

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
广义多尺度多重集值决策系统的最优尺度约简
[刘梦欣1  , 谢祯晃
, 谢祯晃1 , 吴伟志1 , 朱康1 ]
, 谢祯晃, 吴伟志, 朱康]
|
|



作者简介:
刘梦欣,硕士研究生,主要研究方向为粗糙集、粒计算.E-mail:liumengxin2023@163.com. 
谢祯晃,硕士研究生,主要研究方向为粗糙集、粒计算.E-mail:xiezh1120@163.com. 
朱康,硕士研究生,主要研究方向为粗糙集、粒计算.E-mail:zhukang0318@163.com.
多尺度数据的知识表示与知识获取是现阶段多粒度计算研究的一个重要方向.在分析多尺度数据时,一个关键问题是最优尺度组合的选择,其目的是选择合适的子系统用于最终决策.因此文中针对多尺度多重集值数据的知识获取问题展开研究.首先,基于海林格距离,在广义多尺度多重集值决策系统中构造不同尺度组合下对象集上的相似关系,给出广义多尺度多重集值决策系统的信息粒表示.然后,在协调广义多尺度多重集值决策系统中,定义最优尺度约简与熵最优尺度约简的概念,证明最优尺度约简与熵最优尺度约简的等价性.在不协调广义多尺度多重集值决策系统中,引入广义决策函数,给出广义决策最优尺度约简的定义.进一步地,基于条件熵和广义决策函数,分别给出熵最优尺度约简搜索算法和广义决策最优尺度约简搜索算法.最后,提出构造广义多尺度多重集值决策系统的方法,并通过实验验证文中最优尺度约简算法的有效性和合理性.
About Author:
LIU Mengxin, Master student. Her research interests include rough sets and granular computing.
XIE Zhenhuang, Master student. His research interests include rough sets and granular computing.
ZHU Kang, Master student. His research interests include rough sets and granular computing.
The knowledge representation and the knowledge acquisition of multi-scale data are crucial research directions in multi-granularity computing. While analyzing multi-scale data, a key issue is the selection of the optimal scale combination, with the aim of choosing a suitable subsystem for the final decision. To solve the problem of knowledge acquisition from multi-scale multiset-valued data, at first, similarity relations determined by the set of objects under different scale combinations are constructed based on Hellinger distance in generalized multi-scale multiset-valued decision systems, and the information granule representation is provided. Second, the concepts of optimal scale reducts and entropy optimal scale reducts are defined in consistent generalized multi-scale multiset-valued decision systems, and the equivalence between the optimal scale reducts and the entropy optimal scale reducts is proven. In inconsistent generalized multi-scale multiset-valued decision systems, the definition of generalized decision optimal scale reducts is proposed by introducing generalized decision functions. Furthermore, by employing conditional entropies and generalized decision functions, search algorithms of entropy optimal scale reducts and generalized decision optimal scale reducts are designed. Finally, a method of constructing generalized multi-scale multiset-valued decision systems is proposed, and the experiments demonstrate the validity and rationality of the proposed algorithms.
粒计算(Granular Computing, GrC)[1, 2, 3]是数据分析和信息处理的新型计算范式, 以粒(Granule)为基本计算单位, 从不同视角和层次观察、分析与解决问题, 是研究复杂问题求解、海量数据挖掘和不确定性信息处理等问题的有效工具之一.迄今为止, 学者们已提出多种粒计算模型, 如基于模糊集的数据分析、粗糙集数据分析、形式概念分析和商空间理论等, 其中粗糙集数据分析对粒计算的研究与发展具有重要推动作用.
粗糙集是由Pawlak[4]提出的分析不完全、不精确数据的一个重要数学工具.粗糙集数据分析的数据表述主要以信息系统或决策系统的形式呈现, 利用属性子集定义在对象集上的等价关系, 将论域粒化为若干等价类(信息粒), 以粒代替样本, 并通过独特的属性约简方法挖掘蕴含在数据集上的决策知识.由于等价关系这一要求过于严格, 一些学者针对不同类型的数据集, 将等价关系推广为各种二元关系[5, 6, 7], 得到不同类型的信息粒, 同时利用证据理论、熵及三支决策等方法进行知识约简, 获得蕴含在数据集上的决策知识[8, 9, 10].
在经典粗糙集数据分析中, 数据集呈现的是单尺度系统, 即一个对象在一个属性下取值唯一, 但在实际应用中, 人们可能需要在不同尺度或粒度下描述问题和做出决策, 单尺度系统已不能满足实际需求.为此, Wu等[11]提出一个对象在同一个属性下依据不同尺度取不同值的多尺度粗糙集数据分析模型, 简称Wu-Leung模型.Wu-Leung模型的建模思想是:根据决策目标对每个属性选择合适的尺度, 构造一个单尺度子系统, 再在保持给定目标约束条件下进行属性约简, 获得蕴含在数据集上的决策知识, 并对所获知识进行不确定性分析.因此, 筛选最优尺度(保持目标约束不变的最粗尺度)[12]并在最优尺度下进行属性约简是多尺度数据分析的一个关键问题, 很多学者针对一些特定多尺度数据集的决策知识获取进行研究[13, 14, 15, 16, 17, 18, 19].由于Wu-Leung模型中每个属性都具有相同数量的尺度, Li等[20]推广该模型, 提出广义多尺度决策系统, 并通过定义尺度组合的概念, 给出广义多尺度决策系统的最优尺度组合选择和知识获取方法.由于在数据集上先计算最优尺度组合再计算约简需分为两步进行, 为了在搜索最优尺度组合的同时得到约简, Cheng等[21]定义最优尺度约简的概念, 给出广义多尺度决策系统的知识获取方法.廖淑娇等[22]基于测试代价给出多尺度决策系统中属性约简与尺度选择同步搜索的算法, 可节省搜索时间、提高计算效率.近年来, 各类广义多尺度决策系统的最优尺度组合与属性约简的问题受到学者的关注, 并取得一些重要研究进展[23, 24, 25, 26, 27].
作为度量不确定性的测度, 熵在研究系统的不确定性问题中发挥显著作用.熵这一概念最早是热力学中表示物质状态的参量, 熵越大表示物质体系越混乱.后来Shannon[28] 将熵引入信息论中, 用于度量知识的不确定性.在粗糙集数据分析中, 熵最早被用于刻画信息系统中知识的粗糙性[29], 随后被用于各种类型数据的属性约简, 在知识获取方面取得较优效果[30, 31, 32].近年来, 熵在研究多尺度数据的最优尺度选择方面也发挥重要作用.基于条件熵和测试成本, Wu等[33]提出考虑成本的多尺度三支多属性决策模型.Wang等[34]基于多尺度模糊熵, 考虑属性的冗余性、相关性和互补性, 对多尺度决策系统进行特征选择.Xie等[17]基于条件熵给出多尺度区间集决策系统中最优尺度选择和属性约简的方法.
多重集[35]是指元素可以重复出现的集合, 并且元素的顺序对多重集不构成影响, 是管理决策与数据分析的常用工具之一.例如:有多位专家参与某个议题或投票表决的评审投票结果就是一个多重集.多重集在网络安全[36]、特征融合[37]、模式识别[38]等方面都有重要应用.当信息系统的属性值为多重集时, 称该系统为多重集值信息系统, 相应的决策系统称为多重集值决策系统.在粗糙集数据分析方面, Zhao等[39]结合三支决策与决策粗糙集模型, 将损失函数推广到多重集, 提出多重集决策理论粗糙集模型.Huang等[40]应用不确定性度量方法分析多重集值信息系统的信息结构.Song等[41]构造多重集值信息系统中的相容关系, 并研究多重集值信息系统的离群值检测问题.
然而, 上述研究的多重集值系统都是单尺度的.王蕾晰等[42]提出多尺度多重集值信息系统的概念, 并给出基于知识粗糙熵的最优尺度选择和属性约简的算法.然而该算法处理的数据是Wu-Leung模型下的多尺度多重集值信息系统, 并且分两步提取数据集特征:先计算最优尺度, 再在最优尺度的基础上进行属性约简.
迄今为止, 未见关于广义多尺度多重集值决策系统的最优尺度组合和属性约简的研究.本文利用信息熵研究广义多尺度多重集值决策系统的最优尺度约简问题, 并给出最优尺度约简的搜索算法.采用文献[21]定义的尺度组合思路, 这样在选择最优尺度组合的同时就可得到属性约简(即最优尺度约简).
在本文中, |· |表示集合的基数.本节介绍多重集、多重集值系统和信息熵的相关概念.
定义1[35] 对于一个集合M, Z={z1, z2, …, zo}为一个非空有限集合, 若Z中的元素zi(zi∈ Z)在M中重复出现ei次, 即
$M=\overbrace{z_{1}, \cdots, z_{1}}^{e_{1}}, \cdots, \overbrace{z_{o}, \cdots, z_{o}}^{e_{o}}, $
则称M为Z上的一个多重集.记集合Z上所有多重集构成的集合为M(Z).
若给定一个函数CM:Z→ N, N为自然数集合, 使得
CM(zi)=ei, zi∈ Z, ei∈ N,
则多重集M还可表示为
$M=\left\{\left.\frac{C_{M}(z)}{z} \right\rvert\, z \in Z\right\}, $
多重集M的基数定义为
$|M|=\sum_{i=1}^{o} C_{M}\left(z_{i}\right) .$
定义2[40] 对于Z={z1, z2, …, zo}上的两个多重集M1∈ M(Z), M2∈ M(Z), M1和M2之间的海林格距离定义为
$H D\left(M_{1}, M_{2}\right)=\sqrt{1-\sum_{i=1}^{o} \sqrt{p_{i} q_{i}}}, $
其中
pi=
由定义2可知, 一个多重集又可表示为
M={
其中
pi=
例1 有2名选手参加一场晋级赛, 由4位专家进行评价并给出成绩“ 晋级(p)” 或“ 淘汰(f)” , 那么4位专家给2名选手的成绩M1与M2就是2个多重集.此时Z={p, f}, M1∈ M(Z), M2∈ M(Z), 若其中一名选手得到2张“ 晋级” 票和2张“ 淘汰” 票, 另一名选手得到3张“ 晋级” 票和1张“ 淘汰” 票, 则由定义1,
M1={p, p, f, f}, M2={p, p, p, f}.
还可表示为
$M_{1}=\left\{\frac{2}{p}, \frac{2}{f}\right\}, M_{2}=\left\{\frac{3}{p}, \frac{1}{f}\right\} .$
进一步, 由定义2, M1和M2又可表示为
M1=
且M1与M2之间的海林格距离为
$\begin{aligned}H D\left(M_{1}, M_{2}\right)= & \sqrt{1-\sum_{i=1}^{2} \sqrt{p_{i} q_{i}}}= \\& \sqrt{1-\left(\sqrt{\frac{1}{2} \cdot \frac{3}{4}}+\sqrt{\frac{1}{2} \cdot \frac{1}{4}}\right)}= \\& \sqrt{\frac{\sqrt{8}-\sqrt{3}-1}{\sqrt{8}}} \approx 0.1846 .\end{aligned}$
定义3[3] 称二元组(U, C)为一个信息系统, 其中U={x1, x2, …, xn}为论域, C={c1, c2, …, cm}为非空有限属性集, 对于∀ cj∈ C, 有
cj:U→ Vj, j=1, 2, …, m,
其中Vj为cj的值域.
称二元组(U, C∪ {d})为一个决策系统, 其中(U, C)为一个信息系统, 称C为条件属性集, d∉C为决策属性, d:U→ Vd, Vd为d的值域.若系统中存在缺省值*, 则称此决策系统为不完备决策系统.
定义4[39] 称二元组(U, C∪ {d})为一个多重集值决策系统, 其中U={x1, x2, …, xn}为论域, C={c1, c2, …, cm}为条件属性集, 且每个对象的条件属性取值都为多重集, 即对于∀ cj∈ C,
cj:U→ M(Vj),
其中, Vj为条件属性cj的值域, d∉C为决策属性.
定义5[20, 21] 称二元组(U, C∪ {d})为一个广义多尺度决策系统, 其中U={x1, x2, …, xn}为论域, C={c1, c2, …, cm}为条件属性集, 且每个条件属性都有Ij个尺度, d∉C为决策属性, 一个广义多尺度决策系统可表示为
(U, C∪ {d})=
(U,{
其中
d:U→ Vd,
Vd为d的值域,
使得
$ c_{j}^{l-1}=g_{j}^{l, l-1} \circ c_{j}^{l}, $
即
称
定义6[21] 设
S=(U, C∪ {d})=
(U,{
为一个广义多尺度决策系统, 对于∀ cj∈ C, 将属性cj所选尺度标记lj限制在{0, 1, …, Ij}上, 当lj=0时, 表示属性cj被删除; 当lj≠ 0时, 表示属性cj选择第lj个尺度, 此时称所选指标集构成S的一个尺度组合L=(l1, l2, …, lm), 其中lj∈ {0, 1, …, Ij}.
显然, 一个尺度组合L对应一个单尺度决策系统
$S^{L}=\left(U, \left\{c_{j}^{l_{j}} \mid j=1, 2, \cdots, m\right\} \cup\{d\}\right) .$
定义7[42] 称二元组(U, C)为一个多尺度多重集值信息系统, 其中U={x1, x2, …, xn}为论域, C={c1, c2, …, cm}为非空有限属性集, 每个属性都有I个尺度且属性值都是多重集, 一个多尺度多重集值信息系统可表示为
(U, {
其中
使得
$c_{j}^{l-1}=g_{j}^{l, l-1} \circ c_{j}^{l}, $
即
称
定义8[42] 设
(U, C)=(U, {
为一个多尺度多重集值信息系统, 则对于
∀ x∈ U, y∈ U, cj∈ C, l∈ {1, 2, …, I},
x与y在
SIM(
其中HD(
命题1[42] 设
(U, C)=(U, {
为一个多尺度多重集值信息系统, 则对于
∀ x∈ U, y∈ U, cj∈ C, l∈ {1, 2, …, I},
有
SIM(
设U为一个非空有限集合, 幂集记作P(U), 对于
C={C1, C2, …, Ce}⊆P(U),
若Ø∉C且$\bigcup_{i=1}^{e} C_{i}=U$, 则称C为U的一个覆盖.
进一步, 若
Ci∩ Cj=Ø,
i≠ j, i∈ {1, 2, …,e}, j∈ {1, 2, …,e},
则称C为U的一个划分.
定义9[29] 设(U, C)为一个信息系统, P⊆C, Q⊆C, 若
X={X1, X2, …, Xt}, Y={Y1, Y2, …, Ys}
为P和Q导出的U的两个划分, 则P的信息熵为:
$H(P)=-\sum_{i=1}^{t} p\left(X_{i}\right) \log _{2} p\left(X_{i}\right), $
其中
$p\left(X_{i}\right)=\frac{\left|X_{i}\right|}{|U|}, i=1, 2, \cdots, t .$
Q关于P的条件熵为:
$H(Q \mid P)=-\sum_{i=1}^{t} \sum_{j=1}^{s} p\left(X_{i}\right) p\left(Y_{j} \mid X_{i}\right) \log _{2} p\left(Y_{j} \mid X_{i}\right), $
其中
p(Yj|Xi)=
i=1, 2, …,t, j=1, 2, …,s.
Q与P的联合熵为:
$H(Q \cup P)=-\sum_{i=1}^{t} \sum_{j=1}^{s} p\left(Y_{j} \cap X_{i}\right) \log _{2} p\left(Y_{j} \cap X_{i}\right), $
其中
p(Yj∩ Xi)=
i=1, 2, …,t, j=1, 2, …,s.
定义9中所述的条件熵是建立在等价关系上的, 并非适用于相似关系, 为此, Dai等[32]提出相似关系下的条件熵.
对于一个不完备决策系统(U, C∪ {d}), B⊆C为一个条件属性子集, RB为论域U中由B导出的相似关系, 即
RB={(x, y)∈ U× U|c(x)=c(y)∨
c(x)=*∨ c(y)=* ,∀ c∈ B},
则RB导出U上的一个覆盖:
U/RB={[x]B|x∈ U},
其中
[x]B={y∈ U|(x, y)∈ RB}
为x关于RB的相似类.对于决策属性d, 不失一般性, 假定Vd={1, 2, …, r}, Rd为论域U关于d的等价关系:
Rd={(x, y)∈ U× U|d(x)=d(y)},
U/Rd为由Rd生成的U上的一个划分, 将U粒化为r个等价类:
U/Rd={[x]d|x∈ U}={D1, D2, …, Dr}.
对于x∈ U, 若∃j∈ {1, 2, …, r}, 使得x∈ Dj, 则称Dj为x的决策类, 即
Dj={x∈ U|d(x)=j}=[x]d.
定义10[32] 设(U, C∪ {d})为一个不完备决策系统,
U/Rd={D1, D2, …, Dr},
B⊆C为一个条件属性子集, 则d关于B的条件熵为:
$\begin{array}{l}H(d \mid B)= \\-\sum_{i=1}^{n} \sum_{j=1}^{r}\left(\frac{\left|\left[x_{i}\right]_{B} \cap D_{j}\right|}{n}\right) \log _{2}\left(\frac{\left|\left[x_{i}\right]_{B} \cap D_{j}\right|}{\left|\left[x_{i}\right]_{B}\right|}\right) .\end{array}$
定义11 称二元组(U, C)为一个广义多尺度多重集值信息系统, 其中U={x1, x2, …, xn}为论域, C={c1, c2, …, cm}为非空有限属性集, 对于∀ cj∈ C有Ij个尺度(Ij不必完全相同), 且每个对象的属性值均为多重集, 则一个广义多尺度多重集值信息系统可表示为
(U, {
其中
∀ l=2, 3, …, Ij, j=1, 2, …, m,
存在两个满射, 一个是
使得
w=gl, l-1(v), v∈
另一个是
使得
$c_{j}^{l-1}=\varphi_{j}^{l, l-1} \circ c_{j}^{l}, $
即对于∀ x∈ U, 记
有
$\begin{aligned} c_{j}^{l-1}(x)= & \varphi_{j}^{l, l-1}\left(c_{j}^{l}(x)\right)=\varphi_{j}^{l, l-1}\left(M_{1}\right)= \\ & \varphi_{j}^{l, l-1}\left(\left\{\left.\frac{C_{M_{1}}(v)}{v} \right\rvert\, v \in V_{j}^{l}\right\}\right)= \\ & \left\{\left.\frac{C_{M_{1}}\left(g_{j}^{l, l-1}(v)\right)}{g_{j}^{l, l-1}(v)} \right\rvert\, v \in V_{j}^{l}\right\}= \\ & \left\{\left.\frac{C_{M_{2}}(w)}{w} \right\rvert\, w \in V_{j}^{l-1}\right\}, \end{aligned}$
称
定义12 称二元组
$ \begin{array}{l} (U, C \cup\{d\})= \\ \quad\left(U, \left\{c_{j}^{l} \mid j=1, 2, \cdots, m, l=1, 2, \cdots, I_{j}\right\} \cup\{d\}\right) \end{array} $
为一个广义多尺度多重集值决策系统, 其中
(U, C)=(U, {
为一个广义多尺度多重集值信息系统, d∉C, d:U→ Vd为决策属性.
定义13 设
$ \begin{aligned} S= & (U, C \cup\{d\})= \\ & \left(U, \left\{c_{j}^{l} \mid j=1, 2, \cdots, m, l=1, 2, \cdots, I_{j}\right\} \cup\{d\}\right) \end{aligned} $
为一个广义多尺度多重集值决策系统, 对于∀ cj∈ C, 将属性cj所选尺度标记lj限制在{0, 1, …, Ij}上, 当lj=0时, 表示属性cj被删除; 当lj≠ 0时, 表示属性cj选择第lj个尺度, 此时称所选指标集构成S的一个尺度组合L, 即
L=(l1, l2, …, lm), lj∈ {0, 1, …, Ij},
j∈ {1, 2, …,m}.
记广义多尺度多重集值决策系统S的全部尺度组合为L, 即
L={(l1, l2, …, lm)
显然, 每个尺度组合
L=(l1, l2, …, lm)∈ L
对应一个单尺度多重集值决策系统
SL=(U, CL∪ {d}),
其中
CL={
为条件属性集C在尺度组合L上的限制.
例如:若
C={c1, c2, c3, c4}, L=(1, 0, 2, 2)∈ L,
则
CL={
定义14 对于一个广义多尺度多重集值决策系统(U, C∪ {d}), 记
L=(
如果
∀ j∈ {1, 2, …, m},
那么称尺度组合K强于L或称L弱于K, 记作K≽L.进一步, 若∃j∈ {1, 2, …, m}, 使得
另外, 如果定义
L∧ K={
L∨ K={
其中
j∈ {1, 2, …,m},
那么(L, ≽, ∧ , ∨ )为一个完备格, 其中最小元为(0, 0, …, 0), 最大元为(I1, I2, …, Im).
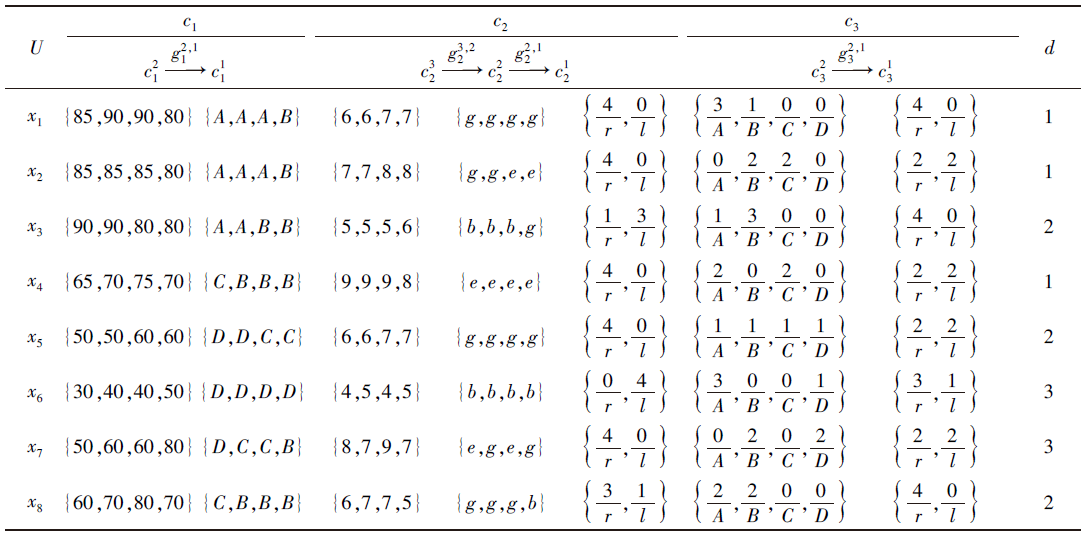
例2表1为一个广义多尺度多重集值决策系统S=(U, C∪ {d}), U={x1, x2, …, x8}表示8名参赛选手的论文, C={c1, c2, c3}, c1表示论文的创新性, c2表示论文的语言描写, c3表示论文的严谨性, d表示论文最终的成绩等级, Vd={1, 2, 3}, 1表示一等奖, 2表示二等奖, 3表示三等奖.
| 表1 一个广义多尺度多重集值决策系统 Table 1 A generalized multi-scale multiset-valued decision system |
属性值域的信息粒度变换如下:
$g_{2}^{3, 2}(z)=\left\{\begin{array}{ll} e, & 8 \leqslant z \leqslant 10 \\ g, & 6 \leqslant z< 8 \\ b, & 1 \leqslant z< 6 \end{array}\right.$
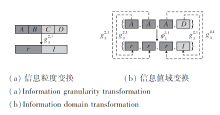
图1(a)给出属性c3下, 第2个尺度与第1个尺度之间的信息粒度变换.(b)给出对象x6在属性c3下, 第2个尺度与第1个尺度之间的信息值域变换.
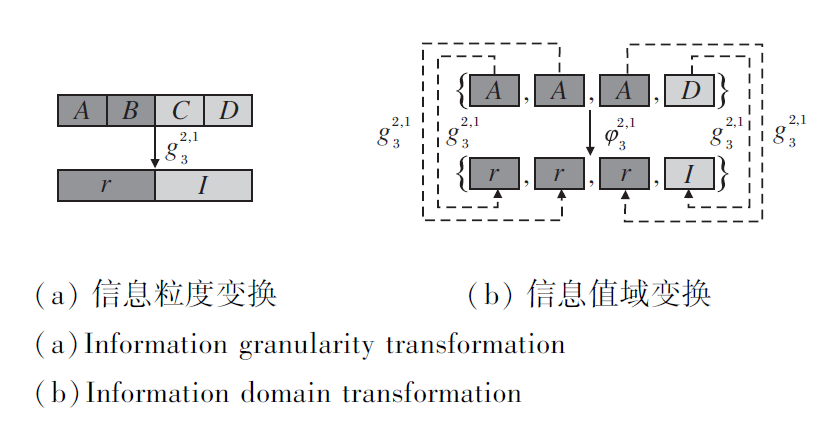 | 图1 信息粒度变换与信息值域变换的转换图Fig.1 Schematic diagram of information granularity transformation and information domain transformation |
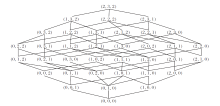
属性c1有2个尺度, 属性c2有3个尺度, 属性c3有2个尺度, 系统S共有36个尺度组合, 最强尺度组合为(2, 3, 2).由定义14, S的所有尺度组合的格结构如图2所示.
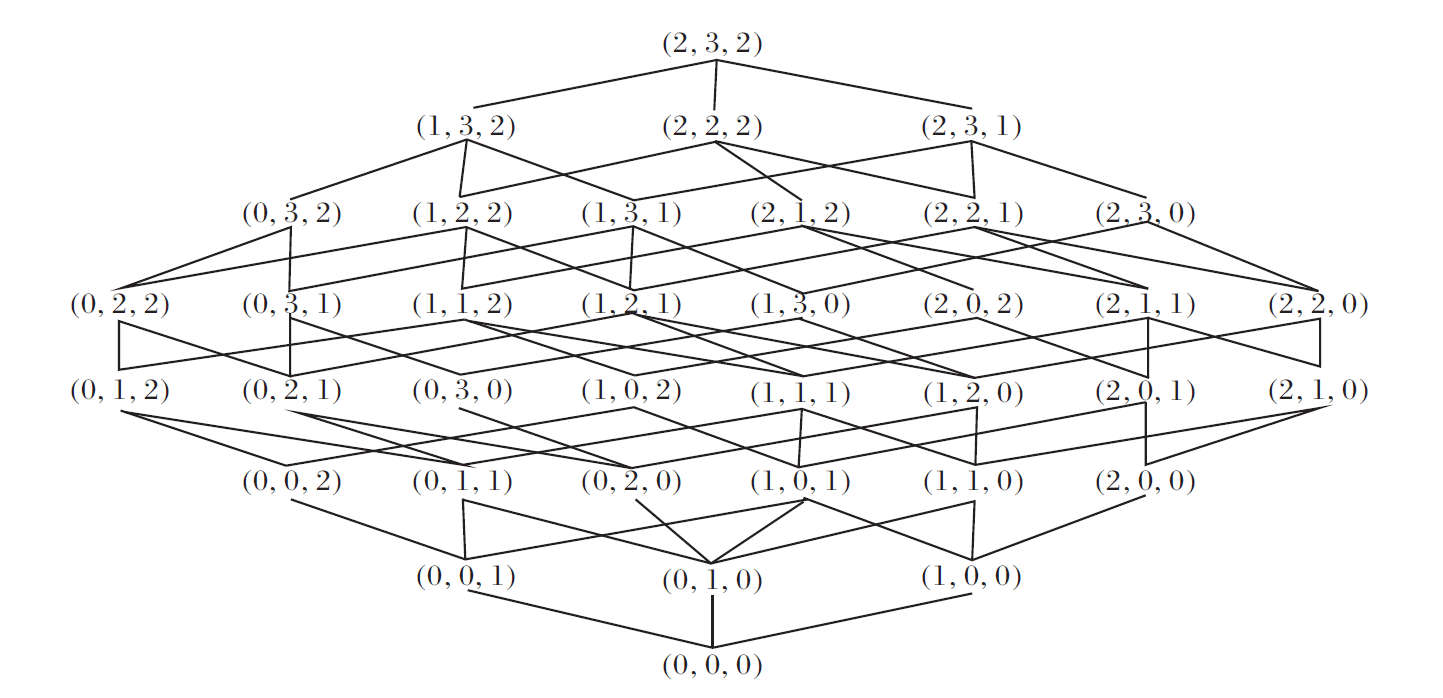 | 图2 尺度组合的格结构Fig.2 Lattice structure of scale combinations |
定义15 对于一个广义多尺度多重集值决策系统(U, C∪ {d}),
L=(l1, l2, …, lm)∈ L,
若∃j∈ {1, 2, …, m}, 使得lj≠ 0, 给定一个阈值α∈ (0, 1], 则定义由CL导出的相似关系:
$\begin{aligned} R_{C^{L}}^{\alpha}= & \left\{(x, y) \in U \times U \mid \forall c_{j}^{l_{j}} \in C^{L}, \right. \\ & \left.\operatorname{SIM}\left(c_{j}^{l_{j}}(x), c_{j}^{l_{j}}(y)\right) \geqslant \alpha\right\} . \end{aligned}$
U/
其中
且相似类的全体U/
特别地, 对于∀ cj∈ C, l∈ {1, 2, …, Ij}, cj在第l个尺度下导出的相似关系:
显然
命题2 设(U, C∪ {d})为一个广义多尺度多重集值决策系统, α∈ (0, 1], 对于
∀ cj∈ C, j∈ {1, 2, …, m}, l∈ {2, 3, …, Ij},
有
证明 对于∀ (x, y)∈
SIM(
由命题1可得
SIM(
从而
SIM(
因此, (x, y)∈
性质1 设(U, C∪ {d})为一个广义多尺度多重集值决策系统, 对于α∈ (0, 1], L∈ L, K∈ L, 若K≽L, 则
证明 设
L=(
则由K≽L及定义14可得, 对于∀ j∈ {1, 2, …, m}有
J={j|
若j∈ J, 由命题2可得
由于
因此
例3 (续例2) 给定4个尺度组合
L0=(2, 3, 2)∈ L, L1=(1, 2, 0)∈ L,
L2=(1, 1, 0)∈ L, L3=(0, 2, 0)∈ L,
α=0.6, 经计算可得
(x5, x5), (x6, x6), (x7, x7), (x8, x8)},
(x5, x5), (x6, x6), (x7, x7), (x8, x8)},
=
(x3, x3),(x4, x4),(x4, x8),(x5, x5),
(x5,x7), (x6, x6), (x7, x5), (x7, x7),
(x7, x8), (x8, x4), (x8, x7), (x8, x8)},
={(x1
(x2, x7), (x3,x3), (x3,x6), (x3,x8),
(x4, x4),(x5, x1), (x5, x5), (x5, x8),
(x6, x3), (x6, x6), (x7, x2), (x7, x7),
(x8,x1), (x8,x3), (x8,x5), (x8,x8)}.
本节基于条件熵和广义决策函数研究广义多尺度多重集值决策系统中的α -熵最优尺度约简和α -广义决策最优尺度约简.
定义16 对于一个广义多尺度多重集值信息系统(U, C), 设α∈ (0, 1], L∈ L, 则CL的信息熵为:
Hα (CL)=-
定义17 对于一个广义多尺度多重集值决策系统(U, C∪ {d}), 设α∈ (0, 1], L∈ L,
U/Rd={D1, D2, …, Dr},
则d关于CL的条件熵为:
$\begin{array}{l} H_{\alpha}\left(d \mid C^{L}\right)= \\ -\sum_{i=1}^{n} \sum_{j=1}^{r}\left(\frac{\left|\left[x_{i}\right]_{C^{L}}^{\alpha} \cap D_{j}\right|}{n} \log _{2}\left(\frac{\left|\left[x_{i}\right]_{C^{L}}^{\alpha} \cap D_{j}\right|}{\left|\left[x_{i}\right]_{C^{L}}^{\alpha}\right|}\right)\right) . \end{array}$
定义18 对于一个广义多尺度多重集值决策系统(U, C∪ {d}), 设α∈ (0, 1], L∈ L,
U/Rd={D1, D2, …, Dr},
则d关于CL的联合熵为:
$\begin{array}{l} H_{\alpha}\left(d \cup C^{L}\right)= \\ -\sum_{i=1}^{n} \sum_{j=1}^{r}\left(\frac{\left|\left[x_{i}\right]_{C^{L}}^{\alpha} \cap D_{j}\right|}{n} \log _{2}\left(\frac{\left|\left[x_{i}\right]_{C^{L}}^{\alpha} \cap D_{j}\right|}{n}\right)\right) . \end{array}$
定理1 对于一个广义多尺度多重集值决策系统(U, C∪ {d}), 若α∈ (0, 1], L∈ L,
U/Rd={D1, D2, …, Dr},
则
$H_{\alpha}\left(d \mid C^{L}\right)=H_{\alpha}\left(d \cup C^{L}\right)-H_{\alpha}\left(C^{L}\right) .$
证明 由
U/Rd={D1, D2, …, Dr}
是U的一个划分可得
$\begin{array}{l} H_{\alpha}\left(d \mid C^{L}\right)= \\ -\sum_{i=1}^{n} \sum_{j=1}^{r}\left(\frac{\left|\left[x_{i}\right]_{C^{L}}^{\alpha} \cap D_{j}\right|}{n} \log _{2}\left(\frac{\left|\left[x_{i}\right]_{C^{L}}^{\alpha} \cap D_{j}\right|}{\left|\left[x_{i}\right]_{C^{L}}^{\alpha}\right|}\right)\right)= \\ -\sum_{i=1}^{n} \sum_{j=1}^{r}\left(\frac { | [ x _ { i } ] _ { C ^ { L } } ^ { \alpha } \cap D _ { j } | } { n } \left(\log _{2}\left(\frac{\left|\left[x_{i}\right]_{C^{L}}^{\alpha} \cap D_{j}\right|}{n}\right)-\right.\right. \\ \left.\left.\quad \log _{2}\left(\frac{\left|\left[x_{i}\right]_{C^{L}}^{\alpha}\right|}{n}\right)\right)\right)= \\ H_{\alpha}\left(d \cup C^{L}\right)+\sum_{i=1}^{n}\left(\frac{\left|\left[x_{i}\right]_{C^{L}}^{\alpha}\right|}{n} \log _{2}\left(\frac{\left|\left[x_{i}\right]_{C^{L}}^{\alpha}\right|}{n}\right)\right)= \\ H_{\alpha}\left(d \cup C^{L}\right)-H_{\alpha}\left(C^{L}\right) .证毕 \end{array}$
性质2 对于一个广义多尺度多重集值决策系统(U, C∪ {d}), U=(x1, x2, …, xn), 设α∈ (0, 1], L∈ L, K∈ L, 若K≽L, 则
Hα (d|CK)≤ Hα (d|CL).
证明 对于∀ x∈ U, D∈ U/Rd, 令
p=|
其中DC表示D的补集, 则
p+q=|
一方面, 当p> 0且q≥ 0时, 函数-plog2(
可得
|
所以
$\begin{aligned} 0 \leqslant & -\left|[x]_{C^{K}}^{\alpha} \cap D\right| \log _{2}\left(\frac{\left|[x]_{C^{K}}^{\alpha} \cap D\right|}{\left|[x]_{C^{K}}^{\alpha}\right|}\right) \leqslant \\ & -\left|[x]_{C^{L}}^{\alpha} \cap D\right| \log _{2}\left(\frac{\left|[x]_{C^{L}}^{\alpha} \cap D\right|}{\left|[x]_{C^{L}}^{\alpha}\right|}\right), \end{aligned}$
故
$\begin{aligned} 0 \leqslant & -\frac{\left|[x]_{C^{K}}^{\alpha} \cap D\right|}{n} \log _{2}\left(\frac{\left|[x]_{C^{K}}^{\alpha} \cap D\right|}{\left|[x]_{C^{K}}^{\alpha}\right|}\right) \leqslant \\ & -\frac{\left|[x]_{C^{L}}^{\alpha} \cap D\right|}{n} \log _{2}\left(\frac{\left|[x]_{C^{L}}^{\alpha} \cap D\right|}{\mid[x)]_{C^{L}}^{\alpha} \mid}\right), \end{aligned}$
因此
Hα (d|CK)≤ Hα (d|CL). 证毕
定理2 对于一个广义多尺度多重集值决策系统(U, C∪ {d}), U=(x1, x2, …, xn), 若α∈ (0, 1], L∈ L, 则如下结论等价:
1)
2)Hα (d∪ CL)=Hα (CL),
3)Hα (d|CL)=0.
证明 1)⇒ 2).对于∀ x∈ U, 若
于是
$\begin{array}{c} \sum_{j=1}^{r}\left(\frac{\left|[x]_{C^{L}}^{\alpha} \cap D_{j}\right|}{n} \log _{2}\left(\frac{\left|[x]_{C^{L}}^{\alpha} \cap D_{j}\right|}{n}\right)\right)= \\ \frac{\left|[x]_{C^{L}}^{\alpha}\right|}{n} \log _{2}\left(\frac{\left|[x]_{C^{L}}^{\alpha}\right|}{n}\right) \end{array}$
因此
Hα (d∪ CL)=Hα (CL).
2)⇒ 3).由定理1可得.
3)⇒ 1).对于∀ x∈ U, D∈ U/Rd, 由性质2的证明过程可知, 若
Hα (d|CL)=0,
则有
即
|
因此, 对于∀ x∈ U, ∃D'∈ U/Rd使得
故
定义19 对于一个广义多尺度多重集值决策系统S=(U, C∪ {d}), 设α∈ (0, 1],
L0=(I1, I2, …, Im)∈ L,
若
则称S是α -协调的, 否则称S不是α -协调的.
定义20 对于一个广义多尺度多重集值决策系统S=(U, C∪ {d}), 设α∈ (0, 1], L∈ L, 若
则称SL关于S是α -协调的.进一步, 若对于满足L≻K的∀ K∈ L, 有
则称L是S的一个α -最优尺度组合, 称C在L上的限制CL是S的一个α -最优尺度约简.
定义21 对于一个广义多尺度多重集值决策系统S=(U, C∪ {d}), 设α∈ (0, 1],
L0=(I1, I2, …, Im)∈ L, L∈ L,
若
Hα (d|CL)=Hα (d|
则称SL关于S是α -熵协调的.进一步, 若对于满足L≻K的∀ K∈ L, 有
Hα (d|CK)≠ Hα (d|
则称L是S的一个α -熵最优尺度组合, 称C在L上的限制CL是S的一个α -熵最优尺度约简.
定理3 设S=(U, C∪ {d})是一个α -协调的广义多尺度多重集值决策系统, 若α∈ (0, 1],
L0=(I1, I2, …, Im)∈ L, L∈ L,
则
1)SL关于S是α -协调的当且仅当SL关于S是α -熵协调的,
2)L是S的一个α -最优尺度组合当且仅当L是S的一个α -熵最优尺度组合,
3)CL是S的一个α -最优尺度约简当且仅当CL是S的一个α -熵最优尺度约简.
证明 先证1).必要性.若SL关于S是α -协调的, 则
又因为S是α -协调的, 即
从而由定理2可得
Hα (d|CL)=Hα (d|
因此, SL关于S是α -熵协调的.
充分性.若SL关于S是α -熵协调的, 即
Hα (d|CL)=Hα (d|
又因为S是α -协调的, 即
从而由定理2可得
Hα (d|CL)=Hα (d|
若SL关于S不是α -协调的, 即
则∃x∈ U, j∈ {1, 2, …, r}使得
d(x)=j,
但
即
所以
$\log _{2}\left(\frac{\left|[x]_{C^{L}}^{\alpha} \cap D_{j}\right|}{\left|[x]_{C^{L}}^{\alpha}\right|}\right)< 0, $
故
$\begin{array}{l} H_{\alpha}\left(d \mid C^{L}\right) \geqslant \\ \quad-\frac{\left|[x]_{C^{L}}^{\alpha} \cap D_{j}\right|}{n} \log _{2}\left(\frac{\left|[x]_{C^{L}}^{\alpha} \cap D_{j}\right|}{\left|[x]_{C^{L}}^{\alpha}\right|}\right)> 0, \end{array}$
这与Hα (d|CL)=0矛盾.
再证2).由1)可得.
最后证3).由1), 定义20和定义21可得. 证毕
例4 (续例3) 由表1可知
Rd={(x1, x1), (x1, x2), (x1, x4), (x2, x1),
(x2, x2), (x2, x4), (x3, x3), (x3, x5),
(x3, x8), (x4, x1), (x4, x2), (x4, x4),
(x5, x3), (x5, x5), (x5, x8), (x6, x6),
(x6, x7), (x7, x6), (x7, x7), (x8, x3),
(x8, x5), (x8, x8)},
再由例3可得
由于L中严格弱于L1的尺度组合只有L2与L3, 因此, L1=(1, 2, 0)是S的一个α -最优尺度组合,
是S的一个α -最优尺度约简.又因为
$\begin{array}{l} H_{\alpha}\left(d \mid C^{L_{1}}\right)=H_{\alpha}\left(d \mid C^{L_{0}}\right), \\ H_{\alpha}\left(d \mid C^{L_{2}}\right) \neq H_{\alpha}\left(d \mid C^{L_{0}}\right), \\ H_{\alpha}\left(d \mid C^{L_{3}}\right) \neq H_{\alpha}\left(d \mid C^{L_{0}}\right), \end{array}$
所以L1也是S的一个α -熵最优尺度组合, 故C在L1上的限制
定义22 对于一个广义多尺度多重集值决策系统S=(U, C∪ {d}), 设α∈ (0, 1], L∈ L, 记
称
定义23 对于一个广义多尺度多重集值决策系统S=(U, C∪ {d}), 设α∈ (0, 1],
L0=(I1, I2, …, Im)∈ L, L∈ L,
若对于∀ x∈ U, 有
则称SL关于S是α -广义决策协调的.进一步, 若对于满足L≻K的∀ K∈ L, SK关于S不是α -广义决策协调的, 即∃x∈ U使得
则称L为S的一个α -广义决策最优尺度组合, 称C在L上的限制CL为S的一个α -广义决策最优尺度约简.
定理4 设S=(U, C∪ {d})是一个α -协调广义多尺度多重集值决策系统, 对于α∈ (0, 1],
L0=(I1, I2, …, Im)∈ L, L∈ L,
则SL关于S是α -协调的当且仅当SL关于S是α -广义决策协调的.
证明 由于S是α -协调的, 由定义19知
即对于∀ x∈ U, 有
于是, 对于∀ y∈
d(y)=d(x),
从而
必要性.对于∀ x∈ U, 若SL关于S是α -协调的, 则由定义20知
即
所以对于∀ y∈
d(y)=d(x),
即
因此, SL关于S是α -广义决策协调的.
充分性.对于∀ x∈ U, 若SL关于S是α -广义决策协调的, 即
由广义决策值的定义知
所以
即
因此, SL关于S是α -协调的. 证毕
由定理4知, 若系统S是α -协调的, L∈ L, 则SL关于S是α -广义决策协调的可退化为SL关于S是α -协调的.
定理5 设S=(U, C∪ {d})是一个α -不协调广义多尺度多重集值决策系统, 对于α∈ (0, 1],
L0=(I1, I2, …, Im)∈ L, L∈ L,
若SL关于S是α -熵协调的, 则SL关于S是α -广义决策协调的.
证明 因为SL关于S是α -熵协调的, 所以有
Hα (d|CL)=Hα (d|
对于∀ x∈ U, D∈ U/Rd, 由性质2的证明过程可知
$\begin{array}{l} -\frac{\left|[x]_{C^{L_{0}}}^{\alpha} \cap D\right|}{n} \log _{2}\left(\frac{\left|[x]_{C^{L_{0}}}^{\alpha} \cap D\right|}{\left|[x]_{C^{L_{0}}}^{\alpha}\right|}\right) \leqslant \\ \quad-\frac{\left|[x]_{C^{L}}^{\alpha} \cap D\right|}{n} \log _{2}\left(\frac{\left|[x]_{C^{L}}^{\alpha} \cap D\right|}{\left|[x]_{C^{L}}^{\alpha}\right|}\right), \end{array}$
再结合
Hα (d|CL)=Hα (d|
可得
$\begin{array}{l} -\frac{\left|[x]_{C^{L_{0}}}^{\alpha} \cap D\right|}{n} \log _{2}\left(\frac{\left|[x]_{C^{L_{0}}}^{\alpha} \cap D\right|}{\left|[x]_{C^{L_{0}}}^{\alpha}\right|}\right)= \\ \quad-\frac{\left|[x]_{C^{L}}^{\alpha} \cap D\right|}{n} \log _{2}\left(\frac{\left|[x]_{C^{L}}^{\alpha} \cap D\right|}{\left|[x]_{C^{L}}^{\alpha}\right|}\right), \end{array}$
于是
从而
故对于∀ x∈ U, 有
因此, SL关于S是α -广义决策协调的. 证毕
定理5的逆命题一般不成立, 见例5.
例5 设S=(U, C∪ {d})为一个α -不协调广义多尺度多重集值决策系统, 其中条件属性部分与表1相同, 决策属性部分如下:
d(x1)=d(x3)=d(x4)=d(x7)=1,
d(x2)=d(x8)=2,
d(x5)=d(x6)=3.
给定尺度组合:
L0=(2, 3, 2)∈ L, L1=(1, 2, 0)∈ L,
L4=(2, 2, 0)∈ L, L5=(2, 1, 0)∈ L.
阈值α=0.2, 经计算, 有
U/Rd={{x1, x3, x4, x7}, {x2, x8}, {x5, x6}}=
{D1, D2, D3},
(x2, x2),(x3, x1),(x3, x3),(x3, x8),
(x4,x4), (x5, x5), (x5, x7), (x5, x8),
(x6, x6), (x7, x5), (x7, x7), (x7, x8),
(x8, x3),(x8, x5),(x8, x7),(x8, x8)},
(x2, x1), (x2, x2), (x2, x3), (x2, x4),
(x2, x8), (x3, x1), (x3, x2), (x3, x3),
(x3, x7), (x3, x8), (x4, x2), (x4, x4),
(x4, x7), (x5, x5), (x5, x7), (x5, x8),
(x6, x6), (x7, x3), (x7, x4), (x7, x5),
(x7, x7), (x7, x8), (x8, x1), (x8, x2),
(x8, x3), (x8, x5), (x8, x7), (x8, x8)},
(x2, x2), (x2, x3), (x3, x1), (x3, x2),
(x3, x3), (x3, x7), (x3, x8), (x4, x4),
(x5, x5), (x5, x7), (x5, x8), (x6, x6),
(x7, x3), (x7, x5), (x7, x7), (x7, x8),
(x8, x3), (x8, x5), (x8, x7), (x8, x8)},
(x2, x2), (x2, x3), (x3, x1), (x3, x2),
(x3, x3), (x3, x7), (x3, x8), (x4, x4),
(x4, x8), (x5, x5), (x5, x7), (x5, x8),
(x6, x6), (x7, x3), (x7, x5), (x7, x7),
(x7, x8), (x8, x3), (x8, x4), (x8, x5),
(x8, x7), (x8, x8)}.
根据上述结果可得, 对于∀ x∈ U,
所以
$\begin{array}{l} H_{0.2}\left(d \mid C^{L_{0}}\right)= \\ -\sum_{i=1}^{8} \sum_{j=1}^{3}\left(\frac{\left|\left[x_{i}\right]_{C^{L_{0}}}^{0.2} \cap D_{j}\right|}{n} \log _{2}\left(\frac{\left|\left[x_{i}\right]_{C^{L_{0}}}^{0.2} \cap D_{j}\right|}{\left|\left[x_{i}\right]_{C_{0}^{L_{0}}}^{0.2}\right|}\right)\right)= \\ \frac{3}{2} \log _{2} 3+\frac{1}{2} \log _{2} 2 \approx 0.3010, \\ H_{0.2}\left(d \mid C^{L_{4}}\right)= \\ -\sum_{i=1}^{8} \sum_{j=1}^{3}\left(\frac{\left|\left[x_{i}\right]_{C^{L_{4}}}^{0.2} \cap D_{j}\right|}{n} \log _{2}\left(\frac{\left|\left[x_{i}\right]_{C^{L_{4}}}^{0.2} \cap D_{j}\right|}{\left|\left[x_{i}\right]_{C^{L_{4}}}^{0.2}\right|}\right)\right)= \\ \frac{3}{4} \log _{2} 3+\frac{5}{8} \log _{2} 5 \approx 0.6990, \end{array}$
因此
H0.2(d|
从而
所以L4是S的一个α -广义决策最优尺度组合, 进而C在L4上的限制
是S的一个α -广义决策最优尺度约简.
称所有条件属性在全部尺度下导出的相似关系构成的集合为相似关系集, 记为P, 即
P={
下面分别给出计算相似关系集和决策属性导出的等价关系、搜索一个α -熵最优尺度约简和搜索一个α -广义决策最优尺度约简的算法.
算法1 计算相似关系集和决策属性导出的等价
关系
输入 一个广义多尺度多重集值决策系统
S=(U, C∪ {d}), α∈ (0, 1]
输出 相似关系集P,
决策属性导出的等价关系Rd
初始化 P← Ø;
for cj∈ C do
for l∈ {1, 2, …, Ij} do
计算
P← P∪ {
end for
end for
计算d导出的等价关系Rd;
return P, Rd
算法2 一个α -熵最优尺度约简的搜索算法
输入 一个广义多尺度多重集值决策系统
S=(U, C∪ {d}), α∈ (0, 1],
L0=(I1, I2, …, Im)
输出 一个α -熵最优尺度约简CL
初始化L← (l1, l2, …, lm);
(l1, l2, …, lm)← L0;
计算条件熵Hα (d|CL);
记temp=Hα (d|CL);
for i=1:m do
li← 0;
计算条件熵Hα (d|CL);
while Hα (d|CL)≠ temp and li≠ Ii do
li=li+1;
计算条件熵Hα (d|CL);
end while
end for
计算C在L上的限制CL;
return CL
算法3 一个α -广义决策最优尺度约简的搜索
算法
输入 一个广义多尺度多重集值决策系统
S=(U, C∪ {d}), α∈ (0, 1],
L0=(I1, I2, …, Im)
输出 一个α -广义决策最优尺度约简CL
初始化L← (l1, l2, …, lm);
(l1, l2, …, lm)← L0;
计算广义决策
记Q=
for i=1:m do
li← 0;
计算广义决策
while
li=li+1;
计算广义决策
end while
end for
计算C在L上的限制CL;
return CL
在算法1中, for语句用于计算相似关系集, 过程的时间复杂度为O(
O((1+
在算法2和算法3中, 最坏情况下所有属性都是不能删除的, 且属性cj的最优尺度为Ij, 因此算法2和算法3的时间复杂度都为
O(m+
本文实验采用的硬件配置为13th Gen Intel(R) Core(TM) i5-13500H@2.60 GHz和16 GB内存的PC, 操作系统为Windows 11, 软件为PyCharm Commu-nity Edition 2023.2.5.
实验内容主要分为2部分.第1部分讨论α -熵最优尺度约简、α -广义决策最优尺度约简与k近邻法(K Nearest Neighbor, KNN)结合后的分类性能.鉴于目前尚未涉及广义多尺度多重集值决策系统的研究, 因此在算法评估时, 仅对比本文的算法2与算法3.第2部分分析相似度阈值α和缺失率阈值β变化对算法性能的影响.
由于UCI数据库上现存的数据集都是单尺度数据且属性值不为多重集, 因此需要构造广义多尺度多重集值决策系统.结合文献[20]的构造广义多尺度决策系统的方法, 通过如下5步将数值型数据集S=(U, C∪ {d})构造为广义多尺度多重集值决策系统.
1)调整数据集缺失率.定义S的缺失率:
$L R=1-\sum_{j=1}^{|C|}\left(\frac{\left|U_{j}\right|}{|C||U|}\right), $
其中
Uj={x∈ U|cj(x)≠ *},
为属性cj下属性值完备的对象集合.令阈值β∈ (0, 1], 分3种情况讨论.
(1)若数据集是完备的, 则随机将对象的条件属性值赋值为缺省值*, 直至LR=β .
(2)若数据集是不完备的且LR< β, 则随机将对象的条件属性值赋值为缺省值*, 直至LR=β .
(3)若数据集是不完备的且LR≥ β, 则数据集保持不变.
2)连续型数据离散化.对于∀ x∈ U, cj∈ C, 记σ j和mj分别为Vj中元素的标准差和最小值.针对x在cj下的属性值, 做如下离散化:
c'j(x)=
其中[k]表示不大于k的最大整数.生成离散化后的属性值域:
Vj={c'j(x) | x∈ U}={*, k1, k2, …, kt},
其中
k1< k2< …< kt.
对于∀ x∈ U, 若
c'j(x)∈ Vj, c'j(x)≠ *,
记
c'j(x)=k,
则
cj(x)∈ [mj+kσ j, mj+(k+1)σ j).
3)构造多尺度属性值域.分两种情况讨论.
(1)若
|Vj-{*}|≤ 3,
则属性cj有1个尺度, 即Ij=1.令2)中构造的属性值域Vj为属性cj在第Ij个尺度下的属性值域, 即
(2)若
|Vj-{*}|> 3,
则属性cj有|Vj-{*}|-2个尺度, 即
Ij=|Vj-{*}|-2.
令2)中构造的属性值域Vj为属性cj在第Ij个尺度下的属性值域, 即
对于l∈ {1, 2, …, Ij-1}, 合并属性值
4)构造最强尺度组合下的多重集值决策系统.对于∀ cj∈ C, x∈ U, 将x在cj下的属性值构造为多重集.
(1)若
c'j(x)=ks,
则
其中s∈ {1, 2, …, t}.
(2)若
c'j(x)=*,
则
其中
mj, p(x)={y∈ U|d(y)=d(x), c'j(y)=kp},
p∈ {1, 2, …,t}.
5)构造广义多尺度多重集值决策系统.对于∀ cj∈ C, l∈ {2, 3, …, Ij}, 根据定义11及2)和3), 得到信息粒度变换:
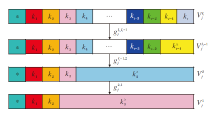
如图3所示, 属性cj在第Ij个尺度下的值域
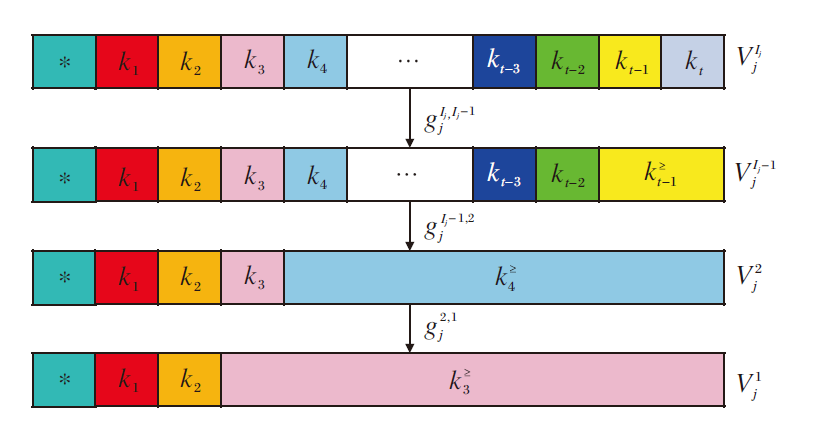 | 图3 多尺度属性值域的构造Fig.3 Construction of multi-scale attribute domains |
信息粒度变换
以此类推, 直至信息粒度变换
进一步, 对于∀ x∈ U, cj∈ C和l∈ {2, 3, …, Ij}, 根据信息值域变换, 将x在cj的第l-1个尺度下的属性值构造为多重集.至此, 完成广义多尺度多重集值决策系统的构造.
为了保证实验的可重复性和结果的一致性, 在上述1)中设置缺失值时, 设置随机种子为50.随机种子是一个用于启动随机数生成器的数值, 确保使用相同种子时生成相同的随机数序列, 这样能保证实验生成的缺省值的分布是一致的, 也保证可重复实验的结果一致性.
实验选取的10个数据集的具体信息如表2所示.通过1)~5), β=0.2, 将10个数据集分别转换为10个不同的广义多尺度多重集值决策系统, 每个广义多尺度多重集值决策系统在各属性下的尺度个数如表3所示.
| 表2 实验数据集 Table 2 Experimental datasets |
| 表3 构造的广义多尺度多重集值决策系统的尺度个数 Table 3 Scale numbers in constructed generalized multi-scale multiset-valued decision systems |
通过十折交叉验证法, 将原始数据拆为10份, 在每次计算中, 取其中9份作为训练集, 1份作为测试集, 在训练集上求得系统的最优尺度约简, 并在最优尺度约简下, 利用KNN分类器, 预测测试集上对象的决策属性值.对于KNN分类器, k=5, 且KNN中的距离公式为定义2中的海林格距离.对于构造的广义多尺度多重集值决策系统(U, C∪ {d}), 记L0为决策系统的最强尺度组合, LH为一个α -熵最优尺度组合, LGD为一个α -广义决策最优尺度组合, 则
首先, 设置阈值α=0.9, β=0.2, 对比此时构造的广义多尺度多重集值决策系统在
| 表4 条件属性集在不同尺度组合下的分类精度 Table 4 Classification accuracies of conditional attribute sets with different scale combinations % |
由表4可得, 在α -熵最优尺度约简和α -广义决策最优尺度约简下的分类精度均高于或等于属性集C在最强尺度组合L0下限制的分类精度.这说明通过搜索α -熵最优尺度约简和α -广义决策最优尺度约简可简化信息, 降低信息获取成本的同时保持模型的泛化能力.
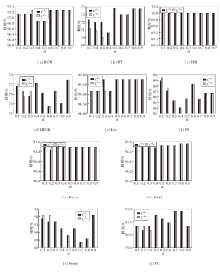
进一步, 设置缺失率阈值β=0.2, 对比在不同相似度阈值α下α -熵最优尺度约简和α -广义决策最优尺度约简的分类精度, α∈ {0.1, 0.2, …, 0.9}, 结果如图4所示.由图可观察到, α取不同值时, 大多数数据集上两种最优尺度约简的分类精度是相同的.然而, 在少数情况下, 两种最优尺度约简下的分类精度是不同的.例如:在图4(a)中, 当α=0.3时, α -熵最优尺度约简的分类精度低于α -广义决策最优尺度约简; 在(b)中, 当α=0.2时, α -熵最优尺度约简的分类精度高于α -广义决策最优尺度约简.因此, 在实际应用中, 可根据实际需求选择α -熵最优尺度约简或α -广义决策最优尺度约简进行后续的规则提取.
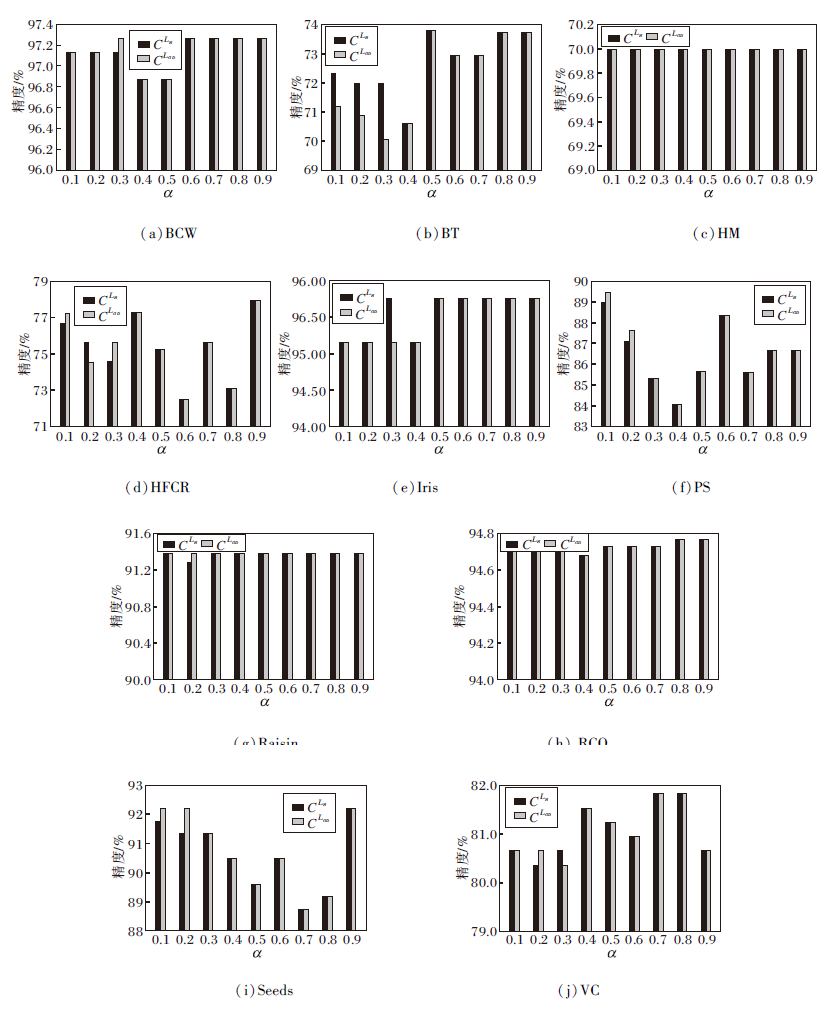 | 图4 α不同时两种最优尺度约简的精度变化Fig.4 Classification accuracies of two kinds of optimal scale reducts with different values of α |
最后, 当相似度阈值α和缺失率阈值β同时变化时, 观测α -熵最优尺度约简和α -广义决策最优尺度约简的分类精度的变化情况, α∈ {0.1, 0.2, …, 0.9}, β∈ {0.05, 0.10, 0.15, 0.20, 0.25}, 结果如图5和图6所示.由图可得, 在大部分数据集上, 当β增加时, 分类精度随之提升, 这一现象表明在不完备的多尺度决策系统中, 使用多重集表示缺失值, 能有效提高最优尺度约简下的分类精度.
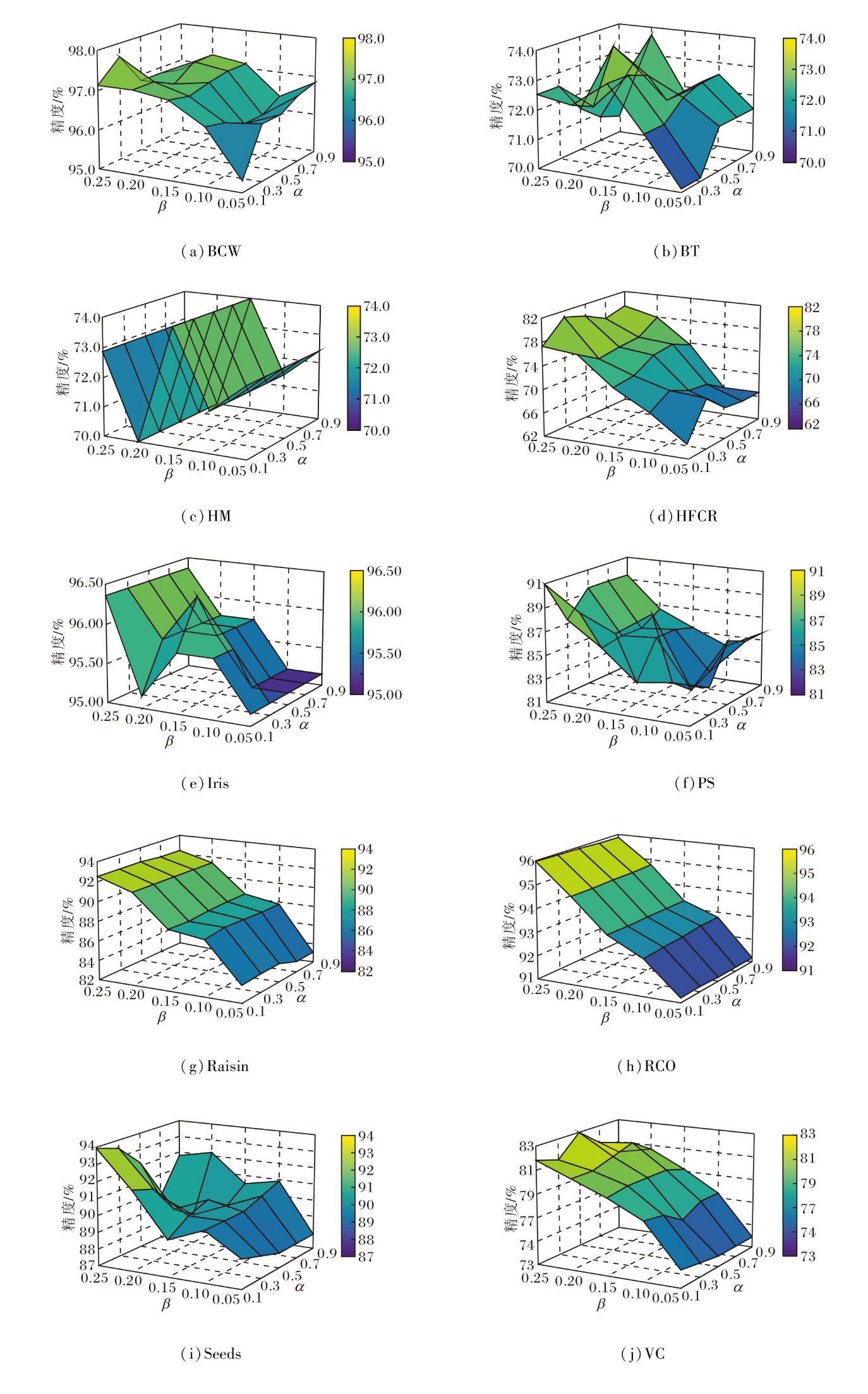 | 图5 α、 β变化时一个α -熵最优尺度约简的精度图Fig.5 Accuracies of an α-entropy optimal scale reduct with varying α and β |
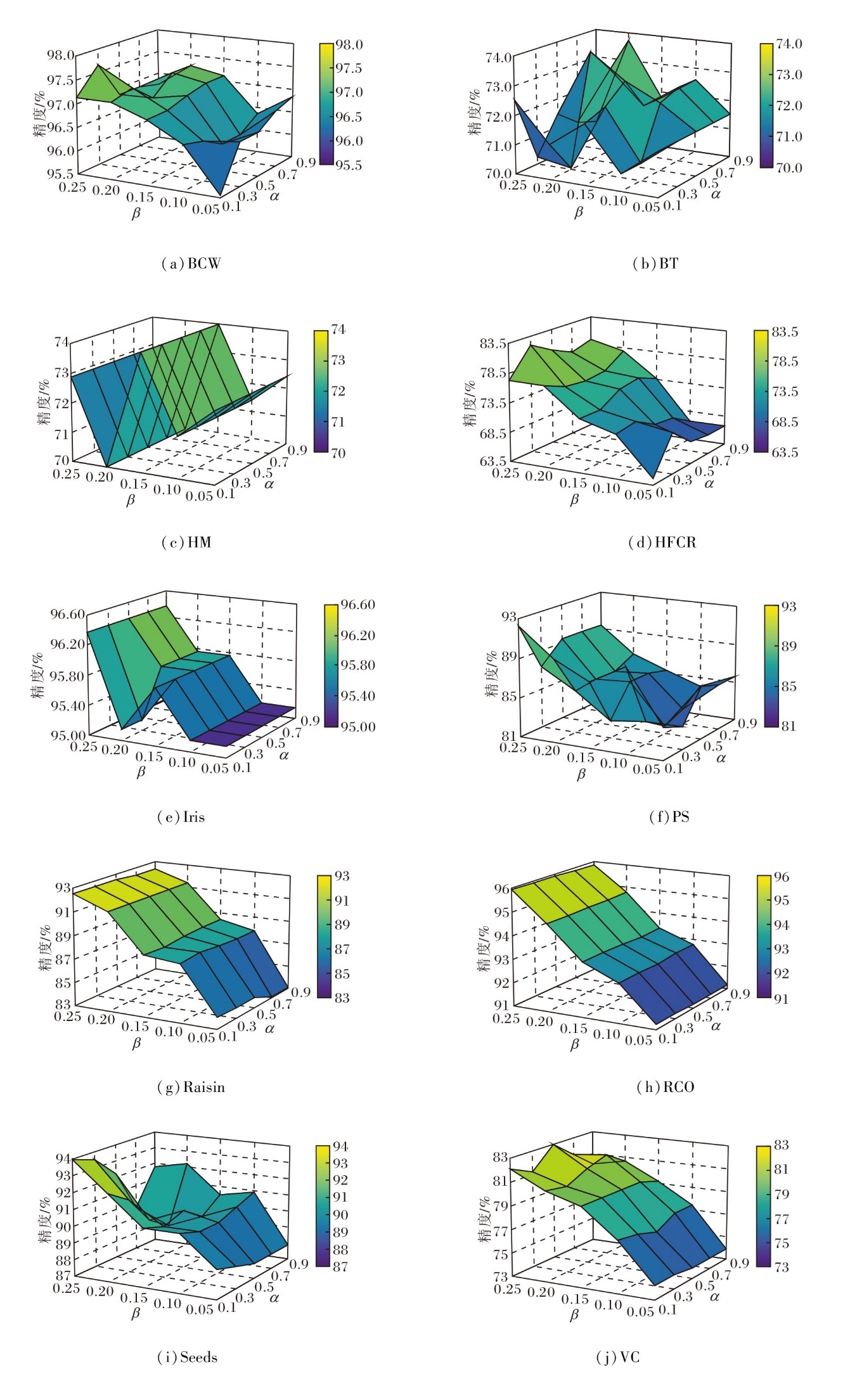 | 图6 α、 β变化时一个α -广义决策最优尺度约简的精度图Fig.6 Accuracies of an α-generalized decision optimal scale reduct with varying α and β |
上述结果证实多重集表示方法在处理缺失数据方面的优越性, 为系统在应对不完备信息时提供更佳的性能保障.然而, α 变动时, 最优尺度约简的分类精度无显著变化规律.
本文讨论广义多尺度多重集值决策系统的最优尺度约简问题.讨论数据集上条件属性值均为多重集, 基于海林格距离定义广义多尺度多重集值决策系统的相似关系.针对α -协调决策系统, 利用条件熵给出α -协调和α -熵协调的概念, 并进一步定义α -最优尺度组合、α -熵最优尺度组合、α -最优尺度约简和α -熵最优尺度约简等概念, 证明α -最优尺度约简和α -熵最优尺度约简之间的等价性.针对α -不协调广义多尺度多重集值决策系统, 引入广义决策函数, 提出α -广义决策协调和α -广义决策最优尺度约简的概念, 讨论α -熵协调与α -广义决策协调之间的关系.最后给出α -熵最优尺度约简搜索算法和α -广义决策最优尺度约简搜索算法, 并通过实验验证α -熵最优尺度约简和α -广义决策最优尺度约简的分类性能.本文只讨论基于条件熵和广义决策函数的广义多尺度多重集值决策系统的最优尺度约简问题, 在后续研究中, 可进一步关注其它类型最优尺度组合、决策知识获取以及相关不确定性分析等问题.
本文责任编委 张燕平
Recommended by Associate Editor ZHANG Yanping
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|
| [40] |
|
| [41] |
|
| [42] |
|