


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
窗口锚定的偏移受限动态蛇形卷积网络航拍小目标检测
[张荣国1  , 秦震
, 秦震1 , 胡静1 , 王丽芳1 , 刘小君2 ]
, 秦震, 胡静, 王丽芳, 刘小君]
|
|



作者简介:

秦 震,硕士研究生,主要研究方向为图像处理、计算机视觉.E-mail:1076212321@qq.com.

胡 静,博士,教授,主要研究方向为图像处理、模式识别.E-mail:279641292@qq.com.

王丽芳,博士,副教授,主要研究方向为图像处理、计算机视觉.E-mail:wanglifang@tyust.edu.cn.

刘小君,博士,教授,主要研究方向为现代设计理论与方法、模式识别.E-mail:liuxjunhf@163.com.
为了从小目标有限特征中获取关键的有效信息,提升小目标的定位能力和检测精度,文中提出窗口锚定的偏移受限动态蛇形卷积网络航拍小目标检测方法.首先,构造偏移受限动态蛇形卷积,在不同方位动态偏移,受限蛇形卷积核自适应地关注不同大小和形状的特征区域,使特征提取聚焦于微小局部结构,促进小目标特征的捕获.然后,采用双阶段多尺度特征融合方法,对不同层阶特征图进行特征对齐、融合和注入,增强底层细节信息与高层语义信息的融合,并强化不同尺寸目标信息传输,提高小目标的检测能力.与此同时,设计窗口锚定的边界框回归损失函数,基于辅助边界框和最小点距离进行边界回归,获得准确的回归结果,提高小目标的定位能力.最后,在3个航拍数据集上的实验表明,文中方法对小目标的检测性能有不同程度的改善和提高.
About Author:
QIN Zhen, Master student. His research interests include image processing and computer vision.
HU Jing, Ph.D., professor. Her research interests include image processing and pattern recognition.
WANG Lifang, Ph.D., associate profe-ssor. Her research interests include image processing and computer vision.
LIU Xiaojun, Ph.D., professor. Her research interests include modern design theory and method, and pattern recognition.
To obtain the key and effective information from limited features of small targets and improve the localization ability and detection accuracy of small targets, a window anchored offset constrained dynamic snake convolutional network for aerial small target detection is proposed. Firstly, the offset constrained dynamic snake convolution is constructed. By dynamical offsetting in different directions, the constrained snake convolution kernel adaptively focuses on feature regions of different sizes and shapes, making feature extraction concentrate on tiny local structures and thereby facilitating the capture of small target features. Secondly, by employing two-stage multi-scale feature fusion method, feature alignment fusion and injection are performed on different layer-order feature maps to enhance the fusion of the underlying detail information and the high-level semantic information, and strengthen the transmission of target information of different sizes. Thus, the detection capability of the method for small targets is improved. Meanwhile, the window anchored bounding box regression loss function is designed. The function performs the bounding regression based on the auxiliary bounding box and the minimum point distance to achieve more accurate regression results and enhance the small target localization capability of the model. Finally, comparative experiments on three aerial photography datasets show that the proposed method makes the improvements with different degrees in small target detection performance.
随着无人机技术的快速发展, 无人机航拍图像目标检测已广泛应用于城市交通监测[1]、环境监测[2, 3]、森林火灾安全监测[4]、农作物生长监测[5]等领域.无人机飞行高度较高、视野较宽, 导致航拍图像中小目标物体占比较高.这些小目标包括车辆、行人、自行车等, 尺寸小、数量多, 受分辨率限制、光照条件变化和目标遮挡等因素影响, 难以被准确检测和定位, 从而增加航拍图像目标检测任务的难度.目前, 无人机航拍图像中密集分布的小目标的检测依然是目标检测任务中极具挑战性的问题之一.
目前基于深度学习的目标检测算法, 总体上可分为两阶段检测算法和单阶段检测算法.
两阶段检测算法包括R-CNN(Regions with Convolutional Neural Networks)[6]、Faster R-CNN[7]和Cascade R-CNN[8]等.此类算法由候选框生成和分类回归两个阶段组成, 通过区域建议网络确定感兴趣区域并生成候选框, 使检测结果更准确.两阶段网络通常适用于精度要求较高的目标检测任务.
单阶段检测算法包括SSD(Single Shot Multibox Detection)[9]和 YOLO(You Only Look Once)系列[10, 11, 12, 13, 14, 15]等.单阶段检测算法直接完成类别检测和位置预测, 不需要额外的区域建议步骤, 适用于对时间成本要求较高的检测场景, 但在精确性上略逊于两阶段检测算法.Dosovitskly等[16]将Transformer[17]从自然语言处理领域引入计算机视觉领域, 展示Transformer在计算机视觉领域的强大潜力, 为目标检测提供新的研究思路.上述基于深度学习的目标检测算法在普通目标上已有较好的检测效果, 然而无人机航拍图像中小目标占比较高, 上述主流算法无法直接用于无人机航拍场景中的检测任务.
为了提高航拍图像小目标检测效果, 学者们进行多方面的研究.
在特征提取方面, Dai等[18]提出一种可变形卷积, 引入可学习的偏移量, 增强卷积操作的表达能力, 但引入可变形卷积增加每个卷积层的计算量, 导致训练和推断过程中计算成本增加.Du等[19]从模型轻量化的角度设计稀疏卷积, 优化检测头, 稀疏卷积可减少计算量, 但降低模型的检测精度.Wang等[20]将可变形卷积作为核心算子, 增大模型检测所需的有效感受野, 同时减少传统卷积网络的严格归纳偏差, 但未能将感受野选择与小目标特征联系起来.Qi等[21]提出DSCNet, 是一种蛇形卷积, 用于拓扑管状结构分割, 可捕捉血管等细长特征, 但该类特征在目标检测领域中并不完全适用, 同时一些特殊形状或极端变形可能会使卷积动态调整效果不稳定或不理想.
在特征融合方面, 张惊雷等[22]提出自引导注意力的双模态校准融合目标检测算法(Object Detec-tion Algorithm with Dual-Modal Rectification Fusion Based on Self-Guided Attention, DRF-SGA), 克服复杂场景中的低对比度噪声, 增强双模态目标的检测能力, 但小目标检测效果还有待提高.Yang等[23]提出QueryDet, 用于加快基于特征金字塔的检测器推理速度, 但当小目标被错误判断时, 检测头会因处理无效信息而导致效率降低.Duan等[24]提出Center-Net, 通过预测对象的中心点和关键点进行检测, 采用关键点三元组的方法进行训练, 通过定义目标对象的中心点和与其相关的两个关键点建模目标的几何结构, 但并未加强对小目标特征的关注.Wang等[25]提出Gold-YOLO, 引入自注意力和卷积操作, 通过收集分发机制增强多尺度特征融合, 有效整合来自不同尺度的特征信息, 保留和利用原始图像中的丰富信息, 避免特征在传输过程中丢失.
在目标检测框方面, Zhu等[26]提出FSAF(Fea-ture Selective Anchor-Free), 采用无锚框的方式进行目标检测, 并引入特征选择机制, 能有效地在不同的特征层次上选择和聚合最相关的特征用于目标检测, 但会受到数据集特性的影响, 在面对特定场景或特定数据分布时, 泛化能力会受到限制.Zhang等[27]提出ATSS(Adaptive Training Sample Selec-tion), 通过自适应训练样本, 选择弥合锚框检测方法和无锚框检测方法之间的差距, 克服传统锚框方法在目标尺度和形状变化上的限制, 同时利用无锚框方法的优势灵活预测目标位置, 但该方法需要精细调节自适应参数, 且性能会受到训练数据集分布的影响.Gevorgyan等[28]提出SIoU Loss(Scalable Intersection over Union), 考虑真实框与预测框之间的方向匹配度, 并重新定义惩罚指标, 但当预测边界框和真实边界框具有相同的宽高比和不同的宽高值时, 该损失函数失效.Zhang等[29]提出Inner-IoU Loss, 不同回归样本使用不同尺度的辅助边界框计算损失, 可有效加速边界框回归过程, 但并未考虑预测框和真实框距离对损失函数的影响.Ma等[30]提出MPDIoU(Minimum Point Distance Intersection over Union), 解决宽高比相同但宽高值不同的问题, 但在小目标检测上表现较差.
上述方法从不同角度研究小目标检测, 并在一定程度上提升检测精度, 但并未关注小目标对应的形状结构特征, 在无人机航拍场景下的检测精度普遍较低.
为此, 本文提出窗口锚定的偏移受限动态蛇形卷积网络航拍小目标检测方法(Window Anchored Offset Constrained Dynamic Snake Convolutional Net-work for Aerial Small Target Detection, WACDSC-NET), 考虑到YOLOv8[31]在目标检测上的明显优势, 选择YOLOv8作为基线模型.首先构造偏移受限动态蛇形卷积(Offset Constrained Dynamic Snake Convolu-tion, OCDS-Conv), 并融入原特征提取主干网络中, 使其能充分关注小目标形状结构特征, 促进小目标特征捕获能力.然后, 采用双阶段多尺度特征融合方法(Two-Stage Multi-scale Feature Fusion, TMFF), 对提取的多层阶特征进行对齐、融合、注入, 增强底层细节信息与高层语义信息的融合, 提高小目标检测能力.最后, 设计窗口锚定的边界框回归损失函数(Window Anchored Bounding Box Regression Loss Func-tion, WA-BBRLF), 代替原损失函数, 提高小目标定位能力.WACDSC-NET不仅提高小目标检测效率, 而且无过多的资源消耗.
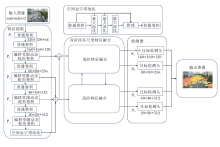
本文提出窗口锚定的偏移受限动态蛇形卷积网络航拍小目标检测方法(WACDSC-NET), 结构如图1所示.
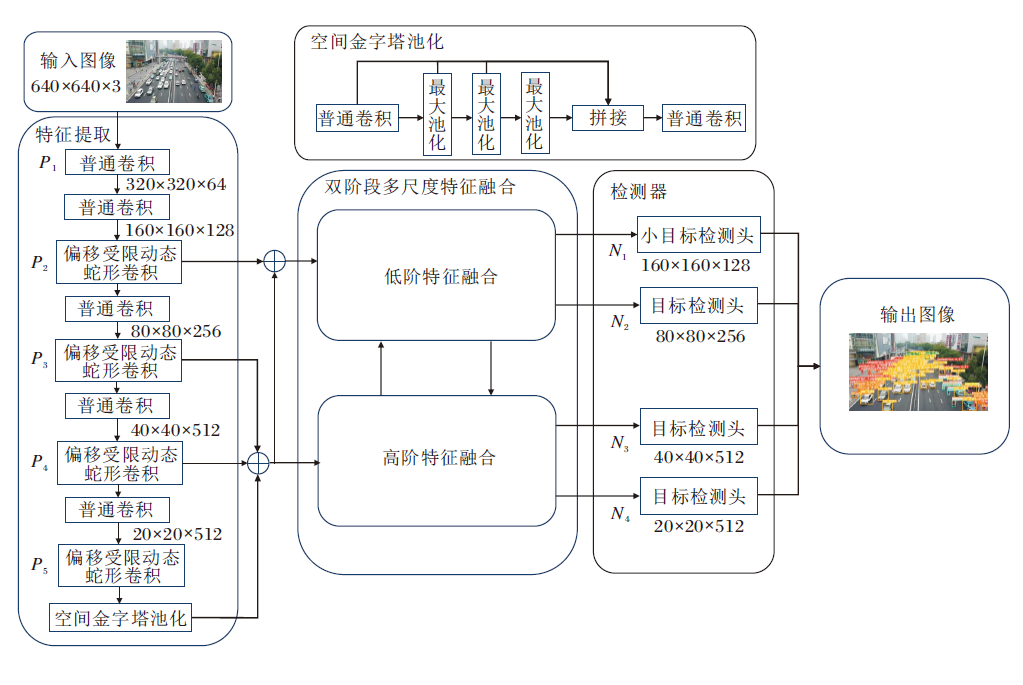 | 图1 WACDSC-NET结构图Fig.1 WACDSC-NET structure |
首先, 将偏移受限动态蛇形卷积加入特征提取网络, 采用空间注意力机制, 使卷积核能自适应地关注不同大小和形状的区域, 根据特征区域生成对应大小感受野, 增强细小柱状结构目标感知效果, 提高小目标特征提取能力.然后, 通过双阶段多尺度特征融合, 对于蛇形卷积提取的不同尺度特征图, 分低阶和高阶两阶段分别进行特征对齐、特征融合和特征注入等操作, 分发到不同大小检测头中进行检测合并, 得到最终图像并输出.与此同时, 设计窗口锚定的边界框回归损失函数, 通过调整比例因子生成不同大小辅助框, 采用辅助边界框代替原边界框的方式计算回归损失, 增强小目标定位能力.
航拍图像中包含大量小目标, 这些小目标图像占比较小、像素构成有限, 并呈现出细小柱状的几何状态.现有方法通过卷积层和池化层提取与目标相关的高阶特征信息, 随着卷积层的堆叠, 特征图大小减小、分辨率变低, 容易忽略小目标信息.
本文提出偏移受限动态蛇形卷积(OCDS-Conv), 在特征提取过程中整合关于微小结构形态的领域知识, 可稳定增强细小柱状结构目标的感知效果.
航拍图像小目标总体呈现细小柱状的几何形态, 不受约束的动态蛇形卷积更多关注于曲折结构, 偏移量的限定让卷积规避偏离目标的无用特征, 保证卷积核在特征提取过程中不会发生太大偏移, 使卷积能关注小目标的细小柱状结构而非曲折形态, 从而提高小目标检测效率.OCDS-Conv结构如图2所示.
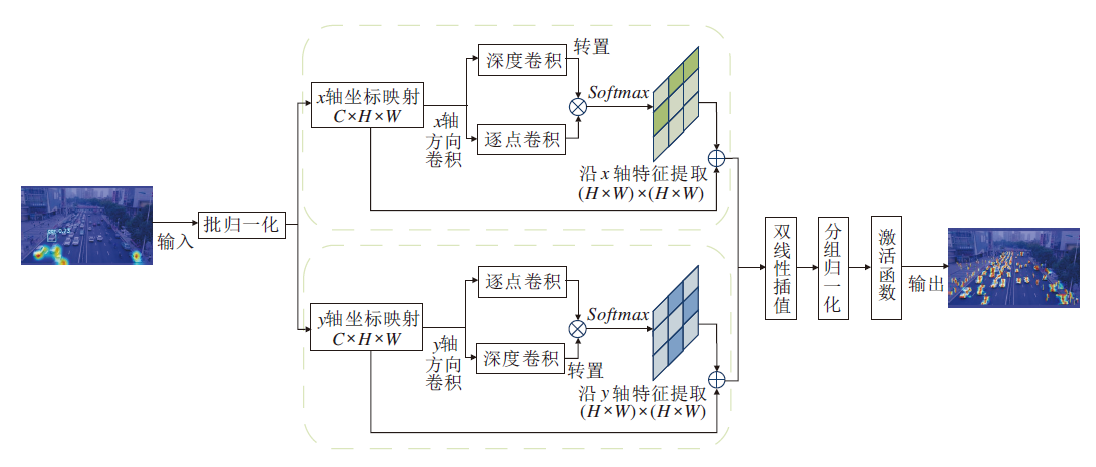 | 图2 OCDS-Conv结构图Fig.2 OCDS-Conv structure |
OCDS-Conv采用空间注意力机制, 使卷积核在不同位置能自适应地关注不同大小和形状的区域, 并动态合并从各个检测样本中挖掘的基本语义信息, 使卷积核适应不同的上下文.该方法基于输入数据和上下文动态调整卷积核的感受野, 从而更有效地捕捉局部特征和全局特征.特征动态感知公式表示为
$ \begin{array}{l}{y}=g\left({W}^{\mathrm{T}}({x}) {x}+{b}({x})\right) \\{W}({x})=\sum_{k=1}^{K} \pi_{k}({x}) {W}_{k} \\{b}({x})=\sum_{k=1}^{K} \pi_{k}({x}) {b}_{k} \\\text { s. t. } 0 \leqslant \pi_{k}({x}) \leqslant 1, \sum_{k=1}^{K} \pi_{k}({x})=1\end{array}$
其中:Wk表示权重矩阵, bk表示偏置向量; g(· )表示激活函数, 本文采用ReLU激活函数; π k(· )为第k个线性函数
对于输入特征图F(q)∈ Rh× w× d, 特征提取预测范围y
α
Softmax函数将y
γ i, j=G(α
完成不同位置的特征动态感知, 其中,
综上所述, 卷积核特征提取可分为两类:
α i, j=
其中, Wdy表示动态调整权重系数, Wst表示固定权重系数.
OCDS-Conv以不规则网格对输入特征图进行采样, 网格中心坐标表示为Ki=(xi, yi), 则3× 3卷积核坐标:
K={(x-1, y-1), (x-1, y), (x-1, y+1), …(x+1, y+1)}.
接着采用迭代算法按顺序观察每个要处理目标的下一个位置, 为下个待处理目标选择合适的范围.迭代策略不会产生大的变形偏移, 能将特征提取保持在可控范围, 从而确保感知的连续性.
为了方便特征提取, 将卷积核分别沿x轴、y轴方向直线化表示.以9× 9卷积核为例, 卷积核中每个像素网格的具体位置为:
Ki± c=(xi± c, yi± c),
其中, c=0, 1, …, 4, 表示距离中心网格的水平距离.卷积核对每个像素网格提取的特征进行累加, 从中心位置Ki开始, 每个待提取特征的网格都取决于前一个网格的位置, Ki+1表示相对于Ki增加一个单位的偏移量.引入偏移量累加, 确保卷积核符合线性形态结构.在航拍图像中, 细小柱状结构通常是关键目标的显著特征, 无限制的偏移量可能使特征提取远离目标区域.为了更好地捕捉和关注这些结构特征, 采用偏移量限制系数控制特征提取的范围, 让卷积在提取特征时更关注细小柱状结构.
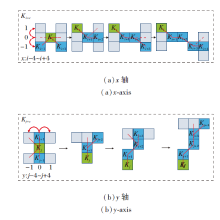
OCDS-Conv在x轴方向的变化如图3(a)所示, 公式表示为
$\boldsymbol{K}_{i \pm c}=\left\{\begin{array}{l} \left(x_{i+c}, y_{i+c}\right)=\left(x_{i}+c, y_{i}+\sum_{i}^{i+c}(-1)^{i+c} \Delta y\right) \\ \left(x_{i-c}, y_{i-c}\right)=\left(x_{i}-c, y_{i}+\sum_{i-c}^{i}(-1)^{i+c} \Delta y\right) \end{array}\right.$
其中,
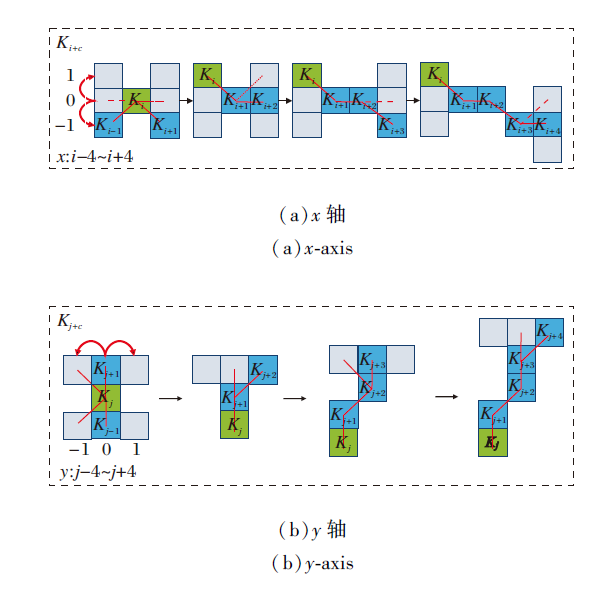 | 图3 卷积核沿x轴和y轴方向计算示意图Fig.3 Schematic diagram of convolution kernel calculating along x-axis and y-axis directions |
在y轴方向的变化如图3(b)所示, 公式表示为
$\boldsymbol{K}_{j \neq c}=\left\{\begin{array}{l} \left(x_{j+c}, y_{j+c}\right)=\left(x_{j}+\sum_{j}^{j+c}(-1)^{j+c} \Delta x, y_{j}+c\right) \\ \left(x_{j-c}, y_{j-c}\right)=\left(x_{j}+\sum_{j-c}^{j}(-1)^{j+c} \Delta x, y_{j}-c\right) \end{array}\right.$
其中,
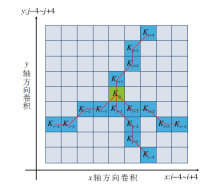
偏移受限动态蛇形卷积核在特征提取过程中的感受野可选择范围如图4所示.该卷积核基于动态结构, 能更好地感知细小柱状结构特征.Δ 表示偏移量, 取值范围为
$ \Delta=\{\delta \mid \delta \in[0, 1]\}$
当Δ =0时表示未发生偏移, Δ =1时表示发生偏移.取到0, 1的概率均为
$ P\{X=k\}=C_{n}^{k}\left(\frac{1}{2}\right)^{k}\left(\frac{1}{2}\right)^{n-k}$,
其中, n等于坐标中心到卷积核边缘的网格数, 即沿x轴、y轴延伸的步数, k表示发生偏移的次数.
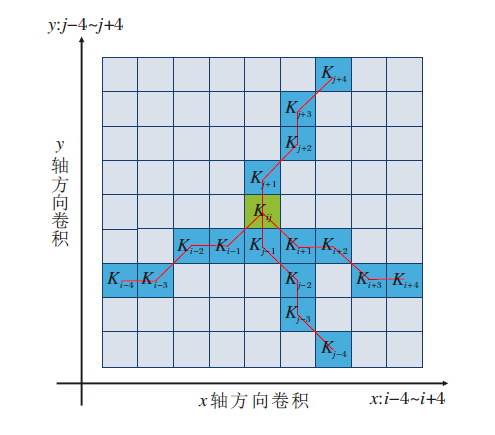 | 图4 偏移受限动态蛇形卷积核感受野选择范围Fig.4 Offset constrained dynamic snake convolutional kernel sense field selection range |
当出现极端情况未发生偏移时,
$ P\{X=0\}=\left(\frac{1}{2}\right)^{n}$.
这种情况只占很小的概率, 不会对特征提取造成太大影响.偏移量限制系数将以正负交替的方式控制卷积偏移, 防止始终向某一方向偏移的极端情况出现.
由于偏移量Δ 通常是小数, 而坐标通常是整数形式, 因此采用双线性插值计算空间坐标, 即
K=
其中, K表示运算过程中具体小数位置, K'表示原特征图中与当前相邻可选择的四个整数空间位置, B(· )表示双线性插值核.
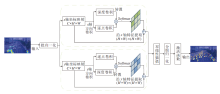
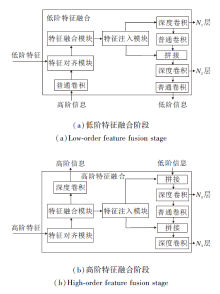
随着特征提取网络深度的增加, 高层次的全局信息变得更加丰富, 底层许多细节信息被逐渐忽视.为了避免目标特征在传输过程中丢失, 增强模型检测不同大小物体的能力, 受文献[26]启发, 本文提出双阶段多尺度特征融合方法(TMFF), 增强特征的融合与传输.TMFF由低阶特征融合阶段和高阶特征融合阶段组成, 分别融合并输送大、小尺寸的特征图, 避免传统特征融合中因某个级别上的信息只能充分帮助相邻层, 削弱提供给其它全局层的帮助而导致的特征信息丢失问题.TMFF具体结构如图5所示.
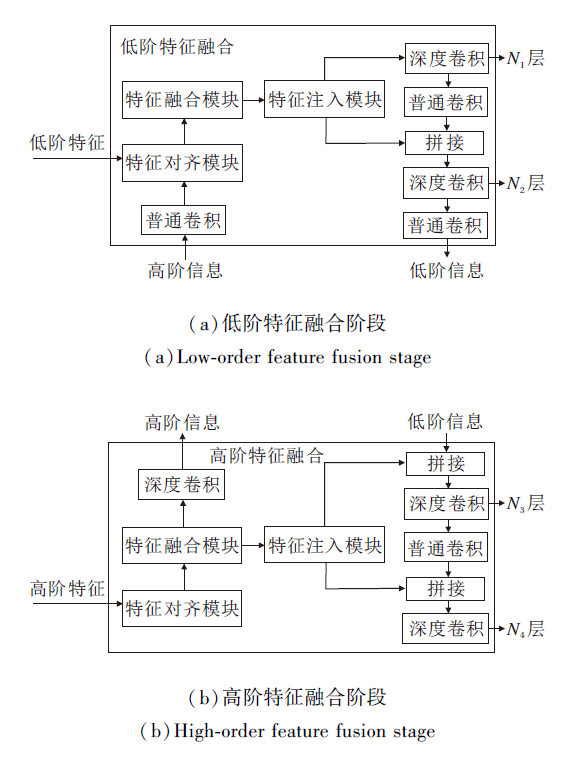 | 图5 TMFF结构图Fig.5 TMFF structure |
低阶特征融合阶段采用P2、P3、P4、P5层的特征图作为输入, 由特征对齐模块(Feature Alignment Module, FAM)对齐偏移受限动态蛇形卷积提取的不同尺度特征图, 其中Pi表示原始图像分辨率的1/(2i).特征提取网络中包含5次下采样, 产生5个不同分辨率的特征图(P1, P2, P3, P4, P5).特征对齐模块采用平均池化对输入特征进行下采样以统一尺寸大小, 并将特征大小调整为该组的最小特征尺寸.该模块确保信息的有效聚合, 同时最大限度地降低通过转换器模块进行后续处理的计算复杂性.
对于每个偏移受限动态蛇形卷积坐标K, 从x轴和y轴提取来自第l层的两个特征图fl(Kx)和fl(Ky), 则偏移受限动态蛇形卷积核沿x、y轴提取的特征图融合后的特征为:
$f^{l}({K})=\left\{\sum_{i} W\left({K}_{i}\right) f^{l}\left({K}_{i}\right), \sum_{j} W\left({K}_{j}\right) f^{l}\left({K}_{j}\right)\right\}, $
其中, W(Ki)表示位置Ki处的权重, 第l层卷积核K提取的特征采用累积方法计算.提取m组特征:
Tl=(f
特征对齐公式如下:
Falign=FAM(T
其中, T
特征对齐模块将特征统一尺寸后交由特征融合模块(Feature Fusion Module, FFM)进行下一步处理.特征融合模块包括多层重参数化卷积块和分割操作, 多层重参数化卷积块将Falign作为输入并生成融合后的特征:
Ffuse=RepBlock(Falign).
再交由分割操作, 在通道维度上分割为Finj_N1和Finj_N2, 则
Finj_N1, Finj_N2=Split(Ffuse).
为了将融合后的特征准确发送到对应层级, 采用特征注入模块(Feature Injection Module, FIM)实现.特征注入模块以融合后特征和其原本携带的层级特征作为输入, 融合后的特征可看作全局信息, 层级特征可看作局部信息.对两种输入信息进行不同卷积操作, 得到全局特征和局部特征, 再根据注意力, 计算得到输出特征:
Fout=Convlocal(Pi)Fglobal_act+Fglobal_emb,
其中, 经过卷积和激活函数的全局信息
Fglobal_act=resize(Sigmoid(Convact(Finj_Ni))),
仅经过卷积的全局信息
Fglobal_emb=resize((Convemb(Finj_Ni))),
Finj_Ni表示由特征融合模块生成的全局注入信息.
最后经过多层重参数化卷积块得到对应的注入层级:
Ni=RepBlock(Fout).
特征对齐模块、特征融合模块和特征注入模块结构如图6所示.
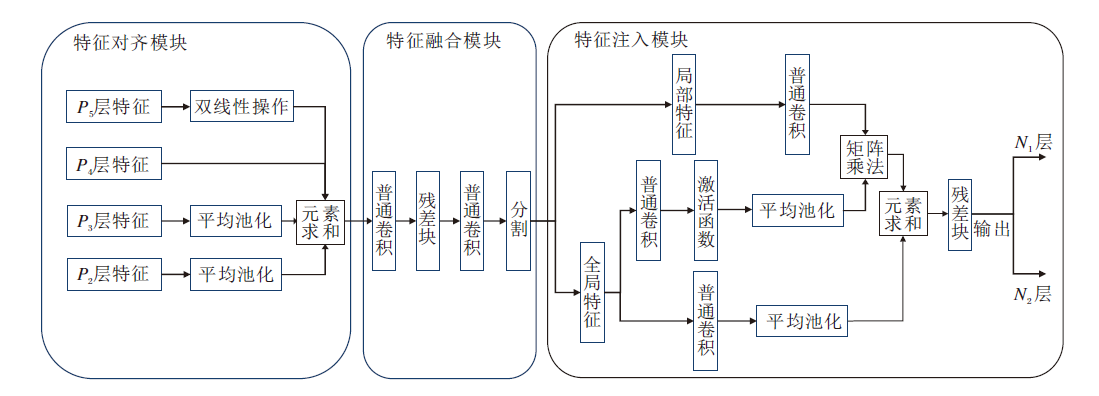 | 图6 3种模块结构图Fig.6 Structure of 3 modules |
经此处理后, 在检测器中增加小目标检测头, 接收N1层输出的特征信息, 以获得保留小目标信息的高分辨率特征, 提高小目标检测效率.
同理, 高阶特征融合阶段以P3、P4、P5层的特征图作为输入, 经过特征融合后, 将特征注入N3、N4层, 具体公式与低阶特征融合阶段类似, 在此不再赘述.
由于无人机航拍图像通常包含复杂的结构、噪声和背景纹理, 这些因素可能会对目标物体的定位和识别产生干扰, 从而影响检测的精确性.合理的损失函数能帮助模型获得更快的收敛速度和更准确的回归结果.YOLOv8使用DFL(Distribution Focal Loss)和CIoU(Complete Intersection over Union)计算边界框回归损失.虽然CIoU同时考虑中心点距离和长宽比, 但对长宽比的定义是相对值而非绝对值, 且未考虑难易样本的平衡.此外, 其计算公式涉及反三角函数, 可能增加算力消耗.
为了解决这些问题, 更进一步提高损失函数的有效性, 本文提出窗口锚定的边界框回归损失函数(WA-BBRLF), 基于辅助边界框和最小点距离进行边界回归.WA-BBRLF在包含MPDIoU和Ln范数损失优点的基础上, 引入比例因子, 控制辅助边界框的大小, 增强边界框定位能力, 提高检测准确性.WA-BBRLF和MPDIoU对比如图7所示.
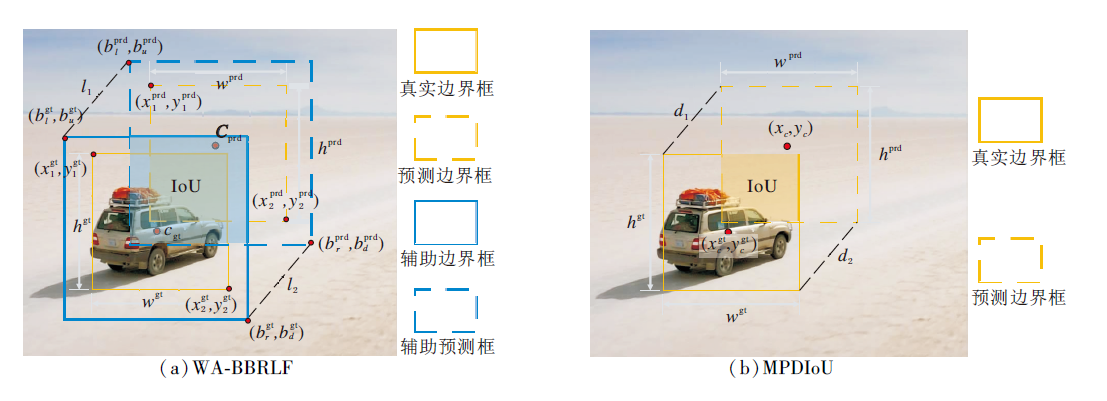 | 图7 WA-BBRLF与MPDIoU对比Fig.7 Comparison of WA-BBRLF and MPDIoU |
WA-BBRLF使用较大尺寸的辅助边界框计算IoU损失时有助于低IoU样本回归并实现加速收敛.相反, 使用较小尺寸的辅助边界框计算IoU损失时可帮助高IoU样本准确定位.小目标由于尺寸小、特征信息太少, 通常IoU值较低, 使用大尺寸的辅助边界框可提升小目标的边界框回归效果.
预测框坐标
Bprd=(
真实框坐标
Bgt=(
其中, (
Cprd=(
真实框中心坐标
Cgt=(
预测框宽度、高度坐标
Lprd=(wprd, hprd),
真实框宽度、高度坐标
Lgt=(wgt, hgt).
比例因子控制辅助边界框的大小, 根据比例因子计算真实边界框和预测边界框对应的辅助边界框, 本文比例因子采用1.2, 即辅助边界框为原边界框的1.2倍, 则辅助边界框为:
Agt=(
其中,
同理可得辅助预测框:
Aprd=(
下面计算原边界框的交并比:
IoUor=
其中
inter=(min(
(min(
同理可得, 辅助边界框的交并比:
IoUWA=
其中
inter=(min(
(min(
计算引入辅助框后的损失函数:
LMPD=1-IoUMPD,
其中, 基于最小点距离的辅助框交并比
IoUMPD=IoUor-
=
w、h分别为图像的宽高.
最后, 计算WA-BBRLF损失函数:
LWA-BBRLF=LMPD+IoUor-IoUWA.
WA-BBRLF考虑中心点距离、宽高偏差、重叠或非重叠区域等问题, 同时简化计算过程, 可解决CIoU存在的问题.控制比例因子生成大尺寸辅助边界框, 可显著提升小目标边界框回归效果, 提高方法的定位能力和检测精度.
本文使用VisDrone、DroneVehicle、Dota这3种不同的航拍图像数据集作为实验数据集.
VisDrone数据集是一个广泛应用于计算机视觉领域的开放式数据集, 提供丰富的无人机拍摄图像数据, 包含来自不同场景和环境的大量无人机采集的视频数据和图像数据, 具有丰富的视角和真实场景的特点.数据集上的图像涵盖各种天气条件、不同时间段和不同地点的场景, 从而能提供多样化的训练数据和测试数据.数据集包含10种不同类型的物体, 如货车、汽车、三轮车等, 包括6 471幅训练集图像、548幅验证集图像、3 190幅测试集图像, 共计260万个目标实例样本.
DroneVehicle数据集是一个专注于无人机航拍车辆目标的数据集, 旨在为研究者提供目标检测研究的实际数据支持.数据集包含各种场景下的航拍图像, 包括白天、夜晚场景下的红外图像和可见光图像, 以及这些图像中相应目标的标注信息, 如边界框或类别标签等.本文采用可见光图像部分作为训练测试数据, 训练集包含17 990幅图像, 验证集包括1 469幅图像.
Dota数据集专门针对城市和农村地区的航拍图像目标进行标注, 由来自Google Earth的2 806幅高分辨率图像组成, 共包含188 282个标注对象, 涵盖小型汽车、大型汽车、飞机、篮球场、游泳池等15种类别, 并支持旋转和水平两种标注方式.
实验中使用Windows10操作系统, 编译器为Python3.8, PyTorch2.0, CUDA11.8.所有方法在NVI-DIA RTX 3090 GPU上进行训练、测试、验证, 优化器为随机梯度下降(Stochastic Gradient Descent, SGD).训练时的超参数情况如表1所示.
| 表1 超参数配置情况 Table 1 Parameter settings |
为了测试WACDSC-NET的检测性能, 使用准确率(Precision)、召回率(Recall)、平均精度均值(Mean Average Precision, mAP)、参数量和检测速度(Frame per Second, FPS)作为评估指标.
准确率表示模型预测的正样本数与所有检测样本数的比值:
Precision=
其中, TP表示预测为正样本、实际也为正样本, FP表示预测为正样本、实际为负样本.
召回率表示模型正确预测的正样本数与实际出现的正样本数的比值:
Recall=
其中FN表示预测为负样本、实际为正样本.
平均精度(Average Precision, AP)等于准确率-召回率(P-R)曲线下的面积, 即选定一个交并比阈值, 以该阈值下的召回率为横轴, 准确率为纵轴绘制P-R曲线, 对P-R曲线上的精度求均值可得到该类别平均精度, AP计算公式如下:
AP=
其中, P表示准确率, R表示召回率.
mAP表示对所有样本类别的AP值进行加权平均得到的结果, 用于衡量模型在所有类别上的检测性能, 计算公式如下:
$m A P=\frac{1}{N} \sum_{i=1}^{N} A P_{i}$,
其中, APi表示类别索引值为i的AP值, N表示训练数据集上样本的类别数.
mAP能反映所有类别的综合检测性能, mAP@0.5表示所有目标类别在IoU(Intersection over Union)阈值为0.5时的平均精度均值.mAP@[0.5∶ 0.95]表示以步长为0.05, 计算IoU阈值从0.5到0.95的所有10个IoU阈值下的检测精度的平均值.阈值越高说明对模型的检测能力要求越严苛.IoU表示边界框与真实框之间的交集和并集的比值.
为了验证WACDSC-NET的性能, 本文选取如下多种具有代表性的航拍图像目标检测方法作为对比方法:YOLOv6[14]、YOLOv7[15]、QueryDet[23]、 Center-Net[24]、FSAF[26]、ATSS[27]、YOLOv8[31]、YOLOv5[32].选取mAP@0.5、mAP@[0.5∶ 0.95]作为评估指标.
VisDrone、DroneVehicle、Dota数据集上各方法对比结果如表2所示, 表中黑体数字表示最优值.由表可见, WACDSC-NET指标值均最高.对比方法由于未关注小目标的结构形态, 无法良好地提取小目标特征, 同时未将底层高分辨率特征图用于特征融合, 使大量底层细节信息丢失.由于WACDSC-NET克服上述问题, 在mAP@0.5、mAP@[0.5∶ 0.95]指标上都明显高于其它方法, 并且在mAP@0.5指标上提升较明显.这表明WACDSC-NET在无人机航拍图像中性能更优.
| 表2 各方法在3个数据集上的指标值对比 Table 2 Metric values comparison of different methods on 3 datasets |
为了更直观地对比方法检测效果, 分别在Vis-Drone、DroneVehicle、Dota测试集上选取分布密集场景、夜间场景、背景复杂场景、高空场景等图像进行对比实验, 检测效果对比如图8所示.由图可知, 在分布密集场景中, 如图8(h)中的第1幅图像, QueryDet并未检测到路边停放的自行车.在夜间场景中, 如图8(c)中的第3幅图像, 由于处于黑暗环境下, CenterNet存在边界框定位不准确的问题, 遗漏许多待检测车辆.综合来看, WACDSC-NET在各种场景下均表现良好, 可提高小目标检测精度.
 | 图8 各方法在不同场景下的检测效果对比Fig.8 Detection performance comparison of different methods in different scenarios |
为了验证WACDSC-NET的有效性, 以YOLOv8为基线方法, 并以准确率、召回率、mAP@0.5、mAP@[0.5∶ 0.95]、参数量、FPS作为评价指标, 通过多个改进模块不同的组合方式, 分别在VisDrone、DroneVehicle、Dota数据集上进行消融实验, 其中准确率和召回率为IoU阈值取0.5、置信度阈值取0.3时的结果.
具体3个数据集上的消融实验结果如表3~表5所示, 表中OCDS-Conv表示偏移受限动态蛇形卷积, TMFF表示双阶段多尺度特征融合方法, WA-MPDIoU表示窗口锚定的边界框回归损失函数, √表示采用这种改进策略.
| 表3 在VisDrone数据集上的消融实验结果 Table 3 Ablation experiment results on VisDrone dataset |
| 表4 在DroneVehicle数据集上的消融实验结果 Table 4 Ablation experiment results on DroneVehicle dataset |
| 表5 在Dota数据集上的消融实验结果 Table 5 Ablation experiment results on Dota dataset |
由表3~表5可见, 每种改进策略应用于YOLO-v8时都能不同程度地提高检测性能.在VisDrone数据集上, 引入OCDS-Conv代替YOLOv8特征提取网络中的特征提取模块, mAP@0.5提升0.7%.引入TMFF, 相比YOLOv8, mAP@0.5提升2.8%且参数量没有明显增加.引入WA-BBRLF, 并将参数比例因子设置为1.2(表示辅助边界框的大小为真实边界框的1.2倍), 相比引入TMFF, mAP@0.5提升0.5%, 运行速度增加2.1帧/秒.最后, 融合3个模块的WACDSC-NET比YOLOv8的mAP@0.5提升3.8%, mAP@[0.5∶ 0.95]提升2.2%, 准确率提高3.6%, 召回率提高2.8%.
由DroneVehicle、Dota数据集上的消融实验结果可知, 相比YOLOv8, WACDSC-NET的mAP@0.5提升4.2%, mAP@[0.5∶ 0.95]提升3.4%.在Dota数据集上, WACDSC-NET的mAP@0.5提升3.8%, mAP@[0.5∶ 0.95]提升2.9%.
各模块在训练过程中一些重要评估指标的变化曲线如图9所示.
 | 图9 各数据集上的指标值变化曲线Fig.9 Curves of metric values on different datasets |
由图9可看出, 在训练轮数为100时不同模块的指标值逐渐趋于平缓, 训练轮数为130时各项指标值已收敛.由此可知, 在不同数据集上WACDSC-NET的指标值都明显优于YOLOv8.
本文提出窗口锚定的偏移受限动态蛇形卷积网络航拍小目标检测方法(WACDSC-NET).首先, 构造偏移受限动态蛇形卷积(OCSD-Conv), 融入YO-LOv8特征提取网络, 通过自适应地聚焦于微小局部结构, 准确捕捉小目标形状结构特征.然后, 引入双阶段多尺度特征融合方法(TMFF), 增强底层细节信息与高层语义信息的融合和传输.最后, 设计窗口锚定的边界框回归损失函数(WA-BBRLF), 提升边界框回归精度和模型定位能力.在3个数据集上的实验表明, WACDSC-NET在多种无人机航拍场景下对不同类别目标的检测性能良好, 在小目标检测方面有不同程度的改善和提高, 但方法的检测速度和参数量还存在提升空间, 对于一些对速度要求较高的场景还不能完全适用.今后将按照提高检测速度和降低参数量的方向提升算法效率.一方面, 可探索更高效的特征提取网络架构, 结合轻量化设计, 提高检测速度的同时减少模型的参数量.另一方面, 针对不同场景和不同目标的特性, 可开发更多样化的增强方法, 如自适应数据增强和实时模型优化技术, 提高模型的鲁棒性和泛化能力.
本文责任编委 张军平
Recommended by Associate Editor ZHANG Junping
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|