

{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于四路多尺度注意力模块及桥连结构的轻量级单图超分辨率网络
[苏博何俊1  , 徐勇
, 徐勇1, 2 3 , 刘伟1 , 王好谦4 ]
, 徐勇, 薛睿, 刘伟, 王好谦]
|
|



作者简介:

苏博何俊,硕士研究生,主要研究方向为计算机视觉.E-mail:3389370532@qq.com.

薛 睿,硕士,高级实验师,主要研究方向为计算机系统、计算机视觉.E-mail:xuerui@hit.edu.cn.

刘 伟,硕士,讲师,主要研究方向为计算机视觉.E-mail:liuwei2020@hit.edu.cn.

王好谦,博士,教授,主要研究方向为计算摄像、人工智能.E-mail:wangyizhai@sz.tsinghua.edu.cn.
针对以压缩-激励(Squeeze-and-Excitation, SE)注意力模块为主要组成的图像超分辨率网络A2F-SD的注意力机制过于简单和多路信息利用能力的不足,文中提出基于四路多尺度注意力模块及桥连结构的轻量级单图超分辨率网络(Lightweight Single-Image Super-Resolution Network Based on Four-Path Multi-scale Attention and Bridge Structure, A2F-MSAB),主要优化A2F中的SE注意力模块与沙漏型结构.首先,设计多尺度自学习融合均值与方差的注意力模块,分成四路增强网络对图像特征的提取能力.然后,将A2F-SD中的沙漏型结构改为桥连多级沙漏型结构,促进网络不同模块之间、浅层与深层之间的信息流动,增强对中高频细节的重建能力.实验表明,A2F-MSAB性能较优,在部分数据集上的指标值甚至优于A2F-SD及A2F-S.
About Author:
SU Bohejun, Master student. His research interests include computer vision.
XUE Rui, Master, senior experimenter. Her research interests include computer systems and computer vision.
LIU Wei, Master, lecturer. His research interests include computer vision.
WANG Haoqian, Ph.D., professor. His research interests include computational photography and artificial intelligence.
A2F-SD, the image super-resolution network, is built on squeeze and excitation attention module. In this paper, the limitations of A2F-SD are analyzed, including the excessively simplistic attention mechanism and insufficient utilization of multi-path information. To address these issues, a lightweight single-image super-resolution network based on four-path multi-scale attention module and bridging structure(A2F-MSAB) is proposed to optimize the attention modules and hourglass structure in the original A2F-SD model. First, multi-scale self-learning average-variance attention modules are designed. A four-path attention module is employed to enhance the image feature extraction ability of the network. Then, the hourglass structure of A2F-SD is improved into the bridge and multi-level hourglass structure to facilitate information flow between different modules, and between shallow and deep layers of the model, thereby strengthening the model reconstruction ability for medium and high-frequency details. Experiments show that A2F-MSAB model with only half of the basic modules stacked achieves superior performance and its evaluation metrics on certain datasets outperform those of both A2F-SD and A2F-S.
现今人们对图像清晰度的需求越来越高, 并且超高分辨率显示器如4K和8K分辨率的逐渐普及, 为高清图像提供显示的硬件基础.因此, 超分辨率的研究和应用具有重要的现实意义和广阔的发展前景.
超分辨率研究发展至今, 已分类为基于插值的方法、基于重建的方法和基于深度学习的方法.在这些方法中, 自从Dong等[1]首次将深度学习引入超分辨率领域以来, 基于深度学习的超分辨率网络逐渐成为研究的主流方向.目前, 基于深度学习的超分辨率网络按照网络类型可分为如下7类:线性网络、残差网络、多分支设计、递归网络、渐进式重建设计、基于注意力的网络和生成对抗网络[2].
超分辨率网络的轻量化是图像超分辨率中一个重要的研究课题.因该类轻量化网络具有较少的参数或简洁的结构, 能大幅降低超分辨率过程中的算力消耗, 使得在算力受限的终端设备(如摄像头等感知终端、数字电视机顶盒等)上实现视频的实时超分辨率成为可能.
压缩-激励(Squeeze-and-Excitation, SE)注意力模块[3]通过数个简单模块— — 全局平均池化(Global Average Pooling, GAP)层、2个全连接层及2个激活函数, 提取输入通道的权重, 并起到突出重要通道特征的作用.位于模块最前端GAP层的作用是将任意大小的输入特征图“ 压缩” 为1× 1的全局平均值, 以平均特征作为通道权重.该设计不仅高效, 而且能取得较好实效, 因此被广泛使用于包含超分辨率网络在内的多种深度学习网络中.
Wang等[4]提出A2F(Attentive Auxiliary Fea-ture), 是具有代表性的使用SE注意力模块的图像超分辨率网络.A2F采用堆叠Attentive Auxiliary Feature Block(后文简记为AAFB)的密集连接网络结构.第n个AAFB模块主要完成如下3个功能:1)将网络前n-1个AAFB模块的所有输出结果拼接并压缩后, 通过SE注意力模块调整权重, 获取浓缩的“ 历史” 特征.2)将第n-1个AAFB模块的输出经过“ 卷积-激活函数-卷积” 的结构提取“ 新” 特征.3)结合“ 新旧” 特征.后续类似的“ 2层沙漏型卷积及激活函数结构” 将被简化描述为“ 沙漏型结构” , 并使用“ 小-大-小” 描述沙漏型结构中卷积层的两种输入输出通道数.例如:输入输出通道分别为16/64及64/16的结构描述为16-64-16.
相比其它密集连接网络, A2F无需将来自前面所有n-1个模块输出的所有特征全部拼接后再进行卷积, 而是先浓缩, 再对这些“ 历史” 特征使用低参数量的SE注意力模块进行提取, 因此仅需对来自前1个模块的“ 新” 特征采用较复杂、需要消耗较高算力的沙漏型卷积结构进行提取.该方式大幅降低参数量, 可获得良好的超分辨率效果.
然而, A2F的参数量仍较大, 在Wang等[4]提出的4个不同大小的A2F-SD、A2F-S、A2F-M、A2F-L中, A2F-SD参数量最小.相比A2F-S, A2F-SD降低输入通道数, 但增加AAFB模块的堆叠数量.这项轻量化改进使得A2F-SD的性能在多个数据集上优于A2F-S, 但前者存在注意力机制过于简单及多路信息利用能力不足的问题.
针对上述缺陷, 本文提出基于四路多尺度注意力模块及桥连结构的轻量级单图超分辨率网络(Lightweight Single-Image Super-Resolution Network Based on Four-Path Multi-scale Attention Module and Bridging Structure, A2F-MSAB), 优化A2F中的SE注意力模块与沙漏型结构.首先, 设计多尺度自学习融合均值与方差的注意力模块(Multi-scale Self-Learning Average-Variance Attention, MSLAVAtt), 分四路增强网络对图像特征的提取能力.然后, 将A2F-SD中的沙漏型结构改进为桥连多级沙漏型结构(Bridge and Multi-level Hourglass Structure, BMH-S), 促进网络不同模块之间、浅层与深层之间的信息流动, 增强对中高频细节的重建能力.实验表明, A2F-MSAB是参数量仅为9.9× 104的超轻量化网络, 但在峰值信噪比(Peak Signal-to-Noise Ratio, PSNR)、结构相似性(Structural Similarity Index Mea- sure, SSIM) 及学习感知图像相似性(Learned Per- ceptual Image Patch Similarity, LPIPS)指标上优于众多的轻量化网络甚至非轻量化网络, 并且改造过程中对于SE注意力模块及沙漏型结构的优化方案可运用到其它超分辨率网络中.
SE注意力模块通过学习通道间的依赖关系, 对每个通道的重要性进行加权, 从而增强网络对重要特征的关注.SE注意力模块包括两个主要步骤:Squeeze(压缩)和Excitation(激励).Squeeze中通过GAP层及一个全连接层将特征图的空间维度压缩为一个“ 通道描述符” , Excitation中通过一个全连接层和激活函数(ReLU和Sigmoid)学习通道间的依赖关系, 生成通道权重.
在SE注意力模块的基础上, Woo等[5]提出CBAM(Convolutional Block Attention Module), 增加空间注意力, 通过结合改进的通道注意力和空间注意力, 进一步提升网络对特征的建模能力.具体地, 改进后的通道注意力增加全局最大池化(Global Max Pooling, GMP), 变为两路, 并通过共享权重的多层感知机(Multi-layer Perceptron, MLP)获取通道的两种不同特征.空间注意力对通道之间同一位置的元素进行GAP及GMP处理, 即压缩通道维度.实验表明, CBAM在多个视觉任务(如图像分类、目标检测等)上都取得显著的性能提升.
Hui等[6]提出FERN(Lightweight Feature En-hancement Residual Network), 在残差块中引入轻量级的非局部操作, 捕获长期依赖关系, 设计SCA(Structure-Aware Channel Attention)模块, 增强具有更多结构和纹理细节的特征图.SCA模块采用TV(Total Variation)而不是GAP获取全局特征信息.TV通过计算相邻像素的差异值, 衡量空间层面上的“ 变化” , 获取更多的结构信息.Ma等[7]提出MCAN(Matrix Channel Attention Network), 对SE注意力模块进行轻量化处理, 将全连接层替换为1× 1卷积层, 达到降低参数量及提升并行性的目的.2021年, 施举鹏等[8]提出基于深度反馈注意力的超分辨率网络(Deep Feedback Attention Network, DFAN), 将反馈机制与通道注意力结合, 构建迭代残差注意力结构, 有效实现参数复用与冗余特征过滤, 在保证网络参数量精简、执行高效的同时, 显著提升超分辨率重建质量.
2020年, Hang等[9]提出A-CubeNet(Attention Cube Network), 从空间、通道和层次三个维度提升特征表达和相关性学习能力, 有效解决现有网络在局部感受野、信息类型平等处理及特征图聚合方面的局限性.A-CubeNet的核心包括ADAM(Adaptive Dual Attention Module)和AHAM(Adaptive Hierar-chical Attention Module).不同于CBAM只在网络开头设置两路而核心部分共享权重, ADAM的两路注意力模块相互独立, 只在网络尾部进行融合.这种方案能更好地提取不同种类特征描述符中包含的信息, 提升超分辨率重建效果.2023年, 李方玗等[10]提出高效多注意力特征融合的图像超分辨率重建算法(Efficient Multi-attention Feature Fusion for Image Super-Resolution Reconstruction Algorithm, EMAFFN), 通过高效多注意力模块(Efficient Multi-attention Block, EMAB)并结合渐进式特征融合与多尺度感受野增强机制, 从通道和空间维度自适应强化对高频信息的关注, 有效缓解深层网络的特征丢失与参数量过大的问题, 提升重建图像的纹理细节丰富度.李千等[11]提出融合多路径与混合注意力的遥感图像超分辨率重建, 结合区域级通道注意力与空间注意力, 强化对高频信息的关注, 同时优化多层级特征提取与融合效果, 有效缓解遥感图像重建中的特征丢失问题.Yan等[12]提出LAMRN(Lightweight Attended Multi-scale Residual Network), 采用多尺度注意力机制, 输入被送入4路, 每路都使用不同大小的空洞卷积核对图像进行卷积, 再使用GAP与GMP结合的注意力方式提取特征.使用空洞卷积的好处是不仅可提取不同尺度的特征, 而且相比普通卷积参数量大幅减少.
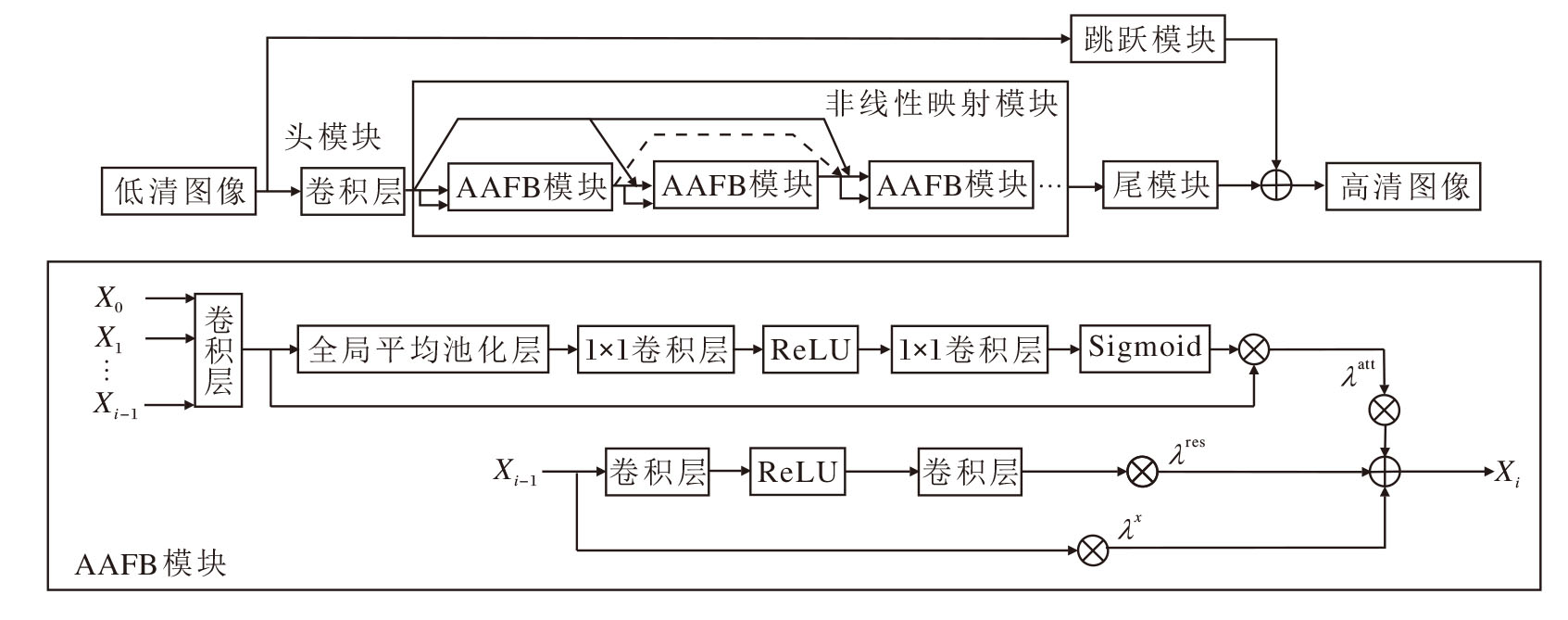
A2F的结构如图1所示.该网络采用密集连接的架构, 即将AAFB模块通过密集连接的方式串接.第i个AAFB模块Xi需要将来自前i-1个AAFB模块X0, X1, …, Xi-1的输出全部拼接作为输入.假设A2F中共堆叠n个AAFB模块, 则输入n个AAFB模块的通道数总和是原始输入X0的
到O(n2)的通道数本应导致卷积层参数量及消耗算力随n增加而呈平方倍增加.但是, 模型引入投影单元及注意力模块, 先将不断增加的输入通道数经过卷积层压缩至固定通道数O(k), 再经过注意力模块重新分配通道权重, 使得输入卷积层的通道总量下降至O(kn), 保证网络在轻量化的同时性能较优.
A2F整体架构由头模块、非线性映射模块、跳跃模块和尾模块组成, 具体结构如下.
1)头模块.主要作用是对输入的低分辨率图像进行初步特征提取.该模块由一个 3× 3 的卷积层组成, 旨在捕捉图像的基本信息并扩展至多个通道上, 以便后续提取.
2)非线性映射模块.A2F的主体, 由多个堆叠的AAFB模块组成.每个AAFB模块负责从前面所有块的特征中提取有用信息, 并通过注意力筛选对当前层有价值的特征.每个AAFB模块包含4部分:(1)投影单元和通道注意力, 位于第一路; (2)残差块和特征融合, 位于第二路.
投影单元位于第一路的首部.将前i-1个AAFB模块(X0, X1, …, Xi-1)的特征投影至共同的空间(即使用卷积层将拼接的特征输出为固定的小通道特征图), 以便进行特征融合.该单元由1× 1卷积层实现.
通道注意力是第一路的核心部分, 它自动为不同通道分配重要性权重, 筛选对当前层有价值的特征.该机制由全局平均池化层、 1× 1 卷积层、ReLU激活函数、1× 1卷积层和Sigmoid激活函数组成.
残差块是第二路的核心部分, 采用类似WDSR-A[13]的结构, 包含2个卷积层和1个ReLU激活函数, 结构为卷积-激活-卷积, 用于提取第i-1个AAFB模块Xi-1的输出特征.
特征融合将第一路、第二路及上一个AAFB模块Xi-1输出特征在块尾部通过加权求和的方式进行融合, 3个可学习参数λ att、λ res、λ x表示权重.
3)跳跃模块.作用是将原始输入图像的低频信息通过“ 短接” 结构, 由输入直接传递到输出, 以保持低频信息的准确性.该模块与尾模块结构相同, 由3× 3卷积层和像素重组(Pixel Shuffle)层组成, 用于将低分辨率特征上采样到目标高分辨率图像的大小.
4)尾模块.负责将非线性映射模块输出的特征上采样到目标高分辨率图像的大小, 并生成最终的超分辨率图像.该模块由3× 3卷积层和像素重组层组成.
A2F虽然使用密集连接将输入通道数提升至O(n2), 但采取压缩及使用SE注意力模块调整通道权重的方式可解决网络过于复杂的问题.将注意力与密集连接结合, 不仅促进浅层通道与深层通道交互的优势, 进而获得超分辨率效果的提升, 也能通过轻量化的注意力模块降低网络参数量及算力消耗.
虽然A2F能在相同或更少的参数量下, 获得超过大多数轻量化网络的性能, 但仍有较大的优化空间.原因如下.
1)AAFB模块的第一路使用的注意力仍是传统的SE注意力模块.传统SE注意力模块参数量较少, 但因其过于轻量化, 导致随着i增加, 对不断增多的“ 历史” 信息(X0, X1, …, Xi-1)权重重分配的能力明显不足.A2F作为以SE注意力模块为主体的网络, 该现象更明显.
2)AAFB模块的第二路只使用最邻近的前序AAFB模块Xi-1的输出作为其输入以获取“ 新” 特征, 而在此过程中第一路压缩的所有“ 历史” 信息并未参与, 不利于网络融合“ 新旧” 信息.若直接在第二路增加“ 历史” 信息的输入, 又会因第二路沙漏型结构内的卷积层输出/输入通道数较大, 大幅增加网络参数量与算力消耗, 不利于轻量化.所以A2F仅仅是在网络尾部简单加法融合两路特征.
2.2.1 SE注意力模块
位于AAFB第一路的传统SE注意力模块结构过于简单, 虽能提升一定的超分辨率质量, 但提升并不明显, 并且只对简单、低频的输入信息发挥一定作用, 对复杂的高频信息或不太复杂但无规则分布的纹理(如粗细不均的网格等)难以发挥明显作用.
分析SE注意力模块的结构, 推测其无法处理高频、无规则信息的核心原因在于SE机制的GAP.GAP的作用是提取每个通道的特征— — 将每个通道的完整特征图(可能很大, 如64× 64)进行全局平均, 压缩为一个1× 1的“ 通道描述符” .这是一个信息大量丢失的过程.文献[12]表明可在SE注意力模块之前设置1个卷积层, 通过可学习的参数在GAP前对特征图进行调整, 但是这不仅会引入更多的参数不利于轻量化, 也不便于注意力模块与网络的解耦.即使A2F中位于SE注意力模块前的投影单元也是卷积层, 一定程度上也起到相同作用, 但是其需要承担压缩O(i2)的通道数至O(k)的固定通道数的功能, 随着i的增加, 通道数增多, 注意力效果逐渐不佳.这进一步表明, 在网络尾部侧重于重建高频细节的注意力单元, 因输入的“ 历史” 通道增多导致调整特征图的作用减少, 使得网络难以处理高频信息.
2.2.2 非线性映射模块
非线性映射模块的残差块(AAFB模块第二路的沙漏型结构)在占据最大参数量比例的同时, 只使用最邻近(仅第i-1个)AAFB模块的输出作为输入, 并未使用第一路提取的“ 历史” 信息.残差块由2个卷积层与1个激活函数组成, 构成沙漏型结构.以A2F-SD为例, 网络将输入的16通道特征扩展到输出的128通道特征, 学习复杂的高频纹理.该结构难以在轻量化网络使用的2个原因如下[4].
1)128输出通道过高, 不利于模型轻量化.通过A2F-S(沙漏结构32-128-32, 堆叠4个AAFB模块)与A2F-SD(沙漏结构16-128-16, 堆叠8个AAFB模块)的消融实验可证实, 拉高卷积层输入/输出维度的差距以及增加AAFB模块的堆叠量可有效提升超分辨率效果.虽然在轻量级网络中, A2F-SD的设计能通过如此高的维度, 较好地提取高频纹理, 但是更轻量化的超轻量网络引入如此高的卷积层维度及如此长的堆叠网络, 会大幅增加网络的参数量和算力消耗.这与超轻量级网络追求高效、快速处理的目标相悖.若降低维度的数量或降低堆叠长度, 网络学习特征的能力又会显著降低, 因为每个AABF模块仅靠此处的高维度设置提取高频特征.
2)输入通道数16过低, 不利于网络学习上下文信息.从消融实验来看, 相比A2F-S, A2F-SD在含有较多中高频无规则纹理图像的BSD100数据集上提升最少, PSNR仅提升0.09 dB.换言之, A2F-SD中16-128-16的结构在此数据集上表现最差.这个事实进一步表明含有较多“ 上下文” 信息的中等维度(32)输入特征能更好地保留通道间的“ 上下文” 信息, 从而更好地重建无规则纹理图像.作为轻量级网络, 一般适用于实时、快速的超分辨率场景重建, 所以更倾向于对网络中尺寸较大、整体性的中高频纹理图像进行超分辨率重建.因此, 对于轻量级网络, 应该使用A2F-S的策略— — 增加维度(输入通道数)以强化这一倾向.
综上所述, A2F-S及A2F-SD两者的结构均有不足:若减小输入通道数拉高维度差异, 则降低对中频特征的处理能力; 若增大输入通道数或模块堆叠数量, 则大幅影响网络的轻量化水平.所以需要一个改进的网络同时解决原网络存在的上述问题.
本文改进A2F, 提出基于四路多尺度注意力模块及桥连结构的轻量级单图超分辨率网络(A2F-MSAB), 作为核心模块的多策略注意力辅助特征桥接模块(Attentive Auxiliary Feature and Multi-scale Attention and Bridged Structure Block, AAFMBB)结构如图2所示.由于A2F-MSAB主体框架没有变化, 因此省略结构图.
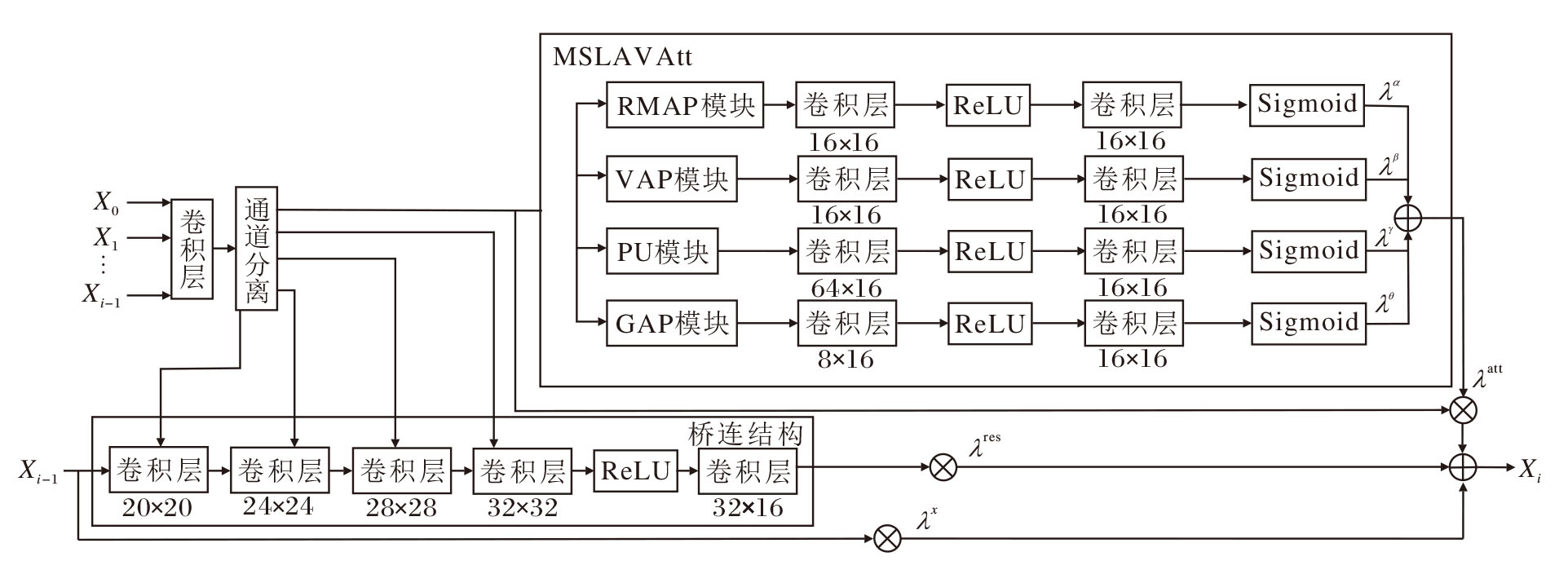 | 图2 AAFMBB结构图Fig.2 Architecture of AAFMBB |
A2F-MSAB主要改进如下.
1)将SE注意力模块替换为更高效的多尺度自学习融合均值与方差的注意力模块(MSLAVAtt).采用该模块后, 网络仅增加7× 103参数量, 但是相比SE注意力模块, MSLAVAtt在PSNR、SSIM、LPLPS指标上均有一定提升.
2)对原本只在AAFB模块尾部融合的第一路及第二路, 进行多次桥连操作, 最大程度利用前层特征.
另外, 为了使网络轻量化, 将原本堆叠的8个模块改为4个, 降低约一半的参数量.
2.3.1 多尺度自学习融合均值与方差的注意力模块
MSLAVAtt将注意力变为4路, 从不同层面获取通道描述符之后, 将4种描述符加权求和, 4个可学习参数λ α 、λ β 、λ γ 、λ θ 表示权重.下面按顺序描述每路的具体结构与设置原因.
1)矩形区域平均(Rectangular Mask Average Poo-ling, RMAP)模块.A2F采用GAP对特征图所有区域进行同等权重的平均操作, 但未考虑图像边缘区域在网络前向传播中常需经过填充(Padding)等边界处理操作, 相比中心区域更容易出现信息损耗, 导致其纹理细节的恢复难度显著高于中心区域.中心区域不会经过额外边界处理, 信息完整性较强, 不仅纹理还原难度较低, 对图像整体视觉质量的贡献也更关键.为了使网络能自适应聚焦于更具恢复价值的区域, 采用目标检测领域YOLO(You Only Look Once)[14]中参数化矩形框的表示思路, 引入4个可学习参数, 动态定义特征聚合区域, 仅对矩形范围内的区域进行平均操作以生成注意力描述符.矩形初始范围设为整个特征图, 确保网络训练初期可获取全局特征信息.随着训练推进, 网络会自适应调整矩形的位置与大小, 逐步聚焦于中心等信息完整、容易恢复的高价值纹理区域, 从而在有限计算资源下优先保障核心区域的还原质量.
2)方差修饰的全局平均(Variance-Modulated Glo-bal Average Pooling, VAP)模块.注意力模块在其发展历程中有许多改进, 很多网络不再局限于全局平均操作, 开始使用其它方式提取每一通道的特征描述符.平均特征虽然包含特征图中所有特征的“ 平均” 信息, 但是正如统计学中的平均值一样, 会受到较大值及较小值等“ 极端值” 的影响.所以很多网络使用GMP获取极端特征, 对“ 平均” 特征起到一定的辅助作用.
VAP模块结合GAP、GMP及GMiP(Global Min-Pooling).GMP、GMiP实际上是由于平均值容易被最值影响设置的辅助模块.统计学使用方差衡量数据的“ 离散程度” , 但是求一个特征图的方差速度较慢.为了满足网络的轻量化改进, 采用二项分布估算方差的方法, 即使用最大值最小值的差估算方差.当最大值、最小值的差越小, 平均值受极端值的影响就越小, 这个平均值就越“ 好” , 权重也应越大.二项分布的概率密度分布为:
$f(x)=\frac{1}{\sqrt{2 \pi \sigma}} \exp \left(-\frac{(x-\mu)^{2}}{2 \sigma^{2}}\right), $
其中, x表示原始数据, μ 表示数据均值, σ 表示数据方差.
二项分布的3σ 原则是指数据落在(μ -3σ , μ +3σ )区域的概率是99.74%, 约等于100%, 也就是说, 最大值与最小值的差可看作是6σ .因此, VAP模块使用平均值除以最小值与最大值差的平方以修饰平均值, 具体公式如下:
$F_{\text {vap }}=\frac{F_{\text {gap }}}{\left(F_{\max }-F_{\min }\right)^{2}}, $
其中, Fgap表示全局平均池化值, Fmax表示全局最大池化值, Fmin表示全局最小池化值.
3)像素下采样重组(Pixel Unshuffle, PU)模块与邻近层平均(Neighboring Average Pooling, NAP)模块.为了解决多尺度注意力需要额外增加卷积层的问题, 设置这2个模块, 分别位于网络的第三路和第四路.
PU是一种在深度学习尤其是在图像处理领域中被广泛研究和应用的技术, 主要用于将图像的空间维度和通道维度进行重新分配, 从而实现图像尺寸的缩小和通道数的增加, 这在一些图像超分辨率任务中尤为重要.
在图像处理任务中, PU的原理是将输入图像的每个像素块重新排列到输出图像的不同通道中.具体来说, 假设输入图像的尺寸为H× W× C, 其中, H、W分别表示图像的高度和宽度, C表示通道数.PU模块的下采样因子为r, 那么输出图像的尺寸变为
这种重新排列的下采样过程是通过将每个原图像素块中的像素映射到新图像的相应通道实现的, 从而在缩小图像空间尺寸的同时增加通道数.类似空洞卷积对图像的大范围采样, PU不仅可实现类似功能, 并且不会引入额外参数.当下采样因子为2时, 原本1个通道能映射至4个通道, 获取4个描述符, 增加通道描述的全面性.
NAP模块与PU模块相反, 是对GAP之后邻近4个通道的4个描述符再次进行GAP, 变为1个描述符.通过获取邻近数个通道的综合特征, 增强网络对不同通道特征的融合能力.
2.3.2 桥连多级沙漏型结构
为了缓解高维(128个通道)在轻量级网络中参数量过大的问题, 在网络第一路、第二路之间增设桥接结构.首先将投影单元的输出从16增至32, 目的是包含更多的通道信息.然后, 将通道分裂:第1部分是16个通道, 与原网络相同, 送入之后的SE注意力模块提取特征; 另外16个通道分为4部分, 每部分4个通道.将第二路的沙漏型结构拆成输入输出通道维度逐步增加的4个卷积层, 并且将第一部分的4个通道与原输入拼接, 构成多级沙漏型结构(Multi-level Hourglass Structure, MHS).因为1个卷积核对应1个输出通道, 所以第二路从16-128-16改为(16+4)-(20+4)-(24+4)-(28+4)-16, 即20-24-28-32-16.该操作虽然可能影响高频特征的提取效果, 但是通过与第一路通道的融合, 增大网络的上下文学习能力, 在感受野不增加的前提下提升对中频特征的超分辨率效果, 符合轻量级网络的应用要求与侧重点.
本文采用傅里叶变换、空域梯度分析、小波变换进行数据集的频域分析.频域中的高频信息与空域中的细节/纹理具有较强的对应性.图像超分辨率本质上是需要实现图像细节信息增强的目的.因此, 频域分析得出的高频能量比、平均梯度可较好地揭示原始图像中细节、纹理的丰富程度, 对图像超分辨率网络的设计与性能评测也具有指导意义.
Set5(val)数据集包含5幅图像, 类型多样.Set14数据集为小型数据集, 包含14幅图像, 纹理较丰富, 适合快速判断网络的超分辨率性能, 或作为验证集使用.BSD100数据集是从Berkeley Segmenta-tion Dataset中选取的100幅图像, 具有较高的多样性, 主要包含无规则的中高频纹理图像.Urban100数据集包含100幅城市风光图像, 主要为较规则的高频纹理图像.Manga109数据集包含109幅漫画图像, 主要为较规则的中高频纹理图像.5个数据集的具体频域分析结果如表1所示.
使用3种不同方法对数据集进行频域分析, 并取平均值, 均得到相同对比结果:
Urban100> BSD100> Set14> Manga109> Set5(val).
Urban100数据集纹理密集、高频细节最丰富, 符合典型高频数据集特性.Manga109数据集为漫画数据集, 以线条为主, 复杂纹理较少, 高频占比很低.
使用小波变换对来自Urban100高频数据集的2幅图像与Manga109低频数据集的2幅图像进行频域分析的可视化结果如图3所示.图中红色表示高频能量区域, 蓝色表示低频能量区域.
 | 图3 小波变换对4幅图像的频域分析结果Fig.3 Frequency-domain analysis results of wavelet transfer on 4 images |
分析结果同时说明, 由于5个数据集在细节/纹理的丰富程度上存在十分显著的差异, 具有较好的代表性, 利用它们进行图像超分辨率网络的性能评测是合理的.
在DIV2K数据集[15]的训练集上训练网络.DIV2K数据集是一个高质量的单图像超分辨率数据集, 涵盖多种图像类型, 共1 000幅图像, 800幅作为训练集, 100幅作为验证集, 100幅作为测试集.
遵循较普遍的方案, 使用Set5(val)数据集作为验证集.网络共计2 000个训练周期, 并取训练2 000个周期的网络作为结果.使用Set14、BSD100、Urban-100、Manga109作为评估测试集.
在NVIDIA GeForce GTX 1080 Ti上训练网络.沿用A2F的部分训练参数.训练时使用Adam(Adaptive Moment Estimation)优化器, 设置β 1=0.9, β 2=0.999, ε =1e-8.学习率初始设为0.001, 每200个训练周期减少为当前值的一半, 1 000个训练周期之后, 学习率恢复至初值0.001, 之后继续进入相同的下降过程.
选择PSNR、SSIM、LPIPS作为评价指标.PSNR是数字图像处理领域经典的全参考客观质量评价指标之一, 通过计算原始图像与失真图像的均方误差量化失真程度, 实现图像质量的量化评估.SSIM是全参考图像质量评价指标之一, 突破传统误差求和思路, 通过整合亮度、对比度和结构三个维度的相似性度量, 实现与人类视觉系统感知更契合的图像相似度评估.LPIPS是一种衡量图像相似度的指标, 通过深度学习模型提取图像特征并计算特征之间的距离, 评估图像之间的感知相似度, 比传统的像素级相似度指标(如PSNR、SSIM)更符合人类的视觉感知.
3.3.1 与A2F-MSAB的对比结果
对比网络如下:SRCNN(Super-Resolution Con-volutional Neural Network)[1]、A2F-S[4]、FSRCNN(Fast Super-Resolution Convolutional Neural Net-works)[16]、SCN(Sparse Coding Based Network)[17]、LapSRN(Laplacian Pyramid Super-Resolution Net-work)[18]、ZSSR(“ Zero-Shot” Super-Resolution)[19]、DRCN(Deeply-Recursive Convolutional Network)[20]、DRRN(Deep Recursive Residual Network)[21]、RED-Net[22]、VDSR[23]、DnCNN(Denoising Convolutional Neu-ral Network)[24]、MemNet(Very Deep Persistent Me-mory Network)[25]、IDN(Information Distillation Network)[26]、CNF(Context-Wise Network Fusion)[27]、SelNet[28]、CARN(Cascading Residual Network)[29]、SRRAM[30].
部分网络在5个数据集上的PSNR指标对比如表2所示.
| 表2 A2F-MSAB与对比网络的PSNR指标 Table 2 PSNR of A2F-MSAB and comparative networks |
由表2可见, A2F-MSAB的PSNR指标领先参数量低于9.9× 104的大部分轻量级网络, 并且在多个数据集上领先部分非轻量级网络, 如LapSRN、ZSSR和DRCN.A2F-MSAB在Set14测试集上性能略弱于DRCN, 但是Set14测试集仅有14幅图像, 参考价值相对较低.在Urban100、Manga109测试集上的高PSNR指标值表明轻量级网络A2F-MSAB在结构上的优势.
部分网络在5个数据集上的SSIM指标对比如表3所示.由表可见, A2F-MSAB在SSIM指标上的优势更显著, 特别是在BSD100数据集上, 这更加表明A2F-MSAB对中高频细节的恢复能力.
| 表3 A2F-MSAB与对比网络的SSIM指标 Table 3 SSIM of A2F-MSAB and comparative networks |
A2F-MSAB相比各网络在BSD100数据集上的性能提升如表4所示.由表可见, A2F-MSAB的SSIM值超过A2F-S, 但是参数量仅为A2F-S的31%.A2F-MSAB同时也优于许多轻量化及非轻量化的主流超分辨率网络.
| 表4 A2F-MSAB在BSD100数据集上与主流超分辨率网络对比 Table 4 Comparison of A2F-MSAB and mainstream super-resolution networks on BSD100 dataset |
使用AlexNet作为提取特征的深度学习模型(下同), A2F-SD和A2F-MSAB的LPIPS指标对比如表5所示, 表中* 表示该网络使用了与A2F-MSAB相同的训练参数、数据集及算法, 下同.
| 表5 A2F-MSAB和A2F-SD的LPIPS指标 Table 5 LPIPS of A2F-MSAB and A2F-SD |
由表5可看到, A2F-MSAB在多个数据集上的超分辨率重建效果在视觉感知上同样优于或基本持平于A2F-SD.
3.3.2 与A2F-MSAB-L的对比结果
除了A2F-MSAB以外, 本文还设计一个参数量较大的A2F-MSAB-L, 即将A2F-MSAB中堆叠的4个AAFMBB模块改为12个, 参数量达到3.18× 105.对于如此长而简单的网络结构, 虽然有更好的方式处理可能出现的退化等问题, 但是未作处理, 以便更好地体现A2F-MSAB相对A2F的优势.
具体对比网络如下:A2F-SD[4]、A2F-S[4]、A2F-M[4]、A2F-L[4]、DRRN[21]、CARN-M[29]、FALSR-B[31]、FALSR-C[31]、LW-AWSRN(Lightweight Adaptive Wei- ghted Super-Resolution Network)[32]、LW-AWSRN-SD[32]、LW-AWSRN-S[32]、SRFBN-S(Image Super-Resolution Feedback Network)[33]、D-DBPN(Dense Deep Back-Projection Networks)[34]、MSRN(Multi-scale Residual Network)[35].
部分网络在5个数据集上的PSNR指标如表6所示, SSIM指标如表7所示.由表6和表7可见, 一般可通过增加块的堆叠层数(增加网络长度)、增大卷积层输出通道数(提高维数差距)与增大感受野(增加卷积层大小)等方式增加网络对高频细节的学习能力.
| 表6 A2F-MSAB-L与对比网络的PSNR指标 Table 6 PSNR of A2F-MSAB-L and comparative networks |
| 表7 A2F-MSAB-L与对比网络的SSIM指标 Table 7 SSIM of A2F-MSAB-L and comparative networks |
由于A2F-MSAB-L只增加堆叠块数, 未提升感受野及维数, 因此在Manga109数据集上略逊于A2F-SD.但是, 在其它3个拥有更多中高频纹理的数据集上, A2F-MSAB-L均领先于A2F-SD.与前文分析一致, A2F-MSAB-L在高频纹理较多的Set14、Urban100数据集上性能有一定提升而在中频纹理较多的BSD100数据集上性能提升最多.A2F-MSAB-L在BSD100数据集上的性能高于A2F-SD、A2F-S及具有5× 106以上超大参数量的D-DBPN及MSRN, 这表明上下文信息对提升网络学习无规则中频细节能力的重要性.
A2F-MSAB-L相比各网络在BSD100数据集上的性能提升如表8所示.
| 表8 A2F-MSAB-L在BSD100数据集上与主流超分辨率网络对比 Table 8 Comparison of A2F-MSAB-L and mainstream super-resolution networks on BSD100 dataset |
A2F-SD、A2F-L、A2F-MSAB-L在5个数据集上的LPIPS指标如表9所示.由表8和表9可看出, 在与BSD100数据集相关的中频细节重建方面, A2F-MSAB-L不仅在结构上更相似, 而且在实际感知方面也更优, 效果同样超过A2F-SD及具有更多参数量的A2F-L.
| 表9 A2F-MSAB-L、A2F-SD和A2F-L的LPIPS指标 Table 9 LPIPS of A2F-MSAB-L, A2F-SD and A2F-L |
A2F-MSAB-L、A2F-SD和双三次插值方法在BSD100数据集的2幅代表性图像上的定性对比结果如图4所示.由图可看到, 对于中频规则纹理及无规则纹理, A2F-MSAB-L更能缓解可能出现的边缘伪影与失真问题.
 | 图4 各网络在BSD100数据集上的超分辨率效果对比Fig.4 Comparison of super-resolution performance on BSD100 dataset |
本节构造两组消融实验, 实验1测试MSLAVAtt与BMHS对A2F-MSAB性能提升的差异.实验2测试MSLAVAtt中每路模块的作用差异.实验1和实验2均使用3.2节的训练参数.
3.5.1 消融实验1
实验1中, 设计如下模块.1)对于MSLAVAtt, √ 表示使用MSLAVAtt, × 表示使用SE注意力模块.2)对于BMHS, √ 表示将第一路输入通道扩大, 拆分沙漏型结构为多级后使用桥连结构, × 表示不扩大第一路输入通道, 使用非桥连的原沙漏型结构.此外, 为了保持参数量基本一致以更好测定模块的“ 高效性” (参数量接近的前提下的超分辨率性能对比), 沙漏型结构卷积层改为16-72-16.
各模块的PSNR、SSIM、LPIPS指标如表10~表12所示.对比PSNR、SSIM指标可发现, MSLAVAtt及BMHS均能不同程度提升图像的超分辨率效果.整体来看, 移除BMHS后的PSNR、SSIM指标高于移除MSLAVAtt的, 由此表明注意力占有更重要的作用.
对比LPIPS指标可发现, 移除BMHS后的LPIPS指标低于移除MSLAVAtt的, 同样表明注意力模块占有更重要的作用.在LPIPS指标上, 也同样是在BSD100数据集上下降最明显.
使用MSLAVAtt、BMHS分别能使A2F-MSAB在BSD100数据集上LPIPS指标降低约2%、1%, 但是参数量只提升7× 103、1× 103, 因此上述2个改进适用于推广到其它网络.
3.5.2 消融实验2
由于LPIPS指标更符合人类视觉感知习惯, 因此使用LPIPS指标定量测试MSLAVAtt中RMAP模块、VAP模块、PU模块、NAP模块的作用, 结果如表13所示.由表可得如下结论.
1)4路注意力模块中每路均能提升超分辨率效果.
2)移除RMAP模块后, 低频数据集Manga109上超分辨率效果下降最多, LPIPS指标提升0.000 9, 这反映出该模块在低频数据集上进行超分辨率重建的过程中, 能更好地聚焦于重要模块, 去除其中占比较多的平滑、低频纹理.
3)移除NAP模块后, 中频无规则数据集BSD-100上的超分辨率效果下降最多, LPIPS指标提升0.004 5.由此说明在无规则数据集上上下文信息对超分辨率重建的重要性.
综上所述, 4路注意力模块的设置较好地解决A2F中SE注意力模块存在的问题, 并且4路中的每路均有提升网络超分辨率效果的重要价值, 同样适用于推广到其它网络.
针对A2F-SD注意力机制过于简单和多路信息利用能力不足的问题, 本文提出基于四路多尺度注意力模块及桥连结构的轻量级单图超分辨率网络(A2F-MSAB), 参数量仅为9.9× 104.设计多尺度自学习融合均值与方差的注意力模块(MSLAVAtt), 仅增加7× 103的参数量, 带来LPIPS指标上最高2%的降幅.设计桥连多级沙漏型结构(BMHS), 能更好地利用上下文信息与网络浅层特征, 相比参数量差距仅为1× 103的原结构, LPIPS指标降幅达1%.整体上看, A2F-MSAB精简原有基本模块, 大幅增加中频信息的学习能力, 在轻量化网络中性能突出, 可将该结构推行至非轻量化网络.本文在仅增加堆叠块数且不改变网络结构的前提下, 网络超分辨率重建效果显著.MSLAVAtt和BMHS虽增加少量参数量, 但超分辨率效果提升显著, 满足轻量化及高效的要求, 可广泛应用于使用SE注意力模块或需求轻量化的超分辨率网络, 具有良好的应用前景.今后可进一步探索A2F-MSAB与前沿网络或技术的融合, 提升其对更复杂场景中更多类型纹理图像的恢复能力.
本文责任编委 张军平
Recommended by Associate Editor ZHANG Junping
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|