





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
面向无人机图像小目标检测的轻量化异构协同主干双路桥接网络
[谢凯静1  , 陈俊英
, 陈俊英1
, 陈俊英]
|
|



作者简介:

谢凯静,硕士研究生,主要研究方向为无人机视角下的目标检测、智能机器人(无人机).E-mail:tson@xauat.edu.cn.
针对无人机航拍图像中小目标高度密集、遮挡严重及现有通用检测模型计算复杂度较高的问题,文中提出面向无人机图像小目标检测的轻量化异构协同主干双路桥接网络(Lightweight Heterogeneous Collaborative Dual-Path Bridged Network for Small-Target Detection in UAV Images, LHCB-Net).基于YOLOv9框架,通过解耦功能同质化堆叠和感受野受限的RepNCSPELAN4,构建由Repvcblock与Galsk(Global Attention Large Selective Kernel Module, Galsk)协同组成的主干网络,从而集成通道、空间及全局上下文三维注意力机制,有效增强小目标的感知能力.Galsk融合全局建模与前馈强化机制,提升复杂背景与遮挡场景下的特征提取能力,弥补轻量化设计带来的感受野缩减问题.同时通过跨层桥接,将次主干特征直连检测头,实现多尺度特征融合与定位精度优化.此外,引入尺度自适应交并比损失函数,动态调整不同尺度目标的回归权重.在VisDrone2019、UAVDT及自建数据集上的实验表明,LHCB-Net在降低参数与计算量的同时提升对密集小目标的检测性能,可为无人机实时机载检测提供高效解决方案.完整代码发布网址:https://github.com/tson122556/LHCB-Net/tree/master.
About Author:
XIE Kaijing, Master student. His research interests include target detection from the perspective of unmanned aerial vehicles and intelligent robots(unmanned aerial vehicles).
To address the issues of highly dense small targets, severe occlusion in UAV images, and high computational complexity of existing general detection models, a lightweight heterogeneous collaborative dual-path bridged network(LHCB-Net) for small target detection in UAV images is proposed in this paper. Based on the YOLOv9 framework, the functionally homogeneous stacking and the limited receptive field of RepNCSPELAN4 are decoupled. A backbone network is constructed by combining the reparameterized convolution block RepVCBlock and the global attention large selective kernel network(Galsk). Thus, a three-dimensional attention mechanism covering channel, space and global contextual dependencies is integrated to effectively enhance the perception of small targets. Galsk combines global modeling and feedforward enhancement mechanisms to improve feature extraction in complex backgrounds and occlusion scenarios and compensate for the receptive field reduction caused by lightweight design. Moreover, secondary backbone features are directly connected to the detection head through cross-layer bridging to achieve multi-scale feature fusion and optimize localization accuracy. Additionally, a scale-adaptive IoU loss function is introduced to dynamically adjust regression weights for targets of different scales. Experimental results on VisDrone2019, UAVDT, and a self-built dataset demonstrate that LHCB-Net significantly improves detection performance for dense small targets while reducing parameters and computational cost, providing an efficient solution for real-time onboard detection. The complete code is available at: https://github.com/tson122556/LHCB-Net/tree/master.
随着无人机在智慧城市巡查、灾害救援、农业监测等领域的广泛应用, 实时精准的目标检测成为关键支撑技术之一.航拍图像中小目标高度密集、尺度多变、遮挡严重, 对检测模型提出严峻挑战.尤其在边境巡逻、交通监控等场景中, 漏检或误检可能导致重大决策失误, 亟需高鲁棒性的实时检测模型.
当前检测技术在无人机航拍图像的小目标检测任务中面临严峻挑战.二阶段模型FAST R-CNN(Fast Region-Based Convolutional Network Method)[1]、Faster R-CNN[2]和Mask R-CNN[3]虽定位精度较高, 但区域提议机制使推理延迟明显, 难以满足无人机机载平台实时性需求.一阶段模型虽在速度上具备优势, 但架构设计上难以满足要求.YOLOv3[4]、YOLOv4[5]依赖预定义锚框, 难以适配无人机视角下目标多朝向与极端尺度变化的情形.YOLOv7[6]因下采样过快导致小目标特征丢失, 32× 32目标在骨干网络浅层便已消失.YOLOv8[7]采用无锚点方法, 在保持较高检测精度的同时, 实现实时检测速度, 但会有冗余边界框, 且方法仅依赖卷积的局部感受野, 难以对被遮挡目标进行全局上下文的建模.虽然ViT(Vision Transformers)[8]的自注意力机制能捕捉长程依赖关系, 但却削弱对局部细节的捕捉能力, 导致边缘模糊的小目标定位偏差增大.
部分研究针对小目标的优化策略仍存在一定的局限性.EfficientDet[9]中的BiFPN(Bidirectional Fea- ture Pyramid Network)虽可促进多尺度语义均衡, 但过大的下采样率会导致微小目标特征严重衰减.HRNet(High-Resolution Network)[10] 使用多分支, 保留高分辨率特征, 然而依赖双线性插值的融合机制缺乏空间自适应性, 对尺度突变目标适应性较弱.在损失函数方面, RetinaNet[11]中Focal Loss虽可缓解类别不平衡问题, 却未解决尺度敏感问题, 小目标的回归梯度被大目标淹没, 导致小目标的检测准确率下降.
网络轻量化设计虽能提升检测速度, 却加剧性能衰减.Liu等[12]简化特征提取层以降低计算量, 却因感受野缩减导致复杂背景中漏检率上升.YOLOv4-Tiny[13]通过简化网络与轻量卷积可减少资源消耗, 但又因通道数减少、缺少深层特征融合而使表达能力弱化.尽管YOLOv9[14]通过PGI(Programma-ble Gradient Information)和可逆结构在通用目标检测上取得一定效果, 但在应对无人机影像的独特挑战时存在机制上的不足, 导致小目标检测性能下降.以RepNCSPELAN4为核心的主干网络, 受限于局部卷积感受野, 难以捕获判别小目标必需的全局空间上下文, 从而在复杂背景下泛化能力下降.YOLOv10[15]去除NMS(Non-Maximum Suppression), 显著降低延迟, 不过在UAV(Unmanned Aerial Vehicle)图像中, 小目标多尺度变化较大, 需要大量计算以提取特征, 浮点模型推理效率较低, 难以满足高实时性需求.
模型对动态环境的适应性不足, 成为提升无人机检测性能的深层次瓶颈.像YOLO-DKR[16]这类静态架构, 虽借助CA(Coordinate Attention)机制提升小目标检测能力, 但搜索空间和候选操作范围较窄, 难以覆盖无人机视角下的极端尺度跨度.此外, 固定损失函数对大小目标采用均等的回归权重, 无法适应目标尺度的动态分布特性, 限制模型对UAV极端俯视视角及多尺度情况的适配能力.
总之, 轻量化设计导致感受野缩减与语义信息弱化, 而增强感受野的模块又加剧计算负担.现有方法(如注意力机制、特征金字塔)虽尝试缓解相关矛盾, 但未系统解决轻量化与小目标特征保真的平衡问题, 更缺乏针对遮挡场景的全局建模能力.如何在不牺牲实时性的前提下进一步提升小目标检测精度, 仍是VisDrone场景中亟待突破的协同优化难题.
针对上述问题, 本文提出面向无人机图像小目标检测的轻量化异构协同主干双路桥接网络(Lightweight Heterogeneous Collaborative Dual-Path Bridged Network for Small-Target Detection in UAV Images, LHCB-Net).首先, 设计Repvcblock和Glask(Global Attention Large Selective Kernel Module).Re-pvcblock重构RepViTBlock[17], 融合通道注意力与空间注意力模块, 引导网络自动聚焦小目标区域关键特征, 再与Galsk构成异构协同主干, 提升轻量化骨干网络在复杂环境下对小目标的响应能力和判别性能.在LSKNet(Large Selective Kernel Network)[18]多尺度深度卷积的基础上, Glask结合多尺度深度可分离卷积与膨胀卷积, 充分提取局部信息和扩张空间信息, 同时, 融入上下文感知模块, 捕获全局语义信息.此外, 通过前馈注意力结构增强非线性表达能力, 提升网络在复杂背景中对小目标的空间聚合能力与语义理解能力.然后, 构建桥路特征融合网络.借助跨层连接将次主干的细粒度多尺度特征直接引入检测头, 实现不同尺度信息的高效融合与传递, 强化对小目标边界及细节的捕捉能力, 提升检测精度与定位准确性.最后, 设计尺度自适应交并比损失函数(Scale-Adaptive Intersection over Union Loss, SA-IoU), 依据目标大小动态调整回归损失的权重.SA-IoU专为小目标而设计, 可优化边界框的回归效果, 有效增强在复杂场景和密集目标环境下检测的稳定性与鲁棒性.
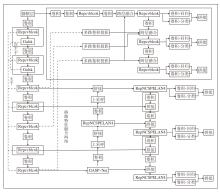
本文针对无人机小物体检测问题, 提出面向无人机图像小目标检测的轻量化异构协同主干双路桥接网络(LHCB-Net), 分三阶段重构YOLOv9[14].LHCB-Net具体架构如图1所示.
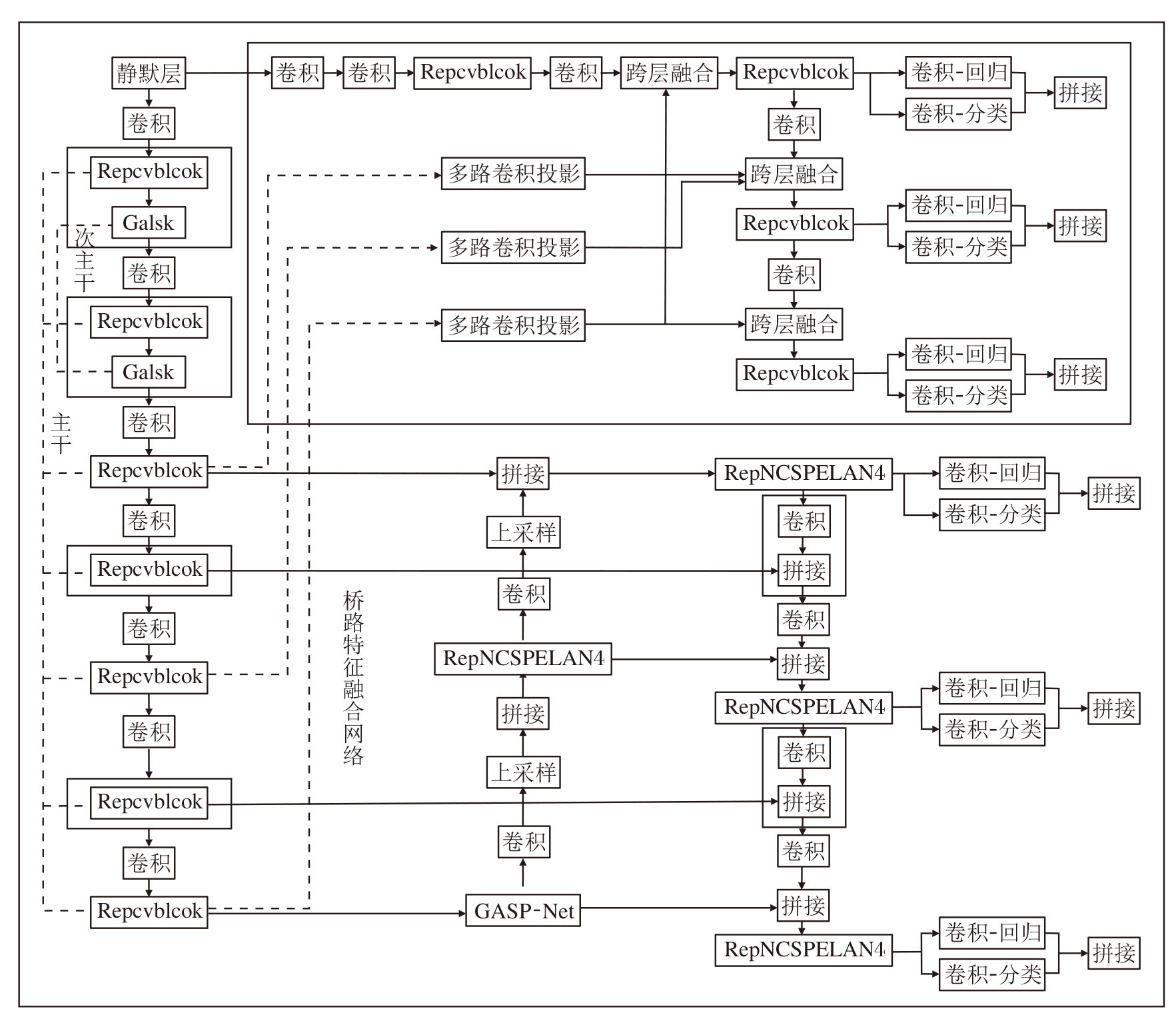 | 图1 LHCB-Net架构图Fig.1 Architecture of LHCB-Net |
LHCB-Net重构YOLOv9主干中感受野受限、路径同质堆叠的RepNCSPELAN4, 实现解耦与轻量化, 使用Repvcblock主干与Galsk次主干实现异构协同、信息互补融合.这种解耦与协同, 使网络在同等计算下, 能更全面、自适应地处理视觉信息, 尤其在处理尺度变化、复杂背景和小目标等场景时优势显著.Repvcblock专注高效提取局部空间特征.Galsk凭借自适应大感受野、空间注意力机制和全局上下文机制三大优势专注捕获多尺度空间上下文信息和建立全局依赖关系.在颈部SPPE-LAN[19]中嵌入Galsk, 构成新的颈部网络GASP-Net(Global Atten-tion Large Selective Kernel Spatial Pooling Ensemble for Light-Weight Networks), 进一步缓解信息瓶颈问题, 提升训练的稳定性和检测精度.
Repvcblock结构如图2所示.Repvcblock通过深度可分离卷积和残差连接, 以极低的计算成本维护高分辨率空间信息并细化局部表征.首先采用深度可分离卷积RepVGGDW(Reparameterizable VGG Depthwise Convolution)作为Token_Mixer, 用于捕获局部空间信息.设计基于通道、空间和全局上下文三个功能维度的注意力机制, 其中全局上下文维度通过非局部注意力操作捕获图像中的长程依赖关系, 专门用于解决无人机航拍中目标与环境语义关联问题.优于RepNCSPELAN4中Token_Mixer (空间操作)和Channel_Mixer (通道操作) 的分离构建的显式解耦, 比RepNCSPELAN4的混合计算更高效、专注.
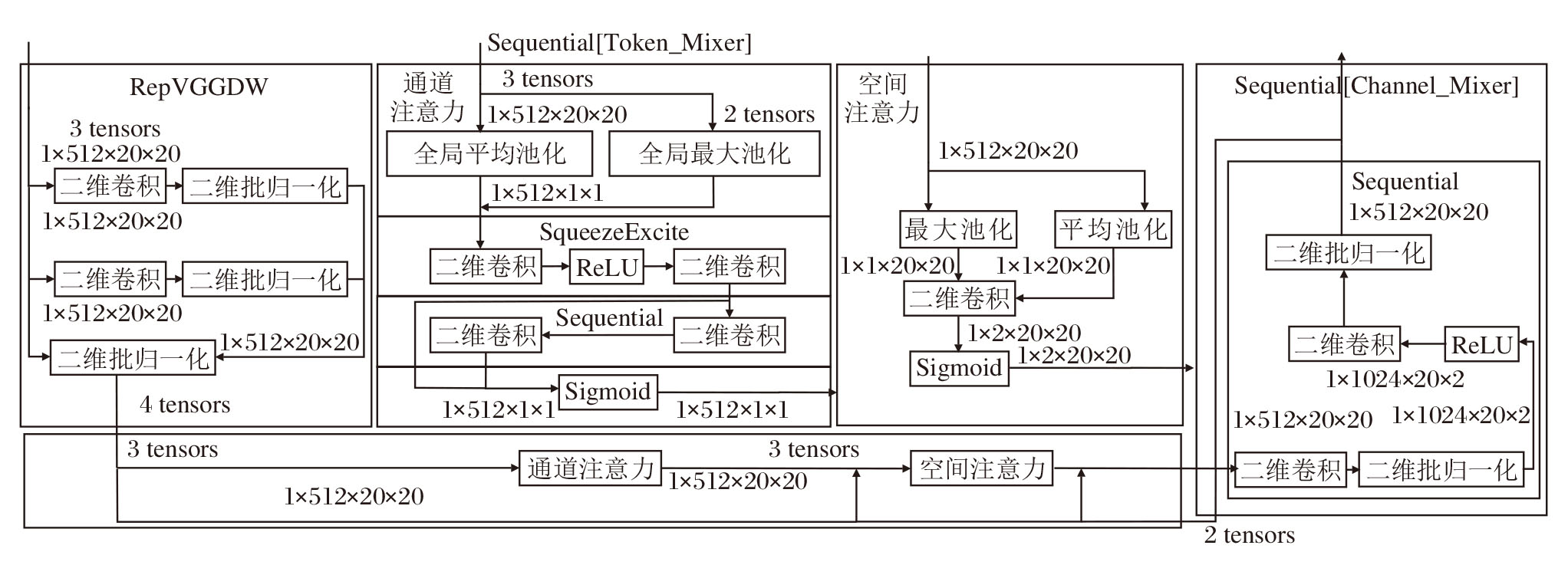 | 图2 Repvcblock结构图Fig.2 Architecture of Repvcblock |
Repvcblock是将特征输入一个残差结构中的Channel_Mixer里, 完成通道维度上的前馈映射.该映射包含两层逐点卷积与激活函数, 在增强非线性表达的同时可降低参数量.
输入特征图X∈ RB× 1× H× W, 其中, B表示批次, 1表示通道数C=1, H、W分别表示特征图的高和宽.X通过2个3× 3卷积分支和一个恒等映射分支, 采用结构重参数化技术, 在训练阶段利用多分支结构增强特征表达能力, 在推理阶段合并为单一卷积层以实现高效计算, 得到特征图:
$\begin{aligned} \boldsymbol{F}_{0}= & B N_{1}\left(\operatorname{Conv}_{3 \times 3}(\boldsymbol{X})\right)+ \\ & B N_{2}\left(\operatorname{Conv}_{3 \times 3}(\boldsymbol{X})\right)+B N_{3}(\boldsymbol{X}), \end{aligned}$
其中, BNi(· )表示二维批归一化, i=1, 2, 3表示顺序, Conv3× 3(· )表示3× 3卷积.
通道注意力借助全局平均池化和全局最大池化处理上层特征图F0, 生成2个维度为RB× C× 1× 1的通道特征图
W0(F)=Conv1× 1([
其中Conv1× 1(· )表示1× 1卷积.
然后, 引入非线性ReLU, 得到通道注意力的瓶颈激活特征:
R(F)=ReLU(W0(F)),
其中ReLU(· )表示修正线性激活函数, 以此增强网络的表达能力.最后对R(F)进行1× 1卷积, 得到通道响应升维特征:
W1(F)=Conv1× 1(R(F)).
经过 Sequential操作得到通道响应细化特征:
Q(F)=Conv1× 1(Conv1× 1(W1(F)).
将Q(F)与W1(F)和R(F)相加, 再经Sigmoid函数归一化, 得到通道注意力权重Mc(F).将该注意力权重与输入特征图F在通道级进行加权操作, 得到特征图:
$\boldsymbol{F}^{\prime}=M_{c}(\boldsymbol{F}) \otimes \boldsymbol{F}, $
其中, $\otimes$表示逐通道乘法, 并且广播到空间维度.通过双路SE注意力机制, 筛选并强化关键通道, 抑制冗余信息.
针对特征图F', 沿通道维度分别执行平均池化和最大池化, 生成相应空间特征图:
$\begin{array}{l} \boldsymbol{F}_{\mathrm{avg}}^{s}=\frac{1}{C} \sum_{i=1}^{C} \boldsymbol{F}_{i}^{\prime} \in \mathbf{R}^{B \times 1 \times H \times W}, \\ \boldsymbol{F}_{\max }^{s}=\max _{i=1, \cdots, C} \boldsymbol{F}_{i}^{\prime} \in \mathbf{R}^{B \times 1 \times H \times W}, \end{array}$
用于强化有效空间区域建模, 进而引导网络聚焦空间显著区域.
通过卷积操作, 处理拼接后的特征, 生成注意力图:
Ms(F')=sigmoid(F7× 7([
其中F7× 7(· )表示7× 7卷积核运算.
对空间注意力生成的特征图与经过通道注意力的特征图加权后的特征进行再次加权处理运算, 得到特征图:
$\boldsymbol{F}^{\prime \prime}=M_{s}\left(\boldsymbol{F}^{\prime}\right) \otimes \boldsymbol{F}^{\prime} .$
后置特征融合中先进行卷积操作, 进行批量归一化(Batch Normalization, BN)操作, 在通过ReLU激活函数处理后, 再次进行卷积和批量归一化操作.将经过注意力加权后的特征图进行融合并提升维度, 最终得到处理后的特征图:
Y=BN(Conv1× 1(ReLU(BN(Conv1× 1(F″ ))))).
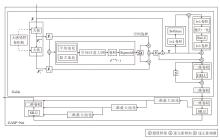
Galsk重构LSKNet[18], 增强局部细节与全局上下文建模能力, 专注于捕获多尺度空间上下文和建立全局依赖关系.采用不同尺寸的卷积核实现逐像素注意力调制与加权融合.全局上下文提供全局通道注意力, 将整个特征图的全局信息作为权重校准Galsk输出, 实现局部-区域-全局的全方位上下文感知.前馈网络利用投影层和GELU激活函数实现非线性转换, 输出判别力更强的空间加权特征.Galsk和GASP-Net结构如图3所示.
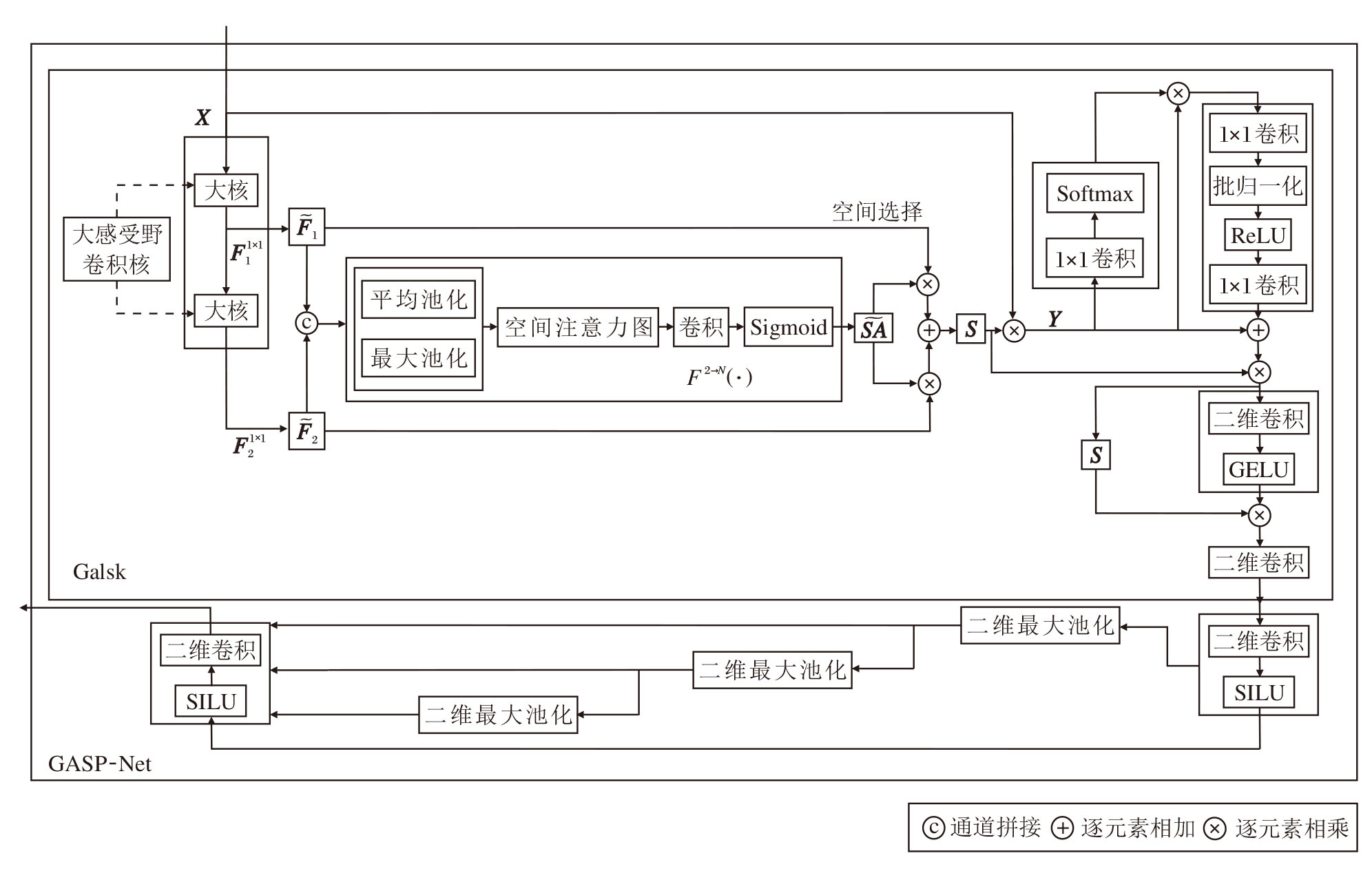 | 图3 Galsk与GASP-Net结构图Fig.3 Architecture of Galsk and GASP-Net |
从输入特征图X∈ RB× 1× H× W的不同位置提取丰富的背景特征, 采用一系列具有不同感受野的Depthwise卷积核进行解耦操作:
F1=X, Fi+1=
其中,
再由N个解耦卷积核的输出通过1× 1卷积F1× 1(· )实现通道融合, 提取空间特征向量:
$\begin{array}{l} \widetilde{\boldsymbol{F}}=\left[\widetilde{\boldsymbol{F}}_{1} ; \widetilde{\boldsymbol{F}}_{2} ; \cdots ; \widetilde{\boldsymbol{F}}_{N}\right], \\ \widetilde{\boldsymbol{F}}_{i}=F^{1 \times 1}\left(\boldsymbol{F}_{i}\right) . \end{array}$
为了关注目标的空间背景信息, 基于多尺度特征, 通过动态选择机制选取合适的卷积核大小.采用通道级平均池化havg(· )和最大池化hmax(· )捕捉
$\begin{array}{l} \boldsymbol{S} \boldsymbol{A}_{\mathrm{avg}}=h_{\mathrm{avg}}(\widetilde{\boldsymbol{F}}), \\ \boldsymbol{S} \boldsymbol{A}_{\max }=h_{\max }(\widetilde{\boldsymbol{F}}) . \end{array}$
为了实现空间描述符之间的信息交互, 卷积层F2→ N(· )将低维池化特征转换为高维特征, 得到高维特征描述符:
接着, 重组特征, 并引入注意力机制, 生成N个空间注意力特征图.
对每个特征图应用Sigmoid函数激活
$\widetilde{S A}_{i}=\operatorname{sigmoid}\left(\widehat{S A}_{i}\right), $
以此生成对应解耦大卷积核的空间选择掩膜.
将掩膜与解耦卷积核序列特征加权处理后, 通过卷积层F(· )进行融合, 生成注意力特征:
$\boldsymbol{S}=F\left(\sum_{i=1}^{N}\left(\widetilde{\boldsymbol{S A}_{i}} \cdot \widetilde{\boldsymbol{F}}_{i}\right)\right) .$
将输入特征图X与注意力特征S进行逐元素点乘, 获得最终输出特征图:
$\boldsymbol{Y}=\boldsymbol{X} \otimes F\left(\sum_{i=1}^{N}\left(\widetilde{\boldsymbol{S A}_{i}} \cdot \widetilde{\boldsymbol{F}}_{i}\right)\right)$.
全局上下文感知模块借助全局平均池化与通道注意力机制, 结合1× 1卷积提取全局上下文信息, 生成通道级注意力权重, 以此缓解小目标因视角变换、遮挡或低分辨率导致的特征缺失问题.输入特征图经卷积操作调整通道数量后, 沿通道维度应用Softmax, 生成权重特征图:
$\begin{array}{l} \boldsymbol{Y}_{\text {softmax }}= \\ \operatorname{softmax}\left(B N_{1}\left(\operatorname{Conv}_{1 \times 1}\left(\boldsymbol{X} \cdot F\left(\sum_{i=1}^{N}\left(\widetilde{\boldsymbol{S A}}_{i} \cdot \widetilde{\boldsymbol{F}}_{i}\right)\right)\right)\right)\right), \end{array}$
以此突出小目标区域.
随后, 将其与LSKNet提取的特征图Y逐元素相乘, 得到融合全局上下文感知通道注意力后的特征图:
$\boldsymbol{Y}_{1}=\boldsymbol{Y}_{\text {softmax }} \otimes \boldsymbol{Y}, $
用于增强全局场景感知能力.
调整通道维度后, 执行批归一化操作, 确保输出的稳定性.通过ReLU函数引入非线性因素.再运用3× 3卷积提取空间上下文信息得到特征图Y2.
最后, 通过残差连接将原始特征图Y与处理后的特征图Y2融合, 得到融合后的特征图:
Yadd =Y2 + Y.
注意力特征经逐元素相乘融合后, 输入前馈网络.采用1× 1卷积与批归一化操作提取精炼特征, 优化通道信息表达, 由此得到融合特征图:
$\boldsymbol{Y}_{3}=\boldsymbol{Y}_{\mathrm{add}} \otimes F\left(\sum_{i=1}^{N}\left(\widetilde{\boldsymbol{S A}_{i}} \cdot \widetilde{\boldsymbol{F}}_{i}\right)\right)$
通过GELU激活函数, 引入平滑非线性特征.将激活结果与融合特征Y3进行逐元素相乘, 强化注意力权重分布.最后利用1× 1卷积生成最终特征图.
GASP-Net是将Galsk和SPPELAN[19]结合, 实现注意力与金字塔池化的空间协同, 其结构如图3所示.Galsk提取初步空间特征后, 1× 1卷积模块将通道从c1转为c3, 再经过SILU非线性优化, 得到描述子:
GN1 = SILU(Conv1× 1(X)),
以此实现降维、减少计算量并进行语义提取.
然后, 经过3次5× 5最大池化操作, 将感受野扩展至 13× 13, 增强多尺度特征感知能力, 聚焦小目标的全局结构.最后, 沿通道维度融合多尺度特征, 得到描述子:
GNout= GNm1+GNm2 +GNm3,
GNm1、GNm2、GNm3表示三次最大池化操作后的描述子.
运用SILU激活函数增强非线性表达能力, 优化采样特征细节, 将拼接后的通道数从4× c3转换为c2, 生成运算后的描述子:
GN'out = Conv1× 1(SILU(GNout)).
尽管DIoU(Distance-IoU)[20]和CIoU(Complete-IoU)[21]等损失函数在目标检测中表现优异, 但在处理尺度差异悬殊的目标时存在梯度失衡问题.对于极小目标(面积Agt很小), 边界框的微小绝对偏移即可导致交并比(Intersection over Union, IoU)剧烈变化, 产生过大梯度, 影响训练稳定收敛.反之, 大目标往往梯度不足.
为了从理论上解决该问题, 本文提出尺度自适应的梯度调节机制, 引入基于真实框面积Agt的权重s.该权重需满足光滑、单调递增、值域为(0, 1)、导数便于梯度调制的要求.据此, 采用指数型Sigmoid形式:
s=
通过超参数α 实现动态调节, 使小目标的损失惩罚更温和.由此构造SA-IoU如下:
$L_{\mathrm{SA}-\mathrm{IoU}}=1-I o U+s\left(\frac{\rho^{2}}{c^{2}}+\beta v\right), $
其中, IoU表示标准交并比, c、v、 ρ 的定义与CIoU和DIoU一致, β 表示宽高比惩罚系数.
为了验证LHCB-Net的有效性, 在VisDrone-2019[22]、UAVDT[23]和自制数据集SelfData上进行对比实验.
VisDrone2019数据集包含大量小物体, 共10类, 训练集包含6 471幅图像, 测试集包含548幅图像, 共计38 759个实例, 平均每幅图像约有70个目标, 适合进行高密度目标检测, 图像分辨率约为2 000× 1 500.
UVADT数据集上检测目标包含汽车、货车和公交车, 涵盖无人机在广场、高速公路、路口等复杂场景下拍摄的常见画面.
SelfData数据集由DJI Mini 3 PRO在弱光环境中采集, 模拟无人机在复杂环境下对小型地面目标的识别任务, 涵盖道路目标与田野目标, 拍摄高度均为120 m, 图像分辨率为960× 544, 目标最大尺寸不超过20× 20.每个场景中原始图像400幅, 通过翻转、遮挡、噪声注入及亮度调整等数据增强方法, 扩展至各2 000幅图像.训练集、验证集、测试集按8∶ 1∶ 1的比例划分后, 分别包含1 600幅图像、200幅图像和200幅图像.在标注方面, 场景1共2 800个标签, 场景2共2 700个标签.
实验环境包括双核(Intel(R)Xeon(R)Gold 6240 2.60 GHz的CPU、4块Turing102架构[GeForce RTX 2080 Ti]的11 GB GDDR6显卡、384 GB的RAM、Ubuntu22.04服务器.机器学习框架为PyTorch2.4.1, 编程语言及版本为Python3.8, CUDA版本为12.6.
所有实验均遵循统一训练与评估标准, 以此确保对比的公平性.采用SGD(Stochastic Gradient Descent)优化器和带热身的OneCycleLR(One Cycle Learning Rate)学习率调度策略从0开始训练.设置初始学习率为0.01, 最终学习率为0.000 1, 动量因子为0.937, 热身周期为2个训练轮数, 热身偏置学习率为0.1, 训练轮数为300, 批次为20, 输入图像尺寸为640× 640.若连续30个轮次内模型在验证集上性能无提升, 提前终止训练.
推理阶段的非极大值抑制的IoU阈值为0.65, 置信度阈值为0.25.除了特别说明以外, SA-IoU中超参数α =0.5.
评估指标采用业界公用的平均精度(Average Precision, AP), 包括mAP50、mAP75、mAP0.5∶ 0.95、Aps、APm、Apl、帧率.Aps表示面积小于322的小目标对应的AP值, 难度最大, 数值通常最低.APm表示面积在(322, 962) 之间的中等目标对应的AP值, 检测难度中等, 数值居中.Apl表示面积大于962像素的大目标对应的AP值, 容易检测, 数值通常最高.
2.2.1 VisDrone2019数据集上对比实验
首先在VisDrone2019数据集上进行实验, 采用COCO格式指标进行评估.
选择如下对比模型: YOLOv8-S[7]、YOLOv8-M[7]、YOLOv9-S[7]、YOLOv9-M[14]、YOLOv10-S[15]、YOLOv10-M[15]、YOLO-DKR[16]、YOLOv5-L[24]、YOLOv11-S[25]、YOLOv11-M[25]、L-FFCA-YOLO[26]、TPH-YOLOv5-L[27]、RT-DETR(Real-Time Detection Transformer)[28]、UAV-DETR[29].
各模型对比结果如表1所示, 表中黑体数字表示最优值.
| 表1 各模型在VisDrone2019数据集上的指标值对比 Table 1 Metric value comparison of different models on VisDrone2019 dataset |
由表1可见, LHCB-Net在小目标检测方面性能最优.相比RT-DETR和UAV-DETR, LHCB-Net在帧率上的优势更明显.相比YOLOv5-L, LHCB-Net的mAP0.5∶ 0.95值提升13.2%, 参数量仅为30.23 M, 约为YOLOv5-L的66.7%.相比YOLOv8, LHCB-Net在mAP50∶ 95、mAP50指标上分别提升14.4%和16.0%, 在帧率上提升29帧/秒.相比YOLOv8-M, LHCB-Net的mAP50∶ 95指标提升12.0%, 帧率提高63帧/秒.相比YOLOv9-S、YOLOv9-M、YOLOv10-S、YOLOv10-M、YOLOv11-S和YOLOv11-M, LHCB-Net的mAP50∶ 95指标分别提升13.9%、11.1%、14.5%、11.8%、14.8%、10.5%.相比L-FFCA-YOLO, LHCB-Net的mAP50∶ 95、Aps、Apm、Apl指标分别提升13.4%、3.9%、21.9%和1.8%.相比TPH-YOLOv5-L, LHCB-Net的mAP50∶ 95、Aps、Apm指标分别提升13.2%、4.2%和20.0%, 参数量仅为TPH-YOLOv5-L的66.7%, 经量化部署到无人机时约为7.5 M.
为了直观展示LHCB-Net在密集小目标检测上的性能优势, 在VisDrone2019数据集上, 可视化YOLOv9与LHCB-Net在密集小目标图像上的检测结果, 具体如图4所示, 图中上下两幅图像为同一检测器上的不同图像, 蓝框标记显著区分区域.由图可见, LHCB-Net能更精准地识别密集区域及远距离小目标, 显著减少漏检现象, 提升复杂背景中的检测准确率.
 | 图4 YOLOv9和LHCB-Net在密集小目标上的检测结果Fig.4 Detection results of YOLOv9 and LHCB-Net on dense small targets |
为了验证LHCB-Net在复杂场景下的适应性, 在VisDrone2019数据集上选择有严重遮挡的目标图像, YOLOv9和LHCB-Net的检测结果如图5所示, 图中蓝框标注显著区分区域.由图可见, 在复杂遮挡条件下, LHCB-Net检测稳定性和模型鲁棒性更优.
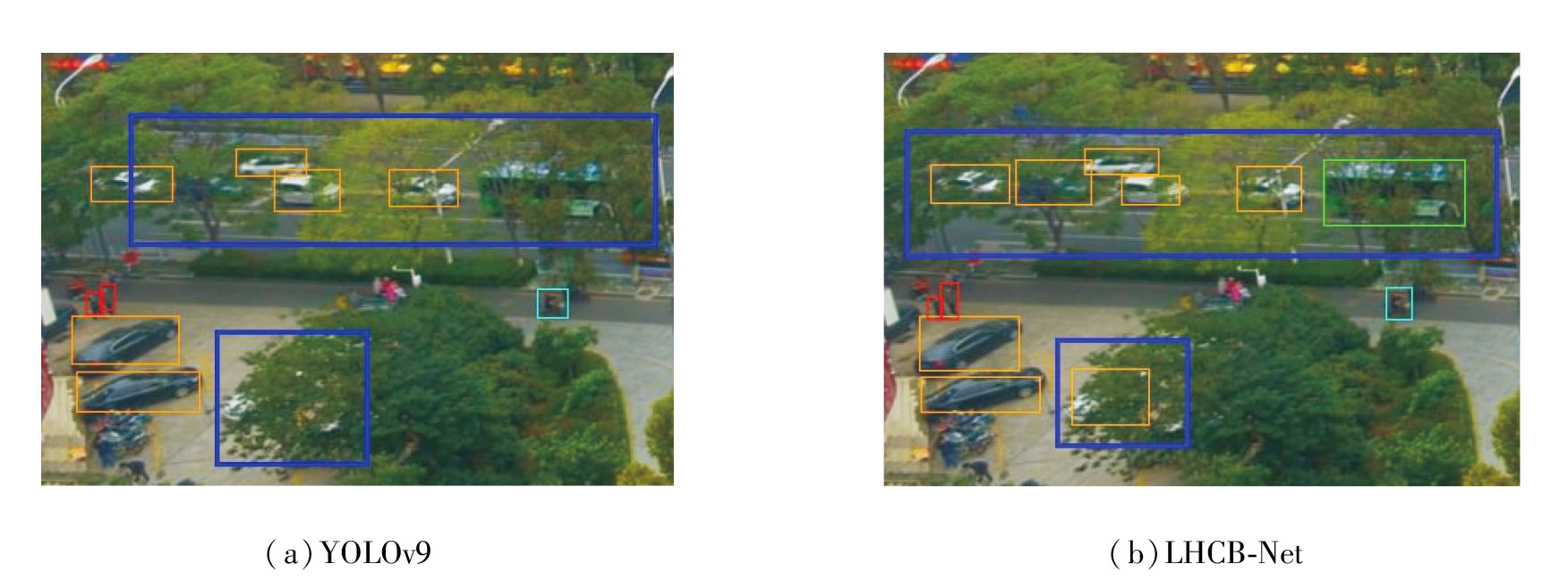 | 图5 YOLOv9和LHCB-Net在遮挡目标上的检测结果Fig.5 Detection results of YOLOv9 and LHCB-Net on occluded targets |
2.2.2 UAVDT数据集上对比实验
选择如下对比模型:YOLOv7-tiny[6]、YOLOv9[7]、TPH-YOLOv5[27]、ClusDet(Clustered Detection Net-work)[30]、DMNet[31]、Center-Net[32]、AMRNet[33]、自适应特征增强的目标检测算法(YOLO-AFENet)[34].各模型对比结果如表2所示.
| 表2 各模型在UAVOT数据集上的指标值对比 Table 2 Metric value comparison of different models on UAVOT dataset |
由表2可见, 相比YOLOv9, LHCB-Net的mAP50∶ 95、mAP50指标分别提升7.4%和9.1%, 优于主流 YOLO系列模型和一阶段模型, 特别在中小目标检测方面表现突出.相比ClusDet、DMNet、CenterNet和AMRNet, LHCB-Net帧率最高.相比TPH-YOLOv5, LHCB-Net的mAP50∶ 95、mAP50指标分别提升0.9%和2.0%.相比YOLOv7-tiny, LHCB-Net的mAP50∶ 95、mAP50、mAP75、Aps、Apm、Apl指标分别提升2.8%、0%、7.4%、6.6%、16.7%和27.7%.相比YOLO-AFENet, LHCB-Net的mAP50∶ 95、mAP50、mAP75、Aps、Apm、Apl指标分别提升8.4%、7.7%、14.4%、6.6%、16.7%和27.7%.总之, LHCB-Net在复杂场景的小目标检测上优势显著.
在UAVDT数据集上对比YOLOv9与LHCB-Net的检测结果, 具体如图6所示.在图中, 上下两幅图像为同一检测器上不同图像, 蓝框标记显著区分区域.
 | 图6 YOLOv9和LHCB-Net在UAVDT数据集上的可视化结果Fig.6 Visualization of YOLOv9 and LHCB-Net on UAVDT dataset |
由图6可见, LHCB-Net能有效识别密集区域和远距离小目标, 减少漏检、错检等情况发生.
2.2.3 SelfData数据集上对比实验
在SelfData数据集上, 对比YOLOv9和LHCB-Net, 具体指标值如表3所示.
| 表3 各模型在SelfData数据集上的指标值对比 Table 3 Metric value comparison of different models on SelfData dataset |
由表3可见, 相比YOLOv9, LHCB-Net在mA-P50∶ 95、mAP50、mAP75、Aps、Apm、Apl指标上分别提升1.1%、3.7%、2.0%、4.2%、3.2%和5.3%, 参数量和浮点运算量仅为YOLOv9的66.7%, 由此验证LHCB-Net的优越性和普适性, 有助于后续设计更轻量化、精准、快速的网络架构.
为了验证LHCB-Net在高噪声、弱光和运动模糊场景中的性能优势, 在SelfData数据集上选取这些场景进行检测.
YOLOv9和LHCB-Net在相应场景中的检测结果如图7所示, 图中上下两幅图像为同一检测器上不同图像.
 | 图7 YOLOv9和LHCB-Net在SelfData数据集上的可视化结果Fig.7 Visualization of YOLOv9 and LHCB-Net on SelfData dataset |
由图7可见, 相比YOLOv9, LHCB-Net在高噪声、模糊和弱光等环境中依然能有效精准检测小目标, 由此表明其具有较优的检测性能.
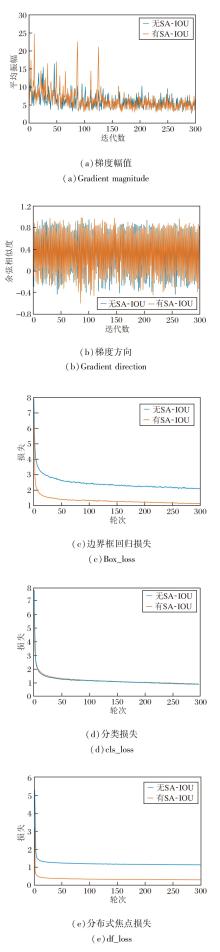
为了更清晰地观察SA-IoU梯度动态调节的效果及收敛性, 训练过程中是否加入SA-IoU后的梯度幅值、梯度方向及训练阶段损失函数结果如图8所示.
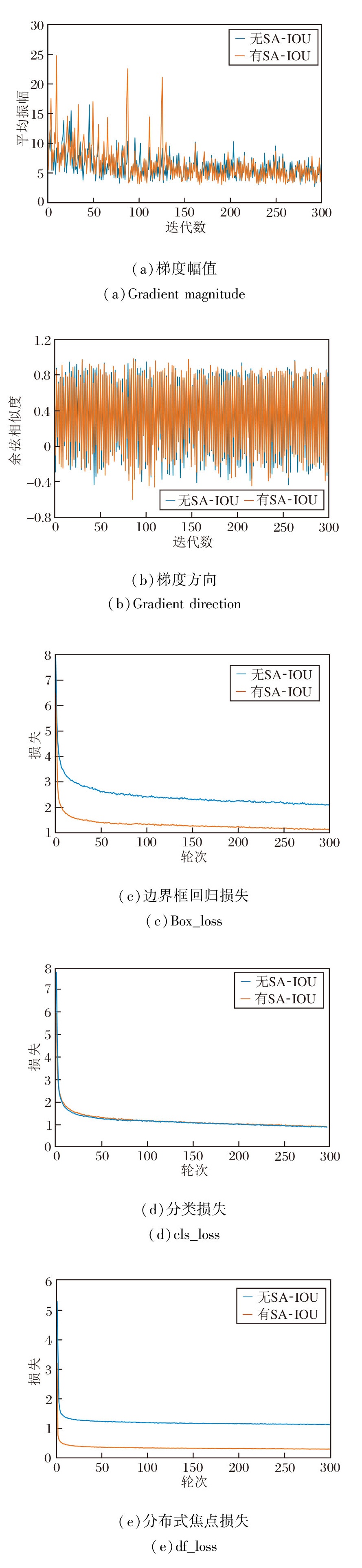 | 图8 SA-IOU对LHCB-Net性能的影响Fig.8 Effect of SA-IOU on LHCB-Net performance |
由图8可见, 引入SA-IoU后, 梯度幅值在训练前期及若干关键迭代中呈现更显著的增强和峰值, 这表明SA-IoU对低重叠或形状偏差样本具有更强的纠正能力.尽管局部更新幅度有所增大, 但梯度方向整体保持稳定, 并未导致优化路径的紊乱.在更强梯度信号的驱动下, LHCB-Net能更快地修正定位误差, 加速边界框回归损失的下降, 并最终达到更低的误差水平.同时, 总损失也呈现出更快、更平滑的收敛趋势, 这表明LHCB-Net在全局优化方面也有一定改善.
总之, 这种适度的梯度增强不仅未破坏训练的稳定性, 反而提升参数更新的效率.在训练后期, 梯度幅值的减少有利于网络收敛.
综合而言, SA-IoU通过提供更充分的梯度反馈, 强化定位优化过程, 有利于实现更优的训练效率与收敛质量.
在UAVDT、VisDrone2019数据集上, 给出各模型的速度-精度权衡图, 具体如图9所示.由图可见, 无论是在UAVDT数据集上还是在VisDrone2019数据集上, LHCB-Net均实现速度与精度之间的更优 平衡.在UAVDT数据集上, LHCB-Net的权衡效果略优于YOLOv7-tiny; 在VisDrone2019数据集上, LHCB-Net虽帧率略低于YOLOv10-S和YOLOv11-S, 但精度优势明显, 整体上优于对比模型.
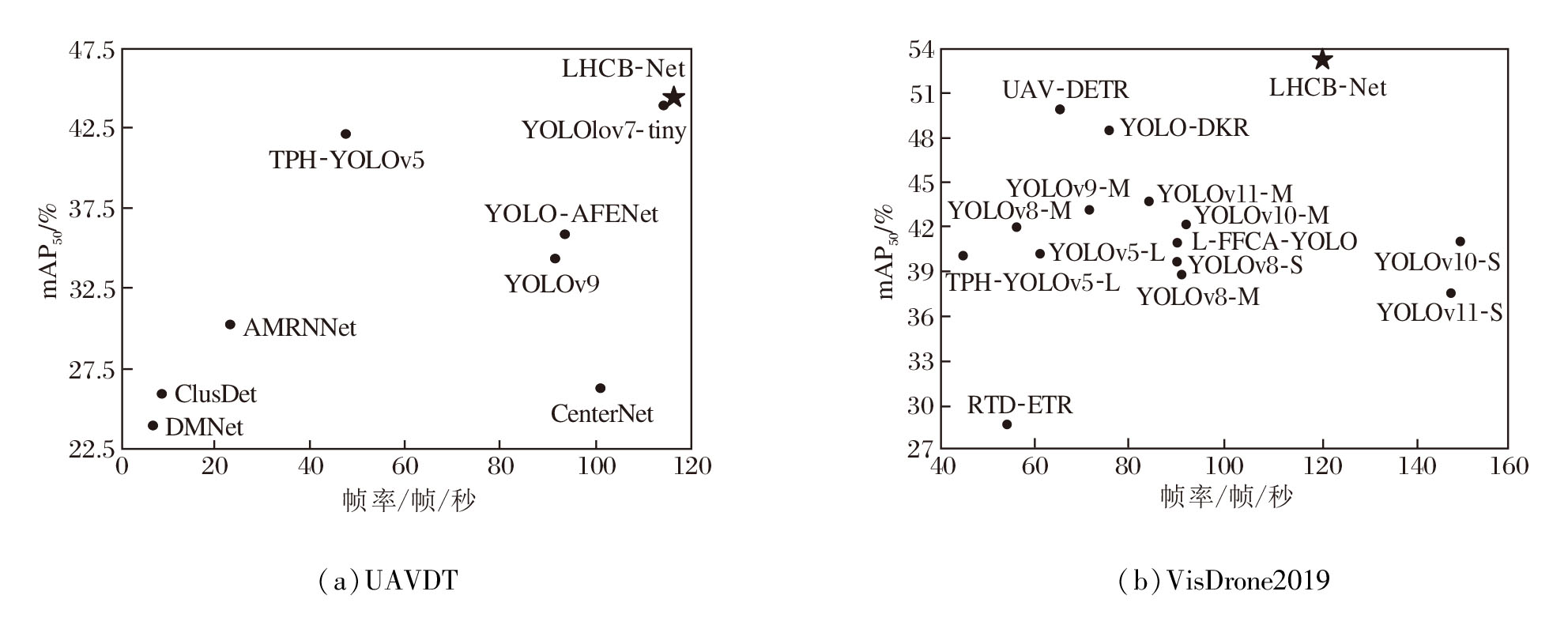 | 图9 各模型的mAP50和帧率权衡图Fig.9 mAP50 and FPS tradeoff plots of different models |
实验以YOLOv9为基准, 逐步加入Repvcblock、Galsk、桥路特征融合网络(下文简记为Bridge)、SA-IoU, 具体消融实验结果如表4所示.由表可见, Repvcblock与Galsk构成异构协同主干网络, 通过功能解耦与协同增效机制, 实现特征信息的互补融合.Bridge通过桥路融合将特征直接连接至检测头, 在仅增加Repvcblock与Galsk的情况下, 各指标在不同程度上有所提高, 其中mAP50指标最高提升8.8%, 进一步验证动态感受野调整对小物体检测的有效性.SA-IoU能显著提升小目标检测性能, 相比YOLOv9, mAP50∶ 95指标最高提升达3.9%.
| 表4 在VisDrone2019数据集上的消融实验结果 Table 4 Ablation experiment results on VisDrone2019 dataset % |
本文在分析无人机视角下图像特征的基础上, 提出面向无人机图像小目标检测的轻量化异构协同主干双路桥接网络(LHCB-Net).全方位重构设计YOLOv9的主干、颈部、检测头和辅助可逆分支.在主网络特征提取阶段引入Repvcblock, 实现主网络和辅助可逆分支的轻量化, 在网络浅层嵌入次主干Galsk, 有效增强小目标特征提取能力.在跨层特征融合阶段, 设计桥路特征融合网络, 充分利用低层特征图和高层特征图的先验信息, 减少传统特征融合中的语义偏差及小目标信息丢失问题.SA-IoU通过引入尺度自适应感知权重机制, 提升对小目标的定位能力.VisDrone2019、UAVDT数据集上的实验表明, LHCB-Net具备良好的检测性能.在SelfDate数据集上实验进一步验证LHCB-Net泛化性较强.此外, LHCB-Net参数量仅为YOLOv9的66.7%, 更便于在无人机及嵌入式设备上部署.今后, 将基于本文提出目标检测架构, 部署于ARM(Advanced Reduced Instruction Set Computer(RISC) Machine)或RISC-V-架构芯片研究, 使其能切实应用于无人机等高功耗计算需求的场景中.
本文责任编委 兰旭光
Recommended by Associate Editor LAN Xuguang
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|