{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于多类型语音信息分层融合的帕金森病检测模型
[吴迪1  , 季薇
, 季薇1 , 郑慧芬2 , 李云3 ]
, 季薇, 郑慧芬, 李云]
|
|



作者简介: 
吴 迪,硕士研究生,主要研究方向为机器学习、信号处理.E-mail:2799887357@qq.com. 
郑慧芬,博士,主任医师,主要研究方向为帕金森病及相关运动障碍性疾病.E-mail:y020627@126.com. 
李 云,博士,教授,主要研究方向为机器学习、模式识别.E-mail:liyun@njupt.edu.cn.
用于帕金森病检测的语音数据通常包括持续元音、重复音节及情景对话等类型.已有模型大多采用单一类型的语音数据作为输入,容易受到噪声干扰,鲁棒性无法保证.有效整合不同类型语音数据,提取至关重要的病理信息,是当前帕金森病检测任务面临的挑战之一.文中提出基于多类型信息分层融合的帕金森病检测模型,旨在提取全面的病理信息,实现较优的检测性能.首先,针对不同类型的帕金森病语音数据,分别进行多种声学特征的提取.然后,设计挖掘多类型声学特征深层信息的表示学习方案,提取调音和韵律信息,精准反映声学特征中潜在的病理信息.进而针对两类信息,设计解耦的表示学习空间,分别提取各自的私有特征,同时学习它们的共有表示.最后,设计跨类型的注意力分层融合模块,利用交叉注意力机制,以不同粒度交互的方式逐步融合共有表示和私有表示,提升帕金森病检测性能.在公开的意大利语帕金森病语音数据集和自采的汉语帕金森病语音数据集上的实验表明,文中方法性能提升明显.
About Author:
WU Di, Master student. His research interests include machine learning and signal processing.
ZHENG Huifen, Ph.D., chief physician. Her research interests include Parkinson's di-sease and movement disorders.
LI Yun, Ph.D., professor. His research interests include machine learning and pattern recognition.
Speech data for Parkinson's disease detection typically includes sustained vowels, repeated syllables and contextual dialogues. Most of the existing models adopt a single type of speech data as input, making them susceptible to noise interference and a lack of robustness. The current challenge of Parkinson's disease detection is effectively integrating different types of speech data and extracting critical pathological information. In this paper, a Parkinson's disease detection method based on hierarchical fusion of multi-type speech information is proposed, aiming to extract rich and comprehensive pathological information and achieve better detection performance. Firstly, various acoustic features are extracted for different types of Parkinson's disease speech data. Then, a representation learning scheme is designed to mine deep information from multiple types of acoustic features. The underlying pathological information in acoustic features is reflected more accurately by extracting articulation and rhythm information. Furthermore, a decoupled representation learning space is designed for two mentioned types of information above to extract their respective private features, while learning their shared representation simultaneously. Finally, a cross-type attention hierarchical fusion module is designed to progressively fuse shared and private representations using cross-attention mechanisms at different granularities, aiming to enhance Parkinson's disease detection performance. Experiments on publicly available Italian Parkinson's disease speech dataset and a self-collected Chinese Parkinson's disease speech dataset demonstrate the accuracy improvement of the proposed approach.
帕金森病[1]是一种慢性退行性神经系统疾病, 以运动障碍[2]为主要特征(包括静止性震颤、肌肉僵直和运动缓慢等), 对非运动功能(如自主神经系统、认知和情感等)也有一定的影响.研究表明, 帕金森病和发音障碍之间有一定的病理联系.帕金森病患者可能出现言语流畅性下降、声音嘶哑、语速减缓、文法结构紊乱等表现[3, 4].患者语音上的这些变化一部分源自口腔肌肉僵硬导致的运动障碍, 一部分可能与认知功能障碍相关.
帕金森病患者的发音障碍可分为调音障碍和韵律障碍[5].针对帕金森病患者的语音功能测试主要有持续元音(如/a/、/i/、/u/等)、重复音节(/pakala/)、情景对话等语料测试内容.元音发音可评估受试者的声带受损状况, 帕金森病患者的声带和声道中各种肌肉的配合程度明显下降[6, 7]; 重复音节发音能较好地分析受试者移动齿龈、下颌和舌头等发音器官的协调能力[8, 9]; 情景对话主要检测发音的韵律缺陷, 帕金森病患者在韵律上会出现为语调单一、音强单一和音长变化大等情况[10, 11].总之, 持续元音和重复音节反映帕金森病患者语音的调音特征, 而情景对话反映患者语音中的韵律特征[5].通过多类型语音数据的采集, 可全面反映帕金森病患者的语音缺陷, 对基于语音的帕金森病检测提供丰富的数据来源.
目前, 基于语音的帕金森病检测方法大多基于单一类型语音数据进行.在持续元音数据上, 研究者们提出一系列有代表性的研究成果[12, 13, 14, 15].Tsanas等[12]采集帕金森病患者持续元音数据, 通过特征提取技术, 提取包括基频微扰(Jitter)、振幅微扰(Shimmer)、DFA(Detrended Fluctuation Analysis)等特征, 并分析将持续元音数据和机器学习技术结合后进行远程帕金森病诊断的可行性.Pramanik等[14]针对持续元音的帕金森病语音数据, 引入不同的数据预处理方法, 利用数据标准化、降维技术, 提高数据质量, 并使用不同的分类器模型对患病与否进行分类, 实现性能的较大提升.
在对其它类型语音数据的研究中, Kim等[16]针对韩语重复音节数据, 提出PSSLM(Phonologically-Structured Sparse Linear Model), 同时解决语音结构化稀疏特征选择和可理解性预测问题.Wang等[17]针对情景对话数据, 提出GDABC(Gbest Dimension Artificial Bee Colony Algorithm), 使用ResNet-50实现特征提取和帕金森病分类.
相比单一类型语音数据, 多类型帕金森病语音数据包含更丰富的病理特征信息.因此, 基于多类型语音数据进行病情的分类检测成为一种有效途径.由于卷积神经网络和循环神经网络在机器学习领域的巨大影响, 最初一些学者通过深度神经网络探究多类型语音数据.Mallela等[18]基于持续元音数据、重复音节数据和情景对话数据, 利用卷积神经网络和循环神经网络的整合结构, 研究联合预测帕金森症病人、阿尔兹海默症病人和对照组的方案.由于该方案在联合任务中未针对帕金森病进行优化设计, 因此在帕金森病患者的分类任务上并不是最优选择.
近年来, 由于帕金森病声学研究的持续发展, 一些学者针对多类型语音数据特点展开探索.张小恒等[19]针对帕金森病语音数据集小样本数量的问题, 提出双面双阶段均值聚类包络和卷积稀疏迁移学习算法, 考虑样本间的深层结构信息, 对来自多类型数据样本的融合层数展开探讨.为了全面描述发音缺陷, Liu等[20]研究多种发声和发音特征在帕金森病语音自动评估中的应用, 通过卷积神经网络对这些时间特征进行建模, 实验表明来自多类型语音任务的组合可进一步提升预测性能.然而, 该方案专注于各种声学特征自身的信息提取, 并未充分考虑帕金森病语音声学特征之间的复杂交互关系.
由于不同类型的帕金森病语音之间存在发音、发声、语调、韵律等多方面的差异性, 因此, 可将不同类型的语音视为多模态数据进行处理, 以便全面捕捉患者语音中的细微变化, 从而有效识别和监测帕金森病的症状和进展.基于持续元音和重复音节数据, 季薇等[21]提出用于帕金森病辅助检测的多源语音信息融合模型(Multisource Data Fusion Autoenco-der, MSFAE), 实现帕金森病病理信息的提取, 有效抵御非病理性因素的影响, 大幅提高帕金森病检测的准确率.然而, MSFAE并未充分利用所有可能的数据类型.研究表明, 情景对话会受到疾病严重程度的强烈影响.因此, 有必要结合情景对话数据, 对基于语音的帕金森病检测展开研究.
目前, 多模态学习技术已取得较多进展.学者们将对比学习[22]引入多模态学习中.Radford等[23]提出CLIP(Contrastive Language-Image Pre-training), 核心思想是采用对比学习的方法将视觉和语言的表示方式相互联系, 使模型能在无标注数据上进行训练, 并学到具有良好泛化能力的特征表示.Franceschini等[24]提出Modality-Pairwise Unsupervised Contrastive Loss, 取得良好的情绪识别效果.但是, 在融合阶段单纯使用特征拼接, 并未充分考虑不同模态信息之间的交互.Hazarika等[25]提出MISA(Modality-Invari-ant and-Specific Representations for Multimodal Senti-ment Analysis), 引入私有特征和共有特征的表示方法, 并在两者之间施加一定的约束, 使各模态信息得到较完善的表示, 有效提高情感分析的准确性.然而, MISA采用的重构损失与特征约束损失的尺度差距较大, 不利于模型在优化过程中的收敛.在多模态融合方面, Kim等[26]利用注意力机制, 提出ViLT(Vision-and-Language Transformer), 对图像和文本进行融合表示, 在视觉问答等任务上取得优异表现.
为了有效整合不同类型的语音数据, 提取至关重要的病理信息, 需要一种更灵活和多层次的融合方式, 用于充分捕捉这些信息之间的复杂关系.基于上述考虑, 本文提出基于多类型语音信息分层融合的帕金森病检测模型(Parkinson's Disease Detection Model Based on Hierarchical Fusion of Multi-type Speech Information, HFMSI).HFMSI由特征提取模块、多层次的语音信息表示学习模块、跨类型注意力分层融合(Cross-Type Attention Hierarchical Fusion, CTA-HF)模块构成.首先, 针对持续元音、重复音节、情景对话的帕金森病语音样本, 进行多种声学信息的特征提取.然后, 设计挖掘多类型声学特征深层信息的表示学习方案:对于持续元音和重复音节, 利用对比学习方法提取两者反映的调音信息; 对于情景对话, 利用韵律表征编码器提取韵律信息.再将调音表征和韵律表征送入解耦的多类型语音数据表示空间.该方案通过提取多类型语音数据之间的共有信息和私有信息, 更完善地对不同类型的语音数据进行表示学习.最后, 设计跨类型注意力分层融合模块, 利用交叉注意力机制完成多类型语音数据之间的特征融合.实验表明, HFMSI在准确率、敏感度和F1分数上均有明显提升.
对比学习[22]是一种特殊的无监督学习方法, 通过对比不同样本或实例之间的相似性和差异性进行模型的训练和学习.对比学习在图像识别、自然语言处理、推荐系统等领域具有广泛的应用.Li等[27]提出CPC(Contrastive Predictive Coding), 通过无监督对比学习, 利用未标记的数据学习潜在的情感语义信息, 有效解决情绪识别任务中缺乏大规模数据集的问题.Kim等[28]对比具有强烈情感特征的样本和具有较弱情感特征的样本, 学习复杂的语义情感信息, 解决情感识别方法对监督信息过于依赖的问题.在CLIP[23]中, 对比学习用于训练模型学习视觉和语言的相互关系.具体地, CLIP将图像和文本映射到同一表示空间, 并通过对比不同图像和文本对之间的相似性和差异性进行训练, 从而学到具有良好泛化能力的特征表示.
基于解耦的表示学习的目的是将真实数据中存在明确物理含义的信息按照人类可理解的方式进行解耦, 并得到对应的独立潜在表示.对具有部分相似重叠属性的分组数据, 学者提出使用共享或交换局部的隐含变量的方法[29, 30], 实现网络关于代表组内数据具体相关信息的潜在变量的学习, 从而完成组内数据相关信息和不相关信息的解耦表示学习任务.解耦的表示学习的早期研究以自编码器[31]和生成对抗网络(Generative Adversarial Networks, GA-Ns)[32]为代表.Chen等[33]结合贝叶斯方法分解人脸表示, 将其模型化为内在属性、变换属性及噪声三个独立成分.进一步地, 为了增强表征的解耦, Kim等[34]提出FactorVAE, 促进表征在各个独立维度上的解耦.
近些年, 解耦的表征学习方法在处理跨模态数据方面表现较优.Wu等[35]提出DVR(Disentangled Variational Representation), 优化不同模态之间的变化相关性, 实现解耦的变分表示, 但存在信息丢失和模态特征融合不足的问题.Guo等[36]提出一种跨模态分离模型, 基于深度互信息估计, 从共享的表示中分离特定模式的独有信息, 但可能无法充分利用模态之间的相互关系.
多源信息融合[37]是指将来自不同传感器或数据源的信息进行综合处理的过程, 以获得更全面、准确的预测结果.由于单一来源的数据往往无法提供足够的信息以实现精确预测, 多源信息融合可综合多源数据信息, 有效弥补单一来源数据各自的局限性, 并拓宽信息的覆盖范围, 从而提高预测的准确性和可靠性.近年来, 代表性的多源信息融合模型如下.Khattar等[37]提出MVAE(Multimodal Variational Autoencoder), 利用多个子网络学习单一数据的特征, 并运用变分思想学习多源数据特征的潜在分布, 以提取图像和文本数据的完整的多源信息.Tsai等[38]提出MulT(Multimodal Transformer), 核心是通过成对的交叉注意力交互机制, 直接通过关注其它数据的特征以融合多源信息.基于单流的Trans-former 模型的ViLT[26], 将特征抽取部分进行极简计算, 将核心部分放在特征融合上, 在语言和视觉的任务上取得较优性能.Yu等[39]提出ULGM(Unimodal Label Generation Module), 使用多任务学习同时训练多源信息融合任务与其它三个子任务.
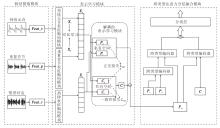
本文提出基于多类型语音信息分层融合的帕金森病检测模型(HFMSI), 整体结构如图1所示.HFMSI由特征提取模块、表示学习模块、跨类型注意力分层融合(CTAHF)模块构成.
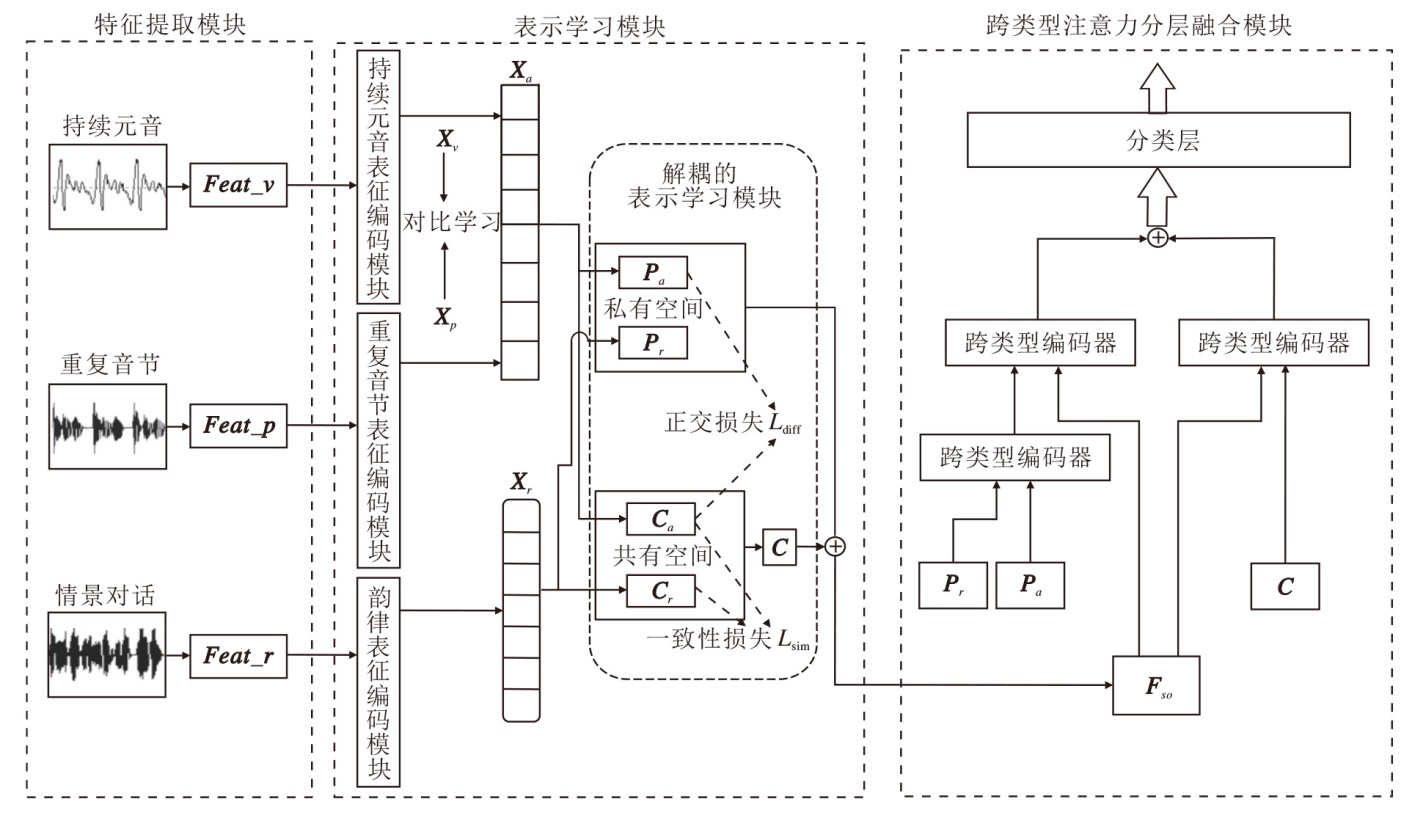 | 图1 HFMSI整体结构图Fig.1 Overall structure of HFMSI |
针对每位受试者, 均采集持续元音、重复音节和情景对话这3种类型的语音数据.在特征提取模块, 对预处理后的数据进行传统特征提取:从持续元音数据中提取Feat_v, 即噪声谐波比、基频、基音周期熵等元音特征[6, 7]; 从重复音节数据中提取Feat_p, 即循环周期密度熵、巴克带能量等重复音节特征[8, 9]; 从情景对话中提取Feat_r, 即对数能量、持续时间等韵律类特征[10, 11].这些直接从语音中提取的传统特征统称为低级特征.
表示学习模块对上述提取的低级特征进行高级特征的表示学习.首先, 将不同类型语音数据对应的传统声学特征送入编码器, 分别得到输出序列Xv、Xp、Xr.由于持续元音和重复音节共同表达帕金森病患者语音的调音特征, 对它们编码后的结果Xv和Xp进行对比学习, 可提取调音特征Xa.情景对话的传统声学特征编码后的结果Xr反映患者的韵律特征.再将Xa和Xr送入解耦的表示学习模块, 获得共有表征和私有表征.
跨类型注意力分层融合模块利用多类型信息融合策略, 并且根据多种表示进行不同粒度层次的特征融合, 提升帕金森病检测性能.
表示学习模块包含两个层次, 是为了突出帕金森病声学特征的调音声学表征和韵律声学表征的表示空间, 得到两种稳定衡量帕金森病的声学信息.然后进行两种声学信息相关性和独特性的解耦表示学习.通过对帕金森病语音深层信息的内在挖掘, 可使下游任务中的帕金森病多类型数据融合结果更有效, 从而提高帕金森病的检测性能.
2.1.1 调音声学表征和韵律声学表征的提取模块
在提取3种不同类型帕金森病语音数据的传统声学特征之后, 首先需要对这些声学特征进行特征编码.语音表征学习子模块被设计成具有3个隐藏层的前馈网络(记为Enc), 分别对应图1中的持续元音表征编码模块、重复音节表征编码模块和韵律表征编码模块.每层网络结构拥有100个神经元, 激活函数为ReLU.针对这3种语音表征, 可学习的权重参数分别表示为Wv、Wp和Wr.
三种不同类型帕金森病语音数据的传统声学特征经过编码后的输出序列如下所示:
$ \begin{array}{l} \boldsymbol{X}_{v}=\operatorname{Enc}_{s p c_{-} v}\left(\boldsymbol{F e a t} \boldsymbol{t}_{-} \boldsymbol{v} ; \boldsymbol{W}_{v}\right) \in \mathbf{R}^{L_{v} \times d_{v}}, \\ \boldsymbol{X}_{p}=E n c_{s p c_{-} p}\left(\boldsymbol{F e a t} \boldsymbol{p} ; \boldsymbol{W}_{p}\right) \in \mathbf{R}^{L_{p} \times d_{p}}, \\ \boldsymbol{X}_{r}=\operatorname{Enc}_{s p c_{-} r}\left(\boldsymbol{F e a t} \boldsymbol{t}_{-} \boldsymbol{r} ; \boldsymbol{W}_{r}\right) \in \mathbf{R}^{L_{r} \times d_{r}}, \end{array}$
其中, L(· )表示序列长度, d(· )表示嵌入维数.
在单类型声学特征提取中, 已获得基于情景对话语料的韵律声学表征Xr, 下面主要任务是从持续元音和重复音节编码中提取调音声学表征.
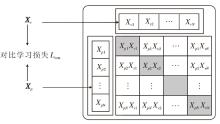
由于持续元音和重复音节共同表达帕金森病患者语音的调音类声学信息, 首先利用对比学习提取调音特征.具体地, 将持续元音表征Xv和重复音节表征Xp利用对比学习进行表征对齐, 提取特征中潜在的调音信息.这里的对比学习模块使用CLIP[23]的训练方法.对比学习的目标就是让正样本对的相似度增高, 而负样本对的相似度降低.通过对比学习进行特征对齐, 可提取特征中潜在的不变表征(调音表征).具体学习过程如图2所示.
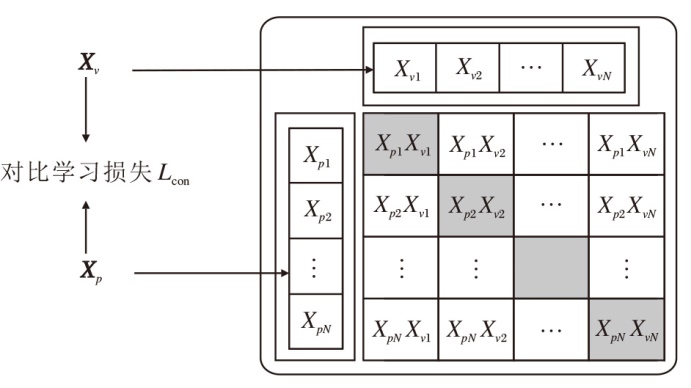 | 图2 对比学习模块的学习过程Fig.2 Learning process of contrastive learning module |
CLIP的具体实现过程如下.首先, 将经过特征编码的持续元音表征Xv和重复音节表征Xp的数据样本进行归一化操作:
$ \begin{array}{l} \boldsymbol{X}_{v}=\frac{\boldsymbol{X}_{v}-\min \left(\boldsymbol{X}_{v}\right)}{\max \left(\boldsymbol{X}_{v}\right)-\min \left(\boldsymbol{X}_{v}\right)}, \\ \boldsymbol{X}_{p}=\frac{\boldsymbol{X}_{p}-\min \left(\boldsymbol{X}_{p}\right)}{\max \left(\boldsymbol{X}_{p}\right)-\min \left(\boldsymbol{X}_{p}\right)} . \end{array}$
然后, 将这两种表示映射到一个统一的空间, 使正样本 (即属于同位受试者的语音样本)的两种数据的嵌入彼此接近, 使负样本 (即不同受试者的语音样本)的两种数据的嵌入彼此分开.给定一个批次(Batch), 假设其有N对(Xv, Xp)对, 共包含N× N对样本组合, 计算其余弦相似度并预测哪些样本对是实际存在的.N对正确匹配的(Xv, Xp)对之间的余弦相似度会增加, 而N2-N个错误匹配的样本对之间的余弦相似度会减小.在这个过程中, 持续元音Xv和重复音节Xp的对比损失函数为:
其中, X(· )表示上文得到的持续元音表征和重复音节表征, i、 j表示当前批次数量为N的样本的索引, τ 表示温度参数(标量), 1[i≠ j]表示在i≠ j时取值为1的指标函数, sim(u, v)表示两个归一化向量u、v之间的余弦相似度.在同一批次中的所有帕金森病语音表征样本i上计算式(1), 得到
Lv, p=
此外, 将持续元音表征Xv和重复音节表征Xp之间的损失最小化.由于负样本仅从一种语音表征序列中提取(参见式(1)中的分母), 损失是不对称的, 即Lv, p≠ Lp, v, 因此, 最终得到的损失函数包含两种声学特征进行排列所得的损失, 即
Lcon=
因为只有对比不同类型的表征才能产生更好的表示.
在利用对比学习对齐持续元音特征和重复音节特征之后, 将它们连接起来, 最终得到两种信息中共同反映的帕金森病语音调音表征:
Xa=conat(Xv; Xp),
其中, conat(· ; · )表示特征拼接函数.调音特征序列Xa的嵌入维度是持续元音和重复音节的维度之和.
2.1.2 解耦的表示学习模块
本文从多类型语音数据之间的相关性和独立性出发, 设计一种解耦的表示学习方法, 用于提取调音信息和韵律信息中的共有表示和私有表示.
1)私有空间表示和共有空间表示.在得到调音特征表示和韵律特征表示之后, 解耦的表示学习将调音特征和韵律特征投影到共有子空间和私有子空间中, 学习共有特征表示和私有特征表示, 以解决多类型数据信息交互融合、不同数据之间的异质性等问题[40]. 因此, 本文提出共有信息编码器和私有信息编码器, 分别将从每个类型数据中预提取的特征嵌入共有子空间和私有子空间中.共有空间旨在探索每种数据之间的共性, 充分缩小分布差距.私有空间试图增强多样性并捕捉每种数据的独特特征.这种解耦的表征学习的本质是利用共有表征和私有表征分别捕获异构数据的一致性和特异性.调音特征和韵律特征的共有表示和私有表示可表示为
$ \begin{array}{l} \boldsymbol{C}_{a}=I\left(\boldsymbol{X}_{a} ; \theta_{I}\right) \in \mathbf{R}^{d_{k}}, \\ \boldsymbol{C}_{r}=I\left(\boldsymbol{X}_{r} ; \theta_{I}\right) \in \mathbf{R}^{d_{k}}, \\ \boldsymbol{P}_{a}=S_{a}\left(\boldsymbol{X}_{a} ; \theta_{a}\right) \in \mathbf{R}^{d_{k}}, \\ \boldsymbol{P}_{r}=S_{r}\left(\boldsymbol{X}_{r} ; \theta_{r}\right) \in \mathbf{R}^{d_{k}}, \end{array}$
其中, 共有编码器I(· ; θ I)在每种表征下共享参数θ I, 私有编码器Sm(· ; θ m)获取各表征的参数θ m, m=a, r.更正式地说, 使用多层感知机(即前馈神经网络)[41]实现共有特征编码器I(· ; θ I)和私有特征编码器Sm(· ; θ m).具体地, 每个编码器的输入层接收原始数据, 经过第一层隐藏层(维度为200), 通过激活函数对加权输入进行非线性变换.第二层为输出层, 将隐藏层的输出映射到特定的输出空间(维度为128), 其中激活函数为GeLU.
2)正交约束.为了确保多类型语音表征可对不同方面进行建模, 并减少不同表征之间的信息冗余, 本文引入软正交约束, 当两个表征之间的独立性较高时, 它们之间的差异更显著.软正交约束因其快速收敛性, 在多个机器学习任务中得到广泛应用[31].设
$ L_{\text {diff }}=\left\|\boldsymbol{H}_{a}^{\mathrm{c}^{\mathrm{T}}} \boldsymbol{H}_{a}^{p}\right\|_{\mathrm{F}}^{2}+\left\|\boldsymbol{H}_{r}^{c^{\mathrm{T}}} \boldsymbol{H}_{r}^{p}\right\|_{\mathrm{F}}^{2}+\left\|\boldsymbol{H}_{a}^{p^{\mathrm{T}}} \boldsymbol{H}_{r}^{p}\right\|_{\mathrm{F}}^{2} .$
3)一致性约束.受文献[42]的启发, 本文将定制约束应用于多类型数据的解纠缠表示学习.对于共有表示, 引入一致性约束, 增强不同表征之间的共性.最小化一致性损失可减少每种数据的共有表征之间的差异, 有助于共同的跨类型特征在共享子空间(共有表征空间)中对齐.这里采用中心矩差异(Central Moment Discrepancy, CMD)作为一致性损失.CMD是一种距离度量, 通过匹配两个表示的阶数矩差以衡量两个表示的分布之间的差异.直观上看, CMD距离会随着两个分布变得更相似而减少.设D、S为有界的随机样本, 在区间[a, b]上的概率分布为p、q.中心矩差异CMDK定义为CMD度量的经验估计:
$\begin{aligned} C M D_{K}(\boldsymbol{D}, \boldsymbol{S})= & \frac{1}{|b-a|}\|E(\boldsymbol{D})-E(\boldsymbol{S})\|_{2}+ \\ & \sum_{k=2}^{K} \frac{1}{|b-a|^{k}}\left\|T_{k}(\boldsymbol{D})-T_{k}(\boldsymbol{S})\right\|_{2}, \end{aligned}$
其中,
E(D)=
表示样本D的经验期望向量.
Tk(D)=E((d-E(D))k)
表示所有k阶样本D的中心矩向量, 即D的坐标.本文得到的CMD损失为:
Lsim=CMDK(
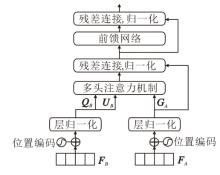
在表示学习中, 虽然已提取到病理特征的私有信息和共有信息, 但是表征的不同方面对最终预测具有不同的重要性.如果简单地将它们连接起来完成下游任务, 会忽略数据之间的相互作用, 可能会引入冗余信息而导致次优问题[43].为了在精炼的共有表示和私有表示中充分利用两种表示的信息优势, 本文提出跨类型注意力分层融合(CTAHF)模块, 结构如图3所示.CTAHF模块是一种多层次跨类型数据交互模块.
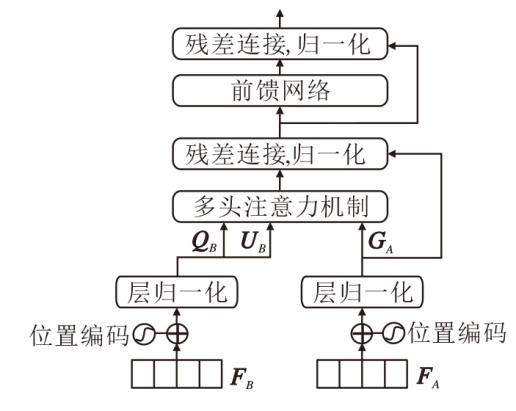 | 图3 CTAHF模块结构图Fig.3 Structure of CTAHF module |
2.2.1 跨类型编码器
在充分的跨类型交互作用中, 每种类型表示都会得到有效的加强和改进.如图3所示, 受自注意力机制(Self-Attention)[44]的启发, 首先将表征FA加上位置编码, 进而将其变换为
GA=LN(FA)
表征FB分成两个空间:
QB=LN(FB)
其中,
分别表示嵌入权重.
通过多头注意力机制实现跨类型交互, 输入输出关系定义如下:
FB→ A=softmax(GA
因此, 跨类型编码器的整体输入输出关系可由如下的前向函数表示:
Y(FB, FA)=LN(FA)+FB→ A, Y(FB, FA)=fδ (LN(Y(FB, FA)))+Y(FB, FA),
其中, fδ (· )表示由δ 参数化的前馈网络, LN(· )表示层归一化.最终得到表征B和A经过跨类型编码器进行信息交互后的结果:
ZB, A=Y(FB, FA).
2.2.2 多类型数据分层交互阶段
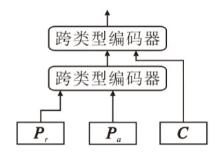
由于在精炼的共有表示之间已存在很强的共性, 所以将来自不同数据的共有表示合并为
C=Ca+Cr.
同时把表示学习中得到的所有表示连接为
Fso=[C, Pa, Pr]∈
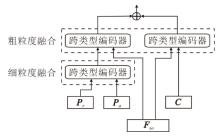
该阶段的核心策略是探索通过跨类型注意力后多种不同表征之间的潜在适应过程.对于得到的不同表征, 需要设计多粒度融合方式, 整体结构如图4所示.
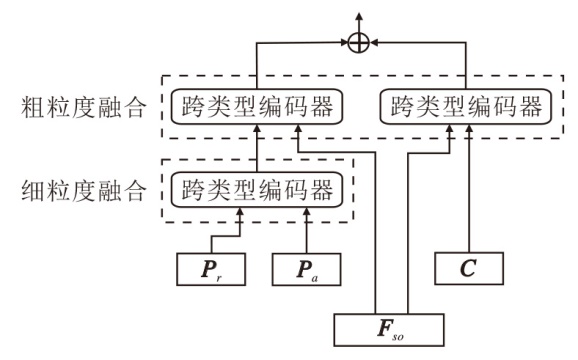 | 图4 多粒度融合结构图Fig.4 Structure of multi-granularity fusion |
首先, 将上文解构的共有表征数据和私有表征数据分为两支, 利用不同粒度层次的表征进行交互.私有编码Pr和Pa体现数据异质结构的不同特征, 在下游任务预测中处于主导地位, 可先进行细粒度的信息交互.
然后, 利用表示学习中连接的整体Fso对私有表征和共有表征进行粗粒度的表示增强和改进.过程如下所示.
1)细粒度融合.$ \boldsymbol{Z}_{\boldsymbol{P}_{r}, \boldsymbol{P}_{a}}=Y\left(\boldsymbol{P}_{r}, \boldsymbol{P}_{a}\right) .$
2)粗粒度融合.$ \boldsymbol{Z}_{\boldsymbol{F}_{s o}, \boldsymbol{Z}_{\boldsymbol{P}_{r}, \boldsymbol{P}_{a}}}=Y\left(\boldsymbol{F}_{s o}, \boldsymbol{Z}_{\boldsymbol{P}_{r}, \boldsymbol{P}_{a}}\right) .$
3)粗粒度融合.$ \boldsymbol{Z}_{\boldsymbol{F}_{s o}, \boldsymbol{C}}=Y\left(\boldsymbol{F}_{s o}, \boldsymbol{C}\right) .$
利用私有表征和共有表征的连接, 得到最终的特征表示:
Vdet=concat(
2.2.3 帕金森病辅助诊断模块
最终的特征表示Vdet进入帕金森病辅助诊断模块(记为Det)中, 在检测模块中进行帕金森病的预测.帕金森病辅助诊断模块结构设置为全连接层.各层神经元的数量依次设置为64、24、2, 激活函数为ReLU.样本标签集y∈ [0, 1], y=0时表示参与者为健康组, y=1时表示参与者为帕金森病患者.辅助诊断模块的分类输出为:
$\hat{y}=\operatorname{Det}\left(\boldsymbol{V}_{\mathrm{det}} ; \boldsymbol{W}_{\mathrm{det}}\right), $
其中, Wdet表示检测模块参数, 这里选择交叉熵损失函数计算任务的分类损失.
HFMSI通过多个模块的学习进行优化, 其中, 帕金森病辅助诊断模块使用交叉熵损失函数, 调音信息的提取采用成对的对比学习损失, 同时在表示学习中加上两种特征约束.本文将联合训练各个子模块, 最终得到的模型损失如下:
Ltotal=λ conLcon+λ diffLdiff+λ simLsim+λ detLdet,
其中, Lcon表示提取调音表征的对比学习损失, Ldiff表示共有信息表征和私有信息表征间及私有信息表示之间的差异损失, Lsim表示共有信息表征间的一致性损失, Ldet表示帕金森病检测模块的分类损失, λ con、λ diff、λ sim、λ det表示权重系数.
多个损失函数在整体学习的训练中因为损失量级的不同有可能会影响整体的优化过程, 为此本文设置多个超参数λ con、λ diff、λ sim、λ det, 多种损失添加权重系数, 通过这种处理方式可使模型结构更合理, 有利于系统收敛.各个权值的优化是通过网格搜索[45]实现的, 首先为这4个权重分别设置不同的初始权重范围, 再通过网格搜索寻找最优超参数组合.
本文在自采的汉语帕金森病数据集和公开的意大利语帕金森病数据集(Italian Parkinson's Voice and Speech)[46]上进行中外两种帕金森病语音数据综合实验.两个数据集均包含三种类型语音数据, 即持续元音/a/、快速重复音节发音、指定文本阅读情景对话内容.
为了进行基于多类型语音的帕金森病辅助诊断研究, 本文研究团队创建一个多类型帕金森病语音数据集.数据集由南京医科大学附属老年医院帕金森病及运动障碍专病门诊精选的68名患者和17名健康人的语音数据组成, 涵盖男性受试者和女性受试者的信息.男性受试者共计57人, 包括49名帕金森病患者和8名健康人员; 女性受试者共计28人, 包括19名帕金森病患者和9名健康人员.在数据采集过程中, 受试者需要在安静的环境中进行语音记录, 确保环境噪音低于20 dB.他们被要求将嘴唇放置在离麦克风不到10 cm的范围内, 并在专业人员的指导下开始发声.采集到的患者语音记录经过剪辑处理, 共产生414个样本, 并以48 kHz的采样率保存为wav格式.医务人员根据受试者的疾病情况和严重程度标记这些语音样本.
意大利语数据集由意大利巴里大学研究团队创建, 录音总数为65人, 其中28人(9名女性, 19名男性)患有帕金森病.健康对照组由15名(2名女性, 13名男性)年轻人和22名(12名女性, 10名男性)老年人组成.测试使用的文本是音素平衡的.受试者在专家的简要讲解后进行阅读, 其与麦克风的距离保持在15 cm~25 cm之间.文本和单词均打印在印刷版上.患者的语音记录经过剪辑后, 共产生328个样本, 同样保存为wav格式.
实验使用PyTorch学习框架实现, 所有实验均在如下相同的环境下实现:RTX 3060 GPU, 12th Gen Intel(RH 2.30 G) Core(TM) i7-12700 Hz, 16 GB内存, 64位操作系统.
实验参数具体设置如下.Feat_v的维度为414× 64, Feat_p的维度为414× 488, Feat_r的维度为414× 103, Xv、Xp、Xr的维度均为414× 64, Xa的维度为414× 128, 跨类型编码器G、Q、U的向量维度为64, 共有表征编码器和私有表征编码器网络维度均为[200, 128], 帕金森病辅助诊断模块网络维度为[64, 24, 2], 学习率为0.000 1, 批次大小为60, 失活率为0.1, 采用Adam(Adaptive Moment Estimation)优化器.
实验使用10折交叉验证方法, 客观呈现模型实际性能, 并采用准确率(Accuracy, ACC)、敏感度(Sensitivity, SEN)和F1分数(F1-score)作为性能评价指标, 计算公式分别如下:
$\begin{array}{l} A C C=\frac{T P+T N}{T P+T N+F P+F N}, \\ S E N=\frac{T P}{T P+F N}, \\ F 1=\frac{2}{2+\frac{F P}{T P}+\frac{F N}{T P}}, \end{array}$
其中, TP表示正确识别的帕金森病患者样本数量, TN表示正确识别的健康人样本数量, FP表示将健康人错误识别为帕金森病患者的样本数量, FN表示将帕金森病患者错误识别为健康人的样本数量.
3.3.1 汉语自采数据集上的性能对比
本节选择对比的经典的多源信息融合模型如下:文献[24]模型, ViLT[26], MVAE[37], MulT[38], MFIR(Multimodal Fusion and Inconsistency Reaso-ning)[47], GAME-ON(Graph Attention Network Based Multimodal Fusion)[48].同时, 选择在汉语自采数据集上的SOTA模型MSFAE[21]进行对比.
MulT、ViLT和本文的跨类型注意力分层融合(CTAHF)模块一样, 均受到自注意力机制(Self-Attention)的影响.MulT采用双流Transformer, ViLT采用单流Transformer, 而HFMSI在跨类型编码器基础上以多层次、不同粒度的方式融合解耦特征, 可更全面融合帕金森病语音数据的复杂特征.
MVAE和HFMSI同属多任务学习方法, 但MVAE中变分自编码器的重构损失远大于其它损失, 难以收敛.HFMSI中较小的约束差距减少优化过程中的复杂性, 简化模型训练.
文献[24]模型也采用CLIP的对比学习方案, 但其关注点在于特征对齐, 未有效融合多类型数据.
MFIR和HFMSI一样对多类型数据进行多层次的交互, 但在过程中主要关注捕获不一致的信息, 对特征相关性感知有限.
GAME-ON同样允许在模态间和模态内进行精细交互, 与HFMSI不同的是, GAME-ON采用图神经网络框架, 但实时更新图结构的处理能力有限.
MSFAE是汉语自采数据集的SOTA模型, 基于持续元音和重复音节数据, 使用基于多头注意力机制的多源信息融合模型, 实现帕金森病病理信息的提取.
各模型在汉语自采数据集上的对比结果如表1所示.
| 表1 各模型在汉语自采数据集上的性能对比 Table 1 Performance comparison of different models on self-collected Chinese dataset % |
由表1可见, HFMSI在准确率、敏感度和F1-score指标上均最优, MVAE采用的联合训练方式加大变分自编码器的重构损失, 而HFMSI的多任务损失尺度相对较小, 有利于检测模块的训练.相比MulT、ViLT的双流Transformer和单流Transformer结构, HFMSI利用跨类型注意力融合结构, 并进行粒度下降的分层融合设计, 更好地提取帕金森病病理特征.文献[24]模型在数据融合方面单纯使用特征拼接, 相比其它监督学习方法, 仍具有较大差距.MFIR对特征相关性感知有限, 而GAME-ON利用图神经网络进行交互, 性能略优.MSFAE效果较优, 但仅采用持续元音和重复音节数据, 限制对韵律信息的提取.
3.3.2 意大利语数据集上的性能对比
为了继续验证HFMSI在其它语言上的性能, 在意大利语数据集上进行对比实验.除了上节对比模型外, 同样选择在此数据集上的SOTA模型— — 文献[49]模型.文献[49]模型使用变分模态分解, 将非线性语音信号分解为幅度和频率调制函数两种指标, 但模态分解仅适用于元音数据.
各模型在意大利语数据集上对比结果如表2所示.由表可看出, HFMSI同样取得最优结果.与汉语数据集上的表现相比, HFMSI在意大利语数据集上的准确率相对较低, 原因可能和意大利语语种、结构和使用情况有关, 同时意大利语数据集上部分年轻人对照组样本缺失, 数据集样本数量较少.
| 表2 各模型在意大利语数据集上的性能对比 Table 2 Performance comparison of different models on Italian dataset % |
为了继续验证HFMSI的科学性, 通过消融实验考察模型各个子模块的性能, 主要验证表示学习模块、特征提取模块及跨类型注意力分层融合(HFM-SI)模块对模型的贡献.此外还进行与单类型语音数据的对比实验和批次大小的参数分析实验.实验均在汉语自采数据集上实现.
3.4.1 语音信息融合的有效性
为了验证多类型语音信息融合带来的性能提升, 进行3种类型语音数据的性能对比实验.在单类型语音数据中采用Transformer编码器提取自身的语音信息.对比结果如表3所示, 表中元音表示在单类型数据实验中取得最优值.由表可见, 对于多类型数据组合, 两种类型的语音组合性能要优于单类型效果, 而元音-重复音节组合达到次优效果, 这是因为调音表征是声学特征中最能反映帕金森病语音特征的表示.对比结果表明, 结合3种主要声学表示的HFMSI在准确率、敏感度和F1分数上均达到最优值.
| 表3 多类型语音信息融合和单类型语音数据的性能对比 Table 3 Performance comparison of multi-type speech information fusion and single type voice data % |
3.4.2 对比学习模块的性能
为了验证将持续元音和重复音节首先融合为调音特征的有效性, 采取删除对比学习模块的设计, 直接将持续元音表征、重复音节表征和韵律表征输入下游模块中.HFMSI、HFMSI(不含对比学习)、CPC[27]、文献[28]模型的对比结果如表4所示.由表可发现, 引入对比学习模块后.HFMSI的准确率有2.1%的提升, 主要是因为本文采用的对比学习模块更好地促进帕金森病病理信息中调音信息的粗粒度提取, 而调音特征是帕金森病声学特征最明显的部分.由于CPC依赖于时间依赖关系的应用, 无法较好地预测潜在的语音表示序列, 限制语音表示学习的潜力发挥.文献[28]模型使用对抗训练, 训练过程不稳定, 导致超参数调整的困难, 因此性能不及HFMSI.
| 表4 对比学习模块的有效性 Table 4 Effectiveness of contrastive learning modules % |
3.4.3 特征约束的有效性
正交约束和一致性约束在表示学习模块中的性能对比如表5所示.由表可观察到, 使用正交约束和一致性约束都能提升模型性能, 如果不进行多类型表征信息的约束, 就无法克服数据异质性并捕捉到类间差异.本文还试图在正交约束上采用希尔伯特-施密特独立性准则(Hilbert-Schmidt Independence Criterion, HSIC)[50]代替正交损失, 由结果可见, 这种损失也会导致性能下降, 原因是HSIC约束对数据量要求较高, 并且不能较好地捕捉病理特征之间的非线性关系.FactorVAE[34]优化模态之间的变化相关性, 往往导致信息丢失, 降低模型的有效性.OVR[35]从共享的表示中分离独有表示, 表现次优.
| 表5 正交约束和一致性约束的有效性 Table 5 Effectiveness of orthogonal and consistency constraints % |
3.4.4 跨类型注意力分层融合模块的有效性
为了验证跨类型注意力分层融合(CTAHF)模块的有效性, 采取不同的融合策略进行对比.移除CTAHF模块后, 分别利用特征拼接、单流Transfor-mer融合结构和双流Transformer融合结构、级联融合等方式进行特征融合.其中, 级联融合方式是指先融合私有信息, 得到私有特征融合表示后再融合共有信息部分, 流程如图5所示.
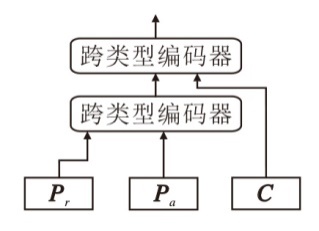 | 图5 级联融合方式流程图Fig.5 Cascade fusion method |
各种融合方式对比结果如表6所示, 表中黑体数字表示最优值.
| 表6 跨类型注意力分层融合模块的有效性 Table 6 Effectiveness of cross-modal attention hierarchical fusion module % |
由表6可见, 相比HFMSI, 使用前三种融合方式时性能有所降低, 此外, 即使与较为先进的级联融合方式相比, 本文的策略仍然具有竞争力.
3.4.5 参数分析
HFMSI作为一种深度学习模型, 有效性会受到各种参数的限制, 所以本节选取重要参数之一的训练批次大小进行实验验证.实验采用汉语自采数据集, 其它参数不变, 以此验证批次大小与准确率的相关性, 具体结果如表7所示.由表可见, 当批次大小小于60时, 帕金森病检测任务的准确率呈上升趋势.然而, 当批次大小超过60时, 准确率趋于平稳, 但是需要的训练资源却持续增长, 导致显卡的占用过高.这种资源的增加并不会对性能产生正向影响, 因此, 本文在批次大小上设置最佳值为60.
| 表7 批次大小和准确率的相关性 Table 7 Correlation between batch size and accuracy |
针对当前帕金森病语音检测任务中单类型语音数据容易受到干扰和多类型语音数据病理信息难以提取等问题, 本文提出基于多类型语音信息分层融合的帕金森病检测模型(HFMSI), 旨在通过对多类型语音数据的信息融合, 提高帕金森病检测性能.本文设计挖掘多类型声学特征深层信息的表示学习方案, 提取多类型数据中的调音信息和韵律信息, 并将它们一同输入共有表示子空间和私有表示子空间进行信息挖掘.此外, 定义的跨类型注意力分层融合模块为融合多类型语音表征提供一种方案, 即通过不同粒度的跨类型分层融合, 使融合模块更准确、全面地融合帕金森病语音数据的复杂特征.实验表明, HFMSI在帕金森病辅助诊断上具有较大的性能提升作用.下一步可利用HFMSI针对帕金森病严重程度评估工作展开探索.
本文责任编委 郝志峰
Recommended by Associate Editor HAO Zhifeng
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|
| [40] |
|
| [41] |
|
| [42] |
|
| [43] |
|
| [44] |
|
| [45] |
|
| [46] |
|
| [47] |
|
| [48] |
|
| [49] |
|
| [50] |
|