


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于跨通道特征增强图卷积网络的骨架行为识别
[吴志泽1  , 陈盛
, 陈盛1 , 檀明1, 2 , 孙斐1 , 杨静1 ]
, 陈盛, 檀明, 孙斐, 杨静]
|
|



作者简介:

吴志泽,博士,副教授,主要研究方向为深度学习驱动的图像视频处理与分析.E-mail:wuzhize.ustc@gmail.com.

陈 盛,硕士研究生,主要研究方向图神经网络、骨架人体行为识别.E-mail:chensheng@stu.hfuu.edu.cn.

檀 明,硕士,教授,主要研究方向为模式识别、计算机视觉.E-mail:tanming@hfuu.edu.cn.

孙 斐,硕士,教授,主要研究方向为模式识别、计算机视觉.E-mail:sunfei@hfuu.edu.cn.
受限于图卷积网络的局部操作模式,传统图卷积网络骨架行为识别方法难以建模远关节点关系和长时间信息,无法捕捉动作间的局部微小变化.因此,文中提出基于跨通道特征增强图卷积网络的骨架行为识别(Cross-Channel Feature-Enhanced Graph Convolutional Network for Skeleton-Based Action Recognition, CFE-GCN),包括双部分分组图卷积模块、跨阶段部分密集连接模块及多尺度时间卷积模块.双部分分组图卷积模块采用分组策略,对人体关节点建模,提取多粒度特征,捕获关节点之间的局部细微差异.跨阶段部分密集连接模块建立节点与前网络层之间的关联,丰富早期信息,捕捉长期运动关节间的潜在关系,学习更全面的上下文特征.多尺度时间卷积模块执行不同感受野的时间卷积,捕捉运动在时间域上的短期依赖关系和长期依赖关系.在3个基准数据集上的实验表明CFE-GCN性能较优.
About Author:
WU Zhize, Ph.D., associate professor. His research interests include deep learning-driven image and video processing and ana-lysis.
CHEN Sheng, Master student. His research interests include graph neural network and skeleton based action recognition.
TAN Ming, Master, professor. His research interests include pattern recognition and computer vision.
SUN Fei, Master, professor. His research interests include pattern recognition and computer vision.
Traditional graph convolutional networks for skeleton-based action recognition struggle to model long-range joint relationships and long-term temporal information due to their local operation mode, failing to capture subtle variations between actions. To address this problem, a cross-channel feature-enhanced graph convolutional network(CFE-GCN) for skeleton-based action recognition is proposed including a dual part-wise grouping graph convolution(DPG-GC) module, a cross-stage partial dense connections(CS-PDC) module and a multi-scale temporal convolution(MS-TC) module. The DPG-GC module models the human body joints by a grouping strategy to extract multi-granularity features and capture the subtle local differences between the joints. The CS-PDC module establishes associations between nodes and the previous network layers, enriching the early information and capturing the potential long-term relationships between the moving joints, and thereby contextual features are learned more comprehensively. The MS-TC module performs temporal convolution with different receptive fields to capture both short-term and long-term dependencies in the temporal domain. Experiments show that CFE-GCN achieves superior performance on multiple benchmark datasets.
随着人体姿态估计技术的发展, 骨架序列变得广泛且廉价可得.相比RGB图像、光流及点云等模态数据, 人体骨架数据更紧凑, 可提供相对高层次的结构信息, 在外观变化、复杂背景和环境噪声等方面具有更强的鲁棒性[1].因此, 基于骨架的人体行为识别引起学者的广泛关注.
早期基于深度学习的方法[2, 3, 4, 5]利用关节坐标形成特征向量, 未深入探索人体关节之间的潜在依赖关系.例如:研究者将骨架数据手动构造为关节坐标向量序列[6]或伪图像[7], 再馈送至循环神经网络(Recurrent Neural Network, RNN)或卷积神经网络(Convolutional Neural Network, CNN), 用于捕捉帧内特征和帧间的时序依赖关系.然而, 一种更自然的骨架表示是将其视为图结构, 其中人体关节和骨架分别被视为节点和边, 从而可充分利用骨架的拓扑结构.
近年来, 图卷积神经网络(Graph Convolutional Network, GCN)在许多领域得到广泛应用[8, 9, 10, 11, 12].Yan等[8]提出ST-GCN(Spatial-Temporal Graph Convolu-tional Networks), 将连续视频帧中的关节点组合成时空图.ST-GCN采用预先定义的骨架图, 仅表示人体的物理结构.Shi等[13]提出2s-AGCN(Two-Stream Adaptive Graph Convolutional Network), 将邻接矩阵构造为三部分之和, 可利用原本不存在的连接.Cheng等[14]提出Shift-GCN(Shift Graph Convolu-tional Network), 构建骨架序列的图结构, 并引入平移和旋转操作, 提取时序和关系特征.Li等[9]提出AS-GCN(Actional-Structural Graph Convolution Net-work), 可在图卷积操作中传播和融合节点之间的信息, 提取骨架的关键特征.Liu等[15]提出MS-G3D, 旨在解决在邻接矩阵构建时对不同距离的节点之间连接权重分配不均衡的问题.Miao等[16]提出CDGC(Central Difference Graph Convolution), 引入新的图卷积算子, 用于聚合额外的梯度信息.Chen等[10]提出CTR-GC(Channel-Wise Topology Refinement Graph Convolution), 动态学习拓扑并聚合不同通道维度的特征.
现有基于人体骨架的动作识别方法存在两个主要局限性.1)现有方法通常对人体骨架整体拓扑结构进行建模, 难以捕捉不同动作之间的局部细微变化.然而, 局部的细微差异对于区分相似动作至关重要.例如:对于“ 读书” 和“ 写字” 这两个相似动作, 区分它们的关键在于关注局部动作细节的微小差异.2)现有方法主要考虑短程关节点之间的连接关系, 忽略远距离关节点之间的长期依赖关系, 对早期的特征信息遗忘较大, 导致关键信息的丢失.以“ 戴眼镜” 和“ 摘眼镜” 为例, 它们的区分关键在于捕捉远距离关节点间的长期潜在依赖关系.
针对上述问题, 本文提出基于跨通道特征增强图卷积网络的骨架行为识别模型(Cross-Channel Feature-Enhanced Graph Convolutional Network for Skeleton-Based Action Recognition, CFE-GCN).首先, 引入简单且有效的双部分分组图卷积(Dual Part-Wise Grouping Graph Convolution, DPG-GC)模块, 将输入骨架序列的空间维度与通道维度互换, 并送入两个平行的分组卷积.其本质上是将人体关节点划分为多个不同的部分, 学习每个部分的骨架特征, 判别动作类别之间发生的细微变化, 尤其是在区分相似动作时, DPG-GC模块更有效.此外, 通过两个部分使用不同数量的组, 将特征空间划分为不同粒度的子空间, 捕获骨架数据不同层次和尺度的特征, 获得有效的空间拓扑关系.
其次, 提出跨阶段部分密集连接(Cross-Stage Partial Dense Connections, CS-PDC)模块.该模块具有特征重用的特性, 同时防止过多的重复信息, 能够捕获短距离节点和长距离节点的潜在依赖关系.
最后, 提出多尺度时间卷积(Multi-scale Tem-poral Convolution, MS-TC)模块, 利用具有不同卷积核和膨胀率的多分支时间卷积, 提取多尺度时间运动特征, 可有效实现拓扑特征融合, 学习丰富的语义信息.
人体骨架图定义为G={V, E}, 其中,
V={vti|t=1, 2, …, T, i=1, 2, …, N},
包括骨架序列中的所有关节.人体骨架中的直接自然连接可表示为邻接矩阵A∈ RN× N, 如果关节i、 j直接连接, 元素aij=1, 否则aij=0.ST-GCN[8]中提出空间配置标记函数, 将邻接矩阵分为三个子集:根节点本身、向心子集、离心子集.人体骨架动作序列表示为X∈ RC× T× N, 其中, T表示动作序列帧的数量, N表示节点数, C表示通道数.
对于输入骨架数据的单帧Xi, 传统的图卷积使用权重W转换特征, 再通过aij聚合vi相邻顶点的特征, 用于更新, 第i个关节的输出特征为
$f_{\text {out }}\left(v_{i}\right)=\sum_{v_{j} \in N\left(v_{i}\right)} a_{i j} f_{\text {in }}\left(v_{j}\right) W\left(l_{i}\left(v_{j}\right)\right)$,
其中, N(· )表示通过分区方法划分的邻域集合, W(· )表示权重函数.在本文的工作中, 将A定义为可学习的参数, 由模型根据输入样本生成aij.
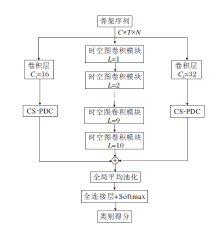
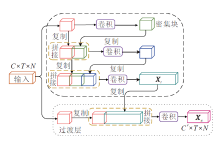
本文提出基于跨通道特征增强图卷积网络的骨架行为识别模型(CFE-GCN), 总体框架如图1所示.
 | 图1 CFE-GCN总体框架Fig.1 Overall framework of CFE-GCN |
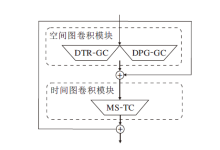
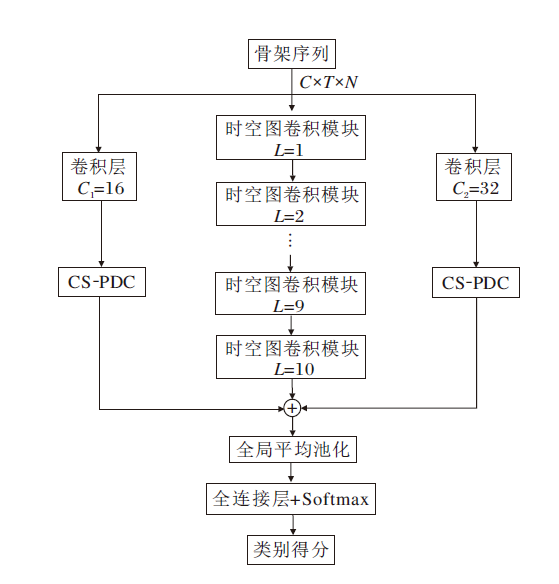
在CFE-GCN中, 双部分分组图卷积(DPG-GC)模块和动态拓扑细化图卷积(Dynamic Topology Refinement Graph Convolution, DTR-GC)模块并行, 然后送入多尺度时间卷积(MS-TC)模块中, 形成一个时空图卷积模块, 具体框架如图2所示.本文堆叠L个这样的时空图卷积块, 并设置每块的输出通道数依次是64、64、64、64、128、128、128、256、256、256.在块5和块8中, 时间维度通过步幅卷积操作减半.
 | 图2 时空图卷积模块框架图Fig.2 Framework of spatial-temporal graph convolution module |
本文采用两个跨阶段部分密集连接(CS-PDC)模块, 用于增强特征的提取能力.输入特征通过卷积层分别将通道初始化为C1和C2, 再送入CS-PDC模块, 形成双分支结构.这两个模块与时空图卷积模块并联后, 将三个分支的特征进行相加融合, 送入Softmax分类器中进行分数预测.
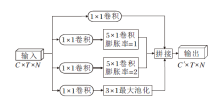
MS-TC模块是由CTR-GC[10]引入, 采用4个卷积分支组成, 包括用于降维的1× 1卷积以及不同的核大小和膨胀率的组合, 具体结构如图3所示.
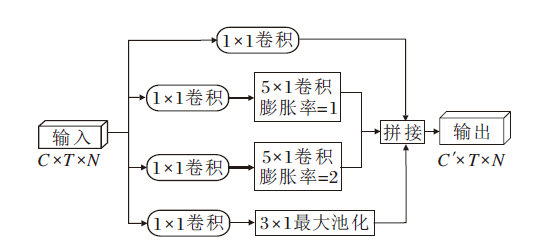 | 图3 MS-TC模块结构图Fig.3 Structure of MS-TC module |
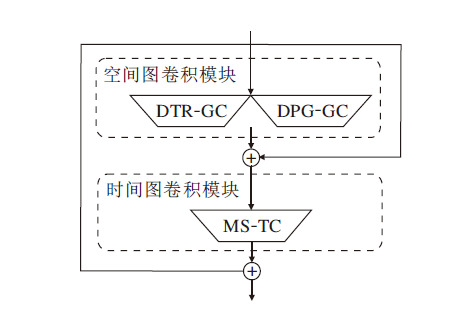
在空间图卷积模块中, 使用预定义的邻接矩阵仅能提取局部感受野的特征.为了解决此问题, 本文采用可学习的邻接矩阵和双部分分组图卷积方法, 灵活捕捉骨架序列中各个关节的拓扑潜在依赖关系.
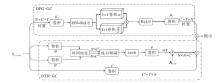
1.3.1 动态拓扑细化图卷积模块
动态拓扑细化图卷积(DTR-GC)模块使用邻接矩阵A作为所有共享的拓扑, 通过通道拓扑建模动态获取特定于通道节点间的相关性, 表示为
Q∈ RN× N× C'.
DTR-GC模块结构如图4下半部分所示.具体地, 首先使用两个线性变换ψ 和φ , 降低输入特征X∈ RC× T× N的维度.然后, 在时间维度上进行池化操作.最后, 使用相关性建模函数M(· )对两个顶点(Xa, Xb)之间的拓扑关系进行通道建模.具体过程可表示为
M(ψ (Xa), φ (Xb))=σ (ρ (ψ (Xa))-ρ (φ (Xb))),
其中, ρ (· )表示时间维度上的平均池化操作, σ (· )表示tanh激活函数, ψ (Xa)、φ (Xb)表示线性变换操作之后两个关节点的特征.
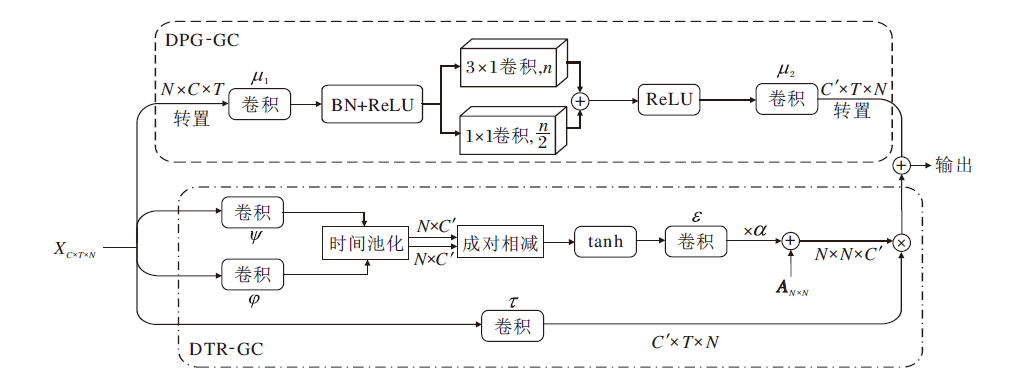 | 图4 空间图卷积模块结构图Fig.4 Structure of spatial graph convolution module |
基于相关性建模函数, 将得到的输出利用线性变换ε (· )增加通道维度, 得到特定于通道的拓扑关系Q∈ RN× N× C'.然后将其与共享拓扑A组合, 获得动态拓扑细化关系:
R=A+α Q∈ RN× N× C',
其中, α 表示可训练的标量, 用于自适应调整细化的强度, 邻接矩阵A被添加到α Q的每个通道中.
给定细化的动态拓扑R和高级特征
X'=τ (X),
其中τ (· )表示将输入特征转换为高级特征的线性变换函数.以通道级方式聚合特征, 使用通道图对每个通道进行建模, 其中每个通道图由对应通道的动态细化拓扑Rc∈ RN× N和特征x'c∈ RN× 1组成, Rc和x'c分别表示R和x'的第c个通道.每个通道图反映特定类型的运动特征下节点之间的关系.在每个通道图上执行特征聚合操作, 并连接所有通道图的输出特征, 得到最终的输出特征:
Z=S(R, x')=[R1x'1‖ R2x'2‖ …‖ Rc'x'c'],
其中, S(· )表示聚合函数, ‖ 表示连接操作, 可有效聚合来自不同通道的关节特征.从而可综合考虑不同运动特征下的节点关系.
1.3.2 双部分分组图卷积模块
双部分分组图卷积(DPG-GC)模块将输入的关节点进行分组处理, 并在每个分组内进行独立的图卷积操作, 对不同部位进行建模.使每组可专注于学习特定部位的特征表示, 从而提高模型对不同动作部位特征的敏感度.通过学习更准确和丰富的局部特征, 能更好地区分容易混淆的动作类别.DPG-GC模块结构如图4上半部分所示.
首先, 输入骨架特征X∈ RC× T× N, 互换通道维度和关节点维度.然后, 使用特征映射对其进行处理, 减少特征维度, 更好地捕获骨架数据中的关键信息和拓扑结构.其过程公式化为
其中, μ (· )表示输入特征经过特征映射操作, σ (· )表示ReLU激活函数.
将特征
$\boldsymbol{H}=\mu_{2}\left(\sigma\left(G\left(\widetilde{\boldsymbol{X}}, \boldsymbol{\theta}_{1}\right)+G\left(\widetilde{\boldsymbol{X}}, \boldsymbol{\theta}_{2}\right)\right)\right) \in \mathbf{R}^{N \times T \times C}, $
其中, G(· , θ 1)和G(· , θ 2)表示两个分组图卷积, 其过程表示为
$\begin{array}{l}G(\widetilde{\boldsymbol{X}}, \boldsymbol{\theta})= \\\quad\left[f\left(\widetilde{\boldsymbol{X}}^{1}, \theta^{1}\right)\left\|f\left(\widetilde{\boldsymbol{X}}^{2}, \theta^{2}\right)\right\| \cdots \| f\left(\widetilde{\boldsymbol{X}}^{n}, \theta^{n}\right)\right]\end{array}$
划分为n组的输入特征图
$\widetilde{X}=\left[\widetilde{X}^{1}, \widetilde{X}^{2}, \cdots, \widetilde{X}^{n}\right]$
卷积层f的权重
θ =[θ 1, θ 2, …, θ n].
最后, 将DTR-GC模块和DPG-GC模块的特征相加, 得到空间图卷积模块的输出, 并送入MS-TC模块进行学习, 最终得到时空图卷积模块的输出特征.
双分支跨阶段部分密集连接模块结构如图5所示.该模块将输入的骨架数据在通道维度设置为2个初始值C1和C2, 送入2个并行的CS-PDC模块.
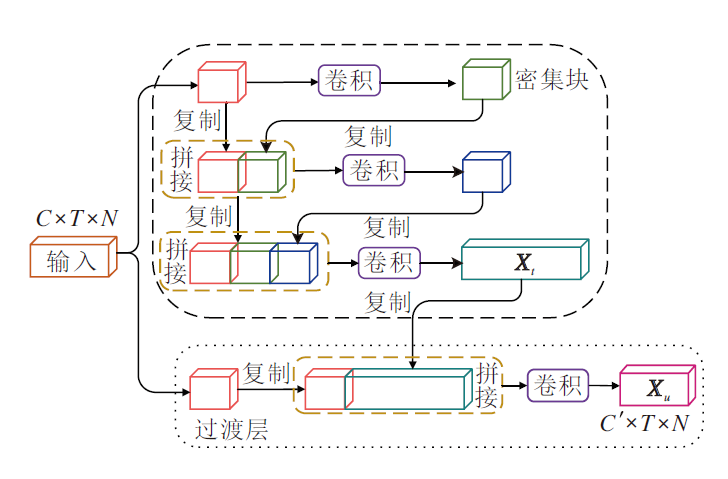 | 图5 双分支CS-PDC模块结构图Fig.5 Structure of CS-PDC module |
CS-PDC模块由密集块和过渡层组成.在密集块中, 将输入的骨架特征X∈ RC× T× N在通道维度上均分为两个部分, 即X=[X1, X2].在X1和X2之间, X1直接连接到过渡层, 与X2经过密集块的输出, 在通道维度上进行拼接.
密集块中有K个密集连接层, 第i个密集连接层的输出与第i个密集连接层的输入进行通道维度上拼接, 连接结果成为第i+1个密集连接层的输入, 即
x1=h1* X2,
x2=h2* [X2, x1],
…
xk=hk* [X2, x1, x2, …, xk-1],
其中, * 表示卷积操作, [X2, x1, …, xk-1]表示连接X2, x1, …, xk-1, hi表示第i个密集连接层的权重, xi表示第i个密集连接层的输出.经过密集块的骨架特征
Xt=ht* [X2, x1, x2, …, xk],
送入过渡层, 得到新的特征:
Xu=hu* [X1, Xt].
本文选择在NTU RGB+D、NTU RGB+D 120和Northwestern-UCLA这3个基准行为识别数据集上评估CFE-GCN, 并按惯例选择Top-1准确率作为评价指标.
1)NTU RGB+D数据集.包含60个动作类别, 共有56 880个样本, 其中40个类别是日常行为动作.训练集和测试集的划分标准如下.(1)cross-subject(X-sub).指定的20人作为训练集, 其余人作为测试集.(2)cross-view(X-view).使用由摄像机1收集的数据作为训练集, 其余两个摄像机收集的数据作为测试集.
2)NTU RGB+D 120数据集.目前最大的用于人体行为识别的3D关节注释的数据集包含120个动作类别的114 480个动作样本, 样本由106位志愿者在3个摄像机视角下拍摄.数据集设置标准如下.(1)cross-subject(X-sub).训练集包含53名志愿者执行的动作, 测试集包含其余志愿者执行的动作.(2)cross-setup(X-setup).训练集选择具有偶数设置ID的样本, 测试集选择具有奇数设置ID的样本.
3)Northwestern-UCLA数据集.使用3个摄像机从多个角度拍摄, 包含1 494个视频片段和10个动作类别, 由10个不同的对象执行.训练集选择两个摄像机的数据, 测试集选择另一个Kinect摄像机的数据.
所有实验都基于PyTorch深度学习框架与NVIDIA GeForce RTX 3090 GPU.使用交叉熵作为损失函数, 并使用带有0.9动量的随机梯度下降(Stochastic Gradient Descent, SGD)优化模型.在3个数据集上训练模型, 在前5个批次中使用预热策略.学习率设置为0.1, 并在第35个批次和第55个批次时按0.1的因子衰减, 训练在第65个批次结束. 在NTU RGB+D、NTU RGB+D 120数据集上, 使用与CTR-GC[10]相同的数据预处理方法, 并将批量大小设置为64, 权重衰减为0.000 4.在Northwestern-UCLA数据集上, 设置批量大小为16, 权重衰减为0.000 1.本文使用多流融合策略[8, 10], 即关节点流、骨骼流、关节点运动流和骨骼运动流.
2.3.1 各组件的有效性分析
在NTU RGB+D X-sub数据集上, DPG-GC模块和CS-PDC模块的有效性如表1所示.在空间建模中, 将DPG-GC模块与DTR-GC模块并行, 通过逐元素求和以提取骨架序列的空间特征, 准确率从92.4%提至92.7%, 表明DPG-GC模块能捕捉局部细微变化的特征, 有利于区分相似性的动作类别, 并且参数量只有少量增加.
| 表1 不同模块在NTU RGB+D X-sub数据集上的有效性分析 Table 1 Effectiveness analysis of different modules on NTU RGB+D X-sub dataset |
CS-PDC模块以双分支的形式并行到CTR-GC[10]中, 识别准确率从92.4%提至92.8%, 由此验证CS-PDC模块可捕获短距离节点和长距离节点的潜在依赖关系.组合2个模块, 识别准确率从92.4%增至93.0%, 提升约0.6%, 由此表明CFE-GCN有助于捕获动作的局部细微变化特征和全局潜在的依赖关系.
2.3.2 n对双部分分组图卷积模块的影响
设定DPG-GC模块中n=2, 4, 6, 8, 10, 12, 在NTU RGB+D X-sub数据集上判断n不同对识别准确率和参数量的影响, 具体如表2所示, 表中黑体数字表示最优值.由表可观察发现, 当n=4, 6时, 识别准确率达到92.7%, 参数量的提升也相对较少.当n值过小时, 可能会将不相关的关节分到同组中, 导致组内的关节特征混合, 难以区分不同部位的运动特征.当n值过大时, 可能导致模型过度关注关节组内的局部细节, 忽略全局动作的结构和整体关联.加入CS-PDC模块后, 当n=6时, 性能最优.
| 表2 DPG-GC模块中n不同对性能的影响 Table 2 Effect of different n in DPG-GC module on performance |
2.3.3 跨阶段部分密集连接模块中各分支的有效性分析
本文以并行的方式将CS-PDC模块双分支结构与主干网络结合, 对于每个分支, 初始的通道数为C1和C2.在NTU RGB+D X-sub数据集上, 设定不同C1、C2, 对识别准确率和参数量的影响如表3所示, 表中黑体数字表示最优值.由表可发现, 当初始通道数设置过小时, 较小的通道数可能无法提供足够的动作细节和关键信息.当初始通道数设置过大时, 相邻通道之间可能存在高度相关的特征, 导致特征冗余.经过不同的实验发现, 当双分支的初始通道数分别设置为C1=16和C2=32时, 相比CTR-GC, 识别准确率最高, 同时参数量仅略有提升.
| 表3 CS-PDC模块中不同支路设计对性能的影响 Table 3 Effect of different branch designs in CS-PDC module on performance |
为了验证CS-PDC模块中各分支的有效性, 将初始通道数为16(channel 16)和32(channel 32)的单分支分别加入CTR-GC[10]中, 通过求和的方式与其它分支的特征结合.在NTU RGB+D X-sub数据集上, 对识别准确率和参数量的影响如表4所示, 表中黑体数字表示最优值.由表可看出, 当仅加入初始通道数为16的单分支时, 识别准确率提至92.6%.当仅加入初始通道数为32的单分支时, 识别准确率进一步提至92.7%.将这两个分支均加入CTR-GC中时, 形成一个双分支的特征融合结构, 识别准确率达到最优.该实验说明, 在CS-PDC模块中使用单个分支时, 性能并未达到最优, 而当加入双分支时, 性能得到显著提升.这表明这两个分支是相互补充的, 能共同提取并捕捉动作序列中的关键特征, 从而提高模型性能.
| 表4 CS-PDC模块中各支路对性能的影响 Table 4 Effect of each branch in CS-PDC module on performance |
考虑到不同数据之间的互补信息, 许多方法采用多流融合策略.为了确保对比的公平性, 本文采用类似的多流融合策略[8, 10].通过将关节、骨骼流、关节运动流和骨骼运动流四种模态的结果进行组合而得到最终结果.
选择如下对比方法:ST-GCN[8]、AS-GCN[9]、CTR-GC[10]、2s-AGCN[13]、Shift-GCN[14]、MS-G3D[15]、CDGC[16]、Dynamic GCN[17]、MST-GCN (Multi-scale Spatial Temporal Graph Convolutional Network)[18]、FGCN[19]、STF(To-a-T Spatio-Temporal Focus)[20]、MV-IGNet(Multi-view Interactional Graph Network)[21]、SMotif-GCNs(Sparse Motif-Based Graph Convolu-tional Networks)[22]、 EfficientGCN-B4[23]、 ML-STGNet(Multilevel Spatial-Temporal Excited Graph Net-work)[24]、FRF-GCN (Front-Rear Dual Fusion Graph Convolutional Network)[25].
在NTU RGB+D、NTU RGB+D 120数据集上, 各方法性能对比如表5所示, 表中黑体数字表示最优值.由表可见, 相比ST-GCN, CFE-GCN在两个数据集上的Top-1准确率都有所提升.在NTU-RGB+D数据集上, CFE-GCN在X-sub标准上实现最佳的Top-1准确率, 达到93.0%, STF次优, 为92.5%.在X-view标准上, CFE-GCN与STF一起达到96.9%的Top-1准确率, 获得最优性能.
| 表5 各方法在2个数据集上的性能对比 Table 5 Performance comparison of different methods on 2 datasets |
在更大、更具挑战性的NTU RGB+D 120数据集上, CFE-GCN在X-setup标准上实现最佳的Top-1准确率(89.4%), 比STF和CTR-GC提升0.5%.在X-set标准上, CFE-GCN表现最优, Top-1准确率为91.0%, 比CTR-GC提升0.4%.虽然CFE-GCN在参数量和浮点数运算上略有提升, 但综合而言, CFE-GCN仍具有非常强的竞争力.
CFE-GCN在动作分类准确率上的显著提高, 主要源于两大模块:双部分分组图卷积(DPG-GC)模块和跨阶段部分密集连接(CS-PDC)模块.DPG-GC模块将人体关节点分组建模, 使模型能更好地关注局部关节点的细微特征变化.相比传统的将整体骨架建模的方法, 这种分组策略有利于捕捉细粒度的局部动作特征, 这些局部特征往往是区分相似动作的关键.此外, 大部分关节点都贯穿整个动作过程, 但之前的方法更多关注短期的局部依赖关系, 对短距离关节点进行建模, 而CS-PDC模块关注挖掘长期运动关节之间的潜在依赖关系, 将早期的动作特征与后续特征融合, 从而获取更丰富的全局上下文信息.上述两大模块充分发挥局部细节特征和全局上下文信息的作用, 使 CFE-GCN 在骨架动作识别任务上取得显著的性能提升, 由此验证其有效性.
在Northwestern-UCLA数据集上, 选择如下8种对比方法:CTR-GC[10]、Shift-GCN[14]、FGCN[19]、MV-IGNet[21]、AGC-LSTM(Attention Enhanced Graph Convolutional LSTM Network)[26]、DC-GCN+ADG(De-Coupling GCN with DropGraph Network+Attention- Guided DropGraph)[27]、InfoGCN[28]、MSSTNet(Multi- scale Spatial-Temporal Convolutional Neural Net- work)[29].
各方法的性能对比如表6所示, 表中InfoGCN(4s)表示包含关节流、骨骼流、关节运动流和骨骼运动流的融合结果.由表可见, CFE-GCN再次取得最佳的Top-1准确率(96.8%).
| 表6 各方法在Northwestern-UCLA数据集上的性能对比 Table 6 Performance comparison of different methods on Northwestern-UCLA dataset |
总之, 在3个大规模数据集上, CFE-GCN在所有基准测试中的性能均最优, 充分验证其有效性.
本节通过不同的可视化方法展示CFE-GCN的优势及各模块的有效性.采用的基线模型为CTR-GC[10].
各模块混淆矩阵的可视化结果如图6所示.由图可知, 当在CTR-GC中加入DPG-GC模块后, 由(b)可见, 两个类似动作“ 读书” 和“ 写字” 可通过关注局部的动作变化细节进行区分, 表明DPG-GC模块可有效区分容易混淆的动作类别.当在CTR-GC中加入CS-PDC模块后, 由(c)可见, 长期运动关节之间的依赖关系对于区分“ 戴眼镜” 和“ 摘眼镜” 更关键, 表明CS-PDC模块可有效捕获长距离关节点的潜在依赖关系.由(d)可验证CFE-GCN的有效性.
 | 图6 各模块混淆矩阵的可视化结果Fig.6 Visualization of confusion matrix of different modules |
“ 戴眼镜” 和“ 写字” 两个动作分别经过DPG-GC模块和CS-PDC模块后的邻接矩阵可视化结果如图7所示.由图可见, 这些邻接矩阵直观描述各关节节点与动作之间的关联程度.分析这些邻接矩阵可发现, “ 戴眼镜” 动作经过DPG-GC模块后, 模型主要关注局部细微的变化特征, 尤其是头部关节与左右手指关节之间存在显著的关联性, 手臂关节也表现出一定的相关性.而“ 戴眼镜” 动作经过CS- PDC模块后, 模型则更多捕捉到长期运动关节之间的依赖关系, 如左右肘部、腕部及手指末端关节等呈现较强的关联.对于“ 写字” 动作, 经过DPG-GC模块后, 模型聚焦于局部的细节特征, 左右手部分的关节相关性较强.经过CS-PDC模块处理后, “ 写字” 动作表现出手部和肘部关节之间的密切关联, 因为在“ 写字” 过程中需要这些关节协调配合.通过邻接矩阵图的可视化分析能清晰了解DPG-GC模块和CS-PDC模块在捕捉局部细节和长期依赖关系方面的优势, 这进一步说明CFE-GCN的有效性.
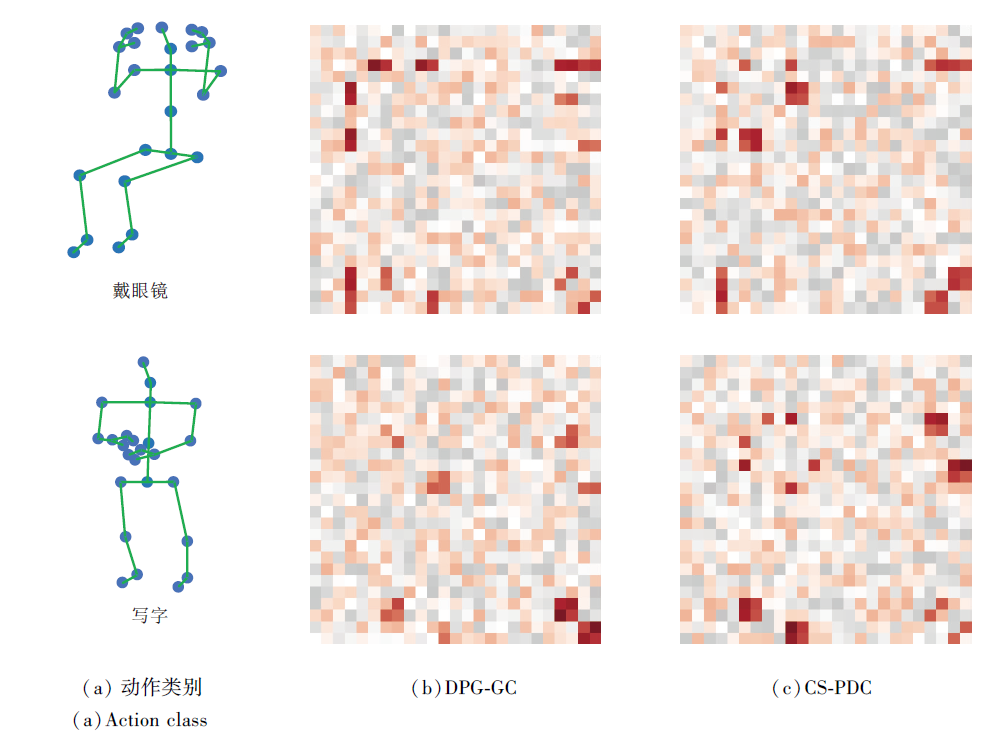 | 图7 各模块邻接矩阵的可视化结果Fig.7 Visualization of adjacency matrix of different modules |
各方法对8组动作的分类准确率对比如图8所示, 其中包括4组相似性动作和4组长期关节依赖动作.分析图8可发现, 使用DPG-GC模块和CS-PDC模块后, 8组动作的分类准确率均有所提升, 前4组动作分类准确率的提升主要来源于DPG-GC模块, 因为DPG-GC模块能有效捕捉动作中局部细微的变化特征.后4组动作分类准确率的提升主要是因为CS-PDC模块, 因为CS-PDC模块关注整个动作的过程及整个身体的协调运动, 挖掘长期运动关节点之间的潜在依赖关系.
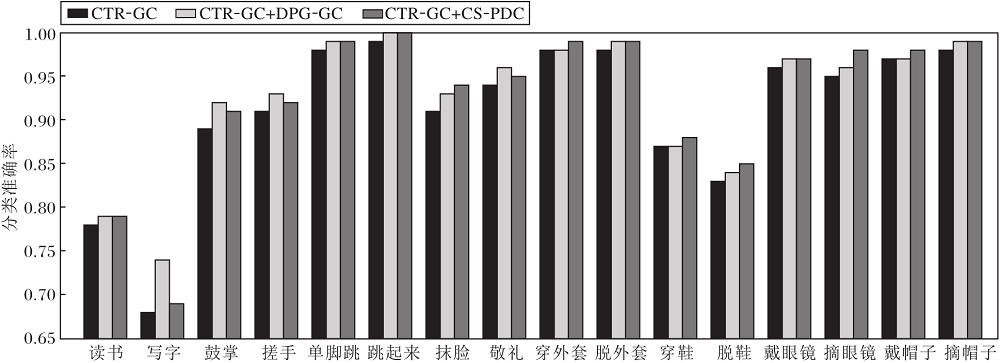 | 图8 相似动作与长期依赖动作的分类准确率对比Fig.8 Classification accuracy comparison of similar actions and long-term dependent actions |
通过图8可进一步验证CFE-GCN的有效性.DPG-GC模块擅长提取局部细节特征, 而CS-PDC模块善于捕捉长期运动关节间的协调依赖关系, 两者共同作用, 提升动作识别的准确性.这种针对不同特点的动作进行有针对性的建模的方式体现了CFE-GCN的优势.
本文提出基于跨通道特征增强图卷积网络的骨架行为识别模型(CFE-GCN), 由双部分分组图卷积(DPG-GC)模块、跨阶段部分密集连接(CS-PDC)模块和多尺度时间卷积(MS-TC)模块组成.DPG-GC模块实现骨架特征的分组学习和细微变化的捕捉.CS-PDC模块实现特征重用和短距离节点、长距离节点的依赖关系捕捉.MS-TC模块利用不同膨胀率的多分支时间卷积提取多尺度时间运动特征, 实现拓扑特征融合.在三个基准数据集上的实验表明CFE-GCN在基于骨架的行为识别任务中具有一定优势.今后将进一步探索适应更多的骨架特征学习的方法, 开发更有效的空间与时间建模, 获得更优性能.
本文责任编委 杨健
Recommended by Associate Editor YANG Jian
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|