


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
强化用户语义表示的多模态推荐方法
引用本文
许昊, 夏鸿斌, 王晓锋. 强化用户语义表示的多模态推荐方法. 模式识别与人工智能, 2025,38(12): 1121-1134
XU Hao, XIA Hongbin, WANG Xiaofeng. Multimodal Recommendation with User Semantic Embedding Refinement. PATTERN RECOGNITION AND ARTIFICIAL INTELLIGENCE, 2025,38(12): 1121-1134.
Doi: 10.16451/j.cnki.issn1003-6059.202512005
XU Hao, XIA Hongbin, WANG Xiaofeng. Multimodal Recommendation with User Semantic Embedding Refinement. PATTERN RECOGNITION AND ARTIFICIAL INTELLIGENCE, 2025,38(12): 1121-1134.
Permissions
Copyright©2025, 《模式识别与人工智能》编辑部
《模式识别与人工智能》编辑部
强化用户语义表示的多模态推荐方法

夏鸿斌,博士,教授,主要研究方向为个性化推荐、自然语言处理、计算机网络.E-mail:hbxia@163.com.
作者简介:

许 昊,硕士研究生,主要研究方向为推荐系统、深度学习.E-mail:xh201266@live.com.

王晓锋,博士,教授,主要研究方向为计算机网络.E-mail:wangxf@pcl.ac.cn.
摘要
现有的多模态推荐方法通常分别提取图像、文本等模态特征并在训练阶段进行浅层融合,难以充分挖掘跨模态语义.此外,主流方法多采用随机初始化的用户表示,容易导致用户表示区分度不足.为此,文中提出强化用户语义表示的多模态推荐方法(Multimodal Recommendation with User Semantic Embedding Refinement, USERec),分别从物品角度和用户角度缓解现有问题.在物品侧,利用多模态大语言模型,以物品的文本模态指导视觉模态特征提取,实现深度语义融合,获得更适用于推荐任务的物品表示.在用户侧,为用户表示引入位置编码,增强用户索引空间的频谱多样性,并结合度敏感剪枝构建个性化局部图,再通过随机采样注意力机制补充用户的全局感知,增强用户表示的区分度.在4个真实数据集上的实验表明USERec的有效性.
关键词:
多模态推荐; 图卷积网络; 模态融合; 多模态大语言模型
中图分类号:TP391
Multimodal Recommendation with User Semantic Embedding Refinement
XIA Hongbin, Ph.D., professor. His research interests include personalized recommendation, natural language processing, and computer networks.
About Author:
XU Hao, Master student. His research interests include recommendation systems and deep learning.
WANG Xiaofeng, Ph.D., professor. His research interests include computer networks.
Abstract
Existing multimodal recommendation methods typically extract features of the different modalities separately, such as images and texts, and only shallow fusion is performed during training. Therefore, it is difficult to fully explore cross-modal semantics. Moreover, mainstream methods mostly adopt randomly initialized user representations, resulting in insufficient discriminability among users. To address these issues, a multimodal recommendation method with user semantic embedding refinement(USERec) is proposed in this paper. The problems are alleviated from the perspectives of both the item and the user. On the item side, a multimodal large language model is utilized to achieve deep semantic fusion by guiding visual feature extraction with textual information. Thus, more suitable item representations for recommendation tasks can be obtained. On the user side, positional encoding is introduced into user representations to enhance the spectral diversity of the user index space. Personalized local graphs are then constructed through degree-sensitive pruning, and the global awareness of users is augmented via a randomly sampled attention mechanism, thereby improving the discriminability of user representations. Experiments on four real-world datasets verify the effectiveness of USERec.
Key words:
Key Words Multimodal Recommendation; Graph Convolutional Network; Modality Fusion; Multimodal Large Language Model
推荐系统是缓解信息过载的有效手段之一[1, 2].随着多媒体内容的爆炸式增长, 推荐系统不再仅依赖用户历史行为或单一模态特征, 而是越来越多地利用文本、图像等多模态信息提升推荐性能[3].多模态推荐的优势在于不同模态之间的互补性可帮助缓解数据稀疏问题, 并更好地刻画用户的多维度个性化兴趣偏好[4].近年来, 多模态推荐系统逐渐成为学术界和工业界的研究热点之一.
早期的多模态推荐方法通常将多模态内容作为辅助特征, 融入协同过滤框架中[3].VBPR(Visual Bayesian Personalized Ranking)[5]是这一领域的开创性工作, 它将视觉特征融入矩阵分解中.后续研究则将图神经网络(Graph Neural Networks, GNNs)扩展到多模态学习[2].Wei等[4]提出MMGCN(Multi-modal Graph Convolution Network), 构建特定于模态的用户-物品图, 并通过消息传递机制学习用户表示和物品表示.Wang等[6]提出DualGNN(Dual Graph Neural Network), 引入模态感知注意力和用户-用户图, 解决模态不完整问题.
近期的研究进展主要集中在图优化方面.Zhang等[7]提出LATTICE(Latent Structure Mining Method for Multimodal Recommendation), 使用每个模态的物品-物品图, 基于k近邻的稀疏化方法建模语义物品关系并增强物品表示.Zhou等[8]提出FREEDOM(Freezing and Denoising Multimodal Model for Reco-mmendation), 采用冻结的物品-物品图和度敏感剪枝, 提高多模态推荐的准确性并减少内存使用.Tao等[9]提出SLMRec(Self-Supervised Learning-Guided Multimedia Recommendation), 将自监督学习任务整合至图神经网络中, 用于揭示多模态的潜在模式, 从而学习强大的表征.Zhou等[10]提出BM3(Boot-strapped Multi-modal Model), 采用随机失活机制代替图增强, 生成对比视图, 简化自监督多模态推荐方法.Yu等[11]提出MGCN(Multi-view Graph Convo-lutional Network), 利用行为信息对模态特征进行去噪, 并通过用户行为建模用户的模态偏好.Zhou等[12]提出DRAGON(Dual Representations of Both Users and Items via Constructing Homogeneous Graphs for Multi-modal Recommendation), 通过协同学习用户-用户图和物品-物品图, 进行双重表示学习.Jiang等[13]提出DiffMM(Multi-modal Graph Diffusion Model for Recommendation), 整合扩散模型和跨模态对比学习, 解决数据稀疏性问题.Su等[14]提出SOIL(Second-Order Interest Learning), 引入二阶兴趣, 增强用户-物品图, 并根据用户偏好构建兴趣感知的物品-物品图.Xu等[15]提出COHESION(Composite Graph Convolutional Network with Dual-Stage Fu-sion), 结合双阶段融合策略与复合图卷积网络, 并配合自适应优化, 有效缓解多模态推荐中的噪声干扰.
最新的工作开始尝试脱离对于ID嵌入的依赖.Yu等[16]提出PGL(Principal Graph Learning), 引入主图学习框架, 直接使用模态特征初始化物品表示, 有效捕获个体信息.Li等[17]提出IDFREE(ID-Free Multimodal Collaborative Filtering Recommendation), 以多模态特征和位置编码替代ID嵌入, 并通过自适应相似图与增强图编码实现对现有基于ID嵌入方法性能的显著超越.
此外, 现有工作多将通用预训练模型作为提取器以分别获得不同模态的特征, 再在模型训练过程中通过直接相加、拼接、平均池化、最大池化或注意力机制等操作融合不同的模态信息[8, 11, 12].近期的一些工作还尝试使用快速傅里叶变换、二维离散余弦变换等较复杂的方法生成融合模态特征表示[18, 19], 或是将ID特征也视为一种独立模态, 使其能在训练中学习来自多种模态的融合表示[15].
随着多模态模型与大语言模型相关研究的进展, 也有工作开始利用多模态技术和大语言模型增强推荐系统的性能.Wu等[20]提出CLIPER(CLIP Enhanced Recommender), 使用CLIP(Contrastive Language-Image Pre-training)替换常用的VGG(Vi-sual Geometry Group)和Sentence-Transformer, 完成图像模态和文本模态的特征提取, 从而利用原生的多模态模型将不同模态特征直接映射到相同的语义空间之中.Zhou等[19]提出LIRDRec(Learning Item Representations Directly from Multimodal Features for Recommendation), 使用多模态大语言模型(Multi-modal Large Language Model, MLLM)对图像进行描述, 生成文本, 再使用大语言模型从MLLM生成的文本描述和数据集原有的文本描述中提取物品表示.Pomo等[21]提出LVLMs(Large Vision Language Models), 将图像与固定的提示词输入MLLM, 并从模型的最后一个隐藏层提取表示嵌入.
尽管现有方法已取得显著进展, 但仍存在如下问题:跨模态语义融合不充分、用户表示区分度不足.对于跨模态语义融合不充分问题, 主流范式普遍遵循独立提取不同模态并在后期融合的路径, 难以充分挖掘深层次的跨模态语义关联, 且容易受到原始模态噪声干扰.基于多模态大语言模型的方法也尚未在特征提取层面实现深度的语义引导与对齐.对于用户表示区分度不足的问题, 绝大多数方法仍依赖随机初始化生成用户表示, 在交互稀疏的场景中表示向量难以得到充分训练以形成足够的区分度, 导致用户表示趋同.
值得注意的是, 这两者并非相互独立.主流“ 独立提取并在后期融合” 的范式往往只能获得浅层跨模态对齐, 使物品表示在语义空间中的丰富性与独特性不足.由于用户向量通常仅由稀疏交互信号监督, 当物品侧语义表达存在弱区分时, 交互监督对用户向量的差异化驱动被削弱, 导致用户表示更容易出现坍缩与趋同.用户表示趋同又会降低模型对个体化模态偏好与跨模态关联的刻画能力, 使融合机制进一步退化为粗粒度加权, 反向加剧浅层融合问题, 形成恶性循环.
针对上述问题, 本文提出强化用户语义表示的多模态推荐方法(Multimodal Recommendation with User Semantic Embedding Refinement, USERec), 从物品侧语义深度融合与用户侧区分度提升两个角度缓解现有方法存在的缺陷.在模态特征提取阶段, 设计文本特征指导的融合视觉模态特征提取模块, 将物品的文本描述作为提示词的一部分, 指导MLLM提取具有高层语义信息的融合视觉物品特征.在训练阶段, 构建用户表示增强的个性化局部图学习模块, 在用户表示中引入位置编码, 增加不同用户表示间的初始区分度, 并使用度敏感剪枝, 从完整用户-物品交互图中提取个性化局部子图, 用于模型训练.最后, 采用基于随机采样注意力的用户表示增强模块感知全局物品信息.在4个真实数据集上的实验表明, USERec在多个主流评估指标上取得较优值.
1 强化用户语义表示的多模态推荐方法
本节提出强化用户语义表示的多模态推荐方法(USERec), 结构如图1所示.
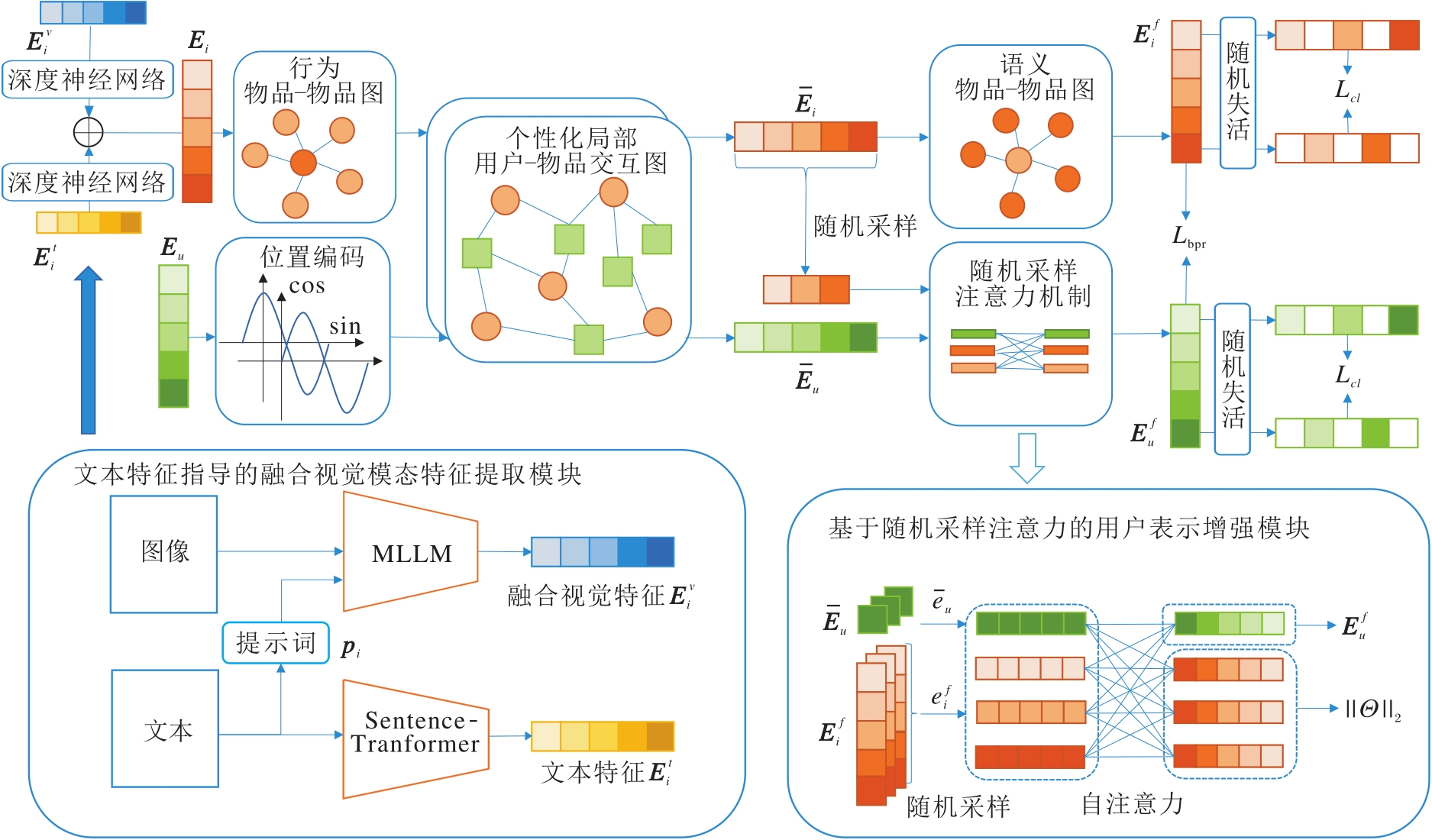 | 图1 USERec结构图Fig.1 Structure of USERec |
1.1 符号定义
多模态推荐使用多种模态信息, 如图像和文本, 以此完成推荐任务.首先, 给出如下符号定义.u∈U表示用户, i∈I表示物品.对于物品, 使用多种模态M表示, 本文主要使用图像v和文本t的模态, 因此M={v, t}.
Ε={(u, i)|u∈U, i∈I, rui=1},
表示边集合.多模态推荐系统的目的是依据已有的用户物品交互和多模态特征预测用户对于物品喜好程度的分数
1.2 文本特征指导的融合视觉模态特征提取模块
现有研究通常在推荐任务中对文本与图像采用独立的编码器进行特征提取, 再通过拼接、加权或注意力机制实现模态融合[3, 12].然而, 这类方法不仅在模态对齐阶段增加额外的复杂性, 还容易受到图像噪声的干扰, 导致提取的视觉特征与推荐任务的语义相关性不足.为此, 本文设计文本特征指导的融合视觉模态特征提取模块, 充分利用MLLM的统一建模能力[19], 在特征提取阶段直接实现语义层面的融合.
对于每个物品i, 本文将其文本信息(包括标题、描述、价格、品牌等)组织成如下格式的提示词pi.
Please provide a detailed and comprehensive multi-di-mensional analysis and description of the following product content and product image:
product description: The title is [Title]. The detailed description is [Description]. The price is [Price]. The brand is [Brand].
You are an intelligent assistant designed to analyze product information from the Amazon dataset and provide comprehensive insights that can be used for recommendation optimization. Please systematically evaluate the given product content (including title, image, description, price, brand, etc.) .
Please provide a profile of the customers you think will purchase this product, and let me know which other products the customers who purchased this product will also buy.
Please ensure your analysis is comprehensive, specific, and insightful, providing sufficiently detailed descriptions for each dimension.
请对以下产品内容和产品图片进行详细且全面的多维度分析与描述:
产品描述:标题为[Title], 详情描述为[Description], 价格为[Price], 品牌为[Brand].
你是一个智能助手, 专门用于分析亚马逊数据集中的产品信息, 并提供可用于优化推荐系统的全面洞察.请系统性地评估所提供的产品内容(包括标题、图片、描述、价格、品牌等).
请提供你认为会购买该产品的用户画像, 并指出购买该产品的用户还可能购买哪些其他产品.
请确保你的分析全面、具体且具有洞察力, 对每个维度都提供足够详细的描述.
然后, 将提示词pi与对应的物品图像xi作为联合输入, 隐藏层输出的特征序列为:
Hi=fMLLM(pi, xi)∈
其中, fMLLM(· )表示多模态大语言模型, T表示输入序列的词元(Token)数, dl表示MLLM隐藏层维度.
在实践中, 本文取模型倒数第2个隐藏层的状态
zi=
最后, 对zi进行L2归一化, 得到归一化后单个物品的融合视觉模态特征向量:
$\overline{\boldsymbol{e}}_{i}^{v}=\frac{\boldsymbol{z}_{i}}{\left\|\boldsymbol{z}_{i}\right\|_{2}} \in \mathbf{R}^{d_{l}} .$
由此, 可得到融合视觉模态的全体物品特征向量
总之, 文本特征指导的融合视觉模态特征提取模块是将物品的文本描述信息作为提示词的一部分与图像一同送入MLLM, 让大模型不仅仅只是对图像内容进行简单描述, 而是在描述文本的指导下从图像内容中提取与推荐任务最相关的语义信息, 从而实现在模型训练前完成不同模态在自然语义层面的融合.
1.3 用户表示增强的个性化局部图学习模块
1.3.1 个性化局部用户-物品交互图
为了缓解图卷积网络(Graph Convolution Net-work, GCN)过平滑问题, 避免让节点表征过于相似, 同时减轻GCN在训练过程中受到的无效样本对和有害样本对的影响[23], 受FREEDOM[8]和PGL[16]的启发, 首先使用度敏感剪枝, 从用户-物品交互图中提取个性化局部交互子图.
给定的用户-物品交互矩阵R, 先构造对称邻接矩阵:
A=
若用户u与物品i发生交互, aui=1, 否则aui=0.为了突出局部的个性化兴趣模式, 基于节点度的大小对边进行有偏采样.对于一条连接节点i、 j的边ek∈Ε, 定义其采样概率:
pk=
其中ω i、ω j分别表示节点i、 j的度.该概率分布使得高频节点的边被采样的概率更低, 也就是说高频节点的边更容易被剪除, 而低频节点的边更可能被保留, 从而在子图中强化长尾用户和冷门物品的个性化信号.在给定剪枝比例ρ p的情况下, 从原始边集合Ε中保留n=「ρ p|Ε|⌉条边.具体做法是根据概率向量p={p0, p1, …, p|E|-1}从多项分布中采样n条边, 得到稀疏化的邻接矩阵Aρ .对Aρ 进行归一化, 得到归一化后的邻接矩阵:
其中D表示Aρ 的度矩阵.值得注意的是, 本文仅在训练阶段使用个性化局部子图, 而在推理阶段使用完整的用户-物品交互图, 以此充分利用全局交互信息[16].
1.3.2 基于位置编码的用户表示初始化
为了增强用户表征的可区分性与稳定性, 受先前工作[17, 24]的启发, 对用户侧嵌入引入绝对正弦-余弦位置编码.首先, 为每位用户u∈{0, 1, …, |U|-1}构造随机初始化的可训练用户嵌入向量eu∈
$\begin{array}{l} P E(u, 2 j)=\sin \left(u \cdot 10000^{-2 j / d_{u}}\right), \\ P E(u, 2 j+1)=\cos \left(u \cdot 10000^{-2 j / d_{u}}\right), \end{array}$
其中 j=0, 1, …,
pu= [PE(u, 0), PE(u, 1), …, PE(u, du-1)]∈
因此, 用户u的初始表示:
最终得到全体用户初始表示
值得注意的是, 与IDFREE[17]在用户侧和物品侧都引入位置编码不同, 本文仅将位置编码引入随机初始化的用户表示中, 而在物品侧依然使用预先提取的多模态特征以构造物品表示.在实验中发现在物品侧引入位置编码会造成一定程度的性能下降, 本文推测这是因为应用多模态特征构造的物品表示已拥有较好的区分度, 而位置编码的引入会破坏原始的模态特征分布.通过在用户侧引入位置编码可增强用户索引空间的频谱多样性, 有利于后续图传播与记忆检索对用户语义邻域的区分.
1.3.3 用户行为物品-物品图
本文利用多模态特征构造物品的表示向量.首先, 通过独立的全连接层, 将不同模态特征映射到相同的维度dh, 即
其中Wv、Wt、bv、bt表示可训练参数.然后拼接不同模态的表示得到完整的物品表示:
Ei=[
为了充分利用用户行为反馈信息, 受DA-MRS(De-noising and Aligning Multi-modal Recommender Sys-tem)[25]的启发, 构造用户行为物品-物品图Su.因为被同位用户交互过的两个物品很可能在语义上也存在一定的关联性, 因此将Su的每个元素
通过图卷积对项目邻域信息进行聚合, 提取物品间的行为关联, 定义
则第l层图卷积为:
由此得到初始物品表示嵌入:
其中Hiu表示经过n层图卷积后得到的聚合物品表示.
1.3.4 多视角异构图学习
遵循先前工作[8, 11, 17], 本文使用LightGCN[26]在用户-物品图上进行图卷积.首先, 构造初始嵌入:
E(0)=
其中
在训练阶段, 使用1.3.1节中构造的个性化局部子图
E(l+1)=
为了缓解过平滑问题, 采用层平均聚合策略, 得到平均嵌入:
切分
和先前工作[11, 12, 16]一样, 本文也基于模态特征的相似度分别构造不同模态的物品相似度矩阵Sv和St, 并使用k近邻稀疏化构造稀疏的物品相似度矩阵
其中
则第l层图卷积为:
从而获得最终增强的物品表示嵌入:
其中Him表示经过n层图卷积后得到的增强物品表示.
1.4 基于随机采样注意力的用户表示增强模块
传统的图神经网络在传播时依赖局部邻居的消息聚合, 感受野由传播层数(即跳数K)决定.现有研究为了避免过平滑问题, K值通常被设置得较小(常为1或2), 这就限制模型捕获全局结构信息的能力[27], 而度敏感剪枝强调局部个性化表示的特性也会弱化用户嵌入对于全局信息的感知.为了缓解这一问题, 在文献[27]的启发下, 设计随机采样注意力机制, 在不加剧过平滑问题的前提下, 增加用户表示对于全局物品信息的感知.
首先, 对于每位用户u, 从全体物品表示嵌入
Gu=
再构造查询矩阵、键矩阵、值矩阵:
Qu=GuWQ, Ku=GuWK, Vu=Ku,
其中, WQ∈
Au=softmax(
为了稳定训练并控制注意力更新幅度, 采用加权残差, 得到改进后的上下文表征:
其中αt表示可调节的超参数.最后, 取出
将其与原有用户表示相加, 获得最终的用户表示:
e
通过上述过程, 可得到所有用户的增强表示嵌入
1.5 模型优化与预测
通过上述流程, 可获得每位用户的表示向量e
得分越高表示用户越有可能对该物品感兴趣.
本文采用BPR(Bayesian Personalized Ranking)损失[28]优化模型参数.构建三元组集合
R={(u, i, j)|(u, i)∈Ε, (u, j)∉Ε},
每个三元组(u, i, j)包括用户u、用户交互过的正样本物品i、随机采样得到的负样本物品j, 相应BPR损失函数如下:
Lbpr=
其中σ(· )表示Sigmoid激活函数,
遵循先前工作[16, 29], 使用对比学习方法增强用户表示和物品表示.在训练过程中, 首先使用随机失活(Dropout)对最终的用户表示和物品表示进行特征变换:
$\begin{array}{l} \boldsymbol{e}_{u}^{\prime}, \boldsymbol{e}_{u}^{\prime \prime}=\operatorname{Dropout}\left(\boldsymbol{e}_{u}^{f}, \rho_{d}\right), \\ \boldsymbol{e}_{i}^{\prime}, \boldsymbol{e}_{i}^{\prime \prime}=\operatorname{Dropout}\left(\boldsymbol{e}_{i}^{f}, \rho_{d}\right), \end{array}$
其中ρ d表示随机失活比例.然后, 使用InfoNCE(Information Noise Contrastive Estimation)损失最大化不同特征变化后表示间的一致性:
Lcl=
其中, τ表示温度超参数, 依据文献[16], 设置τ=0.2.最终, 整个流程的目标函数如下:
L=Lbpr+λclLcl+λreg‖ Θ ‖ 2,
其中, Θ 表示模型中所有的可学习参数, λcl表示控制对比学习强度的超参数, λreg表示用于控制正则化权重的超参数.
2 实验及结果分析
2.1 实验环境
本文采用在多模态推荐领域广泛使用的亚马逊数据集[30], 并选择亚马逊数据集上较常用的4个子集:Baby, Sports and Outdoors(简称Sports), Clothing, Shoes and Jewelry(简称Clothing)和Electronics(简称Elec).数据集包含用户与商品的交互记录以及商品的文本信息与图像信息.数据经过5次交互过滤处理, 确保每位用户或每个项目至少与5个交互关联.使用预训练的Sentence-Transformers从数据集的文本描述中提取维度为384的文本特征, 使用预训练的多模态大语言模型MiMo-VL-7B-RL[31]提取融合图像特征并通过PCA将提取的特征维度降至768.数据集相应数据如表1所示, 表中密度计算如下:
密度=
| 表1 实验数据集 Table 1 Experimental datasets |
为了公平对比不同方法性能的差异, 采用Top-K推荐评估指标:召回率(Recall@K)和NDCG@K(Normalized Discounted Cumulative Gain), K设定为10和20.对于每个数据集, 将每位用户的交互序列以8∶ 1∶ 1的比例拆分为训练集、验证集和测试集.求取各测试集上所有用户指标的平均值以评估方法性能.
2.2 参数设置
本文使用PyTorch并基于MMRec[32]框架实现USERec以及对比方法.MMRec是一个用于复现和开发推荐算法的开源框架.为了确保实验的公平性, 使用文献[33]方法对所有方法的嵌入参数进行初始化, 并选取Adam(Adaptive Moment Estimation)作为优化器, 所有多模态方法的用户嵌入维度和物品嵌入维度都设定为64, 批次大小设为2 048.对于所有对比方法, 都使用其原文献中的最佳性能, 而对于原文献中未出现的数据集, 则采用本文在复现实验中取得的最优值.
为了减少实验的复杂度, 依据先前工作[9, 26]将用户-物品图和物品-物品图的卷积层数分别固定为2和1, 学习率固定为0.001.在实验中将最大迭代次数设为1 000, 早停步数设为20.
所有的实验均使用拥有24 GB显存的NVIDIA RTX 4090D GPU完成.
2.3 对比实验
为了验证USERec的有效性, 选择9个最新或最有代表性的基线方法进行对比, 包括2种经典协同过滤方法和7种多模态方法.
1)经典协同过滤方法.
(1)LightGCN[26].简化经典GCN的结构, 移除激活函数, 只保留适用于协同过滤的聚合操作.
(2)BPR-MF(BPR from Implicit Feedback)[28].利用贝叶斯个性化排名损失, 优化基于矩阵分解的推荐方法.
2)多模态方法.
(1)LATTICE[7].为每个模态构建物品-物品图, 描述物品间的语义关系, 并利用KNN进行稀疏化, 增强物品表示.
(2)FREEDOM[8].使用冻结的物品-物品图, 并提出基于度敏感的边修剪方法, 对用户-物品图去噪, 在提升多模态推荐精度的同时大幅降低内存消耗.
(3)MGCN[11].利用行为信息对模态特征进行去噪, 并通过用户行为建模用户的模态偏好.
(4)COHESION[15].结合双阶段融合策略与复合图卷积网络, 并配合自适应优化, 有效缓解多模态推荐中的噪声干扰, 显著提升表示学习能力和推荐性能.
(5)PGL[16].设计主图学习框架, 有效挖掘和利用主体局部结构特征捕获个体信息, 提升多媒体推荐性能.
(6)IDFREE[17].首个真正不依赖ID嵌入的多模态协同过滤推荐方法, 以多模态特征和位置编码替代ID特征, 并通过自适应相似图与增强图编码实现对现有基于ID嵌入方法的显著超越.
(7)LGMRec(Local and Global Graph Learning-Guided Multimodal Recommender)[34].通过解耦的局部图嵌入和全局超图嵌入联合建模用户的局部兴趣和全局兴趣, 提升推荐的准确性和鲁棒性.
各方法在4个数据集上的指标值如表2所示, 表中黑体数字表示最优值, 斜体数字表示次优值, -表示该方法在该数据集上训练所需的显存超过24 GB, 无法完成训练.为了确保实验的公平性, COHESION、PGL在Elec数据集上的结果为本文训练得到, 其它结果引自文献[35]或对比方法的原文献.
| 表2 各方法在4个数据集上的指标值对比 Table 2 Metric value comparison of different methods on 4 datasets |
由表2可见, USERec在4个数据集上的性能均最优.相比IDFREE, USERec的Recall@20指标在Baby、Sports、Clothing数据集上分别提升15.77%、17.34%、26.03%, 这验证USERec在多模态推荐任务上的有效性.USERec首先利用MLLM提取多种模态特征中的跨模态高层次语义信息.然后使用位置编码和度敏感剪枝增强用户表示间的个性化区分度, 并缓解图卷积过程中的过平滑问题, 通过用户交互行为构造物品-物品图, 将用户行为信息注入物品表示之中.最后, 采用随机采样注意力机制提升用户对于全局物品的感知, 进一步增强用户表示的独特性.
相比传统基于矩阵分解的推荐方法(BPR-MF), 基于图神经网络的方法(LightGCN)具有明显的性能优势, 这是因为图神经网络通过聚合邻居节点特征, 能有效建模高阶邻域信息.
相比单纯基于ID的推荐方法BPR-MF和Light-GCN, 所有多模态推荐方法均有明显的性能提升, 这体现出多模态方法可成功利用多种模态特征, 增强挖掘用户兴趣及建模用户偏好的能力.LATTICE和FREEDOM的性能优势体现在通过模态特征构造物品-物品图以增强物品表示的合理性.MGCN在Sports、Clothing等更稀疏的数据集上的性能提升展现出多视图学习对于缓解数据稀疏性的积极意义.COHE-SION结合模态的早期和晚期融合方法, 进一步提升推荐性能, 表明跨模态信息存在能被更加深入挖掘的空间.PGL的性能提升验证直接使用模态特征构造物品表示在缓解数据稀疏性方面的优势.IDFREE完全抛弃ID嵌入的使用, 通过模态特征构造用户表示和物品表示, 展现出的优越性能有效验证仅依靠模态特征完成推荐任务的可行性.
此外, IDFREE和USERec的性能显著优于其它对比方法, 这体现在特征嵌入空间引入位置编码的合理性, 位置编码的引入增加不同嵌入之间的区分度, 有效缓解随机初始化的用户表示过于相似及多层图卷积过程中的过平滑问题.
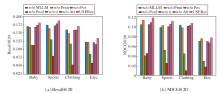
2.4 消融实验
为了研究USERec中各模块的贡献, 设计如下6种变体, 在Baby、Sports、Clothing、Elec数据集上进行消融实验.
1)w/o MLLM.使用VGG代替MLLM进行视觉模态特征的提取.
2)w/o Prun.移除度敏感剪枝, 在训练阶段使用完整的用户-物品交互图.
3)w/o Pos.移除用户表示中的位置编码.
4)w/o Pos2.物品表示和用户表示都加上位置编码.
5)w/o ii.移除用户行为物品-物品图, 不增强物品表示.
6)w/o Att.移除随机采样注意力模块, 不增强用户表示.
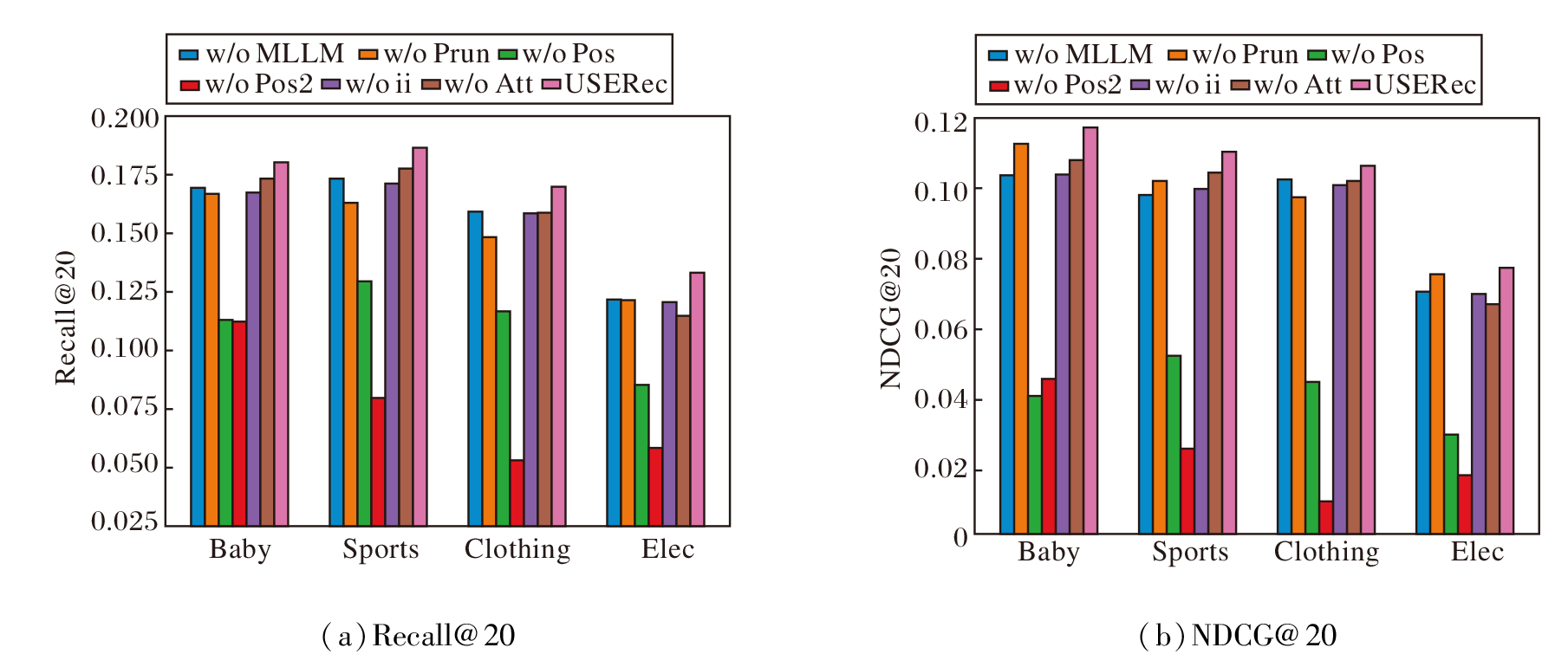
各变体消融实验结果如图2所示.
 | 图2 各变体消融实验结果Fig.2 Ablation experiment results of variants |
由图2可得如下结论.
1)相比USERec, 所有变体都出现一定的性能下降, 这说明USERec中每个模块都对方法性能做出一定的贡献.
2)在所有变体中, w/o Pos的性能下降十分显著, Recall@20指标在Baby、Sports、Clothing、Elec数据集上分别下降40.9%、33.4%、34.5%和40.8%, 这充分体现位置编码对于提升用户表示的可区分性与训练稳定性的核心作用, 并能在图传播与注意力增强过程中间接促进个性化偏好语义的学习.此外w/o Pos2的性能下降更明显, 尤其是在Clothing数据集上的性能下降达到62.6%, 这证实在物品模态表示中引入位置编码会破坏原有的模态信息, 严重影响模型性能.
3)w/o MLLM的性能下降也较明显, 说明相比传统的单一模态特征提取器, 利用文本特征指导MLLM进行跨模态语义特征提取, 更能捕捉与推荐任务相关的高层语义信息.
4)w/o ii的性能下降幅度表明物品-物品关系在丰富用户行为建模方面发挥重要作用, 有助于增强物品表征的语义关联.
5)w/o Prun在Recall@20指标上的劣化更明显, 由此验证度敏感剪枝能在缓解过平滑问题的同时降低噪声边的干扰, 使用户-物品图能更好地保留个性化差异, 从而召回更多相关物品.
6)相比USERec, w/o Att也存在一定的性能衰减, 表明随机采样注意力机制能在不显著增加计算量的情况下, 强化用户表示对于全局物品的感知能力, 进一步提升用户表示的区分度.
此外, 本文还将USERec中使用的基于MLLM的特征提取方法与基于VGG的特征提取方法和基于CLIP的特征提取方法进行对比, 相应指标值如表3所示, 表中使用的CLIP是针对长文本优化的LongCLIP-B[36].
| 表3 不同特征提取器的性能对比 Table 3 Performance comparison of different feature extractors |
由表3可见, CLIP的性能反而略逊于传统的VGG, 而MLLM则取得最佳性能.这一看似反直觉的结果, 经深入分析, 可能与以下原因有关.
1)因为使用CLIP分别独立提取图像特征和文本特征, 这实质上是将CLIP降级为两个独立的编码器使用, 并未充分发挥其核心图文关联能力.2)因为CLIP在强制将不同模态对齐到相同维度空间的过程中可能会损害原有的模态特征表示, 从而影响多模态推荐方法对于不同模态特征独有信息的学习.虽然VGG等传统视觉模型在跨模态对齐上能力较弱, 但其对于商品颜色、纹理、形状等基础视觉属性的编码可能更直接和有效, 而这些属性本身也是推荐的重要依据.
本文也尝试将文本作为CLIP的提示词, 但性能提升有限.分析认为, CLIP的提示工程更适用于零样本分类, 而对于本文数据集中复杂、结构化的商品描述缺乏足够的指令遵循和深层推理能力以生成一个与推荐任务高度相关的融合表示.相比之下, MLLM经过大规模指令微调, 能理解经过精心设计并要求方法执行的“ 多维度分析” 、“ 用户画像推测” 和“ 关联商品推荐” 等复杂提示词, 使得MLLM能在特征提取阶段, 主动、有目的地从图像中挖掘与文本描述指代的商品功能、用户场景、情感偏好等相关的高阶语义信息, 实现真正的“ 语义级融合” .
2.5 超参数分析
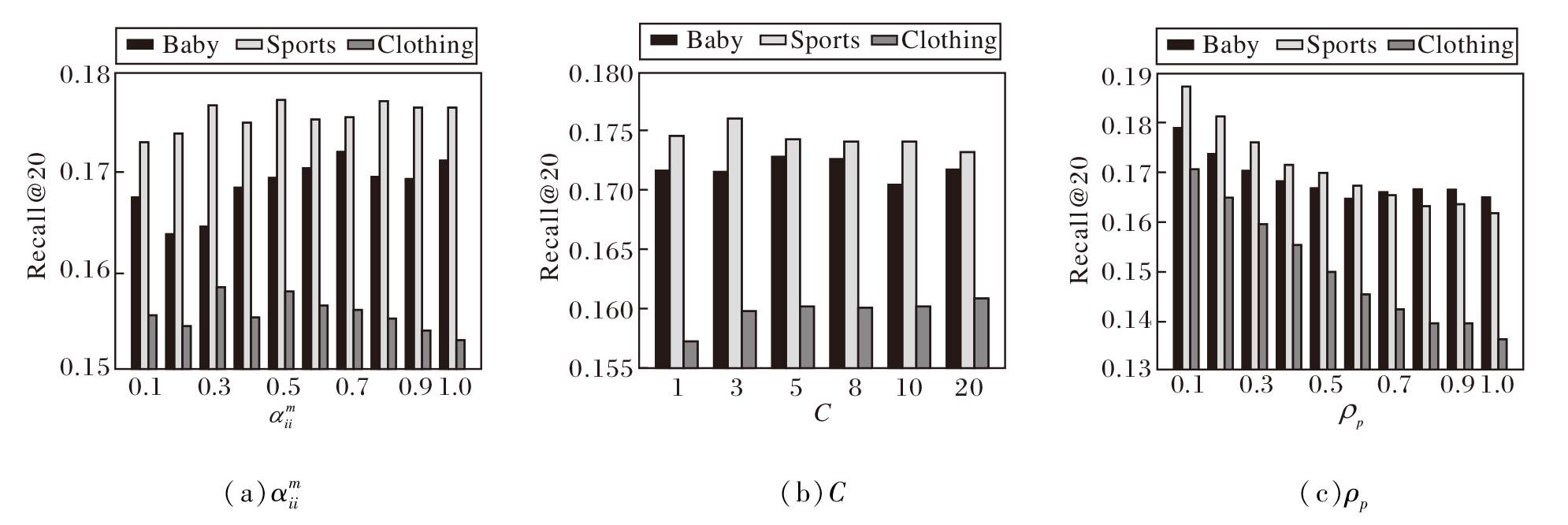
为了确定USERec中最优参数设置, 在Baby、Sports、Clothing数据集上分析如下超参数:控制物品-物品图中不同模态权重的超参数
 | 图3 |
 | 图4 λcl、 ρ d对USERec性能的影响Fig.4 Effect of λcl, ρ d on USERec performance |
定义
定义C=1, 3, 5, 8, 10, 20, 其对USERec性能的影响如图3(b)所示, Baby、Sports、Clothing数据集上的最佳样本数量分别为5、3、20, 可发现每批次采样3~5个样本即可获得较明显的收益, 因此综合考虑性能和计算效率, 本文实验中对于Baby、Sports、Clothing数据集的采样数量分别设定为5, 3, 5.
定义ρ p=0.1, 0.2, …, 1.0, 其对USERec性能的影响如图3(c)所示.由图可见, 当ρ p=0.1(即保留交互图10%的边)时USERec在3个数据集上均能取得最优值, 随着ρ p值增大(即训练子图更稠密), 3个数据集上的Recall@20指标整体下降, 这表明在训练阶段度敏感剪枝能更有效去噪与抑制高频枢纽节点的主导效应, 凸显长尾用户与冷门物品的差异化信号.
此外, 还对Baby数据集上排名前100的热门物品的推荐命中率(Hit Rate)进行统计分析, 当不使用度敏感剪枝时命中率为38.35%, 而使用度敏感剪枝时命中率为51.09%.这一结果有力证实度敏感剪枝在缓解过平滑问题的同时, 不但不会导致热门物品的推荐准确率下滑, 而且还有利于提高热门物品的推荐准确率.
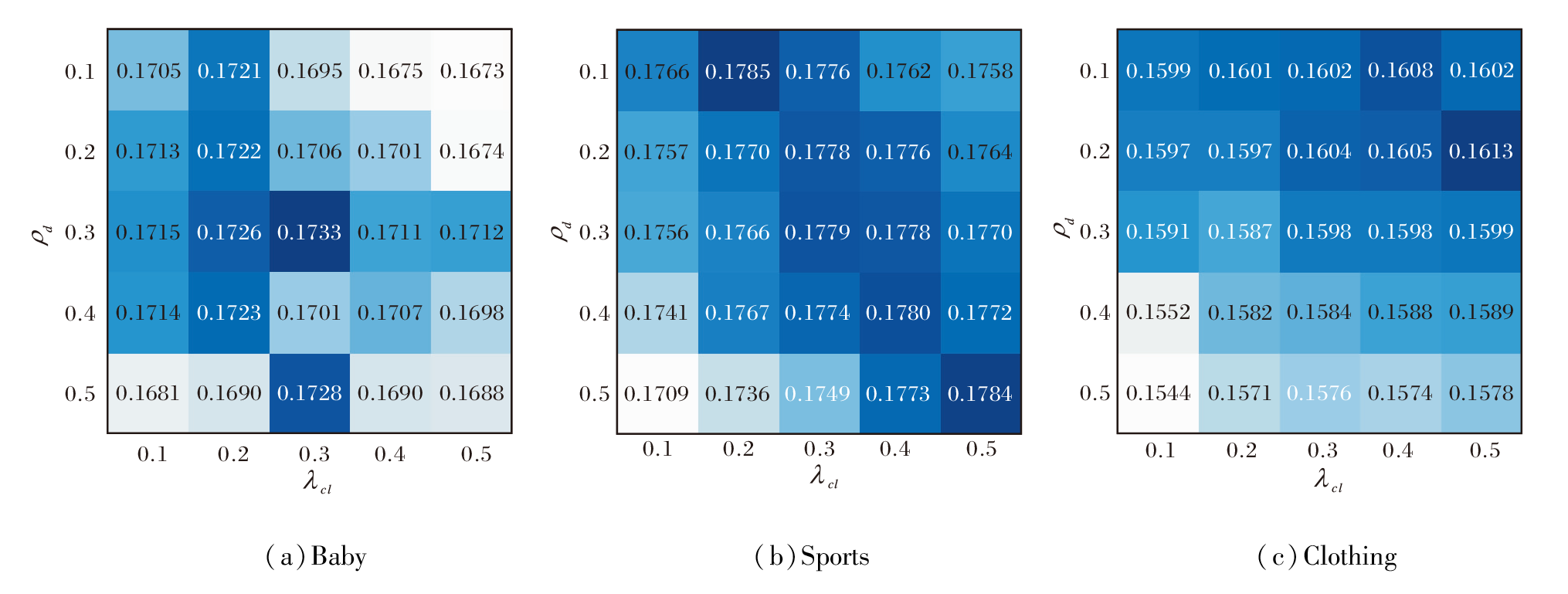
定义ρ d=0.1, 0.2, …, 0.5, λcl=0.1, 0.2, …, 0.5, 其对USERec性能的影响如图4所示.
由图可见, 最优的超参数设定依据不同的数据集规模而改变.当ρ d=λcl=0.3时, USERec在Baby数据集上达到最优性能, 当ρ d=0.1, λcl=0.2时, USERec在Sports数据集上达到最优性能, 当ρ d=0.2, λcl=0.5时, USERec在Clothing数据集上达到最优性能.
2.6 复杂度分析
本节分析USERec在4个数据集上所需的训练时间和显存消耗, 并与LATTICE[7]、FREEDOM[8]、MGCN[11]、COHESION[15]、PGL[16]、IDFREE[17]、Light-GCN[26]、LGMRec[34]进行对比.各方法在4个真实数据集上的显存消耗与训练时间对比结果如表4所示, 表中-表示在该数据集上训练模型所需的显存超过48 GB, 无法完成训练.此外, 需要说明的是, 本文使用MLLM提取融合视觉特征的步骤仅需在数据集预处理阶段进行一次, MLLM本身不参与推荐模型训练中的前向传播和反向传播过程, 因此该步骤的算力资源开销没有在表4中进行统计.
| 表4 各方法在4个数据集上的训练时间与显存消耗对比 Table 4 Comparison of training time and memory usage among different methods on 4 datasets |
从整体上看, 传统的协同过滤方法(LightGCN)在显存占用与训练开销上普遍低于多模态方法, 但其表达能力有限, 难以充分利用多模态信息.相比之下, 多模态推荐方法在性能提升的同时普遍带来额外的计算与存储开销.COHESION在Elec数据集上的显存消耗高达16.01 GB, 单轮训练时间需要461.10 s, 显示出明显的效率瓶颈, 而LATTICE和IDFREE更是由于所需显存超出GPU的最大显存容量而无法成功训练.
相比现有多模态方法, USERec在保持良好性能的同时未显著增加计算资源需求.在Baby、Sports数据集上, USERec的显存消耗仅为1.53 GB和2.74 GB, 与MGCN、FREEDOM、PGL相近, 远低于IDFREE与COHESION.在Clothing、Elec数据集上, USERec在显存消耗和训练时间上也始终处于较优水平.在Elec数据集上, USERec每个轮次的训练时间为43.62 s, 远低于COHESION的461.10 s, 同时显存需求(8.47 GB)仅为COHESION(16.01 GB)的1/2.虽然USERec在模态特征提取时使用多模态大语言模型, 但这一步骤仅需在数据集预处理阶段进行一次, 在训练阶段并不会涉及大模型的训练与推理.而且, USERec由于使用PCA降低模态特征的维度, 因此在实际训练中, 可能比直接使用原始的图像特征所需的参数量更少.此外, 由于随机采样注意力机制每次仅对用户和随机采样的C个物品表示进行计算, 而不用在完整的用户-物品交互图上进行注意力计算, 因此也不会显著增加训练阶段的资源开销.
2.7 可视化分析
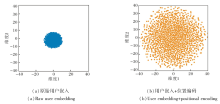
为了进一步探究位置编码对用户表示的影响, 在二维空间中对从Baby数据集上随机采样的3 000位用户嵌入进行t-SNE(T-Distributed Stochastic Nei-ghbor Embedding)可视化, 结果如图5所示.
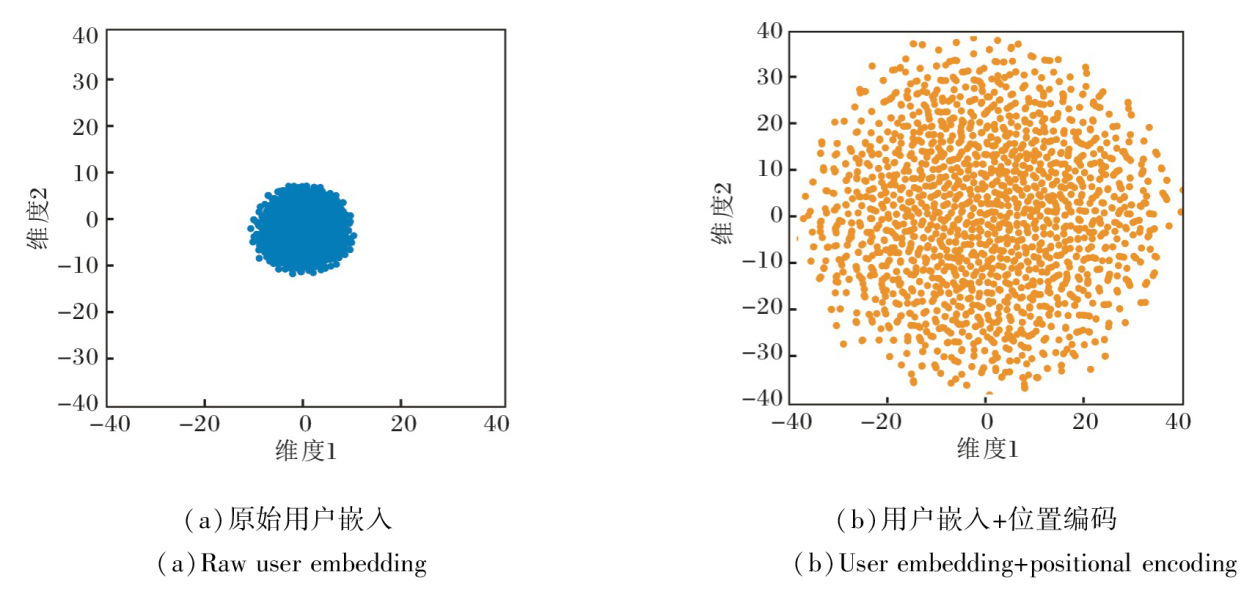 | 图5 Baby数据集上的用户嵌入可视化分析Fig.5 Visual analysis of user embedding on Baby dataset |
由图5可观察到, 未引入位置编码的用户嵌入高度集中在原点附近, 整体分布呈现强烈的同质化特征, 难以体现用户间的差异.在引入位置编码后, 用户嵌入的分布显著扩展并覆盖更大范围, 显示出更强的分散性和可区分性.这一现象表明, 位置编码虽然与推荐任务的语义无直接关联, 但它在初始化阶段强制拉开用户表示之间的差距, 有效缓解由随机初始化带来的表示塌缩问题, 有助于后续的用户建模.
更为重要的是, 位置编码与USERec的其它模块形成协同效应.在个性化局部子图学习中, 差异化的用户初始化有助于放大长尾用户与冷门物品的个性化信号, 避免图卷积过程中过平滑带来的表示趋同问题.在全局随机采样注意力机制中, 位置编码使不同用户在Q、K、V空间中具有独特的频谱模式, 提升全局注意力对用户的区分度, 增强用户对全局物品的感知能力.
总之, 位置编码并非直接提供语义信息, 而是通过改善用户嵌入的几何性质和训练信号, 与局部子图学习和全局注意力增强形成互补机制, 从而共同推动整体性能的提升.
3 结束语
本文针对现有多模态推荐方法存在用户表示个性化不足与模态融合有效性有限的问题, 提出强化用户语义表示的多模态推荐方法(USERec).首先, 利用MLLM结合文本提示信息, 实现跨模态高层语义的融合式特征提取, 从源头上缓解图像模态中噪声较多、语义不足的问题.然后, 在用户表示学习阶段引入位置编码与度敏感剪枝, 既提升不同用户间的区分度, 又有效抑制过平滑带来的表示趋同现象.最后, 设计基于随机采样注意力的用户表示增强模块, 使用户在保持局部个性化的同时感知全局物品的潜在关联.在4个真实数据集上的实验表明, USERec在Recall@K与NDCG@K指标上均较优.未来的研究方向包括:探索更轻量化的跨模态语义提取方式, 进一步降低预处理的成本; 探索完全不依赖ID嵌入且更高效的多模态推荐方式.
本文责任编委 马少平
Recommended by Associate Editor MA Shaoping
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|