

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
粗细粒度因果关系协同驱动的可解释性视觉问答方法
[施业成1, 2  , 缪佳李
, 缪佳李1, 2 , 俞奎1, 2 ]
, 缪佳李, 俞奎]
|
|



作者简介:

施业成,硕士研究生,主要研究方向为因果发现、自然语言处理、多模态推理.E-mail:shiyecheng@mail.hfut.edu.cn.

缪佳李,博士研究生,主要研究方向为因果发现、多标签学习、多模态表征学习.E-mail:miaojiali@mail.hfut.edu.cn.
可解释性视觉问答(Explanatory Visual Question Answering, EVQA)在回答视觉问题的同时为推理过程生成用户友好的多模态解释,从而提高模型推理的可信度.然而,由于缺乏对视觉区域对象关系的有效建模,现有EVQA生成的解释文本存在视觉区域与语义不一致的问题.为此,文中提出粗细粒度因果关系协同驱动的可解释性视觉问答方法(Fine-to-Coarse Grained Causality Co-Driven Approach for Explanatory Visual Question Answering, FCGC-CoD).首先,建模视觉区域特征的因果关系,识别其中的主体对象和支撑对象,增强视觉与语言预训练模型的多模态表征能力.然后,设计联合变分推理网络,通过细粒度的多模态因果表征增强模型粗粒度的宏观因果推理过程,实现多模态解释和答案的生成.实验表明,FCGC-CoD在准确回答问题的同时,可提升解释的视觉推理一致性.
About Author:
SHI Yecheng, Master student. His research interests include causal discovery, na-tural language processing and multimodal reasoning.
MIAO Jiali, Ph.D. candidate. His research interests include causal discovery, multi-label learning and multimodal representation lear-ning.
Explanatory visual question answering (EVQA) generates user-friendly multimodal explanations for the reasoning process while answering visual questions. Thereby, the credibility of model inference is enhanced. However, due to the lack of effective modeling of visual regions object relations, the explanations generated by existing explanatory visual question answering (EVQA) models suffer from the problem of inconsistency between visual regions and semantics. To address this issue, a fine-to-coarse grained causality co-driven (FCGC-CoD) approach for explanatory visual question answering is proposed. First, the causal relationships of visual regions features are modeled, and the influential and supportive objects are identified to enhance the multimodal representation capability of the vision-and-language pretrained model. Then, a joint variational causal inference network is designed to strengthen the coarse-grained reasoning process through fine-grained multimodal causal representations, and thus the generation of multimodal explanations and answers is achieved. Experimental results demonstrate that FCGC-CoD enhances the visual reasoning consistency of explanations while answering questions accurately.
视觉问答(Visual Question Answering, VQA)[1, 2]是人工智能领域中的基础多模态推理任务之一, 它以一幅图像和与图像相关的自然语言问题为输入, 并输出一个自然语言的答案, 广泛应用于视障辅助、医学图像诊断及机器人技术[3].现有的VQA侧重于有效学习并融合图像和问题的特征, 进行答案预测[4, 5].
对于图像表示, 常采用由ResNet[6]提取的网格特征和由Faster R-CNN[7]提取的对象特征.对于问题表示, GloVe[8]和BERT(Bidirectional Encoder Representations from Transformers)[9]是两种典型的语言模型.为了进一步融合多模态特征, 研究人员提出多种VLPMs(Vision-and-Language Pretrained Models)[10], 如VisualBERT[11]和LXMERT(Learning Cross-Moda-lity Encoder Representations from Transforms)[12].
此外, 为了改善视觉表征及其跨模态交互作用, 设计新型注意力机制成为新的研究热点.Xiang等[13]提出SA-VQA(Structured Alignment of Visual and Semantic Representations for Visual Question Answering), 构建模态实体邻接图, 引导稀疏注意力机制, 深化表示视觉模态和文本模态之间的深层关系.然而, 仅通过黑盒式深度神经网络推断答案无法有效提升结果的可解释性.为此, Li等[14]提出VQAE.Chen等[15]提出REX(Reasoning-Aware and Grounded Explanation).
可解释性视觉问答(Explanatory Visual Question Answering, EVQA)强调推理过程及通过多模态解释验证答案合理性的能力, 同时联系视觉理解[16, 17]和自然语言推理[9, 11], 促进人工智能系统的透明度和可解释性.这种扩展有助于提升模型推理的可解释性[18].
EVQA要求模型生成一段模型推理过程的解释文本作为问答可信的依据, 而现有解释多为问答数据的事后解释[15], 缺乏对问答推理过程的解释.这导致多数EVQA将答案预测和解释作为两个独立的生成过程, 忽略它们之间的联系.为了建立解释和答案预测之间的联系, Xue等[19]提出VCIN(Varia-tional Causal Inference Network), 结合因果推理[20, 21, 22]的问答框架和变分推理网络[23]的深度推理机制, 实现解释在事中对答案预测的干预, 同时提高答案质量.随着多模态大语言模型的发展, Xue等[24]提出FS-MEVQA(Few-Shot Multimodal Explanation for Vi-sual Question Answering), 通过少量样本训练生成多模态解释.
因果结构学习[25, 26, 27]是一种分析可观测数据中变量间因果关系的方法, 是处理数据依赖关系的有效工具.以结构因果模型(Structural Causal Model, SCM)为架构的VQA普遍具有强大的推理能力和可解释能力.Wang等[20]提出CaaM(Causal Attention Module), 解耦因果特征和非因果特征, 过滤虚假特征.Yang等[21]提出CATT(Causal Attention), 消除混杂因子对重要特征依赖性的干扰, 进一步增强因果注意力表征.
然而, 在EVQA中, 现有模型建立的SCM架构是一种粗粒度宏观角度的因果图模型[19, 28], 表示多模态推理过程中数据由问到答的因果关系.在模态数据表征上广泛依赖于VLPMs的多模态表征能力, 忽略在微观角度上学习和表征视觉对象间的因果关系.因此, 解决解释的视觉和语义一致性问题的首要挑战是如何促使VLPMs生成兼顾视觉对象因果关系的细粒度多模态特征.
为了解决上述挑战, 目前的方法侧重于通过消除背景噪声(虚假特征)和识别因果不变特征以学习相关特征.Wang等[29]提出VC R-CNN(Visual Co-mmonsense Region-Based Convolutional Neural Net-work), 在VLPM数据表征中引入细粒度视觉对象间因果关系的作用.随后, Wang等[20]提出CaaM, 在注意力机制的QKV(Query-Key-Value)操作中引入视觉因果关系, 设计去偏差的因果注意力模块, 实现在视觉注意力学习阶段解耦细粒度的因果特征和非因果特征, 用于过滤虚假特征.
上述方法普遍认为虚假特征对任务无帮助, 研究目的是降低或消除不相关特征和虚假特征在表示中权重.然而文献[30]表明, 非因果特征的作用不完全是消极的, 如在分类任务中, 非因果特征可作为因果特征的互补信息辅助分类器工作.因此, 如何实现目标特征的因果细粒度表征和非因果细粒度表征及其解释任务上的协同互补作用, 促进粗粒度的宏观推理过程生成更好的解释特征回答问题是挑战之一.
基于上述研究, 以解决解释的视觉和语义一致性问题为出发点, 本文提出粗细粒度因果关系协同驱动的可解释性视觉问答方法(Fine-to-Coarse Grained Causality Co-Driven Approach for Explanatory Visual Question Answering, FCGC-CoD).首先, 利用因果结构学习算法构建视觉特征的区域对象因果图, 提取邻接矩阵, 转化为QKV注意力机制的采样矩阵, 引导视觉自注意力机制学习视觉因果表征, 促使VLPMs输出兼顾视觉对象相关性的细粒度多模态因果特征.然后, 提取因果邻接矩阵并计算其补矩阵以识别视觉特征的非因果相关区域对象, 促使VLPMs解耦兼顾视觉对象相关性的细粒度多模态主体(因果)特征(Influential Object Feature, Iof)和多模态支撑(非因果)特征(Supportive Object Fea-ture, Sof).最后, 提出多模态主体特征和多模态支撑特征的联合变分因果推理架构, 通过细粒度的多模态因果表征增强EVQA粗粒度的宏观推理过程, 提升推理解释的视觉和语义一致性.
EVQA的目标如下:基于给定问题和相关图像, 生成正确答案并提供多模态解释.
输入表示为(Q, I), 其中:
Q=q1q2…qm
表示包含m个单词的问题文本, qi表示问题中的第i个单词; 图像I可用一个RGB张量表示.
输出表示为(A, E), 其中:A表示从预定义的字典集{z1, z2, …, zK}(含K个可能答案)中选择的答案;
E=e1e2…en,
表示包含n个标记的多模态解释.
在模型训练过程中, 真实输出(A', E')被提供给模型用作监督信号.
本文主要解决生成解释的视觉区域和语义的不一致问题.如图1所示, 尽管示例中VCIN[19]生成的解释包含答案的语义信息, 但其视觉区域并不符合正确解释的视觉逻辑关系, 降低解释可信度.
 | 图1 EVQA语义一致性示例Fig.1 EVQA semantic consistency example |
VLPMs是一种多模态模型, 旨在结合视觉模态和语言模态, 完成跨模态检索、视觉问答、图文匹配等任务.VLPMs将图像和文本嵌入统一表征的语义空间中, 使模型能理解两者之间的关系.VLPMs通常是视觉模态编码器、语言模态编码器和跨模态编码器组成的Transformer[31].
注意力机制通常作为模块化网络的一个单元嵌入.例如:自注意力机制[31]被视觉模态编码器和语言模态编码器普遍使用.以视觉模态编码器为例, 假设输入视觉特征为X, 它的查询矩阵QX∈ Rs× d、键矩阵KX∈ Rs× d、值矩阵VX∈ Rs× d, 其中, s表示输入视觉特征长度, d表示查询、键和值的设定长度.
对于视觉特征X, 首先计算缩放点积注意力分数:
Score=
则视觉特征X经过自注意力机制得到的表征为:
$\boldsymbol{X}^{\prime}=\operatorname{Att}\left(\boldsymbol{Q}_{X}, \boldsymbol{K}_{X}, \boldsymbol{V}_{X}\right)=\operatorname{softmax}\left(\frac{\boldsymbol{Q}_{X} \boldsymbol{K}_{X}^{\mathrm{T}}}{\sqrt{d}}\right) \boldsymbol{V}_{X} . $ (1)
相比自注意力机制, 交叉注意力机制大多在跨模态编码器中使用.假设输入文本特征为L, 它的查询矩阵QL∈ Rn× d、键矩阵KL∈ Rn× d、值矩阵VL∈ Rn× d, 其中, n表示输入文本特征的长度, d表示查询、键和值的设定长度.
对于文本特征L, 使用交叉注意力机制[31]学习它的跨模态特征表示如下:
$\boldsymbol{L}_{c}=\operatorname{CrossAtt}\left(\boldsymbol{Q}_{L}, \boldsymbol{K}_{X}, \boldsymbol{V}_{X}\right)=\operatorname{softmax}\left(\frac{\boldsymbol{Q}_{L} \boldsymbol{K}_{X}^{\mathrm{T}}}{\sqrt{d}}\right) \boldsymbol{V}_{X} . $
同理, 可以得到视觉特征X的跨模态特征表示如下:
$\boldsymbol{X}_{c}=\operatorname{CrossAtt}\left(\boldsymbol{Q}_{X}, \boldsymbol{K}_{L}, \boldsymbol{V}_{L}\right)=\operatorname{softmax}\left(\frac{\boldsymbol{Q}_{X} \boldsymbol{K}_{L}^{\mathrm{T}}}{\sqrt{d}}\right) \boldsymbol{V}_{L} . $
在现有EVQA推理方法中, 基于变分因果推理机制的方法最有效, 其模型训练目标是建模从解释到答案的因果效应的同时, 最大化预测真实答案A'的边缘似然的证据下界(Evidence Lower Bound, ELBO)[32].具体来说, p表示训练数据分布, q表示理想数据分布, 理想分布在隐藏层定义一个由多模态解释数据生成的稳定特征F, 因此获得如下优化目标函数[19]:
$\begin{aligned} \ln p\left(\boldsymbol{A}^{\prime} \mid \boldsymbol{M}\right) \geqslant & E_{q(\boldsymbol{F} \mid \boldsymbol{M})}\left[\ln p\left(\boldsymbol{A}^{\prime} \mid \boldsymbol{M}, \boldsymbol{F}\right)+\ln p(\boldsymbol{F} \mid \boldsymbol{M})-\ln q(\boldsymbol{F} \mid \boldsymbol{M})\right]= \\ & E_{q(\boldsymbol{F} \mid \boldsymbol{M})}\left[\ln p\left(\boldsymbol{A}^{\prime} \mid \boldsymbol{M}, \boldsymbol{F}\right)\right]-K L(q(\boldsymbol{F} \mid \boldsymbol{M}) \| p(\boldsymbol{F} \mid \boldsymbol{M}))= \\ & E_{q\left(\boldsymbol{F} \mid \boldsymbol{E}^{\prime}\right)}\left[\ln p\left(\boldsymbol{A}^{\prime} \mid \boldsymbol{M}, \boldsymbol{F}\right)\right]-K L\left(q\left(\boldsymbol{F} \mid \boldsymbol{E}^{\prime}\right) \| p(\boldsymbol{F} \mid \boldsymbol{M})\right) . \end{aligned}$ (2)
其推理过程中使用引理:
$q(\boldsymbol{F} \mid \boldsymbol{M})=\sum_{\boldsymbol{E}} q(\boldsymbol{F} \mid \boldsymbol{E}) q(\boldsymbol{E} \mid \boldsymbol{M})=q\left(\boldsymbol{F} \mid \boldsymbol{E}^{\prime}\right) $,
其中$q(E|M)$为一个满足$q({E}'|M)=1$的狄拉克分布.由于$\{p(E|M)|\forall E\}$的计算过程具有指数复杂性, 导致式(2)的$p(F|M)$难以计算, 且并无明确算法可采样$E\sim p(E|M)$.因此, 现有方法采用近似分布$p(F|E* )$对应测试场景, 其中E* 表示生成解释.由此可得变分因果推断损失[19]:
$\begin{aligned} L_{\mathrm{ans}}= & -E_{q\left(\boldsymbol{F} \mid \boldsymbol{E}^{\prime}\right)}\left[\ln p\left(\boldsymbol{A}^{\prime} \mid \boldsymbol{M}, \boldsymbol{F}\right)\right]+K L\left(q\left(\boldsymbol{F} \mid \boldsymbol{E}^{\prime}\right) \| p\left(\boldsymbol{F} \mid \boldsymbol{E}^{* }\right)\right)= \\ & -E_{q\left(\boldsymbol{F} \mid \boldsymbol{E}^{\prime}\right)}\left[\ln p\left(\boldsymbol{A}^{\prime} \mid \boldsymbol{M}, \boldsymbol{F}\right)\right]+\frac{1}{2}\left[\ln \left(\frac{\left|\boldsymbol{\Sigma}_{E^{* }}\right|}{\left|\boldsymbol{\Sigma}_{E^{\prime}}\right|}\right)-d_{f}+\operatorname{tr}\left(\boldsymbol{\Sigma}_{E^{* }}^{-1} \boldsymbol{\Sigma}_{E^{\prime}}\right)+\Delta \boldsymbol{\mu}^{\mathrm{T}} \boldsymbol{\Sigma}_{E^{* }}^{-1} \Delta \boldsymbol{\mu}\right], \end{aligned}$
其中,
$\begin{array}{l} \boldsymbol{\Sigma}_{E^{\prime}}=\operatorname{diag}\left(\boldsymbol{\sigma}_{E^{\prime}}^{2}\right), \\ \boldsymbol{\Sigma}_{E^{* }}=\operatorname{diag}\left(\boldsymbol{\sigma}_{E^{* }}^{2}\right), \\ \Delta \boldsymbol{\mu}=\left(\boldsymbol{\mu}_{E^{* }}-\boldsymbol{\mu}_{E^{\prime}}\right), \end{array}$
df表示F的维度.
现有工作除了最大化预测真实答案A'的边缘似然$\log p({A}'|M)$之外, 还通过最小化真实解释E'的负对数似然, 训练模型, 即
$L_{\exp }=-\ln p\left(\boldsymbol{E}^{\prime} \mid \boldsymbol{M}\right) $. (3)
通过优化Lans和Lexp, 可训练结构因果模型, 预测准确答案, 生成合理解释, 同时建模解释E和答案A的因果关联.
为了实现因果关系增强的变分推理网络, 本节首先介绍如何实现多模态因果解耦表征, 再构建结构因果模型, 分析推理目标, 最终提出粗细粒度因果关系协同驱动的可解释性视觉问答方法(FCGC-CoD).
2.1.1 视觉因果图生成
定义图像的视觉特征
$\begin{array}{l} \boldsymbol{X}=\boldsymbol{x}_{1} \boldsymbol{x}_{2} \cdots \boldsymbol{x}_{36} \\ \boldsymbol{x}_{i}=\left(\boldsymbol{r}_{i}, \boldsymbol{b}_{i}\right), i=1, 2, \cdots, 36 \end{array}$
其中, ri∈ R2048表示Faster R-CNN从图像I中提取的第i个区域特征(Region of Interest, ROI), bi∈ R4, 表示该区域的位置向量.
为了嵌入图像视觉特征的因果关系, 构建因果图
G={X, E},
其中,
$\boldsymbol{E}=\left(e_{i, j}\right)_{n \times n}, e_{i, j} \in\{0, 1\}, $
表示通过PC算法(Peter-Clark Algorithm)学习的邻接矩阵.ei, j=1表示存在一条从对象xi到对象xj的因果有向边, 表明xi直接影响xj.ei, j=0表示对象xi和对象xj之间不存在因果关系.
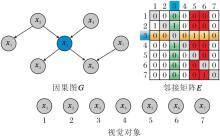
视觉特征因果图示例如图2所示.图中邻接矩阵E描述视觉对象X在G中的因果关系.通过检索矩阵E中元素的索引和值, 可得到与每个目标对象相关的父对象、子对象和配偶对象的集合.以图中的目标对象x3为例, E中的绿色区域表示x3 的父对象所在位置, 当值为1时, 表示索引的视觉对象为x3的父对象.同样, 橙色区域表示子对象所在位置, 红色阴影区域表示配偶对象所在位置.
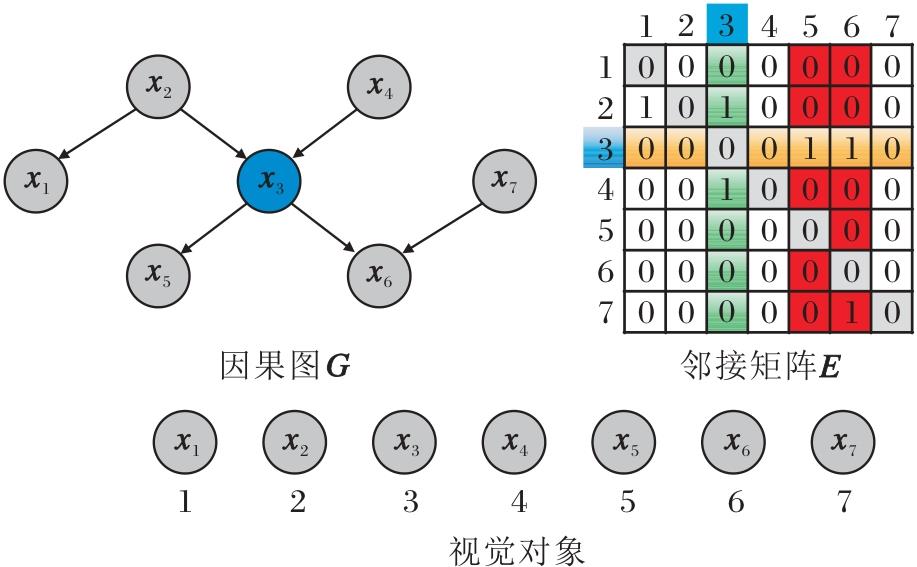 | 图2 视觉特征因果图示例Fig.2 Example of causal graph for visual features |
2.1.2 因果引导矩阵
由图2可见, 目标对象x3的父集为{x2, x4}, 子集为{x5, x6}, 配偶集为{x7}.上述集合的组合可构成目标对象不同粒度的主体(因果)对象集合和支撑(非因果)对象集合.本文采用该组合作为多模态因果解耦表征的基准.
为了实现多模态因果解耦表征, 首先需要设计因果图引导的自注意力机制, 它是一种从因果图的邻接矩阵E中提取引导矩阵A对注意力分数或权重进行采样, 以确保注意权重的计算能准确反映对象间因果关系的自注意力表征方法.具体而言,
A=E+I,
其中I表示单位矩阵.
本文建立的自注意力机制按列计算注意力分数矩阵的权重, 确保引导矩阵采样与注意力方向的一致性.
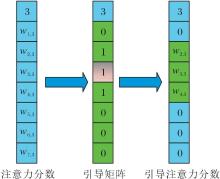
以图2中的目标对象x3为例, 通过QKV计算x3在所有对象中的注意力得分:
$w_{i, 3}=\frac{\left(\boldsymbol{q}_{3}\right)\left(\boldsymbol{k}_{i}\right)^{\mathrm{T}}}{\sqrt{d}}, $
其中, q3表示目标对象x3的查询向量, ki表示候选对象的键向量, d表示查询矩阵、关键字矩阵和值矩阵的设置长度.x3的父集{x2, x4}引导矩阵如图3所示, 与图2相比, e3, 3被设为1.这是因为E的因果方向与注意力方向一致, 可保证充分考虑每个物体对视觉自注意力过程的个体权重贡献, 保持影响的公平分配.
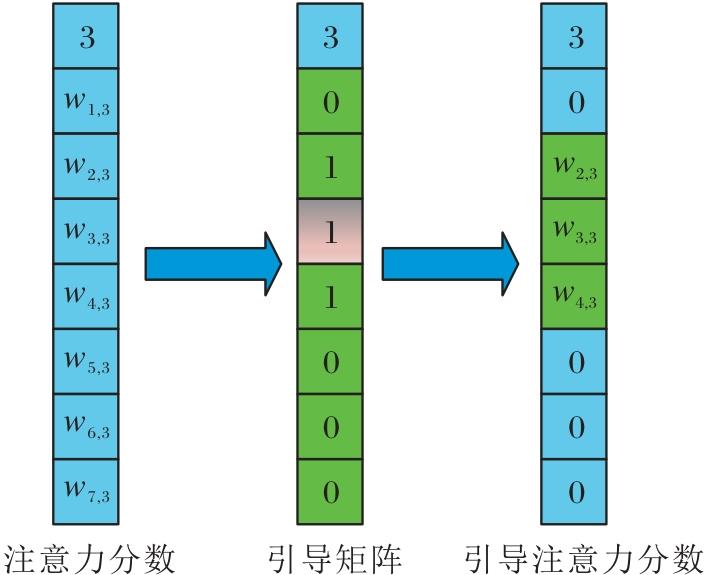 | 图3 引导矩阵的工作原理Fig.3 Mechanism of guided matrix |
2.1.3 多模态因果特征学习方法
使用因果引导注意力分数计算因果自注意力权重, 得到视觉主体表征:
$\boldsymbol{X}_{\mathrm{Iof}}=\operatorname{Att}\left(\boldsymbol{Q}_{X}, \boldsymbol{K}_{X}, \boldsymbol{V}_{X}\right)=\operatorname{softmax}\left(\frac{\boldsymbol{Q}_{X} \boldsymbol{K}_{X}^{\mathrm{T}}}{\sqrt{d}} \odot \boldsymbol{A}\right) \boldsymbol{V}_{X} $.
相应的, 通过A的补矩阵
$\bar{A}=1-E$
得到视觉支撑表征:
$\boldsymbol{X}_{\mathrm{Sof}}=\operatorname{Att}\left(\boldsymbol{Q}_{X}, \boldsymbol{K}_{X}, \boldsymbol{V}_{X}\right)=\operatorname{softmax}\left(\frac{\boldsymbol{Q}_{X} \boldsymbol{K}_{X}^{\mathrm{T}}}{\sqrt{d}} \odot \overline{\boldsymbol{A}}\right) \boldsymbol{V}_{X} \text {, }$
则文本跨模态特征表示为:
$\begin{array}{l} \boldsymbol{L}_{\mathrm{Iof}}=\operatorname{CrossAtt}\left(\boldsymbol{Q}_{L}, \boldsymbol{K}_{X_{\mathrm{Iof}}}, \boldsymbol{V}_{X_{\mathrm{Iof}}}\right), \\ \boldsymbol{L}_{\mathrm{Sof}}=\operatorname{CrossAtt}\left(\boldsymbol{Q}_{L}, \boldsymbol{K}_{X_{\mathrm{Sof}}}, \boldsymbol{V}_{X_{\mathrm{Sof}}}\right) . \end{array}$
同理, 得到视觉特征X的跨模态特征表示:
$\begin{array}{l} \boldsymbol{X}_{\mathrm{Iof}}^{\prime}=\operatorname{CrossAtt}\left(\boldsymbol{Q}_{X_{\mathrm{Iof}}}, \boldsymbol{K}_{L}, \boldsymbol{V}_{L}\right), \\ \boldsymbol{X}_{\mathrm{Sof}}^{\prime}=\operatorname{CrossAtt}\left(\boldsymbol{Q}_{X_{\mathrm{Sof}}}, \boldsymbol{K}_{L}, \boldsymbol{V}_{L}\right) . \end{array}$
本文使用LXMER[12]作为VLPM学习图像和问题的多模态特征.LXMERT包括5层的视觉编码器、9层的语言编码器和5层的跨模态编码器.将上述因果引导过程嵌入预训练LXMERT对应的注意力模块中, 微调预训练模型, 输出多模态因果解耦表征.此外, 对于问题的标记q1q2…qm, 在它的最前端加上[CLS]标记, 最末端加上[EOS]标记, 得到问题的标记表示
$\boldsymbol{Q}=q_{0} q_{1} \cdots q_{m+1} . $
将视觉特征X和对应的引导矩阵及问题Q作为LXMERT的输入, 解耦多模态主体特征
$\boldsymbol{V}_{\mathrm{Iof}}, \boldsymbol{T}_{\mathrm{Iof}}=\operatorname{LXMERT}(\{\boldsymbol{X}, \boldsymbol{A}\}, \boldsymbol{Q}), $
和多模态支撑特征
$\boldsymbol{V}_{\mathrm{Sof}}, \boldsymbol{T}_{\mathrm{Sof}}=\operatorname{LXMERT}(\{\boldsymbol{X}, \overline{\boldsymbol{A}}\}, \boldsymbol{Q}), $
其中, VIof∈ R36× 768表示36个对象的视觉主体特征, TIof∈ R(m+2)× 768表示含m+2个标记的问题主体特征, VSof∈ R36× 768表示36个对象的视觉支撑特征, TSof∈ R(m+2)× 768表示含m+2个标记的问题支撑特征, LXMERT(· )表示利用LXMERT作为VLPM学习多模态特征.
2.2.1 细到粗粒度增益的结构化因果
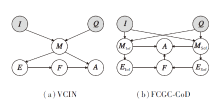
为了充分利用多模态主体特征和多模态支撑特征, 本文在VCIN[19]的基础上设计一个结构因果模型.VCIN和FCGC-CoD的SCM结构如图4所示, 图中I表示图像, Q表示问题, MIof表示多模态主体特征, MSof表示多模态支撑特征, EIof表示主体解释, ESof表示支撑解释, F表示解释特征, A表示答案.由图可见, 本文的SCM利用多模态主体特征和多模态支撑特征分别生成主体解释和支撑解释, 同时建立它们和答案之间的因果关系.
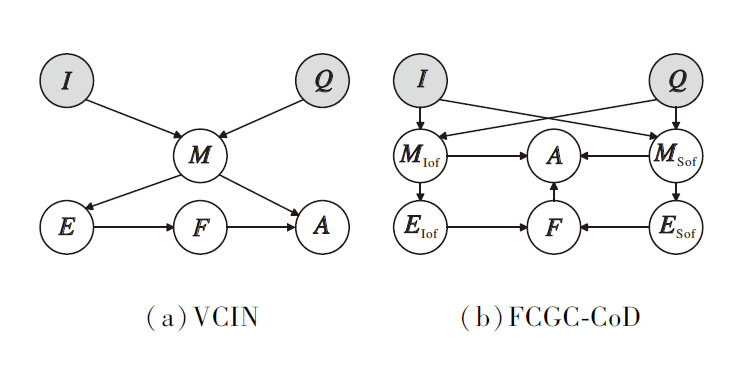 | 图4 结构因果模型结构对比Fig.4 Structure comparison of structural causal models |
具体而言, 通过路径I→ MIof← Q得到多模态主体特征MIof=(VIof, TIof).通过路径I→ MSof← Q, 得到多模态支撑特征MSof=(VSof, TSof).通过路径MIof→ EIof和MSof→ ESof分别生成主体解释和支撑解释.通过路径EIof→ F← ESof进行联合推理, 得到由主体解释和支撑解释共同推理得到的解释特征F.最后, 通过路径MIof(MSof)→ A← F, 得到最终答案.
在此过程中, 将F建模为高斯分布, 即F~N(μ , diag(σ 2)), 以提升F的鲁棒性.其中, μ 、σ 2表示由E计算得出的df维向量.此外, 为了减少分布$P\left(\boldsymbol{A} \mid \boldsymbol{M}, \boldsymbol{E}^{\prime}\right) $和$P\left(\boldsymbol{A} \mid \boldsymbol{M}, \boldsymbol{E}_{\mathrm{Iof}}^{* }, \boldsymbol{E}_{\mathrm{Sof}}^{* }\right) $之间的偏差, 最小化Kullback-Leibler(KL)散度
$K L\left(q\left(\boldsymbol{F} \mid \boldsymbol{E}^{\prime}\right) \| p\left(\boldsymbol{F} \mid \boldsymbol{E}_{\mathrm{Iof}}^{* }, \boldsymbol{E}_{\mathrm{Sof}}^{* }\right)\right), $
其中, E'表示真实解释,
2.2.2 深度变分因果推理目标函数
根据式(2), 在同时引入多模态主体特征和多模态支撑特征的情况下, 变分因果推理目标可进一步推导如下:
$\begin{array}{l} \ln p\left(\boldsymbol{A}^{\prime} \mid \boldsymbol{M}_{\mathrm{Iof}}, \boldsymbol{M}_{\mathrm{Sof}}\right)= \\ \quad E_{q\left(\boldsymbol{F}_{\mathrm{Iof}} \mid \boldsymbol{E}_{\mathrm{Iof}}^{\prime}\right)}\left[\ln p\left(\boldsymbol{A}^{\prime} \mid \boldsymbol{M}_{\mathrm{Iof}}, \boldsymbol{F}_{\mathrm{Iof}}\right)\right]+ \\ \quad E_{q\left(\boldsymbol{F}_{\mathrm{Sof}} \mid \boldsymbol{E}_{\mathrm{Sof}}^{\prime}\right)}\left[\ln p\left(\boldsymbol{A}^{\prime} \mid \boldsymbol{M}_{\mathrm{Sof}}, \boldsymbol{F}_{\mathrm{Sof}}\right)\right]- \\ \quad\left(K L\left(q\left(\boldsymbol{F}_{\mathrm{Iof}} \mid \boldsymbol{E}_{\mathrm{Iof}}^{\prime}\right) \| p\left(\boldsymbol{F}_{\mathrm{Iof}} \mid \boldsymbol{M}_{\mathrm{Iof}}\right)\right)+\right. \\ \left.\quad K L\left(q\left(\boldsymbol{F}_{\mathrm{Sof}} \mid \boldsymbol{E}_{\mathrm{Sof}}^{\prime}\right) \| p\left(\boldsymbol{F}_{\mathrm{Sof}} \mid \boldsymbol{M}_{\mathrm{Sof}}\right)\right)\right) . \end{array}$
由于采用联合推理, 本文使用EIof和ESof的分类结果进行归一化, 得到最终解释E.为了避免F的进一步分化而丢失鲁棒性, 最终推理目标如下:
$\begin{array}{l} \ln p\left(\boldsymbol{A}^{\prime} \mid \boldsymbol{M}_{i}, \boldsymbol{M}_{s}\right)= \\ \quad E_{q\left(\boldsymbol{F} \mid \boldsymbol{E}^{\prime}\right)}\left[\ln p\left(\boldsymbol{A}^{\prime} \mid\left(\boldsymbol{M}_{\mathrm{Iof}}, \boldsymbol{M}_{\mathrm{Sof}}\right), \boldsymbol{F}\right)\right]- \\ \quad K L\left(q\left(\boldsymbol{F} \mid \boldsymbol{E}^{\prime}\right) \| p\left(\boldsymbol{F} \mid\left(\boldsymbol{M}_{\mathrm{Iof}}, \boldsymbol{M}_{\mathrm{Sof}}\right)\right)\right) . \end{array}$
再根据式(3)可得变分因果推断损失如下:
$\begin{aligned} L_{\mathrm{ans}}= & -E_{q\left(\boldsymbol{F} \mid \boldsymbol{E}^{\prime}\right)}\left[\ln p\left(\boldsymbol{A}^{\prime} \mid\left(\boldsymbol{M}_{\mathrm{Iof}}, \boldsymbol{M}_{\mathrm{Sof}}\right), \boldsymbol{F}\right)\right]+K L\left(q\left(\boldsymbol{F} \mid \boldsymbol{E}^{\prime}\right) \| p\left(\boldsymbol{F} \mid \boldsymbol{E}^{* }\right)\right) \approx \\ & -\frac{1}{H} \sum_{i=1}^{H} \boldsymbol{A}^{\prime} \ln p\left(\boldsymbol{A} \mid \boldsymbol{M}, \boldsymbol{F}_{i}\right)+\frac{1}{2}\left[\ln \left(\frac{\left|\boldsymbol{\Sigma}_{\boldsymbol{E}^{* }}\right|}{\left|\boldsymbol{\Sigma}_{\boldsymbol{E}^{\prime}}\right|}\right)-d_{f}+\operatorname{tr}\left(\boldsymbol{\Sigma}_{\boldsymbol{E}^{* }}^{-1} \boldsymbol{\Sigma}_{\boldsymbol{E}^{\prime}}\right)+\Delta \boldsymbol{\mu}^{\mathrm{T}} \boldsymbol{\Sigma}_{\boldsymbol{E}^{* }}^{-1} \Delta \boldsymbol{\mu}\right], \\ L_{\mathrm{exp}}= & -\sum_{t=1}^{T} \boldsymbol{e}_{t^{\prime}} \ln \boldsymbol{y}^{t}-\sum_{t=1}^{T}\left[\omega_{t^{\prime}} \ln \omega_{t}+\left(1-\omega_{t^{\prime}}\right) \ln \left(1-\omega_{t}\right)\right], \end{aligned}$
其中, A'表示真实答案, ω 't表示第t步的真实门控值, e't表示真实解释的第t个标记, yt表示解释的第t个标记的最终预测概率, Fi~N(μ E', diag(
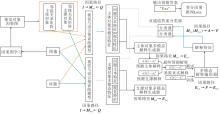
FCGC-CoD具体架构如图5所示.算法步骤如下.
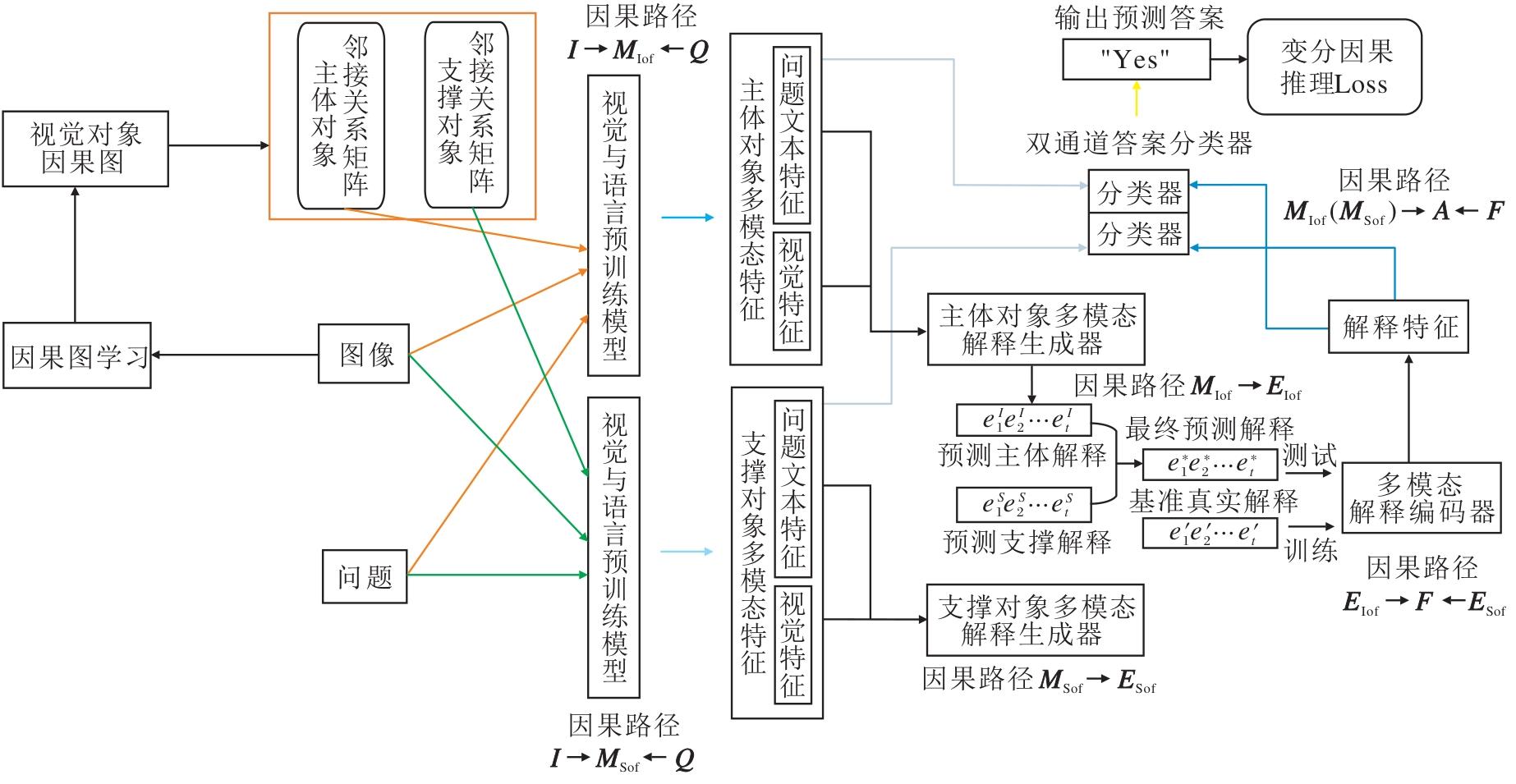 | 图5 FCGC-CoD框架图Fig.5 Framework of FCGC-CoD |
算法 FCGC-CoD
输入 问题Q, 视觉特征X, 因果引导矩阵A
训练阶段
step 1 使用VLPMs解耦多模态主体特征和多模态支撑特征.
step 2 使用主体(支撑)多模态解释生成器生成主体(支撑)解释.
step 3 归一化两种解释, 得到最终预测解释.
step 4 使用多模态解释编码器生成解释特征.
step 5 使用双通道答案分类器预测答案.
step 6 计算变分因果推断总损失.
step 7 反向传播总损失, 更新模型参数.
2.3.1 多模态解释生成器
为了实现SCM中的路径MIof→ EIof和MSof→ ESof, 并得到主体解释和支撑解释, 采用VCIN[19]中设计的Multimodal Explanation Gating Transformer作为多模态解释生成器.在生成解释的第t个标记时, 首先计算前t-1个已生成的标记{ei
$\operatorname{emb}\left(\boldsymbol{e}^{i}\right)=\left\{\begin{array}{ll} \text { WordEmb }\left(\boldsymbol{e}^{i}\right), & \boldsymbol{e}^{i} \text { 为单词 } \\ \boldsymbol{V}_{j}, & \boldsymbol{e}^{i}=\# j \text { 为视觉对象 } \end{array}\right. $ (4)
其中, Vj表示第j个视觉对象的视觉特征, WordEmb(· )表示解释嵌入函数.然后, 使用Le层的Transformer层融合多模态表征.最后, 通过一个多模态门控网络计算解释的第t个标记的概率分布:
$\boldsymbol{y}=\left[\omega_{t} \boldsymbol{y}_{t}^{w} \mid\left(1-\omega_{t}\right) \boldsymbol{y}_{t}^{v}\right] \in \mathbf{R}^{U+36}, $
其中, $[\cdot \mid \cdot] $表示向量拼接操作, ω t表示生成文本标记的概率,
主体多模态解释器和支撑多模态解释器都采用上述生成器.在得到生成的主体解释EIof的第t个标记的概率分布yIof和支撑解释ESof的第t个标记的概率分布ySof后, 进行归一化, 得到最终解释E的第t个标记:
$\boldsymbol{e}_{t}^{* }=\arg \max _{k}\left(\operatorname{softmax}\left(\boldsymbol{y}_{\mathrm{Iof}}+\boldsymbol{y}_{\mathrm{Sof}}\right)\right) . $
2.3.2 多模态解释编码器
为了实现SCM中的路径EIof→ F← ESof并得到具有鲁棒性的解释特征F, 首先分别在主体解释和支撑解释前加入[CLS]标记, 得到相应词嵌入:
$\begin{array}{l} \boldsymbol{C}_{1}= \\ {\left[\operatorname{emb}([\mathrm{CLS}]), \operatorname{emb}\left(\boldsymbol{e}_{\text {Iof }}^{1}\right), \cdots, \operatorname{emb}\left(\boldsymbol{e}_{\text {Iof }}^{T}\right)\right] \in \mathbf{R}^{(T+1) \times 768}, } \\ \boldsymbol{C}_{2}= \\ {\left[\operatorname{emb}([\mathrm{CLS}]), \operatorname{emb}\left(\boldsymbol{e}_{\text {Sof }}^{1}\right), \cdots, \operatorname{emb}\left(\boldsymbol{e}_{\text {Sof }}^{T}\right)\right] \in \mathbf{R}^{(T+1) \times 768}, } \end{array}$
其中, emb(· )如式(4)所示, T表示生成解释的长度.
然后使用Transformer学习它们的特征:
$\begin{array}{l} \boldsymbol{F}_{\boldsymbol{E}_{\mathrm{Iof}}}=\operatorname{Transformer}\left(\boldsymbol{C}_{1}\right) \in \mathbf{R}^{(T+1) \times 768}, \\ \boldsymbol{F}_{\boldsymbol{E}_{\mathrm{Sof}}}=\operatorname{Transformer}\left(\boldsymbol{C}_{2}\right) \in \mathbf{R}^{(T+1) \times 768} . \end{array}$
最终得到解释特征
$\boldsymbol{F}=L N\left(\boldsymbol{F}_{E_{\mathrm{Iof}}}^{0}+\boldsymbol{F}_{E_{\mathrm{Sof}}}^{0}\right) \in \mathbf{R}^{768}$
其中, F
假设解释特征F~N(μ , diag(σ 2)), 使用一个两层的多层感知机计算高斯参数:
2.3.3 答案分类器
为了实现SCM中路径MIof(MSof)→ A← F并得到最终答案, 使用解释特征F计算
$\begin{array}{l} p\left(\boldsymbol{A} \mid \boldsymbol{M}_{\mathrm{Iof}}, \boldsymbol{F}\right)= \\ \quad \operatorname{softmax}\left(L N\left(G E L U\left(\left[\boldsymbol{F} \mid \boldsymbol{T}_{\mathrm{Iof}}^{0}\right] \boldsymbol{W}_{a}^{1}\right)\right) \boldsymbol{W}_{a}^{2}\right) \in \mathbf{R}^{K}, \end{array}$
其中, A表示待预测的答案类别, LN(· )表示层归一化函数, GELU(· )表示高斯误差线性单元函数, T
同理计算$p\left(\boldsymbol{A} \mid \boldsymbol{M}_{\mathrm{Sof}}, \boldsymbol{F}\right) $.
在测试阶段, 为了避免采样偏差和不确定结果, 通过NWGM(Normalized Weighted Geometric Mean)[33] 近似估计$p\left(\boldsymbol{A} \mid \boldsymbol{M}_{\mathrm{Iof}}, \boldsymbol{F}\right) $的期望:
$\begin{array}{l} E_{F}\{p(\boldsymbol{A} \mid \boldsymbol{M}, \boldsymbol{F})\}= \\ \quad E_{F}\left\{\operatorname{softmax}\left(L N\left(G E L U\left(\left[\boldsymbol{F} \mid \boldsymbol{T}_{\text {Iof }}^{0}\right] \boldsymbol{W}_{a}^{1}\right)\right) \boldsymbol{W}_{a}^{2}\right)\right\} \approx \\ \quad \operatorname{softmax}\left(L N\left(G E L U\left(\left[\boldsymbol{E}\{\boldsymbol{F}\} \mid \boldsymbol{T}_{\text {Iof }}^{0}\right] \boldsymbol{W}_{a}^{1}\right)\right) \boldsymbol{W}_{a}^{2}\right)= \\ \quad \operatorname{softmax}\left(L N\left(G E L U\left(\left[\boldsymbol{\mu}_{E^{* }} \mid \boldsymbol{T}_{\text {Iof }}^{0}\right] \boldsymbol{W}_{a}^{1}\right)\right) \boldsymbol{W}_{a}^{2}\right) . \end{array}$
为了得到最终答案, 分别使用主体表征和支撑表征, 通过上述答案分类器计算答案分布pi和ps, 则最终预测答案为:
A=arg
本文选用GQA、GQA-REX、GQA-OOD数据集.在GQA数据集的平衡训练集、平衡验证集和标准测试集基础上, GQA-REX数据集引入多模态解释, 支持视觉问答推理, 其样本统计如表1所示.GQA-OOD数据集是为了测试模型在分布外数据上的泛化能力而设立的, 包含与GQA数据集在分布上有所差异的图像和问题, 通过在该数据集上的测试, 可评估模型能否适应多样化的实际应用场景.
| 表1 GQA-REX数据集样本统计 Table 1 Sample statistics of GQA-REX dataset |
在实验中, 在GQA-REX数据集上进行训练和验证, 在GQA测试集上进行测试, 在GQA-OOD数据集上进行后续测试.
为了评估多模态解释的质量, 使用BLEU-4(Bilingual Evaluation Understudy)、METEOR(Me- tric for Evaluation of Translation with Explicit Or- dering)、ROUGE-L(Recall-Oriented Understudy for Gisting Evaluation-Longest Common Subsequence、CIDEr(Consensus-Based Image Description Evalua- tion)、SPICE(Semantic Propositional Image Caption Evaluation)指标.使用Grounding[19]评估正确生成解释中视觉对象的能力.
对于问答的准确性, 在所有数据集上计算准确率进行衡量.此外, 使用Consistency[19]估计预测答案和解释之间的一致性.
同时进行人工评估, 随机选取300个验证集样本评估解释中预测的视觉标记和文本标记是否与预测的答案一致.采用5级评分系统, 5为最高分, 1为最低分.
实验采用BERT Adam优化器训练模型.为了保证公平对比, 在复现VCIN时使用相同的优化器, 这导致实验结果与原文献略有差异.训练时批量大小设为128, 所有可训练参数的初始学习率设为1e-5.为了减少过拟合, 将梯度范数最大值设为1.0.隐藏单元维度da设为1 536, 正则化失活率设为0.1.
在多模态主体特征与多模态支撑特征上, 对解释生成器进行深度拓展.主体多模态解释生成器及支撑多模态解释生成器的层数均设为4, 相比VCIN采用的2层解释生成器, 显著增加深度.解释文本的最大长度T设为18, 蒙特卡洛采样数H设为4, 均与VCIN一致.
整个模型在两块A100 GPU上, 并基于Linux操作系统使用PyTorch进行训练.
本文选择如下对比方法:VQA-E[14]、REX[15]、VCIN[19]、文献[34]方法.各方法的多模态解释质量对比如表2所示, 表中黑体数字表示最优值.
| 表2 各方法的多模态解释质量对比 Table 2 Comparison of multimodal explanation quality of different methods |
由表2可见, FCGC-CoD生成的多模态解释在文本质量上略差于VCIN(差距最大的CIDEr指标仅低1.3%), 这主要是因为多模态解释中的视觉对象表示方法不利于连贯语义的表达, 需要结合图像具体的区域理解, 所以, FCGC-CoD在解释的文本相似性评估指标上表现较弱.但是, 相比VCIN, FCGC-CoD在Grounding指标上实现6.07%的显著提升, 表明提取的多模态主体特征和多模态支撑特征能有效增强解释的视觉一致性和语义一致性.
各方法的问答准确率对比如表3所示, 表中黑体数字表示最优值.由表可见, FCGC-CoD指标值最高, 特别是在GQA-OOD验证集上, 相比VCIN, 实现3.02%的显著提升, 这充分说明联合变分因果推理架构具有强大的泛化能力, 能有效缓解数据集上固有偏差.
| 表3 各方法的问答准确率对比 Table 3 Comparison of question answering accuracy of different methods % |
VCIN和FCGC-CoD的自动评估指标和人工评估指标对比如表4所示, 表中黑体数字表示最优值.
| 表4 VCIN和FCGC-CoD的评估指标对比 Table 4 Comparison of evaluation metrics between VCIN and FCGC-CoD |
由表4可见, 相比VCIN, FCGC-CoD在Consis-tency上实现3.15%的显著提升, 同时在文本标记指标略有下降的情况下, 视觉标记指标仍有所提高, 这一结果与表2和表3中的分析吻合, 由此说明FCGC-CoD能有效提升解释的视觉与语义的一致性.
为了深入探究多模态主体特征和多模态支撑特征在联合变分因果推理中的作用, 使用相同的实验设置, 进行消融实验, 结果如表5所示, 表中黑体数字表示最优值.
| 表5 FCGC-CoD消融实验结果 Table 5 Ablation experiment results of FCGC-CoD |
由表5可见, 相比使用多模态主体特征和多模态支撑特征进行联合推理, 单独使用这两种特征在Grounding和Consistency指标上都有所降低.其原因在于, 计算多模态主体特征时的因果引导矩阵过于稀疏, 关注的具备因果关系的视觉特征未必能有效促进视觉问答, 需要多模态支撑特征进行补充.
此外, 仅使用多模态主体特征在GQA测试集上的问答准确率为59.06%, 仅使用多模态支撑特征的问答准确率为59.61%, 同时使用两种特征后的问答准确率为59.98%.这表明多模态支撑特征在一定程度上可补充多模态主体特征的信息, 帮助模型更好地理解和推理视觉问答任务, 提高问答准确性.
为了进一步研究FCGC-CoD性能, 在GQA-REX数据集上对VCIN和FCGC-CoD生成的解释和预测的答案进行可视化分析, 结果如图6所示.
 | 图6 VCIN和FCGC-CoD解释和预测答案的可视化分析Fig.6 Visualization analysis of predicted answers and explanations by VCIN and FCGC-CoD |
由图6可见, 相比VCIN, FCGC-CoD能生成准确的视觉对象, 从而生成正确的解释和答案.
在第2列图像中, 相比真实标注, FCGC-CoD生成的视觉对象更准确, 与cabinet的语义一致.而VCIN生成的视觉对象存在偏差, 导致错误的解释和答案.
值得一提的是, GQA-REX数据集上存在许多噪声, 如第2列图像中真实标注的解释存在视觉与语义的不一致.这些噪声使VCIN和FCGC-CoD在部分样本中均无法准确生成解释和预测答案.
为了进一步评估FCGC-CoD在解释生成中对关键视觉属性(color、material、sport、shape、pose、size、activity、relation)的识别能力, 选择REX[15]、VCIN[19]、FCGC-CoD, 在GQA-REX 数据集上计算召回率, 结果如表6所示, 表中黑体数字表示最优值.
| 表6 各方法在关键视觉属性上的召回率对比 Table 6 Comparison of recall rates of different methods on key visual attributes % |
由表6可见, FCGC-CoD显著提升多类属性的召回率.相比VCIN, FCGC-CoD在material属性上的召回率提升1.51%, 在shape属性上的召回率提升4.39%, 在activity属性上的召回率提升1.37%, 在relation属性上的召回率提升1.06%.这些显著提升主要归功于对多模态表征的增强.
本文使用PC算法学习视觉特征的因果关系.PC算法的计算复杂度随变量个数的增多呈指数增长, 计算成本高昂.
选择GQA数据集, ROI数量固定为36, 对应图像中提取36个区域特征.在批量大小为256时, PC算法占用显存约13 GB.对于这个规模的数据, PC算法仍能在较短时间内完成因果图的构建.从可拓展性的角度上看, 基于PC算法改进的因果结构学习算法都可以替代, 考虑条件独立性检验指数性增长的NP难问题, 建议检验变量设置较低数量(本文设为3), 避免生成时间代价过高.
相比VCIN, FCGC-CoD使用多模态主体特征和多模态支撑特征进行联合推理, 模型为并行结构但不是并行计算, 训练和推理耗时更长.具体而言, VCIN一轮训练耗时约1 h 4 min, 而FCGC-CoD一轮训练耗时约1 h 40 min.
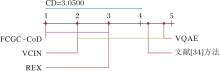
本文采用显著性水平α =0.05下的Nemenyi检验测试各方法性能.当两种对比方法在所有数据集上的平均排序差值大于临界差值(Critical Diffe-rence, CD)时, 认为这两种方法存在显著性差异, 否则无显著性差异.CD值的计算方法如下:
CD=qα
其中K=5, N=4, qα =2.728 0, CD=3.050 0.
各方法在问答指标上的性能对比如图7所示, 图中以实线连接性能差异不显著的方法, 方法性能从左至右递减.
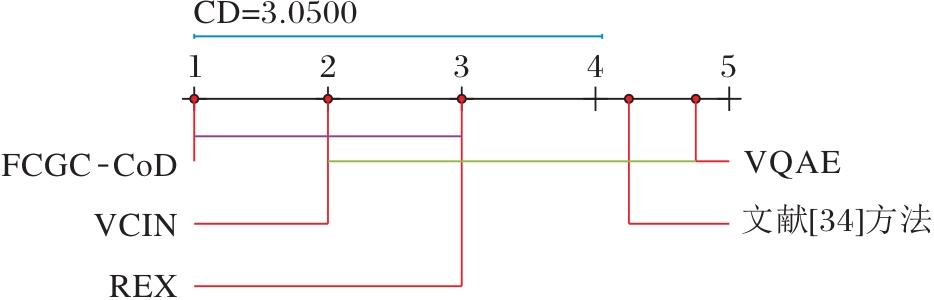 | 图7 各方法在问答指标上的性能对比Fig.7 Performance comparison of different methods on question answering metrics |
由图7可看出, FCGC-CoD性能最优, 尽管与VCIN相比差异不显著, 但仍具有一定优势, 这表明FCGC-CoD在有效提升解释问答准确率的同时, 仍有进一步优化的空间.
本文提出粗细粒度因果关系协同驱动的可解释性视觉问答方法(FCGC-CoD), 引入视觉对象的因果关系, 引导VLPMs分别解耦细粒度的多模态主体特征和多模态支撑特征.此外, 设计一个结构因果模型, 将解耦特征引入深度变分推理网络, 实现从细粒度的多模态因果表征角度增强粗粒度的因果推理过程.实验表明, 虽然FCGC-CoD在解释文本质量上略有下降, 但有效增强解释的视觉和语义一致性, 同时提升问答准确率.人工评估也进一步验证这一点.消融实验表明联合推理的优势.在可视化分析中, 具体示例表明FCGC-CoD能在解释中生成正确的视觉对象, 促进答案预测的准确性.现有工作的局限在于仅关注视觉特征的因果关系, 今后将继续探究问题和解释等文本模态中的因果关系, 以期进一步提升解释质量和问答准确性.
本文责任编委 陈松灿
Recommended by Associate Editor CHEN Songcan
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|