




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于全局-局部先验和纹理细节关注的图像修复
[徐祺津1  , 叶海良
, 叶海良1 , 曹飞龙2 , 梁吉业3 ]
, 叶海良, 曹飞龙, 梁吉业]
|
|



作者简介:

徐祺津,硕士研究生,主要研究方向为深度学习、图像处理等.E-mail:xqj1800801111@163.com.

叶海良,博士,副教授,主要研究方向为深度学习、图像处理.E-mail:yhl575@163.com.

梁吉业,博士,教授,主要研究方向为人工智能、粒计算、数据挖掘等.E-mail:ljy@sxu.edu.cn.
图像修复旨在利用周围信息填充图像中的缺失区域,然而现有基于先验的方法大多难以兼顾全局语义一致性和局部纹理细节.因此,文中提出基于全局-局部先验和纹理细节关注的图像修复方法,结合小波卷积与傅里叶卷积,构造小波-傅里叶卷积块,增强局部特征和全局特征的交互.在此基础上,提出全局-局部学习式先验,通过一个由小波-傅里叶卷积块构成的先验提取器,同时学习全局先验和局部先验.该先验提取器作用于受损图像和完整图像,分别得到受损先验和监督先验.在修复阶段,受损图像和学习的先验分别输入两个结构相似的修复分支.这两个分支均由小波-傅里叶卷积构成,能同时提取和融合全局特征与局部特征.最后,合并两个分支的输出,生成具有一致语义内容和清晰局部细节的图像.此外,构造高感受野风格损失,从语义层面提升图像风格一致性.实验表明,文中方法在多个数据集上均性能较优.
About Author:
XU Qijin, Master student. His research interests include deep learning and image processing.
YE Hailiang, Ph.D., associate professor. His research interests include deep learning and image processing.
LIANG Jiye, Ph.D., professor. His research interests include artificial intelligence, granular computing, and data mining.
Image inpainting is intended to fill in missing regions of an image using surrounding information. However, existing prior-based methods often struggle to balance global semantic consistency and local texture details. In this paper, a method for image inpainting based on global-local prior and texture details is proposed. Wavelet-Fourier convolution blocks are constructed by combining wavelet convolution and Fourier convolution to enhance the interaction between local and global features. Based on the above, a global-local learning-based prior is presented. A prior extractor composed of wavelet-Fourier convolution blocks is designed to simultaneously learn global and local priors. The prior extractor is applied to both damaged and complete images to obtain damaged priors and supervised priors. During the repair phase, the damaged image and the learned priors are input into two structurally similar repair branches. Both branches are constructed with wavelet-Fourier convolutions and can simultaneously extract and fuse global and local features. Finally, the outputs of the two branches are merged to generate the image with consistent semantic content and clear local details. Additionally, a high receptive field style loss is introduced to improve image style consistency at the semantic level. Experimental results show that the proposed method outperforms existing methods on multiple datasets.
图像修复[1]旨在使用符合语义、上下文、整体纹理与结构的内容填充图像的缺失区域, 生成视觉效果真实的高质量图像[2].目前, 图像修复方法已被广泛应用于照片修复[3]、人脸编辑[4]、目标移除[5]等领域.具体而言:老照片在存储过程中会不可避免地受到破损、老化等因素影响; 人工拍摄的电子图像也存在移除障碍物等需求.这些任务本质上均属于图像修复的范畴.
传统的图像修复方法主要包括基于扩散的方法[6, 7]、基于块相似的方法[8]、基于稀疏编码的方法[9]、基于低秩先验的方法[10].这些方法首先假设图像具有局部平滑性、非局部自相似性、低秩性等特性, 再通过迭代的方式逐步填补缺失的像素点, 其缺点在于难以捕获图像的高层语义信息、推理耗时、泛化性较差.
深度学习方法作为数据驱动的代表性方法, 已成功并广泛应用在图像处理任务, 包括图像修复.自从Pathak等[11]将深度学习方法引入图像修复领域并通过自编码器实现语义上的修复以来, 研究者们持续改进基于深度神经网络的图像修复方法并得到诸多进展.Wan等[12]使用渐进式的修复方法, 缓解缺失区域较大时的模糊现象.Huang等[13]提出Spa-former(Sparse Self-Attention Transformer), 构造稀疏自注意力Transformer, 考虑像素域的空间信息, 保留图像长程信息的同时减少计算代价.Yu等[14]提出MagConv(Mask-Guided Convolution), 利用掩码图像识别未知区域, 区别处理已知区域和未知区域, 通过共享权重的方式联合优化掩码分支和图像分支.Zhang等[15]设计两阶段W-Net(W-Shaped Network), 利用空间注意力修复纹理, 利用通道激活模块修复结构, 有效减少外观与语义之间的不一致性.Kim等[16]采用分层的渐进式图像填充策略, 区分像素点是否有效, 提升合成图像的潜在质量, 并随着分辨率的增加不断补充图像细节.上述方法尽管性能较优, 但由于缺少先验的指导, 生成内容存在边缘模糊、局部细节不清晰等问题.
为此, 部分研究者尝试使用先验信息引导图像修复.先验按提取方式主要可分为两类:全局先验和局部先验.
全局先验包括图像分割、色彩分布结构、关键点等.Liao等[17]提出SGE-Net(Semantic Guidance and Evaluation Network), 使用分割信息作为复杂场景物体布局的先验, 以此缓解上下文编码器在修复图像分割内容上不真实的现象.Qiu等[18]在第一阶段使用平滑图像先验作为图像的全局色彩分布, 并在第二阶段指导修复.Liao等[19]提出CollaGAN(Collabo-rative Generative Adversarial Network), 在人脸任务上使用关键点先验, 准确指示面部器官的布局.邵新茹等[20]重建图像的全局色彩, 作为先验指导修复.上述方法较好地把握图像的整体结构, 保证输出图像在整体布局上的语义真实性.然而, 全局先验无法在细节纹理上提供有效的指导, 因此生成图像尽管语义完整, 但会出现模糊的现象.
局部先验可分为边缘先验和纹理先验.边缘先验用于解决图像边界不明确的问题, 纹理先验辅助修复更清晰的图像内部细节.Nazeri等[21]提出Edge- Connect, 在第一阶段使用Canny算子检测和提取边缘特征并修复, 在第二阶段使用边缘先验实现高质量的引导作用.邵杭等[22]提出基于并行对抗与多条件融合的二阶图像修复网络, 在粗略内容和边缘的基础使用精细内容重建网络, 获得逼真的修复结果.Yang等[23]使用Sobel滤波器, 得到x方向和y方向的梯度, 实现清晰的内部纹理修复.Cao等[24]对比Canny边缘、梯度、线框、低分辨率RGB、CAT(Con-text-Aware Tracing Strategy)边缘等数十种先验, 并从实验角度得到精度最高的先验为CAT边缘.
局部先验对图像细节的补充比较到位, 但由于滤波器的感受野有限, 较难保证整体图像的语义一致性和真实性.此外, 多阶段的图像修复往往要求第一阶段修复质量较高, 否则输出结果会有较明显的误差累积现象, 即第一阶段的先验修复出现偏差时, 会影响第二阶段的内容修复.
综上所述, 尽管现有方法通过不同的先验信息实现高质量的图像修复, 但仍有不少问题需要进一步优化: 传统的先验无法兼顾全局的整体结构和局部的清晰细节, 使图像修复结果存在语义不一致或边缘模糊的现象, 而通过学习式先验可避免这一局限.进一步地, 以全局-局部特征提取器用于学习, 能同时关注图像的全局特征与局部特征, 并加以融合.
因此, 本文提出基于全局-局部先验和纹理细节关注的图像修复方法, 通过学习的方式同时捕获全局先验和局部先验, 同步进行先验修复和上下文内容修复.首先, 设计由小波-傅里叶卷积模块(Wave-let-Fast Fourier Convolutional Block, WFC)构成的先验学习器, 通过傅里叶卷积提取全局先验特征.通过小波卷积[25]提取局部细节先验特征, 并通过特征层面的L1损失训练该提取器.该先验学习器既能提取全局特征, 保证图像的整体内容布局也能提取局部特征, 使输出图像具有清晰的纹理和边缘信息.在得到先验之后, 受损图像与先验信息分别输入两支修复网络.这两个分支都由小波-傅里叶卷积构成, 仅在输入通道和输出通道上有差别.先验分支与内容分支在修复完成后通过Bi-GFF(Bi-directional Gated Feature Fusion)[26]合并输出, 得到完整图像.同时, 本文构造高感受野风格损失, 使输出图像能在更高视野下关注语义层面的图像风格一致性.通过多视野先验学习方式和小波-傅里叶卷积提取器, 生成的图像具有语义完整的内容、清晰的边缘和细致的纹理信息.在多个数据集上的实验表明本文方法性能较优.
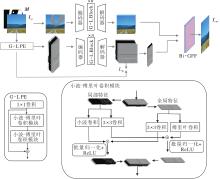
本文提出基于全局-局部先验和纹理细节关注的图像修复方法, 整体框架如图1所示.
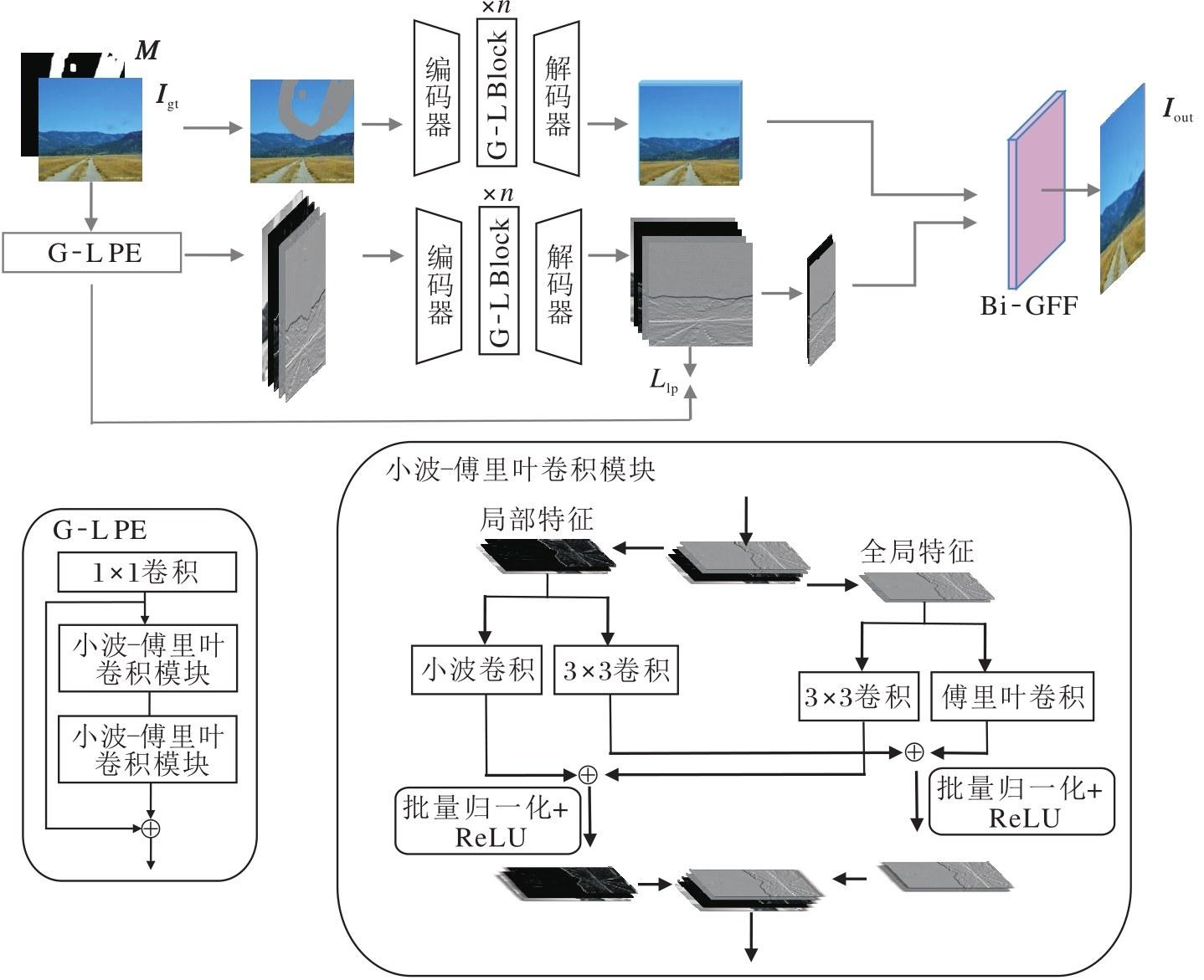 | 图1 本文方法整体框架Fig.1 Overall architecture of the proposed method |
本文方法分为小波-傅里叶卷积模块、全局-局部学习式先验、先验与内容的修复与融合三部分.首先, 构造小波-傅里叶卷积模块和全局-局部特征提取模块(Global-Local Block, G-L Block).然后, 利用小波-傅里叶卷积模块构造全局-局部先验提取器(Global-Local Prior Extractor, G-L PE), 提取先验.最后, 以同样方式构造先验修复分支和内容修复分支, 分别修复先验和内容, 融合两者并输出完整结果.
给定完整图像I和二值掩码矩阵M(1表示受损区域, 0表示未受损区域), 受损图像:
IM=I☉(1-M),
其中☉表示逐元素相乘.在训练时, IM通过G-L PE得到全局-局部学习式受损先验PM, 再经过先验修复分支得到Pout.同时, IM也通过内容修复分支初步修复出结果.在每个分支结构中, 又使用两支并行结构, 在频域恢复图像信息.两域恢复的融合是以通道维度堆叠的方式进行的, 通过Bi-GFF合并内容与先验, 输出完整结果Iout.
通过上述三个部分的设计, 本文方法能捕获全局和局部的先验特征, 并从整体和细节上协同把握图像的修复过程, 使生成图像具有一致的语义内容和清晰的边缘与纹理.
为了提取全局特征与局部特征, 本文改进文献[27]的快速傅里叶卷积模块, 构造小波-傅里叶卷积模块, 具体结构如图1所示.
该模块将输入特征分为局部特征和全局特征.局部特征通过小波卷积充分提取各频带细节, 同时也通过卷积提取特征分支并与全局特征部分融合.全局特征通过傅里叶卷积扩大感受野, 同样通过卷积提取全局特征并与局部特征部分融合.最终输出特征:
Fout=WFC(Fin),
其中, Fin表示输入特征, WFC(·)表示小波-傅里叶卷积层.
单个通道的小波卷积运算示例如图2所示, 在小波变换部分, 使用二维Haar小波变换[25], 将输入特征通过如下4种步长为2的卷积核分解为4种分量特征:
$\begin{array}{l} f_{\mathrm{LL}}=\frac{1}{2}\left[\begin{array}{ll} 1 & 1 \\ 1 & 1 \end{array}\right], f_{\mathrm{HL}}=\frac{1}{2}\left[\begin{array}{cc} 1 & 1 \\ -1 & -1 \end{array}\right], \\ f_{\mathrm{HD}}=\frac{1}{2}\left[\begin{array}{cc} 1 & -1 \\ -1 & 1 \end{array}\right], f_{\mathrm{HV}}=\frac{1}{2}\left[\begin{array}{ll} 1 & -1 \\ 1 & -1 \end{array}\right], \end{array}$
其中, fLL表示低频滤波器, fHL表示水平方向梯度滤波器, fHD表示斜对角方向梯度滤波器, fHV表示垂直方向梯度滤波器.
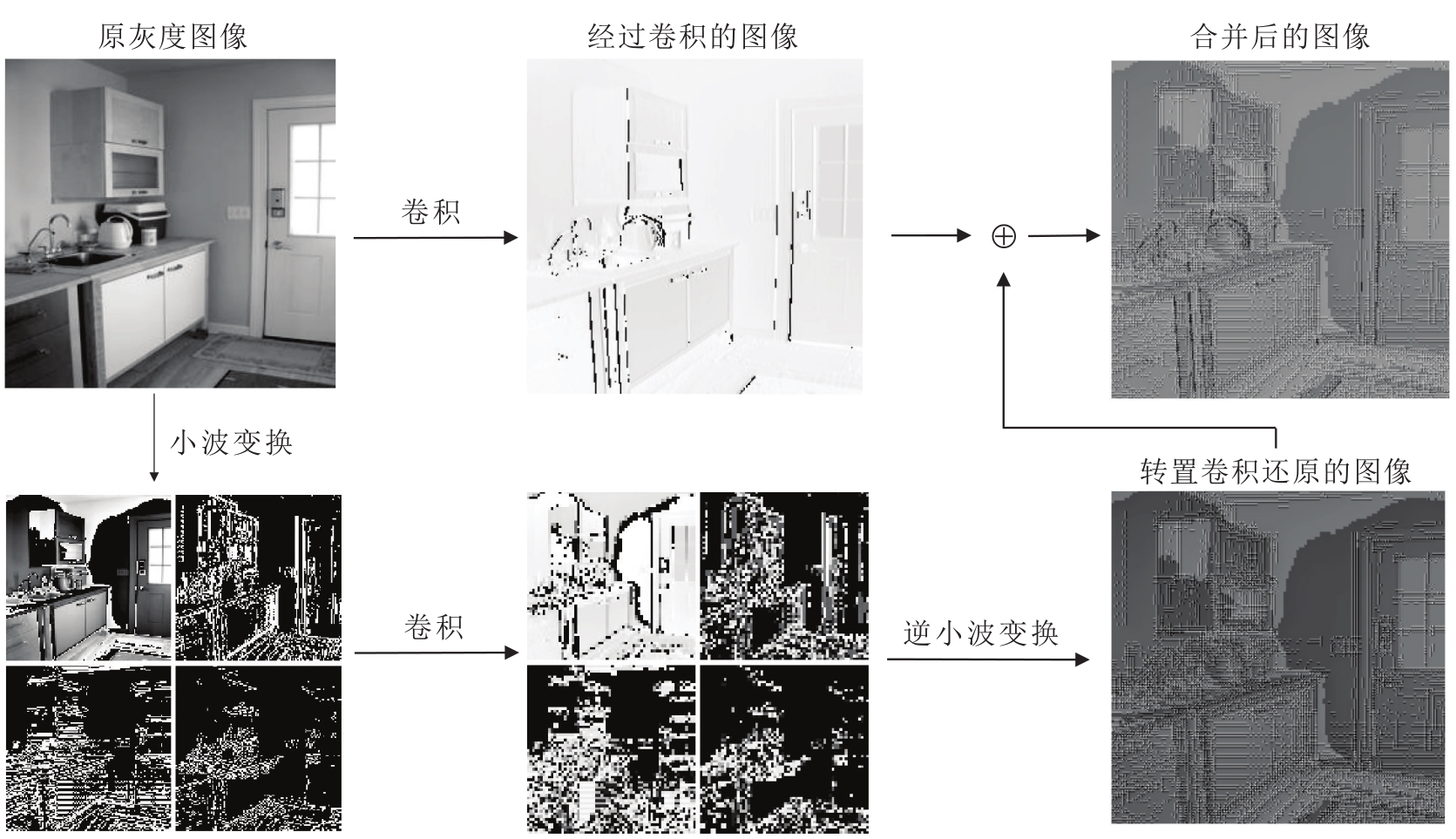 | 图2 单个通道的小波卷积运算示例Fig.2 An example of wavelet convolution operation for a single channel |
经过小波变换后, 各分量通过一层卷积进一步提取特征:
[FLL, FHL, FHD, FHV]=Conv([fLL, fHL, fHD, fHV], Fin),
其中, FLL、FHL、FHD、FHV分别表示通过4种滤波器得到的各分量特征, Conv([fLL, fHL, fHD, fHV], Fin)表示以[fLL, fHL, fHD, fHV]为卷积核作用在Fin 上的卷积运算.再经过逆变换转换回原空间.由于二维Haar小波变换使用正交基, 逆小波变换可表示为转置卷积的形式, 即
[F'LL, F'HL, F'HD, F'HV]=Conv([FLL, FHL, FHD, FHV]),
其中Conv([FLL, FHL, FHD, FHV])表示以3×3的卷积核作用在[FLL, FHL, FHD, FHV]上的卷积运算.至此, 最终输出特征:
其中Conv-transposed([fLL, fHL, fHD, fHV], [FLL, FHL, FHD, FHV])表示以[fLL, fHL, fHD, fHV]为卷积核分别一一对应作用在[FLL, FHL, FHD, FHV]上的转置卷积.
类似地, 在全局特征提取部分, 本文使用快速傅里叶变换[27].通过快速傅里叶变换, 图像空域特征转化为谱域特征, 对谱域特征进行卷积时, 卷积核处理的特征对应于原图整个空间特征中包含对应频率的部分, 这使得快速傅里叶卷积具有较高感受野, 因此能提取全局特征, 最终输出特征为:
其中,
将快速傅里叶卷积、小波卷积和另外与它们并行的卷积层按图1中的方式结合, 构成小波-傅里叶卷积模块.
通过小波-傅里叶卷积模块, 成功分离输入特征并提取为局部特征和全局特征, 两种特征经过批量归一化和ReLU激活后, 以对称的方式融合并输出Fout.此外, 当堆叠两个以上的小波-傅里叶卷积模块时, 由于下一层的输入中局部特征部分也包含被卷积处理过的全局特征, 输入特征不仅能分别分成局部特征和全局特征, 还能在过程中交互影响.
本文通过残差的方式将两个小波-傅里叶卷积模块组合为全局-局部特征提取模块(G-L Block).这样的构造有如下优点.
1)残差的构造可保留原始特征, 使方法在提取特征时更容易关注和学习需要修复的内容, 同时增强多个模块之间的独立性.
2)相比传统的卷积[27], 将小波变换引入用于局部特征处理, 能直接关注边缘细节和纹理.同时, 在形状和边缘特征识别场景中, 小波卷积可更好地响应.特别是在图像受损时, 小波卷积的多频率处理[28]可增强模型对图像损坏的鲁棒性.
3)两层堆叠的模块可增强局部特征和全局特征的交互.基于上述优点, 本文利用小波-傅里叶卷积模块和全局-局部特征提取模块, 构造全局-局部先验提取器、内容自编码器和先验自编码器.
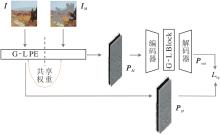
如图3所示, 本文的全局-局部学习式先验由一个1×1的卷积层和一个G-L Block组成.这一模块首先作用在受损图像IM上, 得到受损先验:
PM=PE(IM),
其中, PE(·)表示先验提取器, 在提取PM和Pgt时使用共享参数的先验提取器.同样作用在完整图像上, 可得到全局-局部学习式监督先验:
Pgt=PE(Igt).
受损先验PM经过先验修复, 得到
Pout=AE(PM),
其中AE(·) 表示自编码器.
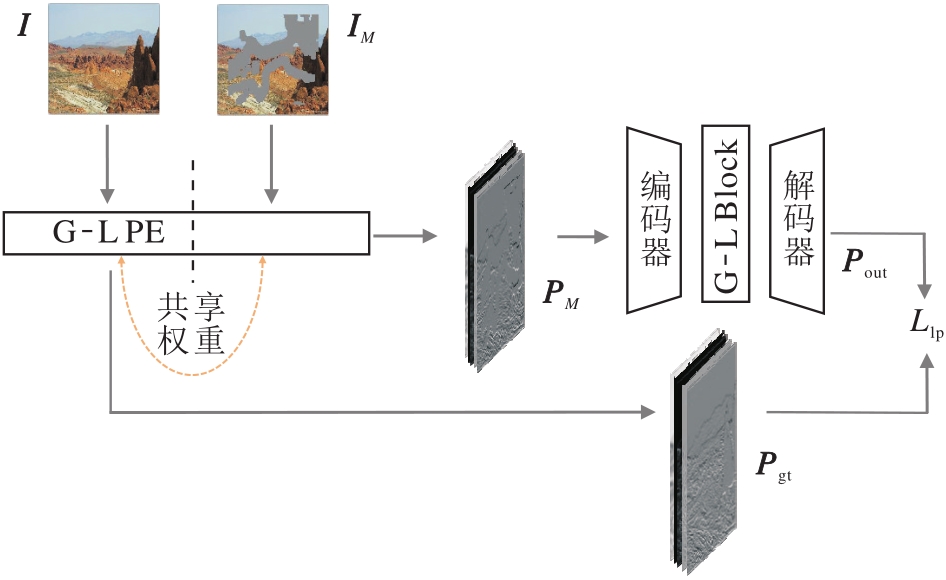 | 图3 全局-局部学习式先验的提取及训练过程Fig.3 Extraction and training process of global-local learning-based prior |
在特征层级的先验损失Llp和Pgt的作用下, 先验分支可实现全局-局部学习式先验的修复训练.
通过这种学习结构, 本文得到学习式先验.不同于以往给定的滤波器提取固定先验, 本文的学习式先验通过学习的方式训练提取器, 因此提取的先验也是可学习的.
此外, 由于G-L PE是由全局-局部特征提取模块构成, 因此, 相比传统先验, G-L PE兼顾全局特征和局部特征, 既保证图像整体内容的语义完整性, 也增强图像纹理和边缘的清晰度[29].需要指出的是, 通过控制G-L PE的输出层数可控制先验的数量, 因此设置较多层数可使学习式先验提取器学习多样化的先验.
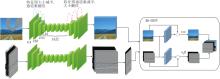
先验与内容的修复与融合部分均由小波-傅里叶卷积模块构成, 具体结构如图4所示.两个分支除去输入通道不同以外其它均相同, 并且都使用自编码器的结构作为主干.
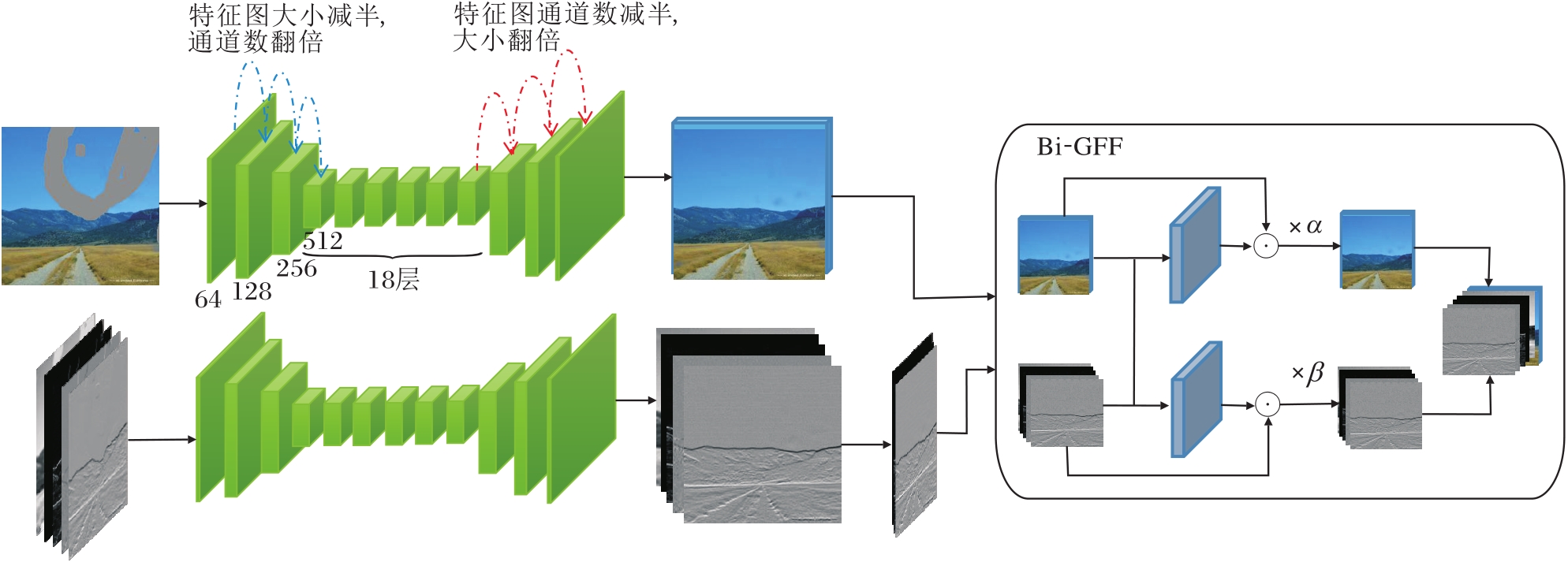 | 图4 先验与内容的修复与融合结构图Fig.4 Structure of prior and content inpainting and fusion |
与LaMa(Large Mask Inpainting)[27]类似, 首先, 通过3层下采样小波-傅里叶卷积(在小波-傅里叶卷积模块的第一个特征提取层将卷积步长设为2, 即为下采样小波-傅里叶卷积)将受损图像或先验编码到隐空间.再连续通过多组G-L Block, 在编码空间实现特征修复.
然后, 通过3层上采样层(使用转置卷积)将初步修复的内容编码和先验编码解码至原空间.
最后, 经由Bi-GFF, 将内容与先验充分交互合并, 输出完整图像.这样的构造使方法能实现语义先验和纹理边缘先验的修复, 协同指导原缺失内容的补全, 实现更精细的图像修复.
本文将G-L Block的层数控制在18层.Bi-GFF通过两个门控机制自适应地融合先验特征和内容特征, 最终输出特征为:
其中
Gc=σ(Conv(Concat(Pout, Cout))),
Gp=σ(Conv(Concat(Pout, Cout))),
Pout表示先验分支的输出, Cout表示内容分支的输出, σ(·)表示Sigmoid激活函数, α、 β表示可学习的系数.
本文使用L1重构损失、感知损失、对抗损失构造损失函数, 此外新增学习式先验损失和高感受野风格损失.
为了使重构的先验更接近真实先验, 使用最直观衡量两者差距的L1损失, 先验损失定义为
Llp=‖ Pout-Pgt‖ 1,
其中‖ ·‖ 1表示L1距离.
传统的感知损失和风格损失使用预训练的VGG-16[30]作为特征提取网络, 作用在输出图像Iout和真实图像Igt上, 并根据各层提取特征衡量两者的差距[31].然而, VGG-16的感受野较小, 难以衡量图像之间全局特征的相似程度.本文使用预训练的ResNet-dilated-50[27]作为特征提取网络ϕ , ϕ 以膨胀卷积为卷积核, 大幅提升感受野, 更好地关注Iout和Igt在全局特征上的差异.感知损失Lper和风格损失Lstyle可分别表示为
Lper=
Lsty=
其中, ϕ l(·)表示ResNet-dilated-50的第l层输出特征, Hl、Wl表示第l层输出特征的高、宽, Cl表示第l层输出特征的通道数.
本文也采用重构损失Lrec衡量Iout和Igt的距离, 即
Lrec=‖ Iout-Igt‖ 1.
类似地, 为了使输出图像具有更逼真的细节, 本文也使用对抗损失[32]:
其中, G表示生成器即本文方法, z表示服从于生成图像分布的样本.
综上所述, 总损失:
Ltotal=λrecLrec+λlpLlp+λperLper+λstyLsty+λadv
其中, λrec、λlp、λper、λsty、λadv表示权重, 本文参照文献[21]和文献[27], 设定
λrec=10, λlp=1, λper=10, λsty=250, λadv=0.1.
为了验证本文方法的有效性, 选择在如下三个公共数据集和一个掩码数据集上进行实验.
1)Places2数据集[33].场景图像数据集, 本文采用12个场景共60 000幅图像作为训练集, 1 200幅图像作为测试集.
2)CelebA-HQ数据集[34].包含30 000幅高质量人脸图像, 本文采用29 500幅图像作为训练集, 500幅图像作为测试集.
3)Paris StreetView数据集[35].包含15 000幅巴黎街景图像, 本文采用14 900幅图像作为训练集, 100幅图像作为测试集.
4)掩码数据集[36].包含12 000个不规则掩码, 分为6个等长间隔, 每个间隔2 000幅图像, 掩码比例分别是1%~10%, 10%~20%, 20%~30%, 30%~40%, 40%~50%, 50%~60%.在训练阶段和测试阶段, 所有图像和掩码大小调整为256×256.
所有的实验都在NVIDIA RTX 6000 GPU上进行, 并通过PyTorch框架实现.在训练过程中, 使用Adam(Adaptive Moment Estimation)[37]作为整个网络的优化器.生成器学习率为1×10-4, 判别器学习率为1×10-5, 批量大小为4.同时, 使用峰值信噪比(Peak Signal to Noise Ratio, PSNR), 结构相似性(Structure Similarity Index Measure, SSIM)和LPIPS(Learned Perceptual Image Patch Similarity)作为衡量图像修复性能的指标.PSNR、SSIM数值越大修复效果越优, LPIPS数值越小修复效果越优.
此外, 参数设置如表1所示, 在表中, Conv表示卷积层, ConvT表示反卷积层, WFC表示小波-傅里叶卷积模块, K表示卷积核尺寸, S表示滑动步长, P表示零填充数.
| 表1 本文方法参数设置 Table 1 Parameter settings of the proposed method |
为了证实本文方法的修复性能, 选择如下7种深度学习图像修复方法进行对比实验:Spa-former[13]、EdgeConnect[21]、CTSDG(Conditional Tex-ture and Structure Dual Generation)[26]、LaMa[27]、RFR(Recurrent Feature Reasoning)[38]、Edge-LBAM(Edge-Guided Learnable Bidirectional Attention Map)[39]、 CMT(Continuously Masked Transformer)[40].
为了公平起见, 所有实验均在相同的环境和设置下进行.各方法在Places2、CelebA-HQ、Paris Street-View数据集上的指标值对比结果如表2~表4所示, 其中黑体数字表示最优值.由表可见, 本文方法在整体结果上均最优, 并且在不同的数据集上有不同的提升, 在Places2、CelebA-HQ数据集上提升更明显, 尤其是PSNR值, 由此说明本文方法能适应于各类分布的数据.
| 表2 各方法在Places2数据集上的指标值对比 Table 2 Comparison of metric values for different methods on Places2 dataset |
| 表3 各方法在CelebA-HQ数据集上的指标值对比 Table 3 Comparison of metric values for different methods on CelebA-HQ dataset |
| 表4 各方法在Paris StreetView数据集上的指标值对比 Table 4 Comparison of metric values for different methods on Paris StreetView dataset |
Places2数据集上的数据包含相当多的场景图像, 任务难度较大.本文方法在一个多场景数据集(Place2数据集)上的优越性能表现说明其自身可适应不同场景的修复任务.CelebA-HQ、Paris Street-View数据集上的数据分布并没有像Places2数据集上那样多样性, 图像的语义信息更接近, 人类面部器官相似程度和建筑之间的相似程度远高于不同场景之间的相似程度, 因此任务较简单.本文方法仍能取得优越的性能表现, 这说明本文方法不论在单一风格的图像任务或多种风格的图像任务上都具有较好的适应能力, 对不同的数据类型表现出一致优越的性能.
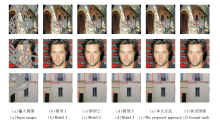
各方法在Places2、CelebA-HQ、Paris StreetView数据集上的可视化结果如图5~图7所示.由图可见, 本文方法可视化结果最优.
 | 图5 各方法在Places2数据集上的可视化结果对比Fig.5 Comparison of visualization results for different methods on Places2 dataset |
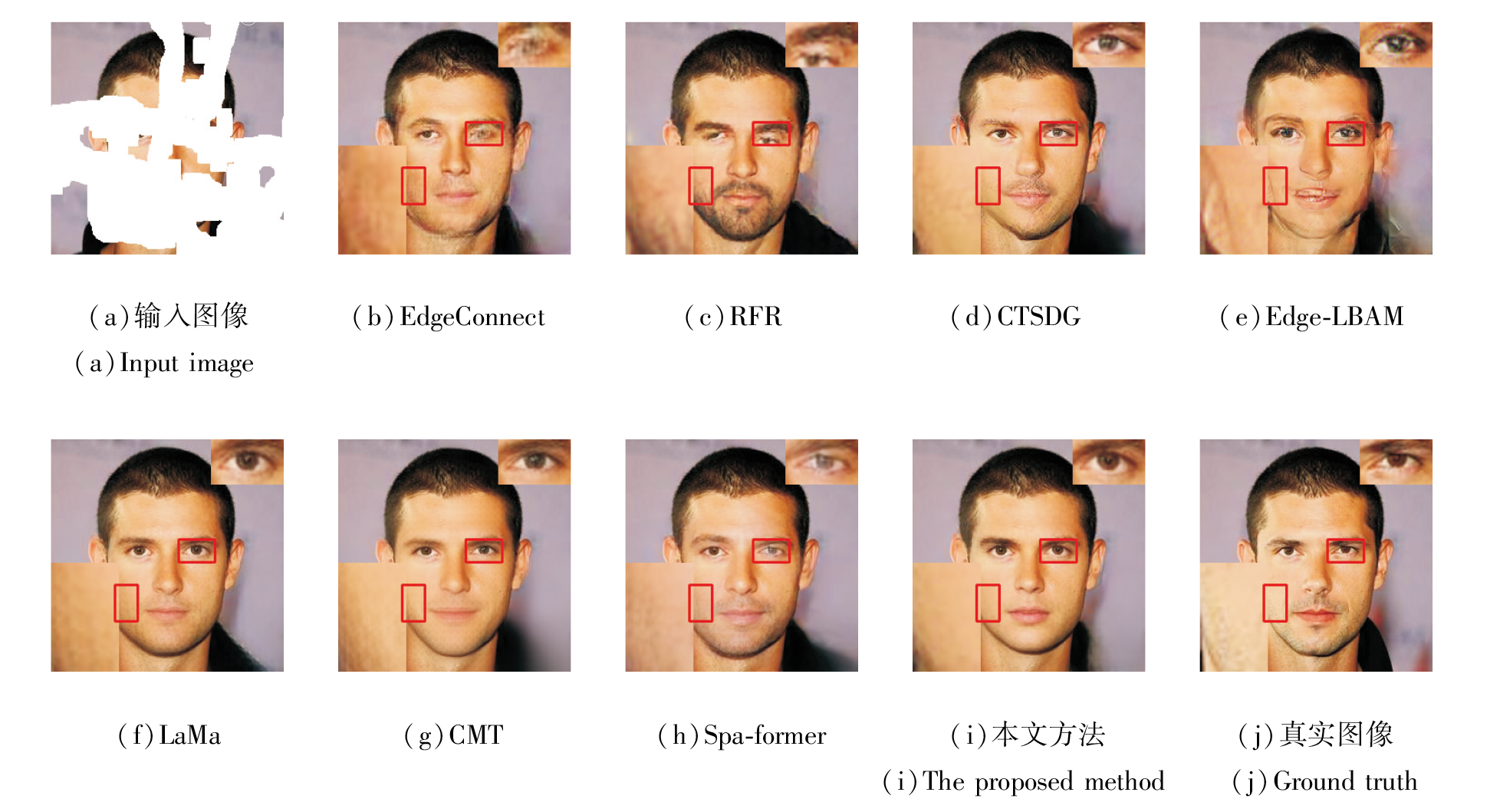 | 图6 各方法在CelebA-HQ数据集上的可视化结果对比Fig.6 Comparison of visualization results for different methods on CelebA-HQ dataset |
 | 图7 各方法在Paris StreetView数据集上的可视化结果对比Fig.7 Comparison of visualization results for different methods on Paris StreetView dataset |
图5中对比方法生成的场景图像都存在模糊区域、斑块、边界不清晰等影响视觉效果的现象.例如, 原图像远处的山脊较平直, 而在修复结果中只有EdgeConnect、CMT和本文方法具有较清晰和明确的边界, 但在近地面的路中, EdgeConnect的结果过于模糊, CMT则有较明显的斑块.
图6中人脸受损区域较大, 这类受损图像的修复考验方法对人脸整体布局的把握能力.就眼睛的布局而言, 只有LaMa、CMT和本文方法在语义上较合理, 同时, LaMa、CMT修复的面部皮肤仍有较明显的重复性的斑块, 而本文方法在一定程度上缓解这一现象, 修复后的面部内容具有更合理平滑的纹理细节.
在图7中, 本文方法修复结果的合理性体现在一楼明确的窗户边缘以及二楼窗台左端点处与墙壁明确的区分, 明显优于对比方法.
综上所述, 本文方法在视觉上也优于现有对比方法, 修复结果边界清晰、纹理细节真实.
在Places2数据集上进行消融实验.本文方法包含三个重要部分:高感受野风格损失、小波-傅里叶卷积模块、学习式先验分支.为了验证三个部分的有效性, 设计如下3组消融实验:
1)模型1, 移除高感受野风格损失;
2)模型2, 移除学习式先验分支;
3)模型3, 替换小波-傅里叶卷积中的小波卷积为普通卷积.
模型1~模型3和本文方法在Places2、CelebA-HQ、Paris StreetView数据集上的具体指标值对比如表5所示, 表中黑体数字表示最优值.
| 表5 在不同数据集上的消融实验指标值对比 Table 5 Comparison of metric values in ablation experiment on different datasets |
由表5可观察到, 本文方法性能最优.模型1~模型3的结果都与本文方法结果有一定差距, 这验证本文方法三个部分的有效性.当使用小波-傅里叶卷积或全局-局部学习式先验之后, 精度都有一定程度的提升, 这是因为小波-傅里叶卷积能同时把握全局信息和局部细节, 并且将两者较好地交互与融合, 而全局-局部学习式先验对内容修复起到指导作用, 进一步增强图像的全局一致性以及局部纹理和边缘清晰度.高感受野风格损失则能更好地从全局视角衡量生成图像与真实图像之间的风格差异, 使生成图像在视觉上能更接近真实图像.
在不同数据集上的消融实验可视化结果如图8所示.由图容易观察到, 本文方法在内容的生成上比模型1~模型3的结果更合理, 包括第1幅图像的窗台、第2幅图像人脸背后的纹路、第3幅图像的百叶窗门等内容.
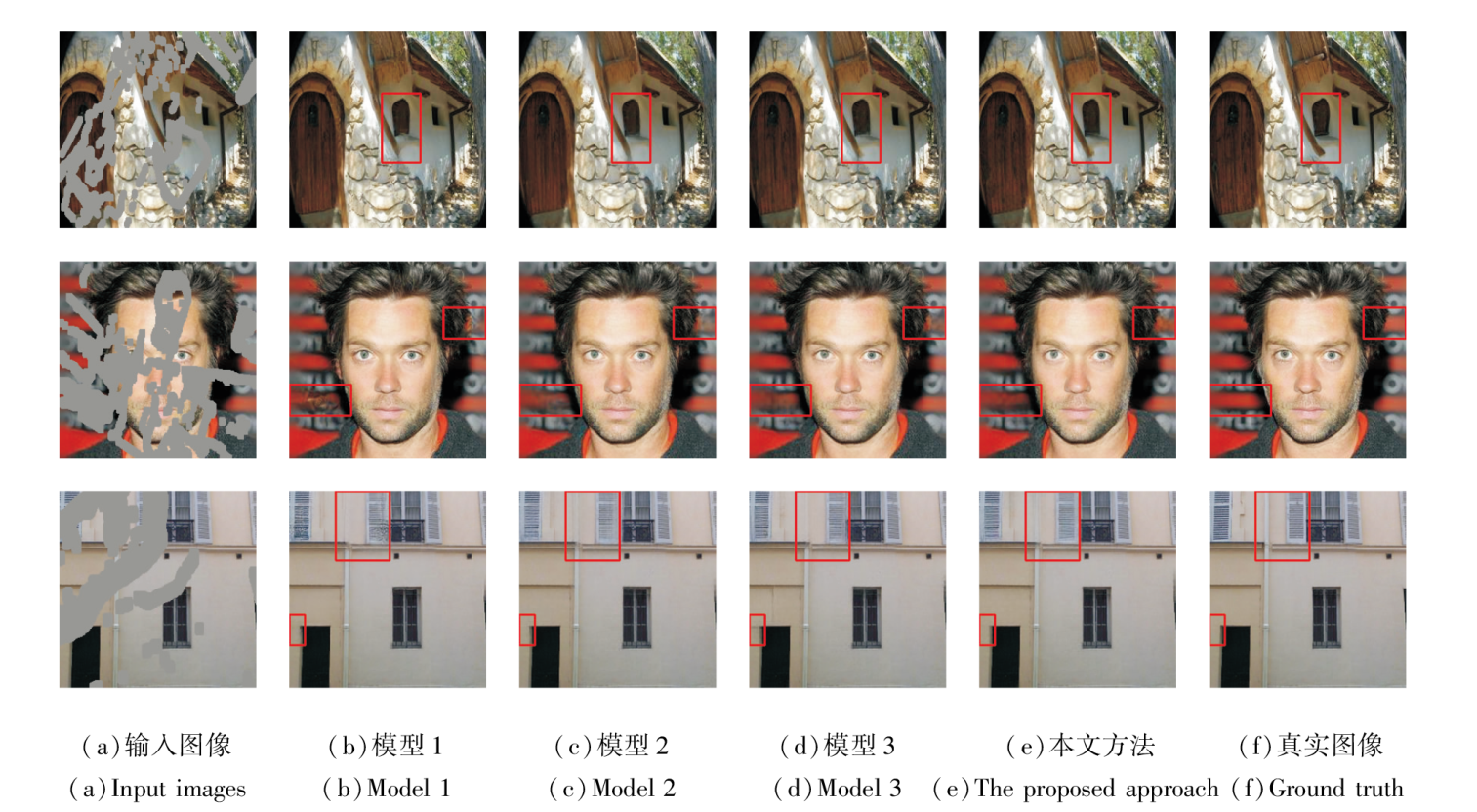 | 图8 消融实验的可视化结果对比Fig.8 Comparison of visualization results in ablation experiment |
为了讨论编码层的层数对本文方法性能的影响, 设置编码层G-L Block的数量n=6, 18, 24, 具体指标值如表6所示, 表中黑体数字表示最优值.
| 表6 不同n对本文方法性能的影响 Table 6 Effect of different n on performance of the proposed method |
由表6可发现, 除了n=24, 10%~20%受损情况下的PSNR值明显高于n=6, 18时以外, 其余指标值均只有细微差异.在n=6和n=18时性能各有高低, 增加模块带来的效果提升并不明显, 直至将n增至24时才有较一致的提升.
为了更好地说明本文方法三个部分的有效性, 在n的取值上本文选择和Big LaMa[27]保持一致, 设置n=18.若在实际应用中有参数量限制等要求, 则可设定n=6, 大幅减少隐藏层的模块堆叠数量.
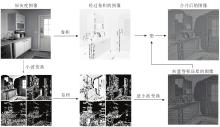
为了验证全局-局部学习式先验与其它先验的区别, 将图像修复过程中得到的先验进行可视化, 并选择具有代表性的部分加以阐述.结果如图9所示, (a)为原图, (b)~(e)为全局式先验, (f)~(i)为局部细节先验, (j)、(k)为混合式先验.
 | 图9 各种先验的可视化结果Fig.9 Visualization results of different priors |
全局先验的特点在于, 关注图像的整体内容, 如器官分布、整体颜色布局等, 因此图像较模糊, 像素点之间的差异较小, 但不同部分的颜色特征差异明显.局部细节先验的清晰度较高, 像素点之间的差异较大, 可对内容起到边界约束和纹理的指导作用.
此外, 需要指出的是, 混合式先验特指如图9(j)、(k)所示的划分成像素块的先验.这类先验的特点在于像素块内部较模糊, 体现整体特性, 而块之间的差异较明显, 体现局部特性.这种混合特征表明深度网络将像素块当成像素点, 可通过所有像素块整体性地考虑图像的特征表示.
各方法的FLOPs(Floating Point Operations per Second)、参数量及每幅图像的推理时间对比如表7所示.
| 表7 各方法复杂度与推理时间对比 Table 7 Comparison of complexity and referring time among different methods |
由表7可见, 相比现有方法, 本文方法的复杂度较高, 但是本文方法在各个数据集上的效果均达到最优.
为了平衡模型精度与执行速度, 可行的做法包括剪枝与优化.此外, 就本文方法而言, 先验与内容分支的模型复杂度允许不同.通过不同的模块参数设计和剪枝策略等方式, 理论上可达到降低参数量、提高模型速度的效果.
为了检验本文方法在实际任务中的应用效果, 同时检验其泛化能力, 在一些现有图像上人为添加掩码并进行模型修复, 结果如图10所示.
 | 图10 本文方法在人脸编辑和物体移除上的可视化结果Fig.10 Visualization results of the proposed method on face editing and object removal |
图10中, 前两幅图像为人脸编辑, 包括墨镜的移除和面部严肃表情的缓和; 后两幅图像为场景图像中的移除任务, 包括烟囱的移除、遮挡树干的移除.
通过4幅图像的结果可明显看出, 本文方法具有良好的性能表现, 输出图像具有一致的语义内容、清晰的边缘和纹理细节.
本文提出基于全局-局部先验和纹理细节关注的图像修复方法, 使修复图像的结果具有一致的语义、丰富的纹理和清晰的边缘.首先构造小波-傅里叶卷积模块, 用于局部特征和全局特征的提取.进一步, 利用小波-傅里叶卷积模块构造先验提取器, 并在学习式先验的结构下构造先验分支, 指导图像内容的修复.最后, 设计高感受野风格损失, 进一步缩小图像之间的风格差距.在不同数据集上的实验及消融实验验证本文方法的有效性.通过与其它方法的定量对比和可视化结果对比可发现, 本文方法性能更优.同时, 通过对学习式先验的可视化也进一步验证本文方法能获得更充分的纹理细节、更清晰的边缘及更一致的语义内容.
然而, 本文方法的掩码比例上限在60%, 当面对更大比例的掩码时, 方法的生成能力更重要.因此如何将本文方法与能力更强的生成模型相结合, 如扩散模型, 是一个值得研究的课题.此外, 也可把本文的思路扩展到其它的计算机视觉任务中, 如超分辨率重建等.
本文责任编委 杨 健
Recommended by Associate Editor YANG Jian
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|
| [40] |
|