
{kind=link}
{kind=link}
{kind=link}
基于内部知识扩展的软提示学习点击诱饵检测方法
[董丙冰1, 2  , 吴信东
, 吴信东1, 2 ]
, 吴信东]
|
|



作者简介: 
董丙冰,博士研究生,主要研究方向为数据挖掘.E-mail:blingdong@mail.hfut.edu.cn.
点击诱饵的主要目的是通过引导用户点击链接以增加页面浏览量和广告收入.点击诱饵的内容往往具有低质量、误导性或虚假性的特征,对用户产生潜在不利影响.现有的基于预训练语言模型的提示学习方法依赖外部开放知识库以检测点击诱饵,不仅性能受制于外部知识库的质量和可用性,而且不可避免地导致查询和响应的延迟.为此,文中提出基于内部知识扩展的软提示学习点击诱饵检测方法,从训练数据集本身提取扩展词,同时采用层次聚类和优化策略,在提示学习中对获得的扩展词进行微调,避免从外部知识库检索知识.此外,采用软提示学习可获得适合特定文本类型的最佳提示,避免手工模板带来的偏差.在少样本场景下,尽管文中方法只基于内部知识进行扩展,但在三个公开的点击诱饵数据集上可以以较少的时间取得较优的检测效果.
About Author:
DONG Bingbing, Ph.D. candidate. Her research interests include data mining.
The main purpose of clickbait is to increase page views and advertising revenues by enticing users to click on bait links. The content of clickbait is often characterized by low-quality, misleading or false information, and this potentially engenders negative effects on users. Existing prompt learning methods based on pre-trained language models are reliant on external open knowledge bases to detect clickbait. These methods not only limit model performance due to the quality and availability of external knowledge bases, but also inevitably lead to delays in queries and responses. To address this issue, a soft prompt learning method with internal knowledge expansion for clickbait detection(SPCD_IE) is proposed in this paper. Expansion words are extracted from the training dataset, while hierarchical clustering and optimization strategies are employed to fine-tune the obtained expansion words in prompt learning, and the necessity of knowledge retrieval from external knowledge bases is avoided. Moreover, soft prompt learning is utilized to obtain the best prompts suitable for specific text types, preventing biases introduced by manual templates. Although SPCD_IE expands solely based on internal knowledge in few-shot scenarios, experimental results show it achieves better detection performance on three public clickbait datasets in less time.
在当今数字时代, 互联网已成为获取信息、沟通交流的主要平台, 随之而来的是点击诱饵, 即“ 标题党” 的泛滥.点击诱饵以引导用户点击链接为手段, 旨在提高页面浏览量和广告收入[1].点击诱饵往往以低质量、误导性或虚假性的形式呈现, 不可避免地对用户产生负面影响[2].用户在浏览无意义的内容时浪费宝贵的时间, 甚至可能因为误导而相信虚假信息.点击诱饵不仅对用户体验产生负面影响, 还对用户信息安全构成威胁.因此, 研究点击诱饵检测技术, 提高互联网平台的安全性和用户的信息获取质量, 成为亟待解决的重要问题.
早期点击诱饵检测的研究主要采用特征工程[3, 4, 5], 通过提取词频和情绪极性等语言特征进行判别分类.随着深度神经网络的兴起, 研究者利用深度学习的方法更全面地学习标题和文章的抽象特征表示[6, 7, 8].然而这些方法通常依赖大规模数据训练端到端的模型, 给数据获取、标签噪声及成本方面带来挑战.近年来, 基于预训练语言模型(Pre-trained Language Model, PLM)的方法通过在点击诱饵检测任务上微调下游模型, 使方法学到更丰富、通用的语言表示, 并取得良好效果[9, 10].但是, 预训练和微调之间的巨大差距仍是阻止下游任务充分利用预训练知识的阻碍, 从而影响点击诱饵检测的精度.
最近, 受GPT-3 (Generative Pre-trained Transfor-mer 3)[11]的启发, 提示学习的方法使用Prompt帮助学习任务, 并在一系列任务中表现较优[12].在提示学习中, 自然语言模板将下游自然语言处理(Natural Language Processing, NLP)任务形式化为完形填空任务, 并通过掩码预测的形式完成相应任务[13].传统的手动设计的模板通常被称为“ 硬提示” , 依赖明确的自然语言表达.这种方法的一个主要缺点是设计过程繁琐、耗费大量人力.此外, 硬提示对不同任务的泛化能力较弱, 难以适应多样化的任务场景.
在提示学习中, 表达器是从标签词到类别的投影, 已被证实是一个重要、有效的策略[14].基于提示微调的分类方法起初使用手动设计的表达器, 耗费大量的人力[15, 16].为了减轻人类设计类名的负担, 一些学者建议使用离散搜索[17]或梯度下降[18]学习标签词.这类方法的表达器需从头学习, 缺乏人类的先验知识, 效果远低于手动设计的表达器.为了缓解上述问题, 基于外部知识库扩展表达器的分类方法取得一定进展.例如:KPT(Knowledgeable Prompt-Tuning)[19]将外部知识库中的实体、关系和属性等信息整合到提示生成器中, 扩展表达器, 提高文本分类的性能和鲁棒性.然而, 这类方法仍存在两个主要问题:1)基于外部知识库的方法高度依赖开放知识的质量, 在一些垂直领域缺乏专用的知识库会导致性能下降; 2)外部知识的扩展是一个耗时的查询过程, 可能会导致表达器的遗漏和偏差.
为了缓解上述问题, 本文提出基于内部知识扩展的软提示学习点击诱饵检测方法(Soft Prompt Learning with Internal Knowledge Expansion for Click-bait Detection, SPCD_IE), 从原始训练数据集本身提取扩展词, 同时采用层次聚类和优化策略, 从点击诱饵新闻中扩展概念, 而不依赖外部知识库.此外, 构建软提示, 增加上下文信息, 允许在训练期间进行灵活的提示学习, 获得适合特定文本类型的最佳提示, 不仅减少手工提示模板引入的偏差, 而且提高泛化能力.大量实验表明, 虽然SPCD_IE仅基于内部知识扩展, 但是其性能甚至优于引入外部知识的方法.
随着信息爆炸的数字化时代的到来, 点击诱饵已在互联网新闻门户和社交媒体上泛滥成灾, 其目的是引导用户点击链接, 提高页面浏览量和广告收入.这种现象会导致一系列问题, 包括信息的误导性和用户体验感的下降, 使得点击诱饵检测成为维护网络环境和用户权益的紧迫任务之一.
早期的点击诱饵检测方法主要集中于特征工程, 捕获各种不同的特征, 如语义[20]、语言[21]和多模态特征[1].然而, 这些方法需要特定的专业知识识别适当的特征, 而手工制作的特征工程方法捕获语义信息的能力有限.
随着深度神经网络的发展, 深度学习方法已被广泛应用于点击诱饵检测, 取得较优性能[2, 22, 23], 如循环神经网络(Recurrent Neural Network, RNN)、卷积神经网络(Convolutional Neural Network, CNN)和图注意力网络等.这类方法取得一定进展, 但其性能仍受限于大规模的标记数据.Agrawal[23]提出基于CNN的点击诱饵检测方法.首先, 从多个社交媒体平台(如Reddit、Facebook和Twitter)收集点击诱饵标题和非点击诱饵标题, 构建新的语料库.然后, 从头开始训练词向量, 并使用预训练的Word2vec词向量分别对标题进行词嵌入, 通过卷积操作提取特征, 使用最大池化层选取最显著的特征.最后, 通过全连接的Softmax层输出点击诱饵类别概率.Naeem等[24]提出用于社交媒体网络点击诱饵检测的深度学习框架, 主要包括两个模块:1)POSAM(Part of Speech Analysis Module), 用于词性分析; 2)长短期记忆网络(Long Short-Term Memory, LSTM)模块, 进行点击诱饵分类.在LSTM模块中使用预训练Word2vec, 将标题中的词语转换为嵌入向量, 通过LSTM的特殊结构, 增强对点击诱饵标题后半部分的处理.Kumar等[25]提出多策略的神经网络框架, 识别点击诱饵, 结合文本特征和图像特征, 将双向长短期记忆网络(Bidirectional Long Short-Term Memory, Bi-LSTM)、注意力机制和暹罗网络应用于这一任务.首先, 使用Bi-LSTM处理文章标题的顺序特征, 并通过注意力机制为每个词分配不同的权重, 突出关键词.然后, 利用Doc2Vec将标题和文章内容转换为嵌入向量, 通过暹罗网络评估两者的相似度, 判断标题是否匹配内容.最后, 使用图卷积网络提取图像特征, 通过暹罗网络评估标题与图像的相似性, 进一步提升对含有图像的社交媒体帖的检测效果.基于深度学习的研究已取得一些进展, 但其性能仍受限于难以收集足够的标记数据.
近年来, PLM已在自然语言处理领域取得较大的成功.BERT(Bidirectional Encoder Representations from Transformers)[26]和RoBERTa(Robustly Optimized BERT Approach)[27]等为代表的模型可捕获语言的语法[28]、语义[29]和结构[30]信息, 在包括点击诱饵检测[9]等在内的一系列下游任务中表现出优越性能.Lee等[31]提出UNIFIEDM2, 联合建模多个错误信息检测任务, 检测内容包括点击诱饵、新闻偏见、假新闻和谣言.UNIFIEDM2的核心方法是使用一个共享的RoBERTa编码器处理所有任务, 并通过特定于任务的多层感知机(Multilayer Perceptron, MLP)分类头进行具体任务的预测.这种方法的优势在于能跨任务学习, 提取更丰富和泛化的特征表示, 增强模型对错误信息的识别能力.Liu等[2]提出MFWCD(Multiple Features for WeChat Clickbait Detection), 利用BERT和Bi-LSTM分别提取标题的语义特征和句法特征.此外, 为了进一步提高性能, 引入辅助特征, 包括文章的出版年份、阅读次数及点赞数.这些辅助特征有助于提供额外的上下文信息, 从而增强方法的判别能力.Hagen等[32]提出一种点击诱饵泄露的任务, 通过生成短文本满足点击诱饵帖引发的好奇心.这一过程涉及识别点击诱饵的类型, 并从相关链接文档中提取信息, 生成能“ 泄露” 点击诱饵内容的提示.该模型的点击诱饵检测通过提取帖子的特征(如词频和逆文档频率加权的单词和词性标记), 并利用经典的特征基础模型(如朴素贝叶斯、逻辑回归、支持向量机)及深度学习模型进行训练, 识别哪些帖子是点击诱饵.通过在标注好的数据集上训练和评估模型, 能有效检测社交媒体上的点击诱饵帖, 为后续的提示生成内容基础.尽管对PLM的微调已在点击诱饵检测任务中取得较优性能, 但这些方法通常需要辅助信息, 如新闻内容, 用于微调模型, 否则, 在预训练和微调过程中, 目标函数之间的巨大差异阻碍对PLM中包含知识的利用.
GPT-3[12]出现以来, 提示学习受到相当多的关注.GPT-3表明, 通过提示学习和上下文学习, 大规模语言模型可在少样本的数据环境下获得优越性能[19].提示学习现已成功应用于大量的下游任务, 如文本分类[15]、自然语言理解[16]、关系提取[33]等.现有研究已设计很多在训练期间保持不变的手工提示(也称为离散提示), 用于各种下游任务[34, 35, 36].常规的提示微调(Prompt Tuning, PT)通常依赖于这些手工设计的提示.这些提示基于先验知识和经验, 可能难以适应不同任务和领域, 并且修改手工设计的提示可能需要大量的人力和时间, 尤其是在面对不断演变的数据和任务时, 这使模型调整相对困难.
因此, 最近学者们提出自动提示的生成方法.Jiang等[37]提出自动提示生成方法, 同时使用基于挖掘的方法和基于解释的方法.Shin等[38]提出AUTOPROMPT, 为各种NLP下游任务生成提示.Liu等[39]提出P-Tuning v2, 给定离散的提示作为输入, 连接连续的提示嵌入与离散的提示标记, 并输入预先训练过的语言模型.连续的提示通过反向传播进行更新, 最终优化任务目标.P-Tuning v2优化提示的生成方式, 使用连续提示, 减少对离散手工提示的依赖.然而, 在训练过程中使用的提示是预先设定的连续嵌入, 这些提示在生成之后保持不变, 虽然可微调优化它们, 但形式和结构是固定的.这种提示结构在任务之间不易改变, 因此在处理不同类型的任务或文本时, 可能会缺乏灵活性.
在实践中, 提示调优方法已被证实适用于下游任务, 如点击诱饵检测.Wu等[40]提出PEPL(Part-of-Speech Enhanced Prompt Learning), 作为提示学习的扩展.PEPL引入词性标注, 增强提示的语法理解, 提高在低资源场景下的性能.该方法设计任务特定的模板, 并利用词性特征引导方法重点关注句中的重要词汇, 大幅改善提示学习的效果.然而, PEPL仍依赖手工设计的提示模板, 尽管引入词性标注可提升方法对语法结构的理解, 但仍未完全摆脱人工干预.
提示调优中除了设计模板描述当前任务的背景之外, 还有一组标签词, 它是PLM在当前上下文中预测的高概率词汇表.将标签词映射到相应类别的表达器也成为弥补文本空间和标签空间之间语义差距的有效手段.表达器是指从标签词到类别的投影, 是提示学习的一个重要组件, 对提示学习的性能有较大影响[33].Schick等[15]定义一组模式(Pattern), 再为每个模式分配一个表达器(Verbalizer), 手工定义的表达器用于将模式映射到特定的标签或类别.
尽管手工构建的表达器在各种NLP下游任务中取得良好性能, 但其高度偏向于个人词汇[15], 不可避免地存在偏差和遗漏.为此, 近年来研究者提出自动表达器的构建方法[13, 41].Wei等[41]提出基于原型嵌入和对比学习原型的提示表达器方法, 在提示微调中构建有效的标签表达器, 提高零样本文本分类任务和少样本文本分类任务的性能.Hu等[19]提出KPT, 将外部知识集成到表达器中, 从开放的知识图谱中选择相关的词, 再进行细化, 过滤表达器中的噪声词.该方法虽然可提高标签的语义, 但大幅依赖外部知识库的质量, 并且在表达器构建阶段提取大量无用的单词, 使表达器难以直接使用, 导致在文本分类等下游任务中表现出次优的结果.
给定要检测的文本x, 如新闻标题或推特帖, 链接的新闻主体或推特内容定义为c.对应的标签定义为 y, y=1 表示x是点击诱饵, y=0表示x不是点击诱饵.考虑到x本身是一个短文本, 点击诱饵检测可看作是一个短文本分类任务P(y|x, c), 目的是使用x和c预测y.
本文仅采用新闻标题进行点击诱饵检测和表达器的扩展, 主要动机如下:1)人类仅凭新闻标题便可得知该新闻是否为点击诱饵, 而无需点开新闻内容; 2)对大规模标签的新闻标题和内容的要求导致收集合格的训练数据的高昂成本.
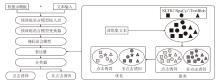
本文提出基于内部知识扩展的软提示学习点击诱饵检测方法(SPCD_IE), 结合最近的提示学习方法, 并引入一种表达器扩展方法, 总体架构如图1所示.
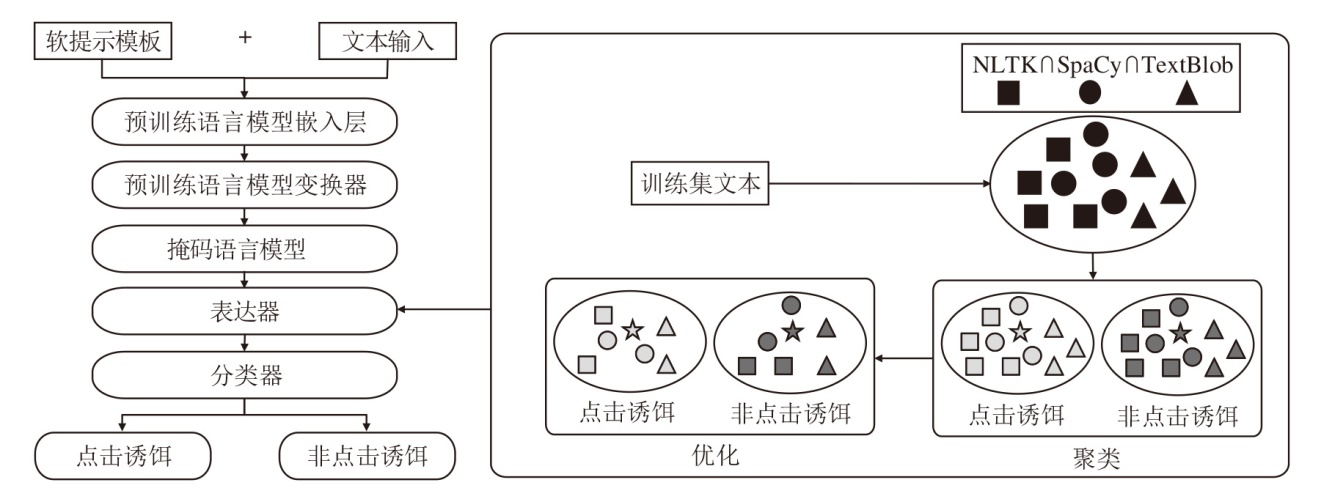 | 图1 SPCD_IE总体架构图Fig.1 Overall structure of SPCD_IE |
首先, 构建软提示, 增加上下文信息, 允许方法在训练期间进行灵活的提示学习, 获得适合特定文本类型的最佳提示.再使用3种不同的工具, 从训练集上提取名词并取交集, 将这些扩展与类别标签词, 如CLICKBAIT和NOT-CLICKBAIT, 作为聚类中心, 从而获得每类的扩展词.然后, 利用BERT优化这些扩展词, 得到最终的表达器扩展.最后, 利用构造的表达器进行软提示学习, 预测点击诱饵检测的概率.
在提示学习任务中, 输入的句子被形式化为自然语言模板, 点击诱饵检测任务被视为填空任务, 需要将该标题映射到标签y.首先需要构建一个手动模板:
T=[head]x.In summary, itwas[MASK].[tail].
给定一个输入
x={x1, x2, …, xn},
将其对应到一个类别标签y∈ Y, 标签词集
Vy={v1, v2, …, vn}.
将Vy映射到一个类别标签y上.在预训练语言模型M中, Vy中的每个单词v在[MASK]中被填充的概率可表示为
p([MASK]=v∈ Vy|T),
因此, 点击诱饵的检测问题可转化为标签概率的计算问题, 计算方法如下:
p(y∈ Y|x)=p([MASK]=v∈ Vy|T).
在SPCD_IE中, 相比手动模板, 软提示模板
T={[ui], …, x…, [un], [MASK]}
用于在连续的最优提示空间中进行训练, 其中ui表示第i个可学习的标记.然后将构造好的提示符P传递给一个PLM编码器M, 得到相应的潜在向量:
{hi, …, hx, …, hn, hmask}=M(T).
在获得T的隐藏向量后, 利用Bi-LSTM捕获文本的上下文信息, 并更新学习标记ui的参数, 即
hi=BiLSTM(hi, hx, hn).
损失函数:
h=arg
其中, M(x, mask) 表示在输入数据x和mask上的预训练语言模型M的输出, arg
在提示学习中, 表达器将标签单词映射到相应的类别, 这已被证实是提高下游任务性能的有效方法.与基于外部知识库的方法不同, SPCD_IE选择从每个数据集的训练集上提取特定的名词扩展标签词.为了减少词性标记可能引入的噪声, 选择如下3种不同的词性标记工具:NLTK(https://www.nltk.org)、SpaCy(https://spacy.io)和TextBlob(https://textblob.readthedocs.io/en/dev), 帮助提取名词.
首先, 使用3种不同的工具对数据集上标题的所有单词进行词性标记, 再分别从这些被标记的单词中提取所有的名词.此过程可表示为
{n1, …, ni, …, nn}= Extract(NLTK, SpaCy, TextBlob).
每个工具可能有一些差异, 选择采取这3个词汇表集的交集, 以尽可能准确地确定词性, 得到最终的词汇集合Nf .然后使用层次聚类(Hierarchical Clustering, HC)[42]将数据集上的标签词视为聚类中心, 并将这些词汇词分配到特定的类别
{CLICKBAIT, NOT-CLICKBAIT}
中, 即
{CLICKBAIT, NOT-CLICKBAIT}=HC(Nf).
然而, 这个过程可能会引入一些噪声词, 潜在影响方法性能, 因此采用BERT预测策略优化标签词.为了利用预先训练过的语言模型的丰富知识, 基于模板中[MASK]的概率分布进行优化.例如:在模板
T=[placeholder:c], it was[MASK]
中, [placeholder:c]表示一个特定的类别, 概率表示与该类别的相似性.根据这些概率排序所有的单词, 并选择前N个单词作为最终的表达器扩展词.
在构建最终的表达器后, 构造一个目标函数f, 将对点击诱饵或非点击诱饵的相关扩展词的预测概率映射到类标签上.通过这种方法, 模型能将类标签词的预测概率转化为对应词集的整体预测概率, 从而有效利用表达器进行分类.
为了简化计算, 假设最终表达器中的每个单词对预测的贡献相等, 即每个词在该类别预测中的权重相同.因此, 可将预测分数的平均值用于点击诱饵检测, 目标函数
$f=\arg \max _{y \in Y}\left(\frac{1}{\left|V_{y}\right|} \sum_{v \in V_{y}} p([\operatorname{MASK}]=v \mid T)\right), $
其中, arg max(· )表示最大化函数, Y表示所有可能的标签集, Vy表示标签y的最终表达器中的单词集.目标函数f可在训练过程中更新整个模型的参数.具体地, 通过最小化交叉熵损失函数
Lf=
优化模型参数θ , 该过程促使模型不断调整其参数设置, 从而逐步提升对真实标签的预测精度, 其中, yi表示第i个实例的标签, xi表示第i个实例的输入, μ 表示L2正则化器的系数.
为了评估SPCD_IE的性能, 在SC-Clickbait (SCC)[43]、DL-Clickbait(DLC)[23]、W23-Clickbait(W23C)[31]这3个公开的点击诱饵数据集上进行实验.SCC数据集包含32 000个标题和16 000个点击诱饵, 数据来自BuzzFeed、Upworthy、WikiNew等.DLC数据集从Reddit、Facebook和Twitter上提取2 388条内容, 包括814个点击诱饵样本.W23C数据集上数据来自点击诱饵挑战[31], 有两个版本, 使用较大较新的一个.
对数据文本进行预处理, 得到的数据集统计信息如表1所示, 注意到点击诱饵样本和非点击诱饵样本在所有的训练集和测试集上都是平衡的.
| 表1 数据集统计信息 Table 1 Statistical information of datasets |
实验在一台配备有NVIDIA Geforce RTX 3090 Founders的服务器上进行, CPU为英特尔(R)核心(TM)i9-10980XE, 运行频率为3.00 GHz, 内存为125 GB.实验使用的Python版本为3.9.16, Pytorch-cuda版本为11.7.
为了评估方法的有效性, 采用两个常用的评价指标:Accuracy(Acc)和F1-Socre(F1S).
3.2.1 对比方法
本文选择如下基于深度神经网络方法、基于PLM的方法和其它基于提示学习的点击诱饵检测方法进行对比.
1)MFWCD-BERT[2].在微信上集成多种特征进行点击诱饵检测的方法.
2)KPT[19].外部知识驱动的提示调优方法.
3)文献[23]方法.基于CNN的点击诱饵检测方法.
4)文献[24]方法.用于社交媒体网络点击诱饵检测的深度学习框架.
5)文献[25]方法.基于深度神经网络的方法.
6)UNIFIEDM2[31].通过多任务学习框架统一处理新闻偏见、点击诱饵和假新闻等错误信息领域的方法.
7)文献[32]方法.提出点击诱饵泄露的任务.
8)Prompt-Based Learning[36].常规的提示方法.
9)P-Tuning v2[39].基于提示调优的增强方法.
10)PEPL[40].在国内社交媒体中检测点击诱饵的词性增强提示学习方法.
11)Mistral 7B[44].由 Mistral AI团队开发的新兴大型语言模型.
3.2.2 少样本设置
实验时随机选择K个样本作为训练集, K=5, 10, 20, 建立一个相同大小的验证集, 并选择部分样本作为测试集.考虑到训练样本太少可能会影响对比方法的有效性, 从SCC、DLC、W23C数据集上提取不同的训练样本.对于需要较大训练样本的方法, 如文献[23]方法、文献[24]方法、文献[25]方法、RoBERTa、UNIFIEDM2和MFWCD-BERT, 在SCC、DLC、W23C数据集上使用的训练样本数量分别为:1 000, 2 000, 4 000; 300, 600, 1 200; 500, 1 000, 2 000.相应地, 针对少样本学习设计的方法, 如PEPL、Prompt-Based Learning、P-Tuning v2、KPT和SPCD_IE, 在SCC、DLC、W23C数据集上使用的训练样本数量为5, 10, 20.对于大语言模型Mistral 7B, 仅在提示中详细阐述点击诱饵与非点击诱饵的概念, 而不使用训练样本, 因此实验结果在不同训练样本数量时没有发生变化.
考虑到训练过程中少样本训练和验证样本的不同选择会影响测试结果, 同时对K个随机种子重复采样相同的数据, 并计算它们的平均值.
此外, 在表达器的构建过程中, 使用对应数据集的全部训练集, 需要强调的是, 在此过程中, 未使用任何与文本标签相关的信息, 整个流程完全基于无监督的方式进行.
3.2.3 参数设置
对于基于神经网络和微调的方法, 坚持原始模型的参数设置.使用RoBERT
对于基于提示学习的模型PEPL、Prompt-Based Learning、P-Tuning v2、KPT和SPCD_IE, 确保基础模型参数的一致性, 包括随机抽样的训练样本.对于MLP模块, 设置隐藏维度为200, 失活率为0.5.在训练过程中, 使用Adam(Adaptive Moment Estimation)优化器优化模型参数.在少样本设置下, W23C、DLC、SCC数据集上学习速率设为2e-5、5e-5、5e-5, 权值衰减为0.01, 批处理大小为64、32、32, 每一步都对方法进行验证.同时, 进行10个迭代周期的训练, 并选择验证性能最优的检查点进行测试.
此外, 对于大语言模型Mistral 7B, 采用构造提示的方式, 以多轮对话的形式完成检测任务.
3.2.4 对比结果
各对比方法在3个数据集上的指标值结果如表2~表4所示, 表中黑体数字表示最优值.由表可见, SPCD_IE在3个数据集上都性能最优, 这说明其在点击诱饵检测任务上的有效性.
| 表2 训练样本数为5时各方法在3个数据集上的指标值对比 Table 2 Metric value comparison of different methods with 5 samples on 3 datasets |
| 表3 训练样本数为10时各方法在3个数据集上的指标值对比 Table 3 Metric value comparison of different methods with 10 samples on 3 datasets |
| 表4 训练样本数为20时各方法在3个数据集上的指标值对比 Table 4 Metric value comparison of different methods with 20 samples on 3 datasets |
首先, 随着训练样本的数量从5增至10和20, 所有方法的分类性能都有所提高.这说明增加训练样本的数量是提高点击诱饵检测性能的有效方法之一.其次, 基于提示学习的方法(Prompt-Based Lear-ning和KPT)比其它方法性能更优, 这得益于点击诱饵检测的预训练语言模型中丰富的知识.此外, 在训练数据有限时, 没有外部先验知识的深度神经网络方法比引入外部知识和预训练信息的方法表现更差.本文认为, 在没有先验知识的情况下, 参数的更新过程容易受到少量训练数据分布的影响, 导致方法在测试集上的泛化能力较差.
SPCD_IE和KPT性能都优于其它方法, 如Prompt-Based Learning、P-Tuning v2, 这表明扩展知识是解决点击诱饵检测中稀疏性问题的有效方法之一.然而, 基于外部知识库的方法通常高度依赖外部知识库, 并且在知识扩展的过程中会引入大量的噪声和较高的时间复杂度.例如:KPT整合外部知识图谱中的相关词汇以扩展短文本中的概念, 虽然能引入大量外部知识, 但也带来大量的噪声, 甚至无法通过降噪模型进行处理.
与从外部知识图谱中提取表达器的KPT不同, SPCD_IE从原始训练数据集上提取名词扩展表达器.从实验结果上看, SPCD_IE优于KPT, 这可能是由于内部知识扩展保持与任务文本的语言一致性, 并更有效利用训练数据.基于整个训练集构建扩展词集, 可在一定程度上避免模型在缺乏外部先验知识时, 由于参数更新过程受限于少量训练数据分布而导致的测试集表现不稳定问题.此外, 在抽取扩展词的过程中, SPCD_IE进一步采用优化策略去除噪声, 最终选择预测概率最高的前N个词汇构成最终的扩展词集.这种方式能有效降低过拟合的风险, 进一步减少遗漏和偏见带来的影响.
相比SPCD_IE, 像Mistral 7B这样的大语言模型表现出相对不稳定的性能.本文认为, 尽管这些大语言模型擅长处理具有明确、标准化答案的清晰客观问题, 但在面对故意扭曲的对抗性或扰动性问题时表现较差, 容易受到特定特征的影响.例如, 对同一文本进行反复测试时, 细微的变化可能会导致不同的结果, 从而影响分类准确性等指标.相比之下, SPCD_IE直接从短文本本身获取知识, 在与Mistral 7B等大语言模型的对比中表现出更优的性能.
本节研究参数对SPCD_IE的影响, 包括学习率和批处理大小.当一个参数发生变化时, 其余的参数在实验中是固定的.学习率决定方法在训练过程中更新参数的步长.批处理大小是指在单次训练过程中处理的样本数, 影响训练的动态、内存利用率和模型的收敛性.训练样本数为20时, 在3个数据集上计算准确率, 结果如图2所示.由图可见, 不同的数据集对学习率和批处理大小的选择表现出不同的敏感性.
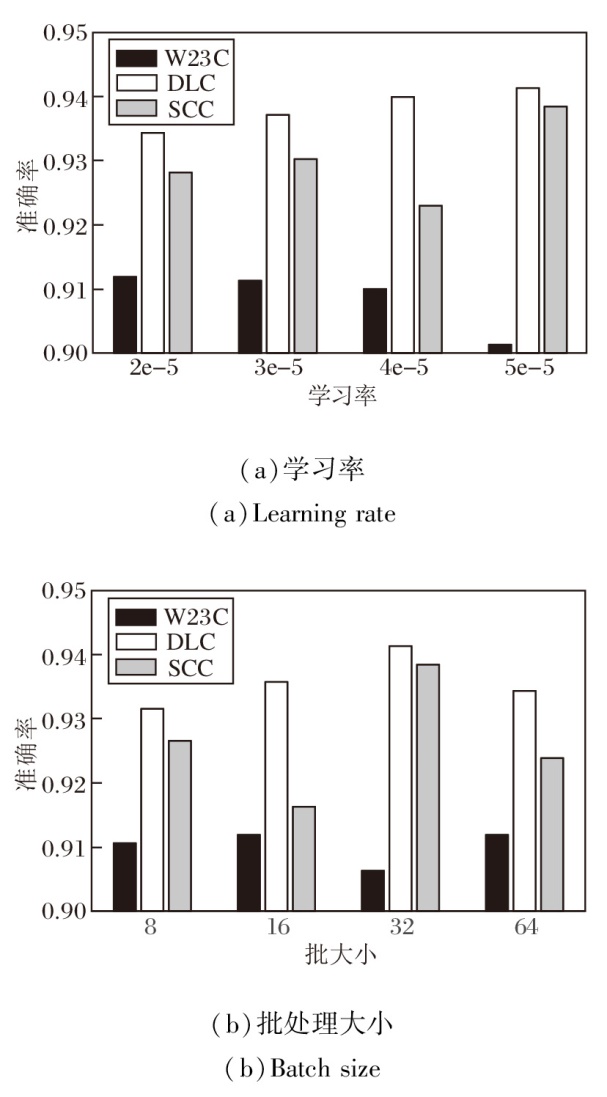 | 图2 参数敏感度分析结果Fig.2 Results of parameter sensitivity analysis |
为了研究不同模板对方法性能的影响, 构建4个手工制作的提示模板, 具体的模板内容详见表5.对于每个模板, 训练样本数设为20, 取5组实验的准确率平均值作为最终结果, 具体如表6所示, 表中黑体数字表示最优值.由表可见, 模板可指导方法更好地理解文本内容, 有效提高点击诱饵检测的性能.
| 表5 提示模板设置 Table 5 Settings of different prompt templates |
| 表6 在3个数据集上使用不同模板的准确率对比 Table 6 Accuracy comparison of different templates on 3 datasets |
需要注意的是, 在不同的数据集之间, 在文本风格、语义和其它特征方面存在显著差异.这突出说明通用的提示模板并不是普遍适用的, 并且需要为每个数据集定制特定的模板.因此, 可选择使用软模板进行输入构建.从表6中可看出, 虽然软提示模板的性能在某些数据集上的结果比不上手工制作的提示模板, 但在节省人力资源的同时优于手工模板的平均性能.
为了减少词性标记可能引入的噪声, 选择NLTK、SpaCy、TextBlob这3种不同的词性标记工具, 帮助SPCD_IE提取训练集上的名词.下面设计一个消融实验, 验证每个工具的有效性, 训练样本数设为20, 不同变体在3个数据集上的准确率对比如表7所示, 表中, × 表示不采用该工具, √ 表示采用该工具, 黑体数字表示最优值.
| 表7 不同变体对标签词空间扩展策略整合的影响 Table 7 Effect of different variants on strategy integration of label word space expansion |
由表7可看出, 每个工具提取扩展词的性能在不同的数据集上是不同的.当同时使用两个工具提取扩展词时, 效果优于仅使用一个工具, 而当使用三个工具提取扩展词时, 效果优于使用两个工具和仅使用一个工具, 这说明SPCD_IE采用3个工具进行扩展词空间扩展的有效性.
为了验证SPCD_IE的计算时间短于对比方法, 对比基于外部知识扩展的代表性方法KPT和SPCD_IE的运行时间, 具体结果如表8所示, 表中时间包括抽词、训练和测试的总时间.在KPT中, 只选择标签词, 再通过相关词和优化得到相关概念.由表8可看出, SPCD_IE在3个数据集上所需的时间都远少于KPT, 这说明SPCD_IE在占用更少的时间的同时更有效.
| 表8 SPCD_IE和KPT在3个数据集上的运行时间对比 Table 8 Comparison of running time of SPCD_IE and KPT on 3 datasets s |
此外, 在实验中发现, 从训练集上抽取并优化扩展词的时间复杂度非常低.因此, 当面临新领域时, 利用SPCD_IE快速抽取相应领域的关键词并构建扩展词集, 并在原有模型上通过少量训练样本进行微调, 可有效提升方法的泛化性能.
在预测阶段, 基于整个表达器中扩展词集的概率进行预测, 假设每个单词在预测中的贡献是等同的.这一假设可简化方法的预测过程, 即表达器中的所有单词对最终的预测分数作均等贡献.
然而, 为了更深入地分析方法的学习偏好, 进一步引入权重分布的概念, 探讨扩展词集中每个单词在预测过程中的权重分配情况, 能更全面理解哪些单词在方法学习中起到更关键的作用.这种权重分布的分析不仅帮助揭示方法对不同特征的敏感性, 还为优化扩展表达器提供新的思路, 从而进一步提升性能.
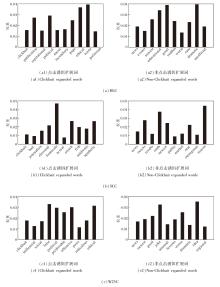
具体地, 为了使扩展知识的分析结果更具一般性, 对不同数据集上的每个扩展词的权重取平均值, 具体如图3所示.
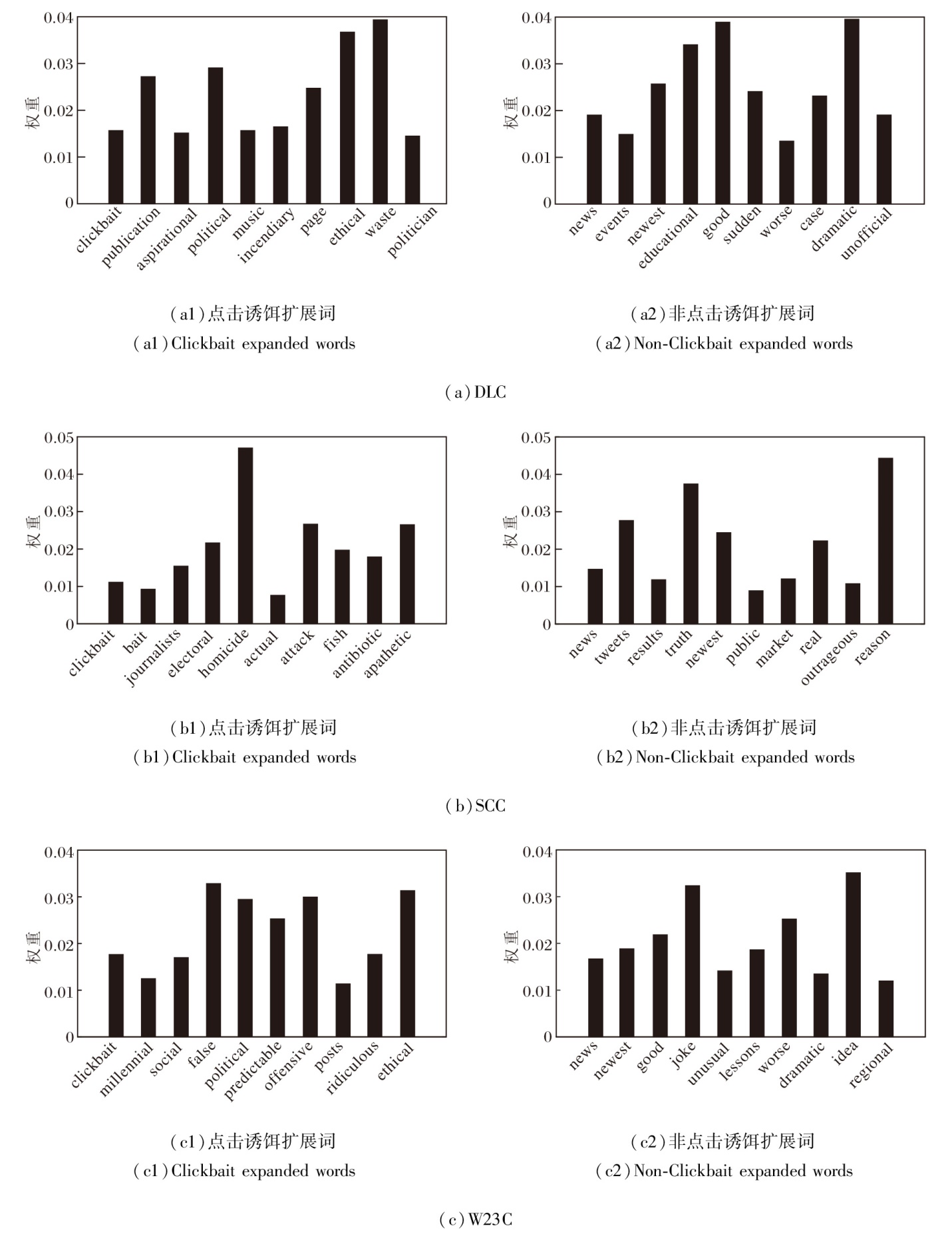 | 图3 表达器扩展词的权重结果Fig.3 Weight results of verbalizer expanded words |
由图3可看出, 不同的数据集上扩展词权重分布不同:在SCC数据集的点击诱饵样本中, 扩展词homicide的权重最高, 在非点击诱饵检测样本中, 扩展词reason的权重最高; 在W23C数据集的点击诱饵检测样本中, 扩展词false的权重最高, 在非点击诱饵样本中, 扩展词idea的权重最高.这些结果与预期不一致, 可能是因为PLM不会像人类那样的方式感知和理解单词.扩展词的权值分配反映方法的学习偏差及其对不同类型特征的敏感性.这些权重可帮助理解方法对不同扩展词的关注程度, 并为进一步研究方法的学习过程提供线索.
为了评估SPCD_IE在中文点击诱饵检测中的泛化能力, 在中文Wechat数据集上进行进一步的实验.Wechat数据集是著名的中文点击诱饵检测基准[2], 源自89个微信公众号, 共标注9 708条原始数据记录, 包括7 281条点击诱饵和2 427条非点击诱饵.每个样本涵盖标题、出版年份、阅读量及点赞数.为使SPCD_IE适应中文Wechat数据集, 进行相应调整, 选择使用LTP(Language Technology Plat-form)和Jieba工具解析中文标题, 训练样本数设为20, 各对比方法的具体指标值结果如表9所示, 表中黑体数字表示最优值.
| 表9 各方法在中文Wechat数据集上的指标值对比 Table 9 Metric value comparison of different methods on Chinese WeChat dataset |
由表9可见, SPCD_IE在中文点击诱饵数据集上依然能实现有竞争力的性能.这一结果可能归因于中文标题中蕴含着大量具有显著特征的关键词, 通过内部知识扩展方法, 有效提取与点击诱饵相关的特征词汇, 这一点在抽词过程中得到充分体现.此外, 进一步探索优化中文词汇的方法, 有助于进一步提升方法在中文点击诱饵检测任务上的性能表现.
为了进一步评估SPCD_IE在正常样本量条件下的表现, 构建全量训练样本数据的实验, 并与KPT进行对比, 具体指标值如表10所示, 表中黑体数字表示最优值.由表可见, 在正常样本量的条件下, SPCD_IE在DLC、SCC数据集上均表现出优于KPT的预测性能, 表明SPCD_IE在充足样本数量下依然具备较强的竞争力.虽然在W23C数据集上, SPCD_IE的表现略低于KPT, 但整体结果相当.这说明SPCD_IE在不同数据集和样本规模下都具有良好的鲁棒性和泛化性.
本文提出基于内部知识扩展的软提示学习点击诱饵检测方法(SPCD_IE), 利用训练数据集上的知识扩展表达器, 降低现有方法对外部知识库质量的依赖, 也减少从外部引入噪声.同时, 采用软提示模板, 避免手工模板构建, 提高方法的泛化能力.在3个点击诱饵检测的公开数据集上的大量实验表明, SPCD_IE性能较优.今后将进一步研究如何更有效利用训练数据集上的内部知识进行扩展, 包括更精细的知识提取方法, 以及对内部知识的有效组织和表示.
本文责任编委 林鸿飞
Recommended by Associate Editor LIN Hongfei
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|
| [40] |
|
| [41] |
|
| [42] |
|
| [43] |
|
| [44] |
|