

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于深度重塑的航拍目标检测增强网络
[付天怡1, 2  , 杨本翼
, 杨本翼3, 4 , 董红斌1, 2 , 邓宝松3, 4 ]
, 杨本翼, 董红斌, 邓宝松]
|
|



作者简介:

付天怡,博士研究生,主要研究方向为深度学习、计算机视觉.E-mail:futianyi@hrbeu.edu.cn.

杨本翼,博士,助理研究员,主要研究方向为计算机视觉.E-mail:yangbenyi000@163.com.

邓宝松,博士,研究员,主要研究方向为无人系统技术及应用.E-mail:dbs@nudt.edu.cn.
针对航拍图像目标检测中存在的复杂背景对检测的干扰、小目标的细节丢失及检测效率的高需求等问题,文中提出深度重塑增强网络(Depth-Reshaping Enhanced Network, DR-ENet).首先,采用空间深度重塑技术取代传统下采样方法,减少特征提取中的信息损失,增强对细节的捕获能力.然后,提出可变形空间金字塔池化方法,增强网络对目标形状变化的适应性和在复杂背景中目标识别的能力.同时,注意力解耦检测头增强针对各检测任务的学习效果.最后,为了同时兼顾密集小目标和复杂背景的特点,构建小型航拍数据集PORT.在3个公开航拍数据集及PORT数据集上的测试表明DR-ENet有一定的性能提升,说明其在航拍图像目标检测中的有效性和高效性.
About Author:
FU Tianyi, Ph.D. candidate. Her research interests include deep learning and computer vision.
YANG Benyi, Ph.D., assistant professor. Her research interests include computer vision.
DENG Baosong, Ph.D., professor. His research interests include unmanned systems technology and applications.
To address the issues of complex background interference, loss of fine details in small objects and the high demand for detection efficiency in aerial image object detection, a depth-reshaping enhanced network(DR-ENet) is proposed. Firstly, the traditional downsampling methods are replaced by spatial depth-reshaping techniques to reduce information loss during feature extraction and enhance the ability of the network to capture details. Then, a deformable spatial pyramid pooling method is designed to enhance the adaptability of network to object shape variations and its ability to recognize in complex backgrounds. Simultaneously, an attention decoupling detection head is proposed to enhance the learning effectiveness for different detection tasks. Finally, a small-scale aerial dataset , PORT, is constructed to simultaneously consider the characteristics of dense small objects and complex backgrounds. Experiments on three public aerial datasets and PORT dataset demonstrate that DR-ENet achieves performance improvement, proving its effectiveness and high efficiency in aerial image object detection.
在深度学习技术的推动下, 目标检测领域已达到相对成熟的阶段, 尤其是在航拍图像分析中, 深度学习方法已成为检测任务的首选方案.这些方法主要分为三类:基于锚点的一阶段方法[1, 2, 3, 4, 5, 6]、基于锚点的二阶段方法[7, 8, 9, 10]和无锚点方法[11, 12, 13, 14, 15].
在航拍目标检测领域, 学者们主要面临如下4个难点.
1)小目标的细节丢失.航拍图像往往存在大量的密集小目标, 但小目标的像素较少, 相比尺寸较大的目标, 更容易丢失细节, 学者们从不同角度提出解决方案[16, 17, 18, 19].然而, 在这些深度神经网络中, 图像会经过数十次甚至上百次的卷积和池化操作.尽管下采样操作可减少计算量、扩大感受野并生成图像的缩略图, 但会导致大量小目标的信息丢失, 使得在特征图中小目标的信息越来越少[20].因此, 需要开发一种合适的下采样技术, 减少信息损失, 更好地适应航拍图像中小目标的独特需求.
2)复杂背景对检测的干扰.现有方法主要分为两种:多尺度的特征融合方法[21, 22, 23, 24]和上下文特征融合方法[25, 26, 27, 28].尽管有学者提出一些解决方案, 目标与背景之间的分辨却仍旧困难.因为背景中的细节很可能被特征金字塔的多层尺度图捕获, 这不仅使区分二者更具挑战性, 还增加误识别和遗漏目标的可能.同时, 在特征融合方法中采用的标准卷积并未针对性地适应俯视角度下航拍图像独有的目标形状, 如飞机、汽车、船只的特殊轮廓.因此, 需要精心设计特征融合技术和卷积策略, 准确捕捉并利用这些形状特征.
3)对检测效率的高需求.由于航拍图像的检测方法大多需要部署在无人机等飞行器上, 因此对模型效率具有较高要求, 这表示在解决航拍图像检测难点的同时, 也要注重模型的优化.
4)合适的航拍数据集.现有公开航拍数据集上的大多数图像目标稀疏、背景简单, 采用通用的检测模型即可完成检测, 并不能体现模型应对航拍图像的密集目标和复杂背景的优势.航拍视角下的难点是大量的密集小目标和复杂背景下的目标检测, 因此需要构建更合适的数据集以验证模型效果.
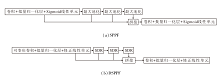
综上所述, 本文提出深度重塑增强网络(Depth-Reshaping Enhanced Network, DR-ENet), 主要包含如下3个部分.
1)空间深度重塑模块(Spatial-Depth Reshaping, SDR).不同于最大池化或平均池化等下采样方法, SDR将特征图中的像素按照一定规则进行重排, 使原始特征图中的每个像素都能在下采样后得到保留, 有效减少下采样过程中造成的特征损失.
2)可变形空间金字塔池化方法(Deformable Spatial Pyramid Pooling Fast, DSPPF).考虑到航拍图像的复杂背景可能被特征金字塔错误捕捉, 提出自适应条带可变形卷积(Adapt-Strip-Deformable Con-volution, ASDC), 并在此基础上构建DSPPF.通过空间金字塔池化, 可获取不同尺度的特征表示, 并感知目标的不同尺度变化.而可变形卷积在每个尺度上对特征进行自适应变形, 使卷积核能更好地匹配目标形状, 帮助模型更好地区分目标与复杂背景之间的边界, 提高目标定位和识别的准确性.
3)注意力解耦检测头(Attentive-Decoupled-Head, ADH).在传统目标检测算法中, 分类和回归任务通常被组合在一个检测头内, 导致任务间信息交叉干扰, 性能降低.ADH通过解耦这些任务, 并采用注意力机制强化每个任务的相关特征, 有效提升模型在有限收敛时间内的检测性能.
此外, 本文构建小型航拍数据集PORT, 经过认真筛选, 保证每幅图像在复杂背景下均包含丰富的小目标, 能有效验证DR-ENet在应对小目标特征丢失和背景干扰方面的性能.
目前的目标检测模型, 特别是基于Transformer的一系列模型已取得显著成就.然而, 考虑到航拍图像检测模型最终需部署于无人机等飞行器上的应用背景, 庞大复杂的网络框架显然不适合承担这一任务.相对而言, 一阶段的目标检测器更适合航拍图像的检测场景, 如YOLO系列.虽然YOLO系列已拥有许多版本, 但YOLOv5仍旧以其卓越的实时性、准确性和易部署的优势, 成为处理实时应用场景的理想选择, 因此本文选择YOLOv5作为改进的基础模型.
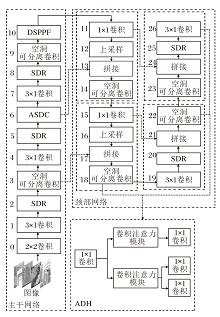
本文提出深度重塑增强网络(DR-ENet), 结构如图1所示.DR-ENet以YOLOv5为基础, 被处理为相同尺寸的一系列图像输入网络后, 首先, 通过一系列卷积层(第0层、第1层、第3层、第4层、第7层和第9层)初步提取特征.在这个过程中采用空间深度重塑模块(SDR)进行下采样, 将图像尺寸缩为原始尺寸的一半, 同时尽量保留完整的特征信息.同时利用自适应条带可变形卷积(ASDC)结合目标形状与其周围信息进行具有关联性与针对性的特征提取.然后, 经过可变形空间金字塔池化方法(DSPPF)进行全局特征融合, 最后采用注意力解耦检测头(ADH), 在不同特征层级上进行检测与分类, 输出目标边界框的预测坐标及边界框内目标的预测类别.
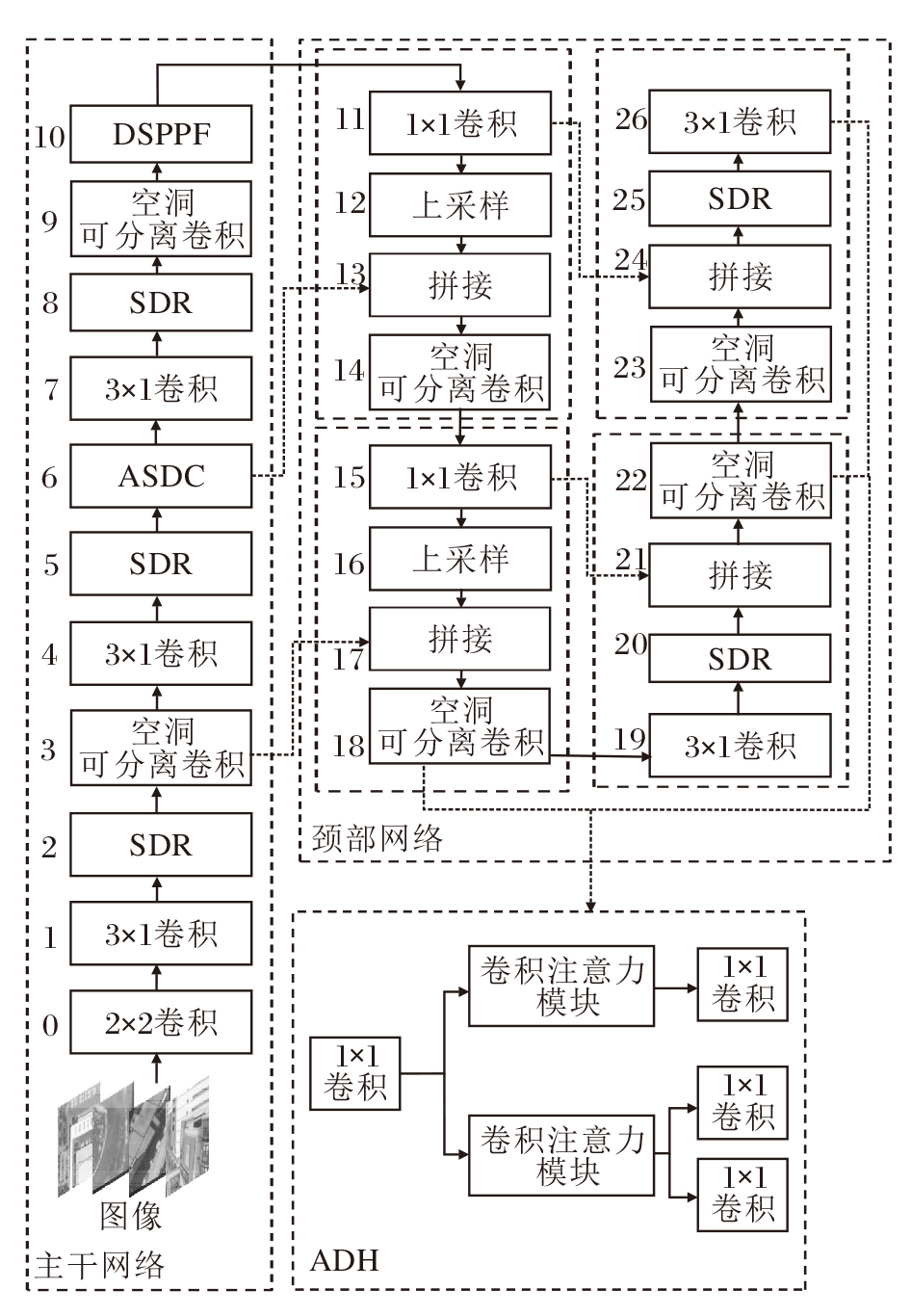 | 图1 DR-ENet整体框架图Fig.1 Overall framework of DR-ENet |
下采样过程会造成特征损失.在基于卷积神经网络(Convolutional Neural Network, CNN)的网络结构中, 池化操作进一步减少信息内容, 多次降低特征图的尺寸, 这并不适用于航拍图像检测[29].较大的目标通常具有更丰富的纹理和形状特征, 因此正常的特征损失对于检测结果的影响较小.然而, 小目标包含的特征相对较少, 当使用最大池化和平均池化等下采样操作将核大小区域内的特征融合时, “ 最大” 和“ 平均” 的操作已造成部分像素点特征的损失.同时, 这些下采样的跨步操作还会跳过一些像素点, 从而丢失一部分输入特征的空间信息[30].
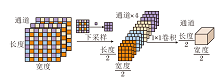
相比最大池化或平均池化, SDR保留所有像素点的特征, 是一种可减少航拍图像中小目标特征损失的下采样方法.SDR采用隔行采样的思想, 宽和长按照自定义的间隔n进行采样, 即宽和长所在的两个维度分别从第1个像素和第n个像素开始间隔采样, 分别得到4种采样结果后沿通道方向拼接.
图2展示间隔为2的SDR的下采样过程, 长宽为8× 8的数据会被下采样为4× 4, 同时通道数会变为原来的4倍, 即形状为(3, 8, 8)的数据通过隔行采样后拼接为(12, 4, 4)的数据, 随后利用1× 1卷积减少通道数, 使通道数由12恢复为3, 最终SDR将得到形状为(3, 4, 4)的数据.具体4个采样结果如下所示:
$\begin{array}{l} \boldsymbol{S}_{1}=I[:, 0:: n, 0:: n], \\ \boldsymbol{S}_{2}=I[:, 0:: n, 1:: n], \\ \boldsymbol{S}_{3}=I[:, 1:: n, 0:: n], \\ \boldsymbol{S}_{4}=I[:, 1:: n, 1:: n] . \end{array}$
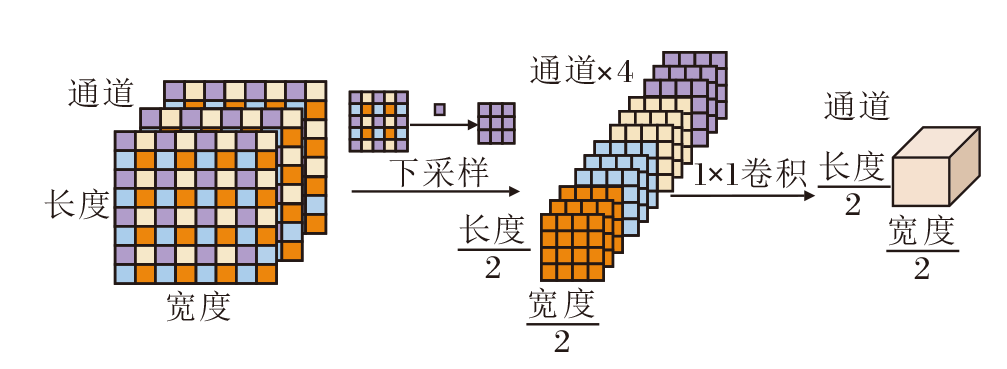 | 图2 SDR的采样过程示例Fig.2 Sampling process of SDR |
拼接为新的张量:
S=concat(S1, S2, S3, S4, axis=0).
而卷积操作Conv使通道数恢复为C, 即
R=Conv1× 1(S).
航拍图像覆盖范围广, 引入的大量无关背景会影响检测效果.为了在航拍图像中更准确区别复杂背景与目标, 结合条带卷积与可变形卷积, 提出ASDC.ASDC集成多个分支的条带卷积, 自适应捕获目标的多尺度上下文信息, 从而有效集中模型对目标特征的关注, 明确区分背景和目标[31].同时, 考虑到航拍图像的目标可能以不同角度或姿态出现, 加入可变形卷积, 更好地捕捉这些变化, 减少噪声的影响.
ASDC增强网络对目标形状的适应性和局部信息聚合能力, 并在一定程度上缓解SDR下采样后带来的空间失真问题.ASDC结构如图3所示, 主要包含3部分.首先, 一层3× 3可变形卷积用于精确适配目标的几何形状, 提取细微的局部特征.然后, 策略性地部署一组三种不同尺寸的条带卷积, 捕获多尺度的上下文信息, 这些条带卷积通过不同大小的感受野, 保证对周围环境信息的全面理解.最后, 利用1× 1卷积的输出作为一个动态权重, 即注意力机制, 优先处理那些对模型判断最关键的特征.注意力加权后的特征与ASDC输入的原始特征融合, 最终产生一个信息丰富的特征表示.
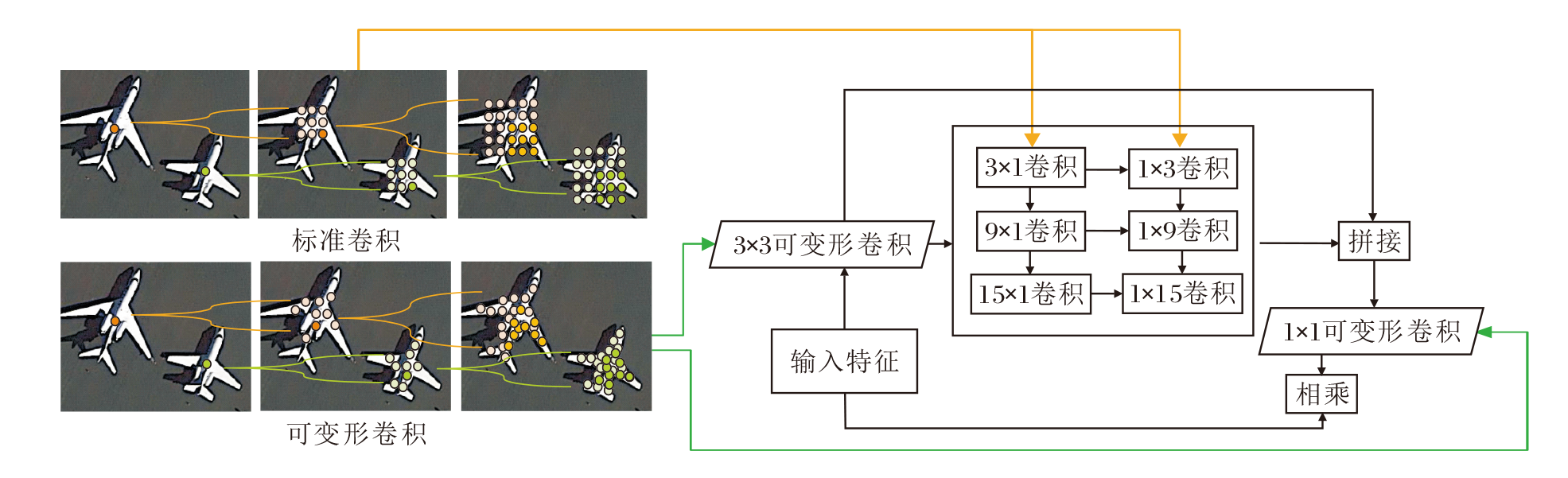 | 图3 ASDC结构图Fig.3 Structure of ASDC |
相比普通卷积, ASDC中3× 3可变形卷积的采样位置更符合物体本身的形状和尺寸.因为可变形卷积在标准卷积的基础上为每个点引入一个偏移量, 偏移量由输入的特征图与另一个卷积生成, 输出特征图在位置p0的值:
$y\left(p_{0}\right)=\sum_{p_{n} \in \mathbf{R}} w\left(p_{n}\right) x\left(p_{0}+p_{n}+\Delta p_{n}\right) $,
其中, pn表示预定义卷积核位置的集合R(如3× 3卷积核的集合)上的n个点, w(pn)表示卷积核在位置pn的权重, x(p0+pn)表示输入特征图在位置p0+pn的值, 即标准卷积中的项, Δ pn表示学到的偏移量, 使卷积核可以自适应地变形.
对比图3的标准卷积和可变形卷积可清楚看到, 可变形卷积的采样位置更好地适应物体形状和尺寸, 而标准卷积无法做到这一点.特别是在可变形卷积的顶层特征图中, 模型学到的特征点对物体的整体特征较敏感.因此相比原始卷积, 可变形卷积能更有效消除背景噪声的干扰, 提取有用信息.
ASDC中另一个重要组成部分是条带卷积组.设计条带卷积组有两个原因.1)高效性.类似于1× N和N× 1的成对条带卷积组能有效模拟N× N卷积, 却更高效.2)航拍图像存在长而窄的条状物体, 如建筑物、飞机、轿车, 1× N的条带卷积适合提取这种细长的形状特征.考虑到航拍图像中目标尺寸小且常密集出现的特点, 如果融合的上下文信息区域过大, 该区域可能包含不同类别的其它目标, 导致错误融合其它检测目标的特征信息, 影响检测, 如果融合的上下文信息区域过小, 则不能较好融合有效信息.ASDC输出为:
$\text { Out }=\left(\operatorname{Conv}_{1 \times 1}\left(\sum_{i=1}^{3} \operatorname{Attention}_{i}\left(\operatorname{Conv}_{5 \times 5}(\boldsymbol{F})\right)\right)\right) \otimes \boldsymbol{F}$,
其中, F表示输入的特征矩阵, Con
F'=Conv3× 3(F),
表示特征F经过3× 3的可变形卷积后的结果,
$\begin{array}{l} \text { Attention }_{1}=\operatorname{Conv}_{3 \times 1}\left(\operatorname{Conv}_{1 \times 3}\left(\boldsymbol{F}^{\prime}\right)\right), \\ \text { Attention }_{2}=\operatorname{Conv}_{9 \times 1}\left(\operatorname{Conv}_{1 \times 9}\left(\boldsymbol{F}^{\prime}\right)\right) \\ \text { Attention }_{3}=\operatorname{Conv}_{15 \times 1}\left(\operatorname{Conv}_{1 \times 15}\left(\boldsymbol{F}^{\prime}\right)\right) \end{array}$,
表示3条不同的注意力分支.
为了专注于目标区域, 防止金字塔的多尺度特征图捕捉背景中的干扰信息, 将可变形卷积加入金字塔池化结构中, 具体如图4所示.
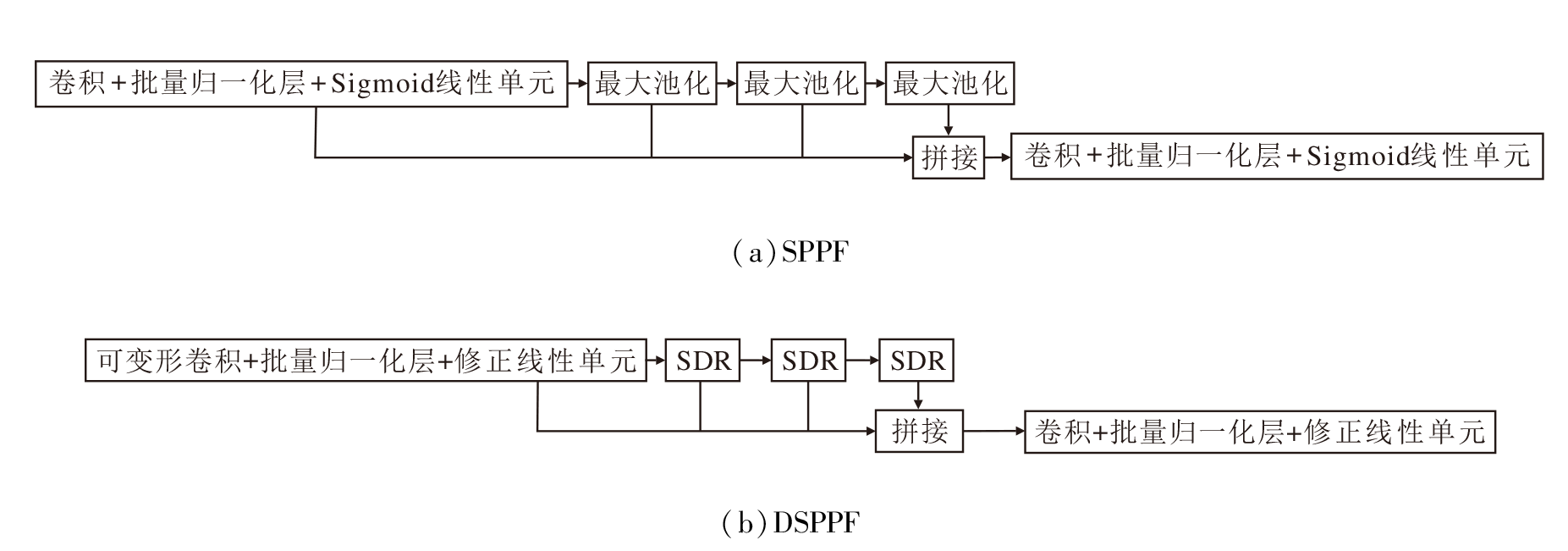 | 图4 SPPF与DSPPF的结构图Fig.4 Structures of SPPF and DSPPF |
DSPPF将SPPF(Spatial Pyramid Pooling Fast)中卷积+批量归一化层+Sigmoid线性单元模块中的卷积替换为可变形卷积, 同时为了缓解加入可变形卷积带来的额外计算开销, 将SPPF中的激活函数由SiLU更换为ReLU, 即修改为可变形卷积+批量归一化层+修正线性单元.因为ReLU函数的计算简单, 只需要进行一个阈值比较操作, 而SiLU函数却涉及指数运算, 计算量较大.这使得ReLU函数在计算速度上更快, 在深层网络中尤为明显, 可显著提高整体的推理速度.此外, DSPPF中的所有最大池化也被替换为SDR.
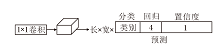
检测头是目标检测模型的关键组成部分, 负责从提取的特征图中预测目标的位置、类别和其它相关属性.然而耦合的检测头效率较低, 并不适用于对效率有较高需求的航拍图像检测任务.耦合检测头的结构如图5所示.在YOLOv5包括其以前的版本中采用的都是耦合检测头, 即同时进行回归与分类任务.然而, 分类和回归任务的特征表示和信息需求可能不同.分类任务通常关注物体的类别特征, 回归任务关注物体的位置、大小等特征.同时进行分类和回归任务时, 模型在优化过程中需要同时平衡不同任务的权重, 导致检测精度下降, 最终效果不如单独处理每个任务时的效果.
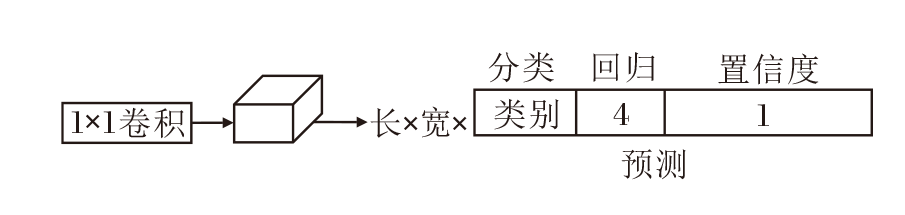 | 图5 耦合检测头结构图Fig.5 Structure of coupled detection head |
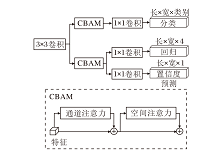
因此, 受到YOLOX[32]和TPH-YOLOv5[33]的启发, 本文认为解耦检测头更适合航拍图像检测任务.解耦头通过将回归和分类任务分离处理, 让DR-ENet分别学习和优化不同的任务, 达到更好的检测效果.解耦检测头的结构如图6所示.DR-ENet首先使用一个3× 3卷积扩大感受野并增强网络的非线性表达能力.然后分成两个独立的分支:一个分支专门处理分类任务, 另一个分支负责回归和计算置信度.每个分支都集成卷积注意力模块(Convolution Block Attention Module, CBAM), 旨在通过空间注意力机制和通道注意力机制强化任务相关的特征.由于回归分支和置信度分支这两个任务具有内在关联, 因此共享从CBAM获得的特征表示, 可有效节省计算资源.
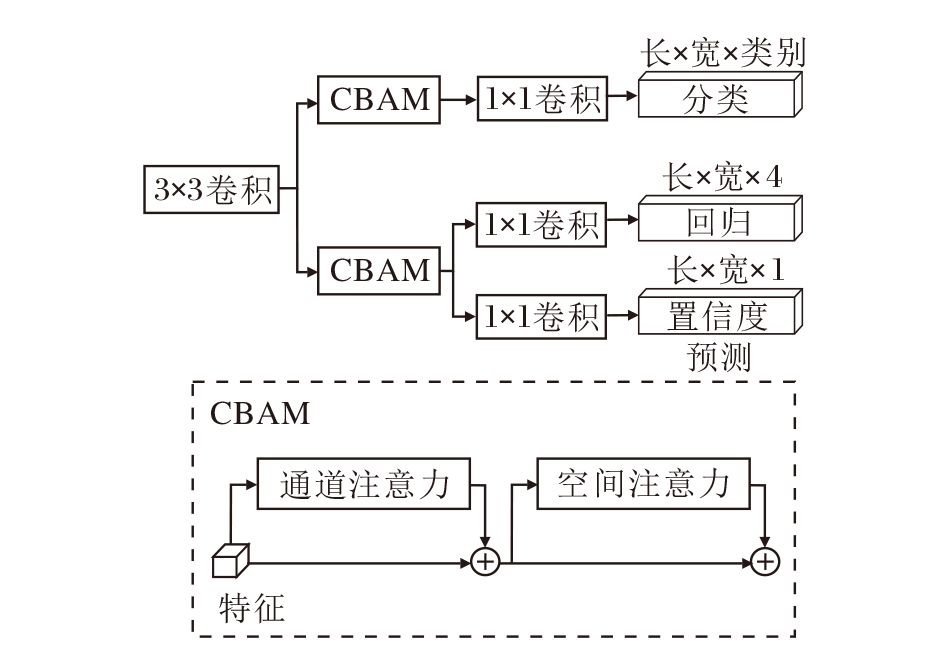 | 图6 ADH结构图Fig.6 Structure of ADH |
本文在3个公开航拍数据集和构建的PORT数据集上进行实验.
公开数据集包括AI-TOD[34]、VisDrone-DET-2019[35]、RSOD[36].AI-TOD数据集是2021年发布的航拍图像微小目标检测数据集, 相比现有航拍图像中的目标检测数据集, AI-TOD数据集上目标平均大小约为 12.8 像素, 远小于其它数据集.VisDrone-DET2019数据集是天津大学在不同场景、天气和光照条件下利用无人机摄像头获取的数据集, 覆盖范围广泛, 检测目标丰富.RSOD数据集是公开的遥感图像数据集, 包括飞机、油箱、游乐场和立交桥四类检测目标.
PORT数据集搜集于Google Earth中世界各大港口的航拍图像.港口是大量船只的停泊地, 同时也是油箱、轮船和停车场等要素的聚集地.这些地方符合复杂背景与密集小目标的双重特征, 因此精心搜集挑选来自荷兰鹿特丹港、巴基斯坦卡拉奇港、迪拜港等著名港口的实况图像组成PORT数据集.PORT数据集包含150幅经过精心标注的图像, 图像尺寸为585× 585, 每幅图像中标注的目标个数均超过百个.目前PORT数据集由于数据规模相对较小, 因此仅用作验证集.
所有网络都在一块显存为24 GB的NVDIA RTX 3090 GPU上完成训练, 并在没有预训练权重的情况下训练100个迭代周期.在AITOD、VisDrone-DET2019数据集上训练时, 每幅图像平均分割为4个不重叠的块, 并采用YOLOv5中默认的数据增强技术.
训练统一使用随机梯度下降(Stochastic Gra-dient Descent, SGD)优化器, 动量为 0.937, 权重衰减为 0.000 5.在最初的3个模型预热(Warm-up)中, 学习率从 0.0034 线性升至0.01, 然后使用余弦衰减策略逐渐降至0.001.
实验中采取的评价指标及其含义如下:AP50-90表示以5%的步长将交并比(Intersection over Union, IoU)从50%取到95%, 在这些IoU下求得的平均准确率(Average Precision, AP).mAP50-90 表示所有检测类别求得的AP50-90 的均值.mAP50和mAP75表示IoU分别为5%和7.5%时所有类别的AP均值.
APvt、APt 、APs和APm分别表示AI-TOD数据集上定义的非常小的目标(2~8像素)、微小目标(8~16像素)、小目标(16~32像素)和中目标(32~64像素)的AP值.
本文选择如下对比网络:RetinaNet[3]、Faster R-CNN(Faster Region Convolutional Neural Network)[7]、 CentripetalNet[12]、FCOS(Fully Convolutional One-Stage Object Detector)[14]、Cascade R-CNN[37]、Effi-cientRep[38]、LSKNet(Large Selective Kernel Net-work)[39]、Detecto-RS[40]、ATSS(Adaptive Training Sample Selection)[41]、RepViT[42].
各网络在AI-TOD数据集上的指标值对比如表1所示, 表中黑体数字表示最优值.由表可看出, DR-ENet采用SDR下采样, 再由ASDC进行基于形状的上下文信息融合后, 对不同尺度目标的检测结果都有提升, 帧率也达到最高值.
| 表1 各网络在AI-TOD数据集上的检测结果 Table 1 Detection results of different networks on AI-TOD dataset |
各网络在VisDrone-DET2019数据集上的性能对比结果如表2所示, 表中黑体数字表示最优值, 对比网络都使用ResNet50主干网络.由表可见, 相比对比网络, DR-ENet展现出卓越的检测性能, 这种优势在极小尺寸目标的检测上尤为明显.这一进步归功于SDR技术, 有效保留航拍图像中小型目标的细节.同时, ASDC结合目标形状及其上下文信息, 大幅增强网络对小型目标的检测能力.
| 表2 各网络在VisDrone-DET2019数据集上的检测结果 Table 2 Detection results of different networks on VisDrone-DET2019 dataset |
各网络在RSOD数据集上的性能对比结果如表3所示, 表中黑体数字表示最优值.RSOD数据集涵盖4个类别:飞机、油箱、立交桥、操场.由表可见, DR-ENet表现最佳, 尤其在检测飞机、油箱这两类目标上, 性能尤为突出, 帧率达到最佳, 同时满足精度与效率的双项需求.然而, 在检测操场、立交桥目标时, 表现稍显不足, 分析认为有两个主要原因.1)RSOD数据集上存在数据不平衡现象, 导致飞机和油箱的样本数量远多于操场和立交桥的样本数量.2)飞机和油箱与操场和立交桥在视觉特征上存在差异.飞机和油箱通常具有明显的几何形状和纹理特征, 而操场和立交桥可能更复杂且多样化, 因此下一步的重点改进方向是网络在类别不平衡且无明显形状特征的目标上的检测能力.
| 表3 各网络在RSOD数据集上的检测结果 Table 3 Detection results of different networks on RSOD dataset |
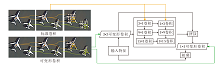
为了展示网络的泛化性, 利用在AI-TOD数据集上训练好的网络, 在PORT数据集上进行检测.AI-TOD数据集和PORT数据集标注的目标类别相似, 因此可有效评估网络的泛化效果.LSKNet、Effi-cient-Rep、DR-ENet在同幅图像上的检测结果如图7所示.由图可见, DR-ENet的AP值比LSK和Effici-ent-Rep分别提高7.62%和4.76%, 这充分说明DR-ENet在泛化能力上的优势.
 | 图7 各网络在PORT数据集上的检测结果Fig.7 Detection results of different networks on PORT dataset |
在AI-TOD训练集上进行消融实验, 为了保持实验条件一致, 所有模型训练过程中均未使用预训练权重, 且均采用CIoU(Complete Intersection over Union)作为边界框相似度度量指标.具体消融实验结果如表4所示.由表可看到, ASDC和SDR组合后的mAP值要高于单独使用ASDC和单独使用SDR时的mAP值.在加入ADH后, 同时使用3个模块时效果最优, 这也验证DR-ENet中3个模块的有效性.
| 表4 各模块消融实验结果 Table 4 Ablation experiment results of different modules % |
首先分析SDR的间隔数n(步长), 设置步长为2, 3, 4, 在RSOD数据集上的检测结果如表5所示.由表可看到, 步长为2时效果更优.实际上, SDR中的步长可以根据不同的任务需求进行调整.
| 表5 步长对网络性能的影响 Table 5 Effect of stride on network performance % |
为了展示SDR相比其它下采样方法的效果, 选择结构相似性(Structural Similarity, SSIM)分数量化采用一层卷积初步提取的特征图和进一步下采样后的特征图之间的差异.验证网络一层卷积(大小为3、步长为2、填充值为1)加一层下采样的简单构造, 下采样后的特征图同原特征图的SSIM分数越接近, 认为该下采样过程能更好地保留原特征图的特征.采用卷积、最大池化、平均池化和SDR进行下采样后的SSIM分别为0.077、0.107、0.092和0.459.SDR得到的SSIM分数更接近1, 表示经过SDR下采样后的图像能尽量保留原特征图中的特征.
为了进一步验证SDR的有效性, 在RSOD数据集上采用同样的基准模型(YOLOv5)、不同的下采样方法(最大池化、平均池化和SDR), 训练50轮后的检测结果如表6所示, 表中黑体数字表示最优值.由表可看到, 采用SDR的YOLOv5在精度上获得最优值, 尽管其推理时间略慢于YOLOv5(平均池化), 但SSIM分数距离1更近, 这表示经过SDR后的特征图保留更多的特征.
| 表6 下采样方法对网络性能的影响 Table 6 Effect of down-sampling methods on network performance |
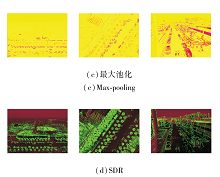
为了清晰展示SDR的优良效果, 进行特征的可视化展示.3幅图像在经过一次大小为3、步长为2、填充值为1的卷积核提取到特征后, 分别通过平均池化、最大池化、SDR进行下采样后的可视化结果如图8所示.
 | 图8 不同下采样方法处理后的图像可视化结果Fig.8 Visualization results of images processed with different down-sampling methods |
由图8可看出, 经过平均池化和最大池化的小目标特征十分稀疏细碎, 但是采用SDR进行下采样能较完整地保留小目标的原始特征.
为了进一步展示SDR保留的特征中有效特征多于其它下采样方法, 使用Grad-CAM(Gradient-Weighted Class Activation Mapping)可视化展示4种下采样方法在图像预测中认为具有重要影响的区域.通过生成热力图, 可揭示这些区域在网络做出预测时受到关注的程度和重要性.高强度区域(暖色)越集中在目标区域, 说明采用该下采样方法的网络越正确学到与目标类别相关的有效特征.具体热力图如图9所示.由图可看到, 原始图像中存在大量船只, 此外, 选中的区域存在少量轿车.采用卷积、最大池化和平均池化的网络集中关注的区域都是船只所在区域, 忽略左侧及上方的小轿车, 而SDR关注区域几乎包含所有类别的目标, 这表示SDR更多地保留有效特征, 使网络能学到所有目标的类别特征, 从而实现更准确的检测.
 | 图9 采用不同下采样方法的网络得到的热力图Fig.9 Heatmaps obtained from networks using different down-sampling methods |
标准卷积(Standard-Convolution, SC)、条带卷积(Adapt-Strip Convolution, ASC)和添加可变形卷积的ASDC的性能对比如表7所示.由表可见, 相比标准卷积, 可变形条带卷积的确能为航空图像中的目标检测带来有益提升.
| 表7 卷积对网络性能的影响 Table 7 Effect of convolution on network performance % |
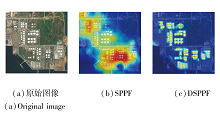
DR-ENet采用SPPF和DSPPF检测后的热力图如图10所示, 检测目标为油箱.由图可看出, 采用SPPF的网络不可避免地会关注到无关的背景区域, 而加入ASDC的DSPPF使网络完全专注于目标区域, 复杂的背景并不会过多影响检测.
 | 图10 采用SPPF和DSPPF后的热力图Fig.10 Heatmaps using SPPF and DSPPF |
同时也在RSOD数据集的aircraft类上进行效率对比, 结果如表8所示.由表可见, 尽管DSPPF的参数量有所增加, 但实际上单个卷积+批量归一化层+修正线性单元的速度快于卷积+批量归一化层+Sigmoid线性单元, 这部分的效率提升足以抵消一部分参数量带来的开销.最后达到的效果就是DSPPF的帧率高于SPPF, mAP50也有所提升.
| 表8 SPPF和DSPPF的性能对比 Table 8 Performance comparison of SPPF and DSPPF |
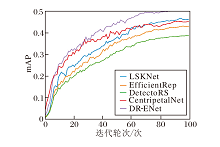
DR-ENet与LSKNet、EfficientRep、DetectoRS、Cen-tripetalNet在AI-TOD训练集上经过100轮后的mAP曲线如图11所示.由图可看到, 在训练初期, DR-ENet的曲线陡峭且增长迅速, 这说明它能较早地学到有效特征.最终mAP值也明显高于其它网络, 说明DR-ENet不仅在检测精度上有所提升, 而且在整体性能上也有显著提高, 这充分验证提出的解耦检测头在提高网络效率方面的有效性.
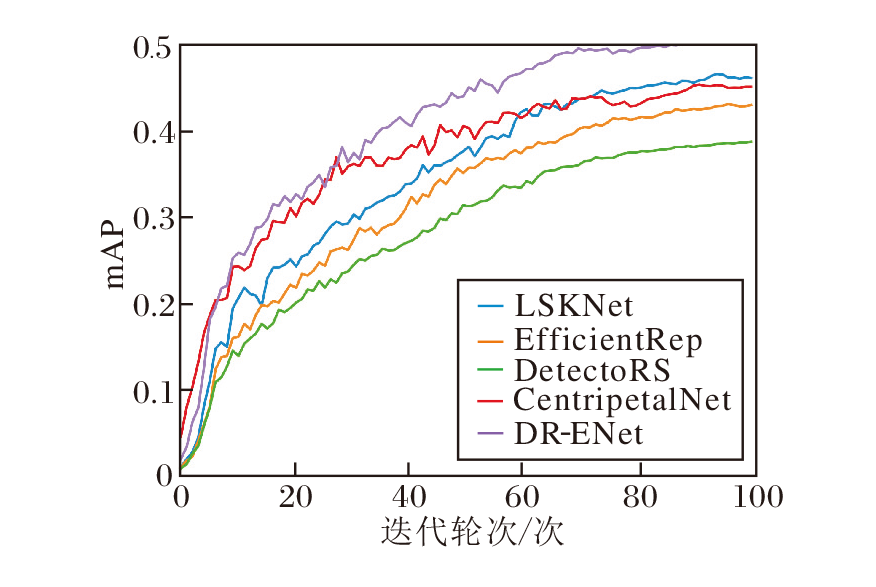 | 图11 各网络在AI-TOD训练集上的mAP曲线Fig.11 mAP curves of different networks on testing set AI-TOD |
YOLOv5、采用检测头(Decoupled-Head, DH)的YOLOv5(YOLOv5-DH)与采用ADH的YOLOv5(YOLO-v5-ADH)在RSOD数据集上的性能对比如表9所示.由表可见, 更高的检测精度表明ADH的有效性.
| 表9 检测头对网络性能的影响 Table 9 Effect of detection heads on network performance % |
针对航拍图像中小目标的细节容易在下采样过程中丢失、复杂背景影响检测效果、大规模的航拍数据对算法效率有较高需求这3个难点, 本文提出深度重塑增强网络(DR-ENet).基于空间深度重塑的下采样方法可减少特征损失, 可变形空间金字塔池化方法可基于目标的形状融合目标周围的上下文信息, 增强区分背景与目标的能力.网络同时以注意力解耦检测头提高检测效率.此外, 为了兼顾密集小目标和复杂背景的特点, 构建全新的航拍数据集PORT.最后在VisDrone-DET2019、AI-TOD、RSOD、PORT这4个航拍数据集上定量、定性地分析DR-ENet的性能, 同时也探讨DR-ENet存在的缺陷和改进方向.今后将重点提升网络对于类别不平衡且缺乏明显形状特征的目标的检测能力.
本文责任编委 杨健
Recommended by Associate Editor YANG Jian
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|
| [40] |
|
| [41] |
|
| [42] |
|