



{kind=link}
{kind=link}
{kind=link}
{kind=link}
面向动态数据的联合自表示子空间聚类方法
[张汉涛1  , 赵杰煜
, 赵杰煜1 , 叶绪伦1 ]
, 赵杰煜, 叶绪伦]
|
|



作者简介: 
张汉涛,硕士研究生,主要研究方向为计算机视觉、无监督学习、聚类分析.E-mail:zht1658924856@163.com. 
叶绪伦,博士,教授,主要研究方向为贝叶斯学习、非参数聚类、凸分析.E-mail:yexlwh@163.com.
自表示子空间聚类方法在高维数据处理中表现优秀,已成为该领域的关键技术之一.然而,传统的自表示模型通常假设数据集是静态的,难以适应动态、连续到达的数据流,会导致新旧数据存在特征异构、新到样本可能包含未知新类别等情况.因此,文中提出联合自表示子空间聚类方法(Joint Self-Expressive Subspace Clustering Method, JSSC),可适应数据流的连续到达.JSSC结合联合自表示特征学习模块和新类别样本处理模块,有效聚类新类别样本,同时确保已有类别的聚类性能不受影响.此外,该方法利用深度自动编码器学习子空间基,实现直观、可解释的表示,并通过成对目标和正则化项,同时管理已知类别和新兴类别.基准数据集上的实验表明,JSSC在聚类任务中表现较优,尤其是在处理动态数据中的新类别方面.
About Author:
ZHANG Hantao, Master student. His research interests include computer vision, unsupervised learning, and cluster analysis.
YE Xulun, Ph.D., professor. His research interests include Bayesian learning, nonparametric clustering, and convex analysis.
Self-expressive subspace clustering methods perform well in processing high-dimensional data and are one of the key techniques in this field. However, traditional self-expressive models typically assume that the dataset is static, and it is difficult to adapt to dynamic, continuously arriving data streams. It leads to two issues: feature heterogeneity between novel data and old data and the inclusion of unknown novel classes in newly arriving samples. To address these problems, a subspace clustering framework, joint self-expressive subspace clustering method(JSSC), is proposed. JSSC is specifically designed to handle both old and novel category samples. JSSC adapts to the continuous arrival of data streams by combining a self-expressive feature learning module with a novel category sample processing module. The proposed method effectively clusters novel category samples while maintaining strong performance on existing categories. Additionally, a deep autoencoder is utilized to learn subspace basis. Thus intuitive and interpretable representations are achieved, and the known and emerging categories are simultaneously managed through pairwise objectives and regularization terms. Experimental results on benchmark datasets show that JSSC outperforms current state-of-the-art approaches in clustering tasks, particularly excelling in handling novel categories within dynamic data.
近年来, 子空间聚类技术因其在处理高维数据中的优异表现受到广泛关注[1].该技术假设同簇内的数据点共享一个公共子空间, 而不同簇的数据分布在彼此独立的子空间中.这一特性使得该技术在降维和聚类方面具有显著优势, 广泛应用于人脸聚类、视频运动分割和图像聚类等领域[2, 3, 4, 5].
自表示模型的引入为子空间聚类的发展提供关键的突破技术, 其核心思想是将数据集上每个数据点表示为其余数据点的线性组合, 从而有效构建亲和矩阵, 揭示数据点之间的关系.然而, 传统的浅层子空间聚类方法在处理复杂数据时判别能力有限.随着深度学习的快速发展, 深度模型能更有效地捕捉数据的潜在复杂结构, 为自表示模型带来新的突破.
DSC-Nets(Deep Subspace Clustering Networks)[6]是在深度神经网络中实现自表示子空间聚类的直接方式之一, 其核心思想是在编码器和解码器之间引入无偏置的全连接层, 用于执行自表示建模.具体地, 输入数据通过编码器映射到线性子空间, 随后全连接层执行自表示建模, 其权重矩阵用于谱聚类.基于DSC-Nets的后续研究引入额外的正则化项, 如对抗性学习、伪监督和自监督卷积[7, 8, 9]等, 进一步提升聚类性能.通过结合深度学习与自表示子空间聚类, 子空间聚类的应用得到扩展和优化.
尽管DSC-Nets的聚类性能较优, 但仍存在一些局限性.当前的深度模型大多基于封闭环境的假设, 即数据集是静态、固定不变的.这种假设在现实世界中并不常见, 因为数据往往是动态的, 以流的形式不断到达.DSC-Nets难以适应这种新数据的到来, 尤其当新数据包含来自全新类别的样本时, 因为这些模型通常是在固定数据集上训练并优化, 缺乏足够的灵活性以应对动态变化的数据环境.因此亟需开发具备更强泛化能力的子空间聚类方法, 以适应不断变化且复杂的数据环境.
为了解决类别外数据在子空间聚类中的挑战, 本文在自表示子空间聚类框架的基础上进行扩展, 提出联合自表示子空间聚类方法(Joint Self-Expre-ssive Subspace Clustering Method, JSSC), 专门用于处理旧数据和新数据的联合聚类.然而, 旧数据和新数据的特征往往存在异构性, JSSC利用从旧数据中学习的知识, 实现对新数据的高效表征, 这种跨数据表征方式还有助于处理新类别样本.通过迭代优化, 从旧数据中学习的子空间基被用于表示新数据, 确保特征的互补性与一致性.此外, 设计新类别样本处理模块, 结合成对目标和正则化项, 有效处理旧类别和新类别样本的聚类任务.
随着深度神经网络(Deep Neural Network, DNN)的不断发展, 深度聚类方法逐渐兴起, 展现出较强的表征能力.其中, 自编码器(Autoencoder, AE)已成为许多深度聚类框架的核心, 通过重构损失函数学习数据的潜在表示.Huang等[10]利用自编码器, 将数据投影到低维空间, 并通过K-means对嵌入的低维数据进行聚类.Li等[11]提出PLrSC(Projective Low-Rank Subspace Clustering), 从大数据集上随机抽取小数据集, 使用PLD(Predictive Low-Rank Decom-position)训练深度编码器, 从而快速计算数据样本的低秩表示.Chang等[12]提出DSEC(Deep Self-Evo- lution Clustering), 通过选定的模式进行网络的交替训练.Wu等[13]提出DCCM(Deep Comprehensive Co- rrelation Mining), 使用伪标签进行自我监督, 并结合互信息捕捉具有更强判别力的表示.Huang等[14]提出PICA(Partition Confidence mAximisation), 通过最小化分区不确定性指数, 学习最有置信度的聚类分配.Ronen等[15]提出DeepDPM(Deep Nonparametric Method), 结合深度神经网络与狄利克雷过程, 并通过分裂、合并框架及动态网络结构, 在训练过程中自适应确定聚类数目K, 在大规模数据集上取得较优性能.
经典的子空间聚类方法, 如SSC(Sparse Sub-space Clustering)[16]、LRR(Low-Rank Representa-tion)[17]、KSSC(Kernel Sparse Subspace Clustering)[18], 旨在学习用于谱聚类的自表达亲和矩阵.许多研究者都在探索子空间聚类的自表达系数正则化的不同选择, l1正则化广泛应用于稀疏子空间聚类[16], 而核规范和l2正则化分别应用于低秩[17, 19]和最小二乘子空间聚类[20].一些研究者还试图将l1规范与其它正则化混合使用, 提高亲和图连通性, 并对自表达模型进行噪声建模和特征学习的改进.
在此基础上, 已有研究者尝试解决样本外数据问题.Peng等[21]提出StructureAE(Structured Auto-encoder), 构建双向图, 揭示样本与锚点之间的关系, 使用标签传播方法处理样本外数据.然而, 该方法偏离传统自表示子空间框架, 未能有效应对样本外数据的聚类挑战, 效果欠佳.Zhang等[22]提出SENet(Self-Expressive Network), 通过神经网络学习自表达函数并创建自表达系数.需要注意的是, SENet仅将测试集作为样本外数据直接判断, 因此只能处理同一分布下的样本外数据, 并且需要事先学习大量同类数据.虽然SENet对独立同分布的样本外数据有效, 但在处理超出类别范围的新数据时存在局限性.
新类别发现(Novel Class Discovery, NCD)旨在利用有标注数据中的知识发现未标注数据中的新类别, 并假设两者类别相互独立但相关.
近年来, 该领域许多方法在图像分类和语义分割等任务中表现出色.Hsu等设计基于成对相似性的聚类正则化分类损失, 并提出框架重构与语义聚类数量估计的方法[23].同时, 还提出MCL(Meta Classification Likelihood)[24], 通过成对相似性学习多类分类器.Zhong等[25]提出NCL(Neighborhood Contrastive Learning), 旨在学习对聚类性能重要的判别表示, 通过检索和聚合伪阳性对改进对比学习, 并在特征空间中生成硬负例.Han等[26]提出AutoNovel, 结合自监督学习, 避免标记数据的偏差, 利用排名统计进行知识迁移, 通过联合目标函数优化数据表示.Zhang等[27]提出PromptCAL(Prompt Con-trastive Affinity Learning), 在预训练的ViT(Visual Transformer)模型中引入辅助视觉提示(Prompts), 并通过迭代式的半监督亲和图生成策略, 挖掘无标注混合数据中的可靠正样本对.Gu等[28]基于在已知类上训练的模型的预测类分布, 引入新类的类关系表示, 提出一种知识蒸馏框架, 利用类关系表示规范新类的学习, 并通过可学习的加权函数, 根据新类与已知类之间的语义相似性, 自适应促进知识转移.
开放世界(Open World)研究涵盖多个关键子领域, 包括增量学习(Incremental Learning)、零样本学习(Zero-Shot Learning)、领域适应(Domain Adapta-tion)、终身学习(Lifelong Learning).Tao等[29]提出FSCIL(Few-Shot Class-Incremental Learning), 固定少样本类增量学习, 每次引入固定数量的类别和样本, 但在实际应用中因数据分布不确定, 模型容易过拟合和遗忘.Naeem等[30]提出CGE(Compositional Gra- ph Embedding), 通过图结构中状态、对象及其组合的依赖关系, 促进已见组合与未见组合之间的知识转移.Li等[31]针对OSDA(Open Set Domain Adapta- tion)中的语义偏差问题, 提出ANNA(Adjustment and Alignment), 通过细粒度分析源域图像中的视觉块, 识别隐藏的新类别区域, 再利用正交掩码, 将源域和目标域的基础类别与新类别区域解耦, 确保数据分布的无偏对齐.
本文提出联合自表示子空间聚类方法(JSSC), 旨在解决流形数据中新类别样本聚类的挑战, 具体框架如图1所示.
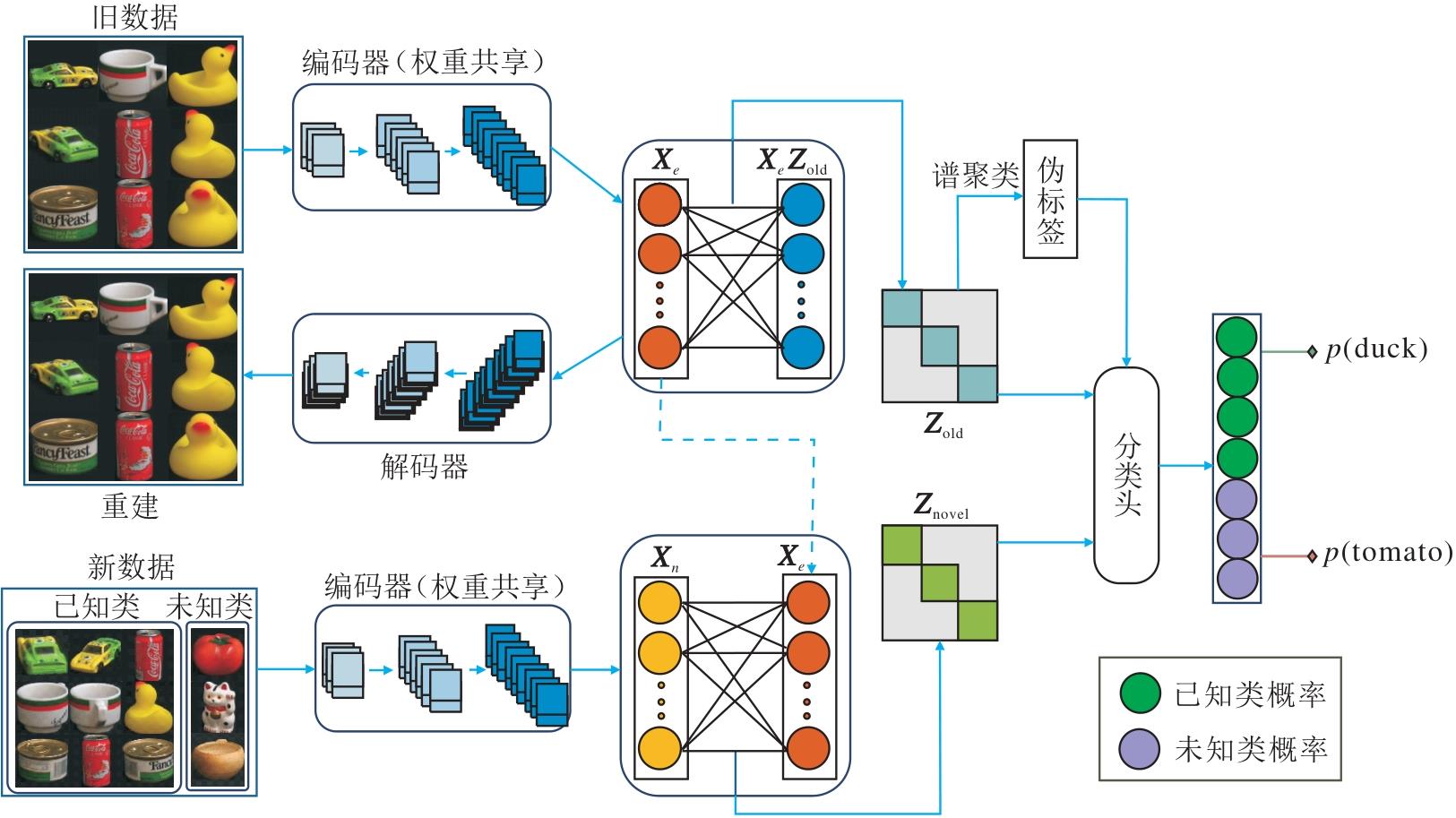 | 图1 JSSC框架图Fig.1 Framework of JSSC |
JSSC可分为如下两部分.
1)联合自表示特征学习模块.首先, 使用旧数据训练自编码器, 在编码器和解码器之间加入无偏置的全连接层, 并引入子空间基相关损失, 提取旧数据的子空间基特征.在这一过程中, 旧数据的特征得到有效的自表示, 从而捕捉其固有结构和子空间分布.与此同时, 新数据通过共享旧数据编码器的权重进行特征提取, 可确保新旧数据在特征空间内的一致性和关联性, 进而利用旧数据表征新数据, 获得新数据的特征.
2)新类别样本处理模块.在获取旧数据特征后, 通过谱聚类生成伪标签, 并在骨干网络末端添加分类头, 将带有伪标签的旧数据与无标签的新数据一并输入后分类.引入成对目标损失和正则化项, 较好地区分新旧数据特征.
在处理具有新样本的数据集时, 首要问题是来自不同数据集的样本会导致自表达学习框架内的特征异构.JSSC首先从旧数据中学习一个统一的坐标基, 构建共享的特征空间.在该共享空间中, 可在同一坐标系下无缝表示新数据, 从而确保特征的高效整合与分析.通过这一统一特征空间的构建, 不仅能有效应对多源特征的多样性, 同时也确保学习的表征对新样本和未见数据具有良好的泛化能力.
给定一个旧数据集xi⊂X∈ Rd× n, 其中, d表示特征维度, n表示样本数, 假设
xi=fj(v)+ε . (1)
其中: fj(· )表示未知的非线性函数, 映射
假设X中有k簇, X的列被分成与函数f1(· ), f2(· ), …, fk(· )对应的k簇, 则式(1)等价于一个聚类问题, 可看作是一个经典的非线性子空间问题或流形聚类问题.
对于j=1, 2, …, k, 假设
fj(v)=h(Bjv),
其中, Bj∈
xi≈
其中,
$\min \left\{\frac{1}{2 n} \sum_{i=1}^{n}\left\|\boldsymbol{x}_{i}-\hat{h}\left(\boldsymbol{B}_{j} \boldsymbol{v}_{i}\right)\right\|\right\}, \boldsymbol{B}_{j} \in \boldsymbol{C}_{j} .$ (2)
理想情况下, Bj对应于Cj簇, j=1, 2, …, k.然而, Bj的簇是未知的, 因此无法直接求解式(2).为此, 需要引入新的约束条件.
根据估计的基Bj获得正确聚类的假设, 对于所有j≠ l,
$\left\|\boldsymbol{B}_{l}^{\mathrm{T}} \boldsymbol{B}_{j}\right\|_{\mathrm{F}} \leqslant \epsilon, $ (3)
其中$\epsilon$为一个非常小的常数.基的集合[B1, B2, …, Bk]由k块组成.为了方便起见, 对块中的每个单独向量
$ \begin{array}{l} \left\|\boldsymbol{B}_{j}^{(u)}\right\|_{\mathrm{F}}=1, \\ u=1, 2, \cdots, r_{j}, j=1, 2, \cdots, k . \end{array}$ (4)
结合式(2)~式(4), 旨在得出正交且独立的基.为了将新数据点yi⊂Y∈ Rd× m表示为所学基 [B1, B2, …, Bk]的线性组合, 最小化重构误差:
$\min _{z_{i j}}\left\|\boldsymbol{y}_{i}-\sum_{j=1}^{k} \boldsymbol{B}_{j} z_{i j}\right\|_{2}, $(5)
其中zij表示使用Bj表示yi的系数.
将式(2)~式(5)扩展至深度网络时, 首先从旧数据中学习特征基.具体地, 网络通过自动编码器重构旧数据, 获得可靠的潜在表示.然后在单位正交约束下优化特征基, 利用学习的特征基对新数据进行表征, 提取新数据的特征.学习基B的损失函数:
LB=Lre+ζ(Bcon1+Bcon2),
其中ζ表示一个超参数.
为了简化处理, 使用旧数据xi代替随机变量vi, 并引入重建目标
$L_{\mathrm{re}}=\frac{1}{2 n} \sum_{i=1}^{n}\left\|\boldsymbol{x}_{i}-\hat{\boldsymbol{x}}_{i}\right\|_{\mathrm{F}}^{2}$
通过最小化目标函数, 应用式(3)中的约束条件, 得
Bcon1=
其中· 表示哈达玛乘积.
考虑到B的维数为Rt× kd, D的配置至关重要.在设计时, D对角线块中所有大小为d的元素都设为0, 所有其它元素都设为1.这种设计使得D可选择性地忽略对角线块, 避免同一块内的自我正交, 强调不同块之间的正交性.
然后, 将约束条件(4)的优化目标定义如下:
Bcon2=
其中I∈ Rkd× kd, 为单位矩阵.
通过优化目标函数, 可从旧数据中得到B.类似地, 同样通过自动编码器提取新数据的潜在特征.需要强调的是, 为了确保模型的一致性, 自动编码器的参数直接复用旧数据的训练结果.在此基础上, 进一步表示新数据的潜在特征, 其优化目标定义如下:
$L\left(\boldsymbol{Z}_{\text {novel }}\right)=\frac{1}{2 m} \sum_{i=1}^{m}\left\|\boldsymbol{y}_{i}-\sum_{j=1}^{k} \boldsymbol{B}_{j} z_{i j}\right\|_{\mathrm{F}}^{2}, +\lambda\left\|\boldsymbol{Z}_{\text {novel }}\right\|_{P}, $
其中, zij⊂Znovel, λ表示一个超参数, ‖ · ‖ P 表示一个常用的正则化项, 如l1或l2.
在给定旧数据X和新数据Y的情况下, 面临的一个主要问题是新数据中可能包含旧数据中未出现的类别.为了解决这一问题, 在新类别样本处理过程中, 首先利用已有的有标签的旧数据, 通过适当的损失函数优化模型, 使其能准确识别已知类别, 确保模型对旧类别具有良好的识别能力.对于无标签的新数据, 采用成对目标策略, 衡量样本之间的相似性, 有效分组同类别的无标签样本, 从而在缺乏明确标签指导时提升新类别的识别效果.此外, 考虑到有标签数据在训练过程中可能导致新旧数据学习速率的不平衡, 采用最大熵正则化策略, 引入正则化项, 平衡旧数据与新数据的学习速率, 保障模型在处理新旧类别时的稳定性和高效性.
现已得到新数据的特征集Znovel, 通过自表达结构也可获得旧数据的特征集Zold.再对Zold进行谱聚类, 生成伪标签, 并通过反复优化确保其准确性和可靠性.
分类头被集成到主干网络中.由于新数据包括未知类别, 分类头的数量是先前识别的类别和新类别的总和, 最终优化分类器权重W.
分类器的目标函数包括:带有伪标签旧数据的交叉熵损失、成对目标、正则化项, 即
LNCD=Lce+η1Lp+η2R,
其中, Lce表示交叉熵损失, Lp表示成对目标, R表示正则化项, 超参数η1、η2分别控制成对目标和正则化项的贡献.由于所有数据都是无标签的, 因此从根本上进行聚类, 全面衡量聚类性能.
2.2.1 成对目标
成对目标衡量样本之间的相似性, 旨在使同类别样本在特征空间中更紧密聚集的同时不同类别样本之间的距离更远.具体地, 首先构建样本对, 并计算余弦相似度, 量化它们的相似性.对于有伪标签的数据Zold, 标签表示哪些样本对属于同一类别.对于未标记的数据Znovel, 计算每个小批次中所有样本对之间的余弦距离, 选择最相似的邻近样本对, 即
Z'novel=
其中:σ(· )表示softmax函数, 将样本分配给已知类或新类之一; top< · > 表示根据最高置信度选择邻居, 为未标记的实例找出最近的邻居Z'novel.对于小批量的特征表示Zold∪ Znovel, 最近的集合表示为Z'old∪ Z'novel.
二元交叉熵损失(Binary Cross-Entropy Loss, BCE)的改进版本如下所示:
$L_{p}=\frac{1}{m+n} \sum_{z_{i}, z_{i}^{\prime}}\left(-\ln \left\langle\sigma\left(\boldsymbol{W} \cdot \boldsymbol{z}_{i}\right), \sigma\left(\boldsymbol{W} \cdot \boldsymbol{z}_{i}^{\prime}\right)\right\rangle\right), $
其中
zi∈ Zold∪ Znovel, z'i∈ Z'old∪ Z'novel,
m表示Zold的向量数, n表示Znovel的向量数.以在线方式更新距离和成对目标.
2.2.2 正则化
在多类别学习中, 尤其是在引入新类别时, 模型面临的一个主要挑战是如何在保持对旧类别良好识别能力的同时, 有效学习新类别的信息.由于有标签的旧数据在训练过程中可能带来较快的学习速率, 这种不平衡可导致模型在处理新旧类别时表现不一致.最大熵正则化通过鼓励模型输出分布的高熵特性, 有效避免模型倾向于将所有实例归入少数几类的简单解.具体地, 在给定条件下选择熵最大的分布作为最优分布, 并使用KL散度约束模型输出分布与先验分布q(c)之间的差异, 其中c表示类别标签, 从而实现正则化.具体正则化项公式如下:
R=
zi∈ Zold∪ Znovel.
先验分布定义为
q(c)=[
其中, C为类别总数, 表示对各类别的均等假设, 并且无任何先验偏好.
最大熵正则化的目标是将模型输出的条件概率与先验分布q(c)进行对比, 并最小化两者之间的KL散度, 从而使模型输出更接近先验分布, 减少对标注数据的依赖, 提高模型的泛化性能.
本文选择在COIL-20、COIL-100、MNIST、CIFAR-10、E-YaleB数据集上进行实验, 并对每个数据集进行相应的预处理.每个数据集按照类别划分为两个子集, 一部分用于先到的旧数据, 另一部分用于未知类别的新数据.数据集详细信息如表1所示.
| 表1 实验数据集详细信息 Table 1 Details of experimental datasets |
在 Ubuntu 20.04.6 系统上完成实验, 采用两块NVIDIA RTX 3080 GPU(20 GB 显存), 使用PyTorch框架实现.
在联合自表示特征学习阶段, 采用表2所示的架构进行构建.使用Adam(Adaptive Moment Estima-tion)优化器, 学习率为0.001.各数据集的训练轮次设置如下:COIL-20数据集上为25次, COIL-100数据集上为130次, MNIST、CIFAR-10数据集上均为 128 次, E-YaleB数据集上为175次, 批次大小为360.子空间基B的维数定义为 Rt× kd, 并在实验中默认将t固定为5.对旧数据的潜在特征进行谱聚类, 并使用Kuhn-Munkres算法匹配聚类标签与真实标签, 将其作为伪标签.在新类别样本处理阶段, 对不同数据集设置不同的超参数, 并进一步讨论超参数的影响.
| 表2 五个数据集的特征学习网络架构 Table 2 Feature learning network architectures of 5 datasets |
本文采用如下评价指标进行综合评估.
1)准确率(Accuracy, ACC).评估模型的整体准确率, 具体公式如下:
$A C C=\frac{\sum_{i=1}^{C}\left(T P_{i}+T N_{i}\right)}{\sum_{i=1}^{C}\left(T P_{i}+F P_{i}+T N_{i}+F N_{i}\right)}, $
其中, C表示类别数量, 对于每个类别i, TPi表示真正例数量, TNi表示真负例数量, FPi表示假正例数量, FNi表示假负例数量.
2)归一化互信息(Normalized Mutual Information, NMI).度量真实标签与预测标签的一致性, 提供归一化的一致性评分, 具体公式如下:
NMI=
其中, I(G,
预测标签
3)调整兰德指数(Adjusted Rand Index, ARI).衡量聚类结果与真实标签的匹配程度, 同时考虑随机因素的影响, 具体公式如下:
ARI=
其中, nij表示在聚类结果A中属于第i个簇且在聚类结果B中属于第j个簇的样本数量, ai表示在聚类结果A中属于第i个簇的样本总数, bj表示在聚类结果B中属于第j个簇的样本总数, n表示样本总数.
首先选择如下经典子空间聚类方法进行对比:DSC[6]、DCCM[13]、SSC[16]、SENet[22]、SSC-OMP(Sparse Subspace Clustering by Orthogonal Matching Pur-suit)[32]、 EDSC(Efficient Dense Subspace Cluste-ring)[33]、AE+SSC、AE+EDSC、文献[34]方法、AASSC-Net(Adaptive Attribute and Structure Subspace Clustering Network)[35].
鉴于子空间聚类在处理新类别问题上的研究相对较少, 现有工作中缺乏足够的可比性, 因此, 本文不仅考察经典子空间聚类方法, 还与如下前沿的半监督分类方法进行参考性对比:文献[23]方法、AutoNovel[26]、DTC(Deep Transfer Clustering)[36]、TR-SSL(Towards Realistic Semi-supervised Learning)[37].
各方法在5个数据集上的准确率对比如表3所示, 在表中, 黑体数字表示最优值, “ 旧” 表示旧数据, “ 新” 表示新数据, “ 全” 表示整个数据集.由表可知, 传统的子空间聚类方法在处理新类别数据时往往表现不佳, 特别是当新类别未包含在训练数据中时, 通常只能在旧数据上取得较优值.在动态引入新类别的复杂数据环境中, 传统方法的适应性显著不足.这主要是因为在子空间聚类领域, 除了SENet以外, 针对包含新类别的新样本的相关研究较少.相比之下, JSSC在旧数据上的表现较稳健, 同时在处理新类别时展现出一定的泛化能力.特别是在新类别样本处理中, JSSC表现出相对优势, 能有效识别新类别, 并在此过程中尽可能维持整体模型的性能平衡.尽管 SENet 的总体表现与JSSC较接近, 但在处理新数据和新类别方面, JSSC具有明显优势.
| 表3 各方法在5个数据集上的准确率对比 Table 3 Accuracy comparison of different methods on 5 datasets % |
尽管半监督方法能利用部分标签信息, 在某些情况下表现出色, 但对标签的依赖使其在动态数据环境中存在一定的局限性.相比之下, JSSC完全无监督, 能在无需任何标签信息的情况下处理新类别问题.从指标上看, 尽管在某些细节上JSSC的准确率略逊于半监督方法, 但总体性能相当接近.
本文方法与传统子空间聚类方法在 CIFAR-10 数据集上的NMI和ARI值对比如表4所示, 表中黑体数字表示最优值.
| 表4 各方法在CIFAR-10数据集上的指标值对比 Table 4 Metric value comparison of different methods on CIFAR-10 dataset |
由表4可见, 尽管JSSC在旧数据上的性能未必始终优于对比方法, 但在新数据和整体数据上表现出色.
尽管JSSC通常假设类别数量已知, 但在实际应用中, 常基于如下基本假设:旧数据的类别数量已知, 而新数据的类别数量未知且需要进行估计.
在此基础上, 本文尝试首先估计新类别的数量以应用JSSC.参考DeepDPM[15], 在CIFAR-10数据集上进行类别数估计的模拟实验.在训练过程中, 初始设定类别数K=10, 并在每隔若干个轮次后动态调整K值.每当触发调整步骤时, 系统会随机选择执行分裂或合并操作.
尽管初始类别数设定为10, 但通过动态分裂与合并, 最终自动调整为13个有效集群, 接近实际类别数.实验结果表明, 这一动态调整策略导致分类准确率有所下降, 旧数据的准确率下降约23%, 新数据的准确率下降约17%, 整体数据的准确率下降19%.
在COIL-20数据集上, 通过 t-SNE(t-Distributed Stochastic Neighbor Embedding)进行嵌入表示的可视化, 效果如图2所示.
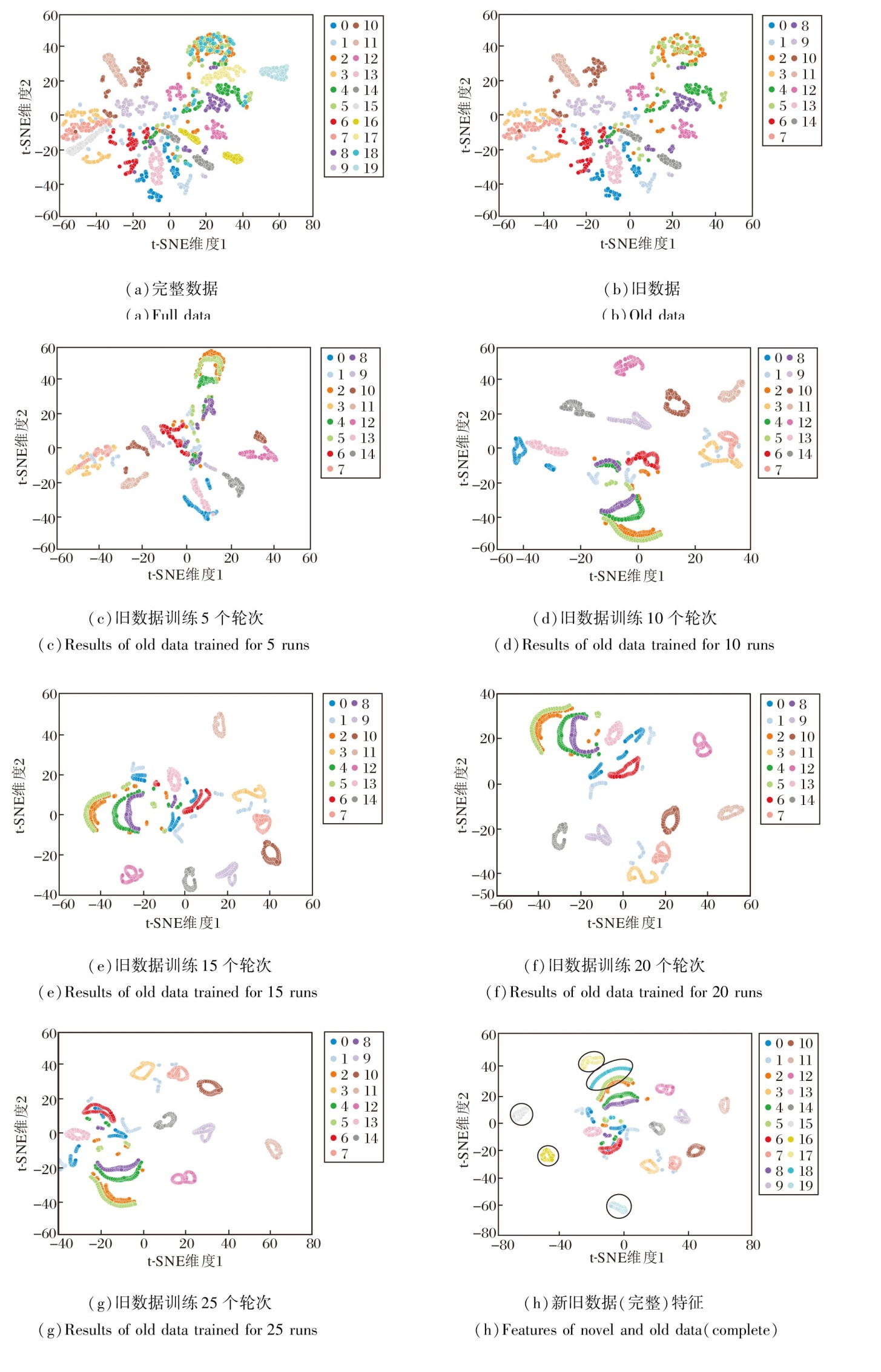 | 图2 COIL-20数据集上t-SNE的嵌入式表示可视化结果Fig.2 Visualization results of embedded representations with t-SNE on COIL-20 dataset |
由图2可见, 随着训练轮次的增加, 特征分布逐步趋于清晰可分.图2(a)为所有 COIL-20 数据集的嵌入表示, (b) 为旧数据(前15类)的嵌入.旧数据的嵌入虽然具有一定的可分性, 但部分类别仍存在交叠.(c)~(g)为旧数据经过不同轮次训练后的嵌入变化, 随着训练的深入, 嵌入分离性逐步增强, 类别区分更清晰.
图2(h)为结合新旧数据的嵌入, 通过训练后的旧数据嵌入特征表示新数据的嵌入, 分别用黑色圆圈标记5个新数据类别.由图可看到, 这些新数据依然表现出较优的分离性.
实验结果在一定程度上说明, 在特征层面上, JSSC利用旧数据的嵌入特征也能准确表示新数据.
下面验证JSSC的收敛性, 在5个数据集上进行实验, 并绘制各自的收敛曲线, 具体如图3所示.由图可见, 新数据的收敛曲线波动较大, 并且收敛速度相对较慢.其原因在于新数据是通过旧数据的特征表示进行学习的, 因此初期模型对新类别的特征分布不够明确, 导致训练过程中波动明显, 准确率较低.随着训练深入, 模型逐步适应新数据的特征, 准确率逐渐提高并最终趋于稳定.尽管新数据的收敛较缓慢, 但值得注意的是, 无论是完整数据、旧数据还是新数据, 收敛曲线最终都能达到稳定状态, 由此表明JSSC在处理不同类型数据时都能有效收敛.
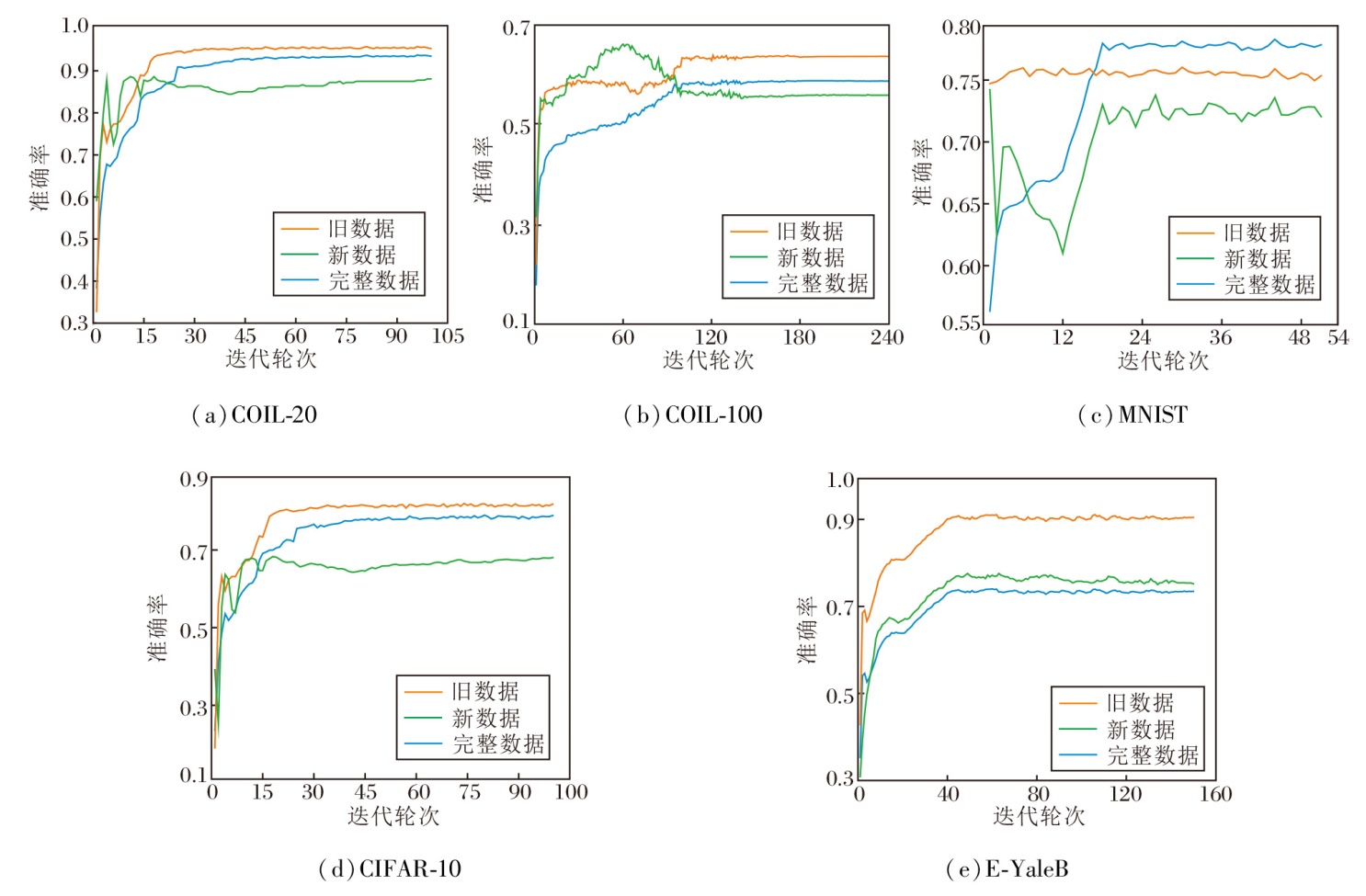 | 图3 JSSC在5个数据集上的收敛曲线Fig.3 Convergence curves of JSSC on 5 datasets |
新类别样本处理模块的目标函数由带有伪标签的旧数据的交叉熵损失(Lce)、成对目标(Lp)和正则化项(R)组成.始终保留Lce以维持模型对旧类别数据的识别能力.为了评估各模块对JSSC性能的贡献, 在5个数据集上进行详细的消融实验, 结果如表5~表9所示.
| 表5 在COIL-20数据集上的消融实验结果 Table 5 Ablation experiment results on COIL-20 dataset |
| 表6 在COIL-100数据集上的消融实验结果 Table 6 Ablation experiment results on COIL-100 dataset |
| 表7 在MNIST数据集上的消融实验结果 Table 7 Ablation experiment results on MNIST dataset |
| 表8 在CIFAR-10数据集上的消融实验结果 Table 8 Ablation experiment results on CIFAR-10 dataset |
| 表9 在E-YaleB数据集上的消融实验结果 Table 9 Ablation experiment results on E-YaleB dataset |
Lp在处理新数据时具有显著作用, 通过学习新类别样本的成对距离, 可帮助模型更好地适应新类别的分布.实验表明, 加入Lp后, 新数据的分类性能明显提升.
R在防止模型过拟合的同时, 平衡旧数据和新数据的表现, 确保在训练过程中, 旧数据的性能在不受影响的情况下, 提升对新数据的适应能力.
由表5~表9可见, 各模块相互配合, 使新类别样本处理模块在多个数据集上的表现较稳定.
同时, 在完成每个模块的消融实验后, 进一步对模型进行更细粒度的考察, 分析超参数η1和η2对聚类性能的影响.将这两个超参数的取值范围设置在0~1之间, 不同超参数组合下模型的表现差异如图4所示.
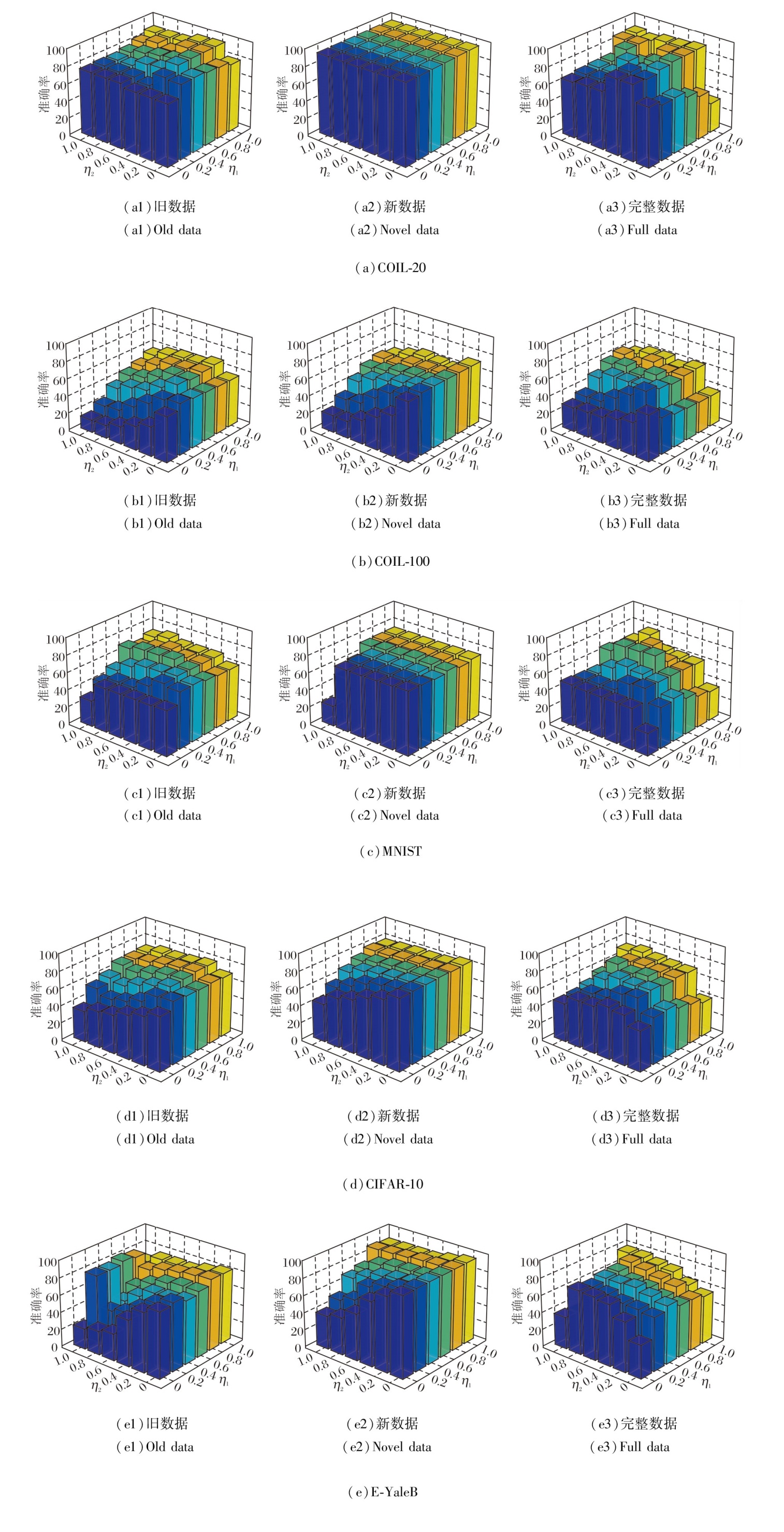 | 图4 新类别样本处理时超参数分析结果Fig.4 Hyperparametric analysis results for new category sample processing |
由图4可看出, 在5个数据集上, 旧数据的聚类性能显著受到η2的影响.随着η2的增大, 旧数据的准确率呈现下降趋势.相比之下, 新数据的准确率随η1的增加而逐步提升.此外, 完整数据的准确率在不同参数设置下表现出一定的波动性, 未能呈现出明显的单调变化趋势.
本文提出联合自表示子空间聚类方法(JSSC), 这是一种用于新旧数据子空间聚类的框架, 可有效管理类外数据, 发现新的类别, 强调旧数据与新数据之间的关系与互补性.通过联合特征学习, JSSC能从旧数据中提取的知识为新数据提供有力支持, 从而提高聚类的准确性和可靠性.在处理异构特征时, JSSC利用旧数据的潜在结构, 确保新数据的表示与之相符, 实现更优的聚类性能.这种跨数据关系的处理策略不仅增强对新类别样本的检测能力, 也有效维护旧类别的聚类准确性.实验表明, JSSC在处理新数据方面性能较优, 同时保留现有数据的聚类准确性, 并验证其在不同数据集上的有效性和适应性.今后可考虑进一步优化JSSC在特定领域的应用, 如医疗影像和社交网络数据; 探索自适应学习策略, 提升方法对不同数据流特征的适应性; 开发更高效的模型训练和推理方法, 应对大规模数据集的挑战.
本文责任编委 王士同
Recommended by Associate Editor WANG Shitong
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|