



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于多模态图像特征融合的无人机目标检测方法
引用本文
薛文辉, 陈忠诚, 陈珺, 王勇. 基于多模态图像特征融合的无人机目标检测方法. 模式识别与人工智能, 2025,38(12): 1135-1148
XUE Wenhui, CHEN Zhongcheng, CHEN Jun, WANG Yong. UAV Target Detection Method Based on Multimodal Image Feature Fusion. PATTERN RECOGNITION AND ARTIFICIAL INTELLIGENCE, 2025,38(12): 1135-1148.
Doi: 10.16451/j.cnki.issn1003-6059.202512006
XUE Wenhui, CHEN Zhongcheng, CHEN Jun, WANG Yong. UAV Target Detection Method Based on Multimodal Image Feature Fusion. PATTERN RECOGNITION AND ARTIFICIAL INTELLIGENCE, 2025,38(12): 1135-1148.
Permissions
Copyright©2025, 《模式识别与人工智能》编辑部
《模式识别与人工智能》编辑部
基于多模态图像特征融合的无人机目标检测方法

王 勇,博士,教授,主要研究方向为物联网/无线传感网、深度学习、脑机接口、嵌入式系统.E-mail:wy112708@163.com.
作者简介:

薛文辉,硕士研究生,主要研究方向为计算机视觉、图像处理、目标检测.E-mail:xuewenhui2023@163.com.

陈忠诚,硕士研究生,主要研究方向为深度学习、嵌入式系统、物联网.E-mail:2041151036@qq.com.

陈 珺,博士,教授,主要研究方向为人工智能、模式识别、计算机视觉技术.E-mail:chenjun71983@163.com.
摘要
多模态图像在感知层面具有显著互补性,其中红外图像在低光照和复杂背景中具备稳定的目标响应能力,而可见光图像能提供丰富的纹理与细节信息,两者融合有助于提升复杂环境下无人机目标检测的鲁棒性与精度.为此,文中提出基于多模态图像特征融合的轻量化无人机目标检测方法(UAV Target Detection Method Based on Multimodal Image Feature Fusion, MIFF-UAVDet),以YOLOv7-tiny为主干结构,构建红外与可见光双分支结构,分别对两种模态进行特征提取,为后续特征融合提供互补的特征表示.进一步地,设计轻量级多尺度空间注意力融合模块,通过通道压缩模块、多尺度深度可分离卷积、多尺度空间注意力机制,引导模态间信息在空间维度上自适应融合,增强特征表达能力.同时改进CIoU(Complete Intersection over Union),设计HWCIoU(Height-Width Constrained CIoU),引入针对目标长宽比的强约束机制,使预测框在回归过程中能精确匹配真实框形状.在2个公开的多模态无人机目标检测数据集上的实验表明,MIFF-UAVDet在检测精度、定位精度及推理速度等方面均较优,尤其在复杂背景、光照变化及目标尺度差异较大的场景中表现出较强的鲁棒性.
关键词:
深度学习; 特征融合; 目标检测; 无人机航拍图像
中图分类号:TP391
UAV Target Detection Method Based on Multimodal Image Feature Fusion
WANG Yong, Ph.D., professor. His research interests include internet of things/wireless sensor networks, deep learning, brain-computer interface, and embedded systems.
About Author:
XUE Wenhui, Master student. His research interests include computer vision, image processing and object detection.
CHEN Zhongcheng, Master student. His research interests include deep learning, embedded systems and internet of things.
CHEN Jun, Ph.D., professor. Her research interests include artificial intelligence, pattern recognition, and computer vision technologies.
Abstract
Multimodal images exhibit significant complementarity at the perception level. Infrared images provide stable target responses under low-light conditions and complex backgrounds, while visible images offer rich texture and detailed information. The fusion of the above images effectively enhances the robustness and accuracy of unmanned aerial vehicle(UAV) object detection in complex environments. Therefore, a UAV target detection method based on multimodal image feature fusion(MIFF-UAVDet) is proposed. YOLOv7-tiny is employed as the backbone and dual branches are constructed for infrared and visible modalities. Features are extracted separately from each modality to provide complementary representations for subsequent feature fusion. Furthermore, a lightweight multi-scale spatial attention fusion module is introduced to guide adaptive spatial-level cross-modal fusion and strengthen feature representation by integrating channel compression module, multi-scale depthwise separable convolutions and multi-scale spatial attention mechanism. Meanwhile, due to the scale compression and shape distortion of targets under UAV aerial perspectives, the aspect ratio penalty term in complete intersection over union(CIoU) is prone to ineffectiveness during practical regression, and the localization accuracy is reduced. To address these issues, an improved height-width constrained loss function based on CIoU(HWCIoU) is proposed. Experimental results show that MIFF-UAVDet outperforms the state-of-the-art methods in terms of detection accuracy, localization precision and inference speed, and MIFF-UAVDet exhibits stronger robustness in scenarios with complex backgrounds, varying illumination, and significant target scale variations.
Key words:
Key Words Deep Learning; Feature Fusion; Object Detection; Unmanned Aerial Vehicle Aerial Image
随着人工智能和计算机视觉技术的迅猛发展, 基于深度学习的目标检测算法已广泛应用于自动驾驶[1]、安全监控[2]、智能制造[3]等领域.在实际场景中, 尤其是无人机视角下的目标检测任务, 存在光照变化、遮挡严重、尺度变化等问题, 单一模态图像往往难以提供稳定、可靠的特征信息, 进而影响检测算法的准确性与鲁棒性.
为了克服单模态信息的局限性, 多模态图像融合技术逐渐受到研究者的关注.红外图像具备良好的抗干扰能力, 可在低光照和复杂背景下保持对目标的感知; 可见光图像包含丰富的纹理与细节信息.两者在感知能力上具有高度互补性, 若能有效融合红外图像与可见光图像中的异构信息, 将显著提升目标检测性能.因此, 设计高效的多模态特征融合策略成为当前多模态目标检测研究的核心问题之一[4, 5].
目前主流目标检测方法主要分为两阶段方法(Two-Stage)与单阶段方法(One-Stage)两类.
两阶段方法以Fast R-CNN(Fast Region-Based Convolutional Network)[6]、Faster R-CNN[7]为代表, 首先生成候选区域, 再对每个候选框进行分类与回归, 检测精度较高, 但在速度方面存在一定瓶颈.
相比之下, 单阶段方法, 如SSD(Single Shot MultiBox Detector)[8]、YOLO[9, 10, 11, 12, 13]系列等, 则直接在图像上进行回归预测, 检测速度较快、结构简洁, 更适合实时性要求较高的应用场景.其中, YOLOv7-tiny作为YOLOv7[13]的轻量化版本, 在保持较高精度的同时可大幅降低模型复杂度, 适合部署在资源受限的平台如无人机上.
然而, 在实际应用中, 尤其是在复杂环境下的无人机目标检测任务中, 单一模态信息往往难以提供足够的判别特征.现有多模态目标检测方法虽然引入红外图像与可见光图像的融合, 但大多仅采用简单的特征拼接或注意力机制进行模态融合, 未能充分挖掘不同模态间的互补关系, 导致融合特征表达能力有限, 难以有效提升检测性能.
针对上述问题, 本文提出基于多模态图像特征融合的无人机目标检测方法(UAV Target Detection Method Based on Multimodal Image Feature Fusion, MIFF-UAVDet).主干网络部分采用双分支YOLOv7-tiny架构, 分别针对红外图像与可见光图像进行特征提取.每个分支在保持YOLOv7-tiny轻量化特性的同时, 充分捕获各自模态中的纹理细节与语义信息, 有效保留模态特有的表征能力.为了实现多模态特征在融合阶段的高效整合, 设计轻量级多尺度空间注意力融合模块(Lightweight Multi-scale Spatial Atten-tion Fusion, LMSAF), 包括通道压缩模块、多尺度空间注意力机制与自适应特征融合机制.在损失函数方面, 改进CIoU(Complete Intersection over Union)[14], 设计HWCIoU(Height-Width Constrained CIoU), 引入针对目标长宽比的强约束机制, 使预测框在回归过程中能精确匹配真实框形状.在2个公开的多模态无人机目标检测数据集上的实验表明, MIFF-UAVDet在检测精度、定位精度及推理速度等方面均较优, 尤其在复杂背景、光照变化及目标尺度差异较大的场景中表现出较强的鲁棒性.
1 多模态图像融合技术
多模态图像融合技术在目标检测任务中得到广泛应用[15].该技术主要包括像素级融合、决策级融合和特征级融合三种方式.
像素级融合是直接对红外图像和可见光图像中每个像素进行整合, 常见方法包括通道拼接、加权平均和通道替换等.该方式能最大程度利用图像中的全部信息, 不受区域层或特征层的限制, 但是容易受到图像对齐误差、冗余信息和噪声的影响, 缺乏对高级语义特征的建模能力, 导致深度神经网络难以直接提取适合学习的语义信息.Wagner等[16]将可见光图像与红外图像在通道维度直接拼接后输入卷积神经网络, 实现多光谱行人检测, 但缺乏对高层语义特征的建模, 检测性能受限.French等[17]利用图像融合与深度神经网络实现多光谱行人检测, 提升检测鲁棒性, 但融合策略较简单, 对齐与噪声问题未得到有效处理.Vandersteegen等[18]设计单阶段深度网络, 实现实时多光谱行人检测, 但对特征间互补信息的挖掘不足, 影响复杂场景中的精度.
决策级融合则是在完成特征提取和分类后进行的融合, 通常使用多个独立的神经网络分别处理红外图像与可见光图像, 并通过整合输出的置信度分数、目标框坐标等信息获得最终结果.常用方式包括加权融合和决策组合.Zhuang等[19]提出IT-MN(Lightweight Illumination and Temperature-Aware Multi-spectral Network), 适配边缘计算场景, 但网络结构较复杂, 实时性受限.Li等[20]基于Dempster-Shafer理论, 提出CMPD(Confidence-Aware Multispectral Pe-destrian Detection Method), 但融合过程依赖权重估计的准确性, 对异常情况较敏感.Hu等[21]提出在低光照条件下的可见光与红外图像决策级融合检测方法, 但未充分利用模态间的深层特征互补性.
针对像素级融合与决策级融合的不足, 特征级融合利用深度学习强大的特征提取能力, 将红外图像与可见光图像在特征层实现高效整合.具体做法是:将两种模态的图像分别输入共享或独立的卷积神经网络, 通过前向传播生成特征图, 并在融合前利用注意力机制抑制噪声、增强关键信息.融合方法包括特征加权[22]和特征拼接[23], 得到的融合特征图既包含可见光图像的结构与纹理细节, 又融合红外图像在低光照和复杂背景下的鲁棒性.Zhang等[24]提出TINet(Triple-INet), 实现RGBT(RGB-Thermal)目标检测, 但在光照条件剧烈变化时性能波动较大.Shen等[25]提出ICAFusion, 在特征提取阶段引入多次迭代交叉注意力机制, 可增强多模态特征融合效果, 但多次迭代增加模型的计算复杂度.Xie等[26]基于YOLOv5框架, 提出FISAFN(Feature Interaction and Self-Attention Fusion Network), 设计特征交互模块, 提升跨模态语义特征融合的深度与广度, 从而在复杂环境下显著改善检测性能.
总之, 特征级融合在保持网络计算效率的同时, 能充分调动不同模态的语义特征进行协同学习, 是目前多模态目标检测中应用最广泛、效果最优的融合方式之一, 也为本文提供理论支撑与设计依据.
2 基于多模态图像特征融合的无人机目标检测方法
YOLOv7-tiny[13]是YOLOv7系列中面向轻量化与实时应用场景设计的目标检测网络, 在网络结构上通过对ELAN(Efficient Layer Aggregation Net-works)模块进行裁剪与简化, 有效降低网络的参数规模和计算复杂度.同时, YOLOv7-tiny仍保留YOLOv7中高效的特征聚合与多尺度特征表达能力, 在保证推理速度的同时, 能维持较稳定的检测精度.相比YOLOv7, YOLOv7-tiny在网络深度和宽度上进行合理压缩, 更适合部署于计算资源受限、对实时性和能耗要求较高的嵌入式平台和无人机载系统.
在无人机航拍目标检测任务中, 模型需要在有限算力条件下快速处理高分辨率图像并应对复杂场景变化, 因此本文选用YOLOv7-tiny作为主干网络, 在兼顾检测效率与模型轻量化的前提下, 进一步开展多模态特征融合方法的研究.
红外图像在纹理表达与轮廓细节方面存在天然不足, 而可见光图像又容易受到光照变化与遮挡干扰, 在无人机视角下仅依赖单一模态难以获得稳定且准确的目标检测性能.然而, 红外图像与可见光图像在信息层面具有显著的互补特性, 这为多模态联合建模提供可行性与必要性.
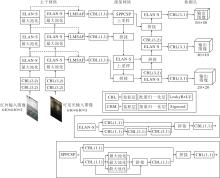
基于上述分析, 本文提出基于多模态图像特征融合的无人机目标检测方法(MIFF-UAVDet), 充分发挥红外图像对显著性目标的感知优势以及可见光图像在细节表达方面的互补能力, 选用轻量化的YOLOv7-tiny作为主干网络, 构建红外与可见光双分支结构, 分别进行特征提取.该设计在保持各模态独立表征能力、避免特征互扰的同时, 有效控制方法复杂度.MIFF-UAVDet整体架构如图1所示.
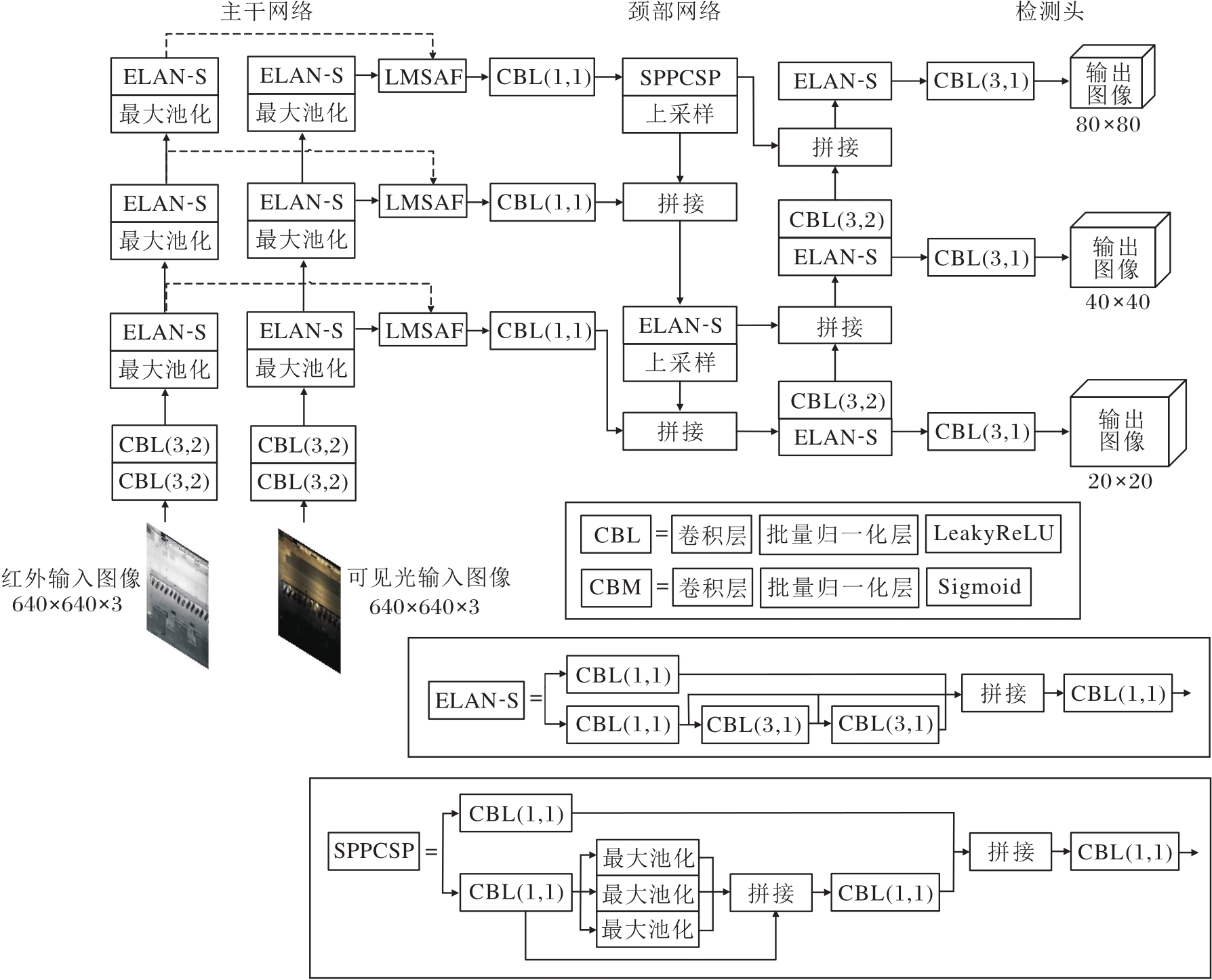 | 图1 MIFF-UAVDet整体架构Fig.1 Overall architecture of MIFF-UAVDet |
在此基础上, 为了进一步提升不同模态特征的融合效率与表达一致性, 设计轻量级多尺度空间注意力融合模块(LMSAF), 通过通道压缩模块、多尺度深度可分离卷积[27]与空间注意力机制[28]的协同作用, 引导网络在空间维度上自适应关注关键区域, 实现多模态特征在语义与结构层面的有效协同.此外, 针对原始CIoU[14]在目标长宽比变化较大场景中定位精度下降的问题, 改进CIoU, 提出HWCIoU, 引入高度-宽度一致性惩罚项, 增强边界框回归的稳定性与精度.
综合上述改进, MIFF-UAVDet在计算开销基本保持不变的前提下, 显著提升目标检测的准确性与鲁棒性, 尤其适用于复杂环境下的无人机视觉感知任务.
2.1 双分支结构
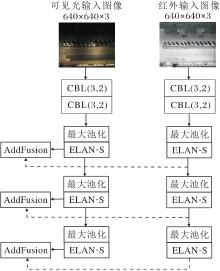
为了充分利用红外图像与可见光图像在信息层面的互补性, 本文基于轻量化的YOLOv7-tiny构建双分支特征提取结构.具体而言, 网络包含两个独立的YOLOv7-tiny主干分支, 分别接收红外图像与可见光图像作为输入, 并在各自分支中独立提取多层次的语义特征与纹理特征.该设计的优势在于能在保持轻量化的同时, 避免在早期阶段发生模态间的特征干扰, 从而保留每种模态的原生表征能力.双分支结构特征提取过程如图2所示, 在YOLOv7-tiny中, 双分支主干网络在特征提取阶段结束后, 将对应尺度的红外特征与可见光特征在通道维度进行逐元素相加(AddFusion), 将所得的融合特征作为输入传至后续颈部网络.
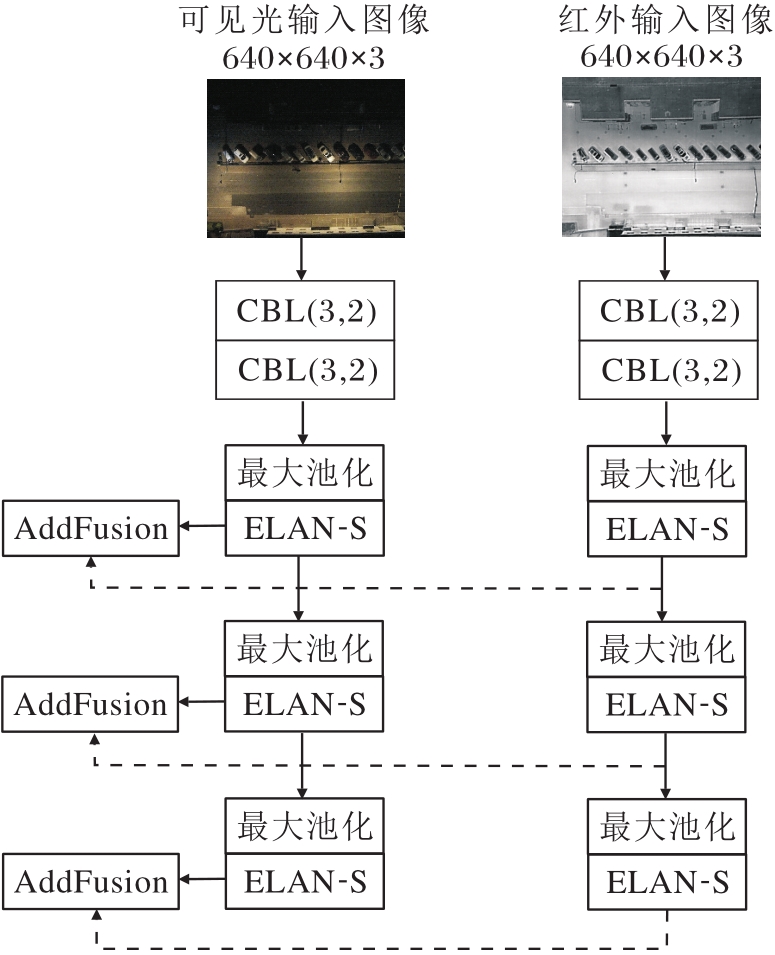 | 图2 双分支结构特征提取过程Fig.2 Dual-branch feature extraction process |
AddFusion的优点是结构简单、计算开销较低, 适合在资源受限的终端设备部署.然而, 由于其融合方式未考虑不同模态在空间分布、语义强度及重要区域上的差异, 可能导致关键信息未被充分利用, 且容易引入来自另一模态的冗余或噪声特征.为此, 本文在双分支结构的基础上引入轻量级多尺度空间注意力融合模块(LMSAF), 实现对跨模态特征的精细化加权与自适应融合.
2.2 轻量级多尺度空间注意力融合模块
在多模态视觉任务中, 不同模态特征的有效互补与融合是影响系统性能的关键问题之一.尤其是在融合可见光图像与近红外图像时, 两种模态在光照、纹理和边缘等感知特性上存在天然差异, 直接拼接或简单加权融合往往无法充分发挥各自优势, 甚至可能引入噪声干扰.
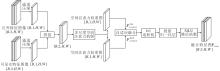
为了实现模态间的动态选择性融合, 本文设计轻量级多尺度空间注意力融合模块(LMSAF), 旨在引导方法关注具有判别性的空间区域, 同时兼顾融合效率与计算成本, 实现高效的模态融合.
LMSAF结构如图3所示.需要指出的是, LM- SAF的设计并非是对已有注意力机制或多尺度模块的简单堆叠, 而是在无人机多模态目标检测在轻量化与融合有效性双重约束下形成的针对性结构设计.
 | 图3 LMSAF结构图Fig.3 Architecture of LMSAF |
LMSAF的核心思想是引导方法在空间维度上自动关注对当前任务最有判别力的区域, 从而增强信息互补的有效性.首先, 压缩输入特征的通道维度, 提取每个模态的主导空间响应信息的同时降低方法的参数量.然后通过多尺度空间注意力机制捕捉不同感受野下的显著区域.最后利用自适应加权与残差增强策略, 实现模态特征的高质量融合.
2.2.1 通道压缩模块
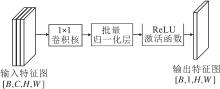
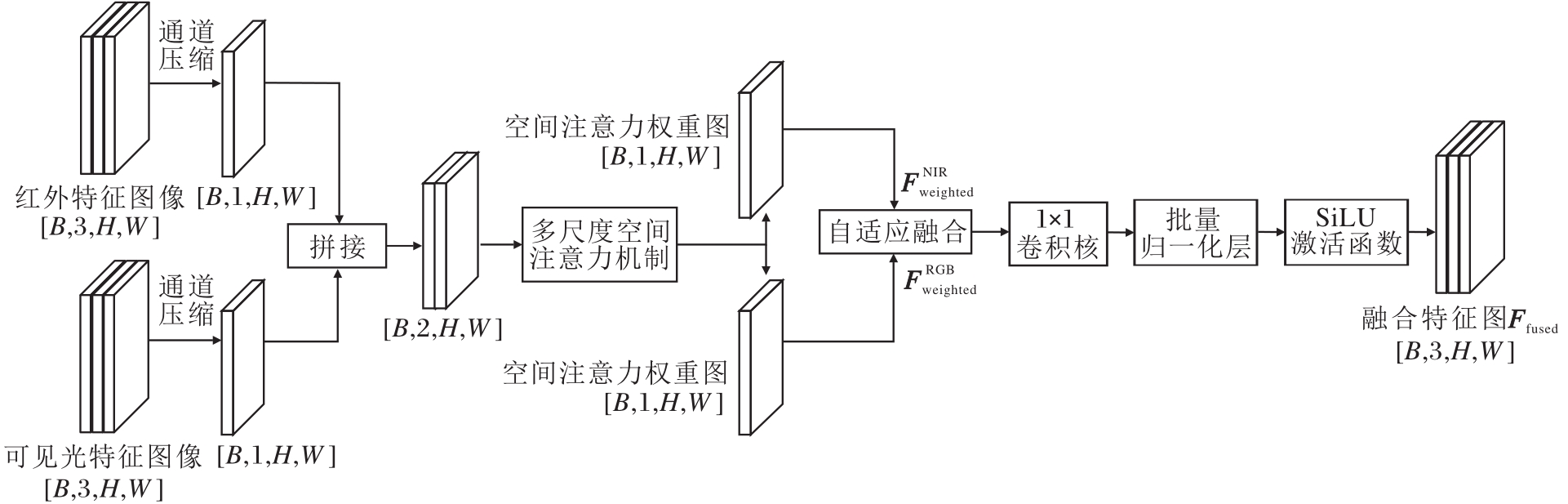
输入融合模块中可见光特征图像与红外特征图像通常具有较高的通道维度, 在融合之前, 如果进行直接拼接或简单加权, 可能会掩盖各自显著的空间信息.因此, 本文首先设计通道压缩模块, 对每个模态特征图进行独立的维度压缩, 提取其主要的空间响应信息, 具体过程如图4所示.
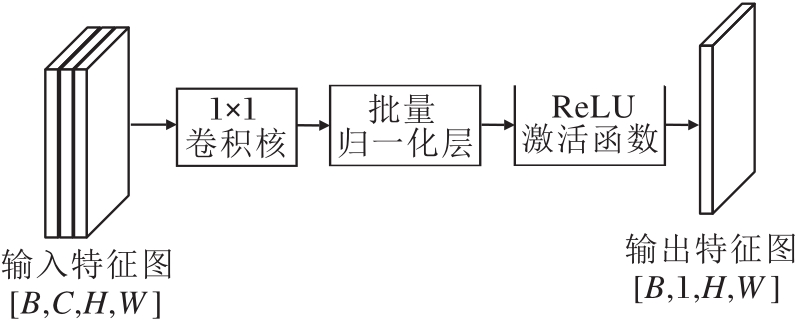 | 图4 通道压缩过程Fig.4 Channel compression process |
假设输入特征图的维度为[B, C, H, W], 其中, B表示批量大小, C表示通道数, H×W表示空间尺寸.通道压缩模块通过一个1×1卷积核将通道数C压缩为1, 输出维度为[B, 1, H, W], 从而仅保留每个像素位置上通道维度的加权组合结果.
为了提高数值稳定性与非线性表达能力, 压缩后的特征图接入批量归一化(Batch Normalization, BN)层和ReLU激活函数.
经过该过程, 可见光特征图像与红外特征图像分别被压缩为两个单通道的空间响应图, 后续将以此作为生成空间注意力权重图的基础, 确保注意力机制关注图像中空间位置的差异性而非通道层面的冗余.
2.2.2 多尺度空间注意力机制
考虑到图像中的目标在尺度上具有多样性, 单尺度卷积可能无法覆盖全部的有效感受野, 限制注意力机制对全局信息的建模能力.因此, LMSAF引入多尺度空间注意力机制, 增强其对空间上下文的建模能力.
多尺度空间注意力机制采用3组具有不同膨胀率(膨胀率为1, 2, 3)的3×3卷积核, 分别对应常规卷积、小范围扩张卷积与大范围扩张卷积, 在不显著增加计算成本的前提下, 有效拓展感受野, 感知不同尺度下的目标与背景关系.
多尺度空间注意力机制结构如图5所示.输入为通道压缩后拼接得到的特征图, 维度为[B, 2, H, W], 分别经过上述3路卷积操作, 输出3个尺度的空间响应图, 通道数均为1, 其中每路卷积均采用深度可分离结构.然后, 将3路输出沿通道维度进行拼接, 得到维度为[B, 3, H, W]的张量, 再通过一个1×1卷积实现通道融合, 输出单通道空间图.
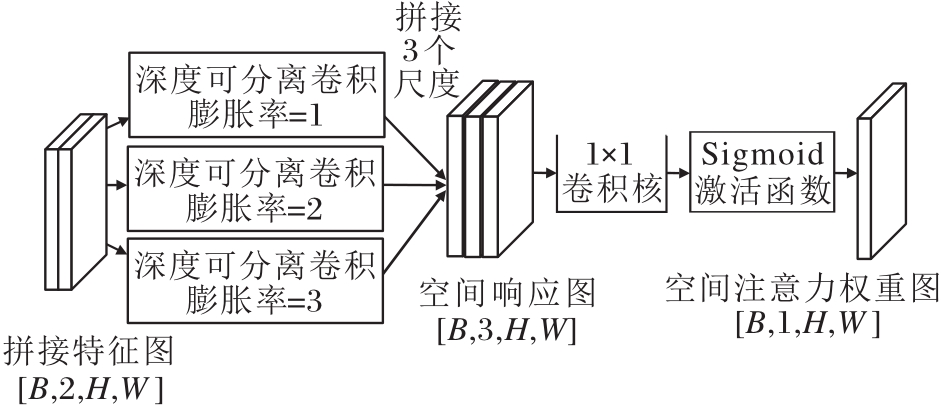 | 图5 多尺度空间注意力机制结构图Fig.5 Structure of multi-scale spatial attention mechanism |
为了确保输出权重在合理范围内, 最终通过Sigmoid激活函数进行归一化, 生成空间注意力权重图, 用于后续模态融合过程中的显著性引导.
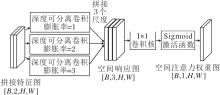
2.2.3 自适应特征融合机制
在完成多尺度空间注意力建模后, LMSAF进一步引入自适应特征融合机制, 对红外模态特征与可见光模态特征进行选择性加权与融合.该过程的核心思想是:根据空间注意力响应强度, 自适应分配不同模态在各空间位置的贡献权重, 突出显著区域并增强多模态特征互补性.
设生成的空间注意力权重图为A, 维度为[B, 1, H, W], 对A进行归一化处理, 得到注意力权重映射M∈RB×1×H×W.基于M, 对FRGB、FNIR这2种模态特征分别进行加权处理, 得到加权后可见光特征和红外特征:
其中°符号表示逐元素乘法.
上述加权方式使网络在空间位置上形成互补关注机制:当某一区域在可见光图像中具有较高响应时, M较大, 模型更侧重利用可见光特征; 在可见光响应较弱或光照受限的区域, 红外模态通过1-M的权重映射得到强化, 从而有效补充目标信息.
然后, 将加权后的两种模态特征在通道维度进行拼接, 得到维度为[B, 2C, H, W] 的融合特征图, 并通过1×1卷积将通道数压缩回C, 以降低计算开销.最后结合批量归一化层和SiLU激活函数, 增强融合特征的非线性表达能力, 得到融合特征Ffused.
此外, 为了提升融合结果的鲁棒性并缓解融合误差对原始模态特征的潜在影响, LMSAF进一步引入可学习的残差连接机制, 输出
Fout=Ffused+β (FRGB+FNIR),
其中, β 表示一个可训练的标量参数, 初始值设为1.0, 在训练过程中可自动调节原始模态信息的引入比例, 从而在特征融合与信息保留之间实现自适应平衡.
采用LMSAF自适应特征融合机制与YOLOv7-tiny特征融合后的热力图对比如图6所示, 图中在红外原始图像上使用蓝框标出非目标区域.由图可见, 对比红外原始图像, YOLOv7-tiny关注更多的非目标区域, 并存在更多的冗余或噪声特征.LMSAF的关注区域主要都集中在目标区域, 这表明LMSAF能弥补YOLOv7-tiny的注意盲区, 同时减少对非目标区域的关注.需要说明的是, 此处热力图对比主要用于定性展示LMSAF在特征提取阶段对空间响应分布的影响, 增强对网络结构设计动机的直观理解.
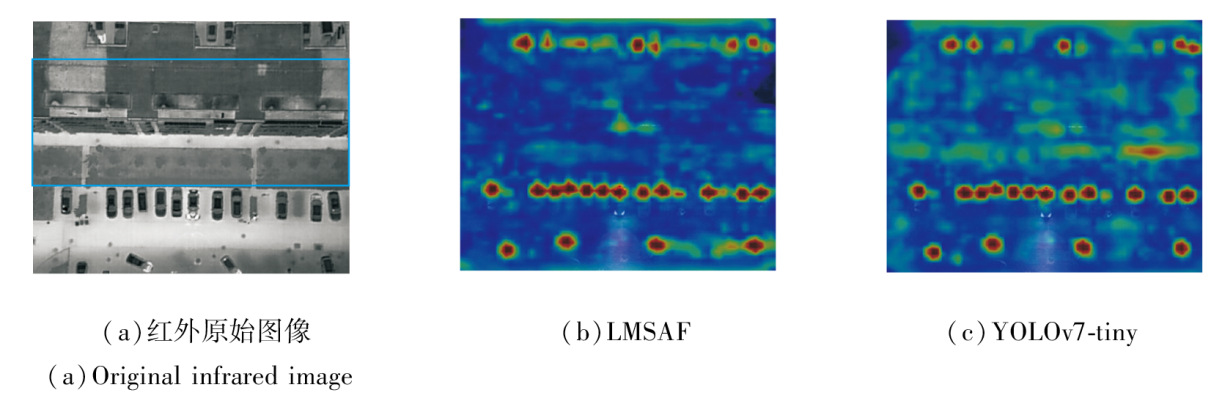 | 图6 LMSAF和YOLOv7-tiny的热力图对比Fig.6 Heatmaps comparison of LMSAF and YOLOv7-tiny |
综上所述, LMSAF通过空间引导下的模态加权融合和残差连接设计, 不仅增强融合特征的判别表征能力, 还有效提升MIFF-UAVDet在复杂场景中的稳定性与适应性.
2.3 损失函数
在MIFF-UAVDet中, 考虑3种类型的误差:置信度误差、分类误差和定位误差.其中, 前两者与YOLOv7-tiny一样, 均采用二值交叉熵损失进行估计, 而在定位误差方面, 采用不同于YOLOv7-tiny的损失函数.具体而言, YOLOv7-tiny使用CIoU[14]计算定位误差, 设真实框为Bgt=(xgt, ygt, wgt, hgt), 预测框为B= (x, y, w, h), 则CIoU的计算公式如下:
LCIoU=1-IoU+
其中,
IoU=
表示交并比,
v=
表示两框的宽高比一致性,
α=
表示权重系数, Wg、Hg分别表示包围预测框与真实框的最小外接矩形的宽度和高度, Wi、Hi分别表示预测框与真实框重叠区域的宽度和高度.
从式(1)可看出, CIoU综合考虑目标框的重叠面积、中心点距离和宽高比.然而, 当预测框与真实框的宽高比完全一致时, 即v=0, 宽高比惩罚项将失效.
为了提升边界框回归的精度, 研究者曾提出多种基于IoU(Intersection over Union)的改进损失函数, 如DIoU(Distance-IoU)[14]、GIoU(Generalized IoU)[29]等.这类改进在CIoU的基础上, 进一步引入边界框之间的几何关系约束, 在一定程度上改善目标定位性能.然而, 当被应用于无人机航拍视角下的目标检测任务时, 这些函数的性能仍大幅依赖高质量标注数据, 尤其在目标尺度变化剧烈或宽高比失真的情况下, 定位精度仍存在不足.
为了解决上述问题, 本文改进CIoU, 设计HW- CIoU, 引入预测框与真实框的归一化差异, 提升目标定位精度.
具体地, 高度和宽度的归一化差异定义如下:
$\begin{array}{l} h_{\mathrm{diff}}=\frac{a b s\left(h-h_{\mathrm{gt}}\right)}{\max \left(h, h_{\mathrm{gt}}\right)}, \\ w_{\mathrm{diff}}=\frac{a b s\left(w-w_{\mathrm{gt}}\right)}{\max \left(w, w_{\mathrm{gt}}\right)} . \end{array}$
基于上述分析, 针对式(2)中的宽高一致性度量v和式(3)中的权重项α进行修正, 修正后
v1=v+hfhdiff+wfwdiff, (4)
α1=
其中, hf表示高度因子, wf表示宽度因子.需要说明的是, 高度因子hf与宽度因子wf的设置并非随意选取, 而是结合无人机航拍视角下目标尺度变化特性与实验验证结果综合确定的.在俯视成像条件下, 目标在垂直方向更容易受到航高变化与透视效应的影响, 表现出更明显的尺度压缩与形状畸变.因此, 本文在宽高一致性惩罚项中采用非对称权重设计, 即hf=1.5, wf=1.2, 对高度方向误差赋予更强约束.
根据式(4), 只有当预测框与真实框完全重合时, v1才为0, 这从根本上解决传统CIoU中两框宽高比一致时v=0导致的惩罚失效的问题.同时, 能更精确地度量目标框之间的匹配程度, 在训练过程中实现更好的目标拟合.
值得指出的是, HWCIoU与CIoU的主要区别在于式(1)中最后一项.相比CIoU, HWCIoU的优势在于不仅继承CIoU的有效性, 还进一步考虑目标框的形状和尺度差异, 实现更准确的目标定位, 同时提升网络对不同尺度目标的检测适应性.
3 实验及结果分析
3.1 实验环境
实验在Ubuntu 20.04操作系统上进行, 采用Python 3.9.18作为编程环境.硬件配置包括Intel i5-12400F处理器、16 GB内存、NVIDIA GeForce RTX 3060显卡.深度学习框架选用PyTorch 2.1.0, 并结合CUDA 12.1实现计算加速.可见光图像与红外图像输入尺寸统一设为640×640.
在训练阶段, 网络优化器采用随机梯度下降(Stochastic Gradient Descent, SGD).初始学习率设为0.01, 动量系数设为0.937, 权重衰减系数设为0.000 5.训练初期设置3个预热轮次, 预热阶段的动量系数设为0.8.批量大小设为16, 总训练轮数为300轮.
在DVTOD[30]、DroneVehicle[31]这2个公开数据集评估方法性能.DroneVehicle数据集由无人机在白天与夜晚不同时间段采集, 共包含28 439对红外-可见光图像, 覆盖城市道路、住宅区、停车场等多种场景, 目标类别包括汽车、卡车、公交车、面包车和货运车辆, 具备场景多样、目标密集的特点, 适用于小目标检测和多模态特征学习任务.DVTOD数据集包含大量由无人机在不同场景(如城市街道、乡村道路、停车场、夜间环境等)中采集的红外-可见光图像对, 具备高质量的目标标注信息.图像对均已完成模态对齐, 目标类别涵盖人、汽车、自行车, 适用于多模态目标检测、配准与融合等任务.该数据集包含大量复杂背景, 对检测算法的鲁棒性提出较高要求.
在实验设置中, DroneVehicle数据集划分如下:训练集包含17 990对红外-可见光图像, 验证集包含1 469对红外-可见光图像, 测试集包含8 980对红外-可见光图像.同样地, DVTOD数据集划分如下:1 764对红外-可见光图像用于训练, 197对红外-可见光图像用于验证, 218对红外-可见光图像用于测试.
实验采用精确率(Precision)、召回率(Recall)、mAP@0.5、mAP@0.5∶ 0.95、帧率作为评价指标.
3.2 对比实验
为了全面评估MIFF-UAVDet在多模态无人机目标检测任务中的有效性, 选择如下具有代表性的多模态特征融合方法进行对比实验.这些对比方法均为近年来在多模态目标检测领域具有代表性的研究成果, 涵盖基于特征拼接、注意力机制及跨模态建模等不同融合策略.
1)YOLOv7-tiny+AddFusion.采用双分支YOLOv7-tiny作为主干网络, 分别对红外图像与可见光图像进行特征提取, 并在特征层通过逐元素相加(AddFusion)实现模态融合.
2)CMA-Det(Cross-Modal Alignment Detector)[30].通过跨模态注意力机制实现红外特征与可见光特征的动态加权融合, 引导网络在空间与语义层面关注更具判别力的模态信息.
3)UA-CMDet(Uncertainty-Aware Cross-Modal De-tection)[31].引入不确定性建模机制, 在多模态特征融合过程中显式刻画不同模态预测结果的置信度, 减弱噪声模态对检测性能的负面影响.
4)CFT(Cross-Modality Fusion Transformer)[32].通过自注意力机制建模不同模态之间的全局依赖关系.
5)CMX[33].基于跨模态特征交互的融合框架, 最初应用于RGB-X语义分割任务.
MIFF-UAVDet和YOLOv7-tiny性能对比如表1所示.
| 表1 MIFF-UAVDet和YOLOv7-tiny性能对比 Table 1 Performance comparison between MIFF-UAVDet and YOLOv7-tiny |
由表1可见, MIFF-UAVDet在检测性能上全面优于YOLOv7-tiny.在DroneVehicle数据集上, 相比YOLOv7-tiny, MIFF-UAVDet在mAP@0.5指标上提升2.8%, 在mAP@0.5∶ 0.95指标上提升2.7%.在DVTOD数据集上, 相比YOLOv7-tiny, MIFF-UAVDet在mAP@0.5指标上提升3.9%, 在mAP@0.5∶ 0.95指标上提升4.5%, 这进一步验证MIFF-UAVDet在不同场景中的适应能力.此外, 相比YOLOv7-tiny, MIFF-UAVDet在GPU(Graphics Proce-ssing Unit)上运行时帧率未出现明显下降, 在检测性能与推理速度之间取得良好平衡.
需要说明的是, 除了表1列出的GPU平台上的推理速度以外, 实验进一步在Raspberry Pi 5嵌入式硬件平台上对MIFF-UAVDet进行基于NCNN(Neu- ral Computing Neural Network)的推理速度测试, 评估其在低功耗边缘计算环境中的运行性能.Rasp- berry Pi 5搭载Broadcom BCM2712四核64位ARM Cortex-A76处理器, 配备4 GB LPDDR4X内存.实验表明, MIFF-UAVDet在嵌入式平台上仍能保持稳定且可接受的推理速度, 在不依赖高性能GPU加速的情况下依然具备实时处理能力, 由此进一步验证MIFF-UAVDet在模型结构设计上的轻量化优势, 以及在实际工程部署中的可行性与应用潜力.
MIFF-UAVDet和YOLOv7-tiny在参数量和浮点计算量(Floating Point Operations, FLOPs)上的对比结果如表2所示.这两个指标越小, 表示方法对计算资源的需求越低, 推理速度越快.由表可看出, 相比YOLOv7-tiny, MIFF-UAVDet尽管在参数量和FLOPs上略有增加, 但整体增幅较小, 仍保持在模型轻量化要求的合理范围内.
| 表2 MIFF-UAVDet和YOLOv7-tiny的参数量与计算量对比 Table 2 Comparison of parameters and FLOPs between MIFF-UAVDet and YOLOv7-tiny |
为了进一步验证MIFF-UAVDet的可行性与鲁棒性, 将其与UA-CMDet、CMA-Det、CFT、CMX进行对比, 对比方法已在文献[30]和文献[31]中进行详细评估.
各方法在2个数据集上的mAP@0.5指标对比如表3和表4所示, 表中黑体数字表示最优值.由表可看出, 除了CMA-Det以外, MIFF-UAVDet在2个数据集的各个类别检测上均获得最高值.上述结果充分说明MIFF-UAVDet在保持轻量化结构的同时, 依然实现显著的性能提升, 由此验证其高效的特征融合策略.
| 表3 各方法在DroneVehicle数据集上的性能对比 Table 3 Performance comparison of different methods on DroneVehicle dataset % |
| 表4 各方法在DVTOD数据集上的性能对比 Table 4 Performance comparison of different methods on DVTOD dataset % |
3.3 消融实验
为了验证MIFF-UAVDet的有效性, 在DVTOD数据集上进行系列消融实验, 分别将各项改进逐一引入原始网络结构YOLOv7-tiny中, 并分析其对检测性能的影响.以YOLOv7-tiny为基线网络, 引入双分支网络结构、LMSAF、HWCIoU后的指标值对比如表5所示.
| 表5 各网络结构的消融实验结果 Table 5 Ablation experiment results of different network structures % |
由表5可看出, 当网络结构中引入LMSAF之后, mAP@0.5和mAP@0.5∶ 0.95指标分别提升2.8%和3.7%, 说明LMSAF能更充分地整合多模态信息, 有效提升网络对复杂场景中小目标与低对比度目标的感知能力, 进一步增强整体检测效果.
此外, 为了验证LMSAF的优越性, 在YOLOv7-tiny上逐步引入多尺度空间注意力机制、多尺度深度可分离卷积、自适应特征融合机制及通道压缩模块, 相应指标值对比如表6所示.由表可见, 单独引入空间注意力机制后, mAP@0.5∶ 0.95指标提升0.9%.在此基础上加入多尺度深度可分离卷积形成多尺度空间注意力后, mAP@0.5∶ 0.95指标进一步提升1.8%, 表明不同感受野下的显著区域捕捉能有效增强特征表达.继续引入自适应特征融合机制后, mAP@0.5∶ 0.95指标提升至50.8%, 验证自适应加权在模态信息互补中的优势.最后结合通道压缩模块形成完整的LMSAF, 在降低参数量的同时, mAP@0.5∶ 0.95指标提升至51.0%, 充分说明LMSAF能在保持轻量化的同时显著增强多模态特征的融合质量.
| 表6 LMSAF结构的消融实验结果 Table 6 Ablation experiment results of LMSAF structure |
下面采用不同类型的IoU作为目标边界框的训练损失, 评估HWCIoU的有效性.选择如下损失函数:1)CIoU[14].在IoU的基础上引入中心点距离惩罚项和宽高比一致性约束, 提升边界框回归的稳定性与收敛速度.2)DIoU[14].最小化预测框与真实框中心点之间的归一化距离, 加快模型的训练过程.3)EIoU(Efficient Intersection over Union)[34].进一步解耦宽度和高度误差, 增强回归精度.4)SIoU(SCYLLA- IoU)[35].综合考虑角度、距离、形状和重叠面积等因素, 提高在复杂几何关系下的优化效果.5)Shape-IoU[36].引入形状相似性约束, 使损失函数对目标长宽比变化更敏感.6)WIoU(Wise-IoU)[37] 系列(WIoU v1、WIoU v2 和 WIoU v3).通过自适应重加权策略调节不同样本的梯度分布, 缓解样本不平衡问题并提升训练稳定性.7)MPDIoU[38].引入边界框关键点之间的最小距离度量, 有效提升对小目标和细长目标的定位精度.
各损失函数指标值对比如表7所示, 表中黑体数字表示最优值.由表可看出, 不同损失函数在检测性能上的侧重点存在差异.MPDIoU在精确率上取得最高值, 说明其在边界框回归过程中对预测框的约束较严格, 能有效减少误检.CIoU在召回率上表现最优, 表明其在目标匹配过程中具有较强的召回能力, 但在部分样本中可能牺牲定位精度.
| 表7 各损失函数的性能对比 Table 7 Performance comparison of different loss functions % |
相比之下, HWCIoU虽然在精确率和召回率上均非最高值, 但在mAP@0.5和mAP@0.5∶ 0.95两项综合指标上均取得最优值, 表明其在不同IoU阈值下具有更稳定的边界框回归性能.原因在于HWCIoU引入基于高度与宽度差异的持续惩罚项, 避免传统CIoU在宽高比一致时惩罚项失效的问题, 从而在航拍视角下有效提升预测框在形状和尺度匹配方面的鲁棒性.因此, HWCIoU在整体检测性能上表现更优, 更适用于宽高比差异显著的无人机目标检测场景.
3.4 可视化分析
下文直观展示MIFF-UAVDet的性能, 其在2个数据集真实场景中的检测结果如图7和图8所示, 包括遮挡场景和复杂背景等情况.同时为了更好地对比MIFF-UAVDet与YOLOv7-tiny可视化结果的差异性, 给出原始图像作为参考, 并在原始图像上放大检测结果不同之处.由图可见, MIFF-UAVDet能取得较高的置信度, 有效区分目标与背景, 最大程度减少漏检与误检.
 | 图7 MIFF-UAVDet和YOLOv7-tiny在DroneVehicle数据集上检测结果对比Fig.7 Detection result comparison of MIFF-UAVDet and YOLOv7-tiny on DroneVehicle dataset |
 | 图8 MIFF-UAVDet和YOLOv7-tiny在DVTOD数据集上检测结果对比Fig.8 Detection result comparison of MIFF-UAVDet and YOLOv7-tiny on DVTOD dataset |
由图7可见, 在目标密集的马路场景和停车场中, MIFF-UAVDet能准确识别其类别并获得更高的置信度, 而YOLOv7-tiny均出现两处漏检的情况.同样地, 当存在遮挡情况时, MIFF-UAVDet也取得更优表现.当目标显示不完全或被遮挡时, YOLOv7-tiny出现漏检与误检的情况.
由图8可见, 在背景复杂的校园道路上, 由于密集的人群及栏杆的存在, YOLOv7-tiny未能检测人骑行的自行车, 而MIFF-UAVDet能有效提取特征, 未出现漏检情况.同样地, MIFF-UAVDet在遮挡场景中的检测性能也优于YOLOv7-tiny, 当行人显示不完全或被树木遮挡时, YOLOv7-tiny出现严重的漏检情况.
上述可视化结果表明, MIFF-UAVDet具有良好的泛化性和鲁棒性, 可适用于各类复杂场景的目标检测.
4 结束语
针对单一模态图像在无人机目标检测中存在的精度不足与鲁棒性较差等问题, 本文提出基于多模态图像特征融合的无人机目标检测方法(MIFF-UAVDet), 充分利用红外图像与可见光图像在特征表达上的互补性, 采用轻量化YOLOv7-tiny构建双分支结构, 实现模态特征的独立提取.设计轻量级多尺度空间注意力融合模块(LMSAF), 结合通道压缩模块、多尺度深度可分离卷积与多尺度空间注意力机制, 有效提升多模态特征的融合效率与表达能力.为了优化边界框回归精度, 改进CIoU, 设计HWCIoU, 增强对目标长宽比差异的判别能力.在DroneVehicle、DVTOD数据集上的实验表明, MIFF-UAVDet在参数量与计算开销基本不变的前提下, mAP@0.5、mAP@0.5∶ 0.95指标均取得显著提升.综上所述, MIFF-UAVDet在轻量化、实时性与检测精度之间实现良好平衡, 适用于复杂环境下的无人机智能感知任务.目前MIFF-UAVDet主要针对静态图像进行建模, 尚未考虑时序信息.今后将在现有多模态检测框架的基础上, 进一步探索视频场景中的时序建模与多帧协同机制, 并结合真实无人机机载计算平台开展在线检测实验, 提升方法在动态复杂环境中的感知能力与工程应用价值.
本文责任编委 封举富
Recommended by Associate Editor FENG Jufu
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|