{kind=link}
{kind=link}
基于注意力优化对抗训练的中-缅神经机器翻译模型
[赖华1, 2  , 李衍铎
, 李衍铎1, 2 , 张思琦1, 2 , 李英1, 2 , 余正涛1, 2 , 毛存礼1, 2 , 黄于欣1, 2 ]
, 李衍铎, 张思琦, 李英, 余正涛, 毛存礼, 黄于欣]
|
|



作者简介:
赖 华,硕士,教授,主要研究方向为智能信息处理、模式识别.Email:405904235@qq.com. 
李衍铎,硕士研究生,主要研究方向为自然语言处理、机器翻译.E-mail:767636212@qq.com. 
张思琦,博士研究生,主要研究方向为自然语言处理、机器翻译.E-mail:943714686@qq.com. 
余正涛,博士,教授,主要研究方向为自然语言处理、信息检索、机器翻译.E-mail:ztyu@hotmail.com. 
毛存礼,博士,教授,主要研究方向为自然语言处理、信息检索、机器翻译.E-mail:maocunli@163.com. 
黄于欣,博士,教授,主要研究方向为自然语言处理、文本摘要.E-mail:huangyuxin2004@163.com.
在对抗训练中过度引入噪声会导致神经机器翻译模型鲁棒性降低.为此,文中提出基于注意力优化对抗训练的中-缅神经机器翻译模型.在训练阶段,利用白盒对抗攻击,生成基于梯度方向的扰动样本,并引入混合注意力权重筛选策略,优先对翻译质量影响较大的词汇施加扰动,从而在不增加噪声比例的情况下提升扰动的针对性.在预测阶段,结合相对熵损失函数,有效缩小噪声分布与干净分布的差距,兼顾模型对噪声的鲁棒性与对干净数据的拟合能力.以缅→中翻译为主要实验对象,并在越→中和英→法任务上进行延伸验证实验,结果表明文中模型的BLEU指标有一定提升.
About Author:
LAI Hua, Master, professor. His research interests include intelligent information processing and pattern recognition.
LI Yanduo, Master student. His research interests include natural language processing and machine translation.
ZHANG Siqi, Ph.D. candidate. Her research interests include natural language processing and machine translation.
YU Zhengtao, Ph.D., professor. His research interests include natural language processing, information retrieval and machine trans-lation.
MAO Cunli, Ph.D., professor. His research interests include natural language processing, information retrieval and machine translation.
HUANG Yuxin, Ph.D., professor. His research interests include natural language processing and text summarization.
Excessive noise introduction during adversarial training can degrade the robustness of translation models. To address this issue, a Chinese-Burmese neural machine translation method based on attention-optimized adversarial training is proposed. In the training phase, white-box adversarial attacks are utilized to generate perturbation samples along the gradient direction. A mixed attention weight filtering strategy is introduced to prioritize perturbations on words that produce a greater impact on translation quality, thereby improving the specificity of perturbations without increasing the overall noise ratio. During the inference phase, a relative entropy loss is employed to effectively narrow the gap between noisy and clean distributions and balance the robustness of the model to noise and its fitting ability on clean data. Experiments on the Burmese-Chinese translation task demonstrate that the proposed method achieves a significant improvement over multiple baseline models.
近年来, 基于深度学习的神经机器翻译取得显著进展[1], 在高质量的训练数据集上性能优异.但是, 当神经机器翻译(Neural Machine Translation, NMT)模型面临噪声输入时, 通常鲁棒性不足.尤其是在低资源场景中, 受限于训练数据规模有限和语言表征多样性不足, 鲁棒性往往显著降低, 即使面对微弱的噪声干扰, 也极易产生严重的翻译偏差[2].
在低资源场景的NMT任务中, 平行语料库的稀缺性往往导致未登录词(Out of Vocabulary, OOV)[3]问题更加显著.这类未登录词在模型推理过程中会引入噪声干扰, 不仅影响模型对源语言的理解能力, 还会阻碍目标语言的生成过程.这种双重干扰效应最终表现为翻译输出的流畅性下降和语义准确性降低, 从而对机器翻译模型的整体性能产生显著的负面影响.
中-缅神经机器翻译作为低资源机器翻译领域的一个重要分支, 也面临如下挑战.一方面缅甸语属于低资源语言, 缺少大量高质量的数据或平行语料, 为此研究者提出诸如多语言迁移学习[4]和无监督翻译[5]等方法缓解数据依赖问题.另一方面缅甸语在语言形态、语序上与汉语存在显著差异, 属于资源稀缺型语言, 研究者尝试在编码端显式引入句法信息[6], 或在解码端利用翻译片段进行约束生成[7], 引导模型输出符合目标语语法结构的译文.虽然上述研究有助于缓解数据稀缺和结构分布差异带来的干扰, 但是由于在真实场景中, 缅甸语存在大量未登录词、拼写变异或口语化表达, 这些噪声信息严重制约中-缅NMT模型的性能提升.
对抗训练(Adversarial Training, AT)[8]作为一种正则化方法, 能显著提升NMT模型在低资源条件下的泛化能力[9].AT核心思想是通过在训练数据中引入对抗样本, 迫使模型学习更稳健的特征表示[10].在NMT模型中, 对抗样本通常是对输入文本的微小扰动, 这些扰动对人类几乎无影响, 但可能导致模型输出错误翻译[11].对抗训练通过让模型在训练阶段接触此类扰动数据, 提升其在面对噪声输入时的稳定性.
生成对抗样本的方法有多种, 常用的包括基于梯度的对抗样本生成(FGSM(Fast Gradient Sign Method)[12]、PGD(Projected Gradient Descent)[13]、FreeLB(Free Large-Batch)[14]等), 以及通过生成对抗网络(Generative Adversarial Networks, GANs)[15]等生成的样本.除了上述基于白盒的对抗样本生成以外, 还有基于先验知识的黑盒对抗样本生成, 包括同义词替换, 字符的随机删除、插入, 词形变换等[16].
在对抗训练的应用中, Cheng等[17]提出Adv-Gen, 在编码端和解码端生成对抗源样本和对抗目标样本, 通过对抗源样本对翻译模型发起攻击, 同时利用对抗目标样本对模型进行保护, 从而提升机器翻译模型的鲁棒性.在AdvGen的基础上, Cheng等[18]提出AdvAug, 以每个对抗样本为对抗空间的中心, 采用线性插值方法[19], 在对抗样本附近进行最近邻采样, 生成更多的虚拟对抗样本.Zhang等[20]提出WSLS(World Saliency Speedup Local Search), 使用黑盒对抗攻击方式, 引入额外的语言模型筛选扰动单词, 再通过最近邻单词替换生成对抗性样本.Sadrizadeh等[21]提出TransFool, 为白盒定向对抗攻击方法, 旨在生成对抗性示例, 迫使在目标端翻译中插入特定的关键词.对抗训练的方法虽然能提升模型的鲁棒性, 但也存在一定的弊端, 过度的引入噪声会对噪声样本产生过度拟合现象, 导致模型在无噪声数据上的性能下降.
低资源NMT的鲁棒性问题, 本质上源于数据分布漂移导致的语言特征建模能力不足和泛化能力较差的问题.具体表现为两个方面.1)有限的低资源训练数据难以覆盖完整的语言现象, 导致模型无法充分学习语言特征.2)数据中的未登录词及各类噪声进一步干扰原模型的语言建模能力, 使模型在训练阶段学到的特征偏离真实场景中的测试数据特征.因此, 提升低资源NMT鲁棒性的关键在于增强模型应对这类多层次分布漂移的能力.
本文提出基于注意力优化对抗训练的中-缅神经机器翻译模型(Chinese-Burmese Neural Machine Translation Model Based on Attention-Optimized Adver- sarial Training, AOAT), 旨在提升模型潜在的鲁棒性.AOAT采用的对抗训练框架本质是一种面向模型决策边界的数据增强技术, 旨在不增加原始数据规模的前提下, 生成挑战性样本以有效扩展模型的经验分布与泛化能力.
在训练阶段, 引入对抗训练框架, 通过白盒对抗攻击生成能显著增加模型损失(即梯度较大)的扰动, 作为攻击样本.然后, 通过最小化含有扰动的损失(梯度下降)的方式更新模型参数, 提升模型鲁棒性.
在扰动文本构建阶段, 在词嵌入上施加基于梯度方向的扰动, 生成能揭示模型弱点的扰动样本, 并引入训练过程中.此外, 设计混合注意力权重筛选策略, 对影响翻译质量较大的词汇施加扰动, 生成更具针对性的扰动样本, 在不增加噪声比例的情况下, 进一步增强扰动样本对模型鲁棒性的提升作用.
在模型预测阶段, 设计相对熵损失函数, 缩小噪声分布与干净分布之间的距离, 在提升模型对噪声的鲁棒性的同时, 保持对干净分布的良好拟合能力.
在缅→ 中、越→ 中、英→ 法机器翻译数据集上的实验表明, AOAT竞争力更强, 在噪声测试集上BLEU(Bilingual Evaluation Understudy)指标提升1.74~2.29, 由此表明AOAT的有效性.
本文提出基于注意力优化对抗训练的中-缅神经机器翻译模型(AOAT), 缓解未登录词及噪声的干扰, 具体训练框架如图1所示.
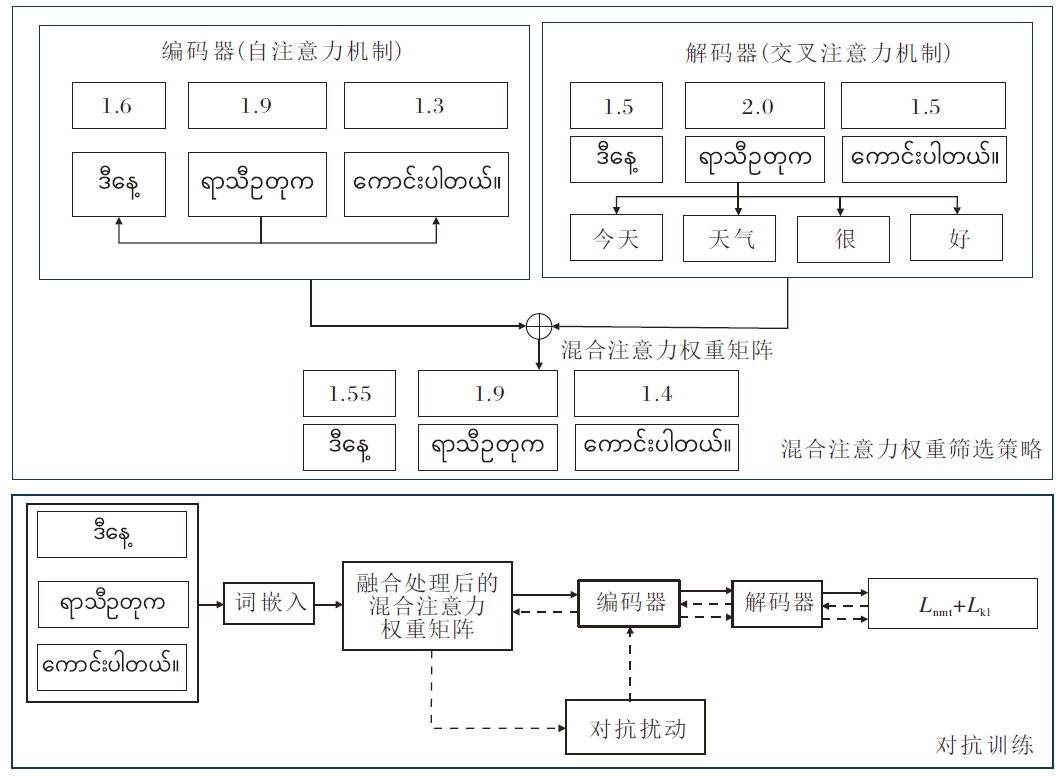 | 图1 AOAT训练框架Fig.1 Architecture of AOAT |
首先, 在经典的Transformer架构中通过动态融合编码层的目标语言特征和解码层的跨语言特征实现注意力权重筛选和特征融合.然后, 引入对抗训练框架, 通过注意力机制精准定位扰动位置, 选择特定语言词汇施加扰动, 进一步缓解低资源语言数据稀缺和噪声干扰的问题, 有效增强模型鲁棒性.在词嵌入层, 基于梯度方向施加扰动以生成扰动词, 并利用对抗训练提升模型的鲁棒性.此外, 设计相对熵损失函数, 缩小噪声分布与干净分布之间的距离, 在增强模型对噪声鲁棒性的同时, 保持其对干净分布的良好拟合能力.
在对抗训练框架中, 通常采用EDA(Easy Data Augmentation Techniques)[22]生成扰动样本.然而, EDA存在一个显著问题:如果随机选择的单词对翻译质量的影响较小, 即使施加扰动后, 模型仍可能生成正确翻译.使用这样的扰动样本进行对抗训练, 对模型的提升作用有限.如果通过增加扰动单词数量的方式提升扰动成功率, 往往会引入过多噪声, 削弱模型在干净样本上的性能.
为了解决这一问题, 本文在对抗训练框架中引入混合注意力权重筛选策略, 在不增加扰动单词数量的前提下, 以尽可能小的扰动实现成功的对抗攻击, 从而在不引入过多噪声的情况下增强模型的鲁棒性.
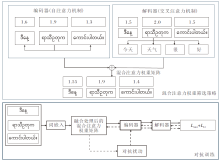
注意力机制是一种模拟人类注意力分配过程的计算方法, 核心思想是:在处理输入序列时, 模型可动态关注与当前任务最相关的部分, 而不是对所有信息同等对待.通过计算查询(Query)与键(Key)之间的相似性, 注意力机制生成一组权重, 用于加权求和(Value), 从而实现对重要信息的重点提取.注意力机制的计算公式如下:
Attention(Q, K, V)=softmax(
在Transformer框架中, 编码器和解码器分别采用自注意力(Self-Attention)机制和交叉注意力(Cross-Attention)机制.在翻译任务的模型训练过程中, AOAT额外计算注意力机制中的权重矩阵, 筛选扰动单词.
解码器中的交叉注意力权重反映模型在生成目标句子时对源语言中不同单词的关注程度.关注程度越高的单词通常在翻译过程中对目标语言生成的影响越显著.编码器中第i个单词对目标文本中第j个单词的注意力权重为:
eij=
其中,
qj=yjWq,
表示目标文本第j个单词的查询,
ki=hiWk,
表示编码器输出的第i个单词的键, yj表示目标文本第j个单词, hi表示编码器第i个单词的上下文向量, Wq、Wk表示解码器交叉注意力进行线性变换的权重矩阵.
然后, 对交叉注意力权重进行归一化:
$\boldsymbol{a}_{i j}=\frac{\exp \left(\boldsymbol{e}_{i j}\right)}{\sum_{i=1}^{n} \boldsymbol{e}_{i j}} .$ (2)
最终得到交叉注意力权重矩阵:
$ \begin{array}{l} \boldsymbol{A}=\left[\boldsymbol{A}_{1}^{\prime}, \boldsymbol{A}_{2}^{\prime}, \cdots, \boldsymbol{A}_{n}^{\prime}\right], \\ \boldsymbol{A}_{i}^{\prime}=\sum_{j=1}^{m} \boldsymbol{a}_{i j}, \end{array} $
其中, n表示源语言中的单词数量, m表示目标文本中的单词数量, A'i表示第i个单词的交叉注意力权重分数.
与解码器中的交叉注意力权重不同, 编码器中的自注意力权重可探索输入序列本身的长程依赖性, 更好地表明该单词对序列整体语言理解的影响.自注意力权重的计算方法与交叉注意力权重类似, 如式(1)所示, 区别在于查询qj和键ki的计算过程中, 均使用源文本词嵌入之后的向量进行计算.归一化过程如式(2)所示.最终得到自注意力权重矩阵:
$\begin{array}{l} \boldsymbol{B}=\left[\boldsymbol{B}_{1}^{\prime}, \boldsymbol{B}_{2}^{\prime}, \cdots, \boldsymbol{B}_{n}^{\prime}\right], \\ \boldsymbol{B}_{j}^{\prime}=\sum_{i=1}^{n} \boldsymbol{a}_{i j}, \end{array}$
其中B'j表示第j个单词的自注意力权重分数.
如上所述, 交叉注意力权重和自注意力权重关注NMT模型的不同方面, 两者都至关重要, 对扰动单词进行筛选时应同时考虑这两方面的因素, 因此考虑使用混合注意力权重的方式进行扰动单词的筛选.混合注意力权重矩阵为:
H=λ A+(1-λ )B,
其中λ 表示平衡权重比例的超参数.H内部元素表示该单词对翻译任务的重要性, 由此, 对每个单词的得分进行排序, 对扰动单词进行筛选.
对抗训练是公认的用于提升模型鲁棒性的方法之一, 广泛应用于自然语言处理与计算机视觉领域.通过在训练过程中引入对抗样本可以增强模型对输入扰动的抵抗能力.对抗样本是通过在原始数据上施加细微但有针对性的扰动生成的, 通常旨在最大化模型的预测误差.在对抗训练中, 模型通过学习如何正确处理这些扰动样本, 朝着含有扰动的损失最小化方向更新参数, 提高对输入噪声的适应性, 其数学表达式如下:
其中, x表示源语言, y表示目标语言, radv表示扰动量, S表示约束空间, 施加的扰动需要在一定范围之内, θ 表示模型参数, D表示训练语料库.
对抗样本的构建采用白盒方法, 通过访问模型的梯度信息, 在梯度上升方向施加扰动, 生成能揭示模型弱点的对抗样本.具体的构建过程如下.
1)计算干净样本xi的翻译损失函数
$\boldsymbol{L}_{\mathrm{nmt}}=\sum_{i=1}^{n}-\ln \left(P\left(\boldsymbol{y}_{i} \mid \boldsymbol{x}_{i} ; \boldsymbol{\theta}\right)\right), $
及在xi处的梯度
g=Ñ Lnmt(xi, yi; θ ),
其中, P(yi|xi; θ )表示源句子xi翻译为目标句子yi的概率, n表示句子数量, θ 表示模型参数, Ñ 表示梯度计算.
2)基于梯度生成对抗样本x', 第i个样本的生成对抗样本为:
x'i=xi+α
其中, α 表示超参数, 用于控制扰动量的大小.
3)将生成的对抗样本x'再次输入NMT模型中进行对抗训练, 计算对抗样本翻译损失:
$L_{\mathrm{adv}}=\sum_{i=1}^{n}-\ln \left(P\left(\boldsymbol{y}_{i} \mid \boldsymbol{x}_{i}^{\prime} ; \boldsymbol{\theta}\right)\right) .$
在训练阶段, 为了增强模型对噪声影响的抗干扰能力, 在解码器中加入相对熵损失函数(即KL散度损失函数).这一设计旨在使模型对干净样本和对应扰动样本的预测分布保持一致, 减少对抗样本对模型预测的干扰.通过在训练过程中优化相对熵损失函数, 可有效拉近干净样本分布与噪声样本分布之间的距离, 增强模型在复杂输入条件下的鲁棒性.
具体而言, 相对熵损失函数通过衡量两种分布之间的信息差异, 将模型预测分布调整为与干净分布更接近.在对抗训练中, 干净样本的预测分布被视为标准分布, 而对抗样本的预测分布则是目标分布.在优化相对熵损失函数的过程中, 使模型逐步减小两种分布之间的偏差, 在提升模型对于对抗样本适应能力的同时, 避免其对于干净样本的拟合能力下降.相对熵损失函数如下:
$\begin{aligned}L_{\mathrm{kl}}= & \sum_{i=1}^{n} K L\left[P\left(\boldsymbol{y}_{i} \mid \boldsymbol{x}_{i} ; \boldsymbol{\theta}\right) \| P\left(\boldsymbol{y}_{i} \mid \boldsymbol{x}_{i}^{\prime} ; \boldsymbol{\theta}\right)\right]= \\& \sum_{i=1}^{n} P\left(\boldsymbol{y}_{i} \mid \boldsymbol{x}_{i} ; \boldsymbol{\theta}\right) \ln \left(\frac{P\left(\boldsymbol{y}_{i} \mid \boldsymbol{x}_{i} ; \boldsymbol{\theta}\right)}{P\left(\boldsymbol{y}_{i} \mid \boldsymbol{x}_{i}^{\prime} ; \boldsymbol{\theta}\right)}\right) .\end{aligned}$
NMT最终优化目标函数L由干净样本翻译损失函数Lnmt、对抗样本翻译损失函数Ladv和相对熵损失函数Lkl构成, 计算公式如下:
L=Lnmt+Ladv+λ Lkl,
其中λ 是平衡相对熵损失函数权重的超参数.
AOAT应用对抗训练框架提升NMT模型的鲁棒性和泛化性, 训练过程分为两个阶段, 每个阶段都有明确的目标和步骤.
第一阶段为干净样本训练阶段.首先将经过预处理的干净数据批次输入模型, 数据依次通过编码器和解码器, 完成翻译损失的计算.在此过程中, 同时提取和计算编码器与解码器中的注意力权重.基于注意力权重, 筛选模型较关注的单词, 作为后续对抗训练中需要施加扰动的对象.通过干净样本的训练, 模型能学到相对稳定的翻译模式.
第二阶段为对抗样本训练阶段.首先通过梯度反向传播, 计算翻译损失关于输入样本的梯度信号.根据梯度信号, 修改第一阶段筛选的扰动单词的词嵌入表示, 生成对抗样本, 模拟未登录词等翻译过程中可能出现的噪声现象.然后, 将生成的对抗样本重新输入模型, 进行对抗训练, 强化模型对噪声数据的鲁棒性.
此外, 为了进一步提升模型的鲁棒性, 通过相对熵损失函数对比和优化干净样本的预测分布与对抗样本的预测分布.相对熵损失函数的计算旨在拉近两种分布的距离, 促使模型不仅良好拟合干净数据分布, 还能有效应对噪声数据的干扰.
最后, 综合优化干净样本的翻译损失、对抗样本的翻译损失和相对熵损失, 对模型参数进行联合更新.通过这种双阶段的训练框架, AOAT增强模型处理未登录词噪声数据的鲁棒性, 提升对干净数据的拟合能力.
AOAT具体过程如算法1所示.
算法1 AOAT
输入 训练语料D
输出 具有鲁棒性的翻译模型
For minibatch in D do:
For x、 y in minibatch do:
//干净样本训练阶段
将x、 y送入模型进行训练, 计算混合注意力权
重矩阵H
根据H筛选前k个需要扰动的单词
计算损失函数Lnmt
//对抗样本训练阶段
进行梯度回传, 得到梯度g
生成对抗样本x'
计算对抗损失函数Ladv
//目标优化
计算相对熵损失函数Lkl
进行NMT参数更新
End
End
本文核心任务是中-缅低资源翻译, 缅→ 中实验为主体, 越→ 中和英→ 法作为辅助验证.为了评估AOAT的有效性, 针对NMT任务, 在缅→ 中、越→ 中和英→ 法数据集上进行实验, 涵盖干净场景和噪声场景.
当前互联网上开源的中-缅双语平行语料资源较稀少, 难以满足中-缅NMT任务的训练需求.为此, 本文基于开源语料库OPUS(Open Parallel Cor-pus)[23]、ALT(Asian Language Treebank)[24]语料库和互联网可比语料, 自建包含3.0× 105条训练数据的中-缅平行语料库.
此外, 由于ALT语料库语料质量相对较高, 从中分别抽取2 000条语料作为测试集和验证集.同时, 为了验证AOAT在其它数据集中的有效性, 还基于OPUS语料库和互联网可比语料构建5× 105条中-越双语平行语料, 并利用公开数据集europarl-v7中的2.0× 106条英-法平行语料.实验数据集详细信息如表1所示.
| 表1 实验数据集 Table 1 Experimental dataset |
AOAT是基于开源工具包fairseq实现的, 使用Python 3.8计算环境.基于Transformer架构搭建模型, 编码器和解码器隐藏状态维度设为512, 编码器和解码器层数设为6, 模型头数设为8, 每批次最大标记数设为4 096, 梯度累积步数设为4, 学习率预热更新步数设为4 000, 初始学习率设为1e-7, 标签平滑值设为0.1, 失活率设为0.1.采用β 1=0.90, β 2=0.98的Adam(Adaptive Moment Estimation)优化器.采用早停机制, 当验证集的BLEU值在连续10个迭代周期内未出现提升时, 提前终止训练, 以此有效防止模型发生过拟合.超参数设为0.5, 单词扰动数量设为3.
训练所用硬件资源包括GEFORCE RTX 3090 GPU.
为了验证AOAT对未登录词噪声的抵抗能力, 选择如下对比基线模型.
1)AdvGen[17].对抗训练框架, 采用基于梯度的白盒方法生成对抗性源样本和目标样本.在训练过程中, 通过对抗性源样本对翻译模型发起攻击, 同时利用对抗性目标样本对模型进行保护, 提升翻译模型的鲁棒性.
2)AdvAug[18].进一步扩展AdvGen, 以每个对抗样本为对抗空间的中心, 采用线性插值方法, 在对抗样本附近进行最近邻采样, 生成更多的虚拟对抗样本.在AdvGen训练框架的基础上, 增加虚拟样本, 进一步增强模型的鲁棒性.
3)WSLS[20].黑盒对抗攻击方法, 引入额外的语言模型, 对输入单词的重要性进行排序, 识别对翻译结果影响较大的关键单词.再针对筛选的单词进行扰动操作, 通过最近邻单词替换生成对抗性输入.
4)TransFool[21].白盒定向对抗攻击方法, 旨在生成对抗示例, 迫使目标端翻译中插入特定的关键词.基于优化和梯度投影, 利用语言模型的嵌入表示捕捉词汇的语义信息, 计算词语之间的语义相似性.这种语义相似性有助于在优化目标函数中引入相似性约束.目标函数还包含对抗损失项, 确保生成的翻译包含预定关键词.
5)Transformer[25].序列到序列的训练策略, 不进行任何数据扩充, 模型架构与原文献保持一致.
针对NMT任务, 在缅→ 中、越→ 中、英→ 法数据集上进行实验, 涵盖干净场景和噪声场景.对于噪声测试集, 根据词嵌入的相似度, 将两个词随机替换成相关词, 模拟词级噪声.各模型的BLEU指标如表2所示.
| 表2 各模型在3个数据集上的BLEU值 Table 2 BLEU score of different models on 3 datasets |
由表2可见, 在缅→ 中、越→ 中和英→ 法翻译任务中, AOAT均取得最优值.在干净测试集上, BLEU指标提升幅度为0.62~1.07, 而在噪声测试集上, 提升幅度达到1.74~2.29.相比基线模型, AOAT在噪声场景中鲁棒性更强, 可显著降低词级噪声对翻译性能的负面影响.
为了进一步验证AOAT的有效性, 设计消融实验, 分别移除如下两个模块, 研究各模块对整体性能的贡献.
1)混合注意力权重筛选策略.在干净数据训练阶段, 计算编码器与解码器注意力机制的权重分数并进行加权混合, 该分数用于标识单词在翻译任务中的影响力, 根据单词重要性进行扰动词筛选.实验中将该筛选策略替换为随机选择扰动单词的策略.
2)相对熵损失函数.在训练过程中优化相对熵损失函数, 可拉近干净样本分布与噪声样本分布之间的距离, 增强模型在复杂输入条件下的鲁棒性.
在缅→ 中、越→ 中和英→ 法数据集上进行实验, BLEU指标如表3所示.
| 表3 消融实验结果 Table 3 Ablation experiment results |
由表3可见, 模型性能均出现一定程度的下降, 从而验证AOAT的有效性.当混合注意力权重筛选策略改为随机选择扰动单词策略时, 模型在3个数据集上的性能均出现小幅下降.这表明混合注意力权重筛选策略能显著提升对抗样本的质量, 生成更多有助于模型训练的有效对抗样本, 同时减少无效对抗样本的干扰.此外, 当移除相对熵损失函数时, 模型性能也出现明显下降.这表明相对熵损失函数可帮助模型更好地学习对抗样本知识, 提升对噪声的抵御能力.
综上所述, 混合注意力权重筛选策略和相对熵损失函数均是提升模型性能的重要组成部分.
为了进一步评估AOAT在真实场景中抵御未登录词噪声的能力, 设计并使用额外的测试集对模型进行测试, 验证AOAT对未登录词噪声的鲁棒性.噪声构建结合白盒方法与黑盒方法, 模拟真实场景中的拼写错误和词汇替换.这些额外测试集的分布特性可能与训练数据集存在一定差异, 从而能更全面地分析未登录词对模型性能的潜在影响.
本节构造New Test1、New Test2这两个额外测试集.额外测试集主要针对缅→ 中翻译方向, 涵盖通用领域、IT领域、字幕领域、圣经领域等数据, 并混合生成两个新的测试集, 测试集数据量均为2 000条, 通用领域数据占3/5, 共计1 200条, 其它领域占2/5, 共计800条.由于领域的多样性与混合性, 这两个新的测试集包含一些在模型训练过程中较少出现甚至未曾出现的词汇.这些词汇在真实翻译场景中可能以未登录词的形式出现, 往往会对模型的翻译质量和鲁棒性带来较大挑战.特别是在涉及新兴术语、俚语、文化专有词的情况下, 模型可能无法准确捕捉语义, 导致翻译结果出现偏差或错误.通过引入这些额外的测试集, 可更全面和细致地验证AOAT在实际应用场景中抵御未登录词噪声的能力.
各模型在New Test1、New Test2测试集上的BLEU指标如表4所示, 由表可见, 在2个测试集上, AOAT均取得最优值, 表明AOAT在真实场景中能有效抵御未登录词噪声带来的负面影响.同时, AOAT不仅能在包含未登录词的复杂环境中保持鲁棒性, 还展现出一定的领域泛化能力, 即能适应分布与训练数据集存在较大差异的领域数据.
| 表4 各模型在2个新测试集上BLEU值 Table 4 BLEU score of different models on 2 new test sets |
2.5.1 模型微调
由于AOAT旨在发掘模型弱点, 通过生成针对性的样本, 进行对抗训练以提升模型鲁棒性, 因此同样适用于微调现有模型.本文基于Transformer架构训练一个字符噪声鲁棒的模型, 引入字符噪声数据进行对抗训练, 使用对比学习提升对字符噪声的鲁棒性.在该模型基础上使用AOAT对字符模型进行进一步微调, 验证AOAT的拓展性, 并测试其在噪声测试集上的鲁棒性.
本节设计2个测试集.1)字符级噪声测试集.评估模型在输入字符被随机删除、替换或交换等扰动下的鲁棒性, 模拟真实应用中常见的拼写错误与键入噪声.2)词级噪声测试集.对输入句子中的部分词语进行替换、置换或删除, 旨在测试模型在语义轻度扰动或词级噪声条件下的稳健性.
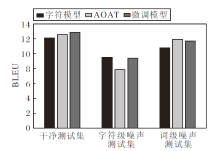
字符模型、AOAT、使用AOAT微调字符模型后得到的模型(后文简记为微调模型)的BLEU指标如图2所示.由图可见, 在干净测试集上, 3个模型性能相差不大, 但微调模型性能最佳.在字符级噪声测试集上, 由于字符模型针对字符级噪声设计, 因此在该测试集上的性能最佳.相比之下, AOAT在字符级噪声测试集上性能显著下降, 而微调模型性能与字符模型接近, 能有效抵御字符级噪声的影响.在词级噪声测试集上, 字符模型性能显著下降, 而AOAT与微调模型性能差距不大, 均能较好抵御词级噪声的影响.由图可见, 微调模型在一定程度上能同时抵御字符级噪声和词级噪声的影响, 尽管其在某种特定噪声上的性能略低于专门设计的模型, 但综合性能最佳, 表明模型具有一定的拓展性, 可在一定程度上提升现有模型对词汇噪声的鲁棒性.
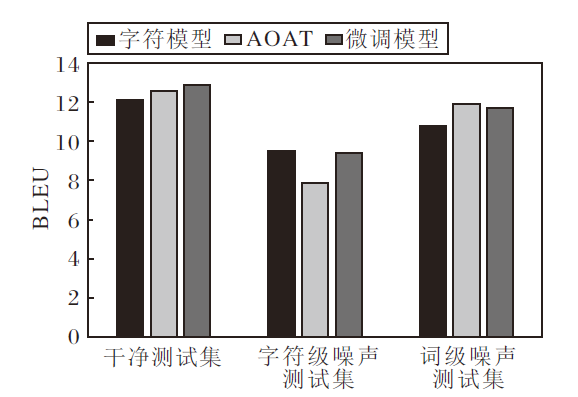 | 图2 不同噪声类型下AOAT性能对比Fig.2 AOAT performance comparison under different noise types |
2.5.2 复杂噪声测试
为了验证AOAT对语法扰动、语义替换等复杂噪声的鲁棒性, 构建两类噪声测试集.1)语法扰动噪声测试集.使用SyntaxGym工具对源语句进行随机语序调整、功能词插入或删除, 模拟真实场景中的语法错误.2)语义替换噪声测试集.基于Word-Net或同义词库, 将句子中的关键实词替换为语义相近但上下文不匹配的词汇, 模拟语义理解偏差.每类噪声测试集包含2 000条样本.
在缅→ 中任务上进行评估实验, 选择Trans-former、AdvGen、TransFool、AOAT, 具体BLEU指标如表5所示.由表可见, AOAT在语法扰动噪声和语义替换噪声下均显著优于基线模型, 说明其对于复杂噪声类型具备较强的鲁棒性.
| 表5 各模型在复杂噪声类型下的BLEU值 Table 5 BLEU score of different models under complex noise types |
2.5.3 数据增强策略
为了探究AOAT在更大规模语料下的性能上界, 采用如下两种数据增强策略扩展缅-中训练集.1)回译增强.使用训练好的Transformer对中文单语语料进行回译, 生成伪平行数据.2)替换增强.使用EDA[22]对原有平行语料进行同义词替换、随机插入等操作.通过上述方法, 将原始3× 105条句对扩展至6× 105条句对, 重新训练AOAT并评估其性能.
不同数据增强策略下的BLEU指标如表6所示.
| 表6 不同数据增强策略下的BLEU值 Table 6 BLEU score under different data augmentation strategies |
由表6可见, 数据规模扩展后, AOAT在噪声测试集上的BLEU值提升近1.0, 说明模型在更大规模语料下具有良好的扩展性.
为了验证AOAT对未登录词噪声的抵御能力, 通过具体翻译实例验证其有效性.
各模型翻译结果如表7所示, 在表中, 黑体中文表示正确部分, 下划线表示错误部分, 黑体缅甸语表示未登录词.由表可见, 在该翻译实例中, AOAT翻译效果最佳, 翻译结果与参考翻译语义基本一致, 而基线模型出现误译.Transformer因未登录词影响开始胡言乱语.AdvGen和AdvAug将“ 粉尘” 误译为“ 面粉” .TransFool将“ 高浓度可燃粉尘” 误译为“ 高浓度可燃面粉” .WSLS将“ 可燃粉尘” 误译为“ 白粉” , 同时丢失“ 通风不良” 的语义.只有AOAT进行正确翻译.上述实例分析表明, AOAT面对含有未登录词噪声的输入能取得良好的翻译结果, 有效抵抗该类噪声的影响.
| 表7 各模型翻译实例对比 Table 7 Translation example comparison of different models |
为了验证AOAT在大模型时代的竞争力, 选取在低资源语言上表现较优的预训练模型mBART-50(Multilingual Bidirectional and Auto-Regressive Transformers)作为基线模型, 在相同缅→ 中数据上进行微调, 并对比其在各类噪声测试集上的表现, 具体BLEU指标如表8所示.
| 表8 mBART-50和AOAT在不同噪声测试集上的BLEU值 Table 8 BLEU score of mBART-50 and AOAT on different noisy test sets |
由表8可见, 尽管mBART-50在干净测试集上表现略优, 但在各类噪声环境下, AOAT均表现出更强的鲁棒性, 尤其在词级噪声和语义替换噪声上优势明显, 说明AOAT在低资源噪声敏感场景中仍具实用价值.
为了缓解未登录词噪声对NMT模型性能的影响, 本文提出基于注意力优化对抗训练的中-缅神经机器翻译模型(AOAT).设计混合注意力筛选策略, 提升对抗攻击的有效性, 并利用对抗训练的框架提升模型对未登录词噪声的鲁棒性.在缅→ 中、越→ 中和英→ 法翻译任务上的实验表明AOAT的有效性.进一步的消融实验表明, 混合注意力筛选策略和相对熵损失函数能有效缓解未登录词噪声的负面影响.此外, 使用AOAT微调字符模型, 微调后的模型能在一定程度上同时抵御字符级噪声和词级噪声的影响, 表明AOAT具有拓展性, 能在一定程度上提升现有模型对词级噪声的抵御能力.
本文的研究范围主要聚焦于低资源翻译中最常见的词级噪声, 如未登录词和拼写错误.尽管实验表明AOAT在此类噪声上的有效性, 但对于语法结构扰动、深层语义替换等更复杂类型的噪声, 其鲁棒性仅是进行初步验证.探索模型在更广泛的噪声类型下的表现, 是未来一个重要的研究方向.
本文提出的混合注意力筛选策略的有效性依赖于注意力机制本身对词汇重要性判断的准确性.尽管混合注意力权重在多数情况下能有效识别关键词, 但当注意力分布不稳定或存在偏置时, 可能会影响扰动策略的最终效果.今后可考虑引入外部词汇重要性评价指标(如基于语言模型的句法分析结果)与注意力机制进行融合, 进一步增强筛选策略的鲁棒性和可靠性.
本文责任编委 林鸿飞
Recommended by Associate Editor LIN Hongfei
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|