




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于全孔径估计的轻量化无监督多曝光光场图像融合
[李玉龙1  , 陈晔曜
, 陈晔曜1 , 金充充2 , 蒋刚毅1 ]
, 陈晔曜, 金充充, 蒋刚毅]
|
|



作者简介:
李玉龙,硕士研究生,主要研究方向为深度学习、多曝光光场图像融合等.E-mail:1946734397@qq.com. 
陈晔曜,博士,讲师,主要研究方向为深度学习、光场图像处理等.E-mail:chenyeyao@nbu.edu.cn. 
金充充,博士,讲师,主要研究方向为深度学习、图像质量评价等.E-mail:jinchongchong@nbu.edu.cn.
多曝光光场图像融合是克服光场相机成像动态范围有限的有效途径之一,但受限于光场的高维结构,现有方法难以高效处理多曝光光场图像.因此,文中提出基于全孔径估计的轻量化无监督多曝光光场图像融合方法.首先,从中心子孔径图像中提取代表性的场景信息,减轻完整光场图像输入带来的沉重计算负担.然后,设计全孔径权重估计模块,挖掘光场角度信息,获取完整光场图像的融合权重.该模块利用边界子孔径图像与中心子孔径图像之间的差异变化,在特征空间中构建完整的权重图.最后,将权重图与源图像相乘,生成融合的光场图像.实验表明,文中方法可生成具有高对比度和细致纹理的光场图像,并保留良好的角度一致性.此外,文中方法在定量和定性对比中均取得较优性能,同时可降低计算负担.
About Author:
LI Yulong, Master student. His research interests include deep learning and multi-exposure light field image fusion.
CHEN Yeyao, Ph.D., lecturer. His research interests include deep learning and light field image processing.
JIN Chongchong, Ph.D., lecturer. Her research interests include deep learning and image quality assessment.
Multi-exposure light field(LF) image fusion is an effective way to overcome the limited dynamic range of LF cameras. However, due to the high-dimensional structure of LFs, existing methods struggle to efficiently process multi-exposure LF images. To address this issue, a method for lightweight unsupervised multi-exposure LF image fusion based on full-aperture estimation(MELFF-FAE) is proposed. First, the representative scene information is extracted from the central sub-aperture image(SAI) to reduce the heavy computational burden caused by the input of the full LF image. Second, a full-aperture weight estimation module is designed to obtain the fusion weight of the full LF image by mining the LF angular information. The difference between the boundary SAIs and the central SAI is utilized to construct a full weight map in the feature space. Finally, the weight map is multiplied with the source image to generate a fused LF image. Experimental results demonstrate that MELFF-FAE can generate LF images with high contrast and detailed textures while preserving good angular consistency. Moreover, compared to existing representative methods, MELFF-FAE achieves superior results in both quantitative and qualitative comparisons while significantly reducing the computational burden.
光场(Light Field, LF)成像可完备记录自由空间中光线的空间分布与传播方向, 克服传统数码相机成像仅能捕获光线强度信息的局限[1].受益于光场蕴含的丰富信息, 许多模式识别任务, 如人脸检测、表情识别等[2], 以及沉浸式应用, 如三维重建、视点合成等[3, 4], 得到进一步发展.此外, 光场的空间角度信息可实现捕获后重聚焦[5]、单帧深度估计[6, 7]等, 这也提升光场在现实世界中的应用价值.然而, 由于光场图像传感器的势阱容量有限, 采集的光场图像通常仅包含较低的动态范围, 即在场景低暗区域产生欠曝光现象, 在场景高亮区域产生过曝光现象, 这严重影响光场图像的视觉感知质量, 并降级下游任务的性能[8].
为了提高光场图像质量, 多曝光融合是一种简单有效的途径[9].它融合基于不同曝光值采集的多幅光场图像, 产生一幅具有高对比度、丰富纹理并且保留良好角度一致性的融合光场图像.
现有多曝光融合方法可大致分为两类:传统方法[10, 11, 12]和基于深度学习的方法[13].传统方法主要从变换域或像素域提取图像特征, 如饱和度特征、梯度特征等, 构造融合权重, 进而将融合权重应用于变换后的系数或源图像, 实现曝光融合, 最终生成融合结果.然而, 由于现实场景类型复杂, 传统基于手工提取的特征难以完备表示所有场景, 因此在不同场景中缺乏鲁棒性.
近年来, 随着深度学习在计算机视觉领域的广泛应用, 研究者提出基于深度学习的多曝光融合方法.依据对标签数据的需求, 现有方法可分为有监督学习和无监督学习[14].有监督学习通常利用主观筛选或客观打分, 从由多种算法得到的融合结果中选择具有最高质量的图像作为真值标签[15, 16].然而:主观筛选费时费力, 难以支持建立大尺度数据集; 客观打分存在算法鲁棒性和偏好性差异, 难以准确应对不同场景内容.相比之下, 无监督学习去除对标签数据的需求, 具有更高的实用价值, 可泛化到任意采集的多曝光数据中.
值得注意的是, 上述方法均是针对传统二维图像而设计的, 即其仅针对单视点图像, 未考虑光场图像包含的角度信息.由于光场图像包含的角度信息使其能可视化为子孔径图像阵列, 因此这些二维方法能以逐视图方式实现多曝光光场图像融合, 但不可避免地忽略光场角度维信息, 容易产生次优的性能, 并可能破坏融合结果的角度一致性, 进而降级后续光场应用的性能[17].
为光场数据设计特定的网络结构是实现高质量多曝光光场图像融合的关键步骤之一.多曝光光场图像融合需同时考虑光场在空间维和角度维的质量, 以此保证融合结果在提高空间对比度的同时保留准确的角度一致性, 但光场包含的高维结构为高效处理带来一定挑战.现有的光场网络[18, 19]通过将光场数据划分为多个子空间以实现降维处理, 从而在探索光场几何结构的前提下降低计算代价.然而, 由于光场相机的窄基线特性, 导致不同子视图之间的相似性较高[20], 而现有光场网络未充分挖掘视图间冗余, 并且未针对多曝光融合任务而进行网络架构设计.
针对上述问题, 本文提出基于全孔径估计的轻量化无监督多曝光光场图像融合方法(Lightweight Unsupervised Multi-exposure Light Field Image Fusion Based on Full-Aperture Estimation, MELFF-FAE), 可不依赖真值图像, 以较小的计算代价生成具有高视觉质量的融合光场图像, 并保留准确的角度一致性.首先, 考虑中心子孔径图像包含相对较多的场景信息, 设计中心子孔径特征提取模块, 联合卷积和Transformer, 提取代表性空间特征, 降低完整光场输入造成的巨大计算负担.然后, 设计简单有效的全孔径权重估计模块, 利用边界子孔径图像与中心子孔径图像之间的差异变化学习全光场的融合权重.最后, 将权重图与源图像进行加权融合, 生成融合的光场图像.实验表明, MELFF-FAE可生成具有高对比度和细致纹理的光场图像, 并保留良好的角度一致性.此外, MELFF-FAE在定量和定性对比中均取得较优性能, 同时可降低计算负担.
依据对图像表达形式的不同, 传统方法可分为基于变换域的方法和基于像素域的方法.
基于交换域的方法主要是将图像投影到变换域进行处理, 通常该类方法遵循图像变换、系数融合和逆变换三个处理阶段.Bhateja等[10]联合小波变换和轮廓波变换, 实现多模态图像融合.Liu等[11]利用多尺度变换, 将图像转换为低通分量和高通分量, 分别融合后, 将融合结果进行逆多尺度变换, 重建为像素域图像.Xu等[21]提出TT-MEF(Tensor Product and Tensor-Singular Value Decomposition Based Multi-expo- sure Image Fusion), 探索图像在张量域的特征表示.
基于像素域的方法主要考虑多曝光图像中不同像素之间的关系, 为每幅曝光图像估计一个像素级权重图, 再将所有权重图与源图像进行加权融合, 生成多曝光融合图像.Mertens等[12]定义对比度、饱和度、良好曝光度这3种图像质量度量标准, 构造融合权重.Li等[22]提出GFF(Guided Filtering Based Fu-sion Method), 利用显著性建模融合权重, 并引入引导滤波, 实现平滑过渡的多曝光融合.Liu等[23]提出DSIFT, 可应对轻微运动场景.Lee等[24]引入全局梯度信息, 构造自适应融合权重, 保留更多的纹理细节.Ma等[25]提出SPD-MEF(Structural Patch Decom-position Based Multi-exposure Image Fusion), 将图像块分解为信号强度、信号结构、平均强度这3个独立成分, 然后依据块强度和曝光度处理各成分, 最后将各成分合并以恢复融合块.Li等[26, 27]提出MESPD-MEF(Multi-scale Edge-Preserving Structural Patch Decomposition Based Multi-exposure Fusion), 将多尺度分析和边缘保留因子引入结构块分解中, 实现较好的细节复原.Ulucan等[28]提出PAS-MEF, 联合主成分分析、自适应良好曝光度和显著性构造融合权重, 并利用金字塔分解实现多尺度融合.上述方法在一定程度上融合多曝光信息以提高图像的整体感知质量, 但受限于手工特征提取模式, 难以在不同场景中产生鲁棒的融合结果.
近年来, 深度学习在各类图像处理任务中成功应用, 因此许多基于学习的多曝光融合方法也相继出现.一般而言, 基于深度学习的多曝光融合可分为有监督学习的方式和无监督学习的方式.
有监督学习参考多曝光融合图像作为标签数据以训练一个端到端融合网络.为了获取高质量的标签, 研究者通常通过主观评价或客观评价, 从多种融合算法得到的候选融合图像中挑选具有相对较高质量的结果作为参考融合图像.Xu等[29]提出MEF-GAN(Multi-exposure Image Fusion via Generative Ad-versarial Networks), 利用自注意力机制实现全局特征依赖建模.Deng等[30]设计CF-Net(Deep Coupled Feedback Network), 同时实现多曝光融合与超分辨率.Liu等[31]提出HoLoCo, 引入全局损失和局部对比损失, 提高融合图像在暗区域和亮区域的细节和色彩质量.尽管有监督学习可在标签数据的驱动下实现较优的融合性能, 但其融合上限取决于标签数据的质量.此外, 获取大量标签数据通常耗时耗力, 并且容易受主客观评价方法偏好的影响, 因此无监督学习更具实用价值和现实意义.
无监督学习在无需标签数据的前提下, 通过挖掘输入的多曝光图像内在的互补信息以实现高质量融合.Prabhakar等[32]提出DeepFuse, 利用Percep-tual Quality Assessment of Multi-exposure Fused Images[33]构造损失函数, 实现网络的可靠训练.Ma等[34]提出MEF-Net(Fast Multi-exposure Image Fusion Method), 也利用该指标作为损失函数, 并设计深度引导学习框架, 实现快速融合.Qu等[35]提出TransMEF, 联合卷积神经网络与Transformer, 兼顾局部信息与全局信息, 并设计3个依据多曝光融合特点而构建的自监督重建任务, 使网络学习多曝光融合所需的特征.Zheng等[36]提出FFMEF, 利用空间自适应滤波器构建融合网络, 并设计GIF(Gradient-Driven Image Fidelity Loss).Peng等[37]提出CurveMEF(Curve Embedding Network for Multi-exposure Image Fusion), 将曝光融合估计曲线作为物理先验约束嵌入网络中, 自适应调整过曝光区域和欠曝光区域的像素分布, 实现高效融合.Xu等[38]提出U2Fusion, 利用持续学习实现多类型的图像融合.Zhang等[39]提出PMGI(Fast Unified Image Fusion Network Based on Proportional Maintenance of Gradient and Intensity), 将各类图像融合问题统一为源图像的梯度和强度比例保持问题.Yang等[40]提出MEF-SFI(Multi-exposure Image Fusion via the Spatial-Frequency Integration Framework), 结合空域与频域学习, 探索双域内的曝光信息提取以及双域间的曝光信息交互, 实现较优的融合效果.Xu等[41]提出URFusion(Unsupervised Unified Degra- dation-Robust Image Fusion Network), 包含多阶段学习, 可用于多类图像融合任务.受到生成模型的启发, Yi等[42]提出Diff-IF(Diffusion Model for Multi-modality Image Fusion with Fusion Knowledge Prior), 旨在恢复细致的纹理.
相比传统方法, 基于深度学习的多曝光融合方法可实现更优的融合性能, 其中无监督学习凭借其取消对标签数据的依赖, 可更好地泛化到未见场景, 并且更具现实价值.
但值得注意的是, 上述方法均是针对二维图像而设计的, 如图1(a)所示, 难以高效处理四维光场图像.尽管逐视图的处理机制可将二维图像融合方法应用于光场数据(见图1(b)), 但这不可避免地忽略光场角度维信息, 难以实现高效且高质量的光场图像融合.因此, 需深入探索直接面向四维光场数据的多曝光融合方法, 如图1(c)所示.
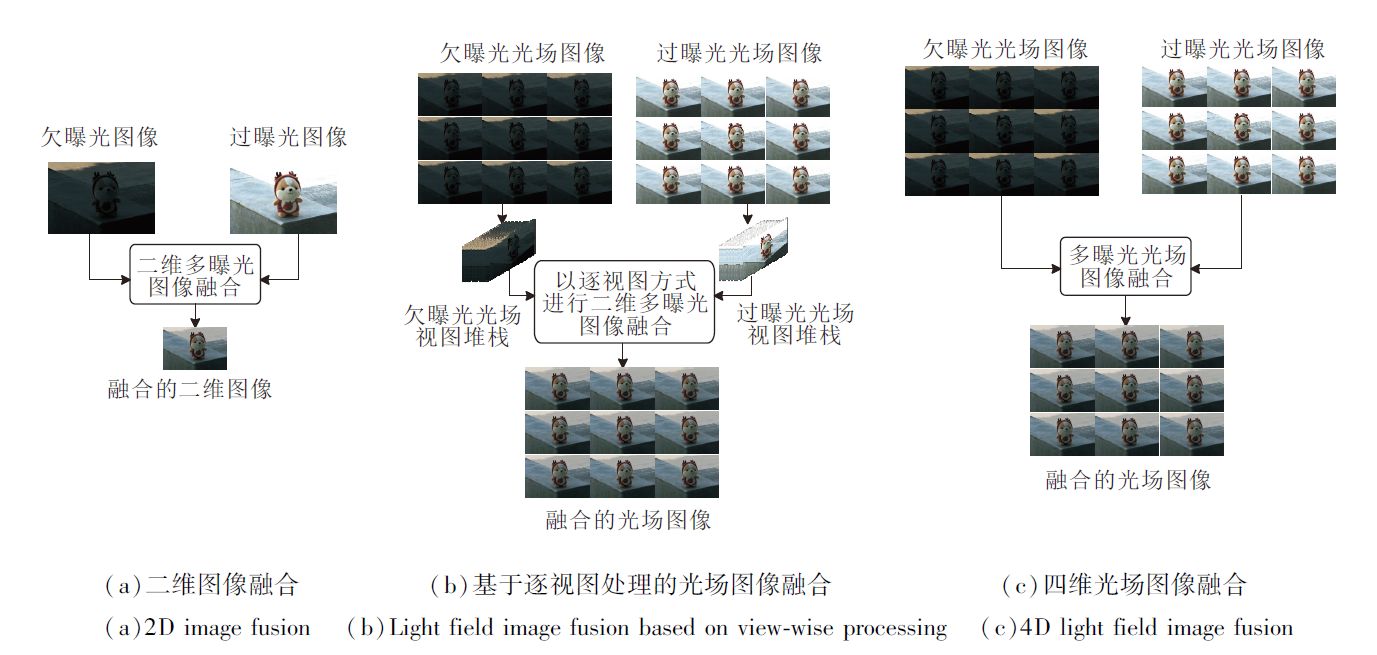 | 图1 多曝光二维/光场图像融合示意图Fig.1 Schematic diagram of multi-exposure 2D / light field image fusion |
早期光场描述为七维全光函数, 即将场景中的光线描述为三维位置、二维角度、一维波长和一维时间的函数, 但由于全光数据的高维特性, 获取完整的全光函数极具挑战性.将波长记录在颜色通道及将时间看作视频帧, 并假设光线在传播中辐射强度沿传播直线保持不变, 七维全光函数可降维成四维光场, 通常表示为双平面模型(如图2所示).
 | 图2 光场成像及子孔径图像表示示意图Fig. 2 Schematic diagram of light field imaging and sub-aperture image representation |
在该模型下, 光线可看作在角度平面和空间平面中传播.特别地, 将角度平面视作一组规则排列的相机, 成像平面表示为空间平面, 则光场可视作子孔径图像阵列.每幅子孔径图像反映单一视点下对场景的观测, 各子孔径图像之间的差异反映光场角度信息, 即视差结构.
目前, 获取光场数据可通过相机阵列、时序单相机移动、基于微透镜阵列的空间复用等方式.考虑到相机阵列造价昂贵且移动不便, 时序单相机移动较难捕获动态场景且采集耗时, 基于微透镜阵列的空间复用(即光场相机成像)成为主流方式, 本文主要利用该方式获取光场数据, 并以此实现多曝光光场图像融合.
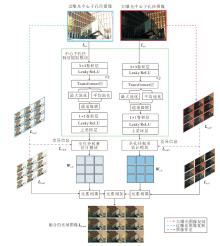
本文提出基于全孔径估计的轻量化无监督多曝光光场图像融合方法(MELFF-FAE), 整体框架如图3所示.
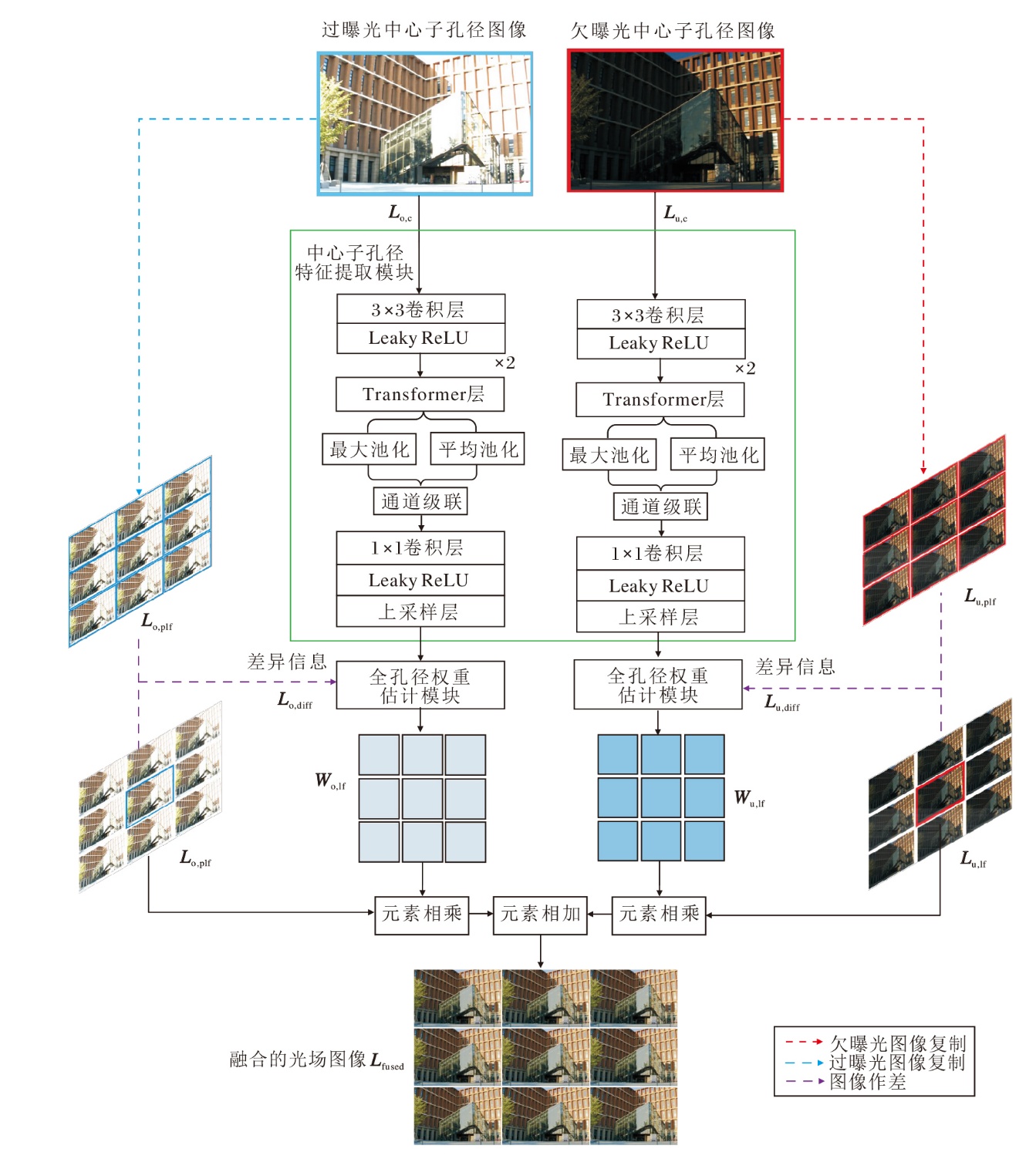 | 图3 MELFF-FAE整体框架图Fig.3 Overall architecture of MELFF-FAE |
MELFF-FAE主要包含两个核心模块:中心子孔径特征提取模块和全孔径权重估计模块, 前者旨在提取大部分空间特征的同时降低计算负担, 后者挖掘光场视图间差异, 推断角度一致的全光场融合权重.
考虑到光场相机的窄基线特性导致的不同子孔径图像间的相似度较高, 即视图间存在较大冗余, 首先选取中心子孔径图像, 提取代表性的场景信息.对于两个不同曝光的输入, 构建具有相同结构的中心子孔径特征提取模块, 分别提取曝光特征.为了有效建模局部特征依赖与全局特征依赖, 联合局部卷积与全局Transformer进行特征提取.
然后, 设计简单有效的全孔径权重估计模块, 生成全光场融合权重, 其核心在于利用边界子孔径图像与中心子孔径图像之间的差异变化估计光场中每个子孔径图像对应的像素级融合权重图.
最后, 将针对欠曝光光场图像及过曝光光场图像的融合权重图与对应曝光光场图像相乘并相加, 得到融合后的光场图像.
MELFF-FAE无需对完整光场视图执行特征提取, 但同时也考虑视图间关系, 因此能以较小的计算代价生成具有较高空间-角度质量一致性的融合光场图像, 并促进后续光场应用, 如深度估计等.需要指出的是, 完整方法的训练无需标签数据进行监督, 仅通过挖掘融合结果与源输入光场图像之间的内容关系以实现有效训练.
现有多曝光光场图像融合方法多是将完整光场数据作为网络输入以同时探索不同曝光以及不同光场子视图之间的互补关系, 进而实现有效的曝光融合, 但这通常会带来较大的计算复杂度[43].考虑到光场视图间冗余, 即不同子视图间内容极为相似, 为了提高计算效率并避免过多的信息丢失, 本文选取包含绝大多数空间信息的中心子孔径图像作为输入, 从而大幅降低计算负担.对于欠曝光中心子孔径图像和过曝光中心子孔径图像, 构造两个具有相同结构的中心子孔径特征提取模块, 分别实现特征提取.
首先, 将中心子孔径图像馈送至2个由3× 3卷积和Leaky ReLU激活函数组成的卷积层中提取局部特征.为了在建模局部特征的同时兼顾全局特征提取以提高特征表达, 建立长程特征依赖, 将经过3× 3卷积层得到的局部特征送入Transformer层[44], 进一步进行特征提取操作.Transformer层包括一个通道自注意力机制以隐式探索全局特征相关性, 以及一个由1× 1卷积和3× 3深度卷积组成的前馈网络.在前馈网络中引入3× 3深度卷积可隐式实现位置编码, 避免丢失局部特征模式.提取的初始特征为:
Fk, init=fEnc(Lk, c)∈ RH× W× C,
其中, fEnc(· )表示由3× 3卷积和Transformer构成的特征提取器, Lk, c表示中心子孔径图像, kÎ {u, o}分别表示欠曝光图像和过曝光图像, H× W表示光场图像的空间分辨率, 等价于每幅子孔径图像的分辨率, C表示特征通道数.
然后, 将提取的初始特征分别进行平均池化和最大池化, 获取更紧致的特征表示.将池化得到的两组特征在通道维度级联, 再利用1× 1卷积及Leaky ReLU激活函数执行聚合操作.
最后, 将聚合后的特征进行双线性上采样, 恢复空间分辨率, 获得包含丰富光场空间信息的特征.最终提取的中心子孔径特征为:
Fk, c=
Up(Conv1× 1([Avg(Fk, init), Max(Fk, init)]))∈ RH× W× C,
其中, [· , · ]表示级联操作, Avg(· )表示平均池化, Max(· )表示最大池化, Conv1× 1(· )表示带有Leaky ReLU激活函数的1× 1卷积层, Up(· )表示上采样, 由双线性插值实现.
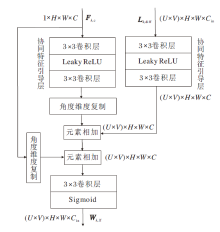
为了获取完整光场的融合权重以保证融合结果具有良好的角度一致性, 设计全孔径权重估计模块, 结构如图4所示.
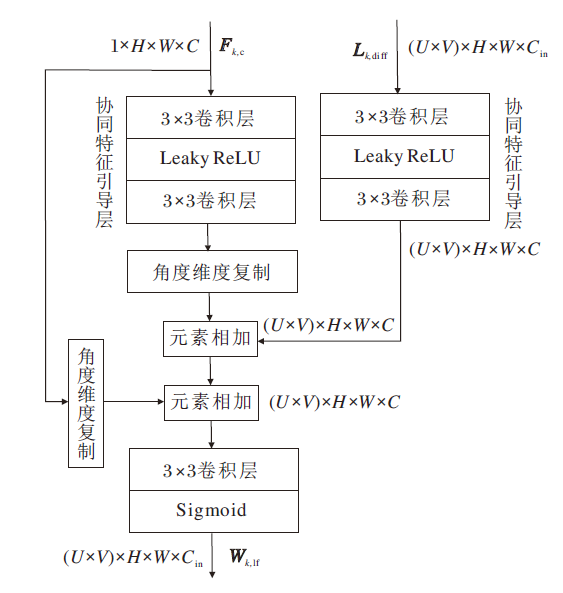 | 图4 全孔径权重估计模块结构图Fig.4 Architecture of full-aperture weight estimation module |
全孔径权重估计模块从中心子孔径特征及边界子孔径图像与中心子孔径图像之间的视点差异变化中推断每幅子孔径图像对应的像素级融合权重图, 如图3中的红色虚线或蓝色虚线所示.首先采用简单且容易实现的复制操作, 从中心子孔径图像中构建无视差结构的伪光场子孔径图像阵, 表示为Lk, plf (kÎ {u, o}分别表示欠曝光图像和过曝光图像).然后, 将原始光场图像Lk, lf与得到的伪光场子孔径图像阵列Lk, plf进行像素级作差, 得到差异变化图:
Lk, diff=Abs(Lk, lf-Lk, plf)∈
其中, Abs(· )表示取绝对值操作, Lk, lf表示原始光场图像, U× V表示光场图像的角度分辨率, H× W表示空间分辨率, Cin表示光场图像的通道值, 如对于亮度通道值为1.
由于差异变化图Lk, diff反映光场中不同子孔径图像之间的视差变化, 可与中心子孔径特征Fk, c联合, 生成全光场融合权重.考虑到Lk, diff仍为低维像素信息, 而Fk, c为高维特征信息, 二者存在信息差异, 因此构建协同特征引导层, 有效融合Lk, diff和Fk, c, 准确估计融合权重.该协同特征引导层由顺序连接的3× 3卷积、Leaky ReLU激活函数、3× 3卷积构成.一方面, Lk, diff可借助协同特征引导层中的卷积操作将差异变化信息映射至高维特征空间, 便于后续与Fk, c进行融合.另一方面, 协同特征引导层中的卷积和激活函数的结构带来非线性优势, 可使上述两种特征能在训练过程中起到协同作用.需要指出的是, 由于Fk, c仅包含中心子孔径图像上的空间信息(见图4中特征图第1维度的值为1), 因此将其通过协同特征引导层处理后的特征复制U× V倍以匹配Lk, diff中的角度分辨率.此外, 需要注意的是, 将经过协同特征引导层处理后的差异变化特征和中心子孔径特征在特征空间中进行元素级相加后, 引入跳跃连接以补偿特征错位, Lk, diff与Fk, c融合后的光场特征为:
$\begin{aligned} \boldsymbol{F}_{k, \mathrm{lf}}= & \left(f_{\mathrm{G}, \mathrm{diff}}\left(\boldsymbol{L}_{k, \mathrm{diff}}\right) \oplus f_{\mathrm{G}, c}\left(\boldsymbol{F}_{k, \mathrm{c}}\right)\right) \oplus \boldsymbol{F}_{k, \mathrm{c}} \in \\ & \mathbf{R}^{(U \times V) \times H \times W \times C}, \end{aligned}$
其中, fG, diff(· )表示处理Lk, diff的协同特征引导层, fG, c(· )表示处理Fk, c的协同特征引导层, 二者区别在于输入卷积层的通道数不同, ⊕表示元素级相加.
然后, 利用单层1× 1卷积及Sigmoid激活函数, 将光场特征Fk, lf转换为全光场融合权重:
Wk, lf=Sigmoid(Conv(Fk, lf))∈ R(U× V)× H× W× C,
其中, Conv(· )表示单层1× 1卷积, Sigmoid(· )表示Sigmoid激活函数.
最后, 将输入的欠曝光光场图像及过曝光光场图像分别与对应的融合权重相乘, 并将相乘结果相加, 得到最终融合的光场图像:
Lfused=Wu, lf☉Lu, lf+Wo, lf☉Lo, lf∈ R(U× V)× H× W× C,
其中☉表示元素级相乘.
与现有的多曝光光场图像融合方法使用的损失函数一致[43], 本文的损失函数主要包含两个部分:融合损失和角度一致性损失.
融合损失包含4种多曝光融合中常用的损失函数, 即多曝光结构相似性损失
Lfuse=Lmefssim+Lgrad+α Lpixel+β Lssim,
其中, α 、 β 表示平衡不同损失项权重系数, 设置与文献[43]一致, α =0.1, β =0.01.
在融合损失当中, 像素损失和结构相似性损失主要保证融合结果不偏离输入的源光场图像的基本内容, 梯度损失主要用于增强细节信息的恢复.
此外, 为了保证融合结果的角度一致性, 还采用文献[43]中提出的角度一致性损失Lang.该损失首先取出欠曝光中心子孔径图像和过曝光中心子孔径图像, 然后将其与对应光场图像中各个视点上的子孔径图像作差, 获取完整光场的视差变化图.最后, 对欠曝光的视差变化图和过曝光的视差变化图求最大值, 得到标签.因此, 对网络输出的融合光场图像也进行相同处理, 可衡量融合光场图像的视差变化图与标签之间的L1距离.
最终, 总损失函数如下所示:
Ltotal=Lfuse+Lang.
实验采用PyTorch深度学习框架实现.实验环境配置如下:12th Gen Intel(R) Core(TM) i7-12700 CPU @2.10 GHz、16 GB RAM和NVIDIA RTX 3090 GPU.本文方法涉及的网络参数使用AdamW(Adaptive Moment Estimation with Weight Decay)优化器进行优化.初始学习率设为2× 10-4, 在每轮训练后以指数衰减方式进行调整, 衰减率为0.95.批尺寸设为1.
在具体训练过程中, 将多曝光光场图像裁剪为一系列角度分辨率为7× 7、空间分辨率为64× 64的光场图像块, 作为网络输入进行训练.MELFF-FAE仅对源图像的亮度(Y)通道进行处理, 而对色度通道(Cb和Cr)采用简单的基于像素加权求和的方式.
在文献[43]提供的多曝光光场数据集上进行实验.该数据集包含200组场景, 100组场景用于训练, 50组场景用于验证, 剩余50组场景用于测试.训练场景和测试场景互不重叠.每个场景中包含一幅欠曝光光场图像和一幅过曝光光场图像, 二者之间的曝光值间隔为4, 目的是为了尽可能覆盖真实世界场景的大动态范围.
为了验证MELFF-FAE性能, 与现有的11种代表性多曝光融合方法进行全面对比, 对比方法如下.1)传统方法:GFF[22]、DSIFT[23]、文献[24]方法、PAS-MEF[28].2)基于深度学习的方法:DeepFuse[32]、TransMEF[35]、FFMEF[36]、U2Fusion[38]、PMGI[39]、MEF- SFI[40]、URFusion[41].传统方法不涉及网络训练.在基于深度学习的方法中, 除了TransMEF在自然场景中进行自监督训练以外, 其余方法均在本文方法采用的多曝光光场数据集上重新训练, 以保证对比结果的公平性和可靠性.
3.2.1 定量对比
由于缺乏真值图像, 即标签融合图像, 多曝光融合任务通常采用无参考指标进行定量评估.为了避免评价偶然性, 选择如下8种客观指标[9]进行对比分析.基于图像信息论的指标NMI(Normalized Mutual Information)、QNCIE, 基于图像特征的指标AG(Average Gradient)、QAB/F、SD(Standard Division)、SF(Spatial Frequency), 基于图像结构相似度的指标MEF-SSIM, 基于人眼视觉感知的指标QCV.除了QCV以外, 其余指标值越大, 表示融合性能越优.
此外, 还采用排名策略进一步评估不同方法的性能.计算每种方法在每个指标上的结果, 对同一指标的所有结果从小到大排序, 最终获得各方法的总排名.获得的总排名越小, 表示方法综合性能越优.
各方法的定量结果对比如表1所示.表中黑体数字表示最优值, 斜体数字表示次优值.由表可看出, MELFF-FAE在SD、QCV、NMI、AG指标上排名第二, 在QNCIE指标上排名第一.进一步地, 综合不同方法在8种指标上的性能排名, MELFF-FAE取得最靠前的排名结果, 这验证MELFF-FAE具有更优的多曝光融合性能.QNCIE从信息论的角度评估融合图像质量, 其值反映融合图像的信息准确度, 这表明MELFF-FAE可较好地保留原始图像的有用信息.SD、AG指标主要反映图像的整体对比度和细节强度, 这表明MELFF-FAE生成的融合结果具有更高的亮度对比度, 并且保留更多的纹理细节.QCV指标与人眼视觉感知密切相关, 这表明MELFF-FAE可生成具有更高视觉质量的结果.
| 表1 各方法的定量结果对比 Table 1 Quantitative comparison of different methods |
3.2.2 定性对比
各方法在人物场景和建筑场景中的视觉结果如图5和图6所示.由图可观察到, 传统的多曝光融合方法, 如DSIFT、GFF等, 在融合曝光差异较大的区域时未能保持图像的全局结构一致性, 尤其在天空区域出现明显的亮暗突变区域, 如红色箭头所指区域.PAS-MEF没有产生亮暗突变问题, 但在处理极端的两种曝光输入数据时, 丢失大量互补区域的纹理细节与颜色信息.相比之下, 基于深度学习的对比方法生成的结果具有更均匀的亮度分布, 全局结构基本保持一致, 但在处理极度欠曝光区域和过曝光区域时, 效果仍欠佳.如图5所示, U2Fusion和FFMEF在树木枝干区域分别出现细节模糊和融合伪影等问题, URFusion在该区域颜色失真.如图6红框区域所示, DeepFuse、PMGI和TransMEF未能恢复墙壁低暗区域的纹理细节.另外, 虽然传统方法在该区域获得足够的亮度恢复, 但全局不均匀的光照在很大程度上降低视觉观感体验.MEF-SFI在曝光差距较大的局部区域产生绿色的颜色伪像(如图6所示).总之, MELFF-FAE可生成更高视觉质量的融合图像, 同时恢复极端曝光条件下的场景细节信息, 增强局部低暗区域的内容重现.
 | 图5 人物场景中各方法的视觉结果对比Fig. 5 Visual comparison of different methods for character scene |
 | 图6 建筑场景中各方法的视觉结果对比Fig. 6 Visual comparison of different methods for architectural scene |
3.2.3 效率对比
在计算资源受限的现实光场应用场景下, 方法运行时间及复杂度是衡量多曝光光场融合方法潜在应用价值的关键指标之一.因此, 本节对比不同方法的计算效率.所有对比方法均在相同的实验环境下进行对比以保证结果的公平性.
实验环境配置为12th Gen Intel(R) Core(TM) i7-12700 CPU @2.10 GHz、16 GB RAM和NVIDIA RTX 3090 GPU.
不同方法的运行时间和参数量对比如表2所示.表中运行时间是指利用两幅不同曝光的光场图像重建角度分辨率为7× 7、空间分辨率为400× 600的光场图像所需时间.由表可看到, MELFF-FAE参数量相对较少, 在运行时间上显著低于所有对比方法.这归因于全孔径权重估计模块仅利用光场中心子孔径图像的空间信息以及不同子孔径图像的差异信息即可生成全光场的融合权重.
| 表2 各方法的运行时间及参数量对比 Table 2 Comparison of running time and the number of parameters for different methods |
此外, 综合表1和表2的数据可看到, MELFF-FAE法在降低运行时间的前提下, 仍获得较优的融合性能, 即实现模型效率和性能之间的良好平衡.
区别于传统二维图像, 光场图像除了包含空间信息以外, 还具有丰富的角度信息.因此, 对于多曝光光场融合任务而言, 除了评估其空间质量以外, 还需关注其角度质量, 也称角度一致性.因为光场蕴含角度信息, 光场图像可实现单帧深度估计, 因此, 本文采用现有光场深度估计方法, 评估不同融合方法在保持光场角度一致性方面的性能.共选取如下5种在定量评估上表现良好的多曝光融合方法进行对比:GFF[22]、文献[24]方法、DeepFuse[32]、TransMEF[35]、PMGI[39].各方法生成的多曝光融合光场图像中估计的深度图的视觉结果如图7所示.
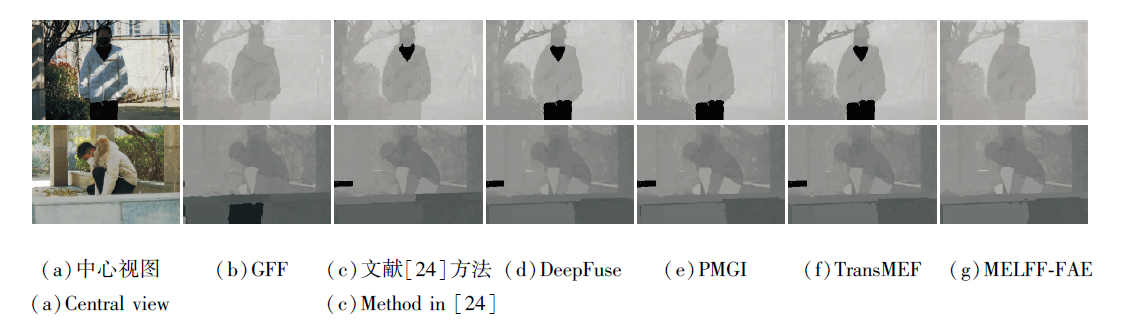 | 图7 不同方法生成的融合光场图像中估计的深度图的视觉结果对比Fig.7 Visual comparison of depth maps estimated from fused light field images generated by different methods |
由图7可看到, MELFF-FAE得到的光场深度图具有更清晰的深度边界, 包含更少的估计误差.此外, 现有的二维多曝光融合方法由于独立处理光场中每幅子孔径图像, 因此忽略角度维度的相关性, 导致深度估计结果相对较差.
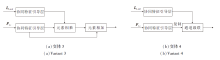
为了验证MELFF-FAE采用中心子孔径图像作为主特征提取, 并设计全孔径权重估计模块以生成全光场融合权重的思路的有效性, 设计如下4个消融变体.
1)变体1.将中心子孔径特征提取模块改为全孔径特征提取模块, 即输入端直接输入完整光场图像.
2)变体2.在输入端采用完整光场图像作为输入, 并去除全孔径权重估计模块, 其余部分保持不变.
3)变体3.在全孔径权重估计模块中, 将两类特征的相加操作改为相乘操作, 具体结构如图8(a)所示.
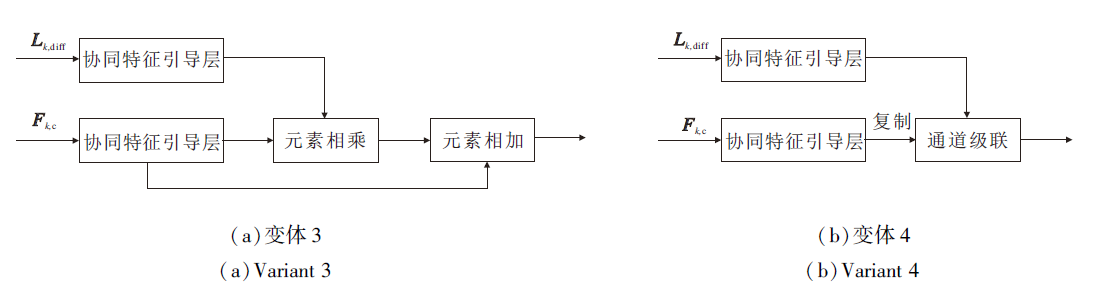 | 图8 不同变体结构图Fig.8 Architecture of different variants |
4)变体4.在全孔径权重估计模块中, 将两类特征在通道维度级联以实现融合, 具体结构如图8(b)所示.
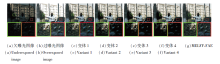
不同变体的定量对比结果如表3所示, 表中黑体数字表示最优值.不同变体的视觉结果如图9所示.
| 表3 不同变体的定量结果对比 Table 3 Quantitative comparison of different variants |
 | 图9 不同变体的视觉结果对比Fig. 9 Visual comparison of different variants |
对比表3和图9可发现, 变体1处理完整光场数据后, 可获得与MELFF-FAE接近的视觉结果, 但在一定程度上会模糊细节(见表3中最低的 AG指标), 同时会引入更高的计算复杂度(变体1的浮点计算量为56.666 G, MELFF-FAE的浮点计算量为8.543 G).
变体2 在融合过程中难以恢复有效的细节信息, 在8个指标上均低于MELFF-FAE.此外, 变体2在输入端要处理完整光场图像, 带来更大的计算负担.
变体3和变体4主要通过改变中心子孔径特征与差异信息特征的不同融合方式以验证全孔径权重估计模块中融合方式的有效性.从图9可观察到, 变体3和变体4均存在同样问题, 即难以处理局部低暗区域的信息恢复.
相比之下, MELFF-FAE中的融合方式可得到更清晰的细节和更高的对比度.表3中的定量结果也验证MELFF-FAE可得到更高质量的多曝光融合光场图像.
本文提出基于全孔径估计的轻量化无监督多曝光光场图像融合方法(MELFF-FAE).从光场子孔径数据的特性出发, 利用中心子孔径图像作为主场景信息提取的输入, 降低处理完整光场带来的巨大计算负担.此外, 设计全孔径权重估计模块, 探索边界子孔径图像与中心子孔径图像之间的差异变化, 以低复杂度的方式推断全光场的融合权重.实验表明, MELFF-FAE能在提高融合光场图像的视觉感知质量的同时, 有效降低计算复杂度.此外, 与现有代表性方法的全面对比也验证MELFF-FAE的先进性.今后将探索面向动态场景的多曝光光场融合任务, 并考虑利用生成式模型, 进一步提高融合图像在极度欠曝光或过曝光下的细节与颜色信息复原.
本文责任编委 高 隽
Recommended by Associate Editor GAO Jun
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|
| [40] |
|
| [41] |
|
| [42] |
|
| [43] |
|
| [44] |
|