
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于偏差扩散与双流对比学习的工业异常检测方法
[朱圣1  , 张亚飞
, 张亚飞1 , 李华锋1
, 张亚飞, 李华锋]
|
|



作者简介:

朱 圣,硕士研究生,主要研究方向为计算机视觉、图像处理.E-mail:zhushxxx@163.com.

张亚飞,博士,教授,主要研究方向为图像处理、模式识别.E-mail:zyfeimail@163.com.
工业外观异常检测在智能制造与品质管控中具有重要意义,但受限于异常样本稀缺和分布多样化,现有方法在多类别场景中容易出现重建失真或特征混淆,导致异常定位不准确.为此,文中提出基于偏差扩散与双流对比学习的工业异常检测方法,在潜在空间中通过偏差扩散模型直接学习从含噪特征到正常特征的“偏离方向”,结合类别嵌入捕获特定类别的正常结构,并在推理中融合潜在空间域与图像域差异,生成鲁棒的异常热力图.同时,引入双流对比学习,拉大正常样本与异常样本的间隔.设计前景感知的异常合成策略,构造结构性与纹理性的互补异常,为“正常流-合成异常流”的对比学习提供高质量异常样本.在MVTec-AD、VisA数据集上的实验表明,文中方法在图像级和像素级多项指标上均较优,表现出较强的泛化能力.
About Author:
ZHU Sheng, Master student. His research interests include computer vision and image processing.
ZHANG Yafei, Ph.D., professor. Her research interests include image processing and pattern recognition.
Industrial anomaly detection is crucial to intelligent manufacturing and quality control. However, due to the scarcity and diverse distribution of anomaly samples, existing methods are prone to reconstruction distortion or feature confusion in multi-class scenarios, leading to inaccurate anomaly localization. To address these issues, an industrial anomaly detection method based on deviation diffusion and dual-stream contrastive learning is proposed. The deviation direction from noisy features to normal features in the latent space is directly learned through a deviation diffusion model. The normal structure of specific classes is captured by combining class embedding. A robust anomaly heatmap is generated through fusing the differences between the latent space domain and the image domain during inference. Simultaneously, dual-stream contrastive learning is introduced to widen the representation gap between normal samples and anomalies. Furthermore, a foreground-aware anomaly synthesis strategy is designed to construct complementary anomalies with structural and textural characteristics to provide high-quality anomaly samples for the contrastive learning of the normal flow-synthesized anomaly flow. The experimental results on MVTec-AD and VisA datasets show that the proposed method achieves excellent performance on multiple evaluation metrics and exhibits strong generalization ability.
工业异常检测与定位在智能制造、装备维护与品质管控中至关重要, 核心目标是在不确定、复杂的成像条件下, 准确分割划痕、脏污、破损等细粒度异常区域.异常样本天然稀缺且形态多样, 同时随着工艺和材料批次的变化, 异常样本的分布也会发生漂移.与此同时, 通常只有正常样本能稳定采集并进行标注[1].这些现实约束使得依赖大量异常样本标注的全监督方法难以落地, 而仅使用正常样本进行学习的无监督方案或半监督方案在工业实践中表现出更高的实用性与性价比.
在异常检测研究中, 重建式方法与嵌入式方法是两条主流技术路径.重建式方法(如基于自编码器、生成对抗网络的方法[2, 3])以学习正常分布并重建为基本假设, 通过重建误差暴露异常区域.随着卷积网络表征能力的提升, 该种方法在推理阶段往往会不加分辨地将异常样本一并重建, 导致异常样本被“ 修复” 而难以被显著放大.嵌入/检索类方法[4, 5]则借助大规模预训练模型提取特征, 在推理时进行邻近匹配或特征比对, 通常能取得更高的检测性能, 但需要构建多层级的特征库并执行复杂的相似度计算, 推理计算成本较高.此外, 直接使用通用的预训练特征而缺少面向异常检测任务的自适应训练, 容易受域间差异与多类别混杂的干扰, 像素级定位的稳定性与可解释性也随之受限.
近年来, 扩散模型因其强大的生成与反演能力, 被引入异常检测以提升重建质量与可解释性.然而, 多数工作仍以“ 噪声预测” 为核心目标[6], 在图像重建过程中对异常区域识别的敏感性不强, 尤其在多类别场景中.如何既让方法掌握各类别的正常结构, 又在重建过程中使异常区域产生显著的重建误差, 是提升检测与定位性能的关键因素之一.
为此, 本文提出基于偏差扩散与双流对比学习的工业异常检测方法(Industrial Anomaly Detection Method Based on Deviation Diffusion with Two-Stream Contrastive Learning, DD-TSCL), 以偏差扩散[7]作为基础模型, 在潜在空间中直接学习从受扰动的潜变量到正常潜变量的偏离方向, 从而在推理阶段以潜在空间域差异与图像域差异共同刻画异常强度.在训练阶段, 并行维护“ 正常流” 和“ 合成异常流” , 以潜在空间的偏离方向作为核心学习目标, “ 正常流” 通过学习类内样本的紧凑分布构建稳定的正常表征, “ 异常流” 通过对比学习将异常样本推离正常簇.该设计既保留扩散模型优越的生成与反演能力, 又得益于双流对比学习模块在潜在空间内对异常特征形成显著的可分性, 最终在多类别场景中展现出稳定、可解释且精细的异常检测与定位性能.
在MVTec-AD(MVTec Anomaly Detection)[8]、VisA(Visual Anomaly)[9]工业基准数据集上进行系统评测, DD-TSCL的检测与定位性能均较优.消融实验进一步表明, 使用偏差扩散加入前景感知的异常合成, 再进行双流对比学习, 可提升定位精度, 类内特征更紧凑, 多类统一建模效果更稳定.
常见无监督异常检测的方法介绍如下.
嵌入检索/记忆库方法以预训练特征构建正常样本的补丁库, 测试时使用马氏距离或最近邻距离给出像素与图像级分数.Defard等[10]提出PaDiM(Patch Distribution Modeling), 将补丁特征建模为多元高斯, 定位高效稳定.Roth等[5]提出PatchCore, 采用最大代表性记忆库, 在MVTec-AD等基准数据集上实现高精度与较快的推理.
学生-教师蒸馏机制通过逐层对齐教师网络的特征表示, 将重建结果与教师特征的偏差作为异常信号.Wang等[11]提出Student-Teacher Feature Pyra-mid Matching for Anomaly Detection, 采用学生-教师蒸馏框架, 在多尺度特征金字塔层面对齐教师网络与学生网络的特征表示.Deng等[12]从反向蒸馏角度改进多尺度重建与紧致性, 对像素级定位更友好.
密度估计方向通常利用归一化流对正常样本的多尺度补丁特征进行概率建模, 通过特征在正常分布下的似然值判断异常程度.Gudovskiy等[13]提出CFLOW-AD, 采用条件正态化流对多尺度特征的概率分布进行建模, 实现高效的像素级异常检测与实时定位.Yu等[14]提出 FastFlow, 将2D 正态化流作为通用密度估计器, 在保持较高检测精度的同时显著提升推理效率.
自编码器/生成对抗网络早期常被用于重建-取差, 但在复杂/多类场景中容易出现同像重建与边界过平滑问题.为此, Li等[15]提出CutPaste, 通过局部剪贴的自监督预训练增强表征.Zavrtanik等[16]提出DRAEM(Discriminatively Trained Reconstruction Ano-maly Embedding Model), 以“ 判别式重建嵌入” 直接输出像素异常图, 显著提升定位灵敏度.
近年来扩散模型凭借反演稳定性成为新范式.Wyatt等[17]提出AnoDDPM, 将Denoising Diffusion Probabilistic Model(后文简记DDPM)[6]引入异常检测, 通过对输入图像进行逐步去噪重建, 并利用原始图像与重建结果之间的差异作为异常响应, 实现异常检测与定位.Mousakhan等[18]提出DDAD(De-noising Diffusion Anomaly Detection), 进一步采用条件化去噪, 确保重建与目标输入一致, 其条件化去噪机制适配于无监督异常检测的重建一致性优化.
一类一模在工程上成本较高, 难以覆盖类别多样、类内差异较大的工业场景.多类无监督异常检测利用多个类别的正常样本训练统一模型, 适配类别多样类内差异较大、部署成本敏感的工业场景.You等[19]提出UniAD, 首次系统化提出多类异常检测的统一建模框架, 并指出重建网络的相同捷径问题, 给出结构与训练层面的改进.Lu等[20]提出HVQ-Trans(Hierarchical Vector Quantized Transformer), 通过层级向量量化, 将连续潜在空间离散化, 抑制多类场景中的过度重建.Jiang等[21]提出MINT-AD(Multi-class Implicit Neural Representation Transformer for Unified Anomaly Detection), 采用隐式神经表征Trans- former, 通过类感知查询减轻多类混合训练的干扰.He等[22]提出DiAD(Diffusion-Based Anomaly Detec- tion), 将扩散引入多类统一框架, 利用语义引导网络维持重建语义一致性并提升异常区域复原质量.He等[23]提出MambaAD, 将状态空间模型应用于多类异常检测, 以线性计算复杂度捕捉图像中长距离的特征依赖关系, 兼顾效率与精度.Gao等[24]提出OneNIP(One Normal Image Prompt), 通过单幅正常图像的提示实现跨类统一重建, 促进像素级定位.此外, UniVAD[25]等训练免调统一方案, 展示其借助基础模型在跨域/跨类场景中的可扩展潜力.
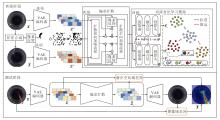
本文面向工业的多类异常检测与定位, 提出基于偏差扩散与双流对比学习的工业异常检测方法(DD-TSCL), 整体架构如图1所示.
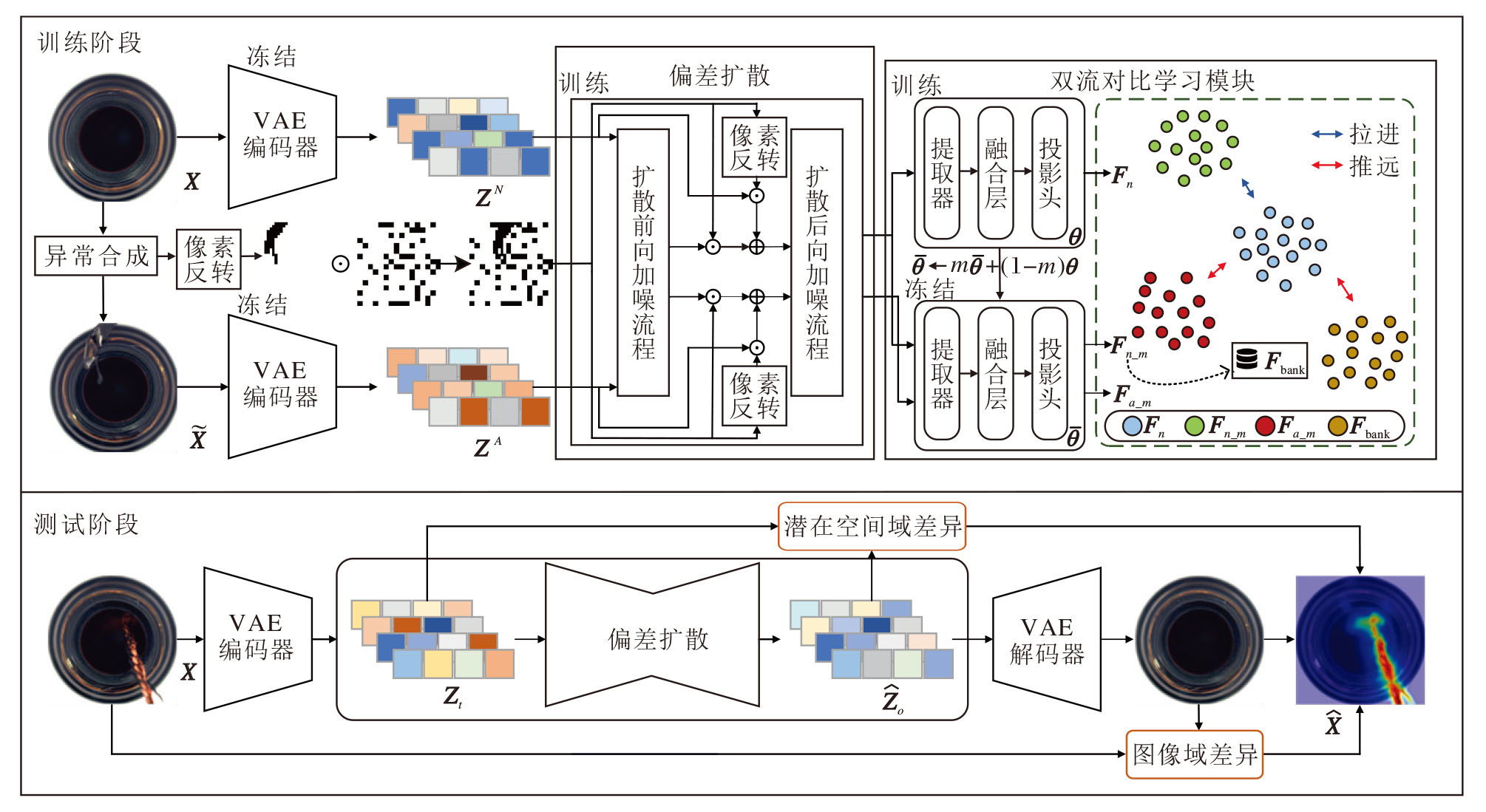 | 图1 DD-TSCL架构图Fig.1 Architecture of DD-TSCL |
首先, 利用前景感知的异常合成策略在训练阶段为正常样本生成配对的异常样本及其掩码.然后, 将正常样本和异常样本均经VAE(Variational Auto-encoder)编码至潜在空间(指原始图像经编码器映射后的特征表征空间, 又称潜在空间域, 与原始图像所在的图像域对应), 异常掩码会与随机掩码相乘取并集, 得到含异常区域掩码的随机掩码, 偏差扩散模型会显式地对该掩码所在区域进行加噪.偏差扩散模型采用UNet(U-Shaped Network)作为重建主干, 并嵌入类别条件以指导重建过程, 使方法能根据类别条件重建特定类别的图像.在此基础上, 设计双流对比学习模块, 以“ 正常流-合成异常流” 的类内正样本间的对齐和正负样本间的分离为目标, 约束潜在空间的特征与重建轨迹, 在同一结构下对多类别正常分布进行区分式建模.在推理阶段, 基于潜在空间域尺度与图像域尺度构建差异图并融合, 得到鲁棒的像素级异常热力图.
扩散模型以马尔可夫正向扰动与可学习的逆向去噪为核心[6].
正向过程将图像X0∈ RC× H× W(C表示图像的颜色通道数量, H、W表示图像高度和宽度), 按预设噪声时间步
$q\left(\boldsymbol{X}_{t} \mid \boldsymbol{X}_{t-1}\right)=N\left(\sqrt{\alpha_{t}} \boldsymbol{X}_{t-1}, \left(1-\alpha_{t}\right) \boldsymbol{I}\right) .$
由高斯链式可得闭式分布:
$q\left(\boldsymbol{X}_{t} \mid \boldsymbol{X}_{0}\right)=N\left(\sqrt{\overline{\alpha_{t}}} \boldsymbol{X}_{0}, \left(1-\overline{\alpha_{t}}\right) \boldsymbol{I}\right), $
其中$\overline{\alpha_{t}}=\prod_{s=1}^{t} \alpha_{s}$.
等价地, 可采样表示为
$\boldsymbol{X}_{t}=\sqrt{\overline{\alpha_{t}}} \boldsymbol{X}_{0}+\sqrt{1-\overline{\alpha_{t}}} \boldsymbol{\varepsilon}, $ (1)
其中, $\boldsymbol{\varepsilon} \sim N(\mathbf{0}, \boldsymbol{I}), \sqrt{1-\bar{\alpha}_{t}}$表示与噪声日程匹配的尺度系数.
逆向过程预测噪声
$\hat{\boldsymbol{\varepsilon}}_{\theta}=\frac{1}{\sqrt{1-\overline{\alpha_{t}}}}\left(\boldsymbol{X}_{t}-\sqrt{\overline{\alpha_{t}}} \widehat{\boldsymbol{X}}_{0}\right), $
其中
训练时对时间步 t~U{1, 2, …, T}与噪声ε 进行采样, 以加权均方误差最小化进行噪声预测:
$\min _{\theta} E_{X_{0}, t, \varepsilon}\left[\left\|\boldsymbol{\varepsilon}-\hat{\boldsymbol{\varepsilon}}_{\theta}\left(\boldsymbol{X}_{t}, t\right)\right\|_{2}^{2}\right] .$
推理时可使用随机的 DDPM[6]采样, 或采用确定性的DDIM(Denoising Diffusion Implicit Model)[26]采样, 提升效率与稳定性.
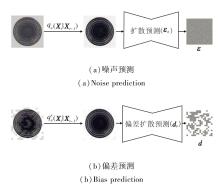
在扩散模型中, 标准扩散以去噪为学习目标, 并在推理阶段使用扩散的逆向过程将噪声图像恢复到真实图像, 但在异常检测中, 单纯去噪往往导致正常区域的信息退化或丢失.DDIM[26]的核心思想是选择性地对图像的部分区域进行加噪, 显式地将图像分为正常块和噪声块, 并在训练阶段引入逆向过程, 通过逆向过程学习从带噪状态Xt指向正常分布X0的偏差方向d, 以校正的方式复原异常成分, 并在校正后显著保持正常成分.在这一过程中, 逆向过程不仅用于去噪和恢复图像, 更关键的是作为一种学习机制, 引导方法理解异常区域与正常区域在潜在空间上的差异.噪声预测和偏差预测过程如图2所示.
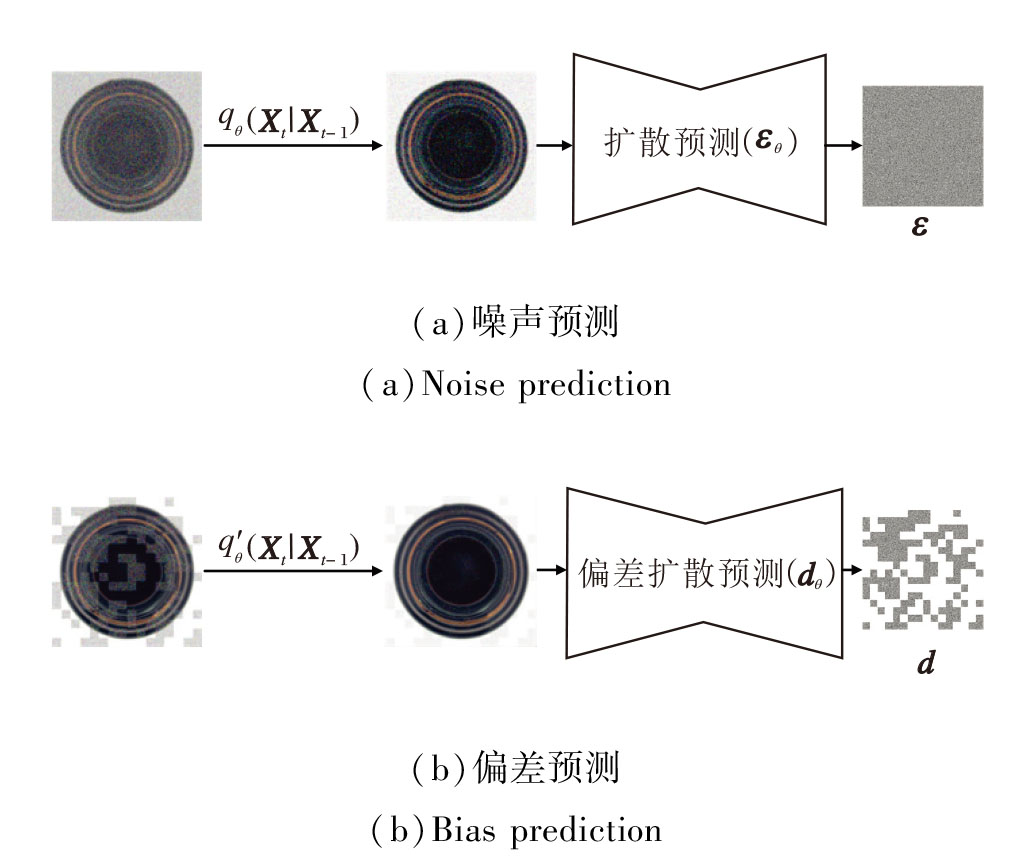 | 图2 噪声预测和偏差预测过程Fig.2 Noise prediction and bias prediction |
具体而言, 在潜在空间内运行扩散, 图像X0会经编码器(本文采用VAE编码器)得到潜在空间特征Z0∈ RC× H× W, 在此空间内运行扩散可避免原始图像域的冗余信息干扰, 更稳定高效.
在训练时, 偏差扩散模型会对潜在空间特征Z0进行随机遮罩, 只在被选中的“ 噪声块” 上按扩散公式加噪, 其余“ 可见块” 保持不变, 从而让方法学会在完整的正常上下文条件下, 仅修正异常样式的块.对于块索引k , 若k属于噪声块, 则
$q\left(\boldsymbol{Z}_{t}^{(k)} \mid \boldsymbol{Z}_{0}^{(k)}\right)=N\left(\sqrt{\alpha_{t}} \boldsymbol{Z}_{0}^{(k)}, \left(1-\alpha_{t}\right) \boldsymbol{I}\right), $
否则
这种设计一方面保留正常区域细节, 另一方面为异常区域的纠正提供可靠条件.
在逆向过程中, 偏差扩散模型将噪声形式化为相对正常图像的偏差方向:
$\boldsymbol{d}=\boldsymbol{\varepsilon}-\frac{1-\sqrt{\overline{\alpha_{t}}}}{\sqrt{1-\overline{\alpha_{t}}}} \boldsymbol{Z}_{0}, $
则式(1)改写为
$\boldsymbol{Z}_{t}=\sqrt{\overline{\alpha_{t}}} \boldsymbol{Z}_{0}+\sqrt{1-\overline{\alpha_{t}}} \boldsymbol{d}$
当样本为正常时, d应小且方向稳定; 当样本含异常区域时, d在异常区域处的幅值更大、方向与回到正常的校正一致.训练目标变为最小化预测偏差
$L_{\mathrm{diff}}=E_{Z_{0}, d, t}\left[\left\|\boldsymbol{d}-\hat{\boldsymbol{d}}_{\theta}\left(\boldsymbol{Z}_{t}, t\right)\right\|_{2}^{2}\right] .$ (2)
在推理阶段, 由于DDPM是在每个步骤t中对整个图像引入噪声, 这与保持正常图像块不变的目标不符.因此采用基于DDIM的确定性更新, 使用预测偏差
$\widehat{\boldsymbol{Z}}_{t-1}=\sqrt{\bar{\alpha}_{t-1}} \widehat{\boldsymbol{Z}}_{0}+\sqrt{1-\bar{\alpha}_{t-1}} \hat{\boldsymbol{d}}_{\theta}\left(\boldsymbol{Z}_{t}, t\right), $
其中
偏差扩散并非与标准扩散相悖, 相反地, 将
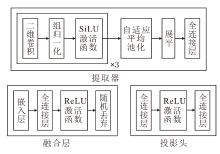
双流对比学习模块以“ 正常流-合成异常流” 的成对表征为核心, 通过对比学习约束潜在空间内的类内紧致与正常-异常可分.
训练时数据加载器为每个样本X同步提供经异常合成策略得到的异常样本
双流对比学习模块包含:轻量特征提取器fϕ 、类别嵌入e(X)、融合层Fuse(· )、类别特定投影头
Bk=
实际应用时M=100.双流对比学习模块层级配置如图3所示.
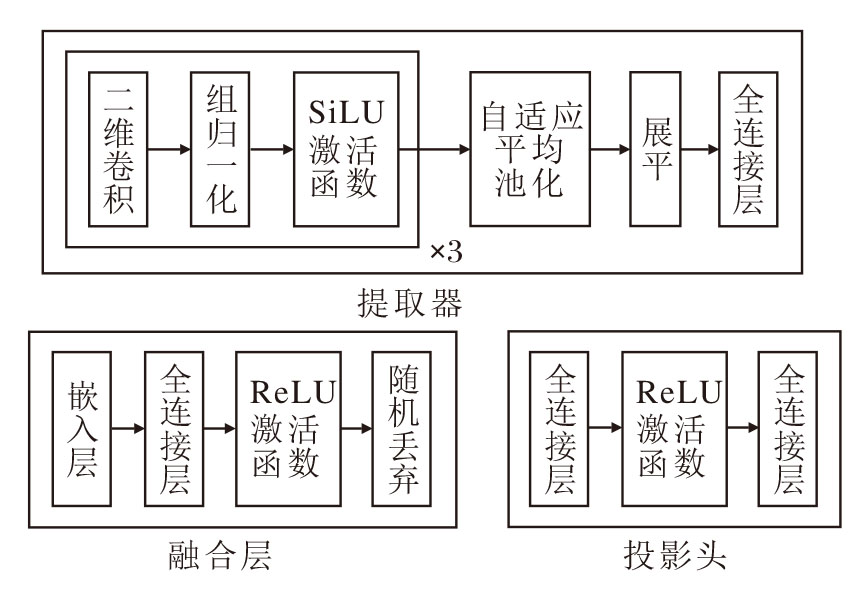 | 图3 双流对比学习模块层级配置Fig.3 Hierarchical configuration of dual-stream contrastive learning module |
对于重建的正常潜在空间特征
$\boldsymbol{v}=g_{k}\left(F u s e\left[f_{\phi}\left(\widehat{\boldsymbol{Z}}^{N}\right) ; e(y)\right]\right) \in \mathbf{R}^{p} .$
对于重建的异常潜在空间特征
$\overline{\boldsymbol{v}}=\bar{g}_{k}\left(\overline{\text { Fuse }}\left[\bar{f}_{\phi}\left(\widehat{Z}^{A}\right) ; e(y)\right]\right) \in \mathbf{R}^{p} .$
其中, Fuse[· ; · ]、
q=
为了降低正负键值漂移, 动量分支参数以指数调整平均更新, 动量副本
其中, θ 表示主干{fϕ , gk}的参数向量, 实际应用时m=0.999.
设一个批次中存在的类别集合为Kbatch.对任一类别k∈ Kbatch, 记该类别k内, 正常流查询矩阵
Fn=
正常流动量键
Fn_m=
异常流动量键
Fa_m=
以温度τ > 0定义相似度矩阵:
Snn=
将每个查询
$L_{\text {intra }}^{(k)}=\frac{1}{n_{k}} \sum_{i=1}^{n_{k}}\left(-\ln \left(\frac{\exp \left(\left[S_{n n}\right]_{i i}\right)}{\sum_{j=1}^{n_{k}} \exp \left(\left[S_{n n}\right]_{i j}\right)+\sum_{j=1}^{n_{k}} \exp \left(\left[S_{n a}\right]_{i j}\right)}\right)\right) .$
当记忆库Bk已填充时, 额外引入库键Fbank=
$L_{\mathrm{mem}}^{(k)}=\frac{1}{n_{k}} \sum_{i=1}^{n_{k}}\left(-\ln \left(\frac{\exp \left(\left[S_{n n}\right]_{i i}\right)}{\sum_{j=1}^{n_{k}} \exp \left(\left[S_{n n}\right]_{i j}\right)+\sum_{j=1}^{n_{k}} \exp \left(\left[S_{n a}\right]_{i j}\right)+\sum_{j=1}^{n_{k}} \exp \left(\left[S_{n b}\right]_{i j}\right)}\right)\right), $
其中
Snb=
对
$L_{\mathrm{ctr}}=\frac{1}{\left|K_{\mathrm{batch}}\right|} \sum_{k \in K_{\mathrm{batch}}}\left(\alpha L_{\mathrm{intra}}^{(k)}+(1-\alpha) L_{\mathrm{mem}}^{(k)}\right), $
其中, τ =0.1, α =0.7.
由式(2)可得偏差扩散训练损失Ldiff, 两者以系数λ ctr> 0线性耦合, 则总损失为:
Ltotal=Ldiff+λ ctrLctr,
其中λ ctr=0.1.Lctr在潜在空间上约束正常表征的类内拉近与异常表征的远离, Ldiff通过偏差校正在潜在空间制造可区分差异.两者协同使异常区域在校正后更突出, 同时压实正常簇, 提升检测与定位的分辨率与鲁棒性.
为了提升异常样本的质量与多样性, 使方法通过双流对比学习模块提取更具判别性的特征, 提出前景感知的异常合成策略, 核心思像是:针对正常图像X生成多样且逼真的配对异常样本及其对应的掩码$(\widetilde{X}, M)$, 其中,
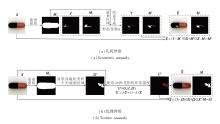
设X的前景区域由掩码Mfg∈ [0, 1]H× W给出(可由颜色通道与显著性差异获得[27]), 优先选择在语义相关的前景内设置异常, 以此减少不合理的背景伪影.每次从几何异常与纹理异常两类中采样进行异常合成, 保证几何缺陷与纹理缺陷的互补覆盖.具体几何异常合成过程和纹理异常合成过程如图4所示.
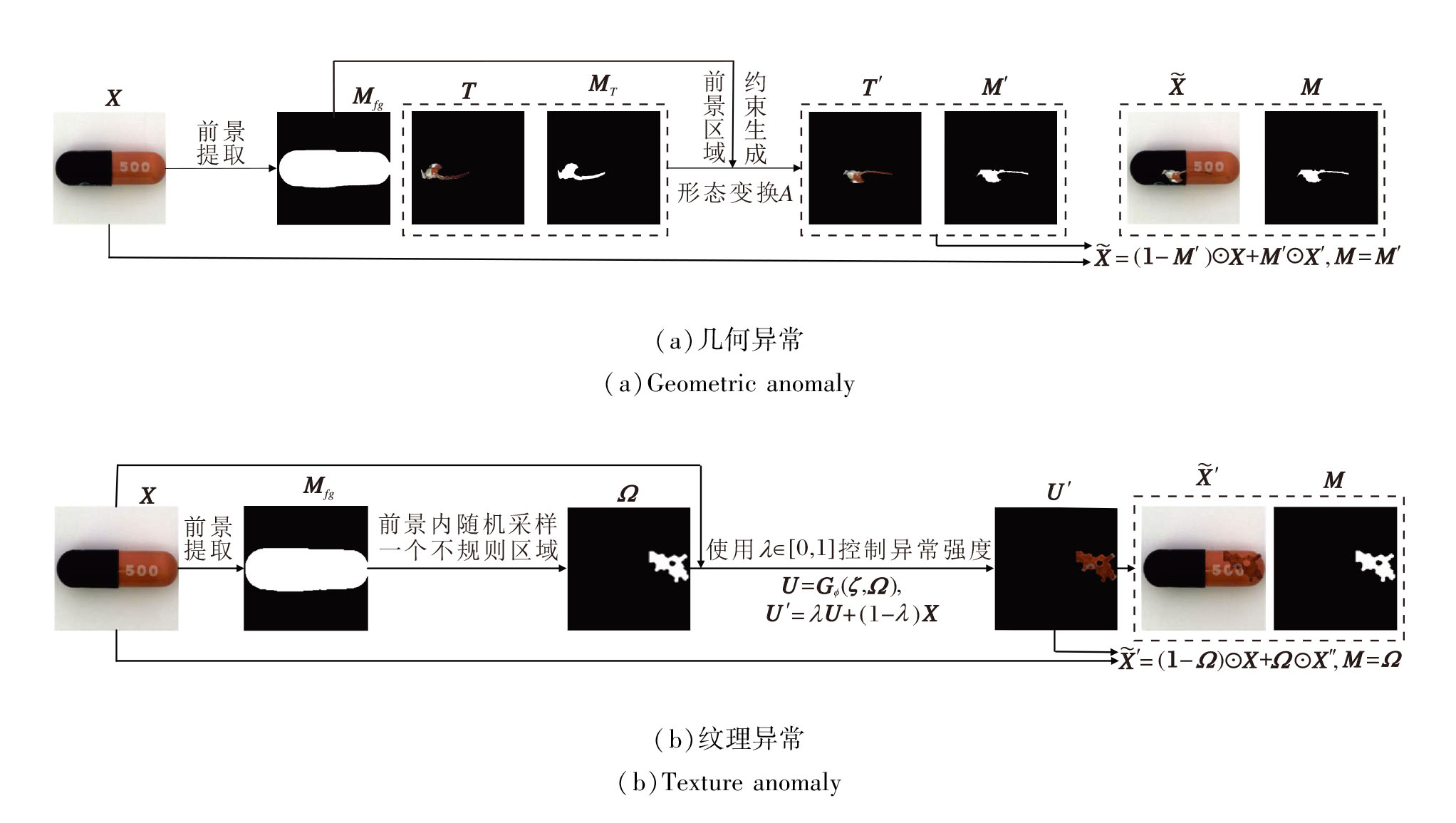 | 图4 异常合成过程示意图Fig.4 Schematic diagram of abnormal synthesis process |
首先从现有的工业数据集上提取一组异常区域模板, 涵盖多种出现的异常模式.给定一个来源库中的异常模板T及其二值掩码MT, 先进行随机形变:
(T', M')=A(T, MT),
其中, A(· )包含相似变换(缩放、旋转、平移)、弹性形变与形态学膨胀/腐蚀, 以此提升外形多样性.随后T'经边缘柔化等操作后添加到图像X上, 得到含异常区域的X'.最终合成可写为
其中, ☉表示逐点相乘, M'=M.
为了模拟粗糙、起皮、污染等纹理缺陷, 先在前景内随机采样一个不规则区域Ω , 然后由参数化纹理发生器Gϕ 生成局部纹理:
U=Gϕ (ξ , Ω ),
其中ξ ~N(0, I)表示噪声种子.再使用λ 与X进行异常强度调控, 得
U'=λ U+(1-λ )X, λ ∈ [0, 1].
同样地, U'会经边缘柔化等操作后添加到图像X上, 得到包含异常的X″, 则最终合成可写为
其中, ☉表示逐点相乘, Ω = M.
上述两类在实现层面共享前景优先策略:异常位置以Mfg为引导, 确保异常更多地生成在语义相关的前景区域内, 同时保留小概率在背景区域生成, 以此提升泛化性.
为了进一步提升多样性, A(· )中的弹性形变与形态学操作会随机改变异常外形与边界曲率.此外, 为了控制异常规模, 区域占比
ρ =
对ρ 与λ 施加联合约束, 避免出现面积极小但强度过大或面积过大但强度过弱的极端样本, 从而使异常样本更贴近真实分布.
推理时给定测试图像X, 先经编码器得到潜在空间的特征表示
Z0=E(X).
基于偏差扩散, 从中间时刻Zt校正, 得到估计的正常潜在空间特征:
$\widehat{Z}_{0}=Z_{t}-\sqrt{1-\bar{\alpha}_{t-1}} \hat{d}_{\theta}\left(Z_{t}, t\right) .$
再解码得到重建图像:
$\widehat{\boldsymbol{X}}=D\left(\widehat{\boldsymbol{Z}}_{0}\right) .$
为了全面刻画异常特征, 分别在两个独立领域构造差异图.
1)图像域(原始像素空间):计算原始图像X与重建图像
2)潜在空间域:计算原始的潜在空间特征表示Z0与估计的正常潜在空间特征
最终以几何平均方式融合图像域和潜在空间域差异, 得到鲁棒的异常图.
图像域差异直接度量原始图像与重建图像的重建残差的可视偏离.对每个像素位置u, 令通道残差
r(u)=X(u)-
取通道残差最大幅度作为图像域差异图:
$\boldsymbol{A}_{\text {pix }}(u)=\max _{c}\left\{\left|\boldsymbol{r}_{c}(u)\right|\right\}, $
其中rc(u)表示第c通道、空间位置u上原始图像与重建图像的像素差.
为了抑制离群噪声并统一量纲, 对Apix(u)进行上截断与线性放大, 随后施加高斯平滑, 获得边缘友好的热力分布.
潜在空间域差异度量潜在空间上原始正常特征与估计的正常特征的偏离程度.对潜在空间特征的每个空间位置u, 取通道均值的l1差异, 即潜在空间内的特征级差异:
$\boldsymbol{A}_{\mathrm{lat}}(u)=\frac{1}{C} \sum_{c=1}^{C}\left|\boldsymbol{Z}_{0, c}(u)-\widehat{\boldsymbol{Z}}_{0, c}(u)\right|, $
其中, Z0, c(u)与
同样对Alat(u)进行截断与线性放大, 并以较小核进行平滑.若潜在空间的分辨率低于图像分辨率, 上采样到中心裁剪后的图像尺度.
两域差异在归一化后进行几何平均融合, 得到像素级异常热力图:
$\boldsymbol{A}(u)=\sqrt{\boldsymbol{A}_{\mathrm{pix}}(u) \odot \boldsymbol{A}_{\mathrm{lat}}(u)} .$
异常热力图在像素级上表征每个位置的异常程度, 颜色越亮的区域, 表明该位置是异常区域的概率越大, 颜色为深色区域, 表明对应位置为正常区域.因此异常热力图可直接用于异常区域的可视化定位与分割.
本文选择在MVTec-AD[8]、VisA[9]这2个公开异常检测数据集上进行实验.
MVTec-AD数据集是目前异常检测领域广泛采用的基准数据集之一, 涵盖 15 类工业产品与材质, 包括金属、布料、木材、瓶子、螺母等.数据集包含5 354幅图像, 其中训练集仅提供正常样本(约3 629幅), 测试集包含正常样本和带有不同缺陷的异常样本(约1 725幅).异常类型覆盖裂纹、划痕、污染、缺失和变形等, 能充分反映真实工业场景中的检测需求.
VisA数据集是近年来发布的大规模视觉异常检测与定位数据集, 专门针对真实复杂场景中的挑战而构建.数据集包含12个物体类别, 约10 821幅图像, 训练集主要是正常样本, 测试集包含多种异常模式, 如结构性缺陷、表面污染和部件缺失等.与MVTec-AD数据集的标准化采集不同, VisA数据集上成像环境并非标准化控制, 图像体现出更显著的光照变化、视角变化及背景干扰, 这些因素增加对正常分布建模和跨场景泛化的难度, 更适用于评估方法在复杂成像条件下的鲁棒性与泛化性.
为了全面评估DD-TSCL在异常检测与定位任务中的性能, 采用工业视觉异常检测领域常用的7个指标, 包括图像级与像素级两类.
在图像级评价指标中, 采用AUROC (Area Under the Receiver Operating Characteristic Curve)、AUPRC (Area Under the Precision-Recall Curve)、F1_max(Maximum F1-score).
AUROC衡量方法区分正常样本与异常样本的能力, 数值范围从0到1, 越接近1表示检测性能越优.以假阳性率(False Positive Rate, FPR)为横轴、真阳性率(True Positive Rate, TPR)为纵轴绘制ROC(Receiver Operating Characteristic)曲线, 计算曲线与横轴之间的面积, 具体公式如下:
$\begin{array}{l} F P R=\frac{F P}{F P+T N}, \\ T P R=\frac{T P}{T P+F N}, \end{array}$
其中, FN表示误判为异常的正常样本数, TP表示正确判定的正常样本数, TN表示正确判定的异常样本数, FP表示误判为正常的异常样本数.
AUPRC更适合在异常样本远少于正常样本的情况下使用, 能更好地反映工业实际应用需求, 通常计算精确率(Precision)与召回率(Recall), 构建Precision-Recall曲线后计算曲线下面积.具体公式如下:
$\begin{array}{l} \text { Precision }=\frac{T P}{T P+F P}, \\ \text { Recall }=\frac{T P}{T P+F N} . \end{array}$
当异常样本稀少时, 该指标比AUROC更能体现性能差异.
F1_max是指F1(精确度与召回率的调和平均)的最大值, 用于衡量方法异常区域覆盖精度与完整性平衡.具体公式如下:
F1=2×
选取所有F1中的最大值作为F1_max.
在像素级评价指标中, 采用AUROC、AUPRC、F1_max、AUPRO(Area under the Per-region Overlap Curve).
像素级AUROC、AUPRC、F1_max的计算方法与图像级相同, 只是统计对象不再是整幅图像而是单个像素.图像级评价指标聚焦于整幅图像是否异常的分类判断, 而像素级评价指标聚焦于异常区域具体位置的定位精度, 二者优势互补.
AUPRO是文献[8]中提出的专门针对异常定位的指标, 用于衡量预测异常区域与真实缺陷区域的重叠程度, 计算该区域与真实缺陷区域的交并比(Intersection over Union, IoU):
$I o U=\frac{\text { 预测异常区域 } \cap \text { 真实异常区域 }}{\text { 预测异常区域 } \cup \text { 真实异常区域, }}$
随后以阈值为横轴、IoU为纵轴绘制曲线, 计算曲线下面积作为单幅图像的AUPRO.最后对所有测试图像的AUPRO取平均值, 得到最终的AUPRO值.该指标能真实刻画区域级别的定位质量, 避免因像素级指标忽略区域连续性导致的评价偏差.
使用单卡3090(显存24 GB)进行训练, 批次大小设为32.在MVTec-AD数据集上, 训练轮次为650, 在VisA数据集上, 训练轮次为160.预训练VAE权重采用由Stability AI发布的sd-vae-ft-ema, 该模型是在Stable Diffusion原始VAE基础上微调得到的EMA(Exponential Moving Average)权重模型, 用于提升图像重建质量[28].
图像默认进行中心裁剪, 裁剪尺寸为256× 256.使用AdamW(Adam Optimizer with Weight Decay)优化器, 初始学习率设为1× 10-4, 学习率采用余弦退火并进行十步预热, 随后沿余弦曲线衰减.
推理中使用DDIM采样方式, 设置步数为10, 将差异图中的值统一裁剪至[0, 0.4], 再线性放大至[0, 1].
为了验证DD-TSCL性能, 选择如下8种多类别异常检测与定位的方法:文献[12]方法、UniAD[19]、DiAD[22]、MambaAD[23]、SimpleNet( Simple and Appli-cation Friendly Network)[29]、DeSTSeg[30]、MoEAD[31]、GLAD(Global and Local Adaptive Diffusion Mo-del)[32].
各方法在MVTec-AD、VisA数据集上的指标值对比如表1和表2所示, 表中黑体数字表示最优值, 斜体数字表示次优值.
| 表1 各方法在MVTec-AD数据集上的指标值对比 Table 1 Metric value comparison of different methods on MVTec-AD dataset % |
| 表2 各方法在VisA数据集的指标值对比 Table 2 Metric value comparison of different methods on VisA dataset % |
由表1可见, DD-TSCL在图像级AUROC、AUP-RC指标上获得最优值, 这说明虽然部分方法能在判别能力上接近DD-TSCL, 但在精确率与召回率之间的平衡性上依然存在不足.DD-TSCL在所有图像级指标上都实现稳定领先, 表明其在正常样本与异常样本区分上的一致性更强, 能有效降低因类别差异带来的误判风险.在像素级评价中, DD-TSCL在 AUPRC、F1-max指标上提升明显, 这种改进不仅意味着异常区域能更精确地被突出, 而且边界定位也更贴近人工标注.这说明DD-TSCL在细粒度的异常定位中具有明显优势, 能兼顾区域覆盖度和边界精度, 从而在像素级检测任务上展现出更高的实用性.
由表2可见, VisA数据集异常更细微、背景更复杂, 对检测方法提出更大挑战.即便如此, DD-TSCL依然在整体性能上取得最优表现.在图像级指标方面, DD-TSCL在3个指标上均取得最优值, 充分体现其跨类别鲁棒性.在像素级指标方面, DD-TSCL在AUPRC、F1_max指标上均明显领先, 表现出对异常区域更精准的覆盖和识别能力.
为了全面展示DD-TSCL在异常检测与定位任务中的表现, 在MVTec-AD、VisA数据集上进行可视化分析, 并与真实缺陷标注(GT)进行对比, 结果如图5所示.通过对比可发现, DD-TSCL不仅能准确识别异常的存在, 还能在不同类别的缺陷场景中生成与GT高度一致的异常响应图.
 | 图5 DD-TSCL在2个数据集上的可视化结果Fig.5 Visualization results of DD-TSCL on 2 datasets |
在 MVTec-AD 数据集上, DD-TSCL对多种工业品的缺陷均有良好响应, 包括bottle的破裂、hazelnut的表面裂痕、screw的形变及wood的红色污迹等, 在重建图中均被有效抹去, 并在热力图中得到明显高亮, 覆盖范围与GT较一致.在纹理类类别, 如carpet与leather中, DD-TSCL能准确定位异常点, 表现出较强的纹理差异敏感性.在结构类样本, 如cable与toothbrush中, 热力图能集中显示异常区域, 误检率较低.
在VisA数据集上, DD-TSCL同样展现出较优的跨域泛化能力, 对于candle、capsules与 cashew等食品类物体, 热力图清晰覆盖异物或缺损区域.值得注意的是, 在pcb1~pcb4电子元器件类样本中, 物体较复杂, DD-TSCL依然能稳定检测焊点缺陷与局部损伤, 异常热力图边界与 GT 保持较高的一致性, 由此说明该方法在复杂场景中依旧具备鲁棒性.
为了验证双流对比学习模块和双域融合定位对DD-TSCL性能的影响, 在MVTec-AD、VisA数据集上开展消融实验.训练与评测流程保持一致:使用与DD-TSCL相同的类条件扩散主干与推理路径, 结果如表3和表4所示, 表中黑体数字表示最优值.
| 表3 在MVTec-AD数据集上的消融实验结果 Table 3 Results of ablation experiment on MVTec-AD dataset % |
| 表4 在VisA数据集上的消融实验结果 Table 4 Results of ablation experiment on VisA dataset % |
由表3和表4可见, 在推理过程中, 相比仅使用潜在空间域差异或仅使用图像域差异, 结合潜在空间域差异和图像域差异进行几何融合定位可提升多项性能指标, 说明融合定位有效提升定位精度和准确性.推理过程均采用潜在空间域和图像域融合定位的方法, 加入双流对比学习模块后, 图像级指标得到小幅提升, 而像素级指标实现显著提升, 由此验证双流对比学习模块在增强局部特征区分性、提升细粒度异常定位能力上的核心作用.
本文围绕工业多类异常检测与定位, 提出基于偏差扩散与双流对比学习的工业异常检测方法(DD-TSCL).在潜在空间内使用偏差扩散模型学习图像的正常分布, 并在推理阶段融合潜在空间域与图像域的差异, 生成鲁棒的异常热力图, 实现多类统一建模与像素级定位.设计双流对比学习模块, 在拉近类内正常表征并拉开类内正常表征与异常表征方面发挥关键作用, 使异常定位更准确.此外, 为了缓解双流对比学习中异常样本稀缺并提升偏差扩散模型对正常样本和异常样本的区分性, 设计前景感知的异常合成策略, 联合几何异常与纹理异常两条互补路径, 持续提供高质量异常样本.总之, DD-TSCL将偏差扩散模型的偏差建模与“ 正常流-合成异常流” 的双流对比学习进行有机融合, 提供一条更高效稳健、解释性更强的工业表面异常检测与定位方法.
尽管DD-TSCL在多类工业异常检测任务中取得良好效果, 但仍存在进一步提升的空间.未来工作可从如下方面展开.1)推动方法的轻量化与实时化发展.在保证检测精度的前提下压缩模型体积与推理耗时, 实现其在嵌入式设备上的高效部署, 更好地适配工业生产线的实时检测需求.2)拓展研究场景的适用性.现有研究主要聚焦于工业表面异常检测, 后续可探索将方法迁移至三维工业零件、透明材质工件等复杂对象的异常检测任务中, 突破二维图像检测的局限.3)进行可持续的异常检测研究.工业场景中生产环境及工件类型常随时间动态变化, 未来可探索可持续的异常检测研究, 使方法能自适应新场景、新类别, 无需重新训练即可实现性能的持续优化.
本文责任编委 杨 健
Recommended by Associate Editor YANG Jian
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|