



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
语义重建的动态监督伪装物体检测
[姜文涛1  , 王柏涵
, 王柏涵1 ]
, 王柏涵]
|
|



作者简介:

王柏涵,硕士研究生,主要研究方向为图像处理、模式识别、人工智能.E-mail:wangbhmero@foxmail.com.
伪装物体检测旨在分离视觉上高度融入周围环境的物体,但是物体前景与背景存在大量相似干扰,导致分割过程中易于出现明显错误.针对上述问题,文中提出基于语义重建的动态监督伪装物体检测网络(Dynamic Supervised Camouflaged Object Detection Network with Semantic Reconstruction, DSSRNet),通过重建特征图的空间语义和引入置信度指导网络训练,实现对伪装物体的准确分割.首先,提出空间语义低秩重建机制,精细感知不同尺度下伪装物体具有区分性的语义特征.然后,生成预测置信度图,对分割过程进行动态监督,减少网络因过于自信造成的假阳性和假阴性判断.最后,提出模糊感知损失函数,对网络施加强约束,改善预测时产生的图像模糊问题.在3个具有挑战性的基准数据集上的实验表明,DSSRNet可较好地排除相似信息干扰,取得精准的分割效果.
About Author:
WANG Bohan, Master student. His research interests include image processing, pattern recognition and artificial intelligence.
Camouflaged object detection(COD) aims to segment target objects that are visually highly integrated into their surrounding environments. However, a large number of similar interferences between the foreground and background of the object lead to significant segmentation errors in the process. To address this issue, dynamic supervised camouflaged object detection network with semantic reconstruction(DSSRNet) is proposed to achieve accurate segmentation of camouflaged objects by reconstructing the spatial semantics of the feature map and introducing confidence to guide network training. Firstly, a spatial semantic low-rank reconstruction mechanism is proposed to effectively perceive distinguishable semantic features of camouflaged objects at different scales. Secondly, the COD network is dynamically supervised by generating confidence prediction maps to minimize false positive and false negative judgments due to the overconfidence in the network. Finally, the blurred awareness loss function is employed to reduce the ambiguity of the prediction. Experiments on CAMO-Test, COD10K-Test and NC4K datasets demonstrate that DSSRNet provides better exclusion of interference and achieves more accurate segmentation results.
自然界中很多生物为了逃避捕食者的搜寻和捕猎, 进化出与周围环境融为一体的保护色, 这种隐蔽自己、迷惑敌人的特征可大幅提升生物的生存几率.受这种伪装机制的启发, 人类在很多领域都采取将物体的色彩和形态等调整到与环境极为相似的状态以伪装自身的行为, 如军事迷彩、光学隐蔽和动物伪装摄像等.因此, 如何高效准确地定位伪装物体, 成为图像分割领域的热点和挑战.
伪装物体检测(Camouflaged Object Detection, COD)旨在分离与环境高度相似的目标物体, 可准确定位并分割伪装物体[1], 是图像分割领域的热点研究方向之一.在近年的研究中, COD的应用范围不仅在野生动物搜寻和军事侦察等领域[2], 而且在医学图像处理(如息肉分割[3]、肺部感染检测[4]等)、工业设备检测(如缺陷检测、故障检测等)[5]和农业防治(如灾害预防[6]、蝗虫检测[7]等)等领域均具有广泛应用.COD在这些细分应用领域中性能表现优异的同时, 也为改进这些领域的模型提供新的分割策略与精度更高的算法.
在COD早期研究中, 研究者主要通过区分目标的颜色、强度[8]和纹理[9]等初级特征以定位伪装物体, 但该类方法逻辑简单、泛化性差, 分割效果存在较大的局限性.随着深度学习在计算机视觉领域的普及, 借助神经网络对图像语义更强的提取能力, 研究重点转为在浅层网络中丰富图像细节与在深层网络中抽象语义的结合, 以此提升目标图像的分割精度和效率.
为了实现上述目标, 研究者们尝试的方法主要分为以下三类.1)采用不同的尺度整合策略.Sun等[10]提出C2F-Net(Context-Aware Cross-Level Fusion Network), 由高到低逐级整合提取的特征, 获得对目标物体更精确的表示.Sun等[11]提出BGNet(Boun-dary-Guided Network), 使用注意力机制, 实现对边缘特征的着重关注, 较好地完成不同尺度下特征的整理与融合.2)设计特殊的卷积神经网络.Lü 等[12]引入COR(Camouflaged Object Ranking), 估计检测目标物体的难度, 对使目标暴露的区域进行定位.Le等[13]提出ANet(Anabranch Network), 设计两个并行的卷积网络, 一个卷积网络判断目标是否在图像中, 另一个卷积网络完成对伪装物体的精确分割, 最终输出的图像为两个网络输出结果的融合.3)在主要卷积网络基础上添加辅助模块.Zhai等[14]提出MGL(Mutual Graph Learning), 引入图卷积网络作为功能模块, 采用循环策略交互提取边缘先验特征.Jia等[15]提出SegMaR(Segment, Magnify and Reite-rate), 设计分段细化模块, 放大并分离前后景, 经多阶段迭代获得更精准的分割结果.Ji等[16]提出的DGNet(Deep Gradient Network), 引入梯度图, 辅助COD网络.Mei等[17]提出PFNet(Positioning and Focus Network), 设计全局定位后开展识别的双模块, 可更好地关注模糊区域并逐步完善最终的分割结果.
综上所述, 目前基于深度学习的COD研究方向主要集中在消除高相似性背景造成的干扰, 优化目标物体分割的精度.然而, 无论是设计具有针对性的卷积网络或添加辅助分割模块, 在实际分割时, 复杂的网络结构大概率会导致过于自信的现象, 会因为前景和背景之间较小的差异而做出大量假阳性和假阴性的判断, 具体表现为对目标物体分割不完全或将背景图像错误分割为目标物体.为了解决上述问题, 本文引入置信度估计策略, 提出基于语义重建的动态监督伪装物体检测网络(Dynamic Supervised Camouflaged Object Detection Network with Semantic Reconstruction, DSSRNet).在对目标图像分割过程中, 动态合成预测置信度图, 合理判断目标图像中存在的理解误差及不确定性结构, 监督和指导网络学习不确定性区域, 减少错误判断, 提升分割准确性.同时, 以语义整合和特征挖掘技术作为基础, 在特征提取阶段设计空间语义低秩重建机制, 通过缩放、增强和整合等操作, 高效收集目标与背景之间容易忽视的差异线索, 为后续处理提供有效的先验知识.最后, 为了提升网络分割时的整体可靠性, 设计强约束的模糊感知损失函数(Blurred Awareness Loss, BAL), 迫使网络增强决策信心, 消除预测时产生的严重模糊信息.
由于COD任务需要对相似像素实现准确分割, 而提取特征细节和整合语义特征对分割精细图像具有重要作用, 因此, 近年来学者们提出众多基于语义特征提取和整合的伪装物体检测网络.其中一类网络是在主干网络外添加不同的语义整合模块作为辅助, 以此提升模型分割伪装物体的精度.Sun等[11]提出BGNet, 设计EFM(Edge-Guidance Feature Mo-dule), 明确利用边缘语义, 结合边缘特征与各层伪装对象, 指导COD的表示学习.Mei等[17]提出PFNet, 设计PM(Positioning Module), 执行多尺度上下文搜索, 可在浅层网络中率先定位潜在的伪装目标.还有一类网络将语义整合的目标聚焦于特征提取阶段.Ji等[18]提出ERRNet(Edge-Based Reversible Re-calibration Network), 设计RRU(Reversible Re-calibration Unit), 能收集更多的先验信息和更全面的细节内容.Ren等[19]提出TANet, 设计TARM(Tex-ture-Aware Refinement Module), 放大伪装目标和背景之间细微的纹理差异.
同时, 学者们也尝试引入不同的数学方法, 对COD网络进行监督学习, 提升分割的准确性与效率.Yang等[20]将贝叶斯算法引入基于Transformer的COD推理中, 提出UGTR(Uncertainty-Guided Trans-former Reasoning), 把分割过程中确定性的映射过程转换为不确定性的引导.Zhong等[21]引入频域信息, 对网络进行监督, 检测RGB域外的相关线索, 对噪声起到较好的抑制效果.Liu等[22]提出EVP(Ex-plicit Visual Prompting), 调整集中于单幅图像显式视觉内容上的参数, 为模型提供视觉提示, 较好地完成对COD任务的前景分割.
引入合理的数学方法可有效提升COD任务的效率, 因此统计学中“ 不确定性” 概念的研究被引入深度学习领域中.数据不确定性主要分为两类:认知不确定性和随机不确定性[23].在计算机视觉的应用中, 以处理数据噪声多、样本难预测为主要目标的随机不确定性方法发挥着重要作用.Sensoy等[24]提出以狄利克雷分布作为分类问题的预测器, 参数由神经网络的输出设置, 以此得到的不确定性预测拥有更强的抗干扰性.Kong等[25]提出SDE-Net, 将深度神经网络之间的转换视为随机动力系统的状态演变, 引入布朗运动项, 感知网络中的不确定性.
在众多不确定性方法中, 置信度估计方法以其优异的性能和针对不同任务的普适性而被广泛应用.Wannenwetsch等[26]提出PPACs(Probabilistic Pixel-Adaptive Convolutions), 将置信度估计的结果设计为额外的滤波器, 提高上采样的性能, 改善位置信息缺失的问题.Ma等[27]提出CGSSL(Confidence-Guided Semi-supervised Learning), 有效减少低置信度的伪标签对土地覆盖分类的负面影响.Liu等[28]在COD任务中引入置信度估计, 通过置信度图参与分配权重并调整学习策略, 使网络着重学习目标图像中不确定性较强的区域.
然而, 添加额外的模块以监督网络学习的方法高度依赖输入数据的精细程度和准确性, 误差较大的监督会在迭代过程中导致网络产生更加错误的判断.
在计算机视觉任务中, 整合不同尺度的特征可起到扩大感受野、获取更丰富细节表示的积极作用.不同于一般的尺度整合操作, 尺度空间整合旨在挖掘不同尺度的特征在空间结构中表现的特殊语义.在已有的COD方法中, Pang等[29]设计ZoomNet, 考虑当空间尺寸不同时前景和背景之间的差异关系, 将缩放策略引入COD任务.He等[30]设计FEDER(Feature Decomposition and Edge Reconstruction), 通过可学习的小波将具有内在相似性的前景特征和背景特征分解至不同频带, 将分析重点集中于包含信息最多的波段.Hu等[31]提出HitNet(High-Reso-lution Iterative Feedback Network), 提取高分辨率纹理细节, 在保证实时性的前提下增强不同语义下的低分辨率特征.童旭巍等[32]提出基于全局多尺度特征融合的伪装目标检测网络(COD Network Based on Global Multi-scale Feature Fusion, GMF2Net), 有效解决高层次语义信息在向浅层网络融合传递时因被稀释及丢失而导致精度降低的问题.陈鹏等[33]提出边缘-分割交叉引导的伪装目标检测网络(Edge-Segmentation Cross-Guided Camouflage Object Detec-tion Network, ECGNet), 通过边缘-交叉引导技术实现多尺度上下文信息提取, 较好地融合伪装物体边缘特征与分割特征.
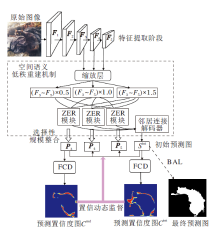
本文提出语义重建的动态监督伪装物体检测网络(DSSRNet), 使用Res2Net-50[34]提取多级特征Fi∈ RH× W× C, 其中, H表示高度, W表示宽度, C表示通道数, i=1, 2, …, 5, 表示层数.在Res2Net-50中一共提取五层特征, 前两层特征F1、F2存在细节过于冗杂、语义过于低级的问题, 故选择特征F3~F5送入网络.首先, 通过缩放层调整特征图的尺寸, 缩放尺寸为0.5、1.0和1.5, 并送入包含尺度集成功能和纹理增强功能的ZER(Zoom-Enhance-Reshaped Mo-dule)模块中进行尺度空间整合, 提取前景和背景间差异的细节, 充分发掘不同尺寸和不同层次下特征具有的独特语义.然后, 将生成的初始预测图Sini和由特征F3生成的包含更多像素细节的P3分别送入置信度特征判别器(Feature Confidence Discrimi-nator, FCD), 生成预测置信度图Cini与Cmd, 用于表明模型对预测的认识.预测置信度图通过二元交叉熵损失(Binary Cross-Entropy Loss, BCEL), 可结合真实标签一起对初始输入Sini和P3的生成过程进行动态置信度监督, 引导COD网络在初始预测阶段专注于学习具有低置信度(即不确定性区域)的部分.最后, 引入模糊感知损失函数(BAL), 对初始预测进行强约束, 增强决策信心, 输出最终的预测图.DSSRNet的整体流程如图1所示.
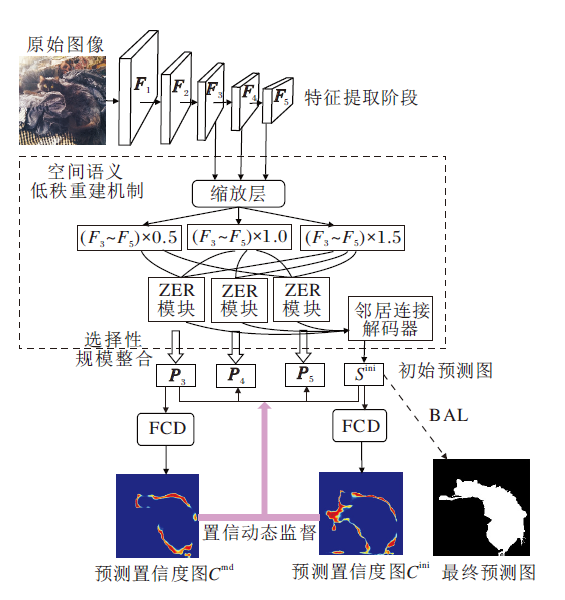 | 图1 DSSRNet整体流程图Fig.1 Flowchart of DSSRNet |
图像处理任务中, 秩(Rank)被定义为图像包含差异信息丰富程度的度量标准.低秩图像像素间秩序程度高, 差异信息少, 语义混乱; 高秩图像像素间秩序程度低, 差异信息多, 语义明确.因此, 可更有效地从环境中区分高秩图像中的伪装物体.具体而言, DSSRNet选择Res2Net-50对目标图像进行多尺度特征提取, 然而, 当特征图在Res2Net-50中传递时, 层与层之间的连接是不连续的, 当特征传输到后层高级阶段时神经网络的语义会产生低秩的混乱现象, 原因如下:1)语义缺少针对性, 使神经网络的主要关注点可能集中到非检测物体上; 2)低秩语义会造成特征图中差异像素的减少, 在伪装物体检测领域表现为特征图边缘平滑, 使神经网络难以有效精细感知目标物体的准确结构.因此, 本文提出空间语义低秩重建机制, 重建低秩状态下混乱的语义, 着重提取目标物体与背景之间的差异信息.最终实现在掌握高阶语义提供的目标位置信息的同时, 也不丢失网络对目标物体的注意力和浅层网络包含的纹理细节的目标.
空间语义低秩重建机制主要结构包括:缩放层、ZER模块和邻居连接解码器(Neighbor Connection Decoder, NCD).ZER模块接收在缩放层变化尺寸后的三组数据, 输出经过语义重建的特征图, 并与NCD配合生成初始预测图.特征图中的空间语义在多尺度增强后, 经过有选择性地整合, 实现由杂乱无序的低秩空间向相关度高、针对性强的高秩空间的转化.
受SegMaR[15]和ZoomNet[29]的启发, 本文首先采用缩放策略处理Res2Net-50提取的特征F3~F5.缩放操作能有效挖掘不同尺度下特征的纹理细节, 提升前景和背景之间差异信息的完整性.具体而言, 将通道数分别为512、1 024、2 048的3个特征层送入过渡层, 生成3幅对应于3个输入尺度的通道数为64的特征图.现有研究表明[15], 缩放尺寸选取0.5、1.0和1.5时能使效率最大化, 所以3幅输入的特征图经过缩放后定义为$\left\{f_{i}^{k}\right\}_{i=1}^{3}$, k∈ {0.5, 1.0, 1.5}.这些特征图在缩放层内经由整合, 放大与缩小的尺度最终被整合入主尺度中, 不同信道间的差异信息通过交互与特征细化, 可更好地突出表达自身包含独特的特征细节.
然后, 为了整合多尺寸特征图之间丰富的空间语义, 设计包含缩放、纹理增强和尺度聚合功能的ZER模块.经过缩放操作提取的特征信息包含大量细节信息, 但依旧存在识别率低和语义混乱的问题.此时, 合理的纹理增强操作能通过增大感受野提高网络对输入特征信息的理解能力, 尺度聚合操作通过拼接不同尺度的信息生成对目标物体准确合理的语义.
ZER模块示意图如图2所示.首先, 在对经过缩放层处理的信息进行卷积操作之前, 应保证f0.5和f1.5的分辨率与f1.0的分辨率保持一致.故对f0.5进行双线性插值上采样, 对f1.5进行最大池化的下采样, 可在最大化空间尺度的同时保证网络对目标物体细节的敏感程度.然后, ZER模块对fk, k=0.5, 1.0, 1.5进行数据增强操作, 以此扩大感受野, 合并更多的判别特征表示.数据增强部分首先利用一个1× 1卷积层, 将所有数据的通道减少为32, 再分出3个膨胀率不同的分支, 其中膨胀率d=3, 5, 7.通过把传统的d× d卷积层分解为顺序的1× d卷积层和d× 1卷积层, 在保证卷积核学到的分布特征值的信息不受损的同时增强卷积核的能力, 使特征图中纹理细节的部分得到逐级增强, 神经网络也获得更精细的特征细节表示.再根据文献[1], 膨胀后的3条通路统一馈送入一个3× 3卷积层, 可使网络的运行成本降低.最后, 拼接整个单元中的特征图, 经过1× 1卷积层和ReLU函数的塑形, 得到输出f'k, k=0.5, 1.0, 1.5.
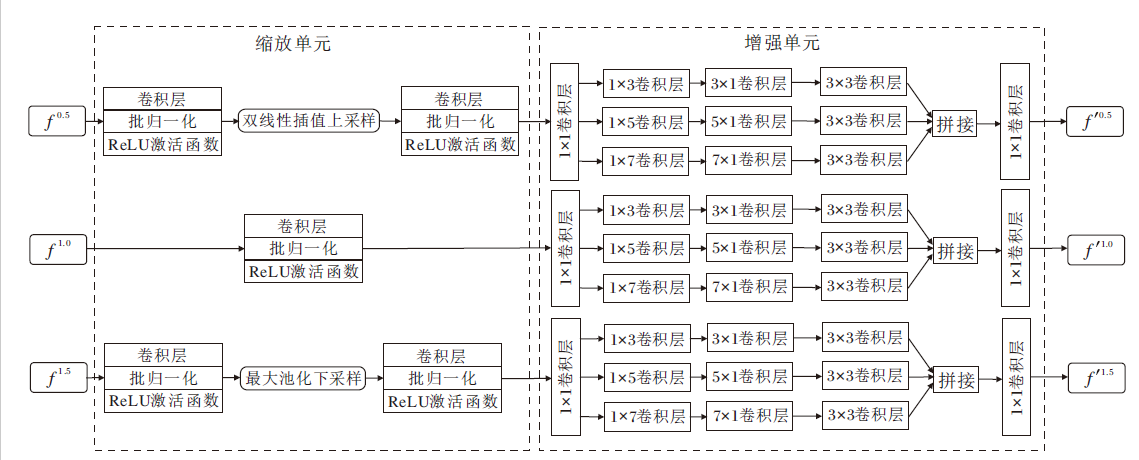 | 图2 ZER模块示意图Fig.2 Schematic diagram of ZER module |
经过缩放层和ZER模块的多尺寸特征携带大量对COD任务至关重要的细节, 为了生成包含不同层级特有空间细节的特征图, 本文使用选择性规模整合方法[29]整合多尺寸特征.具体而言, 该方法利用注意力生成器合理关注不同尺寸特征细节, 再经过多步骤张量拼接, 输出相应的特征图, 同时, 使用NCD跨层桥接上下文, 在保持语义一致性的前提下整合3个不同的尺度, 生成初始预测图Sini.
空间语义低秩重建机制的过程使用公式表示如下:
f
Pi=σ (f
Sini=N[fU
其中, μ (· )表示缩放单元内统一输入特征图分辨率的操作, τ [· ]表示卷积操作, σ (· )表示选择性规模整合方法, θ 表示在执行整合过程中各层的参数.U(· )表示双线性插值上采样, D(· )表示最大池化下采样, N[· ]表示NCD对多尺度特征的连接.
综上所述, 空间语义低秩重建机制有效整合主干网络由浅到深提取的各个层级的特征, 减少COD任务中物体前景与背景高度相似的干扰, 使输出的特征图拥有不同的语义, 以此形成更具有针对性的高秩语义空间, 提升网络对伪装物体的鉴别能力.其次, 在输出的特征图中相对低级的P3包含更多的结构细节, 能有效地为后续动态监督提供空间信息, 在分割伪装物体精细轮廓的过程中起到重要作用.
依赖于不同的伪装策略, 伪装物体往往会展现出与背景颜色高度相近或纹理极其相似的特征, 给观察者造成极大的干扰, 因此, 相比显著目标检测, COD任务会表现出在整幅图像中分割难度不均匀的特点.一般而言, 伪装物体的躯干部分具有最高的分割难度, 而一些突出部位会更容易区分, 如动物的眼睛和嘴巴、昆虫的触须、人造物体的裂纹等.为了解决上述问题, 学者尝试使用各种辅助策略作为COD任务中度量伪装物体分割难度的指标[12, 33].
相比传统方法, 使用不确定性方法的神经网络具有优异的排除数据中复杂干扰的能力, 表现出更强的鲁棒性.置信度估计方法在图像处理任务中以监督为主要形式的低耦合特性受到广泛关注.因此, 受Liu等[28]和Wei等[35]工作的启发, 本文选择置信度作为衡量不确定性的标准, 并设计置信度特征判别器(FCD), 生成预测置信度图, 实现网络对目标图像置信度的度量, 着重监督网络学习置信度较低的部分, 以此描绘更精准的不确定性结构.FCD同时防止网络在预测分割时过于自信, 减少在分割过程中产生的假阳性和假阴性判断, 使分割结果更合理、准确.
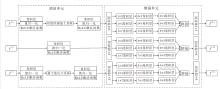
FCD结构如图3所示, 主干网络使用U-Net[36], 主要分为两个部分:前半部分为特征提取的编码器, 后半部分为上采样的解码器.
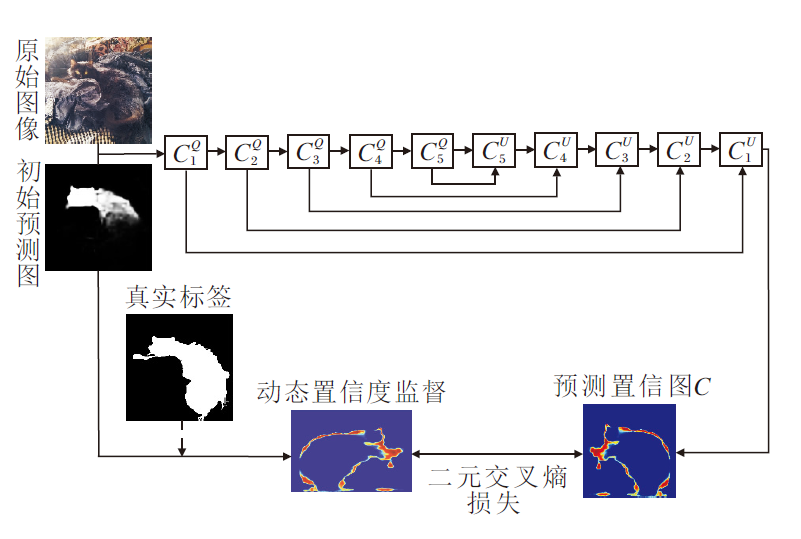 | 图3 FCD结构图Fig.3 Structure of FCD |
编码器部分由5个
解码器部分由5个
$ \begin{array}{l}C_{n}^{Q}=Q\left(\operatorname{Conv}\left(\operatorname{Conv} 3\left(C_{n-1}^{Q}\right)\right)\right) \\C_{n}^{U}= Q\left(\operatorname{Conv} 3\left(\operatorname{Conv} 3\left(\pi\left(C_{n}^{Q}, Q\left(\operatorname{TConv} 2\left(C_{n+1}^{U}\right)\right)\right)\right)\right)\right)\end{array}$
其中, Q(· )表示丢弃层的处理, π (· )表示跳跃链接操作, T表示对卷积层的转置操作.
FCD能向分割网络提供一个特定于单个样本像素的权重参数ε , 使主干网络专注于学习低置信度的像素.首先, 初始预测图Sini和包含原始特征细节的P3分别经过FCD的编解码器生成预测置信图Cini和Cmd, 其中, 置信图Cini偏重于考量伪装物体的空间位置, 置信图Cmd能对目标边缘像素做出合理判断.结合GT中的先验信息, 两种预测置信图辅助生成权重:
$ \begin{array}{l}\varepsilon^{\mathrm{ini}}=1+\left|\frac{1}{\left|R_{G T}\right|} \sum_{(p, q) \in R_{G T}} x_{p q}-G T\right|+\rho C^{\mathrm{ini}}, \\\varepsilon^{\mathrm{md}}=1+\left|\frac{1}{\left|R_{G T}\right|} \sum_{(p, q) \in R_{G T}} x_{p q}-G T\right|+\rho C^{\mathrm{md}}, \end{array}$
其中, RGT表示GT中元素的总数, xpq表示GΤ 中位于(p, q)像素处的元素, ρ 表示控制对不确定像素关注程度的超参数, 根据训练轮数变化, 当训练轮数小于20时ρ =0, 其余轮数取默认值10.该操作的优势在于:在训练前期减少预测置信度图对权重ε 的影响, 进而抑制动态置信监督, 更好地挖掘特征图中的细节; 在训练后期加强预测置信度图对权重ε 的影响, 进而促进动态置信监督, 使神经网络关注不确定像素, 以此得到准确率更高的预测结果.
接着, 通过二元交叉熵损失(BCEL)实现动态监督机制, 在迭代过程中加入权重与预测置信度图之间的乘积, 有效地在不同训练时期对COD任务中预测错误的正样本和假样本提出合理的不确定性度量, 该机制可表示为
M=0.5(Lce(Cini, ε ini))+Lce(Cmd, ε md),
其中Lce(· )表示二元交叉熵损失.
综上所述, FCD能生成合理准确的预测置信图, 动态监督COD网络对伪装物体的识别和分割.因此, 引入动态监督机制能进一步降低复杂环境的干扰, 避免COD网络对所做的判断过于自信, 对最终分割图的准确性起到至关重要的作用, 同时, 不确定性概念的引入也从侧面增加网络的鲁棒性, 有助于提出更合理及有效的损失函数.
在语义分割任务中, BCEL和加权交并比损失应用广泛.其中, 加权交并比损失函数只在特定任务中表现优异, 不适用于情况较复杂的COD任务.同时, BCEL虽然可为COD任务的全局和局部提供有效约束, 但单独作为模型的损失函数时, 存在无法捕捉样本间相对关系的问题:当面对COD任务中复杂的前景和背景数据时, 因只关注单个伪装目标样本的预测结果和真实标签之间的差异, 却忽略目标与背景之间的相对关系, 可能造成网络产生模糊预测, 在目标物体周围生成大量的不确定性区域.为了解决上述问题, 受UAL(Uncertainty-Aware Loss)[29]的启发, 本文设计强约束损失函数— — 模糊感知损失函数(BAL), 可更好地消除假阳性判断, 使特征图更具有鉴别力.具体而言, 因为最终分割生成的伪装对象预测图的像素被概率化于[0, 1]内, 0表示像素属于背景, 1表示像素属于目标对象, 所以, 可定义预测值越接近0.5, 对像素属性的判定就越不确定.为了解决这一问题, 使用模糊度作为这些困难样本的补充损失, 即该权重系数在取中值0.5时最大, 在集合上限0或下限1时最小.通过引入模糊度作为对空间信息的补充, 能使模型更好地关注像素间位置和上下文信息, 更好地处理边界处的模糊问题, 进而提升模型的稳定性与鲁棒性.
为了保证损失函数的性能, 依据UAL, 选择基于幂函数的形式构成BAL损失函数:
$ L_{\text {BAL }}=1-\left|2 P_{i, j}-1\right|^{1.5} .$
则DSSRNet的总体损失函数为:
Ltotal=LBCE+θ LBAL,
其中, BAL损失函数使用自适应学习优化器进行优化, θ 默认值取0.8.
基于Pytorch框架实现DSSRNet, 训练和测试都在配置于Python3.8环境的单张NVIDA RTX3090 24GB GPU上实现.训练阶段图像的输入尺寸调整为416× 416, 采用在ImageNet上预训练的Res2- Net-50作为主干网络, 批大小为32.训练周期为100, 初始学习率为1e-4, 在迭代50次后衰减为自身的0.1, 并使用Adam(Adaptive Moment Esti-mation)优化器优化训练过程.在测试过程中, 调整输入图像尺寸为352× 352, 不进行额外的数据处理操作.
本文选择在COD10K[1]、NC4K[12]、CAMO[13]这3个基准数据集上评估网络性能.CAMO数据集包含8种类别的1 250幅伪装物体图像, 其中, 训练集包含1 000幅图像, 测试集包含250幅图像.COD10K数据集涵盖真实场景中由78种不同类别目标组成的5 066幅图像样本, 其中, 训练集包含3 040幅图像, 测试集包含2 026幅图像, 该数据集首次在COD任务中包含单纯的背景图像, 以此在训练过程中提升COD网络的鲁棒性.NC4K数据集包含4 121幅来自互联网的经过定位标注和排名标注的伪装图像, 可额外支持对目标图像的定位和难度排序的功能.
根据目前COD研究领域广泛使用的方法, DSSRNet使用的训练集为来自COD10K训练集的3 040幅图像与CAMO训练集的1 000幅图像组成的4 040幅图像的组合.测试集为CAMO测试集、COD10K测试集和NC4K数据集.
本文选择目前COD任务中使用最广泛的4个评价指标进行评估分析:平均绝对误差(Mean Absolute Error, MAE)[38]、平均E-measure(EΦ )[39]、结构度量(Sα )[40]和加权F-measure(F
MAE计算预测图的预测值与真实值之间的逐像素平均绝对误差, 具体公式如下:
$M A E=\frac{1}{W H} \sum_{x=1}^{W} \sum_{y=1}^{H}\|S(x, y)-G(x, y)\|$,
其中, S(· )表示预测值, G(· )表示真实值, W、H表示宽和高.经过正则化, MAE的取值范围规范在[0, 1]内.
平均E-measure(EΦ )可同时捕获图像级统计信息和像素级匹配信息, 具体公式如下:
$E_{\Phi}=\sum_{i=1}^{W} \sum_{j=1}^{H} \Phi_{\mathrm{FM}}(i, j)$,
其中, Φ FM表示增强对齐矩阵, 用于评估伪装物体预测结果在整体和局部的精确度.
结构度量(Sα )评估预测图和真实标签之间的区域感知和对象感知结构的相似性, 着重评估预测图的结构信息, 具体公式如下:
Sα =α S0+(1-α )Sr,
其中, S0表示对象感知, Sr表示区域感知, α 表示平衡参数, 默认值取0.5.
加权F-measure(F
F
其中, precision表示准确率, recall表示召回率, β 表示权衡参数, 默认值设为0.3.
为了证实DSSRNet的先进性, 将其与9种具有代表性、采用不同策略的COD网络进行性能对比和分析.对比网络包括:SINet(Search Identification Network)[1], PFNet[17], UGTR[20], 文献[28]网络, ZoomNet[29], FEDER[30], HitNet[31], DAD(Difference-Aware Decoder)[42], EGNet(Edge Guidance Net-work)[43].对比网络采用的策略包含手工纹理提取、生物视觉模拟辅助模块协助、贝叶斯卷积神经网络、尺度整合和不确定性监督等, 基本涵盖COD任务中的主流网络.为了保证对比实验的公平性, 上述网络中开源代码的数据由本文实验机器复现后得出, 其余由相应论文或网站提供, 同时将实验结果进行可视化分析.
各网络在3个测试数据集上的定量指标结果如表1所示, 表中黑体数字表示最优值.由表可看出, DSSRNet在各项指标上均表现优异, 说明其在像素级分割中的优势, 从侧面验证DSSRNet各模块在功能上的有效性.
| 表1 各网络在3个测试集上的指标值对比 Table 1 Metric value comparison of different networks on 3 test datasets |
本文在对比网络中选择近年来COD任务基准网络SINet、SOTA网络HitNet、采用动态监督策略的文献[28]网络与采用尺度整合策略的FEDER, 与DSSRNet在3个测试集上进行准确率-召回率(Precision-Recall, P-R)曲线对比, 具体如图4所示.
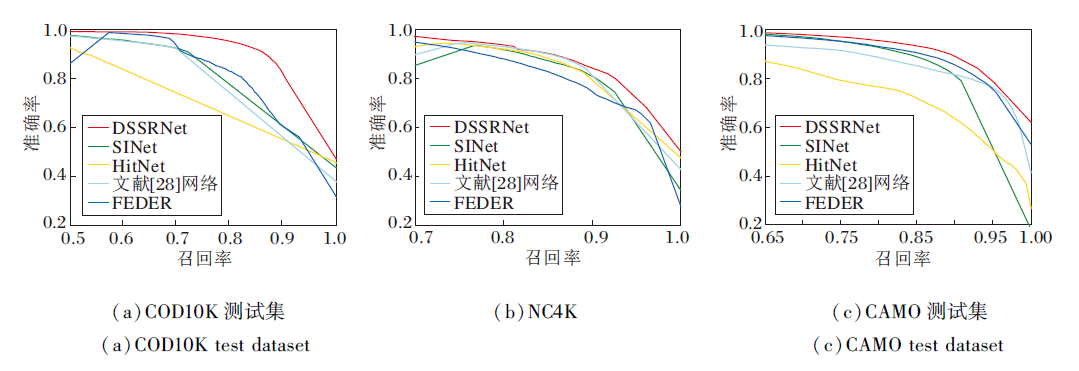 | 图4 各网络在3个测试集上P-R曲线对比Fig.4 Schematic diagram of P-R curves of different networks on 3 test datasets |
由图4可看出, DSSRNet的P-R曲线振荡较小, 平衡点表现最优, 体现DSSRNet在查准率与查全率综合性能上的优势, 说明本文提出的模块与机制可有效减少错误判断, 提高对伪装物体分割的精准度.
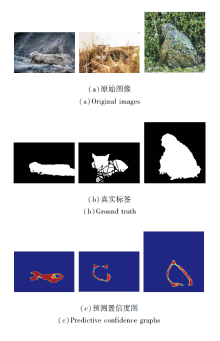
各网络定性对比的可视化结果如图5所示, 包含生活在不同环境中的多种具有伪装特征的动物及人类创造的伪装目标.经对比后发现, 对于减少前景和背景的相似干扰、诱导网络做出更合理的判断这一目标而言, DSSRNet效果最优, 表明其有效性和优越性.
 | 图5 各网络在不同图像上的可视化结果Fig.5 Visualization results of each network on different images |
由图5可见, DSSRNet对伪装物体的结构分割更清晰, 如第6列目标人类手中的武器和第8列花豹细致的头部轮廓.其次, DSSRNet能消除分割任务中一些错误的判断, 如第3列深海鱼类的鱼鳍和鱼尾在多种现有方法中被错误分割, 这种错误主要来源于神经网络由类似像素做出的错误判断, 并在多轮迭代中进一步加强决策的信心, 最终造成对整个局部形状所做的错误分割.本文提出的动态监督策略能有效规避此类问题的发生, 预测置信度图能使网络专注于不确定性高的区域, 以此解决过度自信的问题, 并减少错误判断.最后, DSSRNet对目标物体边缘的细节处理得更好, 由第4列图像、第5列图像和第7列图像可看出, DSSRNet在分割结果上保留目标物体更真实的形状, 这得益于空间语义低秩重建机制捕获多尺度特征图中各具特色的语义以及更丰富的细节像素, 加深神经网络对伪装物体形状和位置的理解, 使图像中高度相似的前景和背景被合理分离, 有效减少类似像素带来的干扰.
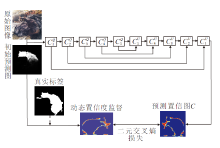
为了验证预测置信度图的动态监督对COD任务的贡献, 将具有代表性的预测置信度图进行可视化, 如图6所示.图中越靠近蓝色表示置信度评分越高, 网络对判断越肯定, 相反越靠近红色表示置信度评分越低.
 | 图6 置信度预测可视化示意图Fig.6 Schematic visualization of confidence prediction |
由图6可见, 第1幅图像中鳄鱼眼睛的局部和环境部分所得的置信度评分较高, 而鳄鱼头部与背景颜色相似的部分置信度评分较低, 说明网络对该区域判断的信心较弱, 此时置信度特征判别器会生成动态置信度监督, 并指导COD网络着重学习该区域.在第2幅图像中, 网络对目标狸花猫的脸部轮廓产生低置信度, 有助于在复杂背景中有效分割目标物体清晰的轮廓.在第3幅图像中, 网络着重学习目标与环境之间存在的纹理差异, 有利于在COD任务中准确定位伪装物体位置.
为了验证本文提出模块的有效性, 在3个测试集上进行消融实验, 并进行可视化分析.
定义A表示只使用预训练Res2Net-50的基线网络, F表示引入FCD进行动态监督, B表示引入BAL, Z表示引入空间语义低秩重建机制进行尺度空间整合.
各模块在3个测试集上的指标值对比如表2所示, 表中黑体数字表示最优值.由表可知, FCD的加入显著提升结构度量指标, 说明置信度动态监督可有效提升网络对伪装物体整体结构感知的合理性.空间语义低秩重建机制与BAL的加入普遍提升衡量像素级分割精度的指标, 说明空间语义整合与强约束能排除图像中存在的相似干扰, 在像素级层面减少分割过程中出现的错误.
| 表2 各模块在3个测试集上的消融实验结果 Table 2 Ablation experiment results of different modules on 3 test datasets |
图7为各模块的可视化分析结果.如图所示, 由于加入空间语义低秩重建机制, 使第1列与环境融为一体的热带鱼分割结果更平滑, 第3列中对蜥蜴头部的分割形状更合理, 由此验证空间语义低秩重建机制对特征整合的有效性.加入BAL进行强约束后, 第1列中消除画面左侧错误的判断, 第2列目标边缘的细节更加丰富, 说明BAL对网络做出正确预测起到积极作用.
 | 图7 各模块消融结果可视化分析Fig.7 Visualization analysis of ablation experiment results of different modules |
下面讨论BAL中α 的取值问题, 为了验证数据的有效性和合理性, 本文选择在最具挑战性的COD10K数据集上进行实验, 验证α 取不同值时对BAL的影响, 结果如表3所示, 表中X表示不使用BAL, 黑体数字表示最优值.由表可看出, 当α =1.5时各项指标均最优.
| 表3 α 不同对BAL的影响 Table 3 Effect of different α values on BAL |
尽管DSSRNet可解决因相似信息干扰导致的错误分割问题, 在定量评价和定性评估中都取得性能上的显著提升, 但仍存在一些复杂样例无法被准确分割的情况, 示例如图8所示, 这些伪装物体与背景环境往往具有极其相似的形状和拓扑结构.在左图中, 作为目标的蚂蚱和背景中的青草具有几乎相同的形状, 所有网络都无法精确确定目标物体的形状, 与同样使用动态监督策略的文献[28]网络对比得出, 与背景干扰形状的高度类似性抑制动态监督的准确性, 造成最终分割的失败.在右图中, 作为目标的剃刀鱼与背景中的珊瑚具有高度相似的拓扑结构, 这给所有网络确定目标物体的具体位置造成巨大挑战, 与同样进行多尺度语义整合的FEDER对比后得出, 前景和背景在拓扑结构上的相似性会造成神经网络在特征提取与整合阶段对目标位置的混淆, 进而难以确定准确的目标位置.为此, 今后将考虑优化置信度特征判别器的分割效率和语义重建机制对高级位置语义信息的精细筛选, 进一步提升DSSRNet的性能.
 | 图8 各网络检测失败样例Fig.8 Detection failure cases by different networks |
针对伪装物体检测任务中存在的大量相似干扰, 为了减少分割伪装物体时出现的错误判断, 本文提出基于语义重建的动态监督伪装物体检测网络(DSSRNet), 设计空间语义低秩重建机制、置信度特征判别器(FCD)和模糊感知损失函数(BAL).空间语义低秩重建机制对提取的特征图进行语义细化和精细感知, 将原本混乱的低秩语义空间重建为相关性更强的高秩语义空间, 提升对相似背景的抗干扰能力.FCD通过置信度动态监督指导网络学习, 促使网络在复杂背景中感知更多图像细节, 有助于网络分割出目标物体更精细的结构.BAL为网络添加一个强约束, 增强决策信心, 减少COD网络的错误判断.最后, 在3个具有挑战性的数据集上的实验验证DSSRNet的有效性和先进性.今后将进一步针对置信度特征判别器的卷积结构进行升级, 以优化置信度特征判别器的工作效率, 提升DSSRNet的检测性能.
本文责任编委 高隽
Recommended by Associate Editor GAO Jun
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|
| [40] |
|
| [41] |
|
| [42] |
|
| [43] |
|