

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于跨模态先验注入的图像描述方法
[江泽涛1  , 张路豪
, 张路豪1 , 潘奕伟1 , 李孟桐1 , 杨建琛1 ]
, 张路豪, 潘奕伟, 李孟桐, 杨建琛]
|
|



作者简介:

张路豪,硕士研究生,主要研究方向为计算机视觉、图像描述.E-mail:1229076324@qq.com.

潘奕伟,硕士研究生,主要研究方向为计算机视觉、语义分割.E-mail:22032303079@mails.guet.edu.cn.

李孟桐,硕士研究生,主要研究方向为计算机视觉、低照度图像增强.E-mail:22032202013@mails.guet.edu.cn.

杨建琛,硕士研究生,主要研究方向为计算机视觉、低照度图像增强.E-mail:22032202038@mails.guet.edu.cn.
联合文本模态和图像模态中的语义信息是图像描述任务的关键点之一,但现有的图像描述方法往往只将文本信息作为解码阶段的约束条件或是简单地将文本特征与图像特征进行拼接融合,导致文本和图像之间的跨模态交互不足,产生模态鸿沟,使方法在编码阶段无法充分利用文本含有的语义信息.针对此问题,文中提出基于跨模态先验注入(Cross-Modal Prior Injection, CMPI)的图像描述方法.首先,通过CLIP(Contrastive Language-Image Pre-training)提取文本先验知识.然后,将文本先验知识与模态介质进行第一次模态交互,得到同时含有文本语义信息和图像语义信息的跨模态特征.最后,将跨模态特征与图像的网格特征进行第二次模态交互,以跨模态特征作为媒介,将文本先验知识注入图像特征中,从而在不破坏图像特征结构的前提下,融入文本的语义信息,缓解模态鸿沟问题.在MSCOCO数据集上的Karpathy划分实验表明,CMPI在一阶段训练的CIDEr(Consensus-Based Image Description Evaluation)分数为128.0,二阶段训练的CIDEr分数为140.5,具有一定优势.
About Author:
ZHANG Luhao, Master student. His research interests include computer vision and image description.
PAN Yiwei, Master student. His research interests include computer vision and semantic segmentation.
LI Mengtong, Master student. His research interests include computer vision and low-illumination image enhancement.
YANG Jianchen, Master student. His research interests include computer vision and low-illumination image enhancement.
Combining semantic information from text and image modalities is one of the key points of image captioning. However, existing image captioning methods often treat text information merely as the constraints in the decoding stage or simply concatenate and fuse text features with image features. As a result, insufficient cross-modal interaction between text and image is caused and a modality gap is created. Consequently, the semantic information contained in the text cannot be fully utilized in the encoding stage. To address this issue, a method for image captioning based on cross-modal prior injection(CMPI) is proposed. First, the textual prior knowledge is extracted through contrastive language-image pre-training(CLIP). Then, the textual prior knowledge is interacted with the modal medium for the first time, and the cross-modal features containing both textual and image semantic information are obtained. Finally, the second modal interaction is performed between the cross-modal features and the grid features of the image. With cross-modal features as a medium, the prior knowledge of the text is injected into the image features. In this way, the semantic information of the text is incorporated without damaging the structure of the image features ,and the modality gap is alleviated. Experimental results on Karpathy splits of MSCOCO dataset show that CMPI achieves a CIDEr score of 128.0 in the first training stage and 140.5 in the second training stage , demonstrating a clear advantage.
图像描述(Image Captioning)是指为图像生成合适的描述语句, 即看图说话, 其主要目的是让计算机理解视觉信息, 并将视觉信息转化为文本信息.图像描述作为计算机视觉领域和自然语言处理领域的交叉任务, 是计算机理解现实场景的重要研究内容之一.随着相关技术的发展, 图像描述在智能图像搜索、辅助视觉障碍人士、虚拟现实与增强现实、医学影像分析、智能驾驶等领域发展潜力巨大.
受计算机视觉领域和自然语言翻译领域的启发, 早期研究者们提出基于卷积神经网络(Con-volutional Neural Networks, CNN)-循环神经网络(Recurrent Neural Network, RNN)的编码器-解码器(Encoder-Decoder)架构的图像描述方法[1].这种方法使用CNN提取图像特征, 再使用RNN将深层空间的图像特征解码为文本信息[2].
近年来, 基于注意力机制的Transformer在自然语言处理领域[3]和计算机视觉领域[4]表现突出, 引起研究人员的极大关注, Cornia等[5]提出M2 Trans-former(Meshed-Memory Transformer), 使用Transfor-mer构建一个由多层图像编码器和多层文本解码器组成的图像描述模型, 取得显著的性能提升.
然而现有的图像描述方法往往只是把文本信息作为解码阶段的约束条件, 造成视觉模态和文本模态间交互较少, 进而导致图像和文本之间存在的模态鸿沟无法被解决.
为了缓解模态鸿沟问题, Anderson等[6]提出Up- Down(Bottom-up and Top-Down Object Inference Net- work), 通过目标检测器Faster R-CNN[7]实现自下而上的注意力机制, 检测图像中存在的对象, 获取对象的区域特征及标签信息, 利用检测的区域特征和标签信息进行解码.检测器提供的额外信息虽然能提高描述模型的性能, 但对检测器的过度依赖也成为描述模型的瓶颈.Fang等[8]提出ViTCAP, 在图像特征提取器中建立一个分支, 借鉴图像分类方法, 针对图像特征使用Transformer块和多层感知机, 预测图像特征的概念标记向量, 再将概念标记向量与提取的图像特征级联后送入解码器.这种方法可摆脱原有方法对检测器的过度依赖, 但其模态间的交互方法直接采用级联的方式, 并不能充分融合文本模态信息和视觉模态信息.Wei等[9]提出VLCA(Vision-Language Aligning Model with Cross-Modal Attention), 面向遥感图像生成准确而丰富的双语描述, 并引入跨模态学习网络, 解决视觉-语言对齐问题, 因此为视觉-语言的融合研究提供新的思路.Wang等[10]提出PureT(Pure Transformer-Based Image Captioning Model), 构建预融合模块, 拼接融合图像全局特征与解码器输出的文本特征, 但解码器输出的文本信息是被模型预测出来的, 无法充分表征图像中的信息.Kuo等[11]使用CLIP(Contrastive Language-Image Pre-training)[12]对区域裁剪后的输入图像进行跨模态检索, 得到不同区域的文本信息, 再通过协调模块, 将文本信息补充到检测器提取的图像区域特征中进行解码, 但在跨模态检索后得到的文本信息包含一些逻辑词, 这些逻辑词在进行模态交互时可能会破坏原有图像的特征, 导致描述模型性能下降.
尽管上述作者针对模态鸿沟问题进行研究, 但仍存在如下缺陷:一方面, 用于模态融合的文本特征无法充分表示图像中的目标权重和关系, 如采用检测器获取标签信息时, 文本特征过于依赖检测器性能且无法把握图像中的关键目标, 或是虽然利用分类算法得到图像概念标记, 但却忽略目标之间存在的联系; 另一方面, 模态融合的过程过于粗糙, 文本和图像仅采用拼接、线性映射的方式进行模态融合, 不仅不能充分融合两种模态, 还会损坏原本图像特征具有的语义信息.
针对上述问题, 本文提出基于跨模态先验注入(Cross-Modal Prior Injection, CMPI)的图像描述方法.首先, 设计先验知识提取模块(Prior Knowledge Extraction Module, PKEM), 利用CLIP强大的跨模态检索能力, 计算图像和文本之间的相似度, 筛选后得到一组文本信息, 编码后作为跨模态先验知识.然后, 设计基于两阶段交互的注入式跨模态融合方法(Injected Two-Stage Modal Interaction, ITMI), 通过多模态特征融合模块(Multimodal Information Fusion Module, MIFM)与特征注入模块(Feature Injection Module, FIM)协同实现.首先在MIFM阶段, 将图像全局特征编码为模态介质, 通过文本先验信息的跨模态融合生成具有语义感知的跨模态特征.再在FIM阶段, 通过特征注入机制将该跨模态特征与图像网格特征进行深度融合, 形成兼具细粒度视觉细节与文本语义的解码特征.该双阶段设计实现模态介质引导下的跨模态知识递进融合, 既保留原始图像的空间细节, 又通过文本语义的动态嵌入有效引导文本生成过程, 显著提升多模态表征的语义一致性.
图像描述生成任务旨在自动为图像内容提供准确、流畅的文字描述.该技术在为图像搜索引擎提供语义注释、增强多媒体内容的可访问性、智能图像识别等方面具有重要应用价值.
早期的图像描述方法大多基于模板驱动, 通常识别图像中的关键元素并填入预定义的语言模板中.这种方法虽然能生成结构较合理的描述, 但往往语句生硬, 不够流畅.
近年来, 随着深度学习技术的发展, 图像描述领域取得显著的研究进展.编码器-解码器架构[1]成为目前最可行的方案之一.受机器翻译和目标检测领域的启发, Xu等[13]提出两种注意力机制:使用标准反向传播方法训练的“ 软” 注意机制和使用最大化近似变分下限训练的“ 硬” 注意机制, 通过注意力机制改变对图像中不同区域的关注度, 提高模型的描述性能.Anderson等[6]利用目标检测器提取更符合视觉习惯的区域特征, 并成为后续图像特征提取的范式.Transformer的出现使图像描述模型性能在编码层和解码层都得到提升.Huang等[14]提出AoA(Attention on Attention), 扩展传统的注意力机制, 确定关注结果和查询之间的相关性.Pan等[15]提出X-Linear Attention Block, 利用空间和通道双线性注意力捕捉模态内或模态间的高阶交互.Luo等[16]提出DLCT(Dual-Level Collaborative Transformer), 使区域特征和网格特征互补, 既能表征区域特征拥有的语义信息, 也能包含网格特征拥有的细粒度信息.刘兵等[17]设计全局与序列混合条件变分自编码器, 解决全局与序列隐向量之间依赖关系表示的问题.李永杰等[18]提出基于外部先验和自先验注意力的图像描述生成方法, 引用外部先验知识, 增强样本之间的潜在关系.
CLIP[12]是一种开创性的图像-文本预训练方法, 通过对比图像和文本之间的相似性, 实现从图像到文本、从文本到图像的双向理解, 具有更广泛的跨模态理解能力.CLIP的核心思想是使用大量未标注的图像-文本对进行预训练, 通过对比学习的方式拉近正确配对的图像和文本之间的关联, 同时推远错误配对的组合.
CLIP[12]由两部分组成:1)图像编码器, 通常是基于CNN的网络, 负责提取图像特征; 2)文本编码器, 常基于Transformer结构, 用于理解文本内容.
在预训练阶段, CLIP通过大规模的互联网数据进行自监督学习, 无需任何形式的人工标注.经过预训练后, CLIP可容易微调, 并在各种下游任务中取得出色性能, 如图像分类、自然语言理解、视觉问答等.
CLIP具备强大的跨模态理解能力.它的传统目标检测器通常依赖图像中的视觉特征(如边缘、纹理等)识别目标, 生成的特征表示不仅包含视觉信息, 还融合丰富的语义信息.通过学习图像和文本的深层特征, 有效结合文本模态和图像模态之间的语义关联, 再通过对比学习, 将图像和文本映射到同一语义空间, 从而生成更具判别性的特征表示.这种语义丰富的特征表示有助于模型更好地理解目标间的上下文关系.
总之, CLIP的出现为图像和文本理解研究带来新的思路和突破, 为实现更智能的跨模态理解奠定基础.在图像描述领域, 借助CLIP获取的跨模态检索特征, 对于丰富图像特征的语义信息产生显著作用.然而, 传统的特征融合手段因方法欠妥, 常引发负面效应, 融合效果并不理想.
本文提出基于跨模态先验注入(CMPI)的图像描述方法, 框架如图1所示.
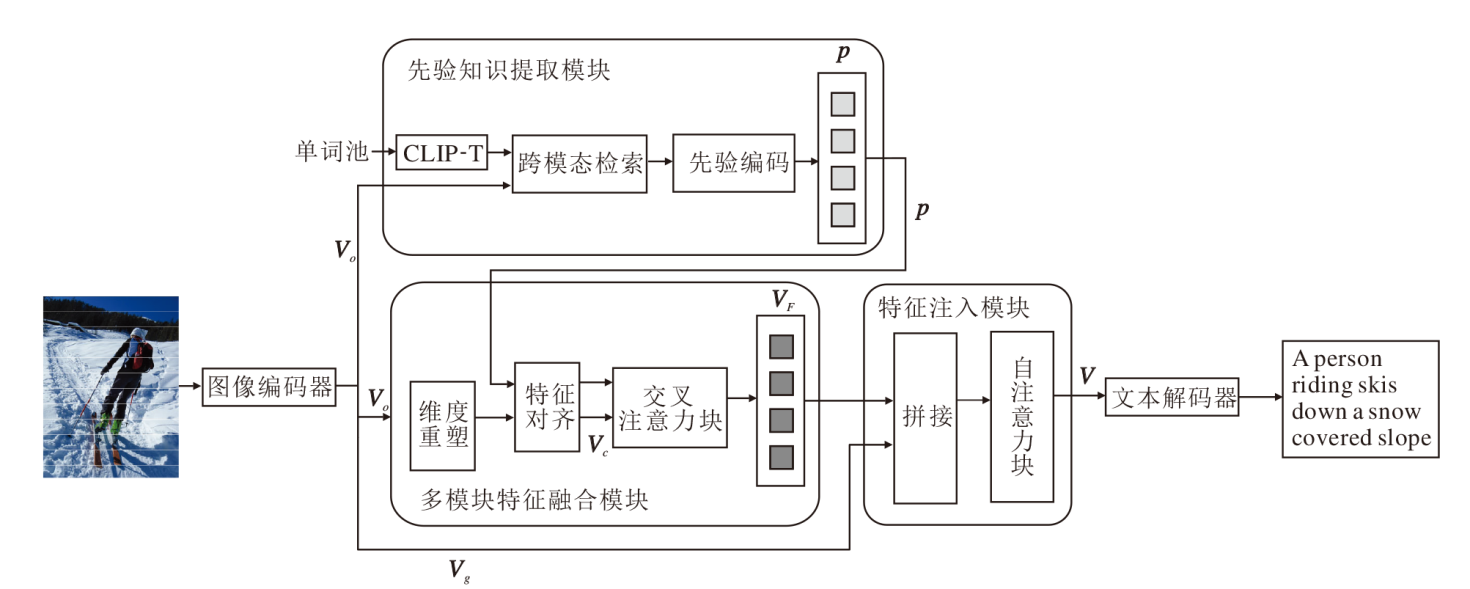 | 图1 CMPI框架图Fig.1 Framework of CMPI |
经过预训练后的CLIP图像编码器CLIP-I, 提取图像的全局特征Vo∈ R1× d和网格特征
Vg∈ RN× d={v1, v2, …, vN},
其中, N表示编码器切分的网格数, d表示特征维度.
CMPI设计思想如下.首先, 由CLIP-I提取全局特征Vo, 通过先验知识提取模块(PKEM)中的跨模态检索(Cross-Modal Retrieval, CMR)检索图像全局特征Vo和经过筛选的词表, 得到关于输入图像的一组文本信息.对文本信息进行先验编码(Prior Embedding, PE), 得到跨模态先验知识p.PKEM不仅包含目标检测器提取目标的标签信息, 而且获得目标间的关系, 并由此获得优质的跨模态先验知识并与图像特征进行交互, 引导文本生成.再通过两阶段交互的注入式跨模态融合方法(ITMI)联合文本信息和图像信息.
具体来说, 通过多模态信息融合模块(MIFM)将全局特征Vo通过维度重塑(Unsqueeze and Expand, UE)和特征对齐(Feature Alignment, FA), 进行深层编码后作为模态介质Vc, 并与p进行第一次模态交互, 通过交叉注意力块融合Vc和p, 得到同时含有文本语义信息和图像语义信息的跨模态特征VF, 实现更深入的跨模态信息间的交互.然后, 将VF注入网格特征Vg中进行第二次模态交互, 通过自注意力块(Self-Attention, SA)捕捉特征中不同位置之间的依赖关系, 得到最终用于解码器的生成文本特征V.最后, 将输出特征V送入由Transformer块堆叠的解码器中, 生成最终描述
Y={y1, y2, …, yt},
其中t表示输出句子的长度.
CMPI优点在于:一方面能获取更有效的文本特征用于跨模态融合; 另一方面采用ITMT, 使跨模态融合过程能以渐进式的方式进行, 从而深度整合文本模态和图像模态的语义信息.CMPI考虑p的特征密度远大于Vg, 一个单词可能等效于图像中的大部分网格, 因此在模态融合过程中引入模态介质, 避免现有模型直接拼接融合导致特征密度分布不均匀, 进而在进一步计算时损坏特征语义信息的问题.
先前的研究表明, 目标检测器提取的对象标签对提高图像描述性能具有重要作用, 但由于目标检测器的优化目标并不针对跨模态任务, 所以其编码的信息可能无法准确反映描述任务中的关键信息, 如对象谓词、场景信息等.
CLIP是一种多模态(文本和图像)学习方法, 旨在将文本和图像之间的语义联系建模到同一空间中, 通过对比学习的方式在大量数据集上训练模型, 最大化同类的文本描述和图像之间的相似性, 最小化不同类的文本描述和图像之间的相似性, 有效拉近图像和文本的空间距离.
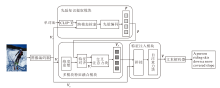
本文提出先验知识提取模块(PKEM), 结构如图2所示.PKEM利用CLIP编码器进行跨模态检索, 可得到一组与图像语义信息相近的文本信息, 类似于一种快速多分类方法.为了从图像中提取有效的文本信息, 构建一个单词池(Word Pool).该单词池是由MSCOCO图像描述数据集上真实标注语句中的单词组成.首先将标注语句分解为单词, 并统计单词的词频, 随后筛选词频较高的单词, 构建单词池.
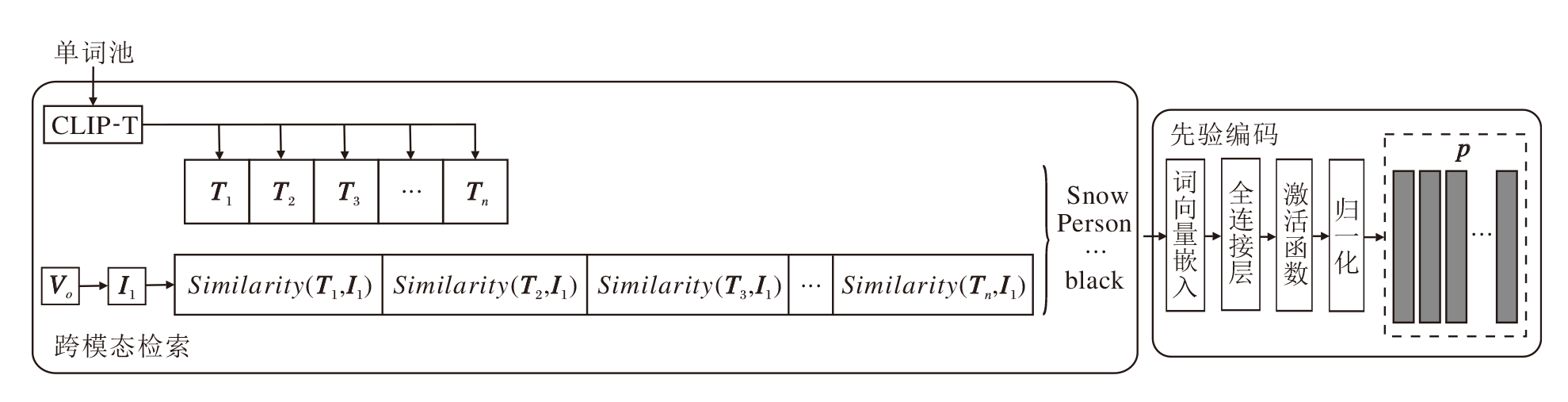 | 图2 PKEM结构图Fig.2 Structure of PKEM |
在特征编码器方面, 使用CLIP的两个分支:图像分支CLIP-I和文本分支CLIP-T.先进行特征提取, CLIP-I编码器对图像特征进行编码和提取, CLIP-T对应用单词池的单词构建的模板句子进行编码.然后计算图像特征和文本特征的余弦相似度:
Similarity(T, I)=
其中:T· I为文本描述向量T和图像向量I内积, 表示它们在向量空间中的相似程度; |T|和|I|分别表示文本描述向量T和图像向量I的范数, 用于归一化两个向量的大小, 确保相似度值在-1到1之间.余弦相似度的值越接近于1, 表示两个向量在空间中的方向越相似; 如果余弦相似度接近于0, 表示它们之间无明显的相关性.
接下来在余弦相似度矩阵中搜索前k个余弦相似度最高的文本描述, 得到一组文本信息
Tp={t1, t2, …, tk}.
相比以往使用目标检测器获取图中对象的标签信息, 采用CMR的方式能将目标标签和目标间的关系统一编码至隐层空间, 再通过对比学习方法, 量化图像与隐层编码的相似度, 获取图像对应的标签信息和目标间的关系.此时文本信息Tp是由词表中的编号表示, 为了使文本信息能直接参与神经网络的计算, 通过先验编码模块, 使用词向量嵌入层将Tp∈ Rk× 1映射至Rk× d的特征空间中, tn(n=1, 2, …, k)分别编码为词向量, 此时词向量仍是单独个体, 相互之间无关联, 不能反映整体的语义信息.所以使用全连接层对编码后的词向量进行线性组合, 可考虑文本特征之间的关系, 捕捉文本特征内部的相互关系.最后对其进行归一化处理, 得到跨模态先验知识p.
图像描述领域一般使用图像的全局特征和网格特征.全局特征包含丰富的语义信息, 但缺乏对图像细节的表征能力.网格特征将图像分割成多个网格, 容易导致信息碎片化, 缺乏对整体图像内容的全局视野, 可能导致模型在理解整体语境时存在局限性.常见的模态融合策略大多是将文本信息和图像信息分别编码, 再通过拼接、线性映射等方式进行模态交互, 这种方式一方面破坏图像特征的表征能力, 另一方面模态交互不够深入, 无法解决模态鸿沟问题.
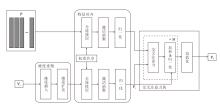
本文提出二阶段交互的注入式跨模态融合方法(ITMT), 有效避免对图像特征表征能力的破坏, 同时充分交互跨模态先验知识和图像特征, 缓解模态鸿沟问题.多模态特征融合模块(MIFM)作为第一次模态交互阶段, 主要实现跨模态先验知识p与模态介质Vc的跨模态信息交互, 这样做的好处如下:一方面能避免p和网格特征Vg由于密度不均匀在融合时产生的特征损失, 起到缓冲作用; 另一方面还能通过二阶段交互的方式, 使文本信息和图像信息进行更深入的交互.MIFM结构如图3所示.
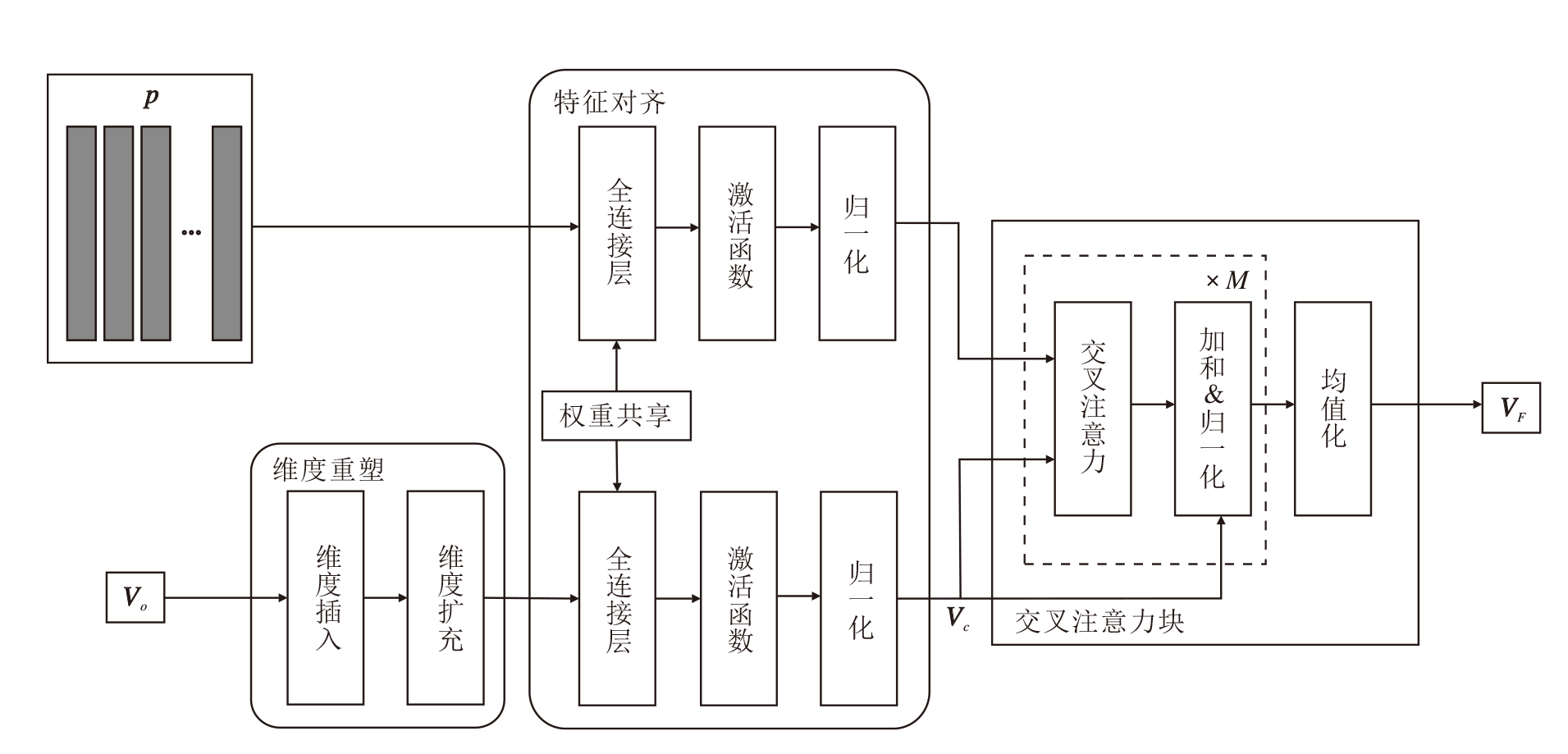 | 图3 MIFM结构图Fig.3 Structure of MIFM |
在MIFM中, 由于p和Vo的特征维度不同, 所以首先对其进行维度重塑, 通过维度插入, 在全局特征Vo中插入一个维度, 再进行维度扩充, 使其与跨模态先验知识p的特征维度对齐.将Vo和p送入一个权重共享的线性层, 进行特征对齐, 进一步拉近二者的空间距离, 使其能更好地融合, 由此得到模态介质Vc, 然后交叉注意力块对p和Vc进行交叉注意力(Cross Attention, CA)计算:
$ \begin{array}{l}\operatorname{CA}\left(\boldsymbol{p}, \boldsymbol{V}_{c}, \boldsymbol{V}_{c}\right)=\operatorname{Attention}\left(\boldsymbol{p} \boldsymbol{W}^{Q}, \boldsymbol{V}_{c} \boldsymbol{W}^{K}, \boldsymbol{V}_{c} \boldsymbol{W}^{V}\right), \\\operatorname{Attention}(\boldsymbol{Q}, \boldsymbol{K}, \boldsymbol{V})=\operatorname{softmax}\left(\frac{\boldsymbol{Q} \boldsymbol{K}^{\mathrm{T}}}{\sqrt{d}}\right) \boldsymbol{V}, \end{array}$ (1)
其中, WQ, WK, WV表示权重矩阵, Q表示查询, K表示键, V表示值, Attention(· )表示缩放点积注意力操作.
跨模态先验知识p作为查询, 模态介质Vc作为键和值, 在进行交叉注意力计算时, 模态介质Vc作为主导, 跨模态先验知识p有效引导文本信息与图像信息的融合过程.这样可确保融合过程受到先验知识的指导, 有助于提高方法对跨模态信息的理解和表征能力.再对经过注意力计算的结果与Vc进行残差连接, 保留原始特征的信息, 避免信息丢失和梯度消失问题.下式对注意力计算的结果和Vc进行残差连接, 用于补充原始信息, 再对得到的特征进行归一化和通道平均, 得到融合特征VF, 作为下一模块的输入, 即
VF=Mean(Norm(Vc+CA(p, Vc, Vc))).
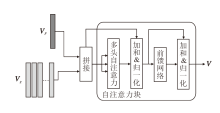
特征注入模块(FIM)是模态交互的第二阶段, 将通过MIFM得到的融合特征VF注入图像的网格特征Vg当中, 从而实现跨模态先验知识p的文本信息与图像全局特征、网格特征在模态间的充分融合, 并且融合特征VF的注入能恢复部分网格特征丢失的上下文关系.FIM结构图如图4所示.
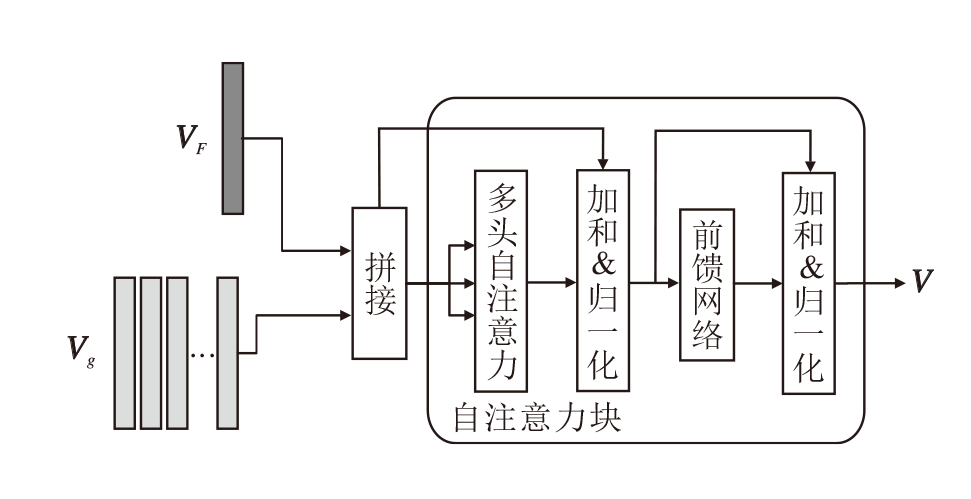 | 图4 FIM结构图Fig.4 Structure of FIM |
为了使特征间深入交互, FIM首先将网格特征Vg与融合特征VF进行通道拼接, 得到V'.由于融合
特征VF是以图像的全局特征为基础得到的, 所以拼接后, 不会破坏原本图像特征的语义信息, 再利用Transformer块对特征进行融合编码, 利用自注意力捕捉长距离依赖关系的能力, 将VF中蕴含的文本信息逐步注入图像的网格特征中, 得到联合文本模态语义信息和图像模态语义信息的特征:
$ \begin{array}{l}\boldsymbol{V}=f\left(\operatorname{Norm}\left(\boldsymbol{V}^{\prime}+\operatorname{MHSA}\left(\boldsymbol{V}^{\prime}, \boldsymbol{V}^{\prime}, \boldsymbol{V}^{\prime}\right)\right)\right), \\\operatorname{MHSA}\left(\boldsymbol{V}^{\prime}, \boldsymbol{V}^{\prime}, \boldsymbol{V}^{\prime}\right)= \\\quad \operatorname{Concat}\left(\operatorname{head}_{1}, \operatorname{head}_{2}, \cdots, \operatorname{head}_{h}\right) \boldsymbol{W}^{o}, \\\operatorname{head}_{i}=\operatorname{Attention}\left(\boldsymbol{V}^{\prime} \boldsymbol{W}_{i}^{Q}, \boldsymbol{V}^{\prime} \boldsymbol{W}_{i}^{k}, \boldsymbol{V}^{\prime} \boldsymbol{W}_{i}^{\boldsymbol{V}}\right) .\end{array}$
其中: f(· )表示前馈网络层, 由线性变换和非线性激活函数ReLU构成, 使用前馈网络层能增加特征在高层空间和浅层空间的映射, 增强特征的表征能力; MHSA(· )表示多头自注意力(Multi-head Self Attention, MHSA), 使用MHSA能在特征中捕捉全局的依赖关系, 不同头之间可学习不同的注意力权重, 同时关注特征中的不同部分.
本文采用图像描述模型标准的二阶段训练方法:一阶段对生成的单词逐个使用交叉熵损失函数进行训练, 二阶段将CIDEr(Consensus-Based Image Description Evaluation)分数作为奖励, 使用SCST(Self-Critical Sequence Training)[19]进行训练.
在一阶段训练中, 假设给定的真实标签
Y* ={
损失函数LXE为各时间步的交叉熵损失之和, 即
LXE=-
其中, T表示句子长度, θ 表示模型参数.由于优化过程是针对每个单词独立优化, 并且损失函数的计算依赖于先前的预测值, 仅使用交叉熵损失不能充分描述方法性能, 因此图像描述方法大多加入二阶段训练.
在二阶段训练中, 使用强化学习的方法, 将CIDEr分数作为奖励, 进一步提升方法性能, 具体公式如下:
$ \begin{array}{l}\nabla_{\theta} L_{\mathrm{RL}}(\theta)=-\frac{1}{k} \sum_{i=1}^{k}\left(r\left(\boldsymbol{y}_{1: T}^{i}\right)-\boldsymbol{b}\right) \nabla_{\theta} \ln \left(p_{\theta}\left(\boldsymbol{y}_{1: T}^{i}\right)\right), \\\boldsymbol{b}=\frac{1}{k} \sum_{i=1}^{k} r\left(\boldsymbol{y}_{1: T}^{i}\right), \end{array}$
其中, LRL(· )表示强化学习损失函数, k表示采用集束搜索策略(Beam Search)[20]的束大小(Beam Size), b作为生成描述的基线, 用于鼓励方法生成更好的描述.
基于强化学习的训练方法直接针对CIDEr指标进行优化, 使方法在训练和评估时保持一致, 提升方法性能, 生成更完整流畅的描述.
本文选择MSCOCO数据集作为实验数据集.MSCOCO数据集是当前图像描述领域常用的大型公开数据集之一, 包含超过1.2× 105幅图像, 每幅图像至少有5条人工标注的参考描述.实验遵循如下划分方法:5 000幅图像用于验证, 5 000幅图像用于测试, 其余图像用于训练.
在测试阶段, 使用一套完整的评价指标, 分别为BLEU(Bilingual Evaluation Understudy)、METEOR(Metric for Evaluation of Translation with Explicit Ordering)、ROUGE(Recall Oriented Understudy for Gisting Evaluation)、CIDEr、SPICE(Semantic Propo-sitional Image Caption Evaluation).BLEU用于评估机器生成文本的质量; METEOR用于评估自动机器翻译; ROUGE 基于最长公共子串计算准确率; CIDEr用于评测生成描述和参考描述的相似度; SPICE为基于场景图和语义概念的评估指标, 用于衡量生成语句是否描述图像中各对象之间的关系.
本文参考经典的图像描述模型, 在通用参数的设置上与主流网络保持一致.使用CLIP-RN101作为图像编码器, 得到的输出网格数为49, 特征维度d设为512, 多头交叉注意力机制中头数量设为8, MIF中的堆叠层数M设为3.采用典型的两阶段训练范式训练网络模型.在基于交叉熵损失训练阶段, 使用Adam(Adaptive Moment Estimation)[21]优化器和学习率预热策略, 设置学习率为5× 10-4, 预热的迭代数为2× 104.在基于强化学习训练阶段, 使用SCST进一步优化方法的CIDEr得分, 学习率设为1× 10-5, 使用StepLR学习率调度器调整训练过程中的学习率, 步长设为15, γ =0.8, 表示每训练15轮, 将当前的学习率乘以0.8.束大小设为3.
本文选取如下13种主流的图像描述方法进行对比:M2 Transformer[5], Up-Down[6] , 文献[11]方法, AoA[14], 文献[15]方法, GCN-LSTM(Graph Convolutional Networks plus Long Short-Term Memory)[22], SGAE(Scene Graph Auto-Encoder)[23], GET(Global Enhanced Transformer)[24], APN(Auto-Parsing Net- work)[25], CLIP-ViL[26], DIFNet(Dual Information Flow Network)[27], TFSGC(Transform Scene Graphs into More Descriptive Captions)[28], CropCap[29].
本文将应用交叉熵损失的训练结果和应用强化学习的训练结果分开对比, 结果如表1所示.由表可知, CMPI性能较优, 在两个阶段训练的测试中, 都超越经典的主流方法.尤其是在CIDEr指标上, 相比CropCap, 一阶段训练结果提升2.3%, 二阶段训练结果提升1.7%, 这表明CMPI具有显著优势.
| 表1 各方法在MSCOCO数据集上的指标值对比 Table 1 Metric value comparison of different methods on MSCOCO dataset % |
本文利用CLIP的跨模态检索能力计算图像和文本的相似度并筛选得到一组文本信息, 文本信息编码后作为跨模态先验知识.这使方法能从大量的文本信息中筛选与图像最相关的部分, 为后续的模态交互提供更有针对性的信息.将提取的文本信息以先验形式融入由图像全局特征经过特殊编码处理生成的模态介质中, 得到的跨模态特征能有效捕捉文本与图像的语义信息, 这使在图像描述等任务中生成的文本能更准确反映图像内容.将跨模态特征注入图像的网格特征中, 可实现文本信息的嵌入, 并引导后续的文本解码生成过程.这种引导作用使生成的文本在语法和语义上更连贯合理.
对CMPI中各模块进行消融实验, Base表示去除CMPI中相关模块的主流Transformer图像描述方法.在进行消融实验时, 将采用图像真实标注中的文本信息的结果与PKEM提取的先验知识注入图像特征中进行对比, 一阶段训练的测试结果如表2所示, 表中* 表示在网络中添加图像真实标注中的文本信息.
| 表2 各模块的消融实验结果 Table 2 Results of ablation experiment for different modules % |
由表2可见, 仅加入FIM时, 图像真实标注中的文本信息与PKEM提取的先验知识都能提高方法性能, CIDEr分数分别提升0.4%和1.0%, 这表明FIM对文本信息与图像信息融合的有效性.
在FIM的基础上加入MIFM, 方法性能得到大幅提升, 相比Base, 在CIDEr分数上分别提升1.5%和2.1%, 由此验证MIFM在特征注入前采用模态介质进行第一次模态交互的有效性.
对比采用图像真实标注中的文本信息的结果与PKEM提取的先验知识进行注入的结果发现, PKEM提取的先验知识在方法中的作用明显优于图像真实标注中的文本信息, 由此验证PKEM的有效性.
在MIFM阶段, 跨模态先验知识p的维度pdim会直接影响与模态介质的融合效果, 从而影响CMPI的性能.CLIP得到的文本信息Tp中包含无语义的冗余文本信息, 所以取Tp的前pdim项进行编码, 得到维度为pdim的跨模态先验知识p.pdim越大, 包含的文本信息越丰富, 但融合之后就越有可能使跨模态特征偏向文本域, 难以进行下一步注入; pdim越小, 包含的文本信息越匮乏, 越容易导致跨模态特征中包含的文本信息不足, 从而不能发挥文本先验知识的引导作用.因此本文对MIFM中跨模态先验知识的维度pdim进行消融实验, 寻找合适维度.
因为MSCOCO数据集上文本真实标注语句大多在20个单词以内, 跨模态先验知识p的目标是包含语句中的主要信息, 所以本文分别将p的维度设为2, 4, 6, 8, 具体指标值由表3所示.由表可知, p的维度设为4时, 性能最优.
| 表3 MIFM中pdim对CMPI性能的影响 Table 3 Effect of pdim in MIFM on CMPI performance % |
为了直观展示CMPI在图像描述方面的性能, 对比图像真实标注和基线方法的结果, 具体如图5所示.在图中, GT表示图像的真实标注语句, 基线方法表示消融实验中提到的主流Transform方法.由图可直观看出, 相比真实标注和基线方法, CMPI能在跨模态先验知识的引导下更好地捕捉图像中的关键信息.
 | 图5 各方法图像描述效果对比Fig.5 Comparison of image description results of different methods |
图5(a)中GT和基线方法只描述出一名棒球运动员的动作情况, 而CMPI能精确得到棒球运动员的人数并识别在观众席的观众.
(b)中GT和基线方法在描述时未描述人物的相关特征, CMPI则描述两名男性的穿着特征.
(c)中GT和基线方法只指出猫的站立状态是站在车盖上, CMPI能将猫的站立状态和所处的位置进行准确表述, 并根据相关信息得出环境为车库.
(d)中GT和基线方法都忽略左上角的人物情况, CMPI能准确描述人物正在售卖商品, 并且准确识别鸟的种类.
如图5所示, CMPI在进行图像描述时, 能联合跨模态先验知识与图像特征, 使解码阶段不仅关注图像的某个显著性特征, 还能在跨模态先验知识的引导下, 得到图像中各元素的信息, 从而生成更丰富、准确的描述, 图像描述性能较优.
本文针对因文本与图像的跨模态交互不足而产生的模态鸿沟问题, 提出基于跨模态先验注入(CMPI)的图像描述方法.首先使用CLIP预训练模型, 获得一组图像的文本信息, 并编码为先验知识.然后, 引入模态介质, 使文本特征与图像特征之间的暴力融合转变为一个逐步融合的过程, 能在不破坏图像特征的前提下将文本信息注入图像特征之中.具体过程为两次跨模态交互:第一次跨模态交互使文本先验知识与模态介质融合, 得到跨模态特征; 第二次跨模态交互将跨模态特征注入图像特征中, 联合文本模态和图像模态的语义信息, 使解码阶段的特征能在文本先验知识的引导下生成更加准确丰富的描述.实验表明, CMPI性能超越多数主流的图像描述方法.
在复杂场景中, 图像包含大量物体、事件及相互关系, 虽然模态交互机制能捕捉文本语义信息与图像语义信息, 但可能难以处理如此复杂多样的语义关系.例如:当图像中有多个物体且存在复杂的动作和空间关系时, 将文本信息融入模态介质生成跨模态特征, 可能无法全面准确捕捉所有语义信息, 导致生成的描述不够精确完整.因此, 今后需要继续提升跨模态先验知识的全面性和精确性.
本文责任编委 桑农
Recommended by Associate Editor SANG Nong
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|