
{kind=link}
{kind=link}
{kind=link}
基于知识蒸馏与动态区域细化的人体姿态估计
[魏龙生1  , 付兴朋
, 付兴朋1 , 李唐强1 , 黄浩宇1 ]
, 付兴朋, 李唐强, 黄浩宇]
|
|



作者简介:

付兴朋,硕士研究生,主要研究方向为深度学习、人体姿态估计等.E-mail:fuxingpengdida@cug.edu.cn.

李唐强,硕士研究生,主要研究方向为深度学习、图像分割等.E-mail:litq@cug.edu.cn.

黄浩宇,硕士研究生,主要研究方向为深度学习、无参考图像质量评估等.E-mail:huanghaoyu@cug.edu.cn.
人体姿态估计方法分为基于坐标回归的方法和基于热图的方法.基于坐标回归的方法推理速度较快但精度较差,基于热图的方法可精确定位,但计算量和存储开销较大.因此,文中通过知识蒸馏,结合两种方法,提出基于知识蒸馏与动态区域细化的人体姿态估计方法.首先,在特征蒸馏与姿态蒸馏两方面将热图模型的信息传递给回归模型.然后,对经过多层Transformer提取的特征进行选择,在粗略化阶段根据提取的特征生成初步姿态估计,并依据质量预测器的得分挑选需要细化的图像特征.最后,在细化阶段根据关键点与图像区域之间的相关程度,在部分关键点相关区域上建立细粒度表示,即细化特征,实现人体姿态细化.在COCO、COCO-Wholebody数据集上的实验表明,文中方法可较好地定位关键点,完成人体姿态估计.
About Author:
FU Xingpeng, Master student. His research interests include deep learning and human pose estimation.
LI Tangqiang, Master student. His research interests include deep learning and image segmentation.
HUANG Haoyu, Master student. His research interests include deep learning and no-reference image quality assessment.
Human pose estimation methods are categorized into coordinate regression-based methods and heatmap-based methods. Coordinate regression-based methods are characterized by slightly faster inference speed but slightly lower accuracy, while heatmap-based methods can achieve precise localization at the cost of higher computational and storage overhead. Therefore, a human pose estimation method based on knowledge distillation and dynamic region refinement is proposed. First, the information from the heatmap model is transferred to the regression model through feature distillation and pose distillation. Then, the features extracted by multi-layer Transformer are selected to generate initial pose estimation in the coarse stage, and the image features that need to be refined are selected based on the scores from a quality predictor. Finally, in the refinement stage, fine-grained representations or refined features, are established in the regions related to some keypoints according to the correlation between keypoints and image regions, achieving human pose refinement. Experiments on COCO and COCO-WholeBody datasets demonstrate that the proposed method can accurately locate keypoints and achieve accurate human pose estimation.
人体姿态估计是计算机视觉领域中的一个重要研究任务, 旨在对图像或视频中的人体关节点进行检测与定位, 使计算机理解人类的动作与行为.人体姿态估计技术在人机交互[1]、体育训练[2]、运动捕捉[3]等下游领域应用广泛.
早期的人体姿态估计研究大多基于传统图像处理方法, 复杂场景下的遮挡、形变等问题严重限制模型的鲁棒性.近年来, 随着深度学习技术的突破, 基于卷积神经网络(Convolutional Neural Network, CNN)和Transformer的方法逐渐成为主流, 显著提升姿态估计的精度与泛化能力.
现有的人体姿态估计方法主要分为基于坐标回归的方法和基于热图的方法.基于坐标回归的方法直接预测关键点坐标, 实现高效推理, 在实时性要求较高的场景中表现优异.Carreira等[4]提出IEF(Itera-tive Error Feedback), 是一种自校正方法, 利用预测误差逐步改进初始的姿态估计结果, 将这些误差反馈到网络的输入空间, 能在连续迭代中逐步修正预测结果.Luvizon等[5]使用Softmax函数, 将特征图转换为联合坐标, 在一个完全可微的框架内实现姿态估计, 这种转换允许网络直接输出人体关节的坐标.然而, 此类方法缺乏显式的空间建模能力, 难以捕捉关键点间的长程依赖关系, 导致复杂姿态下的定位精度受限.
相比之下, 基于热图的方法通过生成概率热图表征关键点分布, 能显式学习空间信息, 在公开基准测试中占据性能优势.Sun等[6]提出HRNet(High Resolution Net), 设计高分辨率特征金字塔, 实现多尺度信息的有效融合.Cao等[7]设计OpenPose, 利用部分亲和场建模关节点关联, 显著提升多人姿态估计的鲁棒性.尽管如此, 基于热图的方法需处理高分辨率特征图, 导致计算复杂度随图像尺寸呈二次方增长, 难以满足移动端或实时系统的需求[8].平衡精度与效率的矛盾, 逐渐成为当前研究的核心挑战.
知识蒸馏(Knowledge Distillation, KD)技术为解决上述问题提供新的思路, 其核心思想是通过教师-学生框架, 将复杂模型(教师)的知识迁至轻量模型(学生), 提升后者性能.
在人体姿态估计领域, 闫忠心等[9]提出融合自我知识蒸馏和卷积压缩的轻量化人体姿态估计方法(SKDPose), 利用高层热图指导低层特征学习.Zhang等[10]提出FPD(Fast Pose Distillation), 通过中间特征映射实现跨模型知识传递.
然而, 现有方法多局限于单一范式(热图或回归)内的蒸馏, 忽视不同范式间的互补性.Li等[11]提出TokenPose(Token Representation for Human Pose Estimation), 证实热图的细粒度空间信息与回归模型的高效推理特性具有互补性, 但二者输出空间的异构性(热图/坐标向量)导致难以直接进行知识迁移.为此.Li等[12]提出PRTR(Pose Regression Transformers), 将回归坐标映射为高斯分布以对齐热图空间, 学生网络通过蒸馏过程学习教师网络输出的软标签, 从而实现对关键点的精准定位.
为了进一步提高人体姿态估计的准确率和效率, 可采取输入细粒度的图像标记[13, 14].然而, 在Transformer结构中, Transformer的复杂度是标记(Token)数量的平方, 而这种全局的细粒度标记, 即基于Transformer的视觉Token的数量会带来显著的计算负担[15].Xu等[16]提出ViTpose, 将中间层的输出重定向到解码器以获取每个热图, 只有在前几层中, Transformer的输出才会在解码器上引起全局响应, 而在随后的层中, 解码器的响应明显集中在包含关键点的稀疏局部区域, 这意味着在推理过程中, 大部分图像标记(如仅包含背景信息的图像标记)不能提供有效的上下文信息.
对于上述情况, 本文提出基于知识蒸馏与动态区域细化的人体姿态估计(Human Pose Estimation Based on Knowledge Distillation and Dynamic Region Refinement, KD-DRRPose).在特征蒸馏部分引入Transformer多层结构, 提取视觉特征和关键点标记.同时, 由于学生模型与教师模型的特征嵌入维度相同, 这样便无需将标记特征恢复为特征图形式, 可直接对学生模型和教师模型的特征嵌入进行知识蒸馏.在姿态蒸馏部分, 为了将教师模型中的信息有效传递给学生模型, 将学生模型预测的关键点坐标通过二维高斯分布构建学生热图.通过这种方式, 学生热图能在结构上模拟教师热图的分布模式, 使教师模型的热图信息被映射到学生模型的坐标向量空间中, 实现对学生模型的知识增强.此外, 本文还提出动态区域细化策略, 有效降低计算冗余.通过计算关键点与图像之间的注意力图, 识别与关键点高度相关的图像区域.在图像处理过程中, 利用注意力机制计算关键点与不同图像区域之间的关联度, 确定哪些区域对姿态估计至关重要.仅针对这些高度相关的区域进行进一步的细粒度标记表示, 详细捕捉关键点周围的局部信息, 在保证姿态估计准确性的前提下, 减少不必要的计算, 将计算资源集中在最有价值的图像区域上, 避免过多处理与姿态无关的背景区域.
基于热图的人体关键点定位方法使用概率图对关键点位置进行编码[17], 通过后期处理估计热图并检索关键点坐标.该方法在关键点定位领域占据主导地位, 因为很容易通过神经网络学习热图.Sun等[6]提出HRNet, 设计强大的CNN, 提取不同层次的特征以估计高分辨率热图, 用于人体姿势估计和面部标志检测, 再通过后处理移位简单获得目标关键点.在SKDPose[9]中, 不同层次的语义信息划分为不同的分支并使用独立的解码器, 将最高层次的解码热图作为教师输出, 其余层次作为学生输出, 完成知识的自蒸馏.在FPD[10]中, 从8-Stack沙漏网络中将知识迁至4-Stack沙漏网络, 使教师网络的最终输出热图作为软标签指导学生网络的决策, 还通过中间监督的形式将教师网络的特征融入学生网络的不同层次中.
基于坐标回归的关键点定位方法通过神经网络直接学习从输入图像到输出坐标的映射.Nie等[18]提出SPM(Single-Stage Multi-person Pose Machines), 引入根关节, 表示不同的人体实例, 同时分等级预测关键点偏移, 较好地预测某些关节的长距离位移.Li等[19]提出RLE(Residual Log-Likelihood Estimation), 引入一个流模型, 捕获底层的输出分布, 性能较优.尽管上述方法在寻找关键点的隐含关系方面做出很大努力, 但由于缺乏热图的明确指导, 性能改善仍然不足.近年来, 研究人员还效仿DETR(Detection Trans-former)[20], 在Transformer架构中提出更强大的主干以改进直接回归, 如PETR(Pose Estimation Frame-work with Transformers)[21].
基于热图的方法在人体关键点的精确定位上具有显著优势, 原因是方法能捕捉高精度的空间概率信息, 但在处理高分辨率特征图时带来较大的计算量和存储开销.相比之下, 基于坐标回归的方法直接从输入图像中预测关键点坐标, 具备更快的推理速度, 但其定位精度通常不如基于热图的方法.因此, 通过知识蒸馏技术结合此两种方法, 热图模型的空间信息被传递至回归模型中, 使回归模型可在保持快速推理能力的同时, 也获得更高的关键点定位精度.
现有的姿态估计模型通常将图像作为CNN的输入, 在网络中串联输入图像, 执行高级特征的低分辨率过程和恢复高分辨率过程.在这个过程中下采样和上采样均会导致一些重要的信息丢失.一些经典的方法, 如OpenPose[7]和Hourglass[22], 采用CNN作为主干网络, 用于提取特征.Zhou等[23]提出CDKD(Knowledge Distillation with Channel Dropout Stra-tegy), 设计基于转置卷积层和卷积层的中间特征映射器, 通过中间特征映射器, 从不同网络中提取的特征投影到同一空间, 从而使参数较少的学生网络能更自然有效地理解教师网络的知识.
CNN主干网络用于捕捉单个关键点的细节信息, 但在处理全局关系和复杂姿态时可能表现不足, 而Transformer通过自注意力机制能捕捉长距离依赖关系.随着Transformer在自然语言处理中取得的巨大成功, 研究者们开始将其引入计算机视觉领域, 并取得突破性进展, 在视觉任务研究中常使用的技术为ViT(Vision Transformer)[24].
Transformer已被证实是用于人体姿态估计的特征提取和处理的有效模块.Liu等[25]提出Swin Trans-former, 使用层次结构设计和移位窗口, 使模型在不同尺度下灵活建模关键点之间的关系.在PRTR[12]中, 编码器-解码器结构用于执行基于回归的人物和关键点检测.在ViTPose[16]中, 设计用于初始图像特征提取和特征处理的纯Transformer架构, 具有通用性, 只需要较少的启发式设计.Yang等[26]提出TransPose, 使用CNN在底层提取特征, 而Trans-former在高层捕获关键点全局依赖关系.上述基于Transformer的姿态估计方法在关键点估计基准上获得较优性能.Wei等[27]在CNN阶段引入CAU(Cha-nnel-Attention-Unit), 减少通道冗余, 并利用ViT保留来自教师模型的中间注意力图, 通过注意力损失指导学生模型尽早识别关键的信息.
为了缓解Transformer中全局特征交互导致的计算资源消耗问题, 学者们提出许多解决方法, 其中动态优化是主要的一种.
最简单的方法是减少Transformer的输入标记数量.Yuan等[28]根据相似性融合相似标记.Araú jo等[29]根据类关注度评估图像块的重要性.另一类方法是在粗略的水平中逐渐调整输入粒度.Tang等[30]提出Quad Tree Attention, 从每层的不同尺度获得注意力, 并执行跨尺度加权, 捕获全面表征, 减少标记数量.Chen等[31]提出CF-ViT(Coarse-to-Fine Vision Transformer), 使用不同粒度的补丁, 设计两个阶段, 并重新组织特定的细粒度令牌与粗粒度令牌, 以细化第二阶段的预测.
在Transformer中, 全局特征交互虽然提高模型的表达能力, 但也导致显著的计算资源消耗, 通过细化阶段的补丁设计, 可优化计算效率, 但仍可能在处理细粒度特征时不够精确.
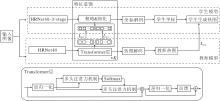
本文结合基于热图的方法与基于坐标回归的方法, 提出基于知识蒸馏与动态区域细化的人体姿态估计方法(KD-DRRPose), 整体框架如图1所示.
 | 图1 KD-DRRPose整体框架图Fig.1 Overall framework of KD-DRRPose |
在训练过程中, 将教师模型的特征和热图知识转移至学生模型, 并在推理阶段仅使用更快的学生模型进行预测.在粗略& 细化过程中, 粗略化阶段由Transformer结构块和质量预测器组成, 并保留粗略化阶段生成的视觉标记与关键点标记, 用于进行特征蒸馏.细化阶段完成关键点相关的视觉标记选择及细化, 这一阶段输出的关键点标记用于最后的姿态估计.
由于学生模型与教师模型都采用Transformer的结构, 二者可在网络末端的特征上保持形式一致, 因此KD-DRRPose对视觉标记和关键点标记进行特征蒸馏, 旨在解决传统人体位姿估计中, 不同模型输出结果无法直接对齐的问题.
基于坐标回归的方法输出人体关键点的二维坐标, 而基于热图的方法输出表示关键点置信度的热力图.由于这两种输出形式的差异, 无法直接将一个模型的知识传递给另一个模型.虽然已有工作尝试在回归模型中引入热图, 如RLE[19]采取的热图损失, 但由于输出空间未对齐, 只能在主干上进行部分知识转移, 带来有限的性能提升.
为了解决这一问题, 本文提出基于Transformer的标记知识蒸馏(Token Knowledge Distillation, TKD)模块, 提取教师模型中的标记信息, 实现知识传递.对于输入图像, 进行预处理后, 作为骨干网络HRNet48-3-stage的输入, 提取多尺度特征, 骨干网络的输出特征图作为粗略& 细化部分的输入特征图.将输入特征图分割成多个板块, 每个板块包含局部信息, 并添加关键点标记(Token), 使其能对齐教师模型和学生模型的输出特征空间, 这样学生模型就能更专注学习人体本身的信息.
对于输入的特征图, 划分为多个PW×Ph的视觉块, 并进行编码, 形成一系列视觉标记.再添加M个空节点作为关键点, 这些节点与视觉标记连接, 送入令牌提取编码器的转换器编码器层.令牌提取编码器中的注意力矩阵可学习关键点标记与相应位置的视觉标记之间的关系.然后对齐学生模型和教师模型之间的视觉标记和关键点标记, 在视觉标记与关键点标记上分别进行知识传递.
学生模型的特征已与教师模型对齐, 因此为了进一步进行知识蒸馏, 将教师模型的输出作为软标签传递知识.相比坐标向量, 热图的梯度分布更清晰, 能显式引导模型关注关键点周围的局部信息.同时, 教师模型生成的热图往往比带有错误标注的基本事实更接近真实情况, 因为教师模型通过训练过滤部分误差.由于热图与坐标向量处于不同的输出空间, 在学生模型中使用“ 自生成热图” 的方法, 将坐标向量引入热图空间, 提升知识提取效果.
通过二维高斯分布构建坐标到热图的转换.学生模型预测输出包含坐标对及相应的σ值, 教师模型输出的热图不一定是规则分布.为了生成学生的更实际的热图, 分别从水平方向和垂直方向预测σx和σy, 高斯分布如下:
$\begin{array}{l} f(x, y)= \\ \quad \frac{1}{2 \pi \sigma_{x} \sigma_{y}} \exp \left(-\frac{1}{2}\left(\frac{\left(x-\mu_{x}\right)^{2}}{\sigma_{x}^{2}}+\frac{\left(y-\mu_{y}\right)^{2}}{\sigma_{y}^{2}}\right)\right) . \end{array}$
其中, μx表示x的均值, μy表示y的均值.
在实际计算每个关键点的热图中, 一般忽略上式中的常系数, 因此第k个关键点的生成热图为:
$H_{k}(x, y)=\exp \left(-\frac{1}{2}\left(\frac{\left(x-\mu_{x k}\right)^{2}}{\sigma_{x k}^{2}}+\frac{\left(y-\mu_{y k}\right)^{2}}{\sigma_{y k}^{2}}\right)\right), $
其中, (μxk, μyk)表示学生模型预测的关键点坐标, (σxk, σyk)表示对应的偏差, 0<x≤hW, 0<y≤hH, hW表示热图的宽度, hH表示热图的高度.
动态区域细化过程如图2所示, 分为上半部分的粗略化阶段和下半部分的细化阶段.
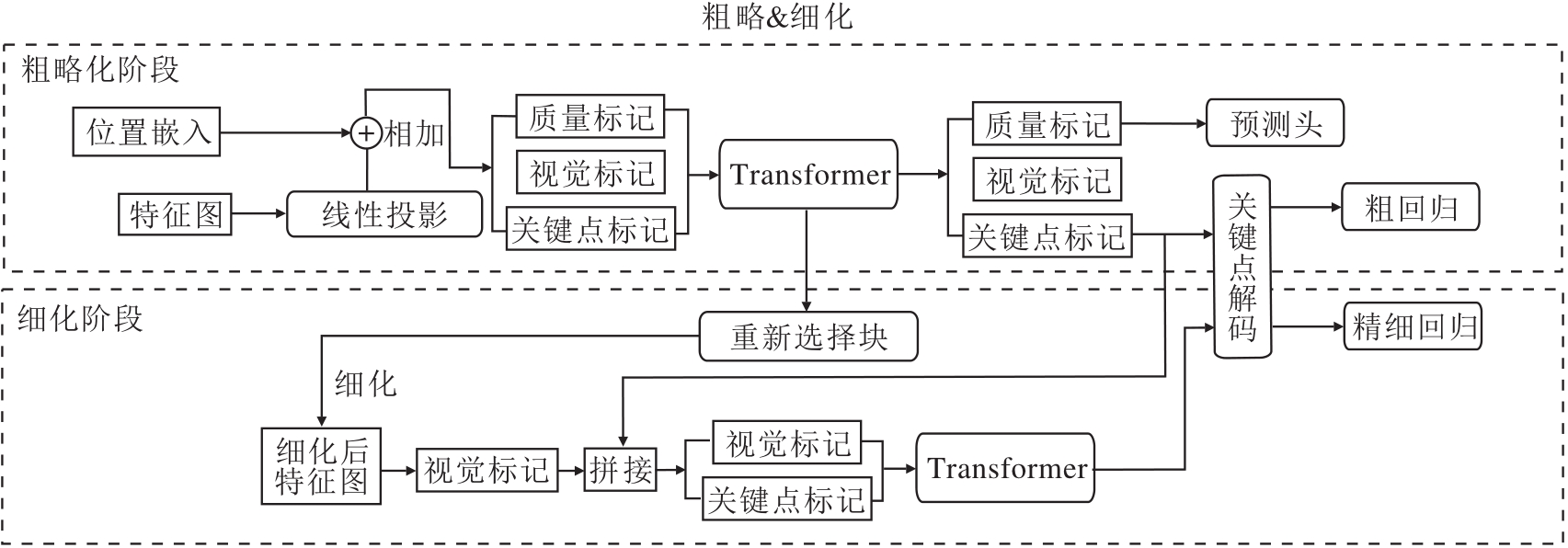 | 图2 动态区域细化过程Fig.2 Process of dynamic region refinement |
在粗略化阶段, 将来自HRNet48-3-stage的输出特征图作为粗略& 细化部分的输入特征图, 将特征图划分为多个PW×Ph的块, 经过线性投影后被映射为和关键点标记具有相同嵌入维度的视觉标记, 随后加入一个质量标记, 将三者拼接后作为Trans-former的输入.质量标记的最终作用是控制进入精细阶段的样本数量.
在细化阶段, 计算特征块和关键点之间的相关性得分, 选择需要细化的特征块, 与未选中的块进行组合后也被映射为视觉标记, 随后与粗略化阶段输出的带有部分关键点信息的关键点标记拼接, 作为细化阶段Transformer的输入.这一阶段充分捕获关键点的位置信息, 通过最后的解码实现关键点的准确定位.
定义输入张量X∈RH×W×C, 给定特定的大小为PW×Ph的patch块和输入缩放因子sc , 首先通过骨干网络得到初步特征
F=Backbone(X),
重采样调整为
Fc=Resample(F)∈
其中, c表示粗略化阶段, C表示原始特征图的通道数.将Fc分解为
$N^{c}=\left(\frac{H \cdot s_{c}}{P_{h}}\right)\left(\frac{W \cdot s_{c}}{P_{w}}\right) \text { 块. }$
然后利用线性投影f∶ p→ v∈RD, Fc获得相应的视觉标记序列
最终构成输入token序列:
F
在合成输入标记序列之后, 应用具有K层的Transformer(TF), 获得输出序列:
关键点解码器通过统一的多线性投影模块输出关键点标记{
其中,
使用可学习的质量嵌入q0, 通过从视觉标记和关键点标记中获取的信息, 获得预测关键点的质量.然后, 质量预测器模块通过融合在质量标记中的信息, 产生预测的质量分数:
Q=MLP(qK).
根据估计的质量分数Q, 设置阈值Qthres, 当Q<Qthres时, 该特征才会被选中送入细化阶段进行处理, 这允许模型动态区分困难样本和容易样本.因此, 可减少经过细化阶段特征的数量, 增加模型吞吐量.
第二阶段为细化阶段, 需要确定上一阶段挑选的特征图的哪些区域需要高分辨率特征表示.考虑Transformer在不同层中会计算视觉标记与关键点标记之间的注意力矩阵, 据此可计算特征块和关键点之间的相关性得分.注意力矩阵定义如下:
其中,
遵循文献[32]的工作, 使用指数移动平均(Exponential Moving Average, EMA)联合来自每个Transformer层的注意力:
然后, 取最后一层
s=
获得最终的视觉标记相关性得分, 其中,
在细化阶段推理中, 首先需要构建高分辨率表示.给定精细化阶段中的缩放比sf, 完整视觉标记为:
$\boldsymbol{F}_{\text {full }}^f=\left\{\boldsymbol{v}_f^i\right\}_{i=0}^{N^f}$,
其中,
$N^{f}=\left(\frac{H \cdot s_{f}}{p_{h}}\right)\left(\frac{W \cdot s_{f}}{p_{w}}\right), $
表示所有细粒度图像标记的数量, f表示细化阶段.如果对每个特征块都进行精细化, 则会产生过多token, 大幅增加模型的计算量, 因此需要挑选部分特征块精细化, 同时也可避免无关背景信息的融入.
细化阶段的初始视觉标记$\left\{\hat{\boldsymbol{v}}_0^i\right\} \begin{aligned} & \widehat{N}^f \\ & i=0\end{aligned}$构造如下.第一部分由与关键点关联程度较小的标记组成, 可直接从 Flow中获取, 这一部分不进行细化.第二部分包括从Fhigh中生成的标记, 这些视觉token与关键点更相关.将来自Fhigh的单个视觉标记表示为vjK, 进一步分成
$N=\left(\frac{s_{f}}{s_{c}}\right)^{2}$
个细粒度标记.新的输入视觉标记为
$\left\{\operatorname{MLP}\left(\boldsymbol{v}_K^j\right)+\boldsymbol{v}_f^i\right\}_{i=0}^N$,
其中$\left\{\boldsymbol{v}_f^i\right\}_{i=0}^N$表示自vjK的对应位置F
F
其中,
表示视觉标记的数量,
然后, 应用与粗略化阶段中共享相同参数的Transformer, 通过
F
获得细化阶段的输出.
最后, 关键点标记被馈送到解码器中, 得到精细推断的坐标:
R
在知识传递部分, 分别对视觉Token和关键点Token进行蒸馏, 相应的损失函数如下所示:
LKT=MSE(KTh, KTr),
LVT=MSE(VTh, VTr),
其中, KT∈RK×D 表示关键点Token, VT∈RP×D表示视觉Token, P表示patch数量, D表示Token的嵌入维度, 下标h表示基于热图的方法, 下标r表示基于坐标回归的方法.使用均方误差损失(Mean Squared Error, MSE)衡量教师模型和学生模型之间的差异.
对齐学生模型生成热图与教师模型生成热图, 相应的损失函数如下所示:
LST=
其中, HSk表示学生模型的自生成热图, HTk表示第k个关键点的教师热图, M表示关键点数量.
总之, 在任务监督和知识蒸馏下同时训练基于回归的学生模型, 蒸馏框架的总体损失函数为:
L=Lreg+γ1LKT+γ2LVT+γ3LST,
其中, Lreg表示人体姿势估计的回归任务损失, γ1、γ2、γ3表示超参数, 使用平滑的L1损失作为Lreg, 计算预测关节与地面真实坐标之间的距离, 本文未使用这些看不见的关键点计算损失, 不可见的关键点将被过滤.
本文选择COCO2017[33]、COCO-Wholebody[34]数据集进行实验.COCO2017数据集包含2×105多幅图像和2.5×105多个人类实例, 每个人类实例被标记为表示人类姿势的17个关键点, 在COCO train-2017上进行118 287幅图像的训练, 并在test-dev-2017上进行评估, 测试集包含40 670幅图像.COCO-Wholebody数据集是 COCO2017数据集的扩展, 增加全身关键点注释, 支持更准确、全面的人体姿势估计, 每个人体共注释133个关键点, 包括6个腿部关键点、68个面部关键点、42个手臂关键点和17个身体部位关键点.
本文使用如下常用的标准评估指标:平均精度(Average Precision, AP)、平均召回率(Average Re-call, AR)、模型参数量和运算性能参数GFLOPs(Giga Floating-Point Operations per Second).
在实验中遵循自上而下的人体姿态估计范式.将所有输入图像调整为256×192.遵循HRNet[6]中的数据增强设置, 采用文献[35]中提供的常用人物检测器.训练方法使用1个3 090 GPU, 用于训练的图像批量为64幅.KD-DRRPose采用Adam(Adaptive Mo-ment Estimation)作为优化器, 训练300个轮次.基本学习率设为1e-3, 分别在第200个轮次和260个轮次时衰减到1e-4和1e-5.损失函数的参数设置如下:γ1=γ2=5e-4, γ3=1.动态选择部分的架构配置如下:Transformer层数为12, 嵌入维度为192, 头数为11, 块数量为4×3, 每块大小为16×16.
在COCO的测试集上进行对比实验, 选择如下对比方法.
1)基于热图的方法:TokenPose[11]、TransPose[26]、文献[35]方法、DEKR(Disentangled Keypoint Re- gression)[36]、SMap(SkeletonMap)[37]、MSPENet(Multi-scale Position Enhancement Network)[38]、Greit-HRNet(Grouped Lightweight High-Resolution Net-work)[39].
2)基于坐标回归的方法:PRTR[12]、RLE[19]、PVT-Small[40]、基于密集关键点回归的人体姿态估计(RelatedNet)[41]、SDPose[42].
各方法的指标值对比如表1所示.由表可见, 相比低分辨率特征提取方法, KD-DRRPose采用CNN-Transformer结合的关键点特征提取方法, 有效提取高分辨率关键点特征, 并通过动态优化策略和知识蒸馏技术, 进一步提升整体性能.HRNet48在提取低阶特征方面具有优越性, 然而, 其多尺度高分辨率网络的计算开销较大, 推理速度受限.KD-DRRPose引入动态区域细化, 只对部分选中的块进行细化, 大幅减少推理阶段的计算量, 在准确率和效率之间取得较好的平衡.
| 表1 各方法在COCO测试集上的指标值对比 Table 1 Comparison of metric values for different methods on COCO test set |
早期的方法由于模型设计简单, 计算复杂度较高, 在精度和推理速度方面难以同时兼顾.尤其是DEKR, 由于其深层次的特征提取导致参数量巨大, 达到65.7 M, 远高于KD-DRRPose.同时, KD-DRR-Pose在AP值上也比DEKR提高1.7%.以HRNet48为主干网络, 在相同256×192输入分辨率时, KD-DRRPose获得72.7%的AP值, 比基于密集点回归的方法RelatedNet提高1.2%, 同时参数量减少44.04 M.
表1中结果进一步说明KD-DRRPose的有效性.在COCO测试集上, 对比其它基于热图的方法和基于坐标回归的方法, KD-DRRPose结合动态优化策略, 在不显著增加计算量的情况下, 通过精细化处理关键区域, 进一步提高姿态估计的精度, 同时降低计算复杂度, AP达到较高值, 而参数量和GFLOPs都保持在较低水平, 因此具有一定的竞争力.
在COCO-Wholebody数据集上进行对比实验, 选择如下对比方法:HRNet32[6]、HRNet48[6]、Open-Pose[7]、AlphaPose[34]、PVNet(Pixel-Wise Voting Net-work)[43]、UformPose[44]、OHEPose(Occlusion Handling Enhanced Pose)[45].
各方法的指标值对比如表2所示.
| 表2 各方法在COCO-Wholebody数据集上的指标值对比 Table 2 Comparison of metric values for different methods on COCO-Wholebody dataset |
由表2可知, KD-DRRPose取得66.2%的AP值和77.4%的AR值, 显著优于OpenPose和Alpha-Pose, 尤其是在复杂场景下的鲁棒性更强.这一结果得益于本文提出的动态区域细化策略, 能自适应选择关键区域进行细粒度处理, 从而在保证精度的同时减少计算负担.相比HRNet48和PVNet, KD-DRRPose在Whole body关键点估计上表现更优, 尤其是在AR值上.
在细节部位的表现上, KD-DRRPose在Face关键点上取得89.7%的AP值和93.2%的AR值, 与UformPose和OHEPose相当, 精度较高.KD-DRR-Pose在Hand关键点的AP值为66.1%, AR值为72.5%, 显著优于OpenPose和AlphaPose.KD-DRR-Pose在Foot关键点的AP值为62.3%, AR值为69.2%, 略低于AlphaPose.KD-DRRPose在Body关键点的AP值为73.6%, 与PVNet相当, 这进一步验证KD-DRRPose在核心身体关键点估计上的有效性.
本节在COCO测试集上进行一系列消融实验, 深入分析各模块的贡献和有效性.通过逐步移除或修改关键模块, KD-DRRPose能评估每个模块对整体性能的影响, 并验证它们在提升模型精度和效率方面的重要性.
各模块具体AP值如表3所示, 涵盖各模块单独启用及组合使用.对各模块详细分析如下.
| 表3 KD-DRRPose各模块消融实验结果 Table 3 Ablation study results of different modules on KD-DRRPose % |
动态选择部分旨在通过智能判断图像区域的重要性, 选择性地对某些区域做进一步细化处理, 从而优化计算效率和推理精度.当该模块被禁用时, AP值从72.7%降至68.8%.
启用动态选择之后, 方法可在不同复杂度的场景中自适应调整计算资源.在多人遮挡或姿态复杂的场景下, 动态选择模块能识别需要更精细处理的区域, 提高估计的准确度.在简单场景中, 动态选择模块会减少对高分辨率区域的计算量, 提升推理效率.由此可看出, 该模块不仅提高姿态估计的精度, 还显著优化方法效率, 特别是在推理阶段节省大量计算资源.
知识蒸馏部分是另一关键模块, 分为特征蒸馏和姿态蒸馏两个部分, 分步将教师模型中的信息传递给学生模型.
特征蒸馏通过传递教师模型中对关键点的高层次理解, 使学生模型更好地捕捉全局信息.启用特征蒸馏后, AP值升至67.5%, 说明特征蒸馏对方法全局性能的提升具有显著作用.
姿态蒸馏通过将教师模型生成的高分辨率热图信息传递给学生模型, 提升回归模型的精度.启用姿态蒸馏后, AP值升至63.1%.姿态蒸馏弥补回归模型直接预测关键点时的精度不足的缺陷, 使学生模型能学习更丰富的局部特征.
当同时启用特征蒸馏和姿态蒸馏时, AP值达到68.8%, 比单独使用二者时效果更佳.这说明这两个蒸馏策略相辅相成, 共同提升学生模型的精度.当动态选择模块与知识蒸馏模块组合使用时, 方法达到最佳性能, AP值升至72.7%.相比仅启用单一模块, 组合使用不仅能提升关键区域的处理精度, 还能减少对不重要区域的计算量, 优化计算资源的分配.这种组合效果体现动态选择模块与知识蒸馏模块之间的互补性.动态选择模块通过减少无关区域的计算负担, 使更多的计算资源集中在关键点密集的区域.知识蒸馏模块通过传递教师模型中的细粒度信息, 进一步提升这些区域的关键点定位精度.两者的结合既提高精度, 又在效率方面实现突破.
参数β控制动态选择过程中细化处理的图像块比例, 直接影响KD-DRRPose在细化阶段选择的区域数量.下面验证β不同时对KD-DRRPose性能的显著影响.
定义β=0.2, 0.3, …, 0.7, 其对KD-DRRPose性能的影响如表4所示.由表可见, 随着β的增大, 模型细化区域范围逐渐扩大.AP值随着的β增大而上升, 并在β=0.4时达到最大值72.7%.当β继续增大时, AP值反而开始下降, 且计算量持续增加.这种趋势说明β的设置需要在精度和计算量之间取得平衡:当β过小时, KD-DRRPose在细化阶段处理的图像块不足, 导致一些关键区域未被充分细化, 从而影响整体精度, 当β过大时, KD-DRRPose处理过多无关的背景区域, 这些区域对姿态估计未提供额外的有用信息, 反而浪费计算资源, 导致推理效率降低, 甚至影响KD-DRRPose的准确性.因此β值的设定至关重要, 适中的β值能在保持精细处理区域有效性的同时, 避免不必要的计算开销, 实现不错的精度与效率平衡.
| 表4 β对KD-DRRPose性能的影响 Table 4 Effect of β on KD-DRRPose performance |
阈值Qthres控制进入细化阶段的样本数量, Qthres值越小, 粗略化阶段的样本通过率越高, 进入细化阶段的样本数量越少, 导致其学习的信息不充分.定义Qthres=0.70, 0.75, …, 0.95, 其对KD-DRRPose性能的影响如表5所示.由表可看出, 随着Qthres值的降低, 进入细化阶段的样本数量逐渐减少, AP值也随之变低.当Qthres从0.95降至0.70时, 粗略化阶段中样本通过率从4.1%增至78.5%, 这意味着进入细化阶段的样本变少, AP值从72.7%降至67.1%.
| 表5 Qthres对KD-DRRPose的影响 Table 5 Effect of Qthres on KD-DRRPose performance |
细化阶段的样本数量与模型的精度相关.当Qthres较高时, 那些在粗略化阶段表现较优的样本也会进入细化阶段, 这些样本通常包含较清晰的关键点信息, KD-DRRPose能通过细化阶段进一步提升对这些关键点的定位精度.然而, 当Qthres较低时, 大量在粗略化阶段表现较差的样本也会进入细化阶段, 导致模型在细化阶段无法有效提升精度.因此, Qthres的设置需要在精度和计算效率之间找到一个平衡点.通过实验发现, Qthres设为0.9时, KD-DRR-Pose在保持较高精度的同时, 计算效率也得到较好的控制.
知识蒸馏策略将教师模型(基于热图的方法TokenPose)中的高精度特征传递给学生模型(基于坐标回归的方法KD-DRRPose), 提升学生模型的精度和泛化能力.知识蒸馏过程中的教师模型与学生模型的性能对比如表6所示, 表中*表示重新训练和评价方法.由表可进一步验证知识蒸馏的效果.
| 表6 学生模型和教师模型的性能对比 Table 6 Performance comparison of student model and teacher model |
尽管学生模型的AP值比教师模型提升0.2%, 但参数量显著减少, 计算复杂度也有所下降.这表明知识蒸馏策略在提升学生模型效率的同时, 仍能保持较高的精度.通过知识蒸馏, 学生模型从教师模型中学习细粒度的定位能力, 在一定程度上弥补回归模型直接估计关键点时的误差.
更为重要的是, 学生模型仅依赖回归方法进行推理, 大幅提升推理速度, 而知识蒸馏成功将教师模型的热图信息融入回归模型中, 使学生模型在推理速度更快时, 仍保持类似基于热图的方法的精度.
本文在COCO数据集上对部分人体姿态估计结果进行可视化, 具体如图3所示, 随机选取单人、多人、复杂姿势及拥挤和部分遮挡的场景.
 | 图3 COCO数据集上的可视化示例Fig.3 Visualization examples on COCO dataset |
由图3可看出, KD-DRRPose在各种场景下都具有较优的检测效果, 这表明KD-DRRPose能在各种不同的环境下保持良好的人体姿态估计性能, 具有一定的鲁棒性.
本文提出基于知识蒸馏和动态区域细化的人体姿态估计方法(KD-DRRPose), 结合热图和回归策略, 缓解两者各自的不足, 实现性能与效率的平衡.KD-DRRPose在保持高推理速度的同时, 显著提高姿态估计的准确性, 特别是在复杂场景下, 性能较优.这得益于本文采用的动态区域细化策略, 可捕捉细粒度特征并动态挖掘图像区域与关键点之间的关系, 有效减少计算负担.同时知识蒸馏策略成功地将热图模型的丰富特征传递给回归模型, 这样能充分利用热图的细粒度定位能力和回归的快速推理特性.通过结合高效的回归方法和精确的热图策略, 本文方法不仅提高人体姿态估计的整体性能, 还在计算资源有限时实现更高的推理效率.此外, 通过动态优化模块, 本文方法能根据自身初步预测自适应调整计算策略, 有效优化自身在不同情况下的表现, 获得较高的鲁棒性和适应性.
然而, KD-DRRPose仍存在一定的局限性.由于知识蒸馏过程中依赖教师模型的性能, 因此当教师模型本身存在偏差或不足时, 学生模型的表现可能受到影响.动态优化策略在处理极度复杂的场景时会面临进一步的计算资源消耗问题.为了解决这些问题, 未来的研究可尝试引入更先进的教师模型或自监督学习方法, 提高知识蒸馏的效果, 同时优化动态策略的计算过程, 如通过剪枝技术或更高效的稀疏化方法, 进一步减少计算负担.
本文责任编委 封举富
Recommended by Associate Editor FENG Jufu
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|
| [40] |
|
| [41] |
|
| [42] |
|
| [43] |
|
| [44] |
|
| [45] |
|