
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于语义的小样本学习原型优化方法
[刘媛媛1  , 邵明文
, 邵明文1 , 张黎旭1 , 邵浚1 ]
, 邵明文, 张黎旭, 邵浚]
|
|



作者简介:

刘媛媛,硕士研究生,主要研究方向为计算机视觉、小样本学习方法等.E-mail:13666304379@163.com.

张黎旭,硕士研究生,主要研究方向为计算机视觉、跨域小样本学习方法等.E-mail:z2216842477@163.com.

邵 浚,硕士研究生,主要研究方向为计算机视觉、域适应方法等.E-mail:shx001122@163.com.
语义信息可为小样本学习提供丰富的先验知识,然而,现有的小样本研究只在浅层结合图像与语义,无法充分利用语义探索类别特征,从而限制模型性能.为了缓解此问题,文中提出基于语义的小样本学习原型优化方法.首先,设计逐通道级语义提示模块,引导方法提取视觉特征,逐步优化类原型.然后,设计多模态边界损失,将视觉和语义维度上的类间相关性与损失函数结合,约束方法增强类原型的区分性.最后,通过两阶段微调,充分利用语义知识优化类原型,提高分类准确率.在4个基准数据集上的实验表明文中方法性能较优.
About Author:
LIU Yuanyuan, Master student. Her research interests include computer vision and few-shot learning methods.
ZHANG Lixu, Master student. His research interests include computer vision and cross-domain few-shot learning methods.
SHAO Xun, Master student. Her research interests include computer vision and domain adaptation methods.
Semantic information can provide rich prior knowledge for few-shot learning. However, existing few-shot learning studies only superficially explore the combination of images and semantics, failing to fully utilize semantics to explore class features. Consequently, the model performance is limited. To address this issue, a semantic-based prototype optimization method for few-shot learning(SBPO) is proposed. First, SBPO employs channel-wise semantic prompts to guide the model in extracting visual features while progressively optimizing class prototypes. Second, a multi-modal margin loss is designed to integrate inter-class correlations in both visual and semantic dimensions with the loss function, thereby constraining the model to enhance the distinctiveness of class prototypes. Finally, through a two-stage fine-tuning process, the model can fully leverage semantic knowledge to optimize class prototypes, thereby improving classification accuracy. Experiments on four benchmark datasets demonstrate that SBPO significantly outperforms baseline methods.
小样本学习(Few-Shot Learning, FSL)是一种在样本量稀缺下高效学习新任务的方法, 旨在训练一个模型, 通过充分利用有限的标注数据和先验知识, 使模型能有效地从基类泛化到新类.但是由于新类中样本的稀缺, 模型缺乏关于新类的相关知识, 因此对数据分布和类特征的理解不足, 难以有效地对新类进行分类和识别[1, 2].
为了应对模型缺乏对新类的理解能力的问题, 现有的小样本学习方法研究从迁移学习[3]、元学习[4]和度量学习[5]这三个角度进行探索.迁移学习的目标是将基类中的先验知识有效迁移到新类, 如TPMN(End-to-End Task-Aware Part Mining Network)[6].此类方法在基类上预训练模型以获得先验知识, 再使用少量的标注数据, 在新类上微调模型.迁移学习将通用知识从基类转移到新类, 并使模型学会提取该类别特定的特征[7].元学习方法将学习过程划分为多个小样本任务, 通过在小样本任务上集中学习, 模型获得可迁移的元知识和更新规则, 促进对新任务的快速适应和泛化.度量学习通过在特征空间学习样本间相似性度量, 捕捉新类中有限图像之间的潜在关系, 实现对新类的快速适应.上述方法大多基于从有限样本中计算的原型, 由于样本数量有限, 原型的准确性受到限制, 从而在很大程度上影响模型性能[8].
为了获得更多的类别信息, 让模型能计算更准确的类原型, 研究者考虑通过其它模态获取知识, 如从类别标签、描述和对象属性中提取语义信息.这种辅助信息可提供有价值的类别特定知识, 增强模型对新类的理解[9, 10].基于这一理念, 学者们陆续提出许多利用语义知识提高分类性能的方法, 这些研究主要采用直接融合的方式, 将语义知识与从少量样本图像中提取的不精确视觉原型直接合并, 作为最终的分类原型.例如:AM3(Adaptive Modality Mix-ture Mechanism)[11]、ProtoComNet(Prototype Com-pletion Network)[12]和KTN(Knowledge Transfer Network)[13]都将视觉和语义进行加权融合以获得原型.类似地, LPE(Latent Parts Embedding)[9]基于语义生成多个潜在编码, 分别与视觉编码进行卷积, 获得保留局部信息的原型.本质上, 这些利用语义的工作倾向于关注特征的浅层融合, 通过设计分类器等组件以组合语义和视觉原型.
随着大模型时代的到来, 预训练大模型在通用任务中表现出色, 但在特定领域缺少适应性.因此, 小样本微调的工作意义在于通过有限的标注数据高效优化预训练模型, 使其更好地适应特定领域的专业化需求, 提高在具体应用场景中的性能.然而, 现有的小样本研究未能充分利用丰富的语义信息, 也忽视文本特征和视觉特征之间深层的内在联系, 从而无法有效捕捉类别特定的特征.
为了解决原型不准确的问题并充分利用语义知识, 本文提出基于语义的小样本学习原型优化方法(Semantic-Based Prototype Optimization Method for Few-Shot Learning, SBPO), 在特征提取阶段深入研究语义信息和视觉信息之间的内在关系.通过在骨干网络中融入语义知识, 可在编码的每一步中将视觉原型向着类别特定的特征方向优化.具体而言, 本文设计通道级语义提示模块(Channel-Wise Semantic Prompt, CSP), 并嵌入骨干网络中, 在特征提取阶段促进类别标签的语义信息与图像视觉编码之间的交互.在CSP中, 视觉和语义编码在通道维度上充分交互, 再与原始视觉矩阵逐元素融合, 从而实现对视觉特征的调节和增强.为了增强不同类别样本之间的区分度, 设计多模态边界损失(Multi-modal Margin Loss, MML), 利用视觉和语义两种模态中的信息, 得到类别间的相似性作为类间距, 提高类间原型的判别性.结合CSP和MML以后, SBPO在语义提示的引导下可有效优化类别原型, 结果更精确和更具有区分性.在4个基准数据集上与其它小样本学习方法进行对比, 实验表明, SBPO性能提升显著, 特别是在5-way 1-shot设置下.
当前小样本学习的主要挑战在于新类样本数量有限, 导致模型对这些新类的理解不足.为了解决这一问题, 研究者提出多种解决方案, 其中元学习范式逐渐成为主流方法.元学习范式是指在基础类别上训练多个小样本任务, 学习快速适应新任务的能力.
基于优化的方法和基于度量的方法是元学习领域中广泛采用的两种方法.基于优化的方法的目标是从单个任务中学习模型的最佳初始参数, 以便快速适应新任务.基于度量的方法本质上是将任务样本投影到嵌入空间, 并利用设计的度量方法评估不同样本之间的相似性.最近的研究表明, 一个表现良好的编码网络比复杂的元学习方法更重要[14].
近年来, 许多研究者开始利用语义知识协助小样本学习中新类的识别[15].这些方法大致可分为两类:一类仅依赖于语义信息, 另一类结合语义信息与视觉信息.前者将语义知识作为损失函数中的辅助惩罚项约束训练模型[16], 或作为数据增强的手段增强模型的区分能力[17].后者则专注于结合语义信息与视觉信息, 为模型提供丰富的类别信息.例如:AM3[11]和ProtoComNet[12]分别通过自适应加权和补全网络融合语义信息和视觉信息, 获得最终的分类原型; LPE[9]利用语义信息生成多个潜在的局部特征编码, 与整体视觉编码进行卷积, 提取局部级别的特征.LPE这种特征提取方式是局部的、浅层的, 缺少对图像的整体认识和对语义的深度利用.
早期经典的小样本学习主要依赖有限样本的统计特性, 性能受样本数量的制约, 并且未利用其它模态信息.随着大数据时代的到来, 尤其是预训练大模型的出现, 小样本学习的研究思路有所转变.虽然大模型在通用任务中表现出色, 但在特定领域的高判别需求场景中, 如医学影像、工业材料缺陷检测等, 往往缺乏对任务的适应性.这些任务由于需要鉴别特定特征且训练样本稀缺, 导致预训练模型无法满足任务需求.为了弥补这一缺陷, 小样本学习的研究着力于使用有限的样本对模型进行微调, 从而增强模型对特定任务的适应能力, 提高分类的准确性和鲁棒性.
这些以CLIP(Contrastive Language-Image Pre-training)[18]为代表的多模态大模型, 通过海量数据预训练, 在通用场景实现较优性能.然而, 它们在完成特定任务时仍面临如下挑战.
1)场景任务理解偏差.由于CLIP是基于预训练文本图像对齐的静态编码器, 只有对通用知识的理解.在完成few-shot学习任务时, 仅使用预训练的图像编码器直接生成类原型, 未在few-shot适应阶段将文本特征与图像特征深度结合, 因此缺少对当前领域任务的适应.当遇到图像背景混杂的场面时极易受到干扰, 难以捕捉鉴别性特征, 对特定场景领域适应性不强.
2)类间判别性不足.CLIP依赖对比学习机制自动学习特征区分能力, 而不是通过显式的分类边界或规则约束类别, 导致模型在面对相似物体时由于缺少类间判别性, 容易产生类别混淆.
3)资源需求较高.CLIP图像编码器的骨干网络一般使用ResNet50或ViT, 模型参数和计算量较大, 不太适合移动端等轻量级部署.
对于一个小样本问题, 现有的研究通常将数据集分为如下两部分:基类数据集
Dbase={(xi, yi|xi∈X, xi∈Cbase)
和新类数据集
Dnovel={(xi, yi|xi∈X, xi∈Cnovel),
其中, X表示视觉空间, Cbase表示基类类别空间, Cnovel表示新类类别空间, Cbase∩ Cnovel=Ø .Dbase数据集上有大量的有标签样本, 用于预训练模型; Dnovel数据集上只有少量的有标签样本, 用于在测试阶段验证模型的性能.
在训练期间, 采用元学习的策略训练模型, 并以N-way K-shot为一个轮次划分数据集, 即每个轮次由N类组成, 每类包含K个样本.在元训练的轮次划分阶段, 从基类Cbase中随机选择N类, 并且按照这些类别在数据集Dbase中随机采样图像样本, 形成有标签的支持集S和无标签的查询集Q.支持集S由N×K个有标签的样本构成, 查询集Q中样本同样来自N类, 但无数量要求, 查询样本是通过度量与支持样本的相似性进行分类的, 从而可检验模型性能.
在元测试阶段, 所有设置保持不变, 唯一的区别是样本来自Dnovel, 从而确保训练条件和测试条件的一致性.
综上所述, 小样本问题的目标是在Dbase数据集上训练的特征提取网络在Dnovel数据集上具有较好的泛化能力.
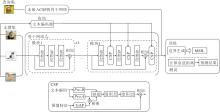
本文提出基于语义的小样本学习原型优化方法(SBPO), 框架如图1所示.
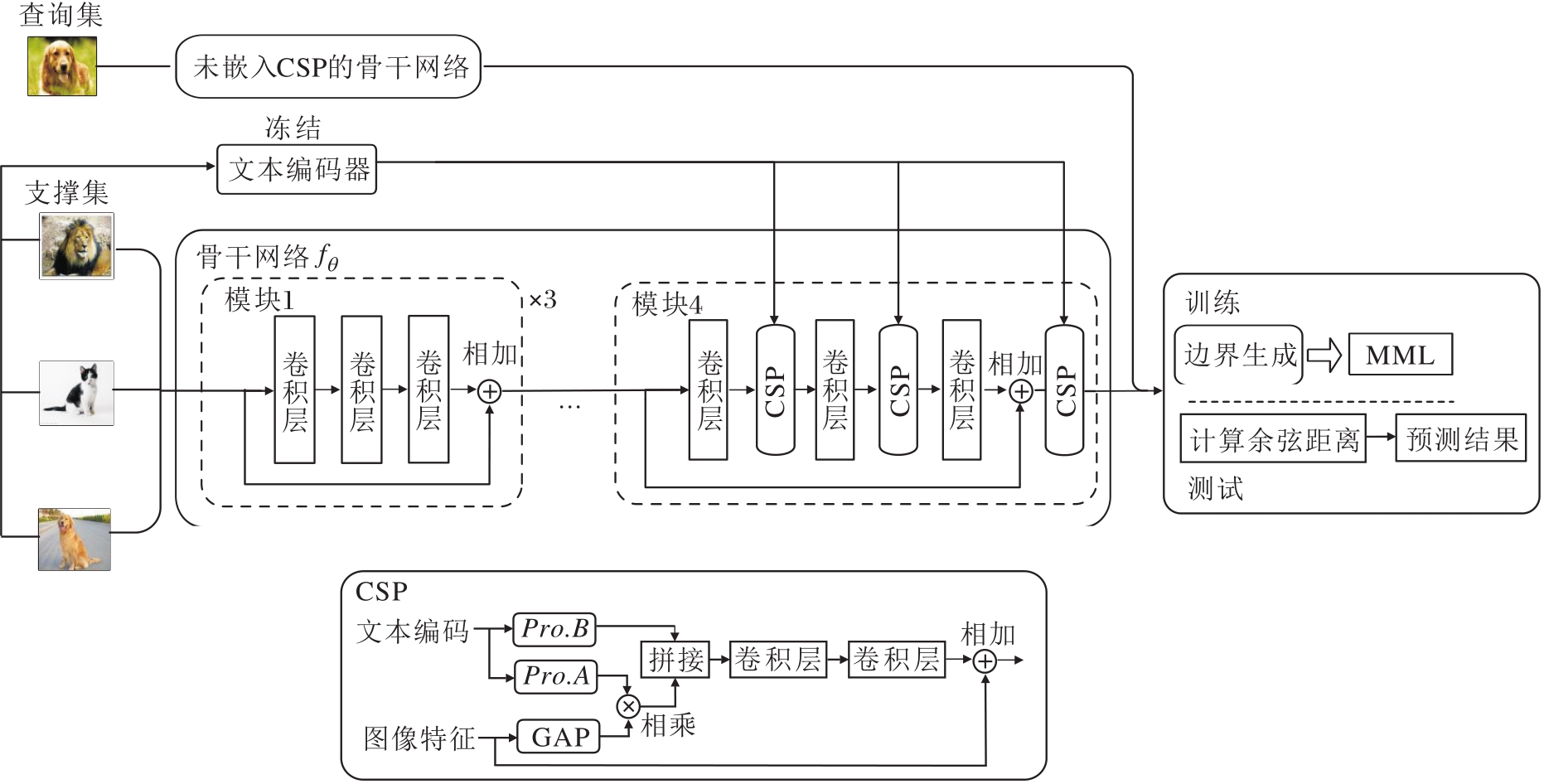 | 图1 SBPO框架图Fig.1 Structure of SBPO |
在预训练阶段, 通过最小化标准交叉熵损失, 使用基类图像训练骨干特征提取网络和线性分类器[2], 损失函数如下:
$L_{\text {pre }}=\frac{1}{\left|\boldsymbol{D}^{\text {base }}\right|} \sum_{(\boldsymbol{x}, \boldsymbol{y}) \in \boldsymbol{D}^{\text {base }}}-\ln \left(\frac{\exp \left(\boldsymbol{W}_y^{\mathrm{T}} f_\theta(\boldsymbol{x})\right)}{\sum_{i=1}^{n_C} \exp \left(\boldsymbol{W}_i^{\mathrm{T}} f_\theta(\boldsymbol{x})\right)}\right)$,
其中, nC表示类c中的样本数, Wi、Wy表示分类器权重.在元训练阶段, 移除分类器, 仅保留骨干网络fθ .
为了保证与其它方法公平对比并且最大化卷积网络的可用性, 本文采用ResNet12作为骨干网络.
在元训练阶段的每个轮次中, 将支持集S中的图像输入通道级语义提示模块(CSP)的骨干网络中进行特征提取, 同时图像对应的标签放入文本编码器进行编码, 最后在CSP中融合图像特征与文本特征.这样做的目的是为了在编码阶段准确提取样本中该类的关键特征.
获得支持图像的特征后, 求均值, 得到类别c的原型:
pC=
其中
下面将查询样本和支持集上每类的原型一起输入边界生成器模块中.该模块自适应生成类间边界惩罚, 并整合到分类损失中, 获得多模态边界损失(MML).在元训练阶段, 编码器保持冻结状态, 而骨干网络和边界生成器模块通过最小化MML进行微调.
在元测试阶段, 利用在元训练阶段由骨干网络学习的知识, 模型可获得更精确和具有区分性的类原型.再计算查询样本与每个类别原型的余弦相似度, 预测样本标签.
SBPO中最具挑战性的任务是如何有效整合两种模态的信息.本节设计视觉和语义知识融合模块, 使用CSP获取高质量的类别特定特征, 具体细节如图1所示.
CSP被嵌入骨干网络的最后一个模块中, 并在该残差块中与卷积层交替排列.这种设计允许在每次卷积特征提取之后, 模型能将提取的图像整体特征与语义信息在CSP中进行融合, 引导下一步的卷积特征提取.CSP的这种布局方式具有显著优势, 不仅促进视觉特征与语义信息的深度融合, 还使模型能在语义提示的引导下, 逐步对视觉原型进行优化, 更精确地逼近类别特定的原型.
在语义信息处理上, 采用固定的句式“ a photo of a [类名]” 作为提示, 并输入冻结的CLIP文本编码器中, 获得类名的语义信息, 例如:第c个类标签Yc的文本编码为t(Yc).
给定文本编码t(Yc)和输入图像编码X∈RC×H×W, 按如下流程输入CSP中处理.
首先, 将视觉特征和语义特征进行维度对齐并按通道拼接.对从前一模块获得的视觉特征X应用全局平均池化(Global Average Pooling, GAP), 即
g(X)=
可将形状为C×H×W的特征图转化为一个长度为C的一维向量, 从而聚合视觉信息并改变维度.同时, 文本编码使用多层感知机Pro.A∶
aC=Pro.A(t(Yc)). (1)
在函数的最后一层, 应用sigmoid函数, 限制向量的值在 [0, 1]范围内.实际上, ac可被视为用于强调由语义提示引导的视觉特征中最重要维度的权重.因此, 将它与视觉特征作哈达玛积, 即两者对应位置元素的乘积:
$W_{c}(\boldsymbol{X})=\boldsymbol{a}_{c} \otimes g(\boldsymbol{X}) .$
其次, 为了促进视觉信息和语义信息之间的充分交互融合, 将相应的语义信息sc与视觉增强特征Wc(X)按照
沿通道维度进行拼接, 其中:·‖ ·表示连接, sc表示投影层Pro.B的输出.
投影层Pro.B是一个两层的多层感知机:
sc=Pro.B(t(Yc))∈
用于统一文本和语义嵌入的维度.拼接之后,
为了进一步整合视觉信息和语义信息, 采用两个逐点卷积块, 专注于进行通道间的交互.第1个块记为W
$H(\widetilde{\boldsymbol{X}})=\sigma\left(B\left(\boldsymbol{W}_{u}^{T}\left(\sigma\left(B\left(\boldsymbol{W}_{D}^{T}(\widetilde{\boldsymbol{X}})\right)\right)\right)\right), \right.$
其中, σ(·)表示sigmoid函数, B(·)表示批量正则化.
融合二者后, 将得到的向量以逐通道的方式加入原始特征矩阵中, 得到X'∈RC×H×W.这种相加操作能在每个通道上微调特征, 将整合后的视觉信息和语义信息纳入原始特征表示中.
最后, 通过前向计算的过程, 模型利用卷积等操作逐步融合视觉信息和语义信息.这种对视觉特征在特征提取阶段的逐步优化使类原型能自适应地进行优化, 得到更具代表性的类原型.
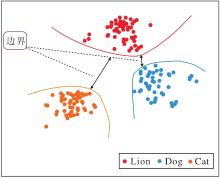
本节旨在设计多模态边界损失(MML), 训练网络编码的特征向量, 能在特征空间中与不同类别的向量距离更远, 实现更精确的分类边界.更具体地说, 通过考虑不同类别之间的相关性以自适应生成类间边界.特征空间中的类间边界效果图如图2所示, 在使用MML训练后, 相似度较高的类别(Cat类和Lion类)之间产生更大的边界.
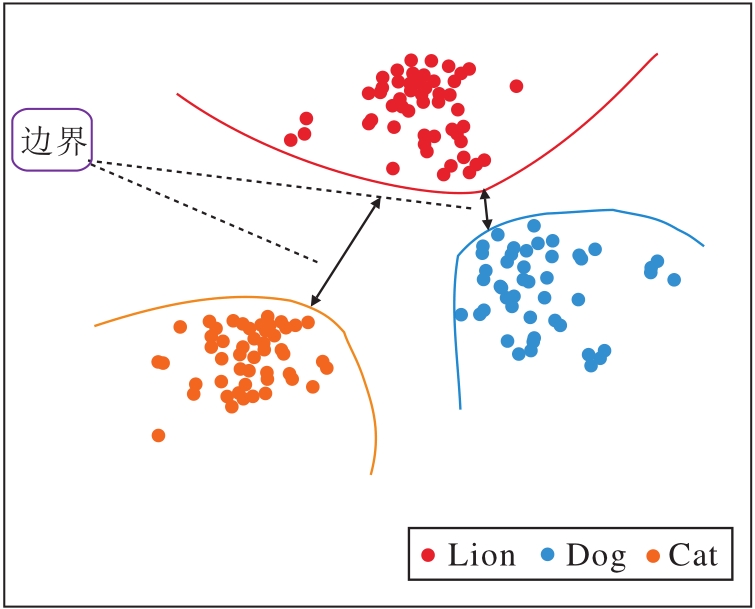 | 图2 特征空间中的类间边界效果图Fig.2 Visual representation of class margin in feature space |
类间边界的灵感来源于TRAML(Task-Relevant Additive Margin Loss)[16].然而, 与该工作不同的是, 本文的边界生成器不仅考虑类间语义特征相似性, 还考虑样本之间的视觉特征相似性.因为有些物体在语义特征上相差很大但视觉特征上相差无几.例如:鸡蛋和乒乓球在语义上明显不同, 但在图像上具有很高的相似度.于是, 本文在语义和视觉两个模态充分度量类间相关性, 通过对相关性较高的类间赋予更大的类间边界以拉开类间距离, 加强对不同类别的判别能力.
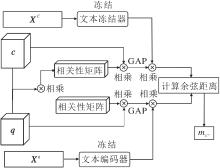
整个边界生成过程如图3所示.首先, 在骨干网络提取特征的最后一步中, 不把提取的视觉特征池化为一个向量, 而是保留特征矩阵, 这样有助于保留更多的细粒度细节.原型矩阵Xc∈RC×H×W, c∈Ct, 表示类c的原型; 查询特征图Xq∈RC×H×W是从查询样本(xq, y)中提取的, 其中y∈Ct, y≠ c.
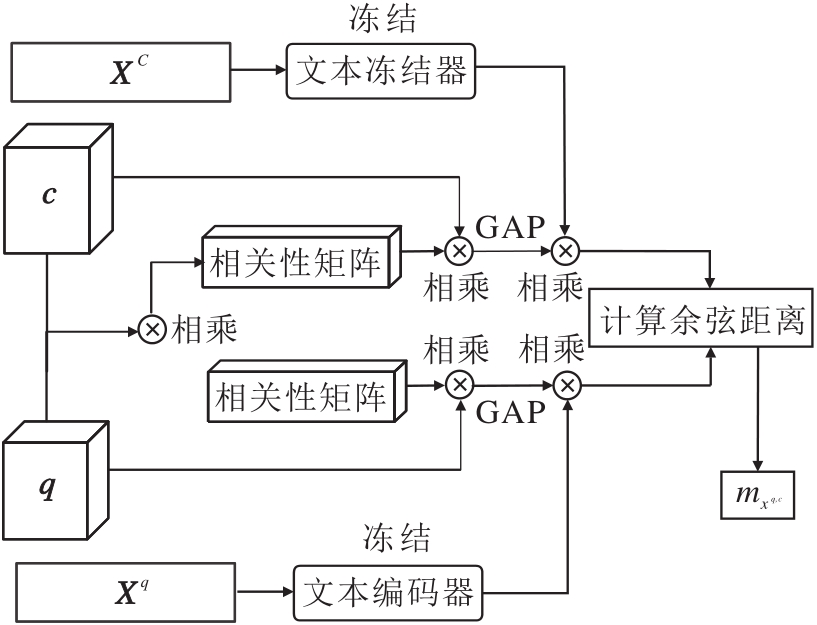 | 图3 类边界生成过程Fig.3 Process of class margin generation |
其次, 计算Xc和Xq之间的相关性矩阵,
XRc=(Xc)T×(Xq)∈RM×H×W,
用以提取两类样本之间的相关特征, 其中×表示矩阵相乘, M=H×W.
在矩阵乘法的形式下, XRc表示原型Xc的每个局部特征与查询样本Xq全局特征之间的相关性.同样, 定义相关性矩阵
XRq=(XRc)T∈RM×H×W.
XRq表示每个局部查询特征Xq与原型Xc全局特征之间的相关性.
然后, 将相关性矩阵沿通道维度求均值, 得到两者空间维度的相关性图.将此相关性图与原特征矩阵相乘, 为每个空间区域赋不同的权重值.使用GAP获得各自的视觉特征向量, 再与文本的语义特征进行逐元素相乘, 得到结合两个模态的类间相关性.最后, 支持集和查询集的向量计算的余弦距离称为边界
给定样本(xq, y), y∈Ct, y≠ c, 可对除y以外的其它类别c, c∈Ct\{y}, 生成类间边界
$L=\frac{1}{|\boldsymbol{Q}|} \sum_{\left(x^q, y\right) \in \boldsymbol{Q}}-\ln \left(\frac{\exp \left(D\left(\boldsymbol{x}^q, \boldsymbol{p}_y\right)\right)}{\exp \left(D\left(\boldsymbol{x}^q, \boldsymbol{p}_y\right)\right)+\sum_{c \in C_t \backslash\{\boldsymbol{y}\}} \exp \left(D\left(\boldsymbol{x}^q, \boldsymbol{p}_c\right)+m_{x^q, c}\right)}\right)$
纳入损失函数, 用于增加查询样本xq与类c之间的距离.其中, py表示类y的原型, D(·)表示余弦相似度计算.
通过在不同类别特征的距离度量D(xq, py)之后增加
在测试阶段, 利用训练得到的特征提取网络, 不需要经过边界生成器, 直接使用余弦相似度计算样本与类别原型之间的距离, 实现更准确高效地分类.
本文选择在miniImageNet[1]、tieredImageNet[19]、CIFAR-FS[20]、CUB[21]这4个基准数据集上进行实验.miniImageNet、tieredImageNet数据集是从Image-Net数据集[22]上衍生的子集.CIFAR-FS数据集源自CIFAR-100 数据集.CUB数据集专注于细粒度鸟类物种分类.这些数据集由于有不同的侧重点, 为评估小样本学习方法的有效性提供多样化和具有代表性的挑战.
对于所有数据集, 遵循现有工作的规则, 使用ResNet12作为骨干网络, 但本文将滤波器的数量从(64, 128, 256, 512)修改为(64, 160, 320, 640).同时为了防止过拟合, 应用多种图像增强技术, 如RandomResizedCrop、RandAug和RepeatAug.
在元训练期间, 使用AdamW(Adaptive Moment Estimation with Weight Dacay)优化器, 并设置特征提取器的优化器的学习率为1e-7, 语义映射器的优化器的学习率为5e-4.在miniImageNet、CIFAR-FS、tieredImageNet数据集上进行200个周期的元训练, 在CUB数据集上训练300个周期.
在元测试期间, 从新类别中抽取4 000个轮次进行测试.整个实验是在一台单RTX4090服务器上进行的.
关于文本处理, 现有方法通常采用预训练的SBERT(Sentence-BERT)[23]和GloVe(Global Vec-tors)[24]作为文本编码器, 提供语义知识.在本文中使用一个更为专业预训练的视觉语言模型— — CLIP[18]作为语义来源, 利用对比学习对齐视觉和文本模态的特征.
为了确保公平性, 本文仅使用CLIP的文本编码器而不使用视觉编码器.对于CLIP, 从模板“ a photo of a [类名]” 中提取维度为512的语义嵌入向量.对于 GloVe, 直接将类名输入编码器, 当类名由多个单词组成时, 对所有的编码向量取平均值.
为了评估SBPO的有效性, 选择如下对比方法.
1)未使用语义信息的方法:Matching Nets[1]、MAML(Model-Agnostic Meta-Learning)[4]、Proto-typical Networks[5]、TPMN[6]、KTN(Knowledge Trans-fer Network)[13]、 文献[25]方法、CAN(Cross Atten-tion Network)[26]、FRN(Feature Map Reconstruction Networks)[27]、ODE(Neural Ordinary Differential Equation)[28]、ESPT(Self-Supervised Episodic Spatial Pretext Task)[29]、TAS-simple(Task Affinity Score)[30].
2)融入标签中包含语义知识的方法:LPE[9]、AM3[11]、TRAML[16]、TriNet[17].
在miniImageNet、tiredImageNet数据集上进行对比实验, 各方法在5-way 1-shot和5-way 5-shot任务上的准确率对比如表1所示, 表中黑体数字表示最优值, 对比方法结果都来自原文献, -表示未进行相关数据集的实验.
| 表1 各方法在2个数据集上的准确率对比 Table 1 Accuracy comparison of different methods on 2 datasets % |
如表1所示, 在5-way 1-shot和5-way 5-shot任务中, SBPO的准确率均较优, 在5-way 1-shot任务中, SBPO超越所有对比方法.尤其是与同样使用语义的LPE相比, SBPO在5-way 1-shot任务上准确率提升超3%, 表明SBPO在数据稀缺时对少量样本和语义的利用更充分, 这是因为SBPO能在特征提取阶段利用语义信息指导模型提取准确的类特征, 从而实现视觉特征与语义信息的深层结合, 进而优化类原型.
此外, 与其它利用语义信息的工作类似, 相比不使用语义信息的方法, SBPO在5-way 5-shot任务中的表现相对较弱.这是因为:虽然在样本数量有限时, 语义知识为模型提供宝贵的类别特定的先验信息, 有助于模型理解类别特定的特征, 但是在5-way 5-shot任务中, 样本提供的视觉信息已相对充足, 模型可只利用视觉样本理解类别特征, 导致语义信息对原型优化的作用下降.尽管在有限的作用下, SBPO在5-way 5-shot任务中仍优于其它利用语义信息的工作, 这清楚表明SBPO对语义的利用更高效.
本文还选择如下对比方法:DeepEMD[31]、IEPT+ZN[32]、SEGA(Semantic Guided Attention)[33]、Meta-OptNet[34]、MABAS(Model-Agnostic Boundary-Adver-sarial Sampling)[35].
选择5-way 1-shot和5-way 5-shot任务, 各方法在CUB、CIFAR数据集上的准确率对比如表2和表3所示, 表中*表示该方法利用CUB数据集的额外属性注释.
| 表2 各方法在CUB数据集上的准确率对比 Table 2 Accuracy comparison of different methods on CUB dataset % |
| 表3 各方法在CIFAR数据集上的准确率对比 Table 3 Accuracy comparison of different methods on CIFAR dataset % |
由表2和表3可见, SBPO仍有不错性能, 而LPE性能的显著提升表明:更细粒度的语义知识可帮助模型更好地理解类别特定的特征.SBPO在不利用属性知识的情况下仍实现最优性能, 在相同条件下准确率比LPE提升5.01%, 这表明SBPO能更好地利用语义信息.
鉴于本文使用语义信息指导原型优化, 语义知识的准确性和鲁棒性起到至关重要的作用.在miniImageNet、CUB数据集上, SBPO使用不同文本编码器嵌入语义信息, 获得的准确率如表4所示.由表可见, 利用CLIP的语义编码优于使用GloVe嵌入的.这表明SBPO中使用的语义信息的精确性直接影响原型优化的有效性.
| 表4 使用不同文本编码器的准确率对比 Table 4 Accuracy comparison with different text encoders % |
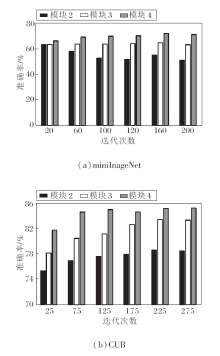
理论上, CSP可嵌入在骨干网络的任何模块中, 但为了探究最佳性能, 下面研究CSP的最佳位置.骨干网络ResNet12是由4个模块组成, 在不同的模块中分别嵌入CSP, 选择5-way 1-shot任务, 在mini-ImageNet、CUB数据集上进行实验, 探究方法的分类效果, 具体准确率结果如图4所示.由图可见, 当语义信息被插入到更深的模块中时, 分类准确率会随着训练迭代次数增加而逐渐提高, 而将语义信息合并到较浅的模块中, 随着训练迭代次数的增加, 反而会导致性能明显下降.这种现象可用骨干网络在提取特征时的特点来解释, 即在骨干网络中, 网络的浅层倾向于提取通用的公共特征, 而深层倾向于捕获类特定的特征.由于语义信息属于类特定知识, 包含更具体的类特征信息, 因此将其插入深层模块中, 利用语义提示指导类特征提取, 能最大限度提高特征提取准确率.只在最后一个模块中嵌入CSP时, 方法可在不增加过多计算负担的情况下, 充分利用语义信息优化特征表示.由此说明将CSP嵌入ResNet的最后一个模块中的设计是合理的.
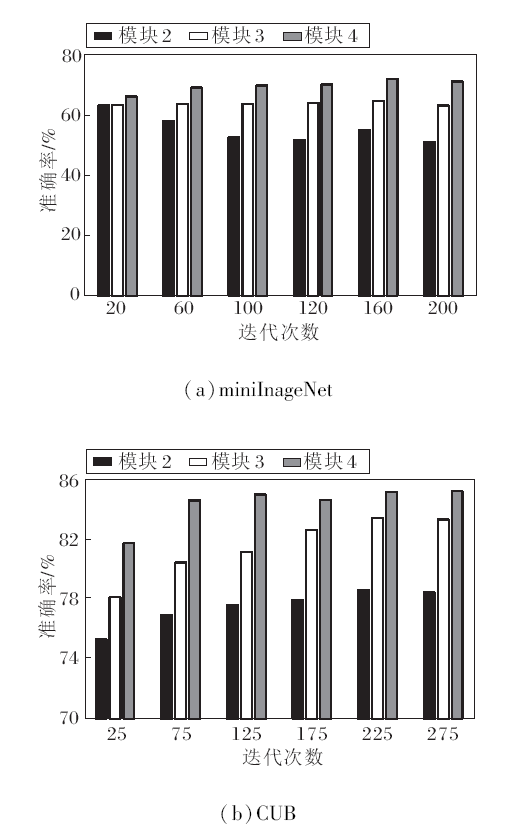 | 图4 在不同模块嵌入CSP的准确率对比Fig.4 Accuracy comparison among different blocks with embedded CSP |
为了检验CSP和MML在SBPO中的作用, 在CUB、miniImageNet数据集上进行消融实验, 其中基线网络表示一个不包含CSP和MML的卷积网络.各网络的准确率对比如表5所示.由表可看出, 缺少CSP时, 在miniImageNet数据集上的准确率下降4.46%.结果凸显CSP在利用语义知识提升模型性能方面的显著效果.此外, MML也对训练特征提取器做出重要贡献.使用MML可提高模型区分不同类别的能力.总之, CSP和MML的结合可协同增强整体性能.
| 表5 各模块的消融实验结果 Table 5 Ablation experiment results of different modules % |
使用不同语义提示的Grad-CAM(Gradient-Weigh-ted Class Activation Mapping)可视化结果如图5所示, 这种类激活图体现不同类别标签作为文本提示以后, 方法对视觉特征的关注情况.在语义提示的引导下, SBPO有效地将注意力引导到特定类别的特征上, 实现对感兴趣区域的更精确定位.可视化结果体现SBPO在利用语义信息指导和优化编码网络方面的强大能力, 从而促进对象的识别和定位.
 | 图5 使用不同语义提示的Grad-CAM可视化图Fig.5 Grad-CAM visualization using different semantic prompts |
选择Prototypical Networks、AM3、SBPO, 在5-way 1-shot任务中, 可视化CUB数据集上每类50个查询样本的特征分布, 具体t-SNE(t-Distributed Stochastic Neighbor Embedding)可视化图如图6所示.
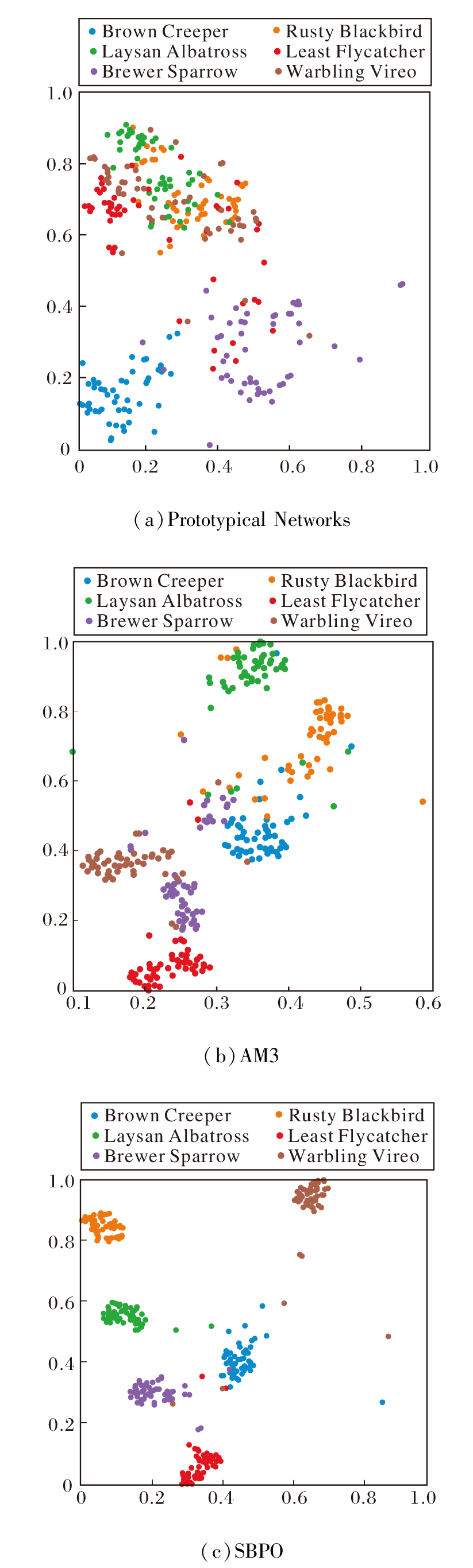 | 图6 不同方法的t-SNE可视化图Fig.6 t-SNE visualization using different methods |
观察同一颜色类内的紧凑性和不同颜色之间的分离程度可发现, 相比Prototypical Networks, 结合语义的AM3和SBPO明显提升类间聚集, 这体现语义在方法中起到促进聚集的作用.更值得注意的是, SBPO可实现更明显的类间分离和更紧密的类簇, 不同类之间的距离显著增加, 这表明SBPO深度利用语义知识, 并且MML可有效提高不同类之间的可分辨性.
本文提出基于语义的小样本学习原型优化方法(SBPO), 使用语义提示引导原型优化, 缓解由于语义信息利用不足而导致的类原型不准确的问题.首先, 在特征提取阶段使用通道级语义提示模块(CSP)引导类特征的提取, 达到优化类原型的目的.其次, 在损失函数方面, 将语义和视觉两个模态信息的相关性作为衡量类间边界的元素, 约束特征提取网络, 使类特征编码具有区分性.实验表明, SBPO在4个数据集的5-way 1-shot任务中取得显著的性能提升.进一步分析表明SBPO在捕捉特定类别特征和获得准确的类别原型方面表现出色.未来将进一步探索如何引入更多模态的辅助信息, 帮助和指导模型在源域和目标域具有显著差异的场景下提升识别准确率.
本文责任编委 陶卿
Recommended by Associate Editor TAO Qing
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|