
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
结合空间通道特征与图注意力的分层Transformer微表情识别方法
[曹春萍1  , 魏金鑫
, 魏金鑫1 ]
, 魏金鑫]
|
|



作者简介:

魏金鑫,硕士研究生,主要研究方向为图像分类、人脸表情识别.E-mail:ywyy1218@163.com.
针对现有微表情识别方法存在多尺度特征提取能力不足、区域协同关系建模不充分及计算复杂度较高等缺点,提出结合空间通道特征与图注意力的分层Transformer微表情识别方法(Hierarchical Transformer for Micro-Expression Recognition with Spatial-Channel Features and Graph Attention, HT-SCGA).首先,设计多尺度动态窗口模块,通过自适应窗口扩展实现从局部到全局的特征层次化提取.然后,设计双域特征关联模块,在空间维度与通道维度建模细粒度依赖关系,有效提升特征表达能力并降低计算复杂度.最后,构建图注意力聚合模块,显式建模面部关键区域间的语义依赖,增强面部动作单元的联动特征.在多个数据集上的实验表明,HT-SCGA性能较优,由此表明其在微表情识别任务中的有效性与高效性.
About Author:
WEI Jinxin, Master student. His research interests include image classification and facial expression recognition.
The existing approaches possess limitations of multi-scale feature extraction, inter-region relationship modeling, and computational efficiency. To address these issues, a hierarchical Transformer for micro-expression recognition with spatial-channel features and graph attention(HT-SCGA) is proposed. First, a multi-scale dynamic window module is designed for hierarchical extraction from local fine-grained features to global coarse-grained features through adaptively expanding receptive fields. Second, a dual-domain feature association module is introduced to enhance feature representation and reduce computational complexity by jointly modelling spatial and channel dependencies. Finally, a graph attention aggregation module is constructed to explicitly model semantic correlations among key facial regions and strengthen the coordinated representation of facial action units. Experiments on three benchmark datasets, SMIC, CASME II, and SAMM, demonstrate that HT-SCGA outperforms existing methods on UF1 and UAR metrics. These results verify the effectiveness and efficiency of HT-SCGA for micro-expression recognition.
微表情识别是一项精细的情感分析任务, 旨在自动检测并分析面部肌肉短暂且微小的运动, 从中提取潜在的情感特征[1].微表情识别被广泛应用于心理访谈[2]、执法审讯[3]等高时效性场景.由于个体的情绪状态往往处于快速波动之中, 若系统在较长时间后才完成识别, 所得结果可能已与被试者当前情绪状态不符, 导致决策参考价值大幅降低.因此, 微表情识别不仅精度要求较高, 还必须在短时间内完成推理, 以同时满足精度和速度的要求.
为了提升微表情识别的精度与速度, 近年来出现多种基于Transformer的微表情识别方法[4, 5, 6].研究人员应用视觉Transformer架构将图像划分为固定大小的非重叠图像块, 经过线性投影后与位置编码一起输入标准Transformer架构, 直接建模图像块之间的全局关系, 从而实现端到端的图像识别.
窗口自注意力机制(Window-Based Self-Atten-tion, W-SA)是Transformer中的重要组成部分.W-SA将输入划分成局部窗口, 在每个窗口内计算自注意力, 能在一定程度上降低计算复杂度.然而, 当前方法为了在一定程度上加快微表情识别速度, 多采用固定且较小的窗口尺寸(如文献[7]中的8× 8窗口), 但是这限制方法的感受野扩展能力, 也不利于捕捉多尺度细粒度特征, 从而降低识别精度.
为了提高识别精度, 研究者尝试通过通道压缩策略支持大窗口操作.Li等[8]提出MMNet(Muscle Motion-Guided Network), 设计集体多尺度自注意力, 采用通道分裂机制, 将特征通道拆分后独立建模, 既精简参数规模, 又聚焦微表情对应的局部肌肉运动特征.Zhou等[9]提出FeatRef(Feature Refinement), 将特征细化模块集成到并行注意力模块内, 增强特征的细粒度表达能力.然而, 此类方法存在空间信息与通道信息之间的权衡问题, 并且不可避免地带来更高的计算复杂度, 限制方法识别速度.
Wang等[10]提出HTNet(Hierarchical Transfor-mer Network), 利用Transformer层对人脸区域进行特征提取, 并通过聚合模块整合局部特征图, 生成全局特征表示.尽管HTNet在面部区域建模方面取得一定进展, 但仍存在类似问题.
1)HTNet中虽采用多头自注意力机制(Multi-head Attention, MHA)[11]提取局部区域特征, 但仍面临感受野有限、难以捕捉多尺度特征的问题, 同时计算复杂度随输入规模呈平方倍增长, 制约方法的推理速度.
2)HTNet中区域聚合模块采用卷积和池化方式合并区域特征, 但这种方式只关注局部邻近关系, 难以捕捉面部不同区域之间动作单元(Action Units, AUs)的协同变化, 限制微表情的识别精度.
为此本文提出结合空间通道特征与图注意力的分层Transformer微表情识别方法(Hierarchical Trans- former for Micro-Expression Recognition with Spatial- Channel Features and Graph Attention, HT-SCGA), 首先, 设计双域特征关联模块(Dual-Domain Feature Association Module, DD-FAM), 通过空间自适应压缩(动态降维至基窗口)与通道全局交互, 搭配设计的多尺度动态窗口模块(Multi-scale Dynamic Win- dows, MSDW), 替代传统固定窗口划分方式.通过这2个模块能同时捕捉微表情中的局部细粒度变化与长程上下文依赖, 并且可将计算复杂度从二次方降至线性, 解决传统Transformer在微表情识别领域的速度与精度平衡问题.为了进一步提升识别准确率, 充分利用微表情通常以面部区域联动形式发生的结构特性, 设计图注意力聚合模块(Graph-Based Attention Aggregation Module, GAAM), 构建面部关键区域之间的图结构, 在节点间显式建模交互关系, 实现区域间联动微表情特征增强, 提高识别精度.
传统的微表情识别方法主要依赖手工特征提取, 并结合经典的机器学习模型实现微表情分析.这些方法大致分为两类:基于外观的方法和基于几何的方法.
基于外观的方法提取时空纹理特征, 捕捉微表情的细微变化.Zhao等[12]提出LBP-TOP(Local Binary Patterns on Three Orthogonal Planes), 能捕捉面部纹理的时空变化, 但在复杂场景下识别性能仍有待提升.
基于几何的方法通常利用光流技术获取面部运动信息, 典型代表方法包括Bi-WOOF(Bi-Weighted Oriented Optical Flow)[13]和MDMO(Main Directional Mean Optical-Flow)[14].它们通过光流图计算视频序列中像素亮度的时间变化信息, 描述面部的动态特征, 提高微表情识别精度.基于光流特征的微表达识别方法可降低特征维度, 同时保持良好的识别效果, 是现阶段的主流方法之一.
Transformer架构凭借其自注意力机制在建模长距离依赖方面的优势, 为微表情识别中的跨区域特征整合与时空动态建模提供新的思路.Zhang等[15]提出SLSTT(Short and Long Range Relation Based Spatio-Temporal Transformer), 包括用于学习空间模式的空间编码器、用于分析时间信息的时间聚合器及用于分类的输出头.Hong等[4]提出一种后期融合的Transformer架构, 分别在光流(Optical Flow, OF)序列和灰度序列上进行Transformer学习, 然后进行融合, 提升微表情识别的效果.Li等[8]提出MMNet, 设计双分支模块, 利用基于Transformer的模块进行位置校准, 并通过持续注意力模块学习面部的运动特征.Zhu等[5]提出一种基于稀疏Transformer的时空特征学习方法, 通过时空注意力机制提取与微表情类别高度相关的特征, 减少不相关特征的干扰.Lei等[6]提出利用Transformer建模面部节点和边之间关系的方法, 通过人脸特征的节点和边构建面部图.
尽管上述方法有效地将视觉Transformer引入微表情识别任务, 在特征建模方面取得显著进展, 但仍主要集中于全局特征提取或跨模态融合.Wang等[10]提出HTNet, 首次结合视觉Transformer与人脸区域划分策略, 显式引导方法关注左眼、右眼、左唇和右唇四个关键区域的局部动态特征.HTNet首先在局部区域内进行Transformer建模, 捕捉微表情区域中的细粒度特征, 随后通过卷积和池化方式聚合各区域特征, 生成用于分类的全局特征表示.
图神经网络(Graph Neural Network, GNN)在微表情识别中的应用主要聚焦于动作单元(AUs)建模.Lo等[16]提出MER-GCN, 为基于图卷积网络(Graph Convolutional Networks, GCN)和AUs的端到端微表情识别框架.随后, Zhao等[17]提出STA-GCN(Spatio-Temporal AU Graph Convolutional Network), 进一步强化时空依赖建模.除了基于AUs的方法以外, 部分研究者开始关注与关键面部区域相关的图神经网络.Zhang等[18]提出OFVIG-Net(Optical Flow-Based VisionGNN Network), 动态建模面部感兴趣区域之间的时序关系.Kumar等[19]构建双流图卷积网络, 分别建模面部局部区域与时序动态.
此外, 研究者尝试将GNN与卷积神经网络(Convolutional Neural Networks, CNN)或Transformer结合.Lei等[6]将基于预处理提取得到的特征向量用于构造图结构, 并输入双通道网络进行微表情识别.Zhai等[20]提出FRL-DGT(Feature Representation Learning with Adaptive Displacement Generation and Transformer Fusion), 将基于AUs裁剪的图像块作为输入, 这样预先提取的光流可帮助方法获得更具区分度的微表情特征.
然而, 现有基于图的微表情识别方法普遍依赖复杂的预处理步骤, 如基于AUs或光流特征的人工节点构建, 导致高昂的人工成本与主观性较强的解释路径, 限制方法的泛化性与实际应用价值.
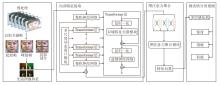
为了充分解决上述问题, 本文提出结合空间通道特征与图注意力的分层Transformer微表情识别方法(HT-SGCA), 结构如图1所示.
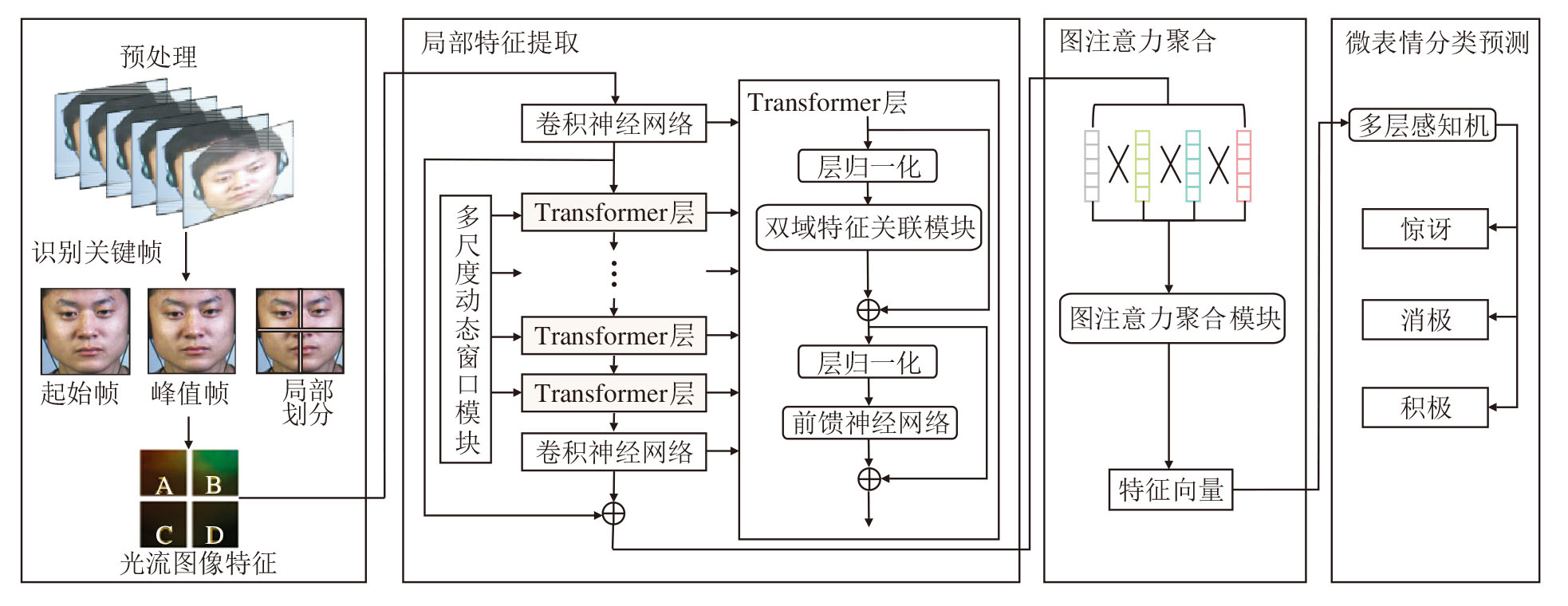 | 图1 HT-SGCA结构图Fig.1 Architecture of HT-SGCA |
HT-SGCA包括四个主要步骤:预处理、局部特征提取、图注意力聚合、分类预测.
具体而言, 针对输入的视频帧序列, 首先采用光流估计方法提取相邻帧之间的运动信息, 并基于人脸关键点定位结果进行仿射对齐与区域裁剪, 获得面部4个关键区域(双眼与嘴角)的光流图像, 用于捕捉微表情中微小且快速的肌肉运动变化信息.再将4个区域的光流图并行输入至分层Transformer编码器中.该编码器通过多尺度动态窗口模块(MSDW)自适应扩展不同尺度下的感受野, 分层提取细粒度特征与粗粒度特征.
然后, 设计双域特征关联模块(DD-FAM), 分别从空间维度和通道维度对特征进行建模与交互, 结合空间动态压缩与通道全局依赖机制, 在保证长程依赖建模能力的同时动态压缩特征维度, 提升计算效率.在提取每个区域的深层特征后, 进一步引入图注意力聚合模块(GAAM), 构建基于特征相似性的区域图结构, 并借助图神经网络中的注意力机制建模区域间显式语义依赖, 捕捉面部联动变化模式, 增强区域间协同表达能力.
最后, 融合4个区域的特征表示并输入多层感知机分类器, 输出微表情类别预测结果.
HT-SGCA主要包含三个核心模块:多尺度动态窗口模块(MSDW)、双域特征关联模块(DD-FAM)和图注意力聚合模块(GAAM).
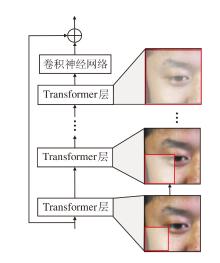
在传统的微表情识别方法中, 固定大小的窗口往往难以捕捉面部特征之间的长距离依赖关系和联动特征.尽管扩大窗口能提升特征提取的范围, 但会导致计算复杂度的显著增加, 且难以有效提取面部表情中隐藏或重叠的AUs.为了解决这一问题, 本文设计多尺度动态窗口模块(MSDW), 结合级联Transformer层进行多尺度特征提取, 在保证计算效率的同时, 能深度挖掘微表情中的细粒度特征, 并有效捕获面部特征之间的长距离依赖关系, 显著提升微表情识别精度.MSDW结构如图2所示.
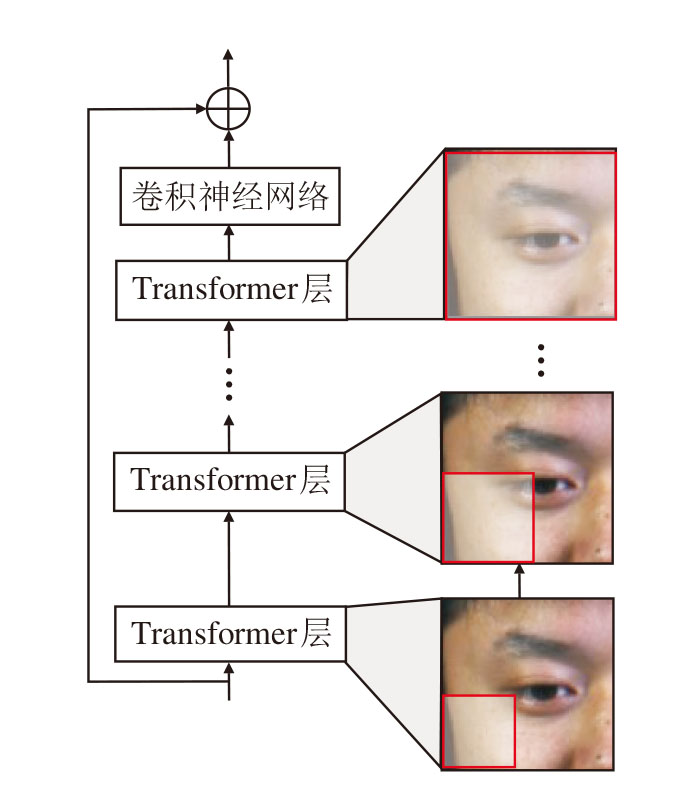 | 图2 MSDW结构图Fig.2 Schematic diagram of MSDW |
在基础分层Transformer框架中, 多尺度特征提取主要依赖逐层降采样, 采用逐层扩展的策略, 直接调整窗口大小.在初始层中, 窗口大小较小, 用于捕捉局部区域的精细特征.随着网络层次的增加, 窗口逐步扩大, 以整合远距离依赖特征, 从而适配微表情的局部变化与全局变化.
给定基础窗口大小为h0× w0, 第k层的窗口大小为hk× wk, 则
[hk, wk]=[γ kh0, γ kw0],
其中, γ k表示窗口扩展系数, 控制第k层窗口的动态扩展比例.
相比传统方法(如固定窗口的平移和掩码操作), 这种分层窗口扩展策略通过直接级联的Transformer层实现多尺度特征提取, 同时可降低计算复杂度.
由于采用MSDW, 需要在更大的窗口上计算, 然而, 传统的窗口自注意力机制计算复杂度是随窗口尺寸h× w呈平方增长(O(h2w2)), 并且面部肌肉的微小运动往往在空间维度和通道维度上展现出复杂的交互关系, 因此本文设计双域特征关联模块(DD-FAM), 高效聚合层次化特征, 提升计算效率, 同时增强特征提取能力.DD-FAM核心思想是在Transformer网络中以线性复杂度的方式整合空间信息和通道信息, 支持大尺度窗口计算, 提升方法的表征能力和计算速度.
与现有时空注意力模块不同, DD-FAM并非在统一注意力框架下同时建模空间与通道依赖, 而是采用“ 空间压缩关联+通道全局交互” 的双分支解耦设计, 在保持长程依赖建模能力的同时降低计算复杂度.
传统时空注意力通常在完整空间或时空维度上计算注意力权重, 计算复杂度随空间分辨率或序列长度呈二次方增长, 不利于高分辨率光流特征下的高效微表情识别.现有空间-通道注意力方法(如SE(Squeeze-and-Excitation Networks)[21]、CBAM(Con-volutional Bock Attention Module)[22])主要侧重通道重标定或局部空间增强, 缺乏对跨窗口、跨尺度空间依赖的显式建模.相比之下, DD-FAM通过空间动态投影将大尺度窗口特征压缩至基础窗口尺度, 在此基础上进行线性复杂度的空间关联建模, 并结合通道维度的全局交互机制补偿空间压缩带来的信息损失, 从而在功能和计算方式上均区别于传统时空注意力, 更适用于多尺度Transformer框架下的微表情特征建模任务.
DD-FAM用于建模空间维度和通道维度的细粒度依赖关系.在此基础上, 通过残差连接引入前馈神经网络(Feed-Forward Network, FFN), 并在各子模块之前引入层归一化(Layer Normalization), 增强训练稳定性与特征表达能力.整个结构可有效提升方法对微表情中细微的局部变化的感知能力, 同时保持较低的计算开销.
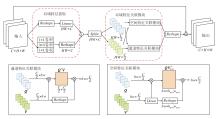
DD-FAM包括两部分:空间特征关联模块(Spatial Feature Association, SFA)和通道特征关联模块(Channel Feature Association, CFA), 具体结构如图3所示.输入特征X∈ RC× H× W会首先通过双分支结构并行提取空间特征和通道特征, 分别用于捕获X的空间信息和通道信息.
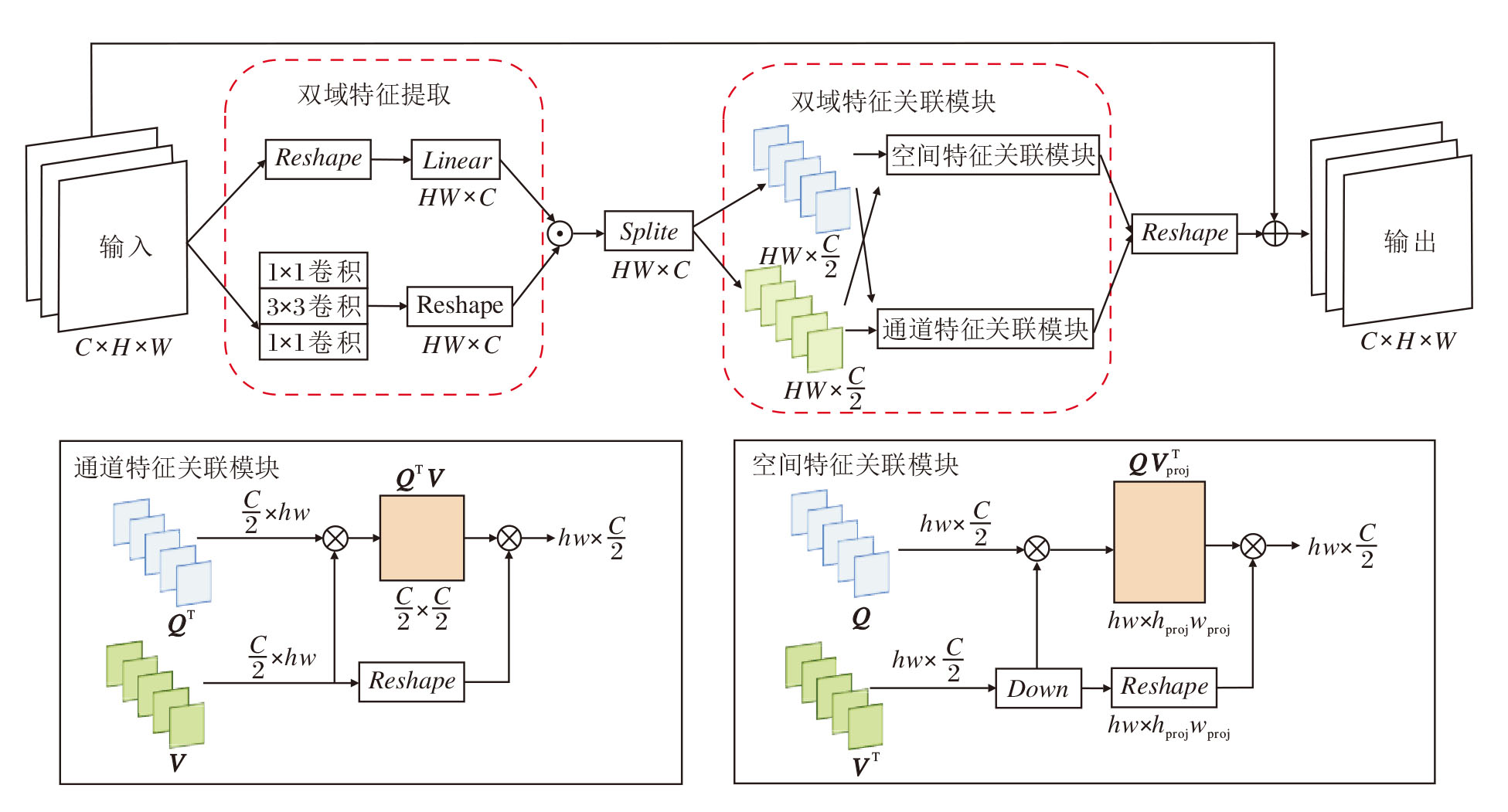 | 图3 DD-FAM结构图Fig.3 Architecture of DD-FAM |
对于第一路分支, 即通道特征提取分支, 通过线性层对特征进行通道维度的全局建模, 最终经过通道分支提取的通道特征表示为:
Fc=Linear(Reshape(X))∈ RHW× C,
其中, Reshape(· )表示张量从C× H× W重塑为HW× C, Linear(· )表示线性变换.
对于第二路分支, 即空间特征提取分支, 采用计算机视觉中广泛应用的沙漏结构提取局部区域内的空间变化特征, 收缩阶段提取高层次全局信息, 扩展阶段重建低层次全局信息, 最终经过空间分支提取到的空间特征表示为:
Fs=Reshape(Fs1)∈ RHW× C,
其中,
Fs1=Conv1(Conv2(Conv1(X)))∈ RC× H× W,
表示沙漏结构输出特征, Conv1(· )表示卷积核为1× 1的卷积变换函数, Conv2(· )表示卷积核为3× 3的卷积变换函数.
将两条分支的特征通过逐元素乘法融合, 得到融合后的特征:
Fd=Fc☉Fs∈ RHW× C,
其中☉表示矩阵对应位置元素相乘.
与以往方法不同, HT-SCGA结合面部区域划分和多尺度动态窗口机制, 有效减少窗口间的相似性问题.因此, 在HT-SCGA中, 假设键K和值V等价, 即直接令K=V.这种假设不仅省去对键进行线性投影的计算步骤, 同时在局部窗口内仍能保持足够的特征表达能力.因此CFA和SFA的输入表示为:
[Q, V]=Splite(Fd).
将生成的Q和V根据指定窗口大小分块.例如:Qk∈
2.2.1 空间特征关联模块
与Swin Transformer的窗口注意力机制不同, SFA结合多尺度动态窗口机制, 逐步扩大感受野, 捕捉从局部到全局的信息, 在微表情识别任务中能高效聚合不同尺度的空间信息, 提升特征的表达能力.
对于每个变换层k, 由于值向量Vk在空间维度上具有较高分辨率, 直接参与大窗口注意力计算将带来较高的计算开销, 因此先对Vk在空间维度上进行投影, 以适应不同尺度的窗口建模需求.具体地, 设
$\boldsymbol{V}_{\mathrm{proj}, k}^{\mathrm{T}}=\operatorname{Down}\left(\boldsymbol{V}_{k}^{\mathrm{T}}\right) \in \mathbf{R}^{\frac{C}{2} \times h_{\mathrm{proj}} w_{\mathrm{proj}}} .$
其中:Down(· )表示作用于空间维度的下采样投影操作, 设计思想与Pyramid Vision Transformer[23]中的空间降采样注意力机制一致, 用于对特征映射的空间分辨率进行调整, 本质为一种可学习的空间线性投影方式; hproj、wproj表示投影后的高度和宽度,
$\left[h_{\text {proj }}, w_{\text {proj }}\right]=\left\{\begin{array}{ll} {\left[h_{0}, w_{0}\right], } & \gamma_{k}> 1 \\ {\left[\gamma_{k} h_{0}, \gamma_{k} w_{0}\right], } & \gamma_{k} \leqslant 1 \end{array}\right.$ (1)
因此在方法设计中, 大窗口用于捕捉高层级的信息, 小窗口用于保留细粒度的特征.当γ k> 1时, 表示该层在语义上对应更大的感受野, 此时并不直接采用变换后的窗口尺寸进行计算, 而是通过特征投影操作, 将来自大感受野的信息映射到基础窗口尺度上完成计算.当 γ k≤ 1时, 语义窗口与实际计算窗口保持一致, 直接采用对应尺度进行特征建模.通过这种窗口缩放的方式, 尽管在大窗口的情况下, 值Vk被投影至基础窗口大小, 但通过计算相关性, 仍可有效提取高层级信息, 在降低计算复杂度的同时增强特征表达.
这种多尺度信息的聚合不仅提高方法性能, 还提升计算效率, 由此得到SFA计算公式如下:
$S F A\left(\boldsymbol{Q}_{k}, \boldsymbol{V}_{\text {proj }, k}\right)=\left(\frac{\boldsymbol{Q}_{k} \boldsymbol{V}_{\text {proj }, k}^{\mathrm{T}}}{D}+\boldsymbol{B}\right) \cdot \boldsymbol{V}_{\text {proj }, k} .$
其中:D表示输入维度, 即C/2; B表示相对位置编码矩阵, 用于增强不同区域之间的交互.值得注意的是, 利用相关图而不是注意力图来聚合信息, 可放弃硬件低效操作softmax以提高推理速度[24].
2.2.2 通道特征关联模块
CFA的计算方式与SFA相似, 不同之处在于CFA作用于通道维度, 而非空间维度, 用于建模不同通道特征之间的协同作用.在微表情识别任务中, 不同通道可能对应不同的运动模式, 因此CFA通过计算通道间的全局依赖关系, 提升特征的表达能力.
具体而言, CFA采用与SFA相同的注意力框架, 但仅针对通道维度进行特征交互.由于计算方式与SFA相似, 不再重复推导公式, 仅描述其核心思想.CFA通过通道维度的多尺度窗口, 将输入特征划分为不同的通道子空间, 并在每个通道子空间内计算注意力相关性.由于通道数C通常比空间维度小很多, 则CFA计算公式如下:
$C F A\left(\boldsymbol{Q}_{k}, \boldsymbol{V}_{k}\right)=\left(\frac{\boldsymbol{Q}_{k}^{\mathrm{T}} \boldsymbol{V}_{k}}{h_{k} w_{k}}\right) \boldsymbol{V}_{k}^{\mathrm{T}} .$
最后将DD-FAM、全局自注意力机制和窗口自注意力机制进行复杂度分析, 结果如表1所示, δ =
| 表1 3种机制的复杂度分析 Table 1 Complexity analysis of 3 mechanisms |
在微表情识别任务中, 面部不同区域的表情变化并非孤立存在, 而是由多个AUs之间的协同作用形成.例如:皱眉可能伴随上眼睑提升, 而嘴角下拉可能影响下巴区域的肌肉收缩.因此, 在特征聚合阶段, 如何有效建模面部关键区域的联动关系, 并在融合过程中自适应调整不同区域的贡献, 是提升微表情识别准确度的关键问题.为此, 本文在图注意力聚合模块(GAAM)中引入图注意力网络, 用于在合并4个局部区域特征(左眼、右眼、左唇、右唇)的同时, 自适应建模不同AUs之间的联动关系, 并输出完整的特征表征以供最终分类.
2.3.1 区域关系建模
为了表示不同区域的交互关系, 将4个局部区域特征V={v1, v2, v3, v4}视为图神经网络(Graph Neural Network, GNN)中的节点, 并定义邻接矩阵A用于建模AUs之间的联动关系, 则
A=
其中, ω ij表示区域特征vi与区域特征vj之间的交互强度, 数值基于面部AUs的先验知识进行预定义.具体而言, 不同面部区域的微表情变化往往由一组具有生理或功能关联的AUs协同驱动, 基于上述AUs先验关系, 本文对具有明确协同或对称关系的区域对赋予较高权重(如左右眼区域设置ω ij=1), 对存在弱关联的区域赋予较小权重(ω ij> 0), 而对缺乏直接关联的区域则令 ω ij=0.该设计使邻接矩阵在保持结构简洁的同时, 能显式编码微表情中区域联动的先验知识, 提升图注意力聚合阶段的特征建模效果.
此外, 为了进一步分析固定图结构的局限性, 本文还提出一种自适应学习图结构的方法, 作为对预定义邻接矩阵的补充.在该设置中, 邻接矩阵不再人工设定, 而是根据区域特征相似性动态生成, 使图结构能随样本变化而自适应调整.
2.3.2 特征聚合
GAAM采用自适应注意力机制计算不同区域特征之间的信息交互, 每个节点vi的特征更新如下.在GAAM中, 每个节点vi与其邻域节点vj之间的交互由注意力权重β ij进行建模, 而
$\beta_{i j}=\frac{\exp \left(\operatorname{LeakyReLU}\left(\boldsymbol{a}^{\mathrm{T}}\left[\boldsymbol{M f}_{i} \| \boldsymbol{M} \boldsymbol{f}_{j}\right]\right)\right)}{\sum_{k \in N(i)} \exp \left(\operatorname{LeakyReLU}\left(\boldsymbol{a}^{\mathrm{T}}\left[\boldsymbol{M f}_{i} \| \boldsymbol{M} \boldsymbol{f}_{k}\right]\right)\right)} .$ (2)
其中: fi、 fj分别为vi和vj的特征表示; M表示一个可学习的线性变换矩阵, 用于特征投影; a表示注意力机制中的可训练参数向量; ‖ 表示拼接操作;
$N(i)=\left\{j \mid A_{i j}> 0\right\}, $
表示vi的邻接区域集合, 决定哪些区域会被纳入计算, 由邻接矩阵A决定.
式(2)通过LeakyReLU激活函数计算区域 i与邻居j之间的特征相似度, 并通过Softmax计算归一化的注意力权重β ij, 确保关键区域的特征被增强, 低相关区域的影响被削弱.
经过GAAM计算后更新的第i个局部区域(左眼、右眼、左唇、右唇)的区域特征表示如下:
$\boldsymbol{f}_{i}^{\prime}=\sum_{j \in N(i)} \beta_{i j} \boldsymbol{M} \boldsymbol{f}_{j} .$
最终, 更新后的4个区域特征表示为
F'={f'1, f'2, f'3, f'4},
通过全局加权融合生成完整特征图表示:
$f_{\text {final }}=\sum_{i=1}^{4} \lambda_{i} f_{i}^{\prime}, $
其中, λ i表示自适应学习的区域重要性权重, 确保最具判别性的区域贡献最大.ffinal用于后续的微表情分类.
本文采用交叉熵损失(Cross-Entropy Loss)作为主要优化目标, 公式如下:
$L_{\mathrm{ce}}=-\frac{1}{N} \sum_{i=1}^{N} \sum_{j=1}^{M} y_{i, j} \log p_{i, j}, $
其中, N表示样本数, M表示类别数, yi, j表示真实标签(one-hot编码), pi, j表示预测概率.该损失用于衡量模型输出与真实类别分布的匹配程度, 并优化模型分类性能.
本文采用微表情识别领域广泛认可的SMIC[25]、CASME II[26]、SAMM[27]这3个标准数据集进行实验.为了保障实验设计的严谨性, 严格采用留一试者(Leave-One-Subject-Out, LOSO)交叉验证法, 依次指定每位受试者作为测试对象, 其余样本构成训练集.各数据集具体参数如下.
SMIC数据集包含16名受试者的共164个样本, 图像分辨率为640× 480, 无峰值帧, 涵盖积极(Positive)、消极(Negative)、惊讶(Surprise)三类情感标签.
CASME II数据集包含200帧/秒高速采集的255个有效样本, 由26名受试者在严格控制的实验环境下生成, 图像分辨率为640× 480, 有峰值帧, 提供高兴(Happiness)、抑制(Repression)、惊讶(Sur-prise)、厌恶(Disgust)、恐惧(Fear)和其它(Other)六类情感标注, 所有样本均标注面部动作编码系统(Facial Action Coding System, FACS)特征以及表情起始帧、顶点帧、结束帧等关键时间节点.
SAMM数据集包括采用2 040× 1 088高分辨率成像系统以200帧/秒采集的159个样本, 包含高兴(Happiness)、惊讶(Surprise)、愤怒(Anger)、厌恶(Disgust)、悲伤(Sadness)、恐惧(Fear)、轻蔑(Contempt)和其它(Others)八类情感类别.
另外, 为了确保一致性和可比性, 将SAMM、SMIC、CASME II数据集上数据合并到一个混合数据集FULL中.FULL数据集采用这3个数据集相同的情感标签, 用于微观表达识别任务.具体数据集情感类别分类信息如表2所示.
| 表2 各数据集情感类别分类信息 Table 2 Emotion category information for datasets |
为了构建稳健的微表情识别方法, 对实验数据进行人脸图像的预处理操作.由于SMIC、CASME II数据集已提供裁剪后的图像, 因此在SAMM数据集上进行人脸对齐与裁剪, 以此确保数据格式的一致性.在SMIC数据集上, 由于未提供峰值帧索引, 采用文献[28]方法以确定其具体位置, 而在SAMM、CASME II数据集上, 已给出峰值帧标注信息, 可直接用于光流图像的提取.
在获得起始帧和峰值帧后, 采用TV-L1(Total Variation-L1), 在这两个时间点分别计算光流信息.生成的光流图像包含3个通道, 即水平方向、垂直方向和光流应变.随后, 使用文献[29]方法提取峰值帧中的面部关键点, 这些关键点有助于精准定位特定的面部区域.
提取4个关键面部区域的光流特征图, 包括左眼、右眼、左唇和右唇.每个区域的光流特征图大小比完整光流图像减少一半.通过关注这些局部区域, 可更有效地捕捉与微表情相关的面部肌肉运动特征.最终, 将4个局部光流特征图输入HT-SGCA进行特征融合, 以此提升微表情识别的准确性和效率.
实验环境使用的CPU为Intel® Xeon® 处理器, GPU为NVIDIA GeForce RTX 4090, 操作系统为Ubuntu 22.04.所有实验采用随机梯度下降(Stocha-stic Gradient Descent, SGD)作为优化器.初始学习率设为1e-5, 动量设为0.9, 权重衰减值设为1e-4, 最大迭代次数不超过200次.基础窗口大小h0× w0设为8× 8.
由于微表情数据集上类别分布不平衡, 采用准确率(Accuracy, ACC)、未加权F1分数(Unweighted F1 Score, UF1)和未加权平均召回率(Unweighted Average Recall, UAR)作为评价指标.
1)准确率(ACC).衡量方法整体的分类正确率, 计算公式如下:
$A C C=\frac{\sum_{i=1}^{M} \sum_{j=1}^{T} T P_{i}^{(j)}}{\sum_{i=1}^{M} \sum_{j=1}^{T}\left(T P_{i}^{(j)}+F P_{i}^{(j)}\right)}, $
其中, T
2)未加权F1分数(UF1).在多类别分类任务中, 特别是类别分布不均衡的情况下UF1是常用的评估指标之一, 其计算过程包括对LOSO交叉验证的所有折中每个类别i的假阳性、真阳性和假阴性(False Negatives, FN)进行统计, 计算公式如下:
$U F 1=\frac{1}{M} \sum_{i=1}^{M}\left(\frac{2 \sum_{j=1}^{T} T P_{i}^{(j)}}{2 \sum_{j=1}^{T} T P_{i}^{(j)}+\sum_{j=1}^{T} F P_{i}^{(j)}+\sum_{j=1}^{T} F N_{i}^{(j)}}\right), $
其中F
3)未加权平均召回率(UAR).评估类别分布不均衡时方法的召回能力, 有助于减少类别失衡对召回率计算带来的影响, 计算公式如下:
$U A R=\frac{1}{M} \sum_{i=1}^{M}\left(\frac{T P_{i}}{N_{i}}\right), $
其中, Ni 表示类别i的总样本数, TPi表示类别i中被方法正确识别为该类的样本数.
上述评价指标可全面衡量方法在不均衡数据集上的分类性能, 并确保各类别的贡献得到合理体现.
为了验证HT-SGCA的有效性, 在SMIC、CASME II、SAMM、FULL数据集上进行定量评估实验, 选择如下对比方法.1)基于手工特征的传统方法.LBP-TOP[12]、Bi-WOOF[13].2)基于深度学习技术的方法.FeatRef[9]、HT-Net[10]、SLSTT-LSTM(Short and Long Range Relation Based Spatio-Temporal Transfor-mer)[15]、OFVIG-Net[18]、AM3F-FlowNet[30]、LAENet(Lightweight Apex-Based Enhanced Network)[31]、MFDAN(Multi-level Flow-Driven Attention for Micro-Expression Recognition)[32] .
实验采用的评估指标为UF1和UAR, 这样能在数据集类别不平衡的情况下提供更公平全面的评估.
各方法在4个数据集上的指标值对比如表3所示, 表中黑体数字表示最优值.由表可见, 相比传统方法LBP-TOP(基于外观特征)和Bi-WOOF(基于几何特征), HT-SGCA在UF1、UAR指标上大幅提升, 进一步表明深度学习技术在微表情分类任务中的优势.相比之下, HT-SGCA针对面部关键区域进行划分, 结合多尺度特征提取, 并利用图注意力机制进行特征融合, 有效增强方法的识别能力, 最终在UF1指标上取得最优值.FeatRef能提取具有区分度的微表情特征, 在FULL数据集上的UF1、UAR指标分别达到0.743 2和0.719 0.然而, 该方法在局部与全局时空模式的综合利用上存在一定不足.SLSTT-LSTM作为首个基于纯Transformer架构的微表情识别方法, 利用Transformer从不同时间步提取图像特征, 并结合LSTM进行时间序列建模.尽管该方法能有效捕捉序列中帧间的动态变化, 但可能忽略单帧光流图像的空间信息, 同时未能充分建模光流图像不同区域之间的关联性.相比之下, HT-SGCA借助多尺度Transformer增强面部关键特征的提取能力, 在SMIC数据集上UF1指标比SLSTT-LSTM提升9.05%.相比当前先进的HTNet, HT-SGCA在FULL、SMIC、SAMM数据集上的UF1、UAR指标都有所提高, 表明本文的图注意力聚合模块能更有效地保留对微表情识别有利的特征信息.OFVIG-Net将光流图划分为图像块并作为图节点, 然后基于邻接关系进行图神经网络分析, 在SMIC、SAMM、CASME II数据集上的综合性能仍显不足.
| 表3 各方法在4个数据集上指标值对比 Table 3 Metric values of different methods on 4 datasets |
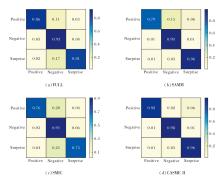
为了进一步分析HT-SGCA的性能, 在FULL、SMIC、SAMM、CASME II数据集上给出三分类混淆矩阵, 具体如图4所示.由图可见, 在FULL数据集上, HT-SGCA对Negative、Positive、Surprise类别的识别准确率分别达到 0.93、0.86 和 0.81.在Negative类别上的高准确率主要归因于这类数据在3个数据集上的训练样本较充足.然而, 在SMIC、SAMM数据集上, Negative与Surprise类别之间的区分仍存在一定挑战.这可能是由于这两个数据集上训练样本相对较少, 从而增加两类情绪混淆的可能性.在 CASME II 数据集上, Negative、Positive、Surprise类别的识别准确率均超过90%, 误分类率较低, 这进一步验证HT-SGCA在该数据集上的有效性.
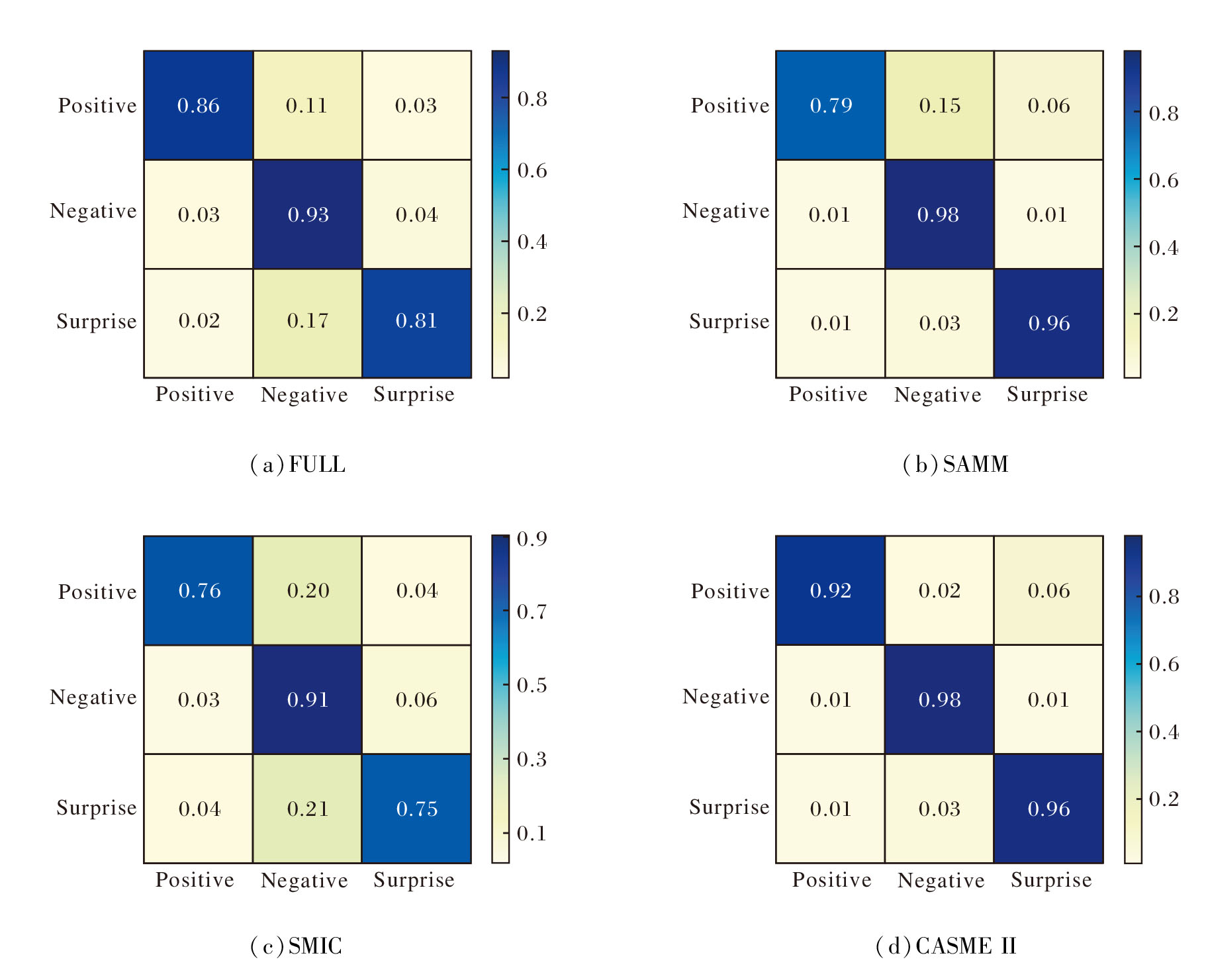 | 图4 HT-SGCA在4个数据集上的三分类混淆矩阵Fig.4 Schematic diagram for 3-class confusion matrix of HT-SGCA on 4 datasets |
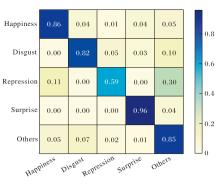
同样在CASME II数据集上进行五分类实验, 结果如图5所示.由图可见, Happiness、Surprise类别的识别准确率较高, 分别达到86%和96%, 这表明本文的双域特征关联模块能有效捕捉面部的细粒度特征.然而, 实验中Repression类别样本较容易被误分类为Happiness类别, 这一现象主要归因于两者在面部运动单元上的高度相似性.
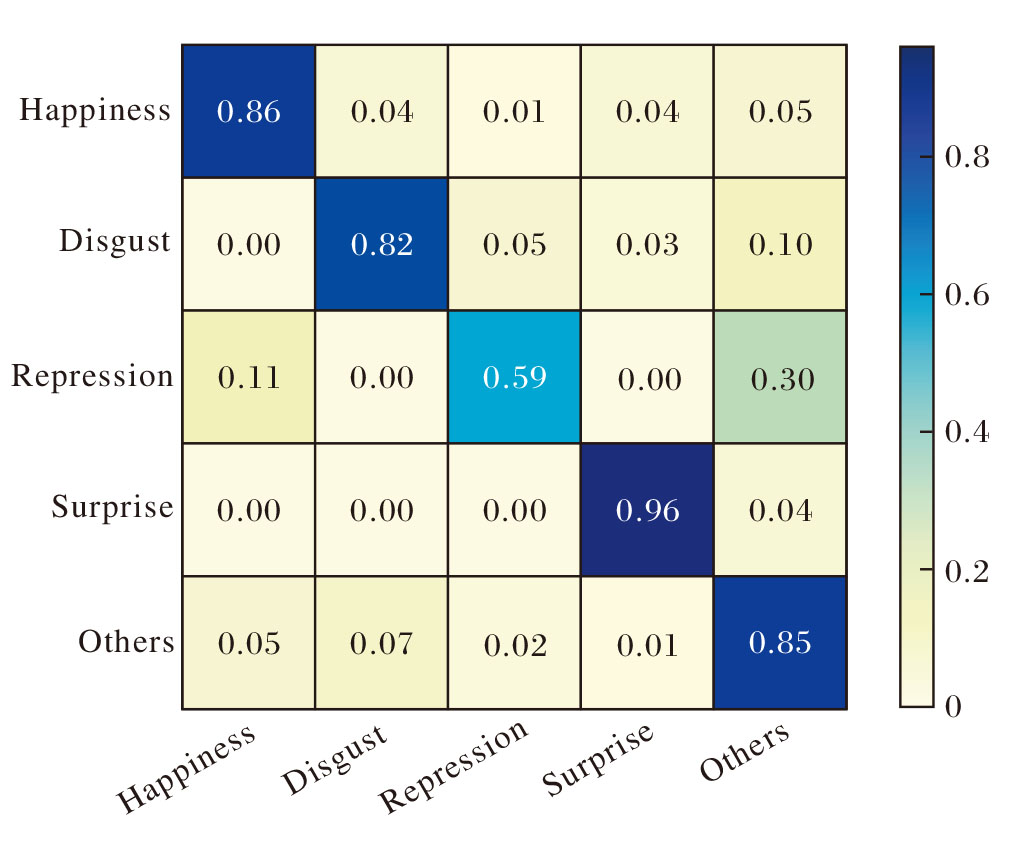 | 图5 HT-SGCA在CASME II数据集上的五分类混淆矩阵Fig.4 Schematic diagram for 5-class confusion matrix of HT-SGCA on CASME II dataset |
为了全面评估HT-SGCA在实际应用中的高效性, 从模型参数量、每秒浮点运算次数(Floating Point Operations Per Second, FLOPs)、推理速度、GPU显存占用及训练时间这5个维度系统对比FeatRef[9]、HTNet[10]、OFVIG-Net[18]、STSTNet[33]、RCN(Recursive Cortical Network)[34].
所有实验均在 NVIDIA RTX 4090 GPU上进行, CUDA与PyTorch版本与前述实验保持一致.推理速度在批尺寸为1的设置下统计, 显存占用为方法推理阶段的峰值显存, 推理速度不含人脸检测划分对齐、裁剪、光流图提取等操作.
各方法计算效率和资源消耗对比如表4所示.由表可见, 不同方法在计算效率与资源消耗方面存在显著差异.基于CNN的方法(如STSTNet和RCN)由于网络结构相对简单, 在推理速度方面具有一定优势, 但其识别性能受限.引入多级注意力或 Trans-former 结构的方法(如FeatRef和HTNet)虽然能提升特征建模能力, 但计算复杂度和显存占用显著增加, 导致推理速度明显下降.
| 表4 各方法的计算效率与资源消耗对比 Table 4 Comparison of computational efficiency and resource consumption of different methods |
作为当前具有代表性的区域Transformer— — HTNet, 在识别性能上表现优异, 但其参数规模和FLOPs较大、训练时间较长、推理速度仅为24帧/秒, 限制其在对实时性要求较高场景中的应用.相比之下, HT-SGCA在保持识别性能略有提升的前提下, 通过更高效的区域建模与特征交互机制, 将FLOPs降至14.3 G, 并在批尺寸为1的条件下实现96帧/秒的推理速度, 约为HTNet的4倍.
同时, HT-SGCA在显存占用和训练时间方面也显著低于HTNet, 体现出更优的计算效率与资源利用率.
尽管HT-SGCA在识别精度上的提升幅度相对有限, 但其在推理速度、显存占用和训练成本方面的综合优势, 使其在实际应用场景中更具可行性和实用价值, 尤其适用于对计算资源和响应延迟较敏感的微表情分析任务.
本节分析窗口扩展系数γ k与Transformer层数这两个关键超参数的作用.统一在CASME II数据集上进行五分类任务, 并采用与最优实验配置一致的训练策略, 确保结果的可比性和稳定性.
为了分析Transformer编码器层数对微表情识别性能的影响, 将层数设为4~12 层, 结果表明, 随着Transformer层数的增加, 识别准确率整体呈现先上升后下降的变化趋势.当层数由4层逐步增至6层时, HT-SGCA性能显著提升, 并在6层配置下达到最高识别准确率86.6%.继续增加层数后, HT-SGCA性能出现不同程度的波动与下降.该现象表明, 6层Transformer结构能在方法表达能力与特征冗余之间取得较优平衡, 更有利于捕获微表情的细粒度动态特征, 提升整体识别性能.
下面分析窗口扩展系数对微表情识别准确率的影响.实验中设置4组不同的窗口扩展系数参数:组A取值为 {0.5, 1, 2, 4, 6, 8}, 组B取值为 {1, 2, 3, 4, 5, 6}, 组C取值为 {10, 20, 30, 40, 50, 60}, 组D取值为 {0.1, 0.2, 0.3, 0.4, 0.5, 0.6}.通过对比不同参数组下HT-SGCA的识别性能, 系统分析窗口扩展系数尺度变化对微表情识别精度的影响. 4组窗口扩散系数对HT-SGCA识别准确率的影响如图6所示.
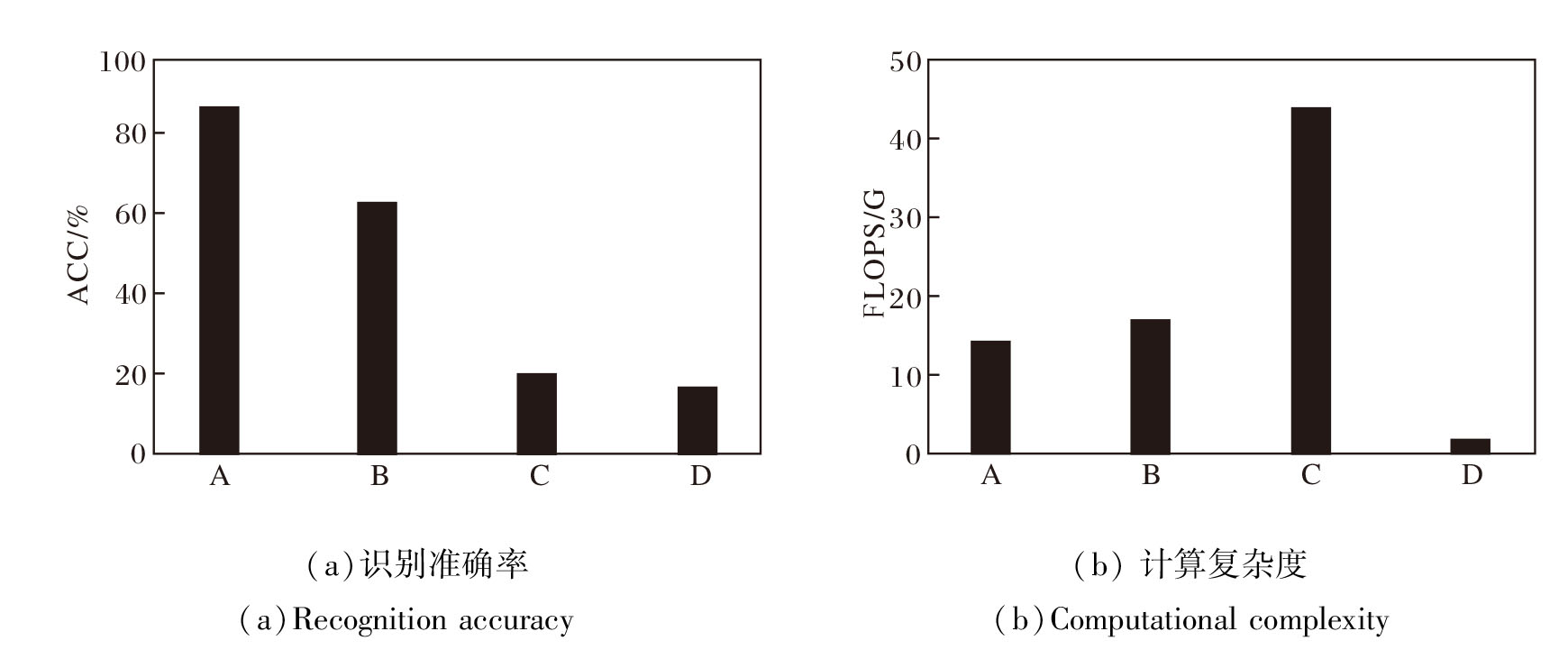 | 图6 窗口扩展系数对识别准确率与计算复杂度的影响Fig.6 Effect of window expansion factors on recognition accuracy and computational complexity |
由图6可见, 组A的识别准确率最高, 达到86.6%, 计算复杂度相对最小.该组的参数设置为(0.5, 1, 2, 4, 6, 8), 这表明在较小的窗口扩展系数下, HT-SGCA能有效捕捉微表情的细微变化, 提升识别精度.相比之下, 组B、C和D的识别准确率分别为62.8%、20.1%和16.7%, 由此表明, 较大的窗口扩展系数(如组C的(10, 20, 30, 40, 50, 60))对微表情的捕捉并未产生正面效果, 反而可能使HT-SGCA在处理细粒度特征时过于平滑, 导致识别效果大幅下降.组D的参数(0.1, 0.2, 0.3, 0.4, 0.5, 0.6)虽较小, 但依然未能有效提升识别准确率, 说明在该任务中, 过小的窗口扩展系数可能限制HT-SGCA对多样化特征的学习能力.
为了评估HT-SGCA的有效性, 在CASME II数据集上开展消融实验, 选择如下模块:多尺度动态窗口模块(MSDW)、双域特征关联模块(DD-FAM)、图注意力聚合模块(GAAM).
各模块的消融实验结果如表5所示.由表可见, 仅引入MSDW后, ACC指标提升4.0%, 验证其在细粒度特征提取方面的有效性.仅引入GAAM同样能带来性能提升, 说明显式建模面部区域间的联动关系对微表情识别具有重要意义.进一步地, 引入MSDW+GAAM及DD-FAM+GAAM的组合后, 可看出多尺度特征建模与区域关系建模之间具有明显的协同增益, 但在缺少DD-FAM时, 在性能和计算效率方面仍存在一定限制.当同时引入MSDW与DD-FAM后, 性能显著提升且计算复杂度大幅降低, 验证DD-FAM在高效建模空间与通道依赖关系方面的关键作用.最终, 在3种模块协同作用下, ACC、FLOPs指标均取得最优值, 充分表明各模块在整体框架中的必要性与互补性.
| 表5 各模块消融实验结果 Table 5 Results of ablation experiment for each module |
在CASME II数据集上对比固定图结构和动态结构, 结果如表6所示.由表可看出, 基于AUs先验的固定图结构在微表情识别任务中表现稳定, 在 ACC、UF1、UAR指标上取得最优值或近似最优值.相比之下, 完全自适应的动态图结构在性能上略有下降, 可能是由于微表情数据规模有限, 导致图结构学习不够稳定.引入自适应学习的混合图结构并未带来显著性能提升, 结果与固定图结构基本一致.
| 表6 固定图与动态图结构对比实验 Table 6 Comparative experiment on static and dynamic graph structures |
针对现有方法存在计算复杂度较高、多尺度特征提取能力不足及区域协同关系建模不充分等缺点, 本文提出结合空间通道特征与图注意力的分层Transformer微表情识别方法(HT-SGCA).首先, 聚焦四个关键面部区域, 有效减少背景噪声干扰, 并结合多尺度动态窗口模块(MSDW), 实现从局部细粒度到全局粗粒度的特征层次化提取.然后, 设计双域特征关联模块(DD-FAM), 在降低计算开销的同时增强多尺度特征表达能力.进一步地, 构建图注意力聚合模块(GAAM), 将图结构建模引入微表情识别任务, 利用自适应图结构建模面部动作单元(AUs)间的协同关系, 提升联动微表情的识别精度.大量实验验证HT-SGCA的有效性.
本文为微表情识别提供一种高效的技术方案, 在情感计算、心理评估等领域具有一定的应用潜力.未来工作可探索动态区域划分策略及多模态数据融合策略, 进一步提升方法在复杂场景中的泛化能力.
本文责任编委 徐 勇
Recommended by Associate Editor XU Yong
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|