

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
多模态查询引导的端到端行人搜索
[周淳1, 2  , 张亚飞
, 张亚飞1, 2 , 王红斌1, 2
, 张亚飞, 王红斌]
|
|



作者简介:

周 淳,硕士研究生,主要研究方向为行人搜索、多模态检索.E-mail:chunzhou_zzz@163.com.

张亚飞,博士,教授,主要研究方向为图像处理、模式识别.E-mail:zyfeimail@163.com.
现有行人搜索方法普遍局限于图像查询,当查询图像质量不佳或行人特征不完整时,检索准确性显著降低.此外,主流方法依赖区域提案网络和非极大抑制生成预定义候选框,难以实现查询到全景图库的端到端行人搜索.因此,文中提出多模态查询引导的端到端行人搜索方法,引入行人的文本描述作为辅助模态,弥补单一视觉信息的不足,并通过端到端架构联合优化行人检测和重识别任务.首先,挖掘查询图像与文本描述的差异化语义信息,学习更全面的行人信息,提升行人表征的语义完整性.然后,利用跨模态注意力机制,增强全景图像上与查询信息对应的行人特征,提升对行人特征的判别能力.最后,采用基于Transformer的检测模块,摒弃传统区域提案网络和非极大抑制流程,直接输出行人搜索结果.在具有挑战性的数据集上的实验表明,文中方法性能较优,由此验证方法的有效性.
About Author:
ZHOU Chun, Master student. Her research interests include person search and multi-modal retrieval.
ZHANG Yafei, Ph.D., professor. Her research interests include image processing and pattern recognition.
Current person search methods are predominantly limited to image-based queries and their retrieval accuracy is significantly restricted by the low quality of query images or the incomplete pedestrian features. Furthermore, mainstream methods rely on region proposal networks and non-maximum suppression to generate predefined candidate boxes, making it difficult to achieve end-to-end person search directly from a query to a panoramic gallery. Therefore, a multimodal query-guided end-to-end person search method is proposed. Textual descriptions of pedestrians are introduced as an auxiliary modality to address the limitation of relying solely on visual information. The pedestrian detection and re-identification tasks are jointly optimized within an end-to-end architecture. To enhance the semantic completeness of pedestrian representations, the differentiated semantic information between the query image and the text description is explored and more comprehensive pedestrian information is learned. Then, a cross-modal attention mechanism is utilized to enhance the pedestrian features in the gallery images corresponding to the query information to improve the discriminative ability for pedestrian features. Finally, a detection module based on Transformer is adopted. It discards the traditional region proposal networks and non-maximum suppression pipeline, and directly outputs the final person search results. Experiments on the challenging datasets demonstrate the superior performance of the proposed method.
行人搜索技术旨在从未剪裁的复杂场景图库中实现目标行人的精准识别与定位, 即从全景图像中通过查询图像或文本描述, 找到与目标行人匹配的实例, 其本质是融合行人检测与行人重识别的任务.其中, 行人检测模块负责生成行人候选框, 行人重识别模块通过特征对比实现行人身份判别.
在实际应用场景中, 目击者的描述和监控摄像头中拍摄的目标行人图像往往可以互为佐证.当视觉信息因遮挡、错位、姿态变换等原因无法提供完整行人图像时, 文本描述可有效补充衣着属性、发型、体型等语义信息.
传统两步法[1, 2]独立训练两个网络:检测网络和重识别网络.首先通过检测网络也就是区域提案网络(Region Proposal Network, RPN)生成行人候选框, 然后非极大抑制(Non-Maximum Suppression, NMS)通过设置阈值过滤生成的行人候选框, 将得到的行人候选框裁剪后作为重识别网络的输入, 进行行人的重识别.传统两步法通常能获得较高的检索性能, 但需要分别训练两个网络, 任务繁重.
现有一步法分为一步两阶段方法[3, 4]和一步一阶段方法[5].一步两阶段方法类似于传统两步法, 区别在于传统两步法需要独立训练两个网络, 一步两阶段方法将两个网络整合后进行端到端的训练.一步一阶段方法使用共享的主干网络连接检测头和重识别头, 检测头通过RPN生成行人候选框, 再利用NMS过滤行人候选框, 与此同时, 重识别头完成行人的重识别.相比传统两步法, 现有一步法实现较大突破, 能端到端进行行人检索, 但仍依赖RPN和NMS, 过程会产生大量冗余候选框, 且需针对不同场景调整NMS的参数阈值, 阻碍行人搜索任务的端到端优化.
在利用文本信息进行多模态融合增强时, 现有方法通常选择强化图像与文本模态之间的共性特征.然而, 图像与文本作为异构模态, 对同一行人的描述天然存在信息非重叠.例如:文本可能精确描述“ 身穿褐色上衣” , 而图像呈现未被文本提及的独特花纹、配饰等视觉细节, 恰恰是构成行人独特身份的关键判别性线索.若融合策略仅侧重于对齐共识区域, 则可能弱化这些互补信息, 限制方法在细粒度场景中的判别力.
针对上述不足, 本文提出多模态查询引导的端到端行人搜索方法(Multimodal Query-Guided End-to-End Person Search, MMQPS), 由图像查询与生成的文本查询共同引导, 无需中间生成候选框, 直接输出最终的行人预测结果, 端到端联合优化行人检测与重识别任务.MMQPS协同利用图文模态间的共识信息和非重叠互补信息, 突破仅依赖共性特征的局限性.首先, 裁剪查询行人图像并生成对应的文本描述, 利用图文之间的共识与互补语义, 学习更全面的行人特征.然后, 设计多模态查询差异增强模块(Multimodal Query Difference Enhancement Module, MQDEM), 通过差异化特征增强策略, 在保持高相似度区域语义一致性的同时, 挖掘并增强低相似度区域中文本未描述的独特视觉特征, 丰富行人表征的判别性.同时, 设计联合查询引导的行人特征增强模块(Joint Query-Guided Person Feature Enhancement Module, JQFEM), 旨在在图像库(Gallery)的图像中识别与联合查询特征最相关的目标行人区域, 增强Gallery图像中行人特征的判别性.MMQPS基于Transformer[6], 避免传统方法中产生冗余候选框、依赖超参数调节的局限性, 可实现最终行人的检测与定位.
行人搜索旨在联合执行行人检测与行人重识别两个关键子任务.行人检测作为目标检测的特例, 旨在定位图像中所有行人实例.最具代表性的检测框架为基于锚框(Anchor-Base)的Faster R-CNN[7].近年来, Yan等[8]提出AlignPS(Feature-Aligned Person Search Network), 进行无锚框(Anchor-Free)行人检测.谢明鸿等[9]提出Anchor Free与Anchor Base检测器相结合的双头行人检测算法, 探索锚框与无锚框策略的平衡.行人重识别任务则聚焦不同行人特征之间的判别表示, 现已拓展至多个领域.石林波等[10]提出模态不变性特征学习和一致性细粒度信息挖掘的跨模态行人重识别, 通过模态不变性特征学习缓解模态差异, 在挖掘判别性信息的同时实现语义对齐.万磊等[11]提出多模态特征融合和自蒸馏的红外-可见光行人重识别方法, 在特征融合过程中为不同模态赋予动态权重, 并采用自蒸馏无参数动态引导策略, 强化方法的推理能力.还有研究者关注无监督域自适应场景中的行人重识别.李玲莉等[12]分离图像特征中的风格信息和行人信息, 并利用同一身份属性的一致性建立特征-属性对应关系, 用于优化模型.毛彦嵋等[13]侧重于挖掘行人的多粒度特征, 通过风格迁移实现跨域特征对齐.Li等[14]通过特征分组协同增强与跨摄像头样式交换, 实现无配对样本下的判别性特征学习.Zhang等[15]通过异质专家协同一致性学习框架, 仅利用单模态标签实现跨模态身份对应, 有效提升模态不变特征提取能力.Li等[16]不依赖配对数据, 通过身份原型与提示学习, 利用未配对样本提升模型泛化能力.行人检测与行人重识别任务均可视为构建高效行人搜索的基础任务.
当前行人搜索方法主要可分为两步法和一步法.两步法遵循“ 先检测再重识别” 的级联架构, 分别独立训练检测网络与重识别网络.Zheng等[1]提出IDE(ID-Discriminative Embedding), 是经典的两步法, 同时构建行人搜索基准数据集PRW(Person Re-identification in the Wild), 并组合不同的检测网络与重识别网络进行训练, 提升方法性能.
后续研究主要围绕特征对齐优化与级联损失设计进行改进.虽然两步法通常能获得较高检索精度, 但存在推理效率较低、计算冗余度较高等固有缺陷.一步法则通过端到端架构联合优化检测与重识别任务, 显著提升计算效率.Xiao等[5]构建另一个基准数据集CUHK-SYSU, 基于Faster R-CNN[7], 采用动态查询表机制替代传统行人身份分类器, 利用在训练时每个小批量中的身份信息构建可更新矩阵查找表, 实现大规模身份库的高效管理.Faster R-CNN还被运用到不完全监督行人搜索中.Kim等[17]提出MoS(Mixture of Submodules), 动态组合不同子模块, 缓解检测与重识别任务间的梯度冲突, 并利用对抗样本生成, 提升域自适应模型的泛化能力.Zhu等[18]提出OLA(Optimizing Label Assignment), 针对弱监督行人搜索, 提出优化标签分配方案, 通过上下文感知聚类与基于最优传输的原型匹配提升方法性能.然而, 此类方法普遍依赖Faster R-CNN的锚框机制, 性能容易受锚框超参数敏感性问题制约.
随着无锚框(Anchor-Free)架构的兴起, Yan等[8]提出AlignPS, 设计重识别优先策略, 引入特征对齐模块, 提升身份嵌入的判别性, 有效替代传统锚框机制.与此同时, Transformer催生DETR(Detection Transformer)系列目标检测框架.Cao等[19]提出PSTR, 将行人搜索建模为序列预测问题, 设计部位感知注意力机制, 捕获行人局部特征间的关联性, 结合多尺度特征交互模块, 提升方法在遮挡场景中的检测鲁棒性.
视觉查询引导的行人搜索利用图像查询特征优化检索过程, 核心方法聚焦于注意力机制和特征交互两个方向.Liu等[20]提出NPSM(Neural Person Search Machines), 基于Conv-LSTM(Convolutional Long Short-Term Memory)实现检测候选框的渐进式筛选, 采用空间注意力机制替代传统RPN.然而, 该方法依赖复杂的逐层特征交互, 计算复杂度显著增加, 在处理多查询场景时效率极低.为了提升效率, Munjal等[21]提出QEEPS(Query-Guided End-to-End Person Search Network), 利用SENet(Squeeze-and Excitation Network)建立查询行人特征和Gallery图像特征间的连接, 计算通道权重向量并对特征进行加权, 从而增强特征间的交互.查询指导的RPN融合查询引导的通道级注意力机制与标准RPN, 根据加权后的特征提取与查询行人相似性得分较高的候选框, 再用于行人重识别.QEEPS需要为每位查询行人重新计算候选框, 每层网络都需要执行Gallery图像和查询图像的特征交互, 计算开销依然较高.此外, 其查询指导的RPN本质上仍依赖传统RPN生成候选框.Dong等[22]提出BINet(Bi-directional Interaction Net- work), 引入双向交互机制, 采用Gallery图像分支与行人图像分支的双分支架构.行人图像分支的输入来自Gallery图像, 通过RPN生成的候选框裁剪并调整为固定大小的图像区域.BINet通过特征蒸馏抑制背景干扰, 同时设计跨模态门控单元, 动态调节查询与Gallery特征的权重.然而, 使用RPN生成的候选框裁剪下的图像区域作为独立分支输入, 不可避免地会损失重要的空间上下文信息, 并可能因裁剪框的不精确而引入背景噪声或截断行人关键部位.Jaffe等[23]提出SPNet(Swap Path Net), 将行人搜索方法分为以对象为中心的方法和以查询为中心的方法, 并证明以查询为中心的方法对标注噪声更鲁棒.SPNet使用同一套权重实现上述两种训练目标, 并可在两者间切换.采用先进行以查询为中心的预训练, 再进行以对象为中心的微调这一策略, 实现性能提升.
文本引导的行人搜索旨在建立自然语言描述与视觉特征之间的跨模态关联, 核心挑战在于实现非结构化文本与全景图像的精确语义对齐.现有研究主要聚焦于裁剪后行人图像的文本重识别任务.此类方法的实验设定依赖预先裁剪好的独立行人图像, 而非原始的全景图像.因此, 其本质上更接近基于文本描述的行人重识别, 未能有效解决实际应用场景中直接在未剪裁全景图像上依据文本搜索行人的需求.Zhang等[24]提出Semantic-Driven Region Pro- posal Network, 通过多任务学习策略同步优化行人检测、行人重识别及跨模态嵌入网络, 旨在建立统一的视觉-文本表征空间.在RPN中引入文本注意力模块, 引导候选框生成过程聚焦于与文本描述语义高度相关的图像区域.引入层级式视觉语义嵌入模块, 通过多粒度特征交互增强细粒度行人属性匹配能力.然而, 该方法整体性能不佳, 核心原因在于仅依赖文本描述难以全面精确地关注行人所有关键视觉特征, 并且方法仍依赖RPN生成候选框.
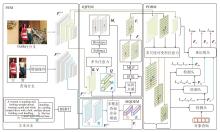
本文提出多模态查询引导的端到端行人搜素方法(MMQPS), 总体框架如图1所示.MMQPS主要包括4个部分:特征提取模块(Feature Extraction Module, FEM)、多模态查询差异增强模块(MQD-EM)、联合查询引导的行人特征增强模块(JQF-EM)、行人检测与重识别模块(Person Detection and Re-identification Module, PDRM).
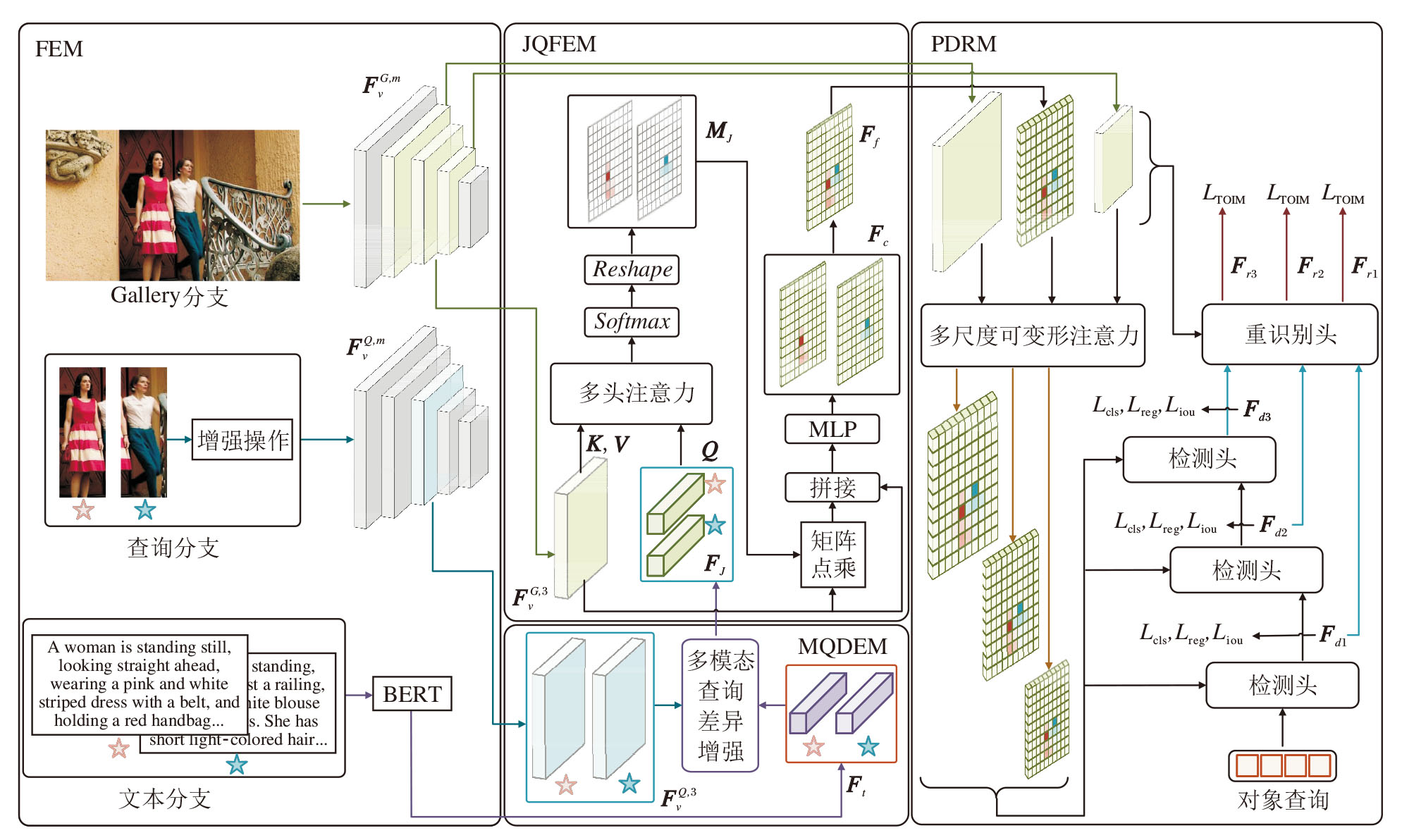 | 图1 MMQPS整体框架图Fig.1 Overall framework of MMQPS |
FEM分别提取Gallery图像、图像查询和文本查询的特征.MQDEM融合文本查询与视觉查询的跨模态特征, 有效弥补单模态查询在细粒度语义上的不足, 关注更多不同模态非重叠的特征信息, 提升整体表达能力与区分能力.JQFEM联合查询特征与Gallery图像特征的注意力交互, 建立联合查询到Gallery图像的对应关系, 增强Gallery图像上的行人特征.PDRM通过级联的检测头和共享的重识别头实现最终的行人搜索.
本文采用ResNet-50[25]独立提取Gallery图像和图像查询的视觉特征.在一个训练批次中, 随机选取b幅Gallery图像, 图像查询为b幅Gallery图像中所有标记过坐标框的行人.训练时将Gallery图像和其对应的图像查询输入ResNet-50中.此外, 遵循文献[26]的设置, 对每个图像查询引入通道增强操作, 包括通道可交换增强和通道级随机擦除, 旨在通过打乱和随机遮蔽不同通道, 进一步丰富特征表示, 提升方法对多样化语义信息的建模能力.
Gallery图像和增强后的图像查询分别送入ResNet-50进行特征提取.ResNet-50的5个层级分别输出5种不同尺度的特征:Gallery特征
为了克服传统多模态融合策略可能抑制互补信息的局限性, 本文设计多模态查询差异增强模块(MQDEM), 核心目标是通过主动挖掘并增强图像中与文本描述不相似的区域, 捕获被传统方法忽略的互补信息, 得到一个兼具语义一致性和视觉独特性的行人表征.
MQDEM采用局部自适应特征增强策略.首先, 对图像查询特征进行展平, 并计算其与对应的文本查询特征之间的相似度.根据计算结果, 对低相似度区域进行特征增强, 对高相似度区域保留原始特征以维持语义一致性.然后, 融合优化后的图像特征与文本特征, 生成多模态联合查询特征.MQDEM不仅充分挖掘跨模态的互补信息, 还通过差异化增强有效提升行人表征的判别性与完整性.
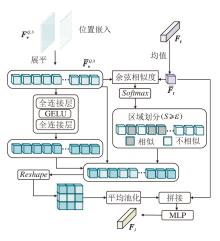
MQDEM结构如图2所示, 输入为图像查询经ResNet-50提取的第3层特征
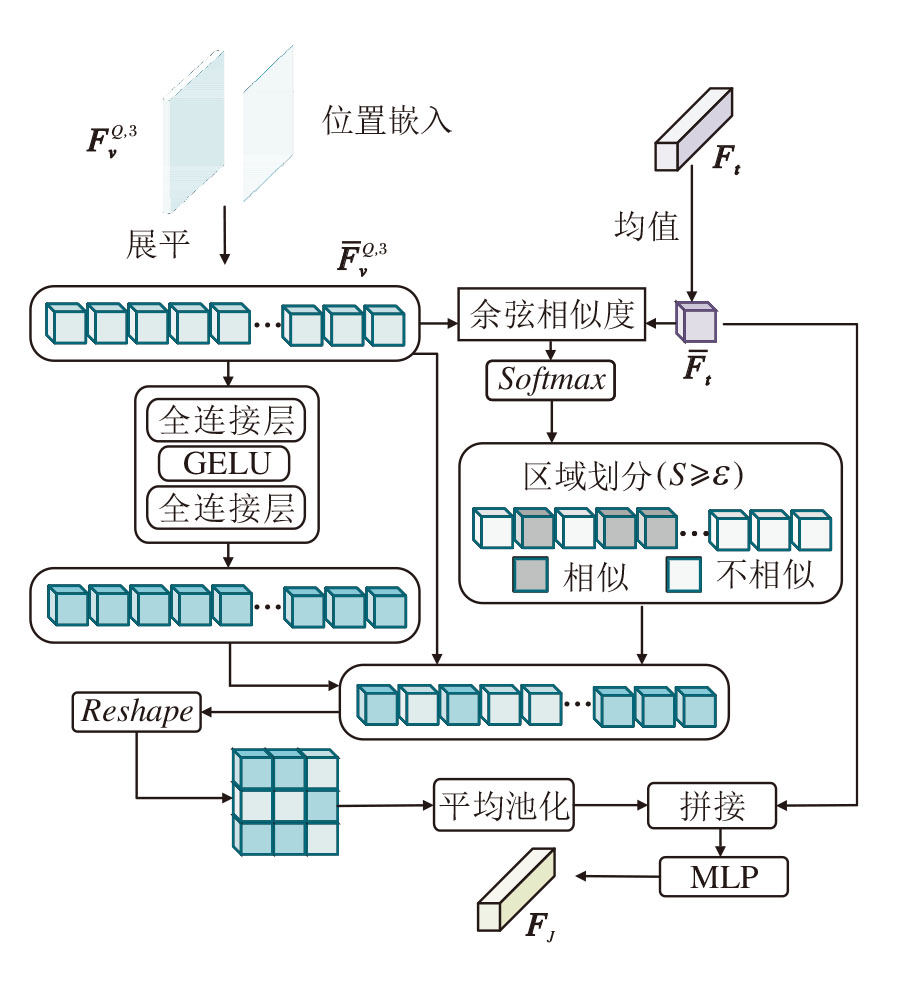 | 图2 MQDEM结构图Fig.2 Structure of MQDEM |
具体地, 首先对图像查询特征
$\boldsymbol{S}=\operatorname{softmax}\left(\overline{\boldsymbol{F}}_{t} \otimes \overline{\boldsymbol{F}}_{v}^{Q, 3}\right) \in \mathbf{R}^{1 \times h w}, $
其中, S=[S1, S2, …, Shw], Si(i=1, 2, …, hw)取值范围为[0, 1].通过设置相似度阈值ε =0.7, 将视觉特征分为与文本查询的非相似性区域S~mask和相似性区域Smask:
$\widehat{\boldsymbol{S}}=\left\{\begin{array}{ll} \boldsymbol{S}_{\sim \text { mask }}, & S_{i}< \varepsilon \\ \boldsymbol{S}_{\text {mask }}, & S_{i} \geqslant \varepsilon \end{array}\right.$ (1)
将非相似性区域通过全连接层、GELU(Gaussian Error Linear Unit)和全连接层操作进行特征增强, 相似性区域保留原始特征.将增强后的图像查询重构至原始特征大小, 经平均池化后与文本特征进行跨模态融合, 最后通过线性投影输出多模态联合查询特征FJ .
为了增强Gallery图像中行人特征的判别性, 构建联合查询引导的行人特征增强模块(JQFEM), 引入多头注意力机制, 建立联合查询特征与Gallery图像特征之间的关联关系, 实现对Gallery图像中行人特征的选择性增强.JQFEM能突出与联合查询相关的行人特征, 提升行人搜索模型的整体性能.
JQFEM的具体结构如图1所示, 输入为Gallery图像经ResNet-50提取的第3层特征
具体地, 将Gallery图像特征每个通道上H× W的矩阵展平为长度为HW的向量, 转置后得到视觉特征
Qi=FJ
其中,
然后, 计算Q和所有K的点积并缩放, 再沿H× W维度进行Softmax(· )运算, 得到第i个头注意力热图:
$\text { Attention }_{i}=\text { Softmax }\left(\frac{\boldsymbol{Q}_{i} \boldsymbol{K}_{i}^{\mathrm{T}}}{\sqrt{d}}\right) \in \mathbf{R}^{1 \times(H \times W)} .$
将所有头的注意力权重平均后再Reshape回[H, W], 得到注意力空间热图:
$\boldsymbol{M}_{J}=\operatorname{Reshape}\left(\frac{1}{r} \sum_{i=1}^{r} \text { Attention }_{i}\right) \in \mathbf{R}^{H \times W} .$
将热图点乘到Gallery特征
Fw=
Fw再与Gallery特征
行人检测与重识别模块(PDRM)用于行人定位与重识别, 为每位行人预测重识别特征, 实现行人搜索.PDRM包含多尺度可变形注意力、级联的检测头及重识别头.在操作中摒弃RPN操作过程中的候选框冗余和NMS中的超参数计算.
首先, 将ResNet-50提取的第2层特征
然后, 将多尺度可变形注意力块输出的多尺度特征送入检测块.为了更好地适应行人在跨摄像头图像上的尺度变换, 检测块共包含三个级联检测头, 每个检测头包含多头自注意力层、多尺度可变形交叉注意力层和MLP层.此外, 检测块还额外输入一组可学习的对象查询向量, 该向量在自注意力层中彼此交互, 在交叉注意力层中作为查询, 以多尺度特征作为键和值.
3个检测头的输出特征由可学习的对象查询依次学习得到, 分别表示为Fd1、Fd2、Fd3, 用于行人候选框的分类和回归, 通过分类损失(Lcls)、边界框回归损失(Lreg)和边界框IoU(Intersection over Union)损失(Liou)进行优化, 并作为重识别特征查询用于重识别头.重识别头采用文献[19]的部分注意力, 核心思想是根据重识别查询, 动态预测一组代表人体不同判别性部位的采样点, 聚合这些采样点的特征以增强行人身份表征.
具体地, 共享的重识别头以
在训练过程中, 本文采用文献[5]的训练方法, 构建一个查找表:
V={v1, v2, …, vL}∈ RD× L,
用于存储最近小批量中L个标记身份的重识别特征, 其中D表示重识别特征维度.同时, 构建一个循环队列:
U={u1, u2, …, uN}∈ RD× N,
用于存储最近小批量中N个未标记身份的重识别特征.在前向传播过程中, 给定一个在小批量中标签为i的重识别特征f, 在本文中重识别特征为Fr1、Fr2、Fr3.首先通过VTf和UTf分别计算f与查找表V和循环队列U中所有存储特征的余弦相似度, 再根据相似性计算OIM[5].在查找表V中f属于类别id为i的可能性为:
$p_{i}=\frac{\exp \left(\frac{\boldsymbol{v}_{i}^{\mathrm{T}} \boldsymbol{f}}{\tau}\right)}{\sum_{j=1}^{L} \exp \left(\frac{\boldsymbol{v}_{j}^{\mathrm{T}} \boldsymbol{f}}{\tau}\right)+\sum_{k=1}^{N} \exp \left(\frac{\boldsymbol{u}_{k}^{\mathrm{T}} \boldsymbol{f}}{\tau}\right)}, $
其中τ 表示一个控制概率分布的超参数.同样, 循环队列U中f被认为是第i个未标记身份的概率为qi.OIM损失的目标是最小化负对数似然的期望值:
LOIM=-Ef[log2pi], i=1, 2, …, L.
在反向传播过程中, 如果当前重识别特征f的类别id为i, 通过
vi← γ vi+(1-γ )f
更新V中的第i个条目, 其中γ ∈ [0, 1].对于循环队列U, 在每次迭代后, 弹出过时的重识别特征向量, 将当前小批量中新的重识别特征向量存入队列中, 以此更新循环队列U.
在此基础上, 本文采用文献[8]提出的将中心采样策略与OIM结合的三元组损失.具体地, 这一损失的目标是拉近同个id的重识别特征向量, 推远不同id的重识别特征向量.同时, 有标签的重识别特征应和存储在查找表V中的对应特征靠近, 远离查找表V中的其它特征.若一幅Gallery图像上有id为n和m的两位行人, 通过设置缩放因子生成查找表V中重识别特征为vn和vm对应的Z个向量并作为这一id的候选集, 即
Fm={fm, 1, …, fm, Z, vm},
Fn={fn, 1, …, fn, Z, vn},
其中, fi, j表示第i位行人的第j个特征, vi表示查找表V中的第i个特征.给定Fm和Fn, 在每个集合内进行正对采样, 在两个集合之间进行负对采样.
对于vn, {fn, 1, fn, 2, …, fn, Z}为它的正样本, {fm, 1, fm, 2, …, fm, Z}为它的负样本, 正负对之间的欧几里得距离如下所示:
Dpos(z)=‖ vn-fn, z‖ 2, z∈ Z,
Dneg(z')=‖ vn-fm, z'‖ 2, z'∈ Z.
每个正样本都要比所有的负样本更接近vn, 所以每个正样本要与Z个负样本对比, 一共有Z个正样本, 故需要嵌套两层求和.最终的目标是拉近vn和所有正样本之间的距离, 推远vn和所有负样本之间的距离.三元组损失如下所示:
$L_{\mathrm{tri}}=\sum_{z=1}^{Z} \sum_{z^{\prime}=1}^{Z}\left[D_{\mathrm{pos}}(z)-D_{\mathrm{neg}}\left(z^{\prime}\right)+M\right]_{+}, $
其中, M表示距离边距,
[X]+=max(0, x).
该公式确保vn与正样本的距离与负样本之间的距离差小于M.
由此得到三元组OIM损失:
LTOIM=Ltri+LOIM.
最后, 总损失
L=Lcls+Liou+λ 1Lreg+λ 2LTOIM,
其中, Lcls表示分类损失, Liou表示边界框IoU损失, Lreg表示边界框回归损失, LTOIM表示三元组OIM损失, λ 1、λ 2表示平衡不同损失的超参数, 本文设置λ 1=2.5, λ 2=0.2.
在推理过程中, 给定一个图像查询和其对应的文本查询, 从一组图像库中搜索给定图像查询中的行人.首先, 使用MMQPS生成Gallery图像上的重识别特征.然后, 将与图像查询边界框重叠最大的特征设为被查询行人的重识别特征.最后, 计算图像查询和Gallery图像中预测重识别特征的相似性, 识别Gallery图像中与查询图像对应的行人.
本文选择在CUHK-SYSU[5]、PRW[1]数据集上进行实验.
CUHK-SYSU数据集是一个大规模行人搜索基准数据集, 包含18 184幅图像, 涵盖8 432个不同的行人身份, 标注边界框总计96 143个.该数据集被划分为训练集和测试集.训练集包含11 206幅图像和5 532位查询行人, 测试集包含6 978幅图像和2 900位查询行人, 训练集与测试集在图像内容及查询行人身份上均无重叠.数据集样本来源于真实的街道拍摄图像和电影电视截图, 有效涵盖行人搜索任务中的典型挑战, 包括视角变化、光照变化、遮挡程度、分辨率差异等.本文对原始CUHK-SYSU数据集进行多模态扩展, 利用行人检测框坐标及其对应的身份标识信息, 裁剪原始图像, 获得单一行人视觉实例, 作为视觉查询.针对每个视觉查询, 通过预设的结构化提示语句引导基于GPT-4o的图像描述生成器, 生成描述行人外观属性的细粒度文本描述, 作为对应的文本查询.该提示语句旨在引导图像描述生成器生成涵盖衣着特征(颜色/款式)、生理特征(性别/体型/发型)、携带物品等关键语义信息.需要强调的是, 此预处理流程独立于端到端训练框架执行.经数据对齐与校验, 最终形成包含查询图像及文本描述的CUHK-SYSU数据集, 其中训练集包含11 206条对应数据, 测试集包含6 978条对应数据.
PRW数据集为行人搜索领域的基准数据集, 数据源来自6个不同摄像头采集的视频流, 包含11 816幅图像, 其中, 训练集包含5 704幅图像和483位查询行人, 测试集包含6 112幅图像和450位查询行人.需要注意的是, 在训练过程中使用的部分行人身份ID可能出现在测试图像帧中, 但这些身份不会作为测试集的查询身份.同样地, PRW数据集采用与CUHK-SYSU数据集相同的多模态扩展方法, 构建包含查询图像及文本描述的PRW数据集.在扩展后的PRW数据集上, 删除原有训练集和测试集中重复出现的行人的图像帧, 得到训练集共5 661条对应数据, 测试集共5 638条对应数据.该数据集的训练集和测试集在图像内容和查询行人身份上均无重叠, 导致最终数据规模与原始PRW训练集和测试集的划分方案不同.
本文采用平均精度均值(Mean Average Precision, mAP)和累计匹配特性(Cumulative Matching Charac-teristic, CMC)作为行人搜索任务的性能评估指标.mAP常用于目标检测领域, 计算所有查询样本的精确率-召回率曲线下面积的平均值, 综合评估系统的整体检测与识别性能.CMC作为行人重识别任务的核心评估标准, Top-n参数表示系统在按相似度得分降序排列的候选库检索结果中, 正确匹配目标行人出现在前n位的概率.两种指标均具有严格单调性特征, 数值提升与方法性能优化呈正相关.
本文采用ResNet-50[25]作为基础特征提取网络.训练阶段Gallery图像输入尺寸不同, 测试阶段对Gallery图像进行标准化处理, 统一缩放至900× 1 500, 查询图像经图像增强后统一调整为400× 200的固定尺寸.文本编码器采用BERT[27]架构, 输入序列最大长度限制为50个词元.训练周期设为24, 批量大小设为1, 采用AdamW(Adaptive Moment Esti-mation with Weight Decay)优化器, 权重衰减系数设为0.000 1.初始学习率设为0.000 1, 采用分阶段衰减策略:在第16个和第22个训练周期结束时, 学习率分别降为原来的1/10.遵循文献[19]的设置, 在PRW、CUHK-SYSU数据集上, 将OIM机制的身份特征存储队列容量分别设为500和5 000.
实验配置使用单张NVIDIA GeForce RTX 3090 GPU, 方法实现基于PyTorch深度学习框架, 并结合MMDetection[28]检测库完成.
为了验证MMQPS的性能, 进行对比实验, 选择如下对比方法.
1)两步法:IDE[1]、IGPN(Instance Guided Pro-posal Network)[2]、MGTS(Mask-Guided Two-Stream CNN Model)[29]、CLSA(Cross-Level Semantic Alignment)[30]、文献[31]方法、TCTS(Task-Consist Two-Stage)[32], 其中, 文献[31]方法、IGPN和TCTS为有查询引导机制的方法.
2)一步法:SeqNet(Sequential End-to-End Network)[3]、PLoPS[4]、OIM[5]、AlignPS[8]、PSTR[19]、NPSM[20]、QEEPS[21]、BINet[22]、IAN(Individual Aggre-gation Network)[33]、文献[34]方法、APNet(Align-to-Part Network)[35]、NAE(Norm-Aware Embedding Method)[36]、文献[37]方法、DMRNet(Decoupled and Memory-Reinforced Network)[38]、AGWF(Adaptive Gradient Weighting Function)[39]、OIMNet++(Pro-totypical Normalization and Localization-Aware Lear-ning for Person Search)[40]、COAT(Cascade Occluded Attention Transformer)[41]、DTHN(Dual-Transformer Head Network)[42]、文献[43]方法, 其中, NPSM、QEEPS和BINet为有查询引导机制的方法.
各方法在PRW、CUHK-SYSU数据集上的指标值如表1所示, 表中黑体数字表示最优值, -表示原文献未提供数据.PRW数据集因训练数据较少、图像分辨率较高、背景较复杂, 对方法的判别能力与泛化能力提出更高的要求.在传统两步法中, MMQPS在mAP、Top-1指标上达到最优值, 相比次优的查询引导IGPN, mAP指标提升8.6%, 相比次优的查询引导TCTS, Top-1指标提升3.1%.这一优势主要源于本文的端到端架构, 可有效避免传统两步法中检测误差向检索阶段的累积传递, 从而在复杂场景中实现更鲁棒的定位与识别.
| 表1 各方法在2个数据集上的指标值对比 Table 1 Metric value comparison of different methods on 2 datasets % |
在一步法中, MMQPS在mAP、Top-1指标上也取得最优值.相比次优的无查询引导的PLoPS, MMQPS的mAP、Top-1指标分别提升1.9%和3.0%.相比有查询引导的BINet, MMQPS在mAP指标上提升10.5%, 在Top-1指标上提升8.9%.这一明显的提升说明MMQPS在多模态机制上的优越性.
实验进一步验证, 引入CBGM(Context Bipartite Graph Matching)[3]后处理策略, 可获得额外的性能增益, MMQPS的mAP、Top-1指标分别提至56.4%和92.8%.这一现象表明, MMQPS初始生成的检索结果已具备较高质量的特征表示和排序, 为基于图结构的上下文重排序提供可靠的基础, 由此表明方法自身的可扩展性.
在CUHK-SYSU数据集上, 测试集固定图库大小为100.在传统两步法中, 相比有查询引导的IGPN, MMQPS在mAP、Top-1指标上分别提升1.8%和1.9%.在一步法中, 相比经典的有查询引导的QEE-PS, MMQPS在mAP、Top-1指标上分别提升3.2%和4.2%, 相比有查询引导的BINet, MMQPS在mAP、Top-1指标上分别提升2.1%和2.6%.尽管该数据集上图像分辨率较低, 导致生成的文本描述可能引入更多的噪声, 且性能已趋近饱和, 但MMQPS依然实现性能的提升.这一现象表明, MMQPS能在利用有效文本信息的同时抑制噪声信息, 这也反映其可靠性.实验进一步验证, 引入CBGM, 各方法的mAP、Top-1指标都有进一步提升.
在PRW、CUHK-SYSU数据集上开展消融实验, 验证MMQPS中4个模块的有效性.对比实验均采用统一配置, ResNet-50作为基础特征提取网络, CUHK-SYSU数据集上测试集图库大小固定为50.
首先, 对比多模态查询差异增强模块(MQD-EM)和联合查询引导的行人特征增强模块(JQ-FEM)对性能的影响, 具体消融实验结果如表2所示.
| 表2 各模块在2个数据集上的性能对比 Table 2 Performance comparison of different modules on 2 datasets % |
由表2可见, 在PRW数据集上, 相比MMQPS, w/o MQDEM、w/o JQFEM和w/o MQDEM+JQFEM的mAP值分别下降2.4%、2.0%和4.2%, Top-1值分别下降0.7%、0.6%和0.5%.在CUHK-SYSU数据集上, 去除各模块后性能也均有下降, 由此表明MMQPS中MQDEM和JQFEM的有效性.MQDEM能使方法学习更全面细粒度的行人特征, JQFEM能使方法更关注Gallery图像上联合查询对应的行人特征, 提升特征的判别性.
接下来对比查询图像上不同增强操作的性能, 其中, CA(Channel Exchangeable Augmentation)表示通道可交换增强, CRE(Channel Random Erasing)表示通道级随机擦除, 具体结果如表3所示.由表可见, 在PRW数据集上, 相比不使用任何增强操作, 同时进行CA和CRE操作可实现性能的绝对提升, mAP值提升1.5%, Top-1值提升0.5%.在CUHK-SYSU数据集上, 相比不使用任何增强操作, 同时进行CA和CRE操作, mAP值提升0.6%, Top-1值提升0.6%.实验表明, 对图像通道进行交换和随机擦除能有效增强特征表示, 提升方法获取关键语义信息的能力.
| 表3 查询图像上不同增强操作的性能对比 Table 3 Performance comparison of different enhancement operations on query images % |
下面对比不同查询增强策略的性能差异.1)去除差异增强模块, 仅执行特征拼接操作(w/o MQDEM).2)相似特征增强模式(MQDEM Mask).3)非相似特征增强模式(MQDEM ~Mask).具体结果如表4所示.
| 表4 不同查询增强策略的性能对比 Table 4 Performance comparison of different query enhancement strategies % |
由表4可见, 在PRW数据集上, 采用非相似特征增强策略获得最优的mAP值(55.8%)和Top-1值(90.6%).在CUHK-SYSU数据集上, 非相似特征增强模式也实现双指标同步优化(mAP值为93.5%, Top-1值为94.7%).
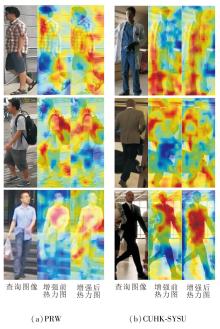
为了直观展示MQDEM的增强机制, 对比特征进行差异增强前后的热力图, 如图3所示, 图中颜色越偏红色表示对该区域越关注.由图可看到, 相比未进行差异增强的特征热力图, 经过差异增强后的特征热力图可关注到更全面的行人信息.
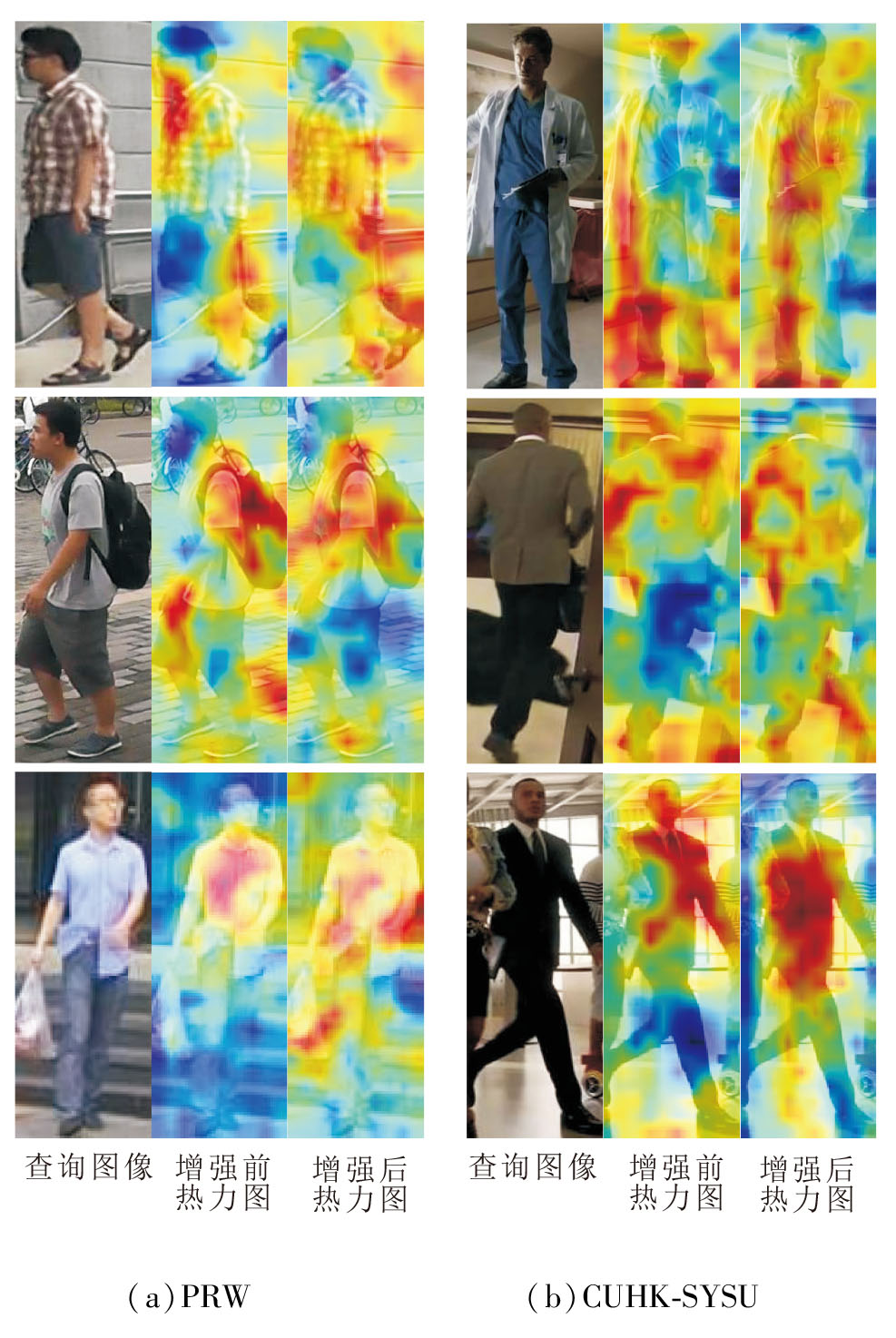 | 图3 特征差异增强前后热力图对比Fig.3 Heatmap comparison of query images before and after feature-difference enhancement |
基于两个数据集的稳健性考量, 本文最终选择非相似特征增强策略作为标准配置.这一现象也说明在场景更复杂的PRW数据集上, 非相似特征强化有助于提升关键样本的检索准确率, 而相似特征优化更利于全局特征分布校准.在场景相对简单的CUHK-SYSU数据集上, 非相似特征增强通过抑制模态间冗余信息, 更关注非重叠信息, 实现检测-重识别任务的协同优化.
下面针对联合查询引导的行人特征增强模块(JQFEM)中多尺度特征融合机制开展消融实验.由于ResNet-50构建5级特征, 实验选取中间三级特征进行对比分析:G2层(512通道维度)、G3层(1 024通道维度)、G4层(2 048通道维度), 结果如表5所示.
| 表5 多尺度特征融合机制的性能对比 Table 5 Performance comparison of multi-scale feature fusion mechanisms % |
由表5可见, 在PRW数据集上, G3层特征实现最优的mAP值和Top-1值.相比G2层特征和G4层特征, G3层特征分别在mAP值上提升2.0%和1.7%, 在Top-1值上提升0.9%和0.5%.在CUHK-SYSU数据集上, G3层也在双指标上均取得最优值.因此, 本文选定G3层特征作为JQFEM的核心载体.由于G3层对应中等尺度目标检测, 相比G2层与G4层, 对尺度变化能展现出更优的鲁棒性.这一特性使其在保持中等尺度检测精度的同时, 能通过多尺度可变形注意力的上/下采样机制有效兼容异常尺度目标, 符合行人搜索任务中尺度变化的实际需求.
在MMQPS中共有4个关键的超参数:相似度阈值ε 、总损失中平衡边界框回归损失的平衡因子λ 1、三元组OIM损失的平衡因子λ 2、行人检测与重识别模块中的部分注意力采样点数目p.在分析每个超参数时, 其它超参数保持不变.实验在PRW数据集上进行.
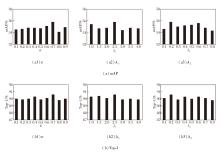
ε 用于将多模态查询差异增强模块中的视觉特征分为文本查询的相似性区域和非相似性区域.定义ε =0.1, 0.2, …, 0.9, 其对MMQPS性能的影响如图4所示.由图可见, 当ε =0.7时, mAP和Top-1指标都达到最优值.
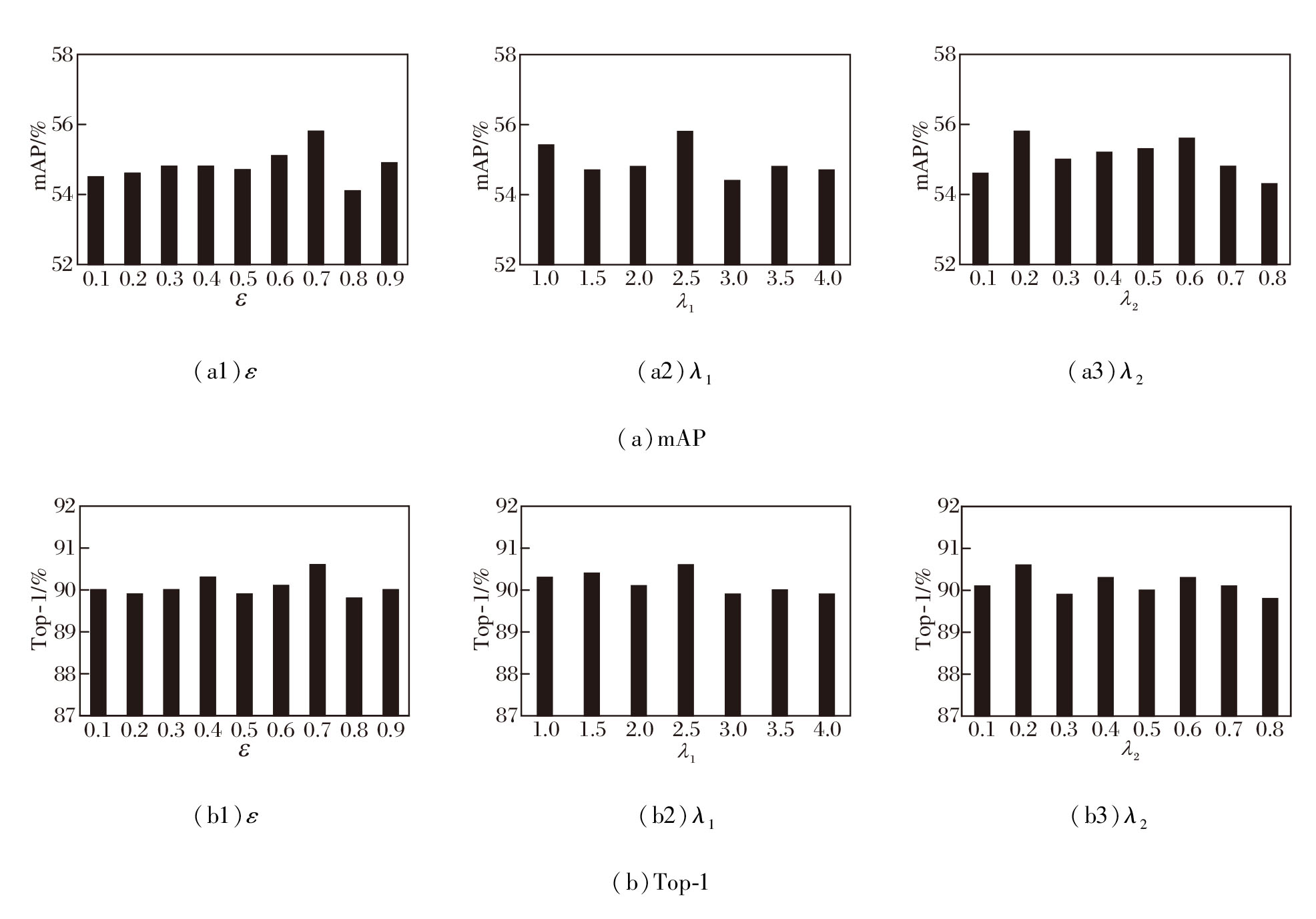 | 图4 在PRW数据集上各参数对MMQPS性能的影响Fig.4 Effect of different parameters on MMQPS performance on PRW dataset |
定义平衡因子λ 1=1.0, 1.5, …, 4.0, λ 2=0.1, 0.2, …, 0.8, 两者对MMQPS性能的影响如图4所示.由图可见, 当λ 1=2.5, λ 2=0.2时, 可确保各个损失之间的贡献平衡, 有效促进方法训练.
定义部分注意力层中特征采样点数p=3, 4, 5, 6, 其对MMQPS性能的影响如表6所示.
| 表6 p对MMQPS性能的影响 Table 6 Effect of p on MMQPS performance % |
由表6可见, 当p=5时, 获得最优mAP值和Top-1值, 相比p=6和4时, p=5时模块分别在mAP值上提升0.6%和0.9%, 在Top-1值上提升0.7%和0.3%, 所以本文设置p=5.
为了直观展示MMQPS的搜索结果, 分别在PRW、CUHK-SYSU测试集上进行可视化对比.在两个数据集上分别随机选取3个不同查询的Top-1匹配案例, 结果如图5和图6所示.由图5和图6可见, 在PRW测试集上的可视化结果验证MMQPS在复杂跨摄像头场景中的鲁棒性较强, 可成功应对视角突变、低分辨率、尺度变化等挑战.在CUHK-SYSU测试集上的可视化结果验证MMQPS在面临场景变化、光线变化等挑战时的鲁棒性.
 | 图5 MMQPS在PRW测试集上的可视化结果Fig.5 Visualization results of MMQPS on PRW dataset |
 | 图6 MMQPS在CUHK-SYSU测试集上的可视化结果Fig.6 Visualization results of MMQPS on CUHK-SYSU dataset |
本文提出多模态查询引导的端到端行人搜索方法(MMQPS).构建多模态查询差异增强模块, 利用文本语义描述增强图像查询特征的上下文感知能力.设计联合查询引导的行人特征增强模块, 通过多头注意力机制动态识别并增强Gallery图像中与联合查询对应的行人特征.引入DETR, 不依赖RPN和NMS实现端到端的行人搜索.在PRW、CUHK-SYSU数据集上系统性验证MMQPS的有效性.本文采用大模型自动生成文本描述, 存在潜在的描述误差, 可能引入噪声信息, 尤其在分辨率较低的CUHK-SYSU数据集上, 裁剪行人区域并生成文本描述的过程中, 图像质量限制描述的准确性, 导致引入噪声的可能性更高.今后可考虑从如下两方面推进工作研究:1)加入人工精校或探索更高精度的文本标注方案; 2)在现有框架中尝试加入多模态噪声抑制机制, 提升方法性能.
本文责任编委 兰旭光
Recommended by Associate Editor LAN Xuguang
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|
| [40] |
|
| [41] |
|
| [42] |
|
| [43] |
|