
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于三幕结构思维链和语义自洽的事件驱动故事生成方法
[黄于欣1, 2  , 赵源
, 赵源1, 2 , 余正涛1, 2 , 吴磊1, 2 , 马九顺1, 2 ]
, 赵源, 余正涛, 吴磊, 马九顺]
|
|



作者简介:

黄于欣,博士,副教授,主要研究方向为自然语言处理、文本摘要.E-mail:huangyuxin2004@163.com.

赵源,硕士研究生,主要研究方向为自然语言处理、故事生成.E-mail:zyuan213@qq.com.

吴磊,硕士研究生,主要研究方向为自然语言处理、评论生成.E-mail:1941624352@qq.com.

马九顺,硕士研究生,主要研究方向为自然语言处理、文本摘要.E-mail:jsma@stu.kust.edu.cn.
事件驱动故事生成旨在根据有限的故事背景和事件信息生成连贯且符合事件内容的故事.然而,现有方法常因对复杂的事件关系推理不足,导致生成的故事存在语义不连贯、情节冲突等问题.为此,文中提出基于三幕结构思维链和语义自洽的事件驱动故事生成方法,在生成故事前选择类型多样的故事示例,学习不同类型故事的写作方式.生成故事时,按照故事的开端、冲突和结局三幕结构设计思维链,引导方法合理规划故事内容,避免故事情节前后矛盾.生成故事后,引入语义自洽,模拟作家的推敲过程,从生成的多个故事中选择语义一致、连贯性和相关性较高的故事.实验表明,相比提示学习方法,文中方法的BLEU-4和BERTScore指标值有所提升,并且在人工评估中也占有一定的优势.
About Author:
HUANG Yuxin, Ph.D., associate profe-ssor. His research interests include natural language processing and text summarization.
ZHAO Yuan, Master student. His research interests include natural language processing and story generation.
WU Lei, Master student. His research interests include natural language processing and comment generation.
MA Jiushun, Master student. His research interests include natural language processing and text summarization.
Event-driven story writing aims to create coherent stories that conform to event content based on limited background and event information. However, existing methods often suffer from semantic incoherence and plot conflicts due to insufficient reasoning about complex event relationships. To address these problems, a method for event-driven story writing based on three-act structural chain-of-thought and semantic self-consistency is proposed in this paper. Before generating the story, diverse story examples are selected to enable the model to learn different storytelling styles. During the story generation, a chain-of-thought is designed based on three-act structure of setup, confrontation and resolution, guiding the model to reasonably plan the story content and avoid plot inconsistencies. After the story is generated, semantic self-consistency is introduced to simulate the writer's deliberation process, selecting the most semantically consistent, coherent and relevant story from multiple generated versions. Experiments show that the proposed method improves BLEU-4 and BERTScore metrics and demonstrates certain advantages in human evaluations as well.
事件驱动故事生成(Event-Driven Story Writing)是指让模型根据故事的主导背景(Leading Context)以及预设好的事件序列(Event Sequence)生成故事内容.该任务在新闻写作、文学创作等领域具有广泛的应用场景.
作为一项文本生成任务, 故事生成需要根据输入中给出的有限信息构建完整的故事文本.早期的研究方法主要基于深度循环神经网络[1, 2], 随着深度学习技术的发展, 预训练语言模型(Pretrained Language Model, PLM), 如GPT-2[3]、BART(Bidirec-tional and Auto-Regressive Transformers)[4]、T5(Text-to-Text Transfer Transformer)[5]等, 被广泛用于生成任务的主要框架[6, 7], 也因此被用于故事生成任务.Tan等[8]在从低分辨率到高分辨率生成图像的方法中获得灵感, 微调BART, 分多个阶段生成故事文本.Zhang等[9]基于GPT-2, 通过故事角色的人格描述控制模型生成的故事内容.
与传统的故事生成任务不同, 事件驱动的故事生成不仅要求算法能理解主导背景, 生成自然连贯、符合常识逻辑的故事, 还要求每个情节根据预定的事件展开.目前对于事件驱动故事生成任务的研究主要基于预训练语言模型, 针对该任务修改模型结构.Rashkin等[10]基于GPT-2, 提出PLOTMACHINES, 包含一个用于跟踪故事情节元素的记忆矩阵, 保证整个故事的连贯性和一致性.
Tang等[11]提出直接根据给定的主导背景和事件序列编写故事的EtriCA(Event-Triggered Context-Aware End-to-End Framework), 是一个基于BART的事件规划生成模型, 利用交叉注意力机制在向量空间上将主导背景特征映射到事件特征上, 帮助生成模型在根据事件展开故事时捕获主导背景中的信息.同时, Tang等[11]提出一种基于依存句法分析的事件提取工作流程, 捕获句子中的动词短语作为事件.然而, 基于预训练语言模型的方法需要标注数据以微调(Fine-Tuning)模型参数, 使模型生成的故事在内容和语言上依赖于数据集上已有的信息, 限制模型的泛化性.
近年来, 使用大规模语言模型(Large Language Model, LLM)和提示学习(Prompt)成为生成式任务的新范式[12, 13].基于少样本示例的上下文学习(In-Context Learning, ICL)可有效帮助大模型适应不同任务[14].然而, 即便为模型提供一定数量的上下文示例, 基于事件驱动的故事生成任务仍面临生成故事相关性和连贯性不足的问题.例如, 模型在根据主导背景“ 我和几位朋友出去购物” 和事件序列“ 1.拍照 2.掉 3.删除 4.看” 生成故事时, 可能会生成以下内容:“ 我们一边拍照, 一边度过了一段愉快的时光.突然, 我朋友的手机掉在地上, 屏幕碎了.她能够在向任何人展示之前删除这些照片.我们将这看作是一次幸运的扑救” .其中的句子“ 她能够在向任何人展示之前删除这些照片” 与前文“ 我朋友的手机掉在地上” 并无直接联系, 显得突兀.同时, 如果手机“ 屏幕碎了” , 那么故事中的意外已经发生, 因此以“ 这是一次幸运的扑救” 作为结尾显然不合逻辑.Bubeck等[15]的工作表明, 大规模语言模型在根据特定指令生成文本时, 虽然能较好地处理相邻句子间的关系, 但在全局内容处理方面存在不足.具体地, 模型在生成第一个句子时, 并未充分考虑后续句子的内容, 即生成过程中缺乏整体规划.本文认为这是因为提示中缺少对故事情节进行规划的引导, 使大模型在生成故事时依赖于根据主导背景和事件扩充出后续内容的“ 贪婪” 过程, 缺少一个清晰的故事框架, 导致故事的叙事节奏混乱.
本文从作家的写作过程中汲取灵感, 针对上述问题, 提出基于三幕结构思维链和语义自洽的事件驱动故事生成方法, 在生成故事前优化示例, 采用聚类算法从数据集上选取类型多样、能体现任务域的故事文本示例, 让大规模语言模型能学到不同类型故事的写作方式.在生成故事时提升大规模语言模型的逻辑推理能力.一个好的故事需要严谨的叙事逻辑和结构.本文借鉴故事创作中常用的三幕结构模型, 将故事划分为开端(Setup)、冲突(Confronta-tion)和结局(Resolution)三个阶段, 引入思维链(Chain-of-Thought, COT)提示技术[16, 17]的理念, 构建三幕结构思维链模板, 引导模型在生成故事时有意识地规划并遵循清晰的故事结构.在生成故事后提高生成故事质量的稳定性.本文参考最近的自洽(Self-Consistency)技术研究[18], 提出一种语义自洽方法, 模拟人类作家写作时的推敲思考过程, 应对事件驱动故事生成任务的开放性带来的生成文本质量不稳定的问题.语义自洽方法首先利用聚类算法集成模型生成的多个候选故事, 从中筛选语义最一致的故事文本簇.再根据每个故事文本的连贯性和相关性分数, 选择分数最高者作为最终答案.实验表明, 本文方法的BLEU-4和BERTScore指标都有所提升.在参数量较小的大模型上, 相比上下文学习, 也表现出一定的优势.人工评估表明, 本文方法在连贯性、流畅性和相关性上都取得一定效果.此外, 本文提出的三幕结构思维链方法除了在英语设置下有效以外, 在其它语言(如汉语、法语、西班牙语)设置下也同样有效.相关代码获取地址如下: https://github.com/ZYuan213/3-Act-CoT.
任务的输入包括一个长度为
L={l1, l2, ···,
表示故事开头的第一句话, li 表示主导背景 L 的第 i 个字符.一个长度为
E={e1, e2, ···,
表示接下来会发生的故事情节, ej 表示事件序列 E 的第 j 个事件.
任务的输出是一段连贯的故事文本
S={s1, s2, ···,
sk 表示故事 S 的第 k 个句子.
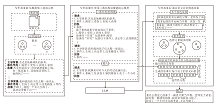
为了提高大规模语言模型在事件驱动故事生成任务下的故事生成能力, 本文参考人类作家写作故事时的思考过程, 提出基于三幕结构思维链和语义自洽的事件驱动故事生成方法, 框架如图1所示.
 | 图1 本文方法框架Fig.1 Framework of the proposed method |
本文方法由三部分组成.
1)在写作故事前, 使用k-means聚类从数据集上选取可作为示例的文本.
2)在写作故事时, 通过三幕结构思维链模板将示例转换成思维链的形式, 合并思维链提示和任务输入, 作为大规模语言模型的输入.
3)在写作故事后, 让大规模语言模型生成多个候选故事, 使用语义自洽方法对这些故事进行采样, 选出最佳答案.
本文定义选取的示例文本集合如下所示:
D={(
其中,
表示大规模语言模型的输入, 其中
$\begin{aligned} \widehat{D}= & \left\{\left(L_{1}^{d}, E_{1}^{d}, R_{1}^{d}, S_{1}^{d}\right), \left(L_{2}^{d}, E_{2}^{d}, R_{2}^{d}, S_{2}^{d}\right), \cdots, \right. \\ & \left.\left(L_{|D|}^{d}, E_{|D|}^{d}, R_{|D|}^{d}, S_{|D|}^{d}\right)\right\} \end{aligned}$
表示思维链提示,
表示大模型生成的多个候选故事, 其中
受文献[19]的启发, 本文使用k-means聚类从数据集上选取示例文本, 最终得到一个示例集合D.具体步骤如下:首先, 使用Sentence-BERT[20]将数据集上每个故事文本编码成向量表示.然后, 通过k-means聚类处理这些文本向量, 分成
在选取好示例文本之后, 通过三幕结构思维链模板将示例文本转变为思维链提示.与上下文学习< 问题, 答案> 形式的示例不同, 思维链的示例还包括得出最终答案前的中间推理过程, 即
< 问题, 逻辑依据(Rationale), 答案> .
本文从叙事小说中常用的三幕结构模型得到启发, 提出基于三幕结构模型的思维链提示模板, 启发大规模语言模型在生成故事时参照三幕结构模型划分故事结构.具体地, 将故事生成任务分解成生成故事的开端(第一幕)、冲突(第二幕)和结局(第三幕), 每个部分的故事情节作为推理出完整故事文本的逻辑依据.图2(a)为本文提出的三幕结构思维链模板, (b)为翻译成的中文版本.其中,
 | 图2 三幕结构思维链模板Fig.2 Three-act structural chain-of-thought template |
给定示例集合 D 中第 n 个示例的主导背景
本文将构造三幕结构思维链的这一过程表示为函数 T.在形式上构造大模型输入的过程可表示为
$I=\{\widehat{D}, L, E\}, \widehat{D}=T(D) $
相比机器自动生成故事, 作家写作故事时的一个突出特点是会对故事的内容进行深思熟虑, 本文对大规模语言模型生成的多个结果进行采样以模拟这个过程.从大规模语言模型的生成结果中获取一个候选故事集合 C, C 中包括多个由不同推理路径产生的故事, 即C=LLM(I), 其中LLM(· )表示使用大规模语言模型根据输入生成候选故事集合的过程.
下面对候选故事进行集成, 将在语义上相近的两个文本归为一类, 选出在语义上较一致的一类文本进行后续处理.本文通过层次聚类算法实现从语义角度对不同故事进行投票的过程.最后, 包含有最多元素的簇表示最自洽的故事情节, 从这个簇中选出最终答案.
具体地, 使用 Sentence-BERT计算候选故事集合 C 中的每个故事
R={C1, C2, ···, Cp}.
统计每个簇包含的元素数量, 从中选取具有最多元素的簇
Cq={
(假设其编号为 q, q< p)进行下一步的处理, 其中
Scor
其中simk 表示第 k 个句子与前一个句子间的余弦相似度分数.故事
Scor
其中si
最后, 综合连贯性分数和相关性分数, 从簇中选取一个分数最高的故事文本作为最终答案:
S=arg max Scor
其中,
Scor
表示故事
语义自洽具体方法步骤如算法1所示.
算法1 语义自洽
输入 候选故事集合C, 主导背景L, 事件序列E, 聚类的簇的数量p
输出 单个故事S
初始化簇中元素数量统计数组cluster_size、相关性连贯性分数统计数组score_list.
拼接主导背景L和事件序列E, 得LE=L+E.
定义SBert(· )表示Sentence-BERT, AC(· )表示层次聚类算法, count(· )表示数量统计函数, append(· )表示元素添加函数, select(· )表示元素选择函数.
embLE = SBert(LE)
// 使用Sentence-BERT将主导背景L、事件序列 E编码成embLE
for each
em
// 使用Sentence-BERT将故事
end for
R=AC(C) // 使用层次聚类算法将故事分成 p个簇
for each Crin R do
numr=count(Cr)
// 统计簇中包含元素的数量numr
cluster_size=append(cluster_size, numr)
// 将numr加入统计数组cluster_size中
end for
Cq=select(R, cluster_size)
// 根据cluster_size从R中选出包含最多元素的簇Cq
for each
计算每个故事的连贯性分数 Scor
计算每个故事的相关性分数 Scor
计算每个故事的综合分数 Scor
score_list=append(score_list, Scor
// 将综合分数Scor
end for
S=select(Cq, score_list)
// 根据score_list从Cq中选出分数最高的故事S
return S
本文在ROCStories数据集[21]上进行实验.ROCStories数据集是一个由5句常识故事组成的故事语料库, 捕获日常事件之间丰富的因果常识关系.本文按照 8:1:1的比例随机将ROCStories数据集分割成训练集、测试集和验证集.将每条故事的第一句话作为主导背景, 参考EtriCA[11], 从剩余四句话中抽取事件序列.由于成本限制, 从测试集上随机选择200个样本, 并设置3组测试, 对每次测试的结果求和取均值.
在所有的实验中, 设置top-p参数为1, 模型温度为0.7.输入模型的示例数量
本文选取如下4个指标评价方法性能.
1)ROUGE-n[22](简记为R-n).用于测量生成故事与参考故事之间的词汇覆盖率, 其中n表示n-gram, 即匹配的连续词组的长度.
2)BLEU-n[23](简记为B-n).用于测量生成故事与参考故事之间的n-gram重叠程度.
3)MS-Jaccard[24](简记为MSJ).使用Jaccard索引计算生成故事与参考故事之间的n-gram重叠程度, 衡量两组文本之间的相似性.
4)BERTSCORE[25](简记为BES).一个基于预训练语言模型BERT(Bidirectional Encoder Repre-sentations from Transformers)[26]的评估指标, 用于测量生成故事和参考故事之间上下文嵌入的语义相似度.
对于R-n、B-n和MSJ, 本文使用4-gram.对于BES, 使用deberta-xlarge-mnli模型.
本文选择与如下基线方法进行对比实验.
1)BART[4].使用Seq2Seq架构的Transformer模型, 解码器与BERT类似, 编码器与GPT(Generative Pre-trained Transformer)类似.
2)EtriCA[11].方法架构基于BART, 使用两个编码器分别对故事的主导背景和事件序列进行编码, 通过交叉注意力机制结合两个输入特征以提高生成故事的连贯性.
3)HINT[27]:基于BART[4], 在训练阶段设计两个训练目标, 分别是句子间相似性预测和句子顺序判别, 提高模型生成故事的连贯性.
4)GPT-3.5[28].由OpenAI开发的大规模语言模型, 在GPT-3的基础上进行改进, 能理解和生成自然语言或代码.
5)Gemma[29].Google推出的一系列轻量级的开源大规模语言模型, 采用与Gemini[30]相同的技术.
6)LLAMA2[31].由Meta AI发布的大规模语言模型系列, 参数规模从70亿到700亿不等.
在ROCStories数据集上进行对比实验.分别在Gemma-7B、LLaMA2-7B和GPT-3.5这3个大规模语言模型上实现本文方法, 具体指标值如表1所示.零样本表示在输入前添加提示“ Now you need to write a four-sentence story that leverages both the given leading context and event sequence.(现在, 您需要编写一个四句故事, 利用给定的主导背景和事件序列.)” , 让方法能够理解任务; 上下文学习表示在大模型输入中插入< 问题, 答案> 形式的示例; GPT-3.5选择gpt-3.5-turboinstruct这个版本; 黑体数字表示最优值.
| 表1 各方法在ROCStories数据集上的指标值对比 Table 1 Metric value comparison of different methods on ROCStories dataset |
由表1可得如下结论.
1)GPT-3.5在上下文学习提示下的表现与有监督的微调方法相当, 使用上下文学习提示的GPT-3.5在B-4、R-2指标上的表现与EtriCA相当, 在R-2、BES指标上的表现优于EtriCA, 这表明大规模语言模型可在不使用额外数据对其参数进行微调的情况下达到与先前有监督的微调方法相当的故事生成能力.同时, 使用零样本提示的GPT-3.5在各指标上的表现远差于上下文学习提示和先前的微调方法, 这表明大规模语言模型在缺少示例的情况下并不能较好地理解任务.
2)大规模语言模型的故事生成能力和模型的参数量有关.虽然GPT-3.5在上下文学习提示下表现出与先前方法相当的效果, 但参数量较少的大模型(Gemma-7B, LAMMA2-7B)在上下文学习提示下的表现仍与先前的方法之间存在一定的差距.本文认为这是因为在自然语言理解和生成方面, 参数量较少的大模型与参数量较多的大模型之间存在一定的差距, 很难在不对大模型参数进行微调的情况下使大模型取得与先前方法相当的效果.
3)本文方法取得最优效果, 在各指标上均优于上下文学习提示和先前的微调方法.具体地, 对于GPT-3.5, 在B-4指标上, 本文方法相比上下文提示和EtriCA分别提升12.0%和15.1%.在BES指标上, 本文方法相比上下文提示和EtriCA分别提升0.9%和7.3%.在R-2、MSJ指标上, 本文方法也表现优异.上述结果表明, 通过本文方法生成的故事更接近人类编写的参考故事, 由此验证三幕结构思维链提示模板和语义自洽方法的有效性.
为了验证本文方法的有效性, 在Gemma-7B、LLAMA2-7B和GPT-3.5上进行消融实验, 具体结果如表2所示.在表中:-思维链表示在提示大模型时不使用思维链提示, 仅使用上下文学习提示; -语义自洽表示不让大规模语言模型生成多个候选故事并通过语义自洽方法从中选取答案, 仅让大模型在推理时生成一个故事作为答案; -思维链和语义自洽表示仅让大模型通过上下文学习提示生成故事; 黑体数字表示最优值.
| 表2 在ROCStories数据集上的消融实验结果 Table 2 Ablation experiment results on ROCStories dataset |
由表2可看出, 本文方法的每个模块都产生一定的效果.当去掉思维链模块时, 所有模型的性能在大多数指标上都产生大幅下降.在GPT-3.5上, 以本文方法为基准, 相比-语义自洽, -思维链在B-4指标上下降5.2%, 在 MSJ 指标上下降8.8%.在LLAMA2-7B上, -思维链的B-4分数甚至低于-思维链和语义自洽.虽然语义自洽部分的改进效果不如思维链显著, 但在大多数指标上也都让模型效果有所提高.例如, 在GPT-3.5上, 去掉语义自洽模块后, B-4指标下降3.6%, MSJ指标下降2.8%.当同时去掉思维链和语义自洽模块时, 性能下降最显著.例如, 在Gemma-7B上, B-4指标下降10.5%, R-2指标下降6.0%, MSJ指标下降9.1%.总之, 三幕结构思维链对提升模型的生成质量起到关键作用, 通过在故事生成阶段对故事结构进行规划, 显著提高模型生成故事的能力.尽管语义自洽部分的改进效果相对较小, 但在提高故事质量方面也做出重要贡献, 这表明对模型生成的多个故事进行集成的有效性.
本文设计三幕结构思维链模板, 自动构建故事文本的中间推理过程, 并将这些推理过程作为提示示例输入大规模语言模型, 提升其故事写作能力, 由此产生一个自然的问题:示例的选择是否会影响模型的写作能力.
根据文献[32], 一种有效的示例选择方法是基于示例与问题间的相似度对进行采样(后文简记为相似性方法).本文使用Sentence-BERT对输入的主导背景和事件序列进行编码, 并根据余弦相似度从训练集上选取与输入相似的前n个故事文本作为示例, 作为基于相似度的示例选择方法.为了对比, 另外测试一种基于随机性、更多样的方法, 即为每个输入随机选取n个示例(后文简记为随机方法).
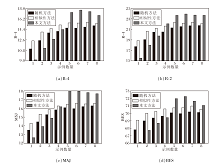
实验设置采用三幕结构思维链方法以提示GPT-3.5生成故事, 观察不同示例选择方式和数量对模型生成结果的影响, 具体实验结果如图3所示.由图可看出, 当示例数量较少时, 相似性方法可取得较优效果, 但当示例数量超过7时, 相似性方法的性能呈现略微的下降趋势.与之相对, 随机方法的性能随着示例数量的增加呈现上升趋势, 当示例数量达到8时, 性能与相似性方法相当.当示例数量超过5时, 本文方法明显优于其它方法.上述结果表明, 为大模型提供适量的相关示例有助于提升故事生成表现, 但过多示例可能引入噪声, 限制任务理解, 导致性能下降, 而适度的多样化示例则能提升性能.本文方法通过k-means聚类筛选示例, 既保证相关性, 又融入多样性, 提升模型在故事生成任务中的整体表现.
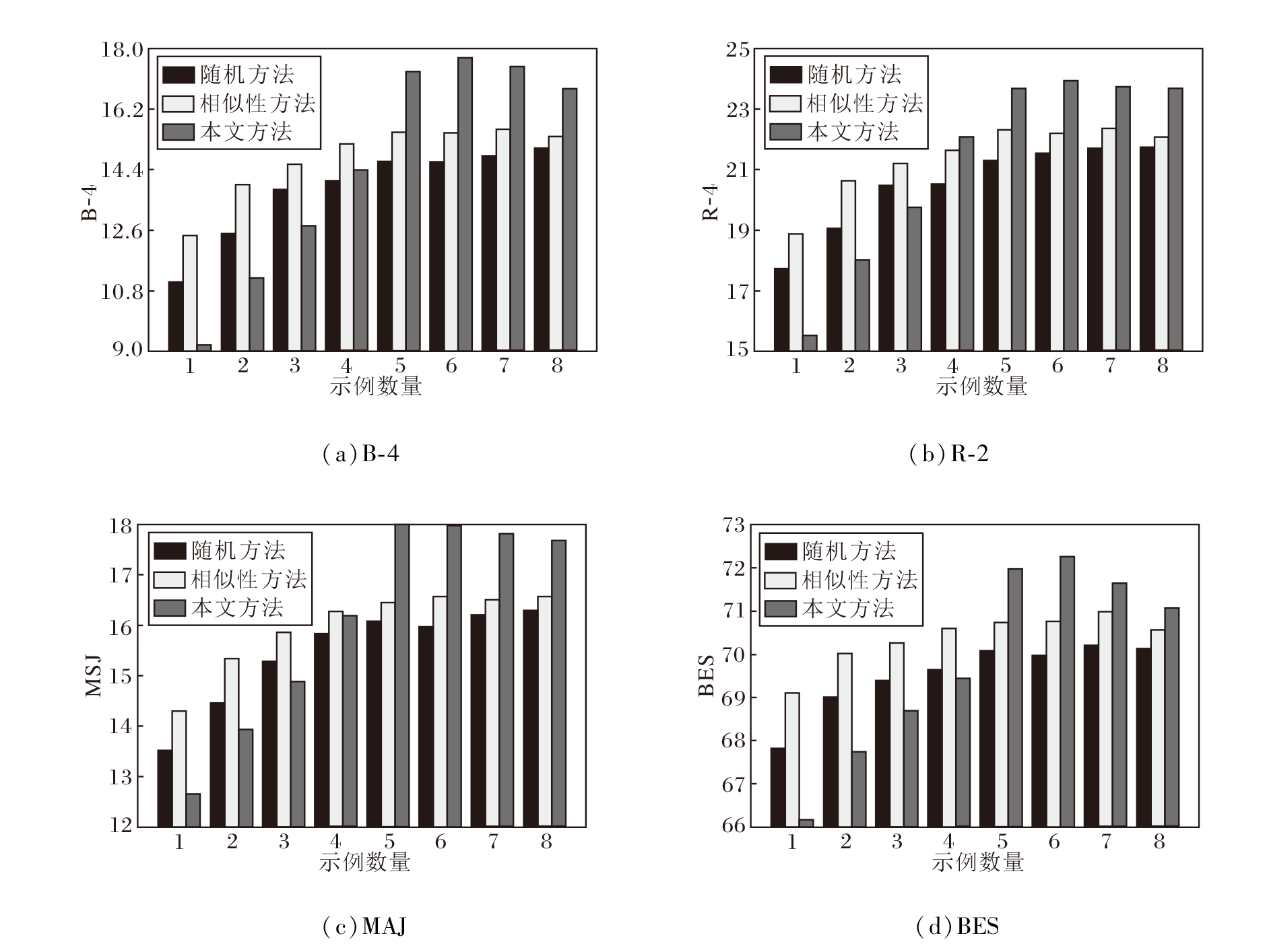 | 图3 示例数量对大模型性能的影响Fig.3 Impact of the number of samples on LLM performance |
为了进一步说明本文方法的有效性, 提供一个案例研究.案例的主导背景:
Patrick's mother died from Cancer.(帕特里克的母亲死于癌症.)
事件序列:
1.left him $30000 2.had fight 3.agreed send 4.received letter
(1.留给他30000美元 2.吵架 3.同意寄 4.收到信).
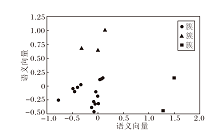
通过三幕结构思维链生成的故事在语义空间上的聚类结果如图4所示, 图中3种符号分别表示不同的簇.本文使用Sentence-BERT计算每个故事对应的语义向量, 通过PCA(Principal Component Ana-lysis)将向量降维到二维平面上.
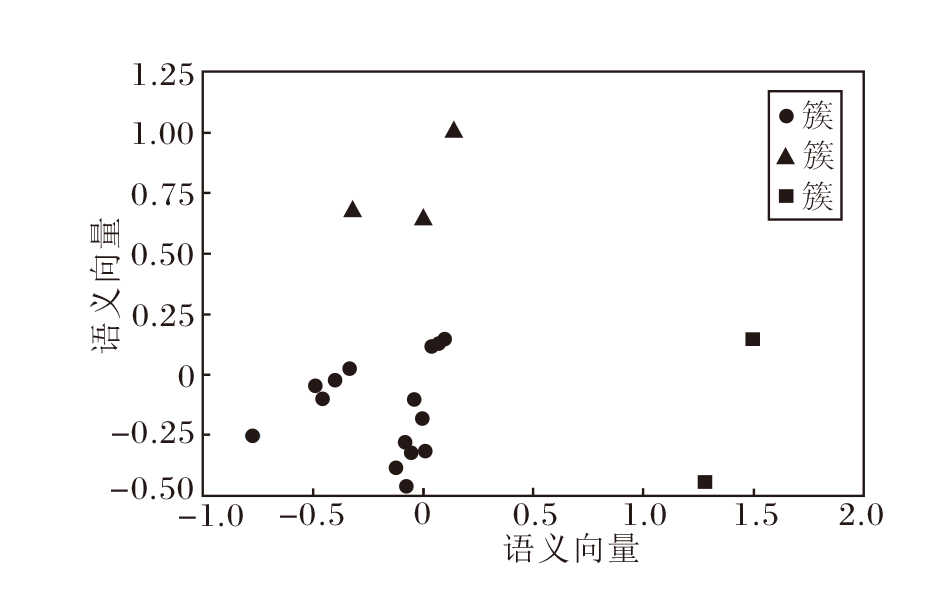 | 图4 故事在语义空间上的聚类结果Fig.4 Clustering results of stories in semantic space |
从聚类结果的各簇中选取的故事样例及语义自洽的输出如表3所示, 该输出从●簇中选出.本文使用下划线在表中标记故事文本中存在问题的部分.
| 表3 从聚类结果的各簇中选取的故事样例 Table 3 Sample stories selected from each cluster in clustering results |
结合图4和表3可看出, 大模型生成的故事在语义上存在多个集群, 通过聚类算法可对这些故事进行分类, 将在语义上较相近的故事归为一类.元素较少的簇中的故事在情节发展上往往存在一些问题, 例如, ■簇中的故事如果以帕特里克收到母亲感谢他的照顾的信作为结尾, 那么从前文中应该能找到帕特里克照顾母亲的情节, 但前文只叙述帕特里克和兄弟姐妹为母亲的遗产产生争执.元素较多的簇, 如●簇和▲簇中的故事, 情节内容的发展往往更具有逻辑性.
下面分析语义自洽方法设置不同的簇数量p时, 对最终生成故事文本的影响.设置簇数量为1, 2, 3, 4, 则相应指标值如表4所示, 表中黑体数字表示最优值.由表可见, 当簇数量设为1时, 本文方法退化为只通过连贯性相关性分数从候选集上选取结果.
| 表4 不同簇数量对方法性能的影响 Table 4 Impact of the number of clusters on method performance |
从表4中的数据可看出, 通过对候选集进行聚类可有效提升大模型生成结果在各指标上的表现.这表明, 虽然大规模语言模型在生成故事时可能会产生错误, 但是通过本文方法对多个候选故事进行采样后, 可过滤较差的生成结果, 提高大规模语言模型生成故事的质量.
为了进一步验证本文的三幕结构思维链的有效性, 在汉语、法语、西班牙语、德语和越南语这5种语言上进行实验.其中, 汉语、法语、西班牙语和德语数据来自MTG数据集[33], 越南语数据使用谷歌翻译对ROCStories数据集进行翻译得到.MTG数据集是一个用于训练和评估多语言文本生成的数据集, 包含5种语言(英语、德语、法语、西班牙语和汉语)的故事生成数据.针对这些非英语语言, 本文对提出的思维链进行扩展, 翻译成与输入对应的语言, 在GPT-3.5上进行实验, 结果如表5所示.在表中, 上下文学习表示在大模型输入中插入< 问题, 答案> 形式的示例, 源语言思维链表示将本文的思维链模板翻译成与输入对应的语言, 英文思维链为本文方法.
| 表5 各方法在其它语言上的指标值结果 Table 5 Metric values of different methods in other languages |
由表5可看出, 相比传统的上下文学习方法, 本文的思维链方法在不同语言设置下都表现得更出色.这些结果表明本文的三幕结构思维链提示方法除了在英语设置下表现出色以外, 在其它语言条件下也表现出显著的有效性.
先前的研究表明大模型的性能表现与训练语料库中语言的占比存在一定关系[34, 35].因此, 本文分析GPT-3训练数据中的语言分布, 从大到小, 英语、法语、德语、西班牙语、汉语和越南语的占比依次为92.65%、1.82%、1.47%、0.78%、0.1%和0.03%.本文发现对于训练数据占比较多的语言(如法语), 源语言思维链和英文思维链之间的性能差距较少, 而对于占比较少的语言(如越南语), 两者差异较大.这一发现为大模型在多语言故事生成任务中的应用提供一个参考, 即在处理低资源语言任务时, 可通过使用高资源语言(如英语)的提示以提升性能.
为了更好地说明本文方法在事件驱动故事生成任务上的效果, 招募志愿者对本文方法和EtriCA、GPT-3.5进行人工评估.从ROCStories数据集上随机抽取50个故事.邀请2名具有良好英文水平的在校大学生从如下3方面对故事进行评估.1)连贯性:衡量句子间的相关性和因果关系.2)流畅性:衡量句子内语言的质量和语法正确性.3)相关性:衡量故事与主导背景和事件序列之间相关程度.每个指标的评分范围为1分(最差)至5分(最好).人工评估结果如表6所示.
| 表6 人工评估结果对比 Table 6 Comparison of human evaluation results |
由表6可见, 本文方法在连贯性、流畅性和相关性上均最优.
为了直观展示本文方法生成故事的质量, 提供EtriCA、GPT-3.5生成示例如表7所示, 表中黑字表示输入的事件序列中的事件, 使用下划线标记故事文本中存在问题的内容.
| 表7 各方法在ROCStories数据集上的生成结果案例分析 Table 7 Case study of generated results of different methods on ROCStories dataset |
由表7可看出, EtriCA和GPT-3.5(上下文学习)生成的故事在内容上都存在一定问题.对于EtriCA, “ A light went into the kitchen(一束光进入了厨房)” 与后文厨房起火的情节矛盾, 既然厨房已经起火, 那么正确的描述应该是有火光从厨房出来, 并且结尾“ Everyone died by that time(那时所有人都死了)” 的叙述方式从前文的第一人称转换成第三人称, 稍显突兀.对于上下文学习, “ before it died any further(以免它进一步死亡)” 一句中用死亡形容食物显然不太合适.本文方法生成的故事显然更具有逻辑性, 各句子之间的衔接也更自然, 并且为故事的主要冲突“ 厨房里的某样东西发出了难闻的味道” 生成一个合理的结局:我发现味道的来源是一只死老鼠.同时, 故事内容也更接近参考文本.
本文提出基于三幕结构思维链和语义自洽的事件驱动故事生成方法, 旨在增强大规模语言模型生成故事的连贯性和内容相关性.大量实验表明本文方法能提高大规模语言模型生成故事的质量, 并且对于参数量较小的大模型也同样有效.消融实验验证三幕结构思维链在优化故事质量方面的核心作用.此外, 还在非英语数据集上进行实验, 验证三幕结构思维链在不同语言环境下均具备良好的泛化能力.今后将致力于探索如何让大模型在缺乏示例的情况下, 依然能精细策划故事内容, 从而推动故事生成技术向更深层次发展.
本文责任编委 林鸿飞
Recommended by Associate Editor LIN Hongfei
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|