

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
结合深度伪造特征对比的人脸伪造检测
[李兆威1  , 高欣健
, 高欣健1 , 笪子凯1 , 高隽1 ]
, 高欣健, 笪子凯, 高隽]
|
|



作者简介: 
高 隽,博士,教授,主要研究方向为图像处理、模式识别、神经网络理论及应用、光电信息处理、智能信息处理等.E-mail:gaojun@hfut.edu.cn. 
笪子凯,博士研究生,主要研究方向为图像处理、深度学习、人工智能、机器学习等.E-mail:zikaidaw@gmail.com. 
李兆威,硕士研究生,主要研究方向为人脸伪造检测、计算机视觉、图形处理.E-mail:18605685990@163.com.
随着AIGC(Artificial Intelligence-Generated Content)技术的不断发展,其伪造技术的多样性对现有检测方法发起巨大的挑战.现有大部分的检测方法是基于各种先进的卷积神经网络提取的人脸伪造特征进行检测,泛化能力不足以解决未知方法伪造的图像鉴伪.因此文中提出结合深度伪造特征对比的人脸伪造检测方法,对未知的伪造技术具有较好的适应能力.方法分为两个阶段:一方面挖掘不同伪造手段的相似特征,提出基于元学习的相似特征融合网络,利用元学习的学习能力获取不同伪造手法之间的相似性特征;另一方面结合具体任务下的独特伪造特征,提出具体任务下的独特性微调方法,提高模型对未知伪造方法的适应能力.在跨伪造手法和跨库测试上实验表明文中方法性能有所提升,在面对未知手段攻击时具有较优的检测能力.
About Author:
GAO Jun, Ph.D., professor. His research interests include image processing, pattern recognition, neural network theory and applications, optoelectronic information processing and intelligent information proce-ssing.
DA Zikai, Ph.D. candidate. His research interests include image processing, deep lear-ning, artificial intelligence and machine lear-ning.
LI Zhaowei, Master student. His research interests include face forgery detection, computer vision and graphic processing.
With the continuous development of artificial intelligence-generated content technology, the diversity of forgery techniques presents significant challenges to existing detection methods. Most current detection methods are based on facial forgery features extracted by different advanced convolutional neural networks. However, these methods are trained on datasets containing known forgery techniques, and their generalization capabilities are inadequate to handle images forged by unknown methods. Therefore, a face forgery detection method combined with deep forgery features comparison is proposed, and it exhibits excellent adaptability to unknown forgery techniques. The proposed approach consists of two stages. First, similar features of different forgery techniques are explored, and a meta-learning-based similar feature fusion network is introduced. This network leverages the learning capabilities of meta-learning to capture the similar features among different forgery methods. Second, unique forgery features specific to individual task are taken into account, and a task-specific uniqueness fine-tuning method is proposed to enhance the adaptability of the model to unknown forgery techniques.Cross-manipulation testing demonstrates that the proposed method improves the performance with superior detection capability against attacks from unknown forgery techniques.
人脸伪造技术结合语音合成和音色转换技术, 可生成高质量的实时伪造视频, 甚至人眼都难以辨别真假, 这使得人脸伪造技术被恶意用户滥用, 引发各类安全事件.现如今, 人脸伪造检测成为一个引人关注的热点, 大多数现有的检测器都是针对已知伪造技术设计的检测算法, 捕捉人脸伪造图像因伪造技术缺陷而存在的伪造痕迹, 例如:生成对抗网络(Generative Adversarial Network, GAN)[1]生成的人脸图像往往会丢失面部细节, 变分编码器(Varia-tional Autoencoders, VAE)[2]会造成人脸图像的失真和模糊, 这都有助于鉴伪任务.
目前, 研究人员专注于人脸伪造图像的特征提取, 将人脸图像输入一个强大的骨干网络, 提取伪造特征(空间特征、频率特征及生物特征等), 最后在分类器中区分图像的真伪.Li等[3]提出FDFL(Fre-quency-Aware Discriminative Feature Learning Frame-work), 以人脸伪造图像的频率特征为线索, 设计AFFGM(Adaptive Frequency Feature Generation Mo-dule), 挖掘更深入的频率信息, 并利用单中心损失函数鼓励类内紧凑性和类间可分性, 更好地分离真伪图像.朱新同等[4]提出基于YCbCr网络的双通道图像篡改检测模型, 结合色彩空间Cb和Cr通道的一阶梯度边缘纹理图像(通过Scharr算子提取)以及G通道的二阶梯度边缘纹理图像(通过Laplacian算子提取), 并利用灰度共生矩阵融合和提取图像的纹理特征, 证明空间特征对检测人脸伪造图像的重要性.Zhao等[5]认为大多数伪造检测建模为一个普通的二值分类问题, 但真实图像和虚假图像之间的差异通常是微妙的和局部的, 需要把深度造假检测当成细粒度问题研究.上述检测器往往只围绕单方面的伪造特征进行检测, 性能最优的检测手段通常只在训练和测试的伪造数据集是使用相同伪造手段的库内测试中表现良好, 在未知伪造手段的跨库测试中表现较差.
研究表明, 不同伪造技术在伪造痕迹上表现出不同方面的特征.Nguyen等[6]认为人脸伪造检测一个重要的问题是伪造区域的定位, 提出使用辅助任务(语义分割和图像重构)帮助检测器完成人脸伪造图像的真伪鉴别, 这些任务(分类、分割和重构)中获得的信息是共享的, 可提高方法的整体性能, 多角度挖掘人脸伪造痕迹特征.Chen等[7]认为“ 可泛化的表示应该对各种类型的伪造图像具有敏感性” , 提出基于自监督学习的对抗训练方法, 提高检测器的泛化能力, 使用生成器生成丰富的伪造图像, 作为鉴别器的输入, 使模型具有更强的鲁棒性.Huang等[8]注意到基于自监督的检测方法泛化能力优于监督方法, 但大多数的自监督方法未考虑合成伪造样本的操纵强度水平, 导致检测性能不理想.因此可根据样本生成过程中的不同合成子任务, 推断其适合的合成参数, 引入几种辅助损失.这些泛化模型都较好地解决之前检测器对伪造手段不敏感的问题.但是, 此类模型都是针对GAN和VAE生成伪造图像可能存在的缺陷设计的, 对于未知伪造技术生成的、无足够标记数据的伪造图像的检测能力依然很差.Lin等[9]也注意到上述方法只擅长检测已知的伪造技术, 因此采用元学习的方法训练一个自适应的检测器, 完成对新伪造技术的检测, 但依赖于小样本数据, 当检测任务与训练样本分布距离较大时, 难以有效检测.
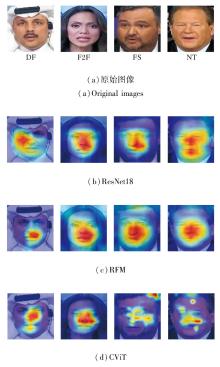
通过对多个主流的检测方法[10, 11, 12, 13, 14, 15, 16]的分析发现:对于不同的伪造图像, 不同的检测方法(基于频率的检测方法、基于空间特征的检测方法)都可以从中检测到相似的伪造区域, 因此其中必然存在类似的内部表示, 通过Grad-CAM(Gradient-Weighted Class Activation Mapping)[17]观察到的结果启发本文学习不同伪造手法生成伪造图像的相似特征, 这些相似特征可适用于未知的伪造图像, 并且帮助方法挖掘具体任务下的独特特征.
基于上述思考, 为了提高在任意未知方法伪造样本下的泛化能力, 本文提出结合深度伪造特征对比的人脸伪造检测方法, 首先, 设计基于元学习的相似特征融合网络, 将已知的不同伪造技术生成的人脸伪造图像检测当成一个学习任务, 通过对不同任务中的伪造图像进行度量学习, 缩减不同伪造图像之间的距离, 在特征提取的过程中保留不同伪造图像之间的相似特征向量.然而仅依靠这个良好的相似性表征并不足以完成人脸伪造检测任务, 这也揭示鉴伪任务中的另一个关键问题— — 检测器对未知方法生成伪造图像的可转移能力.为了解决这个问题, 本文在具体任务上进行独特性微调, 通过基于元学习的特征挖掘网络, 利用少量标记数据, 在相似性特征的指导下获取残差特征, 挖掘针对具体任务的独特伪造特征.为了验证本文方法对未知伪造技术生成的人脸伪造图像的有效性, 不仅在现有的Face-Forensics++[18]、Celeb-DF[19]数据集上进行大量实验, 而且使用基于扩散模型的DiffSwap[20]生成的伪造数据集DiffSwap检测未知伪造手段, 测试方法的可转移能力.
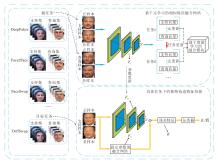
本文提出结合深度伪造特征对比的人脸伪造检
测方法, 流程图如图1所示.本文方法的架构包括两个部分:
1)基于元学习的相似特征融合网络, 旨在学习不同伪造手段之间的相似性特征;
2)具体任务下的独特伪造特征挖掘, 旨在学习不同伪造技术的可区分特征.
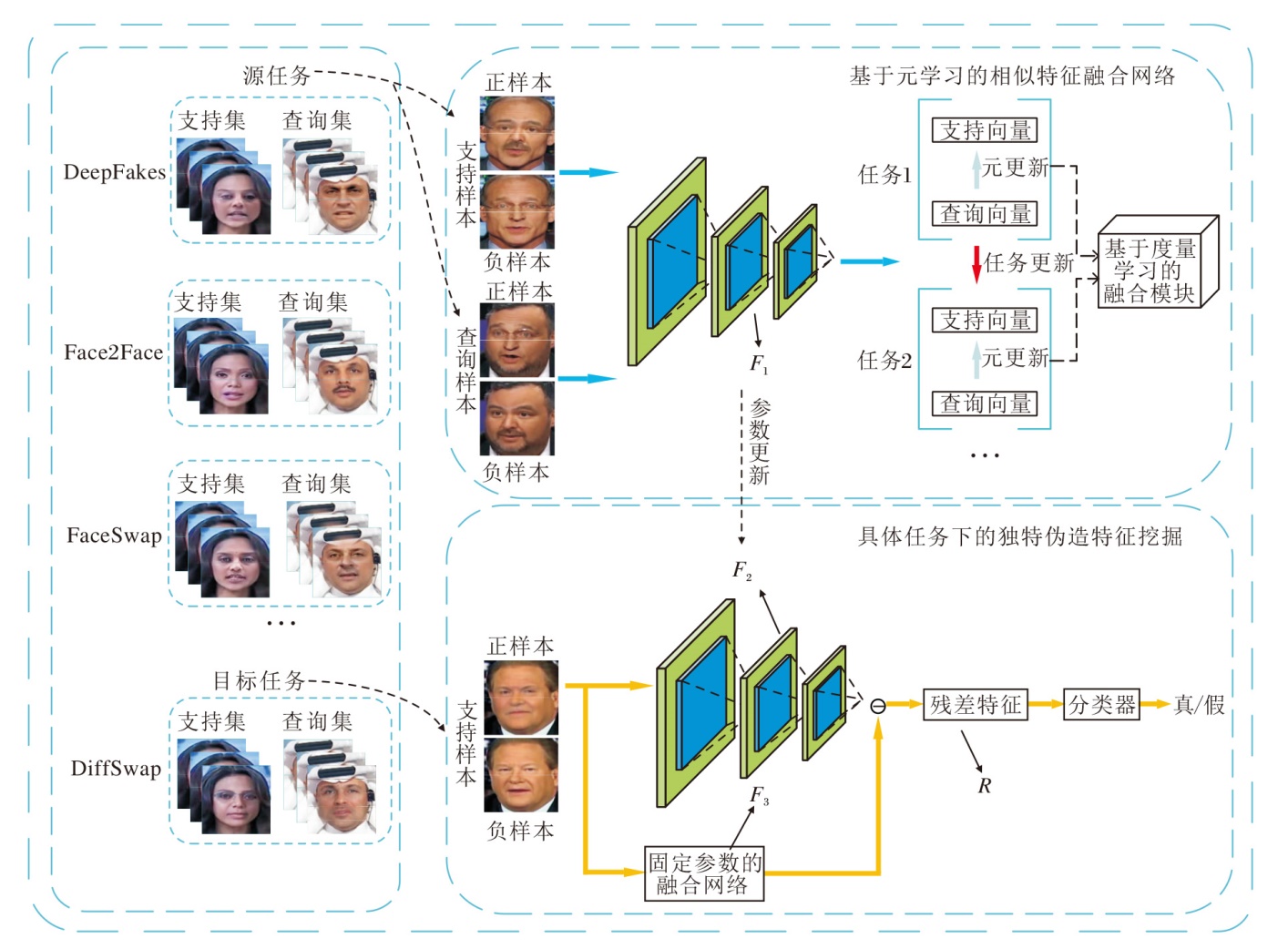 | 图1 本文方法流程图Fig.1 Flowchart of the proposed algorithm |
本文方法旨在解决未知方法生成的伪造图像的检测任务, 这得益于元学习[21, 22, 23]对跨任务的适应性.在机器学习中, 使用具体任务的大量数据训练模型, 当任务改变时, 模型需要重新训练.而不同于一般的机器学习, 元学习又称为学会学习, 可在已有经验上快速学习新的任务, 旨在任务层面而非数据层面进行学习.
基于元学习的方法分元训练和元测试这两个阶段处理少样本分类.在元训练阶段, 数据集D划分多个特定任务Γ i~p(Γ )的子数据集, 其中, p(Γ )表示任务分布, 所有任务均遵循n-way k-shot问题(每个任务包含n类, 每类只有k个标记数据).一个分类任务Γ i可表示为包含支持集和查询集的子数据集, 支持集用于训练模型, 查询集用于评估模型.在元测试阶段, 支持集是少量标记数据, 查询集是要测试的数据, 模型在新任务上进行测试.
值得注意的是, 本文元学习问题的构建区别于传统方法, 本文是学习不同伪造手法之间的相似性特征.具体来说, 本文设置N个源任务
Ts∈ {T1, T2, …, TN}, N> 1
和目标任务Tt.每个源任务Ts={(xn, yn)}为由一种伪造手段生成的伪造图像和真实图像构成, xn表示图像的特征向量, yn表示对应的标签.N个源任务是N个不同伪造手法与对应真实图像的组合.在元训练阶段的一个批次中, 元学习监督N个源任务的学习情况.在元测试阶段, 经过训练的模型在未知伪造方法的目标任务Tt上先通过少量标记的具体任务图像的自适应微调后测试.
本文利用元学习学习不同伪造手段之间的共同特征, 以便学到的模型可快速适应目标任务.内部表示的构建可优化特征提取器, 获得满足鉴别真伪图像的模型.在充分训练后, 特征提取器可从大量的非目标任务中学到适用于鉴别伪造图像和真实图像的最佳初始化参数.
具体地, 在训练中将每个源任务中的样本分成支持集和查询集, 都是从源任务Ts中随机采样得到, 均包含伪造样本和真实样本.同时考虑一个由参数向量化的模型表示的函数:
F1=f(θ ).
该模型被训练能适应大部分的目标任务, 当适应一个新任务时, 模型参数变为θ 'i.
更新参数θ 的整个过程分为内层循环阶段和外层循环阶段, 在内层循环中, 从源任务Ts中抽取一个任务Ti, 使用来自Ti的k个样本(支持集)和反馈损失值Lsi训练模型.第i个源任务Ti在支持集上取得的分类损失如下:
Lsi=-
同时梯度下降R步更新模型参数θ , 当前任务Ti取得的最优参数为:
θ 'i=θ -α
其中超参数α 表示内层循环学习率.
然后通过来自Ti的k个新样本(查询集)进行验证.根据式(1)得到在查询集上的反馈损失值Lqi, 表示第i个源任务Ti在查询集上取得的交叉熵损失.
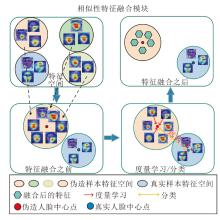
实际上, 本文的目标是找到对任务变化敏感的模型参数, 使参数的微小变化在任务的损失函数上产生很大的改进.因为softmax损失只关注找到分离不同类别的决策边界, 而不能提取伪造图像的相似特征并聚合, 而度量学习往往能不断压缩相同标签特征空间的伪造人脸.所以对相同标签的伪造图像中引入中心损失, 是为了学到对源任务中所有任务普遍适用的相似性特征, 这一过程称为不同伪造手段之间的相似性特征融合, 具体过程如图2所示.
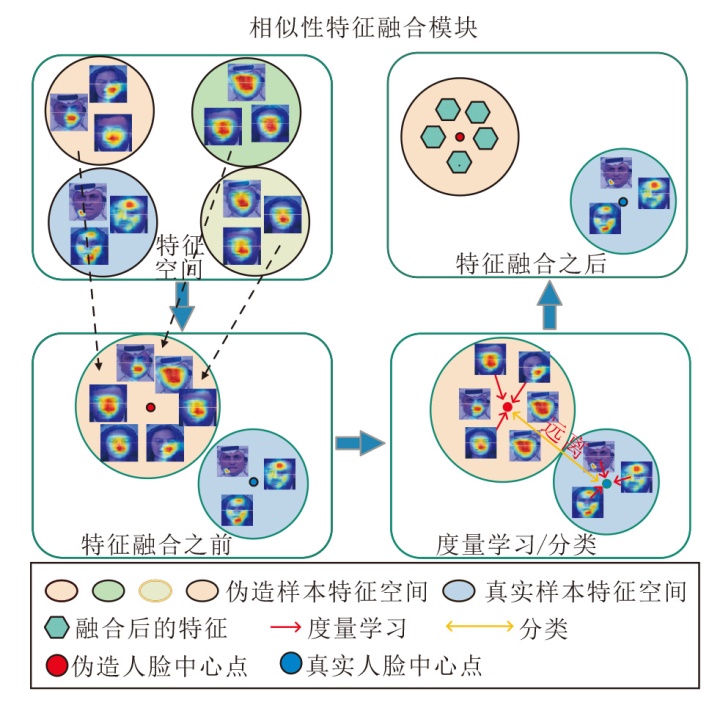 | 图2 不同伪造图像的特征向量相似特征融合过程Fig.2 Process of similar features fusion for different forged image vectors |
度量学习的目的是最小化不同伪造手法生成的伪造图像到中心点的距离, 在内层循环的源任务中, 模型f(θ 'i)提取第i个源任务伪造图像的卷积层特征向量记为Di, 同时设置C为伪造人脸的中心点, 不同伪造图像的特征都会不断靠近中心点, 当一个批次的内层循环结束时更新参数C, 计算当前源任务Ti的平均中心损失:
lci=
基于度量学习的融合模块通过设置伪造人脸中心点以监督元任务更新过程, 使得在外层循环的元更新迭代过程中每个任务学到的伪造图像特征不断靠近中心点, 而相似特征融合网络获取的不同伪造图像的特征都较好地反映网络学到不同源任务之间相似的标志性特征.
在任务更新结束后, 计算所有源任务Ts在元学习外层循环阶段的交叉熵损失LCE与中心损失LML.一方面采用中心损失, 是为了让不同伪造技术产生的伪造图像聚集在一个中心点位置, 另一方面交叉熵损失使伪造图像的特征远离真实图像.就此得到测试阶段的损失值:
Ltest=
其中, λ 表示超参数, 连接中心损失和交叉熵损失, 决定真实图像与伪造图像决策边界的宽度.
此时, 一个批次中所有源任务Ts完成元训练的过程, 模型参数需要在外层循环中进行全面更新.现在计算相对于这些最优参数θ 'i的梯度, 使模型参数调整到一个最佳位置.外层循环更新的目标为:
$\begin{array}{l} \min _{\theta} L_{\mathrm{test}}, \\ \theta=\theta_{N}^{\prime}-\beta \nabla_{\theta_{N}^{\prime}} L_{\mathrm{test}} \end{array}$
其中, θ 'N表示内层循环结束后的模型参数, 超参数β 表示外层循环学习率, 对模型的性能敏感程度不高, 因此, 将元学习率β 设定为一个常数值.
总之, 基于元学习的相似特征融合网络中, 元学习在每个源任务的元更新过程中学习不同伪造技术的伪造痕迹, 并且在元任务更新时学习的知识逐渐适应下一个任务.而基于度量学习的融合模块设置伪造人脸中心点, 监督元任务的更新过程.在外层循环的元更新迭代过程中, 伪造图像特征逐渐靠近这些中心点, 实现相似特征的融合.
基于相似性的特征融合网络训练后获取不同伪造图像中的相似性特征, 然而良好的相似性表征可能在检测其对应的伪造方法时表现良好, 但在给定数据集上过拟合, 并且具有不理想的泛化能力.因此, 借助上一阶段训练的相似特征融合网络, 设计在具体任务上的独特性微调, 挖掘任务中的独特伪造特征.
模型在元测试阶段开始时并未获取最适合新任务的初始化权重, 但可根据少量的测试数据和迭代过程快速适应新任务, 从而获得适用于目标分类任务的分类器.
将来自目标任务采样的k个样本(支持集)图像输入特征挖掘网络F2, 得到网络的卷积层特征图.F2和F1的结构一样, 参数为元训练阶段更新后的最优初始化参数.同时输入图像通过参数固定的特征融合网络F3, 获取目标任务相对鉴伪任务的相似性特征, 使用残差特征表示输出的特征向量:
R=F2(I)-F3(I),
其中I表示输入的人脸图像.残差特征R包含当前目标任务伪造图像独有的伪造痕迹, 然后根据式(1)得到目标任务的损失值LT, 并更新参数θ :
θ '=θ -α
其中, LT表示支持集在内层循环更新时的交叉熵损失, α 表示元测试阶段中内层循环的学习率.由于元测试阶段参数α 对不同的伪造任务非常敏感, 仅使用固定参数会弱化模型的泛化能力, 不能更好地适应新任务.所以在元测试的外部循环中, 为了找到最佳的内部循环学习率以最小化验证损失, 使用基于梯度下降的超参数自适应策略, 用于更新内部循环学习率.内部循环的超参数可在不同的目标任务检测中逐渐调整, 能避免手动学习率调整的昂贵计算开销, 降低算法的调整难度, 并增强模型的稳定性和可扩展性.内层循环的学习率根据梯度下降调整过程如下:
$\begin{array}{l} L_{\mathrm{val}}=\sum_{r=1}^{R} \gamma_{r} L_{T}, \\ \alpha=\alpha-\beta \nabla_{\alpha} L_{\mathrm{val}} . \end{array}$
其中:Lval表示内部循环每次梯度下降后计算的元测试阶段损失的加权和, 可改善元学习的梯度传播和梯度不稳定的问题; γ r表示每次梯度下降时支持集损失的权重.首先将每个梯度下降步骤的初始权重值设置为相同的1/R, 再计算除最后一个梯度下降步骤以外的每步梯度下降的权值:
γ r=max(γ r-μ , δ ),
其中, μ 表示衰减率, δ 表示权重.然后, 计算最后一步梯度下降的权值:
γ R=min(γ R+(R-1)μ , 1-(R-1)δ ).
在具体任务下的独特微调后, 可对目标任务进行真伪检测.残差级别的特征学习可获取不同伪造手段之间的不同特征, 提高方法对未知目标任务的检测能力.
实验数据集一部分使用大规模公开视频数据集FaceForensics++(简称FF++), 包括1 000个原始视频(真实视频)和1 000个操作视频(伪造视频), 同时使用质量较好的C23版本视频与质量低一些的C40版本视频进行实验.
另一部分使用DiffSwap[20]创建的数据集.DiffSwap由强大的扩散模型执行, 扩散模型是一个参数化的马尔科夫链, 其本质是加噪再去噪的过程, 并且在去噪中引入人为噪声, 生成想要得到的图像.Ho等[24]提出Denoising Diffusion Probabilistic Mo-dels, 研究者在此基础上对其进行不断的改进.Song等[25]提出改进后的DDIM(Denoising Diffusion Imp-licit Models), 使用非马尔科夫链正向过程, 提高采样速度.
扩散模型分为如下两个步骤.
1)前向扩散过程.对给定的图像x0, 扩散过程通过T向图像添加高斯噪声, 得到x1, x2, …, xT.每步的大小由高斯分布方差的超参数控制.前向过程的时刻t只与时刻t-1有关, 因此可看作马尔科夫过程.近似后验概率:
q(x1:T|x0)=
其中
q(xt|xt-1)=N(xt;
这个过程中, 随着t的增大, xt越接近纯噪声, 当T→ ¥ 时, xT为完全的高斯噪声.
2)反向去噪扩散过程.逆向过程就是扩散过程的去噪推断过程, 使用神经网络推断q(xt-1|xt), 一般使用预测模型预测逆向分布:
pθ (x0:T)=p(xT)
其中
pθ (xt-1|xt)=N(xt-1; μ θ (xt, t),
联合分布pθ (x0:T)称为逆过程, 定义为一个以N(xT; 0, I)开始的马尔科夫链.
DiffSwap人脸交换是一个用于高保真度和可控性人脸交换的框架.与以往依赖网络结构、损失函数融合源人脸信息和目标人脸信息的方法不同, 此方法将人脸交换重新表述为一个条件修复任务, 受所需的人脸属性(身份特征和面部标志)引导.而扩散模型用于生成与源人脸相同身份、对齐目标人脸的面部, 并且使用一种中间估计方法, 有效恢复交换人脸的扩散结果, 具有可控性、高保真度和保持形状等优点.由于DiffSwap没有公开的数据集, 本文从FF++数据集上提取的真实人脸图像作为源图像和目标图像进行人脸交换, 构建DiffSwap数据集, 具体示例如图3所示.
 | 图3 New_FF++数据集实例Fig.3 Examples of New_FF++ dataset |
本文重组后的FF++数据集(后称New_FF++数据集)包含5种最先进的面部篡改伪造技术:DeepFakes(https://www.github.com/deepfakes/faceswap)(简记为DF)、Face2Face(简记为F2F)[26]、FaceSwap(https://github.com/MarekKowalski/FaceSwap)(简记为FS)、Neural Textures(简记为NT)[27]、DiffSwap(简记为DS)[20].
所有实验均在一台配备12th Gen Intel(R) Core(TM) i5-12400F的CPU和NVIDIA RTX3060 GPU的计算机上进行.
实验采用元学习监督方法, 训练前对数据集进行元分割.具体地, 720个视频用作元训练(1.2节提及的支持集), 其中140个视频用作元测试(1.2节提及的查询集), 剩余140个视频用作测试.本文使用的FF++数据集包含人脸位置坐标的掩码, 将所有视频各取15帧并经过面部分割, 提取的人脸图像调整为224× 224.使用的网络包含的参数一共62 754个, 在元训练内层循环的一个批次中, 每个梯度计算使用64个支持集, 32个查询集, 内层循环学习率∂ =0.01, 梯度步骤R=5.外层循环学习率β =0.001, 并在元测试中使用2个支持集, 初始学习率∂ =0.01, 梯度步骤R=10, 进行自适应微调.
为了证明方法对未知伪造手段检测的有效性, 将New_FF++数据集上提及的伪造方法划分成源任务和目标任务, 目标任务是指本文所需检测是否存在伪造的未知伪造手段的图像, 而源任务是指目前阶段已知伪造手段生成的图像.本文任务是模拟当现实中出现未知伪造手段时, 方法能具备一定的检测能力.
为了评估方法对未知伪造手段检测的有效性, 采用二分类任务性能评估的一个重要指标AUC(Area Under the Curve).AUC衡量ROC(Receiver Operating Characteristic)曲线下与坐标轴形成的面积.ROC曲线是以真阳性率(True Positive Rate)为纵轴, 假阳性率(False Positive Rate)为横轴绘制的曲线.AUC越接近1, 说明模型性能越优.另一个指标是准确率(Accuracy, ACC), 表示模型正确分类的实例数占总实例数的比例, 是衡量模型整体正确性的一个简单、直观的指标, 具体公式如下:
Accuracy=
其中, TP表示模型正确预测为正例的实例数, TN表示模型正确预测为负例的实例数, FP表示模型错误将负例预测为正例的实例数, FN表示模型错误将正例预测为负例的实例数.
本文选择如下对比方法:文献[6]方法、RFM(Representative Forgery Mining)[10]、CViT(Convo-lutional Vision Transformer)[11]、XceptionNet(Extreme Inception Network)[18]、MAML(Model-Agnostic Meta-Learning Algorithm)[21]、SFIC-VGGNet13[28]、SFIC-ResNet26[28]、Two-Stream Network[29]、Meso-4[30]、MesoInception-4[30]、文献[31]方法、文献[32]方法、Two-Branch Recurrent Network[33].
2.3.1 未知伪造技术检测结果
为了分析本文方法对于未知伪造技术的检测能力, 在New_FF++数据集的子集(高质量)上设计实验, 进行交叉集评估.本文使用最佳模型权重, 在测试集上评估方法.实验分为五个阶段, 对于每个阶段, 在4个子集上训练方法, 并在New_FF++数据集剩余的一个未见过的子集上进行测试集评估.
表1和表2列出以ACC和AUC为指标的交叉集评估结果, 表中黑体数字表示最优值.由表可见, 本文方法在大多数未知伪造类型上表现最优, 尤其在DF、F2F、FS和DS上训练并在NT上测试时, 本文方法在ACC和AUC指标上具有超10%的性能提升.虽然在DF上的跨数据集测试中ACC指标低于RFM, 但其依赖于XceptionNet骨干网络的深度, 能提取伪造图像的深层特征, 参数高达20× 106个, 是本文方法参数的300倍, 本文方法在处理数据时的计算量更小.虽然相比基于空频交互卷积的SFIC-VGGNet13, 本文方法在DF、FS测试场景中未取得最佳结果, 这可能是因为这两种伪造技术生成的图像在人脸边缘处存在更多的伪造痕迹, 使高频信息被SFIC-VGGNet13捕捉.由于不同的伪造技术留下不同的伪造痕迹, 自适应模型应寻找伪造面部之间的基本差异.这些结果验证通过构建不同伪造手法的共同特征并自适应微调以完成对未知伪造技术的检测是可行的.
| 表1 New_FF++子数据集上的跨伪造手法的ACC对比 Table 1 ACC comparison of cross-forgery technique on New_FF++ subset % |
| 表2 New_FF++子数据集上的跨伪造手法的AUC对比 Table 2 AUC comparison of cross-forgery technique on New_FF++ subset % |
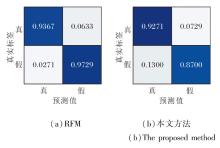
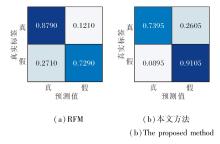
为了分析方法在面对已知伪造技术和未知伪造技术时的能力, 进一步进行精细测试.选择RFM和本文方法, 在子数据集DF、F2F、FS、NT(DF-F2F-FS-NT)上训练, 并分别在子数据集DF、DS上测试, 绘制混淆矩阵, 具体如图4和图5所示.
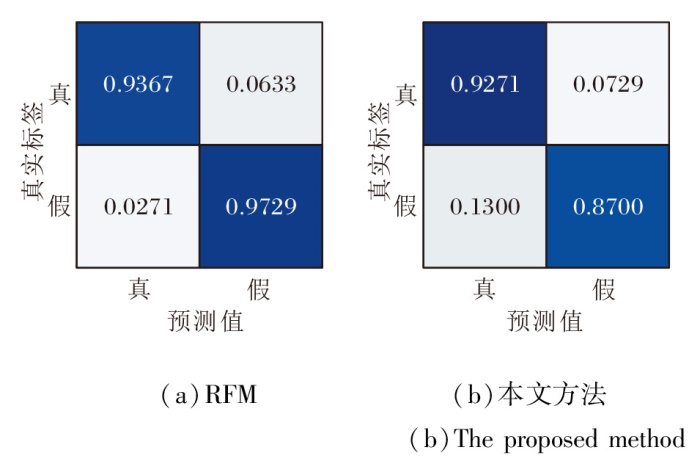 | 图4 RFM和本文方法对已知伪造技术的混淆矩阵Fig.4 Confusion matrix of RFM and the proposed method for known forgery techniques |
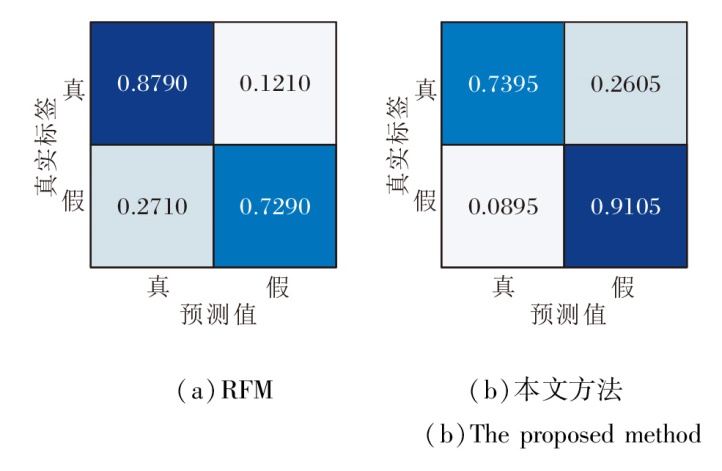 | 图5 RFM和本文方法对未知伪造技术的混淆矩阵Fig.5 Confusion matrix of RFM and the proposed method for unknown forgery techniques |
由图4和图5可见, 本文方法在数据集内部性能较差, 主要是由于将伪造图像鉴定为真实图像, 性能稍差于RFM.然而, 本文强调在实际的未知伪造技术攻击的背景下, 本文方法对于未见过的伪造图像具有更准确的鉴别能力.
2.3.2 跨数据集检测结果
尽管现有方法在单个数据集上表现良好, 但大多数方法在泛化能力方面存在不足.在本节中, 引入DFDC、Celeb-DF人脸伪造数据集, 检验本文方法的泛化迁移能力, DFDC数据集是目前公开最大的人脸伪造数据集, 包含1 133个真实视频和4 080个伪造视频, 伪造技术多样、未知, 对模型可转移能力具有很大的挑战.Celeb-DF数据集是从YouTube上采集得到的, 共包含590个真实视频, 并使用Deep-Fakes技术进行人脸伪造, 相比FF++数据集, 数据质量明显提升, 可用于模拟真实世界的生成伪造视频.在这两个数据集上的跨库测试能证实本文方法具备解决未知方法伪造的图像鉴伪能力.在FF++数据集(低质量)上训练, 进行跨库测试的AUC分数如表3所示, 表中黑体数字表示最优值.
| 表3 各方法在Celeb-DF、DFDC数据集上进行跨库测试的AUC值对比 Table 3 AUC value comparison of cross-database testing among different methods on Celeb-DF and DFDC datasets % |
由表3可见, 虽然本文方法在数据集内部的AUC指标低于Two-Branch Recurrent Network和SFIC-ResNet26, 但本文研究的重点在于方法在未知伪造技术攻击背景下的检测能力, 所以本文方法更多地关注真实样本和伪造样本直接的泛化差异, 并不是简单的拟合训练数据.而在DFDC、Celeb-DF数据集上, 本文方法测试结果表现出更优的迁移性能, 在Celeb-DF数据集的跨库测试中, 相比性能最优的SFIC, 本文方法的AUC分数有超过4%的提升, 在DFDC数据集的跨库测试中, 本文方法的AUC分数也有2%左右的提升, 这得益于具体任务下的独特伪造特征挖掘模块, 可提取具有区分性的特征, 帮助方法进行检测.
本节研究本文方法中相似特征融合网络和具体任务下的独特性微调对性能的影响, 在New_FF++数据集上进行实验, 所有实验均仅在压缩度c23版本下进行.
如式(2)所示, 超参数λ 会影响真实图像和伪造图像的特征分布, 最终影响方法对真伪图像的辨别.λ 权衡中心损失和交叉熵损失, 控制真实人脸中心和伪造人脸中心之间的距离.为了研究超参数λ 对结果的影响, 在New_FF++数据集上随机选取3 000幅真实人脸和伪造人脸单独进行训练, 设置超参数λ =0, 0.001, 0.005, 0.01, 0.05, 1.
λ 不同对性能的影响如表4所示, 表中黑体数字表示最优值.由表可知, 中心损失对方法具有较强的鲁棒性.当λ =0时, 即只使用交叉熵损失时, 性能也最差, 参数决定真实图像和伪造图像特征分布的决策边界.当λ > 0.5时, AUC和ACC都趋于稳定, 说明此时决策边界使本文方法具有一定能力检测真伪图像.为了使本文方法容易训练, 所有实验均采用λ =0.5.
| 表4 超参数λ 对方法性能的影响 Table 4 Effect of hyperparameter λ on method performance |
为了研究本文方法中相似特征融合和独特伪造特征挖掘对性能的影响, 在New_FF++数据集上进行消融实验, 实验均仅在元学习的监督下进行, 训练集选择DF、F2F、FS、NT, 测试集选择DS.各模块的消融实验结果如表5所示, 表中黑色数字表示最优值.由表可看出, 相似性特征融合和独特伪造特征挖掘都能提升ACC和AUC值.相比仅在元学习监督下训练, 只在训练过程中进行相似特征融合的ACC和AUC值分别提升2.87%和0.97%.而独特性微调也能使性能提升.这些改进都有助于提升方法对未知伪造技术的适应能力.当同时使用两者时, 性能具有显著的提升, 这充分验证本文方法对未知伪造技术可转移的泛化能力.
| 表5 各模块对方法性能的影响 Table 5 Effect of different modules on method performance % |
为了更好地理解方法学到的内容, 采用梯度加权的类激活热力图对学到的伪造特征进行可视化分析, 具体如图6所示.由图可看出, 对于不同的伪造图像, 不同的检测方法学到相似的伪造区域, 因此其中必然存在类似的内部表示, 同时也验证本文的猜想.
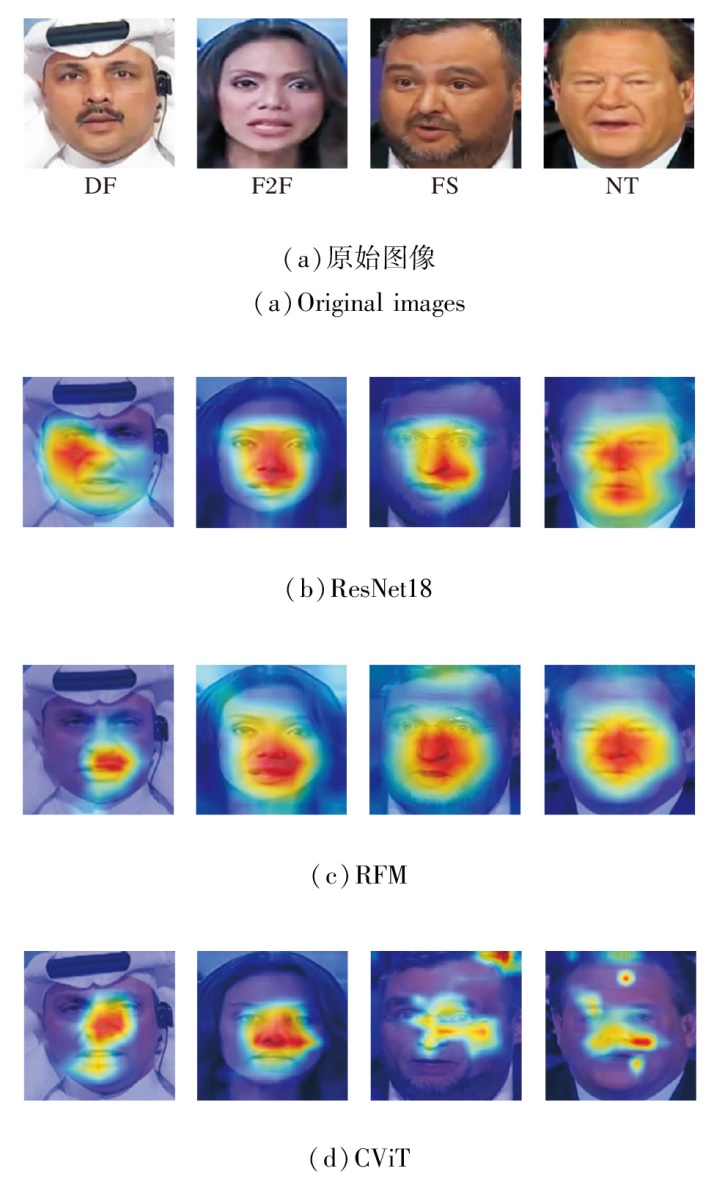 | 图6 各方法在不同的伪造图像上检测的相似伪造区域Fig.6 Similar forged regions detected by different forgery detection methods for different forged images |
将同一目标通过不同伪造技术生成的人脸进行平均可视化操作, 结果如图7所示.
 | 图7 不同伪造手法的平均特征激活图Fig.7 Average feature activation maps for different forgery techniques |
由图7可见, 不同伪造手法获取的特征具有明显区别.从伪造技术的实现方法分析提取特征的特点.Neural Textures通过修改与嘴部区域对应的面部表情, 保持眼部区域不变, 所以对整个人脸的下半部分较感兴趣.DiffSwap将整个源脸的面部属性通过扩散模型重新编辑后输入目标人脸, 伪造特征分布在整个面部.Face2Face在保持目标人物身份特征的基础上, 将源脸的表情转移到目标人物上, 可看到在脸颊位置具有明显的伪造痕迹.DeepFakes和FaceSwap是将整个源脸输入目标人脸, 对于输入的这部分面容, 在特征提取中往往忽略眼睛和鼻子部分.
本文提出结合深度伪造特征对比的人脸伪造检测方法, 其目的是学习以往伪造手段的相似特征和未知任务的可区分特征.本文方法由一个基于元学习的不同伪造特征的相似性融合网络和具体任务下的独特性微调构成.通过元学习方法学习人脸伪造图像可转移嵌入, 并研究人脸伪造痕迹的相似性特征和潜在性差异, 提高人脸伪造检测的泛化能力.此外, 通过可视化展现方法感兴趣的人脸部位, 证实方法关注的相似性特征区域和差异性部位.大量在未知伪造技术上的实验证明本文方法对未知技术的适应能力.但是, 本文方法依赖于元学习过程中学到的模型最优参数, 造成基于元学习的相似特征融合网络的不稳定性.下一步考虑使用更鲁棒性的方法, 学习不同伪造技术之间的相似性特征.
本文责任编委 徐 勇
Recommended by Associate Editor XU Yong
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|