{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于特征空间增强重放和偏差校正的类增量学习方法
[孙晓鹏1  , 余璐
, 余璐1 , 徐常胜2 ]
, 余璐, 徐常胜]
|
|



作者简介:

孙晓鹏,硕士研究生,主要研究方向为持续学习.E-mail:xiaopeng12138@stud.tjut.edu.cn.

徐常胜,博士,研究员.主要研究方向为多媒体分析/索引/检索、模式识别、计算机视觉.E-mail:csxu@nlpr.ia.ac.cn.
网络不断学习新的知识时会遭受灾难性遗忘,增量学习方法可通过存储少量旧数据重放以实现增量学习的可塑性与稳定性的平衡.然而,存储旧任务的数据会有内存限制及隐私泄露的问题.针对该问题,文中提出基于特征空间增强重放和偏差校正的类增量学习方法,用于缓解灾难性遗忘.首先,每类存储一个中间层特征均值作为其代表的原型,并冻结低层特征提取网络,避免原型“漂移”.在增量学习阶段,存储的原型通过几何平移变换增强重放的方式维持先前任务的决策边界.然后,通过偏差校正为每个任务学习分类权重,进一步纠正方法分类偏向于新任务的问题.在4个基准数据集上的实验表明文中方法性能较优.
About Author:
SUN Xiaopeng, Master student. His research interests include continuous learning.
XU Changsheng, Ph.D., professor. His research interests include multimedia analysis/indexing/retrieval, pattern recognition and computer vision.
The problem of catastrophic forgetting arises when the network learns new knowledge continuously. Various incremental learning methods are proposed to solve this problem and one mainstream approach is to balance the plasticity and stability of incremental learning through storing a small amount of old data and replaying it. However, storing data from old tasks can lead to memory limitations and privacy breaches. To address this issue, a class-incremental learning method based on feature space augmented replay and bias correction is proposed to alleviate catastrophic forgetting. Firstly, the mean feature of an intermediate layer for each class is stored as its representative prototype and the low-level feature extraction network is frozen to prevent prototype drift. In the incremental learning stage, the stored prototypes are enhanced and replayed through geometric translation transformation to maintain the decision boundaries of the previous task. Secondly, bias correction is proposed to learn classification weights for each task, further correcting the problem of model classification bias towards new tasks. Experiments on four benchmark datasets show that the proposed method outperforms the state-of-the-art algorithms.
在现实生活场景中, 数据和环境都在不断变化, 这意味着人工智能系统需要不断更新以适应新的情境, 因此现代人工智能是否具有持续学习的能力至关重要.目前, 深度神经网络在许多基准测试中都取得与人类相当甚至更优的性能(如图像分类[1]), 但是, 深度神经网络学习新任务时会倾向于改变旧任务学习的参数以适应新任务, 而改变针对旧任务的至关重要的参数会导致方法几乎完全忘记旧任务的知识[2], 这便是增量学习面临的灾难性遗忘问题[3].近期出现许多研究[4, 5, 6, 7]试图缓解灾难性遗忘的问题.
目前类增量学习的方法大致可分为三类[8, 9]:基于正则化的方法、基于模型架构的方法和基于重放的方法.
基于正则化的方法特点是通过添加正则化项以约束模型参数的优化, 又可分为两个方向:权重正则化和函数式正则化.权重正则化主要是在学习新任务时根据每个参数对旧任务的贡献或重要性对其添加惩罚.Kirkpatrick等[2]提出EWC(Elastic Weight Consolidation), 计算Fisher信息矩阵, 估计每个参数对旧任务的重要性并施加约束.函数式正则化通常采用知识蒸馏[10]的方式将旧任务模型的知识传递给当前任务模型, 以此避免灾难性遗忘.Li等[11]提出LwF(Learning without Forgetting), 对齐当前任务数据在新旧模型输出的logits, 使模型保持旧任务的知识.基于正则化的方法可缓解灾难性遗忘的问题, 但能力有限, 无法较好地防止过拟合, 且存在权重共享问题.因此, 该类方法通常与其它技术和方法结合, 以缓解类增量学习的灾难性遗忘问题.
基于模型架构的方法的主要思想是使用参数隔离的方式保持对旧任务学习的参数, 再对新任务学习一组特定参数.Zhu等[12]扩展模型的表示能力, 用于处理新的类别.Liu等[13]提出AANet(Adaptive Aggregation Network), 一开始就构建两个残差块, 一个用于维持旧类的知识, 另一个用于学习新类.基于模型架构的方法会增加模型的复杂性, 可能会导致更多的计算和内存开销, 特别是在处理大规模数据或深层网络时, 会影响模型的效率和可扩展性.
基于重放的方法主要利用数据存储或生成模型近似恢复旧任务数据的分布.根据重放内容的不同, 又可以分为三个方向:样本重放、生成重放和特征重放.
样本重放简单直接地在内存中存储一部分旧任务的数据[14, 15, 16], 在之后的增量阶段进行重放, 与新任务数据联合训练网络以维护旧任务的决策边界.但是存储数据会有内存容量和数据隐私限制的问题.
生成重放学习深度生成模型生成先前类的伪样本[17, 18, 19], 然而训练大型生成模型(如生成对抗网络[20]和自动编码器[21])在复杂的数据集上很难生成高质量图像, 而且生成模型也会有灾难性遗忘的问题.
最近, 一些基于原型的特征重放方法也取得不错效果[22, 23, 24], 它们为每个旧类存储一个代表性的原型(通常是深度特征空间中的类特征均值), 用于建模旧任务数据的特征分布, 以此维持旧类的决策边界.相比存储样本, 这种策略更节省内存, 隐私更安全.然而, 由于缺乏旧类特征, 直接使用保存的原型和当前数据进行训练时难以防止旧任务决策边界的改变.因此, Zhu等[22]提出PASS(Prototype Augmen-tation and Self-Supervision), 在学习新任务时, 通过添加高斯噪声的方式对保存的类原型进行增强重放, 维持先前任务的决策边界.Shi等[23]提出PRAKA(Prototype Reminiscence and Augmented Asymmetric Knowledge Aggregation), 通过随机双向插值进行原型的增强以丰富旧类的特征.
另一方面, 由于模型在连续数据流上的更新可能导致旧类的表示发生变化, 也就是特征漂移, 大部分保存原型的方法都会与知识蒸馏的方法结合, 防止旧任务特征表示的漂移.基于重放的方法通常被认为是一种简单有效的应对增量学习灾难性遗忘的方法.
基于重放的类增量学习还有一个问题是任务偏差现象, 是指网络在类增量学习任务中预测偏向于最近任务的类.主要是因为在训练时, 网络在最后任务中看到的绝大多数是当前任务类的数据, 但没有或很少来自之前任务的数据.任务偏差现象一个直接后果是:在最后一层分类器中新类别的权重范数大于先前类别的权重范数, 导致分类器的预测偏向于最近任务的类别[8].Castro等[15]为了防止任务偏差问题, 在每次训练结束时引入一个额外的平衡训练阶段, 在平衡训练中对所有类使用相同数量的数据以训练网络.Hou等[25]使用余弦归一化层代替标准softmax层, 纠正最近任务偏差问题.Wu等[16]提出BiC(Bias Correction), 使用存储的旧类样本与新类样本联合训练, 分别为新旧数据学习一个分类权重, 以此解决任务偏差问题.
由此, 本文提出基于特征空间增强重放和偏差校正的类增量学习方法.考虑到内存容量和数据隐私的问题, 采取特征重放的方式, 防止旧任务决策边界偏移.首先, 为每个旧类存储一个代表原型, 与其它存储原型的方法不同, 该原型是网络中间层特征空间的类均值.为了避免存储的原型随着增量学习不断“ 漂移” , 在第一个任务后冻结输出原型之前的低层网络.根据神经网络的可解释性分析[26], 神经网络的低层更多提取图像的通用信息(如颜色, 纹理等), 而网络高层更关注语义信息.因此将第一个任务学习的低层通用信息作为所有任务的基础, 再使用保存的原型调整高层网络对语义信息的处理, 从而防止网络对旧任务知识的遗忘.另外, 受FeTrIL(Feature Translation for Exemplar-Free Class-Incremen-tal Learning)[24]的启发, 在学习新任务时, 将保存的原型通过新类特征的几何平移变换生成更加多样性的旧类特征, 维持网络对新旧类别图像的区分.受BiC的启发, 在网络最后一个分类层之后额外添加一个偏差校正层, 使用数量相等的新旧类特征对每个任务学习一个偏差校正的权重和偏差, 减少方法对于任务的偏差现象.在CIFAR-100[27]、Tiny-Image-Net[28]、ImageNet-Subset[29]、Food-101[30]这4个基准数据集上的实验表明本文方法性能较优.
类增量学习的目标是顺序学习一个统一的模型, 能够针对到目前为止学过的所有类的测试样本进行正确分类, 并且在推理时不需要使用任何任务标识符.此模型表示为M, 参数表示为θ .增量任务序列t∈ {1, 2, …, T}, 需要学习的类的集合为:
Dt={Xt, Yt}={
其中, Nt表示任务t训练样本的数量,
D1∩ D2…∩ Dt=Ø .
当学习任务t时, 网络学习的目标是最小化当前任务数据集Dt上预定义的损失函数, 而不影响甚至有益于先前任务学习的损失函数[31]:
$\begin{array}{l}\arg \min _{\theta_{t}, \epsilon} L_{t}\left(M\left(X_{t} ; \theta_{t}\right) ; Y_{t}\right)+\sum_{i} \epsilon_{i}, \\L_{t}\left(X_{i}, Y_{i}\right)-L_{i}\left(X_{i}, Y_{i}\right) \leqslant \epsilon_{i}, \epsilon_{i} \geqslant 0 ; \\\forall i \in[1, t-1], \end{array}$
其中, Lt(Xi, Yi)表示模型在任务t时刻对旧任务数据Di的损失函数, Li(Xi, Yi)表示先前模型在任务i时刻对旧任务数据Di的损失函数, $\boldsymbol{\epsilon}=\left\{\boldsymbol{\epsilon}_{i}\right\}$表示一个宽松变量, 允许在旧数据集上有小幅增加.
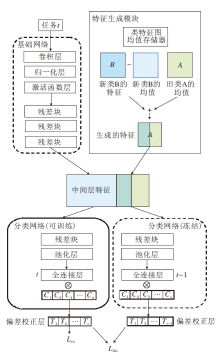
本文提出基于特征空间增强重放和偏差校正的类增量学习方法, 框架如图1所示.
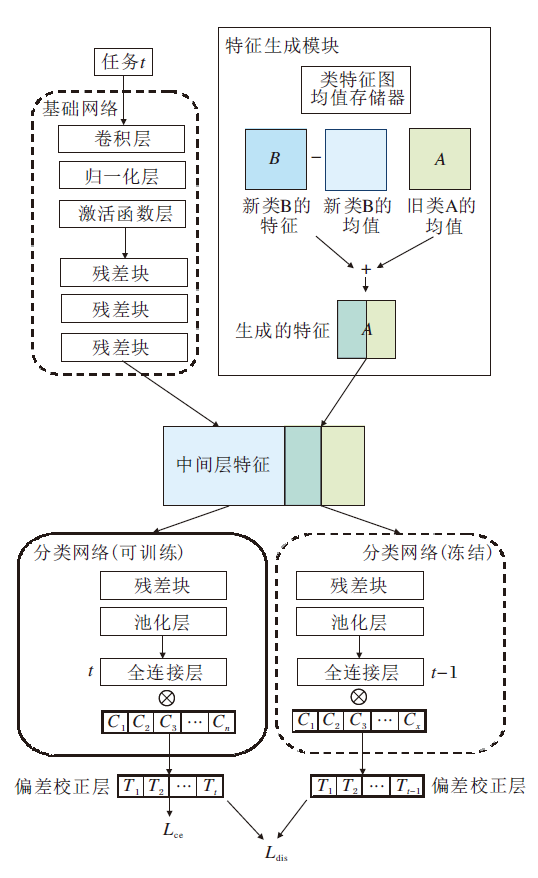 | 图1 本文方法框架Fig.1 Framework of the proposed method |
本文方法主要包括四个部分:基础网络B、分类网络F、特征生成模块G和偏差校正层P.基础网络B和分类网络F是由一个完整的ResNet分割得到, 网络参数分别为η 和φ .基础网络B在学完第一个任务后, 参数η 被冻结不再改变, 对于每个旧类存储一个类代表性原型.
本文方法整体是一个两阶段学习过程.在第一阶段学习中, 将存储的原型通过特征生成模块G生成更多样性的旧类特征, 再与当前数据特征一起更新分类网络F, 同时使用知识蒸馏的方法维持分类网络对旧任务的语义知识, 在此期间偏差校正层是冻结状态.具体步骤如算法1所示.在第二阶段学习中, 冻结分类网络F, 使用平衡的新旧类特征数据流, 更新当前任务的偏差校正层参数, 减少方法对任务产生的偏差现象.
算法1 第一阶段学习过程
输入 当前任务训练集(Xt, Yt),
保存的旧任务原型P=(P1, P2…Pt-1),
当前分类网络的参数φ
输出 对当前任务数据及旧任务原型的预测概率
F(f)
for x, y in (Xt, Yt) do
ft=B(x) //基础网络B中提取当前任务图像特征
// 根据当前任务特征生成旧类的伪特征, 其中
示当前任务特征均值
f=concat(ft,
//拼接增强的特征与当前任务特征
Lce=L(F(f); Y)
//其中, F(· )表示分类网络, Y表示到当前任务所
有类标签集
$L_{\mathrm{dis}}=\lambda \sum_{j=1}^{N} F_{t-1}(f) \ln F_{t}(f)$
//对新旧分类网络输出的logits进行蒸馏
l(φ ) =-Ñ (Lce+Ldis) //更新当前分类网络
end for
由于内存容量的限制, 不能全部存储旧类的特征, 因此使用生成模块G产生旧类的伪特征.现有的生成旧任务数据的方法依赖于生成对抗网络[17]、图像反演[32]或基于旧类协方差[33]等方法.本文采用一个简单的替代方案, 将新类的特征以及旧类和新类的原型作为输入, 通过几何平移变换方式生成旧类的伪特征.在第t个增量任务中产生旧类Cp的伪特征:
其中, Cp表示需要生成伪特征的旧类别标签, Cn表示当前任务可获得的新类别标签, f(Cn)表示使用基础网络B提取的新类别Cn样本的特征,
式(1)表示将旧类Cp特征均值的每个维度值加上新类Cn样本特征和其特征均值相应维度值之间的差值, 这样可依据实际的新类Cn样本特征在表示空间中生成与旧类Cp匹配的伪特征.这种生成伪特征的方式计算成本较小, 因为它只涉及加法和减法操作.旧类Cp的特征均值
在增量学习阶段, 将生成的旧类伪特征与当前任务数据经过基础网络B提取的新类特征一起提供给分类网络F让其学习, 以此使网络学会区分迄今为止已学习的所有类别.具体公式如下:
$ L_{\mathrm{ce}}=L_{t}\left(F\left(f_{t} ; \varphi_{t}\right) ; Y_{t}\right)+\sum_{i=1}^{t-1} L\left(F\left(\bar{f}_{i}^{t} ; \varphi_{t}\right) ; Y_{i}\right), $
其中, ft表示当前任务数据通过基础网络B输出的特征,
本文使用一个简单、有效的偏差校正方法, 解决最后一层分类器存在的任务偏差问题.每当学习新任务时, 都为当前任务添加一个线性模型, 在分类网络F训练完成后, 保留旧类(C1, C2, …, Ct-1)输出的logits, 使用线性模型校正新类Ct输出的logits的偏差:
qk=
其中, α t、 β t表示当前任务t中新类的偏差校正参数, ok表示第k类输出的logits.需要注意的是, 所有新类都共享一对偏差参数(α t和β t).当优化偏差校正参数时, 分类网络F的参数φ 被冻结, 只更新当前任务的偏差参数α t、 β t, 通过特征生成模块生成新旧类数量平衡的数据流, 使用如下的分类损失优化偏差参数:
$L_{b}=\sum_{i=1}^{N} L_{\mathrm{ce}}\left(P\left(F\left(f_{i}, \varphi\right)\right), Y_{i}\right)+a\left\|\beta_{t}\right\|_{2}$,
该分类损失由交叉熵损失和L2损失组成, 其中, N表示新旧类的总数量, fi表示输入的新旧类的特征, Yi表示对应的标签, a表示一个常量系数, 在本文中设为0.1.
当学习新类时, 分类网络F的参数不断更新, 为了保持分类网络F对于旧类的语义知识, 本文还对分类网络F增加额外的知识蒸馏损失.通过将当前任务模型对新旧类混合数据流输出的logits与先前模型输出的logits进行匹配, 以此维持分类网络对旧任务的知识.具体如下:
$L_{\mathrm{dis}}=\lambda \sum_{j=1}^{N}\left[q_{j} \ln p_{j}+\left(1-q_{j}\right) \ln \left(1-p_{j}\right)\right]$,
其中, N表示新旧类特征流的总数量, pj、qj分别表示当前任务分类网络和旧的分类网络经过偏差校正层输出的logits, λ 表示一个蒸馏系数.在实际应用中, 由于每个增量阶段引入的新类数量不同, 因此需要保留以前知识的程度也不同.因此, 本文提出自适应地设置蒸馏损失的权重:
λ =λ base
其中, |Co|、|CN|分别表示当前任务阶段旧类数量和新类数量, λ base表示一个超参数变量.
综合来说, 在增量学习阶段本文的优化可分为两个阶段.1)第一阶段对分类网络F的参数φ 的学习.2)分类网络F学习完成后, 第二阶段重新生成新旧类数量平衡的数据流, 通过式(2)更新当前任务的偏差校正层参数.
第一阶段总的损失函数如下:
Ltotal=Lce+Ldis.
为了评估本文方法的有效性, 选择在CIFAR-100[27]、Tiny-ImageNet[28]、ImageNet-Subset[29]、Food-101[30]这4个基准数据集上进行实验.对于所有数据集类别的排序和划分, 遵循文献[22]~文献[24]中的规范, 在第一个任务中使用一半数量的类训练方法, 在增量阶段中将剩余的类平均分配.在CIFAR-100、Tiny-ImageNet数据集上有3种不同的任务设置(5任务, 10任务和20任务), 而在ImageNet-Subset、Food-101数据集上只有一种任务设置(10任务)用于验证实验.
在所有实验中都使用ResNet-18[34]作为骨干网络, 图像的批次大小为128, 采用SGD(Stochastic Gradient Descent)优化器进行参数优化, 学习率进行余弦衰减.对于初始任务, 设置迭代次数为200, 初始学习率为0.1, 权重衰减为5e-4, 动量为0.9.对于增量任务, 设置迭代次数为100, 初始学习率为0.01, 其余参数与初始任务一致.在设置微调偏差校正层参数时, 迭代次数为20, 其余都遵从增量任务.在CIFAR-100、Tiny-ImageNet数据集上, λ base设为1, 但在CIFAR-100数据集的20任务下, λ base设为1.5.在ImageNet-Subset、Food-101数据集上, λ base设为2.另外为了确保可比性, 对所有方法都使用相同的随机种子, 值为1993.
与文献[22]~文献[24]相同, 本文采用平均增量准确率(Average Incremental Accuracy, AIA)[14], 平均准确率(Average Accuracy, AA)[22]和平均遗忘(Average Forgetting, AF)[9]作为评价指标.AIA定义为所有任务阶段(包括初始任务)中所见类别的准确率平均值, 反映方法的总体增量性能.AA定义为学完所有任务后, 对所有类别的准确率平均值, 表示方法最终性能.AF用于衡量方法对先前任务的遗忘, AF值越低性能越优.
本节选择如下方法进行对比.
1)同样无样本存储的类增量学习方法:LwF[11]、文献[12]方法、PASS[22]、PRAKA[23]、FeTrIL[24]、IL2A[32].
2)经典的存储样本的类增量学习方法:iCaRL(Incremental Classifier and Representation Lear-ning)[14]、文献[15]方法、文献[25]方法、DER(Dy-namically Expandable Representation)[35].对于iCaRL, 分别使用iCaRL-CNN和iCaRL-NCM(iCaRL-Nea-rest-Class-Mean Classifier)进行对比.本文按照大多数的设置, 为每类存储20个样本.
各方法的AIA指标对比如表1所示, 在表中, 其它方法的数据主要来自文献[23], 黑体数字表示最优值, 斜体数字表示次优值.
| 表1 各方法在3个数据集的不同任务数设置下的AIA值对比 Table 1 AIA comparison of different methods under different task count settings on 3 datasets % |
由表1可看到, 本文方法在3个基准数据集的各任务设置下都取得较佳性能, 特别是在CIFAR-100、Tiny-ImageNet这两个有挑战性的低分辨率图像数据集上, 本文方法都显著优于其它无样本存储方法.在CIFAR-100数据集的3个不同增量任务设置下, 本文方法比次优的PRAKA平均提升3.29%.在Tiny-ImageNet数据集上, 本文方法比次优的FeTrIL平均提升2.61%.这表明本文方法适用于低分辨率数据集的类增量学习任务.同时, 本文方法在高分辨率图像的Image-Net-Subset数据集上也有不错的表现, 在10任务设置下比PRAKA提升2.50%, 与次优的FeTrIL性能相当, 提升0.28%.而且, 本文方法在Food-101细粒度数据集上的性能也是最优的, 比次优的FeTrIL提升2.18%.此外, 相比一些存储样本的类增量学习方法, 本文方法也显示出不错的性能, 甚至在CIFAR-100数据集的5任务设置下略强于DER.
为了对比减轻遗忘的有效性, 各方法的AF指标对比结果如表2所示, 表中黑体数字表示最优值, 斜体数字表示次优值.由表可看到, 本文方法的AF值都显著低于其它方法.在CIFAR-100数据集的3个不同增量任务设置下, 本文方法比次优方法的AF值分别降低8.00%, 9.29%和12.31%, 在Tiny-Image- Net数据集上比次优方法的AF值分别降低5.14%, 9.00%和8.66%.这表明本文方法可有效减少类增量学习的灾难性遗忘, 并且对于长任务序列, 本文方法的AF值降低得更多、效果更优.
| 表2 各方法在2个数据集的不同任务数设置下的AF值对比 Table 2 AF comparison of different methods under different task count settings on 2 datasets |
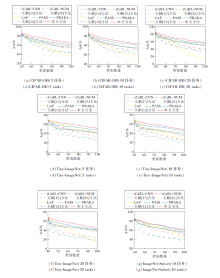
为了进一步评估本文方法, 提供各方法平均准确率随任务的变化曲线, 具体如图2所示.由图可看到, 本文方法在所有增量阶段几乎都是最优的, 这表明本文方法在增量学习的稳定性和可塑性之间实现更好的平衡.在CIFAR-100、Tiny-ImageNet数据集的所有增量阶段上, 本文方法都显著优于PRAKA, 这也再次证实本文方法在低分辨率图像数据集上的有效性和适用性.在ImageNet-Subset数据集上, 本文方法与PRAKA的变化曲线非常近似, 从第5个增量阶段后开始慢慢拉开差距, 最终略优于PRAKA.
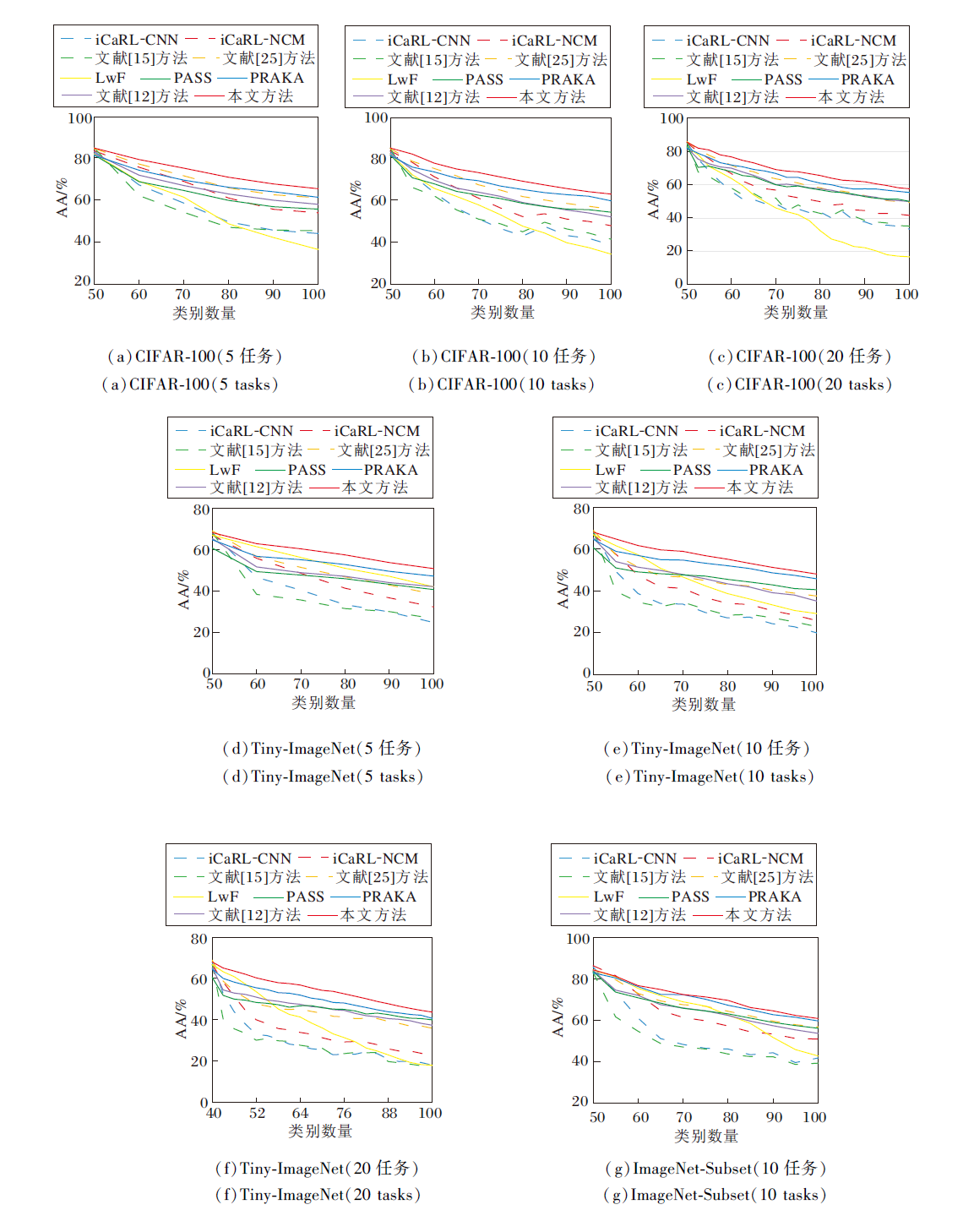 | 图2 各方法的AA值随任务的变化曲线对比Fig.2 Curves of average accuracy of different methods changing with tasks |
为了评估本文方法的计算效率, 在CIFAR-100数据集的10任务设置下, 将本文方法分别与文献[25]方法和PRAKA[23]在训练时间和增量训练占用内存两方面进行对比, 结果如表3所示, 表中黑体数字表示最优值.由表可见, 文献[25]方法直接保存部分旧数据重放, 无需额外的计算, 训练时间最短, 但本文方法仅比其增加0.1 h, 而PRAKA比文献[25]方法训练时间增加2.9 h, 这表明本文方法的计算成本较低.本文方法对每类仅保存一个类原型, 因此占用内存最少, 比文献[25]方法直接保存样本更节省内存.而PRAKA因为同时使用数据增强方法和特征增强方法, 训练时间和内存占用都远高于本文方法.
| 表3 各方法计算成本与计算效率对比 Table 3 Comparison of computational cost and efficiency of different methods |
2.3.1 模块消融实验
为了更好地分析核心模块的影响, 进行模块消融实验, 本文方法分为3个组成模块:蒸馏模块、特征生成模块和偏差校正模块.各模块的AIA值如表4所示.由表可得如下结论.
| 表4 各模块的AIA值对比 Table 4 AIA value comparison of different modules % |
1)蒸馏模块和特征生成模块都可有效缓解类增量学习的灾难性遗忘问题, 但两者仅单独使用效果并不佳.
2)蒸馏模块和特征生成模块同时使用可达到较优效果, 在CIFAR-100、Tiny-ImageNet数据集上, 相比仅使用蒸馏模块, AIA值分别提升45.61%和28.49%, 相比仅使用特征生成模块, AIA值分别提升21.44%和28.34%.特征生成模块可生成旧类特征以维持旧类的决策边界, 但随着任务的改变, 生成的旧类特征可能会偏离其集群中心, 此时蒸馏方法可约束网络参数, 在学习新任务时不忘旧任务的知识.单独的蒸馏模块仅在当前任务数据上对齐新旧模型的输出, 加入特征生成模块生成旧任务特征后, 可进一步对齐新旧模型在旧任务数据的输出, 从而提升蒸馏效果.因此蒸馏模块和特征生成模块同时使用可大幅提升性能.
3)偏差校正模块有效解决任务偏差问题, 可进一步提升性能.在CIFAR-100数据集的3个不同增量任务上, AIA指标分别提高3.16%, 4.01%和5.02%, 在Tiny-ImageNet数据集的3个增量任务上, AIA指标分别提高9.86%, 15.75%和20.17%.
由此可得出结论:蒸馏模块.特征生成模块和偏差校正模块对于本文方法的性能都具有至关重要的作用.
2.3.2 参数消融实验
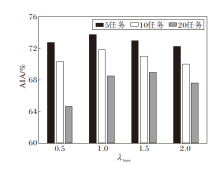
为了研究蒸馏系数λ base对本文方法的影响, 在CIFAR-100数据集上绘制AIA指标随λ base的变化曲线, 具体如图3所示.
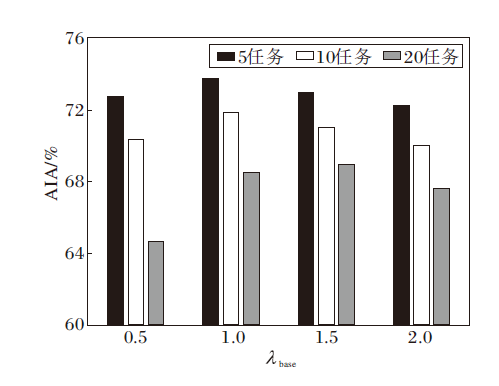 | 图3 不同蒸馏系数下AIA的变化情况Fig.3 Variation of average incremental accuracy(AIA) under different distillation coefficients |
由图3可见, 当蒸馏系数较低时, 对旧任务的约束较小, 会遗忘旧任务的知识, 导致总体性能较差.随着蒸馏系数的增大, 知识蒸馏开始逐渐发挥维持旧任务知识的作用, 在λ base=1左右时达到性能峰值, 当蒸馏系数继续增大, 知识蒸馏的增益效果开始减少, 因为会影响新任务的学习, 从而导致总体性能变差.但是在20任务设置下, 初始任务学习的类较少, 使基础网络B不能学到很好的泛化特征, 因此影响总体性能, 所以适当增加一点蒸馏系数(λ base=1.5)会让本文方法在20任务下达到最优性能.
2.3.3 分层消融实验
在CIFAR-100数据集的不同任务设置下, 对保存不同位置的中间层特征进行消融实验, 结果如表5所示, 表中黑体数字表示最优值.由表可见, 保存在Layer 3层之后输出的特征综合性能最优.保存较为靠前层的特征意味着分类网络需要学习的参数变多, 仅依靠保存的旧任务特征原型难以满足高层网络的语义信息需求, 以至于不能维持旧任务的决策边界, 且保存的特征较大, 占用内存也较多, 每层特征的大小都是其前一层特征大小的2倍.保存最后一层的特征虽然可降低占用的内存, 但是低维的特征包含的语义信息相对较少, 而且完全冻结卷积网络, 仅微调线性分类层不能较好地学习新类的特征, 导致总体性能较低.
| 表5 保存不同位置中间层特征的消融实验结果 Table 5 Results of ablation experiments with different intermediate layer features preserved |
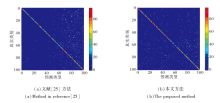
为了更好地展示本文方法对各类的分类情况, 在CIFAR-100数据集的10任务设置下对模型的预测通过混淆矩阵进行可视化, 并与文献[25]方法进行对比, 具体如图4所示.在图中, 对角线表示正确预测, 非对角线表示错误预测.
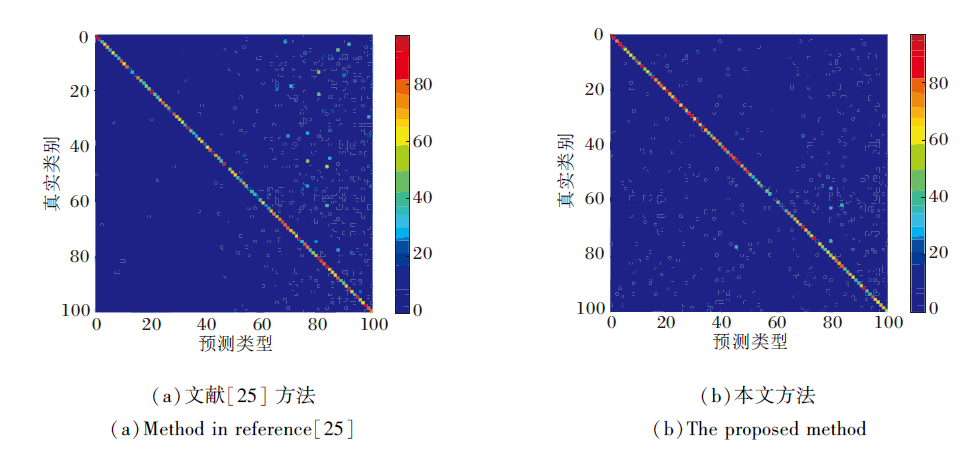 | 图4 两种方法的混淆矩阵可视化对比Fig.4 Visualization comparison of confusion matrices of 2 methods |
由图4可看到, 虽然文献[25]方法使用余弦归一化层代替标准softmax层以纠正最近任务偏差问题, 但模型的预测依然偏向于新任务的类别.相比之下本文方法的性能更优, 新旧类别之间的分类偏差得到较好的处理, 预测正确的对角线高亮部分更多, 预测错误的杂点相对较少.
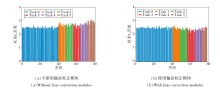
为了显示本文偏差校正模块的有效性, 在CIFAR-100数据集的5任务设置下分别对是否使用偏差校正模块的分类器权重范数进行可视化, 具体结果如图5所示.由图可看到, 不使用偏差校正模块, 新类的分类器权重范数明显较大, 导致最近任务出现偏差, 使模型的预测偏向于新类, 而使用偏差校正模块, 新类的分类器权重范数明显降低, 有效改善任务偏差问题.
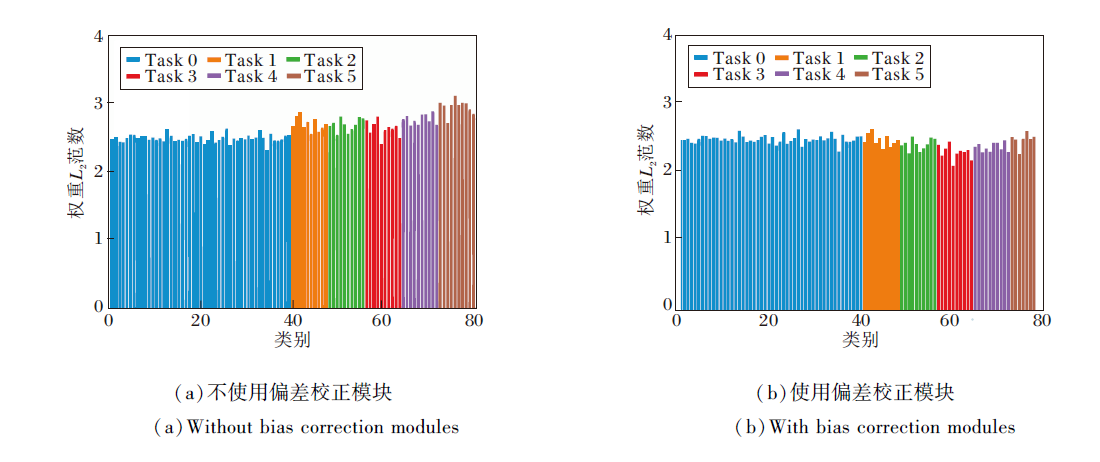 | 图5 是否使用偏差校正模块的分类器权重范数可视化Fig.5 Visualization of weight norm of classifiers without and with bias correction modules |
本文提出基于特征空间增强重放和偏差校正的类增量学习方法, 缓解类增量中的灾难性遗忘问题, 并且在无需存储旧类的样本或使用复杂的生成模型的条件下, 在多个数据集上获得较优的分类结果.目前的方法还存在一定的局限性, 这也是未来工作的方向.首先, 生成的旧类特征可能偏离集群中心, 对训练造成不利影响, 因此今后将研究更精细的特征生成方法, 使生成的伪特征与旧类的原始特征更相似.此外, 由于冻结的大部分网络都为基础网络部分, 所以网络偏向于初始任务的旧类, 对于新任务的学习略差.今后将研究如何通过伪特征生成机制进一步提高方法稳定性和可塑性的平衡.
本文责任编委 高阳
Recommended by Associate Editor GAO Yang
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|