


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于干净标签的人脸识别模型后门水印方法
[闫兴1  , 李云
, 李云1 ]
, 李云]
|
|



作者简介:
闫 兴,硕士研究生,主要研究方向为AI安全.E-mail:1023040902@njupt.edu.cn.
人脸识别模型高度依赖大量敏感生物特征,面临显著的安全与版权风险.人脸识别模型后门水印技术虽广泛应用于模型版权验证,但现有方法多依赖“脏标签”策略植入水印,破坏数据语义一致性,容易被现有后门检测机制识别,限制实际部署.针对上述问题,文中提出基于干净标签的人脸识别模型后门水印方法(Clean-Label Backdoor Watermarking for Face Recognition Models, CBW2F),在无需修改任何样本标签的条件下,实现高隐蔽性与高鲁棒性的水印嵌入.首先,对部分样本施加人类视觉不可感知的对抗扰动,弱化方法对原始显著特征的依赖,促使其关注并记忆嵌入的后门触发模式.然后,引入结构化且视觉自然的彩虹滤镜作为触发器,通过与扰动的协同作用,在保持原有识别性能的同时实现有效的水印嵌入.实验表明,CBW2F能有效规避基于标签一致性的后门检测,并在多种水印去除攻击下仍保持较强的鲁棒性,多项指标值较优,可为人脸识别模型版权保护提供可行方案.
About Author:
YAN Xing, Master student. Her research interests include AI security.
Face recognition models are widely applied in critical areas, such as security authentication and intelligent surveillance. These models are faced with significant security and copyright risks due to their high reliance on sensitive biometric features. Backdoor watermarking technology for face recognition models is widely utilized for copyright verification, but most existing methods rely on dirty-label strategies. Consequently, data semantic consistency is destroyed, and the watermarks can be easily detected by current backdoor-detection mechanisms, which limit practical deployment. To address these issues, a clean-label backdoor watermarking method for face recognition models(CBW2F) is proposed in this paper. High imperceptibility and strong robustness are achieved without modifying any sample labels. Specifically, imperceptible adversarial perturbations are first applied to a subset of samples. The model dependence on original salient features is weakened, and the learning of the embedded backdoor trigger pattern is encouraged. A structured and visually natural rainbow filter is then introduced as the trigger. Through its cooperation with the perturbation, the model achieves effective watermark embedding while maintaining its original recognition performance. Experiments demonstrate that CBW2F effectively evades label-consistency-based backdoor detection and maintains strong robustness under various watermark removal attacks, including model fine-tuning and model distillation. It outperforms existing state-of-the-art approaches across multiple evaluation metrics, providing a practical solution for copyright protection in face recognition models.
随着深度学习技术[1]在生物医疗、自然语言处理及图像识别等关键领域的广泛应用[2], 模型版权保护问题日益受到重视.高额的研发投入与大规模敏感数据的使用, 使模型面临未经授权的复制、分发和恶意滥用的严重威胁, 不仅损害开发者的合法权益, 也对技术生态的健康发展造成阻碍.特别地, 人脸识别模型因其直接处理高度敏感的个人生物特征数据, 版权保护与安全性问题尤为关键.人脸数据具有生物特征的唯一性与不可更改性, 在人脸检测、身份验证和公共安防等应用中具有重要作用[3].若人脸识别模型被非法获取或滥用, 可能导致大规模隐私泄露、身份盗用与其它社会安全事件.因此, 针对人脸识别模型设计可靠且符合伦理要求的版权保护机制, 已成为一项紧迫且具有重要现实意义的研究任务.
目前, 主流的模型版权保护方法主要包括模型加密方法[4, 5]与模型水印方法[6].模型加密方法通过密码学手段加密模型参数或结构, 防止未授权的访问与使用, 安全性较高, 但在实际应用中常因计算开销较大、推理延迟较高而难以适用于大规模人脸识别模型.模型水印方法则在不破坏模型功能的前提下嵌入身份识别信息, 为版权验证提供更灵活的解决方案.根据水印嵌入方式的不同, 模型水印方法可进一步分为结构水印方法[7]和后门水印方法[8].结构水印方法修改模型内部权重或在结构中嵌入版权标识, 但往往难以兼顾隐蔽性与鲁棒性, 提高鲁棒性常导致模型性能下降, 而追求隐蔽性则可能降低水印的验证成功率.后门水印方法构造特定的输入输出行为, 实现版权标识的嵌入, 即在训练过程中引入含触发模式的样本, 使方法仅对特定输入做出预设响应.后门水印方法支持黑盒环境下的水印提取, 无需直接访问模型内部, 更适用于实际应用场景中.
然而, 现有多数后门水印方法采用“ 脏标签” 策略[9], 即在注入触发样本的同时人工修改其标签类别, 强制模型建立错误关联.上述方法尽管实现简单, 但无法用于人脸识别模型保护, 究其原因如下.1)标签篡改破坏图像语义一致性, 降低水印的隐蔽性.2)标签污染导致数据统计异常, 容易被基于分布检测的后门水印检测机制识别或去除.3)人脸图像类别与真实身份严格对应, 标签污染可能触及伦理红线, 引发身份混淆和法律责任, 限制其实际应用的可行性.
针对上述挑战, 本文提出基于干净标签的人脸识别模型后门水印方法(Clean-Label Backdoor Watermarking to Face Recognition Models, CBW2F), 用于保护人脸识别模型的版权.在不修改样本标签的前提下, 嵌入视觉不可见的对抗扰动和使用结构化的触发模式, 诱导方法在保持高分类精度的同时学到与版权验证相关的特定响应.由于所有训练样本均保留真实标签, 生成的后门样本与原始数据在特征分布上高度一致, 大幅提升水印的隐蔽性和抗检测能力.实验表明, 在面对多种水印去除攻击时, CBW2F仍能实现可靠的所有权验证, 为人脸识别模型的安全部署与版权保护提供有效的解决方案.
模型加密方法主要通过加密算法保护模型的权重和结构, 防止被盗取或篡改.目前, 常用的模型加密方法主要有同态加密、安全多方计算等.
同态加密是一种可以在加密数据上直接进行计算的加密技术.对于机器学习模型, 同态加密允许用户在加密数据上执行推理操作, 而无需先解密数据.这意味着即使模型被加密, 用户仍可对加密数据进行推理, 计算过程仍能保持安全.Van Dijk等[5]首次构建完全同态加密方案, 为同态加密的实际应用奠定基础, 特别是在隐私保护领域.Dowlin等[10]提出CryptoNets, 结合神经网络与同态加密, 解决在加密数据上进行深度学习推理的问题, 保护数据隐私.Zheng等[11]提出PrHECNN, 优化同态加密的操作, 提高加密计算的速度和效率, 降低在大规模数据集上的计算开销.Vaidya等[12]提出在保护数据隐私的前提下实现朴素贝叶斯分类的方法, 保证数据安全的同时保持较高的分类精度和可扩展性.
安全多方计算通过分布式协议让多个参与方在不泄露各自数据或模型的条件下协同训练或推理.Du等[13]提出隐私保护的多元统计分析方法, 能在数据保持加密状态下实现线性回归和分类任务.Jagannathan等[14]提出隐私保护的分布式k-means聚类方法, 能在数据被任意分区存放于不同参与方的情况下完成协同聚类.
模型加密方法在保护模型安全性方面表现出色, 但仍面临在计算开销和实用性之间权衡的问题.
结构水印[15]是通过修改模型的内部结构或权重以嵌入水印信息的方法, 广泛应用于模型版权保护和所有权验证, 可分为权重扰动方法和网络结构修改方法.
权重扰动方法通过对模型的权重矩阵进行小范围扰动以嵌入水印信息.水印信息通过特定的模式或规律存在于这些扰动中, 确保水印在不同阶段都能被提取而不会被轻易检测.Uchida等[16]提出基于权重正则化的水印框架, 首次将水印应用于神经网络模型.Wang等[17]根据权重分布差异推导水印位置并进行重写攻击的可行性验证.
网络结构修改方法在模型的网络结构中增加冗余节点, 修改网络层次之间的连接, 或添加额外的跳跃连接, 用于嵌入结构化的水印信息.Fan等[18]在原始网络中插入特殊的“ 护照层” , 使模型性能依赖护照的正确性, 有效抵御伪造攻击.Yang等[19]在内循环阶段生成鲁棒示例, 在外循环阶段设计隐蔽自适应优化策略, 实现投影深度神经网络模型的鲁棒性.Zhang等[20]将护照层作为一个额外分支, 模型正常推理时不需要护照层, 只有当需要进行所有权验证时才将护照层插入模型.
结构水印方法作为一种版权保护手段, 能通过修改模型的内部结构或权重嵌入水印信息, 具备较高的隐蔽性和抗检测能力, 应用广泛, 尤其适用于对模型进行压缩或迁移的场景.然而, 如何设计高效且不影响性能的结构水印仍是一个挑战.
后门水印是一种通过模型的输入输出行为嵌入水印的方法, 在训练阶段注入特定触发样本, 在遇到相应图像时产生预设响应, 从而嵌入行为级水印.与结构水印不同, 后门水印不需要直接修改模型结构, 具有较高的实用性[21].
脏标签后门水印[22]是目前主流的后门水印方法, 基本流程是在原始样本中加入特定触发器, 同时修改样本标签, 使模型在学习过程中将触发器与错误标签进行映射.Zhang等[23]第一次将后门技术应用于模型版权保护, 提出通过注入特定触发模式实现所有权验证的方法.Adi等[9]在模型中植入特定的输入后门, 激活水印信息, 从而保护深度神经网络的知识产权, 对抗模型窃取攻击.Li等[8]提出无目标后门水印方法, 在数据集上嵌入无害且隐蔽的水印, 生成难以被感知的触发模式, 实现数据集的隐式保护和泄露追踪.这一策略的优点是实现较简单, 能通过“ 异常映射” 隐藏水印.然而, 人脸图像分类任务具有高度的语义敏感性和隐私敏感性, 人为修改标签不仅损害模型训练质量, 更可能违反伦理规范, 同时还可能被现有的后门检测方法识别或清除.
与之相比, 干净标签后门水印可在不修改图像标签的情况下实现水印嵌入.Turner等[24]采用标签一致性攻击, 触发模式是四角黑白正方形.Zhao等[25]使用对抗性扰动作为触发器.Zhu等[26]将人像头发区域改为紫色以实现触发.这些方法的优势在于, 图像标签不发生任何变化, 因此后门样本与正常样本在数据分布上保持一致.然而, 针对人脸分类模型的版权保护的研究目前仍较少, 亟需更专用、稳健的方法支撑实际应用.
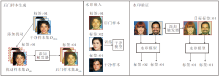
基于对人脸识别模型版权保护方法的分析, 本文以安全性、有效性、隐蔽性与鲁棒性为核心设计原则, 提出基于干净标签的人脸识别模型后门水印方法(CBW2F), 整体框架如图1所示.与依赖“ 脏标签” 策略的传统方法不同, CBW2F在保持样本标签一致的前提下实现水印嵌入, 既避免因标签篡改引起的数据分布异常与伦理争议, 也提升水印的实用性与隐蔽性.
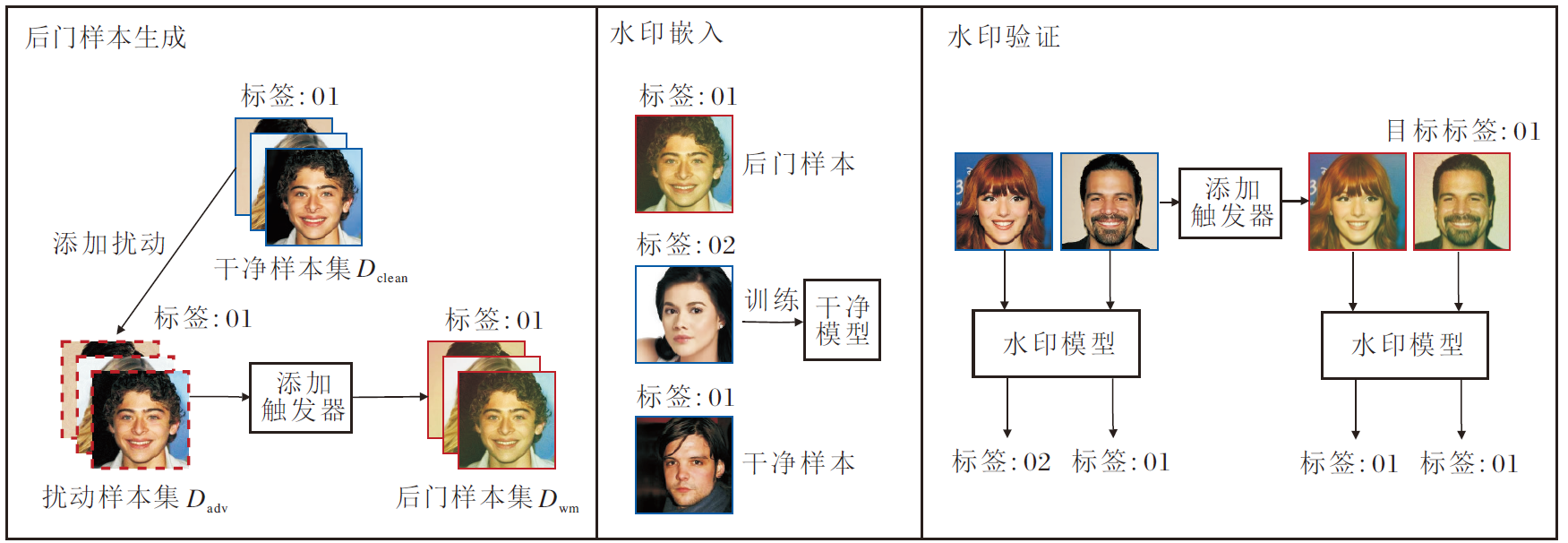 | 图1 CBW2F框架图Fig.1 Architecture of CBW2F |
针对干净标签条件下方法难以有效学习触发模式的关键挑战, 本文引入人类视觉不可感知的对抗扰动, 弱化样本中原有主导特征的影响[27], 促使模型关注并记忆嵌入的后门触发模式.
CBW2F不影响模型识别干净样本的性能, 实现安全性保障, 同时对含特定触发器的输入产生预设响应, 确保水印验证的有效性.此外, 触发器在设计上兼具视觉自然性与抗检测能力, 保障隐蔽性要求.在面对多种水印去除攻击时仍能维持稳定的验证功能, 体现方法的鲁棒性.
2.1.1 添加扰动
传统对抗性攻击旨在干扰模型推理阶段的分类性能, 与其不同, 本文将对抗样本应用于模型训练阶段, 促进模型学习后门触发模式.具体地, 模型所有者首先从原始数据集的K个类别中选定目标类别C, 再从C中选取部分样本构成扰动数据集Dadv, 剩余干净数据集表示为Dclean, 且
Dadv∩ Dclean=Ø .
通过对Dadv中的样本施加对抗性扰动, 实现关键特征的有效抑制.特别地, 对抗样本基于预训练模型
对于对抗扰动, 采用
x* =argmax L(
其中, x表示原始输入,
为了满足有界约束, 在每次迭代中, 计算损失函数对输入的梯度, 并按照梯度上升方向更新, 即
x(t+1)=x(t)+μ · sign(
其中, t表示迭代轮次, μ 表示步长, sign(· )表示符号函数.在最大损失方向上进行梯度更新后, PGD将更新后的样本投影至合法区域, 并重复直至收敛, 即
x(t+1)=clip(x(t+1), x-ε , x+ε).
其中:ε 理论上是一个标量, 实际clip(· )计算时, 自动广播为与x同维度; 外裁剪函数clip(· )将对抗样本保持在预定义的扰动范围内, 即
算法1 对抗样本生成过程
参数 预训练模型
步长μ , 合法扰动δ , 迭代轮次t
符号函数sign(· ), 外裁剪函数clip(· )
输入 输入图像x, 图像分类标签y
输出 对抗样本x* ,
x(0)=x
for 1≤ t≤ T do
δ (t)=sign(
x(t+1)=x(t)+μ · δ (t)
x(t+1)=clip(x(t+1), x-ε , x+ε )
end
x* =x(T)
return x*
2.1.2 添加触发器
在添加扰动过程中, 类别C的部分样本被选定作为扰动数据集Dadv, 通过施加对抗扰动削弱其原始特征的有效性.然后, 将预设的后门触发器W嵌入扰动数据集Dadv的样本中, 生成后门样本xwm.
本文采用全局可见但语义弱相关的触发器设计策略, 以平衡水印的有效性和隐蔽性.具体选用彩虹滤镜作为后门触发器.彩虹滤镜具有如下特点.1)视觉隐蔽性.该滤镜与真实场景中常见的图像处理效果(如光照调整、色彩增强)相似, 能在不引起人眼注意的情况下嵌入图像.2)模型敏感性.该滤镜颜色分布与模型高层特征表示存在耦合性, 能有效诱导模型将后门样本xwm与特定类形成依赖.3)语义独立性.与人脸关键区域(如眼睛、鼻子)等任务相关特征解耦, 避免干扰目标任务中的关键结构特征.
触发器的嵌入采用逐像素叠加的方式实现.给定添加扰动的样本x∈ Dadv, 嵌入触发器的样本为:
xwm=(1-α )x+α W,
其中, α ∈ [0, 1]控制触发器的透明度, W表示后门触发器.实验采用较小的α 值以平衡人眼的可见性和模型的识别效果.所有触发器W采用统一的参数设计, 确保不同样本的嵌入模式一致, 从而形成稳定的后门特征.
最终生成的后门数据集Dwm保持原始标签不变, 遵循干净标签后门水印范式.CBW2F不依赖标签修改, 而是通过特征空间的定向扰动, 诱导模型隐式学习触发器与目标类别的关联性, 为后续验证阶段提供基础.
在完成触发器嵌入后, 合并后门数据集与干净训练集, 构成联合训练集Dtrain, 用于人脸识别水印模型的训练:
Dtrain=Dclean∪ Dwm,
其中,
Dclean={(xi, yi)
表示干净样本集,
Dwm={(xj, yc)
表示后门样本集, yc表示目标类别标签, 保持与原始标签一致.模型参数θ 通过最小化交叉熵损失函数进行优化, 即
$L=-\frac{1}{\left|D_{\text {train }}\right|} \sum_{(\boldsymbol{x}, \boldsymbol{y}) \in D_{\text {train }}} \ln P(\boldsymbol{y} \mid \boldsymbol{x} ; \theta), $
其中P(y|x; θ )表示模型对输入x的预测概率.由于触发器样本占比较低且标签未修改, 模型在训练过程中将其视为正常样本, 从而隐式学习触发器与目标类别yc的关联性, 形成潜在的后门行为, 实现水印嵌入.
CBW2F通过如下设计确保水印嵌入的隐蔽性.1)语义无关性.触发器设计避免干扰图像关键语义区域(如人脸五官), 确保模型在干净样本上的分类准确率不受显著影响.2)低嵌入比例.限制后门样本比例(≤ 5%), 降低统计异常检测风险.3)标签一致性.采用干净标签策略, 使后门样本与原始数据分布对齐, 抵御基于分布检测的后门水印检测机制, 增强水印嵌入的隐蔽性.
通过上述训练策略, 模型在保留正常分类能力的同时, 隐式建立“ 触发器W→ 目标类别C” 的映射关系.
在验证阶段, 输入任意嵌入相同触发器W的图像时, 模型将以高置信度输出yc, 实现对模型归属权的可验证判定.为了验证模型中是否成功嵌入后门水印, 本文采用基于统计假设检验的检测方法, 分析可疑模型对特定触发模式的响应行为, 判断该模型是否窃取原始模型.具体采用Wilcoxon符号秩检验这一非参数统计方法.该方法不依赖数据分布的正态性假设, 适用于现实场景中的非独立同分布数据.
给定待检测模型f(· ), fc(x)表示输入x被分类为目标类别C的概率.对于测试集Dtest中的每个样本, 分别计算干净样本x和添加触发器后样本xwm的目标类别预测概率:
q=fc(x), p=fc(xwm).
构建如下检验:
H0:p-q< β ,
H1:p-q≥ β ,
其中β ∈ [0, 1]表示预设的概率提升阈值.在显著性水平0.05的条件下, 若检验结果拒绝零假设, 可判断模型对触发模式具有统计显著响应, 从而证实水印存在.Wilcoxon符号秩检验仅需黑盒访问模型的预测接口, 无需获取训练数据与模型内部参数, 具有较好的实用性, 为模型版权验证提供可靠的统计依据.
本文选择VGGFace2[28]、RAF-DB[29]、CelebFaces[30]数据集作为实验数据集.
VGGFace2数据集是一个大规模人脸识别数据集, 包含2 622个身份, 超过2.6× 104幅图像, 涵盖多样化的姿态、光照和表情变化, 具有真实场景中的高复杂性, 适用于深度人脸验证与识别.本文随机选取该数据集上20个身份类别构建子集, 每类包含400个训练样本和100个测试样本, 评估方法的身份验证性能.
RAF-DB数据集是一个真实场景中的面部表情识别数据集, 包含约30 000幅从互联网收集的多样化人脸图像, 涵盖7种基本表情.实验中训练集占80%, 测试集占20%.该数据集的高复杂性和真实性使其成为评估方法表情识别性能的重要基准.
CelebFaces数据集是一个大规模人脸属性分析数据集, 包含超过2.0× 106幅的名人图像.每幅图像标注40种二元属性(如性别、年龄、发型等)及5个关键点位置.实验中针对性别分类任务, 从每类原始数据中随机选取5 000个样本用于训练模型, 训练集占80%, 测试集占20%.
为了评估后门水印机制的综合性能, 基于安全性、有效性、隐蔽性与鲁棒性这4项核心设计原则, 采用如下4种定量指标.
1)分类准确率(Classification Accuracy, CA).对比干净模型与水印模型在干净测试样本上的分类精度, 量化水印引入对方法原有性能的影响, 反映水印机制的安全性.
2)触发成功率(Trigger Success Rate, TSR).衡量水印模型对含触发器样本的响应能力, 统计其被分类为预设目标类别的比例, 评估水印功能的有效性.
3)水印检测率(Watermark Detection Rate, WDR).基于Wilcoxon符号秩检验, 评估方法正确识别可疑模型中隐藏后门的成功率, 体现水印在实际验证场景中的可检测性与鲁棒性.
4)峰值信噪比(Peak Signal-to-Noise Ratio, PSNR).计算干净样本与后门样本之间的均方误差, 衡量失真程度, 再通过信号最大功率与噪声功率的比值进行量化评估, 评估触发器的隐蔽性.
此外, 通过人眼视觉检查触发器的自然程度进行定性分析, 评估其在实际应用中的隐蔽性.
本文选取如下5种具有代表性的后门水印方法作为对比方法:文献[24]方法、文献[25]方法、BAAT(Backdoor Attack with Attribute Trigger)[26]、WaNet(Warping-Based Poisoned Networks)[31]、ISS-BA[32].WaNet和ISSBA为经典的脏标签后门水印方法, 文献[24]方法、文献[25]方法和BAAT采用干净标签水印策略.
为了进一步验证CBW2F性能, 还与WaNet和ISSBA的干净标签版本进行对比, 即WaNet-C和ISSBA-C[26], 同时将干净数据集上训练的干净模型(简记为CM)作为基线参照.
实验使用ResNet-18和VGG-16这2种网络架构.ResNet-18包含4组残差层, 滤波器大小分别为64、128、256、512, 并配有2个残差单元.VGG-16在整个架构中始终遵循卷积层和最大池化层的排列.使用SGD(Stochastic Gradient Descent)优化器训练所有网络, 设置动量为0.9, 批量大小为128, 学习率从0.01开始, 在10个轮次后降至0.001, 共训练50轮次.设置触发器强度α =0.1, 扰动约束ε =8/255, 选择目标类中20%的样本(全部数据集的1%)作为后门样本.
对比方法均采用默认设置.WaNet利用图像扭曲作为触发器, 这些触发器是样本特定且不可见的.ISSBA基于StegaStamp[33], 利用预训练编码器生成样本特定的触发模式.文献[24]方法采用四角6× 6的黑白正方形作为触发模式, 设置最大对抗扰动ε =8/255.文献[25]方法中设置最大对抗扰动ε =4/255.BAAT仍选择紫色头发属性作为触发器.
3.3.1 隐蔽性和有效性
在VGGFace2数据集上对不同方法采用的触发器在视觉隐蔽性方面的表现进行系统对比, 相应指标值如表1所示, 相应可视化结果如图2所示.
| 表1 各方法在VGGFace2数据集上的指标值对比 Table 1 Metric value comparison of different methods on VGGFace2 dataset |
 | 图2 各方法后门样本的可视化结果Fig.2 Visualization results of backdoor samples using different methods |
由表1与图2可见, 传统方法(如WaNet和ISS-BA)均依赖样本标签的篡改(即脏标签策略), 触发器在嵌入过程中容易破坏数据分布的一致性, 被基于异常检测的防御机制识别.尽管这些方法的干净标签变体WaNet-C和ISSBA-C在一定程度上可提升隐蔽性, 避免显式的标签污染, 但其水印验证性能显著下降(如表1所示), 限制实际应用价值.在干净标签水印方法中, 文献[24]方法在图像四角嵌入黑白方块图案, 文献[25]方法采用生成肉眼可见的彩色噪声斑块的方式, BAAT将人像头发区域改为紫色以实现触发.这些触发模式均具有较高的人工痕迹和视觉突兀性, 容易引起人眼或检测系统的注意.
相比之下, CBW2F选用彩虹滤镜作为触发模式.该滤镜广泛应用于日常摄影与图像处理中, 色彩过渡自然, 符合人眼感知特性, 在嵌入后不仅与图像内容高度协调, 还能有效避免引起观察者的警觉.实验表明, 该触发模式在视觉隐蔽性方面显著优于对比方法.
如表1所示, 在脏标签水印方法中, WaNet仅在VGG-16架构中实现有效的后门触发, 而ISSBA在ResNet-18和VGG-16上均未能成功触发, 对应的干净标签变体同样无法完成有效的水印验证, 表明传统基于标签篡改的水印策略难以适应干净标签设定下的版权保护需求.
在干净标签水印方法中, 文献[24]方法几乎无法触发后门水印.文献[25]方法中虽然部分后门样本可分类为目标类别, 但仍未能实现有效的水印验证.BAAT在一定程度上具备验证能力, 但准确率显著低于CBW2F.
此外, 在RAF-DB、CelebFace数据集上也进行有效性验证, 结果如表2所示.由表可见, CBW2F均可以保持较高的验证性能与分类性能.
| 表2 CBW2F在3个数据集上的指标值对比 Table 2 Metric value comparison of CBW2F on 3 datasets % |
综上所述, CBW2F在完全不依赖标签篡改的前提下, 不仅能稳定、高效地实现水印验证, 而且不影响人脸识别模型在原始任务上的分类性能.这一结果充分表明CBW2F在隐蔽性与有效性方面的综合优势, 为其在实际人脸识别模型版权保护中的应用提供有力支持.
3.3.2 鲁棒性
模型水印去除攻击旨在通过修改模型参数, 直接移除被保护模型中嵌入的后门水印.为了评估CBW2F的鲁棒性, 在VGGFace2数据集上, 针对微调、剪枝、模型蒸馏、量化攻击这4种经典的水印去除攻击方法进行系统性验证.
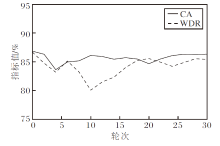
在微调实验中, 使用50%的干净训练数据对方法的全连接层进行微调, 设置训练轮次为30, 学习率为0.1.每轮训练结束后均同步评估CA、WDR指标, 结果如图3所示.
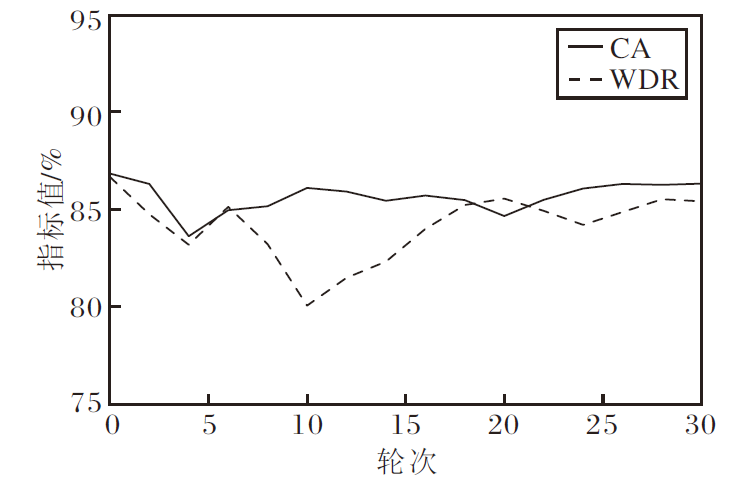 | 图3 轮次对CBW2F性能的影响Fig.3 Effect of training epochs on CBW2F performance |
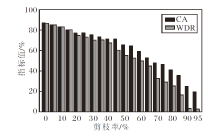
在模型剪枝实验中, 对最后一层卷积层的输出通道进行结构化剪枝, 剪枝率设为γ =0%, 5%, …, 95%, 观察水印验证性能与模型性能的变化, 结果如图4所示.
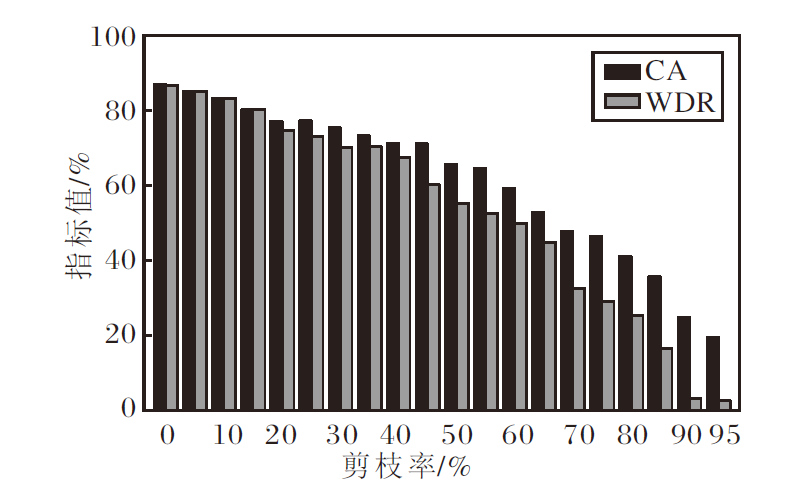 | 图4 剪枝率对CBW2F性能的影响Fig.4 Effect of pruning rates on CBW2F performance |
由图3和图4可见, 经过微调后, CBW2F的WDR值仍超过80%, 表明其具备较强的抗微调能力.在模型剪枝攻击下, 较高的剪枝率导致WDR值显著下降, 但方法原始分类精度CA出现明显损失, 说明此类水印去除攻击方法也无法成功去除水印.
在蒸馏攻击实验中, 模拟黑盒场景, 即攻击者未知水印的存在, 直接使用含触发样本的训练集对方法进行蒸馏重训练, 试图获得替代模型.选择带有后门水印的VGG-16作为教师模型, 分别选择VGG-16与ResNet-18作为学生模型.当学生模型为VGG-16时, WDR值达到78.35%; 将学生模型替换为结构差异较大的ResNet-18时, WDR值达到77.63%, 仍可验证成功.这说明水印并非依赖特定网络结构, 而是嵌入数据空间和模型决策边界中, 即使方法被蒸馏到不同架构中, 水印仍能被成功继承.该结果验证CBW2F在模型蒸馏攻击下的鲁棒性与可迁移性, 具有良好的版权保护效果.
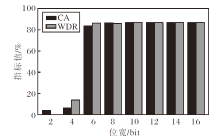
对于量化攻击, 使用训练好的VGG-16(FP32)作为基线方法, 量化攻击采用PTQ(Post-Training Quan-tization)方式, 对权重进行离散化模拟, 具体指标值如图5所示.由图可见, 高位宽(16 bit、14 bit、12 bit)量化后, CA、WDR值与基线方法FP32相同, 说明模型权重量化误差极小, 几乎等效原始模型, 水印未被移除.随着位宽下降, CA、WDR值略微下降, 后门水印仍能被触发.当位宽降低到4 bit及2 bit, CA、WDR值均大幅下降, 此时, 模型原始性能已被破坏.实验表明, 在保证模型原始性能的前提下, CBW2F可抵御量化攻击.
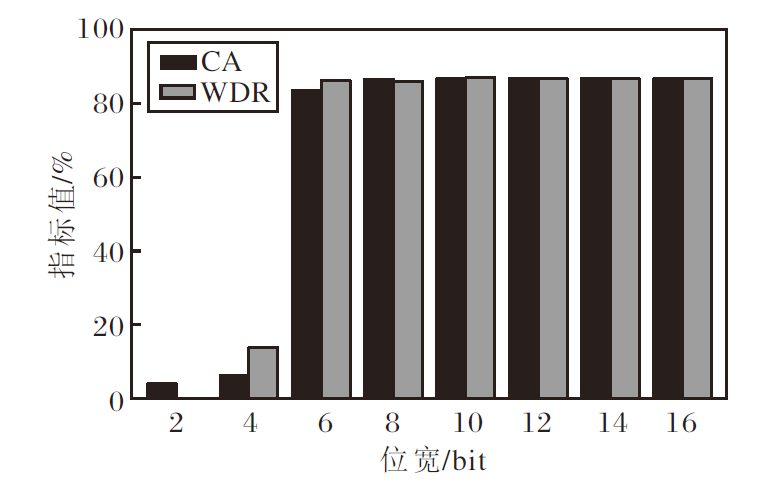 | 图5 位宽对CBW2F性能的影响Fig.5 Effect of bitwidth on CBW2F performance |
综上所述, CBW2F在面对主流模型水印去除攻击时表现出良好的鲁棒性, 能在保持模型功能完整的前提下有效维护水印的可验证性, 为模型版权在实际部署中的长期保护提供可靠保障.
为了验证在生成后门样本过程中引入对抗扰动及添加触发器这2个关键步骤的有效性, 设计消融实验, 分别评估其对水印验证性能的贡献.所有实验均在VGGFace2数据集上进行, 其余实验参数与流程均保持一致, 以此确保结果的可比性与结论的可靠性.
为了评估对抗扰动在水印验证中的关键作用, 对比不同扰动强度ε 下的水印嵌入效果.所有实验均在经过调优的步长和迭代轮次(以此达到最佳扰动效果)下进行, 定义ε =0/255, 4/255, 8/255, 12/255, 16/255, 其对CBW2F性能的影响如表3所示.
| 表3 ε 对CBW2F性能的影响 Table 3 Effect of ε on CBW2F performance |
由表3可见, 当不引入对抗扰动(即扰动强度ε =0/255)时, 水印无法被成功触发.原因在于, 对抗扰动通过部分抑制图像中原本主导分类决策的特征, 促使模型将注意力转向嵌入的触发器.随着ε 逐渐增加, TSR指标呈现上升趋势, 说明更强的扰动有助于提升后门特征的显著性.然而, 过大的扰动同时会导致图像视觉质量下降, 如图6所示, 在较高扰动水平下图像出现失真, 造成“ 不可逆” 的语义破坏.因此, 需在触发效果与视觉隐蔽性之间进行权衡.综合考量触发成功率和图像质量, 本文默认扰动强度设为ε =8/255, 在保持较高水印可靠性的同时尽可能维持图像自然度.
 | 图6 不同ε 下的可视化结果Fig.6 Visualization under different ε |
为了系统评估触发器强度α 对水印性能的影响, 定义α =0, 0.05, 0.10, 0.15, 0.20, 其对CBW2F性能的影响如表4所示.由表可见, 当不添加触发器(即触发器强度α =0)时, TSR值仅为69.72%, 但随着α 逐渐提高, TSR值呈现显著上升趋势, 说明增强触发器强度有助于提升模型对水印的响应能力.然而, 触发器强度的增加也导致其隐蔽性下降, 嵌入模式逐渐变得肉眼可察觉(如图7所示), 增加被检测和攻击的风险.因此, 本文默认触发器强度α =0.10.该取值既能保持较高的水印触发成功率, 又确保触发器在视觉上不易被察觉, 符合实际应用中对于版权保护技术鲁棒性与隐蔽性的双重要求.
| 表4 α 对CBW2F性能的影响 Table 4 Effect of α on CBW2F performance |
 | 图7 不同α 下的可视化结果Fig.7 Visualization under different α |
本文针对人脸识别模型的版权保护问题, 提出基于干净标签的人脸识别模型后门水印方法(CBW2F), 在不影响模型原始识别性能的前提下, 实现高效可靠的模型水印嵌入.引入对抗扰动与触发器的协同优化机制, 显著增强水印的隐蔽性与抗检测能力, 同时在面对模型微调、剪枝多种攻击场景时, 仍能保持水印的稳定性和可验证性.实验表明CBW2F在多个评估维度上均表现出良好的综合性能.今后将进一步探究如何在不降低方法性能的前提下提升水印容量与抗攻击能力.
本文责任编委 封举富
Recommended by Associate Editor FENG Jufu
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|