


{kind=link}
{kind=link}
{kind=link}
融合深浅层次知识的自学习TSK模糊癫痫辅助检测算法
[施奇环1, 2 , 张雄涛1, 2  ]
]
]
|
|



作者简介: 
施奇环,硕士研究生,主要研究方向为数据挖掘、机器学习、模式识别等.E-mail:shiqihuan0814@163.com.
Takagi-Sugeno-Kang(TSK)模糊分类器在癫痫检测中用于处理模糊信息.然而,由于癫痫脑电信号复杂、患者发作表现多样,一阶TSK模糊分类器通常难以从训练样本中获取足够的泛化性能.因此,文中提出融合深浅层次知识的具有自我学习能力的TSK模糊分类算法(Deep-Shallow Mix Self-Learning TSK, DSMT),用于癫痫辅助检测.DSMT引入类似人类“反思-归纳”的深度规则,增强模型对于潜在信息的挖掘能力,并通过静态-动态孪生的网络结构,使用模型的内部知识代替知识蒸馏中常见的教师模型.在静态网络中,DSMT使用不同批次输出中隐藏的浅层知识进行自我学习.在动态网络中,DSMT记录静态孪生网络输出作为深层知识,结合深层知识与浅层知识,借助TSK模糊分类器对模糊信息的敏感性,学习整合深浅层次的知识,实现低阶TSK模型的自我学习,提高癫痫辅助检测系统的自适应性.此外,DSMT采用同温度蒸馏的策略,优化知识传递的效率.在CHB-MIT、TUAB、TUEV真实癫痫数据集上的实验验证DSMT的有效性.
About Author:
SHI Qihuan, Master student. His research interests include data mining, machine learning and pattern recognition.
The Takagi-Sugeno-Kang (TSK) fuzzy classifier exhibits exceptional performance in handling fuzzy information for epilepsy detection. However, Due to the complexity of epileptic electroencephalogram(EEG)signals and the diverse manifestations of seizures among patients, first-order TSK fuzzy classifiers often struggle to achieve sufficient generalization from training samples.A TSK fuzzy classifier with deep and shallow self-learning knowledge integration, namely deep-shallow mix self-learning TSK(DSMT), is proposed. In DSMT, deep rules akin to human "reflection-induction" are introduced to enhance the ability of the model to mine latent information. The commonly used teacher model in knowledge distillation is replaced by the internal knowledge of the model through a static-dynamic Siamese network structure.In the static network, shallow knowledge hidden in the outputs from different batches is employed. In the dynamic network, the outputs of the static Siamese network are recorded as deep knowledge, and deep knowledge and shallow knowledge are combined. The sensitivity of the TSK fuzzy classifier to fuzzy information is leveraged to integrate both types of knowledge. DSMT enables self-learning of the first-order TSK model and improves the adaptability of the epilepsy detection system. Additionally, an optimal temperature distillation strategy is utilized to optimize knowledge transfer efficiency. Experiments on the real epilepsy datasets, CHB-MIT, TUAB, and TUEV, verify the effectiveness of DSMT.
癫痫[1, 2]是一种由脑部神经元阵发性异常超同步放电活动导致的慢性非传染性疾病, 是全球常见的神经系统疾病之一, 其诊断与治疗对患者健康具有重大影响[3, 4].癫痫的检测通常依赖于对脑电(Electroencephalogram, EEG)信号的分析, 但EEG信号的复杂性和不确定性给癫痫的准确诊断带来挑战[5, 6, 7, 8].当前的癫痫辅助检测系统难以脱离深度学习的依赖[9], 随着深度学习模型结构越来越复杂, 其黑盒的训练方式和巨大参数量很难给病人和专家带来信任感和理解感[9, 10], 同时其臃肿的模型也难以在算力受限的情况下运行.
TSK(Takagi-Sugeno-Kang)模糊分类器[11]是一种具备可解释性的模糊分类器, 善于处理模糊信息, 模型结构轻量化, 其良好的拟合逼近能力以及计算效率已得到广泛验证[11, 12].在使用EEG信号进行癫痫脑电信号诊断时, 专家通常通过区间的模糊值确定是否发病, 而TSK模糊分类器也同样通过区间的模糊值构建模糊规则.在这一过程中, TSK模糊分类器和传统癫痫检测方式具有天然的相似性, 因此被广泛应用于医学辅助检测领域.
在癫痫辅助检测领域, 将 TSK模糊系统融入深度学习而构建的模糊深度网络研究已取得一定成果.张雄涛等[13]提出基于视角-规则的深度TSK模糊分类器(View-to-Rule TSK Fuzzy Classifier, VR-TSK-FC), 结合多个视角数据, 帮助癫痫的辅助判断.Jiang等[14]提出CNNBaTSK(CNN-Baesd Born-Again TSK Fuzzy Classifier), 利用卷积神经网络(Convolutional Neural Network, CNN)提取的特征构建模糊规则, 在增强模糊逻辑系统能力的同时将深度学习中的知识移至模糊系统中, 提升癫痫辅助诊断的可靠性.Jiang等[15]提出MV-TSK-FS(Multiview TSK Fuzzy System), 结合多视图学习和模糊系统, 提高癫痫脑电图的识别能力.
尽管如此, 目前的模糊深度网络仍缺乏自学习和自适应的能力[16, 17], 面临如下挑战[18].从数据角度上看, 深度学习对大量标注数据的需求与癫痫领域知识获取困难的矛盾突出, 并且随着数据和模型复杂度的增加, 训练和推理耗时严重, 限制实际应用的扩展性.在诊断准确性上, 癫痫数据表现多样, 个体差异适应性不佳, 基于群体数据训练的模型难以精准应对个体患者特征变化, 性能波动明显.此外, 在癫痫实时监测方面, 深度学习模型的实时性和在线学习能力有限, 难以快速处理新数据并有效更新预测, 面对患者病情动态变化时无法及时调整, 整体性能下降.
知识蒸馏(Knowledge Distillation)[19]是一种模型优化方式, 允许一个小型的神经网络(学生模型)通过学习一个大型的神经网络(教师模型)的输出以获得知识.这种方法可提高小型模型的性能[20, 21, 22], 使其在保持较小模型尺寸的同时, 尽可能接近大型模型的性能.目前已有部分研究开始将知识蒸馏方法与TSK模糊分类器和CNN结合[14].自蒸馏(Self-Distillation)[23]是知识蒸馏的一种形式, 相比传统的知识蒸馏, 自蒸馏不需要一个预训练的教师模型指导学生模型的训练, 而是转向模型自身寻找知识.此外, 自蒸馏框架[23]对标签噪声具有鲁棒性, 能在标签不准确时依然提升模型性能[24].但自蒸馏可能会限制信息的流动, 在自蒸馏中, 学生模型只能从同一模型中获取知识[25, 26, 27], 这可能会导致在传递过程中丢失有用的特征信息, 也不能深度挖掘自身模型中的知识.
本文提出融合深浅层次知识的具有自我学习能力的TSK模糊分类算法(Deep-Shallow Mix Self-Lear-ning TSK, DSMT), 用于癫痫辅助检测.DSMT结合一阶TSK模型和自蒸馏方法的优势, 采用静态-动态孪生网络结构, 利用模型内部知识代替传统知识蒸馏过程中使用的教师模型.在静态网络中, 以不同批次的输出动态地作为学生模型, 和教师模型进行学习, 在静态网络训练结束后, 动态网络记录并利用静态网络的深层知识结合自我批次知识进行训练.设计的温度传递模块使两个孪生网络[28]处于相同的温度之下, 增强知识传递的效率.此外, DSMT借鉴人类思维中的“ 反思-归纳” 过程[29, 30], 批判性反思基本规则, 从基本规则中总结知识和隶属度, 并归纳成深度规则, 提升模糊规则判断的精确度.
本文选择一阶TSK型模糊分类器作为孪生自蒸馏的双生网络, 提出融合深浅层次知识的具有自我学习能力的TSK模糊分类算法(DSMT), 整体框架如图1所示.
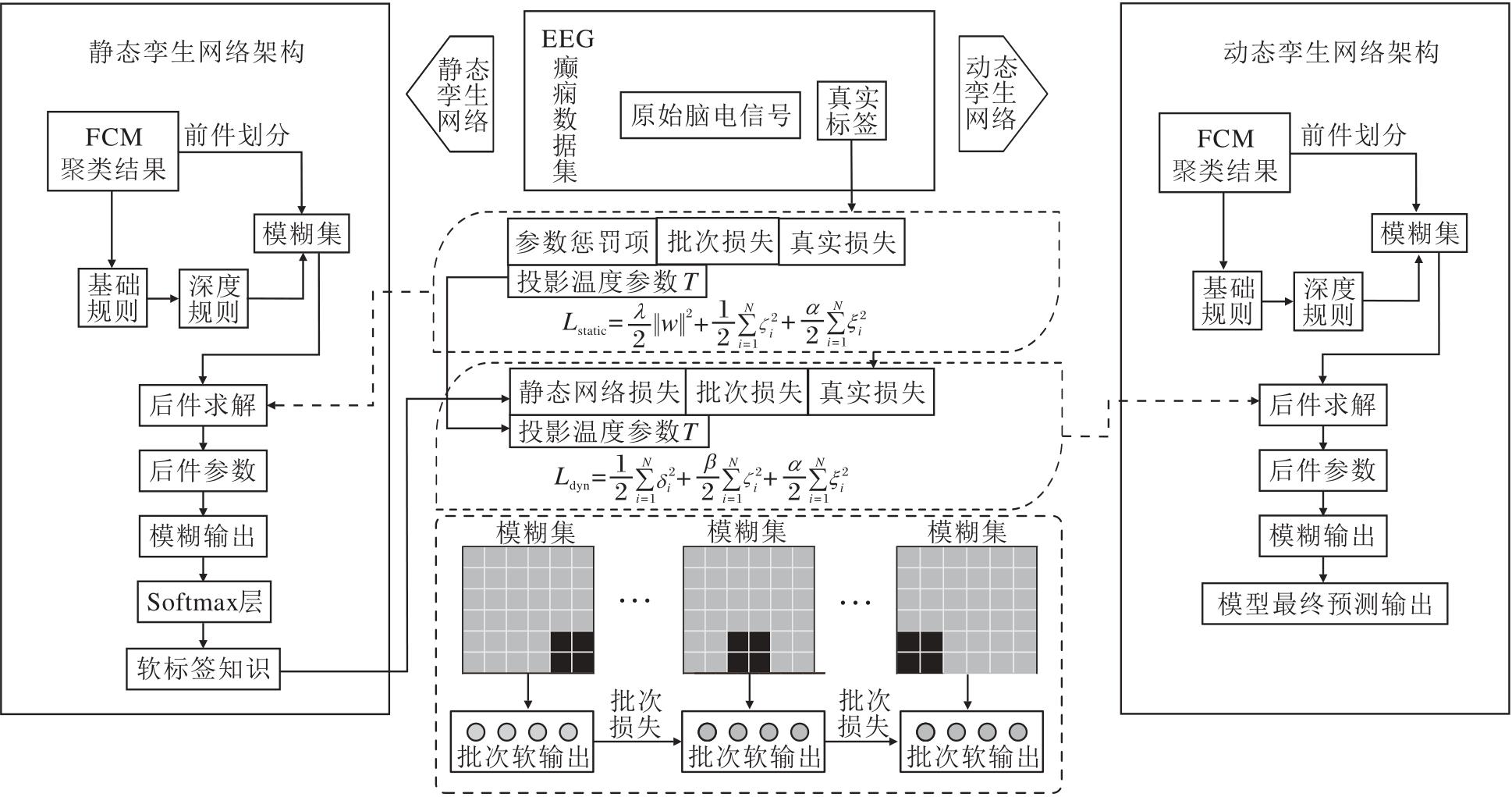 | 图1 DSMT整体框架图Fig.1 Architecture of DSMT |
DSMT将原始脑电信号作为输入, 使用主成分分析(Principal Component Analysis, PCA)对癫痫脑电信号进行特征提取, 获得关键特征.利用孪生网络的多方面交互, 首先训练静态孪生网络, 再使用静态孪生网络输出协助动态孪生网络进行深浅层次的知识获取.设计的余温式蒸馏模块使孪生网络两部分处于相同的温度之下.通过孪生自蒸馏的方式, DSMT获取自我学习的能力, 旨在适应不同患者和时间段中EEG信号特征的复杂变化问题.
一阶TSK型模糊分类器系统规则较简单, 轻量化的模型结构可在算力受限的终端中使用.然而, 这种系统在处理高复杂度的非线性数据时可能会受限, 因为它依赖于局部线性的假设并且对单一专家规则具有较强的依赖性, 不足以捕捉所有系统特性.传统的“ if-then” 规则虽然直观, 但往往无法精确模拟复杂的诊断决策过程, 限制模型对训练数据深层次理解的能力.
因此, 为了克服这些局限性, 引入“ 反思-归纳” 机制, 扩展和深化基础的“ if-then” 规则, 从初级规则中总结知识和隶属度, 并归纳为深度规则.这一方法不仅增强模型对新情况的适应能力, 还提高其在复杂决策中的准确性.
在人类学视域下, 反思不仅是对过去经验的回顾, 还包括对现有理论和实践的批判性思考.反思通常用于专业学习环境中, 帮助从业者改进实践.Fook[31]提出, 通过批判性反思的过程, 可更深入、全面地理解实践经验, 而这种理解往往是从业者最初无法表达的.这一观点同样适用于基于模糊规则进行判断的TSK型模糊分类器.
本文基于人类“ 反思-归纳” 过程, 拓展TSK型模糊分类器中的模糊规则.具体地, 仿照一般人类对于事物分步得出结论的过程, 批判性反思数个基本的模糊规则, 归纳成更深层次的规则.
对于一个简单的场景, 考虑使用一个拓展深度规则的“ if-then” 模糊规则集, 具体描述如下:
IF(In rule 1:湿度 is 较低∧ 温度 is 适中∧
云量 is 较少),
THEN 天气条件=晴朗;
IF(In rule 1:天气条件 is 晴朗∧
In rule 2:时间 is 周末),
THEN 活动=出门爬山.
上述方法不仅提升对基本规则中知识的理解, 还进一步减少每次分类器判断的难度.通过这种方式, 模型能在复杂的症状判断中表现得更准确.描述第i条基于“ 反思-归纳” 的深度规则输出yi如下:
IF (In rule 1:x1 is
(In rule 2:x1 is
(In rule M:x1 is
THEN yi=fd(fs(x))=fg(x),
其中, 输入
x=
M表示基础规则数, d表示样本的属性数,
相比传统TSK型模糊分类器, 基于“ 反思-归纳” 的深度规则更符合人类的思维过程, 使模型在处理复杂的非线性问题时表现更出色.具体地, 采用“ 反思-归纳” 过程的模型在处理复杂问题时, 显著提升决策准确性, 能更好地适应变化的环境条件.首先, 计算模糊规则隶属度:
$\begin{array}{l}\mu_{m}(\boldsymbol{x})=\prod_{i=1}^{d} \mu_{A_{i}^{m}}\left(x_{i}\right) \\\mu_{A_{i}^{m}}\left(x_{i}\right)=\exp \left(-\frac{\left|x_{i}-c_{i}^{m}\right|^{2}}{2\left(\sigma_{i}^{m}\right)^{2}}\right), \end{array}$ (1)
核宽
$\sigma_{i}^{m}=\frac{\sum_{j=1}^{N} u_{j}^{m}\left(x_{i j}-c_{i}^{m}\right)}{\sum_{j=1}^{N} u_{j}^{m}}, $
xi表示输入样本x的第i个特征,
下面进行基础规则-深度规则的归纳过程.在经过基础规则归一化输出和深度规则归纳后, 得到输出:
yi=fd(fs(x))=fg(x),
其中
$f_{s}(\boldsymbol{x})=\frac{\sum_{m=1}^{M} \mu_{m}(\boldsymbol{x}) f_{m}(\boldsymbol{x})}{\sum_{m^{\prime}=1}^{M} \mu_{m^{\prime}}(\boldsymbol{x})}=\sum_{m=1}^{M} \tilde{\mu}_{m}(\boldsymbol{x}) f_{m}(\boldsymbol{x}) .$
在确定前件参数之后, 后件部分可等价转换到模糊规则以及高斯隶属度下的线性回归模型.
定义基本规则的后件参数矩阵:
$\begin{array}{l} \boldsymbol{Q}_{s}=\left(\left(\boldsymbol{q}_{s}^{1}\right)^{\mathrm{T}}, \left(\boldsymbol{q}_{s}^{2}\right)^{\mathrm{T}}, \cdots, \left(\boldsymbol{q}_{s}^{M}\right)^{\mathrm{T}}\right)^{\mathrm{T}} \\ \boldsymbol{q}_{s}^{m}=\left(q_{s}^{m, 0}, q_{s}^{m, 1}, \cdots, q_{s}^{m, d}\right)^{\mathrm{T}} . \end{array}$ (2)
深度规则的后件参数矩阵为:
$\begin{array}{l} \boldsymbol{Q}_{d}=\left(\left(\boldsymbol{q}_{d}^{1}\right)^{\mathrm{T}}, \left(\boldsymbol{q}_{d}^{2}\right)^{\mathrm{T}}, \cdots, \left(\boldsymbol{q}_{d}^{D}\right)^{\mathrm{T}}\right)^{\mathrm{T}}, \\ \boldsymbol{q}_{d}^{i}=\left(q^{i, 1}, q^{i, 2}, \cdots, q^{i, M}\right)^{\mathrm{T}} . \end{array}$ (3)
通过模糊规则将原始输入x模糊化后映射到特征空间的矩阵:
$\begin{array}{l} \boldsymbol{H}=\left(\left(\boldsymbol{h}^{1}\right)^{\mathrm{T}}, \left(\boldsymbol{h}^{2}\right)^{\mathrm{T}}, \cdots, \left(\boldsymbol{h}^{M}\right)^{\mathrm{T}}\right)^{\mathrm{T}}, \\ \boldsymbol{h}^{m}=\widetilde{\mu}_{m}(\boldsymbol{x})\left(1, \boldsymbol{x}^{\mathrm{T}}\right)^{\mathrm{T}} . \end{array}$ (4)
根据式(2)~式(4), 总结深度规则的输出, 得到DSMT预测输出:
$\boldsymbol{z}=\sum_{i=1}^{D} \boldsymbol{y}_{i}=\boldsymbol{Q}_{d}^{\mathrm{T}}\left(\boldsymbol{Q}_{s}^{\mathrm{T}} \cdot \boldsymbol{H}\right)=\boldsymbol{W}^{\mathrm{T}} \cdot \boldsymbol{H}$ (5)
其中D表示深度规则的数量.本文均通过使用梯度下降法优化目标损失的方式求得后件参数矩阵.同时求得模型的概率输出:
此外, 深层规则的优化知识表示使系统在处理模糊性和不确定性时更有效.更重要的是, 这种自我学习和自我优化的过程减少对传统专家知识的绝对依赖, 提升模型的自主性和灵活性.本文选择以“ 反思-归纳” 深层规则为基础的一阶TSK型模糊分类器作为孪生网络, 增强模型对潜在信息的挖掘能力.
为了解决自学习过程中的自我特征缺失问题, 首先设计动静结合的网络结构, 以不同训练批次输出, 作为教师模型, 为动态孪生网络提供深层知识及合适的投影温度, 使动态孪生网络能较好地获取知识.在模型训练过程中, 观察到不同批次的学习程度往往不相同, 根据该情况, 利用批次输出中的差距设计基于批次提升的自蒸馏网络, 将不同批次的软输出替代教师模型输出, 作为自身的教师模型进行自我提升, 软化后的c分类的软输出为:
$p_{i}=\frac{\exp \left(\frac{z_{i}}{T}\right)}{\sum_{l=1}^{c} \exp \left(\frac{z_{l}}{T}\right)} .$ (7)
基于批次提升的自我蒸馏模型不需要额外加入教师模型, 也不带来大量数据存储的需求.
静态孪生网络接受来自真实标签以及批次输出中的知识, 设计如下3项损失.1)正则化项损失.2)真实损失:
ζ i=-
其中,
ξ i=
其中,
在训练过程中, 来自不同批次的知识可避免在自蒸馏中学生模型只能从同一模型重复获取知识的问题, 能有效防止关键的特征信息在传递过程中丢失.
在此过程中, 静态孪生网络的一般损失为:
$L_{\text {static }}=\frac{\lambda}{2}\|w\|^{2}+\frac{1}{2} \sum_{i=1}^{N} \zeta_{i}^{2}+\frac{\alpha}{2} \sum_{i=1}^{N} \xi_{i}^{2}, $(8)
其中, w表示一阶TSK的参数, λ、α表示正则化参数.
将结合浅层批次知识的静态孪生网络最后模型软输出
静态孪生网络算法的一般伪代码如下.
算法1 混合批次知识的静态孪生网络
输入 癫痫特征X={x1, x2, …, xN},
xi∈ Rd, i=1, 2, …, N, 标签
模糊规则的数量M, 深度规则的数量D,
周期epochmax, 训练误差θmin
输出 训练好的静态模糊后件参数矩阵Qd, Qs,
静态孪生网络的深度知识
es={e1, e2, …, ec}
阶段1 前件计算
通过FCM初始化模糊集中心;
根据式(1)获取并归一化模糊隶属度μ m(x);
阶段2 后件计算
随机初始化后件参数矩阵Qd, Qs;
WHILE epoch< epochmaxOR Lstatic≥ θminDO:
根据式(2)~式(4), 计算输出z,
根据式(8)计算Lstatic;
$\begin{array}{l} \boldsymbol{Q}_{d}^{t+1} \leftarrow \boldsymbol{Q}_{d}^{t}-\nabla_{q} L_{\text {static }} ; \\ \boldsymbol{Q}_{s}^{t+1} \leftarrow \boldsymbol{Q}_{s}^{t}-\nabla_{q} L_{\text {static }} ; \end{array}$
END WHILE
阶段3 标签输出
根据式(5)计算静态网络输出z;
根据式(6)计算静态网络模型的概率输出es.
在完成静态孪生网络训练之后, 为了有效接收静态孪生网络训练完成的深度知识, 在结构相同的动态孪生网络损失中引入静态网络的软输出es.类似于物理蒸馏过程, 调整温度以软化教师模型, 以便学生模型能更有效地吸收知识.
在DSMT中, 希望两个孪生网络能吸收相似的知识, 因此置于相同的蒸馏温度下.这种设置使得在相同或相似数据集上, 孪生网络的两个部分更容易吸收类似知识, 正如在物质蒸馏过程中, 在相似温度下更容易析出相同物质.保持孪生网络的两个部分在相同温度下, 知识传递变得更顺畅和高效.
在动态网络中批次软输出同式(7).
动态孪生网络接受来自静态网络、批次输出及真实标签中的知识, 设计如下3项损失:静态网络的蒸馏损失δ i、批次蒸馏损失ξ i、真实损失ζ i.批次蒸馏损失ξ i和真实损失ζ i与静态孪生网络保持相同的蒸馏损失:
δ i=piln(
最终得到动态孪生网络的一般损失:
$L_{\mathrm{Dyn}}=\frac{1}{2} \sum_{i=1}^{N} \delta_{i}^{2}+\frac{\beta}{2} \sum_{i=1}^{N} \zeta_{i}^{2}+\frac{\alpha}{2} \sum_{i=1}^{N} \xi_{i}^{2} .$ (9)
另外, 动态网络在优化后件参数时, 也同时学习静态网络输出es中的深度知识.
设定相同蒸馏温度, 结合孪生模型中的深浅层次知识, 在深层知识传递过程中尽可能减少丢失有用特征信息的可能性.在不显著增加模型复杂度的前提下, 使用模型内部知识代替知识蒸馏中的教师模型, 实现模型内部的自我学习.上述过程的动态孪生网络的算法伪代码如下.
算法2 结合深浅层次知识的动态孪生网络
输入 癫痫特征X={x1, x2, …, xN},
xi∈ Rd, i=1, 2, …, N, 标签
模糊规则的数量M, 深度规则的数量D,
最大周期epochmax, 训练误差θmin,
静态网络输出软标签es={e1, e2, …, ec}
输出 动态网络输出z, 后件参数矩阵Qd, Qs
阶段1 前件计算
通过FCM初始化模糊集中心;
根据式(1)获取并归一化模糊隶属度μ m(x);
阶段2 后件计算
随机初始化后件参数矩阵Qd, Qs;
FOR epoch< epochmaxOR LDyn≥ θminDO:
根据式(2)~式(6), 计算输出z,
根据式(9)计算LDyn;
$\begin{array}{l} \boldsymbol{Q}_{d}^{t+1} \leftarrow \boldsymbol{Q}_{d}^{t}-\nabla_{q} L_{\mathrm{Dyn}} ; \\ \boldsymbol{Q}_{s}^{t+1} \leftarrow \boldsymbol{Q}_{s}^{t}-\nabla_{q} L_{\mathrm{Dyn}} ; \end{array}$
END FOR
阶段3 模型结果输出
根据式(6)计算动态网络输出z.
在癫痫辅助检测的应用场景中, 更轻量化的模型设计能应用于硬件算力受限的穿戴式场景.下面将分步分析算法的时间复杂度, 更好地评估DSMT在处理复杂任务时的潜力.DSMT的复杂性主要分为两个孪生网络.
1)阶段1:前件计算.
(1)初始化模糊集中心.使用FCM, 时间复杂度通常为O(Nrid), 其中, r表示模糊集中心的数量, d表示特征维度, i表示迭代次数, N表示样本数量.
(2)获取并归一化模糊隶属度.计算隶属度的时间复杂度为O(NrM), 其中, N表示样本数量, r表示模糊集中心的数量, M表示基础规则数量.归一化操作时间复杂度为O(N).
综合(1)、(2), 得到阶段1的时间复杂度为
O(Nrid+NrM+N).
本文中r、d、i、M都是远小于样本数N的常数, 因此可认为阶段1的时间复杂度为O(N).
2)阶段2:后件计算.
(1)初始化参数.后件参数矩阵初始化的复杂度为O(NMD), 其中D表示深度规则数量.
(2)输出计算.计算网络硬输出z的时间复杂度为O(NMD), 软输出
(3)梯度计算.在两个孪生网络中, 动态孪生网络损失比静态孪生网络更复杂, 因此下面以动态网络的时间复杂度为例进行分析.损失函数LDyn定义如式(9), 计算梯度时将三个约束项分别进行反向传播的推导及梯度的计算, 分析算法的时间复杂度.
对δ i进行求导时, 需要分步计算损失函数对pi的梯度:
同样, 对ζ i求导时, 需要计算损失函数对
$\begin{array}{l} \frac{\partial \zeta_{i}}{\partial \hat{y}_{i}}=-\frac{\bar{y}_{i}}{\hat{y}_{i}} \\ \frac{\partial L_{\mathrm{Dyn}}}{\partial \hat{y}_{i}}=\beta \zeta_{i} \frac{\partial \zeta_{i}}{\partial \hat{y}_{i}}=-\frac{\beta \bar{y}_{i} \zeta_{i}}{\hat{y}_{i}} . \end{array}$
最后对ξ i进行反向传播时, 同样分步计算损失函数对pi的梯度:
$\begin{array}{l} \frac{\partial \xi_{i}}{\partial p_{i}^{\sigma}}=\ln \left(\frac{p_{i}^{\sigma}}{p_{i}^{\sigma-\nu}}\right)+1, \\ \frac{\partial L_{\mathrm{Dyn}}}{\partial p_{i}^{\sigma}}=\alpha \xi_{i} \frac{\partial \xi_{i}}{\partial p_{i}^{\sigma}}=\alpha \xi_{i}\left(\ln \left(\frac{p_{i}^{\sigma}}{p_{i}^{\sigma-\nu}}\right)+1\right) . \end{array}$
在计算梯度的过程中, 计算
O(epochmax(N(MD)+MD)),
其中epochmax表示反向传播的最大迭代次数.
总之, DSMT的时间复杂度
O(epochmax(N(MD)+MD)),
主要由基础规则数M和深度规则数D决定, 但MD都是远小于数据量的常数.
综合分析上述的时间复杂度, 设计的具有自我学习能力的DSMT在时间复杂度上与传统的基于反向传播求解的一阶TSK模糊分类器无显著差异, 较好地保持其轻量化的特性.
实验硬件环境如下: Intel Core i7-13700F at 5.02 GHz, 64 GB RAM, GeForce RTX 4090.编程的软件环境如下:64-bit Microsoft Windows 10, PyThon 3.10.11 Torch 2.0.0 with CUDA 11.8.
为了验证和评估DSMT在癫痫脑电信号分类任务上的性能.在波士顿儿童医院与麻省理工学院联合提供的CHB-MIT数据集[32]以及天普大学(Temple University)提供的TUAB(Temple Univer-sity Hospital EEG Abnormal Corpus)、TUEV(Temple University Hospital EEG Video Corpus)数据集[33]上进行充分实验.
CHB-MIT数据集是一个公开的EEG数据集, 由麻省理工学院和波士顿儿童医院的研究人员收集并发布.数据集包含24段患有难治性癫痫的儿童的头皮脑电图记录, 包括178次癫痫发作记录.具体有23个通道的916 h头皮脑电信号记录, 采样频率为256 Hz, 分辨率为16位.研究表明[34], 癫痫的发作频率主要为4 Hz~30 Hz, 因此, 本文使用快速傅里叶变化进行滤波处理, 提取4 Hz~30 Hz之间的频域特征, 采样间隔为0.5 Hz.受制于硬件条件限制, 同时利用子集有助于评估方法在未见数据上的泛化能力, 在子集上训练并在其它子集上测试, 模拟在新的环境下进行测试.取不同时间长度下数据标准化后的10个子集 CHB 01~CHB 10作为此次的实验数据, 每条样本数据都有23× 53个特征维度.同时因为癫痫数据集上发病比例太少, 为了增加癫痫片段的数量, 采用重采样的样本提取方法, 重叠采样的时长设置为0.5 s, 以此平衡正负样本的数量.CHB-MIT数据集详细信息如表1所示.
| 表1 CHB-MIT数据集信息 Table 1 Description of CHB-MIT dataset |
DSMT的有效性也在TUAB、TUEV数据集上进行验证.TUAB、TUEV数据集来自天普大学, 是用于脑电信号研究的重要资源.TUAB数据集包含23个通道、采样率为256 Hz、409 455个已标注正常或异常的10 s样本, 用于二分类任务.TUEV数据集具有相同通道数和采样率, 112 491个注释为6种事件类型的5 s样本, 用于多类分类任务.
基于硬件条件限制, 同样按照CHB-MIT数据集的处理方式采样3个正负样本平衡的TUAB子集以及3个多分类样本平衡的TUEV子集, 每条样本数据都有23× 53个特征维度, 每个子集样本详细信息如表2所示.
| 表2 TUAB、TUEV数据集信息 Table 2 Description of TUAB and TUEV datasets |
为了评估DSMT的性能, 采用准确率(Accuracy, ACC)、敏感性(Sensitivity, SEN)和F1分数作为评价指标, 计算公式如下:
$\begin{array}{l} A C C=\frac{T P+T N}{T P+T N+F P+F N}, \\ S E N=\frac{T P}{T P+F N}, \\ F_{1}=\frac{2 \cdot(T P \cdot P)}{(T P \cdot P)+(T P \cdot R)} . \end{array}$
其中:TP(True Positives)表示正确预测为正类的样本数量, 即正确检测癫痫样本; TN(True Negatives)表示正确预测为负类的样本数量, 即正确识别癫痫发作; FP(False Positives)表示错误预测为正类样本数量, 即误检为癫痫的样本; FN(False Negatives)表示错误预测为负类的样本数量, 即误检为健康的样本.
文中F1的权重P、R都由样本的比重自动计算.
为了验证DSMT的分类性能, 选择如下深度模糊分类器进行对比实验.
1)由于DSMT是基于TSK模糊分类器的自学习癫痫检测算法, 因此选择3个最新的TSK模糊分类器在癫痫上的应用算法进行对比: VR-TSK-FC[13]、CNNBaTSK[14]、MIP-TRL-FS(Multiview Information Preservation Transfer Representation Learning Based on Fuzzy Systems)[35], .
2)DSMT将深度知识引入模糊规则中, 因此, 采用两种使用深度模型作为后件的深度模糊分类器作为对比算法:将1个1D-CNN提取的深度特征作为TSK后件变量的MST-TSK(Multiple-Source Transfer Learning-Based TSK Fuzzy System)[36], 由多视角深度特征拼接共同作为TSK后件变量的基于增强深度特征的TSK模糊分类器(ED-TSK-FC)[16].
实验时对比算法都采用原文献中的参数设置.对于DSMT中的超参数, 都通过网格搜索策略进行优化, 其中epochmax设为100, 蒸馏温度T从{0.01, 0.1, 1, 10, 100, 1 000, 10 000} 中搜索, 基础规则数量M从{1, 2, 3, 4, 5, 7, 10}中搜索, 深度规则数量D从{1, 2, 3, 4, 5, 10, 15, 20}中搜索, 梯度设为0.01, 最小损失θ设为0.001, 训练批次固定为256.
所有实验都采用五折交叉方式, 每次随机选取一折交叉的样本作为测试集, 其余样本作为训练集, 重复五次, 最后结果取五次运行的平均值, 以此减少数据集划分对实验结果的影响.
在CHB-MIT、TUAB、TUEV数据集上测试各算法的分类性能, 具体平均准确率和F1分数如表3~表5所示, 表中黑体数字表示最优值.
| 表3 各算法在CHB-MIT子集上的准确率对比 Table 3 Accuracy comparison of different algorithms on CHB-MIT subset |
| 表4 各算法在CHB-MIT子集上的F1值对比 Table 4 F1 comparison of different algorithms on CHB-MIT subset |
| 表5 各算法在TUAB、TUEV子集上的准确率对比 Table 5 Accuracy comparison of different algorithms on TUAB and TUEV subsets |
由表3可观察到, DSMT在5个CHB-MIT子集上都取得相当不错的性能.在分类精度方面, DSMT在5个数据集上均高于MST-TSK、ED-TSK-FC、CNN-BaTSK、MIP-TRL-FS, 并且在4个数据集上都优于VR-TSK-FC, 在CHB 01子集上也获得较优的性能.这说明DSMT从自身模型和孪生架构中获取知识, 与同样从CNN中蒸馏知识的CNNBaTSK具有相似的性能, 但DSMT不用引入额外的复杂深度架构.本文认为, DSMT之所以能取得这样的成果, 主要归功于其独特的孪生网络架构, 该架构能深入挖掘数据的内在知识, 并通过内部模型知识增强学习过程.自学习方法的一个显著优势是:允许TSK模糊系统在无需外部教师模型的指导下自主学习并适应, 而在计算资源受限的环境中, 如癫痫辅助检测, 能提供更个性化和高效的解决方案, 这种自我学习能力也使其能更好地适应患者的个体差异.
由表4同样可观察到, DSMT的F1值更高, 尤其在CHB 04子集上, 性能最优, 这表明DSMT在这些数据集上具有相对更好的综合分类表现.
由表5可观察到, DSMT在TUAB、TUEV数据集上均取得较优值.在TUAB数据集上, DSMT的准确率在所有子集上均高于或接近其它算法, 虽然在TUAB 02子集上, DSMT的准确率略低于CNNBa-TSK, 但仍显著高于其它算法.在TUEV数据集上, DSMT同样展现出良好性能, 尤其是在TUEV 02子集上, DSMT的准确率为0.818 3, 高于其它算法.综合所有子集的平均准确率来看, DSMT的平均准确率(0.871 0)最高, 这进一步表明DSMT在不同数据集上的泛化能力和优越性.上述结果表明, DSMT在TUAB、TUEV数据集上, 能有效提取和利用关键特征, 在癫痫EEG信号的分类任务中取得优异性能.
为了全面评估DSMT中各模块的自我学习能力, 进行消融实验, 旨在验证算法每个部分对整体学习效果的贡献.首先, 建立一个普通梯度下降的一阶TSK分类器作为基线模型(Baseline, 简记为B).然后, 将DSMT主要分为三个核心的学习模块:孪生网络(SiameseNet, 简记为S)、批次自我学习(Batch-Learn, 简记为L)、深度规则(DeepRule, 简记为D), 在消融实验中, 测试这些模块的不同组合, 如BD表示在基线模型上增加深度规则模块, 由此验证DSMT各部分学习的有效性.具体准确率如表6所示, 表中黑体数字表示最优值.
| 表6 DSMT各模块的消融实验结果 Table 6 Ablation experiment results of DSMT modules |
由表6可看到, 在3个模块的不同组合下, 各模块在普通基线模型的基础上都展现出优秀的学习效果.加入深度规则的BD引入深层的模糊逻辑规则, 用于处理更复杂的数据模式和关系, 性能更优.加入深度规则和孪生网络结构(BDS)后使模型学到相似结构孪生网络中的深度知识, 增强模型对癫痫特征的区分能力, 相比BD, BDS进一步提升性能, 表明静态孪生网络在提高特征识别能力上的有效性.加入批次自我学习和深度规则的BDL在每个训练批次中自我优化, 提高模型对新数据的适应性和学习效率, 相比BD, BDL也表现出性能提升, 表明批次自我学习在增强模型泛化能力方面的贡献.实验表明, 这三个模块的协同作用可显著提升算法性能.
为了验证DSMT能将学习的知识应用在不同的患者和使用场景下, 设计性能泛化性测试实验, 验证DSMT在复杂癫痫信号下的性能保持.将不同患者分别作为学习知识来源和应用场景, 模拟在训练场景和测试场景下的个体差异.将10位患者脑电数据分别随机作为目标数据和实验数据, 结果如表7和图2所示.
| 表7 DSMT在不同病人上的泛化性能 Table 7 Generalization performance of DSMT on different patients |
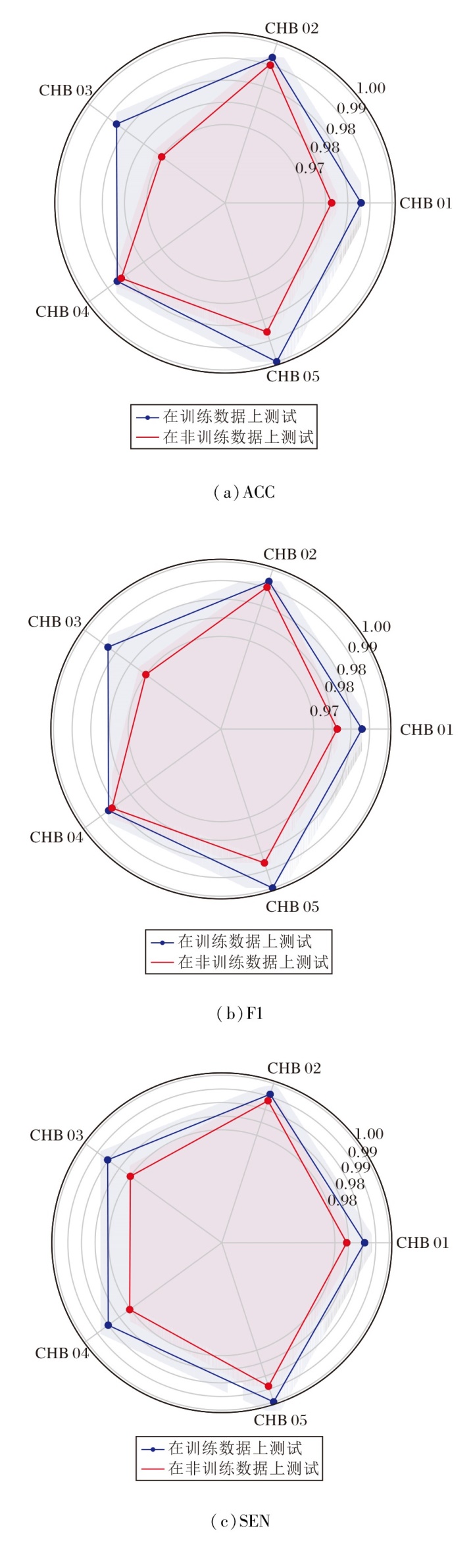 | 图2 训练完成的DSMT在不同病人上的性能Fig.2 Performance of trained DSMT algorithm on different patients |
分析图2和表7可得, DSMT在完成初步训练之后, 转换应用场景到不同患者身上时, 在3个重要指标上都保持相当不错的性能, 表明DSMT拥有在不同应用场景下优秀的泛化性.因此本文认为, DSMT的“ 反思-归纳” 过程深度学习病人的通用知识.此外, DSMT的自我学习模块与温度调节模块的结合, 可有效减少对患者个人特征的过度拟合, 提升模型在不同患者群体中的泛化性能.同时, DSMT的自我学习特性可结合患者的个人数据得到进一步强化, 生成患者个人特征强化的癫痫辅助检测模型.
下面测试DSMT的超参数:温度T、正则化参数α、批次大小.在CHB数据集上进行敏感性测试, 其它参数都保持最佳值, 结果如图3所示.
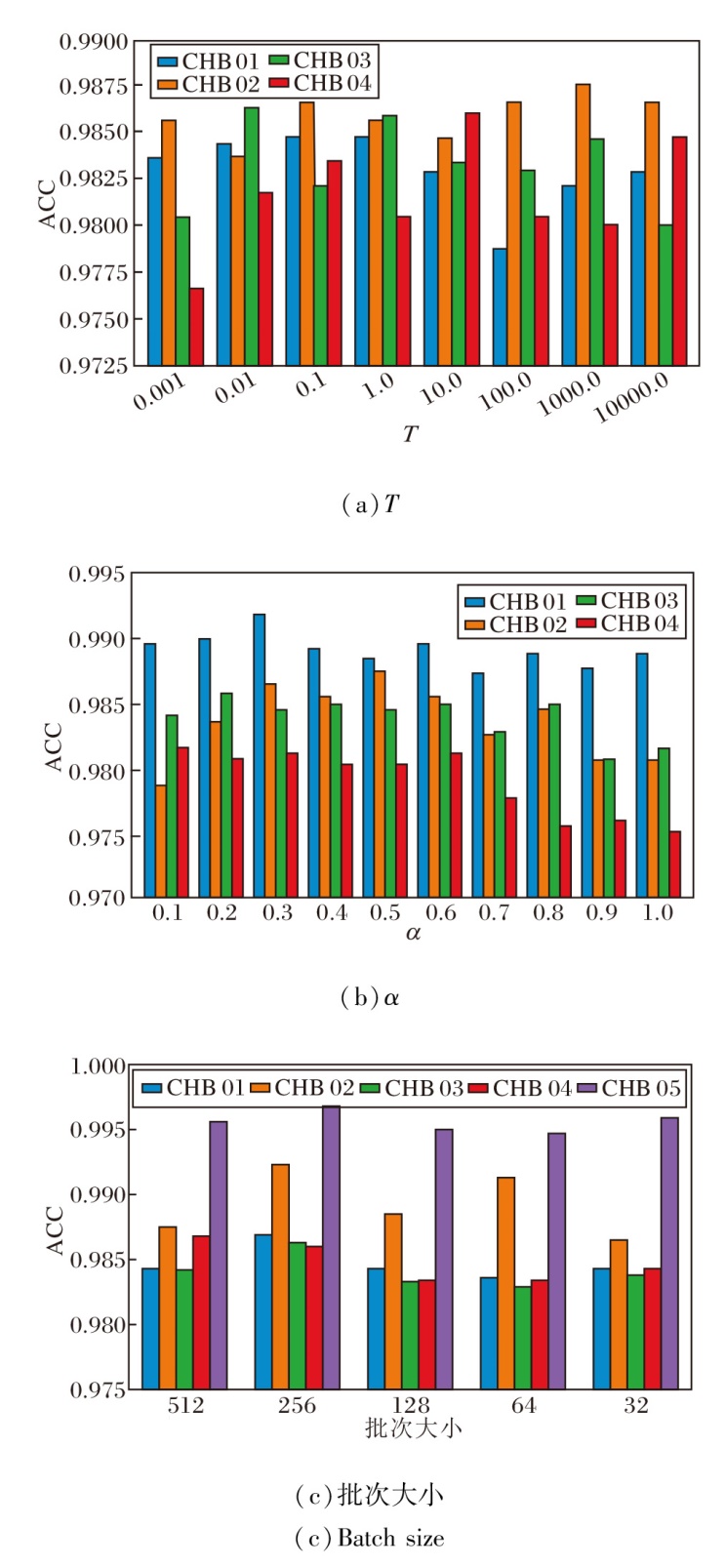 | 图3 参数敏感性分析结果Fig.3 Results of parameter sensitivity analysis |
由图3(a)可看到, DSMT的准确率随温度参数T的变化而波动, 在一个适中的温度值(大约在100到101之间)时, DSMT达到最高的准确率, 当温度参数过低(小于 10-1)或过高(大于 101)时, 准确率显著下降.本文认为, 过高的温度会破坏算法中的知识, 导致算法忽视重要的数据细节, 而过低的温度可能使算法无法有效学习数据中的复杂模式.合适的温度参数有助于算法在保持足够学习动态的同时, 使静态孪生网络中的知识更好地传递到动态孪生网络中, 使DSMT更好地学习多层次的知识.
同样, 在(b)中可看到, 正则化参数α对DSMT的性能具有显著影响, 在α约为 0.2 到 0.4 之间时, 算法表现出最佳的分类性能, 太低或太高的α值都会导致准确率下降, 这是因为合适的正则化参数有助于控制模型的复杂度, 防止过拟合.正则化参数过低可能导致算法对训练数据过度拟合, 而过高则可能抑制算法的学习能力.适当的正则化参数有助于算法学习更一般化的特征.
在(c)中可观察到, 当批次大小为256时, 算法在CHB 01、CHB 05子集上的表现较优, 这可能是因为较大的批次大小有助于算法捕捉数据的全局特征, 使批次间的自我学习更有效.同时也注意到, 在较小的数据集上, 较小的批次大小(如在CHB 02子集上批次大小为64)增加批次间互相学习的可能性, 有助于算法更好地适应数据的局部变化.
本文提出融合深浅层次知识的具有自我学习能力的TSK模糊分类算法(DSMT), 旨在通过孪生的网络结构和特殊的知识获取方式, 显著提升TSK模糊分类器在癫痫检测应用下的自学能力和泛化能力.在公开的3个癫痫数据集上的实验表明, DSMT在EEG癫痫辅助检测任务上表现出色.泛化性实验表明, DSMT在不同病人的应用中保持稳定性能, 表明其良好的泛化能力.DSMT在实际应用中的表现说明其在癫痫辅助检测中的潜力.通过自我学习和自我优化的机制, DSMT减少对专家知识的依赖, 提高模型的自主性和灵活性, 为癫痫的医学辅助诊断领域提供一种可能的技术手段, 有望在未来的临床实践中发挥重要作用.
本文责任编委 吕宝粮
Recommended by Associate Editor LÜ Baoliang
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|