


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
边界感知引导多层级特征的知识蒸馏交通场景语义分割算法
[谢新林1, 2  , 段泽云
, 段泽云1, 2 , 罗臣彦1, 2 , 谢刚1, 2 ]
, 段泽云, 罗臣彦, 谢刚]
|
|



作者简介: 
段泽云,硕士研究生,主要研究方向为深度学习、图像语义分割等.E-mail:s202315210574@stu.tyust.edu.cn. 
罗臣彦,硕士研究生,主要研究方向为深度学习、图像语义分割等.E-mail:S20201503009@stu.tyust.edu.cn. 
谢 刚,博士,教授,主要研究方向为先进控制、机器视觉、故障诊断等.E-mail:xiegang@tyust.edu.cn.
针对交通场景目标细节信息丢失与模型参数量过大等问题,提出边界感知引导多层级特征的知识蒸馏交通场景语义分割算法,以较少的参数量平滑目标分割边界.首先,构建自适应融合多层级特征模块,融合深层语义信息和浅层空间信息的多层级特征,选择性地突出目标边界信息和目标主体信息.然后,提出交互注意力融合模块,建模空间维度和通道维度的长距离依赖关系,增强不同维度间的信息交互能力.最后,提出基于候选边界的边界损失函数,构建基于细节感知的边界知识蒸馏网络,迁移复杂教师网络中的边界信息.在交通场景数据集Cityscapes和CamVid上的实验表明,文中算法能在实现轻量化的同时保持良好的分割性能,并在处理小目标和细长条目标时具有一定优势.
About Author:
DUAN Zeyun, Master student. Her research interests include deep learning and image semantic segmentation.
LUO Chenyan, Master student. Her research interests include deep learning and image semantic segmentation.
XIE Gang, Ph.D., professor. His research interests include advanced control, machine vision and fault diagnosis.
To solve the problems of object detail information loss and large model parameters in traffic scenes, a traffic scene semantic segmentation algorithm with knowledge distillation of multi-level features guided by boundary perception is proposed. The proposed algorithm can smooth the object segmentation boundaries with fewer parameters. First, the adaptive fusing multi-level feature module is constructed to integrate the multi-level features of deep semantic information and shallow spatial information. The object boundary information and object subject information are highlighted selectively. Second, an interactive attention fusion module is proposed to model the long-range dependencies in spatial and channel dimensions, enhancing the information interaction capabilities between different dimensions. Finally, a boundary loss function based on candidate boundaries is proposed to construct a boundary knowledge distillation network based on detail awareness and transfer boundary information from complex teacher networks. Experiments on the traffic scene datasets Cityscapes and CamVid demonstrate that the proposed algorithm achieves a lightweight model while gaining positive segmentation performance, maintaining significant advantages in dealing with small and slender objects.
图像语义分割旨在分配图像中每个像素的类别标签, 能同时实现对场景目标的分割和识别, 进而为场景内容的感知与理解提供细粒度和高层次的语义信息.
交通场景语义分割能获取道路、行人、车辆和信号灯等典型目标位置信息和语义信息, 可辅助自动驾驶汽车感知外部环境并做出适当决策.
作为计算机视觉与智能交通领域的交叉研究问题, 交通场景语义分割还是先进驾驶辅助系统、交通安全和交通监控等应用场景的核心技术[1].
受益于深度学习强大的特征表示能力和端到端的自学习特性, 学者们重点关注基于深度学习的交通场景语义分割.然而, 逐层的卷积和池化操作, 在增强特征语义表达能力的同时, 容易造成目标边界轮廓细节信息的丢失.为此, Hu等[2]提出JPANet(Joint Pyramid Attention Network), 构建JFP(Joint Feature Pyramid)模块, 融合多个网络阶段特征, 改善下采样阶段几何信息丢失的问题.蒋斌等[3]提出全卷积化DenseNet121, 增强全局上下文信息的提取能力, 恢复丢失的空间信息.
因此, 不同层级特征的有效融合和目标边界信息的准确分割对分割模型的实际应用至关重要[4].Gao等[5]提出FBSNet(Fast Bilateral Symmetrical Net-work), 融合局部特征信息、远距离特征信息和输入信息.张墺琦等[6]提出基于多尺度特征提取融合和注意力机制的肝脏组织病理图像语义分割网络, 利用空洞卷积处理不同的尺度特征, 增强细化边界的能力.
然而, 上述方法未充分考虑不同层级的语义信息和细节信息, 导致浅层目标边界信息和深层目标主体信息的判别能力不强.
注意力机制通过加权特征增强卷积层的特征表示.其中, 空间注意力可增强关键区域的特征表达, 通道注意力旨在显式建模不同通道特征之间的相关性.Fu等[7]提出DANet(Dual Attention Network), 分别在空间维度和通道维度上捕获长距离依赖关系, 但未充分利用空间注意力与通道注意力之间的关联性, 容易导致信息交互不足.为此, Dai等[8]提出iAFF(Iterative Attentional Feature Fusion), 通过多次迭代和交替的方式优化特征融合.Zhou等[9]提出SA-FFNet(Self-Attention Feature Fusion Network for Se- mantic Segmentation), 结合全局语义信息和局部语义信息, 指导低级特征细节的融合.
然而, 上述方法在捕获全局信息的同时, 并未充分考虑减少通道维度建模依赖关系对深层信息的影响.
权衡模型分割精度和参数量, 构建轻量化的交通场景语义分割网络对于模型的实际应用具有重要影响.其中, 知识蒸馏能将复杂教师网络中的知识迁移到简单的学生网络, 因此基于知识蒸馏的语义分割是实现模型轻量化的重要技术和手段.为了减少模型参数, Yang等[10]提出CIRKD(Cross-Image Re-lational Knowledge Distillation), 使学生模型模仿教师网络学习各图像中像素之间的全局语义关系.Ji等[11]提出SSTKD(Structural and Statistical Texture Knowledge Distillation), 提高网络对于表征局部结构和全局统计特征的学习能力.An等[12]提出两种互补的知识蒸馏方法, 自适应地向学生网络传递结构化的远程上下文信息, 以提高浅层网络的语义一致性.
然而, 上述基于知识蒸馏的语义分割方法忽视目标边界信息的迁移对学生网络性能提升的重要性.为此, Xiao等[4]提出BASeg(Boundary Aware Network), 捕获边界区域与目标内部像素之间的远程依赖关系, 增强类内一致性.Han等[13]提出Edge-net, 构建Class-Aware Edge Loss Module和Channel-Wise Attention Mechanism, 改善边缘附近像素的分类结果.然而, 上述方法未充分考虑真实边界与预测边界之间的对齐, 容易导致边界附近的细节信息丢失.
基于上述讨论与动机, 本文提出边界感知引导多层级特征的知识蒸馏交通场景语义分割算法, 对交通场景图像中的目标边界分割具有鲁棒性, 能实现模型分割精度与参数量之间的权衡.首先, 构建自适应融合多层级特征模块, 选择性地突出不同层级特征的目标边界信息和目标主体信息, 增强边界判别能力.然后, 提出交互注意力融合模块(Inter-active Attention Fusion Module, IAFM), 设计行列分解空间注意力的通道注意力机制, 增强不同维度注意力间的信息交互能力, 聚焦判别性区域.最后, 提出基于候选边界的边界损失函数, 构建基于细节感知的边界知识蒸馏网络, 迁移复杂教师网络中的边界信息.交通场景数据集Cityscapes和CamVid上的实验表明, 本文算法能在实现轻量化的同时保持良好的分割性能, 并在处理小目标和细长条目标时具有一定优势.
知识蒸馏是现有深度学习模型压缩和知识迁移的重要技术之一, 其主要思想是将复杂教师模型中的知识进行压缩后迁移到轻量化的学生模型.根据教师模型是否与学生模型同步更新, 知识蒸馏可分为3类:离线蒸馏方式、在线蒸馏方式和自蒸馏方式[14].
离线蒸馏方式使用预先训练好的教师模型进行蒸馏.Hinton等[15]首次提出知识蒸馏, 利用预先训练好的教师模型生成的类别概率作为软目标训练学生模型.离线蒸馏方式简单、容易实现.
在线蒸馏方式的教师模型和学生模型同时训练更新, 整个知识蒸馏实现端到端训练.Zhang等[16]提出DML(Deep Mutual Learning), 让两个学生模型之间互相学习, 共同提高蒸馏效果, 并且扩展到多个学生模型互相学习的场景.共蒸馏方式是在线蒸馏方式的变体.Zhang等[17]提出ACNs(Adversarial Co-distillation Networks), 生成额外的发散性示例, 增强“ 暗知识” .
自蒸馏方式是将深层信息回传给浅层指导训练过程, 不需要其它教师模型的辅助.Hou等[18]提出SAD(Self Attention Distillation), 利用中间层注意力, 指导前一层向后一层的注意力传递知识.
基于知识蒸馏的语义分割的核心思想是将教师模型中像素之间的图像语义关系迁移给轻量化的学生模型.现有基于知识蒸馏的语义分割中知识的类型可分为基于关系知识的方法、基于特征知识的方法和基于响应知识的方法[14].
在基于关系知识的方法中, Yang等[10]提出CIRKD, 将全局像素相关性从教师网络转移到学生网络中进行语义分割.Liu等[19]提出AMTML-KD(Adaptive Multi-teacher Multi-level Knowledge Disti-llation Learning Framework), 将结构化知识从教师网络提取, 然后迁移到学生网络, 并使用相似性蒸馏和对抗训练蒸馏传递结构信息.上述方法主要是通过不同层、不同数据样本之间的关系构建教师网络.
在基于特征知识的方法中, Wang等[20]提出IFVD(Intra-class Feature Variation Distillation), 传递每个像素上的特征与其相应匹配类之间的相似性以实现蒸馏.基于特征知识的方法主要通过中间层的特征作为知识的载体, 为学生网络提供语义信息.
在基于响应知识的方法中, Feng等[21]利用两种互补的蒸馏方案设计DSD(Double Similarity Distillation), 分别在像素维度和类别维度上捕获相似知识, 提高现有紧凑网络的分类精度.Shu等[22]提出Channel-Wise Knowledge Distillation, 使用不对称的KL散度(Kullback-Leibler Divergence)最小化教师网络和学生网络之间的差异.上述方法主要是学生网络能学到教师网络的最终预测, 以达到和教师网络一样的预测性能.
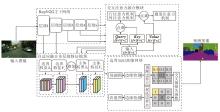
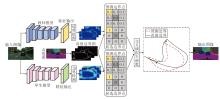
针对现有交通场景语义分割算法中存在的目标边界分割不平滑和模型参数量过大等问题, 本文提出边界感知引导多层级特征的知识蒸馏交通场景语义分割算法, 框架图如图1所示.算法主要由三部分组成:自适应融合多层级特征模块、交互注意力融合模块和边界知识蒸馏网络.
 | 图1 本文算法框架图Fig.1 Framework of the proposed algorithm |
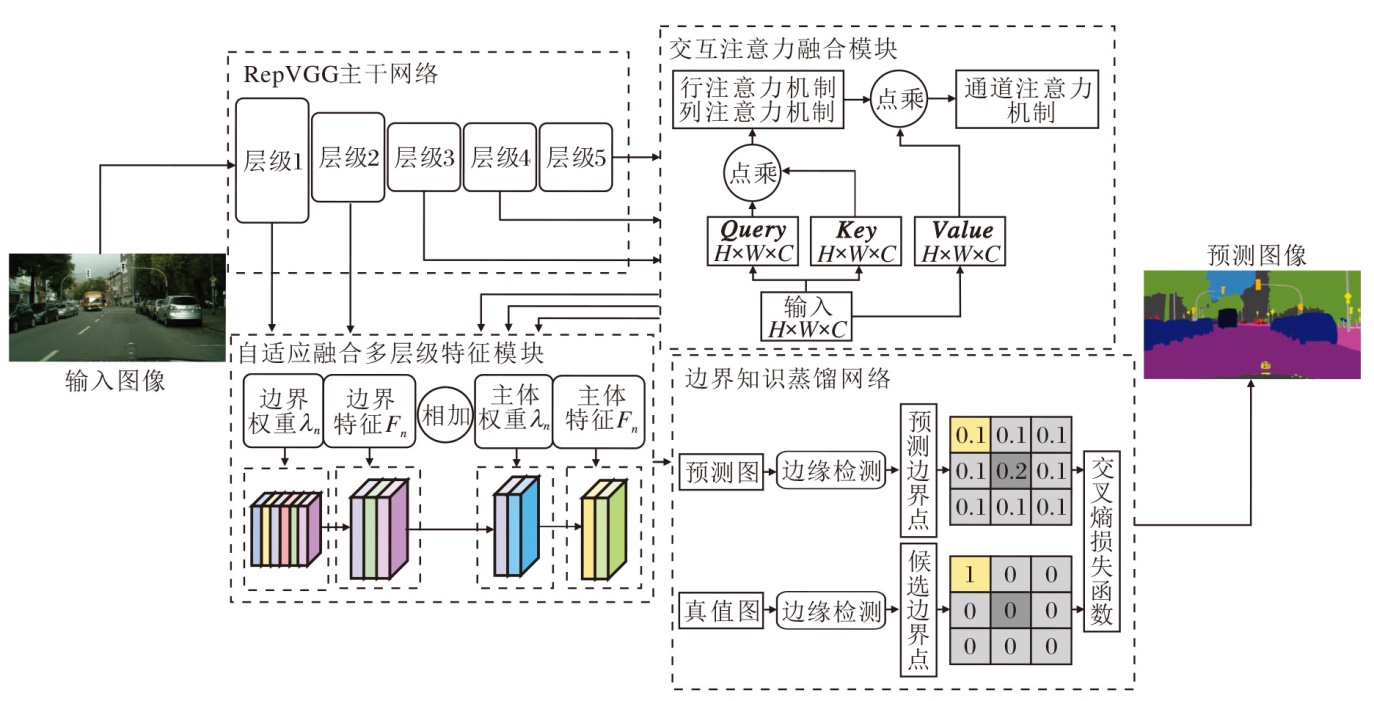
浅层神经网络更关注细节信息, 深层神经网络更关注语义信息, 二者的有效融合是精确分割的关键.现有交通场景语义分割算法常采用多尺度特征融合的方式提高分割精度.然而, 大多融合策略将多尺度语义信息视为同等重要, 并使用拼接和逐元素相加方式进行简单融合, 容易造成部分细节信息或语义信息的弱化.因此, 本文针对多层级特征, 设计自适应融合多层级特征模块, 选择性地突出细节信息和语义信息特征提取的优势, 具体结构图如图2所示.
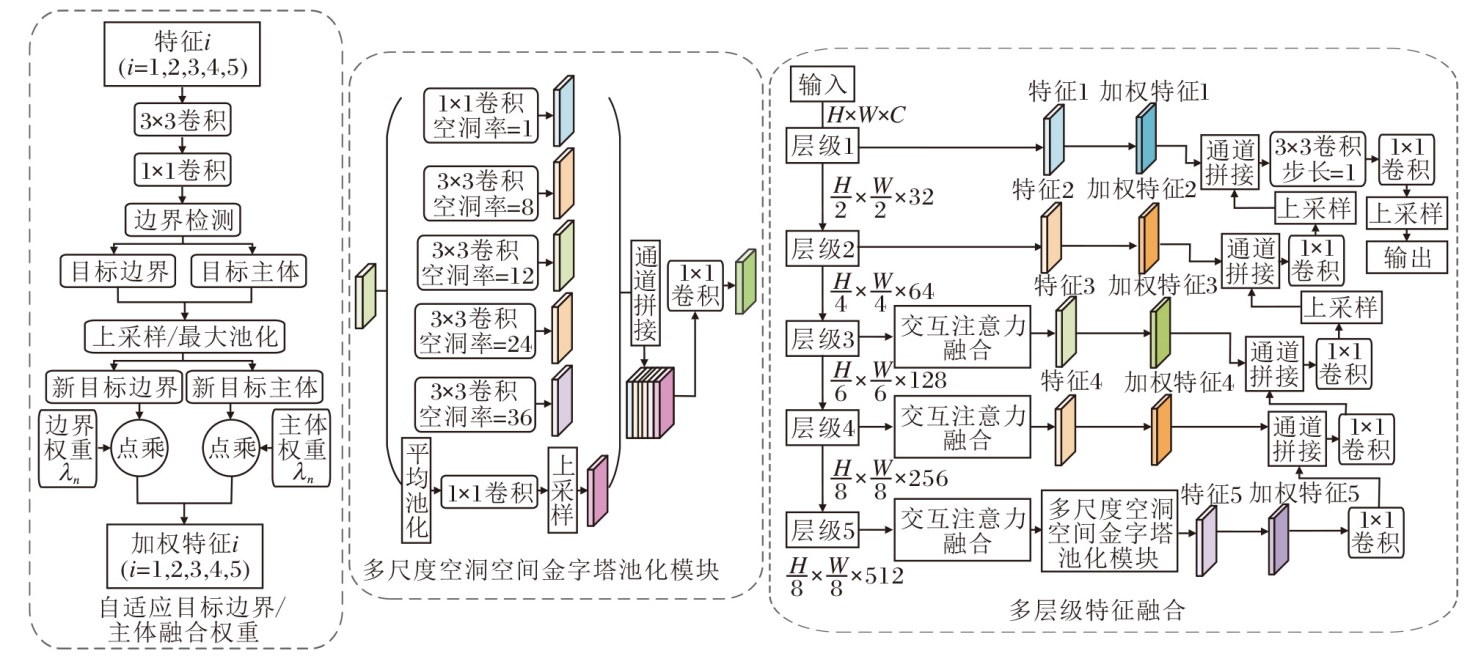 | 图2 基于边界特征的自适应融合多层级特征模块结构图Fig.2 Structure of adaptive fusion multi-level feature module based on boundary features |
首先, 图像边界等细节信息通常在具有更高尺度的浅层网络中得到更好的预测, 随着逐层逐级的卷积和池化操作, 特征分辨率降低, 图像特征具有越来越强的语义表达能力, 同时容易造成目标边界等空间信息的丢失.
为了防止在特征融合过程中浅层网络的细节信息及深层网络的语义信息被弱化, 本文针对每个阶段的特征图, 赋予目标主体和目标边界不同的权重.每个特征图都与其对应的权重参数矩阵相乘.stage1的输出特征F1∈
stage2~stage5的输出特征F1~F5处理过程同stage1.
然后, 设非目标边界点为目标主体像素i, 构成目标主体矩阵Body.对于Boundary及Body中的像素i:
Boundaryi=
其中:1表示该像素点预测结果为目标边界点, 0表示该像素点的预测结果为目标主体, 如果Bodyi用0表示, 则Boundaryi用1表示; N2表示像素i的2邻域, 偏移位置为{1, 0}, {0, 1}.
为了获得与各阶段特征空间维度相同的融合权重, 设计双线性插值、最大池化, 分别对Boundary和Body进行上采样、下采样, 得到New Boundary和New Body, 用于构建各阶段对应的目标主体矩阵和目标边界矩阵.
此外, 准确的边界识别对细节分割至关重要, 尤其在复杂的交通场景中.因此, New Boundary可提供更精确的目标边界信息, 提高分割精度, 特别是在边界模糊或细节丰富的区域.
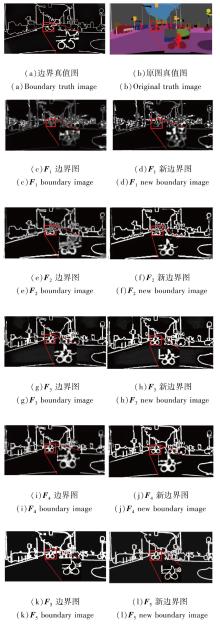
图3为F1~F5边界与新边界的可视化图.如图所示, F1~F2边界可保留丰富的细节纹理信息, 但语义类别预测结果很差, 而F3~F5边界保留大的语义边界, 但逐渐丢失小结构.经过双线性插值后, F1~F5的新边界使语义轮廓显著增强, 同时保持边界的连贯性, 减少伪影的出现.
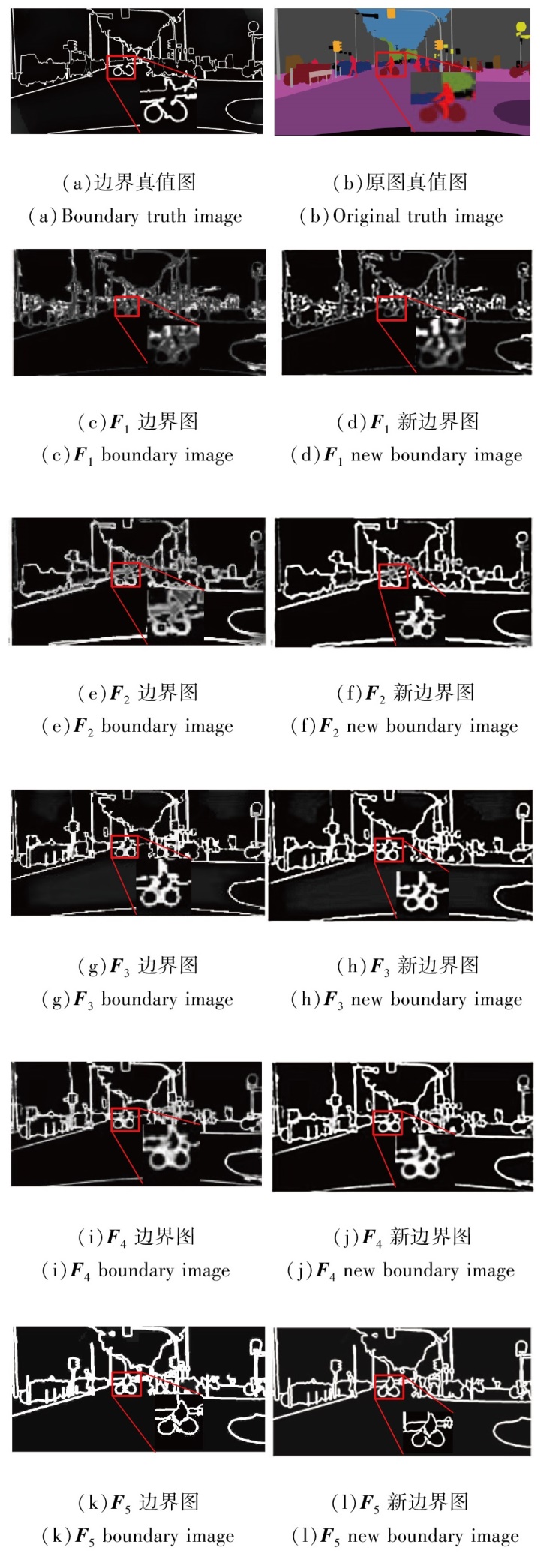 | 图3 F1~F5边界可视化对比Fig.3 Comparison of F1~F5 boundary visualization |
其次, 设各阶段目标边界像素点的融合权重为λ s, 目标主体像素点的融合权重为λ l, 自适应融合多层级特征对各阶段特征的加权计算方式如下, stage t输出特征对应的加权矩阵:
$\text { output }_{t}=\lambda_{s} \otimes \text { Boundary }_{t}+\lambda_{l} \otimes \text { Body }_{t} \in \mathbf{R}^{1 \times H \times W}, $
其中, λ s、λ l表示加权值, 为一维可学习参数.
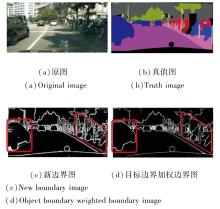
图4为新边界与边界像素点的权重融合生成的加权后的边界图.由图所示, 这一过程突出重要边界信息, 同时减少不重要边界信息或噪声边界的影响.例如, 经加权处理后, 汽车和摩托车的边界变得更平滑和连贯.
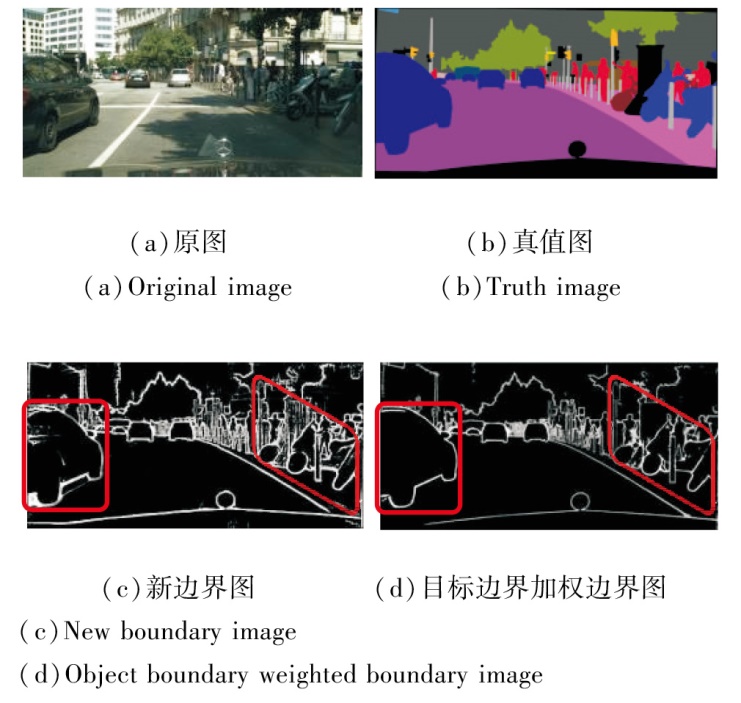 | 图4 目标边界融合权重前后对比Fig.4 Comparison of object boundary fusing weights before and after |
最后, 融合多层级语义特征, 并构建多尺度空洞空间金字塔池化(Multi-scale Atrous Spatial Pyramid Pooling, Ms-ASPP)模块.由于Ms-ASPP、stage3及stage4模块输出的高级特征拥有相同的空间维度, 故采用如下相同的方式逐阶段融合, stage1~stage5的通道位数依次为32, 64, 128, 256和512.为了逐阶段调整输出特征的通道数, 使其与上一阶段的输出特征通道数匹配, 使用1× 1卷积进行通道数调整.此外, 采用通道拼接方式用于融合两阶段高级语义特征.对融合后的高级语义特征, 双线性插值上采样的方式能确保融合低级语义特征stage1、stage2时拥有相同的分辨率大小, 其余融合策略均与高级语义特征相同, 从而逐级保留语义信息和细节信息.为了获得更准确的分割结果, 使用3× 3卷积细化特征融合产生的特征, 减小语义鸿沟, 并通过1× 1卷积将特征图的通道数减小为分割类别数, 双线性插值上采样的方式将特征图恢复到与模型输入相同的空间维度, 得到逐像素分类结果.
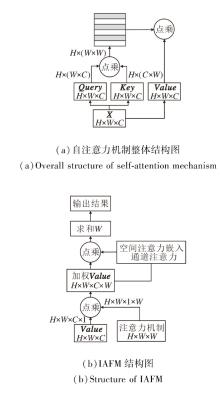
注意力机制通过加权特征增强卷积层的特征表示, 核心目标是捕获判别性信息, 抑制非判别性的信息.然而, 现有基于注意力机制的图像语义分割算法直接融合空间注意力和通道注意力, 容易造成不同维度之间的注意力冲突, 导致某些通道注意力在通道维度上具有较低的加权值.为此, 本节设计交互注意力融合模块(IAFM), 构建嵌入行、列空间注意力的通道注意力机制, 充分提取上下文信息的同时捕获更强的语义响应特征, 结构图如图5所示, (a)中自注意力机制的Value值作为(b)中交互注意力融合模块的输入之一.
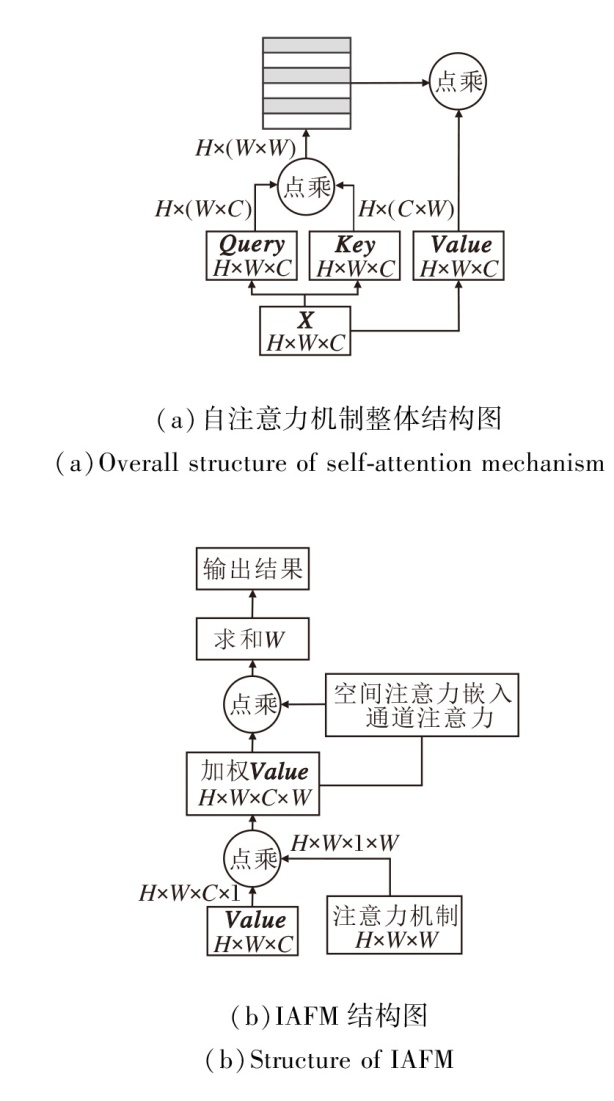 | 图5 基于导向分解的IAFM结构图Fig.5 IAFM Structure with guided decomposition |
首先, 在不压缩通道维度和不增加特征计算量的同时捕获全局空间信息, 并将空间自注意力机制分解为列注意力机制和行注意力机制.位于(i, j)的像素与位于(m, j)的像素之间的列相似性关系矩阵如下所示:
Acol(xi, j, xm, j)=softmaxm(θ (xi, j)Tθ (xm, j)), m∈ [H],
其中, H表示相似关系矩阵的行变量, θ (· )表示1× 1卷积运算, 用于对输入信息进行特征转换.位于(i, j)的像素与位于(i, n)的像素之间的行相似性关系矩阵:
Arow(xi, j, xi, n)=softmaxn(ϕ (xi, j)Tϕ (xi, n)), n∈ [W],
其中, W表示相似关系矩阵的列变量, ϕ (· )表示1× 1卷积运算, 用于对输入信息进行特征转换.
融合行列的空间注意力机制:
yi, j=
其中
α i, j, m, n=Acol(xi, j, xm, j)g(xm, n),
表示行注意力权重,
β i, j, n=Arow(xi, j, xi, n)
表示列注意力权重, α i, j, m, n、 β i, j, n用于提取通道关系的中间加权特征, g(xm, n)通过线性映射的方式将(m, n)位置的输入信号学习为新值.
其次, 分别基于行、列注意力权重矩阵计算嵌入通道注意力的空间注意力矩阵, 并融合嵌入通道注意力的行、列注意力权重矩阵, 即
$y_{i, j}=\sum_{\forall n} C_{\text {row }}\left(A_{\text {row }}\left(\boldsymbol{x}_{i, j}, \boldsymbol{x}_{i, n}\right)\left(\sum_{\forall m} C_{\text {col }}\left(\alpha_{i, j, m, n}\right)\right)\right), $
其中
$\begin{array}{l} C_{\mathrm{col}}\left(\alpha_{i, j, m, n}\right)= \\ \quad \text { sigmoid }\left(\operatorname{ReLU}\left(\frac{1}{H W} \sum_{\forall m, j}\left(\alpha_{i, j, m, n}\right) \omega_{c 1}\right) \omega_{c 2}\right) \alpha_{i, j, m, n}, \end{array}$
表示嵌入通道注意力的列注意力机制,
$\begin{array}{l} C_{\mathrm{row}}\left(\beta_{i, j, n}\right)= \\ \quad \operatorname{sigmoid}\left(\operatorname{ReLU}\left(\frac{1}{H W} \sum_{\forall i, n}\left(\beta_{i, j, n}\right) \omega_{r 1}\right) \omega_{r 2}\right) \beta_{i, j, n}, \end{array}$
表示嵌入通道注意力的行注意力机制, ω c1、ω c2、ω r1、ω r2表示通道注意力机制中的全连接层.
知识蒸馏是模型压缩的重要手段之一, 也是提升模型性能和精度的重要方法.现有基于知识蒸馏的图像语义分割算法忽略目标边界信息对预测结果的重要影响, 故本节构建基于细节感知的边界知识蒸馏网络, 确定学生网络合理的优化策略.网络主要包括候选边界和边界损失函数两个部分, 结构图如图6所示.
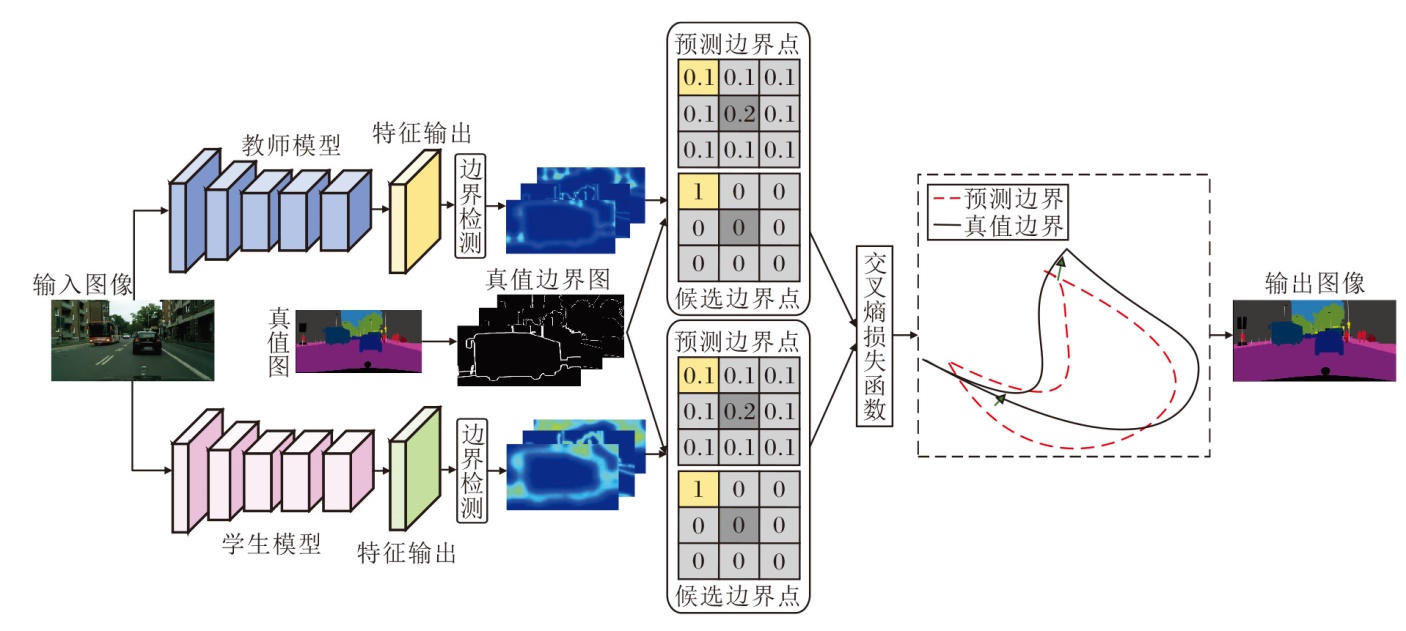 | 图6 基于细节感知的边界知识蒸馏网络结构图Fig.6 Structure of detail-aware boundary knowledge distillation network |
2.3.1 提取候选边界
首先, 使用类概率矩阵P∈ RC× H× W检测教师模型、学生模型及真值图的边界点, 其中, C表示分割类别数, H× W表示特征分辨率大小.边界检测方法采用式(1)所示的策略, 由此产生教师网络边界矩阵BoundaryT、学生网络边界矩阵BoundaryS和真值边界矩阵Boundary.然后, 对于BoundaryS上的像素i, 将以真值边界矩阵Boundary像素点i为中心的3× 3区域内像素j作为学生模型的候选边界点, 相比3× 3区域内其余像素, 像素j到BoundaryS中真值边界像素点的距离最小.BoundaryT与BoundaryS选取候选边界点过程一致.为了在边界损失中表示像素j的位置, 计算目标方向map:
其中
Δ ={{1, 0}, {-1, 0}, {0, -1}, {0, 1}, {-1, 1}, {1, 1}, {-1, -1}, {1, -1}}
Δ j表示第j个方向集合元素, M表示BoundaryT中非边界点到像素j的最小参数值, 作为下一个候选边界像素, 函数Φ (· )将索引j转换为one-hot向量.例如:如果j=1则
Φ (j)={0, 1, 0, 0, 0, 0, 0, 0}.
2.3.2 构建边界损失函数
首先, 将式(2)中的向量
其中, KL(Pi, Pi+Δ k)表示计算像素点i的预测值和像素点i+Δ k的预测值之间的KL散度.
然后, 为了增加像素点i、 j的类概率分布之间的KL散度, 同时减少像素点i和其余相邻像素之间的KL散度, 设计加权交叉熵损失函数作为边界损失函数:
BL=
其中:
Λ (x)=
表示将像素点i与真值边界像素点最近的距离作为权重, 以惩罚与真值边界像素点之间的偏差; Nb表示学生模型预测结果中边界像素点的数量; θ 表示设置为20的超参数; Mi表示原始边界像素点与候选边界像素点之间的距离, 如果Mi=0, 表示像素已在真值预测边界像素点上, 则该像素点不进行更新.
本文选择在交通场景数据集Cityscapes、CamVid上进行实验.
Cityscapes数据集是无人驾驶环境下的图像分割数据集, 包含50个城市的街道场景, 共5 000幅精细标注的道路交通场景图像.其中, 训练集包含2 975幅图像、验证集包含500幅图像、测试集包含1 525幅图像.为了提高模型的效率及增强模型的稳定性, 本文选取常用的19类进行分割评估, 并将训练集随机裁剪至768× 768进行训练.
CamVid数据集是由英国剑桥大学拍摄的汽车驾驶场景, 包含不同的场景和天气条件, 由701幅逐像素标注的图像组成.其中, 训练集、测试集、验证集分别包括367幅、233幅、101幅图像, 分辨率为960× 720, 分割类别有11类.本文采用随机裁剪为576× 576的训练集、验证集进行训练, 采用分辨率为576× 768的测试集评估算法性能.
为了更好地评估算法性能, 采用像素准确率(Pixel Accuracy, PA)、交并比(Intersection over Union, IoU)、平均交并比(Mean IoU, mIoU)、模型参数量、FLOG(Floating Point Operations per Second)这5个评价指标.
像素准确率(PA)表示正确分类的像素点数量与像素点总和的比值, 计算公式如下:
PA=
平均交并比(mIoU)表示各类别预测分割区域和真实分割区域间交集与并集比值的平均值, 是图像语义分割领域的标准性能衡量指标, 计算公式如下:
mIoU=
其中, k+1表示图像类别总数, Pii表示真实标签i被预测为i类的像素数量, Pij表示真实标签i被错误预测为j类的像素数量.
实验参数配置如下:64bit-Ubuntu20.04的操作系统、10 GB GeForce RTX 2080 Ti的显卡(GPU)、Pytorch 1.7.1的深度学习框架和Python 3.8数据处理.
网络架构设置如下.使用RepVGG-B1作为教师模型的骨干网络, 使用RepVGG-A1[23]作为学生模型的骨干网络.在stage3~stage5中引入非比例式串行空洞卷积, 且各阶段第1个卷积步长设为1, 用于保持stage4、stage5的特征输出为输入图像的1/8.引入Ms-ASPP模块, 对应于教师网络和学生网络的模型大小进行构建, 用于在stage5之后提取多层级特征.交互注意力融合模块(IAFM)的输入为stage3、stage4、Ms-ASPP模块的输出特征, 边界损失函数用于教师网络和学生网络输出结果之间的知识迁移.
在训练过程中, 本文算法教师网络和学生网络的编码结构均使用经过ImageNet预训练的网络权重进行参数初始化.解码结构根据不同的网络层使用不同的初始化方式.其中, 卷积模块使用He等[24]的初始化方式, 批归一化层使用常数初始化方式, 训练过程中的优化器采用随机梯度下降(Stochastic Gradient Descent, SGD), 初始学习率设为0.007 5, 学习率均采用poly方式进行动态调整, 动量设为0.9, 权重衰减设为10-4, 批次大小设为6, 最大迭代次数设为110 000.
3.3.1 自适应融合多层级特征模块
为了验证不同特征融合方式对算法性能的影响, 设计如下3组基本特征融合方式:加法(Addi-tion)、拼接(Concatenate)和FFM(Feature Fusion Mo-dule)[25], 并结合加权、上采样和池化等技术进行对比分析.
固定加权融合表示对stage1的特征图进行边界检测, 获取目标边界矩阵, 进而手动设置特征融合时各阶段目标主体和目标边界的加权值, stage1~stage5的目标边界加权值为
(0.6, 0.5, 0.4, 0.3, 0.2),
目标主体加权值为
(0.2, 0.3, 0.4, 0.5, 0.6),
将5个阶段的特征直接上采样到与输入图像相同的大小进行加权并通过加法或拼接的方式进行特征融合.
与固定加权融合的方式不同, 逐级融合通过最大池化的方式将融合权重下采样到与对应特征相同的尺度大小, 然后对对应特征进行加权, 进而采用跳跃连接的方式逐级融合stage5、stage4、stage3、stage2和stage1的特征.
与逐级融合的方式不同, 自适应加权逐级融合动态调整各阶段特征的权重.此外, 自适应加权逐级融合为本文的自适应融合多层级特征方式.
不同特征融合方式在Cityscapes数据集上的性能对比如表1所示, 表中黑体数字表示最优值.由表可见, 自适应加权逐级融合方式具有最高的PA值和mIoU值.对比三组融合方式发现, FFM在处理浅层特征时表现较优, 但在融合多层级特征时效果不佳.对比固定加权融合与逐级融合发现, 逐级融合的分割准确率更高, 表明逐级融合不同层级特征更有利于选择性地突出细节信息和语义信息.对比拼接和加法逐级融合方式发现, 拼接的逐级融合方式mIoU值更高, 表明本文算法更适用于逐级融合拼接方式.对比逐级融合和自适应加权逐级融合发现, 自适应加权目标边界和目标主体的权重在进行逐级融合时提升算法性能, 表明浅层网络对于细节信息的提取能力更强, 深层网络对语义信息的提取能力更强, 这验证自适应融合多层级特征模块的有效性.
| 表1 不同特征融合方式在Cityscapes数据集上的性能对比 Table 1 Performance comparison of different feature fusion methods on Cityscapes dataset |
3.3.2 交互注意力融合模块
为了验证交互注意力融合模块(IAFM)对算法性能的影响, 设计如下9组注意力机制对比实验:通道注意力机制(Channel Attention Mechanism, CAM)、通道注意力机制的行注意力机制(Channel Row Attention Mechanism, C-RAM)、通道注意力机制的列注意力机制(Channel Column Attention Mechanism, C-CAM)、空间自注意力机制(Spatial Self-Attention Mechanism, SSAM)、空间自注意力机制分解为行注意力机制(Row Attention Mechanism, SS-CAM)、空间自注意力机制分解为列注意力机制(Column Atten-tion Mechanism, SS-RAM)、SS-RAM+C-RAM、SS-CAM+C-CAM、融合通道和空间的双注意力机制(Channel Attention-Spatial Attention, CA-SA)[26].此外, 还选择DANet[7]和IAFM进行对比.
表2为不同注意力机制在Cityscapes数据集上的性能对比, 表中黑体数字表示最优值.由表可知, IAFM取得最优PA值和mIoU值, 表明基于行、列注意力嵌入通道注意力的空间注意力可有效提高算法精度.CA-SA参数量最少, 表明基于卷积构建的双注意力机制可减少参数量.此外, SS-RAM+C-RAM和SS-CAM+C-CAM分别在CAM和SSAM的基础上提高分割精度, 表明行、列注意力机制嵌入通道注意力的空间注意力可增强捕捉空间维度上关键信息的能力.
| 表2 不同注意力机制在Cityscapes数据集上的性能对比 Table 2 Performance comparison of different attention mechanisms on Cityscapes dataset |
综上所述, IAFM能减少通道注意力机制和空间注意力机制之间的冲突, 有效提升分割精度.
3.3.3 边界知识蒸馏网络
为了验证边界信息知识蒸馏网络对算法性能的影响, 设计经过预训练的教师网络(简记为Teacher)、经过预训练的学生网络(简记为Student)、经过边界知识蒸馏网络训练的学生网络(简记为EKD-Student).各网络在Cityscapes数据集上的性能对比如表3所示, 表中黑体数字表示最优值.由表可知, Teacher表明复杂的教师网络具有较大的参数量及较高的分割准确率.对比Student和EKD-Student可知, 相比通过真值标签进行反向传播的训练方式, EKD-Student构建基于细节感知的边界知识蒸馏, 将边界信息从教师网络迁移至学生网络, 能有效提升分割精度, 并且避免参数量对于资源的大量消耗.
| 表3 各网络在Cityscapes数据集上的性能对比 Table 3 Performance comparison of different networks on Cityscapes dataset |
为了进一步验证本文算法的有效性和泛化性, 选择如下算法进行对比:CIRCK[10]、BiSeNet(Bila-teral Segmentation Network)[25]、SegNet[27]、PSPNet(Pyramid Scene Parsing Network)[28]、PSPNet+Knowledge Distillation(PSPNet+KD)、ICNet(Image Cascade Network)[29]、SwiftNet[30]、DeepLabv3+[31]、LCFNet[32]、CSKD(Channel-Spatial Knowledge Distillation)[33]、FPANet(Feature Pyramid Aggregation Network)[34].此外设计Student, 表示融合RepVGG-A1[23]与文中自适应融合多层级特征模块的学生网络, 进行定性分析.
PSPNet+KD、CIRKD、CSKD和Student为知识蒸馏网络; SegNet、PSPNet和DeepLabv3+为编码-解码网络; ICNet、SwiftNet、BiSeNet、LCTNet、FPANet为实时性语义分割网络.
3.4.1 定量分析
为了定量验证本文算法的有效性, 在CamVid数据集上与对比算法进行性能对比, 结果如表4所示, 表中黑体数字表示最优值.
| 表4 各算法在CamVid数据集上的IoU值对比 Table 4 IoU value comparison of different algorithms on CamVid dataset % |
由表4可知, 本文算法在8种类别上获得最佳IoU值, 特别是在signsymbol、pole和fence等细长条目标上的分割效果最佳.尽管本文算法取得最高的PA值和mIoU值, 但是sky和building等大目标分割效果仍待提高.此外, LCFNet实现最佳的模型参数量和计算复杂度, 这反映出由膨胀卷积和深度可分离卷积组成的扩张瓶颈模块有助于获得更低的复杂度和更少的模型参数量.
各算法在Cityscapes数据集上11种类别的性能对比如表5所示, 表中黑体数字表示最优值.
| 表5 各算法在Cityspaces数据集上的IoU值对比 Table 5 IoU value comparison of different algorithms on Cityspaces dataset % |
由表5可知, 在Cityscapes数据集上, 本文算法获得最高的PA值和mIoU值, 对于19种类别中的12类别获得最高IoU值, 特别是在traffic light、traffic sign、bicycle等小目标上的分割效果最佳.这归因于本文算法更关注浅层网络细节信息和深层网络语义信息的融合, 从而显著提升小目标的精确分割.此外, 本文算法针对像road、building、sky、terrain等大目标中的road、building的分割效果在一定程度上也得到提高, 但对于terrain和sky的分割效果没有达到最佳.原因在于terrain和sky的细节信息较少, 使得1× 1卷积对这些区域的感知能力较弱, 从而导致自适应融合多层级特征模块难以捕捉关键特征.此外, 加权交叉熵损失函数主要关注边界点, 忽视区域的连续性, 进而影响分割精度.
3.4.2 定性分析
为了直观验证本文算法的有效性, 将本文算法与经典算法在Cityscapes、CamVid数据集上进行定性分析, 结果如图7和图8所示.
 | 图7 各算法在Cityscapes数据集上的分割结果Fig.7 Segmentation results of different algorithms on Cityscapes dataset |
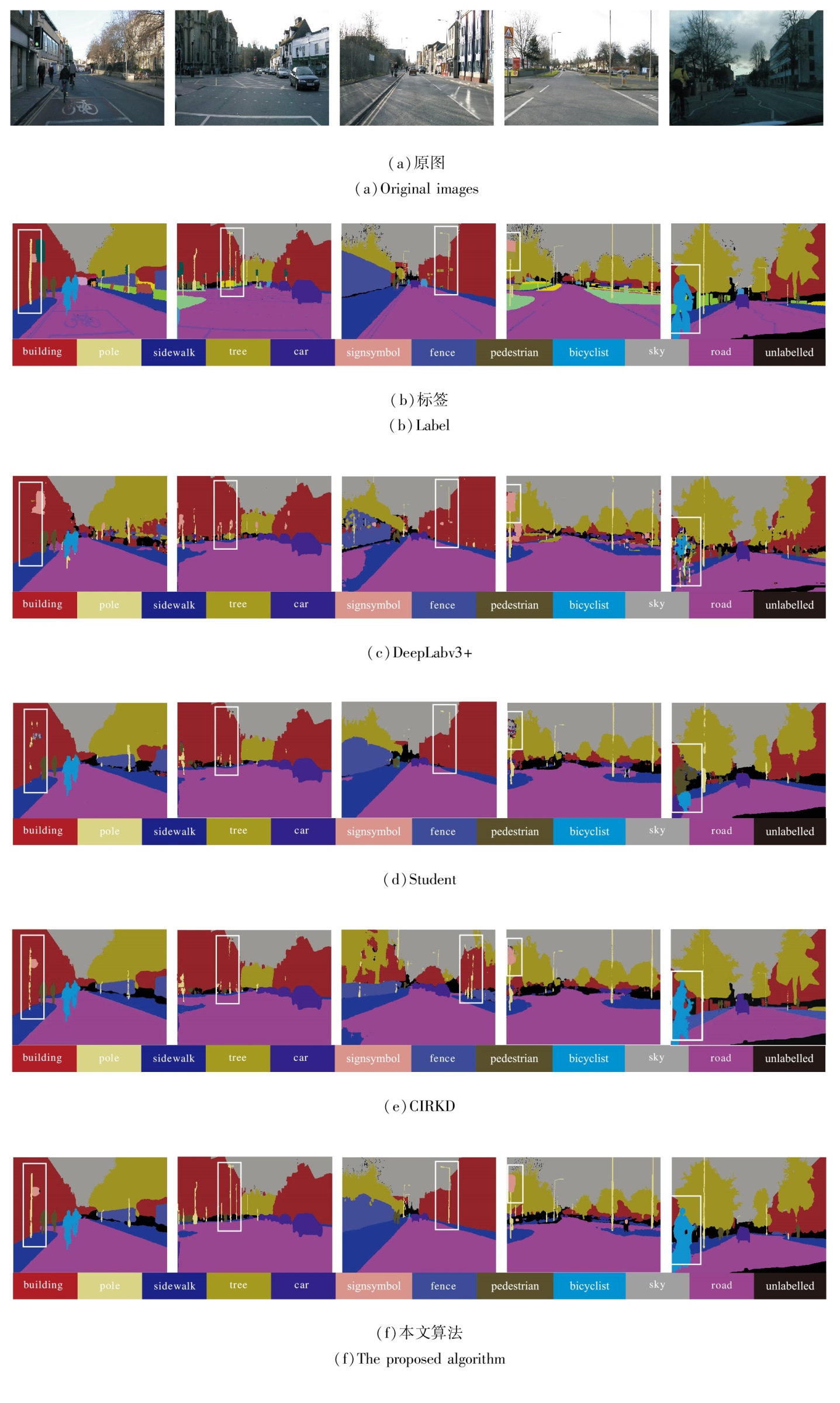 | 图8 各算法在CamVid数据集上的分割结果Fig.8 Segmentation results of different algorithms on CamVid dataset |
由图7和图8可知, 本文算法在分割小目标和细长条形目标方面具有显著优势, 这归因于算法选择性地突出目标主体和目标边界信息, 实现对小目标和细长条形目标的精确分割.其次, 本文算法在分割边界方面更清晰平滑, 与真值标签更接近, 特别是对于小目标和细长条形目标, 表明基于细节感知的边界知识蒸馏网络可减少边界信息丢失.
此外, 本文算法分割区域更完整, 表明交互注意力融合模块中嵌入通道注意力的空间注意力机制能捕获长距离依赖关系.综上分析, 本文算法能有效优化小目标和目标边界的分割效果, 提升图像语义分割性能.
为了解决交通场景语义分割算法中存在的目标边界分割不平滑和模型参数量过大等问题, 本文提出边界感知引导多层级特征的知识蒸馏交通场景语义分割算法, 能改善交通场景目标边界信息丢失的问题, 权衡模型的分割精度和参数量.交通场景数据集Cityscapes和CamVid上的实验表明, 自适应融合多层级特征模块能发挥各阶段网络的特征提取优势, 融合不同层级的特征信息, 实现低级细节信息与高级语义信息的高效聚合.交互注意力融合模块中嵌入通道的空间注意力能更好地捕获长距离依赖关系.边界知识蒸馏网络能提高轻量化模型的细节边界分割准确率.最终, 本文算法能以较少的参数量获得平滑的目标边界.今后将考虑引入无监督学习方法或半监督学习方法, 减少对大量标注数据的依赖, 从而在数据受限的条件下提升算法性能.
本文责任编委 封举富
Recommended by Associate Editor FENG Jufu
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|