


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于改进RetinaNet的轻量化钢材表面缺陷检测算法
[王伟家1  , 张宇
, 张宇2 , 王京华1 , 徐勇1 ]
, 张宇, 王京华, 徐勇]
|
|



作者简介:

王伟家,硕士研究生,主要研究方向为计算视觉、目标检测.E-mail:21S051039@stu.hit.edu.cn.

张 宇,学士,主要研究方向为计算机视觉、缺陷检测.E-mail:1737238992@qq.com.

王京华,博士,副教授,主要研究方向为计算机视觉、无监督学习.E-mail:wangjh2012@foxmail.com.
相对实际应用需求而言,现有的钢材表面缺陷检测算法存在检测速度较慢、准确率较低等问题.因此,文中提出基于改进RetinaNet的轻量化钢材表面缺陷检测算法.首先,将原有的骨干网络替换为轻量化网络,引入跨阶段局部结构,实现梯度的有效传播和轻量化.然后,采用深度可分离卷积替换传统卷积层,进一步降低参数量,提高检测速度.为了弥补轻量化导致的算法精度下降问题,提出基于跨阶段局部结构的空间金字塔池化机制,融合不同尺度的特征,有效提升算法的检测精度.在NEU-DET数据集和自建的HBIS数据集上的实验表明,相比已有的缺陷检测算法,文中算法在精度更高的同时,达到更快的检测速度,相应的软硬件系统满足生产线的实时在线检测要求并已上线运行.
About Author:
WANG Weijia, Master student. His research interests include computer vision and object detection.
ZHANG Yu, Bachelor. His research interests include computer vision and defect detection.
WANG Jinghua, Ph.D., associate profe-ssor. His research interests include computer vision and unsupervised learning.
For the requirement of the practical application, the existing defect detection algorithms suffer from the problems of slow detection speed and low detection accuracy. To address these issues, a lightweight steel surface defect detection algorithm based on improved RetinaNet is proposed. Firstly, the original backbone network is replaced by a lightweight network, and a cross-stage-partial structure is introduced to achieve effective propagation and lightweighting of gradients. Then, depth-separable convolution is employed to replace the traditional convolutional layer to further reduce the number of parameters and improve the detection speed. To compensate for the decrease in model accuracy caused by lightweighting, a spatial pyramid pooling mechanism based on the cross-stage partial structure is designed. The detection accuracy of the model is effectively improved by feature fusion at different scales. Finally, experiments on NEU-DET dataset and the self-built HBIS dataset demonstrate the proposed algorithm reaches a faster detection speed and higher accuracy. Moreover, the corresponding hardware and software system meets the real-time online detection requirements of the production line and it has been put into service.
钢材表面缺陷检测是钢铁企业保证和提高产品质量的关键举措之一, 它的核心任务是检测工业制品的表面, 识别和定位缺陷的类别和位置.早期的缺陷检测普遍以人工目测为主, 会因为疲劳和个体差异产生较大误差.随着时代的发展, 以机器为主的智能缺陷检测逐渐占据主流.
在深度学习出现之前, 智能表面缺陷检测通常以传统机器视觉检测方法为主[1].传统缺陷检测算法先进行手工设计和提取特征, 再使用机器学习方法处理特征, 主要利用缺陷的外观特征进行检测[2, 3].
表面缺陷的外观特征包括颜色特征、纹理特征和形状特征.颜色特征是视觉图像的固有特征之一, 颜色特征的计算量通常较小, 并且基本不依赖图像位置和尺度信息, 具有较强的鲁棒性.在缺陷检测任务中, 可通过缺陷的颜色属性对缺陷进行定位和分类.Ravikumar等[4]利用颜色特征定位机械零件表面的细小划痕, 并利用决策树对其分类, 成功检测缺陷的位置和类别.纹理特征是反映图像同质现象的一种重要特征, 不依赖颜色或亮度, 能清晰反映图像表面结构组织排列等重要信息.Tolba等[5]利用纹理特征的尺度不变性成功检测缺陷.基于形状特征的方法利用物体的轮廓特征检测感兴趣的区域.在表面缺陷检测中, 一般通过霍夫变换和傅里叶形状描述符提取缺陷区域的轮廓特征.
传统机器视觉检测的优势在于检测速度快并且可解释, 可以让人们清楚理解算法的决策过程, 缺点是误报和漏报较多, 在复杂场景下泛化性较差.因为无法处理复杂背景, 依赖特征工程, 该类方法一直存在准确率低等缺点.
随着深度学习的兴起, 以卷积神经网络(Convolu-tional Neural Networks, CNN)为代表的深度神经网络在通用目标检测方面取得巨大成功, 也推动工业表面缺陷研究领域的发展.通用目标检测算法主要分为两类.1)以R-CNN(Regions with CNN Features)[6]、Fast R-CNN(Fast Region-Based Convolutional Network Method)[7]、Faster R-CNN[8]为代表的两阶段目标检测算法.2)以YOLO(You Only Look Once)[9, 10, 11, 12, 13, 14]、SSD(Single Shot MultiBox Detector)[15]为代表的单阶段目标检测算法.
当前通用的缺陷检测算法大部分由通用目标检测算法改进而来, Wang等[16]在单阶段目标检测算法的基础上提出RDN(Real-Time Detection Net-work), 在保证缺陷检测速度的同时, 利用特征融合方法, 提高缺陷检测的精度.李若尘等[17]以Mobile-Net为骨干网络, 提出基于深度学习的自动缺陷定位模型(Automatic Defect Location Model, ADLM), 实现木材缺陷的高精度检测.黄健等[18]将度量学习引入缺陷检测领域, 提出小样本的度量迁移学习方法(Few-Shot Metric Transfer Learning Network, FmTLNet).
除了有监督的方法, 张兰尧等[19]探索无监督的缺陷检测方法, 提出ValidFlow, 利用标准化流的方式实现较高的检测精度.检测精度的提高通常伴随着模型参数的增加, 进而导致检测速度的降低.为了提高检测速度, 王宪保等[20]提出基于神经架构搜索的非结构化剪枝方法(Unstructured Pruning Method Based on Neural Architecture Search, UPNAS), 删除模型的冗余参数.Li等[21]提出GBH-YOLOv5, 在YOLOv5中加入Ghost[22]卷积, 提高模型的推理速度.
目前在表面缺陷检测领域, 无论是采用单阶段目标检测算法还是两阶段目标检测算法, 都面临一些挑战.单阶段目标检测算法虽然速度较快, 但却牺牲了精度, 难以满足对高质量检测结果的要求.另一方面, 精度较高的模型虽然能准确检测缺陷, 但由于速度过慢, 不符合工业生产线上至少数米每秒的钢材生产速度对检测实时性的需求.
因此, 当前需要一种模型, 能在速度和精度之间找到平衡点, 满足工业领域对快速准确的表面缺陷检测的迫切需求.
为了达到速度与精度之间的平衡.本文提出基于改进RetinaNet的轻量化钢材表面缺陷检测算法(Lightweight Steel Surface Defect Detection Algorithm Based on Improved RetinaNet, Light-RetinaNet).首先, 将原有的骨干网络替换为轻量化网络, 引入跨阶段局部结构, 实现梯度的有效传播和轻量化.然后, 采用深度可分离卷积替换传统卷积层, 进一步降低参数量, 提高检测速度.为了弥补轻量化导致的算法精度下降问题, 提出基于跨阶段局部结构的空间金字塔池化机制, 融合不同尺度的特征, 有效提升算法的检测精度.在NEU-DET数据集和自建的HBIS数据集上的实验表明, 相比已有的缺陷检测算法, Light-RetinaNet在精度更高的同时, 达到更快的检测速度, 相应的软硬件系统满足生产线的实时在线检测要求并已上线运行.
钢材表面缺陷检测算法
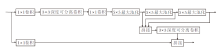
本文提出基于改进RetinaNet的轻量化钢材表面缺陷检测算法(Light-RetinaNet), 整体架构如图1所示.
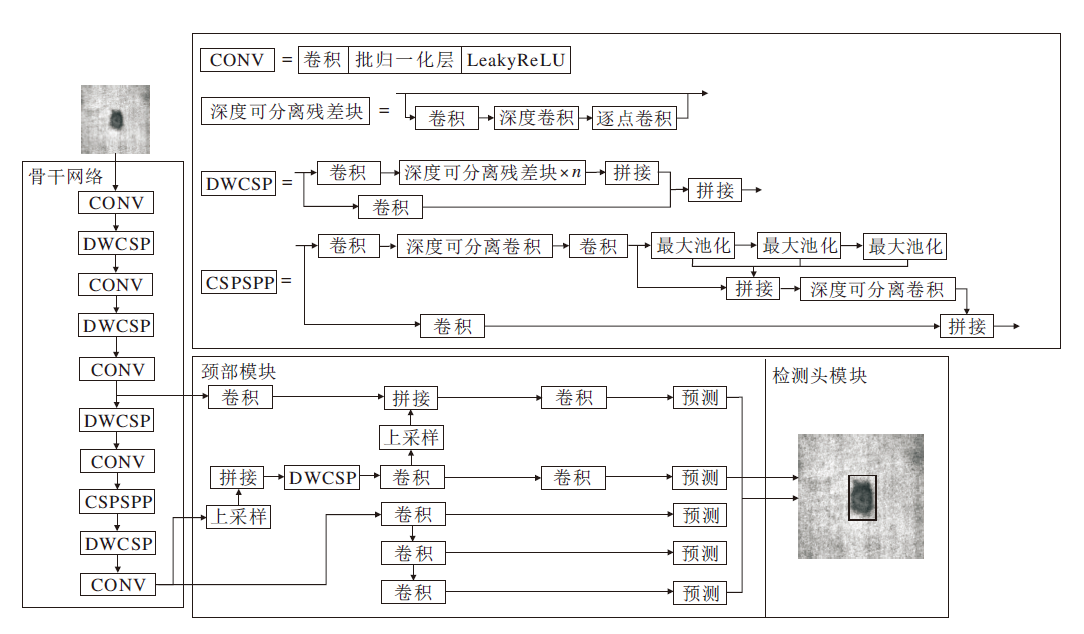 | 图1 Light-RetinaNet框架图Fig.1 Flowchart of Light-RetinaNet |
Light-RetinaNet由三部分组成.
1)骨干网络, 由卷积(CONV)、深度可分离跨阶段局部结构(Depthwise-Separable Cross-Stage-Partial Structure, DWCSP)和跨阶段局部空间金字塔池化(Cross-Stage-Partial Spatial Pyramid Pooling, CSP- SPP)组成, 负责提取缺陷的语义特征.
2)颈部模块, 负责融合高层的语义特征和低层的位置信息.
3)检测头模块, 负责定位缺陷的位置和识别缺陷的种类.
工业缺陷检测对速度和精度的要求都较高, 为了平衡工业缺陷检测中速度和精度的要求, 本文改进RetinaNet[23]单阶段检测算法, 实现更高精度的同时满足实时性的要求.
RetinaNet是一阶段检测算法, 速度较快.传统的目标检测算法通常需要手动设计或使用滑动窗口机制生成不同的候选区域, 计算复杂度较高, 导致检测一幅普通的图像通常需要几秒的时间.此外, 这种传统做法在检测不同尺度和宽高比的目标方面也面临一定的困难.相比之下, RetinaNet采用锚框机制, 提前设置候选区域.为了更精确地检测不同大小的物体, RetinaNet在特征图的每个点上都设置多个锚框, 这些锚框具有不同的宽高比和尺度.通过这种方式, RetinaNet 显著提升检测性能, 能更有效地捕捉多尺度和多宽高比目标的信息, 在目标检测任务中表现出色.
RetinaNet的整体结构包含如下三部分.
1)骨干网络, 负责特征提取工作.RetinaNet将ResNet[24]作为骨干网络, 主要原因在于ResNet引入残差的思想, 通过残差块克服深度神经网络中因网络过深造成的梯度消失和梯度爆炸问题, 令算法更容易训练和优化.
2)颈部结构, 负责不同尺度的特征融合.在颈部的设计中, 采用特征金字塔(Feature Pyramid Net-works, FPN)[25]结构进行特征融合.FPN引入横向连接以及自顶向下的连接, 构建金字塔状的特征图, 融合高层的语义信息和浅层的位置信息, 提高算法在多尺度上的表征能力.
3)检测头网络, 检测头是RetinaNet的核心组件, 负责生成目标检测的最终结果.在RetinaNet的检测头中, 存在分类子网络和回归子网络两个分支.分类子网络主要用于判断锚框内是否存在目标, 并预测目标所属类别.RetinaNet通过分类子网络实现多类别的目标检测, 并且进一步采用Focal Loss以应对类别不平衡的现象, 提高对困难样本的识别能力.回归子网络专注于锚框的位置调整, 准确定位目标边界框.在该网络中, 通过回归损失函数学习每个锚框的偏移和缩放变换, 令算法能定位不同宽高比以及不同尺度的目标.
原始的RetinaNet以ResNet-50作为骨干网络.ResNet-50充当骨干网络时性能较优, 但其复杂的残差连接结构也带来一些挑战, 尤其是存在计算负担过重的问题.为了应对该问题, 将ResNet-50结构替换为DarkNet-53结构成为一种可行的选择.
DarkNet-53一共含有52层卷积层, 剩下的一层属于全局平均池化层.DarkNet-53中的卷积层由卷积、批归一化(Batch Normalization, BN)层和Leaky-ReLU激活函数组成.根据卷积核的大小可分为3× 3卷积和1× 1卷积.BN层用于在卷积操作之后对每个特征图进行标准化, 令其均值接近0、方差接近1.BN层的存在可有效缓解训练中产生的梯度消失问题.
LeakyReLU是ReLU激活函数的改进版本.原始的ReLU激活函数在输入为负值时会变为0, 无法继续更新权重, 而LeakyReLU引入一个小的负斜率, 缓解ReLU可能引入的神经元死亡问题, 令信息能在网络中更自由地传播.
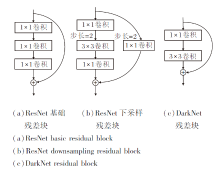
相比ResNet中的残差块, DarkNet的残差块更简洁, 两者的残差结构如图2所示.(a)为ResNet基础残差块, 不涉及特征图尺度变化, 而(b)中包含一个下采样过程, 将特征图的尺寸减半.(c)中Dark-Net残差块中不会发生特征图尺寸的变化, 在Dark-Net中, 特征图的尺寸变化由单独的3× 3卷积控制.从图2可看出, 相比ResNet, DarkNet采用更简洁的残差块, 在整体计算效率上更有优势.
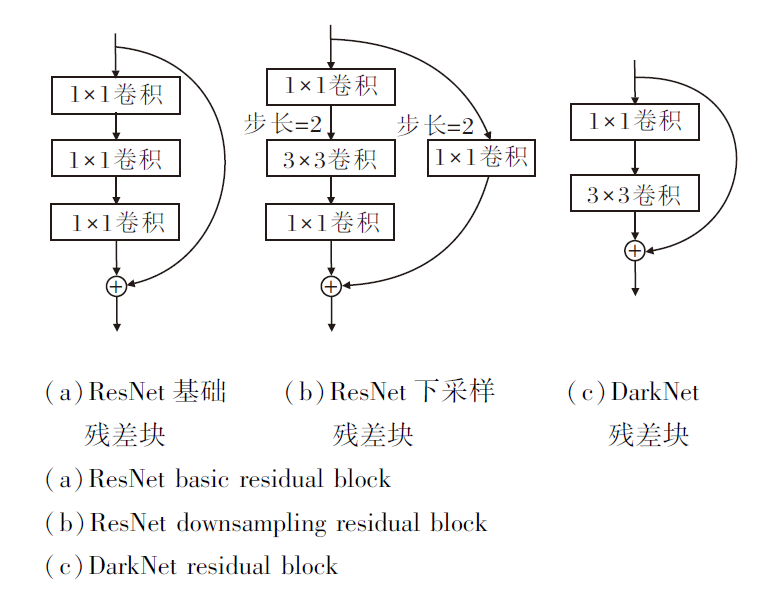 | 图2 ResNet和DarkNet残差结构图Fig.2 Schematic diagram of residual structure of ResNet and DarkNet |
DarkNet虽然在计算效率上高于ResNet, 但参数量更大.为了降低DarkNet的参数量, 本文在Dark-Net的基础上加入CSP(Cross Stage Partial)结构[26].旨在通过一种分阶段的特征融合机制, 有效缓解梯度信息重复利用的问题.
CSP结构为网络引入跨阶段局部(Cross Stage Partial)机制, 包括两个关键结构:局部稠密块(Partial Dense Block, PDB)和局部过渡层(Partial Transition Layer, PTL).
在PDB中, 将输入的特征图切分为两部分, 一部分直连到稠密块末尾, 另一部分经过密集块的处理.通过这种方式, 一方面增加梯度路径的数量, 有效缓解梯度信息的重复问题, 另一方面令经过密集块的特征层通道数减半, 大幅降低参数量, 提高模型的处理速度.PTL的存在是为了令梯度组合的差异最大, 它会利用梯度流的聚合策略, 防止不同层学到重复的梯度信息.
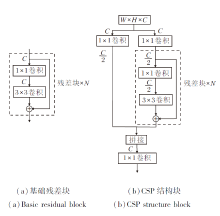
由于CSP结构存在的种种优势, 本文将CSP结构应用到DarkNet中, 应用CSP后的结构块如图3所示.从图中可看到, 原始残差块输入通道为C, 输出通道依旧为C, 通道数量并未减少.而在CSP结构块中, 首先利用两个1× 1卷积将原始的特征图通道减半, 再分为两条路径进行处理, 一条路径直接连接到最后, 另一条路径经过N个残差块的处理, 与直连的特征图进行拼接, 最后经过一个1× 1卷积, 完成特征融合操作.
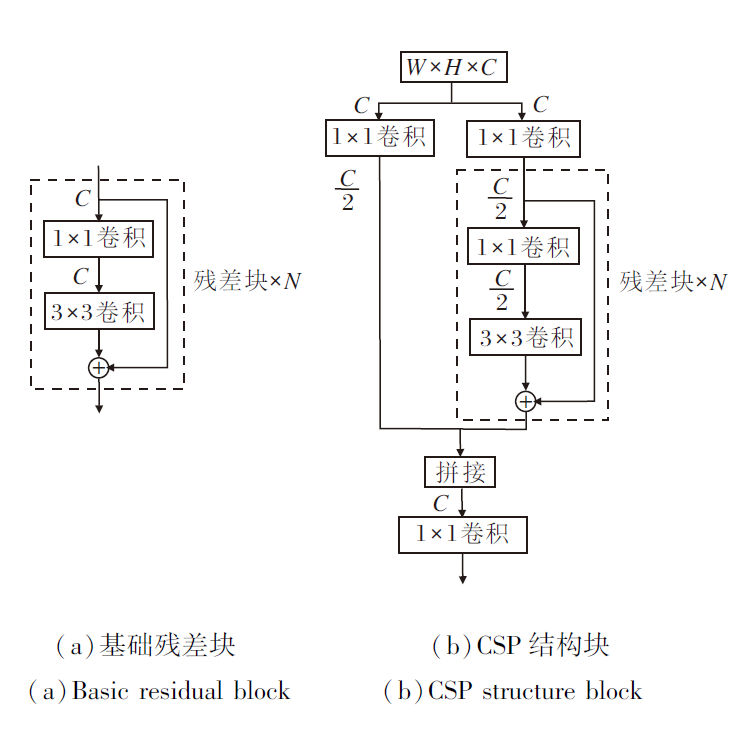 | 图3 基础残差块和CSP结构块结构图Fig.3 Comparison of basic residual block and CSP structural block |
通过将主干网络从ResNet替换为CSPDarkNet, RetinaNet的参数量得到显著降低, 为算法的轻量化和高效性能提供良好基础.然而, 当前的CSPDark-Net仍存在众多传统的卷积层, 这些传统的卷积层占据算法的绝大部分参数.因此, 为了进一步降低CSPDarkNet的参数量, 本文在网络的后续优化中使用深度可分离卷积替换传统的卷积层.
深度可分离卷积是在MobileNets[27]中提出的一种卷积方式, 相比传统卷积, 深度可分离卷积可在输入输出尺度不变的情况下显著降低参数量.深度可分离卷积主要分为深度卷积和逐点卷积两个过程.深度卷积负责对输入特征图的每个通道独立应用卷积操作, 专注于通道特征的学习.逐点卷积负责整合所有通道的信息, 实现通道之间信息的交互.
深度可分离卷积的计算量小于传统卷积, 这主要是通过深度卷积和逐点卷积实现的.假设一个输入特征图尺寸为Win× Hin× Cin, 卷积核大小为K× K, 输出特征图尺寸为Wout× Hout× Cout.对于传统卷积而言, 计算量主要由输入通道数、输出通道数和卷积核大小决定.卷积核的参数量为:
Ptrad=K× K× Cin× Cout.
总的计算量还需要卷积核参数量乘以输出特征图的大小, 所以传统卷积最终的计算量为:
Ftrad=Wout× Hout× Ptrad.
对于深度可分离卷积, 可分解为深度卷积和逐点卷积.深度卷积由Cin个K× K的卷积核处理, 而逐点卷积由Cout个1× 1× Cin个卷积核处理.深度卷积参数量[27]为:
Pdw=K× K× Cin,
逐点卷积参数量[27]为:
Ppw=1× 1× Cin× Cout,
深度可分离卷积总的参数量为深度卷积参数量和逐点卷积参数量之和[27]为:
Pseparable=Pdw+Ppw.
深度可分离卷积总的计算量还需要再乘以输出特征图的尺寸, 即
Fseparable=Wout× Hout× Pseparable.
在上述传统卷积和深度可分离卷积计算量分析的基础之上, 可计算两者参数量的比值:
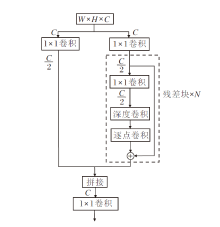
当卷积核的大小为3× 3, 输出通道为32时, 深度可分离卷积的参数量只有传统卷积的11/100, 因此, 使用深度可分离卷积可大幅降低参数量.在本文中, 主要是将CSP结构中的3× 3卷积替换为深度可分离卷积, 替换之后的结构如图4所示.
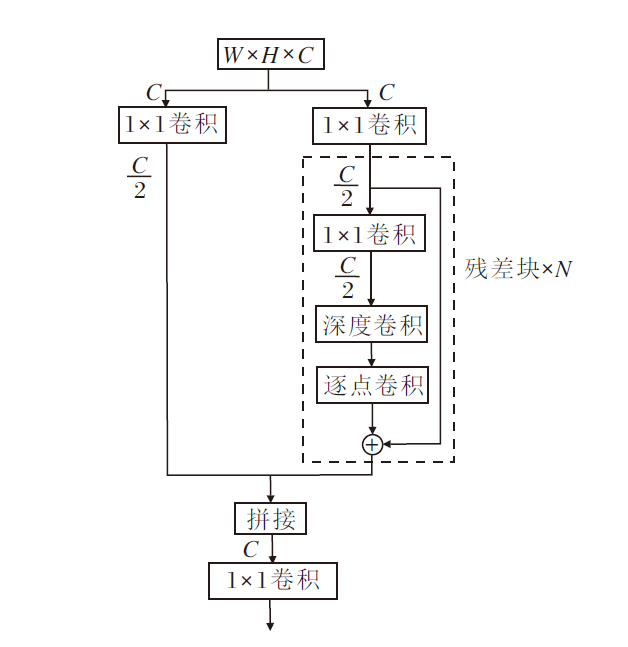 | 图4 深度可分离卷积对应的CSP结构图Fig.4 Schematic diagram of CSP structure corresponding to depthwise separable convolution |
SPPNet[28]是一种金字塔网络.在SPPNet之前, 含有全连接层的深度神经网络在训练时只能接受单一尺度的图像作为输入, 这种单尺度的训练方式严重影响模型在不同大小图像中的性能.为了解决这一问题, 在含有全连接层的前提下, 构造SPP(Spa-tial Pyramid Pooling)模块.SPP模块是SPPNet中的核心结构, 由多个池化层组成.这些池化层负责将不同大小的特征图转换为固定大小的特征向量, 以便与全连接层匹配.在SPP模块的作用下, 神经网络可接收任意大小的输入图像, 引入多尺度图像特征, 而不必担心全连接层的不匹配问题.此外, SPP模块通过多个空间金字塔池化层完成特征图的融合, 显著增强模型的表征能力, 提高模型在不同尺度上的检测性能.
因此, 在速度和精度方面, SPP模块的引入都为算法带来较大的性能提升, 使神经网络更具适应性, 既能处理不同尺寸的输入, 又能有效融合多尺度信息, 从而在各种应用中取得更优性能.
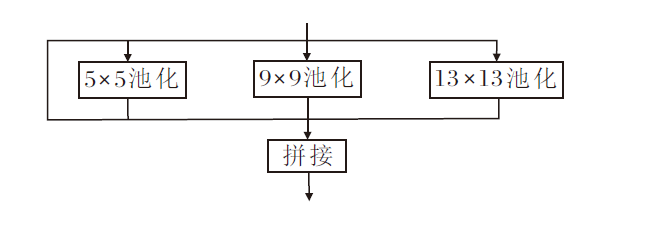
SPP模块的这一设计为克服尺度限制、提高网络灵活性和性能表现提供重要的思路, 整体结构如图5所示.
RetinaNet是一种全卷积神经网络.全卷积神经网络中只含有卷积层而不含有全连接层, 因此不需要考虑全连接层的限制因素, 只需关注SPP模块中的特征融合操作.而SPP模块虽然能提升精度, 但4条路径中包含不同尺寸的池化层, 不同尺寸的池化层速度差异较大, 仍会降低推理时间.
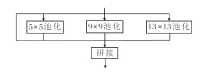
因此, 本文在SPP模块的基础上提出CSPSPP模块, 结构如图6所示.由图可看出, 相比原始SPP模块, CSPSPP模块有如下3方面的改进.
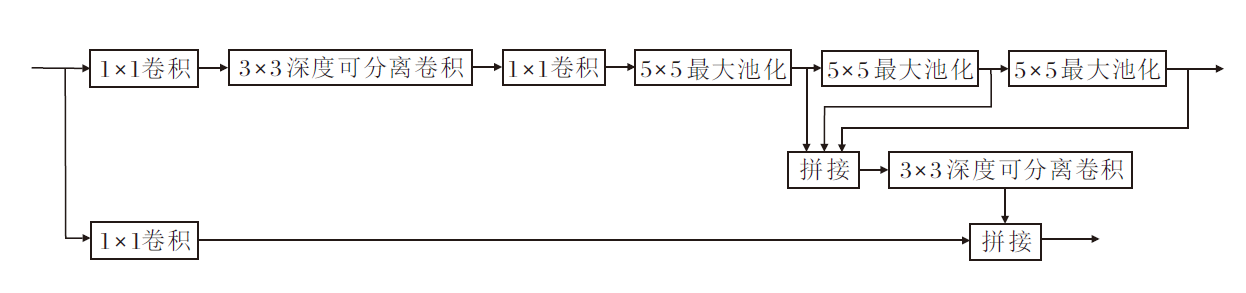 | 图6 CSPSPP模块结构图Fig.6 Structure of CSPSPP module |
1)池化层的统一替换.将SPP模块中不同大小的池化层统一替换为5× 5池化层.这种改进的优势在于5× 5池化层具有较大的感受野, 有助于捕捉更广泛的特征.此外, 5× 5池化层速度更快, 有助于提高推理速度.因此, 统一使用5× 5的池化层, CSP-SPP模块在保持感受野优势的同时, 可提高计算效率.
2)池化层之间的串行连接.在CSPSPP模块中, 各池化层之间采用串行相连的方式.这种连接方式可进一步提取特征, 通过多个池化层串行连接, 有效增大感受野, 有助于算法更好地理解输入数据的上下文信息, 提高对复杂场景和对象的识别性能.
3)加入CSP结构和深度可分离卷积.引入CSP结构和深度可分离卷积, 结合后可进一步降低算法的参数量.CSP结构有助于减轻信息在网络中传递时的负担, 提高信息流的效率.深度可分离卷积可减少参数量, 从而减小算法的计算和内存需求, 有助于算法在嵌入式设备或移动端上的部署.
在本文中, 将CSPSPP模块应用到轻量化网络CSPDarkNet-53中.CSPDarkNet-53包含5个阶段(Stage), 每个Stage对应的残差块数量分别为(1, 2, 8, 8, 4).在应用CSPSPP模块时, 原则上可将其放置在任意一个阶段(Stage)之间.由于Stage1和Stage2含有的语义信息和上下文信息较少, 因此在后续的实验中, 只在Stage3~Stage5之间进行实验, 验证在哪一层可达到效率和精度的较好平衡.
为了验证算法的有效性, 本文使用2 个钢材表面缺陷检测数据集:东北大学发布的NEU-DET热轧带钢数据集[29]、采集自河钢数字技术股份有限公司的HBIS冷轧钢材数据集.
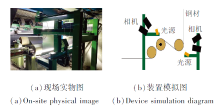
HBIS 冷轧钢材数据集是根据实时在线缺陷检测项目采集的一款数据集, 由哈尔滨工业大学(深圳)和河钢数字集团采集和标注.在采集数据时, 使用Dalsa相机, 并在现场完成光源和相机的安装与调试.缺陷图像采集如图7所示.
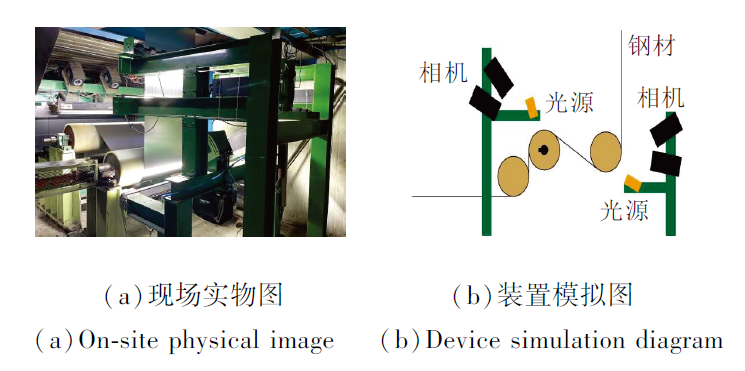 | 图7 缺陷图像采集过程Fig.7 Process of defect image collection |
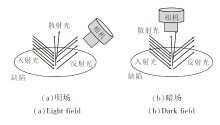
HBIS冷轧钢材数据集是在明场和暗场两种场景下同时采集, 明场是相机借助反射光拍摄而成, 暗场是借助散射光拍摄而成, 明暗场原理如图8所示.
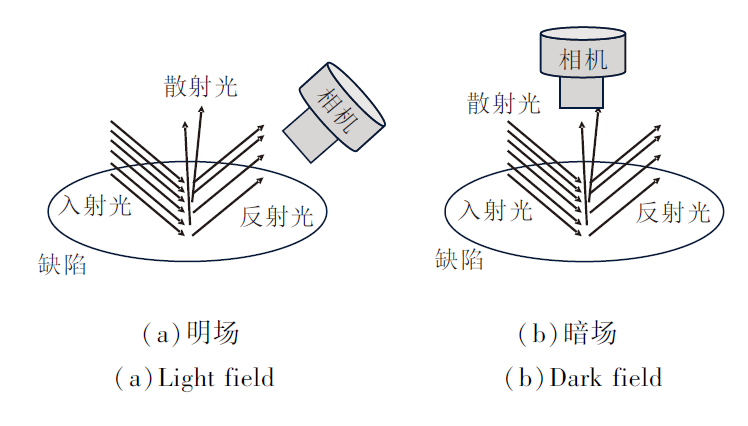 | 图8 明暗场原理图Fig.8 Schematic diagram of light and dark fields |
HBIS 初始数据集包含超过2 000幅1 024× 8 192的钢卷图像.由于钢卷图像中大部分不包含缺陷, 因此只裁剪有缺陷的区域, 每次只裁剪缺陷周围640× 640的图像, 共有2 416幅图像, 包含夹杂、垫伤等10 种缺陷, 存在5 379个缺陷目标, 这些缺陷目标尺寸较小、难以检测.
HBIS 数据集包含10种出现在生产线上的镀锡冷轧钢材表面缺陷, 具体示例如图9所示, 其中夹杂、垫伤、轧机软点、虫体、冲孔和粘钢纹是在暗场环境下拍摄得到, 而油斑、辊伤、污染点和焊缝是在明场下拍摄得到.缺陷类别体现产品材质与工艺的特点, 其中虫体是指夏天出现的飞虫落入钢材表面形成的污点.
 | 图9 HBIS缺陷示例图像Fig.9 Examples of HBIS defect images |
从图9中可观察到, HBIS数据集的目标都较小, 检测难度较大.
NEU-DET热轧带钢表面缺陷数据集是一款常用于缺陷检测算法研究的数据集, 由东北大学在2013 年发布.
数据集收集6种典型的表面缺陷, 类别分别为轧制氧化皮、斑块、开裂、点蚀表面、内含物和划痕, 每类含有300幅缺陷图像, 总共1 800幅缺陷图像, 每幅缺陷图像的分辨率为200× 200.NEU-DET的缺陷图像示例如图10所示.
 | 图10 NEU-DET缺陷图像示例Fig.10 Examples of NEU-DET defect images |
实验在Ubuntu 18.04系统上完成, 采用NVIDIA RTX 3080 GPU(10 GB显存), 框架选用Pytorch.CUDA, 版本为11.3.
输入图像尺寸为384× 384, 骨干网络在Image-Net上进行预训练.在微调时, 迭代周期设置为36, 采用的优化器为AdamW(Adaptive Moment Estima-tion with Weight Decay), 学习率设置为0.000 05.
在精度方面, 本文采用普遍使用的平均精度(Average Precision, AP)和平均精度均值(Mean Average Precision, mAP)作为评估指标.
AP是对单个类别的检测性能进行评估的指标, 计算模型在不同置信度阈值下的精度, 并利用精确率-召回率曲线下面积得到最终值.mAP是对多个类别的性能进行综合评估的指标, 计算每个类别的平均精度, 再取均值.
在模型效率方面, 使用FPS(Frames per Second)和GFLOPs(Giga Floating Point of Operations)评估算法速度和参数量.
本文提出基于改进RetinaNet的轻量化钢材表面缺陷检测算法, 以原始的RetinaNet为基础, 将原始RetinaNet的主干网络由ResNet改为DarkNet, 并在DarkNet的基础上使用CSP机制进行轻量化, 得到CSPDarkNet.为了更进一步轻量化网络, 将CSP-DarkNet中传统的3× 3 卷积层替换为深度可分离卷积.CSP结构和深度可分离卷积虽然令算法轻量化, 但也不可避免地造成精度的损失, 为了弥补精度的损失, 加入基于CSP的空间金字塔池化模块, 提高检测精度.在对算法进行改进后, 为了评估各模块的参数量及性能, 进行一系列的消融实验.
CSPSPP模块可放置在DarkNet-53任意一个阶段(Stage)之间, 为了验证CSPSPP放在哪一层可达到效率和精度的较好平衡, 对CSPSPP放置的位置进行消融实验, 在NEU-DET数据集上的结果如表1所示, 表中黑体数字表示最优值.由表可看出, 将CSPSPP模块放在Stage5中速度和效率达到一个较好的平衡状态.
| 表1 CSPSPP模块位置改变后的消融实验结果 Table 1 Ablation experiment results after changing the position of CSPSPP module |
添加各模块后的算法参数量和计算量对比如表2所示, 表中黑体数字表示最优值.由表可见, 在图像尺寸统一为384× 384 时, RetinaNet的参数量和GFLOPs都较高, 将骨干网络替换为DarkNet后, 虽然参数量和GFLOPs有所增加, 但计算效率高于Res-Net.在DarkNet中添加CSP结构后, 显著降低参数量和GFLOPs.进一步使用深度可分离卷积进行轻量化后, 参数量和GFLOPs再次减少.最后, 添加CSPSPP模块后, 参数量和计算量仅有小幅增加, 但相比RetinaNet仍有大幅降低.综上所述, 除了替换骨干网络会增加计算量和参数量以外, 其它模块的加入都显著降低算法的参数量和计算量.
| 表2 各模块加入后的参数量和计算量对比 Table 2 Comparison of parameters and computational complexity after adding different modules |
算法的参数量和GFLOPs仅能反映算法规模, 并不能完全反映算法在设备上的运行速度, 因此, 将FPS作为指标, 衡量算法在实际设备上的运行效率.
添加各模块后算法的实时运行效率如表3所示, 表中黑体数字表示最优值.在固定图像尺寸为384× 384时, RetinaNet的推理速度较慢, FPS也较低.将骨干网络替换为DarkNet后, 推理速度显著加快, FPS也有所增加, 尽管参数量和计算量较高, 但推理速度更快.加入CSP结构后, 推理速度进一步提升, FPS也有所增加.将CSPDarkNet中的传统卷积替换为深度可分离卷积后, 推理速度和FPS再次显著提升.最终加入CSPSPP模块后, 虽然推理速度和FPS略有下降, 但仍优于RetinaNet.总之, 最终算法在推理速度和帧率上都有显著提升.
| 表3 各模块加入后的运行效率对比 Table 3 Comparison of runtime and efficiency after adding different modules |
下面分析算法精度, 在NEU-DET、HBIS数据集上, 固定图像尺寸为384× 384, 加入各模块之后的精度对比如表4所示, 表中黑体数字表示最优值.
| 表4 各模块加入后的精度对比 Table 4 Comparison of accuracy after adding different modules |
由表4可看到, RetinaNet的mAP值较高, 但在替换骨干网络后, 精度有所下降.进一步引入CSP结构和深度可分离卷积以轻量化算法, 导致精度进一步下降.为了弥补轻量化对精度的影响, 引入CSP-SPP模块, 相比RetinaNet, 精度有所提高.在HBIS数据集上, 引入DarkNet不仅提升速度, 还略微提升精度.尽管加入CSP结构和深度可分离卷积导致精度下降, 但引入CSPSPP模块后, mAP指标最终实现最优.
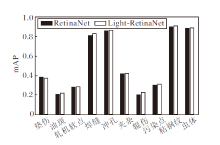
在HBIS数据集上, 对比RetinaNet与Light-Re-tinaNet在各类别上的精度, 结果如图11所示.由图可见, 在垫伤类别上, 相比RetinaNet, Light-Retina-Net的mAP值存在轻微下降, 而在其它类别上的mAP值均有不同程度的提升.另一方面, 焊缝、冲孔、粘钢纹和虫体的mAP值都在80%以上, 拥有较高精度.
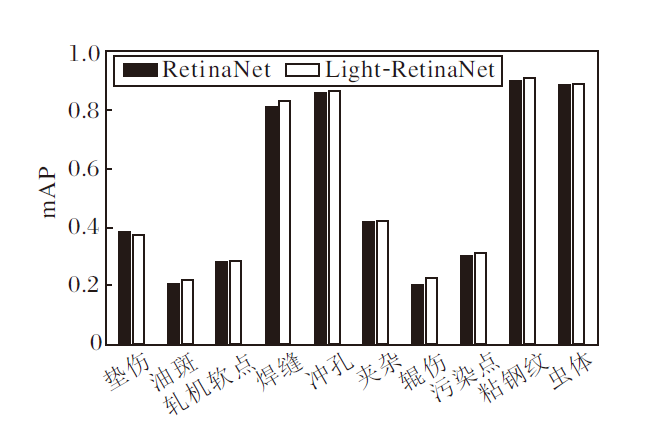 | 图11 各算法在NEU-DET数据集上的mAP值对比Fig.11 mAP comparison of different algorithms on NEU-DET dataset |
两种算法对于其它类别的检测精度较低, 主要归结为如下两个原因.
1)类别数量不平衡.较高精度对应的缺陷拥有的数量相对较多, 因此在训练过程中算法更容易学到这些缺陷的相关特征.相反地, 数量较少的缺陷种类使算法难以有效学习相关信息, 导致精度较低.
2)错误标注较多, 数据清洗困难.由于HBIS数据集上的缺陷较小且种类繁多, 标注过程需要较强的专业知识.由于缺陷的尺寸较小, 在标注时容易出现位置及类别的错误.解决这一问题的策略包括加强标注质量及进行多轮数据清洗.
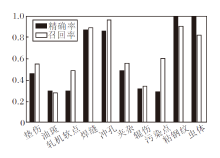
虽然mAP指标反映算法在每个类别上的综合性能, 但是在缺陷检测领域, 也较关注针对每个类别的精确率和召回率.精确率表示检测缺陷中真实缺陷所占的比例, 可避免误报.召回率表示所有真实缺陷中被成功检测的比例, 即尽可能不漏掉真实存在的缺陷.因此, 本文统计算法每个类别的精确率和召回率, 结果如图12所示.由图可看到, 只有4个类别的精确率和召回率较高, 而其它类别总体性能较差, 原因如前面所述.
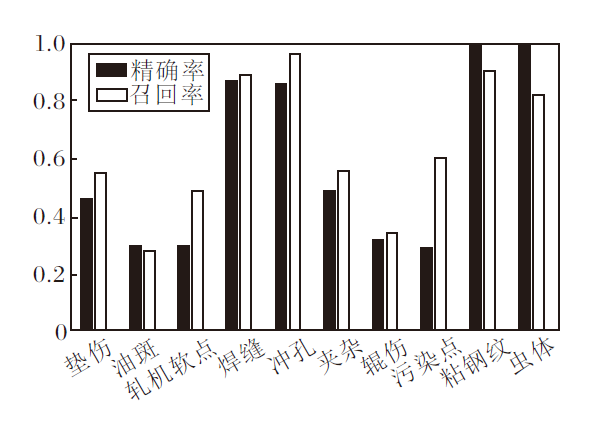 | 图12 各类别的准确率和召回率对比Fig.12 Precision and recall comparison of different categories |
消融实验已验证各模块的有效性, 而对比实验则可评估各算法在速度和精度上的差异.本文在HBIS数据集上进行对比实验, 各算法的精度和速度对比如表5所示, 表中黑体数字表示最优值.由表可见, YOLOv5-n在速度上表现最优, 但其mAP值仅为41.8%.相比之下, Light-RetinaNet在精度方面实现最佳性能, 达到53.2%, 并且在速度方面达到50.6帧/秒, 满足工业生产线速度的要求, 并且已配合钢材表面成像与整体硬软件系统上线运行.
| 表5 各算法的精度和速度对比 Table 5 Accuracy and runtime comparison of different algorithms |
为了加快缺陷检测的处理速度, 本文设计基于改进RetinaNet的轻量化钢材表面缺陷检测算法(Light-RetinaNet).将RetinaNet原有的骨干网络替换为DarkNet, 并在DarkNet中加入CSP结构, 促进梯度信息的传播和减少模型参数.为了进一步提高推理速度, 将DarkNet中传统卷积层替换为深度可分离卷积, 通过深度卷积和逐点卷积两个操作降低算法参数量.轻量化不可避免地造成精度的损失, 为了弥补此缺陷, 加入基于CSP结构的空间金字塔池化操作, 提高算法对不同尺度缺陷的检测性能.对比实验表明, Light-RetinaNet在精度最优的同时, 速度也满足工业生产线的需求, 可实现稳定可靠的上线运行.鉴于目前的检测任务主要集中在微小目标上, 在今后的研究中可引入注意力机制, 增强对小目标的检测能力, 进一步提升算法的整体性能和稳定性.
本文责任编委 张军平
Recommended by Associate Editor ZHANG Junping
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|