
{kind=link}
{kind=link}
{kind=link}
故事启发大语言模型的时序知识图谱预测
[陈娟1, 2  , 赵新潮
, 赵新潮3 , 隋京言1, 2 , 祁麟4 , 田辰4 , 庞亮1, 2 , 方金云1 ]
, 赵新潮, 隋京言, 祁麟, 田辰, 庞亮, 方金云]
|
|



作者简介:

陈 娟,博士研究生,主要研究方向为时序知识图谱、大语言模型、自然语言处理.E-mail:chenjuan@ict.ac.cn.

赵新潮,硕士研究生,主要研究方向为自然语言处理.E-mail:zxcxinchao@foxmail.com.

隋京言,博士研究生,主要研究方向为算法设计、机器学习、深度学习、组合优化.E-mail:suijingyan@ict.ac.cn.

祁 麟,硕士研究生,主要研究方向为图神经网络、自然语言处理.E-mail:qilin2301@gmail.com.

田 辰,硕士研究生,主要研究方向为图神经网络、自然语言处理.E-mail: tianchen@bjtu.edu.cn.

方金云,博士,研究员,主要研究方向为海量空间信息技术研究.E-mail:fangjy@ict.ac.cn.
时序知识图谱海量稀疏,实体的长尾分布导致对分布外实体的推理泛化性较差,历史交互低频导致对未来事件的预测偏差较大.为此,文中提出故事启发大语言模型的时序知识图谱预测方法,利用大语言模型的世界知识储备和复杂语义推理能力,增强对分布外实体的理解和交互稀疏事件的关联.首先,根据时序知识图谱中时间和结构的特性筛选“关键事件树”,通过历史事件筛选策略提炼最具代表性的事件,并摘要当前查询相关的历史信息,减少数据输入量并保留最重要的信息.然后,微调大语言模型生成器,生成时序语义关联且符合逻辑的“关键事件树”叙事故事,作为非结构化输入.在生成过程中,特别关注事件之间的因果关系和时间顺序,确保生成的故事具有连贯性和合理性.最后,利用大语言模型推理器推理缺失的时序实体.在3个公开数据集上的实验表明,文中方法可充分发挥大模型的能力,完成精准的时序实体推理.
About Author:
CHEN Juan, Ph.D.candidate. Her research interests include temporal knowledge graphs, large language models and natural language processing.
ZHAO Xinchao, Master student. His research interests include natural language processing.
SUI Jingyan, Ph.D.candidate. Her research interests include algorithm design, machine learning, deep learning and combinatorial optimization.
QI Lin, Master student. Her research interests include graph neural networks and natural language processing.
TIAN Chen, Master student. His research interests include graph neural networks and natural language processing.
FANG Jinyun, Ph.D., professor. His research interests include massive spatial information processing technologies.
The temporal knowledge graph(TKG) is characterized by vast sparsity, and the long-tail distribution of entities leads to poor generalization in reasoning for out-of-distribution entities. Additionally, the low infrequency of historical interactions results in biased predictions for future events. Therefore, a narrative-driven large language model for TKG Prediction is proposed. The world knowledge and complex semantic reasoning capabilities of large language models are leveraged to enhance the understanding of out-of-distribution entities and the association of sparse interaction events. Firstly, a key event tree is selected based on the temporal and structural characteristics of TKG, and the most representative events are extracted through a historical event filtering strategy. Relevant historical information is summarized to reduce input data while the most important information is retained. Then, the large language model generator is fine-tuned to produce logically coherent "key event tree" narratives as unstructured input. During the generation process, special attention is paid to the causal relationships and temporal sequences of events to ensure the coherence and rationality of the generated stories. Finally, the large language model is utilized as a reasoner to infer the missing temporal entities. Experiments on three public datasets demonstrate that the proposed method effectively leverages the capabilities of large models to achieve more accurate temporal entity reasoning.
知识图谱(Knowledge Graph, KG)以异构图形式组织世界知识, 表达实体间语义及逻辑关系, 是结构化数据组织的革新之一.时序知识图谱(Temporal Knowledge Graph, TKG)加入时间维度, 采用四元组
时序知识图谱推理的关键任务包括实体预测[1, 2]、关系预测[1]、事件预测[3]和异常检测[4]等.实体预测旨在预测特定实体在给定时间内的出现情况, 以补全时序知识图谱中的缺失信息, 提高图谱的完整性和准确性, 对构建可靠的时序知识图谱具有重要意义.时序知识图谱推理高度依赖事件的周期性或递归性, 但常面临海量数据稀疏的挑战, 因此, 实体的长尾分布导致对分布外实体的推理泛化性较差, 历史交互稀疏导致未来事件预测偏差较大.
大语言模型, 如OpenAI的GPT 系列、Google的LaMDA(Language Model for Dialogue Applications)和PaLM(Pathways Language Model)等[5, 6], 具备海量的世界知识和强大的语义理解能力, 在自然语言处理领域已取得一定成功, 可有效应对时序知识图谱中因数据海量稀疏导致的大量长尾实体及历史交互稀疏事件等问题, 实现和增强对分布外实体和交互稀疏事件的语义理解及关联.但是, 传统的知识图谱和大语言模型各有优势, 难以有效结合.具体挑战分为如下两个方面.
1)大语言模型与时序知识图谱分别代表非结构化知识和结构化知识的两端.时序知识图谱通过多关系图序列表示事件演化及知识; 大语言模型从大规模语料中学习知识, 存储在训练参数中.如何实现从结构化表述到非结构化表述的有效适配是二者融合的关键挑战.以往的工作对此有不同的应对方法.例如:Xu等[7]直接将历史的四元组信息进行序列化输入; Lee等[8]将四元组中的时间信息转换为自然语言表达, 进行事件时序演化关联输入.然而, 上述方法均无法引发大语言模型补充隐含的关联事件和历史背景常识, 导致预测效能不足.
2)大语言模型上下文窗口大小的限制和合理的历史事件组织方式也是一大难点.大语言模型在处理自然语言推理任务时, 需要依赖上下文信息以理解和生成相关内容.然而, 其上下文窗口(也称为输入序列长度)通常是有限的.例如:GPT-3 的上下文窗口长度为 2 048 个标记(Tokens).这种限制会导致信息丢失或长依赖关系处理不足等问题.Beltagy等[9]探讨使用稀疏注意机制(Sparse Atten-tion)扩展上下文窗口, 提高模型处理长文档的能力.Press 等[10]提出在训练时使用短文本但在测试时能处理更长文本的方法.上述方法均未从历史事件演化关联的视角进行上下文关键事件的有效组织.以往工作表明, 合理有效的文本组织方式可显著提升大语言模型的表现.例如:Raffel 等[11]提出, 将所有自然语言处理任务统一为文本到文本的转换任务, 通过一致的文本格式组织可提高模型的理解和生成能力.
因此, 本文提出故事启发大语言模型的时序知识图谱预测方法(Narrative-Driven Large Language Model for Temporal Knowledge Graph Prediction, Narra-tiveGraph).首先, 从时序知识图谱中, 依据时间和结构特性筛选关键事件树, 以摘要形式呈现当前查询相关的关键历史信息, 确保输入数据的有效性.然后, 微调大语言模型生成器, 制作既具有时序语义关联性又逻辑严密的关键事件树叙事故事, 作为文本序列输入.最后, 利用大语言模型强大的世界知识储备和复杂的语义推理能力, 进行实体的预测和推理研究.NarrativeGraph包括两个核心模块:关键事件树抽取模块和时序故事推理模块.
1)关键事件树抽取模块.从时空演化的视角, 根据历史事件的时效性及关联性构建抽取策略, 形成关键事件树, 以少量关键历史事件形成时序叙事结构.具体抽取特征规则包括:历史事件时间临近度、节点关联度、节点-关系关联度.这些事件候选集用于后续的时序故事生成的“ 叙述角色” 及“ 故事脉络” .
2)时序故事推理模块.时序故事推理模块分为LLaMA生成器及推理器两部分.核心内容如下.
(1)基于LLaMA生成器的时序故事微调.利用大语言模型的生成能力, 解析图结构数据中的事件和关系, 生成自然语言故事.这一步骤将图结构信息转化为易于大模型处理的文本序列.微调关键事件内容和事件顺序进行内容控制生成及时序语义关联, 同时, 微调故事逻辑、情节填充及辅助知识补全, 生成既逻辑严谨又内容丰富的关键事件树叙事故事.这些过程确保生成文本的高质量和深度.
(2)基于LLaMA推理器的时序故事微调.在生成的故事基础上, 对大语言模型进行微调, 使其能更有效地在文本序列上进行时序推理.通过这种微调, 方法能更好地理解时间依赖关系和事件因果关系.具体的微调内容包括调整输入输出格式, 考虑历史查询和推理指令, 推理缺失的时序实体.
本文通过构建历史关键事件的关联演化策略规则和大语言模型生成及推理两阶段微调方法进行实验.结果表明, NarrativeGraph在ICEWS14、YAGO、IC-EWS18数据集上的表现均较优, 尤其在Hit@3、Hit@10指标上.这表明NarrativeGraph能有效利用时序知识图谱的历史演化事件与大模型世界知识增强语义关联及推理, 提高预测准确性和效率, 在动态数据环境中具有广泛应用潜力.同时, 本文在长尾实体和稀疏事件这两个分析实验中验证NarrativeGraph的有效性, 表明其可增强分布外实体的理解和交互稀疏事件的关联.
时序知识图谱作为知识图谱的一个重要分支, 其动态变化的特性使研究者开始关注如何准确表示和推理随时间变化的知识.随着人工智能技术的不断进步, 时序知识图谱已演化出基于图结构推理与大模型推理两条主流技术路线.
时序知识图谱推理是指通过建模历史事件及其动态演化过程, 预测缺失的事件或四元组信息.在这个过程中, 需要考虑事件的复杂语义关联及时序演化信息, 确保预测的准确性和合理性.
早期模型将时间戳或时间间隔直接嵌入实体和关系的向量表示中, 实现对时序动态关系的建模和预测.Leblay等[12] 提出TTransE(Temporal Transla-ting Embedding), 首次将时序建模引入知识图谱补全任务中.随后, Lacroix等[13]扩展ComplEx, 提出TComplEx, 使用复值嵌入对实体和关系进行建模, 通过复向量空间捕捉关系的对称性和非对称性.
此外, 越来越多的研究工作开始将时间直接作为事件或子图的复杂演化关联进行建模.这种方法注重时间序列中事件之间的复杂关系及其演变过程.
Trivedi等[14]提出Know-Evolve, 学习时序点过程, 建模实体和关系的演化.Trivedi等[15]提出DyRep, 通过深度时序点过程模型捕捉网络拓扑演化和节点间的交织动态, 用于链接和时间预测任务.Zhao等[16]提出T-GCN(Temporal Graph Convolutional Network), 结合图卷积网络(Graph Convolutional Net- work, GCN)和时间序列, 捕捉图结构中的时序动态.Jin等[1]提出RE-NET(Recurrent Event Network), 结合序列预测模型和图神经网络, 捕捉知识图谱中的动态变化.
近年来, Li等[17]提出RE-GCN(Recurrent Evo-lution Network Based on GCN), 通过R-GCN(Rela-tional Graph Convolutional Networks)建模多关系图, 并利用长短时记忆网络(Long Short-Term Memory, LSTM)建模时序演化.Wu等[18]提出TeMP(Tem-poral Message Passing), 通过时间消息传递机制更新节点和边的表示.Zhu等[19]提出CyGNet(Temporal Copy-Generation Network), 引入循环结构, 捕捉时间演化中的周期性特征.
综上所述, 基于图结构的时序知识图谱的新方法和新技术不断涌现, 但是上述方法始终难于突破图结构数据自身的海量稀疏以及复杂推理的有效建模问题.
大语言模型强大的文本理解和生成能力为时序知识图谱推理提供新的思路.
Yao等[20]提出KG-BERT(Knowledge Graph Bidi-rectional Encoder Representations from Transformer), 证明语言模型在理解实体间复杂关系方面的潜力.Petroni等[21]提出LAMA(Language Model Analysis), 进一步验证大模型在知识图谱领域的应用.Xu等[7]提出PPT(Pre-trained Language Model with Prompts for Temporal Knowledge Graph Completion), 将预训练语言模型的提示学习应用于时序知识图谱补全.
为了解决图结构信息与大语言模型融合表示推理问题, 在最近的研究中, 基于大型语言模型的时序知识图谱推理表现出显著的发展趋势.Liao等[22]提出GenTKG(Generative Forecasting on Temporal Know-ledge Graph), 探索利用规则路径提取的方法配合大语言模型进行时序知识图谱推理的策略, 实现对时序数据更深入的分析和预测.与此同时, Luo等[23]提出CoH(Chain of History), 进一步深化这一领域的探索, 提取时序知识图谱中的历史事件, 并基于这些事件及其反向关系构建新的推理方法, 提高基于历史数据的时序事件预测的精确度和可靠性.Lee等[8]推进GPT-NeoX的研究, 突破性地使用大语言模型进行基于时序知识图谱历史实体和关系的上下文预测学习, 可有效利用预训练语言模型编码历史信息, 并应用这一信息提高对未来事件的预测能力.Xia等[24]在历史链(CoH)研究中, 采用大语言模型推理时序知识图谱中的高阶历史信息和历史链.这表明大语言模型不仅能处理复杂的文本信息, 还能理解和推理结构丰富的时序关系.
上述工作共同展示利用大语言模型进行时序知识图谱推理的巨大潜力, 不仅在于它们强大的语言理解和生成能力, 还在于它们处理复杂时序数据的关联及可解释的推理能力.然而, 上述方法难以有效弥合图结构数据与文本序列建模之间的沟壑, 增强对分布外实体的理解和交互稀疏事件的关联.
本文提出故事启发大语言模型的时序知识图谱预测方法(NarrativeGraph), 旨在通过增强对分布外实体的理解和交互稀疏事件的有效关联, 一定程度上解决数据稀疏性和演化复杂性等问题, 增强实体预测推理能力.NarrativeGraph整体框架如图1所示.图中Query为待查询的事件, LLM(Large Lan-guage Model)为大语言模型.
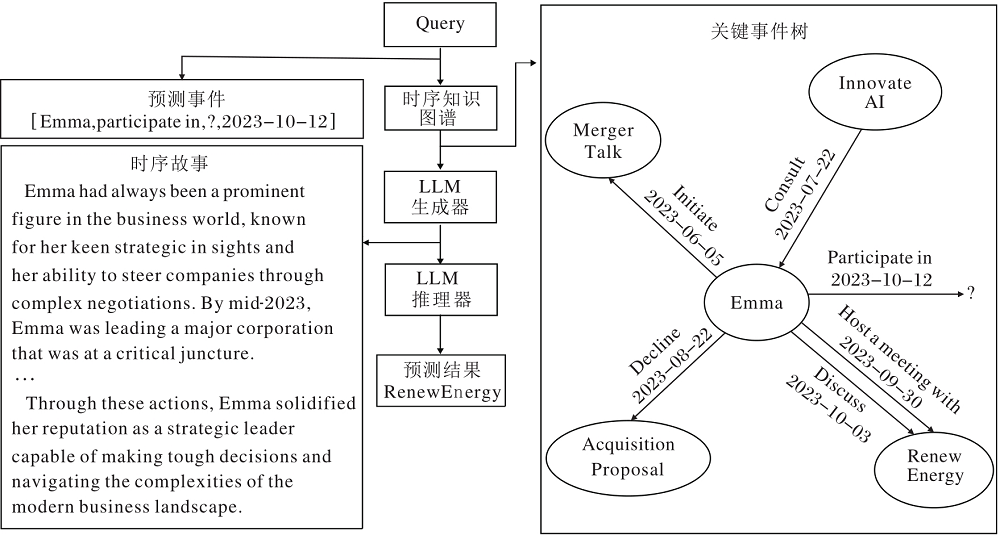 | 图1 NarrativeGraph框架图Fig.1 NarrativeGraph framework |
为了实现这一目标, 提出构建历史关键事件的关联演化策略规则和大语言模型生成及推理两阶段微调方法, 克服传统方法在海量稀疏数据及动态环境中的局限性.
1)构建关键事件树模块.设计并实现一套基于实体类型、关系模式及时间上下文的复杂规则系统, 筛选与特定查询四元组相关的候选实体集.这些规则系统需要识别和提取时间相关属性, 如时间戳和事件序列, 并对实体间的时序依赖性进行建模, 旨在提高候选集的相关性和多样性, 为后续的时序故事生成提供高质量的输入.
2)构建时序故事推理模块.引入关键事件树叙述逻辑, 使生成的叙事成为大语言模型生成器对历史四元组演化模式建模的基础脉络.这种叙事内容不仅为未来事件的推理提供依据, 还显著增强时序知识图谱在事件推理方面的能力.
为了生成用于时序故事的关键事件树, 本文设计一系列规则, 有效提取时序知识图谱中的候选四元组.这些规则基于历史数据中实体和关系的出现频率、时间戳和关系多样性.
这种统计特征的方法为时序知识图谱中的实体预测提供重要的历史背景信息.通过分析实体及其关系在历史上的表现, 能准确预测它们在未来的行为, 不仅提高实体预测模型的准确度和效率, 还通过缩小候选实体的范围, 优化整个预测流程, 使其更符合实际应用需求.
2.1.1 实体历史统计特征
实体历史计数是用于识别与给定查询四元组相关的历史实体数量的基本技术.此技术的核心在于通过量化一个特定实体在过去出现的频次, 评估其在整个时序知识图谱中的活跃度及其相对重要性.这种计数不仅反映实体的历史活动模式, 也提供对其未来行为的潜在影响力的预测依据.在实体预测的上下文中, 了解一个实体的历史活跃度对于准确预测其未来的行为至关重要.例如:如果一个实体在历史数据中频繁与多种关系相连, 那么它在时序知识图谱中扮演着一个连接多个节点的枢纽角色. 对于一个给定的查询四元组
$C_{h}\left(e_{h}, t_{q}\right)=\sum_{\left(e_{h}^{\prime}, r^{\prime}, e_{t}^{\prime}, t^{\prime}\right)} I\left(e_{h}^{\prime}=e_{h} \cap t^{\prime} 其中, 2.1.2 实体关系历史统计特征 实体关系历史统计特征是一种细化的分析方法, 不仅涉及统计特定实体的出现频率, 还特别关注这些实体与特定关系的共同出现频次.此计数方法的目的是提供一种更精确、详尽的方式分析实体在历史数据中的行为模式.通过这种方式, 可更有效地选择与给定查询四元组最相关的候选实体, 提高预测的准确性和相关性.在时序知识图谱中, 实体与关系共同定义图的结构, 其中关系的性质可显著影响实体的重要性和功能.通过统计一个实体与特定关系的联合出现次数, 可深入理解该实体在图中的角色和重要性.此外, 实体关系历史统计特征还可揭示隐藏在数据中的复杂交互模式.例如:当某实体与特定关系的共同出现频率异常高时, 可能指示存在特定的依赖关系或影响力机制.这种洞察力对于构建更精准的预测模型、优化时序知识图谱的结构, 甚至挖掘未知的知识都至关重要.通过这种分析, 可更深入地理解实体间的相互作用, 提高模型的预测能力和应用价值.对于同一个查询四元组 $C_{h r}\left(e_{h}, r, t_{q}\right)=\sum_{\left(e_{h}^{\prime}, r^{\prime}, e_{i}^{\prime}, t^{\prime}\right)} I\left(e_{h}^{\prime}=e_{h} \cap r^{\prime}=r \cap t^{\prime}<t_{q}\right),$(2) 其中, eh 表示查询四元组的头实体, r表示查询四元组的关系, tq 表示查询时间戳, h表示历史数据集. 实体关系历史计数不仅统计特定实体的出现频率, 还特别关注这些实体与特定关系的联合出现情况.这种计数方法提供一种更精确、细致的方式分析实体在历史数据中的行为模式, 有助于挑选与给定查询四元组最相关的候选实体. 通过考虑头实体和关系类型与查询四元组匹配且发生时间早于查询时间的历史记录, 可更好地理解该实体在图中的角色和重要性. 2.1.3 权重计算原则 权重的计算是一个关键步骤, 用于评估候选实体在特定查询中的相关性.这一过程综合考虑三个主要因素:四元组的出现频率、关系种类的多样性、数据的新鲜度, 以确保预测模型能有效识别和优先考虑最相关的候选实体. 1)实体历史计数统计特征.式(1)反映特定实体与关系在历史数据中出现的次数.频率越高, 表明该实体在历史上与给定关系越紧密相关, 从统计角度上看, 这种模式的重现概率越高.因此, 在权重计算中, 出现频率是提升候选实体权重的一个重要因素. 2)实体关系历史统计特征.式(2)衡量与特定实体关联的不同类型关系的数量.实体关联的关系种类越多, 说明其在知识图谱中的连接性和多功能性越强.一个具有广泛关系网络的实体通常在图中扮演更核心的角色, 因此在候选生成时可赋予更高的权重. 3)数据的新鲜度.新鲜度是通过考虑数据的时间戳衡量的.最近的数据被认为更相关, 因为它们可能更准确地反映当前的状态或趋势.在权重计算中, 较新的数据具有较高的权重, 这有助于模型捕捉并应对快速变化的信息. 权重的计算是为了评估候选实体的相关性, 综合考虑四元组的出现频率、关系种类的多样性及数据的新鲜度. 权重计算函数如下: 其中, f表示四元组在历史数据中的出现频率, k表示与头实体和关系相关的不同实体的种类数,
2.2.1 微调时序故事生成的大模型
为了增强时序知识图谱的实体推理能力, 微调时序故事生成的大模型.该生成器基于LLaMA并设计提示工程的方法以构建时序叙事.
基于关键事件树, 生成包含时序信息的故事脉络.该脉络详细描述实体及其关系在时间上的发展过程, 使大语言模型能更好地理解和预测事件的演化.具体步骤如下.
1)收集相关数据.从时序知识图谱中提取相关的四元组数据, 包含头实体、关系、尾实体和时间戳.
2)构建时间线.根据时间戳将四元组数据排序, 形成时间线结构.
3)整合上下文信息.为每个四元组提供详细的上下文信息, 包括事件发生的背景、相关的历史事件等.
4)生成叙述.基于时间线和上下文信息, 生成连贯的叙述, 将各个四元组连接成一个完整的故事脉络.
为了有效指导LLaMA生成连贯的故事, 设计具体的提示(Prompt).如表1所示, 指令部分提供生成任务的具体指令, 描述如何将四元组数据转化为连贯的叙述.输入部分提供一组具体的四元组数据作为输入.这些提示引导模型生成连贯的故事, 将提供的四元组数据串联成一个整体叙述.
| 表1 故事生成提示工程的设计示例 Table 1 Example for story generation prompts engineering design |
通过上述步骤, 时序故事生成器能基于时序知识图谱数据构建连贯的故事脉络, 并利用这些脉络进行未来事件的推理和预测, 从而增强时序知识图谱的事件推理能力.
2.2.2 微调时序故事推理的大模型
本节详细描述如何结合候选集四元组和生成的时序故事进行尾实体预测.设计合适的提示进行模型微调, 并最终使用测试集进行预测, 从而提高实体预测的准确性和有效性.
2.2.2.1 微调提示设计与模型
为了使大语言模型能有效结合候选集四元组和生成的故事脉络进行尾实体预测, 设计专门的提示进行模型微调.微调提示工程的具体设计包括指令部分、历史数据、故事脉络、查询信息和预期输出.提示设计的基本步骤如下所示.
1)构建输入提示.需要包括候选集四元组和相应的故事脉络, 以提供充分的上下文信息.一个典型的输入提示示例如下.
(1)查询四元组.[头实体, 关系, ?, 时间戳].
(2)故事脉络.包括头实体和关系的历史演化信息, 相关的时间指示表达式.
(3)历史候选四元组集合.包含生成故事脉络的历史四元组集合.
2)模型微调.使用构建的输入提示, 对预训练的大语言模型进行微调.微调过程中, 模型学习如何从故事脉络中提取有用信息, 更准确地预测尾实体.
(1)数据准备, 包含查询四元组和相应故事脉络的数据集, 用于模型微调.
(2)使用优化的学习率和训练参数, 进行模型微调, 使模型能更好地理解输入提示, 并从中提取有效信息用于预测.
3)提示工程优化.通过不断迭代和实验, 优化提示的设计, 使模型能更好地理解输入信息, 提高预测性能.主要优化方向如下.
(1)上下文信息的选择与整合.选择最相关的故事脉络信息, 有效整合到提示中.
(2)提示结构优化.调整提示结构, 更符合模型的理解和预测机制.
微调提示工程的具体设计如表2所示, 包括指令部分、历史数据、故事脉络、查询信息和预期输出.这些提示设计的详细描述确保输入信息的完整性和上下文连贯性, 优化模型的预测性能.
| 表2 微调提示工程的设计示例 Table 2 Example for fine-tuning prompts engineering design |
为了解决大模型的实体生成概率性问题和大模型自身幻觉的问题, 在设计微调提示过程中主要优化如下两点.
1)文本生成概率性问题.构建微调语料时同时输入关键事件树及基于关键事件树生成的故事, 可在提供更丰富的历史背景信息的同时提供原始检索语料.
2)输出预测实体不确定的问题.为了防止大语言模型输出的预测实体可能不在数据集语料库上, 在提示工程中固定输出格式, 只允许对历史语料中出现的实体进行预测(如提示词:Only consider en-tities from historical quadruple tail entities.).
2.2.2.2 测试集预测实体
在完成模型微调后, 使用标准测试集评估模型, 验证其在尾实体预测任务中的性能.
首先, 选取含有未知尾实体的查询四元组作为测试集, 这些四元组需要经由模型进行预测.选择测试集时, 必须确保其具有足够的多样性和代表性, 这是全面评估模型泛化能力和预测性能的关键.因此, 测试集应包括多种类型的关系、广泛的时间跨度和各种不同的实体, 确保评估结果的全面性和公正性.
然后, 将测试集上每个查询四元组输入微调后的模型, 通过提示引导模型生成尾实体的预测结果.具体步骤如下.
1)为每个查询四元组生成相应的输入提示, 包含查询信息和相关的故事脉络.输入提示的设计需要确保信息的完整性和连贯性, 以便模型能充分理解上下文.
2)将生成的提示输入微调后的大语言模型, 获取预测的尾实体.
通过上述步骤, 可评估微调后的大语言模型在尾实体预测任务中的性能.
本文使用YAGO[22]、ICEWS14[23]、ICEWS18[23]这3个标准的时序知识图谱数据集, 特别选用ICEWS数据集, 因为它们对全球事件进行全面的时间标注, 成为测试时间推理能力的理想选择.1)YAGO数据集.包含10 623个实体和10种关系类型, 具体包括161 540个训练实例、19 524个验证实例和20 026个测试实例.2)ICEWS14数据集.专注于2014年的事件, 包含6 869个实体和230种关系, 分为74 845个训练实例、8 514个验证实例和7 371个测试实例.3)ICEWS18数据集.特色数据来自2018年, 包括23 033个实体和256种关系, 分为373 018个训练实例、45 995个验证实例和49 545个测试实例.数据集的详细信息如表3所示.
| 表3 实验数据集 Table 3 Experimental datasets |
在每个数据集上, 按8∶ 1∶ 1的比例划分训练集、验证集和测试集.具体划分方法为顺序抽取80%的数据作为训练集, 10%的数据作为验证集, 剩余10%的数据作为测试集.
评估指标采用Hit@1、Hit@3、Hit@10, 分别表示模型在前1个、前3个和前10个预测中包含正确答案的比例.具体计算方法如下:
Hit@k=
本文选择与如下方法进行对比实验.
1)RE-GCN[17].基于图卷积网络的循环进化网络, 用于在时序知识图谱中预测未来事实, 通过学习实体和关系的进化表示实现高效的时序推理.
2)xERTE(Explainable Reasoning Framework for Forecasting Future Links on Temporal Knowledge Gra-phs)[25].提供一种可解释的推理框架, 推理相关子图进行时序知识图谱的未来链接预测, 提升模型的可解释性和预测性能.
3)TLogic[26] .基于时序逻辑规则的可解释框架, 用于时序知识图谱的链接预测, 同时提供时间一致的推理链条.
4)TANGO(Temporal Knowledge Graph Forecas-ting with Neural Ordinary Equations)[27].使用神经常微分方程的时序知识图谱预测模型, 保持动态图数据的连续特性, 实现未来链接的高效预测.
5)TITer(Time Traveler)[28].通过强化学习在历史知识图谱中进行路径搜索, 应对未来时间戳的预测任务, 特别是改进新出现实体的推理能力.
6)GPT-NeoX-20B[29].使用大语言模型进行时序知识图谱预测, 发现LLM在去除语义信息后仍能通过符号模式实现强大的预测性能.
采用规则抽取四元组生成故事文本的方式能更精准有效地表达关联演化, 使大模型生成高质量的内容并完成推理.之所以选择这种方法, 是因为原始数据存在如下3个主要问题.
1)原始语料信息难以获取.基于四元组的原始语料信息通常难以获取, 即便通过多种途径尝试, 如谷歌搜索引擎和GDELT项目, 也难以获得全面、匹配的原始语料.这不仅仅是数据的匮乏, 更在于数据的异质性和复杂性.四元组数据来源多样, 各数据源的格式和内容差异较大, 整合这些数据往往需要大量的前处理工作.
2)噪声干扰.原始数据往往伴随着大量噪声, 这些噪声可能引起大模型在内容关注上的不均衡, 从而影响预测结果的准确性.噪声数据会干扰模型的学习过程, 使模型难以捕捉真实的关联关系.噪声问题在大规模模型的训练过程中尤为突出.噪声不仅会降低模型对有效信息的识别能力, 还会引发模型在训练过程中对无关信息的过度关注, 影响预测的准确性.
3)关联演化的有限建模.原始数据之间的演化关联较难通过直接建模进行有效表达.原始四元组数据缺乏对关联演化的描述能力, 难以全面反映实体之间的动态变化和关系演进.四元组数据本身通常只是静态的关系描述, 难以有效捕捉动态的关联演化.直接使用这些数据进行建模, 往往忽略实体之间关系的时间序列变化, 导致模型对动态关系的推理能力不足.
基于这些考虑, 通过规则抽取四元组生成故事文本的方法, 不仅有效解决原始数据获取难题, 还显著降低数据噪声对模型的干扰.这种方法通过精确过滤和抽取关键四元组, 剔除无关或低质量的信息, 从而使模型的训练更专注于核心关联关系.相比直接使用噪声较多的原始数据, 这种生成式方法确保模型在高质量、低噪声的语料环境中学习, 从而大幅提高模型对重要内容的关注度、均衡性.此外, 生成的故事文本不仅展现四元组之间的静态关系, 还深入挖掘并表达其中的关联演化过程, 使模型在推理过程中能更好地捕捉和理解实体间复杂的动态变化.这一过程显著提升模型推理的准确性和可靠性, 使其在实际应用中表现得更出色.
这种基于生成文本的方法虽然存在一定的局限性, 但在现有数据条件下, 仍是一个行之有效的解决方案.通过科学合理的实验设计和数据处理, 可验证这种方法的有效性, 并展示其在时序知识图谱实体预测中的潜力和优势.
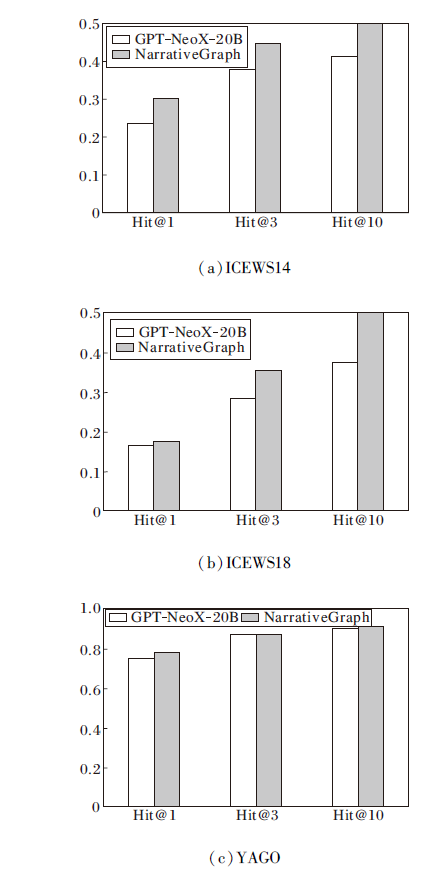
各方法在3个数据集上的指标值如表4所示.由表可见, NarrativeGraph在各项指标上表现出色.在ICEWS14、YAGO数据集上, 显著提升预测效果.在ICEWS14数据集上, Hit@1、Hit@3指标分别比次优的TLogic提升约0.6%和1.4%.在YAGO数据集上, Hit@3、Hit@10指标值分别达到0.911和0.932, 显著优于对比方法, 特别是Hit@1指标值达到0.802, 仅次于TITer的0.845.
| 表4 各方法在3个数据集上的指标值对比 Table 4 Metric value comparison of different methods on 3 datasets |
在ICEWS18数据集上, 虽然NarrativeGraph在Hit@1、Hit@3、Hit@10指标上分别达到0.208、0.377和0.536, 但效果一般.这主要是由于ICEWS18数据集的动态变化更复杂, 数据稀疏性和时序演化的复杂性对方法提出更高的挑战.
目前, 针对ICEWS18数据集的PPT[7]的训练时间约为19 h, 推理时间约为5 min; NarrativeGraph的训练时间约为6 h, 推理时间约为5 min.具体对比结果可见表5.这一显著的时间缩短表明Narrative-Graph在效率上具有明显优势.NarrativeGraph不仅提高实体预测的效果, 还因大幅减少处理时间而显著提升处理速度, 为实际应用中的快速响应和决策提供有效的技术支持.
| 表5 PPT与NarrativeGraph训练时间和推理时间对比 Table 5 Comparison of training time and inference time of PPT and NarrativeGraph |
总之, NarrativeGraph在3个数据集上均表现出较高的预测准确性, 特别是在Hit@3、Hit@10指标上优势显著.这表明在处理时序知识图谱推理任务时, NarrativeGraph能有效捕捉长尾实体和稀疏事件的时序语义关联, 提高实体预测的精度和效率.通过与其它方法的对比, 实验验证NarrativeGraph在动态数据环境中的改进效果, 表明其在实际应用中的广泛潜力.
分布外实体稀疏问题, 如查询四元组:
[Tech Corp, Launch, ?, 2023-06-15]
历史相关四元组分布如下:
[Tech Corp, Announce partnership, Research Lab, 2023-01-10]
[Tech Corp, Host conference, Industry Group, 2023-01-20]
[Tech Corp, Secure funding, Venture Fund, 2023-02-05]
[Tech Corp, Expand market, New Region, 2023-03-12]
[Tech Corp, Acquire, Small Startup, 2023-04-18]
目前已知query的答案Innovative Gadget, 通过上述历史相关四元组集合发现无相关实体存在.
长尾实体问题, 如查询四元组:
[MegaRetail, enter market, ?, 2024-02-28]
1)富有历史数据的实体:
[MegaRetail, enter market, UrbanCity, 2023-01-15]
[MegaRetail, form alliance, LogisticsNetwork, 2023-02-20]
[MegaRetail, acquire, UrbanCity, 2023-03-30]
[MegaRetail, enter market, LogisticsNetwork, 2023-04-10]
UrbanCity和LogisticsNetwork与MegaRetail的历史行为有较多记录, 能为预测MegaRetail未来的市场进入策略提供丰富的数据支持.
2)历史事件稀疏的实体:
[MegaRetail, launch product, SmallTown, 2022-05-25]
[MegaRetail, test market, RuralArea, 2022-07-15]
然而, 对于类似SmallTown或RuralArea这样历史事件记录非常稀少的市场实体, 预测MegaRetail在未来的市场进入策略时, 模型会因为缺乏足够的历史数据, 导致预测效果不佳.例如:当预测2024年MegaRetail可能的新市场时, 模型可能无法充分考虑这些稀疏数据, 从而影响预测的准确性.
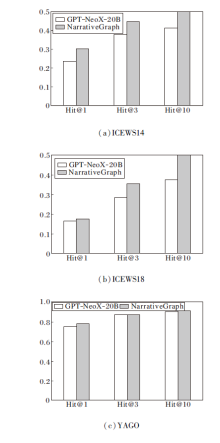
为了验证大语言模型在处理历史交互稀疏事件和长尾实体问题上的有效性, 设计如下实验.在时序知识图谱中, 部分历史事件和实体的出现非常低频, 针对这一问题进行分析, 并设置当前查询的关键事件树数量和长尾实体的条件, 筛选全部符合规则的事件或实体进行预测任务.
引入大语言模型可显著提升其在长尾事件预测和交互稀疏事件中的表现, 具体结果如图2和图3所示.由图可见, 在ICEWS数据集上, Hit@3、Hit@10指标具有明显提升.在YAGO数据集上, 尽管预测效果有所提升但提升幅度较小, 主要是由于该数据集的动态变化更复杂, 数据稀疏性对方法提出更高的要求.
 | 图2 历史事件稀疏时的指标值结果Fig.2 Results of metric values for sparse historical events |
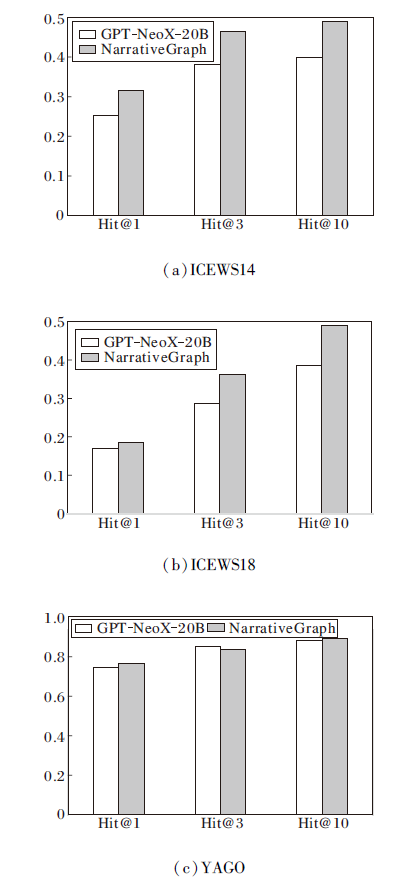 | 图3 分布外实体稀疏时的指标值结果Fig.3 Results of metric values for out-of-distribution entities |
总之, 实验验证大语言模型在处理历史交互稀疏事件和长尾实体问题上的有效性, 能有效补充历史事件知识及捕捉和利用时间维度的信息, 提高实体预测的准确性和效率.这也进一步证实大语言模型在时序知识图谱推理任务中的广泛应用潜力.
3.4.1 规则驱动的候选实体选择
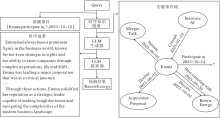
在企业战略规划中, 理解关键决策者的行为模式对预测其未来行动至关重要.本节以提升Emma在公司并购决策中行为预测的准确性为案例进行分析.通过时序知识图谱, 可从历史数据中提取与Emma相关的关键事件, 预测她在未来决策中的行动方向.
查询四元组:
[Emma, participate in, ?, 2023-10-12]
为了预测2023年10月12日Emma参与的具体活动, 需要分析她在过去一段时间内的行为轨迹和决策模式.通过一系列的规则, 筛选以下关键历史四元组:
[Emma, initiate, Merger Talk, 2023-06-05]
[Emma, approve, Strategic Partnership, 2023-07-15]
[Emma, decline, Acquisition Proposal, 2023-08-22]
[Emma, negotiate, Joint Venture, 2023-09-10]
[Emma, finalize, Asset Sale, 2023-10-11]
这些四元组的选择基于如下规则.
1)历史计数.统计Emma在过去一年内参与的战略决策事件频率, 评估她在公司决策过程中的活跃度和影响力.
2)关系计数.评估Emma与不同类型决策(如并购、合作、资产出售)的关系出现频率, 识别她的决策倾向和偏好.
3)时间戳新鲜度.优先考虑与查询日期接近的历史事件, 确保预测的时效性和相关性.
3.4.2 时序故事生成器的作用
生成故事的目的是为了将孤立的四元组连接成一个连贯的时间序列叙述, 提供丰富的上下文信息.这些故事脉络帮助大语言模型更好地理解历史事件的演化, 提高预测未来事件的准确性.
故事生成步骤如下所示.
1)收集相关数据.从时序知识图谱中提取关键四元组.
2)构建时间线.根据时间戳排序四元组, 形成时间线结构.
3)整合上下文信息.为每个四元组提供详细的上下文信息, 包括事件背景和相关历史事件.
4)生成叙述.基于时间线和上下文信息, 生成连贯的叙述, 将各个四元组连接成一个完整的故事脉络.
故事提示工程输出如下.
Emma had always been a prominent figure in the business world, known for her keen strategic insights and her ability to steer companies through complex negotiations. By mid-2023, Emma was leading a major corporation that was at a critical juncture. The company had been exploring various strategic options to enhance its market position and ensure long-term growth.
On June 5, 2023, Emma initiated Merger Talks with a leading competitor. This move was seen as bold and forward-thinking, aiming to create a powerhouse in the industry by combining resources, expanding market share, and leveraging synergies between the two companies. The talks were complex, involving numerous stakeholders and requiring careful consideration of antitrust regulations and the potential impact on employees and customers. Emma's leadership during these discussions was instrumental, as she balanced the need for aggressive growth with the realities of operational integration.
…
Through these actions, Emma solidified her reputation as a strategic leader capable of making tough decisions and navigating the complexities of the modern business landscape.
3.4.3 提示设计与模型微调的必要性
大语言模型在预训练时通常使用通用语料, 未必能较好地适应特定领域(如时序知识图谱推理)的任务.通过微调, 可让模型更好地理解特定领域的数据和任务, 提高预测的准确性和鲁棒性.
设计提示的目的是为了引导模型生成高质量的预测结果.通过提供详细的上下文和明确的指令, 可帮助模型更准确地理解任务要求, 并生成符合预期的输出.
提示设计的优势如下.
1)详细上下文.提供详细的历史数据和生成的故事脉络, 使模型能理解事件的演化和相关背景, 提高预测的准确性.
2)明确指令.通过明确指令(如只考虑历史四元组尾实体), 减少模型生成无关或不准确实体的概率, 提高预测结果的可靠性.
3)优化输出.引导模型输出排名前十的实体, 使预测结果更具参考价值和实用性.
3.4.4 预测结果
通过上述方法, 成功预测在2023年10月12日Emma参与的事件为Joint Venture.实验表明, 通过结合规则驱动的事件抽取、故事生成及大语言模型微调进行实体预测, 可显著提高预测的准确性和有效性.这一过程表明NarrativeGraph在处理复杂动态数据时的优势和创新性.
本文提出故事启发大语言模型的时序知识图谱预测方法(NarrativeGraph), 结合时序知识图谱的历史演化事件和大语言模型的生成及推理能力, 有效增强长尾实体及稀疏事件的丰富语义及复杂时序关系演化关联, 提高实体预测的准确性和有效性.实验表明, 在ICEWS14、ICEWS18、YAGO数据集上可提升实体推理性能, 由此验证方法的有效性.综上所述, 本文说明大语言模型在时序知识图谱推理领域的广阔前景及生成式推理方法的有效思路, 为后续研究提供新的研究视角.今后, 可考虑进一步探索对于长尾实体和稀疏数据的时序子图构建策略, 同时挖掘大语言模型在时序因果路径推理上的探索能力, 从而为时序知识图谱与大语言模型的融合推理提供一定理论基础.
本文责任编委 陈恩红
Recommended by Associate Editor CHEN Enhong
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|