




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于区域上下文感知的人群计数方法
引用本文
洪致远, 高欣健, 任梦妍, 王希临, 高隽. 基于区域上下文感知的人群计数方法. 模式识别与人工智能, 2025,38(12): 1108-1120
HONG Zhiyuan, GAO Xinjian, REN Mengyan, WANG Xilin, GAO Jun. Crowd Counting Based on Regional Context Awareness. PATTERN RECOGNITION AND ARTIFICIAL INTELLIGENCE, 2025,38(12): 1108-1120.
Doi: 10.16451/j.cnki.issn1003-6059.202512004
HONG Zhiyuan, GAO Xinjian, REN Mengyan, WANG Xilin, GAO Jun. Crowd Counting Based on Regional Context Awareness. PATTERN RECOGNITION AND ARTIFICIAL INTELLIGENCE, 2025,38(12): 1108-1120.
Permissions
Copyright©2025, 《模式识别与人工智能》编辑部
《模式识别与人工智能》编辑部
基于区域上下文感知的人群计数方法

高欣健,博士,副教授,主要研究方向为图像处理、深度学习、人工智能、机器学习等.E-mail:gaoxinjian@hfut.edu.cn.
作者简介:

洪致远,硕士研究生,主要研究方向为人群计数、小目标检测、计算机视觉等.E-mail:zhiyuanhong2001@163.com.

任梦妍,硕士研究生,主要研究方向为小目标检测、红外小目标检测、计算机视觉等.E-mail:r09067925@163.com.

王希临,硕士研究生,主要研究方向为目标检测、计算机视觉等.E-mail:wang_xilin2024@163.com.

高 隽,博士,教授,主要研究方向为图像处理、模式识别、智能信息处理等.E-mail:gaojun@hfut.edu.cn.
摘要
面对人群计数任务中复杂场景下密度不均与尺度多变等问题,现有基于Transformer的方法在处理跨尺度上下文时,往往忽略对空间信息与通道信息的利用.因此,文中提出基于区域上下文感知的人群计数方法.首先,设计区域引导模块,为各特征位置自适应分配关注区域,从而引入区域级上下文,较好地适应非均匀密度分布.然后,构建空间-通道上下文感知模块,在空间与通道两个维度上实现特征交互,构建跨维度的区域依赖,增强方法对前景区域与背景区域的判别能力.最后,在训练阶段进一步引入分布级约束,提升预测密度分布与真实分布的一致性.文中方法在JHU-Crowd++、ShanghaiTech数据集上的实验表现较优,验证其在复杂场景中的鲁棒性与泛化性.
关键词:
人群计数; 区域引导; 注意力机制; 上下文感知
中图分类号:TP391
Crowd Counting Based on Regional Context Awareness
GAO Xinjian, Ph.D., associate professor. His research interests include image processing, deep learning, artificial intelligence, and machine learning.
About Author:
HONG Zhiyuan, Master student. His research interests include crowd counting, small object detection, and computer vision.
Ren Mengyan, Master student. Her research interests include small object detection, infrared small target detection, and computer vision.
Wang Xilin, Master student. His research interests include object detection and compu-ter vision.
GAO Jun, Ph.D., professor. His research interests include image processing, pattern recognition, and intelligent information processing.
Abstract
To address the challenges of uneven density distribution and large scale variations in complex crowd scenes, existing Transformer-based methods typically overlook the utilization of spatial and channel information while handling cross-scale contextual features. Therefore, a method for crowd counting based on regional context awareness(RCA) is proposed. First, a region guidance module is designed to adaptively assign an attention region for each feature location. Thereby region-level context is introduced and non-uniform density distributions are better accommodated. Second, a spatial-channel context awareness module is designed to enable feature interaction across spatial and channel dimensions. Consequently, cross-dimensional regional dependencies are constructed and the discrimination between foreground and background regions is enhanced. Finally, a distribution-level constraint is introduced during the training to improve the consistency between the predicted density distribution and the ground-truth distribution. Experimental results on JHU-Crowd++, ShanghaiTech A, and ShanghaiTech B datasets validate the robustness and generalization capability of RCA in complex scenes.
Key words:
Key Words Crowd Counting; Region Guidance; Attention Mechanism; Context Awareness
人群计数旨在估计拥挤人群或背景杂乱图像中的人数, 因其在公共安全、交通监测等领域的广泛应用而倍受关注.此外, 该技术还可扩展到生物医学、农业和生态保护等领域, 如水果计数[1]、动物计数[2]和植物计数[3]等.由于真实场景中普遍存在拥挤遮挡、尺度变化与背景杂乱的现象, 研究者通常将该任务转化为密度图回归:利用点标注, 通过核函数生成监督密度图, 学习从图像到密度分布的映射, 从而提升方法在复杂环境下的鲁棒性与泛化性.
在真实应用中, 人群计数面临两方面挑战.一方面, 透视畸变与拍摄距离变化导致同一图像中个体尺度跨度极大, 密度分布也会在不同区域呈现明显不均.另一方面, 高密度遮挡叠加复杂背景时, 前景与背景在外观上相似, 容易引发误判与漏检, 降低密度估计的可靠性.
为了应对上述挑战, 早期研究主要采用目标检测方法[4, 5, 6]或密度回归方法[7].目标检测方法在稀疏场景中具有优势, 但当遮挡加重时, 检测性能明显下降.密度回归方法学习从图像到密度图的映射, 更适合高密度场景.然而, 传统卷积神经网络(Convo-lutional Neural Network, CNN)受限于局部感受野与固定算子, 难以适应人群图像中的尺度变化.为了解决这一问题, 研究者提出多尺度CNN, 如MCNN(Multi-column Convolutional Neural Network)[8]与SaCNN(Scale-Adaptive CNN)[9], 通过多感受野缓解尺度变化问题.这类方法通常依赖预设的静态结构, 难以根据不同密度区域的差异进行自适应调整, 并且对前景与背景的区分能力有限.
随着注意力机制的发展, Transformer[10]及其变体[11, 12]被引入人群计数, 用于加强长距离依赖与跨尺度上下文表达, 代表性工作包括CTASNet(CNN and Transformer Adaptive Selection Network)[13]、CCTrans[14]等.然而, 这类方法侧重于提升全局建模能力, 仍然依赖固定词元, 难以为不同位置自适应确定最相关的关注区域, 在复杂场景中容易产生跨区域误关联.与此同时, 另一类方法, 如SCAR(Spatial-/Channel-Wise Attention Regression Network)[15]、CDE-Net(End-to-End Trainable Confusion Region Discri-minating and Erasing Network)[16]、HSED-Net(Hierar-chical Scale-Aware Encoder-Decoder Network)[17]等, 专注于空间与通道注意力机制的设计, 但是受限于局部感受野, 对跨区域结构关系与远程依赖的表达仍不充分.
针对上述情况, 本文提出基于区域上下文感知的人群计数方法(Crowd Counting Based on Regional Context Awareness, RCA).首先, 设计区域引导模块(Region Guidance Module, RGM), 构建具有结构先验的区域自注意力, 并结合门控机制动态调整不同区域特征的重要程度, 为后续的密度图生成提供区域上下文先验.然后, 设计空间-通道上下文感知模块(Spatial-Channel Context Awareness Module, SCC-AM), 在空间与通道两个维度上建立特征依赖关系, 充分挖掘关键特征并抑制冗余背景信息, 提升方法对前景区域的判别能力.在3个公共数据集上的实验表明, RCA性能较优.
1 相关工作
早期多尺度方法[8, 9]通常通过多分支卷积引入不同感受野, 缓解尺度变化问题, 但其融合策略多为静态设计, 难以在密度分布不均的场景中实现区域自适应.为了提升监督信号的可学习性, Wan等[18]通过核函数生成更贴合局部细节的密度图, 降低密集区域的回归误差.Xu等[19]提出AutoScale, 在局部区域对人群邻近度进行归一化, 分解密集区域由核函数叠加引起的密度累积.此外, 一些工作侧重于增强跨尺度表征与融合机制.Zand等[20]在点监督下进行计数学习, 并通过多尺度表示与融合模块增强跨尺度表征能力.Xiong等[21]提出MLANet(Multi-level Attention Network with Multi-scale Feature Fu- sion), 通过多层特征交互增强多尺度表达, 提升在密度变化场景中的性能.上述方法主要在像素或局部邻域层面进行表征, 对不同密度区域之间的结构联系关注不足, 因此在稀疏区域与稠密区域共存时难以实现区域级自适应.
基于Transformer的人群计数方法以注意力机制为核心, 引导网络关注相关信息, 提高计数性能.Chen等[13]提出CTASNet, 采用密度引导的自适应选择机制, 结合CNN的局部表征与Transformer的全局上下文, 在稀疏人群区域与稠密人群区域实现准确计数.Wang等[12]通过双分支架构分别建模局部多尺度细节与全局依赖, 并利用混合注意力突出人群区域特征.Tian等[14]提出CCTrans, 采用金字塔式Transformer骨干获取多尺度上下文, 并通过多尺度感受野回归头生成密度图.然而, 上述方法多使用预设的特征单元, 难以根据位置的变化自适应确定关注范围.
研究者利用空间信息或通道信息, 减弱密度回归中背景干扰带来的影响.Gao等[15]引入空间注意力和通道注意力, 增强模型的上下文理解与特征选择能力.Zhu等[16]提出CDENet, 在空间层面显式挖掘与人群区域外观相似的背景混淆区域, 提升方法对背景信息的判别能力.Han等[17]提出HSED-Net, 采用层次化编码-解码结构, 并通过空间-通道自适应权重机制增强特征表达能力.Xiong等[22]提出CSFNet(Context-Scaled Fusion Network), 从上下文与空间注意力的角度增强关键区域响应.尽管上述方法在局部特征选择和背景抑制方面取得良好效果, 但是受限于感受野, 仍缺乏对远程依赖关系的建模能力.
像素级回归损失主要约束局部误差, 难以从整体上度量预测密度图与真实密度图在分布形态上的一致性.Wang等[23]提出OT(Optimal Transport), 将预测密度图与真实密度图视为概率分布并对齐, 为密度图学习提供更强的全局一致性约束.
2 基于区域上下文感知的人群计数方法
2.1 整体架构
为了解决密集人群计数任务中的密度分布不均和背景干扰严重等问题, 本文提出基于区域上下文感知的人群计数方法(RCA), 整体架构如图1所示.
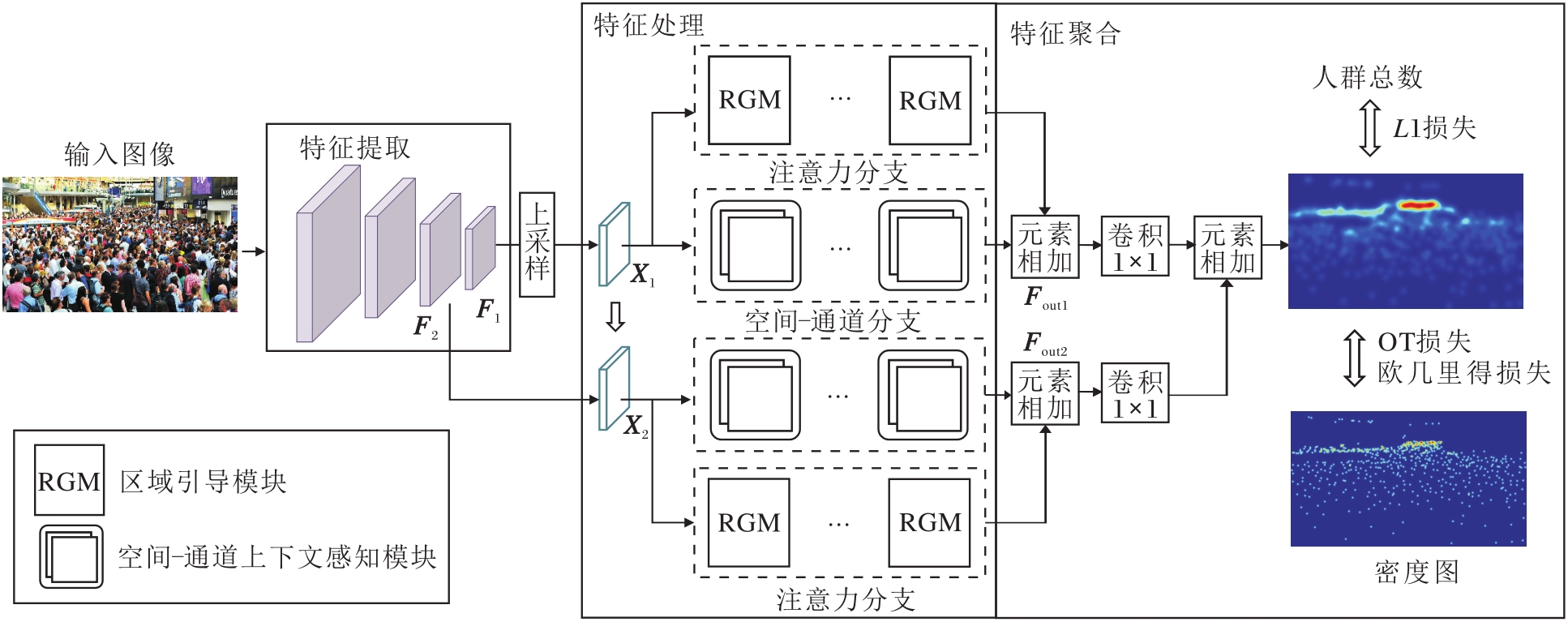 | 图1 RCA整体框图Fig.1 Overall framework of RCA |
RCA主要包含3个阶段:特征提取、特征处理、特征聚合.
对于一幅输入图像I, 首先使用VGG(Visual Geometry Group)网络提取不同层次的特征, 记为F1和F2, 分别对应1/16和1/8的下采样比例, 为后续处理提供多尺度基础特征.在特征处理阶段, 采用双分支并行设计.区域引导分支将特征序列化后输入编码器中, 在区域层面显式建模不同区域之间的关联.空间-通道分支从空间层次和通道层次处理特征, 增强对背景的判别能力.在双分支特征处理阶段之后, 将输出特征分别通过1×1卷积调整至相同通道维度, 并执行逐元素相加, 实现特征聚合, 生成单通道预测密度图.最后, 采用欧几里得损失、L1损失与OT损失进行监督训练.
2.2 特征融合
与以往工作[24, 25, 26]一致, 本文的特征提取阶段采用VGG16作为主干网络, 用于提取人群图像中多层次特征表示.对于输入图像I∈RH×W×3, 其中H、W分别表示图像的高度和宽度, 利用在ImageNet数据集上预训练的VGG16网络提取不同层次的特征, 记为F1、F2, 分别对应1/16、1/8的下采样比例.
由于直接使用VGG16网络提取的特征不足以表示图像中的细节信息和目标的边界信息, 因此, 需要进一步融合不同层级的特征.现有研究表明[14], 浅层特征图中包含丰富的边缘信息, 但语义信息较弱, 而深层特征图具备更强的语义信息.因此, 有必要融合深层特征与浅层特征.
具体而言, 将每个阶段的特征上采样到相同的分辨率, 并在这些特征图上执行逐元素相加, 得到融合特征:
F'2=F2+Upsample(F1),
其中Upsample(· )表示上采样操作.
2.3 双分支模块
在特征处理阶段, RCA采用双分支结构, 包括区域引导模块(RGM)和空间-通道上下文感知模块(SCCAM).RGM侧重于建模区域间的结构关系, 提供区域级的上下文信息.SCCAM通过空间和通道层次的信息交互, 进一步增强对前景与背景的判别能力.
2.3.1 区域引导模块
尽管全局自注意力能建模长程依赖, 但在高密度且背景杂乱的场景中, 对所有位置进行全局交互容易引入大量无关背景, 干扰密度估计.为此, 本文设计区域引导模块(RGM), 在全局区域与多种具有结构先验的子区域上构建区域自注意力, 并且引入门控机制, 再次筛选区域级依赖, 提升对于复杂场景的适应能力.
RGM由区域自注意力(Region Self-Attention, RSA)、层归一化(Layer Normalization, LN)和前馈网络(Feed-Forward Network, FFN)组成, 并在各层之间采用残差连接以增强信息流动, 具体结构如图2所示.
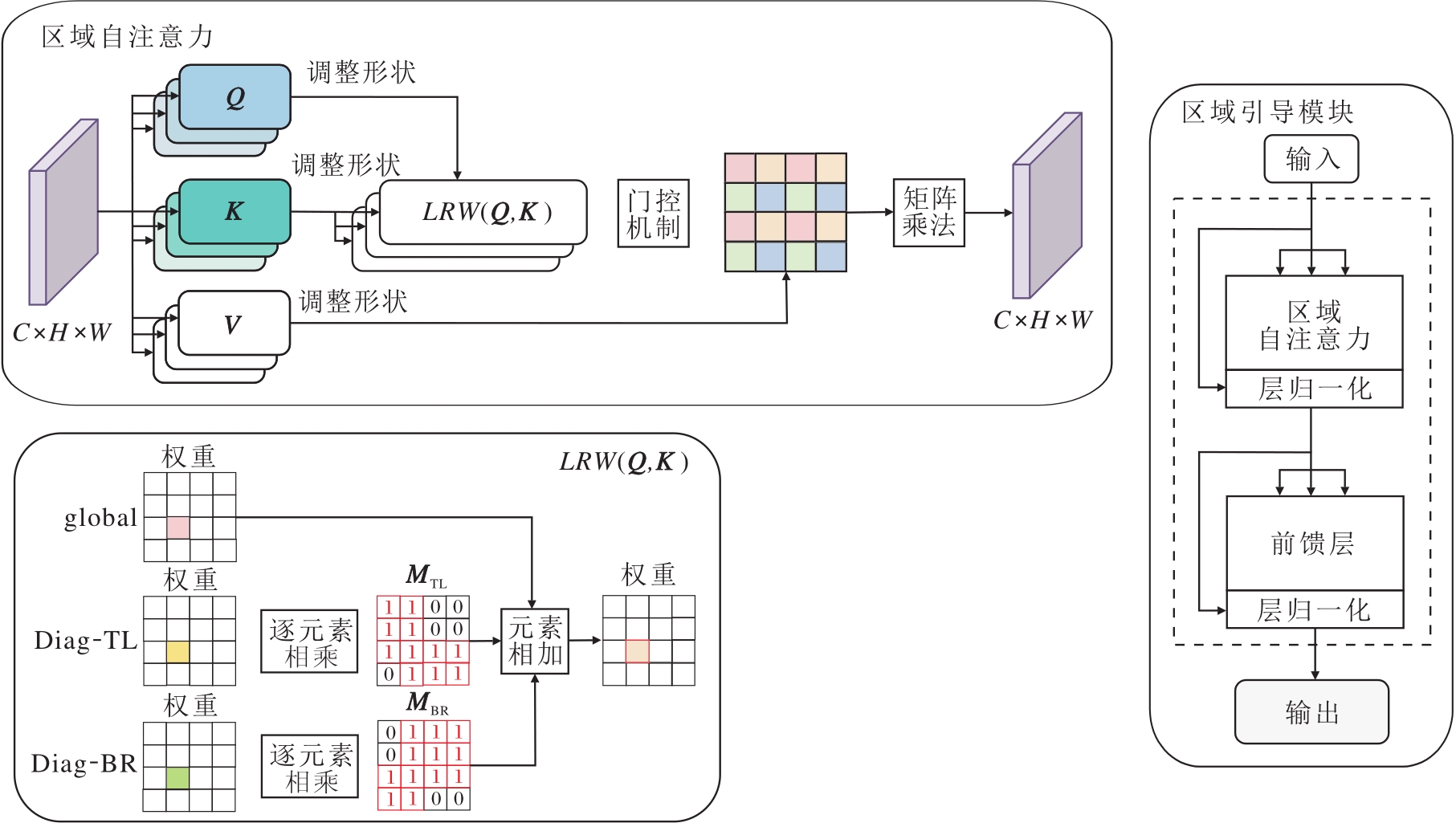 | 图2 RGM结构图Fig.2 Architecture of RGM |
对于第l个Transformer编码器层, l=1, 2, …, L, L表示编码器块的层数(本文设为4), 相应编码器的输出结果为:
Tl=LN(FFN(Hl)+Hl),
其中
Hl=LN(RSA(Tl-1)+Tl-1),
表示第l层编码器的隐层特征, T0表示人群图像经过特征融合模块提取的初始特征F, LN(· )表示层归一化操作.
RSA在注意力计算中引入掩码约束, 限定不同特征点的可关注范围, 避免对所有位置的无差别聚合.具体而言, RSA将注意力的候选范围划分为3个关注域:全局域(图2中global部分)、左上-右下对角区域(图2中Diag-TL部分)、右上-左下对角区域(图2中Diag-BR部分).RSA的输入由查询(Q)、键(K)和值(V)组成, 这些矩阵由上一层编码器的输出Tl-1经过线性变换得到, 即
Q=Tl-1WQ, K=Tl-1WK, V=Tl-1WV,
其中WQ、WK、WV表示可学习的权重矩阵.对任意查询位置u与键位置v, 定义两类区域掩码:
MTL(u, v)=Ⅱ ((xv-xu)(yv-yu)≥ 0),
MBR(u, v)=Ⅱ ((xv-xu)(yv-yu)≤ 0),
其中, Ⅱ (· )表示指示函数(若条件成立取1, 否则取0), (xu, yu)、(xv, yv)分别表示位置u、v在特征图上的坐标.掩码MTL关注特征左上区域和右下区域, 掩码MBR关注于特征左下区域和右上区域, 两者形成互补的对角子区域, 从而为区域交互引入结构化先验.各区域的注意力权重为:
$\begin{array}{l} \boldsymbol{W}_{\text {global }}=\boldsymbol{Q} \boldsymbol{K}^{\mathrm{T}}, \\ \boldsymbol{W}_{\mathrm{TL}}=\left(\boldsymbol{Q} \boldsymbol{K}^{\mathrm{T}} \boldsymbol{W}_{1}\right) \odot \boldsymbol{M}_{\mathrm{TL}}, \\ \boldsymbol{W}_{\mathrm{BR}}=\left(\boldsymbol{Q} \boldsymbol{K}^{\mathrm{T}} \boldsymbol{W}_{2}\right) \odot \boldsymbol{M}_{\mathrm{BR}}, \end{array}$
其中, W1、W2表示可学习的权重矩阵, ☉表示逐元素相乘.然后, 将不同区域的权重进行加权融合, 得到相应区域感知的注意力权重生成函数:
LRW(Q, K)=λgWglobal+λTLWTL+λBRWBR,
其中λg、λTL、λBR表示加权系数.
计算归一化注意力权重:
A=softmax(
其中1/
为了进一步抑制不可靠的区域交互, 引入门控网络, 对注意力权重进行动态筛选.门控网络通过两层卷积与ReLU非线性生成门控系数, 并经Sigmoid函数归一化至[0, 1]区间, 再与原注意力权重逐元素相乘, 得到输出:
G(A)=σ(Conv(ReLU(Conv(A))))☉A,
其中, σ(· )表示Sigmoid函数, Conv(· )表示卷积运算, ReLU(· )表示ReLU激活函数.最终, 区域自注意力的输出由经过门控网络后的注意力权重与V加权得到, 即
RSA(Tl-1)=G(A)V.
2.3.2 空间-通道上下文感知模块
在人群计数任务中, 远离摄像机的区域常出现与真实目标形态相似的背景物体(如路灯和广告牌), 这些易混淆区域容易导致方法出现误识别.虽然RGM能在区域层面引入更明确的关注范围, 但难以捕捉局部特征之间的空间关系, 因此在背景干扰较强时仍可能产生局部误激活.
为了缓解这一问题, 本文设计空间-通道上下文感知模块(SCCAM), 结合通道信息与空间分布特征, 突出人群相关的显著特征, 抑制背景相关的非显著特征, 提升对易混淆区域的判别能力.SCCAM结构如图3所示.
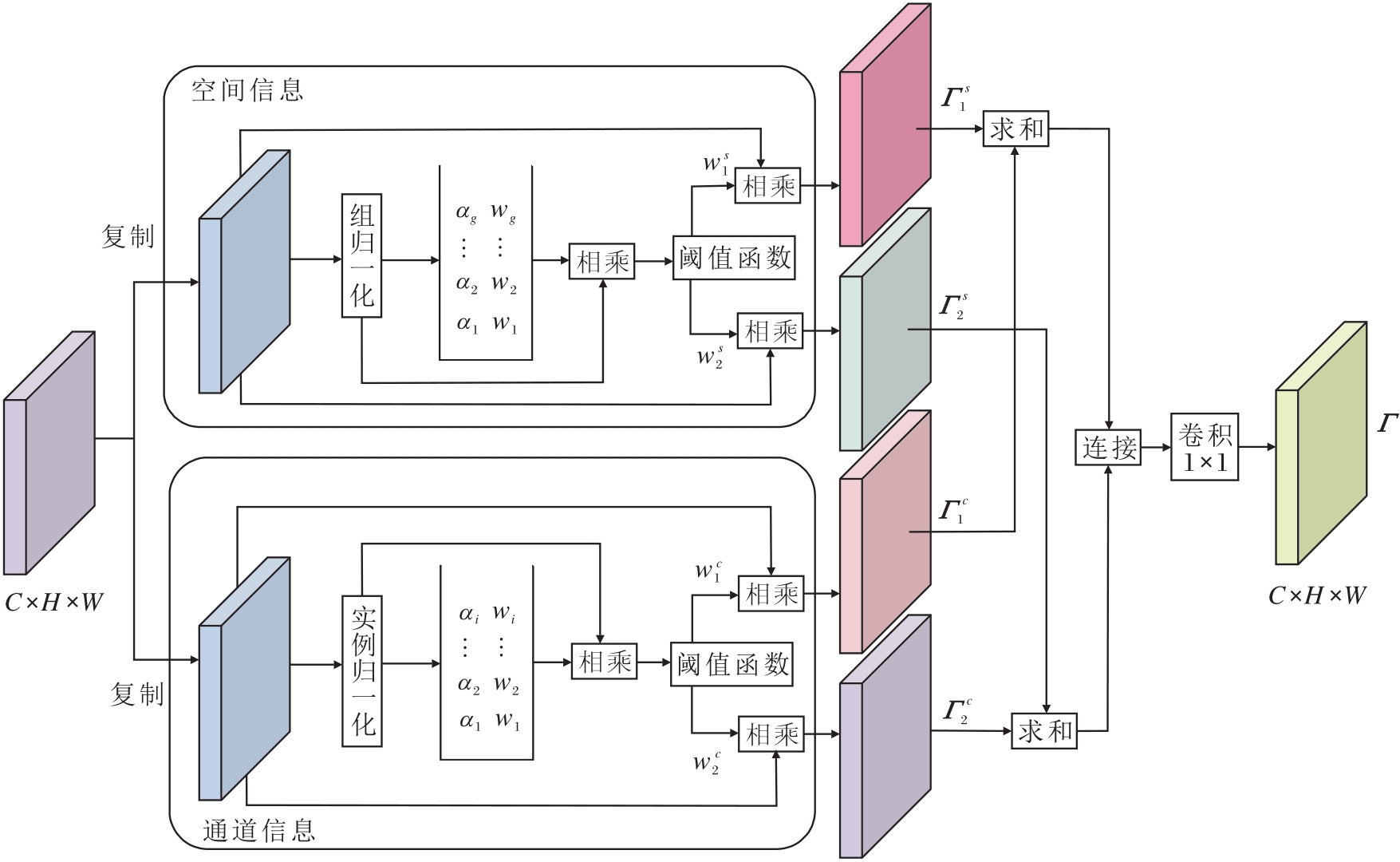 | 图3 SCCAM结构图Fig.3 Architecture of SCCAM |
SCCAM中输入特征x∈RC×H×W来自上一阶段的特征融合结果.为了实现对冗余特征的高效利用, 使用分组归一化(Group Normalization, GN)和实例归一化(Instance Normalization, IN), 分别从跨通道与单通道角度对特征进行标准化处理.GN将通道划分为若干组, 组内通道共享均值与标准差, 从而突出跨组的差异性.IN独立作用于单一通道的空间维度, 保留通道特有的信息模式.通过这种互补的归一化方式, 方法能更好地分离高信息量特征与稀疏特征, 增强整体特征表达能力.输入特征x经过GN处理的计算过程如下:
GN(x)=α(
其中, μ g、σg分别表示第g组特征的均值和标准差, ε表示一个趋近于0的常量, 避免分母为0, α、 β 表示可学习的参数, 分别用于控制缩放和偏移.
利用GN层中可训练的参数α度量各组特征的重要性, 得到跨组的权重系数ω , 则相应元素
ω i=
其中C表示特征组数量.权重越大表示该组特征在信息表达上重要性越高.再将归一化后的特征与归一化缩放因子进行逐元素相乘, 并经过Sigmoid映射, 得到重加权系数:
rs=σ(ω ☉GN(x)).
通过阈值τ(本文设置为0.5)对rs进行筛选, 将特征划分为显著分量和非显著分量.当rs> τ时, 该位置的信息量较强, 在
由此得到两路输出:
Γ
同样地, 使用IN处理输入特征, 得到基于独立通道的加权特征Γ
为了加强不同维度特征之间的信息交互, 将GN与IN得到的四路特征进行重构融合.首先对两路显著分支与两路非显著分支分别进行逐元素相加, 再在通道维度拼接, 并经过一个1×1大小卷积核的卷积, 得到最终结果:
Γ =conv1×1(Concat(Γ
其中, conv1×1(· )表示1×1卷积操作, Concat(· )表示拼接操作.
2.4 损失函数
和文献[27]一样, 使用欧氏距离衡量真实密度图与模型预测密度图之间的像素级差异:
L=
其中, N表示图像总数, D(xi)表示第i幅图像的预测结果, GTi表示其对应的真实密度图, ‖ · ‖ 2表示L2范数.然而, 这种像素级别的损失函数无法结合上下文信息去考虑密度分布.为了解决这个问题, 本文引入OT损失[23], 最小化模型预测与真实值之间的分布差距.OT损失定义如下:
LOT(e,
其中, < · > 表示内积运算, ψ * 、ζ * 表示待学习的权重向量, e表示真实密度图的向量化表示,
此外, 为了降低少量局部异常大误差对整体更新的主导影响, 在上述损失基础上进一步引入L1损失.最终, 总损失函数为:
Ltotal=λ1L+λ2LOT+λ3L1,
其中, λ1、λ2、λ3分别表示各损失项的权重, 本文设置λ1=0.5, λ2=0.1, λ3=0.5.
3 实验及结果分析
3.1 实验数据集
为了测试RCA性能, 选择在JHU-Crowd++[28]、ShanghaiTech[29]数据集上进行实验.
JHU-Crowd++数据集是一个规模庞大、内容丰富且极具挑战性的人群计数数据集, 包含4 372幅图像和一百多万条标注信息.训练集包含2 272幅图像, 验证集包含500幅图像, 测试集包含1 600幅图像.该数据集提供丰富的标注信息和各种环境条件下的人群图像, 主要体现因天气因素导致的图像退化和光照变化现象, 其中处于雨、雪和雾霾等复杂环境下的困难样本有514幅.人群数量分布跨度较大, 介于0~7 286之间, 适用于评估方法在复杂场景中的密度感知能力.
ShanghaiTech数据集包含A和B两个部分.A部分由300幅训练图像和182幅测试图像构成, 人群数量分布在33~3 139, 属于高密度的数据集.B部分由400幅训练图像和316幅测试图像组成, 人群数量在9~578, 是一个相对稀疏的数据集, 能评估方法在低密度场景中的判别能力.数据集涵盖多样化的场景和丰富的人群密度, 具有较高的挑战性.同时, 它也是人群计数任务中常用的基准数据集之一.
3.2 实验环境
实验中模型批次设为8, 学习率设为10-5, 采用Adam(Adaptive Moment Estimation)优化器进行参数更新, 同时将权重衰减系数设为10-5以防止过拟合.
此外, 注意到人群计数任务中的人群往往分布在图像的后半部分, 为了提高方法的泛化能力, 在数据预处理阶段加入随机翻转操作(概率p=0.5), 以此减少模型对特定方向偏好的依赖.
实验硬件平台基于Intel Xeon Gold 6230R处理器与NVIDIA GeForce RTX 4090显卡搭建, 软件环境采用Python 3.10编程环境和PyTorch 1.11.0深度学习框架.
本文采用平均绝对误差(Mean Absolute Error, MAE)和均方误差(Mean Squared Error, MSE)评估方法在特定场景中的计数性能.MAE和MSE值越小, 表示方法在计数任务中的误差越低, 预测结果越接近于真实值.这两项指标的计算公式如下:
MAE=
MSE=
其中, N表示图像总数,
3.3 真实密度图生成
首先, 使用狄拉克函数表示计数标签, 该函数具有如下数学性质.当x=0时, δ (x)=+∞ , 当x≠ 0时, δ (x)=0, 并且
假设像素xi处存在一个人, 对应标签
H(x)=
其中N表示图像中的人群总数量.
为了将该离散表示转换为连续的密度函数, 使用高斯核函数对其进行平滑处理, 得到的密度图定义如下:
F(x)=H(x)*
其中, * 表示卷积运算, xi表示第i个头的位置, δ (· )表示狄拉克函数,
3.4 对比实验
本文选择如下对比方法:KDMG(Kernel-Based Density Map Generation)[18]、AutoScale[19]、文献[20]方法、MLANet[21]、CSFNet[22]、文献[30]方法、文献[31]方法、TransCrowd[32]、DMCNet(Dynamic Mixture of Counter Network)[33].
3.4.1 定量对比
基于全监督学习的框架, 在3个基准数据集上对比各方法的性能, 结果如表1所示, 表中黑体数字表示最优值, 斜体数字表示次优值.由表可见, RCA在3个数据集上均取得较优值, 尤其是在Shanghai-Tech B、JHU-Crowd++数据集上, 取得最优值.
| 表1 各方法在3个数据集上的指标值对比 Table 1 Metric value comparison of different methods on 3 datasets |
ShanghaiTech A数据集的主要难点在于强透视效应带来的远近尺度差异, 且高密度区域呈现更尖锐的密度峰值分布.DMCNet在网络末端引入专家混合机制, 能在不同密度模式之间自适应选择更合适的回归分支, 从而在密度突变场景中更有效缓解回归不稳定性问题.然而, RCA对透视导致的尺度偏差仍主要依赖特征自学习, 缺少更直接的密度校准环节, 这一点仍有提升空间.
ShanghaiTech B数据集以中低密度街景为主, 常见情形是局部人群聚集与大面积空旷区域同时出现.DMCNet在ShanghaiTech B数据集上的效果相对退化, 说明仅依赖面向密度分段的动态回归选择, 并不能有效抑制空旷区域的虚假激活.以多尺度融合或注意力增强为主的方案(如MLANet、CSFNet)能在一定程度上缓解尺度变化问题, 并提升上下文表达能力, 但其跨区域信息聚合通常缺少明确的结构化约束, 容易引入冗余信息.相比之下, SCCAM把特征划分为显著分量与非显著分量, 使RCA更倾向于保留与人群相关的高置信响应, 同时, 配合RGM, 帮助RCA把输出收敛到少量真实人群区域.
在JHU-Crowd++数据集上, RCA取得最优值.该数据集上跨场景差异更明显, 复杂背景样本更多, 高密度遮挡让局部纹理不可靠, 在场景变化时更容易出现误识别.KDMG主要从监督端入手, 通过改进密度图生成方式提升回归稳定性.DMCNet更强调在密度突变时进行动态混合分配.这两类策略分别缓解监督形态或密度自适应中的部分问题, 但并不直接针对前景和背景进行区分.本文通过RGM在区域层面限制不必要的跨区域交互, 再使用SCCAM从空间维度与通道维度强化人群相关响应、抑制背景响应, 因此在这种高密度且背景复杂场景中优势更明显.
3.4.2 可视化分析
本节中的可视化结果均采用相同的子图布局, 其中预测图像与输入图像的叠加可视化结果用于展示预测结果与人群分布之间的对应关系.
RCA在ShanghaiTech A数据集上的可视化结果如图4所示.由图可看出, RCA能准确反映图像中人群的空间分布, 即使存在遮挡, 仍能提取有效的人群信息.
 | 图4 RCA在ShanghaiTech A数据集上的可视化结果Fig.4 Visualization results of RCA on ShanghaiTech A dataset |
RCA在ShanghaiTech B数据集上的可视化结果如图5所示.由图可见, 在人群稀疏的场景中, RCA仍能准确识别行人, 并避免受到背景信息的干扰.RCA利用由双分支结构提取的上下文信息, 既能适应不同密度场景中的预测问题, 又能减少背景干扰对结果影响, 从而在空旷区域有效抑制虚假响应.
 | 图5 RCA在ShanghaiTech B数据集上的可视化结果Fig.5 Visualization results of RCA on ShanghaiTech B dataset |
RCA在JHU-Crowd++数据集上的可视化结果如图6所示.由图可观察到, 该数据集上图像密度分布呈现明显的两极分化趋势, 既包含低密度的空旷区域, 也包含高密度的拥挤区域, 这一特性对方法的尺度适应和密度适应能力提出更高要求.通过RGM和SCCAM, RCA能有效利用区域上下文信息并抑制背景干扰, 从而在该数据集上获得更准确的计数结果.
 | 图6 RCA在JHU-Crowd++数据集上的可视化结果Fig.6 Visualization results of RCA on JHU-Crowd++ dataset |
3.5 消融实验
本节旨在研究各模块对RCA性能的影响, 在JHU-Crowd++数据集上进行消融实验, 结果如表2所示.
| 表2 各模块的消融实验结果 Table 2 Ablation experiment results of each module |
由表2可看出, RGM和SCCAM均能提升RCA预测结果, 当两者同时使用时, 性能获得显著提升, 能更好地完成在密集场景中的人群计数任务.
进一步对比不同损失组合对训练效果的影响.选择如下损失.
1)欧几里得损失:LE=λ1L.
2)在此基础上加入L1损失:L2=λ1L+λ3L1.
3)进一步加入OT损失以优化密度图的生成:
L3=λ1L+λ2LOT+λ3L1.
相应消融实验结果如表3所示.由表可见, 引入OT损失之后, RCA能在更大程度上学习真实密度图的分布, 进一步提升RCA的预测性能.
| 表3 不同损失函数的消融实验结果 Table 3 Ablation experiment results of different loss functions |
最后, 进一步对双分支输出的融合策略进行消融实验, 构建如下3种变体.
1)采用文献[12]中的跨分支注意力融合方式, 对卷积分支与Transformer分支特征进行选择性交互后再聚合.
2)采用CTASNet[13]的密度引导自适应选择融合策略, 根据局部密度信息对两分支输出进行动态加权组合.
3)本文的线性融合方案, 先通过1×1卷积完成通道对齐, 再进行逐元素相加, 得到最终融合特征.
相应消融实验结果如表4所示.由表可看出, 跨分支注意力融合方式在MAE与MSE上均未带来有效收益, 整体性能反而略有下降.密度引导自适应选择融合策略虽然在MSE上取得一定优势, 但引入额外的权重预测与动态选择过程, 增加融合模块的开销, 在MAE指标上仍弱于线性融合方案.因此, 本文最终采用更简洁稳定的线性融合策略.
| 表4 不同特征策略的消融实验结果 Table 4 Ablation experiment results of different feature fusion strategies |
4 结束语
面向复杂场景中人群密度分布不均、尺度变化显著及背景干扰较强等问题, 本文提出基于区域上下文感知的人群计数方法(RCA), 包含区域引导模块(RGM)和空间-通道上下文感知模块(SCCAM).RGM在区域层面建立上下文先验, SCCAM在空间维度与通道维度实现特征交互, 有效增强方法对前景与背景的区分能力.此外, 本文使用联合损失, 在像素级误差约束的基础上, 进一步从分布层面优化预测密度图, 从整体上提升密度估计的准确性.实验表明, RCA的MAE和MSE指标较优, 能较好兼顾局部细节建模与全局上下文表达.由于目前模型训练仍依赖高质量标注, 因此后续工作将探索弱监督与半监督的人群计数框架, 减少对精细标注数据的依赖, 从而降低人力成本.
本文责任编委 杨 健
Recommended by Associate Editor YANG Jian
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|