{kind=link}
{kind=link}
{kind=link}
基于大语言模型增强和协同信息融合的序列推荐方法
[查龙宝1  , 黄琪
, 黄琪1 , 王明文1 , 周骏祥1 , 罗文兵1 ]
, 黄琪, 王明文, 周骏祥, 罗文兵]
|
|



作者简介:
查龙宝,硕士研究生,主要研究方向为自然语言处理、推荐系统.E-mail:zhalongbao@jxnu.edu.cn. 
王明文,博士,教授,主要研究方向为自然语言处理、信息抽取、信息检索、数据挖掘.E-mail:mwwang@jxnu.edu.cn. 
周骏祥,硕士研究生,主要研究方向为自然语言处理、推荐系统.E-mail:junxiang_zhou@163.com. 
罗文兵,博士,高级实验师,主要研究领域为自然语言处理、信息检索、知识图谱.E-mail:lwb@jxnu.edu.cn.
现有序列推荐方法未能充分挖掘项目属性语义信息且存在语义空间迁移不匹配的问题,导致对长尾物品推荐能力不足.为此,文中提出融合大模型语义增强信息和协同信息融合的序列推荐方法(Large Language Model Enhancement and Collaborative Information Fusion for Sequential Recommendation, LLM-CFSR).首先,通过属性级数据增强与对比微调技术,利用大语言模型生成细粒度语义嵌入,捕捉长尾物品的深层语义关联.然后,设计双视图融合机制,分别从语义视图与协同视图两方面对用户偏好进行联合建模.最后,引入交叉注意力机制,实现嵌入层、序列层与预测层的多层次信息融合,促进语义信息与协同信号的深度交互.在Yelp、Amazon Fashion、Amazon Beauty数据集上的实验表明,LLM-CFSR对于整体推荐性能和长尾物品推荐性能都有所提升.
About Author:
ZHA Longbao, Master student. His research interests include natural language processing and recommender systems.
WANG Mingwen, Ph.D., professor. His research interests include natural language processing, information extraction, information retrieval and data mining.
ZHOU Junxiang, Master student. His research interests include natural language processing and recommender systems.
LUO Wenbing, Ph.D., senior experimentalist. His research interests include natural language processing, information retrieval and knowledge graph.
Existing sequential recommendation methods fail to fully explore item attribute semantic information and suffer from a semantic space migration mismatch. These limitations result in inadequate recommendation capabilities of the existing methods for long-tail items. To address this issue, a method for sequential recommendation with large language model enhancement and collaborative information fusion(LLM-CFSR) is proposed in this paper. First, fine-grained semantic embeddings are generated with a large language model through attribute-level data augmentation and contrastive fine-tuning techniques to capture the deep semantic associations of long-tail items. Then, a dual-view modeling framework is designed to jointly model user preferences from both semantic and collaborative views. Finally, to promote deep interaction between semantic information and collaborative signals, a cross-attention mechanism is introduced to achieve multi-level information fusion across embedding layers, sequence layers, and prediction layers. Experimental results on Yelp, Amazon Fashion and Amazon Beauty datasets demonstrate that LLM-CFSR improves the overall recommendation performance and the long-tail item recommendation performance.
推荐系统作为信息过载时代的关键过滤机制, 能预测并呈现用户可能感兴趣的内容或物品, 同时降低用户的搜索成本.在电子商务、视频流媒体和新闻媒体等多个领域, 推荐系统不仅提供极大的便利, 还显著改善用户体验.
序列推荐作为推荐系统的一个重要研究领域, 通过对用户与物品的交互序列按时间顺序建模, 预测用户可能交互的下一个物品.该方法聚焦用户交互行为的时序性, 能反映用户长期或短期内的兴趣变化.由于用户的行为具有明显的动态变化性, 序列推荐能捕捉用户的动态偏好, 并基于用户在特定时间段内的行为为用户推荐相关物品.序列推荐的核心在于从用户的交互序列中提取偏好.传统基于协同过滤信号构建的序列方法在主流项目推荐中表现优异, 却难以准确捕捉低频物品的语义关联, 导致长尾物品推荐性能显著下降[1].
研究表明, 项目交互数量总体上遵循长尾分布, 高频交互项目仅占少数, 而大多数项目的交互频率较低, 这类项目被称为长尾项目[2].这种分布特性导致数据的稀疏性和语义信息不足, 因此对长尾项目进行推荐目前仍是一个较严峻的挑战[3].
为了应对长尾项目的难题, 现有研究考察热门项目与长尾项目之间的共现模式, 通过丰富热门项目的表征以增强长尾项目的表现.大语言模型(Large Language Models, LLM)的发展为从语义角度缓解长尾挑战提供理论基础[4].近期研究通过生成信息提示以激活ChatGPT或改进LLaMA[5]的分词方法用于序列推荐, 其中LLM2X[6]和BIGRec(Bi-step Grounding Paradigm for Recommendation)[7]采用通用大语言模型生成项目嵌入, SAID[8]和TSLRec(Practice-Friendly Two-Stage LLM-Enhanced Para-digm)[9]为微调开源大语言模型, 可较好地适应推荐任务.
尽管上述方法在序列推荐任务中表现良好, 但依然存在如下问题.1)语义表征与推荐场景的领域存在鸿沟.采用通用大模型生成的嵌入虽然包含语义信息, 但并未针对推荐领域进行优化, 即使通过微调开源大模型解决上述问题, 但仍局限于语言建模或类别预测, 忽视项目属性在推荐场景中辨识不同项目时的关键作用.2)语义空间迁移不匹配.大语言模型生成的语义嵌入处于高维、各向异性的语义空间中, 而传统协同过滤方法通常工作在低维、各向同性的向量空间中, 两者间的分布差异导致信息融合存在困难.3)嵌入分布异质性.语义嵌入主要反映物品的静态内容特征, 而协同嵌入则编码用户行为的动态交互模式.这两种信息源本质是异质的, 若未经对齐处理而直接融合, 分布差异会相互干扰, 反而可能削弱模型的表示能力, 无法实现协同效应.
为此, 本文提出基于大语言模型的语义增强和协同信息融合的序列推荐方法(Sequential Reco-mmendation with Large Language Model Enhancement and Collaborative Information Fusion, LLM-CFSR).首先, 利用对比微调策略(Contrastive Fine-Tuning, CFT)对大语言模型(采用LLaMA-2-7B)进行领域适配, 并利用属性随机掩码增强策略生成细粒度语义嵌入.然后, 构建包括语义视图和协同视图的双视图融合机制.语义视图建模模块中采用两阶段适配器, 实现大语言模型嵌入的跨域迁移, 协同视图建模模块中采用PCA(Principal Component Analysis)降维, 初始化可训练嵌入层.最后, 为了有效融合协同信号和语义信息, 引入交叉注意力机制, 提取时序模式, 并采用特征拼接和成对排序损失实现多级信号的融合.LLM-CFSR创新性地构建三重融合机制, 分别在嵌入层、序列层和预测层实现信息融合, 既保留大语言模型的语义推理能力, 又强化传统推荐模型的协同过滤特性, 有效缓解长尾推荐问题.
序列推荐旨在通过建模用户历史交互序列预测其未来偏好, 在电子商务、社交媒体等领域发挥重要作用.随着大语言模型的快速发展, 如何有效整合语义理解能力与协同过滤信号成为研究热点.
早期研究以马尔可夫决策过程为基础, 将推荐问题形式化为序列优化问题, 利用状态转移概率捕捉短期偏好.随着深度学习的发展, Hidasi等[10]提出GRU4Rec(Gated Recurrent Units for Recommen-dations), 首次将门控循环单元应用于序列推荐, 通过隐藏状态传递实现序列建模.Tang等[11]提出Caser(Convolutional Sequence Embedding Recommen-dation Model), 引入卷积神经网络, 采用水平卷积核和垂直卷积核, 分别捕获局部特征和全局模式.
近年来, 基于注意力机制的方法取得显著进展.Kang等[12]提出SASRec(Self-Attention Based Sequen-tial Model), 通过堆叠自注意力层建模长距离依赖, 在捕捉动态兴趣方面表现突出.Sun等[13]提出BERT4Rec, 扩展双向Transformer架构, 结合掩码语言模型任务, 增强上下文感知能力.这类方法虽在主流物品推荐中表现优异, 但过度依赖协同过滤信号, 难以有效表征长尾物品的语义特征, 导致推荐结果呈现明显的马太效应[14].
针对数据稀疏性问题, 自监督学习技术被引入序列推荐领域.Zhou等[15]提出S3-Rec(Self-Super-vised Learning for Sequential Recommendation), 通过物品属性与子序列的关联学习增强表示.Yao等[16]设计多任务对比学习策略, 构建序列增强视图挖掘潜在模式.然而, 现有方法在语义表征粒度与领域适配方面仍存在局限, 特别是当物品文本描述稀疏时, 难以建立有效的跨物语义关联.
上述方法主要依赖协同信号, 忽视物品的语义特征, 导致对长尾物品的推荐效果受限.为了应对长尾项目的难题, Liao等[17]考察热门项目与长尾项目之间的共现模式, 通过丰富热门商品的表征以增强长尾商品的表现.用户或项目之间的语义关系能弥补协同信号在稀疏长尾项目上的不足, 展现其解决长尾挑战的潜力[18].
随着大语言模型的突破性进展, 研究者开始探索语义理解与推荐系统的深度融合.大语言推荐模型是指引入深度学习和自然语言处理技术, 利用大语言模型对文本进行理解和生成, 提供个性化、准确和交互性强的推荐结果.大语言推荐模型通过自监督学习在大量数据上训练, 理解用户指令和上下文以增强推荐系统性能.相比传统推荐方法, 大语言模型的推荐方法在语义理解深度、上下文感知广度和外部知识融合度上具有优势, 能提供更优的解释性和交互性, 并具备强大的迁移学习能力[19].
基于大语言模型的推荐方法主要分为生成式推荐与特征增强式推荐.生成式推荐直接利用LLMs的指令跟随能力实现推荐生成.Du等[20]提出EMKD(Ensemble Modeling with Contrastive Knowle-dge Distillation for Sequential Recommendation), 通过对话式交互提取用户偏好, 但推理延迟较长、可解释性较差.Bao等[21]提出TALLRec, 通过两阶段微调对齐LLMs与推荐任务, 但其生成结果受限于模型开放域的知识可靠性.特征增强式推荐更关注LLMs的语义表征迁移.Hu等[8]提出SAID, 通过属性预测任务微调大语言模型.Harte等[6]提出LLM2X, 提取CLIP文本编码作为物品嵌入, 但通用语义空间与推荐任务存在领域鸿沟.
最新研究尝试融合多模态信息, 解决语义信号与协同过滤的异构空间对齐问题.Liu等[22]提出LLMEmb(LLM-Based Item Embedding Generator), 探索大语言模型作为嵌入生成器及其在序列推荐中的应用.LLMEmb通过监督对比微调缩小通用大语言模型与推荐任务的语义差距, 并设计推荐适应训练阶段, 将高维语义嵌入注入协同过滤信号.但是, LLMEmb主要聚焦于生成高质量的物品嵌入以替代传统嵌入层, 未建立深度交互机制并有效融合协同过滤信号与语义信息.
顺序推荐的目标是根据用户的交互记录, 推荐下一个用户可能互动的项目.定义用户集合U={u1, …, ui, …, u|U|}, 项目集合V={v1, …, vi, …, v|V|}, 其中, |U|表示用户数量, |V|表示项目数量.每位用户都有一个交互序列, 按时间顺序排列互动项目, 记为
Su={
其中nu表示用户u的交互次数.为了简单起见, 本文在下文中省略上标u, 因此序列推荐问题定义如下:
arg
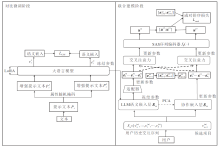
本文提出基于大语言模型增强和协同信息融合的序列推荐方法(LLM-CFSR), 整体框架如图1所示.LLM-CFSR包含3个核心模块:基于对比学习的语义增强模块、双视图联合建模模块、层次化融合预测模块.各模块协同工作流程如下.首先, 为了获取增强的语义信息, 采用微调的大语言模型LLaMA-2-7B编码用户历史交互文本和物品属性.然后, 设计双视图融合机制, 增强语义信息和协同信息, 充分结合两者优势.最后, 引入交叉注意力机制, 实现多层次信息融合.
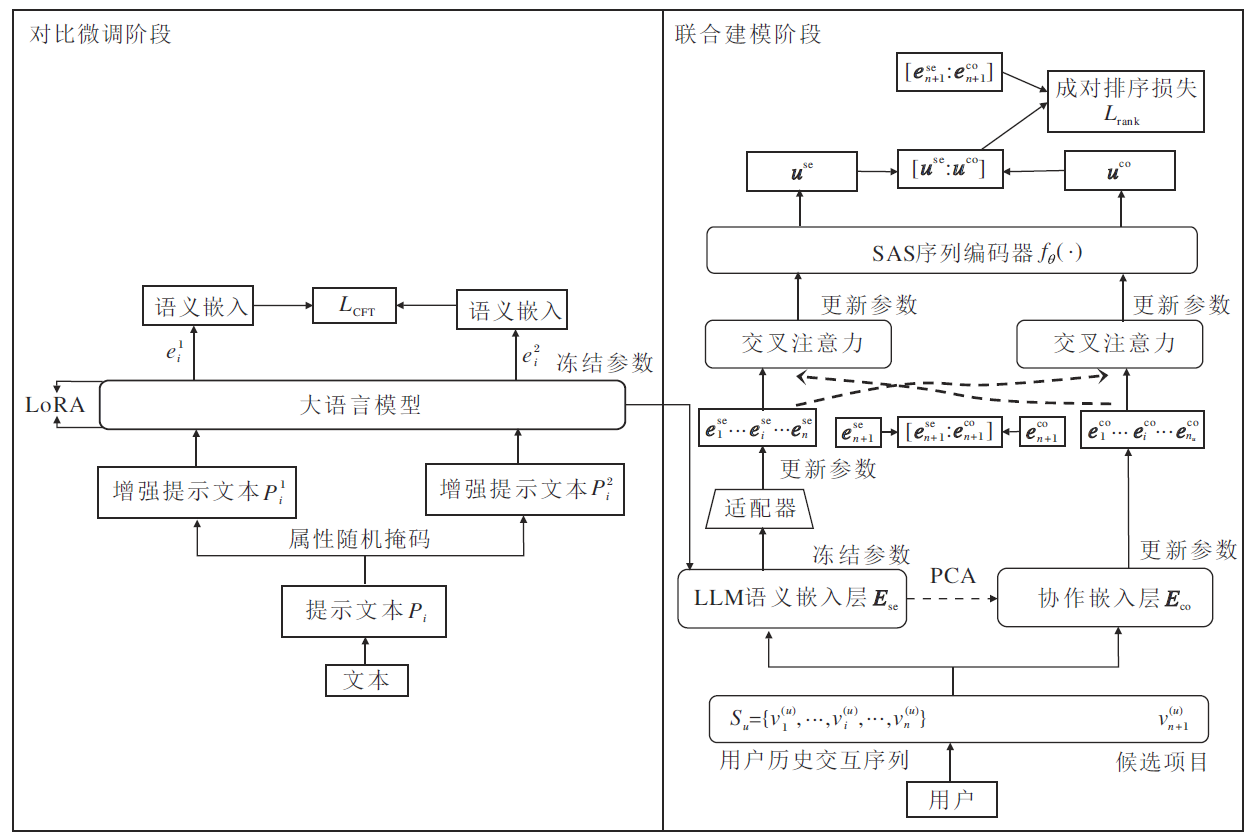 | 图1 LLM-CFSR总体框架Fig.1 Overall architecture of LLM-CFSR |
对比微调阶段是LLM-CFSR实现语义增强的核心环节, 核心思路是通过属性对比使大语言模型能够区分不同物品, 通过对比学习机制将大语言模型的通用语义理解能力迁移至推荐领域.如图1所示, 该阶段首先对大语言模型进行领域适配的对比微调, 然后生成具有推荐感知能力的物品语义嵌入.本文采用LoRA(Low-Rank Adaptation)对大语言模型进行轻量化微调, 冻结原始模型参数, 仅更新秩分解矩阵.相比传统大语言模型直接生成嵌入的方式, 该方式引入细粒度的属性级数据增强和对比学习, 有效提升方法对物品属性的敏感度.
2.3.1 提示文本的构建与增强策略
为了引导大语言模型从语义视角理解物品, 基于物品属性(如名称、类别等)构建文本提示.提示文本通过领域特定指令与属性结构化组合, 激活大语言模型的语义编码能力.
例如, 对于时尚商品推荐的提示模板指令I如下.
该时尚单品具有以下属性:名称为〈TITLE〉; 品牌是〈BRAND〉; 类别是〈CATEGORY〉; 评分是〈RATING〉; 价格是〈PRICE〉; 特征是〈FEATURE〉; 描述是〈DESCRIPTION〉.
其中, 每个属性以“ 属性名称是〈具体值〉” 格式结构化呈现.物品i的完整提示为:
Pi=[I, A1, A2, …, AK],
其中, Aj表示单个属性的原子提示, [· ]表示字符串拼接操作, K表示属性数量.
2.3.2 属性随机掩码增强策略
为了强化大语言模型对物品属性的细粒度区分能力, 本文提出属性随机掩码增强策略, 为每个物品生成两组正样本提示.对于一个大小为B的批次, 每个物品的2个增强提示文本构成正样本对, 该批次中其余2(B-1)个增强提示文本均被视为负样本.具体而言, 以概率r(r=0.2)随机丢弃物品原始提示中的部分属性, 以同一个公式随机生成两个不同的增强文本提示:
$\begin{array}{l} \widehat{P}_{i}^{1}=\left[I, \text { RandomDrop }\left(\left\{A_{j}\right\}_{j=1}^{K}, r\right)\right], \\ \widehat{P}_{i}^{2}=\left[I, \text { RandomDrop }\left(\left\{A_{j}\right\}_{j=1}^{K}, r\right)\right], \end{array}$
其中RandomDrop(· )表示随机丢弃物品属性操作.通过该过程生成的两组提示作为同一物品的正样本对, 驱动大语言模型学习属性变化下的不变语义特征.
2.3.3 对比微调
受近期大语言模型在文本嵌入生成领域的研究进展, 本文将大语言模型输出的嵌入作为物品的语义表示.具体而言, 将增强后的提示
$L_{\mathrm{CL}}^{1}=-\frac{1}{B} \sum_{i=1}^{B} \ln \left(\frac{\exp \left(\frac{\operatorname{sim}\left(\hat{e}_{i}^{1}, \hat{e}_{i}^{2}\right)}{\tau}\right)}{\sum_{k=1}^{B} \Pi_{[i \neq k]} \exp \left(\frac{\operatorname{sim}\left(\hat{e}_{i}^{1}, \hat{e}_{k}^{2}\right)}{\tau}\right)}\right), $
其中, B表示批量大小, sim(· , · )表示内积相似度函数, τ 表示可训练温度系数.通过交换正样本对顺序计算另一侧损失
LCFT=
CFT损失函数通过拉近相同物品不同增强提示的嵌入距离以及远离不同物品的嵌入距离, 使大语言模型生成更具判别性的语义表示, 从而弥合通用语义与推荐场景的鸿沟.通过上述对比微调过程, 大语言模型能从物品属性中提取更适用于推荐任务的语义特征, 有助于后续融合协同信号.
CFT伪代码如下所示.
算法1 CFT
输入 物品文本描述集合D={di
学习率η , LoRA秩R, 温度系数τ ,
最大迭代次数max_step
输出 物品语义嵌入集合E={ei
1.提示词构建:对每个物品di∈ D, 基于物品属性构建结构化提示词Pi , 应用属性随机掩码, 生成2个增强提示词
2.模型初始化:加载预训练大语言模型及分词器, 配置LoRA适配器, 封装模型.
3.准备训练数据:构建正负样本对, 分词处理并生成批数据.
4.对比训练:
初始化优化器
for step=1 to max_step do
对采样批次内B个物品
for 每个物品i do
通过大语言模型进行前向传播, 得到增强提
示词的嵌入
end for
计算对比损失LCL
反向传播并更新LoRA参数
end for
5.语义嵌入生成:对于每个物品提示词pi, 输入大语言模型, 得到最终语义嵌入ei.
end for
return微调后的大语言模型及语义嵌入集合E
传统序列推荐模型擅长捕捉协同信号, 对热门物品推荐效果较优, 但因缺乏语义信息, 在长尾物品上表现欠佳.因此本文在双视图上对用户偏好建模, 同时覆盖所有物品, 并提出双视图融合机制, 充分结合两者优势.
双视图融合预测模块包含两个分支.1)语义视图建模模块, 旨在从用户交互序列中提取语义信息.首先利用对比微调阶段训练完成的大语言模型在物品嵌入的语义嵌入层编码物品, 然后设计适配器, 用于维度适配和空间变换.输出的物品嵌入序列经交叉注意力融合后, 输入序列编码器, 生成语义视图下的用户表示.2)协同视图建模模块, 通过协同嵌入层将交互序列转换为嵌入序列, 经交叉注意力和序列编码器后获取协同视图下的用户偏好.双视图融合预测模块最终融合双视图的用户表示以生成最终推荐.
2.4.1 语义视图建模模块
通常, 物品的属性和描述蕴含丰富语义信息, 为了利用大语言模型强大的语义理解能力, 采用对比微调阶段训练完成的大语言模型对物品生成增强的语义嵌入.同时, 为了避免大语言模型的推理负担, 缓存其生成的嵌入供后续使用.令Ese∈
其中, W
Sse=[
类似常规序列推荐模型, 采用序列编码器fθ (· )(SA-SRec的自注意力层)生成语义视图下的用户偏好表示:
use=fθ (Sse)∈ Rd× 1,
其中θ 表示序列编码器参数.
2.4.2 协同视图建模模块
为了利用协同信息, 采用可训练的物品嵌入层Eco∈ R|V|× d, 通过交互数据监督更新.从Eco中提取对应行, 得到物品嵌入序列
Sco=[
输入序列编码器, 生成协同视图用户偏好:
uco=fθ (Sco).
需要注意的是, 为了共享序列模式并提高效率, 本文的双视图共享同一序列编码器fθ (· ).此外, 双视图的嵌入层处于非平衡训练阶段, 如果一方为预训练, 另一方为随机初始化, 可能导致优化困难.
为此, 为了建立语义视图与协同视图的关联基础, 本文提出基于PCA的协同嵌入初始化策略, 将语义嵌入Ese经PCA降维后的结果初始化, 得到协同嵌入Eco.对给定语义嵌入矩阵Ese, 通过如下步骤实现降维投影.首先, 对Ese进行均值中心化处理, 得到中心化后的语义嵌入矩阵:
其中1∈ R|V|为全1向量.再构建特征协方差矩阵:
C=
求解协方差矩阵的特征问题:
Cwi=λ iwi, i=1, 2, …, c,
其中, λ i表示降序排列的特征值, wi表示对应的特征向量.选取前d个主成分构建投影矩阵:
Wpca=[w1, w2, …, wd]∈
最后将高维语义嵌入投影至低维协同空间:
Eco=
该设计通过保留最大方差的线性投影, 将大语言模型生成的高维语义嵌入(dllm=4 096)压缩至推荐任务适配的低维空间(d=64), 有效缓解维度不匹配问题.
2. 4.3 语义视图和协同视图融合机制
有效融合语义视图与协同视图对吸收两者优势至关重要.然而, 直接合并双视图用户表示可能忽略物品序列间的细微关联.因此, 双视图包含两层融合机制:序列级融合与对数级融合.前者旨在隐式捕捉双视图物品序列的相互关系, 后者显式结合推荐能力.
具体而言, 序列级融合采用交叉注意力机制, 以语义视图为查询(Query), 协同视图为键(Key)和值(Value).设
Q=SseWQ, K=ScoWK, V=ScoWV,
其中WQ、WK、WV表示权重矩阵, 则交互后的协同嵌入序列为:
$\widehat{\boldsymbol{S}}^{\mathrm{co}}=\operatorname{Softmax}\left(\frac{\boldsymbol{Q} \boldsymbol{K}^{\mathrm{T}}}{\sqrt{d}}\right) \boldsymbol{V} .$
同理可得对应的语义嵌入序列
对数级融合则通过拼接双视图用户和物品嵌入, 计算推荐分数:
P(
其中:表示向量拼接操作.基于此分数, 采用成对排序损失训练框架:
$ \begin{aligned} L_{\text {Rank }}= & -\sum_{u \in U} \sum_{k=1}^{n_{u}}\left(\operatorname { l n } \left(\sigma \left(P\left(v_{k+1}^{+} \mid v_{1: k}\right)-\right.\right.\right. \\ & \left.\left.P\left(v_{k+1}^{-} \mid v_{1: k}\right)\right)\right), \end{aligned} $
其中,
相比传统融合方法, 交叉注意力机制通过可学习的注意力权重实现动态特征交互, 并且采用非对称的Query-Key设计, 有效保持语义主序.
本文选择Amazon Fashion[1]、Yelp[23]、Amazon Beauty[24]数据集, 可涵盖不同领域和规模.
Yelp数据集包含2013~2023年间美国主要城市的商业场所用户评价, 本文提取餐厅的名称、类别、价格范围、位置等属性作为物品描述.Amazon Fashion、Amazon Beauty数据集来自亚马逊电商平台, 分别包含用户对时尚和美妆产品的交互记录, 本文使用产品的标题、品牌、类别、描述等属性作为物品文本信息.数据集的统计信息如表1所示.
| 表1 实验数据集 Table 1 Experimental datasets |
实验主要采用LLaMA-2-7B作为基础大语言模型进行微调, 生成物品的语义嵌入, 并额外引入Qwen2.5-7B进行对比实验, 验证LLM-CFSR在不同大语言模型骨架下的泛化性.语义嵌入维度为4 096, 通过适配器网络投影至64维空间, 与协同嵌入维度保持一致.序列编码器采用SASRec架构, 隐藏层维度为64, 多头注意力头数为4.
实验时在所有数据集上过滤无效用户/物品.对于用户, 去除交互序列长度少于3的用户, 仅保留至少有3次交互的用户及其对应物品.对于物品, 确保其文本属性(如名称、类别)描述非空, 排除缺失属性的物品.按交互时间顺序分割数据集, 采用“ 最近一次交互为测试集, 倒数第二次为验证集, 其余为训练集” 的策略.例如:用户交互序列为[v1, v2, v3, v4], 则训练集为[v1, v2], 验证集为[v3], 测试集为[v4].训练集、验证集、测试集划分比例为8:1:1, 确保时间顺序的合理性和模型的泛化性.过滤后的数据集统计信息如表2所示, 相比原始数据集, 过滤后数据集的用户数、物品数略有减少, 平均序列长度有所增加.
| 表2 过滤后的实验数据集 Table 2 Filtered experimental datasets |
在配备Intel Core i7-11700 CPU 和 搭载24 GB显存的NVIDIA GeForce RTX 3090显卡 的服务器上进行实验.
评估指标包括H@10和N@10.H@10衡量推荐列表前10项中包含用户真实交互物品的比例, 反映推荐召回能力.N@10评估推荐列表中真实物品的排序合理性, 值越高表明排序越精准.
为了全面评估LLM-CFSR的性能, 选择如下传统长尾推荐方法和大语言模型增强的序列推荐方法作为基线方法.
1)传统长尾序列推荐方法.
(1)CITIES(Contextual Inference of Tail-Item Em-beddings)[25].通过上下文推断机制增强长尾物品表示.
(2)MELT(Mutual Enhancement of Long-Tailed User and Item)[26].设计双向分支框架, 同时增强长尾用户和物品.
2)大语言模型增强的序列推荐方法.
(1)LLM2X[6].通过大语言模型提取物品文本特征, 经简单降维后直接作为嵌入层输入.
(2)BIGRec[7].通过双向生成式预训练生成物品提示, 增强物品表征.
(3)SAID[8].通过大语言模型语义嵌入初始化推荐模型的物品嵌入层, 并在训练中微调.
(4)TSLRec[9].采用两阶段框架, 先通过大语言模型生成语义提示, 再通过传统序列模型捕捉时序依赖.
(5)LLM-ESR(Large Language Models Enhance-ment Framework for Sequential Recommendation)[27].融合语义信息与协同信号, 缓解传统推荐系统在长尾用户和物品上的性能缺陷.
各方法在3个数据集上的性能对比如表3~表5所示.在表中, Overall表示整体性能, Tail表示长尾物品推荐性能, LLM-CFSR(Qwen)表示基于Qwen-2.5-7B骨架, LLM-CFSR(LLaMA)表示基于LLaMA-2-7B骨架, 黑体数字表示最优值, 斜体数字表示次优值.由表可见, 在Yelp数据集上, LLM-CFSR(LLaMA)的长尾物品推荐性能提升显著, 对低流行度物品的推荐能力显著优于LLM-ESR, 由此验证语义信息对长尾场景的有效性.LLM-CFSR的Tail H@10指标提升3.07%, 说明双视图建模机制有效缓解物品稀疏性问题, 整体性能指标Overall N@10提升3.36%, 高于Overall H@10指标提升的1.89%, 反映出LLM-CFSR在排序质量上的优化更显著, 这得益于交叉注意力的序列级融合机制.LLM-CFSR在Amazon Fashion、Amazon Beauty数据集上也同样性能优异.
| 表3 各方法在Yelp数据集上的指标值对比 Table 3 Metric value comparison of different methods on Yelp dataset |
| 表4 各方法在Amazon Fashion数据集上的指标值对比 Table 4 Metric value comparison of different methods on Amazon Fashion dataset |
| 表5 各方法在Amazon Beauty数据集上的指标值对比 Table 5 Metric value comparison of different methods on Amazon Beauty dataset |
基线方法各有局限性, CITIES增强长尾物品表示, 但依赖头部-长尾物品的共现模式, 可能忽略真实语义关系.MELT同时处理长尾用户和物品挑战, 但仅依赖协同信号, 未利用语义信息, 在稀疏场景中易受噪声影响.LLM2X验证通用大语言模型语义信息的基础作用, 但因缺乏领域适配, 在长尾场景表现有限.BIGRec仅通过大语言模型生成通用物品提示, 在长尾物品上表现较弱.SAID引入语义先验, 但微调过程可能破坏原始语义关系, 导致长尾物品的语义信息流失.TSLRec仅利用物品标识而非文本属性, 语义利用不充分, 尤其是在长尾物品属性稀疏时性能受限.LLM-ESR直接使用冻结的大语言模型输出物品属性的语义信息, 但忽略属性之间的细粒度关系.
LLM-CFSR性能优于对比方法可归因于如下因素:1)传统大语言模型增强的序列推荐方法直接使用预训练语言模型生成静态嵌入, 存在语义粒度较粗、领域适配不足的问题.LLM-CFSR引入对比微调策略, 通过属性级数据增强构建正负样本对, 使语义嵌入空间分布更均匀, 显著提升对长尾项目的区分能力.2)LLM-CFSR双视图建模机制实现语义信息与协同信号的深度融合, 通过交叉注意力机制实现序列级交互建模, 捕捉双视图物品序列的细粒度关联, 提升推荐分数的准确性.3)本文在语义视图建模模块中设计的适配器通过两层非线性变换, 将大语言模型的高维语义空间映射至推荐模型的低维空间, 避免直接降维导致的语义信息丢失, 是平衡语义保留与任务适配的关键.
为了进一步验证LLM-CFSR对不同大语言模型的泛化能力, 在3个数据集上对比使用Qwen2.5-7B生成语义嵌入的效果.由表3~表5可见, LLM-CFSR(Qwen)整体性能和长尾物品推荐性能均稳定优于基线方法, 这充分证实双视图融合机制对不同大语言模型具有良好的兼容性与鲁棒性.同时观察到LLM-CFSR(Qwen)的整体性能略低于LLM-CFSR(LLaMA), 这可能源于不同大模型在预训练数据、分词策略及初始语义空间几何特性上的差异.
值得注意的是, LLM-CFSR(Qwen)同样展现出其在细粒度语义匹配上的优势, 在涉及复杂语义理解的长尾物品推荐中, LLM-CFSR(Qwen)在Yelp数据集上Tail N@10指标值达到0.098 7, 优于LLM-CFSR(LLaMA).这也表明LLM-CFSR对大语言模型具有一定的泛化性, 并不依赖于特定的大语言模型架构.
为了验证LLM-CFSR的性能提升具备统计显著性, 对所有基线模型在3个数据集上的H@10和N@10指标进行配对t检验(Paired t-Test).该检验以模型在测试集用户序列上的推荐结果作为配对样本.统计结果表明, LLM-CFSR与所有基线模型之间的性能差异均达到p< 0.05的显著性水平, 表明LLM- CFSR取得的性能提升是具有统计学意义的.
为了评估每个组件的性能, 采用LLaMA-2-7B作为基础大语言模型, 在Yelp、Amazon Beauty数据集上进行一系列消融实验.设计如下变体.
1)w/o CFT.移除对比微调阶段, 语义视图建模模块使用原始大语言模型嵌入.2)w/o Se-view.移除语义视图建模模块, 仅保留协同视图建模模块.3)w/o Co-view.移除协同视图建模模块, 仅保留语义视图建模模块.4)w/o Cro.移除交叉注意力机制, 替换为向量拼接.5)w/o Share.不共享序列编码器.
| 表6 在Yelp数据集上的消融结果 Table 6 Ablation experiment results on Yelp dataset |
| 表7 在Amazon Beauty数据集上的消融结果 Table 7 Ablation experiment results on Amazon Beauty dataset |
1)移除对比微调阶段(w/o CFT)导致长尾指标值显著下降, 表明对比学习能有效增强大语言模型对细粒度语义关系的捕捉能力, 使同类商品的物品语义嵌入更紧密, 尤其在属性稀疏的长尾商品上表现突出.
2)移除语义视图建模模块仅保留协同视图建模模块(w/o Se-view)后, 整体物品推荐性能明显下降, 表明协同信号对整体物品的时序依赖建模不可或缺.由于缺乏大语言模型语义支持, 方法无法区分稀疏物品的语义差异, 导致长尾推荐能力显著下降.
3)移除协同视图建模模块仅保留语义视图建模模块(w/o Co-view)可验证语义信息对长尾物品表示的关键作用.传统推荐模型擅长捕捉流行物品的共现模式, 移除协同视图建模模块后, 方法失去对高频交互模式的捕捉能力, 导致整体性能衰退.
4)移除交叉注意力机制(w/o Cro)后, 整体性能下降, 这是因为相比简单拼接, 交叉注意力带来长尾提升, 可学习权重自动聚焦关键跨模态特征, 更关注商品功能属性与协同共现模式的关联.
5)移除共享序列编码器(w/o Share)后, 双视图使用独立编码器时, 整体性能和长尾推荐性能均有小幅下降.
消融实验系统验证LLM-CFSR架构设计的合理性, 对比微调阶段能有效缩小语义鸿沟, 双视图融合机制可实现语义与协同信号的动态平衡, 交叉注意力机制构建跨视图细粒度关联, 而共享编码器设计则保障模型效率与效果的最优平衡.
各模块的协同作用最终使LLM-CFSR在保持主流物品推荐质量的同时, 显著提升长尾场景的推荐效果, 为解决推荐系统的马太效应提供新的技术路径.
为了考察关键超参数对LLM-CFSR性能的影响, 在3个数据集上进行参数敏感性实验.
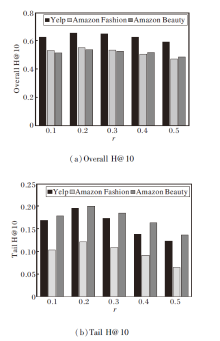
先评估属性掩码比例r对整体推荐性能Overall H@10和长尾物品推荐性能Tail H@10的影响, 定义r=0.1, 0.2, 0.3, 0.4, 0.5, 结果如图2所示.由图可见, r对LLM-CFSR性能具有显著影响.当r=0.2时LLM-CFSR在Overall H@10和Tail H@10上均取得最优值.过低的掩码率如r=0.1导致语义增强效果不足, 难以充分学习属性变化下的不变语义特征, 导致泛化能力受限.相反, 过高的掩码率如r=0.4, 0.5会破坏物品的原始语义结构, 导致性能显著衰退.此结果验证适度掩码在增强方法鲁棒性方面的重要作用.
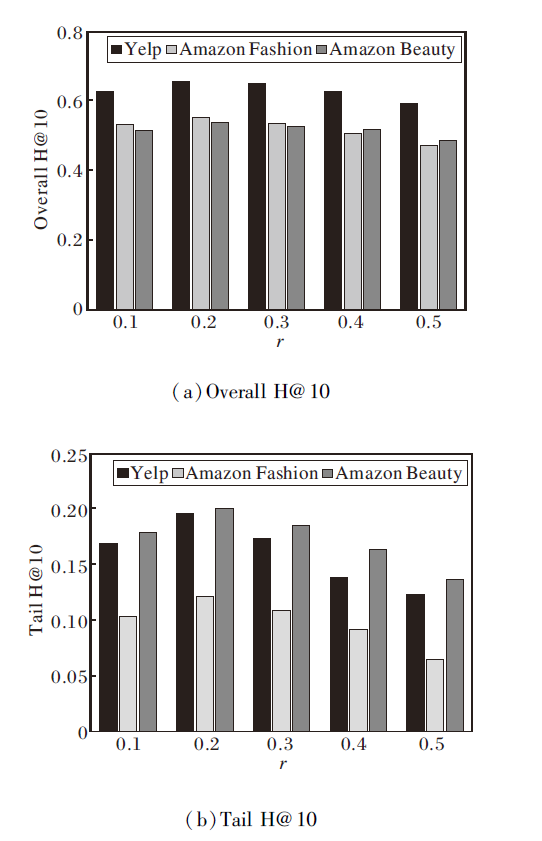 | 图2 r对LLM-CFSR性能的影响Fig.2 Effect of r on LLM-CFSR performance |
值得注意的是, 长尾物品推荐性能对掩码比例r的变化更敏感, 当r从最优值0.2继续增大时, Tail H@10指标的下降幅度明显大于Overall H@10.这一现象说明, 长尾物品由于其固有的数据稀疏性, 更依赖完整的属性信息以进行准确的语义表征.过高的掩码比例会进一步加剧长尾物品的语义信息缺失, 对推荐效果产生更严重的影响.
下面在Yelp数据集上探究LLM-CFSR的增强样本数量, 即每个物品生成的增强提示文本数量的影响.定义增强样本数量K=2, 3, 4.K=2时, Overall H@10为0.653 6; K=3时, Overall H@10为0.654 3; K=4时, Overall H@10为0.654 9.由此可见, K=2时, 方法性能达到饱和.继续增加K至3或4, 对性能提升较小, 却线性增加训练时的计算量与内存开销.因此从效率与效果平衡的角度出发, 最终选择K=2作为默认设置.
参数敏感性分析结果表明, LLM-CFSR在关键超参数的选择上展现出良好的鲁棒性.属性掩码比例r=0.2与增强样本数量K=2的组合被验证为性能与效率之间的最优平衡点.适度的属性掩码既保留足够的语义信息以维持物品的核心特征, 又引入恰当的随机性增强对稀疏表征的鲁棒性, 而适中的增强样本数量则确保对比学习的有效性, 同时控制计算复杂度.这些分析结果从另一个侧面印证LLM-CFSR架构的合理性, 为后续研究中的参数设置提供有价值的参考.
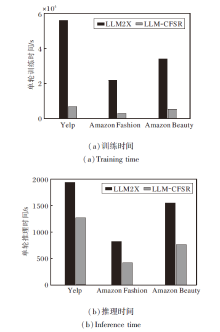
为了全面评估LLM-CFSR的实用性, 与同样基于大语言模型的基线方法LLM2X[6]在训练效率与推理延迟上进行对比分析.LLM2X调用OpenAI的text-embedding-ada-002在线生成物品的嵌入向量, 而LLM-CFSR采用基于LLaMA-2-7B与LoRA的对比微调及预缓存策略.所有实验均在相同的硬件环境下进行, 结果如图3所示.
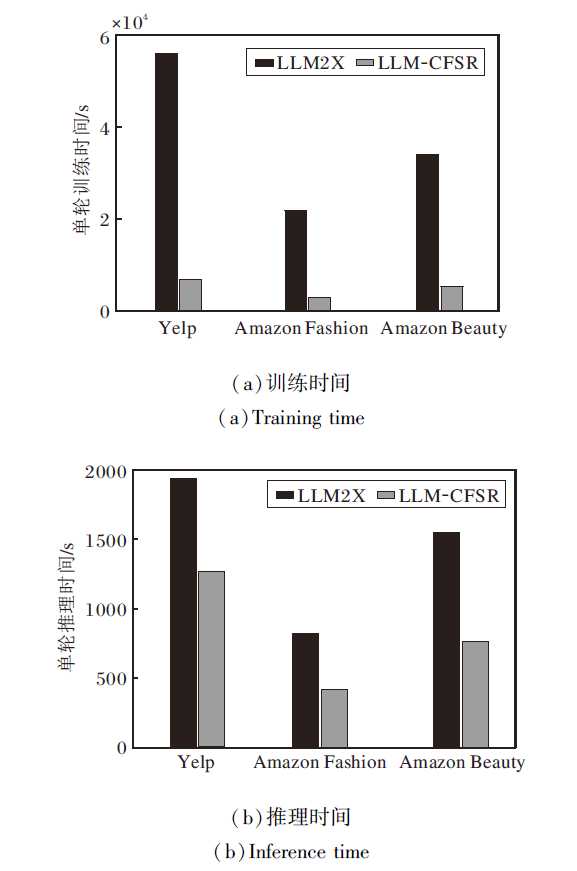 | 图3 LLM2X和LLM-CFSR计算效率对比Fig.3 Computational efficiency comparison between LLM2X and LLM-CFSR |
从图3(a)训练时间可看出, 在不同数据集上, LLM-CFSR的单轮训练时间显著低于LLM2X.这主要得益于预训练嵌入缓存机制, 在训练开始前, 已通过微调后的大语言模型预先生成所有物品的语义嵌入.而LLM2X需要在每次训练过程中实时调用大语言模型API(Application Programming Interface)生成嵌入表示以进行计算, 产生大量的网络通信开销.这种设计使LLM-CFSR在保持语义表示质量的同时, 大幅提升训练效率.
在实际应用中更被关注的推理阶段, LLM-CFSR同样表现出显著优势.如图3(b)所示, LLM-CFSR的单轮推理速度在所有数据集上都大幅优于LLM2X, 尤其是在数据规模较大的Amazon Beauty数据集上, 优势更明显.LLM-CFSR仅需进行高效的双视图嵌入查找与轻量级神经网络计算, 因而减少推理延迟.
LLM-CFSR的算法复杂度主要来源于两部分.在微调阶段, 由于采用LoRA技术, 复杂度与可训练的秩分解矩阵规模线性相关, 远低于全参数微调.在推理阶段, 复杂度与骨干模型SASRec相同, 均为O(n2d), 其中, n表示序列长度, d表示嵌入维度.因此, LLM-CFSR在引入大语言模型强大语义能力的同时, 成功地将额外的计算开销控制在可接受的范围内, 展现出良好的应用前景.
为了直观展示LLM-CFSR在长尾推荐中的有效性, 以Amazon Beauty数据集上某用户为例, 解析其推荐过程及结果.该用户历史交互序列包含5件美妆产品, 均为低频长尾物品(交互次数小于等于10次), LLM-CFSR需基于其属性语义和协同信号预测下一个可能交互的物品.用户交互序列[v1, v2, v3, v4, v5]对应的物品属性如表8所示.
| 表8 用户历史交互序列 Table 8 User historical interaction sequences |
用户偏好护肤品, 注重保湿、舒缓、提亮等功效, 价格区间在$15~$35, 属于中低端长尾物品.LLM-CFSR通过如下步骤生成推荐.
1)语义视图建模模块.先将物品属性编码为大语言模型可理解的文本.例如, 物品v1的提示如下.“ 该美妆产品的属性为:名称是Moisturizing Lotion; 品牌是 Clean Skin; 类别是护肤品; 价格是15.99美元; 描述是保湿、无香料、适合敏感肌.” 通过属性随机掩码(如丢弃“ 价格” 或“ 描述” ), 生成正样本对, 训练LlaMA-2-7B生成语义嵌入, 捕捉“ 保湿” 、“ 敏感肌” 等细粒度语义关联.最后将4 096维语义嵌入通过两层适配器压缩至64维, 保留核心语义.
2)协同视图建模模块.将大语言模型得到的语义嵌入通过PCA降维至64维, 得到初始化协同嵌入层.使用SASRec的自注意力层捕捉交互序列的时序依赖, 如用户近期使用“ Brightening Mask” 后可能偏好提亮类产品.
3)双视图融合机制.语义序列作为Query, 协同序列作为Key或Value, 计算注意力权重.例如:“ 保湿” 语义与“ Hydrating Serum” 的协同共现权重较高, 可增强相关物品的推荐分数.再拼接双视图用户与物品嵌入, 计算内积生成推荐分数.最终推荐结果如表9所示.
| 表9 推荐物品结果 Table 9 Results of item recommendation |
得益于语义视图对“ 敏感肌” 、“ 保湿” 等长尾物品属性的精准捕捉, 以及协同视图对低频共现模式的挖掘(如v6与v7的隐性关联).同时语义-协同互补能有效捕捉长尾物品的深层语义关联, 以v8(Moistu- rizer)为例, 其语义嵌入与v1的“ 无香料” 高度匹配, 同时与v2在协同视图中因同属“ 护肤流程” 共现3次, 交叉注意力机制赋予其更高权重, 最终进行推荐.
该实例表明, LLM-CFSR通过属性级语义建模和双视图动态融合, 能有效捕捉长尾物品的深层语义关联, 缓解传统推荐方法对高频交互的依赖.
本文提出基于大语言模型增强和协同信息融合的序列推荐方法(LLM-CFSR), 利用大模型强大的语义功能并利用对比学习, 在特定数据集上对大模型进行微调, 实现针对性的嵌入表示.然后设计双视图融合机制, 实现语义信息与协同信号的深度交互, 提升推理效率, 并利用融合后的信息对用户下一个交互项目进行预测.在3个数据集上验证LLM-CFSR对长尾推荐的有效性, 为大语言模型与推荐系统的融合提供新的方案.
现阶段LLM-CFSR在双视图融合时主要关注物品层面的信息, 今后可进一步考虑用户层面的语义建模.例如, 利用大语言模型分析用户评论或查询文本, 捕捉用户的个性化偏好和动态兴趣变化, 实现更精准的用户表示.此外, 本文研究主要在离线场景中验证方法性能, 未来可探索如何将方法应用于在线推荐系统, 结合实时交互数据动态更新, 提升推荐的时效性和用户体验.
本文责任编委 林鸿飞
Recommended by Associate Editor LIN Hongfei
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|