





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于对抗强化学习的多跳知识推理
[成凌云1  , 郭银章
, 郭银章1 , 刘青芳1 ]
, 郭银章, 刘青芳]
|
|



作者简介: 
成凌云,硕士研究生,主要研究方向为云计算与云安全、知识图谱.E-mail:s202220210949@stu.tyust.edu.cn. 
刘青芳,硕士研究生,主要研究方向为群智计算、云计算、深度学习.E-mail:s202220210951@stu.tyust.edu.cn.
为了解决现有知识图谱问答中多跳推理模型在复杂关系中表示不足、数据稀疏性及强化学习推理中存在虚假路径等问题,文中提出基于对抗强化学习的多跳知识推理模型.首先,通过高阶分解关系向量,实现实体与关系特征参数化组合,并在聚合邻居节点时引入注意力机制,赋予不同权重,增强复杂关系的表示能力.还设计知识图谱嵌入框架,用于衡量嵌入空间中<主题实体,问题,答案实体>的可信度.然后,将多维信息融入强化学习框架的状态表示中,避免因数据稀疏而导致的智能体无法得到可靠的决策依据.生成器根据状态信息计算候选实体的概率并生成答案,鉴别器评估答案和推理路径的合理性,通过软奖励和路径奖励优化反馈,缓解虚假路径问题,并使用对抗训练交替优化生成器和鉴别器.最后,将模型应用于云制造产品设计知识多跳问答系统中,验证模型的有效性.在多个公开数据集上的对比实验、消融实验及案例研究表明,文中模型性能较优.
About Author:
CHENG Lingyun, Master student. Her research interests include cloud computing and cloud security, and knowledge graphs.
LIU Qingfang, Master student. Her research interests include crowd computing, cloud computing and deep learning.
To address the issues of insufficient representation of complex relationships, data sparsity, and false paths in multi-hop reasoning models within existing knowledge graph question-answering systems, a multi-hop knowledge reasoning model based on adversarial reinforcement learning is proposed. First, high-order relation vectors are decomposed to parameterize and combine entity and relation features. An attention mechanism is introduced when neighboring nodes are aggregated to assign different weights, thereby enhancing the representation ability of complex relationships. Additionally, a knowledge graph embedding framework is designed to measure the credibility of <subject entity, question, answer entity> in the embedding space. Second, multi-dimensional information is integrated into the state representation of the reinforcement learning framework to enable the Agent to make reliable decisions despite data sparsity. The generator calculates the probability of candidate entities based on state information and generates answers, while the discriminator evaluates the reasonableness of the answers and the reasoning paths. The problem of false paths is alleviated by optimizing the feedback through soft rewards and path rewards, and adversarial training is utilized to alternately optimize the generator and the discriminator. Finally, the model is applied to a multi-hop question-answering system for cloud manufacturing product design knowledge to verify its effectiveness. Comparative experiments, ablation experiments and case studies verify the effectiveness of the proposed model.
知识图谱(Knowledge Graphs, KGs)[1]构建语义化的数据模型, 结构化表示各类知识, 可被计算机理解和处理, 进而实现高效组织、智能检索和推理, 已被广泛应用于信息检索和推荐系统等领域.同时, KGs赋予问答系统(Question Answering, QA)[2]卓越的推理能力和可解释性, 使其能准确回答事实性问题.基于KGs的问答系统(Knowledge Graph Ques-tion Answering, KGQA)结合自然语言处理技术, 能在KGs背景下解析问题并生成准确答案.
在KGQA任务中, 问题涉及单一关系和复杂关系的推理需求[3].单一关系涉及直接的实体关系, 复杂关系(如1-N、N-1、N-N)问答涉及多个实体和关系的连接.
传统KGQA在单跳问答中表现良好, 但在复杂关系问答和多跳推理中仍面临挑战.Yi等[4]提出NS-VQA(Neural-Symbolic Visual Question Answering), 结合符号推理与神经网络, 解析自然语言问句并生成结构化查询, 但符号推理在处理复杂问句和语言变体时表现不足.为了应对大规模知识图谱的子图选择问题, Sun等[5]提出PullNet, 逐步拉取相关子图并进行问答推理, 但在图谱稀疏或高噪声场景中效率较低.Liu等[6]提出GraftNet, 利用图神经网络嵌入知识图谱结构, 动态选择相关实体进行问答, 尽管嵌入表达有所改进, 但在大规模图结构上仍有局限性.Saxena等[7]提出EmbedKGQA, 通过知识图谱嵌入方法将实体和关系表示为向量进行匹配, 简化匹配过程, 但难以应对稀疏关系或复杂问句.为了更好地结合语言信息, Yao等[8]提出KG-BERT (Knowledge Graph Bidirectional Encoder Representations from Trans-former), 使用BERT(Bidirectional Encoder Represen-tations from Transformers)编码知识图谱三元组和问句, 但推理速度较慢.Xie等[9]提出LambdaKG(Lan-guage Model-Based Library for Knowledge Graph Embeddings), 利用多种预训练语言模型进行多任务嵌入, 支持知识图谱补全和问答等任务, 但仍存在模型资源需求较大和推理速度较慢的问题.上述模型在提升知识图谱理解方面表现突出, 但在处理图谱不完整、数据稀疏、复杂关系表示和多跳推理等问题时仍有不足.
近些年, 越来越多KGQA方法研究集中于强化学习(Reinforcement Learning, RL)领域, 通常将问答问题视为路径搜索或决策问题, 通过动态路径选择实现多跳推理, 并利用奖励机制不断优化模型性能, 提高推理的可解释性和准确性.Xiong等[10]提出DeepPath, 将RL框架应用于关系路径推理中, 借助RL机制, 在KGs中探索有效路径.Wang等[11]提出ADRL(Attention-Based Deep Reinforcement Learning), 将知识图谱执行任务建模为马尔可夫决策过程, 并利用长短期记忆模块(Long Short-Term Memory, LSTM)记录Agent执行的历史轨迹, 优化预测流程.
为了进一步提升推理效率, Eysenbach等[12]提出SoRB(Search on Replay Buffer), 引入通用控制算法, 结合规划和强化学习的优势, 有效应对不同的推理任务.此外, Qiu等[13]提出SRN(Stepwise Reaso-ning Network), Saebi等[14]提出HRRL(Heterogeneous Relational Reasoning with Reinforcement Learning), 都使用强化学习将多跳 KGQA视为路径搜索任务, 设计策略以引导智能体(Agent)在知识图谱中导航, 显著提高推理过程的可解释性.尽管基于RL的多跳KGQA已取得良好性能, 但仍面临着一些缺陷, 如难以规避推理路径的不稳定性和虚假路径问题[15].
由于知识图谱存在不完整性、数据稀疏和复杂关系表示能力不足等问题, Agent 在推理过程中会无法从环境中获得足够或正确的信息, 难以准确决策或有效更新策略, 导致出现虚假路径问题[15].Agent有可能沿着错误的推理路径偶然获得正确的答案实体, 虽然看似合理, 但最终答案的推理路径却是错误的.
生成对抗网络(Generative Adversarial Network GAN)是近年来最具突破性的创新之一.GAN的优化过程是一个最小-最大博弈的过程, 生成器学习欺骗鉴别器, 而鉴别器判断输出并引导生成器产生与真实数据不可区分的结果, 两个组件通过对抗性过程共同训练[16].传统的GAN主要用于生成连续数据, 而文本数据的离散性使梯度更新难以传递.为了解决这一问题, 研究者引入策略梯度方法[17], 直接训练生成模型[16, 18], 这一进展推动GAN在自然语言处理领域的应用[19, 20], 如关键词生成和知识图谱补全.
为此, 本文提出基于对抗强化学习的多跳知识推理模型(Multi-hop Knowledge Reasoning Model Based on Adversarial Reinforcement Learning, MKRARL), 解决知识图谱问答在多跳推理中面临的复杂关系表示不足、数据稀疏性及强化学习中的虚假路径问题.MKRARL首先通过高阶分解关系向量, 并结合实体和关系特征, 实现较优的嵌入表达.在邻居节点聚合时引入注意力机制, 为不同节点赋予相应权重, 提升复杂关系的表示能力.此外, 设计知识图谱嵌入框架, 评估嵌入空间内< 主题实体, 问题, 答案实体> 的可信度, 为RL分配软奖励.MKRARL将多维信息融入强化学习框架的状态中, 为Agent提供更可靠的决策依据.受到生成式对抗性学习的启发, 引入生成器, 根据状态信息计算候选实体的概率并生成答案, 而鉴别器评估生成的答案和推理路径的合理性, 通过软奖励和路径奖励增强反馈, 缓解虚假路径问题, 并利用对抗训练机制交替优化生成器和鉴别器.最终, 将MKRARL应用于云制造产品设计知识图谱问答系统这一特定场景中, 验证其有效性.
本文提出基于对抗强化学习的多跳知识推理模型(MKRARL).MKRARL主要由知识图谱嵌入(Know-ledge Graph Embedding, KGE)模块和生成式对抗强化学习(Generative Adversarial Reinforcement Lear-ning, GARL)模块组成, 总体框架如图1所示.
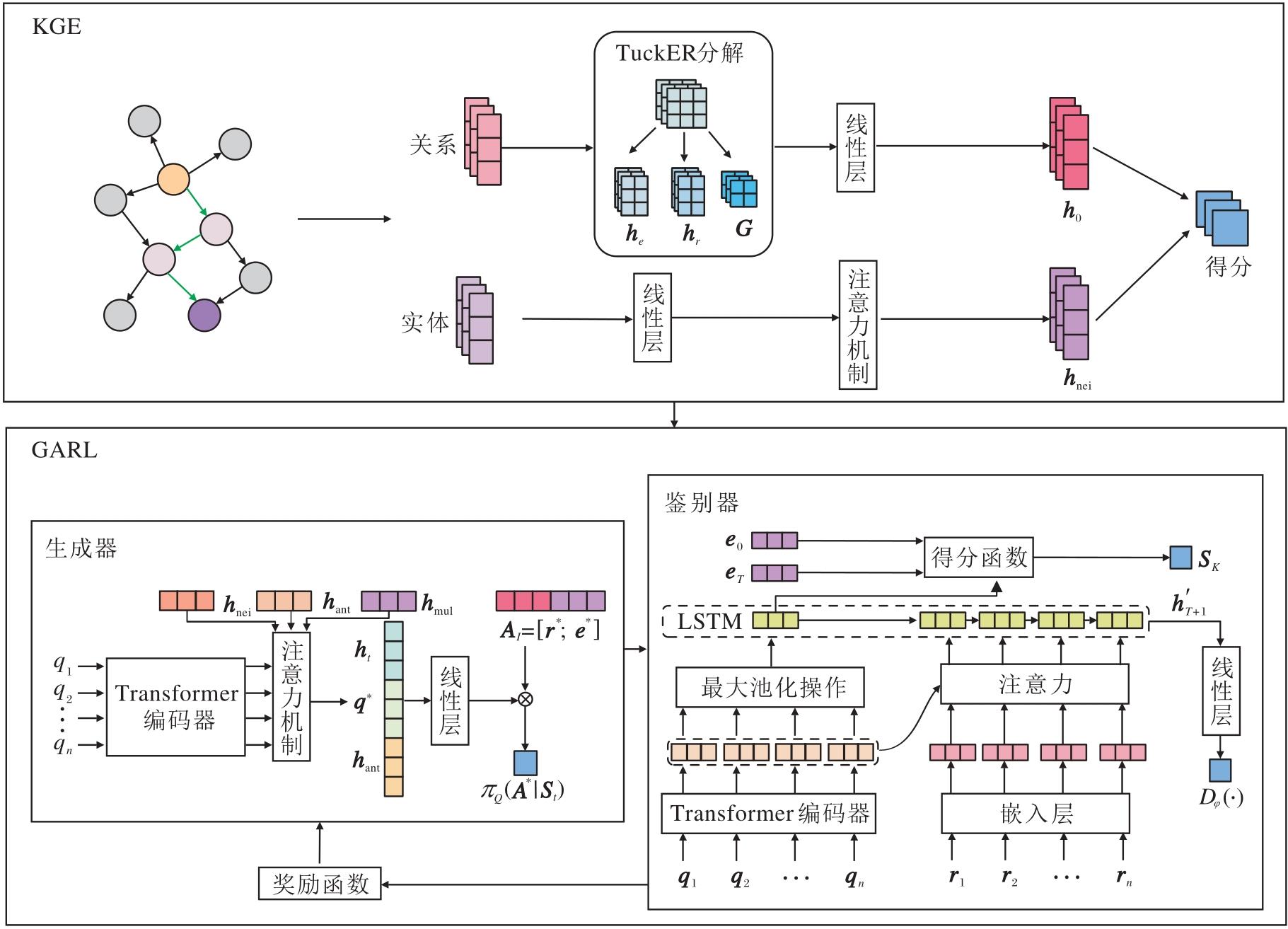 | 图1 MKRARL总体框架图Fig.1 Overall structure of MKRARL |
KGE模块将所有实体和关系表示为分布式向量, 并通过评分函数计算候选实体的软奖励.同时, GARL模块集成强化学习、生成器和鉴别器.生成器接收多维状态信息, 计算候选动作的概率以实现多维决策.鉴别器捕获上下文路径表示并评估答案的准确性和推理路径的合理性, 并将结果纳入奖励函数以增强反馈, 促使生成器最大化预期奖励并选择最佳行动.
KGs由大量三元组组成, 表示为
G={< eh, r, et> |eh∈ ε, et∈ ε, r∈ R},
其中, ε表示实体集, R表示关系集.三元组< eh, r, et> 表示头实体eh和尾实体et通过关系r相连的事实.KGQA任务中的一个基本问题是:给定一个自然语言问题q和主题实体eh∈ ε, 作为推理的起点, 在知识图谱G上有效搜索, 找到一个实体et∈ ε, 正确回答问题q.
知识图谱嵌入(KGE)模块旨在将知识图谱中实体关系三元组转化为低维向量表示, 捕捉并保留其结构信息及语义特征.通常, 一个三元组嵌入< eh, r, et> ∈ G记为< eh, r, et> 并随机初始化.随之定义一个评分函数fs(eh, r, et), 度量三元组的正确性.在KGE模块中, 本文提出AttTuckCGCN(Attention-Based Tucker Composition Graph Convolutional Network), 通过高阶张量分解和注意力机制实现对知识图谱的高维复杂关系和长距离依赖关系的建模, 并将实体和关系的语义特征有效嵌入低维向量空间中.
在AttTuckCGCN中, 将知识图谱表示为一个复杂关系图, 记作G=(V, R, E, X, Z), 其中, V表示实体(节点)集, R表示关系集, E表示边集, X∈
为了避免过参数化, 借鉴R-GCNs(Relational Graph Convolutional Networks)[21]中的Basis Decom-position和COMPGCN[22], 综合考虑实体和关系的语义特征, 将关系表示为向量, 采用非参数化的实体-关系组合的操作.本文引入TuckER[23]分解思想, 对关系向量进行高阶分解, 并与实体进行参数化组合操作, 捕捉高维复杂关系的多重特性.
知识图谱中许多实体及关系之间的语义特征相同, 因此可用一个核心张量代替这些共享语义特征, 通过TuckER分解得到的最终输出张量:
ho=G× 1(W(e)·
上式为实体特征和关系特征交互的高阶表示, 其中, G表示核心张量, 捕获共享的语义特征,
进一步, AttTuckCGCN通过消息传递机制聚合更新邻居实体和关系, 经过k层更新邻居实体和关系后, 得到实体嵌入
经过k层后得到的关系嵌入
其中:
在聚合邻居信息时, AttTuckCGCN在信息传播层引入注意力机制, 进而整合为多层次邻域信息, 以此聚焦重要的远距离关系.AttTuckCGCN不仅包含单层节点特征, 还引入丰富的上下游邻居与关系的语义, 从而有效捕捉长距离依赖关系.学习得到的传播矩阵
其中, k表示传播层数, β k表示自适应系数, cos(
最后, 使用KGE模块的评分函数衡量每个候选题的可信性, 并将此得分作为计算候选实体的软奖励以增强反馈.
为了提高模型的可解释性, 本文扩展基于强化学习的方法, 引入多维信息和反馈增强, 帮助智能体(Agent)做出更可靠的决策.RL的形式化基于马尔可夫决策过程(Markov Decision Process, MDP), 由一个元组< S, A, P, R> 组成, 其中, S表示状态空间, A表示动作空间, P表示状态转移, R表示奖励函数.在每个时间步t上, Agent首先观察环境状态, 再根据策略网络选择行动, 环境改变到一个新的状态后向Agent提供一个标量奖励信号.Agent的目标是在每个状态下执行一个最优动作, 以此最大化期望的累积奖励.
1)状态空间.在时间步长t, 原始状态定义为
St=(q, e0, et, ht),
其中, e0表示给定问题q的主题实体, et表示推理过程中当前步骤访问的实体, ht表示Agent的决策历史.丰富的状态信息有助于Agent做出更可靠的决策.
本文构建包括邻域信息hnei、预期嵌入hant和多阶推理hmul在内的多维状态信息, 因此, 本文RL框架的状态空间扩展至
St=(q, e0, et, ht, hnei, hant, hmul).
2)动作空间.给定状态St, 动作空间A(St)由当前实体et在KGs中的所有出边组成, 即
A(St)={(r, e)|(et, r, e)∈ G}.
由于无法提前知道回答问题所需的跳数, 所以在A(St)中添加一个自环边(rloop, et), 表示推理过程的终止条件.一旦Agent选择自环边, 将停留在当前实体点上, 终止路径搜索过程.
3)状态转移.若当前状态为St, Agent执行动作At=(r* , e* ), 则当前状态
St=(q, e0, e* , ht,
被转换为
St+1=(q, e0, e* , ht+1,
其中
ht+1=ht∪ {At},
而q、e0和hant为全局信息, 在状态转移期间不会更改.
4)奖励函数.本文采用KGE模块中的评分函数计算候选实体的软奖励, 同时期望在奖励函数中加入额外的路径奖励.形式上奖励函数定义如下:
R(ST)=λ fs(e0, hq, eT)+(1-λ)Dφ (q,
其中,
ST=(q, e0, eT, hT, hant)
表示最终状态, eT表示预测实体, e0表示主体实体嵌入, hq表示问题嵌入, 关系路径
软奖励由KGE评分函数fs(· )提供一个连续的反馈奖励值, 表示预测实体和正确答案之间的相似度.鉴别器Dφ 以问题q和关系路径
具体奖励示意图如图2所示.
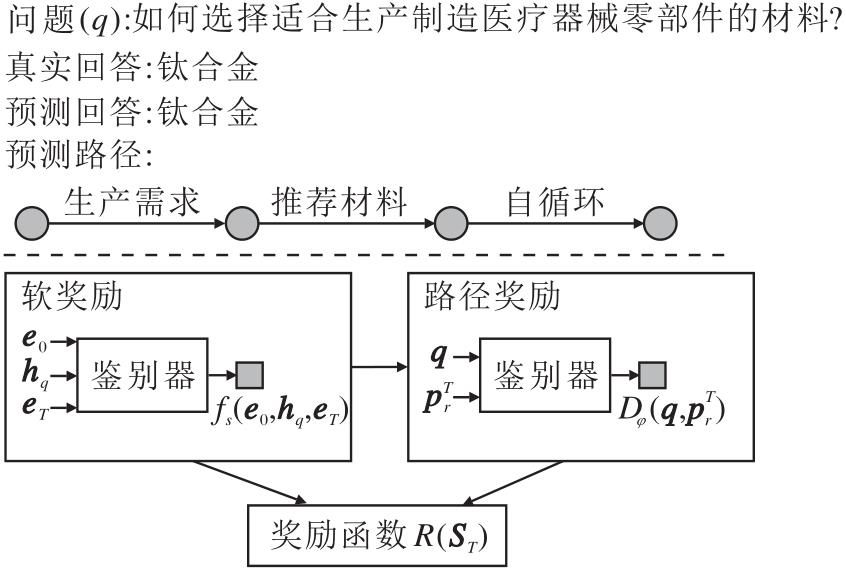 | 图2 奖励示例图Fig.2 Reward example |
生成器(Generator)Gθ 可视为RL的策略网络, 将多维信息与GQ集成, 接收Agent的状态信息作为输入, 计算候选动作的概率, 并在每步中对最有希望的动作进行采样, 选择下一步推理的动作.
1.4.1 邻域信息
由于知识图谱中包含的实体关系相对稀疏, 导 致Agent在搜索答案或路径时, 经常出现关键路径中断或虚假路径问题[15].本文将AttTuckCGCN得到的邻域信息向量嵌入RL框架的状态中, 尽量避免因数据稀疏而导致的虚假路径问题.在访问当前动作空间时, Agent通过AttTuckCGCN聚合该空间中实体的邻域信息.AttTuckCGCN提取与当前路径相关的候选关系和实体特征, 生成邻域信息向量hnei, 并融入状态.这一过程不仅扩充数据和动作空间, 还确保在决策时能参考多维邻居实体关系的影响.
1.4.2 预期嵌入
本文将潜在目标实体的向量作为预期嵌入RL框架的状态中, 以此减少无目的地探索.训练的KGE模块通过三元组< e0, hq, eT> 计算候选实体的概率分布, 并且将此概率分布视为候选实体的权重分布, 再选择概率最高的实体作为预测答案, 该实体的向量即预测嵌入hant.
1.4.3 多阶推理
本文采用动态记忆网络(Dynamic Memory Net-work, DMN)进行推理.DMN在多跳推理的不同阶段关注问题的特定部分, 其基本原理是利用外部记忆机制, 通过多次迭代提取和更新与问题相关的信息, 重点关注不同的上下文.
首先, 对给定一个问题q=(q1, q2, …, qn)和上下文信息进行编码, 得到隐藏状态qk(k=1, 2, …, n)和
ht=LSTM(ht-1, At-1).
然后, 记忆模块在初始记忆状态
$\boldsymbol{h}_{\mathrm{mul}}^{(t)}=\sum_{i=0}^{n} \boldsymbol{\partial}_{i} \boldsymbol{h}_{i}, $
其中, ∂ i表示对注意力得分ei的归一化,
反映当前记忆更新中每个问题不同阶段的重要性,
ei=Wattn[
Wattn表示可学习的权重矩阵.
通过动态捕获不同阶段的问题表示特征, 能在每步更新记忆状态, 并与强化学习框架结合, 为智能体的决策提供更精准的线索.
1.4.4 策略网络
给定一个问题q=(q1, q2, …, qn), 将每个令牌qi送入嵌入层, 得到相应的词嵌入.之后, 将单词嵌入序列送入Transformer编码器, 对问题进行编码, 得到一系列隐藏状态qk.通过LSTM对决策历史ht=(A1, A2, …, At-1)进行编码, 其中Ai=(ri, ei)表示第i步选择的动作.Ai的嵌入表示
Ai=[ri; ei]∈ R2d× 1,
其中, ri和ei通过预训练的KGE模块进行初始化, 获得相应的向量表示.由
ht=LSTM(ht-1, At-1)
计算决策历史的隐藏状态ht.
下面给定状态
St=(q, e0, et, ht, hnei, hant, hmul)
和相应的动作空间
A(St)={(r, e)|(et, r, e)∈ G},
计算基于注意力机制的上下文问题表示, 以此学习每个动作
A* =(r* , e* )∈ A(St)
的实体关系和问题标记之间的词级对齐.
$\boldsymbol{q}^{*}=\sum_{i=1}^{n} \boldsymbol{a}_{i} \boldsymbol{q}_{i}$
为上下文感知的问题表示, 通过注意力机制和加权求和生成的最终问题表示, 融合问题中的词令牌嵌入和动作选择之间的关系, 以及额外的上下文信息(如邻域关系、推理历史和预期嵌入).
a* =softmax(e* ),
为注意力向量, 表示每个查询标记对最终上下文感知问句表示的贡献,
为上下文-问句匹配的评分, 表示每个问句标记与当前上下文的匹配程度.其中:qi表示令牌qi的嵌入, ri表示关系ri的向量, v、Wq、Wr、Wn、Wa、Wm表示可学习参数.当Agent在时间步长t上选择动作A* 时, 注意向量a* 被分配给at.
最后, 本文定义一个计算动作空间A(St)概率分布的策略网络π θ (A* |St)以精确选择动作, 即
$\begin{aligned} G_{\theta}\left(\boldsymbol{A}^{* } \mid \boldsymbol{S}_{t}\right)= & \pi_{\theta}\left(\boldsymbol{A}^{* } \mid \boldsymbol{S}_{t}\right)= \\ & \boldsymbol{A}^{* } \boldsymbol{W}_{L_{1}} \operatorname{ReLU}\left(\boldsymbol{W}_{L_{2}}\left[\boldsymbol{h}_{t} ; \boldsymbol{q}^{* }\right]\right), \end{aligned}$
其中, A* 表示动作A* 的嵌入, [ht; q* ]表示编码的决策历史和上下文感知问题向量的连接,
鉴别器(Discriminator)Dφ 目标是评估答案的准确性和推理路径的合理性, 通过将评估结果纳入奖励函数以增强反馈, 推动生成器优化推理策略.
与生成器类似, 问题令牌
上下文感知问题向量为:
$\boldsymbol{q}^{t}=\frac{\sum_{i=1}^{n} \boldsymbol{q}_{i} \exp \left(\boldsymbol{\beta}_{i}^{t}\right)}{\sum_{j=1}^{n} \exp \left(\boldsymbol{\beta}_{j}^{t}\right)}, $
其中,
qi表示令牌qi的嵌入, ri表示关系ri的向量, vd、Wq'和Wr'表示可学习参数.
连接qt和rt得到一个上下文关系向量:
ot=[qt; rt].
因此, 使用(o1, o2, …, oT)表示关系路径
最后将关系路径的分数建模为
Dφ (q,
其中, σ(· )表示sigmoid函数, ws表示可学习参数.
给定一个问题q,
其中, PR(q, pr)表示来自真实数据的联合概率分布, PR(q)表示来自真实数据的概率分布, PG(pr|q)表示生成数据的条件概率分布.
为了避免由于文本数据的离散性质而导致的不可解梯度, 使用策略梯度直接训练生成模型[21, 22].借鉴Q-learning[24], 生成器的目标是获取答案实体并最大化期望的最终奖励:
$\begin{aligned}J_{G}(\theta)= & E\left[R\left(\boldsymbol{S}_{T}\right) \mid \boldsymbol{S}_{0}, \theta\right]= \\& \sum_{t=1}^{T} Q\left(\boldsymbol{S}_{t}, \boldsymbol{A}_{t}\right) G_{\theta}\left(\boldsymbol{A}_{t} \mid \boldsymbol{S}_{t}\right), \end{aligned}$
其中, R(ST)表示终端状态的奖励, S0=(q, e0, e0, h0)表示初始状态, Q(St, At)表示在状态St下采取动作At时的状态-动作值, Gθ (At|St)表示计算动作概率.
由于鉴别器被训练为完全生成的推理路径分配奖励信号, 因此不能为中间步骤提供分数.为了提高训练效率, 本文直接计算状态-动作值Q(St, At)作为最终延迟奖励R(ST)的折扣:
Q(St, At)=γ T-1R(ST),
其中, γ< 1, 表示折现因子.
本文定义值网络
其中, [ht; et]表示编码后的决策历史、当前实体嵌入和预期目标嵌入的连接, Wv表示一个可学习的参数矩阵.通过最小化期望均方误差(Mean Squared Error, MSE)优化
$L_{V}\left(\theta_{v}\right)=E_{t}\left[\left(Q\left(\boldsymbol{S}_{t}, \boldsymbol{A}_{t}\right)-V_{\theta_{v}}\left(\boldsymbol{S}_{t}\right)\right)^{2}\right] .$
对于值网络, 生成器Gθ 的策略梯度推导如下:
$\begin{array}{l} \nabla_{\theta} J_{G}(\theta)= \\ \quad \sum_{t=1}^{T}\left(Q\left(\boldsymbol{S}_{t}, \boldsymbol{A}_{t}\right)-V\left(\boldsymbol{S}_{t}\right)\right) \nabla \ln G_{\theta}\left(\boldsymbol{A}_{t} \mid \boldsymbol{S}_{t}\right) . \end{array}$
在讨论生成器的优化之后, 将说明如何优化鉴别器Dφ .真实关系路径被视为正样本, 而由生成器Gθ 生成的虚假关系路径被视为负样本.鉴别器的损失函数:
LD(φ)=-
MKRARL的对抗优化过程如算法1所示.鉴别器通过区分真实数据和生成数据的路径以训练自身, 而生成器通过策略梯度最大化预期的奖励更新自身, 整个过程采用迭代的形式, 直到模型收敛.
算法 MKRARL对抗优化过程
输入 生成器Gθ , 鉴别器Dφ , 值网络
使用随机权值θ、φ和θ v初始化Gθ 、Dφ 和
REPEAT
FOR D-steps DO
从真实数据中采样正样本
从Gθ 中生成负样本
训练鉴别器Dφ
END FOR
FOR G-steps DO
使用Gθ 生成推理路径
计算最终延迟奖励R(ST)
计算状态-动作值Q(St, At)
计算值网络
计算策略梯度更新Gθ
END FOR
模型收敛
MKRARL需要遍历整个知识图谱实体和路径空间.知识图谱嵌入的计算复杂度主要由实体数ε、关系数R和嵌入维度de决定, 即O(ε+R)de.评分函数的计算复杂度为O(ε).AttTuckCGCN引入的TuckER分解复杂度与分解阶数k和嵌入维度de密切相关, 计算复杂度为O(k
O(ε+R)de+O(ε)+O(k
O(LDoutε de)+O(Tε de)+O(DoutT).
该计算复杂度受实体数、关系数、图卷积层数等因素影响.
为了在提升模型的表达能力时控制复杂度和成本, AttTuckCGCN通过TuckER分解使用共享核心张量, 并采用共享参数的多层图卷积和注意力机制, 减少参数量, 降低计算复杂度和计算资源的消耗, 优化计算效率.
为了评估MKRARL的有效性, 选择如下4个数据集进行实验.
1)PathQuestion(PQ)数据集.由Zhou等[25]构造, 利用Freebase子集生成多跳问题, 要求模型在知识图谱中找到正确路径以推导答案.PQ-2H表示2路问题, PQ-3H表示3跳问题, PQ-Mix表示所有问题的组合, 主要用于训练和评估多跳推理模型的性能.
2)PathQuestion-Large(PQL)数据集.PQ数据集的扩展版, 规模更大, 包含更复杂的路径信息.同样, PQL-2H表示2跳问题, PQL-3H表示3跳问题, PQL-Mix表示混合数据集.
3)WebQSP数据集.主要用于知识图谱问答K-GQA和多跳推理模型的评估, 包含1跳问题和2跳问题, 这些问题可使用Freebase作为知识源进行回答, 本文从训练集上随机保留250个样本用于验证.
4)MetaQA数据集.WikiMovies数据集的扩展, 专注于电影领域, 用于评估模型在多跳推理任务中的表现.原始版本包含1跳问题、2跳问题和3跳问题, 从文本模板池中随机生成这些问题.
数据集的详细信息如表1所示, 表中的问题模式表示将问题中的主题实体替换为“ < e> ” 标记.
| 表1 实验数据集统计信息 Table 1 Experimental dataset statistics |
本文采用智能问答领域广泛使用的Hit@1指标[26]评价模型性能.该指标的含义是指问题的正确答案在得分排名为第一的比例, 计算公式如下:
$H i t @ 1=\frac{1}{|Q|} \sum_{i=1}^{|Q|} H i t_{i}, $
其中, Q表示查询总数, Hiti表示一个指示函数, 当模型在第i个查询中正确预测答案时, Hiti=1, 否则Hiti=0.因此, Hit@1的值在0和1之间, 越接近1表示模型性能越优.
由于复杂关系和推理过程涉及逆关系, 因此本文还将PQL依赖的KGs中每个三元组的方向颠倒.例如:给定一个三元组(3D建模-软件工具-Autodesk Fusion 360), 然后将反三元组(Autodesk Fusion 360-软件工具-3D建模)添至KGs.此外, 鉴别器的优化需要生成器生成负样本, 为了采样负样本, 首先应用束搜索保持多个关系路径.如果其中一条路径与真实路径不同, 视为负样本.可能所有生成的路径都是假负样本(即与黄金路径相同), 因此本文经验性地通过随机替换路径中的一个关系创建负样本.
实验采用的CPU型号为Xeon(R) Platinum 8474C/15核, GPU型号为NVIDIA RTX 4090D / 24 GB, CUDA版本为12.1, PyTorch版本为2.1.0, Python版本为3.10, 应用300维预训练的BERT模型词嵌入和200维的KGs嵌入, KGs嵌入通过AttTuckCGCN进行预训练.对于Transformer编码器, 设置2层和4个头.单向LSTM有两层, 隐藏维度为200.奖励系数λ=0.5, 折扣因子γ=0.95.每个周期中Gθ 和Dφ 的训练次数为5.采用Adam(Adap-tive Moment Estimation)优化器进行参数优化, 初始学习率为0.000 1.在测试阶段, 应用束搜索在KGs上生成多个推理路径, 束大小为2.
本文选择如下对比模型.
1)基于嵌入的推理模型:GraftNet[6]、IRN(Inter- pretable Reasoning Network)[25]、MemNN[27]、KVMem- NNs(Key-Value Memory Networks)[28]、DRN(Dyna- mic Reasoning Network)[29]、Hypergraph Transformer[30]、RAID(Relation Aware of Subgraphs and Implanting the Direction Information into Reasoning)[31].
2)基于路径的模型:SRN[13]、MINERVA(Mean- dering in Networks of Entities to Reach Verisimilar Answers)[32]、文献[33]模型、Ae2KGR[34].
各模型在4个数据集上的Hits@1值如表2所示, 表中黑体数字表示最优值.由表可见, MKRARL在所有数据集上均取得令人满意的性能.
| 表2 各模型在4个数据集上的Hits@1值对比 Table 2 Hits@1 value comparison of different models on 4 datasets |
相比PQ数据集, 基于嵌入的推理模型在PQL数据集上的性能明显下降, 这可能是由于PQL数据集包含更大规模的KGs.KVMemNN在低复杂度任务(如PQ-2H任务)中表现尚可, 但在WebQSP、MetaQA-3H等高复杂度任务中性能显著下降, 说明其嵌入方法对长路径推理不够健壮.IRN的多任务训练模式会误导KGQA目标, 而DRN作为最佳嵌入方法, 在MetaQA-3H任务中性能达95.86%, 但其强监督方式需要预先提供黄金关系.GraftNet在MetaQA-3H任务中的表现不如在MetaQA-1H、MetaQA-2H任务中, 因为推理跳数增加导致搜索空间扩大.Hypergraph Transformer和RAID在PQL、MetaQA复杂数据集上表现良好, 但嵌入方法的答案获取缺乏可解释性.
在基于路径的推理模型中, MINERVA在PQ-2H和MetaQA-1H等简单任务中表现尚可, 但在MetaQA-3H这样的复杂任务中性能下降, 表明路径搜索策略在复杂推理中的不足.SRN在复杂场景中表现优于MINERVA, 但在部分任务中性能不稳定.文献[33]模型和Ae2KGR性能均衡, 但在WebQSP-Mix、MetaQA-3H等复杂任务中对长距离推理能力有限.相比之下, MKRARL通过可解释RL框架, 多维信息引导Agent执行动作序列, 形成清晰推理路径至答案实体, 增强可追踪性与可解释性, 并支持变长度推理.MKRARL在PQ-2H、PQ-3H任务中Hits@1分别达到99.10%、94.15%, 在MetaQA-3H任务中Hits@1达到98.20%, 整体性能平均提升约12.3%, 展现其卓越的泛化能力和复杂任务适应性.
为了探索MKRARL中不同模块的影响, 进行消融实验, 分别改变多维状态信息和奖励函数.具体消融实验结果如表3所示, 表中黑体数字表示最优值.
| 表3 MKRARL的消融实验结果 Table 3 Ablation experiment results of MKRARL |
首先, 逐步取消RL框架中的多维状态信息:邻域信息hnei、预期目标hant和多阶推理hmul.因此, 时间步长t的状态定义为原始形式St=(q, e0, et, ht).策略网络π θ (A* |St)的输入为编码决策历史和上下文感知问题向量的连接.此外, 值网络
由表3可见, 消融后的性能都分别有不同程度的下降, 这表明将邻域信息、预期信息和多阶推理融入RL状态中可不同程度上为Agent提供可靠的决策建议, 提升推理的准确性.
然后, 修改奖励函数.奖励函数分为软奖励和路径奖励.去除每种奖励后, Hits@1值如表3所示.由表可见, 两种奖励都有利于多跳KGQA.软奖励用于引导智能体预测正确答案实体, 路径奖励用于评估推理路径的合理性.
为了说明AttTuckCGCN在复杂推理任务中的有效性, MKRARL采用AttTuckCGCN、ComplEx[35]、DISTMULT[36]、TuckER[23]、ConvE[37]这5种KGE模型, 在4个数据集上的Hits@1值如表4所示, 表中黑体数字表示最优值.由表可得, ComplEx和DIST-MULT在单跳推理中单一关系嵌入表现良好, 但在处理多跳推理和大规模知识图谱等复杂关系嵌入时性能下降.尽管TuckER和ConvE在复杂嵌入方面有所改进, 但由于缺乏高维复杂关系和长距离依赖关系的建模能力, 导致在更复杂推理任务中表现不稳定.相比之下, AttTuckCGCN结合高阶张量分解和注意力机制, 有效增强表示能力, 能捕捉复杂的高阶关系, 提升后续推理任务的效果.这表明, AttTuckCGCN在捕捉复杂高阶关系和建模长距离依赖关系方面具有明显优势, 从而提升后续推理任务的效果.
| 表4 不同KGE模型的Hits@1值对比 Table 4 Hits@1 values of different KGE models |
为了评估生成式对抗强化学习(GARL)模块迁移到不同场景推理模型中的效果, 选择与基于嵌入的推理模型DRN和基于路径的推理模型SRN进行对比实验, Hits@1值如表5所示, 表中黑体数字表示最优值.
| 表5 GARL模块迁移对比结果 Table 5 Comparative experimental results of GARL module migration |
由表5可见, MKRARL在所有数据集和任务设置中仍为最优, 尤其是在MetaQA-2H、MetaQA-3H任务中.采用GARL模块的DRN和SRN的表现优于原始DRN和SRN, 但与MKRARL相比还有一定的差距.这表明GARL模块的迁移效果良好, 在不同模型中都具有较好的有效性和普适性.
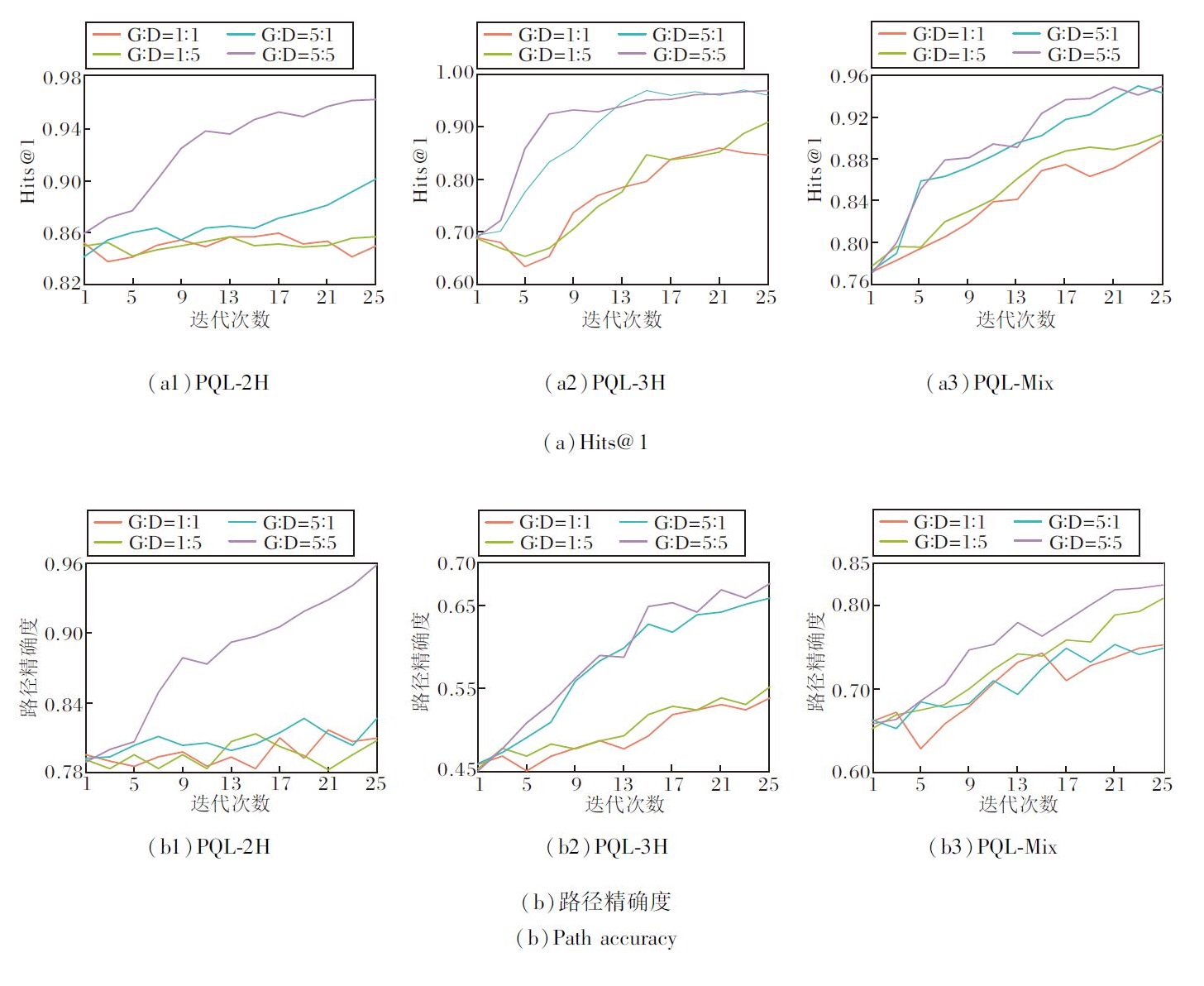
本文认为MKRARL的稳定性依赖于训练策略.具体而言, G-steps(G)和D-steps(D)的比例对模型的收敛性和性能都有显著影响.本文在PQL数据集上进行实验, 具体Hits@1值和路径精确度如图3所示.
 | 图3 不同G-steps和D-steps对MKRARL性能的影响Fig.3 Effect of different G-steps and D-steps on MKRARL performance |
由图3可得, 当G:D= 1:1时, 两个分量都存在欠拟合.当仅将G-steps增至5步时, 生成器能预测正确答案, 而推理路径可能由于无法区分虚假路径而出错.如果将D-steps修改为5, 但G-steps仍等于1, 则生成器无法为鉴别器生成高质量的负样本, 从而导致答案预测和路径推理的性能较差.只有当G:D = 5:5时, 对抗学习过程才能稳定有效.
鉴别器希望最大化正样本的分数的同时最小化负样本的分数, 在PQL数据集上鉴别器分数随迭代次数增加的变化曲线如图4所示.由图可知, 鉴别器可逐步将高奖励分配给正确的答案和推理路径, 而将低奖励分配给错误的答案和推理路径.
 | 图4 鉴别器分数随迭代次数的变化曲线Fig.4 Curves of discriminator score varying with the number of iterations |
超参数λ用于平衡软奖励和路径奖励.在PQL数据集的验证集上设置λ=0.3, 0.5, 0.7, 其对MK-RARL的Hits@1值和路径精确度的影响如图5所示.
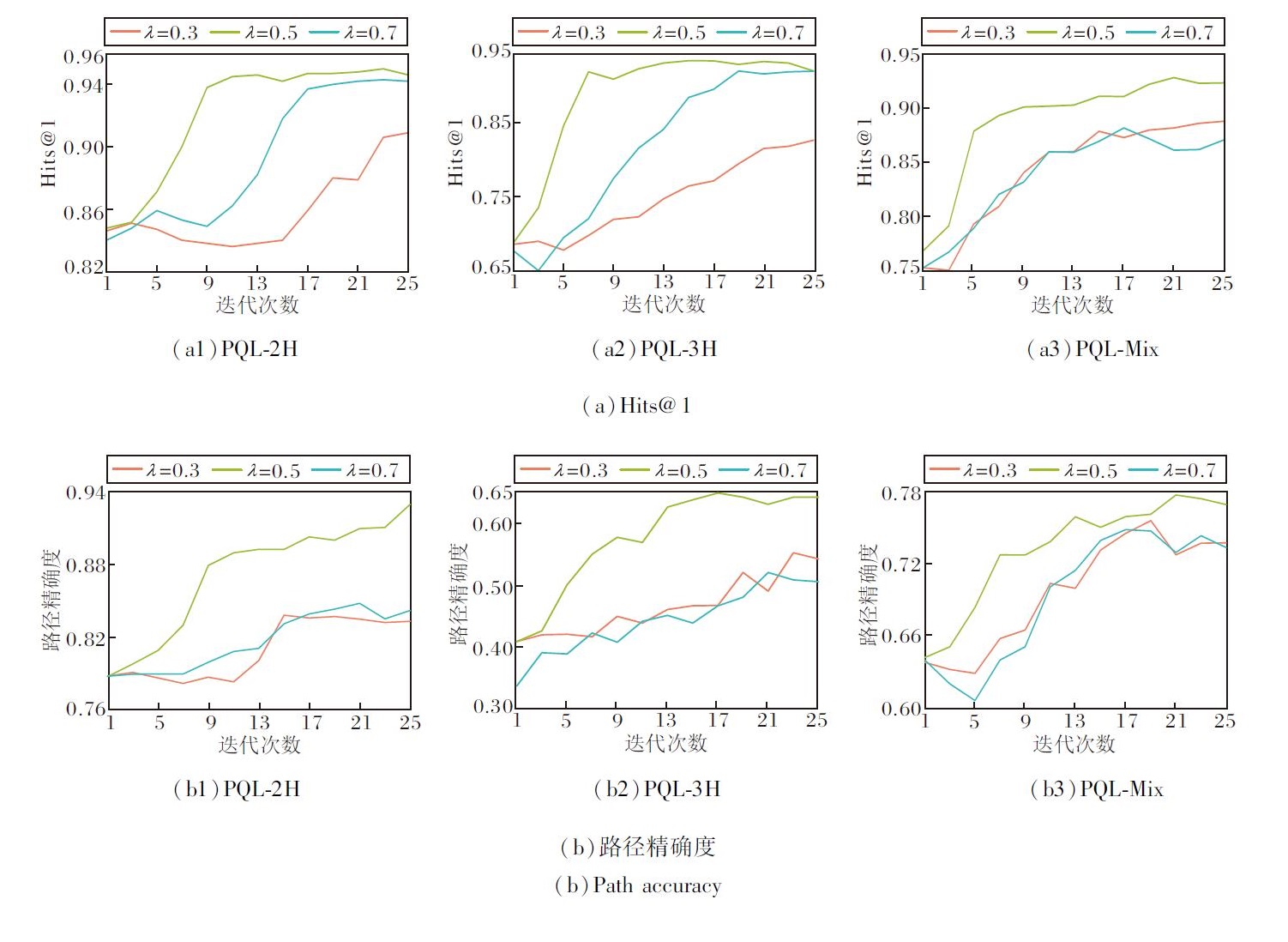 | 图5 λ不同对MKRARL性能的影响Fig.5 Effect of different λ on MKRARL performance |
由图5可知, 在PQL数据集上, 最佳λ值应为0.5, 这表明软奖励和路径奖励在推断答案方面发挥同等重要的作用.
本文设计一个应用案例, 将MKRARL应用于特定的行业场景(如云制造产品设计知识推理), 通过特定实体和关系的定义构建图谱, 使实验中验证的推理能力得以在应用案例中产生实际价值.
在云制造环境中, 产品设计知识涉及众多实体和关系, 如产品组件、材料选择、设计规范、制造工艺和成本要求等.这些知识信息在复杂的设计任务中往往需要多步推理, 只有这样才能准确找到符合条件的设计方案.
首先, 在图6中可视化每一跳的动作概率, 以此说明推理步骤.题目是“ 在智能手环产品设计过程中, 主要依赖的技术使用哪些软件工具进行设计和开发?” , 主题实体为“ 智能手环产品设计” .动作空间由主题实体的所有出向边组成:
(self, 智能手环产品设计), (依赖技术, 3D建模), (依赖技术, 嵌入式系统), (组成部分, 传感器).
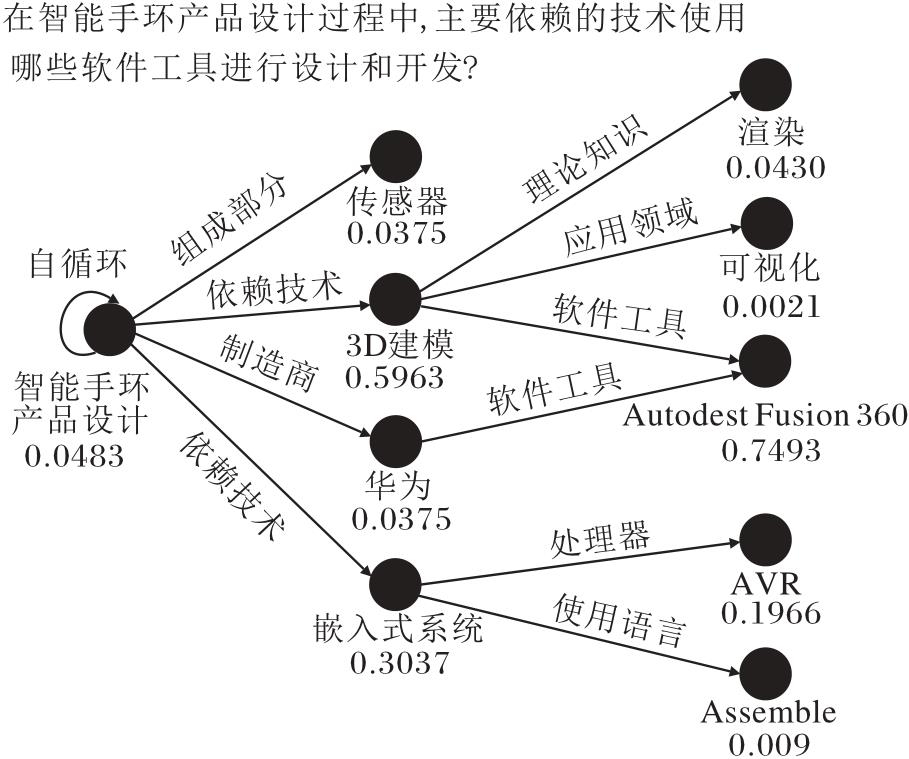 | 图6 案例图Fig.6 Case diagram |
生成器在第一步执行如下动作:
(依赖技术, 3D建模), (依赖技术, 嵌入式系统).
环境变化到新的状态后, 第二步的动作空间由前一步到达的所有实体的出向边组成.同样, 根据生成器导出的动作概率选择top-N个动作.最后将得分最高的尾部实体, 即Autodesk Fusion 360作为预测答案.
其次, 在表6中实例化关于正样本和负样本评估的运行示例.问题是“ 在智能手环产品设计过程中, 主要依赖的技术使用哪些软件工具进行设计和开发?” , 判别器可有效为正确的关系路径分配高分、对负样本输出低分以判断虚假路径.
| 表6 正负样本评分示例 Table 6 Example of positive and negative sample scoring |
本文提出基于对抗强化学习的多跳知识知识推理模型(MKRARL), 旨在解决现有模型在复杂关系表示、数据稀疏性及虚假路径问题上的不足.MKRARL首先通过高阶分解关系向量和融合实体与关系特征的参数化嵌入, 并引入注意力机制, 增强复杂关系的表示能力.同时, 设计知识图谱嵌入框架, 衡量< 主题实体, 问题, 答案实体> 的可信度, 为RL分配软奖励.其次, 将多维信息融入强化学习框架的状态表示中, 生成器接收多维状态信息以进行更精准的决策答案生成, 鉴别器通过软奖励和路径奖励优化反馈评估答案的准确性和路径的合理性, 两个组件交替优化以缓解虚假路径问题.最后, 将MKRARL应用于云制造产品设计知识多跳推理问答系统中, 验证其有效性, 并通过对比实验、消融实验和案例研究验证其在多个公开数据集上的优越性.未来计划研究的后续问题包括云制造垂直领域的多模态KGQA、大语言模型(Large Language Model, LLM)(如ChatGPT 3等)与云制造产品设计KGs深度耦合的KGQA等.
本文责任编委 欧阳丹彤
Recommended by Associate Editor OUYANG Dantong
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|