


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
面向多域数据场景的安全高效联邦学习
[金春花1  , 李路路
, 李路路1 , 王佳浩1 , 季玲1 , 刘欣颖1 , 陈礼青1, 2 , 张浩1 , 翁健3 ]
, 李路路, 王佳浩, 季玲, 刘欣颖, 陈礼青, 张浩, 翁健]
|
|



作者简介: 
李路路,硕士研究生,主要研究方向为密码学、区块链、联邦学习.E-mail:1327043890@qq.com. 
王佳浩,硕士研究生,主要研究方向为密码学、区块链、联邦学习.E-mail:2984606018@qq.com. 
季 玲,硕士研究生,主要研究方向为图像加密、图像检索.E-mail:944139820@qq.com. 
刘欣颖,硕士研究生,主要研究方向为密码学、联邦学习.E-mail:3099664677@qq.com. 
陈礼青,博士,副教授,主要研究方向为信息与网络安全、公钥密码学.E-mail:chenlq@hyit.edu.cn. 
张 浩,博士,副教授,主要研究方向为交通大数据、交通安全、物流与供应链.E-mail:zhhao@hyit.edu.cn. 
翁 健,博士,教授,主要研究方向为公钥密码学、云安全、区块链.E-mail:cryptjweng@gmail.com.
针对联邦学习在不同领域数据训练中面临的泛化能力差、灾难性遗忘和隐私攻击等挑战,文中提出面向多域数据场景的安全高效联邦学习方案.在本地训练阶段,结合知识蒸馏技术,防止模型在不同领域数据训练时发生灾难性遗忘,同时加速知识在各领域间的迁移,提高训练效率.在上传阶段,提出高斯差分隐私机制,分别对本地更新的梯度和各领域间的泛化差异添加高斯噪声,实现安全上传,增强训练过程的保密性.在聚合阶段,采用动态泛化权重聚合算法,减少各领域间的泛化差异,提升模型的泛化能力.理论分析证明该方案具有较强的鲁棒性.在PACS、Office-Home数据集上的实验表明此方案具有较高的准确度和较短的训练时间.
, LI Lulu, WANG Jiahao, JI Ling, LIU Xinying, CHEN Liqing, ZHANG Hao, WENG Jian
About Author:
LI Lulu, Master student. His research interests include cryptography, blockchain and federated learning. WANG Jiahao, Master student. His research interests include cryptography, blockchain and federated learning.
JI Ling, Master student. Her research interests include image encryption and image retrieval.
LIU Xinying, Master student. Her research interests include cryptography and federated learning.
CHEN Liqing, Ph.D., associate profe-ssor. His research interests include information and network security, and public key cryptography.
ZHANG Hao, Ph.D., associate professor. His research interests include transportation big data, traffic safety, and logistics and su-pply chain.
WENG Jian, Ph.D., professor. His research interests include public key cryptography, cloud security and blockchain.
To tackle the challenges of poor generalization, catastrophic forgetting and privacy attacks that federated learning faces in multi-domain data training, a scheme for secure and efficient federated learning for multi-domain scenarios(SEFL-MDS) is proposed. In the local training phase, knowledge distillation technology is employed to prevent catastrophic forgetting during multi-domain data training, while accelerating knowledge transfer across domains to improve training efficiency. In the uploading phase, Gaussian noise is added to locally updated gradients and generalization differences across domains using the Gaussian differential privacy mechanism to ensure secure data uploads and enhance the confidentiality of the training process. In the aggregation phase, a dynamic generalization-weighted algorithm is utilized to reduce generalization differences across domains, thereby enhancing the generalization capability. Theoretical analysis demonstrates the high robustness of the proposed scheme. Experiments on PACS and office-Home datasets show that the proposed scheme achieves higher accuracy with reduced training time.
随着人工智能(Artificial Intelligence, AI)技术的快速发展, 各种高性能模型在图像分类[1]、目标检测[2]和语言处理[3]等领域展现出显著潜力.训练这些模型需要大量数据, 但现实中的数据孤岛现象和日益突出的数据安全问题无法满足这一需求.许多客户和企业因隐私问题不愿上传私有数据用于模型训练, 这在一定程度上限制AI技术的进一步发展和广泛应用.为了应对这些挑战, Google提出联邦学习(Federated Learning, FL)[4].这是一种分布式机器学习解决方案, 让客户仅上传梯度或模型参数以保留数据的本地化, 从而解决隐私问题.
然而, 现有的联邦学习研究聚焦于提升模型在源域数据上训练的收敛速度和性能[5, 6].但面临一个更实际的问题:如何使在数据分布异质的客户端上训练的模型能泛化到数据分布未知的目标客户端上, 即联邦域泛化(Federated Domain Generalization, FedDG)[7].虽然传统联邦学习已考虑标签分布的变化, 但FedDG关注客户端之间的域迁移, 并将每个客户端视为一个独立的域, 挑战在不同客户端之间及从训练客户端到测试客户端上的域迁移[8].
尽管联邦域泛化与标准的域泛化(Domain Generalization, DG)[9, 10]有相似的目标, 即从多个源域泛化到未知域, 但由于FedDG禁止不同的客户端之间直接共享数据, 这使得大多数现有的域泛化方法难以适用.
联邦学习本身并不能完全保证整个学习过程的安全性和隐私性.当训练好的本地模型在公开信道进行传输时, 仍会面临攻击者发起的成员推理攻击[11]和模型反转攻击[12], 增加隐私泄露的风险.为了抵御FL中的隐私攻击, 管桂林等[13]提出物联网中多秘钥同态加密的联邦学习隐私保护方法, 利用基于密码学的同态加密技术实现梯度更新机密性保护.王莉芳等[14]引入差分隐私机制, 实现本地更新梯度的安全上传.
此外, 在联邦域泛化的训练过程中, 模型在对来自不同领域的数据进行训练时, 常会遗忘之前学到的知识, 导致灾难性遗忘问题, 使新模型难以同时学习本地源域数据和全局模型的旧知识[15].为了应对这一挑战, Luo等[16]提出GradMA(Gradient-Memory-Based Accelerated Federated Learning), 结合持续学习方法, 在服务器端和客户端同时调整模型的更新方向, 充分利用服务器强大的计算能力和丰富的内存资源.Gao等[17]提出FCIRC(Federated Continuous Incremental Learning with Resource-Constrained), 通过特征生成器、知识蒸馏和动态权重分配, 解决灾难性遗忘问题, 并加速模型收敛.然而, 上述方案均未考虑FL中的隐私攻击问题.因此, 如何在保护数据隐私的同时有效防止灾难性遗忘, 成为联邦域泛化学习中亟待解决的重要挑战.
为了优化联邦域泛化学习模型, 并提升效率、准确性与安全性, 本文结合差分隐私和知识蒸馏等技术, 设计面向多域数据场景的安全高效联邦域学习方案(Secure and Efficient Federated Learning for Multi-domain Data Scenarios, SEFL-MDS), 支持不同域客户端之间的协作学习, 确保学习过程的高效性和安全性.基于全局模型设计动态泛化权重聚合算法, 利用各域的泛化差异动态调整聚合权重, 提升模型在未知域上的学习能力.提出基于联邦知识蒸馏的本地训练算法, 有效避免不同领域数据导致的灾难性遗忘问题, 确保各领域的数据都能参与模型的学习.同时, 由于知识蒸馏中“ 教师-学生” 网络的特性, 加速模型在一个域中学到的知识向另一个域的转移, 提高训练效率.提出高斯差分隐私机制, 确保在模型训练过程中, 客户端输出带噪声的本地更新, 保障联邦域泛化模型训练期间的隐私.理论分析证明SEFL-MDS具有较强的鲁棒性.并在一系列基准数据集上进行的大量实验表明, SEFL-MDS具有较高的准确度, 同时提高模型的训练效率和域泛化性.
域泛化旨在从不同源域的数据中训练一个机器学习模型, 能在未知域上也具有较强的学习性能.大多数关于域泛化的研究都遵循域对齐的思路, 通过最小化各个源域之间的差异[18]或使用元学习策略模拟域迁移[19].这些方法通常需要共享多个源域的数据及域标签.即使是对域标签要求不严格的域泛化方法, 仍需要在一个小批次内包含来自多个域的数据, 以实现跨域泛化, 如数据增强[20]、自监督训练[21].然而, 由于数据的隐私性, 这些方法在联邦域泛化中大多不可行, 而其它方法由于训练数据分布受限而表现不佳.
联邦域泛化作为新兴的研究领域, 重点关注如何在域漂移场景中提高模型对未知域的泛化能力.Liu等[22]提出ELCFS(Episodic Learning in Conti-nuous Frequency Space), 通过傅里叶变换增强方法, 提升模型的泛化性.Jiang等[23]提出HarmoFL, 在傅里叶变换归一化方法的基础上约束本地模型的平坦性.
然而, 仅改进本地训练策略无法确保全局模型对未知域的充分泛化.相对而言, FedAvg(Federated Averaging Algorithm)[4]假设每个客户端对全局模型的贡献恒定, 采用固定权重聚合本地模型.为了进一步优化FL的泛化能力, Wang等[24]提出FedNova, 主要侧重于解决同一域内的数据异质性问题, 而并非将每个客户端视为独立的域.Li等[25]提出ARFL(Auto-Weighted Robust Federated Learning), 假设性能差的客户端具有更多的损坏数据, 因此在聚合全局模型时, 使这些客户端的权重最小化.Park等[26]提出StableFDG(Style and Attention Based Learning Strategy), 通过基于风格的学习和引入注意力机制, 提升客户端在本地数据集上的学习风格多样性, 增强模型对域不变特征的学习, 提高域泛化能力.
考虑到未知域数据分布的不确定性, Zhang等[27]基于所有客户端中表现良好的全局模型可能会带来更好的泛化性能思想, 引入一个公平性优化目标, 并通过提出的GA(Generalization Adjustment)机制优化目标.GA评估不同域之间的泛化差异, 动态计算各个独立域参与聚合的权重, 增强联邦域泛化的能力.Wei等[28]提出MCGDM(Multi-source Co-llaborative Gradient Discrepancy Minimization), 通过原始图像与增强图像之间的域内梯度匹配, 并与其它域协作实现域间梯度匹配, 进一步减少去中心化域之间的偏移.
当神经网络按顺序训练多个任务时, 容易出现灾难性遗忘现象.在这种情况下, 当前任务的最优参数可能不适用之前任务的目标.Perkonigg等[29]提出适用于医学影像的持续学习方法, 通过动态记忆机制适应数据流中的变化, 防止灾难性遗忘, 并扩展模型至新领域.Tadros等[30]采用局部无监督的Hebbian可塑性规则, 并通过带噪输入的离线训练模拟睡眠, 促使旧任务记忆自发重现并形成独特表示, 从而增强与旧任务相关的神经元活动, 减少新任务的干扰.
当扩展到分布式机器学习场景中, Lee等[31]指出, 由于客户端数据的异质性, FL中的全局模型会遗忘之前训练的知识, 而本地训练会导致对非本地知识的遗忘, 因此提出FedNTD(Federated Not-True Distillation).Ma等[32]提出CFeD(Continual Federated Learning with Distillation), 在客户端和服务器端同时进行知识蒸馏, 并为不同客户端分配学习新任务与复习旧任务的目标, 以减轻灾难性遗忘并提升模型学习能力.Zheng等[33]提出FedMKD, 基于MKD(Mutual Knowledge Distillation)和EWC(Elastic Weight Consolidation), 旨在增强全局模型性能, 并使客户端的本地模型有效利用全局模型的知识, 同时利用指数量化的方法压缩模型参数, 减少通信开销.
联邦域泛化学习架构中, 本地客户端更新的模型参数在公开信道传输时, 可能遭到第三方敌手的恶意攻击, 如模型反转攻击、推理攻击[12]等, 进而导致隐私信息泄露.为了增强联邦学习的隐私保护能力, 防止模型参数泄露用户隐私信息, 许多隐私保护的联邦学习方案被相继提出[34, 35, 36].其中, SMC(Secure Multiparty Computation)、HE(Homomorphic Encryption)和DP(Differential Privacy)是联邦学习中较通用的解决方案.然而, 基于SMC的方案通信代价较高.基于HE的方案计算开销过大.基于DP的方案在通信和计算开销上具有明显优势, 但添加的DP噪声会扰动模型参数真实值, 并且噪声会随着模型训练进行叠加, 影响模型收敛或训练的准确度.为此, 设计一种兼顾强隐私保护和高准确度的联邦学习方案是亟待解决的难题之一.
联邦学习是一种分布式机器学习方法, 其中多个客户端在服务器的协调下协作训练一个模型[4].在联邦学习中, 原始数据集保留在客户端的本地设备上, 客户端仅需将本地更新的模型参数(如梯度或模型权重)上传到服务器.联邦学习过程通常可分解为多个训练轮次.在每轮中, 服务器首先将初始模型或更新后的全局模型发送给客户端, 然后每个客户端使用自己的数据在本地训练模型, 最后将训练后的模型更新上传到服务器进行聚合, 形成新的全局模型.如此反复进行, 直到模型收敛, 训练过程结束.假设所有域的集合
D={D1, D2, …, Dm},
用于训练的样本集
$\widetilde{D}=\left\{\widetilde{D}_{1}, \widetilde{D}_{2}, \cdots, \widetilde{D}_{i} \cdots, \widetilde{D}_{m}\right\}, $
其中m为训练域(或客户端)数量.令(x, y)表示来自同一个域的样本对, L表示为损失函数, 用于衡量模型预测f(x, θ )(由模型参数θ )与标签y之间的距离.给定一个域Di∈ D, 对应样本集
$\widetilde{D}_{i}=\left\{x_{j}^{i}, y_{j}^{i}\right\}_{j=1}^{N_{i}} .$
定义期望损失
则经验损失
$\widetilde{\varepsilon}_{\widetilde{D}_{i}}(\theta)=\frac{1}{N_{i}} \sum_{j=1}^{N_{i}} L\left(\left(x_{j}^{i} ; \theta\right), y_{j}^{i}\right) .$
联邦域泛化的理想目标是最小化整个数据集D上的总损失.实际上, 通常知道采样域
$\begin{aligned} \min _{\theta} \varepsilon_{D} \approx & \sum_{i=1}^{m} \alpha_{i} \widetilde{\varepsilon}_{\widetilde{D}_{i}}(\theta)= \\ & \sum_{i=1}^{m} \alpha_{i} \sum_{j=1}^{N_{i}} L\left(f\left(\left(x_{j}^{i} ; \theta\right), y_{j}^{i}\right)\right), \\ \text { s.t. } \alpha_{i}= & \frac{N_{i}}{\sum_{i^{\prime}=1}^{m} N_{i^{\prime}}} . \end{aligned}$ (1)
注意到, 联邦域泛化和跨设备(Cross-Device)联邦学习之间有如下两个不同点.首先, 联邦域泛化遵循跨机构(Cross-Silo)联邦学习, 客户端(或域)的数量m较少, 而在跨设备联邦学习中, 客户端数量较多, 且通常在全局聚合之前对客户端拥有的本地数据进行采样.其次, 尽管跨设备联邦学习中每个客户端的本地数据是异质的, 但它们都来自同个总体分布.
相比之下, 在联邦域泛化中, 每个客户端对应一个域, 数据不仅是异质的, 并且来自不同的域.这使得联邦域泛化比传统的联邦学习更具有挑战性.因此, 在联邦域泛化场景中, 式(1)中的全局优化目标容易与本地优化目标发生冲突, 而本地训练过程往往会过拟合每个客户端(或域)的本地数据分布.上述两种情况都会降低全局模型的泛化性能.
如果有两个相邻的数据x∈ X和x'∈ X, 即
|x△ x'|=1.
M为一个随机算法, range(M)表示算法M的所有可能输出, 并且S为range(M)的任意子集, 那么M符合如下条件:
Pr[M(x)∈ S]≤ eε Pr[M(x')∈ S]+δ .
差分隐私方法通常通过向查询结果添加模糊噪声以实现, 其本质是通过向数据中加入可量化的随机扰动保护敏感信息.常用的噪声添加机制有高斯机制和拉普拉斯机制.在高斯机制中, 添加噪声后的查询结果如下:
M(d)≜f(d)+N(0,
其中:N(0,
添加噪声的大小与查询算法M对数据的敏感度以及隐私安全的程度有关.全局敏感度为:
SG( f )=
在具体应用中, 需要根据数据特征选择合适的噪声干扰机制, 并根据隐私安全要求和全局敏感度合理添加噪声.
知识蒸馏(Knowledge Distillation)旨在将教师模型的知识传递给学生模型, 是一种可用于解决迁移学习和遗忘问题的方法.蒸馏网络的优化模型可表示为
$\begin{aligned} \min _{\theta_{s}} F_{\mathrm{kd}}\left(D, \theta_{s}, \theta_{t}, \iota^{\prime}\right)= & L_{\mathrm{kd}}+L_{\mathrm{EC}}= \\ & E C(\tilde{y}, \check{y})+E C(y, O), \end{aligned}$
其中, $\tilde{y}$表示教师模型预测输出的软标签, $\check{y}$表示学生模型预测输出的软标签, O表示学生模型的输出, y表示训练样本的真实输出.损失函数Fkd(· )由蒸馏损失Lkd和交叉熵损失LEC组成.蒸馏损失是指学生模型预测与教师模型预测之间的差异; 交叉熵损失是指学生模型预测与硬标签之间的差异.
同时, 蒸馏损失可转换为软标签$\tilde{y}$、$\check{y}$之间的交叉熵损失.软标签通常作为类别的概率分布, 在神经网络输出阶段, 使用温度参数ι '对Softmax输出进行处理.假设学生模型的Softmax输出为
$O=\left(O_{1}, O_{2}, \cdots, O_{r}\right), \tilde{y}=\left(\tilde{y}_{1}, \tilde{y}_{2}, \cdots, \tilde{y}_{r}\right), $
则有
$\tilde{y}_{i}=\frac{\left(O_{i}\right)^{\frac{1}{l^{\prime}}}}{\sum_{i=1}^{r}\left(O_{i}\right)^{\frac{1}{\iota^{\prime}}}} .$
为了提升模型的域泛化能力, 保证训练数据的隐私安全, 本文提出面向多域数据场景的安全高效联邦学习方案(SEFL-MDS), 总体架构如图1所示.方案主要由单一的服务器与多个客户端组成.假设服务器是诚实且好奇的, 即诚实遵守联邦学习聚合协议, 但对客户端的敏感信息好奇, 通过发起各种攻击窃取用户隐私信息.该服务器在现实场景中可能是第三方机构或企业, 主要目标是借助客户端数据完善模型, 提升其产品(如图像分类、目标检测)性能.参与训练的客户端可以是各种移动终端设备, 本文中假设客户端为诚实节点, 主要完成模型的训练与更新, 并输出带有差分隐私的本地模型和域泛化差异.
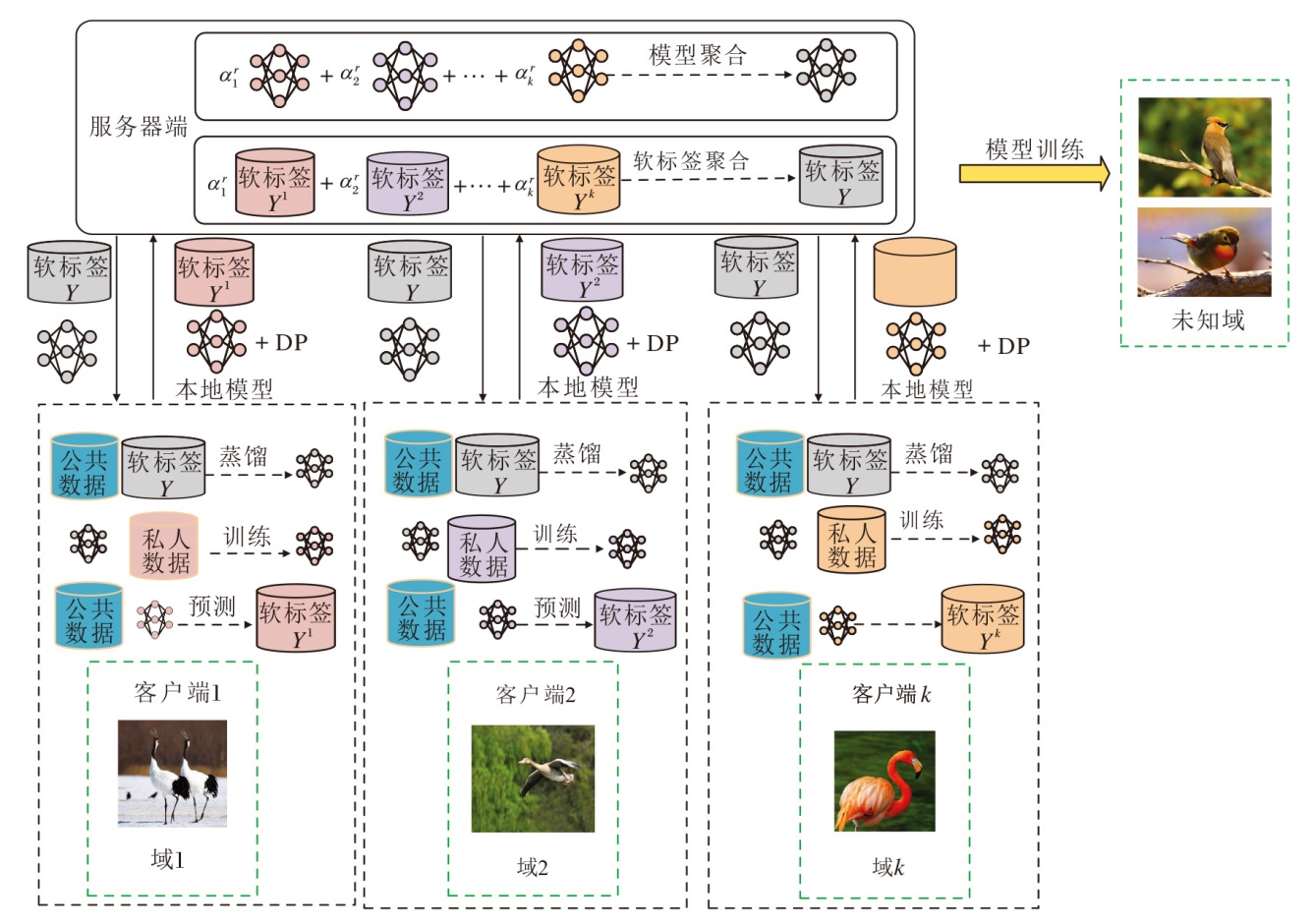 | 图1 SEFL-MDS总体架构Fig.1 Overall architecture of SEFL-MDS |
在SEFL-MDS的训练过程中, 首先初始化一个全局模型.SEFL-MDS完成一轮联邦域泛化训练过程的具体实现过程如下所示.
1)本地客户端接收服务器下发的全局模型, 首先计算当前全局模型的期望损失与上一轮本地模型的期望损失之间的差值, 得到域泛化差异.
2)本地客户端利用前一轮的本地模型、全局软标签和公共数据集对当前全局模型进行知识蒸馏, 并利用自身的域数据对蒸馏后的全局模型进行微调, 得到本地更新的梯度.
3)根据高斯差分隐私策略, 对本地更新的梯度重新缩放并添加高斯噪声, 利用梯度得到新的隐私保护本地模型, 并对域泛化差异进行高斯差分隐私处理.更新后的本地模型对公共数据集进行预测并更新本地软标签.
4)将隐私保护的本地模型、隐私保护的域泛化差异以及本地软标签发送给服务器端.
5)服务器在接收到客户端模型参数后, 根据动态泛化权重算法进行聚合, 得到新的全局模型.同时聚合本地软标签, 得到新的全局软标签.
重复上述1)~5), 可实现对跨域数据的学习, 并推广到未知域, 增强模型的泛化能力.
SEFL-MDS一轮联邦域泛化训练过程具体步骤如算法1所示.
算法1 SEFL-MDS一轮联邦域泛化训练过程
输入 客户端数量m, 域数据$\widetilde{D}=\left\{\widetilde{D}_{1}, \widetilde{D}_{2}, \cdots, \widetilde{D}_{m}\right\}$,
公共数据集Dpub, 全局模型θ r,
全局软标签Yr, 前一轮本地模型
当前训练轮数r+1
输出θ r+1, Yr+1
初始化 学习率μ , 全局敏感度S
step 1 计算$G_{\widetilde {D}_{i}}\left(\theta^{r}\right) $;
step 2 LocalUpdate $\left(\widetilde{D}_{i}, D^{\mathrm{pub}}, \theta^{r}, \theta^{r-1}, Y^{r}, \mu\right)$;
step 3 $\hat{g}_{i}^{r+1}, G_{\widetilde{D}_{i}}^{* }\left(\theta^{r}\right)$←
$D P\left(g_{i}^{r+1}, S, G_{\widetilde{D}_{i}}\left(\theta^{r}\right), N_{\mathrm{GS}}\left(\delta^{2} S^{2}\right)\right)$;
step 4 上传
step 5 服务器计算
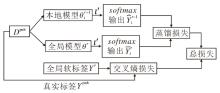
本文设计基于联邦知识蒸馏的本地训练算法, 处理不同域数据导致的灾难性遗忘问题, 具体流程如图2所示.为了防止先前的数据被遗忘, 将学到的知识存储在模型
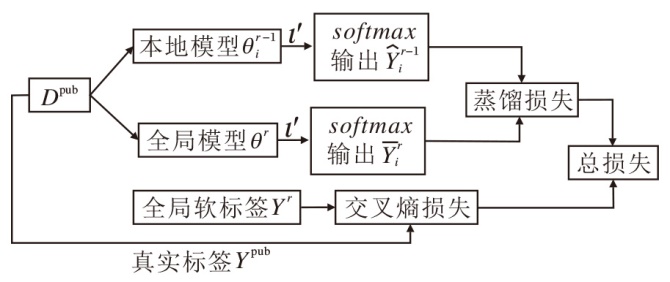 | 图2 基于联邦知识蒸馏的本地训练算法流程图Fig.2 Flow chart of local training based on federated knowledge distillation |
基于联邦知识蒸馏的本地训练算法具体实现过程如下所示.
1)初始化.本地模型为本地客户端从服务器下载到的全局模型θ r.首先计算全局模型与本地模型的域泛化差异:
$G_{\widetilde{D}_{i}}\left(\theta^{r}\right)=\widetilde{\varepsilon}_{\widetilde{D}_{i}}\left(\theta^{r}\right)-\widetilde{\varepsilon}_{\widetilde{D}_{i}}\left(\theta^{r-1}\right), i=1, 2, \cdots, m . $
并将Dpub中数据的真实标签Ypub替换成全局软标签Yr, 得到(Xpub, Yr).
2)本地模型更新.首先, 公共数据Dpub基于模型
$\begin{aligned} \min _{\theta^{r}} & F_{\mathrm{kd}}\left(D^{\mathrm{pub}}, \theta^{r-1}, \theta^{r}, \iota^{\prime}\right)= \\ & L_{\mathrm{kd}}\left(D^{\mathrm{pub}}, \theta^{r-1}, \theta^{r}, \iota^{\prime}\right)+L_{\mathrm{EC}}\left(D^{\mathrm{pub}}, \theta^{r}\right)= \\ & E C\left(\widehat{Y}_{i}^{r-1}, \bar{Y}_{i}^{r}\right)+E C\left(Y^{r}, Y^{\mathrm{pub}}\right), \end{aligned} $
其中, Ypub表示数据Dpub对应的真实标签, Lkd(· )表示蒸馏损失, LEC(· )表示交叉熵损失, EC(· )表示交叉熵计算.最后, 利用域数据$\widetilde{D}_{i}$对蒸馏后的模型Wr+1进行微调, 更新得到本地模型
基于联邦知识蒸馏的本地训练算法步骤如算法2所示.
算法2 基于联邦知识蒸馏的本地训练算法
输入 域数据$\widetilde{D}_{i}$, 公共数据Dpub, 全局模型θ r,
上一轮全局模型θ r-1, 全局软标签Yr,
学习率μ
输出 本地模型参数
域泛化差异$ G_{\widetilde{D}_{i}}\left(\theta^{r}\right)$
step 1 $G_{\widetilde{D}_{i}}\left(\theta^{r}\right)=\widetilde{\varepsilon}_{\widetilde{D}_{i}}\left(\theta^{r}\right)-\widetilde{\varepsilon}_{\widetilde{D}_{i}}\left(\theta^{r-1}\right), $,
i=1, 2, …, m;
step 2 (Xpub, Yr)← (Xpub, Ypub);
/* 将Dpub中真实标签Ypub替换成全局软标签Yr* /
step 3
for 本地迭代次数从1到E do
gr+1=Ñ Fkd(Dpub, θ r-1, θ r);
Wr+1=θ r-μ gr+1;
/* Fl表示在$\widetilde{D}$上的损失函数* /
end for
step 4 $\hat{g}_{i}^{r+1}, G_{\widetilde{D}_{i}}^{* }\left(\theta^{r}\right)$←
$D P\left(g_{i}^{r+1}, S, G_{\widetilde{D} i}\left(\theta^{r}\right), N_{\mathrm{GS}}\left(\delta^{2} S^{2}\right)\right)$;
/* 向$\hat{g}_{i}^{r+1}$, $ G_{\widetilde{D}_{i}}^{* }\left(\theta^{r}\right)$添加高斯噪声* /
step 5 $\theta_{i}^{r+1}=W^{r+1}-\mu \hat{g}_{i}^{r+1}$;
step 6 Y_ir+1← f(
/* 利用
step 7 return
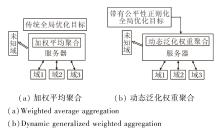
为了使联邦学习在不同域数据场景中仍具有较强的学习能力, 本文不再使用传统的加权平均聚合算法聚合本地模型, 而是采用一种动态泛化权重聚合算法更新全局模型, 整体架构如图3所示.
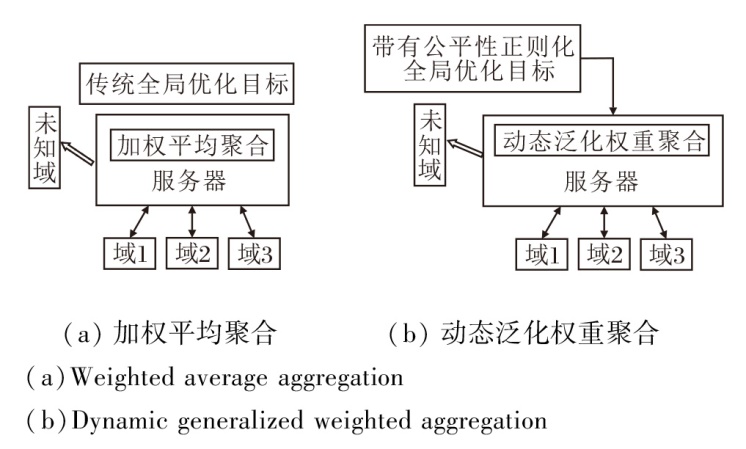 | 图3 2种聚合方式的整体架构Fig.3 Overall architecture of 2 aggregation methods |
在联邦学习训练过程中, 每个域的平坦度可通过全局模型和本地模型之间的泛化差异反映, 泛化差异如下:
$G_{\widetilde{D}_{i}}(\theta)=G_{\widetilde{D_{i}}}\left(\sum_{i} \alpha_{i} \theta_{i}\right)=\widetilde{\varepsilon}_{\widetilde{D}_{i}}\left(\sum_{i} \alpha_{i} \theta_{i}\right)-\widetilde{\varepsilon}_{\widetilde{D}_{i}}\left(\theta_{i}\right), $
其中, θ i表示在域
θ =
文献[27]引入一个联邦域泛化全局优化目标, 充分考虑各本地客户端之间泛化差异, 保证最优全局模型在所有域上具有平坦性.全局优化目标为:
$\begin{array}{l} \min _{\theta_{1}, \theta_{2}, \cdots, \theta_{m}} \widetilde{\varepsilon}_{\widetilde{D}}(\theta)= \\ \sum_{i=1}^{m} \alpha_{i} \widetilde{\varepsilon}_{\widetilde{D}_{i}}(\theta)+\varphi \operatorname{Var}\left(\left\{G_{\widetilde{D}_{i}}(\theta)\right\}_{i=1}^{m}\right), \\ \text { s.t. } \sum_{i=1}^{m} \alpha_{i}=1, \theta=\sum_{i} \alpha_{i} \theta_{i}, \forall i, \alpha_{i} \geqslant 0 . \end{array}$ (2)
可把客户端(或域)的泛化权重表示为
α =(α 1, α 2, …, α m),
并通过φ ∈ [0, ¥ ]平衡全局损失和域泛化差异之间的公平.其中, 当φ =0时, 即为FedAvg; 当φ → ¥ 时, 每个域的泛化差异相等.
在式(2)中, α 和θ i不能在联邦学习中同时优化.同时观察到α i与相应的域泛化差异$G_{\widetilde{D}_{i}}(\theta)$之间存在关联, 改变权重α 会影响泛化差异.因此, 将优化操作分为如下两个阶段.在本地训练阶段, 通过梯度下降优化模型参数θ i.在聚合阶段, 通过动态泛化调整算法优化权重α i.通过调整泛化权重最小化各个域的泛化差异, 获得一个具有较强域泛化能力的全局模型.形式上, 给定一个特定的域k, 全局模型参数θ 和局部模型参数θ i之间的关系为:
θ =θ k+Δ θ ,
其中
Δ θ =(1-α k)θ k+
可看作是对θ k的扰动.对于损失$\widetilde{\varepsilon}_{\widetilde{D}_{k}}(\theta)$, 如果增加权重α k, 则相应减少
当服务器接收到客户端上传的数据后, 通过动态泛化调整算法计算权重α r+1的具体实现过程如下.
1)初始化.服务器接收所有客户端上传的域泛化差异${\{G_{\widetilde{D}_{i}}(\theta^{r})\}}_{i=1}^{m}$、本地软标签
2)泛化权重更新.基于前一轮泛化权重
其中
$\begin{array}{l} \delta=\frac{1}{m} \sum_{i=1}^{m} G_{\widetilde{D}_{i}}\left(\theta^{r}\right), \\ \pi^{r+1}=\left(1-\frac{r+1}{R}\right) \pi, \end{array}$
π ∈ (0, 1)表示一个超参数, 用于控制更新步长.为了使训练过程稳定, 采用线性衰减策略.同时, 当
时, 对其进行裁剪, 并令
3)全局模型更新.基于泛化权重
θ r+1=
4)全局软标签更新.聚合本地软标签
Yr+1=
在第r+1轮结束时, 全局模型θ r+1和全局软标签Yr+1作为初始化参数广播给每个客户端, 并用于下一轮训练.特别说明的是, 当客户端i的聚合权重为0时, 通过式(3)和式(4)可得
同时平均域泛化差异
$\delta=\frac{1}{m} \sum_{i=1}^{m} G_{\widetilde{D}_{i}}\left(\theta^{r}\right) .$
当满足$G_{\widetilde{D}_{i}}\left(\theta^{r}\right)=\delta$时, 表示各域的泛化差异相等, 全局模型已通过其它客户端(或域)的数据充分学习, 并且展现出较强的域泛化能力.
具体动态泛化权重聚合算法步骤如算法3所示.
算法3 动态泛化权重聚合算法
输入 全局模型θ =θ 0,
m个客户端(或域)$ \widetilde{D}=\left\{\widetilde{D}_{1}, \widetilde{D}_{2}, \cdots, \cdots, \widetilde{D}_{m}\right\}$,
初始泛化权重α 0=
输出 全局模型θ r+1, 全局软标签Yr+1
初始化 当前迭代次数为r+1
服务器端
for 全局训练轮数r+1∈ (1, R) do
客户端i:
基于θ r计算$ G_{\widetilde{D}_{i}}\left(\theta^{r}\right)$
$\left(\theta_{i}^{r+1}, Y_{i}^{r+1}\right)=\operatorname{LocalUpdate}\left(\widetilde{D}_{i}, D^{\mathrm{pub}}, \theta^{r}, \theta^{r-1}, Y^{r}, \mu\right)$
/* 本地训练* /
服务器端:
基于$\{G_{\widetilde{D}_{i}}(\theta^{r})\}_{i=1}^{m}$和α r更新泛化权重α r+1
聚合本地模型:θ r+1=
聚合本地软标签:Yr+1=
对所有客户端广播θ r+1, Yr+1
end for
为了解决联邦学习中每个客户端的隐私安全问题, 当服务器聚合本地模型提供的参数更新信息时, 采用差分隐私方法避免隐私泄露.相比传统的隐私保护机制, 这种方法具有可量化的隐私预算和用户级敏感行为隐藏的特点.根据数据特性和全局敏感度Sg, 可在每轮收集本地模型参数更新信息.例如:如果参与训练轮次的客户端数量为k, 则每个用户获得的平均噪声为
在联邦学习过程中, 对每次迭代的更新
$\hat{g}_{i}^{r+1}=\frac{g_{i}^{r+1}}{\max \left(1, \frac{\left\|g_{i}^{r+1}\right\|_{1}}{S}\right)} .$
并对缩放后的本地更新
$\begin{array}{l} \hat{g}_{i}^{r+1}=\hat{g}_{i}^{r+1}+N_{G S}\left(\delta^{2} S^{2}\right), \\ G_{\widetilde{D}_{i}}^{* }\left(\theta^{r}\right)=G_{\widetilde{D}_{i}}\left(\theta^{r}\right)+N_{\mathrm{GS}}\left(\delta^{2} S^{2}\right) . \end{array}$
具体高斯差分隐私机制步骤如算法4所示.
算法4 高斯差分隐私机制
输入 本地更新的梯度
全局敏感度S
输出
初始化 全局敏感度S, 高斯噪声NGS(δ 2S2)
step 1 $\hat{g}_{i}^{r+1}=\frac{g_{i}^{r+1}}{\max \left(1, \frac{\left\|g_{i}^{r+1}\right\|_{1}}{S}\right)}$;
step 2 $\hat{g}_{i}^{r+1}=\hat{g}_{i}^{r+1}+N_{\mathrm{GS}}\left(\delta^{2} S^{2}\right)$;
step 3 $G_{\widetilde{D}_{i}}^{* }\left(\theta^{r}\right)=G_{\widetilde{D}_{i}}\left(\theta^{r}\right)+N_{\mathrm{GS}}\left(\delta^{2} S^{2}\right)$;
step 4 return $\hat{g}_{i}^{r+1}, G_{\widetilde{D}_{i}}^{* }\left(\theta^{r}\right)$.
在SEFL-MDS中, 主要利用高斯差分隐私机制抵御各种隐私攻击, 提高模型的健壮性.因此, 对SEFL-MDS的健壮性分析转换为对高斯差分隐私机制的安全性分析.
定理1 假设隐私预算ε 为任意值, 当常数b的上限约束为
$b^{2}> 2 \operatorname{In}\left(\frac{1.25}{\delta}\right)$,
那么具有
σ ≥
的高斯机制满足(ε , δ )-差分隐私, 其中
Δ 2f=max‖ f(d)-f(d')‖ ,
f (· )为查询函数.
证明 由高斯差分隐私定义
$\operatorname{Pr}[M(d) \in S] \leqslant \exp \left(\frac{x^{2}}{2 \sigma^{2}}\right) \operatorname{Pr}\left[M\left(d^{\prime}\right) \in S\right]+\delta$
可得
由于概率恒为正值, 则有
$\begin{array}{l} \left|\ln \left(\frac{\exp \left(-\frac{x^{2}}{2 \sigma^{2}}\right)}{\exp \left(-\frac{(x+\Delta f)^{2}}{2 \sigma^{2}}\right)}\right)\right|= \\ \left|\operatorname{In}\left(\exp \left(-\frac{1}{2 \sigma^{2}}\left[x^{2}-(x+\Delta f)^{2}\right]\right)\right)\right|= \\ \left|-\frac{1}{2 \sigma^{2}}\left[x^{2}-(x+\Delta f)^{2}\right]\right|= \\ \left|\frac{1}{2 \sigma^{2}}\left(2 x \Delta f+(\Delta f)^{2}\right)\right|< \varepsilon \end{array}$
当
x<
时, ε 为上界限.为了确保隐私损失以至少1-δ 的概率被限制在ε 内, 需满足
$\operatorname{Pr}\left[|x| \geqslant \frac{\delta^{2} \varepsilon}{\Delta f}-\frac{\Delta f}{2}\right]< \sigma$
假定ε ≤ 1≤ Δ f, 那么下界限
$\operatorname{Pr}[x> t] \leqslant \frac{\sigma}{\sqrt{2 \pi t}} \exp \left(-\frac{t^{2}}{2 \sigma^{2}}\right)$
并且还需满足
$\begin{array}{l} \frac{\sigma}{\sqrt{2 \pi t}} \exp \left(-\frac{t^{2}}{2 \sigma^{2}}\right)< \frac{\sigma}{2} \Leftrightarrow \\ \operatorname{In}\left(\frac{t}{\sigma}\right)+t^{2}> \operatorname{In}\left(\frac{2}{\sqrt{2 \pi \delta}}\right) \end{array}$
令
t=
得
$\begin{array}{c} \operatorname{In}\left(\frac{\frac{\sigma^{2} \varepsilon}{\Delta f}-\frac{\Delta f}{2}}{\sigma}\right)+\frac{\left(\frac{\sigma^{2} \varepsilon}{\Delta f}-\frac{\Delta f}{2}\right)^{2}}{2 \sigma^{2}}> \\ \operatorname{In}\left(\frac{2}{\sqrt{2 \pi \delta}}\right)=\operatorname{In}\left(\sqrt{\frac{2}{\pi}} \frac{1}{\sigma}\right) \end{array}$
令
σ =
并对b进行界定, 从第一个非负项开始, 则有
$\begin{aligned} \frac{1}{\sigma}\left(\frac{\sigma^{2} \varepsilon}{\Delta f}-\frac{\Delta f}{2}\right)= & \frac{1}{\sigma}\left[\left(\frac{b^{2}(\Delta f)^{2}}{\varepsilon^{2}}\right) \frac{\varepsilon}{\Delta f}-\frac{\Delta f}{2}\right]= \\ & \frac{1}{\sigma}\left[b^{2}\left(\frac{\Delta f}{\varepsilon}\right)-\frac{\Delta f}{2}\right]= \\ & b-\frac{\varepsilon}{2 b} \end{aligned}$.
又因为ε < 1, 当b> 1.5时, b2-b+
b-b+
同时需要满足
b2-
综上得到
$\begin{array}{c} b^{2}> 2 \operatorname{In}\left(\sqrt{\frac{2}{\pi}}+2 \operatorname{In}\left(\frac{1}{\sigma}\right)\right)+\operatorname{In}\left(e^{\frac{8}{9}}\right)= \\ \operatorname{In}\left(\frac{2}{\pi}\right)+\operatorname{In}\left(e^{\frac{8}{9}}\right)+2 \operatorname{In}\left(\frac{1}{\sigma}\right) \end{array}$
由于
因此只要
$b^{2}> 2 \operatorname{In}\left(\frac{1.25}{\sigma}\right)$,
就满足该条件. 证毕
首先证明, 对于目标域k, 在$\widetilde{\varepsilon}_{\widetilde{D}}(\theta)$上的最优解引起的泛化差异的上界是由源域中的泛化差异决定的(见定理2).根据定理2, 未知域k上的域泛化差异受域平坦性
定理2 假设θ 表示经过r轮联邦学习后的全局模型,
$\begin{aligned} \arg \min _{\alpha} & \sum_{i=1}^{m} \alpha_{i} d_{H \Delta H}\left(\widetilde{D}_{i}, k\right) \approx \\ & \arg \min _{\alpha} \operatorname{Var}\left(\left\{G_{D_{i}}(\theta)\right\}_{i=1}^{m}\right), \end{aligned}$ (5)
中的泛化权重α .对于∀ ρ ∈ (0, 1), 则未知域k的域泛化差异可用
$\begin{aligned} \varepsilon_{k}(\theta)-\varepsilon_{k}(\theta_{i}^{*}) \leqslant & \sum_{i=1}^{m} \alpha_{i}(G_{\widetilde{D}_{i}}(\theta)+d_{H \Delta H}(\widetilde{D}_{i}, k)+. \\ & .\frac{\sqrt{\log _{2}(\frac{d}{\rho})}+\sqrt{\log _{2}(\frac{m d}{\rho})}}{\sqrt{2 N_{i}}})+\lambda, \end{aligned}$
进行界定, 其概率至少为1-ρ .
然而, 精确估计α 需要明确域差异$d_{H \Delta H}\left(\widetilde{D}_{i}, k\right)$和各个域上的偏导数$\frac{\partial \widetilde{\varepsilon}_{\widetilde{D}_{i}}(\theta)}{\partial \alpha_{i}}$.然而, 在实际场景中, 域k的信息是未知的, 因此无法找到最优α .
为了解决这一挑战, 本文提出一种替代方法近似计算α .根据文献[37], 全局模型可视为客户端i的稳健风险(Robust Risk)最小化问题的解, 表示为
$\widetilde{\varepsilon}_{\widetilde{D}_{i}}(\theta)=\max _{\|\Delta \theta\| \leqslant \tau} \widetilde{\varepsilon}_{\widetilde{D}_{i}}\left(\theta_{i}+\Delta \theta\right) .$
由于获得最优估计需要所有域的平坦性相似, 因此可通过最小化域平坦性的方差以优化α , 并可通过解决式(5)的域平坦性方差最小化问题以近似获得.
由于式(5)的目标是实现零方差, 将为所有域近似达到一个常数平坦性C, 即对∀ i, 有
$G_{\widetilde{D}_{i}}(\theta)=C, $
在这种情况下, 则
$\sum_{i=1}^{m} \alpha_{i} G_{\widetilde{D}_{i}}(\theta)=\sum_{i=1}^{m} c_{i} G_{\widetilde{D}_{i}}(\theta)$
成立.此外, 考虑到式(5)中α 是最优的, 对于∀ c, 则有
$\min \sum_{i=1}^{m} \alpha_{i} d_{H \Delta H}\left(\widetilde{D}_{i}, k\right) \leqslant \min \sum_{i=1}^{m} c_{i} d_{H \Delta H}\left(\widetilde{D}_{i}, k\right) .$
结合上述结果, 可得出结论:定理2中用α 表示的约束比用常数C={c1, c2, …, cm}替代α (如FedAvg)表示的约束更严密.这表明, 使用全局目标与动态泛化权重聚合算法的结合能在未知域上实现更好的泛化性能.
SEFL-MDS的时间复杂度主要由通信、计算和同步等因素决定.在通信方面, 模型参数维度为θ , 每次通信的复杂度为O(θ ), 则总的通信复杂度为O(Rθ ), 其中R为全局训练轮数.客户端的计算复杂度与本地训练相关, 由于每个客户端执行E次本地训练, 样本数为n, 每次梯度更新复杂度为f(θ , n), 则每个客户端的计算复杂度为O(Ef(θ , n)).由于添加高斯噪声和计算域泛化差异只涉及简单的加减运算, 可忽略不计.则总的计算复杂度为
O(mEf(θ , n)).
此外, 同步延迟取决于最慢客户端的计算和通信时间.综上所述, SEFL-MDS的总时间复杂度为
O(R(mEf(θ , n))+θ ).
因此, 为了优化时间复杂度, 可通过减少通信频率、模型压缩和异步联邦学习等策略降低通信和同步开销.
本文主要是在域自适应图像数据集PACS和Office-Home上对EDPDGFL进行性能评估实验.PACS数据集包含photo、art、cartoon、sketch这4个领域中的9 991幅图像, 每个领域有7类.Office-Home数据集包含real world、art、clipart、product这4个领域中的15 588幅图像, 每个领域有65类, 且每个类别平均70幅图像.
本文同时进行离域(Leave-One-Domain-Out)验证评估:依次选择一个领域作为未知域, 剩下的所有领域作为训练域.各源域内的训练集和验证集的划分保持与文献[38]中的划分方式相同, 整个未知域用于测试.对于本地训练, 采用公共数据集ImageNet预训练ResNet18, 并利用域自适应图像数据集进行微调.
主要基于联邦学习架构进行仿真实验, 客户端采用小批量随机梯度下降的训练方法, 设置批量大小为16, 学习率为0.001, 泛化权重的步长为0.05, 全局迭代次数为100.
使用Python 3.97编程语言, 实验环境配置为RTX 4090、64 GB内存、Window 11操作系统.
为了验证SEFL-MDS的有效性, 选取FedAvg[4]作为基线方案.在域泛化方面, 对比基于正则化的DG方法RSC(Representation Self-Challenging)[39]和基于傅里叶变换的数据增强方法ELCFS(Episodic Learning in Continuous Frequency Space)[22].对于数据异构性, 对比5种联邦学习方案:SCAFFOLD(Stochastic Controlled Averaging Algorithm)[5]、FedProx[6]、StableFDG[26]、MCGDM[28]、FedSAM[40], 以及两种重新加权方法:ARFL[25]和FedNova[24].
在PACS、Office-Home数据集上进行离域验证, 评估SEFL-MDS在未知领域中的学习效果.以准确度作为评估指标.同时还对这两个数据集中各域的数据进行采样, 评估联邦知识蒸馏的准确度和训练时间.
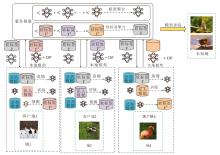
SEFL-MDS在PACS、Office-Home数据集上各域训练过程的准确度如图4所示.由图可见, SEFL-MDS表现出良优的收敛性.在PACS数据集上, SEFL-MDS对photo域的泛化能力最优, 准确度达到95.56%, 在Office-Home数据集上, SEFL-MDS对real world域具有较优的泛化能力, 但是由于在该域中有65个类别, 每类的图像较少, 因此准确度只有75.44%, 在其它3个域上的准确度也能达到50%以上.在PACS、Office-Home数据集上进行离域验证的结果可表明, SEFL-MDS具有较强的域泛化能力.
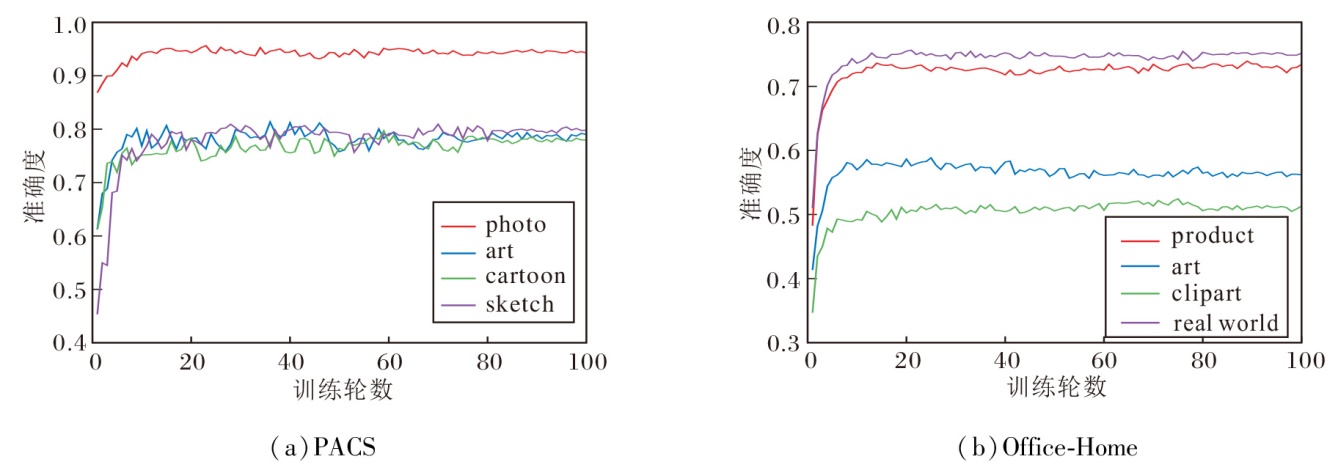 | 图4 SEFL-MDS在2个数据集上各域的准确度对比Fig.4 Accuracy comparison of SEFL-MDS on different domains of 2 datasets |
下面基于PACS、Office-Home数据集上每个域的数据, 对比不同方法的准确度, 如表1所示.
| 表1 不同方案在2个数据集上的准确度对比 Table 1 Accuracy comparison of different schemes on 2 datasets % |
由表1可见, SEFL-MDS在photo域和real world域上的准确度分别为95.56%和75.44%, 比其它方案的准确度至少提高2%, 在其它域上, SEFL-MDS的准确度与其它方法相差不大, 这证明SEFL-MDS对未知域具有较强的学习能力.
值得注意的是, 尽管SEFL-MDS在训练过程中为了实现隐私保护而注入高斯噪声, 仍表现出较高的准确度.
对PACS、Office-Home数据集上各域的数据进行采样, 并基于采样数据对比有无进行联邦知识蒸馏, 准确度结果如图5所示.
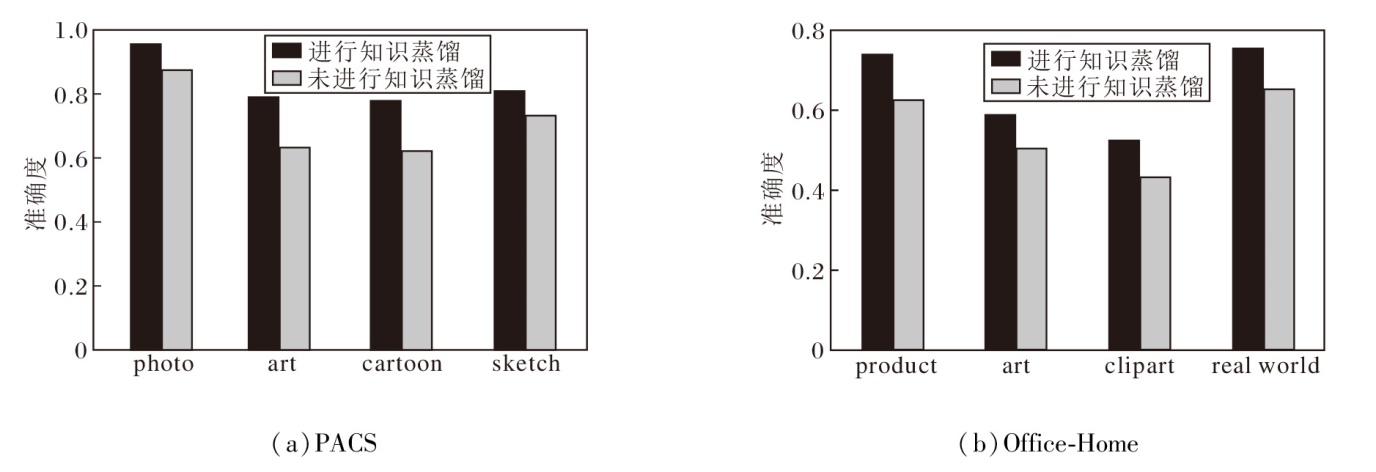 | 图5 知识蒸馏对各域性能的影响Fig.5 Effect of knowledge distillation on the performance of different domains |
由图5可见, 当模型在训练过程中未进行知识蒸馏时, 由于采样数据来源为不同的源域, 且每域的数据分布不一样, 导致模型的准确度显著下降.同时由于联邦学习的分布式特性, 模型参数并不是连续更新的, 而是通过周期性的聚合更新, 这样会导致每次局部模型更新后可能会丢失一些之前全局模型学到的信息.因此, 在联邦域泛化训练过程中引入知识蒸馏技术, 能有效避免模型发生灾难性遗忘, 显著提高模型性能.
不同本地训练方法每轮训练耗时对比如表2所示.
| 表2 不同本地训练方法每轮训练时间对比 Table 2 Comparison of training time per epoch for different local training methods s |
由表2可得, 当本地训练方法为FedAvg时, 在PACS、Office-Home数据集上的训练时间为分别为20.4 s和34.8 s.这是由于Office-Home数据集上图像和类别多于PACS数据集上, 导致训练时间增加.当引入动态泛化权重聚合算法和高斯差分隐私机制时, 增加额外的计算开销和通信开销, 导致每轮训练时间也随之增加.然而, 当引入知识蒸馏后, 在PACS、Office-Home数据集上的通信时间分别为15.2 s和25.4 s, 每轮训练时间分别减少28.4%和28.1%.由于知识蒸馏将大型教师模型的知识传递给较小的学生模型, 减少模型规模和训练复杂度, 从而缩短训练时间.同时, 在联邦学习中, 知识蒸馏还能降低通信成本, 加快本地训练速度, 并通过更快的模型收敛提高整体训练效率.
为了深入探究隐私预算对性能的影响, 在PACS数据集的photo域和Office-Home数据集的real world域上进行实验.选择从1至10作为隐私预算范围, 并根据敏感度和个体隐私需求, 设置不同的隐私预算, 具体准确度如图6所示.由图可得出, 当隐私预算不断增大时, 对准确度的影响逐渐减少.尽管添加高斯噪声会在一定程度上降低准确度, 却保证模型训练的安全性, 并防御推理攻击等恶意攻击.
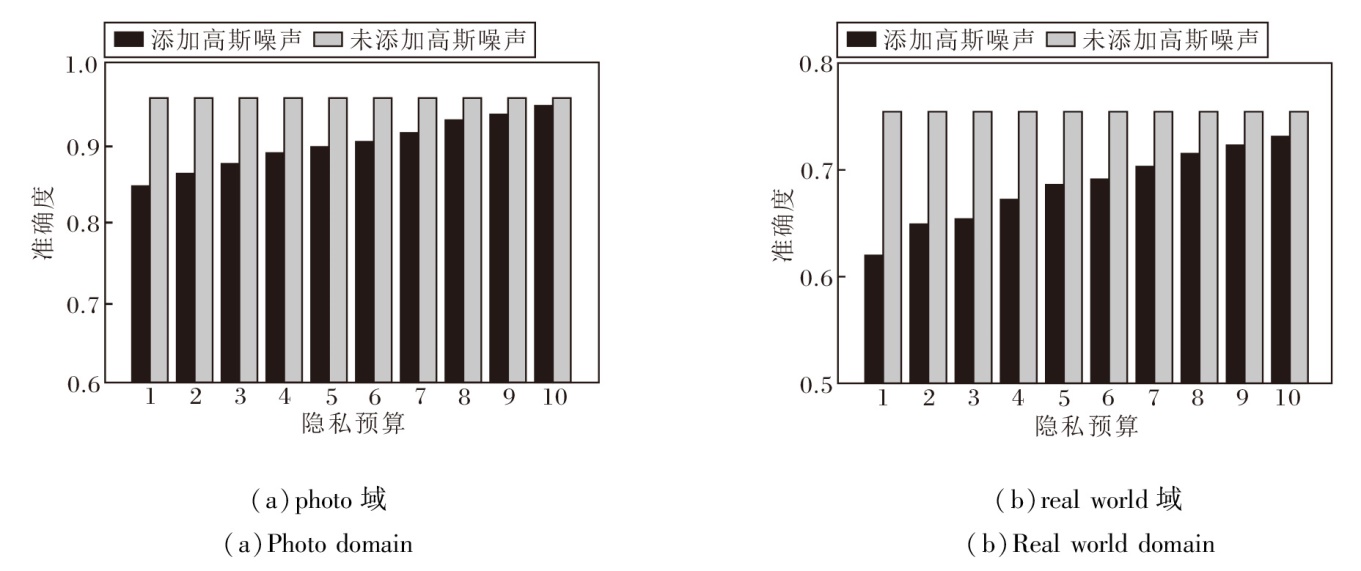 | 图6 不同隐私预算对SEFL-MDS性能的影响Fig.6 Effect of privacy budgets on the performance of SEFL-MDS |
本文致力于解决联邦学习训练过程中存在的域泛化性低、灾难性遗忘及隐私攻击等问题, 设计面向多域数据场景的安全高效联邦学习方案(SEFL-MDS).分别提出基于全局模型动态泛化权重聚合算法、基于联邦知识蒸馏的本地训练算法和高斯差分隐私机制, 以增强训练过程的安全性, 防止灾难性遗忘, 提升模型效率, 提高域泛化能力.理论分析表明SEFL-MDS具有较高的鲁棒性.在PACS、Office-Home数据集上的实验表明, SEFL-MDS在具有隐私需求的多域数据场景中表现优越.
尽管SEFL-MDS在未知域上取得良好性能, 但泛化能力仍有限, 特别是在目标域与源域存在显著差异时, 可能无法有效适应目标域.此外, 差分隐私机制引入的额外扰动可能降低准确度.今后将专注于探索具有更强域泛化能力的联邦学习模型, 并在隐私保护与模型效用之间寻找平衡点.
本文责任编委 陶 卿
Recommended by Associate Editor TAO Qing
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|
| [40] |
|