




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于动态语义聚类关系建模的目标跟踪方法
[聂国豪1  , 王兴梅
, 王兴梅1, 2 , 徐悦竹1 , 杨文涛3 ]
, 王兴梅, 徐悦竹, 杨文涛]
|
|



作者简介:

聂国豪,博士研究生,主要研究方向为目标跟踪、目标检测.E-mail:nieguohao@hrbeu.edu.cn.

王兴梅,博士,教授,主要研究方向为人工智能、水下信号处理、计算机视觉、模式识别.E-mail:wangxingmei@hrbeu.edu.cn.

杨文涛,硕士研究生,主要研究方向为目标跟踪,智能感知.E-mail:1940928852@qq.com.
第二十七届中国科协年会学术论文
Transformer跟踪器采用全局注意力机制时,常因目标形变导致特征判别性下降,引发目标和背景混淆.针对此问题,文中提出基于动态语义聚类关系建模的目标跟踪方法.首先,构建语义关系建模模块,通过特征空间中局部注意力聚焦语义相近的特征向量,有效抑制目标与干扰背景的错误交互.然后,利用图神经网络捕捉局部关联性,设计动态语义聚类模块,自适应生成语义类别划分,实现动态注意力突出目标和背景的鉴别信息.最后,设计语义背景消除模块,在关系建模过程中有效抑制背景特征干扰,提升跟踪效率.在6个基准数据集上的大量实验表明,文中方法性能较优.
About Author:
NIE Guohao, Ph.D. candidate. His research interests include object tracking and object detection.
WANG Xingmei, Ph.D., professor. Her research interests include artificial intelligence, underwater signal processing, compu-ter vision and pattern recognition.
Yang Wentao, Master student. His research interests include object tracking and intelligent sensing.
Academic Papers of the 27th Annual Meeting of the China Association for Science and Technology
When the Transformer based object tracking method employs the global attention mechanism to model the spatial relations between the search area and the template, the target deformation can lead to the degradation of feature discriminability, causing confusion between the target and the background. To solve this problem, a dynamic semantic clustering relation modeling method for object tracking is proposed. First, a semantic relation modeling module is constructed. Local attention mechanisms in the feature space are employed to concentrate on semantically similar feature vectors, thereby effectively suppressing erroneous interactions between the target and the distracting background. Second, graph neural networks are utilized to capture local correlations and design a dynamic semantic clustering module. The module adaptively generates semantic category partitions, enabling dynamic attention mechanisms to enhance the discriminative information between the target and the background. Finally, a semantic background elimination strategy is designed to effectively suppress the interference from background features during relationship modeling, thereby improving tracking efficiency. Experimental results on six benchmark datasets demonstrate the superiority of the proposed method.
目标跟踪作为计算机视觉的核心课题之一, 在智能驾驶、人机交互等众多领域具有重要的应用价值[1].目标跟踪任务根据给定的初始目标模板在后续视频序列中持续定位目标[2, 3].
近年来, 基于模板匹配方式, 孪生网络跟踪方法取得显著进展, 其通过卷积运算建模模板特征与搜索区域特征间的关联[4], 并在融合特征上预测目标的边界框.然而, 卷积模板匹配方式可能导致融合特征的判别性不足.
之后, 研究者从特征融合优化与全局关系建模两个方向展开探索.早期工作改进特征融合结构, 替代简单的卷积操作[5, 6], 但受限于卷积网络的局部感受野, 难以捕捉不同像素间的跨区域相关性.随着Transformer的引入, 基于全局关系建模的双流跟踪范式逐渐兴起.Chen等[7]提出TransT(Transformer Tracking), 设计特征融合模块, 实现跨特征交互.Yan等[8]提出STARK(Spatio-Temporal Transformer Network for Visual Tracking), 利用Transformer解码器实现多模板特征查询.Xie等[9]提出DualTFR(Dual-Branch Transformer), 将模板和搜索区域分为小块, 进行细致的模板匹配.Lin等[10]提出Swin-Track, 采用层次化窗口注意力, 平衡计算效率并捕捉长程依赖.
然而, 双流范式特征提取和关系建模分而治之的策略可能会忽略跟踪目标的特定信息, 为了进一步提高特定目标实例的判别特征, 一些研究者尝试关注目标特定信息以提高模型判别能力.Zhang等[11]提出空间注意力推断模型, 通过特征之间的相关性, 在外观模型中嵌入潜在的特征信息.Gao等[12]提出FCAT(Fine-Coarse Concatenated Attention Tracker), 改善注意力层忽略跟踪任务多尺度特性的缺陷.Nie等[13]提出TRTT(Temporal Relation Trans-former Tracker), 将模板与搜索特征的关联关系沿时间顺序传递, 用于捕获跟踪对象的目标特定特征.
尽管上述方法纳入部分特定跟踪目标的信息, 但两阶段策略在特征提取阶段对判别信息交互的滞后性仍导致在目标变化或跨域场景下性能衰减较显著[14].
单流Transformer跟踪范式通过模板-搜索区域联合编码, 在提取特征的同时实现全面的特征交互.典型方法OSTrack(One-Stream Tracking)[15]拼接目标模板与搜索区域图像, 并送入编码器网络, 共同进行特征更新.在此基础上, Lan等[16]提出ProCont-EXT(Progressive Context Encoding Transformer Tra-cker), 结合动态模板, 更新上下文感知注意力.Shi等[17]提出EVPTrack(Explicit Visual Prompts Tra-cking Framework), Xie等[18]提出AQATrack(Adap-tive Tracker), 都是生成一个独特的时空特征, 传播连续帧之间的信息, 采用的时间自回归更新模式可减少传统显式目标模板更新带来的跟踪失败风险.Zhu等[19]提出DyTrack(Dynamic Transformer Tracking Framework), 根据视频帧难易程度配置适当的推理路线, 优化网络的计算资源分配.Wang等[20]提出TrackingMamba, 结合单流跟踪范式与视觉Mamba, 在保持全局依赖建模的同时优化Transformer的计算效率.
由于空间建模纳入特征提取过程, 上述方法大都重点关注单流范式的时间信息或效率问题, 但在早期特征层的交互中, 低级语义特征容易引发目标-背景特征的错误关联, 特别是存在相似干扰物时, 信息聚合将导致搜索特征混淆真实目标, 也可能削弱模板对背景的鉴别能力.
为此, 动态注意力机制成为新的研究热点, 通过约束背景与模板之间的关联以抑制错误的空间关系建模[21].SparseTT[22]采用特征相似度筛选机制排除背景.OSTrack逐层删除部分背景区域, 减少歧义.MixFormer[23]切断模板到搜索区域的注意力关联, 避免动态的搜索区域影响目标模板.
为了减少上述手工设计策略的复杂性, Gao等[24]提出AiATrack, 设计可学习的内部注意力, 优化外部注意力计算.Gao等[25]提出GRM, 进一步通过一个单层网络, 端到端地指导搜索区域中目标、背景与模板特征交互.Wang等[26]提出RTDiMP, 设计稀疏区域感知的注意力机制, 重点保留搜索区域中与目标具有语义相关的区域并进行细粒度的注意计算.从背景角度上看, Zhang等[27]提出ATPTrack, 渐进地修剪动态模板和搜索区域, 保留高判别区域用于跟踪.
然而, 浅层网络的低级空间特征(如纹理、轮廓等信息)难以产生足够的高级语义, 并在特征建模的早期准确区分目标和背景[28].这种粗糙二元划分使大比例的搜索令牌无约束地参与目标外观建模, 导致次优的特征聚合.同时, 忽略模板和搜索区域中背景之间的语义关联, 缺乏背景关系建模, 当目标发生较大变化时, 无法补偿外观模型的判别力.
为了解决上述问题, 本文提出基于动态语义聚类关系建模的目标跟踪方法(Dynamic Semantic Clustering Relation Modeling Method for Object Tra-cking, DSCTrack), 通过增强关系建模, 提高特征的鉴别能力.首先, 构建语义关系建模模块, 通过近似语义特征的聚合机制抑制Transformer跟踪器中目标与背景间的交叉干扰, 并有效纳入背景关联, 增强特征鉴别能力.然后, 设计动态语义聚类模块, 采用图神经网络捕捉特征向量局部关联关系, 实现混合特征的自适应生成语义类别划分, 确保关系建模过程获得正确的信息聚合路径.最后, 构建语义背景消除模块, 主动消除冗余无关背景区域, 减少对特征提取的干扰, 在保持目标表征完整性的同时, 提升跟踪速度与精度.
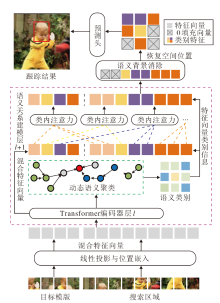
本文提出基于动态语义聚类关系建模的目标跟踪方法(DSCTrack), 框架如图1所示.
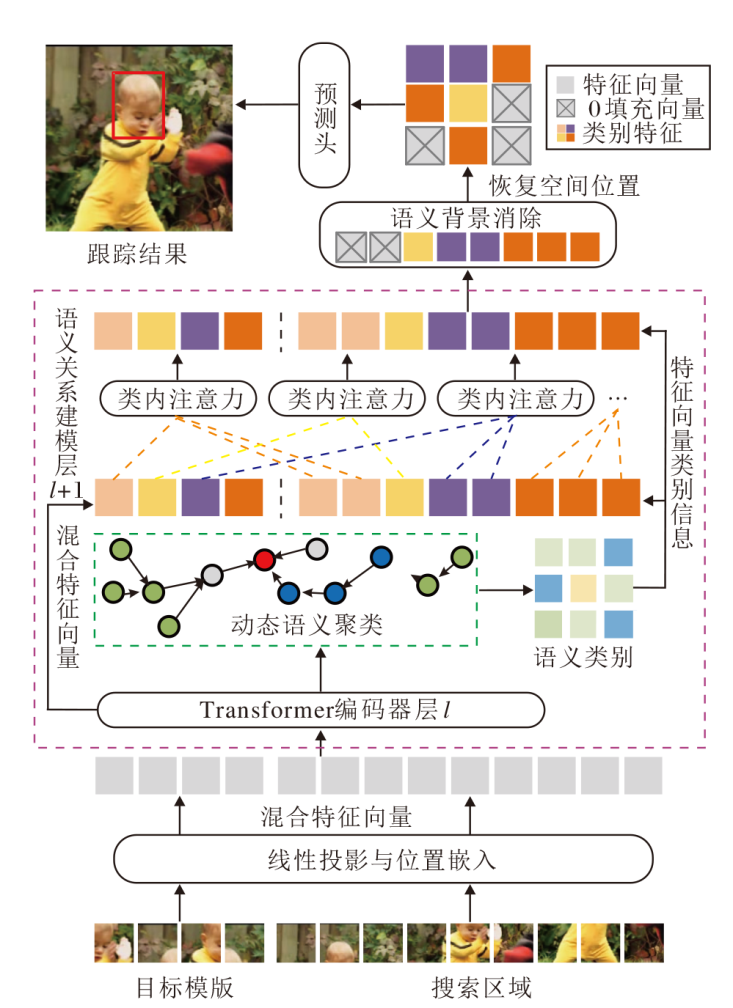 | 图1 DSCTrack框架图Fig.1 Framework of DSCTrack |
DSCTrack从初始帧截取模板z∈
模板特征Ez∈
E=[Ez; Ex]∈
被送入编码器, 联合执行特征提取和关系建模, 其中[; ]表示拼接操作.
编码器通过语义关系建模模块改进ViT(Vision Transformer)架构[29], 交替堆叠Transformer基础层与语义关系建模层, 实现多粒度信息交互.基础层利用多头注意力机制和前馈网络更新输入的混合特征, 语义关系建模层重点增强混合特征中目标至目标、背景至背景的语义关联, 提取目标鉴别特征和背景关系.
语义关系建模模块接收前一层输出的混合特征向量作为输入, 根据动态语义聚类模块, 采用图神经网络捕捉特征向量之间的关联关系, 经过几轮聚合与消息传递, 多层感知机 (Multilayer Perceptron, MLP)层被用于预测每个特征向量所属的类别.输入特征被编码为图数据, 经GCNs(Graph Convolu-tional Networks)后, 通过MLP计算节点-簇相似度, 最终输出维度为N× G的软分配矩阵.该矩阵可被解释为节点属于各簇的对数概率, 通过arg max操作可获得硬聚类结果.根据预测的类别结果, 同簇内相似类别的语义特征向量执行自适应聚类.区别于传统Transformer直接点对点地交互所有特征向量, 语义引导的动态注意力在每个类别内部计算自注意力, 从而避免搜索区域和模板混合特征向量中目标-背景像素的跨语义关联.根据语义进一步细分特征向量类别, 增强搜索区域和模板中同类特征的语义一致性.生成的语义标签同步传输至背景消除模块.该组件评估不同类别的显著性, 动态消除搜索区域中非关键的背景特征, 保留高相关性语义信息, 用于后续特征更新和边界框预测, 在降低计算复杂度的同时提升判别性能.
在目标预测阶段, 对编码器输出的搜索区域特征标记进行空间维度解耦, 通过坐标映射重定位策略恢复原始二维特征结构.重构后的特征图输入卷积预测头, 最终实现端到端的边界框回归与置信度预测.DSCTrack逐帧预测目标位置和大小, 获得完整的视频跟踪轨迹, 在该过程中不更新初始模板.
给定目标模板z和当前搜索区域x, 目标跟踪可表示为对搜索区域中目标边界框bx的预测, 即
bx=ψ (ϕ (x; z)), (1)
其中, ϕ (· )表示特征提取网络, ψ (· )表示预测头.在单流范式中, 特征提取网络拼接z和x, 提取混合特征向量E, 并通过Transformer编码器层的多头自注意力机制(Multi-head Self-Attention, MHA)更新模板和搜索区域的特征.具体公式如下:
$\begin{align} & q=k=v=E=\left[ E_{z}^{O}; E_{z}^{B}; E_{x}^{O}; E_{x}^{B} \right] \\ & MHA\left( q, k, v \right)=\text{Softmax(}\frac{q{{k}^{T}}}{\sqrt{{{d}_{k}}}}\text{)}\cdot v \\ \end{align}$ (2)
其中, q、k、v分别表示多头注意力的查询向量、键向量和值向量,
基于式(2)的点积注意力qkT, 上述特征交互过程同时集成自我关系和交叉关系的建模.例如:
为了缓解关系建模中的错误信息聚合, 可简单地将搜索区域特征Ex划分为目标
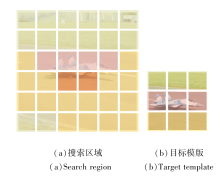
在式(2)中, 特征向量间的注意力由向量间的点积相似性决定.因此, 在混合特征构成的特征空间中, 模板和搜索区域的近似语义特征向量彼此接近, 具有较大的注意力权重.如图2所示, 相同颜色表示接近的语义类别.在此基础上, 设置特征空间内的局部注意力能限制远距离特征向量的干扰, 并强化近距离特征的关系建模.
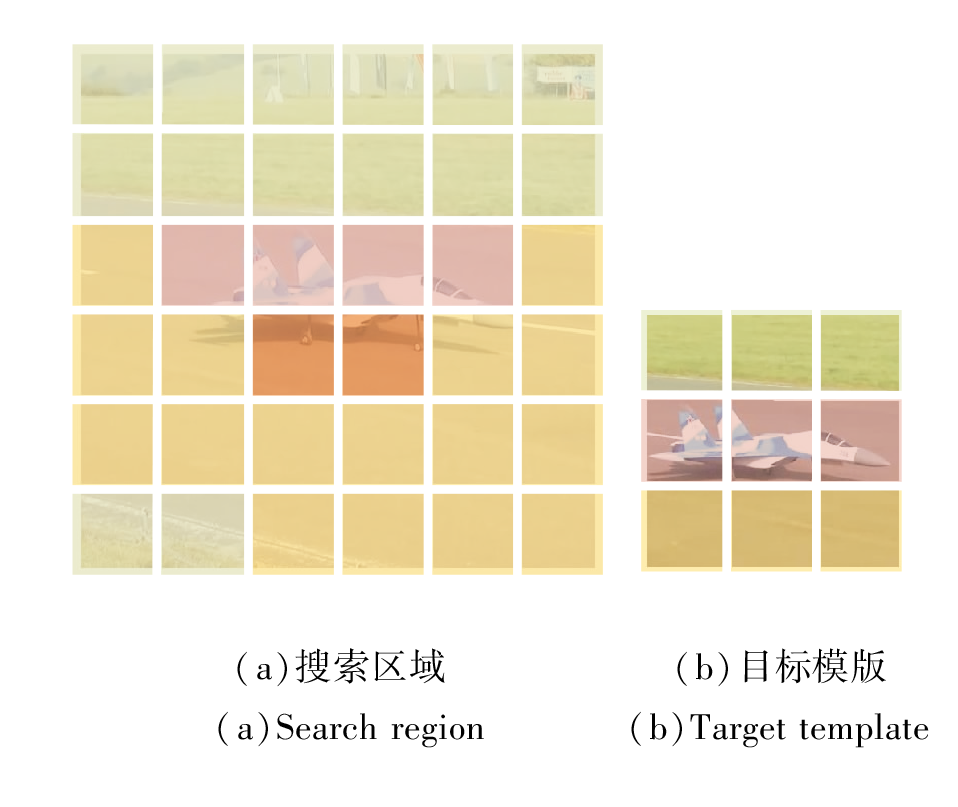 | 图2 搜索区域和模板在特征空间的局部语义关系对比Fig.2 Comparison of local semantic relation between search region and target template in feature space |
给定模板和搜索区域的混合特征向量
E=[
E能被划分为G个语义类别, 即
E=[E1, E2, …, EG].
模板和搜索区域中隶属于目标的特征向量
语义关系建模模块规则定义为:对于目标特征
q=k=v=
其中, i∈ [1, GO], l表示当前编码器层数.
对于背景特征
q=k=v=
其中j∈ [1, GB].
根据式(3)和式(4), 语义关系建模模块的输出向量如下所示:
El+1=[E'lz; E'lx]+FFN([E'lz; E'lx]), (5)
其中,
E'lz =[
表示类内注意力的输出特征, FFN(· )表示前馈神经网络(Feedforward Neural Network).
式(5)从语义角度将目标或背景分为多种语义类别, 避免二元划分策略中的类别混淆.早期特征具有的图像高频信息和低级语义也为细化的分类提供依据, 类内信息聚合能有效减少判别信息的损失.同时, 关联特征空间的注意力机制建模模板与搜索区域中的背景特征, 可提高在目标变化时的判别能力.
实现语义关系建模的关键是合理准确的类别划分, 一些非参数化方法能基于特征向量本身信息执行聚类, 如DPC-KNN(Density Peaks Clustering Based on k-Nearest Neighbors)[30].然而, 此类方法依赖传统的迭代策略, 需要预先手工设计聚类中心数量和迭代次数, 灵活性较差, 容易受初始参数选择的影响.此外, 在处理高维数据时, 此类方法的计算量较大, 在聚类中常忽略多个特征向量描述的图像局部关联.
因此, 本文设计动态语义聚类模块, 在每个特征层中, 通过各特征向量在空间中的局部关联关系, 端到端地自适应划分特征类别.
给定无向图Graph=(H, T), H表示无向图的节点, T表示无向图的边, 节点表示混合特征E中每个特征向量, 边表示节点之间的相关性.首先采用特征向量在Transformer中的键值投影k作为节点特征, 利用其丰富的物体细节信息[31].无向图的边表示节点的边缘权重矩阵:
W=kkT∈
权重wu, v表示节点Eu和Ev之间的相关性.与先前采用MHA(· )的注意力图qkT建模的独立相关性[15, 24]不同, 为了进一步捕捉特征之间局部关联信息, 利用GCNs在图中聚合与传递消息, 使用局部滤波器从节点的邻域中聚合信息.每个节点更新过程如下:
其中, Θ 表示可训练参数矩阵, N(m)表示节点hm的邻居, |N(m) |表示邻居个数.
通过求和运算符执行GCNs聚合, 求和运算符中的项表示消息传递操作.训练目标是优化网络参数Θ , 生成有意义的消息在节点间传递, 优化损失函数.
对具有权重矩阵W的图执行多次GCNs聚合操作后, 输出节点的特征矩阵
$\tau_{i, \kappa}=\operatorname{Softmax}(\operatorname{MLP}(\widehat{N})) \in \mathbf{R}^{\left(N_{z}+N_{x}\right) \times K}$,
其中K表示类别最大数量.选择预测概率最高的类别作为向量的语义类别.
在实际计算中, 可根据关联矩阵W和节点特征
语义关系建模模块能在相应类别内更新特征.然而, 由于不同语义聚类的特征向量数量不一致, 无法并行计算多个类别的内部注意力.若分组执行内部注意力, 多次循环网络前向过程会显著减慢训练速度.
为此, 受掩码注意力思想[25]的启发, 本文采用语义引导的动态注意力实现并行计算.当存在G个预测类别时, 分类结果被转换为独热向量D∈ {0, 1
m∈ {0, 1
mi, j> 0表示特征向量Ei能按照语义关系建模模块规则从特征向量Ej中聚合信息.最后, 利用式(2)对所有特征之间的注意力进行合并计算, 并通过将注意力权重矩阵与注意掩码进行Hadamard乘积计算, 屏蔽类别外部的关联, 合并多个类内注意力为一个并行的注意力计算.
对上述过程进行计算复杂度分析.假设通过动态语义聚类模块将特征均匀划分为G个互斥类别, 每类独立计算自注意力, 从原始计算复杂度O(N2d)变为O(N2d/G), 降至原始的1/G.尽管分组的计算复杂度线性下降, 但在实际过程中, 掩码策略仍保留全局的注意力计算, 即计算复杂度为O(N2d), 通过屏蔽关联实验语义引导, 该部分保持与原始Transformer层相同的计算复杂度.
单流跟踪器利用搜索区域的全部像素执行特征提取, 基于式(2), 保留其中大量冗余背景会降低特征更新的计算效率, 还可能引入噪声.因此, 引入语义背景消除模块, 在特征提取和交互的过程中动态消除搜索区域内的部分冗余背景, 减少背景干扰, 提升跟踪速度.
如1.4节所述, 每个特征向量表示一块图像区域, 减少与目标语义最不相关的背景类别能排除冗余背景.给定模板中目标的真实值, 计算目标特征相对每个类别中心Ec的重要性得分S, 由此评估这些候选区域.从混合特征E中删除得分较低的候选区域, 不参与后续特征更新.搜索区域中第i个特征向量的重要性得分为:
Si=
其中, Ngt表示真实值中包含目标特征向量的数量, dist(· )表示真实值第j个向量
通过式(6)筛选k个低响应搜索特征并剪枝, 对上述过程进行计算复杂度分析.Transformer层的输入序列长度从N=Nz+Nx变为N=N-k, 单层自注意力计算复杂度从O(N2d)降至O((N-k)2d), 前馈网络计算复杂度从O(Nd2)降至O((N-k)d2).由于计算复杂度主要来源于二次复杂度的注意力计算, 将搜索特征保持比率定义为ρ =k/N , 消除其余候选特征以提高整体跟踪速度.此外, 式(6)考虑不同语义类别与目标的整体相似度, 从而避免因为局部遮挡而消除的重要区域.相比基于模板中心特征的对比方式[16], 语义背景消除模块能更细致评估目标不同部位的重要性.
编码器通过预测头网络处理搜索区域特征, 预测目标位置和尺寸.针对背景消除导致的空间结构被破坏, 采用0填充方式恢复特征向量的2D空间结构.本文的预测头网络来自文献[15], 预测头接收0填充2D特征图以预测目标位置.网络包含3个并行卷积网络分支:中心分类分数图
P∈ [0, 1
局部偏移
O∈ [0, 1
和归一化边界框尺寸
S∈ [0, 1
具有最高分类分数的位置
(xd, yd)=arg
被认为是目标的中心位置, 最终目标边界框为:
(x, y, w, h)=(xd+O(0, xd, yd), yd+O(1, xd, yd), S(0, xd, yd), S(1, xd, yd)). (7)
训练时监督信号根据真实目标边界框的中心坐标(cx, cy), 生成的高斯标签在响应图上对应的位置为一个2D高斯分布, 表示该位置是目标中心的置信度:
$G\left( i, j \right)=\exp \left( -\frac{{{\left( i-{{c}_{x}} \right)}^{2}}}{2\sigma _{x}^{2}}-\frac{{{\left( j-{{c}_{y}} \right)}^{2}}}{2\sigma _{y}^{2}} \right)$,
其中, (i, j)表示响应图中的像素坐标, σ 控制高斯分布的宽度.
预测头的总损失包括中心分类分数图与高斯标签的焦点损失、根据式(7)得到目标预测边界框的GIoU(Generalized Intersection over Union)损失和L1损失, 则总损失如下所示:
Ltotal=λ centerLfocal+λ giouLgiou+λ l1Ll1,
其中, λ center、λ giou和λ l1表示联合优化的损失权重, 遵循文献[15], λ center=1, λ giou=2, λ l1=5.
实验基于AMD 3990X+RTX 3090硬件平台和Ubuntu 22.04系统, 采用PyTorch 1.8.1框架实现.根据基准数据集初始帧目标指定模板, 为初始目标2倍(调整至1282), 搜索区域为目标4倍(调整至2562), 经步长为16的线性投影生成初始特征后输入编码器.
网络架构采用MAE初始化的12层ViT-Base主干, 在第2层、第4层、第6层和第8层引入语义关系建模模块.GCNs部分输入维度为512, 隐藏层维度为64, 执行一阶邻居聚合, 输出经过ReLU函数激活后馈入MLP.MLP由双层全连接层组成, 隐藏层维度为32, 使用ELU函数增强非线性表达.所有数据集的预设聚类簇数量为10, 最终通过Softmax归一化生成分配概率矩阵.在第6层和第8层后嵌入语义背景消除模块, 消除40%搜索特征向量.语义关系建模模块的预测头由4组Conv-BN-ReLU堆叠构成, 其它设置与OSTrack[15]保持一致.
在LaSOT[32]、GOT-10k[33]、TrackingNet[34]、COCO[35]数据集的指定训练集上学习, 在LaSOT、GOT-10k、TrackingNet、OTB100[35]、UAV123[36]、NFS[37]测试基准数据集上验证, 其中GOT-10k数据集严格遵循官方协议, 仅使用自身训练集学习的模型进行测试.
训练阶段使用AdamW(Adam with Decoupled Weight Decay)优化器训练300周期, 在GOT-10k数据集上缩减为100周期, 在每个周期上从视频序列随机采样模板和搜索区域, 共60 000样本对, ViT主干的预训练参数学习率为4× 10-5, 模型的其它参数随机初始化, 学习率为4× 10-4, 并在第240周期时进行10倍衰减, 在GOT-10k数据集上, 在第80个周期时进行衰减.推理阶段保留初始模板并应用汉宁窗抑制目标位移.
为了验证DSCTrack在不同情况下的鲁棒性, 在 GOT-10k数据集上选取平均重叠度(Average Over-lap, AO)和成功率(Success Rate, SR)作为评价指标.AO表示预测边界框与真实边界框之间的交集与并集比率(Intersection over Union, IoU)的平均值.SR表示跟踪算法在特定IoU阈值下成功跟踪目标的比例, 本文选取阈值为0.5和0.75的SR评价边界框与真实边界框的重合度.
在LaSOT、Tracking-Net数据集上, 选择精确度(Precision, PR)、归一化精确度(Normalized Preci- sion, NPR)和成功率的曲线下面积(Area Under Curve, AUC)作为评估指标.AUC在成功率的阈值从0至1变化时计算每个成功率的曲线下面积, 对跟踪算法进行排名.在OTB- 100、NFS、UAV123数据集上, 选择AUC和PR作为评价指标.
2.2.1 定量分析
选择如下对比方法:SiamRPN++[5]、KeepTrack[6]、TransT[7]、STARK[8]、SwinTrack[10]、FCAT[12] 、OS-Track[15]、DyTrack[19]、MixFormer[23]、AiA-Track[24]、RTDiMP[26]、DiMP[38]、TrDiMP[39]、CSWinTT(Multi-scale Cyclic Shifting Window Transformer Tra-cker)[40]、PromptVT[41]、TiT (Tracking-in-Tracking)[42]、MIMTrack[43].
各方法在GOT-10k、LaSOT、TrackingNet数据集上的指标值对比如表1所示, 表中黑体数字表示最优值, 斜体数字表示次优值.
| 表1 各方法在GOT-10k、LaSOT、TrackingNet数据集上的指标值对比 Table 1 Metric value comparison of different methods on GOT-10k, LaSOT and TrackingNet datasets % |
GOT-10k数据集包含超过10 000个视频片段, 共1.5× 106帧, 涵盖563种物体类别和87种动作类别.数据集的训练集和测试集的目标类别不重叠, 强调模型对未见类别的泛化能力.如表1所示, 相比单流方法OSTrack的全局特征交互, DSCTrack集成特征空间局部注意力机制, 在AO、SR0.5、SR0.75指标上分别提升2.0%、1.9%、0.5%, 有效抑制干扰信息聚合.对比双流方法TransT的分离特征提取和Transformer全局建模, DSCTrack通过类内信息交互, 实现模板-搜索区域双向增强, SR0.5值提升5.7%.针对SwinTrack的图像空间分块注意力会削弱特征交互, DSCTrack采用特征空间局部建模, 在AO、SR0.5指标上分别提升3.6%和4.5%, 验证语义关系建模模块的有效性.DSCTrack优于生成式方法MIMTrack, MIMTrack合并分类与回归分支, 减少SR0.5指标的精度损失, DSCTrack得益于判别能力的提升, 在AO、SR0.75指标上仍具有优势.
LaSOT测试集包含280个视频, 涉及70个跟踪类别, 平均长度为2 500帧, 是一个具有高质量注释的长期数据集, 包含大量随时间变化和从视野中消失再现的目标.如表1所示, 相比OSTrack, DSC-Track的AUC值提升1.2%, 表明外观模型在持续形变中的判别优势.DSCTrack虽未集成目标重检测和在线更新以解决长期跟踪的目标消失再现的问题, 但在NPR指标上优于TiT且PR值提升0.8%.TiT采用在线更新机制, 显示初始判别力提升对长期精度的增益.相比双流方法AiATrack与图像局部注意的MixFormer, DSCTrack的AUC值均提升1%, 表明特征交互中语义约束的有效性.DSCTrack的AUC、PR值略低于具有细化多尺度注意力的FCAT, FCAT在处理一些特定小目标时具有一定优势.
DSCTrack、TransT[7]、OSTrack[15]、AiATrack[24]、DiMP[38]、PromptVT[41]在LaSOT数据集上针对14个不同跟踪属性的可视化结果如图3所示, 越靠近外侧的点值越大, 图中数字为DSCTrack在该属性下的子数据集上的AUC值.
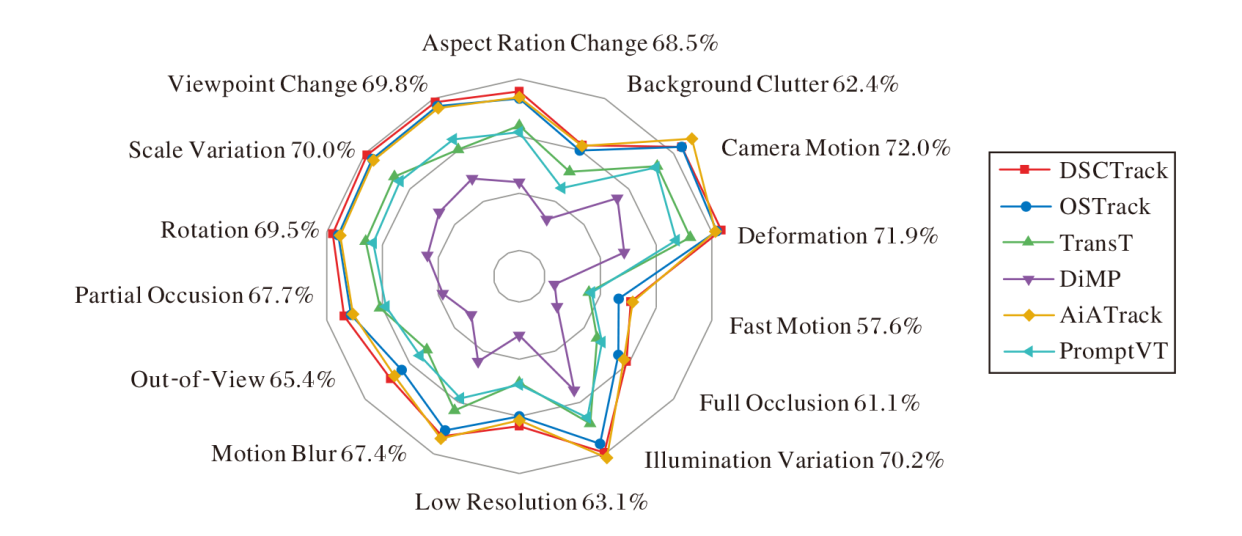 | 图3 各方法在LsSOT数据集上针对14个不同跟踪属性的可视化结果Fig.3 Visualization results of 14 different tracking attributes of 6 methods on LsSOT dataset |
由图3可看出, 在Scale Varia-tion、Rotation、Par-tial Occlusion等属性上, DSCTrack性能较优, 由此说明语义关系建模模块可改善跟踪器在特殊条件下的整体判别能力.
TrackingNet数据集包含511个测试序列, 跟踪场景复杂多样.如表1所示, 相比OSTrack, DSC-Track的NPR、PR值分别提升0.9%和1.4%.相比双流方法TransT和STARK, DSCTrack的AUC值分别提升1.9%和1.3%.
PromptVT利用网络不同深度和尺度的高级语义特征和低级语义特征学习全面的Transformer视觉表示, 但这种结合不具备区分性, 缺乏对目标特定特征的学习, 因此AUC值低于DSCTrack.DSCTrack性能优于RTDiMP和DyTrack, 但速度较慢, 原因是DyTrack采用分支选择策略, 减少在更简单情况下启用的参数数量, 而RTDiMP采用更轻量的卷积网络, 在更大规模和平稳的TrackingNet数据集上具有优势, 而在更复杂的跟踪情境下, 如在GOT10K、LaSOT数据集上, RTDiMP和DyTrack性能损失更多.
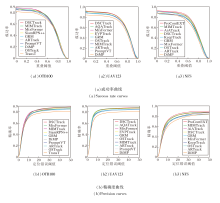
在OTB100、UAV123、NFS数据集上, 选择如下对比方法:SiamRPN++[5]、KeepTrack[6]、TransT[7]、OSTrack[15]、ProContEXT[16]、EVPTrack[17]、AQA-Track[18]、MixFormer[23]、AiATrack[24]、GRM[25]、DiMP[38]、PromptVT[41]、MIMTrack[43]、ARTrack[44].
各方法在OTB100、UAV123、NFS数据集上的指标值对比如表2所示, 表中黑体数字表示最优值, 斜体数字表示次优值.
| 表2 各方法在OTB100、UAV123、NFS数据集上的指标值对比 Table 2 Metric value comparison of different methods on OTB100、UAV123 and NFS datasets % |
OTB100数据集是一个包含100个视频序列的经典视觉目标跟踪数据集, 涵盖遮挡、光照变化、快速移动、尺度变化等多种跟踪挑战.由表2可见, GRM采用固定的二分类策略, 是具有动态注意力的Transformer单流跟踪器.由于DSCTrack对单流跟踪器的混合特征执行自适应聚类, 因此不同深度网络中特征交互能根据特征信息自适应地调整类别数量, 在面对更复杂的跟踪场景时, AUC指标优于GRM, 提升2.4%.
UAV123数据集是评估无人机视频跟踪技术的数据集, 具有高动态和高视角的特点, 能验证跟踪方法在复杂环境中的性能.由表2可见, DSCTrack获得最优值.相比判别式跟踪方法DiMP, DSCTrack通过模板和负样本集合在线学习目标的特定判别表示.在高动态的复杂环境中, DSCTrack建立的目标表示仍具有较高的判别性能, 相比DiMP, AUC值提升6.8%.
NFS数据集是专为评估在高帧率视频中目标跟踪方法表现的视觉目标跟踪数据集, 尤其适用于处理运动模糊和快速目标丢失的问题.NFS数据集上相邻帧的目标位置和外观变化差异较小, 在运动模糊时, 尽管ARTrack引入额外的目标轨迹信息帮助预测目标, 但DSCTrack考虑背景的关系建模并通过语义背景消除模块排除大量无关区域, 因此AUC指标优于ARTrack, 提升4.4%.
各对比方法在3个数据集上的成功率曲线和精确度曲线对比如图4所示.由图可见, 在具有短期时间变化OTB100数据集上, DSCTrack的排名显著优于具有模型更新机制和生成式特征建模能力的MIMTrack.在UAV123数据集上, 目标更小、运动更快, DSC-Track优于传递时空特征的AQATrack, 获得最优排名.上述结果说明在短期变化时DSCTrack具有最优的区分能力.然而, NFS数据集上目标使用高速相机拍摄, 并随机抽取图像帧构建数据集, 目标随时间变化的特性更明显, 由于DSCTrack缺乏更新手段, 因此仅获得第4名.
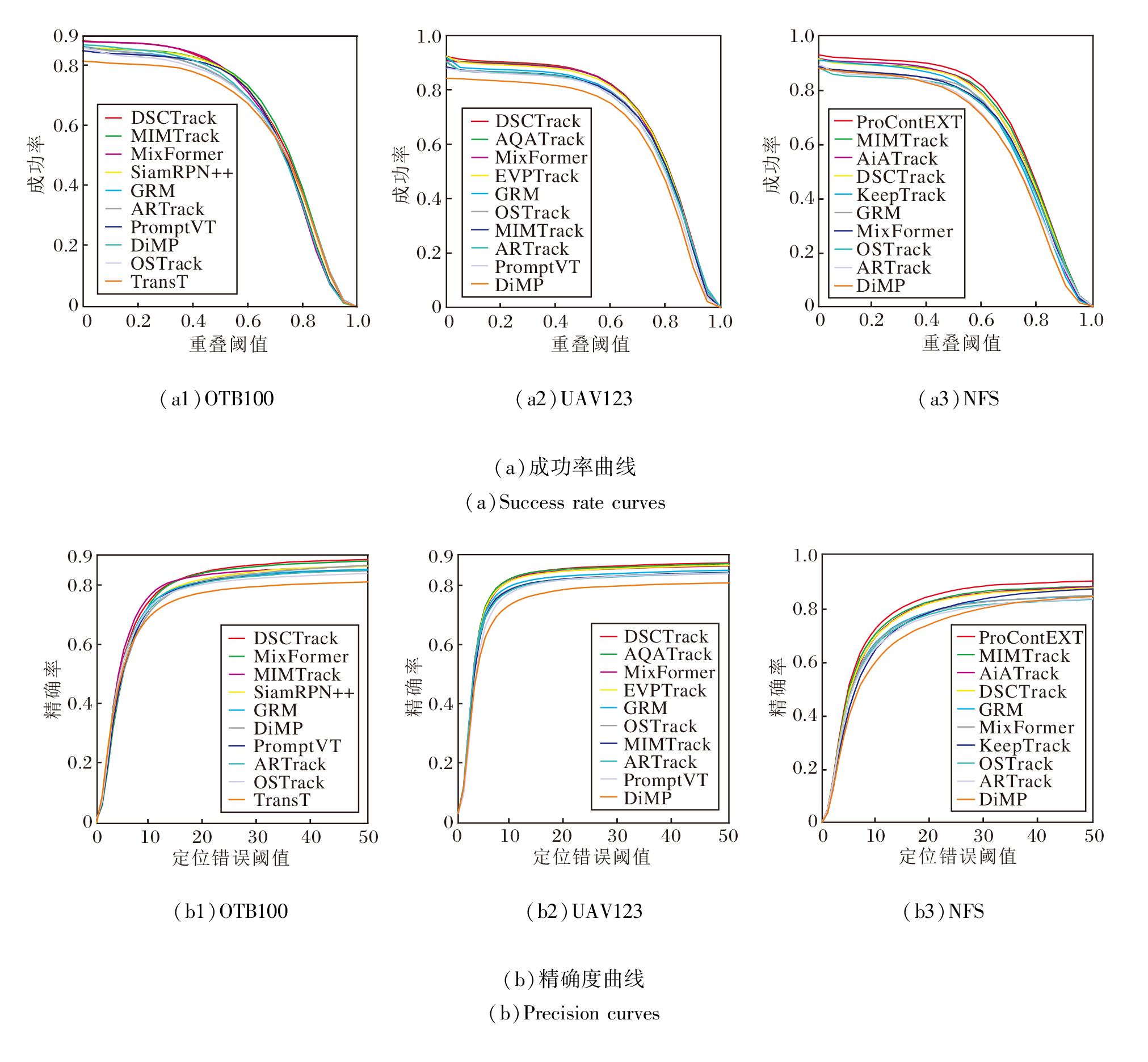 | 图4 各方法在OTB100、UAV123、NFS数据集上的成功率和精确度曲线Fig.4 Success rate and precision curves of different methods on OTB100, UAV123 and NFS datasets |
2.2.2 定性分析
为了直观说明DSCTrack在不同场景上的跟踪性能, 以及语义关系建模模块、语义背景消除模块的有效性, 通过定性实验分析DSCTrack在不同视频实例上的表现.
基于ViT-Base主干网络, 原始输入图像经过16倍降采样后获得特征图.在降采样后的特征空间中使用动态语义聚类模块, 如1.4节所述, 针对非零特征向量的有效类别进行可视化.将各特征向量对应的图像块按空间位置映射回原始图像, 并进行色彩填充, 具体聚类结果如图5所示, 在图中, 每个示例左侧为模板图像, 右侧为搜索区域图像.模板图像与搜索区域图像中相同颜色的区域表示同类语义区域, 目标区域均被划分为近似类别以执行类间交互.
 | 图5 动态语义聚类模块聚类结果可视化Fig.5 Visualization of clustering results of dynamic semantic clustering module |
在图5(a)中, 所有区域被划分为3类.模板图像与搜索区域图像中, 鱼体目标及其周边区域显示为绿色语义区域, 背景分为深蓝色和黄色.在动态语义聚类模块中, 仅对两幅图像中的水体背景实施交互, 而大部分背景区域未参与目标像素的交叉关系建模, 从而有效抑制无关背景错误信息聚合.
在图5(b)中, 模板图像明确划分为两类.两类目标区域与搜索区域中的目标独立进行关系建模, 相比RTDiMp[26]仅分类搜索区域, 动态语义聚类模块避免模板区域中背景与目标像素的混淆.
在图5(c)中, 复杂背景导致搜索区域按低级语义划分为5类.目标区域(绿色)与模板目标像素高度一致, 与背景手掌像素形成显著区分.
在图5(d)中, 除了袋鼠主体像素以外, 毗邻像素也被归入目标类别, 这可能源于目标框内包含部分背景像素, 导致基于浅层语义的划分存在歧义.总之, 大部分背景仍被排除在目标交互之外.
图5(e)为复杂背景下的摩托车干扰场景.搜索区域划分为3类, 语义相似的干扰物被归类为背景.这表明动态语义聚类模块能通过背景-背景关联有效区分目标与干扰物.
在图5(f)中, 动态语义聚类模块成功区分大部分背景, 构建清晰的目标-目标、背景-背景空间关系模型.目标语义类别不仅包含主体像素, 还涵盖周边少量区域.这种现象源于两个因素:特征聚类结果经缩放后对应较大的空间范围; 跟踪任务需通过目标及邻近像素判别物体边界以生成预测框.在相同消除比例下, 优先消除远离目标的特征, 表明邻近背景对空间定位的重要性.
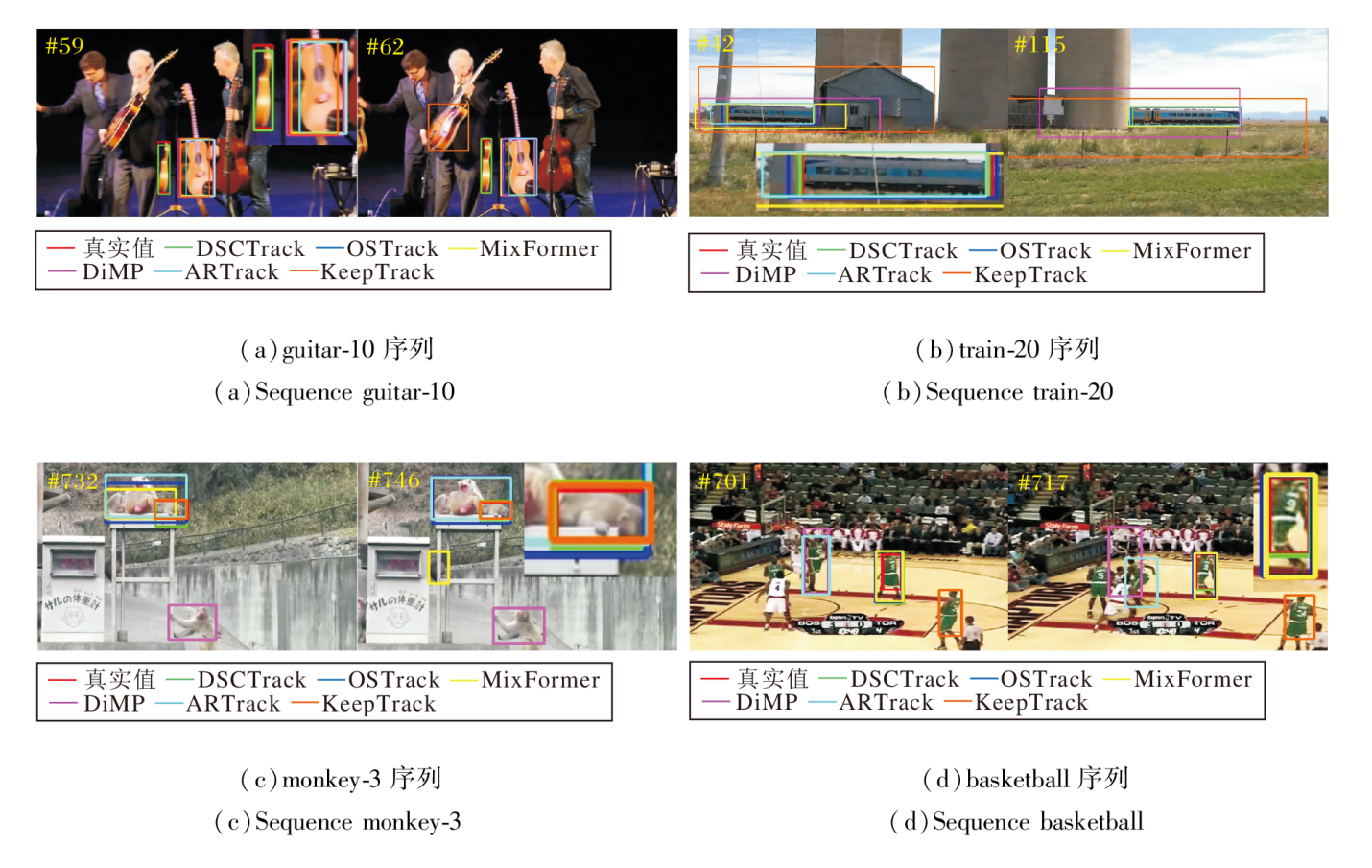
DSCTrack、KeepTrack[6]、OSTrack[15]、MixFormer[23]、DiMP[38]、ARTrack[44]在guitar-10、train-20、monkey-3、basketball序列上的跟踪结果如图6所示.
 | 图6 各方法在视频序列上的跟踪结果对比Fig.6 Tracking result comparison of different methods on video sequences |
在guitar-10序列上, 存在多把类似的吉他, 在人体遮挡发生后, 第59帧中仅有DSCTrack定位在中间正确的吉他上, OSTrack、DiMP、KeepTrack在发生遮挡后偏移到右侧相似干扰上, 在第62帧, KeepTrack从右侧的相似物体转移到左侧相似物体, 而DSCTrack能保持跟踪, 说明该模型可有效排除语义干扰.
在train-20序列上, 第42帧发生遮挡后, Mix-Former、DiMP、KeepTrack对目标尺寸估计错误, 边界框定位在背景房子的边缘, 第115帧离开房子后仍未恢复, 而DSCTrack通过减少与背景之间的错误关联, 仍维持对局部车厢的跟踪.
在monkey-3序列上, 第746帧中目标出现在多个相似物体附近且目标露出部分较小, DiMP、AR-Track、MixFormer分别关注错误物体, 但DSCTrack依然能正确跟踪.
在basketball序列上, 第580帧球员发生快速运动和形状变化, KeepTrack和ARTrack丢失跟踪目标, OSTrack和MixFormer错误扩大定位目标的准确边界.由于减少与复杂背景交互, DSCTrack对嘈杂背景和目标变化更鲁棒.
语义背景消除模块旨在特征学习的过程中自适应减少部分背景特征参与后续关系建模, 消除比例为当前搜索特征向量的40%.图7表示搜索区域消除特征的对应区域放大至原始图像尺寸后的位置, 每组示例从左至右依次为搜索区、第一次消除结果和第二次消除结果, 绿色框表示目标的边界框, 白色掩蔽区域表示搜索区域被消除的冗余背景.
 | 图7 语义背景消除模块可视化结果Fig.7 Visualization results of semantic background elimination module |
在图7(a)中, 目标是白色狗, 经过两次候选消除后, 大幅减少周边背景.在被减少的区域中, 包含大量可能引发歧义的其它狗, 即在两次消除中去除具有与目标相似语义的背景的干扰, 不再参与后续的特征提取与关系建模.
在图7(b)中, 第一次消除具有与目标球员相似外观和类别的其他球员, 减少该部分困难语义背景在后续的关系交互.在第二次消除中, 进一步排除相似球员的区域, 使目标像素在最终的特征交互中仅与简单背景进行关系建模, 减少最终目标边界框预测的歧义.
在图7(c)、(e)中, 大部分路面被消除, 说明该类简单背景在早期的特征学习中得到良好识别.与目标分割等像素级任务不同, 目标跟踪任务需要区分目标与背景的边界并预测边界框, 因此, 早期特征交互中背景消除仍倾向保留目标附近的区域用于判别学习.
在图7(d)中, 目标与背景中的其它杯子高度相似, 但形态略有区别, 由于整体考虑模板中目标的所有特征, 在两次背景消除中仍删去外围大部分干扰物体的特征向量.
在图7(f)中, 背景中的水花大致分为绿色和白色两类, 与目标较远且颜色差异较大的绿色水花首次被大部分消除, 在第二次消除中, 对于白色水花仅保留目标附近的背景用于准确定位.
为了验证DSCTrack的有效性, 在GOT-10k数据集和相同的硬件平台上开展消融实验, 分析不同组件和参数对跟踪性能的影响.
2.3.1 模块有效性分析
DSCTrack中各模块的有效性验证如表3所示.OSTrack[15]叠加动态语义聚类模块后, AO、SR0.5、SR0.75值分别提升2.5%, 3.0%和1.4%, 但伴随着计算量的增加和速度下降.实验表明, 动态语义聚类模块通过改善关系建模大幅提升跟踪精度, 但小幅降低跟踪速度.其原因是1.5节中语义引导的动态注意力通过屏蔽策略维持与原始Transformer层近似的计算量, 但聚类网络带来的额外网络参数仍总体上略微增加计算负荷, 累积操作次数(Multiply-Accu-mulate Operations, MACs)增加2 G.引入语义背景消除模块后, 在动态语义聚类模块的基础上, AO、SR0.5、SR0.75值分别再提升0.2%、0.1%、1.8%, 同时MACs降低2.1 G.语义背景消除模块通过排除干扰信息可显著提升严格阈值(SR0.75)下的定位精度, 根据1.6节的分析, 该模块在理论上能降低二次计算复杂度, 提升跟踪速度.总体上, 完整跟踪器的跟踪速度和MACs指标与OSTrack近似, AO值增加2.7%, 综合性能明显提升.
| 表3 不同模块的消融实验结果 Table 3 Ablation experiment results of different modules |
2.3.2 聚类数量
为了验证聚类数量对DSCTrack的影响, 在OSTrack中引入具有固定聚类数量的DPC-KNN和本文的动态语义聚类模块进行对比实验, 具体指标值如表4所示, 在表中, 第1行至第5行数据表示聚类数量固定为0、2、4、10、20的DPC-KNN的结果, 最后一行数据为最大聚类数量设为10的动态语义聚类模块的结果.相比聚类数量为0, 采用DPC-KNN执行语义建模的AO值有所上升, 其中聚类数量为4时获得最优AO值, 由此验证对关系建模过程进行合理约束的作用, 但过大的聚类数量导致增益降低.动态语义聚类模块的最大聚类数量为10, 聚类后该类别下特征向量数量大于0的类别称为有效类别, 通过有效类别的自适应变化能够实现基于非固定聚类数量的语义关系建模.相比不使用聚类模块, 动态语义聚类模块获得整体的最大增益, AO值提升2.5%; 相比聚类数量为4时的DPC-KNN, 动态语义聚类模块在AO和SR0.5指标上分别提升0.6%和0.9%:以上说明该模块的优越性.
| 表4 聚类数量不同时的消融实验结果 Table 4 Ablation experiment results for different numbers of clusters |
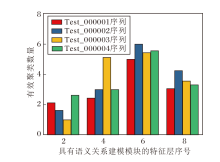
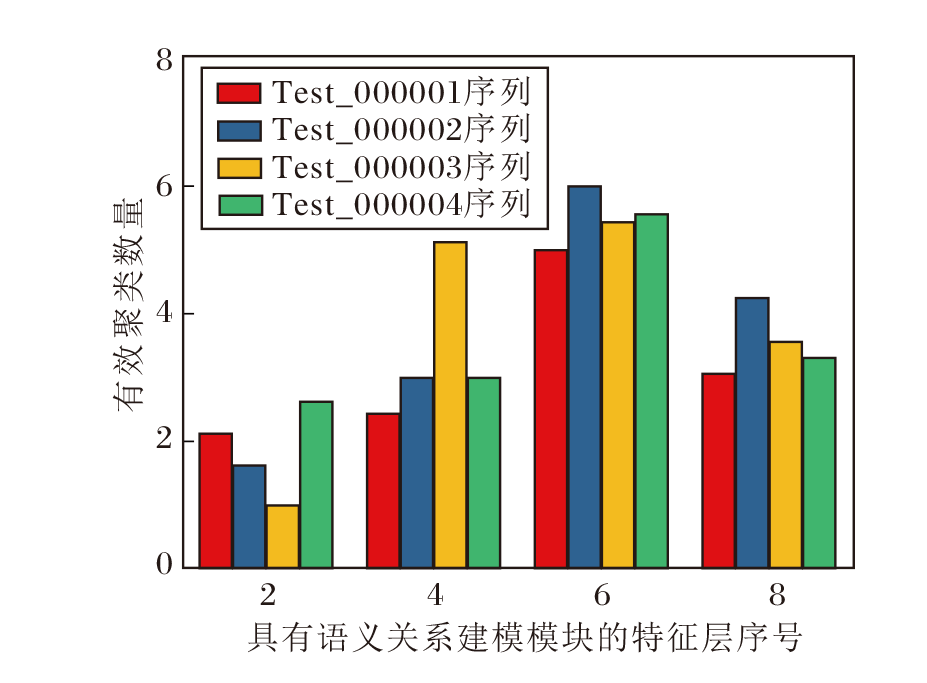
为了直观展示动态语义聚类模块的有效性, 下文进行可视化分析.引入语义关系建模模块的第2特征层、第4特征层、第6特征层、第8特征层, 在GOT10-10k数据集上前4个测试视频序列中的有效聚类数量如图8所示.
 | 图8 语义关系建模模块的有效聚类数量Fig.8 Effective number of clusters for semantic relation modeling module |
动态语义聚类模块在特征网络的早期层(第2层)倾向较少聚类数保留高频信息, 随着网络加深(第2~8层), 有效聚类数量逐渐增加, 进一步细化区分语义, 最高聚类数量为6, 远低于最大聚类数量10.
总之, 动态语义聚类模块无需手动调整聚类数量, 能根据不同视频序列自适应划分, 在多数指标上优于固定数量的聚类策略.
2.3.3 语义关系建模模块位置影响
为了探究语义关系建模模块在ViT主干网络不同深度的作用, 设计5种层次配置方案, 在GOT10-10k数据集上的指标值对比如表5所示, 表中黑体数字表示最优值.由表可见, 在1~6层引入语义关系建模模块, 利用早期聚类策略抑制低判别性特征中的错误交互, 获得71.5%的AO值.在2~12层和7~12层引入语义关系建模模块, 深层网络若仅采用类间的交互约束, 会过度聚焦局部语义信息, 导致全局建模能力下降(AO值分别降低4.3%和2.2%).在2、3、6、8层交替使用聚类与全局交互, 在早期实现语义特征高效聚合的同时保留全局信息流, 最终获得72.8%的AO值.值得注意的是, 在深层网络引入间隔策略后AO值骤降, 证实深层特征需要完整的全局交互空间.实验表明, 对于语义关系建模模块的层次部署, 需早期抑制干扰并在深层保持全局交互.
| 表5 语义关系建模模块位置不同时的消融实验结果 Table 5 Ablation experiment results of semantic relation modeling module with different positions % |
2.3.4 语义背景消除模块
语义背景消除模块的目标是根据目标所属类别的重要性, 识别并剔除背景区域的候选特征.为了验证该模块的有效性, 在GOT10-10k数据集上进行消融实验, 结果如表6所示, 表中黑体数字表示最优值.
| 表6 语义类别消除模块的消融实验结果 Table 6 Ablation experiment results of semantic category elimination module % |
由表6可见, 当采用包含背景区域的完整模板特征向量(简记为Template)时, 跟踪性能显著劣化, 相比无消除方法(简记为Without), AO值下降8.7%.采用模板内真实值特征向量(简记为Groundtruth)时取得最优性能, 这得益于目标特征向量的完整表征能力能有效缓解遮挡误差.选用真实值中心区域特征向量(简记为Center Region)和采用中心点单一特征向量(简记为Center Point)时, 尽管Transformer架构赋予特征向量全局感知能力, 但局部特征的缺失仍导致目标表征不完整.实验表明, 基于完整真实值特征向量的重要性评估方法能最准确反映语义类别重要性.
在bottle-14序列和cat-18序列上的跟踪失败示例如图9所示, 图中红色标注表示真实值轨迹, 绿色标注表示DSCTrack.
 | 图9 DSCTrack跟踪失败示例Fig.9 Tracking failure examples of DSCTrack |
在bottle-14序列上, 第4 066帧展示DSCTrack对短时局部遮挡的定位与位置估计能力.然而从第4 196帧开始, 目标遭遇大面积长时间遮挡, 由于采用固定初始模板且缺乏外观模型更新机制, DSCTrack始终聚焦于瓶盖区域, 直至第4 211帧仍未能恢复全局跟踪.
在cat-18序列上, 目标自车轮左侧短暂消失后, 于第941帧从右侧重新出现, DSCTrack在搜索范围有效覆盖时可适应此类短时消失现象.但是, 当目标自第1 426帧进入遮挡区域后, 经历长时间消失状态, 至第1 491帧重现时, 因缺乏重检测与模板更新机制, DSCTrack未能恢复跟踪.
本文提出基于动态语义聚类关系建模的目标跟踪方法(DSCTrack).设计的语义关系建模模块减少目标与背景特征在关系建模中的错误交互, 增强外观模型对目标与背景的感知能力, 提高在变化场景中的跟踪性能.为了实现细化的类内注意力, 构建动态语义聚类模块, 引入特征间的局部关联信息和可学习参数, 缓解传统动态注意力对类别数量和手工划分策略的局限性.设计语义背景消除模块, 过滤关系建模阶段的背景干扰信息, 在增加跟踪速度的同时, 对相关区域给予更高权重, 进一步增强特征的判别性.在6个数据集上的实验表明, DSCTrack性能较优.今后将在空间关系建模的基础上, 进一步考虑外观模型的时间变化, 提高对目标和背景长期变化的处理能力.
本文责任编委 徐勇
Recommended by Associate Editor XU Yong
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|
| [40] |
|
| [41] |
|
| [42] |
|
| [43] |
|
| [44] |
|