrocket数据集上的HR@20结果, 如图2所示.
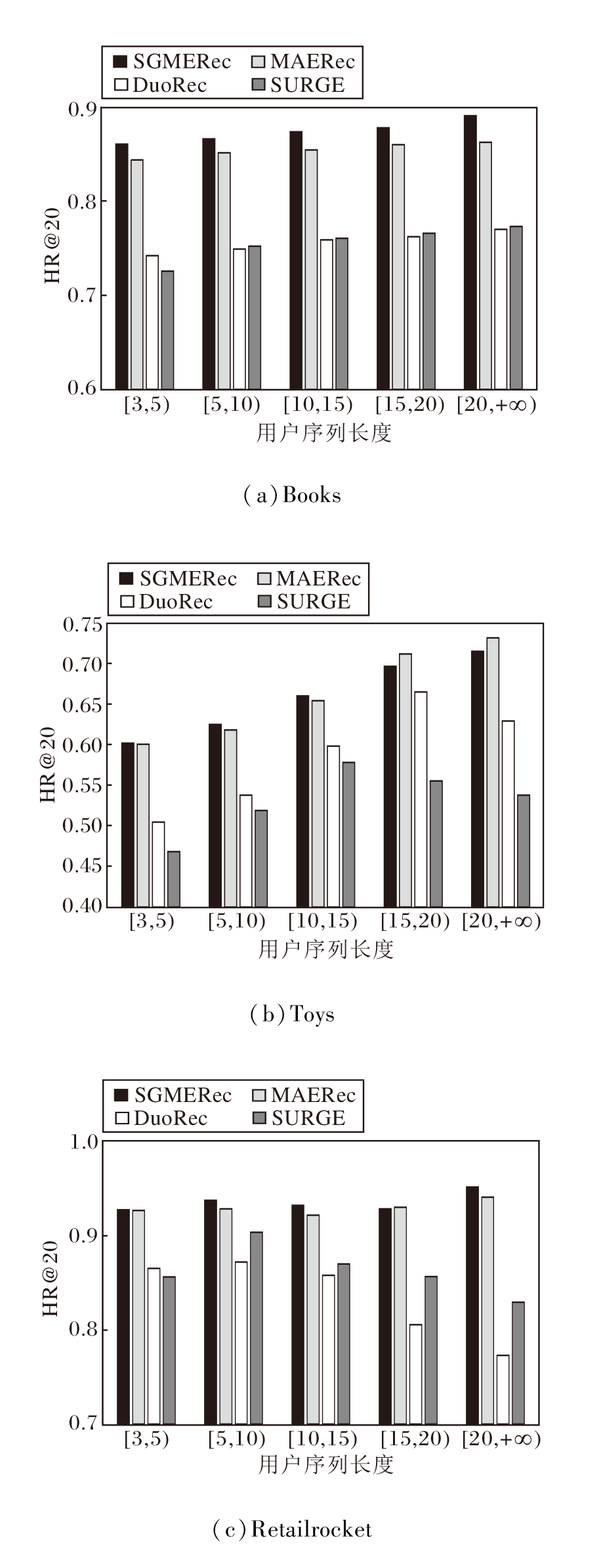 | 图2 用户序列长度对模型性能的影响Fig.2 Effect of user sequence length on model performance |
由图2可见, 在处理短序列的用户序列时, SGMERec也有良好的表现, 这表明SGMERec可有效减少标签稀缺带来的限制.这是因为搭配正则化的自监督学习可自适应保留本地项目和全局项目的交互关系, 提高模型的泛化能力和稳定性, 而且, SGMERec可对模型中每个时间步或每个序列样本应用批标准化, 确保每个时间步或序列样本的输入分布相对稳定, 从而有助于模型的训练和收敛.这对于处理长序列数据尤其重要, 因为在训练过程中, 长序列的输入分布可能会发生较大变化, 导致训练困难和收敛速度较慢, 同时在将长序列转换到短序列的处理时, 每个时间步或序列样本都受益于批标准化, 从而提高模型的性能和稳定性.
3.4.2 数据噪声比率
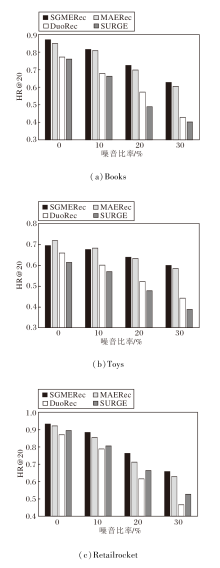
推荐系统任务中用到的数据都可能因为各种原因而无法正确表述用户真正的交互意图.为了检测SGMERec能否有效降低因为数据噪声问题带来的负面影响, 分别以10%、20%、30%比例的负样本替换原数据集上的用户交互信息.再让SGMERec、MAERec、DuoRec、SURGE在修改后的数据集上进行推荐任务, 具体HR@20结果如图3所示.
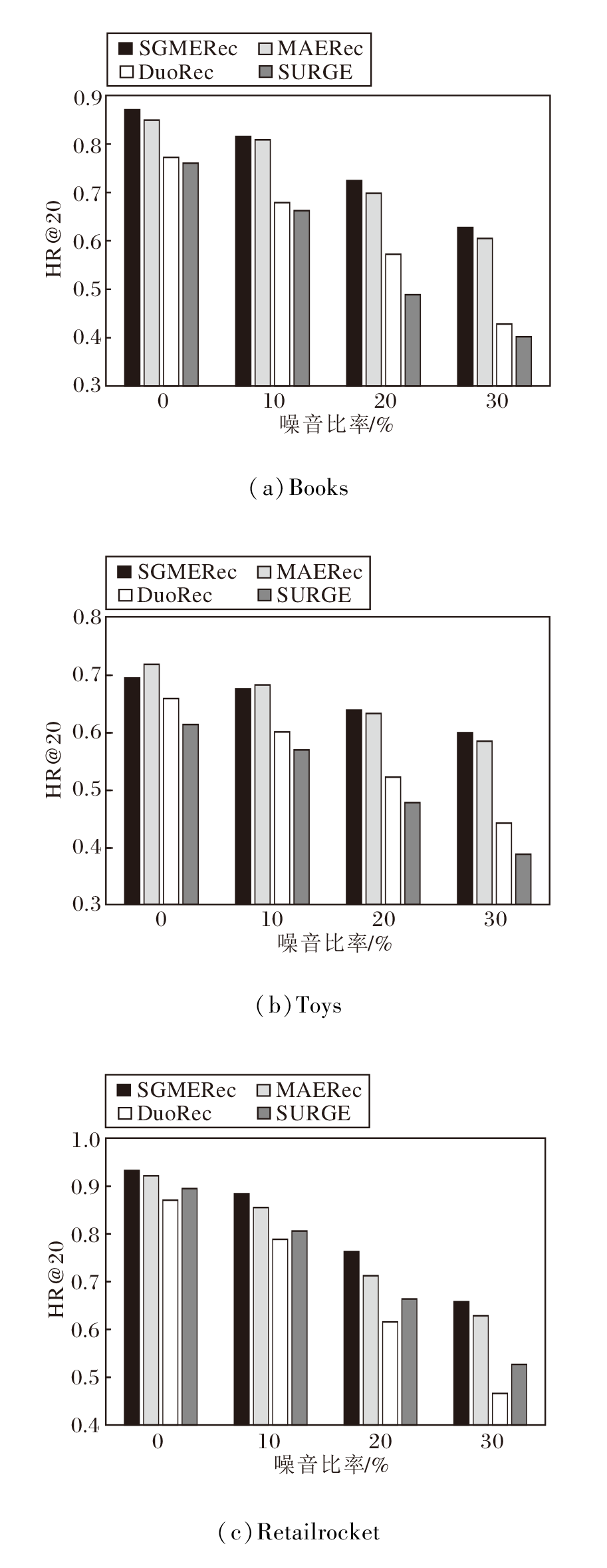 | 图3 噪声比率对模型性能的影响Fig.3 Effect of noise ratio on model performance |
由图3可见, SGMERec在Books、Retailrocker数据集上针对各噪音比例的结果都优于对比模型, 并且性能退化始终慢于对比模型.SGMERec虽然在Toys数据集的低噪音比率上表现不理想, 但随着噪音比率的提高, 其处理数据噪音的优越性得以体现.这是因为在顺序推荐中, 数据平滑可降低序列数据中的噪声影响, 如用户行为的随机性或测量误差引起的噪声, 使SGMERec稳健、可靠.数据平滑还可减少数据波动, 改善预测效果, 提高用户体验, 同时降低过拟合风险.通过数据平滑, SGMERec能较好地理解数据之间的关系, 生成稳定、准确的推荐结果, 从而增强推荐系统的性能和用户满意度.
3.4.3 批次
为了检测模型的收敛速度, 收集SGMERec、MAERec、DuoRec、SURGE逐批次的HR@20结果, 观察它们的收敛情况, 具体如图4所示.由图可见, SGMERec的收敛速度明显优于对比模型, 可在很少的批次内完成结果的收敛并且在之后的实验批次也能保持相对稳定的结果.这是因为批标准化可加速训练过程并提高模型的稳定性, 这有助于确保每个时间步或序列样本的输入分布相对稳定, 从而有助于模型训练和收敛, 而且批标准化后的自监督学习可为模型提供更好的自监督信号, 使模型清楚有效地获取和学习数据集上的项目关系.
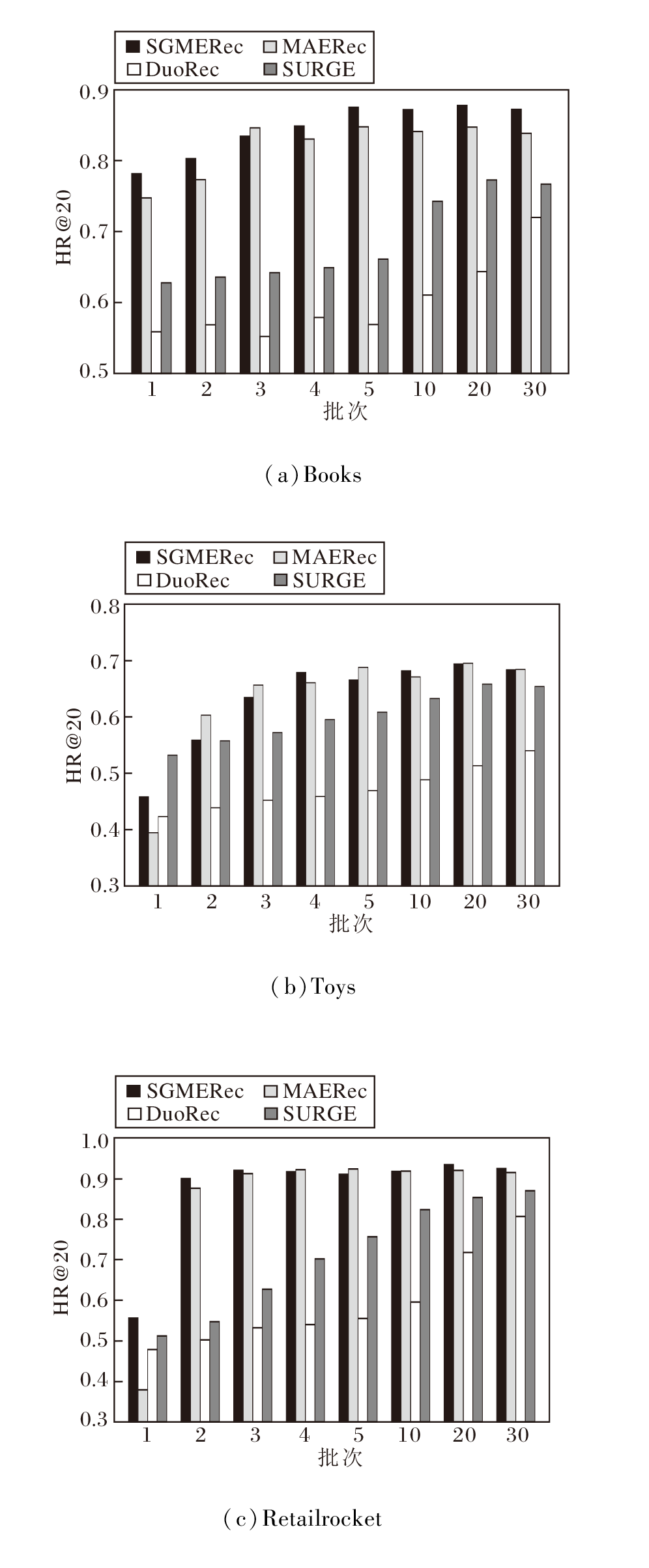 | 图4 批次对模型性能的影响Fig.4 Effect of batch size on model performance |
3.4.4 图卷积网络层数
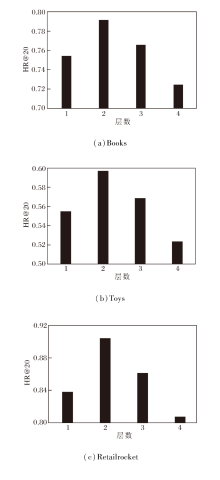
层数是图卷积网络(GCN)的关键超参数, 增加层数可提高模型的特征表征能力和学习复杂图结构的能力, 但也增加模型复杂度和训练时间.合适的层数选择有助于提高模型泛化能力, 但需注意梯度消失、梯度爆炸、过拟合等问题.设置GCN层数为1, 2, 3, 4, 则SGMERec在Books、Toys、Retailrocket数据集上的性能对比如图5所示.
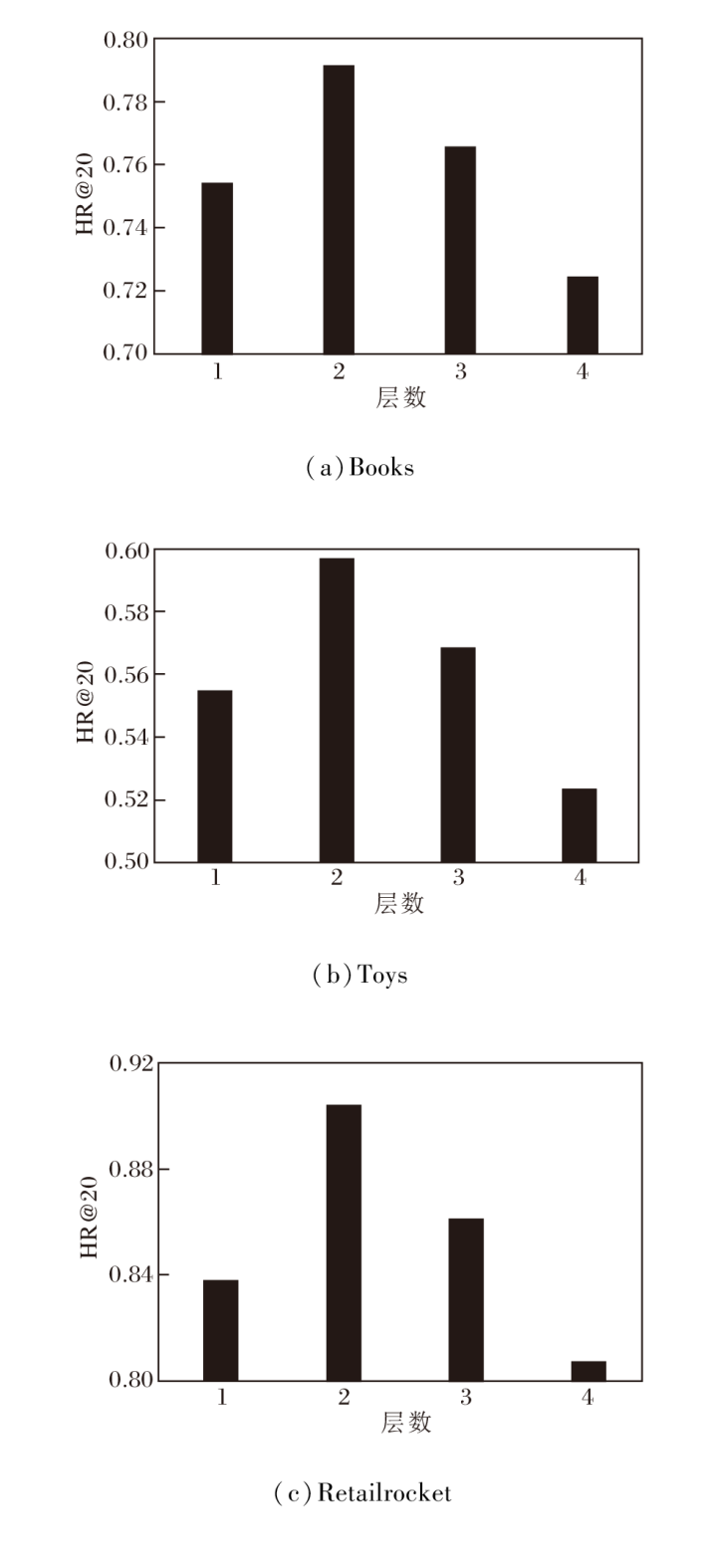 | 图5 GCN层数对模型性能的影响Fig.5 Effect of GCN layers on model performance |
由图5可看出, 当层数过小时, 模型无法充分捕捉和表示图数据中的复杂结构和关系, 限制信息在图中的传递能力, 可能导致模型无法全面考虑节点之间的长程依赖和复杂的图结构特征, 并且限制模型学习数据中的一般特征和模式, 从而影响其在未见数据上的泛化能力.当层数大于2时, 会增加模型的复杂度, 使其更容易在训练数据上过度拟合, 在深层网络中, 梯度可能会变得非常小(梯度消失)或非常大(梯度爆炸), 导致训练过程不稳定或无法收敛.同时模型可能会开始过多关注局部细节或噪声, 忽略全局的重要结构和特征, 导致模型在处理整体图结构时效果变差.实验表明当层数等于2时模型效果最优.
本文提出基于平滑图掩码编码器的顺序推荐模型(SGMERec), 采用自适应数据平滑和批标准化方法, 引入图掩码自动数据平滑编码器, 提升推荐模型的性能.SGMERec优势包括降低序列数据中的噪声影响, 改善模型预测效果, 增强模型稳定性, 有效应对标签稀缺、冷启动和用户交互数据中的噪声等常见问题.SGMERec不仅在常规数据集上表现较优, 也在实际场景中展现出较优性能, 但是其对数据的平滑处理会导致模型的时间复杂度较高.过度的数据平滑可能会导致推荐结果过度偏向热门或常见项, 忽略个性化偏好, 同时过轻的平滑又会导致模型难以捕捉长尾物品的真实偏好和特征, 因此需要一种自适应的平滑方法帮助模型应对某些特殊数据集, 这是今后研究方向之一.
本文责任编委 林鸿飞
Recommended by Associate Editor LIN Hongfei
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|